
GCP – Optimizing your bucket options in Cloud Storage
You’ve got the data, and we’ve got the buckets. In this post, we’ll review why buckets are the cornerstone of everything you’ll do in Cloud Storage, and go over some of the options you’ll need to understand to get things set up.
Why Buckets?
Anything you want to store in Cloud Storage needs to be in a bucket in order for you to do anything with it. You can use buckets to organize and control access to your data, but unlike directories and folders, you cannot nest buckets. Additionally, there are limits to bucket creation and deletion, so we recommend that you design your storage applications to favor intensive object operations and relatively few bucket operations (more on that here).
With that said, there are some initial configuration considerations to take into account when creating your bucket: Name, Location, and Storage Class. We’ll take a closer look at each of these, and even link some documentation. Let’s get to it!
What’s in a Name?
First, your bucket needs a globally-unique name. Additionally, note that this name can’t be changed* (*unless you’re looking to copy and rename, in which case, here’s documentation on “workarounds”).
Our best advice is choose a name that will be relevant and useful to you; Something that will help you remember what’s in it, why, and what you’re doing with it. As for specific characters, limitations, and other guidelines, I’ll leave that to the documentation on bucket naming, as it’s fairly comprehensive.
Location! Location! Location!
Once that bucket has a name, you’ll need to select a geographic location. General guidance here states that you should choose location based upon what type of redundancy options you need, where your primary users are, and what your expected first-time-to-byte is when caching is turned off. This is because a good bucket location choice will balance latency, availability, and bandwidth costs for data consumers. We’ve got plenty of options for you to choose from, so check out the documentation for a location listing.
Once you’ve settled on a geographic location, you’ll need to select from 3 location types—and we’ve got region, dual-region, and multi-region to give you plenty of flexibility in choosing the location that will work best for you and your users. Please note that location also can’t be changed once the bucket is created.
As for the types:
Use a region to help optimize latency and network bandwidth for data consumers, such as analytics pipelines, that are grouped in the same region.
Use a dual-region when you want similar performance advantages as regions, but also want the higher availability that comes with being geo-redundant.
Use a multi-region when you want to serve content to data consumers that are distributed across large geographic areas, or when you want the advantages as geo-redundancy.
For more specific information, including available locations and pricing, check out the documentation.
Storage Class
And finally, you should choose a storage class, which you can update later on, and will default to Standard if you don’t initially select something more specific (although you can change the default storage class, if needed—details here). For now, let’s go over the basics.
Cloud Storage has 4 different storage classes which all offer low latency and high durability, but vary based on their availability and minimum storage duration, along with pricing for storage and access.
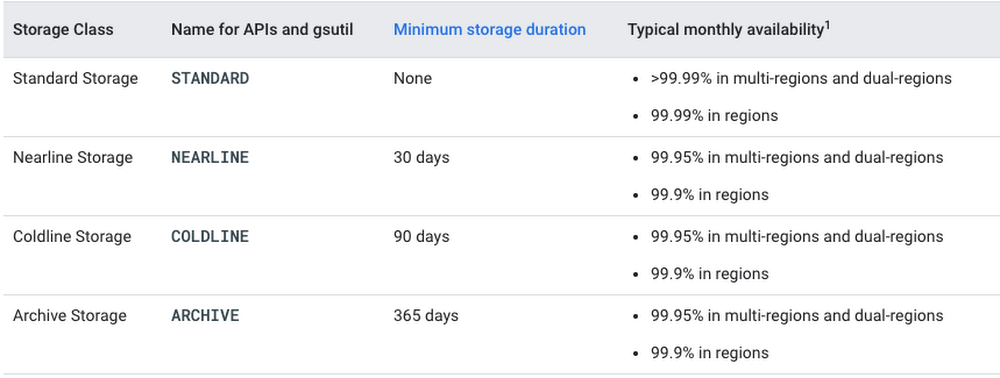
Data that will be served at a high rate with high availability should use the Standard Storage class. This class provides the best availability with the trade-off of a higher price.
Data that will be infrequently accessed and can tolerate slightly lower availability can be stored using the Nearline Storage, Coldline Storage, or Archive Storage class. Your choices here are going to vary depending on your specific needs, and cost considerations; you wouldn’t want to pay to have something stored for all-the-time access when you only need it biannually.
I like to think about using Nearline for something I’ll need to access once a month, and Archive for something I’ll need once a year, and Coldline for the stuff in between. The documentation will help you make the best choice, and provide additional pricing information.
Post-Bucket Creation Goodness
Now that you’ve got your buckets configured, we’ll be able to review the up(loads) and down(loads) of data in Cloud Storage, so stay tuned!
Learn more about your storage options in Cloud Storage Bytes, or check out the documentationfor more information, including tutorials, on creating buckets.
Would you rather listen than read? Check out our new tech blog podcast.
Read More for the details.