GCP – How maintenance windows affect your error budget — SRE tips
So, you’ve started down the site reliability engineering (SRE) path at your organization. You have set up your service. You have analyzed how your users interact with it, which helped you identify some key metrics that correlate with user happiness. You set your service-level objectives, which in turn gives you an error budget. Great work!
Now, the next consideration is that your organization maintains a schedule of maintenance windows that bring your service down. Should this downtime count toward your error budget? Let’s analyze it!
Error budget
In a nutshell, an error budget is the amount of error that your service can accumulate over a certain period of time before your users start being unhappy. You can think of it as the pain tolerance for your users, but applied to a certain dimension of your service: availability, latency, and so forth.
If you followed our recommendation for defining an SLI, you’re likely using this SLI equation:

Your SLI is then expressed as a percentage, and once you define an objective for each of those SLIs—that is, your service-level objective (SLO)—the error budget is the remainder, up to 100.
Here’s an example. Imagine that you’re measuring the availability of your home page. The availability is measured by the amount of requests responded with an error, divided by all the valid requests the home page receives, expressed as a percentage. If you decide that the objective of that availability is 99.9%, the error budget is 0.1%. You can serve up to 0.1% of errors (preferably a bit less than 0.1%), and users will happily continue using the service.
Remember that selecting the value for your objectives is not just an engineering decision, but a business decision made with input from many stakeholders. It requires an analysis of your users’ behavior, your business needs, and your product roadmap.
Maintenance windows
In the world of SRE practices, a maintenance window is a period of time designated in advance by the technical staff, during which preventive maintenance that could cause disruption of service may be performed.
Maintenance windows are traditionally used by service providers to perform a variety of activities. Some systems require a homogeneous environment—for example, where you need to update the operating system of terminals in bulk. You may need to perform updates that introduce incompatible API/ABI changes. Some financial solutions need the database server and client software to be version-compatible, which means that major software upgrades require all the systems to be upgraded at the same time. Other examples of traditional maintenance windows are the ones required during database migrations to allow the synchronization of the data tables between the old and the new release during the downtime, and physical moves when computers are shut down to allow physical relocation of the devices.
Similar to deciding your SLO, scheduling a maintenance window is a business decision that requires taking into account the agreements you may have with your users, the technical limitations of your system, and the wellbeing of the people responsible for those systems. It’s inevitably a compromise.
The type of maintenance window that we are discussing in the rest of this post is the one that you, as a service provider, may perform and that affects your users directly, effectively causing a degradation of your service, or even a full outage.
How to choose your maintenance windows
In recent years, technologies like multithreaded processors, virtualization, and containerization have emerged. Using these paired with microservice architectures and good software development practices helps to reduce or completely eliminate the use of maintenance windows.
However, while almost all business owners and product managers seek to minimize downtime, sometimes that is not possible. Usage of legacy software, regulations that apply to your business, or simply working in an environment in which the decision makers believe that the best way of maintaining the service is having a regular, scheduled downtime, forces us to bring our service down for a certain amount of time.
So, in any of these situations, how should these maintenance windows affect your error budget? Let’s analyze some different scenarios where maintenance windows are necessary.
Business hours
Imagine you work at a company that serves a market with a trading window, like a Wall Street exchange. Every day your service starts operating at 9:30am and closes at 4:00pm sharp. No delays are permitted, either at the start or the end of the window.
You can assume in this case that you have a maintenance window of ~15 hours a day. Should it burn through your error budget, then?
Let’s remember the purpose of your error budget: It is a tool that helps identify when the reliability metrics for user journeys (your SLIs) have performed, over a period of time, at levels that are hurting your users.
In this scenario, users are not able to use the service outside of business hours. In fact, users most likely should not be able to interact with the service at all. So, effectively, there is no harm in having this service down, and over this period of time, the error budget should not be affected at all.
Burning your error budget in saw shapes
Let’s move on to a different type of service, one that is extremely localized in space, serving only users in a single country. Think of a retailer with presence only in a small region. Your service may have a traffic pattern like this one:
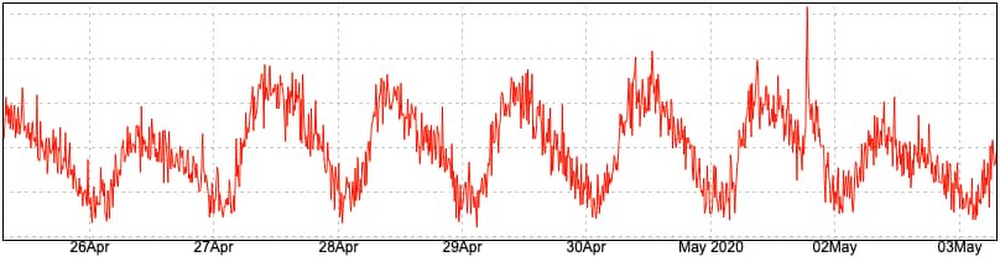
There are easily identifiable lows of traffic, where your users are probably sleeping, but even over those valley periods, you still receive a non-zero amount of requests. If you plan your maintenance windows during these periods, you have plenty of time to recover from errors, but at the risk of running into rising traffic if your maintenance overruns.
For these saw-shape cases, let’s analyze a few strategies:
Traffic projection
For this approach, you’ll look at your past data and extrapolate the amount of valid traffic you’ll receive during the period of time your service will be unavailable by analyzing previous traffic and calculating what you expect to receive. Even if you have limited data to work with, use whatever data you have collected to calculate your traffic pattern.
An important factor you have to take into account for this approach is that it is based on past performance, and it does not account for unforeseen events. To make sure the traffic that your site receives during a downtime window is not out of the ordinary, set up a captive portal that registers the incoming requests and redirects all traffic (including deep links) to a maintenance page. From those requests, you can easily analyze the traffic logs and count the valid ones. This way, you are not measuring the actual traffic, but the traffic pattern. Correlating this pattern with the actual missed traffic, using a reasonable multiplier, allows you to calculate the number of errors you are serving, and thus the error budget you are burning.
Treat maintenance as downtime
When burning through the error budget associated with the availability of a service, it is usually done by counting the errors produced by the service. But when the service is down, you can also do it by measuring the time the service is down in relation to the total downtime your SLO allows you, as a percentage.
Say that the SLO on availability for your service is 99%. Over a period of 28 days (measured using a rolling window) your service can be down a total of about seven hours and 20 minutes. If your maintenance window stretches for a period of two hours, that means you have consumed 27% of your error budget. That means that for the rest of the 28 days of your rolling window, your service can only throw (100 – 27) * 0.01 = 0.73% of errors, down from the initial 1% of total errors. Once your maintenance is finished, you can go back to using the SLI equation, and knowing how much traffic you are receiving (your valid requests) and how many errors you are returning to your users, you can calculate how much error budget you are burning over time.
This approach has the disadvantage of treating all the traffic received as equal, both in size and in importance. A maintenance window occurring in the middle of the day when you are having a peak of traffic will burn the same amount of error budget as one happening in the middle of the night when traffic is low. So this approach should be used cautiously for traffic shapes that change wildly throughout the day.
Considering the edge case
In the situations described above, you need to take into account a small detail about the error budget. Say that you have an outage that burns a big chunk of your error budget, enough to bring the remaining budget close to zero (or even below), and the upcoming planned maintenance window is scheduled to happen inside the time window you use to calculate that error budget. If that scheduled downtime risks depleting your error budget, what are you supposed to do?
We approach these situations by defining a number of “silver bullets”: a very small number of exceptions for truly business-critical emergency launches, despite the budget maintenance window freeze. Assuming the service still needs to be brought down, even for small updates, the use of a silver bullet lets you perform a short, very targeted maintenance window, during which only critical bug fixes can be released.
In general, we don’t recommend looking for other types of exceptions, since these will most likely create a culture in which failure to maintain the reliability of the service is accepted. That nullifies the incentive to work on the reliability of your service, as the consequences of outages can simply be bypassed by escalating the problem.
The curious case of not burning your error budget
Let’s, once more, remember how the error budget is used. As defined, the error budget is a tool to balance how you prioritize the time engineering teams spend between feature development and reliability improvements. It assumes that exhausting your error budget is a result of low availability, high latency, or other low score in any metric used to represent the reliability of your service.
If you burn part of your error budget during maintenance windows, but you aren’t planning to get rid of them altogether (or at least reduce the length of those windows), there is no reliability work targeted at reducing your maintenance windows that you may need to prioritize as a result of burning through the budget. You are implicitly accepting a recurring error budget burn, without a plan to eliminate the maintenance window that is causing it. You have no consequences defined in your error budget policy that will prioritize work to stop your maintenance windows from consuming error budget in the future.
So the lesson here is that the decision to burn through your error budget during your maintenance windows should be made only if you consider those downtime periods as part of your reliability work, and you plan to work on reducing them to minimize that downtime.
If you decide to assume the risk of having a period of time when your service is down and the business owners have agreed that they are OK with scheduled downtime, with no plans in place to change the status quo, you probably don’t want it to count it toward your error budget. This acceptance of risk has some very strong implications for your business, as your maintenance windows need to:
-
be as short as possible, to cause as little disruption as possible
-
be clearly and properly communicated to your users/customers, well in advance, using channels that reach as many as possible
-
be internally communicated to avoid disrupting other parts of your business
-
have a clearly defined plan of execution, exit criteria, expected results, and rollback action plan
-
be scheduled during expected low traffic hours
-
be executed according to its planned time slot
-
have well-defined (and in some cases, severe) consequences for your error budget when the windows go over time
Remember, according to the way the error budget is defined: During a maintenance window that does not count toward that error budget, you are taking a free pass for having your service down—possibly hurting your users but not accounting for it.
Flat(ish) profile in global services
In a global service, things are quite different. While your traffic profile may have valleys of traffic, they are likely less pronounced than those deep valleys of traffic you see in a localized service, when you can bring your service down and only affect a relatively small number of users.
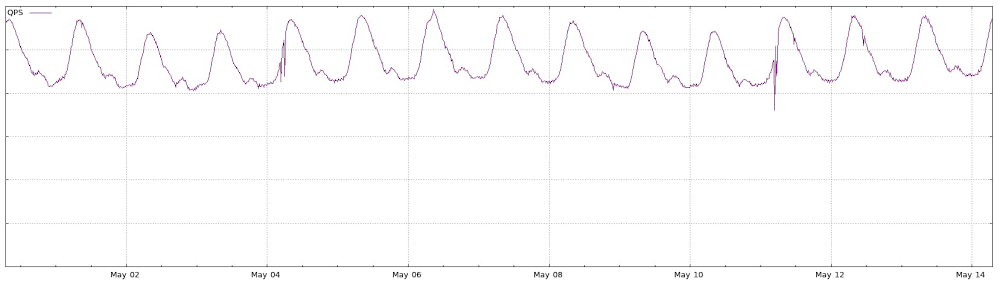
But at the same time, due to the global nature of the service, you will probably require multi-regional presence. It’s in this situation where you can take advantage of the multi-region architecture and work to avoid localized maintenance windows by diverting traffic from the low-traffic areas to others.
Our recommendation for this case is to take advantage of the distributed nature of your architecture and design your service to allow for regions to be disconnected at any given time, if you still need to bring some of your systems down for maintenance. This approach should, of course, take into account your capacity needs, so that your remaining serving capacity will be able to respond to all the active requests previously served from the disconnected regions. Additionally, you should design circuit breakers that trip whenever there is a need to blackhole some of the overflowing traffic in order to avoid creating a cascading outage.
If this is your long-term goal, and assuming that your global service has no defined times of operation (like in our first scenario), any request that is not served (or served with an error) should be accounted for, and count toward your error budget burn.
Putting it all together
Although no single recommendation will fit all services, you can make informed decisions for your service once you examine maintenance windows in the context of SLOs and error budgets. You and your product owners are best positioned to know both your service and your users, understand their behavior, and make a decision that works best for your business.
The most important analysis you need to make is how your maintenance windows affect your users (if at all), and whether depleting your error budget is going to imply a change in your reliability focus to reduce the impact of your maintenance windows.
If you are considering introducing maintenance windows for your service, evaluate the pros and cons against the criteria outlined here. And if you already have them, check to see if you should change how you do them, or when you do them.
Further reading
If you want to learn more about the SRE operational practices, how to analyze a service, identify SLIs, and define SLOs for your application, you can find more information in our SRE books. You can also find our Measuring and Managing Reliability course on Coursera, which is a more thorough, self-paced dive into the world of SLIs, SLOs, and error budgets.
Read More for the details.

