Cloud infrastructure reliability is foundational, yet even the most sophisticated global networks can suffer from a critical issue: slow or failed recovery from routing outages. In massive, planetary-scale networks like Google’s, router failures or complex, hidden conditions can prevent traditional routing protocols from restoring service quickly, or sometimes at all. These brief but costly outages — what we call slow convergence or convergence failure — critically disrupt real-time applications with low tolerance to packet loss and, most acutely, today’s massive, sensitive AI/ML training jobs, where a brief network hiccup can waste millions of dollars in compute time.
To solve this problem, we pioneered Protective ReRoute (PRR), a radical shift that moves the responsibility for rapid failure recovery from the centralized network core to the distributed endpoints themselves. Since putting it into production over five years ago, this host-based mechanism has dramatically increased Google’s network’s resilience, proving effective in recovering from up to 84%1 of inter-data-center outages that would have been caused by slow convergence events. Google Cloud customers with workloads that are sensitive to packet loss can also enable it in their environments — read on to learn more.
The limits of in-network recovery
Traditional routing protocols are essential for network operation, but they are often not fast enough to meet the demands of modern, real-time workloads. When a router or link fails, the network must recalculate all affected routes, which is known as reconvergence. In a network the size of Google’s, this process can be complicated by the scale of the topology, leading to delays that range from many seconds to minutes. For distributed AI training jobs with their wide, fan-out communication patterns, even a few seconds of packet loss can lead to application failure and costly restarts. The problem is a matter of scale: as the network grows, the likelihood of these complex failure scenarios increases.
Protective ReRoute: A host-based solution
Protective ReRoute is a simple, effective concept: empower the communicating endpoints (the hosts) to detect a failure and intelligently re-steer traffic to a healthy, parallel path. Instead of waiting for a global network update, PRR capitalizes on the rich path diversity built into our network. The host detects packet loss or high latency on its current path, and then immediately initiates a path change by modifying carefully chosen packet header fields, which tells the network to use an alternate, pre-existing path.
This architecture represents a fundamental shift in network reliability thinking. Traditional networks rely on a combination of parallel and series reliability. Serialization of components tends to reduce the reliability of a system; in a large-diameter network with multiple forwarding stages, reliability degrades as the diameter increases. In other words, every forwarding stage affects the whole system. Even if a network stage is designed with parallel reliability, it creates a serial impact on the overall network while the parallel stage reconverges. By adding PRR at the edges, we treat the network as a highly parallel system of paths that appear as a single stage, where the overall reliability increases as the number of available paths grows exponentially, effectively circumventing the serialization effects of slow network convergence in a large-diameter network. The following diagram contrasts the system reliability model for a PRR-enabled network with that of a traditional network. Traditional network reliability is in inverse proportion to the number of forwarding stages; with PRR the reliability of the same network is in direct proportion to the number of composite paths, which is exponentially proportional to the network diameter.
How Protective ReRoute works
The PRR mechanism has three core functional components:
End-to-end failure detection: Communicating hosts continuously monitor path health. On Linux systems, the standard mechanism uses TCP retransmission timeout (RTO) to signal a potential failure. The time to detect a failure is generally a single-digit multiple of the network’s round-trip time (RTT). There are also other methods for end-to-end failure detection that have varying speed and cost.
Packet-header modification at the host: Once a failure is detected, the transmitting host modifies a packet-header field to influence the forwarding path. To achieve this, Google pioneered and contributed the mechanism that modifies the IPv6 flow-label in the Linux kernel (version 4.20+). Crucially, the Google software-defined network (SDN) layer provides protection for IPv4 traffic and non-Linux hosts as well by performing the detection and repathing on the outer headers of the network overlay.
PRR-aware forwarding: Routers and switches in the multipath network respect this header modification and forward the packet onto a different, available path that bypasses the failed component.
Proof of impact
PRR is not theoretical; it is a continuously deployed, 24×7 system that protects production traffic worldwide. Its impact is compelling: PRR has been shown to reduce network downtime caused by slow convergence and convergence failures by up to the above-mentioned 84%. This means that up to 8 out of every 10 network outages that would have been caused by a router failure or slow network-level recovery are now avoided by the host. Furthermore, host-initiated recovery is extremely fast, often resolving the problem in a single-digit multiple of the RTT, which is vastly faster than traditional network reconvergence times.
Key use cases for ultra-reliable networking
The need for PRR is growing, driven by modern application requirements:
AI/ML training and inference: Large-scale workloads, particularly those distributed across many accelerators (GPUs/TPUs), are uniquely sensitive to network reliability. PRR provides the ultra-reliable data distribution necessary to keep these high-value compute jobs running without disruption.
Data integrity and storage: Significant numbers of dropped packets can result in data corruption and data loss, not just reduced throughput. By reducing the outage window, PRR improves application performance and helps guarantee data integrity.
Real-time applications: Applications like gaming and services like video conferencing and voice calls are intolerant of even brief connectivity outages. PRR reduces the recovery time for network failures to meet these strict real-time requirements.
Frequent short-lived connections: Applications that rely on a large number of very frequent short-lived connections can fail when the network is unavailable for even a short time. By reducing the expected outage window, PRR helps these applications reliably complete their required connections.
Activating Protective ReRoute for your applications
The architectural shift to host-based reliability is an accessible technology for Google Cloud customers. The core mechanism is open and part of the mainline Linux kernel (version 4.20 and later).
You can benefit from PRR in two primary ways:
Hypervisor mode: PRR automatically protects traffic running across Google data centers without requiring any guest OS changes. Hypervisor mode provides recovery in the single digit seconds for traffic of moderate fanout in specific areas of the network.
Guest mode: For critical, performance-sensitive applications with high fan-out and in any segment of the network, you can opt into guest-mode PRR, whichenables the fastest possible recovery time and greatest control. This is the optimal setting for demanding mission-critical applications, AI/ML jobs, and other latency-sensitive services.
To activate guest-mode PRR for critical applications follow the guidance in the documentation and be ready to ensure the following:
Your VM runs a modern Linux kernel (4.20+).
Your applications use TCP.
The application traffic uses IPv6. For IPv4 protection, the application needs to use the gVNIC driver.
Get started
The availability of Protective ReRoute has profound implications for a variety of Google and Google Cloud users.
For cloud customers with critical workloads: Evaluate and enable guest-mode PRR for applications that are sensitive to packet loss and that require the fastest recovery time, such as large-scale AI/ML jobs or real-time services.
For network architects: Re-evaluate your network reliability architectures. Consider the benefits of designing for rich path diversity and empowering endpoints to intelligently route around failures, shifting your model from series to parallel reliability.
For the open-source community: Recognize the power of host-level networking innovations. Contribute to and advocate for similar reliability features across all major operating systems to create a more resilient internet for everyone.
With the pace of scientific discovery moving faster than ever, we’re excited to join the supercomputing community as it gets ready for its annual flagship event, SC25, in St. Louis from November 16-21, 2025. There, we’ll share how Google Cloud is poised to help with our lineup of HPC and AI technologies and innovations, helping researchers, scientists, and engineers solve some of humanity’s biggest challenges.
Redefining supercomputing with cloud-native HPC
Supercomputers are evolving from a rigid, capital-intensive resource into an adaptable, scalable service. To go from “HPC in the cloud” to “cloud-native HPC,” we leverage core principles of automation and elastic infrastructure to fundamentally change how you consume HPC resources, allowing you to spin up purpose-built clusters in minutes with the exact resources you need.
This cloud-native model is very flexible. You can augment an on-premises cluster to meet peak demand or build a cloud-native system tailored with the right mix of hardware for your specific problem — be it the latest CPUs, GPUs, or TPUs. With this approach, we’re democratizing HPC, putting world-class capabilities into the hands of startups, academics, labs, and enterprise teams alike.
Key highlights at SC25:
Next-generation infrastructure: We’ll be showcasing our latest H4D VMs, powered by 5th generation AMD EPYC processors and featuring Cloud RDMA for low-latency networking. You’ll also see our latest accelerated compute resources including A4X and A4X Max VMs featuring the latest NVIDIA GPUs with RDMA.
Powering your essential applications: Run your most demanding simulations at massive scale — from Computational Fluid Dynamics (CFD) with Ansys, to Computer-Aided Engineering with Siemens, computational chemistry with Schrodinger, and risk modeling in FSI.
Dynamic Workload Scheduler: Discover how Dynamic Workload Scheduler and its innovative Flex Start mode, integrated with familiar schedulers like Slurm, is reshaping HPC consumption. Move beyond static queues toward flexible, cost-effective, and efficient access to high-demand compute resources.
Easier HPC with Cluster Toolkit: Learn how Cluster Toolkit can help you deploy a supercomputer-scale cluster with less than 50 lines of code.
High-throughput, scalable storage: Get a deep dive into Google Cloud Managed Lustre, a fully managed, high-performance parallel file system that can handle your most demanding HPC and AI workloads.
Hybrid for the enterprise: For our enterprise customers, especially in financial services, we’re enabling hybrid cloud with IBM Spectrum Symphony Connectors, allowing you to migrate or burst workloads to Google Cloud and reduce time-to-solution.
AI-powered scientific discovery
There’s a powerful synergy between HPC and AI — where HPC builds more powerful AI, and AI makes HPC faster and more insightful. This complementary relationship is fundamentally changing how research is done, accelerating discovery in everything from drug development and climate modeling to new materials and engineering. At Google Cloud, we’re at the forefront of this transformation, building the models, tools, and platforms that make it possible.
What to look for:
AI for scientific productivity: We’ll be showcasing Google’s suite of AI tools designed to enhance the entire research lifecycle. From Idea Generation agent to Gemini Code Assist with Gemini Enterprise, you’ll see how AI can augment your capabilities and accelerate discovery.
AI-powered scientific applications: Learn about the latest advancements in our AI-powered scientific applications including AlphaFold 3 and Weather Next
The power of TPUs: Explore Google’s TPUs, including the latest seventh-generation Ironwood model, and discover how they can enhance AI workload performance and efficiency.
Join the Google Cloud at SC25: At Google Cloud, we believe the cloud is the supercomputer of the future. From purpose-built HPC and AI infrastructure to quantum breakthroughs and simplified open-source tools, let Google Cloud be the platform for your next discovery.
We invite you to connect with our experts and learn more. Join the Google Cloud Advanced Computing Community to engage in discussions with our partners and the broader HPC, AI, and quantum communities.
We can’t wait to see what you discover.
See us at the show:
Visit us in booth #3724: Stop by for live demos of our latest HPC and AI solutions, including Dynamic Workload Scheduler, Cluster Toolkit, our latest AI agents, and even see our TPUs. Our team of experts will be on hand to answer your questions and discuss how Google Cloud can meet your needs.
Attend our technical talks: Keep an eye on our SC25 schedule for Google Cloud presentations and technical talks, where our leaders and partners will share deep dives, insights, and best practices.
Passport program: Grab a passport card from the Google booth and visit our demos, labs, and talks to collect stamps and learn about how we’re working with organizations across the HPC ecosystem to democratize HPC. Come back to the Google booth with your completed passport card to choose your prize!
Play a game: Join us in the Google booth and at our events to enjoy some Gemini-driven games — test your tech trivia knowledge or compete head-to-head with others to build the best LEGO creation!
Join our community kickoff: Are you a member of the Google Cloud Advanced Computing Community? Secure your spot today for our SC25 Kickoff Happy Hour!
Celebrate with NVIDIA and Google Cloud: We’re proud to co-host a reception with NVIDIA, and we look forward to toasting another year of innovation with our customers and partners. Register today to secure your spot!
Editor’s note: The post is part of a series that highlights how organizations leverage Google Cloud’s unique data science capabilities over alternative cloud data platforms. Google Cloud’s vector embedding generation and search features are unique for their end-to-end, customizable platform that leverages Google’s advanced AI research, offering features like task-optimized embedding models and hybrid search to deliver highly relevant results for both semantic and keyword-based queries.
Zeotap’s customer intelligence platform (CIP) helps brands understand their customers and predict behaviors, so that they can improve customer engagement. Zeotap partners with Google Cloud to build a customer data platform that offers privacy, security, and compliance. Zeotap CIP, built with BigQuery, enables digital marketers to build and use AI/ML models to predict customer behavior and personalize the customer experienc
The Zeotap platform includes a customer segmentation feature called lookalike audience extensions. A lookalike audience is a group of new potential customers identified by machine learning algorithms who share similar characteristics and behaviors with an existing, high-value customer base. However, sparse or incomplete first-party data can make it hard to create effective lookalike audiences, preventing advertising algorithms from accurately identifying the key characteristics of valuable customers that they need to find similar new prospects. For such rare features, Zeotap uses multiple machine learning (ML) methodologies that combine Zeotap’s multigraph algorithm and high-quality data assets to more accurately extend customers’ audiences between the CDP and lookalike models.
In this blog, we dive into how Zeotap uses BigQuery, including BigQuery ML and Vector Search to solve the end-to-end lookalike problem. By taking a practical approach, we transformed a complex nearest-neighbour problem into a simple inner-join problem, overcoming challenges of cost, scale and performance without a specialized vector database. We break down each step of the workflow, from data preparation to serving, highlighting how BigQuery addresses core challenges along the way. We illustrate one of the techniques, Jaccard similarity with embeddings, to address the low-cardinality categorical columns that dominate user-profile datasets.
The high-level flow is as follows, and happens entirely within the BigQuery ecosystem. Note: In this blog, we will not be covering the flow of high-cardinality columns.
Jaccard similarity
Among a couple of other similarity indexes, which return the most similar vector that are closest in embedding space, Zeotap prefers the Jaccard similarity to be a fitting index for low-cardinality features, which is a measure of overlap between two sets with a simple formula: (A B) / (AB). The Jaccard similarity answers the question, “Of all the unique attributes present in either of the two users, what percentage of them are shared?” It only cares about the features that are present in at least one of the entities (e.g., the 1s in a binary vector) and ignores attributes that are absent in both.
Jaccard similarity shines because it is simple and easily explainable over many other complex distance metrics and similarity indexes that only measure distance in the embeddings space — a real Occam’s razor, as it were.
Implementation blueprint
Generating the vector embeddings After selecting the low-cardinality features, we create our vectors using BigQuery one-hot encoding andmulti-hot encoding for primitive and array-based columns.
Again, it helps to visualize a sample vector table:
Challenge: Jaccard distance is not directly supported in BigQuery vector search!
BigQuery vector search supports three distance types: Euclidean, Cosine and Dot product, but not Jaccard distance — at least not natively. However, we can represent the choice of binary vectors where the Jaccard Distance (1 – Jaccard Similarity) as:
Jd(A,B) = 1 – |A∩B|/|A∪B| = (|A∪B| – |A∩B|)/|A∪B|
Using only the dot product, this can be rewritten as:
So we can, in fact, arrive at the Jaccard distance using the dot product. We found BigQuery’s out-of-the-box LP_NORM function for calculating theManhattan norm useful, as the Manhattan norm for a binary vector is the dot product with itself. In other words, using the Manhattan norm function, we found that we can support the Jaccard distance in a way that it can be calculated using the supported “dot product” search in BigQuery.
Building the vector index
Next, we needed to build our vector index. BigQuery supports two primary vector index types: IVF (Inverted File Index) and TREE_AH (Tree with Asymmetric Hashing), each tailored to different scenarios. The TREE_AH vector index type combines a tree-like structure with asymmetric hashing (AH), based onGoogle’s ScaNN algorithm, which has performed exceptionally well on variousANN benchmarks. Also, since the use case was for large batch queries (e.g., hundreds of thousands to millions of users), this offered reduced latency and cost compared to alternate vector databases.
Lookalike delivery
Once we had a vector index to optimize searches, we asked ourselves, “Should we run our searches directly using the VECTOR_SEARCH function in BigQuery?” Taking this approach over the base table yielded a whopping 118 million user-encoded vectors for just one client! Additionally, and most importantly, since this computation called for a Cartesian product, our in-memory data sizes became very large and complex quickly. We needed to devise a strategy that would scale to all customers.
The rare feature strategy
A simple but super-effective strategy is to avoid searching for ubiquitous user features. In a two-step rare-feature process, we identify the “omnipresent” features, then proceed to create a signal-rich table that includes users who possess at least one of the rarer/discriminative features. Right off the bat, we achieved up to 78% reduction in search space. BigQuery VECTOR_SEARCH allows you to do this with pre-filtering, wherein you use a subquery to dynamically shrink the search space. The catch is that the subquery cannot be a classic join, so we introduce a “flag” column and make it part of the index. Note: If a column is not stored in the index, then the WHERE clause in the VECTOR_SEARCH will execute a post-filter.
Use the BQUI or system tables to see if a vector is used to accelerate queries
Batch strategy
Vector search compares query users (N, the users we’re targeting) against base users (M, the total user pool, in this case 118M). The complexity increases with (M × N), making large-scale searches resource-intensive. To manage this, we applied batches to the N query users, processing them in groups (e.g., 500,000 per batch), while M remained the full base set. This approach reduced the computational load, helping to efficiently match the top 100 similar users for each query user.We then used grid search to determine the optimal batch size for high-scale requirements.
To summarize
We partnered with Google Cloud to enable digital marketers to build and use AI/ML models for customer segmentation and personalized experiences, driving higher conversion rates and lower acquisition costs. We addressed the challenge of Jaccard distance not being directly supported in BigQuery Vector Search by using the dot product and Manhattan norm. This practical approach, leveraging BigQuery ML and vector offerings, allowed us to create bespoke lookalike models with just one single SQL script and overcome challenges of cost, scale, and performance without a specialized vector database.
Using BigQuery ML and vector offerings, coupled with its robust, serverless architecture, we were able to release bespoke lookalike models catering to individual customer domains and needs. Together, Zeotap and Google Cloud look forward to partnering to help marketers expand their reach everywhere.
The Built with BigQuery advantage for ISVs and data providers
Built with BigQuery helps companies like Zeotap build innovative applications with Google Data Cloud. Participating companies can:
Accelerate product design and architecture through access to designated experts who can provide insight into key use cases, architectural patterns, and best practices.
Amplify success with joint marketing programs to drive awareness, generate demand, and increase adoption.
BigQuery gives ISVs the advantage of a powerful, highly scalable unified Data Cloud for the agentic era, that’s integrated with Google Cloud’s open, secure, sustainable platform. Click here to learn more about Built with BigQuery.
In the fast-evolving world of agentic development, natural language is becoming the standard for interaction. This shift is deeply connected to the power of operational databases, where a more accurate text-to-SQL capability is a major catalyst for building better, more capable agents. From empowering non-technical users to self-serve data, to accelerating analyst productivity, the ability to accurately translate natural language questions into SQL is a game-changer. As end-user engagements increasingly happen over chat, conversations become the fundamental connection between businesses and their customers.
In an earlier post, “Getting AI to write good SQL: Text-to-SQL techniques explained,” we explored the core challenges of text-to-SQL — handling complex business context, ambiguous user intent, and subtle SQL dialects — and the general techniques used to solve them.
Today, we’re moving from theory to practice. We’re excited to share that Google Cloud has scored a new state-of-the-art result on the BIRD benchmark’s Single Trained Model Track. We scored 76.13, ahead of any other single-model solution (higher is better). In general, the closer you get to the benchmark of human performance (92.96), the harder it is to score incremental gains.
BIRD (BIg Bench for LaRge-scale Database Grounded Text-to-SQL Evaluation) is an industry standard for testing text-to-SQL solutions. BIRD spans over 12,500 unique question-SQL pairs from 95 databases with a total size of 33 GB. The Single Trained Model Track is designed to measure the raw, intrinsic capability of the model itself, restricting the use of complex preprocessing, retrieval, or agentic frameworks often used to boost model accuracy. In other words, success here reflects an advancement in the model’s core ability to generate SQL.
Gemini scores #1 place in BIRD (October ‘25)
From research to industry-leading products
This leap in more accurate natural-language-to-SQL capability, often referred to as NL2SQL, isn’t just an internal research or engineering win; it fundamentally elevates the customer experience across several key data services,and our state-of-the-art research in this field is enabling us to create industry-leading products that customers leverage to activate their data with agentic AI.
Consider AlloyDB AI’s natural language capability, a tool that customers use to allow end users to query the most current operational data using natural language. For instance, companies like Hughes, an Echostar Corporation, depend on AlloyDB’s NL2SQL for critical tasks like call analytics. Numerous other retail, technology, and industry players also integrate this capability into their customer-facing applications. With NL2SQL that is near-100% accurate, customers gain the confidence to build and deploy applications in production workloads that rely on real-time data access.
The benefits of NL2SQL extend to analysis, as exemplified with conversational analytics in BigQuery. This service lets business users and data analysts explore data, run reports, and extract business intelligence from vast historical datasets using natural language. The introduction of a multi-turn chat experience, combined with a highly accurate NL2SQL engine, helps them make informed decisions with the confidence that the responses from BigQuery-based applications are consistently accurate.
Finally, developers are finding new efficiencies. They have long relied on Google Code Assist (GCA) for code generation, aiding their application development with databases across Spanner, AlloyDB, and Cloud SQL Studio. With the availability of more accurate NL2SQL, developers will be able to use AI coding assistance to generate SQL code too.
BIRD: a proving ground for core model capability
BIRD benchmark is one of the most commonly used benchmarks in the text-to-SQL field. It moves beyond simple, single-table queries to cover real-worldchallenges our models must handle, such as reasoning over very large schemas, dealing with ambiguous values, and incorporating external business knowledge. Crucially, BIRD measures a critical standard: execution-verified accuracy. This means a query is not just considered ‘correct’ if it appears right; it must also successfully run and return the correct data.
We specifically targeted the Single Trained Model Track because it allows us to isolate and measure the model’s core ability to solve the text-to-SQL task (rather than an ensemble, a.k.a., a system with multiple components such as multiple parallel models, re-rankers, etc.). This distinction is critical, as text-to-SQL accuracy can be improved with techniques like dynamic few-shot retrieval or schema preprocessing; this track reflects the model’s true reasoning power. By focusing on a single-model solution, these BIRD results demonstrate that enhancing the core model creates a stronger foundation for systems built on top of it.
Our method: Specializing the model
Achieving a state-of-the-art score doesn’t happen only by using a powerful base model. The key is to specialize the model. We developed a recipe designed to transform the model from a general-purpose reasoner into a highly specialized SQL-generation expert.
This recipe consisted of three critical phases applied before inference:
Rigorous data filtering: Ensuring the model learns from a flawless, “gold standard” dataset.
Multitask learning: Teaching the model not just to translate, but to understand the implicit subtasks required for writing a correct SQL query.
Test-time scaling: “Self consistency” a.k.a., picking the best answer.
Let’s break down each step.
Our process for achieving SOTA result
Step 1: Start with a clean foundation (data filtering)
One important tenet of fine-tuning is “garbage in, garbage out.” A model trained on a dataset with incorrect, inefficient, or ambiguous queries may learn incorrect patterns. The training data provided by the BIRD benchmark is powerful, but like most large-scale datasets, it’s not perfect.
Before we could teach the model to be a SQL expert, we had to curate a gold-standard dataset. We used a rigorous two-stage pipeline: first, execution-based validation to execute every query and discard any that failed, returned an error, or gave an empty result. Second, we used LLM-based validation, where multiple LLMs act as a “judge” to validate the semantic alignment between the question and the SQL, catching queries that run but don’t actually answer the user’s question. This aggressive filtering resulted in a smaller, cleaner, and more trustworthy dataset that helped our model learn from a signal of pure quality rather than noise.
Step 2: Make the model a SQL specialist (multitask learning)
With a clean dataset, we could move on to the supervised fine-tuning itself. This is the process of taking a large, general-purpose model — in our case, Gemini 2.5-pro — and training it further on our narrow, specialized dataset to make it an expert in a specific task.
To build these skills directly into the model, we leveraged the publicly available Supervised Tuning API for Gemini on Vertex AI. This service provided the foundation for our multitask supervised finetuning (SFT) approach, where we trained Gemini-2.5-pro on several distinct-but-related tasks simultaneously.
We also extended our training data to cover tasks outside of the main Text-to-SQL realm, helping enhance the model’s reasoning, planning, and self-correction capabilities.
By training on this combination of tasks in parallel, the model learns a much richer, more robust set of skills. It goes beyond simple question-to-query mapping — it learns to deeply analyze the problem, plan its approach, and refine its own logic, leading to drastically improved accuracy and fewer errors.
Step 3: Inference accuracy + test-time scaling with self-consistency
The final step was to ensure we could reliably pick the model’s single best answer at test time. For this, we used a technique called self-consistency.
With self-consistency, instead of asking the model for just one answer, we ask it to generate several query candidates for the same question. We then execute these queries, cluster them by their execution results, and select a representative query from the largest cluster. This approach is powerful because if the model arrives at the same answer through different reasoning paths, that answer has a much higher probability of being correct.
It’s important to note that self-consistency is a standard, efficient method, but it is not the only way to select a query. More complex, agentic frameworks can achieve even higher accuracy. For example, our team’s own research on CHASE-SQL (our state-of-the-art ensembling methodology) demonstrates that using diverse candidate generators and a trained selection agent can significantly outperform consistency-based methods.
For this benchmark, we wanted to focus on the model’s core performance. Therefore, we used the more direct self-consistency method: we generated several queries, executed them, and selected a query from the group that produced the most common result. This approach allowed us to measure the model’s raw text-to-SQL ability, minimizing the influence of a more complex filtering or reranking system.
The BIRD Single-Model Track explicitly allows for self-consistency, which reflects the model’s own internal capabilities. The benchmark categorizes submissions based on the number of candidates used (‘Few’, ‘Many’, or ‘Scale’). We found our “sweet spot” in the “Few” (1-7 candidates) category.
This approach gave us the final, critical boost in execution accuracy that pushed our model to the top of the leaderboard. More importantly, it proves our core thesis: by investing in high-quality data and instruction tuning, you can build a single model that is powerful enough to be production-ready without requiring a heavy, high-latency inference framework.
A recipe for customizing Gemini for text-to-SQL
A combination of clean data, multi-task learning, and efficient self-consistencyallowed us to take the powerful Gemini 2.5-pro model and build a specialist that achieved the top-ranking score on the BIRD single-model benchmark.
Our fine-tuned model represents a much stronger baseline for text-to-SQL. However, it’s important to note that this score is not the upper bound of accuracy. Rather, it is the new, higher baseline we have established for the core model’s capability in a constrained setting. These results can be further amplified by either
creating an ensemble, aka integrating this specialist model into a broader system that employs preprocessing (like example retrieval) or agentic scaffolding (like our CHASE-SQL research), or
optimizing model quality for your unique database by enhancing metadata and/or query examples (which is how our customers typically deploy production workloads).
Nevertheless, the insights from this research are actively informing how we build our next-generation AI-powered products for Google Data Cloud, and we’ll continue to deliver these enhancements in our data services.
Explore advanced text-to-SQL capabilities today
We’re constantly working to infuse our products with these state-of-the-art capabilities, starting with bringing natural language queries to applications built on AlloyDB and BigQuery. For AI-enhanced retrieval, customers especially value AlloyDB and its AI functions. AlloyDB integrates AI capabilities directly into the database, allowing developers to run powerful AI models using standard SQL queries without moving data. It offers specialized operators such as AI.IF() for intelligent filtering, AI.RANK() for semantic reranking of search results, and AI.GENERATE() for in-database text generation and data transformation.
And if you want to write some SQL yourself, Gemini Code Assist can help. With a simple prompt, you can instruct Gemini as to the query you want to create. Gemini will generate your code and you can immediately test it by executing it against your database. We look forward to hearing about what you build with it!
Editor’s note: Waze (a division of Google parent company Alphabet) depends on vast volumes of dynamic, real-time user session data to power its core navigation features, but scaling that data to support concurrent users worldwide required a new approach. Their team built a centralized Session Server backed by Memorystore for Redis Cluster, a fully managed service with 99.99% availability that supports partial updates and easily scales to Waze’s use case of over 1 million MGET commands per second with ~1ms latency. This architecture is the foundation for Waze’s continued backend modernization.
Real-time data drives the Waze app experience. Our turn-by-turn guidance, accident rerouting, and driver alerts depend on up-to-the-millisecond accuracy. But keeping that experience seamless for millions of concurrent sessions requires robust and battle hardened infrastructure that is built to manage a massive stream of user session data. This includes active navigation routes, user location, and driver reports that can appear and evolve within seconds.
Behind the scenes, user sessions are large, complex objects that update frequently and contribute to an extremely high volume of read and write operations. Session data was once locked in a monolithic service, tightly coupled to a single backend instance. That made it hard to scale and blocked other microservices from accessing the real-time session state. To modernize, we needed a shared, low-latency solution that could handle these sessions in real time and at global scale. Memorystore for Redis Cluster made that possible.
aside_block
<ListValue: [StructValue([(‘title’, ‘Build smarter with Google Cloud databases!’), (‘body’, <wagtail.rich_text.RichText object at 0x7f65a9750eb0>), (‘btn_text’, ”), (‘href’, ”), (‘image’, None)])]>
Choosing the right route
As we planned the move to a microservices-based backend, we evaluated our options, including Redis Enterprise Cloud, a self-managed Redis cluster, or continuing with our existing Memcached via Memorystore deployment. In the legacy setup, Memcached stored session data behind the monolithic Realtime (RT) server, but it lacked the replication, advanced data types, and partial update capabilities we wanted. We knew Redis had the right capabilities, but managing it ourselves or through a third-party provider would add operational overhead.
Memorystore for Redis Cluster offered the best of both worlds. It’s a fully managed service from Google Cloud with the performance, scalability, and resilience to meet Waze’s real-time demands. It delivers a 99.99% SLA and a clustered architecture for horizontal scaling. With the database decision made, we planned a careful migration from Memcached to Memorystore for Redis using a dual-write approach. For a period, both systems were updated in parallel until data parity was confirmed. Then we cut over to Redis with zero downtime.
Waze’s new data engine
From there, we built a centralized Session Server – our new command center for active user sessions – as a wrapper around Memorystore for Redis Cluster. This service became the single source of truth for all active user sessions, replacing the tight coupling between session data and the monolithic RT server. The Session Server exposes simple gRPC APIs, allowing any backend microservice to read from or write to the session state directly, including RT during the migration. This eliminated the need for client affinity, freed us from routing all session traffic through a single service, and made session data accessible across the platform.
We designed the system for resilience and scale from the ground up. Redis clustering and sharding remove single points of contention, letting us scale horizontally as demand grows. Built-in replication and automatic failover are designed to keep sessions online. While node replacements may briefly increase failure rates and latency for a short period, sessions are designed to stay online, allowing the navigation experience to quickly stabilize.And with support for direct gRPC calls from the mobile client to any backend service, we can use more flexible design patterns while shaving precious milliseconds off the real-time path.
Fewer pit stops, faster rides
Moving from Memcached’s 99.9% SLA to Memorystore for Redis Cluster’s 99.99% means higher availability and resiliency from the service. Load testing proved the new architecture can sustain full production traffic, comfortably handling bursts of up to 1 million MGET commands per second with a stable sub-millisecond service latency.
Because Memorystore for Redis supports partial updates, we can change individual fields within a session object rather than rewriting the entire record. That reduces network traffic, speeds up write performance, and makes the system more efficient overall – especially important when sessions can grow to many megabytes in size. These efficiencies translate directly into giving our engineering teams more time to focus on application-level performance and new feature development.
Session data in Memorystore for Redis Cluster is now integral to Waze’s core features, from evaluating configurations to triggering real-time updates for drivers. It supports today’s demands and is built to handle what’s ahead.
The road ahead
By proving Memorystore for Redis Cluster in one of Waze’s most critical paths, we’ve built the confidence to use it in other high-throughput caching scenarios across the platform. The centralized Session Server and clustered Redis architecture are now standard building blocks in our backend, which we can apply to new services without starting from scratch.
With that initial critical path complete, our next major focus is the migration of all remaining legacy session management from our RT server. This work will ultimately give every microservice independent access to update session data. Looking ahead, we’re also focused on scaling Memorystore for Redis Cluster to meet future user growth and fine-tuning it for both cost and performance.
Learn more
Waze’s story showcases the power and flexibility of Memorystore for Redis Cluster, a fully managed service with 99.99% availability for high-scale, real-time workloads.
Learn more about the power of Memorystore and get started for free.
Welcome back to The Agent Factory! In this episode, we’re joined by Ravin Kumar, a Research Engineer at DeepMind, to tackle one of the biggest topics in AI right now: building and training open-source agentic models. We wanted to go beyond just using agents and understand what it takes to build the entire factory line—from gathering data and supervised fine-tuning to reinforcement learning and evaluations.
This post guides you through the key ideas from our conversation. Use it to quickly recap topics or dive deeper into specific segments with links and timestamps.
Before diving into the deep research, we looked at the latest developments in the fast-moving world of AI agents.
Gemini 2.5 Computer Use: Google’s new model can act as a virtual user, interacting with computer screens, clicking buttons, typing in forms, and scrolling. It’s a shift from agents that just know things to agents that can do tasks directly in a browser.
Vibe Coding in AI Studio: A new approach to app building where you describe the “vibe” of the application you want, and the AI handles the boilerplate. It includes an Annotation Mode to refine specific UI elements with simple instructions like “Change this to green.”
DeepSeek-OCR and Context Compression: DeepSeek introduced a method that treats documents like images to understand layout, compressing 10-20 text tokens into a single visual token. This drastically improves speed and reduces cost for long-context tasks.
Google Veo 3.1 and Flow: The new update to the AI video model adds rich audio generation and powerful editing features. You can now use “Insert” to add characters or “Remove” to erase objects from existing video footage, giving creators iterative control.
Ravin Kumar on Building Open Models
We sat down with Ravin to break down the end-to-end process of creating an open model with agent capabilities. It turns out the process mirrors a traditional ML lifecycle but with significantly more complex components.
Ravin explained that training data for agents looks vastly different from standard text datasets. It starts with identifying what users actually need. The data itself is a collection of trajectories, complex examples of the model making decisions and using tools. Ravin noted that they use a mix of human-curated data and synthetic data generated by their own internal “teacher” models and APIs to create a playground for the open models to learn in.
Training Techniques: SFT and Reinforcement Learning
Once the data is ready, the training process involves a two-phase approach. First comes Supervised Fine-Tuning (SFT), where frameworks update the model’s weights to nudge it into new behaviors based on the examples. However, to handle generalization—new situations not in the original trainin data—they rely on Reinforcement Learning (RL). Ravin highlighted the difficulty of setting rewards in RL, warning that models are prone to “reward hacking,” where they might collect intermediate rewards without ever completing the final task.
Ravin emphasized that evaluation is the most critical and high-stakes part of the process. You can’t just trust the training process; you need a rigorous “final exam.” They use a combination of broad public benchmarks to measure general capability and specific, custom evaluations to ensure the model is safe and effective for its intended user use case.
Conclusion
This conversation with Ravin Kumar really illuminated that building open agentic models is a highly structured, rigorous process. It requires creating high-quality trajectories for data, a careful combination of supervised and reinforcement learning, and, crucially, intense evaluation.
Your turn to build
As Ravin advised, the best place to start is at the end. Before you write a single line of training code, define what success looks like by building a small, 50-example final exam for your agent. If you can’t measure it, you can’t improve it. We also encourage you to try mixing different approaches; for example, using a powerful API model like Gemini as a router and a specialized open-source model for specific tasks.
Check out the full episode for more details, and catch us next time!
In a world of increasing data volume and demand, businesses are looking to make faster decisions and separate insight from noise. Today, we’re bringing Conversational Analytics to general availability in Looker, delivering natural language queries to everyone in your organization, removing BI bottlenecks. With Conversational Analytics, we’re transforming the way you get answers, cutting through stale dashboards and accelerating data discovery. Our goal: make analytics and AI as easy and scalable as performing a Google search, extending BI to the broader enterprise as you go from prompt to full data exploration in seconds.
Instant AI-powered insights with Conversational Analytics in Looker
Now, with Conversational Analytics, getting an answer from your data is as simple as chatting with your most knowledgeable colleague. By tapping into human conversation, Conversational Analytics relieves you from struggling with complex dashboard filters, obscure field names, or the need to write custom SQL.
“At YouTube, we’re focused on helping creators succeed and bring their creativity to the world. We’ve been testing Conversational Analytics in Looker to give our partner managers instant, actionable data that lets them quickly guide creators and optimize creator support.” – Thomas Seyller, Senior Director, Technology & Insights, YouTube Business
The general availability of Conversational Analytics combines the reasoning power of Gemini, new capabilities in Google’s agentic frameworks, and the trusted data modeling of the Looker platform. Together, these set the stage for the next chapter in self-service analytics, making reliable data insights accessible to the entire enterprise. Conversational Analytics agents can understand your questions and provide insightful answers to questions about your data.
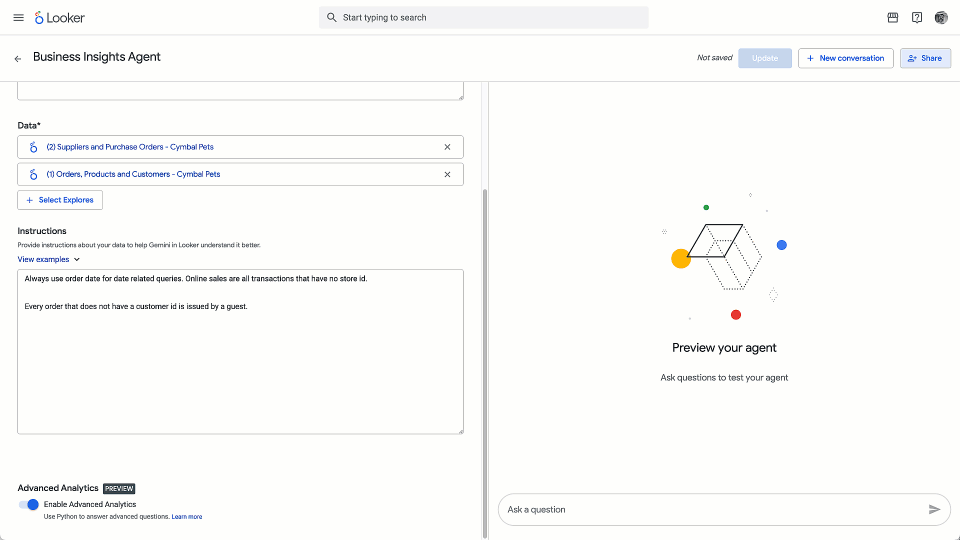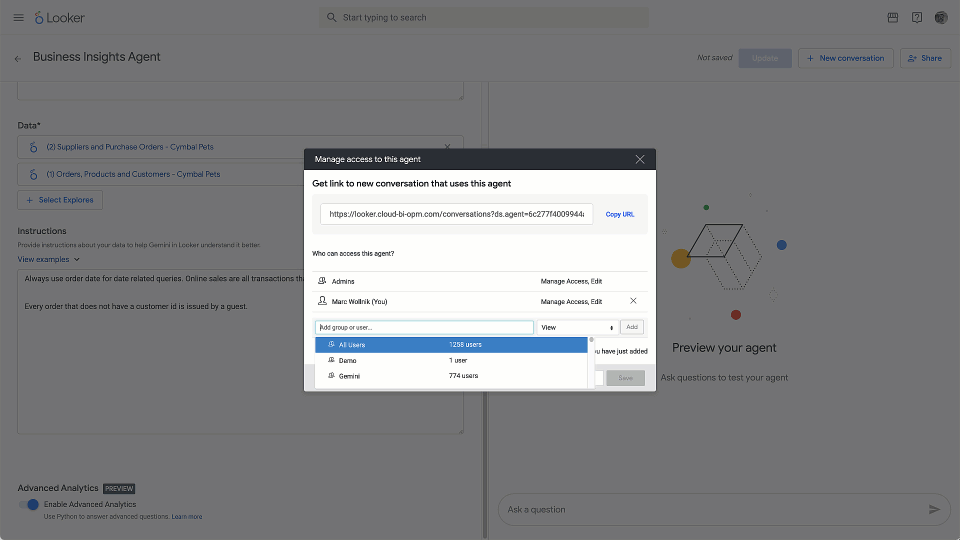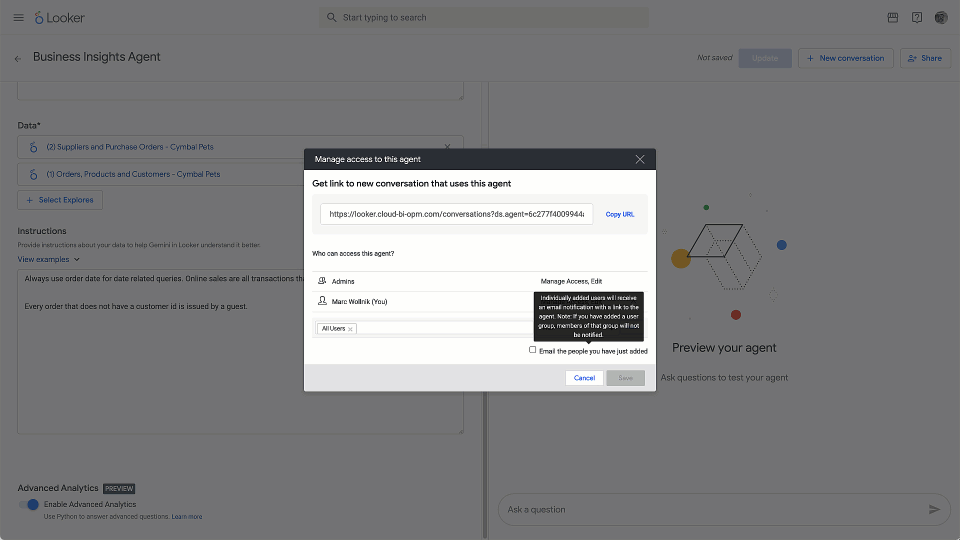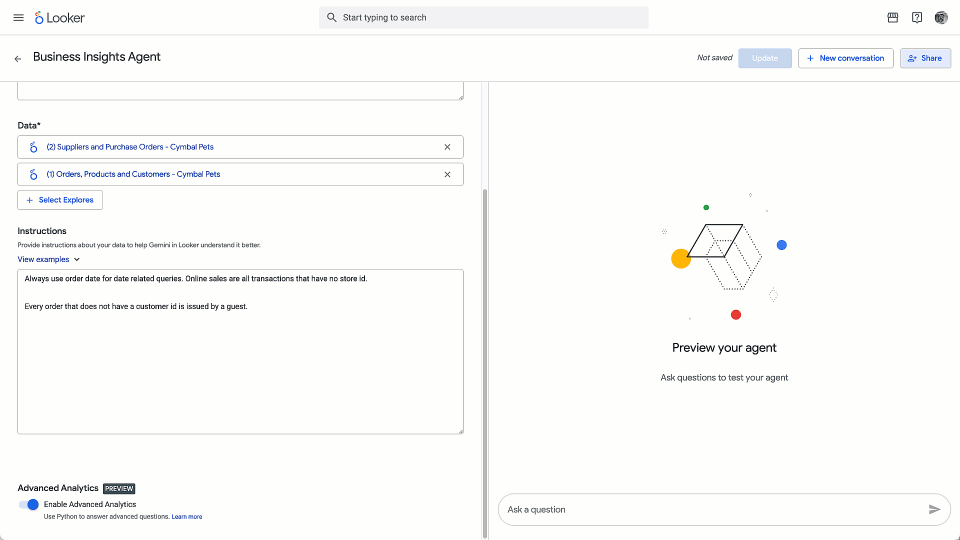
New at general availability is the ability to analyze data across domains. You can ask questions that integrate insights from up to five distinct Looker Explores (pre-joined views), spanning multiple business areas. Additionally, you can share the agents you build with colleagues, giving them faster access to a single source of truth, speeding consensus, and driving uniform decisions.
You can build and share agents with colleagues to have a consistent data picture.
Built on a trusted, governed foundation
The power of Conversational Analytics isn’t just in the conversation it enables; it’s in the trust of the underlying data. Conversational Analytics is grounded in Looker’s semantic layer, which ensures that every metric, field, and calculation is centrally defined and consistent, acting as a crucial context engine for AI. As more of your colleagues rapidly use these expanded capabilities, you need to know the results they see and act on are accurate.
For analysts looking to explore data or everyday users receiving insights in the context of their business, Conversational Analytics also improves data self-service, minimizing technical friction that can create bottlenecks and leaves insights locked away.
You can now:
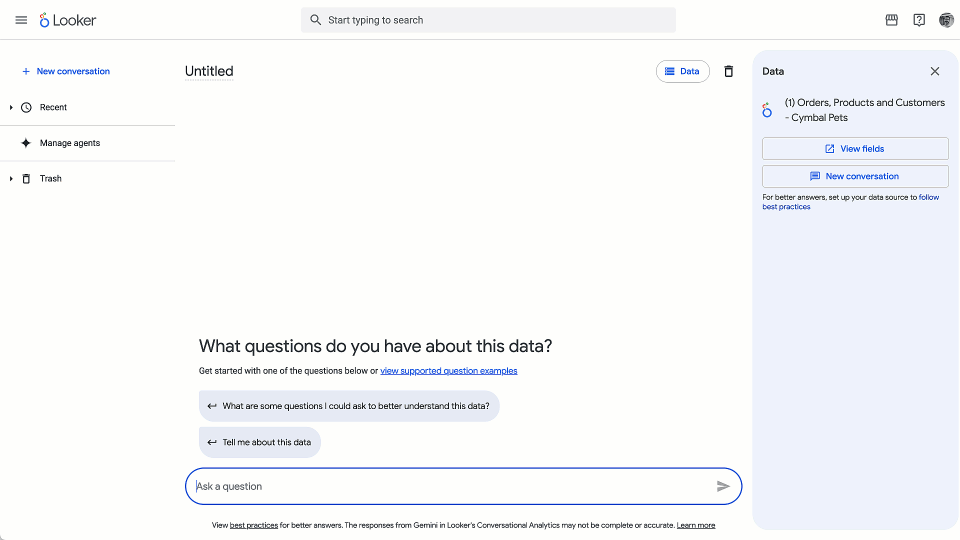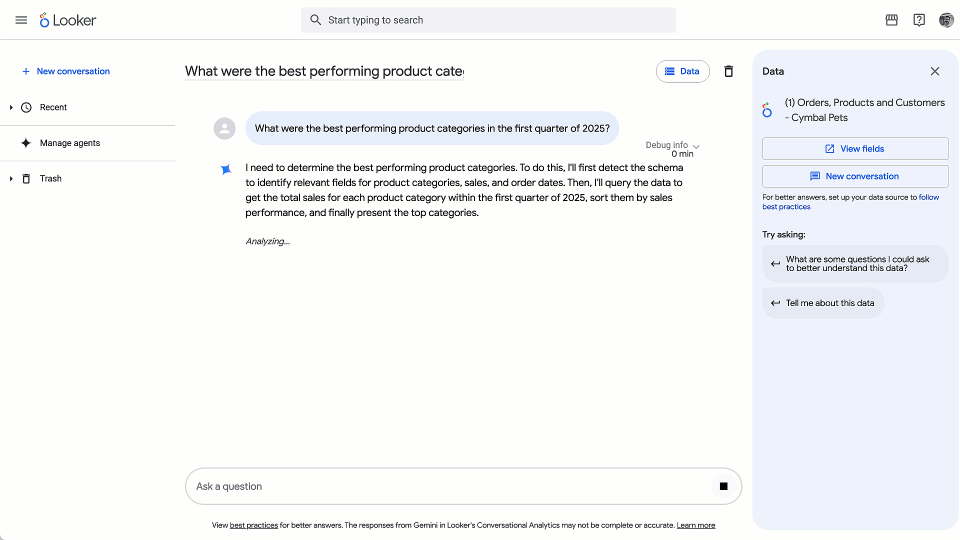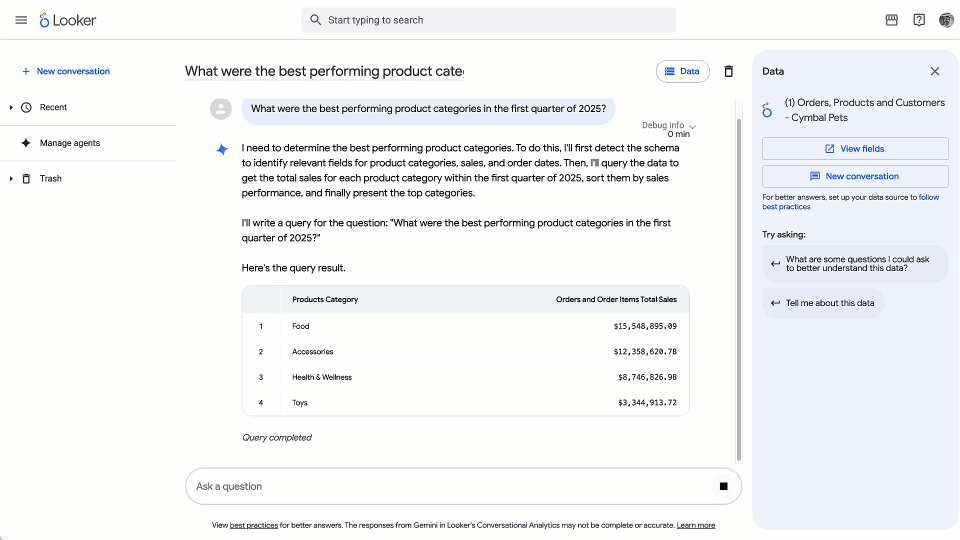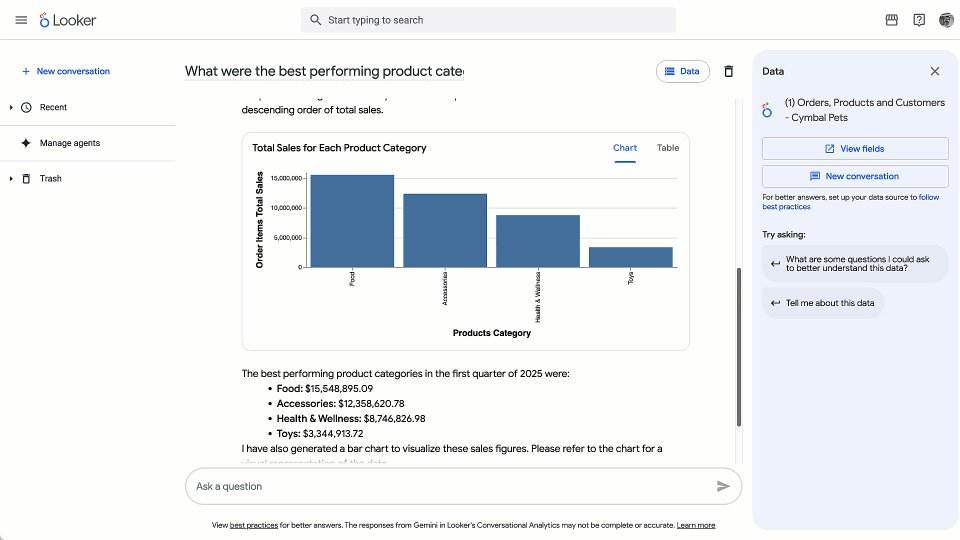
Ask anything, anytime: Get instant answers to simple questions like “Show me our website traffic last month for shoe sales,” leading to deeper questions and greater insights across business areas and domains.
Deepen the discovery: Move beyond the constraints of static dashboards and ask open-ended questions like, “Show me the trend of website traffic over the past six months and filter it by the California region.” The system intelligently generates the appropriate query and visualization instantly.
Extend enterprise BI: Connect your Looker models to your enterprise BI ecosystem, centralize and share agents, and create new dashboards, starting with a prompt. Built on top of Looker Explores, Conversational Analytics’ natural language interface usesLookML for fine tuning and output accuracy.
Pivot quickly: The conversational interface supports multi-turn questions, so you can iterate on your findings. Ask for total sales, then follow up with, “Now show me that as an area chart, broken down by payment method.”
Gain full transparency: To build confidence and data literacy, the “How was this calculated?” feature provides a clear, natural language explanation of the underlying query that generated the results, so that you understand the source of your findings.
Empower the BI analyst and business user
Conversational Analytics is democratizing data for business teams, helping them govern the business’s data. At the same time, it’s also enhancing productivity and influence for data analysts and developers.
When business users can self-serve trusted data insights, data analysts see fewer interruptions and “ad-hoc” ticket requests, and can instead focus on high-impact work. Analysts can customize their client teams’ BI experiences by building Conversational Analytics agents that define common questions, filters, and style guidelines, so different teams can act on the same data in different ways.
Get ready to start talking
Conversational Analytics is available now for all Looker platform users. Your admin can enable it in your Looker instance today and you will discover how easy it is to move from simply asking “What?” to confidently determining “What’s next?” For more information, review the product documentation or watch this video tutorial.
At Google Cloud, we believe that being at the forefront of driving secure innovation and meeting the evolving needs of customers includes working with partners. The reality is that the security landscape should be interoperable, and your security tools should be able to integrate with each other.
Google Unified Security, our AI-powered, converged security solution, has been designed to support greater customer choice. To further this vision, today we’re announcing Google Unified Security Recommended, a new program that expands strategic partnerships with market-leading security solutions trusted by our customers.
We welcome CrowdStrike, Fortinet, and Wiz as inaugural Google Unified Security Recommended partners. These integrations are designed to meet our customers where they are today and ensure their end-to-end deployments are built to scale with Google in the future.
Google Unified Security and our Recommended program partner solutions.
Building confidence through validated integrations
As part of the Google Unified Security Recommended program, partners agree to adhere to comprehensive technical integration across Google’s security product portfolio; a collaborative, customer-first support model that reflects our intent to collectively protect our customers; and invest jointly in AI innovation. This program offers our customers:
Enhanced confidence: Select partner products that have undergone evaluation and validation to ensure optimal integration with Google Unified Security.
Accelerated discovery: Streamline your evaluation process with a carefully curated selection of market-leading solutions addressing specific enterprise challenges.
Prioritize outcomes: Minimize integration overhead, allowing your team to allocate resources towards building security solutions that deliver business outcomes.
We’re working to ensure that customers can use solutions that are powerful today — and designed for future advancements. Learn more about the product-level requirements that define the Google Unified Security Recommended designation here.
Our inaugural partners: Unifying your defenses
Our collaborations with CrowdStrike, Fortinet and Wiz exemplify our “better together” philosophy by addressing tangible security challenges.
CrowdStrike Falcon (endpoint protection): Integrations between the AI-native CrowdStrike Falcon® platform, Google Security Operations, Google Threat Intelligence, and Mandiant Threat Defense can enable customers to detect, investigate, and respond to threats faster across hybrid and multicloud environments.
Customers can use Falcon Endpoint risk signals to define Context-Aware access policies enforced by Google Chrome Enterprise. The collaboration also supports integrations that secure the AI lifecycle — and extends through the model context protocol (MCP) to advance AI for security operations. Together, CrowdStrike and Google Cloud deliver unified protection across endpoint, identity, cloud, and data.
“CrowdStrike and Google Cloud share a vision for an open, AI-powered future of security. Together, we’re uniting our leading AI-native platforms – Google Security Operations and the CrowdStrike Falcon® platform – to help customers harness the power of generative AI and stay ahead of modern threats,” said Daniel Bernard, chief business officer, CrowdStrike.
Fortinet cloud-delivered SASE and Next-Generation Firewall (network protection): Integrating Fortinet’s Security Fabric with Google Security Operations combines AI-driven FortiGuard Threat Intelligence with rich network and web telemetry to deliver unified visibility and control across users, applications, and network edges.
Customers can integrate FortiSASE and FortiGate solutions into Google Security Operations to correlate activity across their environments, apply advanced detections, and automate coordinated response actions that contain threats in near real-time. This collaboration can help reduce complexity, streamline operations, and strengthen protection across hybrid infrastructures.
“Customers are demanding simplified security architectures that reduce complexity and strengthen protection,” said Nirav Shah, senior vice president, Product and Solutions, Fortinet. “As an inaugural partner in the Google Cloud Unified Security Recommended program, we are combining the power of FortiSASE and the Fortinet Security Fabric with Google Cloud’s security capabilities to converge networking and security across environments. This approach gives SecOps and NetOps shared visibility and coordinated controls, helping teams eliminate tool sprawl, streamline operations, and accelerate secure digital transformation.”
Wiz (multicloud CNAPP): Customers can integrate Wiz’s cloud security findings with Google Security Operations to help teams identify, prioritize, and address their most critical cloud risks in a unified platform.
In addition, Wiz and Security Command Center integrate to provide complete visibility and security for Google Cloud environments, including threat detection, AI security, and in-console security for application owners. Wiz is actively developing a new Google Threat Intelligence (GTI) integration that allows existing GTI customers to access threat intelligence seamlessly in the Wiz console, enabling threat intelligence-driven detection and response processes.
“Achieving secure innovation in the cloud requires unified visibility and radical risk prioritization. Our inclusion in the Google Unified Security Recommended program recognizes the power of Wiz to deliver code-to-cloud security for Google Cloud customers. By integrating our platform with Google Security Operations and Security Command Center, we enable customers to see their multicloud attack surface, prioritize the most critical risks, and automatically accelerate remediation. Together, we are simplifying the most complex cloud security challenges and making it easier for you to innovate securely,” said Anthony Belfiore, chief strategy officer, Wiz.
Powering the agentic SOC with MCP
A critical aspect of Google Unified Security Recommended is our shared dedication to strategic AI initiatives, including MCP support. Because it enables AI models to interact with and use security tools, MCP can enhance security workflows by ensuring Gemini models possess contextual awareness across multiple downstream services.
MCP can help facilitate an enhanced, cross-platform agentic experience. With MCP, our new AI agents — such as the alert triage agent in Google Security Operations that autonomously investigates alerts — can query partner tools for telemetry, enrich investigations with third-party data, and orchestrate response actions across your entire security stack.
We are proud to confirm that all of our inaugural launch partners support MCP and have developed recommended approaches for how to activate MCP-supported agentic workflows across our products, a crucial step towards realizing our vision of an agentic SOC where AI functions as a virtual security assistant, proactively identifying threats and guiding you to faster, more effective responses.
Our open future on Google Cloud Marketplace
The introduction of the Google Unified Security Recommended program is only the beginning. We are dedicated to expanding this program to include a wider array of most trusted partner solutions with substantial investment across the Google Unified Security product suite, helping our customers build a more scalable, effective, and interoperable security architecture.
For simplified procurement and deployment, all qualified Google Unified Security Recommended solutions are available in the Google Cloud Marketplace. We offer Google Unified Security and Google Cloud customers streamlined purchasing of third-party offerings, all consolidated into one Google Cloud bill.
To learn more about the program and explore Google-validated solutions from our partners, visit the Google Unified Security Recommended page. Tech partners interested in program consideration are encouraged to reach out for guidance.
AI agents are transforming the nature of work by automating complex workflows with speed, scale, and accuracy. At the same time, startups are constantly moving, growing, and evolving – which means they need clear ways to implement agentic workflows, not piles of documentation that send precious resources into a tailspin.
Today, we’ll share a simple four-step framework to help startups build multi-agent systems. Multi-agentic workflows can be complicated, but there are easy ways to get started and see real gains without spending weeks in production.
In this post, we’ll show you a systematic, operations-driven roadmap for navigating this new landscape, using one of our projects to provide concrete examples for the concepts laid out in the official startups technical guide: AI agents.
Step #1: Build your foundation
The startups technical guide outlines three primary paths for leveraging agents:
Pre-built Google agents
Partner agents
Custom-built agents (agents you build on your own).
To build our Sales Intelligence Agent, we needed to automate a highly specific, multi-step workflow that involved our own proprietary logic and would eventually connect to our own data sources. This required comprehensive orchestration control and tool definition that only a “code-first” approach could provide.
That’s why we chose Google’s Agent Development Kit (ADK) as our framework. It offered the balance of power and flexibility necessary to build a truly custom, defensible system, combined with high-level abstractions for agent composition and orchestration that accelerated our development.
Step #2: Build out the engine
We took a hybrid approach when building our agent architecture, which is managed by a top-level root_agent in orchestrator.py. Its primary role is to act as an intelligent controller using an LLM Agent for flexible user interaction, while delegating the core processing loop to [more deterministic ADK components like LoopAgent and custom BaseAgent classes.
Conversational onboarding: The LLM Agent starts by acting as a conversational “front-door,” interacting with the user to collect their name and email.
Workflow delegation: Once it has the user’s information, it delegates the main workflow to a powerful LoopAgent defined in its sub_agents list.
Data loading: The first step inside the LoopAgent is a custom agent called the CompanyLoopController. On the very first iteration of the loop, its job is to call our crm_tool to fetch the list of companies from the Google Sheet and load them into the session state.
Tool-based execution in a loop: The loop processes each company by calling two key tools: the research_pipeline tool that encapsulates our complex company_researcher_agent and the sales_briefing_agent tool that encapsulates the sales_briefing_agent. This “Agent-as-a-Tool” pattern is crucial for state isolation (more in Step 3).
This hybrid pattern gives us the best of both worlds: the flexibility of an LLM for user interaction and the structured, reliable control of a workflow agent with isolated, tool-based execution.
Step #3: Tools, state, and reliability
An agent is only as powerful as the tools it can wield. To be truly useful, our system needed to connect to live data, not just a static local file. To achieve this, we built a custom tool, crm_tool.py, to allow our agent to read its list of target companies directly from a Google Sheet.
To build our read_companies_from_sheet function, we focused on two key areas:
Secure authentication: We used a Google Cloud Service Account for authentication, a best practice for production systems. Our code includes a helper function, get_sheets_service(), that centralizes all the logic for securely loading the service account credentials and initializing the API client.
Configuration management: All configuration, including the SPREADSHEET_ID, is managed via our .env file. This decouples the tool’s logic from its configuration, making it portable and secure.
This approach transformed our agent from one that could only work with local data to one that could securely interact with a live, cloud-based source of truth.
Managing state in loops: The “Agent-as-a-Tool” Pattern A critical challenge in looping workflows is ensuring state isolation between iterations. ADK’s session.state persists, which can cause ‘context rot’ if not managed. Our solution was the “Agent-as-a-Tool” pattern. Instead of running the complex company_researcher_agent directly in the loop, we encapsulated its entire SequentialAgent pipeline into a single, isolated AgentTool (company_researcher_agent_tool).
Every time the loop calls this tool, the ADK provides a clean, temporary context for its execution. All internal steps (planning, QA loop, compiling) happen within this isolated context. When the tool returns the final compiled_report, the temporary context is discarded, guaranteeing a fresh start for the next company. This pattern provides perfect state isolation by design, making the loop robust without manual cleanup logic.
Step 4: Go from Localhost to a scalable deployed product
Here is our recommended three-step blueprint for moving from a local prototype to a production-ready agent on Google Cloud.
1. Adopt a production-grade project template Our most critical lesson was that a simple, local-first project structure is not built for the rigors of the cloud. The turning point for our team was adopting Google’s official Agent Starter Pack. This professional template is not just a suggestion; for any serious project, we now consider it a requirement. It provides three non-negotiable foundations for success out of the box:
Robust dependency management: It replaces the simplicity of local tools like Poetry with the production-grade power of PDM and uv, ensuring that every dependency is locked and every deployment is built from a fast, deterministic, and repeatable environment.
A pre-configured CI/CD pipeline: It comes with a ready-to-use continuous integration and deployment pipeline for Google Cloud Build, which automates the entire process of testing, building, and deploying your agent.
Multi-environment support: The template is pre-configured for separate staging and production environments, a best practice that allows you to safely test changes in an isolated staging environment before promoting them to your live users.
The process begins by using the official command-line tool to generate your project’s local file structure. This prompts you to choose a base template; we used the “ADK Base Template” and then moved our agent logic into the newly created source code files ( App) .
code_block
<ListValue: [StructValue([(‘code’, ‘# Ensure pipx is installedrnpip install –user pipxrnrn# Run the project generator to create the local file structurernpipx run agent-starter-pack create your-new-agent-project’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x7fd594f984f0>)])]>
The final professional project structure:
code_block
<ListValue: [StructValue([(‘code’, ‘final-agent-project/rn├── .github/ # Contains the automated CI/CD workflow configurationrn│ └── workflows/rn├── app/ # Core application source code for the agentrn│ ├── __init__.pyrn│ ├── agent_engine_app.pyrn│ ├── orchestrator.py # The main agent that directs the workflowrn│ ├── company_researcher/ # Sub-agent for performing researchrn│ ├── briefing_agent/ # Sub-agent for drafting emailsrn│ └── tools/ # Custom tools the agents can usern├── tests/ # Automated tests for your agentrn├── .env # Local environment variables (excluded from git)rn├── pyproject.toml # Project definition and dependenciesrn└── uv.lock # Locked dependency versions for speed and consistency’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x7fd594f98550>)])]>
With the local files created, the next step is to provision the cloud infrastructure. From inside the new project directory, you run the setup-cicd command. This interactive wizard connects to your Google Cloud and GitHub accounts, then uses Terraform under the hood to automatically build your entire cloud environment, including the CI/CD pipeline.
code_block
<ListValue: [StructValue([(‘code’, ‘# Navigate into your new project directoryrncd your-new-agent-projectrnrn# Run the interactive CI/CD setup wizardrnpipx run agent-starter-pack setup-cicd’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x7fd594f982b0>)])]>
2. Cloud Build Once the setup is complete with the starter pack, your development workflow becomes incredibly simple. Every time a developer pushes a new commit to the main branch of your GitHub repository:
Google Cloud Build fetches your latest code.
It builds your agent into a secure, portable container image. This process includes installing all the dependencies from your uv.lock file, guaranteeing a perfect, repeatable build every single time.
It deploys this new version to your staging environment. Within minutes, your latest code is live and ready for testing in a real cloud environment.
It waits for your approval. The pipeline is configured to require a manual “Approve” click in the Cloud Build console before it will deploy that exact same, tested version to your production environment. This gives you the perfect balance of automation and control.
3. Deploy on Agent Engine and Cloud Run The final piece of the puzzle is where the agent actually runs. Cloud Build deploys your agent to Vertex AI Agent Engine, which provides the secure, public endpoint and management layer for your agent.
Crucially, Agent Engine is built on top of Google Cloud Run, a powerful serverless platform. This means you don’t have to manage any servers yourself. Your agent automatically scales up to handle thousands of users, and scales down to zero when not in use, meaning you only pay for the compute you actually consume.
Get started
Ready to build your own?
Explore the code for our Sales Intelligence Agent on GitHub.
The technical journey and insights detailed in this blog post were the result of a true team effort. I want to extend my sincere appreciation to the core collaborators whose work provided the foundation for this article: Luis Sala, Isaac Attuah, Ishana Shinde, Andrew Thankson, and Kristin Kim. Their hands-on contributions to architecting and building the agent were essential to the lessons shared here.
For those building with AI, most are in it to change the world — not twiddle their thumbs. So when inspiration strikes, the last thing anyone wants is to spend hours waiting for the latest AI models to download to their development environment.
That’s why today we’re announcing a deeper partnership between Hugging Face and Google Cloud that:
reduces Hugging Face model download times through Vertex AI and Google Kubernetes Engine
offers native support for TPUs on all open models sourced through Hugging Face
provides a safer experience through Google Cloud’s built-in security capabilities.
We’ll enable faster download times through a new gateway for Hugging Face repositories that will cache Hugging Face models and datasets directly on Google Cloud. Moving forward, developers working with Hugging Face’s open models on Google Cloud should expect download times to take minutes, not hours.
We’re also working with Hugging Face to add native support for TPUs for all open models on the Hugging Face platform. This means that whether developers choose to deploy training and inference workloads on NVIDIA GPUs or on TPUs, they’ll experience the same ease of deployment and support.
Open models are gaining traction with enterprise developers, who typically work with specific security requirements. To support enterprise developers, we’re working with Hugging Face to bring Google Cloud’s extensive security protocols to all Hugging Face models deployed through Vertex AI. This means that any Hugging Face model on Vertex AI Model Garden will now be scanned and validated with Google Cloud’s leading cybersecurity capabilities powered by our Threat Intelligence platform and Mandiant.
This expanded partnership with Hugging Face furthers that commitment and will ensure that developers have an optimal experience when serving AI models on Google Cloud, whether they choose a model from Google, from our many partners, or one of the thousands of open models available on Hugging Face.
The prevalence of obfuscation and multi-stage layering in today’s malware often forces analysts into tedious and manual debugging sessions. For instance, the primary challenge of analyzing pervasive commodity stealers like AgentTesla isn’t identifying the malware, but quickly cutting through the obfuscated delivery chain to get to the final payload.
Unlike traditional live debugging, Time Travel Debugging (TTD) captures a deterministic, shareable record of a program’s execution. Leveraging TTD’s powerful data model and time travel capabilities allow us to efficiently pivot to the key execution events that lead to the final payload.
This post introduces all of the basics of WinDbg and TTD necessary to start incorporating TTD into your analysis. We demonstrate why it deserves to be a part of your toolkit by walking through an obfuscated multi-stage .NET dropper that performs process hollowing.
What is Time Travel Debugging?
Time Travel Debugging (TTD), a technology offered by Microsoft as part of WinDbg, records a process’s execution into a trace file that can be replayed forwards and backwards. The ability to quickly rewind and replay execution reduces analysis time by eliminating the need to constantly restart debugging sessions or restore virtual machine snapshots. TTD also enables users to query the recorded execution data and filter it with Language Integrated Query (LINQ) to find specific events of interest like module loads or calls to APIs that implement malware functionalities like shellcode execution or process injection.
During recording, TTD acts as a transparent layer that allows full interaction with the operating system. A trace file preserves a complete execution record that can be shared with colleagues to facilitate collaboration, circumventing environmental differences that can affect the results of live debugging.
While TTD offers significant advantages, users should be aware of certain limitations. Currently, TTD is restricted to user-mode processes and cannot be used for kernel-mode debugging. The trace files generated by TTD have a proprietary format, meaning their analysis is largely tied to WinDbg. Finally, TTD does not offer “true” time travel in the sense of altering the program’s past execution flow; if you wish to change a condition or variable and see a different outcome, you must capture an entirely new trace as the existing trace is a fixed recording of what occurred.
A Multi-Stage .NET Dropper with Signs of Process Hollowing
The Microsoft .NET framework has long been popular among threat actors for developing highly obfuscated malware. These programs often use code flattening, encryption, and multi-stage assemblies to complicate the analysis process. This complexity is amplified by Platform Invoke (P/Invoke), which gives managed .NET code direct access to the unmanaged Windows API, allowing authors to port tried-and-true evasion techniques like process hollowing into their code.
Process hollowing is a pervasive and effective form of code injection where malicious code runs under the guise of another process. It is common at the end of downloader chains because the technique allows injected code to assume the legitimacy of a benign process, making it difficult to spot the malware with basic monitoring tools.
In this case study, we’ll use TTD to analyze a .NET dropper that executes its final stage via process hollowing. The case study demonstrates how TTD facilitates highly efficient analysis by quickly surfacing the relevant Windows API functions, enabling us to bypass the numerous layers of .NET obfuscation and pinpoint the payload.
Basic analysis is a vital first step that can often identify potential process hollowing activity. For instance, using a sandbox may reveal suspicious process launches. Malware authors frequently target legitimate .NET binaries for hollowing as these blend seamlessly with normal system operations. In this case, reviewing process activity on VirusTotal shows that the sample launches InstallUtil.exe (found in %windir%Microsoft.NETFramework<version>). While InstallUtil.exe is a legitimate utility, its execution as a child process of a suspected malicious sample is an indicator that helps focus our initial investigation on potential process injection.
Figure 1: Process activity recorded in the VirusTotal sandbox
Despite newer, more stealthy techniques, such as Process Doppelgänging, when an attacker employs process injection, it’s still often the classic version of process hollowing due to its reliability, relative simplicity, and the fact that it still effectively evades less sophisticated security solutions. The classic process hollowing steps are as follows:
CreateProcess (with the CREATE_SUSPENDED flag): Launches the victim process (InstallUtil.exe) but suspends its primary thread before execution.
ZwUnmapViewOfSection or NtUnmapViewOfSection: “Hollows out” the process by removing the original, legitimate code from memory.
VirtualAllocEx and WriteProcessMemory: Allocates new memory in the remote process and injects the malicious payload.
GetThreadContext: Retrieves the context (the state and register values) of the suspended primary thread.
SetThreadContext: Redirects the execution flow by modifying the entry point register within the retrieved context to point to the address of the newly injected malicious code.
ResumeThread: Resumes the thread, causing the malicious code to execute as if it were the legitimate process.
To confirm this activity in our sample using TTD, we focus our search on the process creation and the subsequent writes to the child process’s address space. The approach demonstrated in this search can be adapted to triage other techniques by adjusting the TTD queries to search for the APIs relevant to that technique.
Recording a Time Travel Trace of the Malware
To begin using TTD, you must first record a trace of a program’s execution. There are two primary ways to record a trace: using the WinDbg UI or the command-line utilities provided by Microsoft. The command-line utilities offer the quickest and most customizable way to record a trace, and that is what we’ll explore in this post.
Warning: Take all usual precautions for performing dynamic analysis of malware when recording a TTD trace of malware executables. TTD recording is not a sandbox technology and allows the malware to interface with the host and the environment without obstruction.
TTD.exe is the preferred command-line tool for recording traces. While Windows includes a built-in utility (tttracer.exe), that version has reduced features and is primarily intended for system diagnostics, not general use or automation. Not all WinDbg installations provide the TTD.exe utility or add it to the system path. The quickest way to get TTD.exe is to use the stand-alone installer provided by Microsoft. This installer automatically adds TTD.exe to the system’s PATH environment variable, ensuring it’s available from a command prompt. To see its usage information, run TTD.exe -help.
The quickest way to record a trace is to simply provide the command line invoking the target executable with the appropriate arguments. We use the following command to record a trace of our sample:
C:UsersFLAREDesktop> ttd.exe 0b631f91f02ca9cffd66e7c64ee11a4b.bin
Microsoft (R) TTD 1.01.11 x64
Release: 1.11.532.0
Copyright (C) Microsoft Corporation. All rights reserved.
Launching '0b631f91f02ca9cffd66e7c64ee11a4b.bin'
Initializing the recording of process (PID:2448) on trace file: C:UsersFLAREDesktopb631f91f02ca9cffd66e7c64ee11a4b02.run
Recording has started of process (PID:2448) on trace file: C:UsersFLAREDesktopb631f91f02ca9cffd66e7c64ee11a4b02.run
Once TTD begins recording, the trace concludes in one of two ways. First, the tracing automatically stops upon the malware’s termination (e.g., process exit, unhandled exception, etc.). Second, the user can manually intervene. While recording, TTD.exe displays a small dialog (shown in figure 2) with two control options:
Tracing Off: Stops the trace and detaches from the process, allowing the program to continue execution.
Exit App: Stops the trace and also terminates the process.
Figure 2: TTD trace execution control dialog
Recording a TTD trace produces the following files:
<trace>.run: The trace file is a proprietary format that contains compressed execution data. The size of a trace file is influenced by the size of the program, the length of execution, and other external factors such as the number of additional resources that are loaded.
<trace>.idx: The index file allows the debugger to quickly locate specific points in time during the trace, bypassing sequential scans of the entire trace. The index file is created automatically the first time a trace file is opened in WinDbg. In general, Microsoft suggests that index files are typically twice the size of the trace file.
<trace>.out: The trace log file containing logs produced during trace recording.
Once a trace is complete, the .runfile can be opened with WinDbg.
Triaging the TTD Trace: Shifting Focus to Data
The fundamental advantage of TTD is the ability to shift focus from manual code stepping to execution data analysis. Performing rapid, effective triage with this data-driven approach requires proficiency in both basic TTD navigation and querying the Debugger Data Model. Let’s begin by exploring the basics of navigation and the Debugger Data Model.
Navigating a Trace
Basic navigation commands are available under the Home tab in the WinDbg UI.
Figure 3: Basic WinDbg TTD Navigation Commands
The standard WinDbg commands and shortcuts for controlling execution are:
Replaying a TTD trace enables the reverse flow control commands that complement the regular flow control commands. Each reverse flow control complement is formed by appending a dash (–) to the regular flow control command:
g-: Go Back – Execute the trace backwards
g-u: Step Out Back – Execute the trace backwards up to the last call instruction
t-: Step Into Back – Single step into backwards
p-: Step Over Back – Single step over backwards
Time Travel (!tt) Command
While basic navigation commands let you move step-by-step through a trace, the time travel command (!tt) enables precise navigation to a specific trace position. These positions are often provided in the output of various TTD commands. A position in a TTD trace is represented by two hexadecimal numbers in the format #:# (e.g., E:7D5) where:
The first part is a sequencing number typically corresponding to a major execution event, such as a module load or an exception.
The second part is a step count, indicating the number of events or instructions executed since that major execution event.
We’ll use the time travel command later in this post to jump directly to the critical events in our process hollowing example, bypassing manual instruction tracing entirely.
The TTD Debugger Data Model
The WinDbg debugger data model is an extensible object model that exposes debugger information as a navigable tree of objects. The debugger data model brings a fundamental shift in how users access debugger information in WinDbg, from wrangling raw text-based output to interacting with structured object information. The data model supports LINQ for querying and filtering, allowing users to efficiently sort through large volumes of execution information. The debugger data model also simplifies automation through JavaScript, with APIs that mirror how you access the debugger data model through commands.
The Display Debugger Object Model Expression(dx) command is the primary way to interact with the debugger data model from the command window in WinDbg. The model lends itself to discoverability – you can begin traversing through it by starting at the root Debugger object:
0:000> dx Debugger
Debugger
Sessions
Settings
State
Utility
LastEvent
The command output lists the five objects that are properties of the Debugger object. Note that the names in the output, which look like links, are marked up using the Debugger Markup Language (DML). DML enriches the output with links that execute related commands. Clicking on the Sessions object in the output executes the following dx command to expand on that object:
The -r# argument specifies recursion up to # levels, with a default depth of one if not specified. For example, increasing the recursion to two levels in the previous command produces the following output:
0:000> dx -r2 Debugger.Sessions
Debugger.Sessions
[0x0] : Time Travel Debugging: 0b631f91f02ca9cffd66e7c64ee11a4b.run
Processes
Id : 0
Diagnostics
TTD
OS
Devices
Attributes
The -g argument displays any iterable object into a data grid in which each element is a grid row and the child properties of each element are grid columns.
0:000> dx -g Debugger.Sessions
Figure 4: Grid view of Sessions, with truncated columns
Debugger and User Variables
WinDbg provides some predefined debugger variables for convenience which can be listed through the DebuggerVariables property.
@$cursession: The current debugger session. Equivalent to Debugger.Sessions[<session>]. Commonly used items include:
@$cursession.Processes: List of processes in the session.
@$cursession.TTD.Calls: Method to query calls that occurred during the trace.
@$cursession.TTD.Memory: Method to query memory operations that occurred during the trace.
@$curprocess: The current process. Equivalent to @$cursession.Processes[<pid>]. Frequently used items include:
@$curprocess.Modules: List of currently loaded modules.
@$curprocess.TTD.Events: List of events that occurred during the trace.
Investigating the Debugger Data Model to Identify Process Hollowing
With a basic understanding of TTD concepts and a trace ready for investigation, we can now look for evidence of process hollowing. To begin, the Calls method can be used to search for specific Windows API calls. This search is effective even with a .NET sample because the managed code must interface with the unmanaged Windows API through P/Invoke to perform a technique like process hollowing.
Process hollowing begins with the creation of a process in a suspended state via a call to CreateProcess with a creation flag value of 0x4. The following query uses the Calls method to return a table of each call to the kernel32 module’s CreateProcess* in the trace; the wildcard (*) ensures the query matches calls to either CreateProcessA or CreateProcessW.
This query returns a number of fields, not all of which are helpful for our investigation. To address this, we can apply the Select LINQ query to the original query, which allows us to specify which columns to display and rename them.
0:000> dx -g @$cursession.TTD.Calls("kernel32!CreateProcess*").Select(c => new { TimeStart = c.TimeStart, Function = c.Function, Parameters = c.Parameters, ReturnAddress = c.ReturnAddress})
The result shows one call to CreateProcessA starting at position 58243:104D. Note the return address: since this is a .NET binary, the native code executed by the Just-In-Time (JIT) compiler won’t be located in the application’s main image address space (as it would be in a non-.NET image). Normally, an effective triage step is to filter results with a Where LINQ query, limiting the return address to the primary module to filter out API calls that do not originate from the malware. This Where filter, however, is less reliable when analyzing JIT-compiled code due to the dynamic nature of its execution space.
The next point of interest is the Parameters field. Clicking on the DML link on the collapsed value {..} displays Parameters via a corresponding dx command.
Function arguments are available under a specific Calls object as an array of values. However, before we investigate the parameters, there are some assumptions made by TTD that are worth exploring. Overall, these assumptions are affected by whether the process is 32-bit or 64-bit. An easy way to check the bitness of the process is by inspecting the DebuggerInformation object.
0:00> dx Debugger.State.DebuggerInformation
Debugger.State.DebuggerInformation
ProcessorTarget : X86 <--- Process Bitness
Bitness : 32
EngineFilePath : C:Program FilesWindowsApps<SNIPPED>x86dbgeng.dll
EngineVersion : 10.0.27871.1001
The key identifier in the output is ProcessorTarget: this value indicates the architecture of the guest process that was traced, regardless of whether the host operating system running the debugger is 64-bit.
TTD uses symbol information provided in a program database (PDB) file to determine the number of parameters, their types and the return type of a function. However, this information is only available if the PDB file contains private symbols. While Microsoft provides PDB files for many of its libraries, these are often public symbols and therefore lack the necessary function information to interpret the parameters correctly. This is where TTD makes another assumption that can lead to incorrect results. Primarily, it assumes a maximum of four QWORD parameters and that the return value is also a QWORD. This assumption creates a mismatch in a 32-bit process (x86), where arguments are typically 32-bit (4-byte) values passed on the stack. Although TTD correctly finds the arguments on the stack, it misinterprets two adjacent 32-bit arguments as a single, 64-bit value.
One way to resolve this is to manually investigate the arguments on the stack. First we use the !tt command to navigate to the beginning of the relevant call to CreateProcessA.
0:000> !tt 58243:104D
(b48.12a4): Break instruction exception - code 80000003 (first/second chance not available)
Time Travel Position: 58243:104D
eax=00bed5c0 ebx=039599a8 ecx=00000000 edx=75d25160 esi=00000000 edi=03331228
eip=75d25160 esp=0055de14 ebp=0055df30 iopl=0 nv up ei pl zr na pe nc
cs=0023 ss=002b ds=002b es=002b fs=0053 gs=002b efl=00000246
KERNEL32!CreateProcessA:
75d25160 8bff mov edi,edi
The return address is at the top of the stack at the start of a function call, so the following dd command skips over this value by adding an offset of 4 to the ESP register to properly align the function arguments.
The value of 0x4 (CREATE_SUSPENDED) set in the bitmask for the dwCreationFlags argument (6th argument) indicates that the process will be created in a suspended state.
The following command dereferences esp+4 via the poi operator to retrieve the application name string pointer then uses the da command to display the ASCII string.
0:000> da poi(esp+4)
0055de74 "C:WindowsMicrosoft.NETFramewo"
0055de94 "rkv4.0.30319InstallUtil.exe"
The command reveals that the target application is InstallUtil.exe, which aligns with the findings from basic analysis.
It is also useful to retrieve the handle to the newly created process in order to identify subsequent operations performed on it. The handle value is returned through a pointer (0x55e068 in the earlier referenced output) to a PROCESS_INFORMATION structure passed as the last argument. This structure has the following definition:
After the call to CreateProcessA, the first member of this structure should be populated with the handle to the process. Step out of the call using the gu(Go Up) command to examine the populated structure.
0:000> gu
Time Travel Position: 58296:60D
0:000> dd /c 1 0x55e068 L4
0055e068 00000104 <-- handle to process
0055e06c 00000970
0055e070 00000d2c
0055e074 00001c30
In this trace, CreateProcess returned 0x104 as the handle for the suspended process.
The most interesting operation in process hollowing for the purpose of triage is the allocation of memory and subsequent writes to that memory, commonly performed via calls to WriteProcessMemory. The previous Calls query can be updated to identify calls to WriteProcessMemory.
Investigating these calls to WriteProcessMemory shows that the target process handle is 0x104, which represents the suspended process. The second argument defines the address in the target process. The arguments to these calls reveal a pattern common to PE loading: the malware writes the PE header followed by the relevant sections at their virtual offsets.
It is worth noting that the memory of the target process cannot be analyzed from this trace. To record the execution of a child process, pass the -children flag to the TTD.exe utility. This will generate a trace file for each process, including all child processes, spawned during execution.
The first memory write to what is likely the target process’s base address (0x400000) is 0x200 bytes. This size is consistent with a PE header, and examining the source buffer (0x9810af0) confirms its contents.
The !dh extension can be used to parse this header information.
0:000> !dh 0x9810af0
File Type: EXECUTABLE IMAGE
FILE HEADER VALUES
14C machine (i386)
3 number of sections
66220A8D time date stamp Fri Apr 19 06:09:17 2024
----- SNIPPED -----
OPTIONAL HEADER VALUES
10B magic #
11.00 linker version
----- SNIPPED -----
0 [ 0] address [size] of Export Directory
3D3D4 [ 57] address [size] of Import Directory
----- SNIPPED -----
0 [ 0] address [size] of Delay Import Directory
2008 [ 48] address [size] of COR20 Header Directory
SECTION HEADER #1
.text name
3B434 virtual size
2000 virtual address
3B600 size of raw data
200 file pointer to raw data
----- SNIPPED -----
SECTION HEADER #2
.rsrc name
546 virtual size
3E000 virtual address
600 size of raw data
3B800 file pointer to raw data
----- SNIPPED -----
SECTION HEADER #3
.reloc name
C virtual size
40000 virtual address
200 size of raw data
3BE00 file pointer to raw data
----- SNIPPED -----
The presence of a COR20 header directory (a pointer to the .NET header) indicates that this is a .NET executable.The relative virtual addresses for the .text (0x2000), .rsrc (0x3E000), and .reloc (0x40000) also align with the target addresses of the WriteProcessMemory calls.
The newly discovered PE file can now be extracted from memory using the writemem command.
Using a hex editor, the file can be reconstructed by placing each section at its raw offset. A quick analysis of the resulting .NET executable (SHA256: 4dfe67a8f1751ce0c29f7f44295e6028ad83bb8b3a7e85f84d6e251a0d7e3076) in dnSpy reveals its configuration data.
This case study demonstrates the benefit of treating TTD execution traces as a searchable database. By capturing the payload delivery and directly querying the Debugger Data Model for specific API calls, we quickly bypassed the multi-layered obfuscation of the .NET dropper. The combination of targeted data model queries and LINQ filters (for CreateProcess* and WriteProcessMemory*) and low-level commands (!dh, .writemem) allowed us to isolate and extract the hidden AgentTesla payload, yielding critical configuration details in a matter of minutes.
The tools and environment used in this analysis—including the latest version of WinDbg and TTD—are readily available via the FLARE-VM installation script. We encourage you to streamline your analysis workflow with this pre-configured environment.
While 90% of IT leaders indicate that the future of their end user computing (EUC) strategy is web-based, those same leaders admit that 50% of the applications their organizations rely on today are still legacy client-based apps.1 Similarly, IT leaders note that enabling end users to take advantage of AI on the endpoint is their top priority in the next 12 months. Clearly, something needs to bridge the gap between today’s reality and tomorrow’s strategy.
Announcing Cameyo by Google: Virtual app delivery for the modern tech stack
To provide today’s organizations with a more modern approach to virtualization, we are thrilled to launch Cameyo by Google, bringing a best-in-class Virtual App Delivery (VAD) solution into the Google enterprise family of products.
Cameyo is not VDI. It is a modern alternative designed specifically to solve the legacy app gap without the overhead of traditional virtual desktops. Instead of streaming a full, resource-heavy desktop, Cameyo’s Virtual App Delivery (VAD) technology delivers only the applications users need, securely to any device.
With Cameyo, those legacy Windows or Linux apps can either be streamed in the browser or delivered as Progressive Web Apps (PWAs) to give users the feel of using a native app in its own window. This allows users to run critical legacy applications — everything from specialized ERP clients, Windows-based design programs like AutoCAD, the desktop version of Excel, and everything in between — and access them alongside their other modern web apps in the browser, or access them side-by-side with the other apps in their system tray as PWAs. For the user, the experience is seamless and free from the context-switching of managing a separate virtual desktop environment. For IT, the complexity is eliminated.
“The beauty of Cameyo is its simplicity. It lets users access applications on any device with security built in, allowing us to reach any end user, on any device, without it ever touching our corporate systems or the complexity or overhead — no VPNs or firewall configurations needed,” said Phil Paterson, Head of Cloud & Infrastructure, PTSG. He added, “VPNS were taking up to 15 minutes to log in, but with Cameyo access is instant, saving users upwards of 30 minutes every day.”
Completing the Google Enterprise stack
Today’s enterprises have been increasingly turning to Google for a modern, flexible, and secure enterprise tech stack that was built for the web-based future of work, not modified for it. And Cameyo by Google is a critical unlock mechanism that bridges the gap between those organizations’ legacy investments and this modern stack.
Google’s enterprise tech stack provides organizations with a flexible, modular path to modernization. Unlike all-or-nothing enterprise ecosystems, Google’s enterprise stack doesn’t force you to abandon existing investments for the sake of modernization. Instead, it gives you the freedom to modernize individual layers of your stack at your own pace, as it makes sense for your business — all while maintaining access to your existing technology investments. And Google’s flexible enterprise stack is built for interoperability with a broad ecosystem of modern technologies built for the web, giving you freedom along your modernization journey.
A secure browsing first: Cameyo + Chrome Enterprise
Speaking of enabling organizations to modernize at their own rate, we’ve seen a distinct pattern popping up throughout our conversations with enterprises today. And that pattern is the interest in migrating to Secure Enterprise Browsers (SEBs) to provide a more secure, manageable place for people to do their best work.
And while the market for SEBs is growing rapidly, most enterprise browser solutions share a fundamental blind spot: they are only built to secure web-based SaaS applications. They have no direct answer for the 50% of client-based applications that run entirely outside the browser.1
This is where the combination of Cameyo by Google and Chrome Enterprise Premium provides a unique solution. This combination is the only solution on the market that delivers and secures both modern web apps and legacy client-based apps within a single, unified browser experience.
Here’s how it works:
Chrome Enterprise Premium serves as the secure entry point, providing advanced threat protection, URL filtering, and granular Data Loss Prevention (DLP) controls – like preventing copy/paste or printing – for all sensitive data and web activity.
Cameyo takes your legacy client apps (like your ERP, an internal accounting program, SAP client, etc.) and publishes it within that managed Chrome Enterprise browser.
This unifies the digital workspace. Those legacy applications, which previously lived on a desktop, now run under the single security context of the secure browser. This allows Chrome Enterprise Premium’s advanced security and DLP controls to govern applications they previously couldn’t see, providing a comprehensive security posture across all of your organization’s apps, not just the web-based apps.
Bringing AI to legacy apps. The combination of Cameyo and Chrome Enterprise not only brings all your apps into a secure enterprise browser, but thanks to Gemini in Chrome, all of your legacy apps now have the power of AI layered on top.
Unlocking adoption of a more secure, web-based OS and more collaborative, web-first productivity
Moving all of your apps to the web with Cameyo doesn’t just provide a more unified user experience. It can also provide a significantly better, more flexible, and more secure experience for IT. Compared to traditional virtualization technologies that take weeks or months to deploy, IT can publish their first apps to users within hours, and be fully deployed in days. All while taking advantage of Cameyo’s embedded Zero Trust security model for ultra-secure app delivery.
And that added simplicity, flexibility, and security opens up other opportunities for IT, too.
For organizations that have been looking for a more secure alternative to Windows in the wake of years of security incidents, outages, and forced upgrades to the next Windows version, Cameyo now makes it possible for IT to migrate to ChromeOS — including the use of ChromeOS Flex to convert existing PCs to ChromeOS — while maintaining access to all of their Windows apps.
For years, the primary blocker for deeper enterprise adoption of ChromeOS has always been the “app gap” — the persistent need to access a few remaining Windows applications within an organization. Cameyo eliminates this blocker entirely, enabling organizations to confidently migrate their entire fleet to ChromeOS, the only operating system with zero reported ransomware attacks, ever.
Similarly, Cameyo allows organizations to fully embrace Google Workspace while retaining access to essential client apps that previously kept them tethered to Microsoft™, such as legacy Excel versions with complex macros or specific ERP clients. Now, teams can move to a more modern, collaborative productivity suite that was built for the web, and they can still access any specialized Windows apps that their workflows still depend on.
Your flexible path to modernization starts now
For too long, legacy applications have hindered organizations’ modernization efforts. But the age of tolerating complex, costly virtualization solutions just to keep legacy apps alive is coming to an end.
Cameyo by Google, like the rest of the Google enterprise stack, was built in the cloud specifically to enable the web-based future of work. And like the rest of Google’s enterprise offerings, Cameyo gives you a flexible path forward that enables you to build a modern, secure, and productive enterprise computing stack at the pace that works for you.
Identifying patterns and sequences within your data is crucial for gaining deeper insights. Whether you’re tracking user behavior, analyzing financial transactions, or monitoring sensor data, the ability to recognize specific sequences of events can unlock a wealth of information and actionable insights.
Imagine you’re a marketer at an e-commerce company trying to identify your most valuable customers by their purchasing trajectory. You know that customers who start with small orders and progress to mid-range purchases will usually end up becoming high-value purchasers and your most loyal segment. Having to figure out the complex SQL to aggregate and join this data could be quite the challenging task.
That’s why we’re excited to introduce MATCH_RECOGNIZE, a new feature in BigQuery that allows you to perform complex pattern matching on your data directly within your SQL queries!
What is MATCH_RECOGNIZE?
At its core, MATCH_RECOGNIZE is a tool built directly into GoogleSQL for identifying sequences of rows that match a specified pattern. It’s similar to using regular expressions, but instead of matching patterns in a string of text, you’re matching patterns in a sequence of rows within your tables. This capability is especially powerful for analyzing time-series data or any dataset where the order of rows is important.
With MATCH_RECOGNIZE, you can express complex patterns and define custom logic to analyze them, all within a single SQL clause. This reduces the need for cumbersome self-joins or complex procedural logic. It also lessens your reliance on Python to process data and will look familiar to users who have experience with Teradata’s nPath or other external MATCH_RECOGNIZE workloads (like Snowflake, Azure, Flink, etc.).
How it works
The MATCH_RECOGNIZE clause is highly structured and consists of several key components that work together to define your pattern-matching logic:
PARTITION BY: This clause divides your data into independent partitions, allowing you to perform pattern matching within each partition separately.
ORDER BY: Within each partition, ORDER BY sorts the rows to establish the sequence in which the pattern will be evaluated.
MEASURES: Here, you can define the columns that will be included in the output, often using aggregate functions to summarize the matched data.
PATTERN: This is the heart of the MATCH_RECOGNIZE clause, where you define the sequence of symbols that constitutes a match. You can use quantifiers like *, +, ?, and more to specify the number of occurrences for each symbol.
DEFINE: In this clause, you define the conditions that a row must meet to be classified as a particular symbol in your pattern.
Let’s look at a simple example. From our fictional scenario above, imagine you have a table of sales data, and as a marketing analyst, you want to identify customer purchase patterns where their spending starts low, increases to a mid-range, and then reaches a high level. With MATCH_RECOGNIZE, you could write a query like this:
code_block
<ListValue: [StructValue([(‘code’, ‘SELECT *rnFROMrn Example_Project.Example_Dataset.SalesrnMATCH_RECOGNIZE (rn PARTITION BY customerrn ORDER BY sale_datern MEASURESrn MATCH_NUMBER() AS match_number,rn ARRAY_AGG(STRUCT(MATCH_ROW_NUMBER() AS row, CLASSIFIER() AS symbol, rn product_category)) AS salesrn PATTERN (low+ mid+ high+)rn DEFINErn low AS amount < 50,rn mid AS amount BETWEEN 50 AND 100,rn high AS amount > 100rn);’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x7f692c19cb50>)])]>
In this example, we’re partitioning the data by customer and ordering it by sale_date. The PATTERN clause specifies that we’re looking for one or more “low” sales events, followed by one or more “mid” sales events, followed by one or more “high” sales events. The DEFINE clause then specifies the conditions for a sale to be considered “low”, “mid”, or “high”. The MEASURES clause decides how to summarize each match; here with match_number we are indexing each match starting from 1 and creating a ‘sales’ array that will track every match in order.
Below are example matched customers:
customer
match_number
sales.row
sales.symbol
sales.product_category
Cust1
1
1
low
Books
2
low
Clothing
3
mid
Clothing
4
high
Electronics
5
high
Electronics
Cust2
2
1
low
Software
2
mid
Books
3
high
Clothing
This data highlights some sales trends and could offer insights for a market analyst to strategize conversion of lower-spending customers to higher-value sales based on these trends.
Use cases for MATCH_RECOGNIZE
The possibilities with MATCH_RECOGNIZE are vast. Here are just a few examples of how you can use this powerful feature:
Funnel analysis: Track user journeys on your website or app to identify common paths and drop-off points. For example, you could define a pattern for a successful conversion funnel (e.g., view_product -> add_to_cart -> purchase) and analyze how many users complete it.
Fraud detection: Identify suspicious patterns of transactions that might indicate fraudulent activity. For example, you could look for a pattern of multiple small transactions followed by a large one from a new account.
Financial analysis: Analyze stock market data to identify trends and patterns, such as a “W” or “V” shaped recovery.
Log analysis: Sift through application logs to find specific sequences of events that might indicate an error or a security threat.
Churn analysis: Identify patterns in your data that lead to customer churn and find actionable insights to reduce churn and improve customer sentiment.
Network monitoring: Identify a series of failed login attempts to track issues or potential threats.
Supply chain monitoring: Flag delays in a sequence of shipment events.
Sports analytics: Identify streaks or changes in output for different players / teams over games, such as winning or losing streaks, changes in starting lineups, etc.
Get started today
Ready to start using MATCH_RECOGNIZE in your own queries? The feature is now available to all BigQuery users! To learn more and dive deeper into the syntax and advanced capabilities, check out the official documentation and tutorial available on Colab, BigQuery, and GitHub.
MATCH_RECOGNIZE opens up a whole new world of possibilities for sequential analysis in BigQuery, and we can’t wait to see how you’ll use it to unlock deeper insights from your data.
For decades, SQL has been the universal language for data analysis, offering access to analytics on structured data. Large Language Models (LLMs) like Gemini now provide a path to get nuanced insights from unstructured data such as text, image and video. However, integrating LLMs into standard SQL flow requires data movement, at least some prompt and parameter tuning to optimize result quality. This is expensive to perform at scale, which keeps these capabilities out of reach for many data practitioners. Today, we are excited to announce the public preview of BigQuery-managed AI functions, a new set of capabilities that reimagine SQL for the AI era. These functions — AI.IF, AI.CLASSIFY, and AI.SCORE — allow you to use generative AI for common analytical tasks directly within your SQL queries, no complex prompt tuning or new tools required. These functions have been optimized for their target use cases, and do not need you to choose models or tune their parameters. Further through intelligent optimizations on your provided prompt and query plans we keep the costs minimal.With these new functions, you can perform sophisticated AI-driven analysis using familiar SQL operators:
Filter and join data based on semantic meaning using AI.IF in a WHERE or ON clause.
Categorize unstructured text or images using AI.CLASSIFY in a GROUP BY clause.
Rank rows based on natural language criteria using AI.SCORE in an ORDER BY clause.
Together, these functions allow answering new kinds of questions previously out of reach for SQL analytics, for example, companies to news articles which mention them even when an old or unofficial name is used.
Let’s dive deeper into how each of these functions works.
Function deep dive
AI.IF: Semantic filtering and joining
With AI.IF, you can filter or join data using conditions written in natural language. This is useful for tasks like identifying negative customer reviews, filtering images that have specific attributes, or finding relevant information in documents. BigQuery optimizes the query plan to reduce the number of calls to LLM by evaluating non-AI filters first. For example, the following query finds tech news articles from BBC that are related to Google.
code_block
<ListValue: [StructValue([(‘code’, ‘SELECT title, body rnFROM bigquery-public-data.bbc_news.fulltext rnWHERE AI.IF((“The news is related to Google, news: “, body), rn t connection_id => “us.test_connection”)rn AND category = “tech” t– Non-AI filter evaluated first’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x7f692c1b92e0>)])]>
You can also use AI.IF() for powerful semantic joins, such as performing entity resolutionbetween two different product catalogs. The following query finds products that are semantically identical, even if their names are not an exact match.
code_block
<ListValue: [StructValue([(‘code’, ‘WITH product_catalog_A AS (SELECT “Veridia AquaSource Hydrating Shampoo” as productrn UNION ALL SELECT “Veridia Full-Lift Volumizing Shampoo”),rn product_catalog_B AS (SELECT “Veridia Shampoo, AquaSource Hydration” as product)rnSELECT *rnFROM product_catalog_A a JOIN product_catalog_B brnON AI.IF((a.product, ” is the same product as “, b.product),rn connection_id => “us.test_connection”)’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x7f692c1b92b0>)])]>
AI.CLASSIFY: Data classification
The AI.CLASSIFY function lets you categorize text or image based on labels you provide. You can use it to route support tickets by topic or classify images based on their style. For instance, you can classify news articles by topic and then count the number of articles in each category with a single query.
code_block
<ListValue: [StructValue([(‘code’, “SELECTrn AI.CLASSIFY(rn body, rn categories => [‘tech’, ‘sport’, ‘business’, ‘politics’, ‘entertainment’],rn connection_id => ‘us.test_connection’) AS category,rn COUNT(*) num_articlesrnFROM bigquery-public-data.bbc_news.fulltextrnGROUP BY category;”), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x7f692c1b9550>)])]>
AI.SCORE: Semantic ranking
You can use AI.SCORE to rank rows based on natural language criteria. This is powerful for ranking items based on a rubric. To give you consistent and high-quality results, BigQuery automatically refines your prompt into a structured scoring rubric. This example finds the top 10 most positive reviews for a movie of your choosing.
code_block
<ListValue: [StructValue([(‘code’, ‘SELECTrn review,rn AI.SCORE((“From 1 to 10, rate how much does the reviewer like the movie :”, review),rn connection_id => ‘us.test_connection’) AS ai_rating,rn reviewer_rating AS human_rating,rnFROM bigquery-public-data.imdb.reviewsrnWHERE title = ‘Movie’rnORDER BY ai_rating DESCrnLIMIT 10;’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x7f692c1b9820>)])]>
Built-in optimizations
These functions allow you to easily mix AI processing with common SQL operators like WHERE, JOIN, ORDER BY, and GROUP BY. BigQuery handles prompt optimization, model selection, and model parameter tuning for you.
Prompt optimization: LLMs are sensitive to the wording of a prompt, the same question can be expressed in different ways which affect quality and consistency. BigQuery optimizes your prompts into a structured format specifically for Gemini, helping to ensure higher-quality results and an improved cache hit rate.
Query plan optimization: Running generative AI models over millions of rows can be slow and expensive. BigQuery query planner reorders AI functions in your filters and pulls AI functions out from join to reduce the number of calls to the model, which saves costs and improves performance.
Model endpoint and parameter tuning: BigQuery tunes model endpoint and model parameters to improve both result quality and results consistency across query runs.
Get started
The new managed AI functions — AI.IF() , AI.SCORE() and AI.CLASSIFY() — complement the existing general-purpose Gemini inference functions such as AI.GENERATE from BigQuery. In addition to optimizations discussed above, you can expect future optimization and mixed query processing between BigQuery and Gemini for even better price-performance. You can indicate your interest for early access here.
What to use and when: When your use case fits them, start with the managed AI functions as they are optimized for cost and quality. Use the AI.GENERATE family of functions when you need control on your prompt and input parameters, and want to choose from a wide range of supported models for LLM inference.
To learn more refer to our documentation. The new managed AI functions are also available in BigQuery DataFrames. See this notebook and documentation for Python examples.
When a major vulnerability makes headlines, CISOs want to know fast if their organization is impacted and prepared. Getting the correct answer is often a time-consuming and human-intensive process that can take days or weeks, leaving open a dangerous window of unknown exposure.
To help close that gap, today we’re introducing the Emerging Threats Center in Google Security Operations. Available today for licensed customers in Google Security Operations, this new capability can help solve the core, practical problem of scaling detection engineering, and help transform how teams operationalize threat intelligence.
Enabled by Gemini, our detection-engineering agent responds to new threat campaigns detected by Google Threat Intelligence, and includes frontline insights from Mandiant, VirusTotal, and across Google. It generates representative events, assessing coverage, and closing detection gaps.
The Emerging Threats Center can help you understand if you are impacted by critical threat campaigns, and provides detection coverage to help ensure you are protected going forward.
Introducing campaign-based prioritization with emerging threats
Protecting against new threats has long been a manual, reactive cycle. It begins with threat analysts pouring over reports to identify new campaign activity, which they then translate into indicators of compromise (IoCs) for detection engineers. Next, the engineering team manually authors, tests, and deploys the new detections.
Too often, we hear from customers and security operations teams that this labor-intensive process leaves organizations swimming upstream. It was “hard to derive clear action from threat intelligence data,” according to 59% of IT and cybersecurity leaders surveyed in this year’s Threat Intelligence Benchmark, a commissioned study conducted by Forrester Consulting on behalf of Google Cloud.
By sifting through volumes of threat intelligence data, the Emerging Threats Center can help security surface the most relevant threat campaigns to an organization — and take proactive action against them.
Instead of starting in a traditional alert queue, analysts now have a single view of threats that pose the greatest risks to their specific environment. This view includes details on the presence of IOCs in event data and detection rules.
For example, when a new zero-day vulnerability emerges, analysts don’t have to manually cross-reference blog posts with their alert queue. They can immediately see the campaign, the IOCs already contextualized against their own environment, and the specific detection rules to apply. This holistic approach can help them proactively hunt for the most time-sensitive threats before a major breach occurs.
Making all this possible is Gemini in Security Operations, transforming how we engineer detections. By ingesting a continuous stream of frontline threat intelligence, it can automatically test our detection corpus against new threats. When a gap is found, Gemini generates a new, fully-vetted detection rule for an analyst to approve. This systematic, automated workflow can help ensure you are protected from the latest threats.
Our campaign-based approach can provide definitive answers to the two most critical questions a security team faces during a major threat event: How are we affected, and how well are we prepared.
How are we affected?
The first priority is to understand your exposure. The Emerging Threats Center can help you find active and past threats in your environment by correlating campaign intelligence against your data in two ways:
IOC matches: It automatically searches for and prioritizes campaign-related IoCs across the previous 12 months of your security telemetry.
Detection matches: It instantly surfaces hits from curated detection rules that have been mapped directly to the specific threat campaign.
Both matches provide a definitive starting point for your investigative workflow.
Emerging Threat Center Feed View
How are we prepared?
The Emerging Threat Center can also help prove that you are protected moving forward. This capability can provide immediate assurance of your defensive posture by helping you confirm two key facts:
That you have no current or past IOC or detection hits related to the campaign.
That you have the relevant, campaign-specific detections active and ready to stop malicious activity if it appears.
Emerging Threat Center Campaign Detail View
Under the hood: The detection engineering engine
The Emerging Threat Center is built on a resilient, automated system that uses Gemini models and AI agents to drastically shorten the detection engineering lifecycle.
Agentic Detection Engineering Workflow
Here’s how it works.
First, it ingests intelligence. The system automatically ingests detection opportunities from Google Threat Intelligence campaigns, which are sourced from Mandiant’s frontline incident response engagements, our Managed Defense customers, and Google’s unique global visibility. From thousands of raw sample events from adversary activity, Gemini is able to extract a distinct set of detection opportunities associated with the campaign.
Next, it generates synthetic events. We generate high-fidelity anonymized, synthetic event data that accurately mimics adversary tactics, techniques, and procedures (TTPs) described in the intelligence. We use an automated pipeline to generate a corpus of high-fidelity synthetic log events, providing a robust dataset for testing.
Then, it tests coverage. The system uses the synthetic data to test our existing detection rule set, providing a rapid, empirical answer to how well we are covered for a new threat. This automated testing pipeline quickly provides an answer on detection coverage.
After that, it accelerates rule creation. When coverage gaps are found, the process uses Gemini to automatically generate and evaluate new rules. Gemini drafts a new detection rule and provides a summary of its logic and expected performance, reducing the time to create a production-ready rule from days to hours.
Finally, it requires human review. The new rule is submitted to a human-in-the-loop security analyst who can vet and verify the new rule before deploying it. AI has helped us transform a best-effort, manual process into a systematic, automated workflow. By enabling us to tie new detections directly to the intelligence campaign it covers, we can help you be prepared for the latest threats.
“The real strategic shift is moving past those single indicators to systematically detecting underlying adversary behaviors — that’s how we get ahead and stay ahead. Out-of-box behavioral rules, based on Google’s deep intel visibility, help us get there,” said Ron Smalley, senior vice-president and head of Cybersecurity Operations, Fiserv.
The way we work is rapidly transforming, and AI is quickly becoming a connection point across workflows and tasks both big and small. Whether it’s saving time by converting automated meeting notes into a follow-up email to a client, or getting help with brainstorming your next big campaign idea, Generative AI, driven by models like Gemini, offers seamless, intelligent help for employees. Google is able to bring the power of AI seamlessly into every work surface, from the browser, to the operating system to core work applications, across an expanding collection of new devices.
So how does this come to life for our customers? Our platforms like Chrome Enterprise, the most trusted enterprise browser, and Android, the flexible OS that powers mobile and beyond, have hundreds of millions of business users relying on these technologies at work, and AI continues to make them more helpful for the workforce.
Hardware like Google Pixel and Chromebook Plus devices are infused with AI, built for these new AI experiences, and are already growing in adoption among businesses. But it doesn’t stop there. We’re also expanding to new surfaces with Android XR, the extended reality operating system for next-gen headsets and smart glasses. And Google Beam, our AI-first video communication platform is redefining how we connect.
Together, Google’s enterprise platforms and devices build for the connected future.
Let’s look at how this comes together with recent and exciting new capabilities for enterprises:
Empowering your employees to work smarter and be more productive
Across our platforms and devices, we’re offering familiar user experiences, so employees get the right apps and information they need. Whether that’s Google’s productivity apps, third party SaaS apps, custom apps or even legacy apps. And we make sure that help from Gemini is just a tap, click or prompt away.
To help organizations continue to move towards a more modern endpoint computing experience, we’re excited to announce the general availability of Cameyo by Google, allowing users to run any application, legacy or modern, side-by-side. Built in the cloud as part of the Google enterprise stack, Cameyo delivers a seamless, web-based experience for users and eliminates complexity for IT.
We recently announced Gemini in Chrome, an AI browsing assistant that enables end users to work more efficiently. It can be used to quickly summarize long reports or documents, grab key information from a video or brainstorm ideas for a new project. Gemini in Chrome can understand the context of a user’s tabs, and recall recent tabs they had open. By combining Gemini in Chrome with an app virtualized by Cameyo, organizations can bring the helpfulness of AI to legacy apps on the web.
Gemini in Chrome is available with enterprise grade protections to Google Workspace customers giving IT and security teams control over how their users use AI. These capabilities are rolling out to Android, iOS, Mac, and Windows users already. We’re excited to announce that in addition to the built-in Gemini capabilities on ChromeOS, these Gemini in Chrome capabilities will also be available to Workspace customers on their Chromebook and Chromebook Plus devices soon.
Endpoints for a new work era
Organizations need devices that are purpose-built for the AI era, with powerful hardware and AI integrations directly in the operating system. Google is integrating Gemini and Google AI across a wide set of devices and form factors to deliver a consistent experience, wherever work happens.
Chromebook Plus provides a line of devices designed with more powerful hardware to deliver AI-powered experiences at a great value. This year, we launched new features like Text capture and Select to search with Lens. We also launched two new devices, the Lenovo Chromebook Plus 14” and the Acer Chromebook Plus Spin 514 equipped with Mediatek NPU processors delivering up to 50 TOPS. We will continue to bring powerful laptop experiences to support the needs of workers today and into the future.
Similarly, employees need the flexibility to be productive, especially on the go. Google Pixel uses on-device AI through Gemini Nano to enable features such as offline summarization in the Recorder app,1 Call Notes,2 Magic Cue,3 Live Translate (Voice)4 and more. Additionally, features like Gemini Live5 with screen sharing and camera sharing help bring new levels of productivity to users on the go.
We’re also starting to see new emerging form factors like extended reality (XR) as ways to extend our workplace. The introduction of Android XR marks a major shift for the modern enterprise, extending the reach of contextual AI beyond mobile devices and into the physical workspace. This platform, running on a new ecosystem of headsets and smart glasses, integrates Gemini to provide a true hands-free, contextual assistant. For employees in fields like field service, manufacturing, healthcare, or logistics, this means real-time, heads-up support overlayed onto their view of the world. For example, a technician could receive step-by-step repair instructions or access complex schematics on an optional in-lens display while keeping both hands on the equipment.
Improving security controls and visibility
For IT teams, we know there is a need larger than ever for more visibility and protections. We’re delivering security intelligence and flexible management to AI-powered end user computing environments.
Comprehensive data protection at the browser and OS level is crucial for navigating today’s evolving threat landscape, especially with the rise of AI services. To deliver this essential protection where work primarily happens, within the browser, we’ve embedded robust data loss prevention directly into Chrome Enterprise Premium. This provides IT and security teams with an extensive, easily configurable set of tools in Chrome to proactively guard against accidental or intentional data loss across all web applications.
We’ve expanded many of the data loss prevention capabilities to mobile platforms as well. Admins now can:
Audit, warn or block access to sites or categories of sites on iOS or Android
Set limitations on copying and pasting sensitive data in mobile
Restrict downloads including when users are in Incognito mode
Provision client certificates to Chrome managed profiles on Android, this capability is coming to iOS soon
Organizations leveraging Google’s security ecosystem can now benefit from a new one-click integration with Google SecOps. This integration delivers unprecedented browser intelligence, including data loss events and risky activity, to SecOps, empowering security teams to conduct more thorough investigations and make faster, better-informed decisions.
The rapid rise of Generative AI, powered by Gemini, fundamentally changes what we expect from our enterprise technology, offering seamless, intelligent assistance across every workflow. Google is committed to delivering a unified vision, ensuring this help is immediately available by empowering your employees across every surface—from Chrome and Android to web applications virtualized by Cameyo by Google. By creating endpoints built for the AI era like Chromebook Plus and extending the workplace with Android XR, we ensure powerful hardware and AI integrations go hand-in-hand. Discover how you can equip your teams for the future with Chrome Enterprise, ChromeOS, and Cameyo.
1Available on select devices, languages, and countries. Works with compatible accounts and some features may not be available based on corporate account settings. Check responses for accuracy.
2Available in select countries and languages. Available to 18+ users. Availability may vary by account and profile type.
3Works on calls at least 30 seconds long. Not available in all languages or countries. Requires compatible Pixel phone. See here for more details.
4Results may vary. Check responses for accuracy. Available in select countries and languages.
5 Results for illustrative purposes and may vary. Check responses for accuracy. Compatible with certain features and accounts. Internet connection required. Available in select countries, languages, and to users 18+. Availability may vary by account and profile type.
Embeddings are a crucial component at the intersection of data and AI. As data structures, they encode the inherent meaning of the data they represent, and their significance becomes apparent when they are compared to one another. Vector search is a technique that uncovers the relative meaning of those embeddings by evaluating the distances between them within a shared space.
In early 2024, we launched vector search in the BigQuery data platform, making its powerful capabilities accessible to all BigQuery users. This effectively eliminated the need for specialized databases or complex AI workflows. Our ongoing efforts to democratize vector search has resulted in a unique approach that provides the scale, simplicity, and cost performance that BigQuery users expect. In this article, we reflect on the past two years, sharing insights gained from product development and customer interactions.
In the before-times: Building vector search the hard way
Before we added native support for vector search in BigQuery, building a scalable vector search solution was a complex, multi-step process. Data professionals had to:
Extract data from their data warehouse
Generate embeddings using specialized machine learning infrastructure
Load the embeddings into a dedicated vector database
Maintain this additional infrastructure, including server provisioning, scaling, and index management
Develop custom pipelines to join vector search results back to their core business data
Deal with downtime during index rebuilds, a critical pain point for production systems
This disjointed, expensive, and high-maintenance architecture was a barrier to entry for many teams.
In the beginning: Focus on simplicity
We kicked off BigQuery vector search with one goal: to make the simplest vector database on the market. We built it to meet some core design requirements:
It needs to be fully serverless: We knew early on that the best way to bring vector search to all BigQuery customers was to make it serverless. We first built the IVF index, combining the best of clustering and indexing, all within BigQuery. As a result, you don’t need to provision any new servers whatsoever to use vector search in BigQuery. This means you don’t have to manage any underlying infrastructure for your vector database, freeing up your team to focus on what matters most: your data. BigQuery handles the scaling, maintenance, and reliability automatically. It can scale effortlessly to handle billions of embeddings, so your solution can grow with your business.
Index maintenance should be as simple as possible: BigQuery’s vector indexes are a key part of this simplicity. You create an index with a simple CREATE VECTOR INDEX SQL statement, and BigQuery handles the rest. As new data is ingested, the index automatically and asynchronously refreshes to reflect the changes. And if the ingested data results in data distribution changes in the dataset, and in turn, in search accuracy degradation, it’s no problem: You can use the Model Rebuild feature to completely rebuild your index, without any index downtime, and with just one SQL statement.
It should be integrated with GoogleSQL and Python: You can perform vector searches directly within your existing SQL workflows using a simple VECTOR_SEARCH function. This makes it easy to combine semantic search with traditional queries and joins. For data scientists, the integration with Python and tools like LangChain and BigQuery DataFrames makes it a natural fit for building advanced machine learning applications.
Consistency needs to be guaranteed: New data is searchable via the VECTOR_SEARCH function immediately after ingestion, providing accuracy and consistency of the search results.
You only pay for what you use: The BigQuery vector search pricing model is designed for flexibility. This “pay as you go” model is great for both ad-hoc analyses and highly price-performant batch queries. This model emphasizes the ease of trying out the feature without a significant upfront investment.
Security is a given: BigQuery’s security infrastructure offers robust data -access control through row-level security (RLS) and column-level security (CLS). This multi-layered approach guarantees that users can only access authorized data, thereby bolstering protection and ensuring compliance.
The early days: Growing with our customers
As customers found success with early projects and moved more data into BigQuery, they told us about many data science workflows that they were “updating” to use new embedding-based approaches. Here are a few examples of the various applications that vector search can enhance:
LLM applications with retrieval augmented generation (RAG): By providing relevant business data, vector search helps ensure accurate and grounded responses from large language models.
Semantic search on business data: Enable powerful, natural-language search capabilities for both internal and external users. For instance, a marketing team could search for “customers who have a similar purchasing history to Jane” and receive a list of semantically similar customer profiles.
Customer 360 and deduplication: Use embeddings to identify similar customer records, even if details like names or addresses differ slightly. This is an effective way to cleanse and consolidate data for a more accurate, single view of your customer.
Log analytics and anomaly detection: Ingest log data as embeddings and use vector search to quickly find similar log entries, even if the exact text doesn’t match. This helps security teams identify potential threats and anomalies much faster.
Enhance product recommendations: Suggest visually or textually similar items (e.g., clothing) or semantically related complementary products.
Where we are now: Improving scale and cost performance
As customer usage grew, we enhanced our offering, observing significant demand for batch processing beyond RAG and generative AI workloads. Unlike traditional vector databases, improved batch vector search in BigQuery excels at high-throughput, analytical similarity searches on massive datasets. This allows data scientists to analyze billions of records simultaneously within their existing data environment, enabling previously prohibitive tasks such as:
Large-scale clustering: Grouping every customer in a database based on their behavioral embeddings
Comprehensive anomaly detection: Finding the most unusual transaction for every single account in a financial ledger
Bulk item categorization: Classifying millions of text documents or product images simultaneously
In the second phase of development, we launched many new features to further improve the vector search experience:
TreeAH, built using the ScaNN index, provides significant product differentiation in price / performance. Our customers’ data science teams were moving more of their recommendation, clustering, and data pipelines to use vector search. We saw great improvements using TreeAH.
Various internal improvements to help increase the training and indexing performance and usability. For example, we added asynchronous index training, which increases usability and scalability as massive index training jobs are moved into the background. We also performed various internal optimizations to improve indexing performance, and reduce indexing latency without incurring additional costs for users.
Stored columns to help improve vector search performance:
Users can apply prefilers on the stored columns in the vector search query to greatly optimize search performance without sacrificing search accuracy.
If users only query stored columns in the vector search query, search performance can be further improved by avoiding expensive joins with the base table.
Partitioned indexes to dramatically reduce I/O costs and accelerate query performance by skipping irrelevant partitions. This is especially powerful for customers who frequently filter on partitioning columns, such as a date or region.
Index model rebuilds to help ensure that vector search results remain accurate and relevant over time. As your base data evolves, you can now proactively correct for model drift, maintaining the high performance of your vector search applications without index downtime.
Looking ahead: Indexing all the things
As businesses look to agentic AI, the data platform has never been more important. We imagine a world in which every business has their own AI mode for productivity, and retrieving relevant data is at the heart of productivity, including intelligent indexing of all relevant enterprise data, structured or unstructured, to automate AI and analytics. Indexing and search is core to Google. We look forward to sharing relevant technology innovations with you!
Training large video diffusion models at scale isn’t just computationally expensive — it can become impossible when your framework can’t keep pace with your ambitions.
JAX has become a popular computational framework across AI applications, now recognized for its capabilities in training large-scale AI models, such as LLMs and life sciences models. Its strength lies not just in performance but in an expressive, scalable design that gives innovators the tools to push the boundaries of what’s possible. We’re consistently inspired by how researchers and engineers leverage JAX’s ecosystem to solve unique, domain-specific challenges — including applications for generative media.
Today, we’re excited to share the story of Lightricks, a company at the forefront of the creator economy. Their LTX-Video team is building high-performance video generation models, and their journey is a masterclass in overcoming technical hurdles. I recently spoke with Yoav HaCohen and Yaki Bitterman, who lead the video and scaling teams, respectively. They shared their experience of hitting a hard scaling wall with their previous framework and how a strategic migration to JAX became the key to unlocking the performance they needed.
Here, Yoav and Yaki tell their story in their own words. – Srikanth Kilaru, Senior Product Manager, Google ML Frameworks
The creator’s challenge
At Lightricks, our goal has always been to bring advanced creative technology to consumers. With apps like Facetune, we saw the power of putting sophisticated editing tools directly into people’s hands. When generative AI emerged, we knew it would fundamentally change content creation.
We launched LTX Studio to build generative video tools that truly serve the creative process. Many existing models felt like a “prompt and pray” experience, offering little control and long rendering times that stifled creativity. We needed to build our own models—ones that were not only efficient but also gave creators the controllability they deserve.
Our initial success came from training our first real-time video generation model on Google Cloud TPUs with PyTorch/XLA. But as our ambitions grew, so did the complexity. When we started developing our 13-billion-parameter model, we hit a wall.
Hitting the wall and making the switch
Our existing stack wasn’t delivering the training step times and scalability we needed. After exploring optimization options, we decided to shift our approach. We paused development to rewrite our entire training codebase in JAX, and the results were immediate. Switching to JAX felt like a magic trick, instantly providing the necessary runtimes.
This transition enabled us to effectively scale our tokens per sample (the amount of data processed in each training step), model parameters, and chip count. With JAX, sharding strategies (sharding divides large models across multiple chips) that previously failed now work out of the box on both small and large pods (clusters of TPU chips).
These changes delivered linear scaling that translates to 40% more training steps per day — directly accelerating model development and time to market. Critical issues with FlashAttention and data loading also worked reliably. As a result, our team’s productivity skyrocketed, doubling the number of pull requests we could merge in a week.
Why JAX worked: A complete ecosystem for scale
The success wasn’t just about raw speed; it was about the entire JAX stack, which provided the building blocks for scalable and efficient research.
A clear performance target with MaxText: We used the open-source MaxText framework as a baseline to understand what acceptable performance looked like for a large model on TPUs. This gave us a clear destination and the confidence that our performance goals were achievable on the platform.
A robust toolset: We built our new stack on the core components of the JAX ecosystem based on the MaxText blueprint. We used Flax for defining our models, Optax for implementing optimizers, and Orbax for robust checkpointing — all core components that work together natively.
Productive development and testing: The transition was remarkably smooth. We implemented unit tests to compare our new JAX implementation with the old one, ensuring correctness every step of the way. A huge productivity win was discovering that we could test our sharding logic on a single, cheap CPU before deploying to a large TPU slice. This allowed for rapid, cost-effective iteration.
Checkpointing reliability: For sharded models, JAX’s checkpointing is much more reliable than before, making training safer and more cost-effective.
Compile speed & memory: JAX compilation with lax.fori_loop is fast and uses less memory, freeing capacity for tokens and gradients.
Smooth scaling on a supercomputer: With our new JAX codebase, we were able to effectively train on a reservation of thousands of TPU cores. We chose TPUs because Google provides access to what we see as a “supercomputer” — a fully integrated system where the interconnects and networking were designed first, not as an afterthought. We manage these large-scale training jobs with our own custom Python scripts on Google Compute Engine (GCE), giving us direct control over our infrastructure. We also use Google Cloud Storage and stream the training data to the TPU virtual machines.
Architectural diagram showing the Lightricks stack
Build your models with the JAX ecosystem
Lightricks’ story is a great example of how JAX’s powerful, modular, and scalable design can help teams overcome critical engineering hurdles. Their ability to quickly pivot, rebuild their stack, and achieve massive performance gains is a testament to both their talented team and the tools at their disposal.
The JAX team at Google is committed to supporting innovators like Lightricks and the entire scientific computing community.
Share your story: Are you using JAX to tackle a challenging scientific problem? We would love to learn how JAX is accelerating your research.
Help guide our roadmap: Are there new features or capabilities that would unlock your next breakthrough? Your feature requests are essential for guiding the evolution of JAX.
Please reach out to the team viaGitHub to share your work or discuss what you need from JAX. Check out documentation, examples, news, events and more at jaxstack.ai and jax.dev.
Sincere thanks to Yoav, Yaki, and the entire Lightricks team for sharing their insightful journey with us. We’re excited to see what they create next.
The past decade of cloud native infrastructure has been defined by relentless change — from containerization and microservices to the rise of generative AI. Through every shift, Kubernetes has been the constant, delivering stability and a uniform, scalable operational model for both applications and infrastructure.
As Google Kubernetes Engine (GKE) celebrates its 10th anniversary, its symbiotic relationship with Kubernetes has never been more important. With the increasing demand for Kubernetes to handle AI at its highest scale, Google continues to invest in strengthening Kubernetes’ core capabilities, elevating all workloads — AI and non-AI alike. At KubeCon North America this year, we’re announcing major advancements that reflect our holistic three-pronged approach:
Elevate core Kubernetes OSS for next-gen workloads – This includes proactively supporting the agentic wave with our new Kubernetes-native AgentSandbox APIs for security, governance and isolation. Recently, we also added several capabilities to power inference workloads such as Inference Gateway API, and Inference Perf. In addition, capabilities such as Buffers API, and HPA help address provisioning latency from different angles for all workloads.
Provide GKE as the reference implementation for managed Kubernetes excellence – We continuously bring new features and best practices directly to GKE, translating our Kubernetes expertise into a fully managed, production-ready platform that integrates powerful Google Cloud services, and provides unmatched scale and security. We are excited to announce the new GKE Agent Sandbox, and we recently announced GKE custom compute classes, GKE Inference Gateway, and GKE Inference Quickstart. And to meet the demand for massive computation, we are pushing the limits of scale, with support for 130k node clusters.This year, we’re also thrilled to announce our participation in the new CNCF Kubernetes Kubernetes AI Conformance program, which simplifies AI/ML on Kubernetes with a standard for cluster interoperability and portability. GKE is already certified as an AI-conformant platform.
Drive frameworks and reduce operational friction – We actively collaborate with the open-source community and partners to enhance support for new frameworks, including Slurm and Ray on Kubernetes. We recently announced optimized open-source Ray for GKE with RayTurbo in collaboration with Anyscale. More recently, we became a founding contributor to llm-d, an open-source project in collaboration with partners to create a distributed, Kubernetes-native control plane for high-performance LLM inference at scale.
Now let’s take a deeper look at the advancements.
Supporting the agentic wave
The Agentic AI wave is upon us. According to PwC, 79% of senior IT leaders are already adopting AI agents, and 88% plan to increase IT budgets in the next 12 months due to agentic AI.
Kubernetes already provides a robust foundation for deploying and managing agents at scale, yet the non-deterministic nature of agentic AI workloads introduces infrastructure challenges. Agents are increasingly capable of writing code, controlling computer interfaces and calling a myriad of tools, raising the stakes for isolation, efficiency, and governance.
We’re addressing these challenges by evolving Kubernetes’ foundational primitives while providing high performance and compute efficiency for agents running on GKE. Today, we announced Agent Sandbox, a new set of capabilities for Kubernetes-native agent code execution and computer use environments, available in preview. Designed as open source from the get-go, Agent Sandbox relies on gVisor to isolate agent environments, so you can confidently execute LLM-generated code and interact with your AI agents.
For an even more secure and efficient managed experience, the new GKE Agent Sandbox enhances this foundation with built-in capabilities such as integrated sandbox snapshots and container-optimized compute. Agent Sandbox delivers sub-second latency for fully isolated agent workloads, up to a 90% improvement over cold starts. For more details, please refer to this detailed announcement on Supercharging Agents on GKE today.
Unmatched scale for the AI gigawatt era
In this ‘Gigawatt AI era,’ foundational model creators are driving demand for unprecedented computational power. Based on internal testing of our experimental-mode stack, we are excited to share that we used GKE to create the largest known Kubernetes cluster, with 130,000 nodes.
At Google Cloud, we’re also focusing on single-cluster scalability for tightly coupled jobs, developing multi-cluster orchestration capabilities for job sharding (e.g., MultiKueue), and designing new approaches for dynamic capacity reallocation — all while extending open-source Kubernetes APIs to simplify AI platform development and scaling. We are heavily investing into the open-source ecosystem of tools behind AI at scale (e.g. Kueue, JobSet, etcd), while making GKE-specific integrations to our data centers to offer the best performance and reliability (e.g., running the GKE control plane on Spanner). Finally, we’re excited to open-source our Multi-Tier Checkpointing (MTC) solution, designed to improve the efficiency of large-scale AI training jobs by reducing lost time associated with hardware failures and slow recovery from saved checkpoints.
Better compute for every workload
Our decade-long commitment to Kubernetes is rooted in making it more accessible and efficient for every workload. However, through the years, one key challenge has remained: when using autoscaling, provisioning new nodes took several minutes — not fast enough for high-volume, fast-scale applications. This year, we addressed this friction head-on, with a variety of enhancements in support of our mission: to provide near-real-time scalable compute capacity precisely when you need it, all while optimizing price and performance.
Autopilot for everyone
We introduced the container-optimized compute platform — a completely reimagined autoscaling stack for GKE Autopilot. As the recommended mode of operation, Autopilot fully automates your node infrastructure management and scaling, with dramatic performance and cost implications. As Jia Li, co-founder at LiveX AI shared, “LiveX AI achieves over 50% lower TCO, 25% faster time-to-market, and 66% lower operational cost with GKE Autopilot.” And with the recent GA of Autopilot compute classes for Standard clusters, we made this hands-off experience accessible to more developers, allowing you to adopt Autopilot on a per-workload basis.
Tackling provisioning latency from every angle
We introduced faster concurrent node pool auto-provisioning, making operations asynchronous and highly parallelized. This simple change dramatically accelerates cluster scaling for heterogeneous workloads, improving deployment latency many times over in our benchmarks. Then, for demanding scale-up needs, the new GKE Buffers API (OSS) allows you to request a buffer of pre-provisioned, ready-to-use nodes, making compute capacity available almost instantaneously. And once the node is ready, the new version of GKE container image streaming gets your applications running faster by allowing them to start before the entire container image is downloaded, a critical boost for large AI/ML and data-processing workloads.
Non-disruptive autoscaling to improve resource utilization
The quest for speed extends to workload-level scaling.
The HPA Performance Profile is now enabled by default on new GKE Standard clusters. This brings massive scaling improvements — including support for up to 5,000 HPA objects and parallel processing — for faster, more consistent horizontal scaling.
We’re tackling disruptions in vertical scaling with the preview of VPA with in-place pod resize, which allows GKE to automatically resize CPU and memory requests for your containers, often without needing to recreate the pod.
Dynamic hardware efficiency
Finally, our commitment to dynamic efficiency extends to hardware utilization. GKE users now have access to:
New N4A VMs based on Google Axion Processors (now in preview) and N4D VMs based on 5th Gen AMD EPYC Processors (now GA). Both support Custom Machine Types (CMT), letting you create right-sized nodes that are matched to your workloads.
New GKE custom compute classes, allowing you to define a prioritized list of VM instance types, so your workloads automatically use the newest, most price-performant options with no manual intervention.
A platform to power AI Inference
The true challenge of generative AI inference is how to serve billions of tokens reliably, at lightning speed, and without bankrupting the organization?
Unlike web applications, serving LLMs is both stateful and computationally intensive. To address this we have driven extensive open-source investments to Kubernetes including the Gateway API Inference Extension for LLM-aware routing, the inference performance project, providing a benchmarking standard for meticulous model performance insights on accelerators and HPA scaling metrics and thresholds, and Dynamic Resource Allocation (developed in collaboration with Intel and others) to streamline and automate the allocation and scheduling of GPUs, TPUs, and other devices to pods and workloads within Kubernetes. And we formed the llm-d project with Red Hat and IBM to create a Kubernetes-native distributed inference stack that optimizes for the “time to reach SOTA architectures.”
On the GKE side we recently announced the general availability of GKE Inference Gateway, a Kubernetes-native solution for serving AI workloads. It is available with two workload-specific optimizations:
LLM-aware routing for applications like multi-turn chat, which routes requests to the same accelerators to use cached context, avoiding latency spikes
Disaggregated serving, which separates the “prefill” (prompt processing) and “decode” (token generation) stages onto separate, optimized machine pools
As a result, GKE Inference Gateway now achieves up to 96% lower Time-to-First-Token (TTFT) latency and up to 25% lower token costs at peak throughput when compared to other managed Kubernetes services.
Startup latency for AI inference servers is a consistent challenge with large models taking 10s of minutes to start. Today, we’re introducing GKE Pod Snapshots which drastically improves startup latency by enabling CPU and GPU workloads to be restored from a memory snapshot. GKE Pod Snapshots reduces AI inference start-up by as much as 80%, loading 70B parameter models in just 80 seconds and 8B parameters models in just 16 seconds.
No discussion of inference is complete without talking about the complexity, cost, and difficulty of deploying production-grade AI infrastructure. GKE Inference Quickstart provides a continuous, automated benchmarking system kept up to date with the latest accelerators in Google Cloud, the latest open models, and inference software. You can use these benchmarked profiles to save significant time qualifying, configuring, deploying, as well as monitoring inference-specific performance metrics and dynamically fine-tuning your deployment. You can find this data in this colab notebook.
Here’s to the next decade of Kubernetes and GKE
As GKE celebrates a decade of foundational work, we at Google are proud to help lead the future, and we know it can only be built together. Kubernetes would not be where it is today without the efforts of its contributor community. That includes everyone from members writing foundational new features to those doing the essential, daily work — the “chopping wood and carrying water” — that keeps the project thriving.
We invite you to explore new capabilities, learn more about exciting announcements such as Ironwood TPUs, attend our deep-dive sessions, and join us in shaping the future of open-source infrastructure.
Google and the cloud-native community have consistently strengthened Kubernetes to support modern applications. At KubeCon EU 2025 earlier this year, we announced a series of enhancements to Kubernetes to better support AI inference. Today, at KubeCon NA 2025, we’re focused on making Kubernetes the most open and scalable platform for AI agents, with the introduction of Agent Sandbox.
Consider the challenge that AI agents represent. AI agents help applications go from answering simple queries to performing complex, multi-step tasks to achieve the users objective. Provided a request like “visualize last quarters sales data”, the agent has to use one tool to query the data and another to process that data into a graph and return to the user. Where traditional software is predictable, AI agents can make their own decisions about when and how to use tools at their disposal to achieve a user’s objective, including generating code, using computer terminals and even browsers.
Without strong security and operational guardrails, orchestrating powerful, non-deterministic agents can introduce significant risks. Providing kernel-level isolation for agents that execute code and commands is non-negotiable. AI and agent-based workloads also have additional infrastructure needs compared to traditional applications. Most notably, they need to orchestrate thousands of sandboxes as ephemeral environments, rapidly creating and deleting them as needed while ensuring they have limited network access.
With its maturity, security, and scalability, we believe Kubernetes provides the most suitable foundation for running AI agents. Yet it still needs to evolve to meet the needs of agent code execution and computer use scenarios. Agent Sandbox is a powerful first step in that direction.
Strong isolation at scale
Agentic code execution and computer use require an isolated sandbox to be provisioned for each task. Further, users expect infrastructure to keep pace even as thousands of sandboxes are scheduled in parallel.
At its core, Agent Sandbox is a new Kubernetes primitive built with the Kubernetes community that’s designed specifically for agent code execution and computer use, delivering the performance and scale needed for the next generation of agentic AI workloads. Foundationally built on gVisor with additional support for Kata Containers for runtime isolation, Agent Sandbox provides a secure boundary to reduce the risk of vulnerabilities that could lead to data loss, exfiltration or damage to production systems. We’re continuing our commitment to open source, building Agent Sandbox as a Cloud Native Computing Foundation (CNCF) project in the Kubernetes community.
Enhanced performance on GKE
At the same time, you need to optimize performance as you scale your agents to deliver the best agent user-experience at the lowest cost. When you use Agent Sandbox on Google Kubernetes Engine (GKE), you can leverage managed gVisor in GKE Sandbox and the container-optimized compute platform to horizontally scale your sandboxes faster. Agent Sandbox also enables low-latency sandbox execution by enabling administrators to configure pre-warmed pools of sandboxes. With this feature, Agent Sandbox delivers sub-second latency for fully isolated agent workloads, up to a 90% improvement over cold starts.
The same isolation property that makes a sandbox safe, makes it more susceptible to compute underutilization. Reinitializing each sandbox environment with a script can be brittle and slow, and idle sandboxes often waste valuable compute cycles. In a perfect world, you could take a snapshot of running sandbox environments to start them from a specific state.
Pod Snapshots is a new, GKE-exclusive feature that enables full checkpoint and restore of running pods. Pod Snapshots drastically reduces startup latency of agent and AI workloads. When combined with Agent Sandbox, Pod Snapshots lets teams provision sandbox environments from snapshots, so they can start up in seconds. GKE Pod Snapshots supports snapshot and restore of both CPU- and GPU-based workloads, bringing pod start times from minutes down to seconds. With Pod Snapshots, any idle sandbox can be snapshotted and suspended, saving significant compute cycles with little to no disruption for end-users.
Built for AI engineers
Teams building today’s agentic AI or reinforcement learning (RL) systems should not have to be infrastructure experts. We built Agent Sandbox with AI engineers in mind, designing an API and Python SDK that lets them manage the lifecycle of their sandboxes, without worrying about the underlying infrastructure.
code_block
<ListValue: [StructValue([(‘code’, ‘from agentic_sandbox import Sandboxrnrn# The SDK abstracts all YAML into a simple context manager rnwith Sandbox(template_name=”python3-template”,namespace=”ai-agents”) as sandbox:rnrn # Execute a command inside the sandboxrn result = sandbox.run(“print(‘Hello from inside the sandbox!’)”)’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x7efc469ef5e0>)])]>
This separation of concern enables both an AI developer-friendly experience and the operational control and extensibility that Kubernetes administrators and operators expect.
Get started today
Agentic AI represents a profound shift for software development and infrastructure teams. Agent Sandbox and GKE can help deliver the isolation and performance your agents need. Agent Sandbox is available in open source and can be deployed on GKE today. GKE Pod Snapshots is available in limited preview and will be available to all GKE customers later this year. To get started, check out the Agent Sandbox documentation and quick start. We are excited to see what you build!