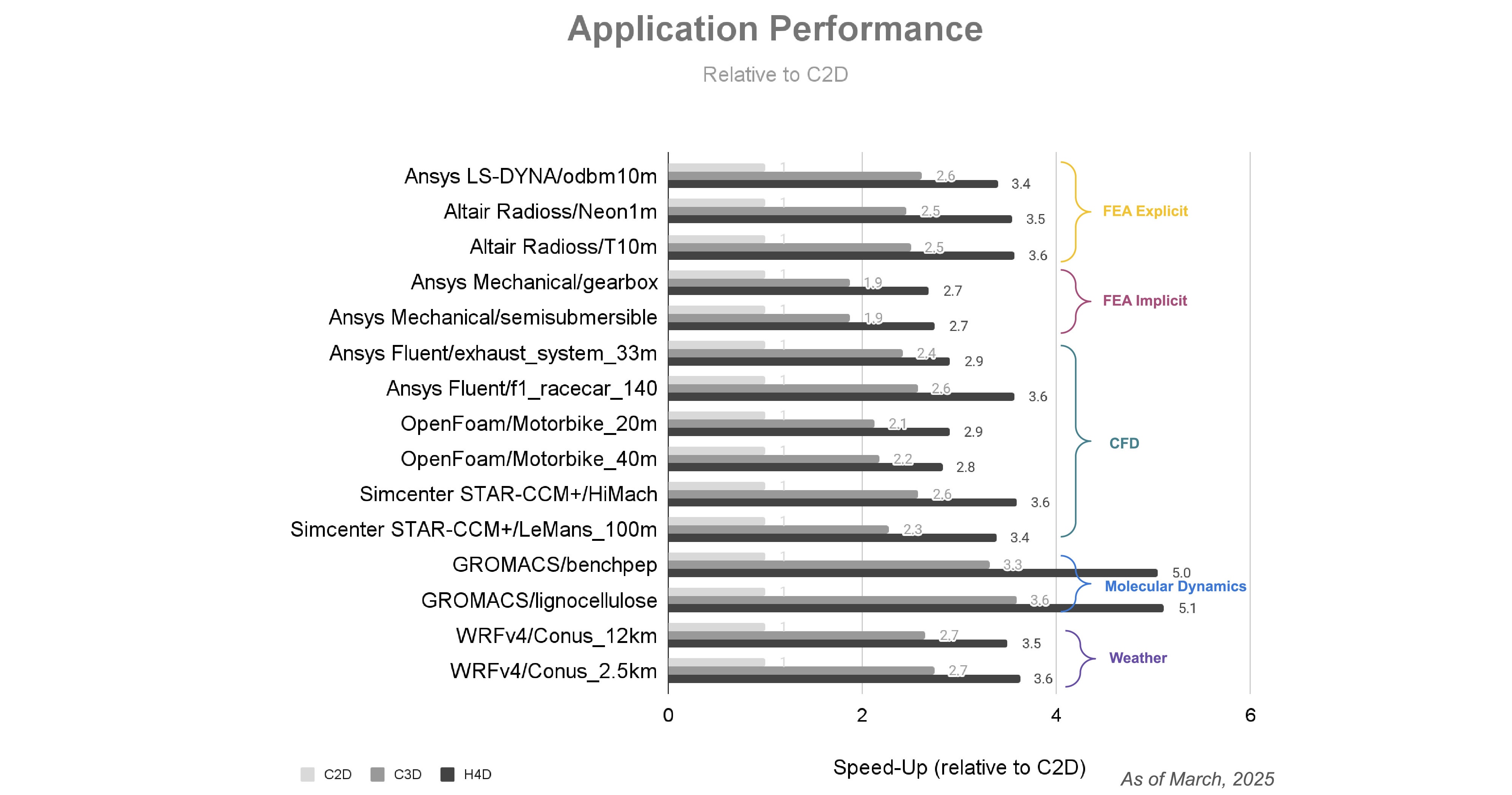
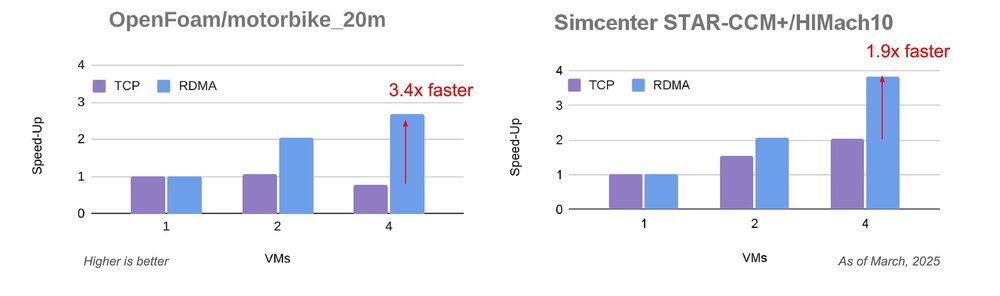
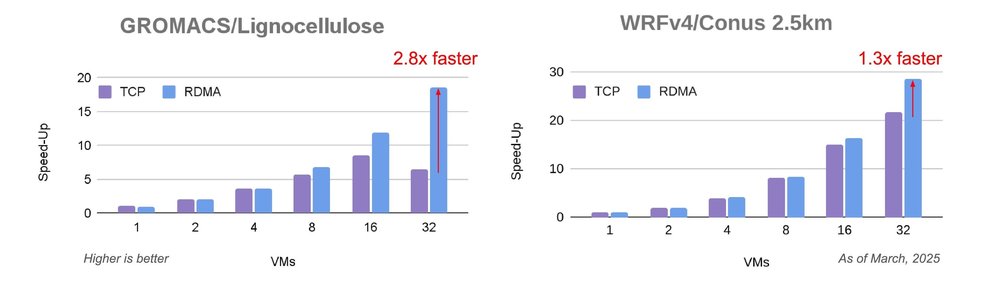
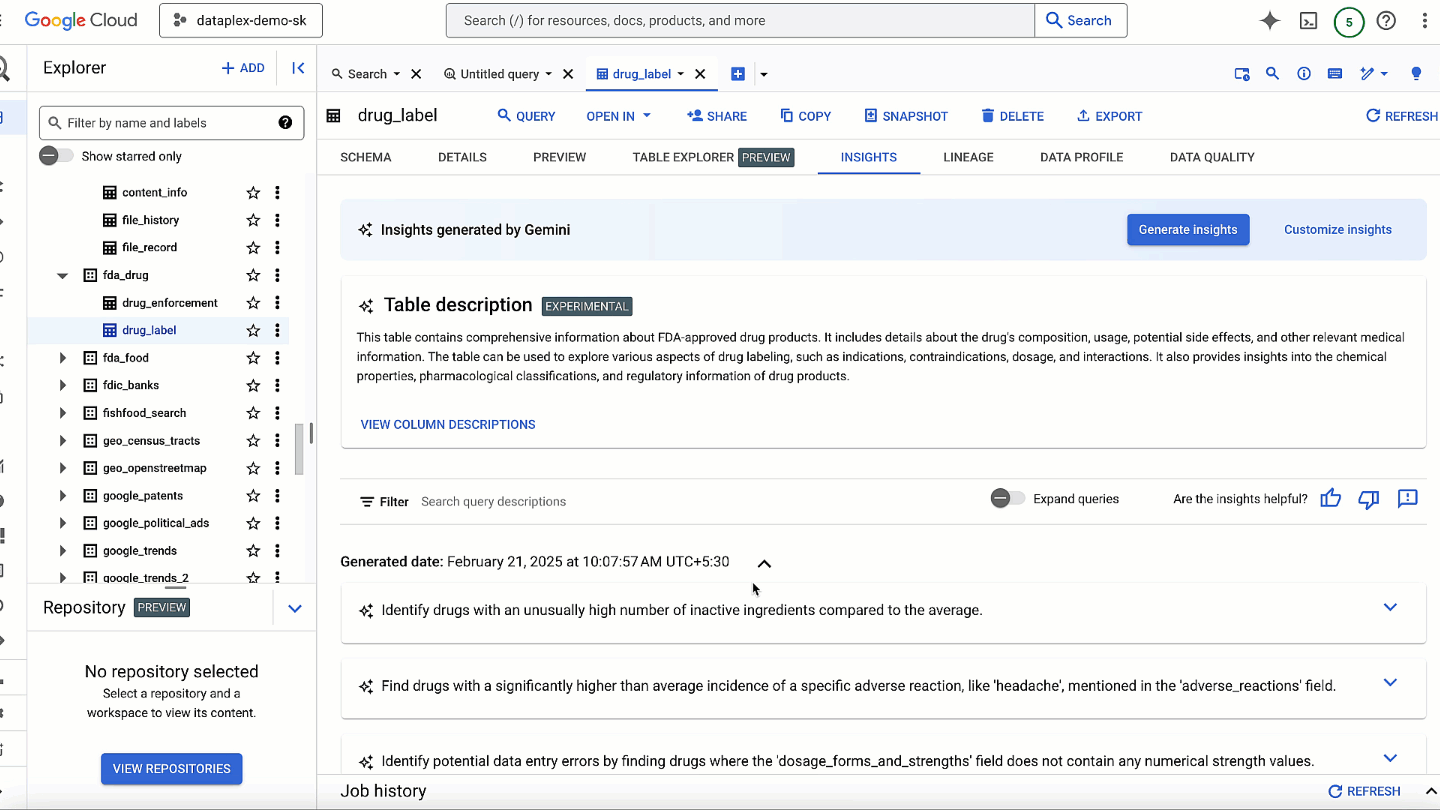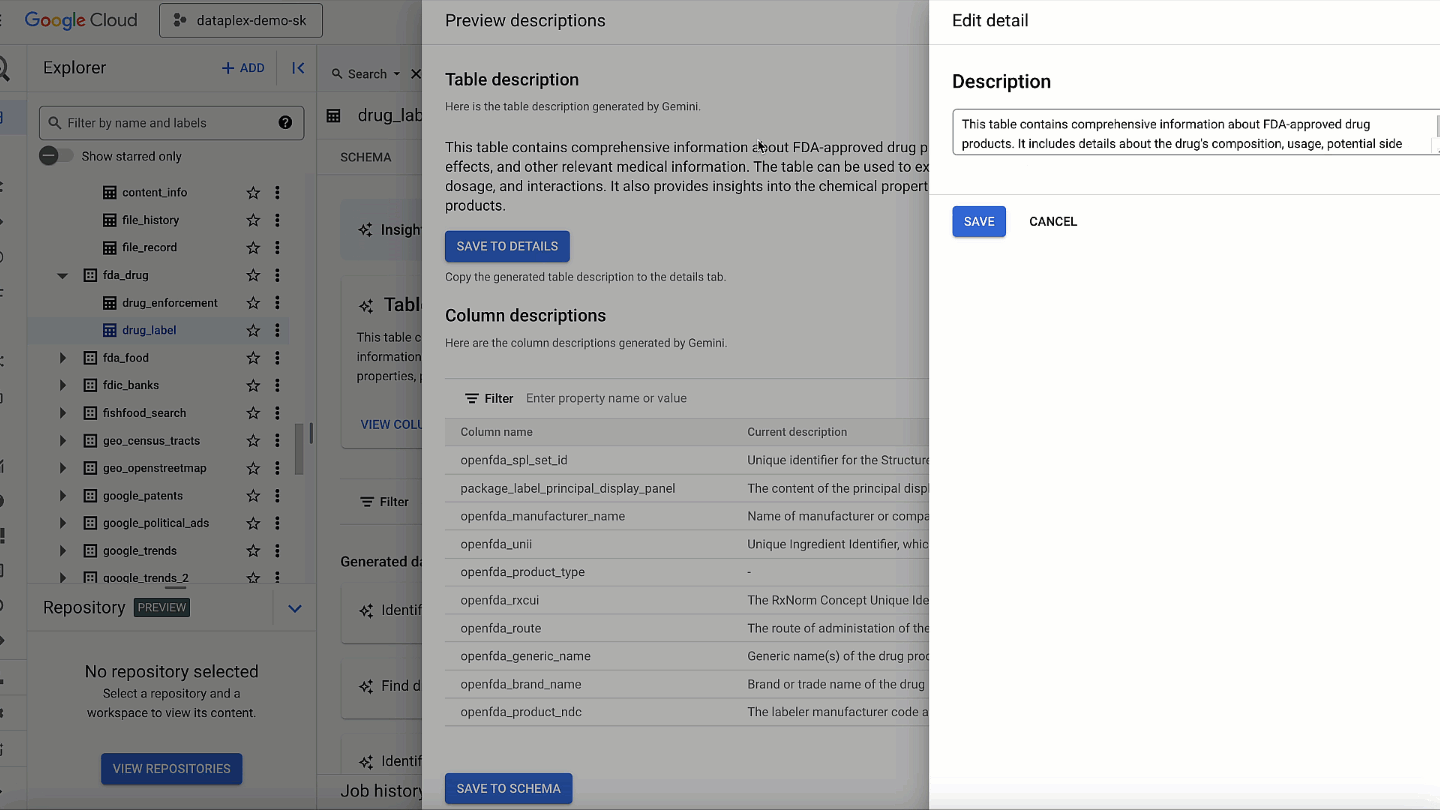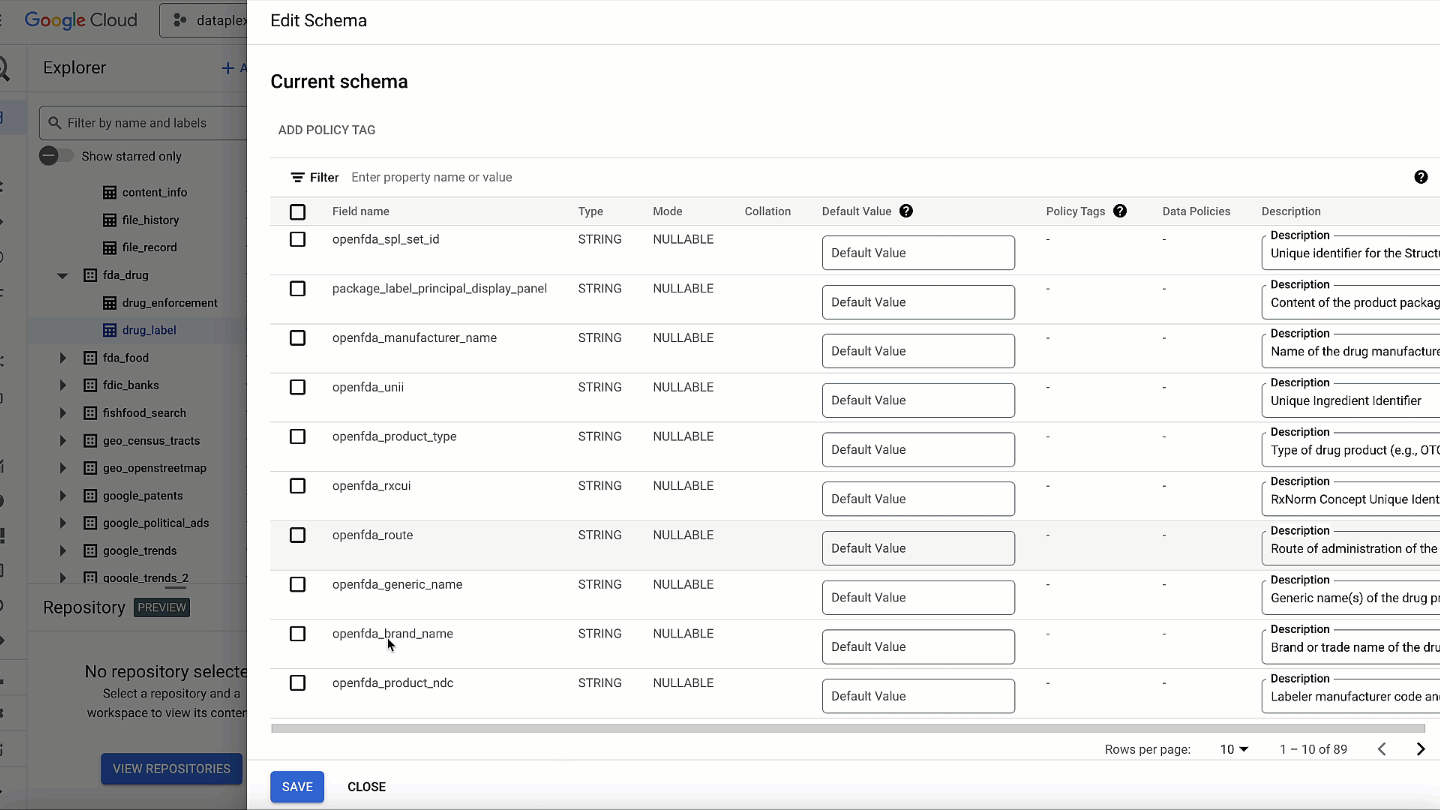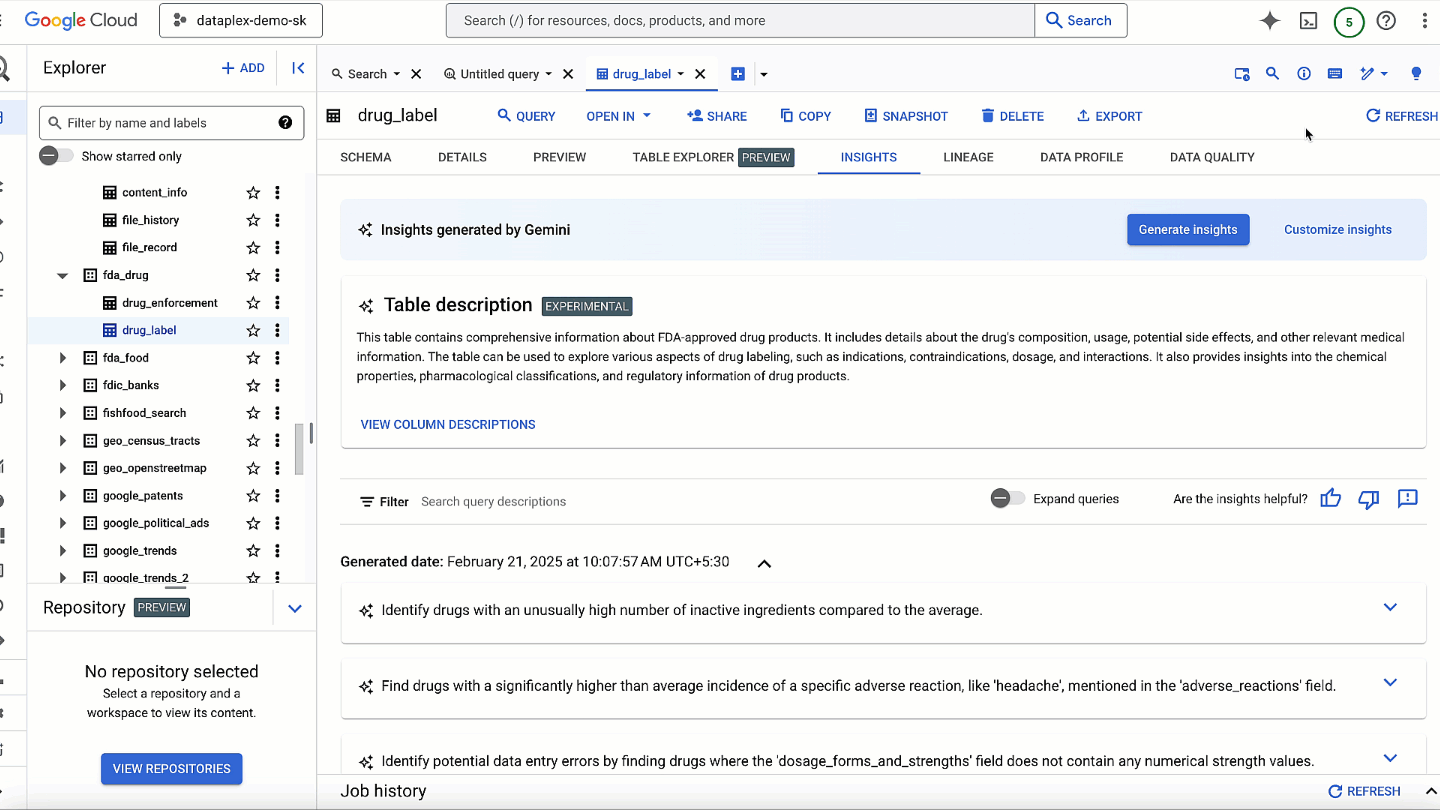
Gaining comprehensive visibility into threats across your entire digital landscape is paramount for security teams. We’re excited to bring our capabilities, products, and expertise to the upcoming RSA Conference in San Francisco, where you can learn more about our latest innovations, and where we’ll be sharing insight from this year’s highly-anticipated M-Trends report.
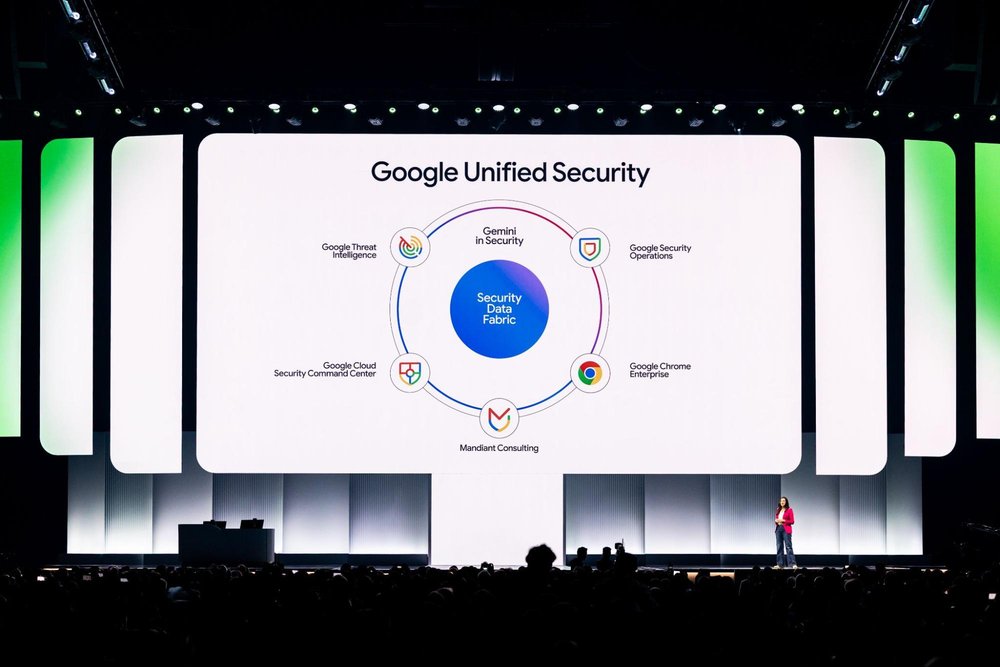
We now offer a streamlined, effective way to make Google an integral part of your security team with Google Unified Security, announced at Google Cloud Next earlier this month. This converged solution brings together the best of Google — unmatched threat visibility, faster threat detection, continuous virtual red-teaming, the most trusted browser, and Mandiant expertise — supercharged by Google Gemini and running on a planet-scale security fabric.
In addition to exploring Google Unified Security firsthand at the RSA Conference, you can take a deep dive into our newest M-Trends report, showcasing the results of more than 450,000 hours of frontline incident response investigation analysis from 2024.
From connecting with Google’s security experts to witnessing innovative cloud security technology in action, Google Cloud Security is the place to be at the RSA Conference. We’ve got a packed schedule of booth activities, insightful keynotes, deep-dive sessions, and exclusive events you won’t want to miss.
Here’s your guide to everything Google Cloud Security is bringing to RSA Conference 2025.
Meet us at our booth: Dive into demos and test your knowledge
Find the Google Cloud Security team on the show floor at booth #N-6062 in the Moscone Center, North Hall. Here you can:
Meet with our security experts: Engage in one-on-one conversations and discover how making Google a part of your security team can strengthen your defenses with Google Unified Security.
Check out live presentations and 1:1 demos: Experience our latest security innovations firsthand and see how Google Unified Security can address your specific challenges.
Test your knowledge at M-Trends trivia: Put your threat intelligence skills to the test for a chance to win exciting prizes.
Gain insights directly from Google Cloud Security leaders
Beyond speculation: Data-driven insights into AI and cybersecurity Hear Sandra Joyce, VP, Google Threat Intelligence, assess the real-world and future impacts of AI in cybersecurity. This session cuts through the noise to expose practical applications of AI, drawing on Mandiant’s incident response engagements and analysis of attacker use of Gemini.
Tuesday, April 29 | 10:50 AM | Moscone West Keynote Stage
Cybersecurity Year-in-Review and The Future Ahead Kevin Mandia, one of industry’s most prominent and respected voices, will present his annual report on the cyber landscape, including the evolving CISO role, emergence of AI, and need for resilience. He’ll be joined by former New York Times cyber reporter Nicole Perlroth to discuss the data and share firsthand stories and actionable strategies to strengthen defenses and prepare for the future.
Wednesday, Apr 30 | 9:40 AM – 10:30 AM PDT | Moscone South Keynote Stage
Explore expert-led sessions
We have an exciting lineup of Google Cloud Security speakers who will be presenting at RSAC this year — on the mainstage, in track sessions, and at our Google Cloud Security hub in the Marriott Marquis. Below are the highlights of our Google-led sessions from RSAC, and see our website for a complete list.
Speakers: Anton Chuvakin, Senior Staff Security Advisor, Google Cloud; Michael Bernhardt, Director for Information Security, DATEV;John Dickson, CEO, Bytewhisper Security; Diana Kelley, CISO, Protect AI
Speaker: Daniel Fabian, Principal Digital Arsonist, Google
Wednesday, Apr 30 | 8:30 AM – 9:20 AM PDT
Visit the Google Cloud Security Hub for exclusive events
Join us at the Marriott Marquis for exclusive sessions and networking opportunities at the Google Cloud Security Hub. Register now to secure your spot:
Executive breakfast | Modern cyber defense: Building resilient organizations in a complex world: Join us for an exclusive breakfast briefing where we’ll address the unprecedented challenges facing modern cyber defense. This session will explore the critical role of information sharing and AI in Google Unified Security, and how it helps build more robust and resilient organizations in today’s increasingly complex world.
Tuesday, April 29 | 8:00 AM | Marriott Marquis – Google Cloud Security Hub
Threat Intelligence briefing and luncheon: Learn the latest frontline intelligence over lunch with Google Threat Intelligence Group VP, Sandra Joyce and Chief Analyst, John Hultquist. Don’t miss this exclusive threat overview, where they’ll share observations and analysis of the current threat landscape and how to build a resilient cybersecurity program.
Tuesday, April 29 | 12:00 PM – 1:15 PM | Marriott Marquis – Google Cloud Security Hub
Unwind and connect at our Customer Lounge
During the week, relax and connect with Google Cloud Security experts and partners at the Marriott Marquis for breakfast, lunch, snacks, coffee, and boba. Participate in additional Google Cloud Security sessions, play games, and get a new headshot while networking with other security professionals.
Join us in the space for the return of Tasting Tuesday and Wine Down Wednesday (both starting at 5:30 PM), brought to you in collaboration with Google Cloud Security partners.
Tasting Tuesday: A Delicious Start to RSAC: Enjoy a vibrant atmosphere, eat San Francisco-inspired cuisine, listen to great live music while connecting with industry peers, and savor the start of a successful conference.
Wine Down Wednesday: Celebrate Success: Join us for the ultimate RSAC closing event. Enjoy pairings of great wine and food and live music, and raise a glass to new connections and a successful week of achievements.
Meet you there
RSA Conference 2025 promises to be an insightful week, and Google Cloud Security is ready to contribute valuable knowledge and innovative solutions. We encourage you to make the most of your time by visiting our booth, attending our sessions, re-energizing at the Google Cloud Security Hub in the Marriott Marquis, and connecting with our team.
We’re eager to discuss your security challenges and demonstrate how Google can be your strategic security partner in the face of evolving threats. If you can’t join us in person, we encourage you to stream the RSA Conference sessions here to stay one step ahead of threats.
Editor’s note: Ping Xie is a Valkey maintainer on the Valkey Technical Steering Committee (TSC).
Memorystore, Google Cloud’s fully managed in-memory service for Valkey, Redis and Memcached, plays an increasingly important role in our customers’ deployments — in fact, over 90% of the top 100 Google Cloud customers use Memorystore. Today, we’re excited that the Memorystore for Valkey service is now generally available, a significant step forward for open-source in-memory data management on the cloud. With the GA, you can now run your production workloads on Memorystore for Valkey backed by a 99.99% availability SLA along with features such as Private Service Connect, multi-VPC access, cross-region replication, persistence, and many more.
When we launched the preview of Memorystore for Valkey in August 2024, hundreds of Google Cloud customers like Major League Baseball (MLB) and Bandai Namco Studios Inc. jumped in and deployed the service. In the last few months, they’ve provided us with invaluable feedback that has shaped the service we’re announcing today:
“At Major League Baseball, our use of Memorystore has been a key part in optimizing how we bring data to our fans. We are excited about the general availability of Memorystore for Valkey, a truly open-source alternative. We believe its inherent flexibility and the power of community-driven development will further enhance our speed, scalability, and real-time data processing capabilities, allowing us to better serve our fans, players, and operations.” – Rob Engel, Vice President of Software Engineering, Major League Baseball
“Bandai Namco Studios uses Memorystore to power the low-latency and high-scale performance essential for many of our titles. We’re excited about the GA launch of Memorystore for Valkey. Its speed, features, and truly open-source nature will empower us to enhance real-time gameplay and scale for our global player base. We look forward to leveraging Memorystore for Valkey’s capabilities to continue pushing the boundaries of gaming innovation.”– Motoo Fukuda, Technical Director at Bandai Namco Studios Inc.
aside_block
<ListValue: [StructValue([(‘title’, ‘$300 in free credit to try Google Cloud databases’), (‘body’, <wagtail.rich_text.RichText object at 0x3e573ddbe580>), (‘btn_text’, ‘Start building for free’), (‘href’, ‘http://console.cloud.google.com/freetrial?redirectPath=/products?#databases’), (‘image’, None)])]>
What’s new at GA
At GA,Memorystore for Valkeyis backed by a 99.99% SLApowered by Google’s advanced high availability and zonal placement algorithms, and ships with a comprehensive suite of enterprise-grade features such as:
Support for Private Service Connect: Memorystore for Valkey is built on top of Private Service Connect, which allows customers to connect to up to 250 shards using just two IP addresses. Memorystore’s discovery endpoint being highly available ensures no single point of failure for your cluster.
Zero-downtime scaling: Memorystore for Valkey offers zero downtime scaling (in and out) so your cluster can grow with your application’s needs, and so it’s cost-optimized for your workloads. It supports cluster sizes ranging from 1 to 250 nodes.
Integrated Google-built vector similarity search: Memorystore for Valkey supports ultra-low latency, in-memory vector search, and can perform vector search at single-digit millisecond latency on over a billion vectors, with greater than 99% recall.
This performance is powered by Google’s vector search module, the official search module for the Valkey OSS project, which is integrated into Memorystore for Valkey. The module enables modern AI applications for gen AI use cases such as retrieval-augmented generation (RAG), recommendation systems, and semantic search. With hybrid search support, users can achieve more accurate and contextually relevant search results, leading to improved application performance and a better user experience.
Managed backups: Access to built-in managed backups enables both automated and on-demand backups for migrations, disaster recovery, and compliance.
Cross-region replication (CRR): Using CRR, you can achieve disaster recovery prepared-ness and low-latency reads across regions. At this time, in addition to the primary region, we support up to two secondary regions with clusters that in turn can have varying numbers of replicas. Memorystore for Valkey ensures both the data plane and control plane remain in sync across regions.
Multi-VPC access: Memorystore for Valkey supports multiple client-side VPCs to connect to one Private Service Connection endpoint on the Valkey cluster. Using this technology, you can securely connect clients across multiple projects and VPCs.
Persistence: Memorystore for Valkey offers both RDB-snapshot and AOF-logging based persistence to meet varying data durability requirements.
Memorystore for Valkey supports both Valkey 7.2, and our engine of choice, Valkey 8.0, which offers many enhancements over its predecessors:
Exceptional performance: With asynchronous I/O improvements, Memorystore for Valkey 8.0 delivers better throughput and achieves up to 2x Queries Per Second(QPS) of Memorystore for Redis Cluster at microseconds latency, helping applications handle demanding internet-scale workloads with ease.
While priced in-line with Memorystore for Redis Cluster, Memorystore for Valkey’s performance optimizations can lead to substantial cost savings by potentially requiring fewer nodes to handle the same workload.
Optimized memory efficiency: Valkey 8.0’s optimized memory management delivers improved memory savings, reducing operational costs across various workloads.
Enhanced reliability: Valkey 8.0 offers significantly more reliable scaling with Google-contributed features like automatic failover for empty shards and highly available migration states. Additionally, we also introduced migration states auto-reparing to further strengthen system resilience.
In addition, Memorystore for Valkey also provides other capabilities, such as maintenance windows, single zone clusters, single shard clusters, no-cost inter-zone replication, etc.
Our commitment to open source and customer trust
Following licensing updates to Redis OSS by Redis Inc. in March 2024, the open-source community established Valkey OSS as an alternative that’s supported by organizations including Google, Amazon, Snap and others.
We deeply value the trust you place in us. To ensure you continue to have access to powerful, open technology, we launched Memorystore for Valkeyon Google Cloud. Unlike Redis, the Valkey OSS project is under the BSD 3-clause license and backed by the Linux Foundation. The momentum behind Valkey has been exhilarating.
In addition to Memorystore for Valkey, we are also committed to supporting and delivering new capabilities for Memorystore for Redis Cluster and Memorystore for Redis. And when Memorystore for Redis customers are ready to adopt Valkey — for its price-performance, reliability and open-source nature — we offer full migration support. Memorystore for Valkey is fully compatible with Redis OSS 7.2 APIs and your favorite clients, making it easy to switch to open source. Further, you can reuse your Memorystore for Redis and Memorystore for Redis cluster committed use discounts (CUDs), smoothing the transition.
Try Memorystore for Valkey today
The best way to experience the power of Memorystore for Valkey is to try it out. Get started with the documentation or deploy your first Valkey instance. Don’t let having to self-manage Redis hold you back. Experience the simplicity and speed of Memorystore for Valkey today and see how it can power your applications, so you can focus on what matters: innovating and creating impactful applications for your business!
Welcome to the first Cloud CISO Perspectives for April 2025. Today, Google Cloud Security’s Peter Bailey reviews our top 27 security announcements from Next ‘25.
As with all Cloud CISO Perspectives, the contents of this newsletter are posted to the Google Cloud blog. If you’re reading this on the website and you’d like to receive the email version, you can subscribe here.
–Phil Venables, strategic security advisor, Google Cloud
aside_block
<ListValue: [StructValue([(‘title’, ‘Get vital board insights with Google Cloud’), (‘body’, <wagtail.rich_text.RichText object at 0x3e19d6588220>), (‘btn_text’, ‘Visit the hub’), (‘href’, ‘https://cloud.google.com/solutions/security/board-of-directors?utm_source=cloud_sfdc&utm_medium=email&utm_campaign=FY24-Q2-global-PROD941-physicalevent-er-CEG_Boardroom_Summit&utm_content=-&utm_term=-‘), (‘image’, <GAEImage: GCAT-replacement-logo-A>)])]>
27 top security announcements at Next ‘25
By Peter Bailey, VP/GM SecOps, Google Cloud Security
We just wrapped our annual Google Cloud Next conference in Las Vegas, where we introduced innovations across AI, app development, infrastructure, data cloud, partners, and more — including security.
Peter Bailey, VP/GM SecOps, Google Cloud Security
From the moment the curtain went up at our opening keynote, we showcased 229 new products, new capabilities, and new enhancements that highlight Google Cloud’s commitment to how our AI-optimized platform can help transform the way that companies work and our skyrocketing customer momentum.
Google Unified Security brings together our visibility, threat detection, AI powered security operations, continuous virtual red-teaming, the most trusted enterprise browser, and Mandiant expertise — in one converged security solution running on a planet-scale data fabric.
(Be sure to check out the reimagining of the Wizard of Oz at The Sphere, a collaboration between Sphere Entertainment, Google DeepMind, Google Cloud, Hollywood production company Magnopus, and five others.)
For the first time this year, we also hosted CISO Connect at Next, a unique opportunity for security and business leaders to delve into the ever-evolving cybersecurity landscape with experts from Google on the current threat landscape, breach mitigation strategies, and the transformative potential of AI in fortifying your organization’s security posture.
“We are all solving for the same security challenges; CISO Connect offers a safe environment to collaborate and share, unlike any other conference,” said Mike Orosz, CISO, Vertiv.
We also focused heavily on innovations across our security portfolio, designed to deliver stronger security outcomes and enable every organization to make Google a part of their security team. Fresh from Next ‘25, here’s our top 27 security announcements.
Google Unified Security brings together our visibility, threat detection, AI powered security operations, continuous virtual red-teaming, the most trusted enterprise browser, and Mandiant expertise — in one converged security solution running on a planet-scale data fabric.
The alert triage agent in Google Security Operations will perform dynamic investigations on behalf of users. Expected to preview for select customers in Q2 2025, it analyzes the context of each alert, gathers relevant information, and renders a verdict on the alert, along with a history of the agent’s evidence and decision making.
The malware analysis agent in Google Threat Intelligence will investigate whether code is safe or harmful. Expected to preview for select customers in Q2 2025, it builds on Code Insight to analyze potentially malicious code, including the ability to create and execute scripts for deobfuscation.
Google Security Operations
New data pipeline management capabilities, now generally available, can help customers better manage scale, reduce costs, and satisfy compliance mandates.
The new Mandiant Threat Defense service, now generally available, provides comprehensive active threat detection, hunting, and response. Mandiant experts work alongside customer security teams, using AI-assisted threat hunting techniques to identify and respond to threats, conduct investigations, and scale response through security operations SOAR playbooks, effectively extending customer security teams.
Security Command Center
Model Armor is now integrated directly with Vertex AI. As part of our recently-announced AI Protection capabilities that can help manage risk across the AI lifecycle, developers can automatically route prompts and responses for protection without any changes to applications.
New Data Security Posture Management (DSPM) capabilities, coming to preview in June, can enable discovery, security, governance, and monitoring of sensitive data including AI training data. DSPM can help discover and classify sensitive data, apply data security and compliance controls, monitor for violations, and enforce access, flow, retention, and protection directly in Google Cloud data analytics and AI products.
A new Compliance Manager, launching in preview at the end of June, will combine policy definition, control configuration, enforcement, monitoring, and audit into a unified workflow. It builds on the configuration of infrastructure controls delivered using Assured Workloads, providing Google Cloud customers with an end-to-end view of their compliance state, making it easier to monitor, report, and prove compliance to auditors with Audit Manager.
Integration with Snyk’s developer security platform, in preview, to help teams find and fix software vulnerabilities faster.
New Security Risk dashboards for Google Compute Engine and Google Kubernetes Engine. Now generally available, they can deliver insights into top security findings, vulnerabilities, and open issues directly in the product consoles.
An expandedRisk Protection Program, with new program partners Beazley and Chubb, two of the world’s largest cyber-insurers. They will provide discounted cyber-insurance coverage based on cloud security posture.
Chrome Enterprise Premium
New employee phishing protections use Google Safe Browsing data to help protect employees against lookalike sites and portals attempting to capture credentials.
Data masking in Chrome Enterprise Premium is now generally available.
We are also extending key enterprise browsing protections to Android, including copy and paste controls, and URL filtering.
Mandiant Cybersecurity Consulting
The Mandiant Retainer provides on-demand access to Mandiant experts. Customers now can redeem prepaid funds for investigations, education, and intelligence to boost their expertise and resilience.
Mandiant Consulting is partnering withRubrik andCohesity to create a solution to minimize downtime and recovery costs after a cyberattack. As part of the program, our partners provide affirmative AI insurance coverage, exclusively for Google Cloud customers and workloads. Chubb will also offer coverage for risks resulting from quantum exploits, proactively helping to address the risk of quantum computing attacks.
Sovereign Cloud
We’ve partnered with Thales to launch theS3NS Trusted Cloud, now in preview, designed to meet France’s highest level of cloud certification. As part of our broad portfolio of sovereign cloud solutions, it is the first sovereign cloud offering based on Google Cloud platform, that is in this case operated, majority-owned and fully controlled by a European organization.
Identity and Access Management
Unified access policies, coming to preview in Q2, create a single definition for IAM allow and IAM deny policies, enabling you to more consistently apply fine grained access controls.
We’re also expanding our Confidential Computing offerings. Confidential GKE Nodes with AMD SEV-SNP and Intel TDX will be generally available in Q2, requiring no code changes to secure your standard GKE workloads. Confidential GKE Nodes with NVIDIA H100 GPUs on the A3 machine series will be in preview in Q2, offering confidential GPU computing without code modifications.
Single-tenant Cloud Hardware Security Module (HSM), now in preview, provides dedicated, isolated HSM clusters managed by Google Cloud, while granting customers full administrative control.
Network security
Network Security Integration allows enterprises to easily insert third-party network appliances and service deployments to protect Google Cloud workloads without altering routing policies or network architecture. Out-of-band integrations with ecosystem partners are generally available now, while in-band integrations are available in preview.
DNS Armor, powered by Infoblox Threat Defense, coming to preview later this year, uses multi-sourced threat intelligence and powerful AI/ML capabilities to detect DNS-based threats.
Cloud Armor Enterprise now includes hierarchical policies for centralized control and automatic protection of new projects, available in preview.
Cloud NGFW Enterprise supports L7 domain filtering capabilities to monitor and restrict egress web traffic to only approved destinations, coming to preview later this year.
Secure Web Proxy (SWP) now includes inline network data loss protection capabilities through integrations with Google’s Sensitive Data Protection and Symantec DLP using service extensions, available in preview.
To learn more about how your organization can benefit from our announcements at Next ‘25, check out our CISO Insights Hub, and stay tuned for our announcements later this month at the RSA Conference in San Francisco.
aside_block
<ListValue: [StructValue([(‘title’, ‘Join the Google Cloud CISO Community’), (‘body’, <wagtail.rich_text.RichText object at 0x3e19d65880a0>), (‘btn_text’, ‘Learn more’), (‘href’, ‘https://rsvp.withgoogle.com/events/ciso-community-interest?utm_source=cgc-blog&utm_medium=blog&utm_campaign=2024-cloud-ciso-newsletter-events-ref&utm_content=-&utm_term=-‘), (‘image’, <GAEImage: GCAT-replacement-logo-A>)])]>
In case you missed it
Here are the latest updates, products, services, and resources from our security teams so far this month:
Demystifying AI security: How to use SAIF in the real world: Our new paper, “SAIF in the real world,” takes a deep look at how to apply Google’s Secure AI Framework (SAIF) throughout the AI development lifecycle. Read more.
Shadow AI strikes back: Following our previous spotlight on shadow AI, we look at a new, more insidious form of shadow AI — emerging from within organizations themselves. Read more.
Google announces Sec-Gemini v1, a new experimental cybersecurity model: Sec-Gemini v1 is our new experimental AI model focused on advancing cybersecurity AI frontiers. It can power security operations workflows with state-of-the-art reasoning capabilities and extensive, current cybersecurity knowledge. Read more.
Building sovereign AI solutions with Google Cloud: The world has changed a lot since we started to speak about the options for data residency, operational transparency, and privacy controls in Google Cloud. Organizations are increasingly seeking AI solutions that drive innovation and enforce regional regulations. Here’s how Cloud Run can help. Read more.
Detecting IngressNightmare without the nightmare: To help detect the IngressNightmare vulnerability chain affecting Kubernetes Ingress Nginx Controllers, discovered by Wiz, we’ve developed a novel non-intrusive technique. Read more.
Please visit the Google Cloud blog for more security stories published this month.
aside_block
<ListValue: [StructValue([(‘title’, ‘Fact of the month’), (‘body’, <wagtail.rich_text.RichText object at 0x3e19d6588310>), (‘btn_text’, ‘Learn more’), (‘href’, ‘https://security.googleblog.com/2025/04/google-launches-sec-gemini-v1-new.html’), (‘image’, <GAEImage: GCAT-replacement-logo-A>)])]>
Threat Intelligence news
DPRK IT workers expanding in scope and scale: Google Threat Intelligence Group (GTIG) has identified an increase of active North Korean IT insider worker operations in Europe, confirming the threat’s expansion beyond the United States. This growth is coupled with evolving tactics, such as intensified extortion campaigns and the move to conduct operations in corporate virtualized infrastructure. Read more.
Suspected China-nexus threat actor actively exploiting critical Ivanti Connect Secure vulnerability: Ivanti disclosed a critical security vulnerability impacting many Ivanti Connect Secure VPN appliances on April 3. GTIG has linked UNC5221, a suspected China-nexus espionage actor, to some of the exploits of the vulnerability. Read more.
Windows RDP, going from remote to rogue: GTIG observed a novel phishing campaign in October 2024 that targeted European government and military organizations. Unlike typical remote desktop protocol (RDP) attacks focused on interactive sessions, this campaign creatively used resource redirection and malicious remote apps including a RDP proxy tool to automate malicious activities. The campaign likely enabled attackers to read victim drives, steal files, capture clipboard data (including passwords), and obtain victim environment variables. Read more.
Please visit the Google Cloud blog for more threat intelligence stories published this month.
Now hear this: Podcasts from Google Cloud
Decoding cyber-risk and threat actors in Asia-Pacific: From big-picture views to nuanced details only an expert could know, Steve Ledzian, APAC CTO, Mandiant at Google Cloud, shares his insight and knowledge with hosts Anton Chuvakin and Tim Peacock. Listen here.
The state of IAM, from cloud to AI: Henrique Teixeira, senior vice-president of strategy, Saviynt, explores with hosts Anton and Tim how identity and access management has evolved from the beginning of the cloud era through to today’s AI sea change. Listen here.
What not to do when red teaming AI: From uncovering surprises to facing new threats and exposing the same old mistakes, Alex Polyakov, CEO, Adversa AI, discusses how and why his company focuses on red teaming AI systems. Listen here.
Behind the Binary: Inside the mind of a binary ninja: Jordan Wiens, developer of the widely-used Binary Ninja and cofounder of Vector 35, brings his expertise as an avid CTF player to a discussion about the complexities of building a commercial reverse engineering platform. Listen here.
To have our Cloud CISO Perspectives post delivered twice a month to your inbox, sign up for our newsletter. We’ll be back in a few weeks with more security-related updates from Google Cloud.
Spring is a great reminder to spring clean – an annual tradition that should extend not only to your household, but also to your virtual cloud infrastructure. Why not start with Google Cloud’s FinOps Hub?
As Google Cloud customers have adopted the FinOps hub to guide their optimization initiatives, we started getting additional feedback from our business community. For example, while DevOps users have access to tools and utilization metrics to identify waste, business teams often lack clear insights into resource consumption, leading to a significant blind spot. The most recent State of FinOps 2025 Report reinforces this need, underscoring the importance of workload optimization and waste reduction as the #1 Top FinOps concern. It’s extremely difficult to optimize workloads or applications if customers cannot fully understand how much is even being used. Why purchase a committed use discount for compute cores that you might not even be fully using?
Sometimes the easiest optimizations our customers can make are really just using more efficiently the resources they are actually paying for. That’s why, in 2025, we are focused on the deep clean of your optimization opportunities and have upgraded FinOps Hub to help you find, highlight, and eliminate wasted spend.
aside_block
<ListValue: [StructValue([(‘title’, ‘Try Google Cloud for free’), (‘body’, <wagtail.rich_text.RichText object at 0x3ea0a47c7610>), (‘btn_text’, ‘Get started for free’), (‘href’, ‘https://console.cloud.google.com/freetrial?redirectPath=/welcome’), (‘image’, None)])]>
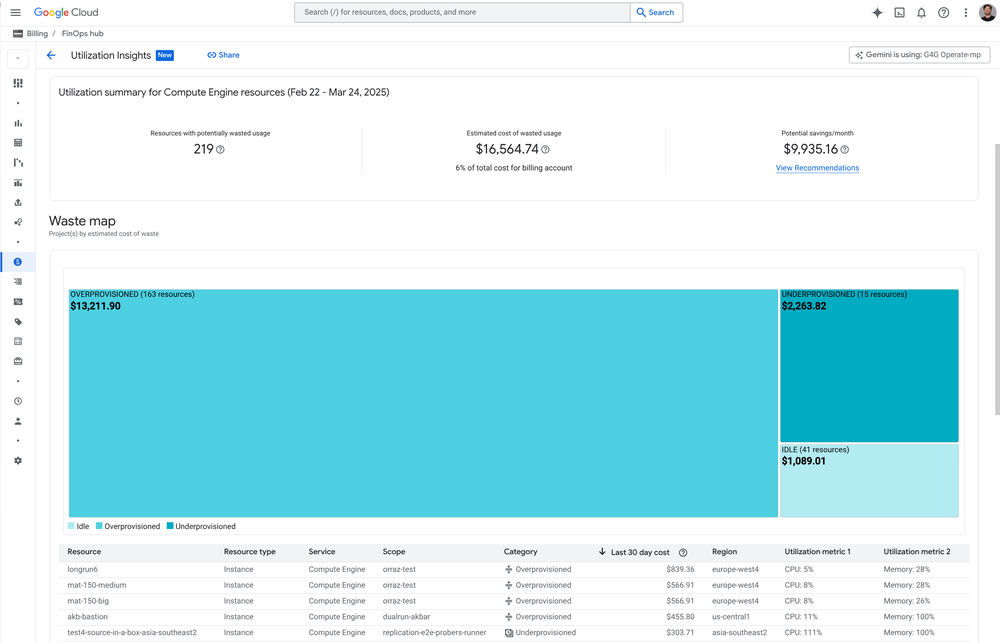
1. Find waste: FinOps Hub 2.0 now comes with new utilization insights to zero in on optimization opportunities.
At Google Cloud Next 2025, we introduced FinOps Hub 2.0,focused exclusively on bringing utilization insights on your resources to the forefront so you can see what potential waste may exist and take action immediately. Waste can come in many forms: from a VM that is barely getting used at 5% (overprovisioned), to a GKE cluster that is actually running hot at 110% utilization and might fail (underprovisioned), to managed resources like Cloud Run instances that may not be optimally configured (suboptimal configuration) or, worse yet, a VM that might not ever have been used (idle). FinOps users can now quickly view the most expensive waste category in one, easy-to-understand heatmap by service or AppHub application. But FinOps Hub doesn’t just show you where there may be waste; it also includes more cost optimizations for Kubernetes Engine (GKE), Compute Engine (GCE), Cloud Run, and Cloud SQL to remedy the waste too.
Waste map showing identified resources with their corresponding utilization metrics
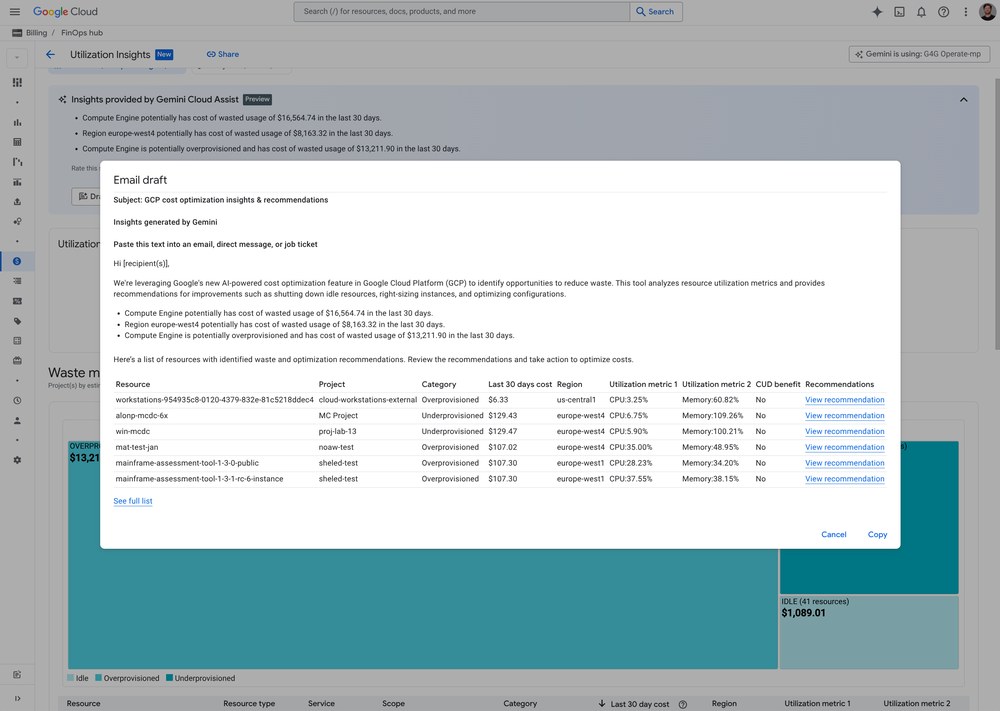
2. Highlight waste: Gemini Cloud Assist supercharges FinOps Hub to summarize optimization insights and send opportunities to engineering.
But perhaps what really makes this a 2.0 release is that we supercharged the most time-consuming tasks on FinOps Hub with Gemini Cloud Assist. Our first launch of Gemini Cloud Assist, which helps create personalized cost reports and synthesize insights, has resulted in >100k FinOps hours saved by our customers annually (from January 2024 to January 2025). The power of Gemini Cloud Assist to supercharge and automate workflows is a huge benefit, so we applied that to FinOps Hub in two ways. First, FinOps can now see embedded optimization insights on the hub itself –similar to cost reports – so you don’t need to solve the “needle in the haystack” problem of optimization. Second, you can now use Gemini Cloud Assist to summarize and send top waste insights to your engineering teams to take action and remediate fast.
Gemini summary and draft emails with top optimization opportunities
3. Eliminate waste: introducing a NEW IAM role permission for your tech solution owners to see & directly take action on these optimization opportunities.
Finally, perhaps our most exciting feature – and long overdue for FinOps – is that we are unlocking access to the Billing console for tech solution owners, so that these owners can get FinOps insights and Gemini Cloud Assist insights across all their projects, in a single pane. For example, if you want to give access to FinOps Hub or cost reports to an entire department that only uses a subset of projects for their infrastructure – without providing them with broader billing data access, but still allowing them to see all of their data in a single view – now you can, with multi-project views in the billing console. Multi-project views are enabled using the new Project Billing Costs Manager IAM role (or related granular permissions). These new permissions are currently in private preview so sign-up to get access. Now you can truly extend the power of FinOps tools across your organization with these new access controls.
So take this Spring to try FinOps Hub 2.0 with Gemini Cloud Assist, and do some spring cleaning on your cloud infrastructure, because as the saying goes, “With clouds overgrown, like winter’s old grime, Spring clean your servers, save dollars and time.” – well at least that’s what they say according to Gemini.
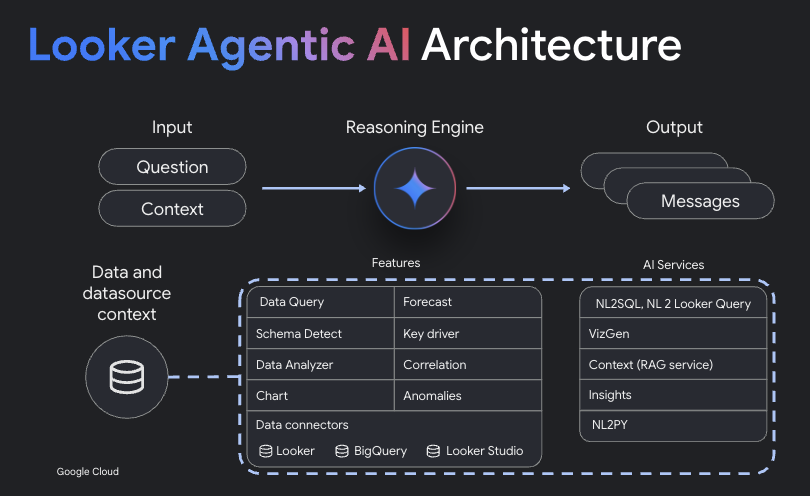
Driven by generative AI innovations, the Business Intelligence (BI) landscape is undergoing significant transformation, as businesses look to bring data insights to their organization in new and intuitive ways, lowering traditional barriers that have often kept discoveries out of the hands of the broader organization.
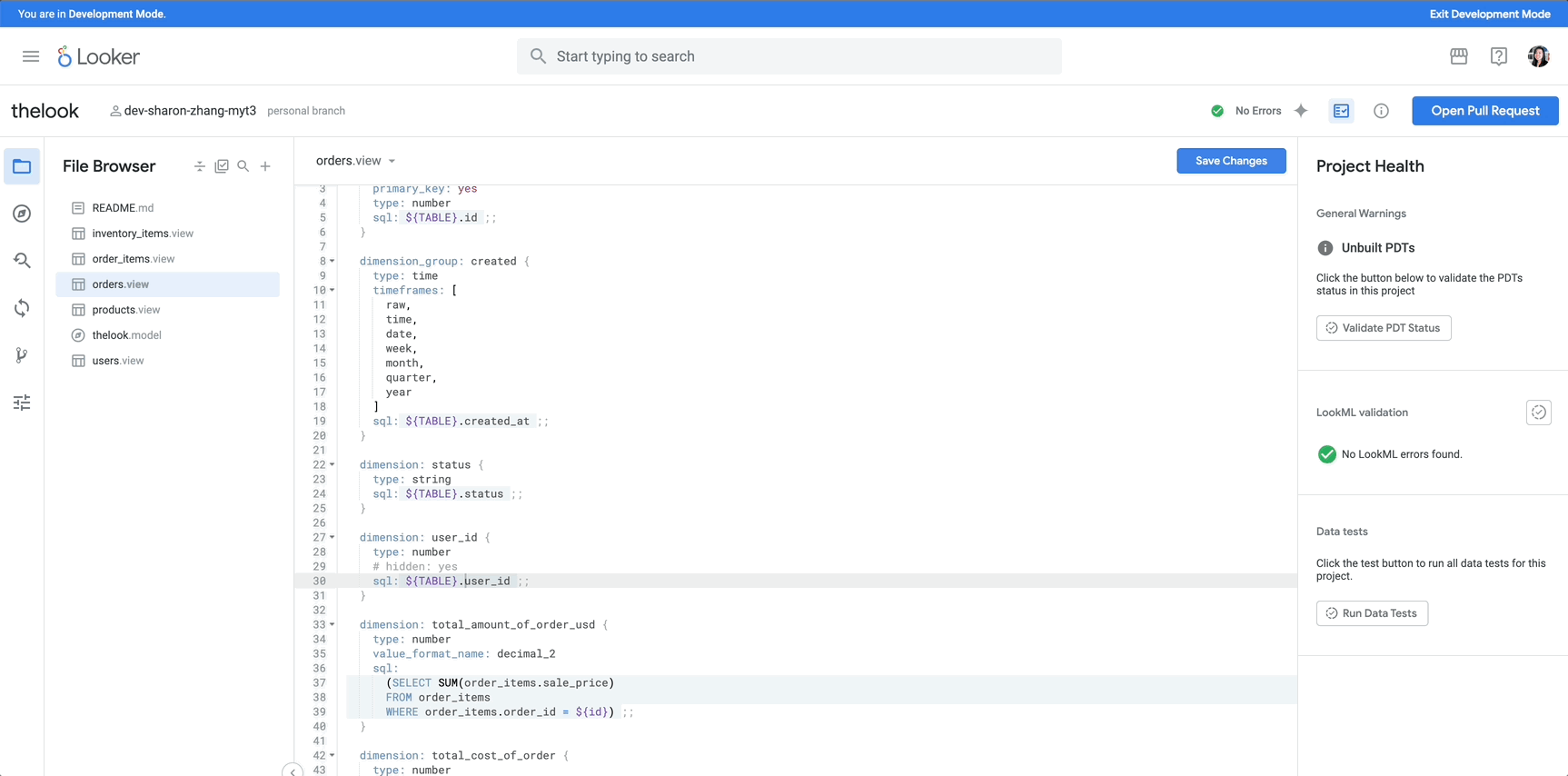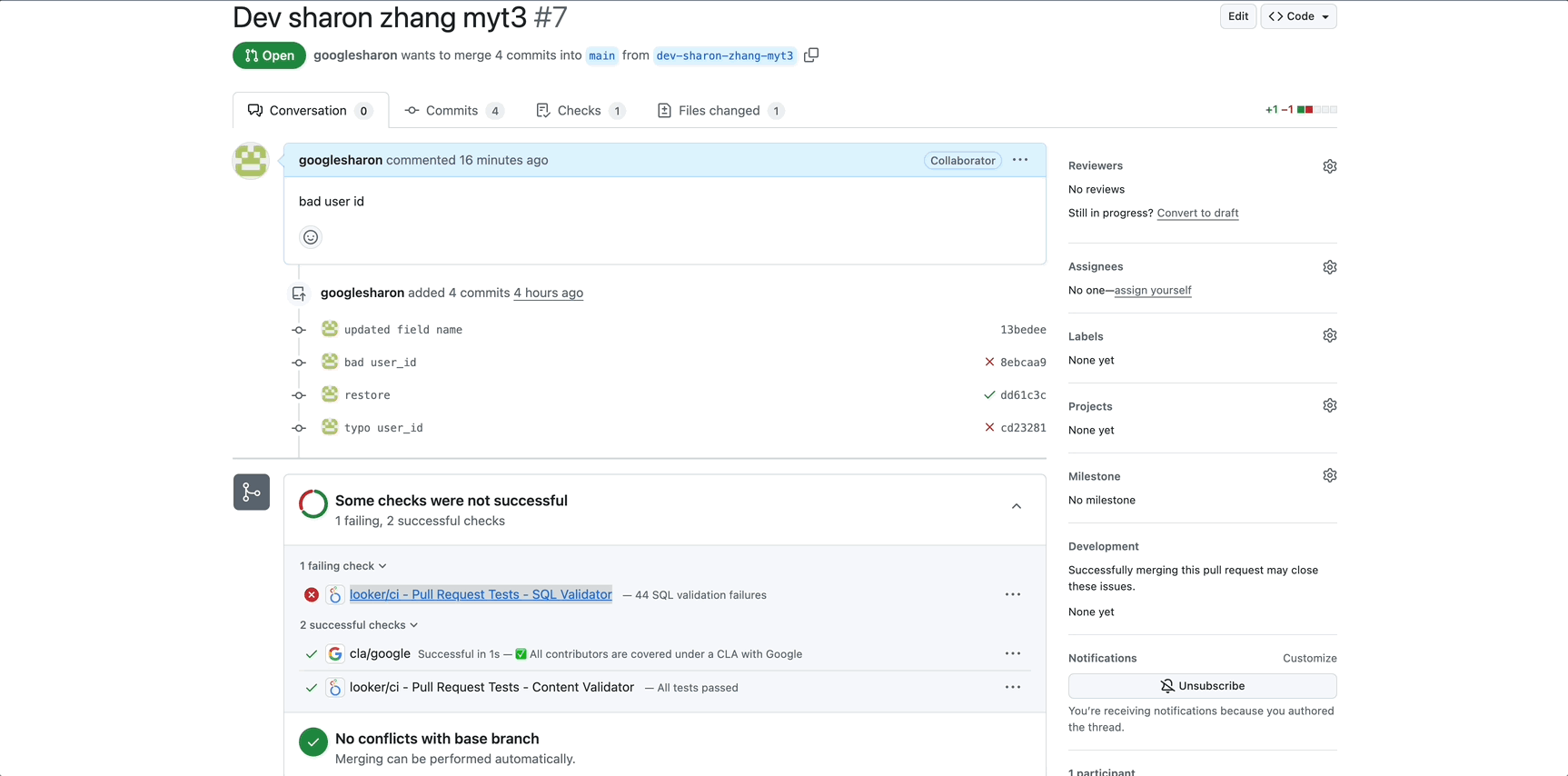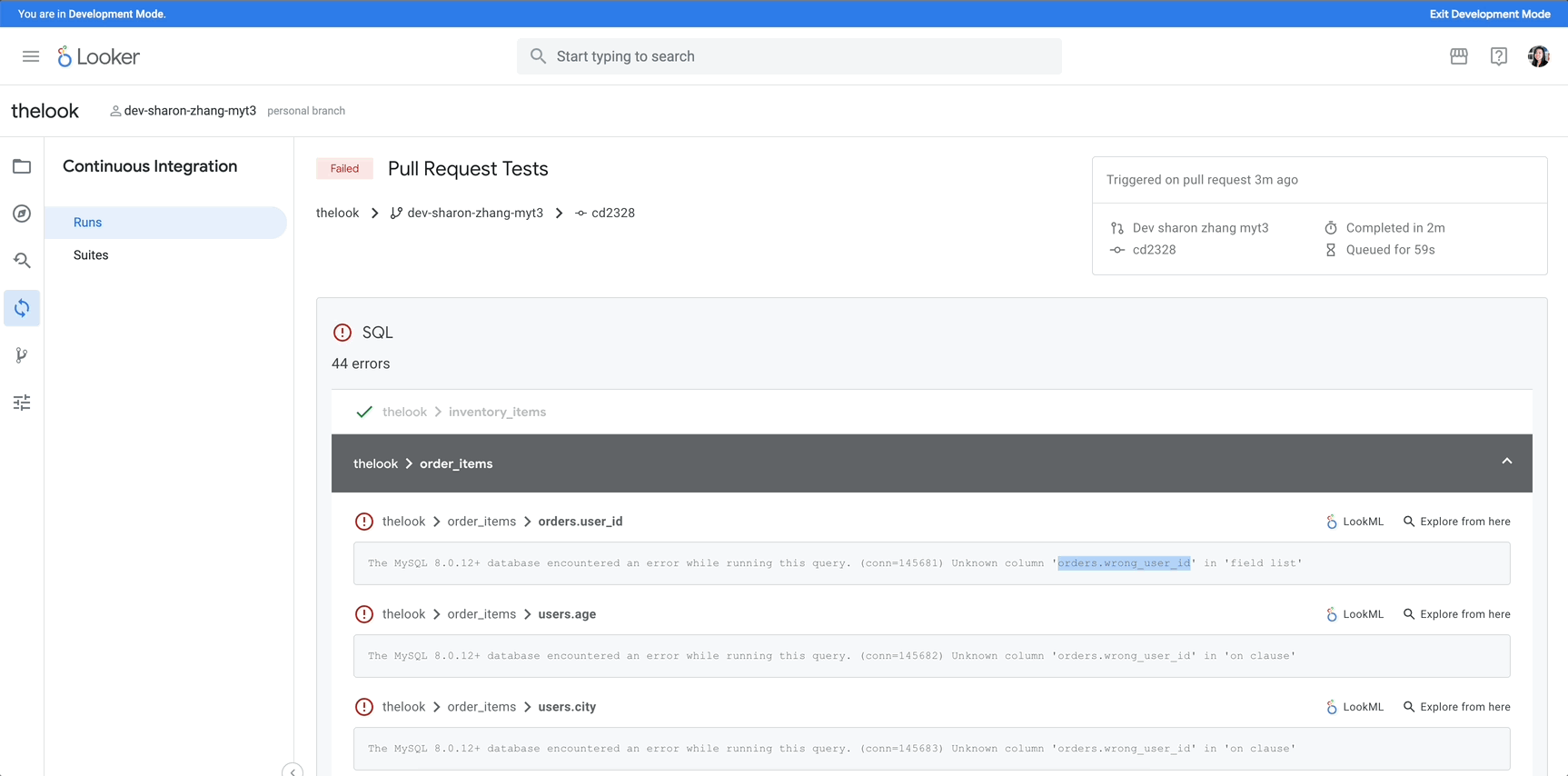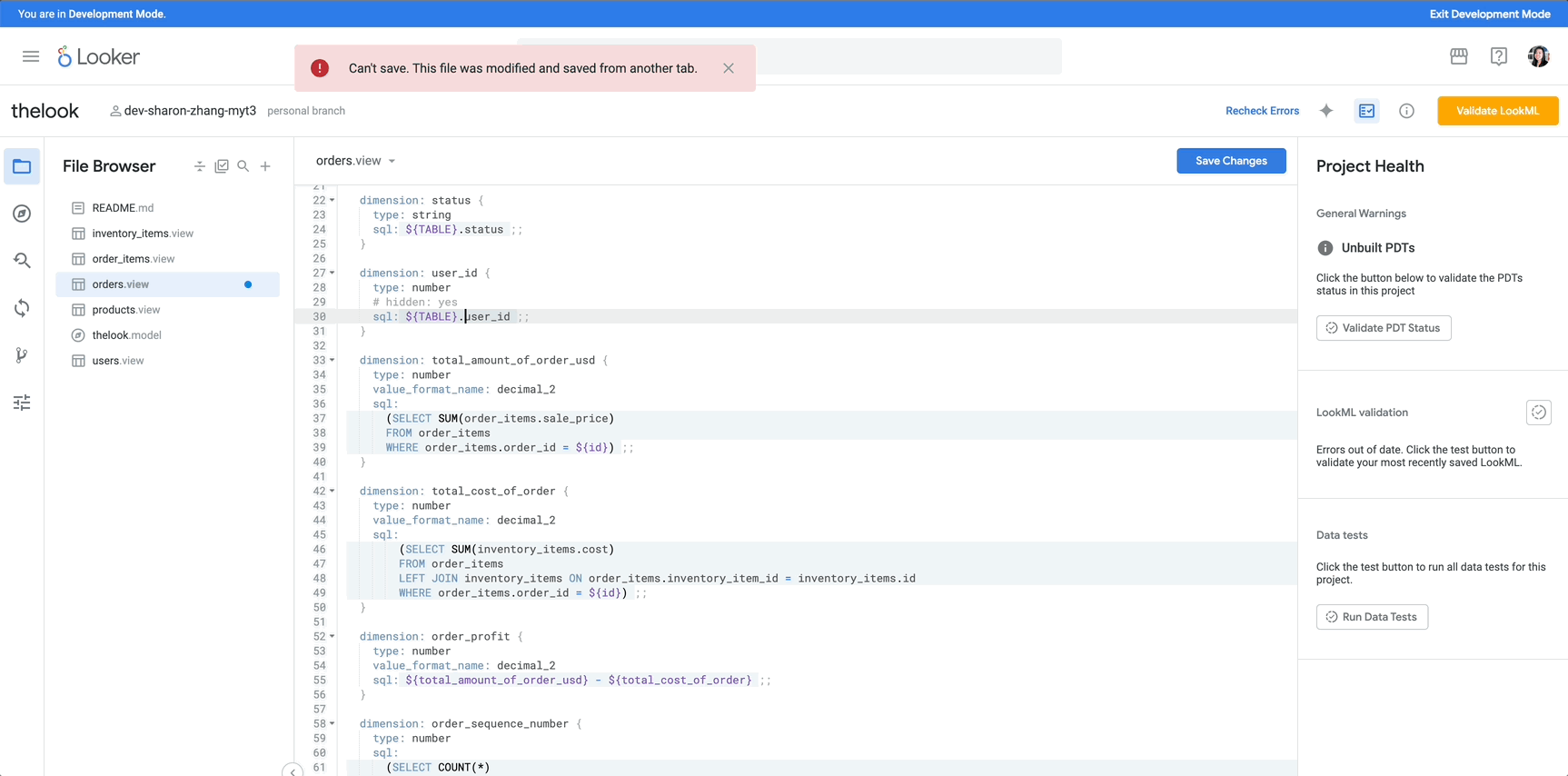
We’re spearheading this trend with Gemini in Looker, which builds upon Looker’s history as a cloud-first BI tool underpinned by a semantic layer that aligns data and that changes how users interact with it: with intelligent, AI-powered BI powered by Google’s latest AI models. The convergence of AI and BI stands to democratize data insights across organizations, moving beyond traditional methods to make data exploration more intuitive and accessible.
Gemini in Looker lowers technical barriers to accessing information, enhancing collaboration, and accelerating the process of turning raw data into actionable insights. As we announced at Google Cloud Next 25, we are expanding access to Gemini in Looker, making it now available to all Looker platform users. In this post, we discuss its key features, underlying architecture, and its transformative potential for both data analysts and business users.
aside_block
<ListValue: [StructValue([(‘title’, ‘$300 in free credit to try Google Cloud data analytics’), (‘body’, <wagtail.rich_text.RichText object at 0x3e322d85fbe0>), (‘btn_text’, ‘Start building for free’), (‘href’, ‘http://console.cloud.google.com/freetrial?redirectPath=/bigquery/’), (‘image’, None)])]>
Using AI to enhance productivity and efficiency
We designed Gemini in Looker with a clear objective: to improve productivity for analysts and business users with AI. Gemini in Looker makes it easier to prepare data and semantic models for BI, and simplifies building dashboard visualizations and reports. Additionally, Gemini in Looker can help business users’ efficiency by improving their data literacy and fluency, enabling them to tell data stories in their presentations, and use natural language to go beyond the dashboard to get answers to their questions. The result is analysts can do their jobs faster and business users can tell data stories and get answers.
Gemini in Looker does this through a suite of gen-AI-powered capabilities that make analytics tasks and workflows easier:
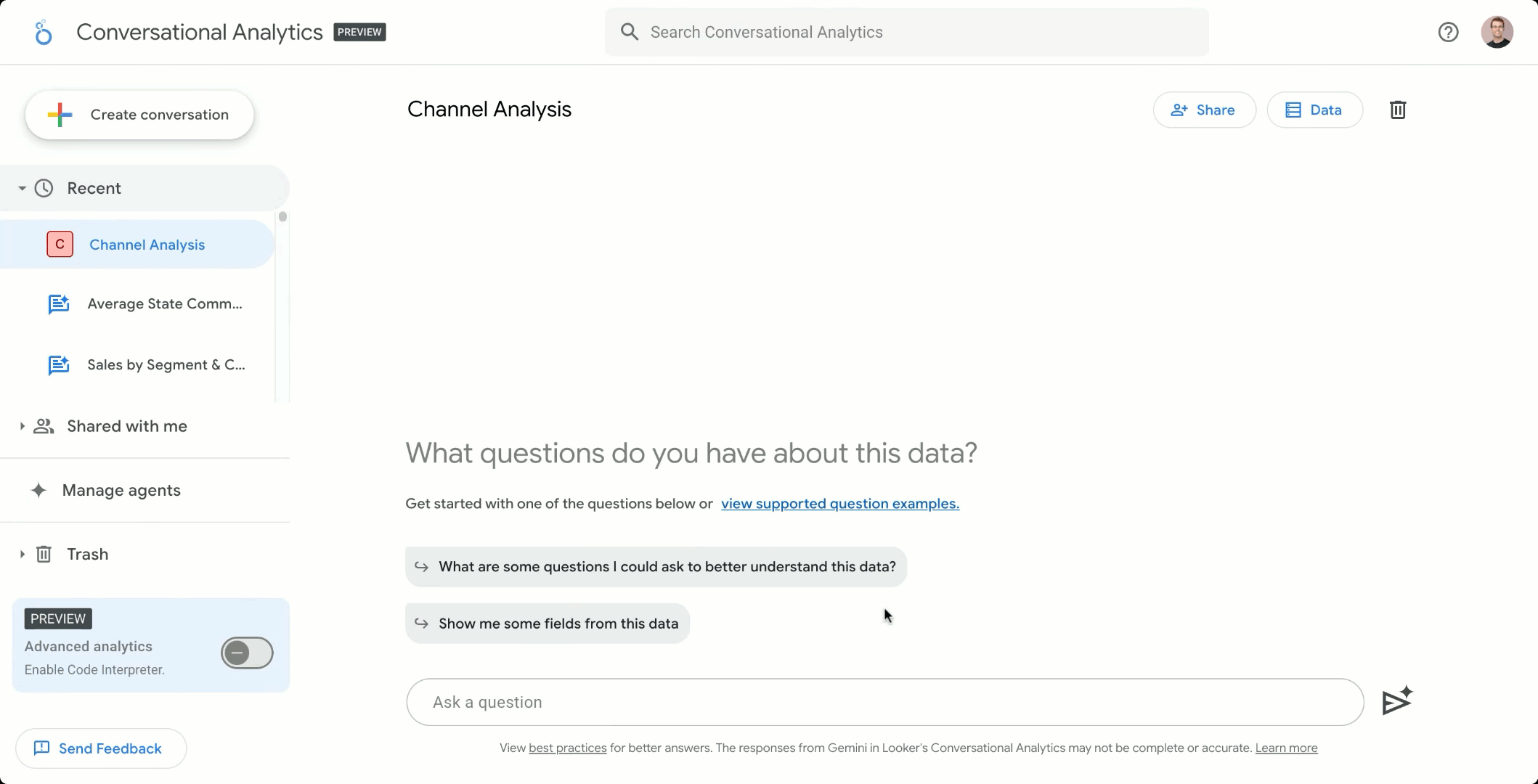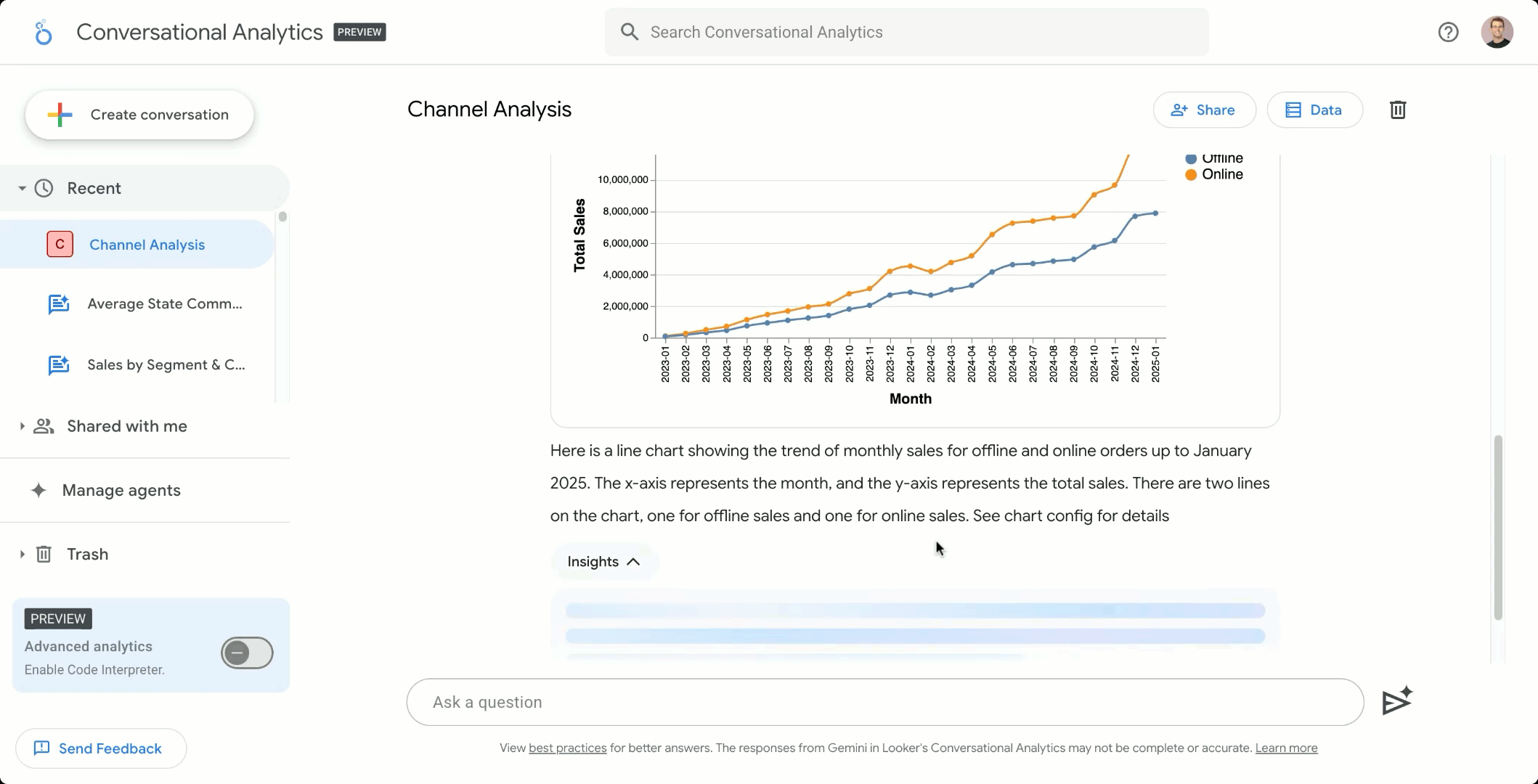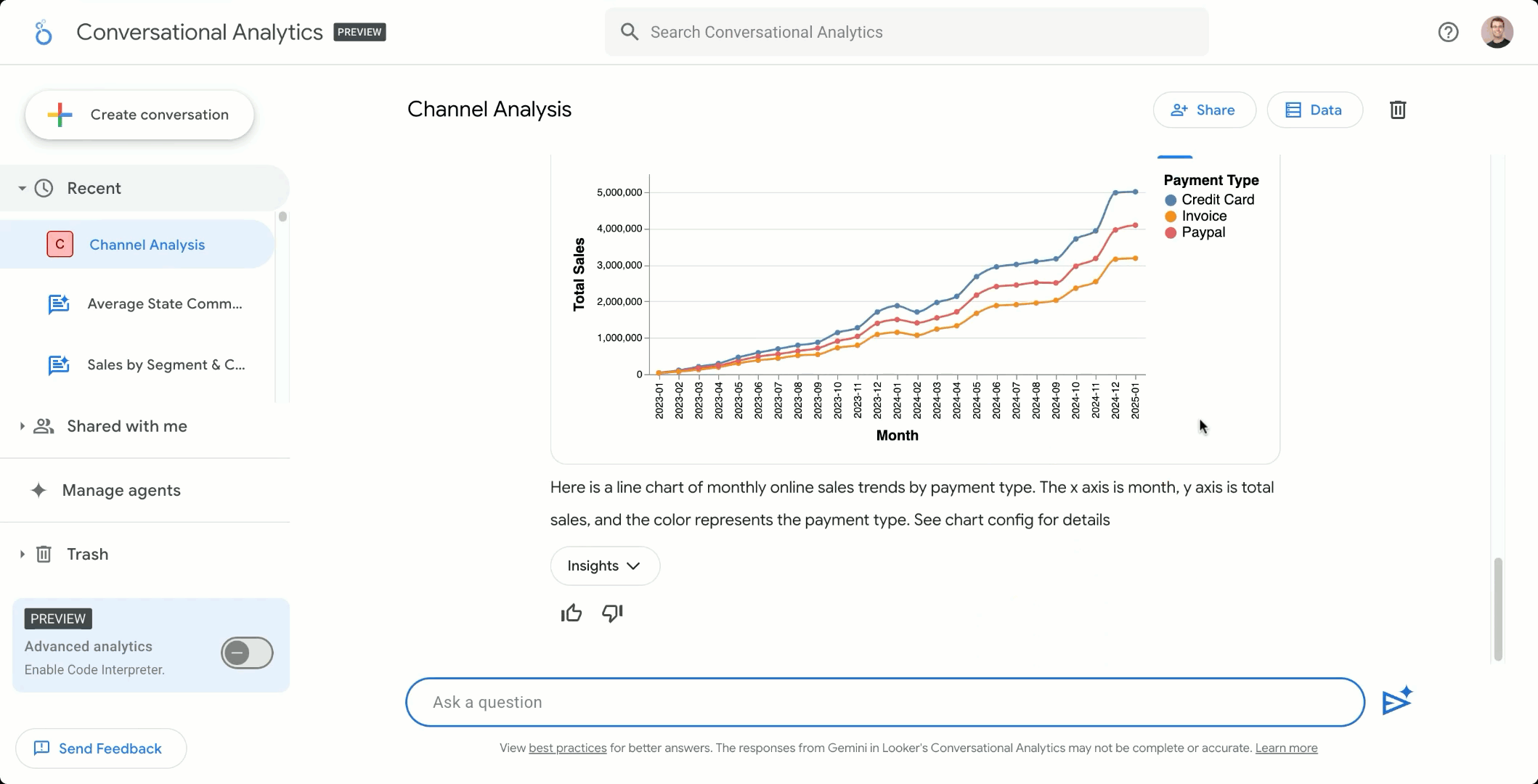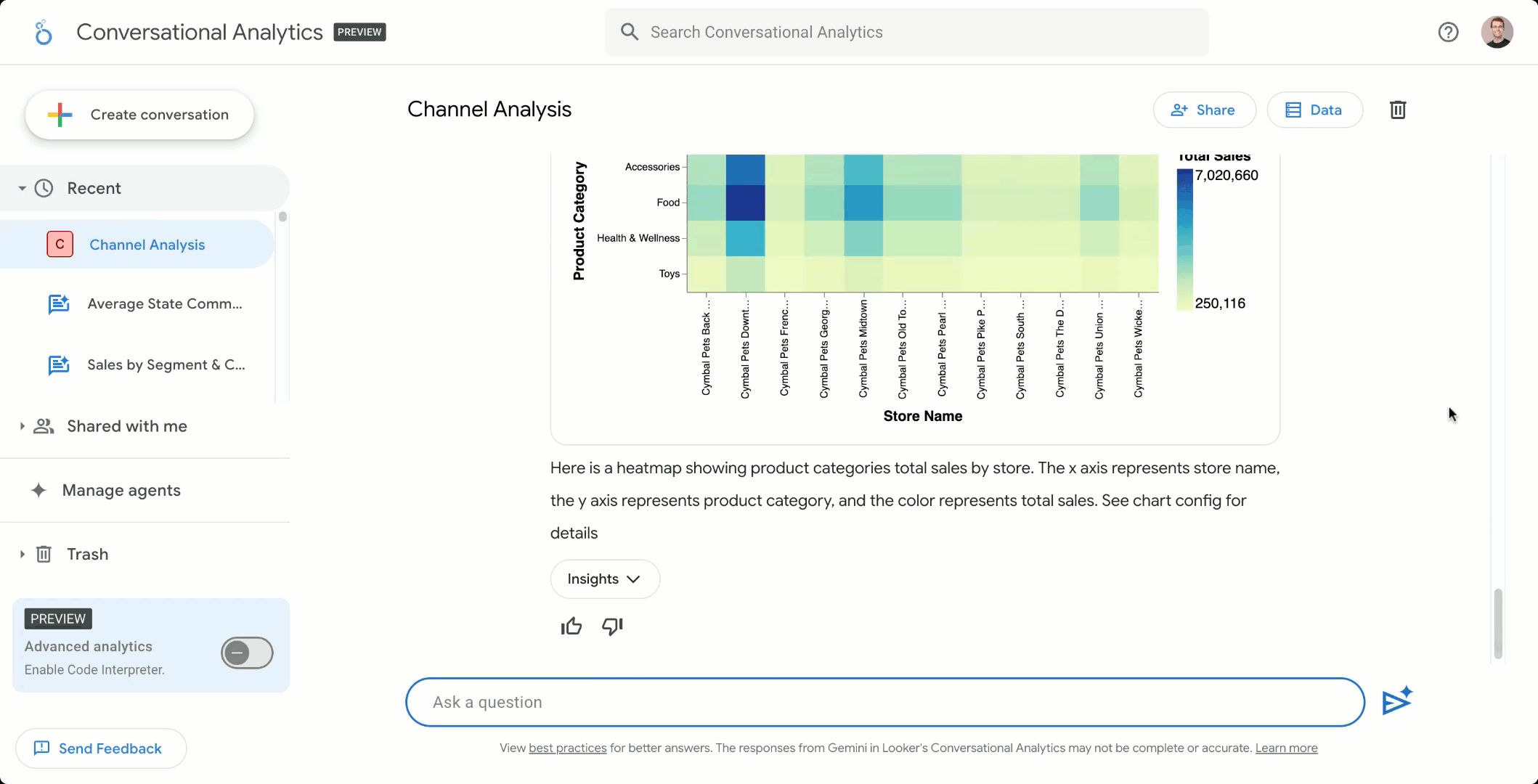
Looker Conversational Analytics allows users to ask questions about their data in natural language, gaining instant, highly visual answers powered by AI and grounded in Looker’s semantic model. Data exploration is now as simple as chatting with your team’s data expert.
Talk to your data the same way you talk to your data analyst, only faster.
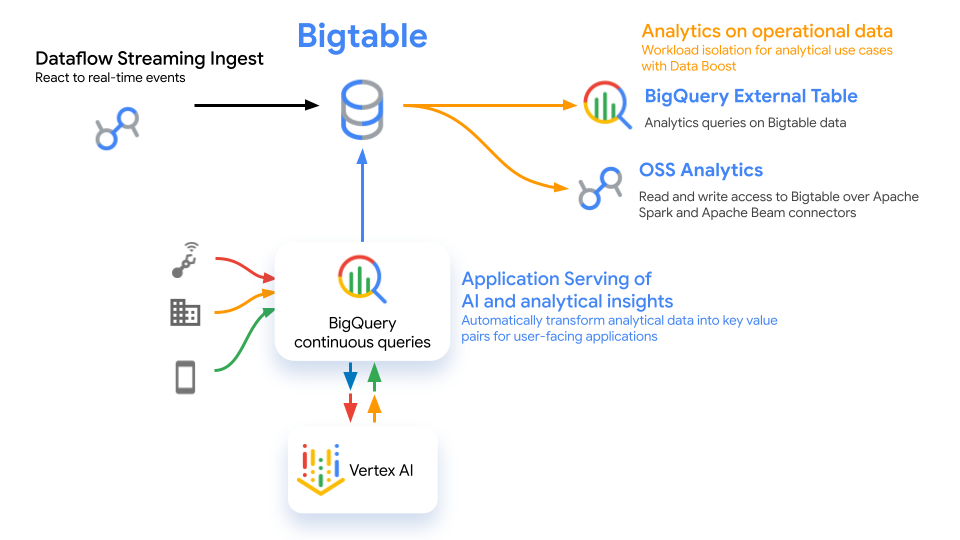
Automatic Slide Generation exports Looker reports to Google Slides, as well as AI-generated summaries of charts and their key insights, to automate creating presentations. With Automatic Slide Generation, presentations stay current and relevant, as the slides are directly connected to the underlying reports, so that the data they present is always up-to-date.
Rapidly transform your reports into live presentations you can share.
Formula Assistant simplifies the creation of calculated fields for ad-hoc analysis by allowing analysts to describe the desired calculation in natural language. The formula is automatically generated using AI, saving time and effort for analysts and report builders.
LookML Assistant simplifies LookML code creation by letting users describe what they are looking to build in natural language and automatically creating the corresponding LookML measures and dimensions. This helps streamline the process of creating and maintaining governed data.
Advanced Visualization Assistant creates customized data visualizations that users describe with natural language, while. Gemini in Looker creates the necessary JSON code configurations.
The semantic layer: The foundation of AI accuracy
A critical component of Looker’s AI architecture is the LookML semantic modeling layer, which in conjunction with LLMs like Gemini, provides the necessary context for the LLM to comprehend the data, and helps ensure centralized metric definitions, preventing inconsistencies that can derail AI models. Without a semantic layer, AI answers may be inaccurate, leading to unreliable results, lack of adoption, and wasted effort. Looker’s semantic model enables data governance integration, maintaining compliance and trust with existing controls, and evolves with your business, iteratively updating data sets and measures so that AI answers are accurate. According to our own internal tests, Looker’s semantic layer reduces data errors in gen AI natural language queries by as much as two thirds.
How Google protects your data and privacy
You can use Gemini in Looker knowing that your data is protected. Gemini prioritizes data privacy, and does not store customer prompts and outputs without permission. Critically, customer data, including prompts and generated output, is never used to train Google’s generative AI models.
Looker’s agentic AI architecture powers intelligent BI
Announced at Next 25, the Looker Conversational Analytics API serves as the agentic backend for Looker AI. It answers questions using a reasoning agent that uses multiple tools to answer analytical questions. It also uses conversation history to answer multi-turn questions and enable more efficient Looker queries, including the ability to open them in the Explore UI.
Looker’s AI architecture is designed for accuracy and quality, taking a multi-pronged approach to gen AI quality:
Agentic reasoning
A semantic layer foundation
A dynamic knowledge graph that provides context for Retrieval Augmented Generation (RAG)
Fine-tuned models for SQL and Python generation
This robust architecture enables Looker to move beyond simply answering “What?” questions to addressing more complex queries like “How does this compare?” “Why?” “What will happen?” and ultimately, “What should we do?”
Looker’s AI and BI roadmap
With Looker, we’re committed to converging AI and BI, and are working on a number of new offerings including:
Code Interpreter for Conversational Analytics makes advanced analytics easy, enabling business users to perform complex tasks like forecasting and anomaly detection using natural language, without needing in-depth Python expertise. You can learn more about this new capability and sign up here for the Preview.
Centralize and share your Looker agents with Agentspace, which offers centralized access, faster deployment, enhanced team collaboration, and secure governance.
Automated semantic model generation with Gemini helps democratize LookML creation, boost developer productivity, and unlock data insights with multi-modal inputs. Gemini leverages diverse input types like natural language descriptions, SQL queries, and database schemas.
Embracing BI’s AI-powered future
Gemini in Looker is a significant milestone in the AI/BI revolution. By integrating the power of Google’s Gemini models with Looker’s robust data modeling and analytics capabilities, organizations can empower their analysts, enhance the productivity of their business users, and unlock deeper, more actionable insights from their data. Gemini in Looker is transforming how we understand and leverage data to make smarter, more informed decisions. The journey from asking “What?” to confidently determining “What next?” is now within reach, powered by Gemini in Looker. Learn more at https://cloud.google.com/looker, or click here to learn more about Gemini in Looker and how to enable it for your Looker deployment. You can also choose to enable Trusted Tester features to gain access to early features in development.
We’re at an inflection point right now, where every industry and entire societies are witnessing sweeping change, with AI as the driving force. This isn’t just about incremental improvements, it’s about total transformation. The public sector is already experiencing sweeping change with the introduction of AI, and that pace will only intensify. This is the promise of AI, and it’s here and now. At our recent Google Cloud Next ‘25 we showcased our latest innovations and reinforced our commitment to bringing the latest and best technologies to help public sector agencies meet their missions.
Key public sector announcements at Next
It was an exciting week at Next ‘25 with hundreds of product and customer announcements from Google Cloud. Here are key AI, security, and productivity announcements that can help the public sector deliver improved services, enhance decision-making and operate with greater efficiency.
Advancements in Google Distributed Cloud that let customers bring Gemini models on premises. This compliments our GDC air-gapped product, now authorized for U.S. Government Secret and Top Secret levels, and on which Gemini is available, provides the highest levels of security and compliance. This enables public sector agencies to have greater flexibility in how and where they access the latest Google AI innovations.
Support for a full suite of generative media models and Gemini 2.5 – Our most intelligent model yet, Gemini 2.5 is designed for the agentic era and now available in Vertex AI platform. This builds on our recent announcement that Vertex AI Search and Generative AI (with Gemini) achieve FedRAMP High authorization,providing agencies with a secure platform and the latest AI innovations and capabilities.
Simplifying security with the launch of Google Unified Security– We are offering customers a security solution powered by AI that brings together our best-in-class security products for threat intelligence, security operations, cloud security, and secure enterprise browsing, along with Mandiant expertise to provide a unified view and improved threat detection across complex infrastructures.
Transforming agency productivity and unlocking significant savings – We are offering Google Workspace, our FedRAMP High authorized communication and collaboration platform, at a significant discount of 71% off for U.S. federal government agencies. This offering in combination with Gemini in Workspace being authorized at the FedRAMP High level gives unprecedented access to cutting edge AI services for U.S. government workers.
Helping customers meet their mission
All of this incredible technology – and more – came to life on stage and across the showfloor at our Google Public Sector Hub, where we showcased our solutions for security, defense, transportation, productivity & automation, education, citizen services, health & human services, and Google Distributed Cloud (GDC). In case you missed our live demos on Medicaid redetermination, unemployment insurance claims, transportation coordination, and research grant sourcing, contact us to schedule a virtual demo or discuss a pilot. To get hands on with the technology register for an upcoming Google Cloud Days training for the public sector here.
We are proud to work with customers across the public sector, as they apply the latest Google innovations and technologies to achieve real mission-value impact. Ai2 and Google Cloud announced a partnership with Google Cloud to make its portfolio of open AI models available in Vertex AI Model Garden. The collaboration will help set a new standard for openness that leverages Google Cloud’s infrastructure resources and AI development platform with Ai2’s open models that will advance AI research and offer enterprise-quality deployment for the public sector. This builds on our announcement that Ai2 and Google Cloud will commit $20M to advance AI-powered research for the Cancer AI Alliance. You can catch the highlights from my conversation at Next with Ali Farhadi, CEO of Ai2 here.
CEO perspectives: A new era of AI-powered research and innovation
All of this incredible innovation with our customers is further enabled by our ecosystem of partners who help us scale our impact across the public sector. At Google Cloud Next, Accenture Federal Services and Google Public Sector announced the launch of a joint Managed Extended Detection and Response (MxDR) solution. The new MxDR for government solution integrates Google Security Operations (SecOps) platform with Accenture Federal’s deep federal cybersecurity expertise. This solution uses security-specific generative artificial intelligence (Gen AI) to significantly enhance threat detection and response, and the overall security posture for federal agencies.
Lastly, Lockheed Martin and Google Public Sector also announced a collaboration to advance generative AI for national security. Integrating Google’s advanced generative artificial intelligence into Lockheed Martin’s AI Factory ecosystem will enhance Lockheed Martin’s ability to train, deploy, and sustain high-performance AI models and accelerate AI-driven capabilities in critical national security, aerospace, and scientific applications.
A new era of innovation and growth
AI presents a unique opportunity to enter a new era of innovation and economic growth, enabling the public sector to get more out of limited resources to improve public services and infrastructure, make public systems more secure, and better meet the needs of their constituents. Harnessing the power of AI can help governments become agile and more secure, and serve citizens better. At Google Public Sector, we’re passionate about applying the latest cloud, AI and security innovations to help you meet your mission.
Subscribe to our Google Public Sector Newsletter to stay informed and stay ahead with the latest updates, announcements, events and more.
Google Cloud Next 25 took place this week and we’re all still buzzing! It was a jam-packed week in Las Vegas complete with interactive experiences, including more than 10 keynotes and spotlights, 700 sessions, and 350+ sponsoring partners joining us for an incredible Expo show. Attendees enjoyed hands-on learning across AI innovation, data cloud, modern infrastructure, security, Google Workspace, and more.
At our opening keynote, we showcased cutting-edge product innovations across our AI-optimized platform and featured hundreds of customers and partners building with Google Cloud as well as five awesome demos. You can catch up on all the highlights in our 10-minute keynote recap.
Our developer keynoteshowed how AI is revolutionizing the developer workflow, and featured seven incredible demos on everything from building with Gemini to creating multi-agent systems.
1_next25 wrap
2_next25 wrap
3_next25 wrap
4_next25 wrap
5_next25 wrap
6_next25 wrap
Last year, we shared how customers were exploring the exciting potential of generative AI to transform the way they work. This year, we showcased how customers are getting real business value from Google AI, celebrating hundreds of customer stories across the event, including the amazing story of how The Sphere is using Google AI to enrich their fully immersive The Wizard of Oz experience.
It was a busy week, so we’ve prepared a summary of all the 228 announcements from Next ‘25 below:
AI and Multi-Agent Systems
Models: Building on Google DeepMind research, we announced the addition of a variety of first-party models, as well as new third-party models to Vertex AI Model Garden.
1. Gemini 2.5 Pro is available in public preview on Vertex AI, AI Studio, and in the Gemini app. Gemini 2.5 Pro is engineered for maximum quality and tackling the most complex tasks demanding deep reasoning and coding expertise. It is ranked #1 on Chatbot Arena.
2. Gemini 2.5 Flash — our low latency and most cost-efficient thinking model — is coming soon to Vertex AI, AI Studio, and in the Gemini app.
3. Imagen 3: Our highest quality text-to-image model now has improved image generation and inpainting capabilities for reconstructing missing or damaged portions of an image.
5. Lyria: The industry’s first enterprise-ready, text-to-music model, transforms simple text prompts into 30-second music clips.
6. Veo 2: Our advanced video generation model has new editing and camera control features to help customers refine and repurpose video content with precision.
9. Vertex AI Dashboards: These help you monitor usage, throughput, latency, and troubleshoot errors, providing you with greater visibility and control.
10. Model Customization and Tuning: You can also manage custom training and tuning with your own data on top of foundational models in a secure manner across all first-party model families including Gemini, Imagen, Veo, embedding, and translation models, as well as open models like Gemma, Llama, and Mistral.
11. Vertex AI Model Optimizer: Automatically generate the highest quality response for each prompt based on your desired balance of quality and cost
12. Live API: Offers streaming audio and video directly into Gemini. Now your agents can process and respond to rich media in real time, opening new possibilities for immersive, multimodal applications.
13. Vertex AI Global Endpoint: Provides capacity-aware routing for our Gemini models across multiple regions, maintaining application responsiveness even during peak traffic or regional service fluctuations.
We also introduced new capabilities to help you build and manage multi-agent systems — regardless of which technology framework or model you’ve chosen.
14. Agent Development Kit (ADK): This open-source framework simplifies the process of building sophisticated multi-agent systems while maintaining precise control over agent behavior.Agent Development Kit supports the Model Context Protocol (MCP)which provides a unified way for AI models to access and interact with various data sources and tools, rather than requiring custom integrations for each.
15. Agent2Agent (A2A) protocol: We’re proud to be the first hyperscaler to create an open Agent2Agent protocol to help enterprises support multi-agent ecosystems, so agents can communicate with each other, regardless of the underlying framework or model. More than 50 partners, including Accenture, Box, Deloitte, Salesforce, SAP, ServiceNow, and TCSare actively contributing to defining this protocol, representing a shared vision of multi-agent systems.
16. Agent Garden: This collection of ready-to-use samples and tools is directly accessible in ADK. Leverage pre-built agent patterns and components to accelerate your development process and learn from working examples.
17. Agent Engine: This fully managed agent runtime in Vertex AI helps you deploy your custom agents to production with built-in testing, release, and reliability at a global, secure scale.
18. Grounding with Google Maps1: For agents that rely on geospatial context, you can now ground your agents with Google Maps, so they can provide responses with geospatial information tied to places in the U.S.
19. Customer Engagement Suite: This latest version includes human-like voices; the ability to understand emotions so agents can adapt better during conversation; streaming video support so AI agents can interpret and respond to what they see in real-time through customer devices; and AI assistance to build agents in a no-code interface.
We announced exciting enhancements to Google Agentspace to help scale the adoption of enterprise search and AI agents across the enterprise. Agentspace puts the latest Google foundation models, Google-quality search, powerful AI agents, and actionable enterprise knowledge in the hands of every employee.
20. Integrated with Chrome Enterprise: Bringing Agentspace directly into Chrome helps employees easily and securely find information, including data and resources, right within their existing workflows.
21. Agent Gallery: This provides employees a single view of available agents across the enterprise, including those from Google, internal teams, and partners — making agents easy to discover and use.
22. Agent Designer: A no-code interface for creating custom agents that automate everyday work tasks or enhance knowledge. Agent Designer helps employees adapt agents to their individual workflows and needs, no matter their technical experience.
23. Idea Generation agent: Helps employees innovate by autonomously developing novel ideas in any domain, then evaluating them to find the best solutions via a competitive system inspired by the scientific method.
24. Deep Research agent: Explores complex topics on the employee’s behalf, synthesizing information across internal and external sources into comprehensive, easy-to-read reports — all with a single prompt.
We brought the best of Google DeepMind and Google Research together with new infrastructure and AI capabilities in Google Cloud, including:
25. AlphaFold 3: Developed by Google DeepMind and Isomorphic Labs, the new AlphaFold 3 High-Throughput Solution, available for non-commercial use and deployable via Google Cloud Cluster Toolkit, enables efficient batch processing of up to tens of thousands of protein sequences while minimizing cost through autoscaling infrastructure.
26. WeatherNext AI models: Google DeepMind and Google Research WeatherNext models enable fast, accurate weather forecasting, and are now available in Vertex AI Model Garden, allowing organizations to customize and deploy them for various research and industry applications.
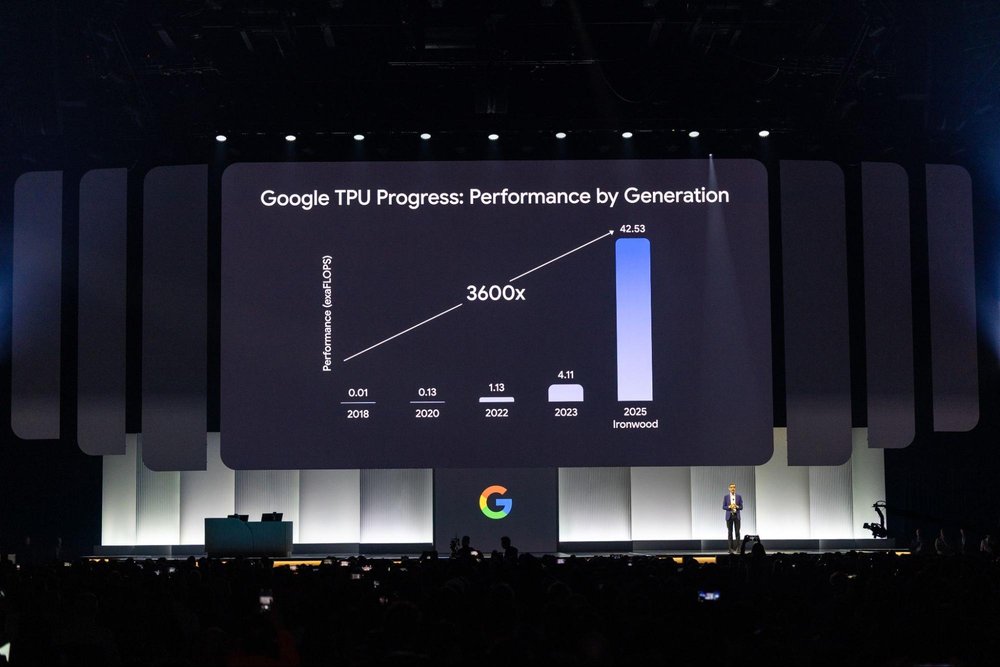
27. Ironwood: Our 7th generation TPUjoins our AI-optimized hardware portfolio to power thinking, inferential AI models at scale (coming later in 2025). Read more here.
28. Google Distributed Cloud (GDC): We have partnered with NVIDIA to bring Gemini to NVIDIA Blackwell systems, with Dell as a key partner, so Gemini can be used locally in air-gapped and connected environments. Read more here.
29. Pathways on Cloud: Developed by Google DeepMind, Pathways is a distributed runtime that powers all of AI at Google, and is now available for the first time on Google Cloud.
30. vLLM on TPU: We’re bringing vLLM to TPUs to make it easy to run inference on TPUs. Customers who have optimized PyTorch with vLLM can how run inference on TPUs without changing their software stack, and also serve on both TPUs and GPUs if needed.
31. Dynamic Workload Scheduler resource management and job scheduling platform now features support for Trillium, TPU v5e, A4 (NVIDIA B200), and A3 Ultra (NVIDIA H200) VMs in preview via Flex Start mode, with Calendar mode support for TPUs coming later this month.
32. A4 and A4X VMs: We’ve significantly enhanced our GPU portfolio with the availability of A4 and A4X VMs powered by NVIDIA’s B200 and GB200 Blackwell GPUs, respectively, and A4X VMs are now in preview. We were the first cloud provider to offer both of these options.
33. NVIDIA Vera Rubin GPUs: Google Cloud will be among the first to offer NVIDIA’s next-generation Vera Rubin GPUs, which offer up to 15 exaflops of FP4 inference performance per rack.
34. Cluster Director (formerly Hypercompute Cluster) lets you deploy and manage a group of accelerators as a single unit with physically colocated VMs, targeted workload placement, advanced cluster maintenance controls, and topology-aware scheduling. New updates coming later this year include Cluster Director for Slurm, 3600 observability features, and job continuity capabilities. Register to join the preview.
Application Development
Developing on top of Google Cloud, and with Google Cloud tools, gets better every day.
35. The new Application Design Center, now in preview, provides a visual, canvas-style approach to designing and modifying application templates, and lets you configure application templates for deployment, view infrastructure as code in-line, and collaborate with teammates on designs.
36. The new Cloud Hub service, in preview, is the central command center for your entire application landscape, providing insights into deployments, health and troubleshooting, resource optimization, maintenance, quotas and reservations, and support cases. Try Cloud Hub here.
38. Application Monitoring, in public preview, supports automatically tagging telemetry (logs, metrics, and traces) with application context, application-aware alerts, and out-of-the-box application dashboards.
39. Cost Explorer, in private preview, provides visibility into granular application costs and utilization metrics, allowing you to identify efficiency opportunities; sign up here to try it out.
40. Gemini Code Assistagents can help with common developer tasks such as code migration, new feature implementation, code review, test generation, model testing, and documentation, and their progress can be tracked on the new Gemini Code Assist Kanban board.
41. Gemini Code Assist is now available in Android Studio for professional developers who want AI coding assistance with enterprise security and privacy features.
42. Gemini Code Assist tools, now in preview, helps you access information from Google apps and tools from partners including Atlassian, Sentry, Snyk, and more.
43. An App Prototyping agent in preview for Gemini Code Assist within the new Firebase Studio development environment turns your app ideas into fully functional prototypes, including the UI, backend code, and AI flows.
44. Gemini Cloud Assist is integrated with Application Design Center in preview to accelerate application infrastructure design and deployment.
45. Gemini Cloud Assist Investigations leverages data in your cloud environment to accelerate troubleshooting and issue resolution. Register for the private preview here.
46. Gemini Cloud Assist is now integrated across Google Cloud services including Storage Insights, Cloud Observability, Firebase, Database Center, Flow Analyzer, FinOps Hub, as well as security- and compliance-related services.
47. FinOps Hub 2.0 now includes waste insights and cost optimization opportunities from Gemini Cloud Assist.
48. The new Enterprise tier of the Google Developer Program is in limited preview, providing a safe and affordable way to explore Google Cloud and its AI products for a set monthly cost of $75/month per seat. Learn more here.
Compute
Whatever your workload, there’s a Compute Engine virtual machine to help you run it at the price, performance and reliability levels you need.
49. New C4D VMs built on AMD’s 5th Gen EPYC processors and paired with Google Titanium deliver impressive performance gains over prior generations— up to 30% vs C3D on the estimated SPECrate®2017_int_base benchmark. Currently in preview,try out C4D today.
50. C4 VMs built on the 6th generation Intel Granite Rapids CPUs feature the highest frequency of any Compute Engine VM — up to 4.2 GHz.
51. C4 shapes with Titanium Local SSD offer improved performance for I/O-intensive workloads like databases and caching layers, achieving Local SSD latency reductions of up to 35%.
52. C4 bare metal instances provide performance gains of up to 35% for general compute and up to 65% for ML recommendation workloads compared to the prior generation.
53. New, larger C4 VM shapes scale up to 288 vCPU, with 2.2TB of high-performing DDR5 memory and larger cache sizes. Request preview access here.
Compute Engine also features a variety of specialized VM families and unique capabilities:
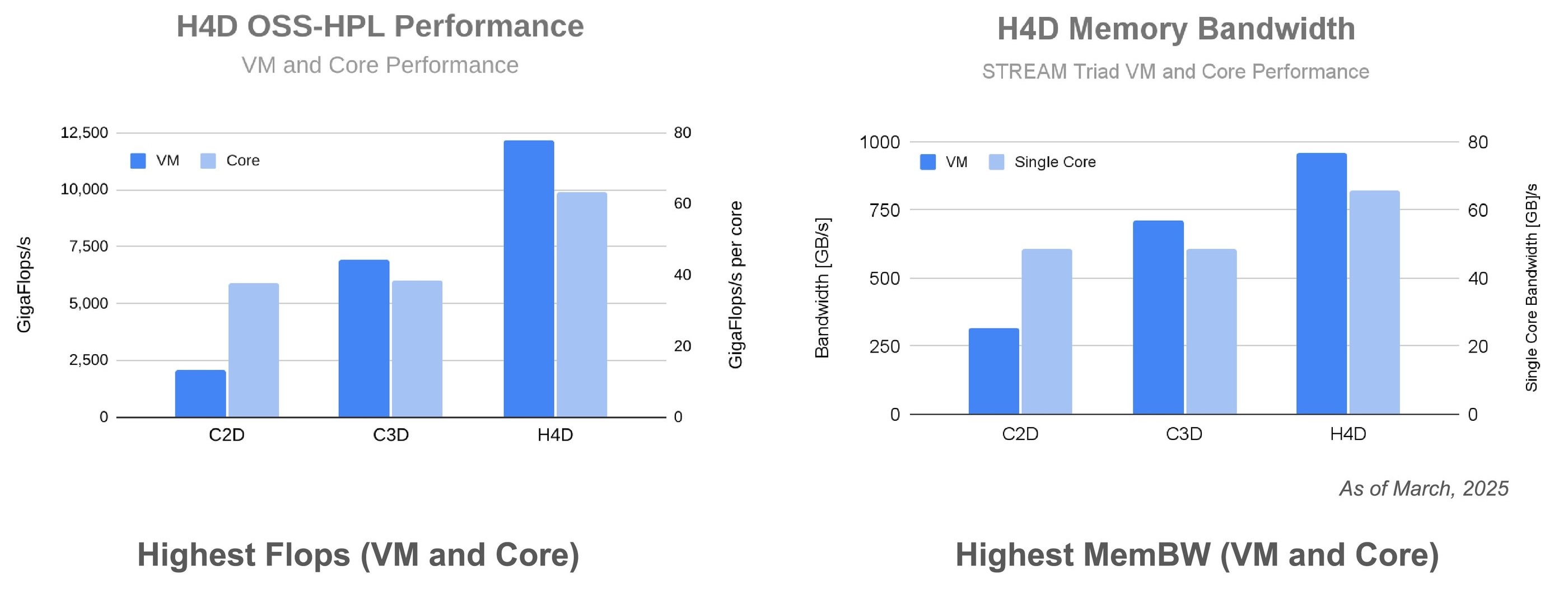
54. New H4D VMs for demanding HPC workloads are built on the 5th gen AMD EPYC CPUs, and offer the highest whole-node VM performance of more than 12,000 flops, the highest per-core performance, and the best memory bandwidth of more than 950 GB/s of our VM families. Sign up for the H4D preview.
55. M4 VMs are certified for business-critical, in-memory SAP HANA workloads ranging from 744GB to 3TB, and for SAP NetWeaver Application Server, and offer up to 65% better price-performance and 2.25x more SAP Application Performance Standard (SAPS) compared to the previous memory-optimized M3.
56. The Z3 storage-optimized family now features new Titanium SSDs and offers nine new smaller shapes, ranging from 3TB to 18TB per instance. The Z3 family also introducing new storage-optimized bare-metal instance which include up to 72TB of Titanium SSDs and direct access to the physical server CPUs. Now in preview, register your interest here.
57. Nutanix Cloud Clusters (NC2) on Google Cloud let you run, manage, and operate apps, data, and AI across private and public clouds. Sign up for the public preview here.
58. Google Cloud VMware Engine now comes in 18 additional node shapes, bringing the total number of node shapes across VMware Engine v1 and v2 to 26.
59. Within the Titanium family, Titanium ML Adapter securely integrates NVIDIA ConnectX-7 network interface cards (NICs), providing 3.2 Tbps of non-blocking GPU-to-GPU bandwidth.
60. Titanium offload processors now integrate our GPU clusters with the Jupiter data center fabric, for greater cluster scale.
62. MIGs now support committed use discounts (CUDs) and reservation sharing with Vertex AI and Autopilot.
Containers & Kubernetes
The case for running on Google Kubernetes Engine (GKE) keeps on getting stronger, across an ever expanding class of workloads, most recently — AI.
63. GKE Inference Gatewayoffers intelligent scaling and load-balancing capabilities,helping you handle request scheduling and routing with gen AI model-aware scaling and load-balancing techniques.
64. With GKE Inference Quickstart, you can choose an AI model and your desired performance, and GKE configures the right infrastructure, accelerators, and Kubernetes resources to match.
66. Cluster Director for GKE (formerly Hypercompute Cluster) is now generally available, letting you deploy and manage large clusters of accelerated VMs with compute, storage, and networking — all operating as a single unit.
67. We announced performance improvements to GKE Autopilot, including faster pod scheduling, scaling reaction time, and capacity right-sizing.
68. Starting in Q3, Autopilot’s container-optimized compute platform will also be available to standard GKE clusters, without requiring a specific cluster configuration.
Customers
We shared hundreds of new customer stories across every industry and region, highlighting the ways they’re using Google Cloud to drive real impact. Here are some highlights:
69. Agoda, one of the world’s largest digital travel platforms, creates unique visuals and videos of travel destinations with Imagen and Veo on Vertex AI.
70. Bayer built an agent that uses predictive AI and advanced analytics to predict flu trends.
71. Bending Spoonsintegrated Imagen 3 into its Remini app to launch a popular new AI filter, processing an astounding 60 million photos per day.
72. BloombergConnects is using Gemini to explore new ways to help museums and other cultural institutions make their digital content accessible to more visitors.
73. Citi is using Vertex AI to rapidly deploy generative AI-powered productivity tools to more than 150,000 employees.
74. DBS, a leading Asian financial services group, is using Customer Engagement Suite to reduce customer call handling times by 20%.
75. Deutsche Bankbuilt DB Lumina, a new Gemini-powered tool that can synthesize financial data and research, turning, for example, a report that’s hundreds of pages into a one-page brief, delivering it in a matter of seconds to traders and wealth managers.
76. Deutsche Telekom has announced an expanded strategic partnership with Google Cloud, focusing on cloud and AI integration to modernize Deutsche Telekom’s IT, networks, and business applications, including migrating its SAP landscape.
77. Dun & Bradstreet is using Security Command Center to centralize monitoring of AI security threats.
78. Fanatics is partnering with Google Cloud to use AI technology to enhance every aspect of the fan journey. With Vertex AI Search for Commerce, Fanatics has developed an intelligent search ecosystem that understands and anticipates fan preferences, improves quality assurance and delivers intelligent customer service, and more.
79. Freshfieldsis using Gemini for Google Workspace and Google Cloud’s Vertex AI to enhance client services, including powering Freshfields’ Dynamic Due Diligence solution.
80. Globo, Latin America’s largest media company, used Vertex AI Search to create a recommendations experience inside its streaming platform that more than doubled their click-through-play rate on videos.
81. Gordon Food Services is simplifying insight discovery and recommending next steps with Agentspace.
82. The Home Depot built Magic Apron, an agent that offers expert guidance 24/7, providing detailed how-to instructions, product recommendations, and review summaries to make home improvement easier.
83. Honeywell has incorporated Gemini into its product development.
84. KPMG is building Google AI into in its newly formed KPMG Law firm and implementing Agentspace to enhance its own workplace operations.
85. L’Oreal is using Gemini, Imagen and Veo to accelerate creative ideation and production for marketing and product design, significantly speeding up workflows while maintaining ethical standards.
86. Lloyds Banking Group has taken a significant step in its strategic transformation by migrating its major platforms to Google Cloud. The transition is unlocking new opportunities to innovate with AI, enhancing the customer experience.
87. Lowe’sis revolutionizing product discovery with Vertex AI Search to generate dynamic product recommendations and address customers’ complex search queries.
89. Nokia built a coding tool to speed up app development with Gemini, enabling developers to create 5G applications faster.
90. Nuro, an autonomous driving company, uses vector search in AlloyDB to identify challenging scenarios on the road.
91. Mercado Libre deployed Vertex AI Search across 150M items in 3 pilot countries that is helping their 100M customers find the products they love faster, already delivering millions of dollars in incremental revenue.
92. Papa Johns is using AI to transform the ordering and delivery experience for its global customers. With Google Cloud’s AI, data analytics, and machine learning capabilities, Papa Johns can anticipate customer needs and personalize their pizza experience, as well as provide a consistent customer experience both inside the restaurants and online.
93. Redditis using Gemini on Vertex AI to power “Reddit Answers,” Reddit’s AI-powered conversation platform. Additionally, Reddit is using Enterprise Search to improve its homepage experience.
94. Samsung is integrating Gemini on Google Cloud into Ballie, its newest AI home companion robot, enabling more personalized and intelligent interactions for users.
95. Seattle Children’s hospitalis launching Pathway Assistant, a gen AI-powered agent with Gemini that improves clinicians’ access to complex information and the latest evidence-based best practices needed to treat patients.
96. Government of Singapore uses Google Cloud Web Risk to protect their residents online.
97. The Wizard of Oz at The Sphere is an immersive experience that reconceptualizes the 1939 film classic through the magic of AI, bringing it to life on a whole new scale for the colossal 160,000-square-foot domed screen at The Sphere in Las Vegas. It’s a collaboration between Sphere Entertainment, Google DeepMind, Google Cloud, Hollywood production company Magnopus, and five others.
98. Spotify uses BigQuery to harness enormous amounts of data to deliver personalized experiences to over 675 million users worldwide.
99. Intuitis using Google Cloud’s Document AI and Gemini models to simplify tax preparation for millions of TurboTax consumers this tax season, ultimately saving time and reducing errors.
100. United Wholesale Mortgage is using Google Cloud’s gen AI and data analytics to improve the mortgage process for 50,000 mortgage brokers and their clients, focusing on speed, efficiency, and personalized service.
101. Verizon is using Google Cloud’s Customer Engagement Suite to enhance its customer service for more than 115 million connections with AI-powered tools, like the Personal Research Assistant.
102. Vodafoneused Vertex AI along with open-source tools and Google Cloud’s security foundation to establish an AI security governance layer.
103. Wayfairupdates product attributes 5x faster with Vertex AI.
104. WPP built Open as a platform powered by Google models that all of its employees worldwide can use to concept, produce, and measure campaigns.
106. The next-generation of AlloyDB natural language lets you query structured data in AlloyDB securely and accurately, enabling natural language text modality in apps.
108. AlloyDB AI includes three new AI models: one that improves the relevance of vector search results using cross attention reranking; a multimodal embeddings model that supports text, images, and videos, and a new Gemini Embedding text model.
109. The new AlloyDB AI query engine lets developers use natural language expressions and constructs within SQL queries. Sign up for the preview of these AlloyDB features here.
111. Firestore with MongoDB compatibility, in preview, lets developers take advantage of MongoDB’s API portability along with Firestore’s multi-region replication with strong consistency, virtually unlimited scalability, a 99.999% SLA, and single-digit milliseconds read latency. Get started here today.
112. The new Oracle Base Database Service offers a flexible and controllable way to run Oracle Databases in the cloud.
113. Oracle Exadata X11M is now GA, bringing the Oracle Exadata platform to Google Cloud and adding additional enterprise-ready capabilities, including customer managed encryption keys (CMEK).
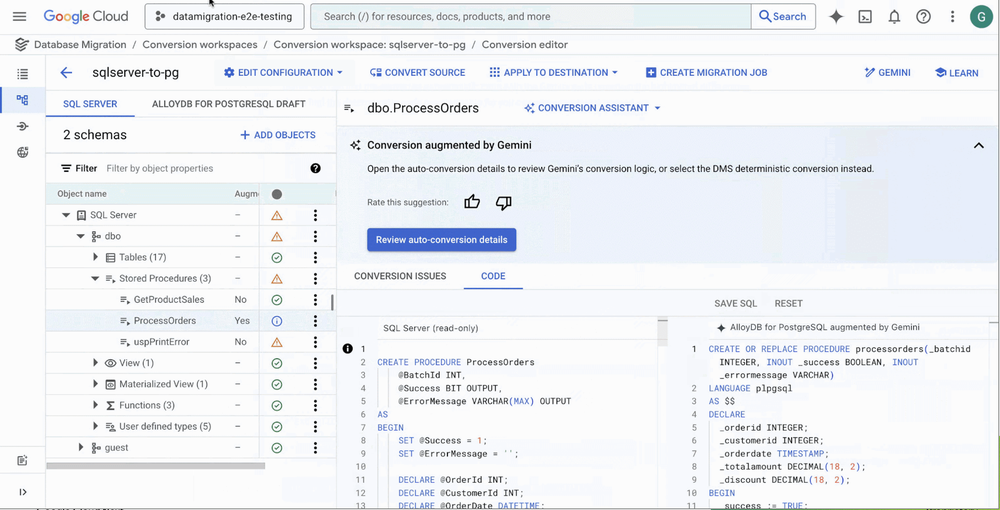
114. Database Migration Service (DMS) now supportsSQL Server to PostgreSQL migrationsfor Cloud SQL and AlloyDB, allowing you to fully execute on your database modernization strategy.
115. Cloud SQL and AlloyDB are available on C4A instances, our Arm-based Google Axion Processors delivering higher price-performace and throughput. Learn more here.
116. Database Center is now generally available and supports every database in our portfolio, providing a unified, AI-powered fleet management solution.
117. Spanner vector search is now generally available, designed to work with our SQL, Graph, Key-Value, and Full-Text Search modalities.
118. Graph Visualization for Spanner is now generally available, allowing users to visually explore valuable information from graph data.
120. Aiven for AlloyDB Omni, a fully-managed AlloyDB Omni service from our partner Aiven that runs on AWS, Azure, and Google Cloud, is now generally available.
122. New Cassandra-compatible APIs and live-migration tooling for zero-downtime migrations from Cassandra to Bigtable and Spanner.
123. Memorystore for Valkey is now generally available, with support for 7.2 and 8.0 engine versions.
124. Firebase Data Connect is now GA, offering the reliability of Cloud SQL for PostgreSQL with instant GraphQL APIs and type-safe SDKs
Data analytics
We announced several new innovations with our autonomous data to AI platform powered by BigQuery, alongside our unified, trusted, and conversational Looker BI platform:
127. BigQuery anomaly detection, now in preview, maintains data quality and automates metadata generation.
128.Data science agent, now GA, is embedded within Google’s Colab notebook, provides intelligent model selection, enabling scalable training, and faster iteration.
131. BigQuery knowledge engine, in preview, leverages Gemini to analyze schema relationships, table descriptions, and query histories to generate metadata on the fly, model data relationships, and recommend business glossary terms.
132. BigQuery semantic search, is now GA, providing AI-powered data insights and across BigQuery, grounding AI and agents in business context.
133. BigQuery’s contribution analysis feature, now GA, helps you pinpoint the key factors (or combinations of factors) responsible for the most significant changes in a metric.
135. BigQuery pipe syntax is GA, letting you apply operators in any order and as often as you need, and is compatible with most standard SQL operators.
Then, for data science and analyst teams, we added AI-driven data science and workflows as part of BigQuery notebook:
136. New intelligent SQL cells understand your data’s context and provide smart suggestions as you write code, and let you join data sources directly within your notebook.
137. Native exploratory analysis and visualization capabilities in BigQuery make it easy to explore data, as well as add features to enable easier collaboration with colleagues. Data scientists can also schedule analyses to run and refresh insights periodically.
138. The new BigQuery AI query engine lets data scientists process structured and unstructured data together with added real-world context, co-processing traditional SQL alongside Gemini to inject runtime access to real-world knowledge, linguistic understanding, and reasoning abilities.
139. Google Cloud for Apache Kafka, now GA, facilitates real-time data pipelines for event sourcing, model scoring, messaging and real-time analytics.
141. New dataset-level insights in BigQuery data canvas, in preview, surface hidden relationships between tables and generate cross-table queries by integrating query usage analysis and metadata.
142. BigQuery ML includes the new AI.GENERATE_TABLE in preview to capture the output of LLM inference within SQL clauses.
144. BigQuery vector search includes a new index type, now GA, based on Google’s ScaNN model that’s coupled with a CPU-optimized distance computation algorithm for scalable, faster and more cost-efficient processing.
145. The preview of BigQuery ML’s pre-trained TimesFM model developed by Google Research simplifies time-series forecasting.
146. We integrated new Google Maps Platform datasets directly into BigQuery, to make it easier for data analysts and decision makers to access insights.
147. In addition, Earth Engine in BigQuery brings the best of Earth Engine’s geospatial raster data analytics directly into BigQuery. Learn more here.
148. GrowthLoopintroduced its Compound Marketing Engine built on BigQuery with Growth Agents powered by Gemini, so marketing can build personalized audiences and journeys that drive rapidly compounding growth.
149. Informaticaexpanded its services on Google Cloud to enable sophisticated analytical and AI governance use cases.
150. Fivetranintroduced its Managed Data Lake Service for Cloud Storage with native integration with BigQuery metastore and automatic data conversion to open table formats like Apache Iceberg and Delta Lake
151. DBTis now integrated with BigQuery DataFrames and DBT Cloud is now on Google Cloud.
152. Datadogintroduced expanded monitoring capabilities for BigQuery, providing granular visibility into query performance, usage attribution, and data quality metrics.
BigQuery’s autonomous data foundation provides governance, orchestration for diverse data workloads, and a commitment to flexibility via open formats. Announcements in this area include:
153. BigQuery makes unstructured data a first-class citizen with multimodal tables in preview, bringing rich, complex data types alongside structured data for unified storage and querying via the new ObjectRef data type.
154. BigQuery governance in previewprovides a single, unified view for data stewards and professionals to handle discovery, classification, curation, quality, usage, and sharing.
156. BigQuery metastore, now GA, enable engine interoperability across BigQuery, Apache Spark, and Apache Flink engines, with support for the Iceberg Catalog.
157. BigQuery business glossary, now GA, lets you define and administer company terms, identify data stewards for these terms, and attach them to data asset fields.
158. BigQuery continuous queries, now GA,enable instant analysis and actions on streaming data using SQL, regardless of its original format.
159. BigQuery tables for Apache Iceberg in preview, lets you connect your Iceberg data to SQL, Spark, AI and third-party engines.
160. New advanced workload management capabilities, now GA,scale resources, manage workloads, and help ensure their cost-effectiveness.
161. BigQuery spend commit, now GA,simplifies purchasing, unifying spend across BigQuery data processing engines, streaming, governance, and more.
162. BigQuery DataFrames now has AI code assist capabilities in preview, letting you use natural language prompts to generate or suggest code in SQL or Python, or to explain an existing SQL query.
163. SQL translation assistance, now GA, is an AI-based translator that lets you create Gemini-enhanced rules to customize your SQL translations, to accelerate BigQuery migrations.
164. Catalog metadata export, GA, enables bulk extract of catalog entries into Cloud Storage.
165. BigQuery can now perform automatic at-scale cataloging of BigLake and object tables, now GA.
166. BigQuery managed disaster recovery is now GA, featuring automatic failover coordination, continuous near-real-time data replication to a secondary region, and fast, transparent recovery during outages.
167. Newworkload management capabilities in preview include reservation-level fair sharing of slots, predictability in performance of reservations, and enhanced observability through reservation attribution in billing.
Looker, is adding a host of new conversational and visual capabilities, aimed at making BI accessible and useful to all users, accelerated by AI.
168. Gemini in Looker features are now available to all Looker platform users, including Conversational Analytics, Visualization Assistant, Formula Assistant, Automated Slide Generation, and LookML Code Assistant.
169. Code Interpreter for Conversational Analytics is in preview, allowing business users to perform forecasting and anomaly detection using natural language without needing deep Python expertise. Learn more and sign up for it here.
170. New Looker reports feature an intuitive drag-and-drop interface, granular design controls, a rich library of visualizations and templates, and real-time collaboration capabilities, now in the core Looker platform.
171. With Google Cloud’s acquisition of Spectacles.dev, developers can automate testing and validation of SQL and LookML changes using CI/CD practices.
Firebase
172. The new Firebase Studio, available to everyone in preview, is a cloud-based, agentic development environment powered by Gemini that includes everything developers need to create and publish production-quality full-stack AI apps quickly, all in one place. Gemini Code Assist agents are available via private preview.
173. Genkit, an open-souce framework for building AI-powered applications, using your preferred language, now has early support for Python and expanded support for Go. Try this template in Firebase Studio to build with Genkit.
174. Vertex AI in Firebase now includes support for the Live API for Gemini models, enabling more conversational interactions in apps such as allowing customers to ask audio questions and get responses.
175. Firebase Data Connectis now GA,offering the reliability of Cloud SQL for PostgreSQL with instant GraphQL APIs and type-safe SDKs.
176. Firebase App Hosting is also GA, providing an opinionated, git-centric hosting solution for modern, full-stack web apps.
177. A new App Testing agent within Firebase App Distribution, also in preview, prepares mobile apps for production by generating, managing, and executing end-to-end tests.
Google Cloud Consulting
Google Cloud Consulting introduced several new pre-packaged service offerings:
178. Agentspace Accelerator provides a structured approach to connecting and deploying AI-powered search within organizations, so employees can easily gain access to relevant internal information and resources when they need it.
180. Oracle on Google Cloud lets customers combine Oracle databases and applications with Google Cloud’s advanced platform and AI capabilities for enhanced database and network performance.
181. We expanded access to Delivery Navigator, a series ofproven delivery methodologies and best practices to help with migrations and technology implementations to customers as well as partners, in preview.
182. Cloud WAN, a Cross-Cloud Network solution, is a fully managed, reliable, and secure enterprise backbone that makes Google’s global private network available to all Google Cloud customers. Cloud WAN delivers up to 40% improved network performance, while reducing total cost of ownership by up to 40%. Read more here.
183. The new 400G Cloud Interconnect and Cross-Cloud Interconnect, available later this year, offers up to 4x more bandwidth than our 100G Cloud Interconnect and Cross-Cloud Interconnect, providing connectivity from on-premises or other cloud environments to Google Cloud.
184. Build massive AI services with networking support for up to 30,000 GPUs per cluster in a non-blocking configuration, available in preview now.
185. Zero-Trust RDMA security helps you secure your high-performance GPU and TPU traffic with our RDMA firewall, featuring dynamic enforcement policies. Available later this year.
186. Get accelerated GPU-to-GPU communication, with up to 3.2Tbps of non-blocking GPU-to-GPU bandwidth with our high-throughput, low-latency RDMA networking, now generally available.
188. Cloud Load Balancing has optimizations for LLM inference,letting you leverage NVIDIA GPU capacity across multiple cloud providers or on-prem infrastructure.
189. New Service Extensions plugins, powered by WebAssembly (Wasm), let you automate, extend, and customize your applications with plugin examples in Rust, C++, and Go. Support for Cloud Load Balancing is now generally available, and Cloud CDN support will follow later this year.
190. Cloud CDN‘s fast cache invalidation delivers static and dynamic content at global scale with improved performance, now in preview.
191. TLS 1.3 0-RTT in Cloud CDN boosts application performance for resumed connections, now in preview.
192. App Hub provides streamlined service discovery and management by automating service discovery and cataloging.
193. App Hub service health enables resilient global services with network-driven cross-regional failover. Available later this year.
194. Later in 2025, you’ll be able to use Private Service Connect to publish multiple services within a single GKE cluster, making them natively accessible from non-peered GKE clusters, Cloud Run, or Service Mesh.
Then, to help you secure your workloads, we introduced enhancements to protect distributed applications and internet-facing services against network attacks:
195. The new DNS Armor detects DNS-based data exfiltration attacks performed using DNS tunneling, domain generation algorithms (DGA) and other sophisticated techniques. Available in preview later this year.
196. New hierarchical policies for Cloud Armor let you enforce granular protection of your network architecture.
197. There are new network types and firewall tags for Cloud NGFW hierarchical firewall policies, coming this quarter in preview.
198. Cloud NGFW adds new layer 7 domain filtering, allowing firewall administrators to monitor and control outbound web traffic to only allowed destinations. Coming later in 2025.
199. Inline network DLP for Secure Web Proxy and Application Load Balancer provides real-time protection for sensitive data-in-transitvia integration with third-party (Symantec DLP) solutions using Service Extensions. In preview this quarter.
200. Network Security Integration, now generally available, helps you maintain consistent policies across hybrid and multi-cloud environments without changing your routing policies or network architecture.
We’ve always taken an open approach to AI, and the same is true for agentic AI. With updates this week at Next ‘25, we’re now infusing partners at every layer of our agentic AI stack to enable multi-agent ecosystems. Here’s a closer look:
202. Expert AI services: Our ecosystem of services partners — including Accenture, BCG, Capgemini, Cognizant, Deloitte, HCLTech, Infosys, KPMG, McKinsey, PwC, TCS, and Wipro — have actively contributed to the A2A protocol and will support its implementation.
203. AI Agent Marketplace: We launched a new AI Agent Marketplace — a dedicated sectionwithin Google Cloud Marketplace that allows customers to browse, purchase, and manage AI agents built by partners including Accenture, BigCommerce, Deloitte Elastic, UiPath, Typeface, and VMware, with more launching soon.
204. Power agents with all your enterprise data: We are partnering with NetApp, Oracle, SAP, Salesforce, and ServiceNow to allow agents to access data stored in these popular platforms.
205. Better field alignment and co-sell: We introduced new processes to better capture and share partners’ critical contributions with our sales team, including increased visibility into co-selling activities like workshops, assessments, and proofs-of-concept, as well as partner-delivered services.
206. More partner earnings: We are evolving incentives to help partners capitalize on the biggest opportunities, such as a 2x increase in partner funding for AI opportunities over the past year. We also introduced new AI-powered capabilities inEarnings Hub, our destination for tracking incentives and growth.
207. We partnered with Adobe, the leader in creativity, to bring our advanced Imagen 3 and Veo 2 models to applications like Adobe Express.
208. Together with Salesforce’s Agentforce, we’re leading the digital labor revolution, driving massive gains in human augmentation, productivity, efficiency, and customer success.
Security
We offer critical cyber defense capabilities for today’s challenging threat environment, and introduced a number of new innovations:
209. Google Unified Security: This solution brings together our visibility, threat detection, AI powered security operations, continuous virtual red-teaming, the most trusted enterprise browser, and Mandiant expertise — in one converged security solution running on a planet-scale data fabric.
210. Alert triage agent: This agent performs dynamic investigations on behalf of users. It analyzes the context of each alert, gathers relevant information, and renders a verdict on the alert, along with a history of the agent’s evidence and decision making.
211. Malware analysis agent: This agent investigates whether code is safe or harmful. It builds onCode Insight to analyze potentially malicious code, including the ability to create and execute scripts for deobfuscation.
212. In Google Security Operations, new data pipeline management capabilities can help customers better manage scale, reduce costs, and satisfy compliance mandates.
213. We also expanded our Risk Protection Program, which provides discounted cyber-insurance coverage based on cloud security posture, to welcome new program partners Beazley and Chubb, two of the world’s largest cyber-insurers.
214. New employee phishing protections in Chrome Enterprise Premium use Google Safe Browsing data to help protect employees against lookalike sites and portals attempting to capture credentials.
215. TheMandiant Retainer provides on-demand access to Mandiant experts. Customers now can redeem prepaid funds for investigations, education, and intelligence to boost their expertise and resilience.
216. Mandiant Consulting is also partnering with Rubrik and Cohesity to create a solution to minimize downtime and recovery costs after a cyberattack.
Storage
Storage is a critical component for minimizing bottlenecks in both training and inference, and we introduced new innovations to help:
217. We expanded Hyperdisk Storage Pools to store up to 5 PiB of data in a single pool — a 5x increase from before.
218. Hyperdisk Exapools is the biggest and fastest block storage in any public cloud, with exabytes of storage delivering terabytes per second of performance.
219. Hyperdisk ML can now hydrate from Cloud Storage using GKE volume populator.
220. Rapid Storage is a new Cloud Storage zonal bucket with <1ms random read and write latency, and compared to other leading hyperscalers, 20x faster data access, 6 TB/s of throughput, and 5x lower latency for random reads and writes.
221. Anywhere Cacheis a new strongly consistent cache that works seamlessly with existing regional buckets to cache data within a selected zone. Reduces latency up to 70% and 2.5TB/s accelerating AI workloads; maximizing goodput by keeping data close to GPU/TPUs.
222. The new Google Cloud Managed Lustre high-performance, fully managed parallel file system built on DDN EXAScaler. This zonal storage solution provides PB scale <1ms latency, millions of IOPS, and TB/s of throughput for AI workloads.
223. Storage Intelligence, the industry’s first offering enabling customers to generate storage insights specific to their environment by querying object metadata at scale, uses LLMs to provide insights into data estates, as well as take actions on them.
Startups
224. We announced a significant new partnership with the leading venture capital firm Lightspeed, which will make it easier for Lightspeed-backed startups to access technology and resources through the Google for Startups Cloud Program. This includes upwards of $150,000 in cloud credits for Lightspeed’s AI portfolio companies, on top of existing credits available to all qualified startups through the Google for Startups Cloud Program.
225. The new Startup Perks program provides early stage startups with preferred access to solutions from our partners like Datadog, Elastic, ElevenLabs, GitLab, MongoDB, NVIDIA, Weights & Biases, and more.
226. Google for Startups Cloud Program members will receive an additional $10,000 in credits to use exclusively on Partner Models through Vertex AI Model Garden, so they can quickly start using both Gemini models and models from partners like Anthropic and Meta.
Google Workspace: AI-powered productivity
Gemini not only powers best-in-class AI capabilities as a model, but through its own products, like Google Workspace, which includes popular apps like Gmail, Docs, Drive and Meet. We announced a number of new Workspace innovations to further empower users with AI, including:
227. Help me Analyze: This powerful feature transforms Google Sheets into your personal business analyst, intelligently identifying insights from your data without the need for explicit prompting, empowering you to make data-driven decisions with ease.
228. Docs Audio Overview: With audio overviews in Docs, you can create high-quality, human-like audio read-outs or podcast-style summaries of your documents.
229. Google Workspace Flows: Workspace Flows helps you automate daily work and repetitive tasks like managing approvals, researching customers, organizing your email, summarizing your daily agenda, and much more.
There’s no place like home
And with that, we’ve come to the end of Next 25. We hope you’ve enjoyed your time in Las Vegas, and wish you safe travels.
See you in Vegas next year for Google Cloud Next: April 22 – 24, 2026.
aside_block
<ListValue: [StructValue([(‘title’, ‘Turn your new insights from Google Cloud Next into action’), (‘body’, <wagtail.rich_text.RichText object at 0x3e62dd34bfa0>), (‘btn_text’, ”), (‘href’, ”), (‘image’, <GAEImage: next 25>)])]>
1. Grounding with Google Maps is currently available as an experimental release in the United States, providing access to only places data in the United States.
Attending a tech conference like Google Cloud Next can feel like drinking from a firehose — all the news, all the sessions, and breakouts, all the learning and networking… But after a busy couple of days, watching the developer keynote makes it seem like there’s a method to the madness. A coherent picture starts to emerge from all the things that you’ve seen, pointing the way to all the cool things you can do when you get back to your desk.
This year, the developer keynote was hosted by the inimitable duo of Richard Seroter, Google Cloud Chief Evangelist, and Stephanie Wong, Head of Developer Skills and Community, plus a whole host of experts from around Google Cloud product, engineering, and developer advocacy teams. The keynote itself was organized around a noble, relatable goal: Use AI to help remodel AI Developer Experience Engineer Paige Bailey’s 1970s era kitchen. But how?
It all starts with a prompt
The generative AI experience starts by prompting a model with data and your intent. Paige was joined on stage by Logan Kilpatrick, Senior Product Manager at Google DeepMind. There, Logan and Paige prompted AI Studio to analyze Paige’s kitchen, supplying it with text descriptions, floor plans, and images. In return, it suggested cabinets, a cohesive design, color palette, and materials, relying on Gemini’s native image generation capabilities to bring its ideas to life. Then, to answer important questions on cost, especially for Paige’s area, they used Grounding with Google Search to pull in real-world material costs, local building codes and regulations, and other relevant information.
As Logan said, “From understanding videos, to native image generation, to grounding real information with Google Search – these are things that can only be built with Gemini.”
Gemini 2.5 Flash — our workhorse model optimized specifically for low latency and cost efficiency — is coming soon to Vertex AI, AI Studio, and the Gemini app.
From prompt to agent
We all know that a prompt is the heart of a generative AI query. “But what the heck is an agent?” asked Richard. “That’s the million-dollar question.”
“An agent is a service that talks to an AI model to perform a goal-based operation using the tools and context it has,” Stephanie explained. And how do you go from prompt to agent? One way is to use Vertex AI, our comprehensive platform for building and managing AI applications and agents, and Agent Development Kit (ADK), an open-source framework for designing agents.ADK makes it easier than ever to get started with agents powered by Gemini models and Google AI tools.
Dr. Fran Hinkelman, Developer Relations Engineering Manager at Google Cloud, took the stage to show off ADK. An agent needs three things, Fran explained: 1) instructions to define your agent’s goal, 2) tools to enable them to perform, and 3) a model to handle the LLM’s tasks.
Fran wrote the agent code using Python, and in a matter of minutes, deployed it, and got a professionally laid out PDF that outlined everything a builder might need to get started on a kitchen remodel. “What a massive time-saver,” Fran said.
New things that make this possible:
Agent Development Kit (ADK)is our new open-source framework that simplifies the process of building agents and sophisticated multi-agent systems while maintaining precise control over agent behavior. With ADK, you can build an AI agent in under 100 lines of intuitive code.
ADK support for Model Context Protocol (MCP), which creates a standardized structure and format for all the information an LLM needs to process a data request.
From one agent to many
It’s one thing to build an agent. It’s another to orchestrate a collection of agents — exactly the kind of thing you need for a complex process like remodeling a kitchen. To show you how, Dr. Abirami Sukumaran, Staff Developer Advocate at Google Cloud, used ADK to create a multi-agent ecosystem with three types of agents: 1) a construction proposal agent 2) a permits and compliance agent 3) an agent for ordering and delivering materials.
And when the multi-agent system was ready, she deployed it directly from ADK to Vertex AI Agent Engine, a fully managed agent runtime that supports many agent frameworks including ADK.
It gets better: After deploying her agent, Abirami tested it out in Google Agentspace, a hub for sharing your own agents and those from third-parties.
There was a problem, though. Midway through, the agent system appeared to fail. Abirami sprung into action, launching Gemini Cloud Assist Investigations, which used Logs Explorer to return relevant observations and hypotheses about the source of the problem. It even supplied a recommended code fix for the agents. Abirami examined the code, accepted it, redeployed her agents, and saved the day.
This is really key. “It’s hard enough to build systems that orchestrate complex agents and services,” Abirami said. “Developers shouldn’t have to sit around debugging multiple dependencies — getting to the logs, going through the code, all of this can take a lot of time and resources that devs typically don’t have.”
New things that make this possible:
Vertex AI Agent Engine is a fully managed runtime in Vertex AI that helps you deploy your custom agents to production with built-in testing, release, and reliability at a global, secure scale.
Cloud Assist Investigations helps diagnose problems with infrastructure and even issues in the code.
Agent2Agent (A2A) protocol: We’re proud to be the first hyperscaler to create an open protocol to help enterprises support multi-agent ecosystems, so agents can communicate with each other, regardless of the underlying technology.
Choose your own IDE and models
“Have you heard of vibe coding?” i.e., agentic coding, asked our next presenter, Debi Cabrera, Senior Developer Advocate at Google Cloud. Essentially, people can prompt an agent with ideas as well as code to get to an effective programming output. People are doing it more and more using Windsurf, a popular new Integrated Development Environment (IDE), and she’s a fan.
Debi also showed using Gemini in Cursor and IntelliJ with Copilot, but you could also use Visual Studio Code, Tabnine, Cognition, or Aider. (She even wrote her prompts in Spanish, which Gemini handled sin problema). At the end of the day, “we’re enabling devs to use Gemini wherever it suits you best,” Debi said.
Conversely, if you don’t want to use Gemini as your model, you can also use one of the more than 200 models in Vertex AI Model Garden, including Llama, Gemma 3, Anthropic, and Mistral, or open source models from Hugging Face.
“No matter what you use, we’re excited to see what you come up with!”
Android Studiosupport for Gemini Code Assist is now available in preview.
Gemini in Firebase provides complete AI assistance in the new Firebase Studio.
In a field of dreams
Next up, presenters took a break from Paige’s kitchen remodel to tackle another high-value problem: how to throw a pitch.
With all the data that Major League Baseball processes with Google Cloud — 25 million data points per game — pitching technique is a problem that’s ripe for AI.
Jake DiBattista, winner of the recent Google Cloud x MLB Hackathon, started by analyzing a video of a great left-handed pitcher, Clayton Kershaw. He pre-processed the video using a computer vision library, and stored it in Google Cloud, using selections such as pitch type and game state to pull MLB data. Finally, after sending all this information to the Gemini API, he got his answer: Kershaw threw his signature curveball with nearly no deviation from his ideal.
Impressive, but how well does it work for those of us who aren’t pros? Jake created an “amateur mode” for less experienced players, and used a video of our host, Richard, throwing a pitch! After some prompt engineering to adapt from the professional model for Kershaw to an amateur model for Richard, the results were a little more prescriptive: He has potential, he just needs to tighten up his arm a little, and use more leg drive to maximize his power.
Jake shared the inspiration for his project: As a shot putter in college, he wanted to measure the accuracy of his throwing technique. How can you improve if you don’t know what you’re doing wrong – or right? Back then, having this kind of data would have been incredibly valuable for his development.
But what’s truly amazing is that Jake built this fully customizable prompt generator for analyzing pitches in just one week. “This essentially worked out of the box,” Jake said. “I didn’t need to implement a custom model or build overly complex datasets.”
Get back to work
Meanwhile, back at his day job, our next presenter Jeff Nelson, Developer Advocate at Google Cloud, took the stage with a clear goal: to turn raw data into a data application for use by sales managers. He started in BigQuery Notebook to build a forecast and wrote some SQL code. BigQuery loaded the results into a Python DataFrame, because Python makes it easy to use libraries to execute code over tables of any size.
But how can you actually use this agent to forecast sales? Jeff selected the Gemini Data Science Agent built into the Notebook, hit “Ask Agent,” and inputted a prompt that asked for a sales forecast from his table. The best part – from that point onward, all code was generated and executed by the Gemini Data Science Agent.
Plus, he pointed out that the agent used Spark for feature engineering, which is only possible because of our new Serverless Spark engine in BigQuery. Switching between SQL, Spark, and Python is easy, so you can use the right tool for the job.
To build the forecast itself, Jeff used a new Google foundation model, TimesFM, that’s accessible directly from BigQuery.Unlike traditional models, this one’s pre-trained and on massive times-series datasets, so you get forecasts by simply inputting data. “The forecast becomes a data app accessible to everyone,” Jeff said.
As a developer, how would you like it if you could hand off boring things like creating technical design or product requirement docs? Scott Densmore, Senior Director of Engineering, closed out the demos to show us an incredible way to cut through tedious work: Gemini Code Assist and its new Kanban board.
Code Assist can help you orchestrate agents in all aspects of the software development lifecycle, including with what Scott calls a “backpack” that holds all your engineering context. Using a technical design doc for a Java migration as an example, Scott created a comment and assigned it to Code Assist right from the Google doc. Instantly, the new task shows up on the Kanban board, ready to be tracked. Nor is this capability limited to Google Docs — you can also assign tasks directly from your chatrooms and bug trackers, or have Code Assist proactively find them for you.
Then, he took a tougher example: he asked Code Assist to create a prototype for a product requirement doc. He told Code Assist the changes he wanted, and hit repeat until he was happy with what he saw. Easy.
“Gemini Code Assist provides an extra pair of coding hands to help you create applications and remove repetitive and mundane tasks — so you can focus on the fun stuff.”
New things that make this possible:
Gemini Code Assist Kanban boardlets you interact with our agents, review the workplan that Gemini creates to complete the tasks, and track the progress of the various jobs/requests.
Pretty amazing, right? But don’t just take our word for it, for a true sense of all the magic that we demonstrated here, go ahead and rewatch the full developer keynote. We promise that it will be an hour well spent.
At Google Cloud Next, we introduced H4D VMs, our latest machine type for high performance computing (HPC). Building upon existing HPC offerings, H4D VMs are designed to address the evolving needs of demanding workloads in industries such as manufacturing, weather forecasting, EDA, and healthcare and life sciences.
H4D VMs are powered by the 5th Generation AMD EPYCTM Processors, offering improved whole-node VM performance of more than 12,000 gflopsand improved memory bandwidth of more than 950 GB/s. H4D provides low-latency and 200 Gbps network bandwidth using Cloud Remote Direct Memory Access (RDMA) on Titanium, the first of our CPU-based VMs to do so.This powerful combination enables you to efficiently scale your HPC workloads and achieve insights faster.
VM and core performance, as well as memory bandwidth for H4D vs. C2D and C3D, showing generational improvement
For open-source High-Performance Linpack (OSS-HPL), a widely-used benchmark for measuring the floating-point computing power of supercomputers, H4D offers 1.8x higher performance per VM and 1.6x higher performance per core compared to C3D. Additionally, H4D offers 5.8x higher performance per VM and 1.7x higher performance per core compared to C2D.
For STREAM Triad, a benchmark to measure memory bandwidth, H4D offers 1.3x higher performance per VM and 1.4x higher performance per core compared to C3D. Additionally, H4D offers 3x higher performance per VM and 1.4x higher performance per core compared to C2D.
aside_block
<ListValue: [StructValue([(‘title’, ‘$300 in free credit to try Google Cloud infrastructure’), (‘body’, <wagtail.rich_text.RichText object at 0x3ece6d2a1f70>), (‘btn_text’, ‘Start building for free’), (‘href’, ‘http://console.cloud.google.com/freetrial?redirectPath=/compute’), (‘image’, None)])]>
Improved HPC application performance
H4D VMs deliver strong compute performance and memory bandwidth, significantly outperforming previous generations of AMD-based VMs like C2D and C3D, allowing for faster simulations and analysis, and delivering significant performance gains (relative to a prior generation AMD-based HPC VM, C2D) across various HPC applications and benchmarks, as illustrated below:
Manufacturing
CFD apps like SiemensTM Simcenter STAR-CCM+TM/HIMach show up to 3.6x improvement.
CFD apps like Ansys Fluent/f1_racecar_140 show up to 3.6x improvement.
FEA Explicit apps like Altair Radioss/T10m show up to 3.6x improvement.
CFD apps like OpenFoam/Motorbike_20m show up to 2.9x improvement.
FEA Implicit apps like Ansys Mechanical/gearbox shows up to 2.7x improvement.
Healthcare and life sciences:
Molecular Dynamics (GROMACS) shows up to 5x improvement.
Weather forecasting
Industry standard benchmark WRFv4 shows up to 3.6x improvement.
Figure 2: Single VM HPC Application performance (speed-up) of H4D, C3D and C2D relative to C2D. Applications ran on single VMs using all cores.
“Our deep collaboration with Google Cloud powers the next generation of cloud-based HPC with the announcement of the new H4D VMs. Google Cloud has leveraged the architectural advances of our 5th Gen AMD EPYC CPUs to create an offering that delivers impressive performance uplift compared to previous generations across a variety of HPC benchmarks. This will empower customers to achieve fast insights and accelerate their most demanding HPC workloads.” – Ram Peddibhotla, corporate vice president, Cloud Business, AMD
Faster HPC with Cloud RDMA on Titanium
H4D’s performance is made possible with Cloud RDMA, a new Titanium offload that’s available for the first time on these VMs. Cloud RDMA is specifically engineered to support HPC workloads that rely heavily on inter-node communication, such as computational fluid dynamics, weather modeling, molecular dynamics, and more. By offloading network processing, Cloud RDMA provides predictable, low-latency, high-bandwidth communication between compute nodes, thus minimizing host CPU bottlenecks.
Under the hood, Cloud RDMA uses Google’s innovative Falcon hardware transport for reliable, low-latency communication over our Ethernet-based data center networks, effectively resolving the traditional challenges of RDMA over Ethernet while helping to ensure predictable, high performance at scale.
Cloud RDMA over Falcon speeds up simulations by efficiently utilizing more computational resources. For example, for smaller CFD problems like OpenFoam/motorbike_20m and Simcenter Star-CCM+/HIMach10, which have limited inherent parallelism and are typically challenging to accelerate, H4D results in 3.4x and 1.9x speedup, respectively, on four VMs compared to TCP.
Figure 3: Left: OpenFoam/Motorbike_20m offers a 3.4x improvement with H4D Cloud RDMA over TCP at four VMs. Right: Simcenter STAR-CCM+/HIMach10 offers a 1.9x improvement with H4D Cloud RDMA over TCP at four VMs.
For larger models, Falcon also helps maintain strong scaling. Using 32 VMs, Falcon achieved a 2.8x speedup over TCP for GROMACS/Lignocellulose and a 1.3x speedup for WRFv4/Conus 2.5km.
Figure 4: Left: GROMACS/Lignocellulose offers a 2.8x improvement with H4D Cloud RDMA over TCP at 32 VMs. Right: WRFv4/Conus 2.5km offers a 1.3x improvement with H4D Cloud RDMA over TCP at 32 VMs.
Cluster management and scheduling capabilities
H4D VMs will support both Dynamic Workload Scheduler (DWS) and Cluster Director (formerly known as Hypercompute Cluster).
DWS helps schedule HPC workloads for optimal performance and cost-effectiveness, providing resource availability for time-sensitive simulations and flexible HPC jobs.
Cluster Director, which lets you deploy and scale a large, physically-colocated accelerator cluster as a single unit, is now extending its capabilities to HPC environments. Cluster Director simplifies deploying and managing complex HPC clusters on H4D VMs by allowing researchers to easily set up and run large-scale simulations.
VM sizes and regional availability
We offer H4D VMs in both standard and high-memory configurations to cater to diverse workload requirements. We also provide options with local SSD for workloads that demand high-speed storage, such as CPU-based seismic processing and structural mechanics applications (e.g., Abaqus, NASTRAN, Altair OptiStruct and Ansys Mechanical).
VM
Cores
Memory
Local SSD
h4d-highmem-192-lssd
192
1488
3.75TB
h4d-standard-192
192
720
N/A
h4d-highmem-192
192
1488
N/A
H4D VMs are currently available in us-central1-a (Iowa), and europe-west4-b (Netherlands), with additional regions in progress.
What our customers and partners are saying
“With the power of Google’s new H4D-based clusters, we are poised to simulate systems approaching a trillion particles, unlocking unprecedented insights into circulatory functions and diseases. This leap in computational capability will dramatically accelerate our pursuit of breakthrough therapeutics, bringing us closer to effective precision therapies for blood vessel damage in heart disease.” – Petros Koumoutsakos, Jr. Professor of Computing in Science and Engineering, Harvard University
“The launch of Google Cloud’s H4D platform marks a significant advancement in engineering simulation. As GCP’s first VM with RDMA over Ethernet, combined with higher memory bandwidth, generous L3 cache, and AVX-512 instruction support, H4D delivers up to 3.6x better performance for Ansys Fluent simulations compared to C2D VMs. This performance boost allows our customers to run simulations faster, explore a wider range of design options, and drive innovation with greater efficiency.” – Wim Slagter, Senior Director of Partner Programs, Ansys
“The generational performance leap achieved with Google H4D VMs, powered by the 5th Generation AMD EPYC™, is truly remarkable. For compute-intensive, highly non-linear simulations, such as car crash analysis, Altair® Radioss® delivers a stunning 3.6x speedup. This breakthrough paves the way for faster and more accurate simulations, which is crucial for our customers in the era of the digital thread!” – Eric Lequiniou, SVP Radioss Development and Altair Solvers HPC
“The latest H4D VMs, powered by 5th Generation AMD EPYC Processors and Cloud RDMA, allow our customers to realize faster time-to-results for their Simcenter STAR-CCM+ simulations. For HIMach10, we’re seeing up to 3.6x performance gains compared to the C2D instance and 1.9x speedup on four H4D Cloud RDMA VMs compared to TCP. Our partnership with Google has been key to achieving these reduced simulation times.”– Lisa Mesaros, Vice President, Simcenter Solution Domains Product Management, Siemens
Want to try it out?
We’re excited to see how H4D VMs will empower you to achieve faster results with your HPC workloads! Sign up for the preview by filling out thisform.
For decades, businesses have wrestled with unlocking the true potential of their data for real-time operations. Bigtable, Google Cloud’s pioneering NoSQL database, has been the engine behind massive-scale, low-latency applications that operate at a global scale. It was purpose-built for the challenges faced in real-time applications, and remains a key piece of Google infrastructure, including YouTube and Ads.
This week at Google Cloud Next, we announced continuous materialized views, an expansion of Bigtable’ SQL capabilities. Bigtable SQL and continuous materialized views enable users to build fully-managed, real-time application backends using familiar SQL syntax, including specialized features that preserve Bigtable’s flexible schema — a vital aspect of real-time applications.
Whether you’re building streaming applications, real-time aggregations, or global AI analysis on a continuous data stream, Bigtable just got a whole lot easier — and much more powerful.
Bigtable’s SQL interface, now generally available
Bigtable recently transformed the developer experience by adding SQL support, now generally available. SQL support makes it easier for development teams to work with Bigtable’s flexibility and speed.
Bigtable SQL interface in Bigtable Studio
The Bigtable SQL interface enhances accessibility and streamlines application development by facilitating rapid troubleshooting and data analysis. This unlocks new use cases, like real-time dashboards utilizing distributed counting for instant metric retrieval and improved product search through K nearest neighbors (KNN) similarity search. A wide range of customers, spanning innovative AI startups to traditional financial institutions, are enthusiastic about Bigtable SQL’s potential to broaden developer access to Bigtable’s capabilities.
“Imagine coding with AI that understands your entire codebase. That’s Augment Code, an AI coding platform that gives you context in every feature. Bigtable’s robustness and scaling enable us to work with large code repositories. Its ease of use allowed us to build security features that safeguard our customers’ valuable intellectual property. As our engineering team grows, Bigtable SQL will make it easier to onboard new engineers who can immediately start to work with Bigtable’s fast access to structured, semi-structured, or unstructured data while using a familiar SQL interface”saidIgorOstrovsky, cofounder and CTO, Augment.
“Equifax leverages Bigtable within our proprietary data fabric for the high-performance storage of financial journals. Our data pipeline team evaluated Bigtable’s SQL interface and found it to be a valuable tool for directly accessing our enterprise data assets and improved Bigtable’s ease of use for SQL-experienced teams. This means more of our team can work efficiently with Bigtable and we anticipate boosted productivity and better integration capabilities,” said Varadarajan Elangadu Raghunathan and Lakshmi Narayanan Veena Subramaniyam, vice-presidents, Data Fabric Decision Science.
Bigtable SQL has also been praised for offering a smooth migration path from databases with distributed key-value architectures and SQL-based query languages, including Cassandra (CQL) and HBase with Apache Phoenix.
“At Pega, we are building real-time decisioning applications that require very low latency query responses to make sure our clients get real-time data to drive their business. The new SQL interface in Bigtable is a compelling option for us as we look for alternatives to our existing database,” said Arjen van der Broek, principal product manager, Data and Integrations, Pega.
This week, Bigtable is also adding new preview functionalities to its SQL language including GROUP BYs and aggregations, an UNPACK transform for working with timestamped data, and structured row keys for working with data that is stored in a multi-part row key.
aside_block
<ListValue: [StructValue([(‘title’, ‘$300 in free credit to try Google Cloud databases’), (‘body’, <wagtail.rich_text.RichText object at 0x3ece6c19bf70>), (‘btn_text’, ‘Start building for free’), (‘href’, ‘http://console.cloud.google.com/freetrial?redirectPath=/products?#databases’), (‘image’, None)])]>
Continuous materialized views, now in preview
Bigtable SQL integrates with Bigtable’s recently introduced continuous materialized views (preview), offering a solution to traditional materialized view limitations like data staleness and maintenance complexity. This allows for real-time aggregation and analysis of data streams across applications such as media streaming, e-commerce, advertising, social media, and industrial monitoring.
Bigtable materialized views are fully managed and make updates incrementally without impacting your user queries from applications. Bigtable materialized views also support a rich SQL language including functions and aggregations.
“With Bigtable’s new Materialized Views, we’ve unleashed the full potential of low-latency use cases for clients of our Customer Data Platform. By defining SQL-based aggregations/transformations at ingestion, we’ve eliminated the complexities and delays of ETL in our time series use cases. Moreover, using data transformations during ingestion, we’ve unlocked the ability for our AI applications to receive perfectly prepared data with minimal latencies,” said Sathish KS, Chief Technology Officer, Zeotap.
Continuous Materialized Views workflow
Ecosystem integrations
To get useful real-time analytics, you often need to pull data from many sources and do so with very low latency. As Bigtable expands its SQL interface, it is also expanding its ecosystem compatibility making it easier to build end to end applications using simple connectors and SQL.
Open-source Apache Kafka Bigtable Sink Customers often rely on Google Cloud Managed Service for Apache Kafka to build pipelines that stream data into Bigtable and other analytics systems. To help customers build high-performance data pipelines, the Bigtable team has open-sourced a new Bigtable Sink for Apache Kafka so you can send data from Kafka to Bigtable in milliseconds.
Open-source Apache Flink Connector for Bigtable Apache Flink is a stream-processing framework that lets you manipulate data in real time. With the recently launched Apache Flink to Bigtable Connector, you can construct a pipeline that lets you transform streaming data and write the outputs into Bigtable using both the high-level Apache Flink Table API and the more granular Datastream API.
“BigQuery continuous queries enables our application to use real-time stream processing and ML predictions by simply writing a SQL statement. It’s a great service that allows us to launch products quickly and easily,” said Shuntaro Kasai and Ryo Ueda, MLOps Engineers, DMM.com.
Real-time Analytics in Bigtable overview
Bigtable CQL Client: Bigtable is now in preview and Cassandra-compatible
The Cassandra Query Language (CQL) is the query language of Apache Cassandra. With the launch of Bigtable CQL Client, developers can now migrate their applications to Bigtable with minimal to no code change, and enjoy the familiarity of CQL on enterprise-grade, high-performance Bigtable. Bigtable also supports common tools in the Cassandra ecosystem like the CQL shell (CQLsh), as well as Cassandra’s own data migration utilities which enable seamless migrations from Cassandra, with no downtime significantly reducing operational overhead.
Get started using the Bigtable CQL Client and migration utilities here.
Convergence: NoSQL’s embrace of SQL power
In this blog, we discussed a significant advancement that empowers developers to use SQL with Bigtable. You can easily get started with the flexible SQL language from any existing Bigtable cluster using Bigtable Studio and start to create materialized views on streams of data coming from Kafka and Flink.
As an object storage service, Google Cloud Storage is popular for its simplicity and scale, a big part of which is due to the stateless REST protocols that you can use to read and write data. But with the rise of AI and as more customers look to run data-intensive workloads, two major obstacles to using object storage are its higher latency and lack of file-oriented semantics. With the launch of Rapid Storage on Google Cloud, we’ve added a stateful gRPC-based streaming protocol that provides sub-millisecond read/write latency and the ability to easily append data to an object, while maintaining the high aggregate throughput and scale of object storage. In this post, we’ll share an architectural perspective into how and why we went with this approach, and the new types of workloads it unlocks.
It all comes back to Colossus, Google’s internal zonal cluster-level file system that underpins most (if not all) of our products. As we discussed in a recent blog post, Colossus supports our most demanding performance-focused products with sophisticated SSD placement techniques that deliver low latency and massive scale.
Another key ingredient in Colossus’s performance is its stateful protocol — and with Rapid Storage, we’re bringing the power of the Colossus stateful protocol directly to Google Cloud customers.
aside_block
<ListValue: [StructValue([(‘title’, ‘Try Google Cloud for free’), (‘body’, <wagtail.rich_text.RichText object at 0x3ece8b51b9d0>), (‘btn_text’, ‘Get started for free’), (‘href’, ‘https://console.cloud.google.com/freetrial?redirectPath=/welcome’), (‘image’, None)])]>
When a Colossus client creates or reads a file, the client first opens the file and gets a handle, a collection of state that includes all the information about how that file is stored, including which disks the file’s data is stored on. Clients can use this handle when reading or writing to talk directly to the disks via an optimized RDMA-like network protocol, as we previously outlined in our Snap networking system paper.
Handles can also be used to support ultra-low latency durable appends, which is extremely useful for demanding database and streaming analytics applications. For example, Spanner and Bigtable both write transactions to a log file that requires durable storage and that is on the critical path for database mutations. Similarly, BigQuery supports streaming to a table while massively parallel batch jobs perform computations over recently ingested data. These applications open Colossus files in append mode, and the Colossus client running in the application uses the handle to write their database mutations and table data directly to disks over the network. To ensure the data is stored durably, Colossus replicates its data across several disks, performing writes in parallel and using a quorum technique to avoid waiting on stragglers.
Figure 1: Steps involved in appending data to a file in Colossus.
The above image shows the steps that are taken to append data to a file.
The application opens the file in append mode. The Colossus Curator constructs a handle and sends it to the Colossus Client running in-process, which caches the handle.
The application issues a write call for an arbitrary-sized log entry to the Colossus Client.
The Colossus Client, using the disk addresses in the handle, writes the log entry in parallel to all the disks.
Rapid Storage builds on Colossus’s stateful protocol, leveraging gRPC-based streaming for the underlying transport. When performing low-latency reads and writes to Rapid Storage objects, the Cloud Storage client establishes a stream, providing the same request parameters used in Cloud Storage’s REST protocols, such as the bucket and object name. Further, all the time-consuming Cloud Storage operations such as user authorization and metadata accesses are front-loaded and performed at stream creation time, so subsequent read and write operations go directly to Colossus without any additional overhead, allowing for appendable writes and repeated ranged reads with sub-millisecond latency.
This Colossus architecture enables Rapid Storage to support 20 million requests per second in a single bucket — a scale that is extremely useful in a variety of AI/ML applications. For example, when pre-training a model, pre-processed, tokenized training data is fed into GPUs or TPUs, typically in large files that each contain thousands of tokens. But the data is rarely read sequentially, for example, because different random samples are read in different orders as the training progresses. With Rapid Storage’s stateful protocol, a stream can be established at the start of the training run before executing massively parallel ranged-reads at sub-millisecond speeds. This helps to ensure that accelerators aren’t blocked on storage latency.
Likewise, with appends, Rapid Storage takes advantage of Colossus’s stateful protocol to provide durable writes with sub-millisecond latency, and supports unlimited appends to a single object up to the object size limit. A major challenge with stateful append protocols is how to handle cases where the client or server hangs or crashes. With Rapid Storage, the client receives a handle from Cloud Storage when creating the stream. If the stream gets interrupted but the client wants to continue reading or appending to the object, the client can re-establish a new stream using this handle, which streamlines this flow and minimizes any latency hiccups. It gets trickier when there is a problem on the client, and the application wants to continue appending to an object from a new client. To simplify this, Rapid Storage guarantees that only one gRPC stream can write to an object at a time; each new stream takes over ownership of the object, transactionally locking out any prior stream. Finally, each append operation includes the offset that’s being written to, ensuring that data correctness is always preserved even in the face of network partitions and replays.
Figure 2: A new client taking over ownership of an object.
In the above image, a new client takes over ownership of an object, locking out the previous owner.
Initially, client 1 appends data to an object stored on three disks.
The application decides to fail over to client 2, which opens this object in append mode. The Colossus Curator transactionally locks out client 1 by increasing a version number on each object data replica.
Client 1 attempts to append more data to the object, but cannot because its ownership was tied to the old version number.
To make it as easy as possible to integrate Rapid Storage into your applications, we are also updating our SDKs to support gRPC streaming-based appends and expose a simple application-oriented API. Writing data using handles is a familiar concept in the filesystems world, so we’ve integrated Rapid Storage into Cloud Storage FUSE, which provides clients with file-like access to Cloud Storage buckets, for low-latency file-oriented workloads. Rapid Storage also natively enables Hierarchical Namespace as part of its zonal bucket type, providing enhanced performance, consistency, and folder-oriented APIs.
In short, Rapid Storage combines the sub-millisecond latency of block-like storage, the throughput of a parallel filesystem, and the scalability and ease of use of object storage, and it does all this in large part due to Colossus. Here are some interesting workloads we’ve seen our customers explore during the preview:
AI/ML data preparation, training, and checkpointing
Distributed database architecture optimization
Batch and streaming analytics processing
Video live-streaming and transcoding
Logging and monitoring
Interested in trying Rapid Storage? Indicate your interest here or reach out through your Google Cloud representative.
As organizations continue to prioritize cloud-first strategies to accelerate innovation and gain competitive advantage, legacy databases remain a bottleneck by hindering modernization and stifling growth with unfriendly licensing, complex agreements, and rigid infrastructure.
That’s why this week at Google Cloud Next, we’re announcing that Database Migration Service (DMS) is extending its comprehensive database modernization offering to support SQL Server to PostgreSQL migrations, enabling you to unlock the potential of open-source databases in the cloud and build modern, scalable, and cost-effective applications.
While holding great benefits, migrating from SQL Server to a modern, managed PostgreSQL offering like AlloyDB or Cloud SQL can be a highly complex task. Even though SQL Server and PostgreSQL both adhere to SQL standards, they still have fundamental differences in their architectures, data types, and procedural languages which require deep expertise in both technologies for a successful migration.
For example, SQL Server’s T-SQL syntax and built-in functions often require manual translation to PostgreSQL’s PL/pgSQL. Data type mappings can be intricate, as SQL Server’s DATETIME precision and NVARCHAR handling differ from PostgreSQL’s equivalents.
Furthermore, features like SQL Server’s stored procedures, triggers, and functions often necessitate significant refactoring to align with PostgreSQL’s implementation. This requires deep knowledge in both database systems, as well as specific migration expertise that developers typically don’t possess, and it requires hours of painstaking work, even with the benefit of an automated conversion tool.
aside_block
<ListValue: [StructValue([(‘title’, ‘$300 in free credit to try Google Cloud databases’), (‘body’, <wagtail.rich_text.RichText object at 0x3ece6c0c5460>), (‘btn_text’, ‘Start building for free’), (‘href’, ‘http://console.cloud.google.com/freetrial?redirectPath=/products?#databases’), (‘image’, None)])]>
Simplifying database modernization with Database Migration Service
DMS is a fully-managed, serverless cloud service that offers a complete set of capabilities to simplify database “lift and shift” migrations and database modernization journeys.
For modernization efforts, DMS offers an interactive experience that includes data migration, as well as schema and resident code conversion, all in the same powerful user interface. For data migration, it offers high-throughput database initial loads followed by low-latency change data capture to reduce downtime and minimize the impact on business critical applications.
Announcing SQL Server to PostgreSQL migration
The new SQL Server to PostgreSQL.migration experience supports the migration of both self-managed and cloud-managed SQL Server offerings to Cloud SQL for PostgreSQL and AlloyDB to accelerate your database modernization journey. Similar to the existing database modernization offerings, this new experience features a high-throughput initial load of the database followed by seamless change data capture (CDC) replication to synchronize the SQL Server source and PostgreSQL destination, all while the production application is up and running to ensure minimal business interruption.
Database Migration Service is designed to automate the most difficult SQL Server to PostgreSQL migration steps.
For SQL Server schema and code conversion, DMS offers a fast, customizable algorithmic code conversion engine that automates the conversion of most of the database schema and code to the appropriate PostgreSQL dialect, leaving minimal manual conversion work for the user to complete.
The algorithmic conversion engine maps the source database data types and SQL commands to the most suitable PostgreSQL ones, and even refactors complex source features which have no direct PostgreSQL equivalents to achieve the same functionality using available PostgreSQL capabilities. Algorithmic engines are extremely accurate, by nature, for the scenarios they are programmed for. However, they’re limited to just those scenarios, and in real-life usage some of the database code will consist of scenarios that can’t be anticipated.
For these situations, we’re pushing the boundaries of automated database modernization with the introduction of the Gemini automatic conversion engine. This new engine automatically augments the output of the algorithmic conversion, further automating the conversion tasks and reducing the amount of remaining manual work. It also provides a comprehensive conversion report, highlighting which parts of the code were enhanced, why they were changed, and how they were converted.
Instead of spending time researching suitable PostgreSQL features and fixing conversion issues, you can simply review the Gemini recommendations in the conversion report and mark the conversion as verified. Reviewing the completed conversions instead of having to research and fix issues can significantly reduce the manual migration effort and speed up the conversion process.
To further empower SQL Server DBAs, DMS offers a Gemini conversion assist with targeted yet comprehensive SQL Server to PostgreSQL conversion training. Gemini analyzes both the source and the converted code and explains the conversion rationale, highlighting the chosen PostgreSQL features, why they were used, and how they compare to the SQL Server ones. It can then optimize the migrated code for better performance and automatically generate comprehensive comments, for better long-term maintainability.
Database Migration Service provides detailed explanations of SQL Server to PostgreSQL conversions.
At Google Cloud, we’ve been working closely with customers looking to modernize their database estate. One of them is Wayfair LLC, an American online home store for furniture and decor.
“Google Cloud’s Database Migration Service simplifies the process of modernizing databases. Features like Change Data Capture to reduce downtime and AI-assisted code conversion help evolve our database usage more efficiently. This makes the migration process less manual and time-consuming, allowing teams to spend more time on development and less on infrastructure,” said Shashank Srivastava, software engineering manager, Data Foundations, Wayfair.
How to get started
To start your Gemini-powered SQL Server migration, navigate to the Database Migration page in the Google Cloud console, and follow these simple steps:
Create your source and destination connection profiles, which contain information about the source and destination databases. These connection profiles can later be used for additional migrations.
Create a conversion workspace that automatically converts your source schema and the code to a PostgreSQL schema and compatible SQL. Make sure you choose to enable the new Gemini-powered conversion workspace capabilities.
Review the converted schema objects and SQL code, and apply them to your destination Cloud SQL for PostgreSQL or AlloyDB for PostgreSQL instance.
Create a migration job and choose the conversion workspace and connection profiles previously created.
Test your migration job and get started whenever you’re ready.
To learn more about how Database Migration Service can help you modernize your SQL Server databases, please review our DMS documentation and start your migration journey today.
Supporting customers where they want to be is a core value at Google Cloud, and a big part of the reason that we have partnered with Oracle — so that you can innovate faster with the best of Google and the best of Oracle.
This week at Google Cloud Next, we announced significant expansions to our Oracle Database offerings, including the preview of Oracle Base Database Service for a flexible and controllable way to run Oracle databases in the cloud; general availability of Oracle Exadata X11M,bringing the latest generation of the Oracle Exadata platform to Google Cloud; and additional enterprise-ready capabilities including customer managed encryption keys (CMEK).
We are continuing to invest in global infrastructure for Oracle, with a total of 20 locations available in the coming months, adding Oracle Database@Google Cloud presence in Australia, Brazil, Canada, India, Italy, and Japan.
These announcements follow our developments with Oracle since last July, when we launched Oracle Database@Google Cloud. This partnership enables customers to migrate and modernize their Oracle workloads and start taking advantage of Google’s industry-leading data and AI capabilities such as BigQuery, Vertex AI platform, and Gemini foundation models.
Additional features provide customers with even more options in their modernization journey, such as the fully managed Oracle Autonomous Database Serverless. They can also benefit from increased reliability and resiliency features, such as cross-region disaster recovery and Oracle Maximum Availability Gold certification.
“Banco Actinver is committed to providing innovative financial solutions to our clients. By combining the security and performance of Oracle Database with Google Cloud’s data analytics and AI tools, we’re gaining deeper insights into market trends, enhancing our services, and delivering personalized experiences to our customers,” said Jorge Fernandez, CIO, Banco Actinver.
aside_block
<ListValue: [StructValue([(‘title’, ‘$300 in free credit to try Google Cloud databases’), (‘body’, <wagtail.rich_text.RichText object at 0x3ece8b0a2370>), (‘btn_text’, ‘Start building for free’), (‘href’, ‘http://console.cloud.google.com/freetrial?redirectPath=/products?#databases’), (‘image’, None)])]>
Innovative new capabilities
We’re expanding our offerings to empower customers with the flexibility to manage a diverse set of database workloads cost effectively.
Oracle Base Database Service: The new Base Database Service delivers a highly controllable and customizable foundational database platform, built on Oracle Cloud Infrastructure (OCI) virtual machines and general-purpose infrastructure. It can empower businesses with the flexibility to manage a diverse range of database workloads directly.
Enhanced Oracle Database Services: In addition to the availability of Exadata Cloud Service, Autonomous Database Service, Oracle Linux, and Oracle on Google Compute Engine (GCE) and Google Kubernetes Engine (GKE), we are pleased to share general availability of Oracle Exadata X11M. Oracle Database@Google Cloud now offers the latest generation of Oracle Exadata machines, the X11M, with enhanced performance and scalability for demanding database workloads. These new machines provide significant performance gains and increased capacity, enabling customers to run even the most intensive Oracle applications with ease. X11M will be available in all new regions.
Customers are embracing Oracle Database@Google Cloud, and to support their global needs, we’re expanding our footprint while maintaining the highest standards of application performance and reliability.
Expanding to 20 Oracle Database@Google Cloud Locations in the coming months: To further support the growing demand for Oracle workloads on Google Cloud, we are launching in more locations, including U.S. Central 1 (Iowa), North America-Northeast 1 (Montreal), North America-Northeast 2 (Toronto), Asia-Northeast 1 (Tokyo), Asia-Northeast 2 (Osaka), Asia-South 1 (Mumbai), Asia-South 2 (Delhi), South America-East 1 (Sao Paulo), Europe-West (Italy), Australia-Southeast2 (Melbourne), and Australia-Southeast1 (Sydney) — and additional zones in Ashburn, Frankfurt, London, Melbourne, and Italy. The new regions and expanded capacity are in addition to Google Cloud regions across U.S. East (Ashburn), U.S. West (Salt Lake City), U.K. South (London), and Germany Central (Frankfurt) that are available today.
New Partner Cross-Cloud Interconnect availability: Partner Cross-Cloud Interconnect for OCI is pleased to expand our global network offerings with new multicloud connectivity between Google and Oracle Cloud Infrastructure in Toronto and Zurich. This further complements our existing 11 regions already served, ensuring the lowest possible latency between both clouds while keeping traffic private and secure.
Cross Region Disaster Recovery: Cross Region Disaster Recovery support for Oracle workloads on Oracle Autonomous Database ensures high availability and resilience, protecting against potential outages and providing continuous operation for critical applications.
Enterprise-grade networking upgrades: Advanced networking upgrades enable enterprises to efficiently deploy their Oracle resources along with Google Cloud and share resources.
Industry-leading certifications and user experience
Google Cloud is committed to providing a seamless and efficient experience for Oracle customers, ensuring that managing and utilizing Oracle databases is straightforward and effective. We offer a combination of native Google Cloud tools and Oracle Cloud Infrastructure (OCI) interfaces, along with robust support for various applications and systems.
Enhanced user experience: Google Cloud is committed to providing an easy-to-use experience for Oracle customers, offering a Google Cloud integrated user experience for application developers and routine database operations, alongside an OCI-native experience for advanced database management. This includes support for Shared VPC, APIs, SDKs, and Terraform.
Application support: Google Cloud is pleased to announce the support for Oracle applications running on Google Cloud, ensuring compatibility and optimal performance, including Oracle E-Business Suite, Peoplesoft Enterprise, JD Edwards Enterprise One, Hyperion Financial Management, and Retail Merchandising.
SAP and Oracle Capability: Oracle workloads on Google Compute Engine are now supported by SAP and Oracle, further validating Google Cloud as a trusted platform for running enterprise applications.
Integration with Google Cloud Monitoring: Provides enterprises a unified monitoring and alerting mechanism across all their Google Cloud database services, now including Oracle Database.
New support in Google Cloud Backup and DR: Our backup service now provides central, policy-based management for backup of Oracle workloads along with other Google Cloud services using secure backup vaults for data protection — isolating and protecting data from threats like ransomware and accidental deletion.
Google Cloud’s strengths make it the preferred hyperscaler for running mission-critical Oracle workloads.
Get started right away from your Google Cloud Console or learn more here.
The high-performance storage stack in AI Hypercomputer incorporates learnings from geographic regions, zones, and GPU/TPU architectures, to create an agile, economical, integrated storage architecture. Recently, we’ve made several innovations to improve accelerator utilization with high-performance storage, helping you to optimize costs, resources, and accelerate your AI workloads:
Rapid Storage: A new Cloud Storage zonal bucket that provides industry-leading <1ms random read and write latency, 20x faster data access, 6 TB/s of throughput, and 5x lower latency for random reads and writes compared to other leading hyperscalers.
Anywhere Cache: A new, strongly consistent cache that works with existing regional buckets to cache data within a selected zone. Anywhere Cache reduces latency up to 70% and 2.5TB/s, accelerating AI workloads; and maximizes goodput by keeping data close to GPU or TPUs.
Google Cloud Managed Lustre: A new high-performance, fully managed parallel file system built on the DDN EXAScaler Lustre file system. This zonal storage solution provides PB scale at under 1ms latency, millions of IOPS, and TB/s of throughput for AI workloads.
Storage Intelligence, the industry’s first offering for generating storage insights specific to their environment by querying object metadata at scale and using the power of LLMs. Storage Intelligence not only provides insights into vast data estates, it also provides the ability to take actions, e.g., using ‘bucket relocation’ to non-disruptively co-locate data with accelerators.
aside_block
<ListValue: [StructValue([(‘title’, ‘Try Google Cloud for free’), (‘body’, <wagtail.rich_text.RichText object at 0x3ece885d0310>), (‘btn_text’, ‘Get started for free’), (‘href’, ‘https://console.cloud.google.com/freetrial?redirectPath=/welcome’), (‘image’, None)])]>
Rapid Storage enables AI workloads with millisecond-latency
To train, checkpoint, and serve AI models at peak efficiency, you need to keep your GPU or TPUs saturated with data to minimize wasted compute (as measured by goodput). But traditional object storage suffers from a critical limitation: latency. Using Google’s Colossus cluster-level file system, we are delivering a new approach to colocate storage and AI accelerators in a new zonal bucket. By “sitting on” Colossus, Rapid Storage avoids the typical regional storage latency of having accelerators that reside in one zone and data that resides in another.
Unlike regional Cloud Storage buckets, a Rapid Storage zonal bucket concentrates data within the same zone that your GPUs and TPUs run in, helping to achieve sub-millisecond read/write latencies and high throughput. In fact, Rapid Storage delivers 5x lower latency for random reads and writes compared to other leading hyperscalers. Combined with throughput of up to 6 TB/s per bucket and up to 20 million queries per second (QPS), you can now use Rapid Storage to train AI models with new levels of performance.
And because performance shouldn’t come at the cost of complexity, you can mount a Rapid Storage bucket as a file system leveraging Cloud Storage FUSE. This lets common AI frameworks such as TensorFlow and PyTorch access object storage without having to modify any code.
Anywhere Cache puts data in your preferred zone
Anywhere Cache is a strongly consistent zonal read cache that works with existing storage buckets (Regional, Multi-regional, or Dual-Region) and intelligently caches data within your selected zone. As a result, Anywhere Cache delivers up to 70% improvement in read-storage latency. By dynamically caching data to the desired zone and close to your GPUs or TPUs, it delivers performance of up to 2.5 TB/s, keeping multiple epoch training times minimized. Should conditions change, e.g., there’s a shift in accelerator availability, Anywhere Cache ensures your data accompanies the AI accelerators. You can enable Anywhere Cache in other regions and other zones with a single click, with no changes to your bucket or application. Moreover, it eliminates egress fees for cached data — among existing Anywhere Cache customers with multi-region buckets, 70% have seen cost benefits.
Anthropic leverages Anywhere Cache to improve the resilience of their cloud workload by co-locating data with TPUs in a single zone and providing dynamically scalable read throughput up to 6TB/s. They also use Storage Intelligence to gain deep insight into their 85+ billion objects allowing them to optimize their storage infrastructure.
Google Cloud Managed Lustre accelerates HPC and AI workloads
AI workloads can access small files, random I/O, while needing the sub-millisecond latency of a parallel file system. The new Google Cloud Managed Lustre is a fully managed parallel file system service that provides full POSIX support and persistent zonal storage that scales from terabytes to petabytes. As a persistent parallel file system, Managed Lustre lets you confidently store your training, checkpoint, and serving data, while delivering high throughput, sub-millisecond latency, and millions of IOPS across multiple jobs — all while maximizing goodput. With its full-duplex network utilization, Managed Lustre can fully saturate VMs at 20GB/s and can deliver up to 1TB/s in aggregate throughput, while support for the Cloud Storage bulk import/export API makes it easy to move datasets to and from Cloud Storage. Managed Lustre is built in collaboration with DDN and based on EXAScaler.
Analyze and act on data with Storage Intelligence
Your AI models can only be as good as the data you train them on. Today, we announced Storage Intelligence, a new service that can help you find the right set of data by querying the metadata across all of your buckets to be used for AI training, improving your AI cost-optimization efforts. Storage Intelligence queries object metadata at scale using the power of LLMs, helping to generate storage insights specific to an environment. The first such service from a cloud hyperscaler, Storage Intelligence lets you analyze the millions — or billions — of object metadata in your buckets, and projects across your organization. With the insights from this analysis, you can make informed decisions about eliminating duplicate objects, identifying objects that can be deleted or tiered to a lower storage class through Object Lifecycle Management or Autoclass, or identifying objects that violate your company’s security policies, to name a few.
Google’s Cloud Storage’s Autoclass and Storage Intelligence features have helped Spotify understand and optimize its storage costs. In 2024, Spotify took advantage of these features to reduce its storage spend by 37%.
High performance storage for your AI workloads
We built our Rapid Storage, Anywhere Cache, and Managed Lustre, high-performance storage solutions to deliver availability, high throughput, low latency, and durable architectures. Storage Intelligence adds to that, providing valuable, actionable insights into your storage estate.
Today at Google Cloud Next ‘25, we’re announcing a major step in making Looker the most powerful platform for data analysis and exploration,by enhancing it with powerful AI capabilities and a new reporting experience, all built on our trusted semantic model — the foundation for accurate, reliable insights in the AI era.
Starting today, all platform users can now leverage conversational analytics to analyze their data using natural language and Google’s latest Gemini models. We’re also debuting a brand-new reporting experience within Looker, designed for enhanced data storytelling and streamlined exploration. Both innovations are now available to all Looker-hosted customers.
Modern organizations require more than just accurate insights; they need AI to uncover hidden patterns, predict trends, and drive intelligent action. Gemini in Looker and the introduction of Looker reports makes business intelligence simpler and more accessible for everyone. This empowers users across the organization, reduces the burden on data teams, and frees analysts to focus on higher-impact work.
With Conversational Analytics, ask questions of your data and get AI-driven insights.
Looker’s unique foundation is its semantic layer, which ensures everyone works from a single source of truth. Combined with Google’s AI, Looker now delivers intelligent insights and automates analysis, accelerating data-driven decisions across your organization.
aside_block
<ListValue: [StructValue([(‘title’, ‘$300 in free credit to try Google Cloud data analytics’), (‘body’, <wagtail.rich_text.RichText object at 0x3ece8b55ad60>), (‘btn_text’, ‘Start building for free’), (‘href’, ‘http://console.cloud.google.com/freetrial?redirectPath=/bigquery/’), (‘image’, None)])]>
Gemini in Looker now available to all platform users
At Google Cloud Next ’24, we introduced Gemini in Looker to bring intelligent AI-powered BI to everyone, featuring a suite of capabilities, or assistants, that let users ask questions of their data in natural language and simplify tasks and workflows like data modeling, and chart and presentation generation.
Since then, we’ve brought those features to life in preview, and we are now expanding their access to all platform users, given the product’s level of maturity and accuracy. These include Conversational Analytics, for gaining insights into your data through natural language queries; Visualization Assistant for custom visuals initiated by natural language, letting you easily configure charts and visualizations for dashboard creation; Formula Assistant for powerful on-the-fly calculated fields and instant ad-hoc analysis; Automated Slide Generation for impactful presentations with insightful and instant text summaries of your data; and LookML Code Assistant to simplify code creation, including guidance and suggestions to create dimensions, groups, measures and more.
Also available in preview is our cCode iInterpreter for Conversational Analytics, which enables business users to perform complex tasks and derive advanced analytics, including forecasting and anomaly detection using natural language without needing deep Python expertise. You can learn more about this new capability and sign up here.
With Automated Slide Generation, you can create colorful and informative slides from Looker reports
Conversational Analytics API
To bring the power of conversational analytics beyond the Looker interface, we are introducing the Conversational Analytics API. Developers can now embed natural language query capabilities directly into custom applications, internal tools, or workflows, backed by trusted data access and scalable, reliable data modeling that can adapt to evolving needs.
This API allows you to build custom BI agent experiences, leveraging Looker’s trusted semantic model for accuracy and Google’s advanced AI models (including NL2SQL, RAG, and VizGen). Developers can embed this functionality easily to create intuitive data experiences, enable complex analysis via natural language, and even share insights generated from these conversations within the Looker platform.(Sign up here for preview access to the Conversational Analytics API.)
Introducing Looker reports
Self-service analysis is key to empowering line-of-business users and fostering collaboration. Building on the success and user-friendliness of Looker Studio, we’re bringing its powerful visualization and reporting capabilities directly into the core Looker platform with the introduction of Looker reports.
Looker reports are now available with Studio in Looker unification
Looker reports bring enhanced data storytelling, streamlined exploration, and broader data connectivity to users, including reports generated from native Looker content, direct connections to Microsoft Excel and Google Sheets data, first-party connectors and ad-hoc access to various data sources.
Creating compelling, interactive reports is now easier than ever. Looker reports features the intuitive drag-and-drop interface users love, granular design controls, a rich library of visualizations and templates, and real-time collaboration capabilities.
This new reporting environment lives alongside your existing Looker Dashboards and Explores within Looker’s governed framework. Importantly, Looker Reports seamlessly integrates with Gemini in Looker, allowing you to leverage conversational analytics within this new reporting experience.
Faster, more reliable development with continuous integration
With Google Cloud’s acquisition of Spectacles.dev, we are enabling developers to automate testing and validation of SQL, LookML changes, leading to faster, more reliable development cycles. Robust CI/CD practices build data trust by ensuring the accuracy and consistency of your semantic model — crucial for dependable AI-powered BI.
Continuous integration in Looker lets developers build and test faster than ever.
These advancements – the expanded availability of Gemini in Looker, the new Conversational Analytics API, the introduction of Looker reports, and native Continuous Integration capabilities – represent a major leap forward in delivering a complete AI-for-BI platform. We’re making it easier than ever to access trusted insights, leverage powerful AI, and foster a truly data-driven culture.
Join us at Google Cloud Next and be sure to watch our What’s new in Looker: AI for BI session on demand after the event to experience the future of BI with Looker, and discover how complete AI for BI can transform your data into a strategic advantage.
When it comes to AI, inference is where today’s generative AI models can solve real-world business problems. Google Kubernetes Engine (GKE) is seeing increasing adoption of gen AI inference. For example, customers like HubX run inference of image-based models to serve over 250k images/day to power gen AI experiences, and Snap runs AI inference on GKE for its ad ranking system.
However, there are challenges when deploying gen AI inference. First, during the evaluation phase of this journey, you have to evaluate all your accelerator options. You need to choose the right one for your use case. While many customers are interested in using Tensor Processing Units (TPU), they are looking for compatibility with popular model servers. Then, once you’re in production, you need to load-balance traffic, manage price-performance with real traffic at scale, monitor performance, and debug any issues that arise.
To help, this week at Google Cloud Next, we introduced new gen AI inference capabilities for GKE:
GKE Inference Quickstart to help you set up inference environments according to best practices enhancements
GKE Inference Gateway, which introduces gen-AI-aware scaling and load balancing techniques
Together these capabilities help reduce serving costs by over 30%, tail latency by 60%, and increase throughput by up to 40% compared to other managed and open-source Kubernetes offerings.
GKE Inference Quickstart helps you select and optimize the best accelerator, model server and scaling configuration for your AI/ML inference applications. It includes information about instance types, their model compatibility across GPU and TPUs, and benchmarks for how a given accelerator can help you meet your performance goals. Then, once your accelerators are configured, GKE Inference Quickstart can help you with Kubernetes scaling, as well as new inference-specific metrics. In future releases, GKE Inference Quickstart will be available as a Gemini Cloud Assist experience.
aside_block
<ListValue: [StructValue([(‘title’, ‘$300 in free credit to try Google Cloud containers and Kubernetes’), (‘body’, <wagtail.rich_text.RichText object at 0x3ece88cb05b0>), (‘btn_text’, ‘Start building for free’), (‘href’, ‘http://console.cloud.google.com/freetrial?redirectpath=/marketplace/product/google/container.googleapis.com’), (‘image’, None)])]>
GKE TPU serving stack
With support for TPUs and vLLM, one of the leading open-source model servers, you get seamless portability across GPUs and TPUs. This means you can use any open model, select the vLLM:TPU container image and just deploy on GKE without any TPU-specific changes. GKE Inference Quickstart also recommends TPU best practices so you can seamlessly run on TPUs without any switching costs. For customers who want to run state-of-the-art models, Pathways, used internally at Google for large models like Gemini, allows you to run multi-host and disaggregated serving.
GKE Inference Gateway
GKE Gateway is an abstraction backed by a load balancer to route incoming requests to your Kubernetes applications, and traditionally, it has been tuned for web serving applications, using load-balancing techniques such as round-robin, whose requests have very predictable patterns. But LLMs have high variability in their request patterns. This can result in high tail latencies and uneven compute utilization, which can negatively impact the end-user experience and unnecessarily increase inference costs. In addition, traditional Gateway does not support routing infrastructure for popular Parameter-Efficient Fine-Tuning (PEFT) techniques like Low-Rank Adaptation (LoRA), which can increase GPU efficiency by model reuse during inference.
For scale-out scenarios, the new GKE Inference Gateway provides gen-AI-aware load balancing, for optimal routing. With GKE Inference Gateway, you can define routing rules for safe rollouts, cross-regional preferences, and performance goals such as priority. Finally, GKE Inference Gateway supports LoRA, which lets you map multiple models to the same underlying service, for better efficiency.
To summarize, the visual below shows the needs of the customers during the different stages of the AI inference journey, and how GKE Inference Quickstart, GKE TPU serving stack and GKE Inference Gateway help simplify the evaluation, onboarding and production phases.
What our customers are saying
“Using TPUs on GKE, especially the newer Trillium for inference, particularly for image generation, has reduced latency by up to 66%, leading to a better user experience and increased conversion rates. Users get responses in under 10 seconds instead of waiting up to 30 seconds. This is crucial for user engagement and retention.” – Cem Ortabas, Co-founder, HubX
“Optimizing price-performance for generative AI inference is key for our customers. We are excited to see GKE Inference Gateway with its optimized load balancing and extensibility in open-source. The new GKE Inference Gateway capabilities could help us further improve performance for our customers’ inference workloads “ – Chaoyu Yang, CEO & Founder, BentoML
With GKE’s new inference capabilities, you get a powerful set of capabilities to take the next step with AI. To learn more, join our GKE gen AI inference breakout session at Next 25, and hear how Snap re-architected their inference platform.
Data is the fuel for AI, and organizations are racing to leverage enterprise data to build AI agents, intelligent search, and AI-powered analytics for productivity, deeper insights, and a competitive edge. To power their data clouds, tens of thousands of organizations already choose BigQuery and its integrated AI capabilities.
This decade requires AI-native, multimodal, and agentic data-to-AI platforms, with BigQuery leading the way as the autonomous data-to-AI platform. Finally, we have a platform that infuses AI, makes unstructured data a first class citizen, accelerates open lakehouses and embeds governance.
As an autonomous data-to-AI platform, BigQuery enables a self-managing multimodal data foundation that’s built for processing and activation of all data types, with advanced engines that can be operated on by specialized agents. The platform’s shared catalog and governance layer helps ensure consistent data access, metadata understanding, and security policies across all data and engines, minimizing silos and simplifying management. BigQuery is built on Google’s global infrastructure, leveraging high-bandwidth networks, low-latency storage, and AI-accelerated hardware (TPUs, GPUs), for virtually unlimited scalability. With our commitment to open standards and AI embedded at every layer, this fully integrated architecture accelerates your journey to AI-driven insights at the lowest cost possible.
AI assistance across the entire data lifecycle
Gemini in BigQuery brings a set of AI-powered assistive capabilities to automate data discovery and exploration, data preparation and engineering, analysis and insight generation, covering the entire data journey.
Thousands of organizations are using Gemini in BigQuery. In fact, usage of code assist in BigQuery grew 350% over the last 9 months, with over a 60% code generation acceptance rate across SQL and Python.
Yesterday we announced the general availability of several additional Gemini in BigQuery features and added new capabilities that further enhance and automate your analytics workflows.
Simplify data preparation: BigQuery Gemini-assisted data preparation (GA)provides intelligent suggestions for data enrichment, easily identifies and rectifies data inconsistencies, provides low-code visual data pipelines, and automates the execution and monitoring of your data pipelines.
Faster time to insights with data canvas: BigQuery data canvas allows you to find, transform, query, and visualize data using natural language prompts and a graphic interface. New dataset-level insights (preview) can surface hidden relationships between tables and generate cross-table queries by integrating query usage analysis and metadata.
Boost productivity with coding assistance for DataFrames: With AI code assistance in BigQuery, you can use natural language prompts to generate or suggest code in SQL or Python, or to explain an existing SQL query. We are now extending this code assist capabilities to BigQuery DataFrames (preview).
Improve data and AI governance: New automated metadata generation (preview) uses profile scans and Gemini to create clear and consistent descriptions for columns, tables, and glossary terms, even with large datasets. This metadata improves governance and helps AI agents find the data they need for exploration and analysis.
Accelerate BigQuery migrations: SQL translation assistance (GA) is an AI-based translator that lets you create Gemini-enhanced rules to customize your SQL translations. You can describe changes to the SQL translation output using natural language prompts or specify SQL patterns to find and replace. This can also help in rapidly increasing familiarity with BigQuery SQL.
<ListValue: [StructValue([(‘title’, ‘$300 in free credit to try Google Cloud data analytics’), (‘body’, <wagtail.rich_text.RichText object at 0x3ece8ad7a070>), (‘btn_text’, ‘Start building for free’), (‘href’, ‘http://console.cloud.google.com/freetrial?redirectPath=/bigquery/’), (‘image’, None)])]>
A multimodal autonomous data foundation
BigQuery helps you develop an autonomous data foundation by unifying analytics capabilities across diverse data types and enabling the seamless, concurrent analysis of both structured and unstructured data within a single platform. In fact, customer data in BigQuery grew nearly 30% last year, adding to the multiple exabytes already stored. Furthermore, its native, first-party integration with Vertex AI allows you to apply powerful AI models directly to your data, eliminating the requirement for complex data movement or replication.
“BigQuery and Vertex AI bring all our data and AI together into a single platform. This has transformed how we take action on customer feedback from a lengthy manual process, to a simple natural language query in seconds, allowing us to get to customer insights in minutes instead of months.” – TJ Allard, Lead Data Scientist, Mattel
Yesterday we announced several innovations to enhance our unstructured data support and AI processing:
BigQuery tables for Apache Iceberg (preview:)Connect your Apache Iceberg data to SQL, Spark, AI and third-party engines in an open and interoperable manner so you can get the flexibility of an open data lakehouse alongside the performance and integrated tooling of BigQuery. This offering provides adaptive and autonomous table management, delivers high-performance streaming, auto-AI-generated insights, near-infinite serverless scale and advanced governance.
Native multimodal support for BigQuery tables: Built on object tables, the new ObjectRef data type (preview) enables storage and querying of unstructured and structured data using Python and SQL functions.
Multimodal capabilities for Python users: The BigQuery DataFrames library now has multimodal capabilities for unified structured and unstructured analytics, AI operators for semantic insights, and Gemini code assistance.
Easy capture of Unstructured Data Processing: BigQuery ML new capabilities in preview include AI.GENERATE_TABLE for capturing the output of LLM inference within SQL clauses. Additionally, we’ve expanded model choice to include Anthropic’s Claude, Llama, and Mistral models, and open-source models hosted on Vertex AI.
Scalable, faster and cost-efficient vector search: BigQuery vector search allows you to generate, manage, and search embeddings within a serverless, fully integrated environment for powerful analytics. We are introducing a new index type (GA) based on Google’s ScaNN model coupled with a CPU-optimized distance computation algorithm, enabling scalable, faster and more cost-efficient processing.
Easier time-series forecasting in BigQuery ML: BigQuery ML simplifies time-series forecasting with the new TimesFM model (preview). This pretrained model, developed by Google Research, is user-friendly, accurate, fast, and scalable.
Pinpoint the key factors driving changes in your metrics: Organizations constantly need to answer questions like “Why did our sales drop last month?”. ” Answering these “why” questions accurately is vital, but often involves complex manual analysis. BigQuery’scontribution analysis feature (GA) helps you pinpoint the key factors (or combinations of factors) responsible for the most significant changes in a metric.
Simplified and unified governance in BigQuery
BigQuery offers built-in governance capabilities that simplify how you discover, manage, monitor, govern, and use your data and AI assets. BigQuery universal catalog brings together a data catalog (formerly known as the Dataplex Catalog) and a fully managed, serverless metastore. Yesterday, we announced the following new capabilities for BigQuery governance:
Enable engine interoperability across BigQuery, Apache Spark, and Apache Flink engines with BigQuery metastore (GA). With support for the Iceberg Catalog it simplifies data discovery and querying across engines, mirroring the open-source experience.
Empower your organization with a business glossary (GA),which provides a shared understanding of data. Customers can define and administer company terms in a business glossary, identify data stewards for these terms, and attach them to data asset fields, to improve context, collaboration, and search.
Perform bulk extract of catalog entries into Cloud Storage with Catalog metadata export (GA). This enables a wide range of use cases including metadata analytics by making the export output queryable from BigQuery, programmatic workloads requiring access to a large scope of metadata, and metadata integration.
Automatic at-scale cataloging of BigLake and object tables (GA): BigQuery harvests up-to-date metadata for structured and unstructured data from Cloud Storage and automatically creates query-ready BigLake tables at scale.
Enhanced enterprise capabilities
BigQuery offers easy managed disaster recovery (GA) for compute and storage. It features automatic failover coordination, continuous near-real-time data replication to a secondary region, and fast, transparent recovery during outages. This provides business continuity with industry-leading recovery point objectives (RPO) and recovery time objectives (RTO).
We are also introducing new workload management capabilities (preview) for isolation, resource control, and observability. Users gain granular controls with flexible, securable reservations that allow users to assign to different jobs in the same project to different reservations. Features include reservation level fair sharing of slots, predictability in performance of reservations, and enhanced observability through reservation attribution in billing for better cost tracking.
Improved query performance
To further simplify analytics, we introduced several new innovations to help you get the most out of SQL and make your queries work better for you automatically. Query performance optimizations (GA) improve query performance and automatically identify and accelerate relevant workloads with no changes required to the schema or queries. These include:
Low latency API for short queries enables short-query-optimized mode to improve overall latency of short queries that are common in workloads such as data exploration or building dashboards by executing the query and returns the results inline for SELECT statements.
History-based optimizations use information from already-completed executions of similar queries to apply additional optimizations and further improve query performance such as query latency and slot-time consumed.
Column metadata index (CMETA) provides (almost) infinitely scalable and highly performant metadata management for BigQuery, where you can go from 10GB tables to 100PB and still get great price/performance, without having to worry about redesign or replatforming.
New analytics capabilities
SQL-based continuous queries (GA): Simplify real-time data processing by enabling users to express complex transformations in SQL. You can runcontinuously processing SQLstatements to help analyze, transform, and reverse ETL data the moment new events arrive in BigQuery. This feature now supports slot autoscaling, greater monitoring through Cloud Monitoring, and exports to other clouds.
Simplify SQL with BigQuery pipe syntax (GA): This unique feature extends standard SQL to make it simpler, more concise, and flexible. Pipe syntax lets you apply operators in any order and as often as you need, streamlining SQL queries for tasks like data exploration, dashboard creation, and log analysis. Pipe syntax enhances clarity, efficiency, and maintainability, and its compatibility with most standard SQL operators ensures broad usability.
Geospatial analytics (preview): We’re integrating rich, analysis-ready geospatial datasets from Earth Engine and Google Maps Platform directly into BigQuery data clean rooms. And with the ST_RegionStats function, BigQuery users can now use Earth Engine to efficiently extract statistics from raster data. For the first time, data analysts and decision-makers can access geospatial insights from Google Maps Platform and Earth Engine that lead to more informed and faster business and sustainability outcomes. Key decisions such as optimal site selection for a new business location, how to optimize operations and maintenance of your infrastructure assets, how to enable sustainable sourcing, and more are now enabled directly in BigQuery.
Continued innovation with the ISV ecosystem
Finally, BigQuery’s capabilities are being significantly extended by its vibrant partner ecosystem, through new and enhanced AI integrations and solutions. Anthropic’s Claude models are now accessible via BigQuery ML, facilitating functions like text generation and summarization. GrowthLoop introduced its Compound Marketing Engine built on BigQuery with Growth Agents powered by Gemini, so marketing can build personalized audiences and journeys that drive rapidly compounding growth. Furthermore, Informatica is expanding their services on Google Cloud to enable sophisticated analytical and AI governance use cases.
Significant advancements have also occurred in data management and observability. Fivetran introduced its Managed Data Lake Service for Cloud Storage with native integration with BigQuery metastore and automatic data conversion to open table formats like Apache Iceberg and Delta Lake, improving data lake management and discoverability. DBT is now integrated with BigQuery DataFrames and DBT Cloud is now on Google Cloud. Finally, Datadog has introduced expanded monitoring capabilities for BigQuery, providing granular visibility into query performance, usage attribution, and data quality metrics.
These partner innovations provide customers with expanded functionality, improved operational control, and streamlined access to sophisticated capabilities within the BigQuery ecosystem.
A data-to-AI platform for the autonomous era
BigQuery is evolving beyond a data warehouse and becoming the autonomous data-to-AI platform for all your data teams. The Gemini-powered agents, unified architecture, and commitment to open standards are lowering the barriers to entry for AI-powered analytics and enabling you to focus on what you do best: building innovative models and driving data-driven decisions.
As we bring together more capabilities within a unified platform we are making it easy for you to consume and use the platform with unified commercials with our new BigQuery spend commit. This provides commitments across our BigQuery unified platform, giving you the flexibility to move spend across data processing engines, streaming, governance and more.
Learn more about BigQuery and start exploring how these new features can transform your organization.
Special thanks to Geeta Banda, Head of Outbound Product Management, for her contributions to this blog post.
Data is the critical foundation for AI, yet a vast amount of data’s potential remains untapped. Why? Data quality remains a top barrier. To use enterprise data to drive analytics-driven decisions and build differentiated AI, businesses need to be able to find, understand, and trust their data assets. This requires effective data governance encompassing discovery, cataloging, metadata management, quality assurance, sharing, and access control.
The stakes are high. According to Gartner, “through 2026, those organizations that don’t enable and support their AI use cases through an AI-ready data practice will see over 60% of AI projects fail to deliver on business SLAs and be abandoned.”
At Google Cloud Next 25, we’re announcing BigQuery unified governance, powerful data governance capabilities that help enterprises keep pace with governance complexities. Data silos, fragmented metadata, and ambiguous ownership create significant risks and impede innovation. BigQuery unified governance provides services and tools organizations need to simplify data management and unlock actionable insights.
BigQuery’s built-in, intelligent governance simplifies data and AI management, helping organizations discover, understand, and leverage their assets, transforming governance from a burden into a powerful tool for data activation. Central to BigQuery governance is BigQuery universal catalog, a unified, AI-powered data catalog that natively integrates Dataplex, BigQuery sharing, security and metastore capabilities, bringing together business, technical, and runtime metadata.
BigQuery’s unified governance capabilities are:
1. Unified: BigQuery brings governance directly into the heart of your data-to-AI lifecycle, enabling discovery, understanding, governance, and utilization of your data assets and AI models. This gives data administrators, stewards, and custodians robust tools for metadata management and policy enforcement, providing end-to-end data-to-AI lineage, data profiling, insights, and secure sharing. And with the new universal semantic search, finding the right data is as simple as asking a question in natural language.
2. Intelligent: New governance capabilities powered by gen AI stand to revolutionize data management. By harnessing the power of large language models (LLMs), BigQuery universal catalog can help you uncover hidden relationships between BigQuery data assets, enable automated metadata curation and intelligent query recommendations at scale, automate governance, and democratize data-driven insights across the organization.
3. Open: BigQuery universal catalog insulates you from change with support for open storage standards such as Apache Iceberg, and a unified runtime metastore across SQL, open-source engines, and AI/ML. The BigQuery metastore, which is included in the BigQuery universal catalog, is Iceberg-compliant, enabling a multi-engine, multi-vendor architecture for governance and use of fully managed Iceberg data.
ANZ Bank, a multinational banking and financial services provider, uses the BigQuery universal catalog for comprehensive data governance, discovery, and observability.
“With BigQuery universal catalog, ANZ has significantly improved the reliability and trustworthiness of our data. The centralized data quality monitoring and automated validation features are increasing confidence and efficiency in critical business outputs and decisions based on accurate and consistent information. BigQuery governance has become a cornerstone of our data governance strategy, ensuring our data is not just available, but dependable.” Artur Kaluza, Head of Data Strategy and Transformation, Risk, ANZ
aside_block
<ListValue: [StructValue([(‘title’, ‘$300 in free credit to try Google Cloud data analytics’), (‘body’, <wagtail.rich_text.RichText object at 0x3ece8b947df0>), (‘btn_text’, ‘Start building for free’), (‘href’, ‘http://console.cloud.google.com/freetrial?redirectPath=/bigquery/’), (‘image’, None)])]>
Noteworthy features
The new unified governance experience in BigQuery provides a centralized interface within the BigQuery UI for managing, securing, and sharing data and AI assets. In addition, we are introducing a wide range of key new features and capabilities across governance, sharing, and security.
Governance
1. Full-catalog search with semantic understanding (preview): Users can now discover data and AI resources across projects and data silos within BigQuery using full-catalog semantic search. This feature introduces natural-language search capabilities, making it easier for both technical and non-technical users to search the catalog.
2. Automated metadata curation (preview): BigQuery universal catalog can now automatically generate metadata for BigQuery tables, including table and column descriptions, improving data discovery and support gen AI applications.
3. AI-powered knowledge engine (preview): Users can efficiently discover hidden relationships within a dataset with automated entity-relationship visualization. By leveraging inferred relationships, BigQuery universal catalog generates suggestions for cross-table queries and natural language questions, getting new data teams up to speed fast on unfamiliar data assets.
4. Data products (preview): BigQuery data products allow data owners to create, share, and govern collections of data assets by use case, packaging and sharing them within and across organizations in a way that’s consistent, governed, and that follows security best practices.
5. Business glossary (GA): The BigQuery business glossary provides organizations with a shared understanding of their data. Customers can define and administer company terms, identify data stewards for these terms, and attach them to data asset fields, improving context, collaboration, and search.
6. Automatic at-scale cataloging of BigLake and object tables (GA): BigQuery universal catalog harvests up-to-date metadata for structured and unstructured data from Cloud Storage, and uses it to automatically create query-ready BigLake tables at scale.
7. Automated anomaly detection (preview): BigQuery universal catalog automates data anomaly detection to help you identify data errors, inconsistencies, and outliers in your data, reducing the time you spend identifying and resolving data issues.
Full catalog search with semantic understanding
Automated metadata curation
Sharing
8. BigQuery sharing integration with Google Cloud Marketplace (preview): Data owners can monetize datasets in BigQuery sharing (formerly Analytics Hub) through Google Cloud Marketplace.
9. Stream sharing in BigQuery (GA): Curate and share valuable real-time streams with Pub/Sub topics in BigQuery sharing.
10. Stored procedure sharing in BigQuery (preview): Share SQL stored procedures and enable execution in the subscriber’s project without revealing the actual code.
11. Query template sharing in BigQuery (preview): Customize, reuse, and restrict SQL queries in a clean room through publisher-defined query templates.
Security
12. Data policies on columns (preview): Create raw access and data-masking policies associated directly to a column and that can be reused across columns and tables.
13. Subquery support with row-level security (GA): BigQuery universal catalog now supports SQL subqueries in security access policy definitions, enabling row filtering without changing existing data models.
These built-in governance advancements within the BigQuery platform help organizations unlock the full potential of their data and AI initiatives.
In addition to the innovation in BigQuery, we continue to partner with third-party catalog providers to complement their governance capabilities. For example, Collibra’s enterprise-wide governance for data and AI extends BigQuery universal catalog capabilities to provide end-to-end visibility, quality and stewardship across hybrid and multicloud environments. This partnership helps ensure more teams can discover and trust the data they need to do AI, no matter where it lives, accelerating and strengthening every use case.
By embedding governance into BigQuery and automating metadata management, BigQuery universal catalog is helping businesses move beyond the challenges of data silos and operational inefficiency, ultimately driving innovation and accelerating business impact. Ready to learn more? You can join several sessions covering the latest in BigQuery governance, sharing, and security featuring customer speakers:
From unraveling the mysteries of our planet and the universe, to accelerating medical research and industrial innovation, scientific discovery impacts nearly every facet of human life. Today, scientific progress depends on the interplay of theory, experimentation, and computation, and increasingly, the most important and challenging problems require high-performance computing (HPC) and other advanced computing technologies and techniques.
In recent years, artificial intelligence (AI) has emerged as a powerful tool for information assessment and generation, while also becoming a powerful tool for scientific discovery, business innovation, and productivity. More recently, advances in quantum computing are increasing our confidence in shortening the timelines to solving problems beyond the reach of classical computers. Quantum computers under development now will lead to larger production systems that will catalyze the creation of new drugs and materials, reduce costs and risks in complex financial and logistics scenarios, and enable the development of more capable AI models.
At Google, our vision is to be the most comprehensive, capable, and accessible platform for science. Since 2008, Google Cloud has powered scientific discoveries, providing computational and data storage capabilities — including HPC clusters — to scientists, engineers, and developers worldwide. And this week, to enable continued revolutionary new science, we are bringing the best of Google DeepMind and Google Research together with new infrastructure and AI capabilities in Google Cloud, providing researchers with highly capable, cloud-scale tools for scientific computing. These new capabilities include:
Supercomputing-class infrastructure for scientific computing: Researchers can now deploy and use supercomputing clusters powered by the latest H4D VMs powered by AMD CPUs, and A4/A4X VMs powered by the latest NVIDIA GPUs. These VMs have new low-latency networking that provides supercomputer-like scaling and performance. We’re also announcing Google Cloud Managed Lustre for high performance storage I/O. These resources will enable scientists to tackle large-scale, complex science problems.
Advanced scientific applications powered by AI models for weather forecasting and biology: We’re now offering our first AI-powered science applications for the broader science community: AlphaFold 3 for predicting the structure and interactions of biomolecules, and WeatherNext models for weather forecasting.
AI agents for quicker ideas and faster discovery: Two new AI agents in Google Agentspace – Deep Research and Idea Generation – can help prepare comprehensive research reports and rapidly generate new scientific hypotheses.
Let’s take a look at these new capabilities in more detail.
aside_block
<ListValue: [StructValue([(‘title’, ‘Try Google Cloud for free’), (‘body’, <wagtail.rich_text.RichText object at 0x3e318d9f9d30>), (‘btn_text’, ‘Get started for free’), (‘href’, ‘https://console.cloud.google.com/freetrial?redirectPath=/welcome’), (‘image’, None)])]>
Supercomputing-class infrastructure and tools for science
Supercomputers are designed to achieve maximum performance on very large problems, as well as to train large AI models. With ongoing advances in science and AI, quick and easy access to supercomputing resources is critical.
Researchers can now deploy and use supercomputering-class HPC clusters in Google Cloud based on newH4D VMs (virtual machines), our most powerful CPU-based VMs that use 5th Generation AMD EPYCTM Processors. H4D clusters are connected with Remote Direct Memory Access (RDMA) networking utilizing Google’s Falcon and Titaniumoffload technologies, providing low-latency communications for HPC applications. By using standard message-passing libraries over RDMA, H4D VMs can efficiently scale applications up to tens of thousands of cores, resulting in faster time-to-solution. You can register for the H4D VM preview here.
Harvard University is using Google Cloud to advance heart disease research by simulating large-scale systems of red blood cells and other structures, including magnetically controlled artificial bacterial flagella (ABF), with the goal of developing therapies to attack and dissolve blood clots and circulating tumor cells in human vasculatures.
“With the power of Google’s new H4D-based clusters, we are poised to simulate systems approaching a trillion particles, unlocking unprecedented insights into circulatory functions and diseases. This leap in computational capability will dramatically accelerate our pursuit of breakthrough therapeutics, bringing us closer to effective precision therapies for blood vessel damage in heart disease.” – Petros Koumoutsakos, Harvard University
Professor Koumoutsakos’ research involves the simulation of blood flowing in a microfluidics device which is designed to capture circulating tumor cells.
HPC clusters based on our recently announced A4 and A4X VMs are also a critical component of our scientific discovery portfolio. A4 VMs,built on NVIDIA’s latest HGX B200 GPUs, are a versatile and powerful tool for multiple scientific computing applications, offering excellent performance for direct numerical simulation, and for AI training. A4X VMs, accelerated by NVIDIA GB200 NVL72 GPUs, are purpose-built for training and serving the most demanding, extra-large-scale AI workloads.
Clusters using these GPU-powered VMs can also unlock supercomputing-class performance for the next frontier of innovation: quantum computing. In the future, quantum computing systems will allow scientists to solve problems that are intractable even with the most powerful traditional supercomputers. In the meantime, HPC clusters based on A-series VMs can be used to design tomorrow’s quantum computers and optimize quantum algorithms, by simulating large quantum circuits using the quantum simulation solution blueprint.
For example, Google Research’s Quantum AI team leverages Google Cloud to simulate the intricate device physics of quantum hardware, develop sophisticated hybrid quantum-classical algorithms, and explore and test novel quantum algorithms. This robust simulation environment facilitates scientific breakthroughs by delivering the performance and scalability essential for demanding quantum research workflows.
“We observed excellent scalability simulating a 43-qubit circuit with a depth of 30 on Google Cloud’s new GPU-based supercomputers. These results underscore the potential for researchers to develop and test larger and deeper quantum circuits, which is important for understanding the performance of quantum algorithms and accelerating progress toward applications for today’s quantum computers.” – Sergio Boixo, Director, Computer Science, Google Quantum AI
HPC clusters demand high I/O performance to keep computational performance from stalling. Our new Google Cloud Managed Lustre storage service, developed in collaboration with DataDirect Networks and based on EXAScaler technology, provides the I/O performance needed for supercomputing-scale applications. Google Cloud Managed Lustre delivers a high-performance, fully-managed parallel file system optimized for HPC and AI applications. With petabyte-scale capacity and up to 1 TB/s throughput, Managed Lustre ensures researchers have the I/O performance they need to power their scientific discoveries. Request access to the Managed Lustre preview by contacting your account representative.
Advanced scientific applications powered by AI models
We recently announced our first AI-powered science applications for researchers and enterprises on Google Cloud: the groundbreaking AlphaFold 3 molecular structure and interaction prediction model, and the WeatherNext weather forecasting models.
AlphaFold 3,developed by Google DeepMind and Isomorphic Labs, is revolutionizing biology through its ability to predict the structure and interactions of all of life’s molecules with unprecedented accuracy. Understanding molecular structures and their interactions helps researchers better grasp complex interactions in human health and disease. AlphaFold 3 is now available for non-commercial use on Google Cloud.
“Having access to the scientific capabilities of AlphaFold on Google Cloud can help our research rapidly predict and explore the structure and interactions of all biomolecule classes. This change in capability will accelerate our understanding of diseases and enable the generation of therapeutic hypotheses.” – Sumaiya Iqbal, Senior group lead of the Ladders to Cures Accelerator, Broad Institute
To further support users, we’re simplifying access to AlphaFold 3 through a new high-throughput solution deployable via Cluster Toolkit. This turnkey solution enables efficient batch processing of hundreds to tens of thousands of sequences while minimizing costs by autoscaling infrastructure.
In the domain of weather, Google DeepMind and Google Research WeatherNext models use AI for fast and accurate weather forecasting, and we recently released live WeatherNext AI forecasts on BigQuery and Earth Engine. Today, we’re introducing access to WeatherNext AI models via Google Cloud’s Vertex AI Model Garden, enabling practitioners to customize and deploy these advanced models for energy prediction, logistics, agriculture, risk management, and more.
With easier and more affordable access to faster and more accurate weather forecasting models, researchers can study far more scenarios, and organizations can better prepare for weather events — such as heat waves, floods, and hurricanes — to reduce their impact on infrastructure, personnel, supply chains, and communities.
WeatherNext Graph forecasts visualized in Google Earth Engine, showing forecasted wind speed, wind direction, and precipitation as of September 8, 2023. The visualization demonstrates the projected path of Hurricane Lee over the Atlantic Ocean.
For instance, Carrier plans to leverage Google Cloud’s WeatherNext AI models as part of its Home Energy Management System (HEMS) to help enhance grid flexibility and enable smarter energy management. Once deployed, WeatherNext AI models are expected to help HEMS intelligently manage energy flows in real time — charging, discharging, and redirecting energy based on grid conditions, energy demands, and weather forecasts — contributing to a more balanced and sustainable energy grid.
Using AI as the ultimate research partner
Google’s robust ecosystem of information, productivity, and advanced AI tools has long helped drive scientific research, providing researchers with information and insight. Google Scholar is an indispensable resource for navigating the vast landscape of scientific literature and for discovering and tracking relevant publications. Then there’s Gemini, which can synthesize, summarize and explain information from highly scientific and technical content. And NotebookLM, an AI-powered research assistant, intelligently processes and summarizes selected research papers and datasets, dramatically accelerating literature reviews and extracting crucial information.
We’re excited to announce two new AI agents in Agentspace that have the potential to further accelerate scientific research and to revolutionize hypothesis generation. Deep Researchcondenses hours of research by synthesizing information across internal and external sources to generate in-depth research reports. Idea Generation helps rapidly develop novel ideas through AI agents that create ideas, then test them against each other to find the best hypotheses.
Scientists can also leverage AI StudioandVertex AIon Google Cloud to develop customized AI applications and advanced machine learning workflows. We also recently announced Gemma 3, a collection of lightweight, state-of-the-art open models built from the same research and technology that powers our Gemini 2.0 models. These are our most advanced, portable and responsibly developed open models yet, and can be used to create scientific applications on local devices. Finally, Google Research’s Geospatial Reasoning framework, leveraging Vertex AI Agent Engine, will allow scientists and analysts to unlock powerful insights about the world through new geospatial foundation models and generative AI.
Enabling transformational science today and tomorrow
Together, these new advanced infrastructure, AI applications, and AI productivity technologies provide new cloud-scale scientific capabilities for all kinds of computational science research. Combined with our discovery, collaboration, and productivity tools, we are providing scientists and researchers with a comprehensive array of cloud-powered scientific capabilities.
Argonne National Laboratory, a leading laboratory for open science computational research, is working with Google Cloud to explore how advanced computing technologies and AI tools can empower scientists and engineers to make groundbreaking discoveries faster than ever. Through the collaboration, ANL will use and evaluate Google Cloud solutions for computational research, providing feedback and guidance to further advance the design, performance, and usefulness of Google Cloud for supercomputing-scale science.
“Having access to powerful computational capabilities is critical for making new scientific discoveries and accelerating innovations that power business and society.We are eager to work with Google Cloud to leverage their comprehensive, global-scale AI and HPC infrastructure, software technologies and AI-powered applications such as AlphaFold 3. Argonne National Laboratory’s collaboration with Google Cloud will effectively drive innovation and enable discoveries that change the world — and bring these capabilities to researchers everywhere.” – Rick Stevens, Associate Laboratory Director for Computing, Environment and Life Sciences, Argonne National Laboratory
Scientific discoveries are more important than ever for solving the world’s greatest challenges. At Google, we’re building powerful advanced computing technologies to enable scientific discoveries and innovations, and we are excited to bring all these capabilities together in Google Cloud.
The transformative power of AI and intelligent agents is driving profound changes, where software can understand natural language questions and commands — and even autonomously act on our behalf. At the heart of this revolution is the “AI-ready” enterprise database, an active, intelligent engine that understands the semantics of structured and unstructured data, and uses the power of foundation models to create a platform where you can unlock unprecedented opportunities from enterprise data.
This week at Google Cloud Next, we’re announcing several new capabilities in AlloyDB AI to accelerate intelligent agent and application development. These include advanced semantic search with high-performance filtered vector search, automatic vector index maintenance, and a major increase in the quality of searches using the newly launched AlloyDB AI query engine and the Vertex AI Ranking API. The AI query engine brings AI-powered operators to SQL queries for filtering, as well.
We’re also launching natural language capabilities to provide users and agents with deep insights from natural language questions. Taken together, these innovations position AlloyDB as the foundation for agentic AI, evolving the database beyond data storage and conventional SQL querying to a future where intelligent agents can converse with the data and autonomously explore it on our behalf.
aside_block
<ListValue: [StructValue([(‘title’, ‘$300 in free credit to try Google Cloud databases’), (‘body’, <wagtail.rich_text.RichText object at 0x3e318d9d2040>), (‘btn_text’, ‘Start building for free’), (‘href’, ‘http://console.cloud.google.com/freetrial?redirectPath=/products?#databases’), (‘image’, None)])]>
High-performance, high-quality, and easy semantic search
Modern apps require smart data retrieval that combines structured data with unstructured, multimodal data such as text and images. Previously, AlloyDB AI enabled semantic queries over unstructured data, deeply integrating vector search with PostgreSQL so search results are always up to date. Our next set of AlloyDB AI capabilities addresses customer requests for higher performance, better search result quality, and low-cost automated maintenance.
Adaptive filtering: This innovative technique, now in preview, can help ensure that filters, joins, and vector indexes deliver optimal performance when used together. Adaptive filtering optimizes the query plan once it learns the actual filter selectivity as it access data, and then can appropriately switch between filtered vector search methods.
Vector index auto-maintenance, also in preview, reduces how often you need to rebuild your vector indexes, while ensuring that vector indexes remain accurate and performant even as data changes. You can enable vector index auto-maintenance during index creation or when altering the index.
Reranking: The newly-released AlloyDB AI query engine can enhance semantic search by combining vector search with high-accuracy AI reranking, through the new Vertex AI cross-attention Ranking API. Our reranking capability uses vector search to efficiently generate initial candidates (such as Top N) and then apply the high quality cross-attention Ranking API to accurately determine the final best results (such as Top 10) from those candidates. To give you as much flexibility as possible, AlloyDB AI can connect with any third-party ranking API, including custom ones.
Recall evaluator: Now generally available, this capability provides the transparency you need for managing and tuning the quality of vector search results. With a simple stored procedure, you can evaluate end-to-end recall for any query, including complex ones with filters, joins, and reranking.
Parallel index build: Now generally available, index build parallelization allows developers to build indexes of up to 1 billion rows in just hours, down from several times that number. To support this capability, AlloyDB AI spins up parallel processes to distribute the workload and create indexes faster.
These improvements are made possible by the deep integration of AlloyDB AI’s Scalable Nearest Neighbors (ScaNN) vector index with the PostgreSQL query planner, and they lead to notably faster performance:
10x faster index creation when compared to the HNSW index in standard PostgreSQL.
4x faster vector search when compared to the HNSW index in standard PostgreSQL.
AlloyDB AI natural language
Natural language interfaces on databases showed great progress in 2024, backed by AI technology that turns questions, posed either by end users or by agents, into SQL queries that provide answers.
To further improve accuracy, a quantum leap was needed. Building on the natural language support announced last year, we’re introducing new capabilities to help you build interactive natural language user interfaces that decipher user intent accurately, and can build highly-accurate mappings of user questions to SQL queries that answer them.
Disambiguation: Natural language is inherently ambiguous. The AlloyDB AI natural language interface will ask follow-up questions when it needs more information about user intent. Since ambiguity is often rooted deep in the data, the database is the best at solving it.
For example, a question may refer to “John Smith,” but there may be two John Smiths in the database, or perhaps there’s a “Jon Smith,” whose first name was spelled differently, or even misspelled. AlloyDB concept types and the AlloyDB values index enable finding the relevant entities and their concepts when they’re not obvious from the question.
High accuracy and intent explanation: AlloyDB AI natural language uses plain templates, which correspond to parameterized SQL queries, and faceted templates for providing highly-accurate, virtually-certified answers to predictable and important classes of questions.
For example, a retailer’s product search page could theoretically include dozens of product properties — far too daunting for a screen-based faceted search interface. In contrast, a faceted search template, even with one simple search field, can answer any question that directly or indirectly poses any combination of property requirements. AlloyDB can automatically produce templates from query logs, and you can provide additional templates to boost query coverage. To ensure confidence in results, AlloyDB offers a transparent explanation of its interpretation of user inquiries.
High accuracy and flexibility: For cases where questions are not predictable but question answering must provide flexibility, AlloyDB enables the user to raise accuracy by automatically enriching the context that is used in the mapping of the question to SQL with the rich data found in the schema, the data (such as sample data that can greatly enhance accuracy), and the query logs.
Parameterized secure views: AlloyDB offers parameterized secure views, a new kind of database view that locks down access to end-user data at the database level, to help protect against prompt injection attacks.
Beyond AlloyDB with Agentspace: AlloyDB AI natural language is available in Google Agentspace for building your own agents that, for example, may answer questions by combining AlloyDB data with data from other sources, such as the web or another database.
AlloyDB AI query engine
To empower you to build intuitive and powerful AI applications, AlloyDB AI query engine can unlock deep semantic insights from enterprise data through AI-powered SQL operators. AI query engine leverages Model Endpoint Management, a mechanism for calling any AI model on any platform.
Let’s review AlloyDB AI query engine and other capabilities newly available in AlloyDB AI via new AI models:
AI query engine: AlloyDB SQL now features simple but powerful AI operators — AI.IF() for filters and joins, and AI.RANK() for ordering. These operators use natural language in SQL queries to express the filtering conditions and the ranking criteria. They can use foundation models to bring reasoning and real-world knowledge to SQL queries, and they can use cross-attention models, which also draw their power from foundation models and their real-world knowledge. In particular, AI.RANK() can use the Vertex AI Ranking API to find the most relevant results.
Multimodal embedding generation: Previously, AlloyDB AI enabled a SQL developer to easily generate embeddings from text in SQL statements. We’ve expanded this capability to generate embeddings for any modality (text, images, and videos) so you can search using any modality.
Updated text embedding generation: AlloyDB AI query engine provides out-of-the-box integration with the text-embedding generation model from Google DeepMind.
Getting started
We believe today’s AlloyDB AI announcements — enhanced filtered vector search, next-generation natural language support, and the AI query engine — are the foundation for the future of databases. They provide proactive insights for agents that anticipate and act decisively, powered by AI-ready data. AlloyDB AI is building a database revolution, empowering you to step boldly into this intelligent future and unlock your data’s boundless potential.