Welcome to the first Cloud CISO Perspectives for June 2025. Today, Anton Chuvakin, security advisor for Google Cloud’s Office of the CISO, discusses a new Google report on securing AI agents, and the new security paradigm they demand.
As with all Cloud CISO Perspectives, the contents of this newsletter are posted to the Google Cloud blog. If you’re reading this on the website and you’d like to receive the email version, you can subscribe here.
aside_block
<ListValue: [StructValue([(‘title’, ‘Get vital board insights with Google Cloud’), (‘body’, <wagtail.rich_text.RichText object at 0x3e598bb2a580>), (‘btn_text’, ‘Visit the hub’), (‘href’, ‘https://cloud.google.com/solutions/security/board-of-directors?utm_source=cloud_sfdc&utm_medium=email&utm_campaign=FY24-Q2-global-PROD941-physicalevent-er-CEG_Boardroom_Summit&utm_content=-&utm_term=-‘), (‘image’, <GAEImage: GCAT-replacement-logo-A>)])]>
How Google secures AI Agents
By Anton Chuvakin, security advisor, Office of the CISO
Anton Chuvakin, security advisor, Office of the CISO
The emergence of AI agents promises to reshape our interactions with information systems — and ultimately with the real world, too. These systems, distinct from the foundation models they’re built on, possess the unique ability to act on information they’ve been given to achieve user-defined goals. However, this newfound capability introduces a critical challenge: agent security.
Agents strive to be more autonomous. They can take information and use it in conjunction with tools to devise and execute complex plans, so it’s critical that developers align agent behavior with user intent to prevent unintended and harmful actions.
With this great power comes a great responsibility for agent developers. To help mitigate the potential risks posed by rogue agent actions, we should invest in a new field of study focused specifically on securing agent systems.
While there are similarities to securing AI, securing AI agents is distinct and evolving, and demands a new security paradigm.
Google advocates for a hybrid defense-in-depth approach that combines the strengths of both traditional (deterministic) and reasoning-based (dynamic) security measures. This creates layered defenses that can help prevent catastrophic outcomes while preserving agent usefulness.
To help detail what we believe are the core issues, we’ve published a comprehensive guide covering our approach to securing AI agents that addresses concerns for both AI agent developers and security practitioners. Our goal is to provide a clear and actionable foundation for building secure and trustworthy AI agent systems that benefit society.
We cover the security challenges of agent architecture, the specific risks of rogue actions and sensitive data disclosure, and detail the three fundamental agent security principles: well-defined human controllers, limited agent powers, and observable agent actions.
Agents must have well-defined human controllers: Agents must operate under clear human oversight, with the ability to distinguish authorized user instructions from other inputs.
Agent powers must have limitations: Agent actions and resource access must be carefully limited and dynamically aligned with their intended purpose and user risk tolerance. This emphasizes the least-privilege principle.
Agent actions and planning must be observable: Agent activities must be transparent and auditable through robust logging and clear action characterization.
Google advocates for a hybrid defense-in-depth approach that combines the strengths of both traditional (deterministic) and reasoning-based (dynamic) security measures. This creates layered defenses that can help prevent catastrophic outcomes while preserving agent usefulness.
We believe that the most effective and efficient defense-in-depth path forward secures agents with both classic and AI controls. Our approach advocates for two distinct layers:
Layer 1: Use traditional, deterministic measures, such as runtime policy enforcement. Runtime policy engines act as external guardrails, monitoring and controlling agent actions before execution based on predefined rules. These engines use action manifests to capture the security properties of agent actions, such as dependency types, effects, authentication, and data types.
Layer 2: Deploy reasoning-based defense strategies. This layer uses the AI model’s own reasoning to enhance security. Techniques such as adversarial training and using specialized models as security analysts can help the agent distinguish legitimate commands from malicious ones, making it more resilient against attacks, data theft, and even model theft.
Of course, each of the above two layers should have their own layers of defense. For example, model-based input filtering coupled with adversarial training and other techniques can help reduce the risk of prompt injection, but not completely eliminate it. Similarly, these defense measures would make data theft more difficult, but would also need to be enhanced by traditional controls such as rule-based and algorithmic threat detection.
Key risks, limitations, and challenges
Traditional security paradigms, designed for static software or general AI, are insufficient for AI agents. They often lack the contextual awareness needed to know what the agent is reasoning about and can overly restrict an agent’s utility.
Similarly, relying solely on a model’s judgment for security is also inadequate because of the risk posed by vulnerabilities such as prompt injection, which can compromise the integrity and functionality of an agent over time.
In the wide universe of risks to AI, two risks associated with AI agents stand out from the crowd by being both more likely to manifest and more damaging if ignored.
Rogue actions are unintended, harmful, and policy-violating behaviors an agent might exhibit. They can stem from several factors, including the stochastic nature of underlying models, the emergence of unexpected behaviors, and challenges in aligning agent actions with user intent. Prompt injections are a significant vector for inducing rogue actions.
For example, imagine an agent designed to automate tasks in a cloud environment. A user intends to use the agent to deploy a virtual machine. However, due to a prompt injection attack, the agent instead attempts to delete all databases. A runtime policy engine, acting as a guardrail, would detect the “delete all databases” action (from its action manifest) and block it because it violates predefined rules.
Sensitive data disclosure involves the unauthorized revelation of private or confidential information by agents. Security measures would help ensure that access to sensitive data is strictly controlled.
For example, an agent in the cloud might have access to customer data to generate reports. If not secured, the agent might retain this sensitive data and then be coaxed to expose it. A malicious user could then ask a follow-up question that triggers the agent to inadvertently disclose some of that retained data.
However, securing AI agents is inherently challenging due to four factors:
Unpredictability (non-deterministic nature)
Emergent behaviors
Autonomy in decision-making
Alignment issues (ensuring actions match user intent)
Practical security considerations
Our recommended hybrid approach addresses several critical areas.
Agent/plugin user controls: Emphasizes human confirmation for critical and irreversible actions, clear distinction between user input and other data, and verifiable sharing of agent configurations.
Agent permissions: Adherence to the least-privilege principle, confining agent actions to its domain, limiting permissions, and allowing for user authority revocation. This level of granular control often surprises security leaders because such a traditional 1980s-style security control delivers high value for securing 2020s AI agents.
Orchestration and tool calls: The intricate relationship between AI agents and external tools and services they use for orchestration can present unique security risks, especially with “Actions as Code.” Robust authentication, authorization, and semantic tool definitions are crucial risk mitigations here.
Agent memory: Data stored in an agent’s memory can lead to persistent prompt injections and information leakage.
Response rendering: Safely rendering AI agent outputs into user-readable content is vital to prevent classic web vulnerabilities.
Assurance and future directions
Continuous assurance efforts are essential to validate agent security. This includes regression testing, variant analysis, red teaming, user feedback, and external research programs to ensure security measures remain effective against evolving threats.
Securing AI agents requires a multi-faceted, hybrid approach that carefully balances the utility of these systems with the imperative to mitigate their inherent risks. Google Cloud offers controls in Agentspace that follow these guidelines, such as authentication and authorization, model safeguards, posture assessment, and of course logging and detection.
To learn more about how Google is approaching securing AI agents, please read our research paper.
aside_block
<ListValue: [StructValue([(‘title’, ‘Join the Google Cloud CISO Community’), (‘body’, <wagtail.rich_text.RichText object at 0x3e59a87e8b20>), (‘btn_text’, ‘Learn more’), (‘href’, ‘https://rsvp.withgoogle.com/events/ciso-community-interest?utm_source=cgc-blog&utm_medium=blog&utm_campaign=2024-cloud-ciso-newsletter-events-ref&utm_content=-&utm_term=-‘), (‘image’, <GAEImage: GCAT-replacement-logo-A>)])]>
In case you missed it
Here are the latest updates, products, services, and resources from our security teams so far this month:
Project Shield blocked a massive recent DDoS attack. Here’s how: Project Shield, Google’s free service that protects at-risk sites against DDoS attacks, kept KrebsOnSecurity up during a recent, massive one. Here’s what happened. Read more.
Don’t test in prod. Use digital twins for safer, smarter resilience: Digital twins are replicas of physical systems using real-time data to create a safe test environment. Here’s how they can help business and security leaders. Read more.
How to build a digital twin with Google Cloud: Digital twins are essentially IT stunt doubles, cloud-based replicas of physical systems for testing. Learn how to build them on Google Cloud. Read mo11re.
Enhancing protection: 4 new Security Command Center capabilities: Security Command Center has a unique vantage point to protect Google Cloud environments. Here are four new SCC capabilities. Read more.
Please visit the Google Cloud blog for more security stories published this month.
aside_block
<ListValue: [StructValue([(‘title’, ‘Tell us what you think’), (‘body’, <wagtail.rich_text.RichText object at 0x3e59a87e8df0>), (‘btn_text’, ‘Vote now’), (‘href’, ‘https://www.linkedin.com/feed/update/urn:li:activity:7338626074882240512’), (‘image’, <GAEImage: GCAT-replacement-logo-A>)])]>
Threat Intelligence news
The cost of a call, from voice phishing to data extortion: Google Threat Intelligence Group (GTIG) is tracking threat actors who specialize in voice phishing (vishing) campaigns designed to compromise Salesforce instances for large-scale data theft and subsequent extortion. Here’s several defensive measures you can take. Read more.
A technical analysis of vishing threats: Financially motivated threat actors have increasingly adopted voice-based social engineering, or “vishing,” as a primary vector for initial access, though their specific methods and end goals can vary significantly. Here’s how they do it — and what you can do to stop them. Read more.
Please visit the Google Cloud blog for more threat intelligence stories published this month.
Now hear this: Podcasts from Google Cloud
Debunking cloud breach myths (and what DBIR says now): Everything (and we mean everything) you wanted to know about cloud breaches, but were (legitimately, of course) afraid to ask. Verizon Data Breach Report lead Alex Pinto joins hosts Anton Chuvakin and Tim Peacock for a lively chat on breaching clouds. Listen here.
Is SIEM in 2025 still too hard: Alan Braithwaite, co-founder and CTO, RunReveal, discusses the future of SIEM and security telemetry data with Anton and Tim. Listen here.
Cyber-Savvy Boardroom: Jamie Collier on today’s threat landscape: Jamie Collier, lead Europe advisor, GTIG, joins Office of the CISO’s David Homovich and Anton Chuvakin to talk about what boards need to know about today’s threat actors. Listen here.
Defender’s Advantage: Confronting a North Korean IT worker incident: Mandiant Consulting’s Nick Guttilla and Emily Astranova join Luke McNamara for an episode on the AI-driven use of voice-based phishing, or “vishing,” and how they use it during red team engagements. Listen here.
Behind the Binary: Protecting software intellectual property: Tim Blazytko, chief scientist and head of engineering, Emproof, talks with host Josh Stroschein about the essential strategies for protecting software intellectual property. Listen here.
To have our Cloud CISO Perspectives post delivered twice a month to your inbox, sign up for our newsletter. We’ll be back in a few weeks with more security-related updates from Google Cloud.
As a scalable, distributed, high-performance, Cassandra- and HBase-compatible NoSQL database, Bigtable processes more than 5 billion sustained queries per second and has more than 10 Exabytes of data under management. At this scale, we optimize Bigtable for high-throughput and low-latency reads and writes.
In a previous blog post, we shared details of how our single-row read projects delivered 20-50% throughput improvements while maintaining low latency. Since then, we’ve continued to innovate on our single-row read performance, delivering a further 50% throughput improvement. These improvements are immediately available and are reflected in our updated performance metrics: Bigtable now supports up to 17,000 point reads per second. This increases Bigtable’s read throughput by up to 1.7x, or 7,000 point reads per second from our 10k point reads per second baseline at no additional cost to you (see figure 2).
Figure 2. Single-row read throughput improvements over time
And thanks to Bigtable’s linear scaling, clusters of all sizes, from a single node through to thousands of nodes, benefit equally from this performance.
For example, Stairwell leverages Bigtable performance for their cybersecurity workload. Their largest table has over 328 million rows and column counts ranging from 1 to 10,000. This table stores hundreds of billions of data points all while maintaining an average read latency of just 1.9 milliseconds and maxing out at 4 milliseconds.
“We’ve noticed the incremental throughput improvements over time, resulting in reduced node count when using Bigtable autoscaling. This means less cost for us, along with the improved performance.” – Ygor Barboza, Engineer, Spotify
Where we look for performance gains
Here on the Bigtable team, we continue to seek out opportunities to evolve and improve performance to meet customer expectations and business objectives. Let’s take a look at how we approach the problem.
1. Performance research and innovation We use a suite of benchmarks to continuously evaluate Bigtable’s performance. These represent a broad spectrum of workloads, access patterns and data volumes that we see across the fleet. Benchmark results give us a high-level view of performance improvement opportunities, which we then enhance using sampling profilers and pprof for analysis. Building on the insights and successes from our work in2023, we identify larger and more complex opportunities detailed below.
2. Improved caching for read performance Like many high performance systems, Bigtable caches frequently accessed data in DRAM to achieve high throughput and low latency. This low-level cache holds SSTable data blocks which reduces I/O costs associated with block retrieval from Colossus. The cache operates at the same abstraction layer as disk access, so request processing requires block-centric traversal of the in-memory data structures to build a full-stack row result from the log-structured merge tree SSTable stack (see figure 3).
Figure 3. Block-centric traversal of the in-memory SSTable stack data structures
This caching strategy works well in the general case and has been a pillar of Bigtable’s read throughput performance. However, in use cases where specific row-key queries are more frequent than other key ranges in a block, it can be advantageous to reduce block processing overhead for those rows. This can be especially beneficial for access patterns that read many blocks but return only a fraction of the data:
Reading the latest values from columns with frequent write traffic, i.e., high SSTable stack depth
Reading a row with many columns where the width of the row spans many blocks
Bigtable’s new row cache builds on the block cache to cache data at row granularity. This reduces CPU usage by up to 25% for point read operations. In contrast to cached block storage, cached rows use a sparse representation of the block data, maintaining only the data accessed by a query within any row. This format allows queries to reuse row-cache data so long as the cached row contains the required data. In the event that a new query requires data that is not present in the cache entry, the request falls back to block reads and populates the row cache structure with the missing data.
Both row and block caches share the same memory pool and employ an innovative eviction algorithm to optimize performance across a diverse set of query types, balancing block caching for breadth of response versus row caching for high-throughput access to the most frequently accessed data. Row caching also considers row size in its storage optimization algorithm to maintain high cache hit rates.
Figure 4. Read request row cache lifecycle and population
3. Single-row read operation efficiency Single-row read operations, Bigtable’s most common access pattern, are key to many critical serving workloads. To complement the throughput improvements delivered by the row-cache, we took further opportunities to tune the single-row read path and deliver larger throughput gains.
The complexity of processing queries for a single row versus row ranges can be substantial. Row-range queries can involve high levels of fan-out with RPCs to many tablet servers and complex async processing to merge the results into a single client response. For point operations, this complexity can be bypassed as the read is handled by one node, allowing the associated CPU overhead to be reduced. More efficient point operations led to a 12% increase in throughput. Further, we introduced a new query optimizer step that streamlined 50% of point-read filter expressions into more efficient queries.
4. Scheduler improvements In addition to internal database performance enhancements, we’ve added user-driven throughput improvements for point operations. These are enabled via user-configurable app-profile prioritization, made possible by the launch of request priorities. Users can annotate their most important traffic with a scheduling priority, which can bring higher throughput and lower latency to that traffic versus lower priority traffic. We built this feature to improve Bigtable’s support for hybrid transactional/analytical processing (HTAP) workloads after researching how to improve isolation between transactional operations, typically single row reads, and analytical operations, which are complex queries with multi-row results. This work identified two core opportunities for Bigtable’s scheduling algorithm:
Smarter scheduling of operations to reduce point operation latency
5. Request prioritization Request priorities allow the addition of a per application profile priority to be set, allowing Bigtable to more effectively prioritize incoming queries between application profiles. Bigtable supports three different priority levels:
PRIORITY_HIGH
PRIORITY_MEDIUM
PRIORITY_LOW
As might be expected, application profiles with PRIORITY_HIGH are given higher scheduling priority than application profiles with PRIORITY_MEDIUM or PRIORITY_LOW. This improves throughput and latency consistency on the PRIORITY_HIGH application profiles. In the context of HTAP workloads, transactional traffic can be run at a higher-priority application profile and analytical work can be performed with a low or even medium priority, protecting the latency profile (and in particular the p99 latency) of the serving workload from elevating — especially during periods of CPU-intensive batch/analytical processing.
The diagram below illustrates how request profiles may prioritize operations. This is simplified to avoid the complexities of our multithreaded parallel execution environments.
6. Point-operation scheduling Multiple application profiles within a single cluster can have the same request priority, and within a single application profile there can be a mix of traffic types. With this in mind, we worked to improve latency between operations at a single priority level by introducing scheduling improvements that aim to distribute CPU time in a more balanced manner across all operations types. Consider an HTAP workload that has complex analytical operations interleaved with point operations. If that workload contains an equal number of point operations and complex operations, complex operations may use a disproportionately large amount of CPU within a given time window, which can increase point-operation latency, as those operations remain queued behind larger and more complex operations. This helps to protect the latency profile of point operations by continuously monitoring operation execution time and adding yield points to long-running operations. This allows point operations to interleave with long-running operations (as shown below).
A commitment to Bigtable performance
Our dedicated focus on performance over the past few years has yielded significant results, delivering up to 1.7x single-row read throughput gains while crucially maintaining the same low-latency profile. What this means in practice is that each Bigtable node can now handle 70% more traffic than before, allowing you to improve cluster efficiency and manage workloads without compromising responsiveness. We’re incredibly excited about these advancements and remain committed to continuously evolving Bigtable to push the boundaries of its core performance characteristics. You can learn more about Bigtable performance and find resources for testing and troubleshooting in our documentation.
Give Bigtable a try today and make sure you check out newly announced product capabilities:
Over the past year, an exponential surge in data, the widespread rollout of 5G, and heightened customer expectations have placed unprecedented demands upon communications service providers (CSPs). To thrive in this challenging landscape, telecommunications leaders are rethinking traditional network management, embracing digital transformation, and using the power of AI to build smarter, more efficient, and self-managing networks.
Today, to help CSPs address these pressures, we are announcing the Autonomous Network Operations framework — enabling CSPs to enhance service reliability, proactively detect and resolve network issues, and turn fragmented data into value. This new framework takes an AI-first approach, leveraging the latest in Google Cloud AI, infrastructure, and analytics products to understand and make sense of complex network data, risks, and operations. The framework also offers an extensive ecosystem to help deploy these solutions, including partners and Google Cloud Consulting.
The Autonomous Network Operations framework draws on Google’s extensive expertise in operating its own global network, which has leveraged AI at scale for more than 25 years and is one of the industry’s most advanced and resilient autonomous networks. CSPs are already using the framework to improve service reliability and minimize mean time to repair (MTTR) by 25%, and now we’re making it broadly available to accelerate their autonomous network operations journeys.
Navigating network complexity in the AI era
Managing complex telecom networks is a costly and resource-intensive undertaking for CSPs. Legacy infrastructure, often built for previous generations of mobile technology, struggles to keep pace with the immense data demands of 5G and beyond. This has led to several challenges:
Increased operational costs and network demands: Manual tasks like alarm triage, troubleshooting, configuration, and service provisioning across diverse systems consume significant resources for CSPs, hindering innovation and modernization.
Sub-optimal customer experience: Network operations traditionally focus on technical KPIs (utilization, latency, etc.) without real-time visibility into how specific network events or degradations are actually affecting the quality of experience for individual subscribers or services. Taking action usually happens reactively, leading to eroded customer satisfaction and increased churn.
Fragmented and siloed data: In many legacy platforms, vital network-performance and customer-experience data reside in separate systems, and often are difficult to integrate. But without a unified view, correlating network events with their impact on the customer experience is hard, and can lead to ineffective resource prioritization and delayed root cause analysis.
Difficulty implementing advanced technologies: Adopting autonomous networking operations can be resource intensive and costly, presenting challenges such as integration with existing infrastructure, data management, cybersecurity, upskilling talent, and identifying a clear path to a positive return on investment.
Yet, we’ve heard from our customers that successfully embracing autonomous network operations has the potential to dramatically improve service uptime for subscribers, significantly reduce network complexity, and unify fragmented data for actionable insights.
aside_block
<ListValue: [StructValue([(‘title’, ‘Try Google Cloud for free’), (‘body’, <wagtail.rich_text.RichText object at 0x3eb2c6750190>), (‘btn_text’, ‘Get started for free’), (‘href’, ‘https://console.cloud.google.com/freetrial?redirectPath=/welcome’), (‘image’, None)])]>
Google Cloud’s Autonomous Network Operations framework
Google Cloud’s Autonomous Network Operations framework supports CSPs’ strategic pathways to achieving true network autonomy, building on our unique strengths in AI, infrastructure, and global expertise.
The framework integrates critical Google Cloud products to transform operations, enhance service reliability, and unlock new value in three key ways:
1. Differentiated building blocks for sophisticated use cases
Google Cloud uniquely helps CSPs build intelligent networks with cutting-edge, AI-powered tools tailored to their specific needs. At its core is Cloud Spanner, Google Cloud’s globally distributed database that acts like a real-time virtual copy (a “digital twin”) of national networks. Spanner tracks billions of changing data points across all network components, providing a single, reliable record that even retains historical network conditions. This is crucial for advanced analysis and quickly pinpointing the root cause of issues. BigQuery then adds data analysis that can handle massive amounts of live network information. Finally, Google’s Gemini, our most capable AI model available through Vertex AI, and specialized Graph Neural Network (GNN) models, deeply understand the network’s complex and evolving connections.
Together, these tools let CSPs move beyond simple automation to tackle advanced autonomous network operations like finding problems before they happen, linking issues across different network areas, and making quick, precise decisions based on live information, at any scale.
2. Extensive integration to accelerate time-to-value
What truly sets Google Cloud’s framework apart is how smoothly all of its pieces fit together, reducing complexity and helping CSPs get things done much faster. Our services are designed to work hand-in-hand from the start, cutting down on time-consuming data engineering. For instance, BigQuery can directly access data in Cloud Spanner, providing a unified view of current operations and historical trends. Additionally, with BigQuery ML, CSPs can build and deploy AI models using simple SQL commands, leveraging powerful AI capabilities like Gemini through Vertex AI. This tight integration across our data storage, analytics, and AI tools allows CSPs to quickly pilot, launch, and expand their AI initiatives. The entire system is AI-ready from day one, facilitating the ingestion of live network data and even enabling automated problem resolution, unlocking value in days, not months.
3. Google’s AI and network operations expertise through Google Cloud Consulting
Google’s global network, one of the most advanced and resilient networks in the world, has leveraged AI at scale for more than 25 years. Through Google Cloud Consulting, we bring this operational expertise directly to CSPs to help them design and implement their own autonomous network operations frameworks. Our teams work closely with CSPs to tailor the framework to their environments. This includes everything from setting up data pipelines to operationalizing use cases like predictive maintenance, fault correlation, and closed-loop automation — helping to ensure rapid and reliable data activation.
To help ensure these intelligent, automated operations remain secure, we also bring in Mandiant, Google’s frontline cybersecurity team. Mandiant helps CSPs embed security by design into our framework — securing data flows, detecting adversarial AI threats, and protecting automated decision loops from compromise. With this unified approach, CSPs can scale autonomous operations with the same level of resilience, visibility, and protection that underpins Google’s own global infrastructure.
A tightly integrated, open ecosystem
We strengthened the Autonomous Network Operations framework with a deep ecosystem of leading independent software vendors (ISVs) and global system integrators (GSIs), who bring specialized expertise and solutions to accelerate CSPs’ transformation journeys.
For example, Amdocs, Ericsson, and Nokia now offer their own autonomous network solutions as comprehensive offerings built on the Autonomous Network Operations framework’s capabilities, enabling their customers to easily adopt and accelerate their journey toward network autonomy. These partners bring crucial expertise in handling diverse network data from various vendors, facilitating the creation of a unified data model. This unified model is essential for building sophisticated, AI-driven automation.
“As CSPs navigate the complexities of modern networks—ranging from high operational costs to the need for enhanced resiliency and uptime—intelligent automation and the evolution to autonomous networks become essential. By leveraging Google Cloud’s AI infrastructure, our Amdocs Network AIOps solution and the network agents it includes empower CSPs to proactively manage their networks through predictive analytics, automated workflows, and closed-loop operations. This collaboration enables a transformative shift toward autonomous networks, enhancing efficiency and delivering superior customer experiences.” – Anthony Goonetilleke, group president of Technology and head of Strategy, Amdocs
“The transformation to full autonomy will shape the success of CSPs, paving the way for a transition to next-generation technologies. Ericsson and Google Cloud are committed to empowering this transformation. Our collaboration is driving a fundamental shift in how mobile core networks are built and operated on public cloud infrastructure. Ericsson and Google continue to combine their expertise on multiple fronts — technology innovation, streamlined delivery models, and, most importantly, a shared culture of relentless innovation — to empower operators in realizing their vision of autonomous networks.” — Razvan Teslaru, head of Strategy, Cloud Software and Services, Ericsson.
“The industry needs to work together to realize the benefits of Level 4/5 autonomous networks. Nokia has a long history of meaningful innovation in network automation and applied Telco AI. We’re excited about deepening our collaboration with Google Cloud, which is already delivering tangible benefits to CSPs on their own, unique journeys to fully autonomous networks.” – Kal De, senior vice president, Product and Engineering, Cloud and Network Services, Nokia.
Complementing the ISVs, GSIs including Accenture and Capgemini act as the execution arm for the CSP, playing a pivotal role in helping create the specific autonomous networking deployments, and scaling these autonomous operations across the entire organization.
Customers embracing the framework with Google Cloud
CSPs are already transforming their operations and enhancing customer experiences with the Google Cloud AI, infrastructure, and expertise provided in the Autonomous Network Operations framework:
Bell Canadaachieved a 25% reduction in customer-generated reports and increased software delivery productivity by 75%. By leveraging Autonomous Network Operations framework capabilities such as Spanner Graph to dynamically assess network relationships and changes in traffic and Google Cloud AI to identify and prioritize network issues before they escalate, Bell’s new AI operations (AI Ops) solution enables faster detection and resolution of network problems, improving network performance.
Deutsche Telekomensures high service uptime for its customers, even during peak demand, with the RAN Guardian agent built using capabilities from Google Cloud’s Autonomous Network Operations framework. This RAN Guardian is a multi-agentic system that constantly analyzes key network details in real time to predict and detect anomalies. It also prioritizes network issues by combining data from monitoring, inventory, performance, and coverage. Then, it automatically implements fixes, such as reallocating resources or adjusting configurations, to keep service quality high.
Telstra and Google Cloud are also co-developing a new approach to optimizing its radio access network (RAN) with an AI-powered agent. This agent uses Telstra’s network data to rapidly pinpoint incidents and detect anomalies before they impact service. This project is a key step in Telstra’s ambition for an autonomous network. If successful, it will unlock a future of advanced AI capabilities, enabling dynamic RAN optimization and intelligent capacity management to deliver a more resilient and higher-performing network.
Customers such as MasOrange and VMO2 have also expressed interest in leveraging advanced autonomous network capabilities to enhance their operations and customer experiences.
“By achieving a 25% reduction in customer-generated reports and boosting software delivery productivity by 75%, we’re transforming our operations into a customer-centric ‘techco’ model. This lean approach, with the customer as our #1 priority, is paving the way for full network autonomy. This future-forward strategy promises not only self-healing and resilient systems but also significant cost efficiencies.” – Mark McDonald, EVP and Chief Technology Officer, Bell Canada
“Transforming our network operations is fundamental to delivering best-in-class connectivity and services. By deeply integrating Google Cloud’s cutting-edge capabilities like Spanner Graph with its robust data and AI tools that we use today — such as BigQuery and Vertex AI — we will better understand network behavior and anticipate service incidents. This integration is key to achieving a truly autonomous operation in our future NOC, ensuring the best experience for MasOrange customers.” – Miguel Santos Fernández, Chief Technology Officer, MasOrange
Unlock autonomous network operations today with Google Cloud
If you are a CSP who is looking to enhance service reliability, proactively detect and resolve network issues, and turn data into value, the Autonomous Network Operations framework can help. Contact a Google Cloud account manager or explore our framework on our telecommunications industry page to learn more about starting a proof-of-concept with the Google Cloud Autonomous Network Operations framework.
In today’s rapidly evolving landscape, the need to protect highly sensitive government data remains paramount. Today, we reinforce our commitment to providing the highest level of assurance that sensitive agency data is protected while also streamlining the adoption of secure and modern cloud technologies, with another significant achievement – FedRAMP High authorization for Agent Assist, Looker (Google Cloud core) and Vertex AI Vector Search.
These services are foundational components of broader AI and Data Cloud solutions that can help automate institutional knowledge, bolster efficiency, drive greater worker productivity, and surface insights for more informed decision making. In today’s landscape, these are critical priorities. Findings from a recently released study that Google commissioned with GovExec show top current and future federal AI use cases which include data analysis and reporting, predictive analytics, and decision support. We believe secure, AI-powered technologies will play a critical role in scaling these AI use cases across the public sector.
Now, let’s dive deeper into our latest FedRAMP High authorizations and what they mean for public sector agencies.
Agent Assist: Empower call center operators with real-time support
Our AI-powered Agent Assist empowers call center operators with real-time support and guidance during the call, providing important context as the conversation unfolds and enabling employees to find information for callers more efficiently. Agent Assist improves accuracy, reduces handle time and after call work, drives more personalized and effective engagement, and enhances the overall service delivery.
Let’s take a closer look at how Agent Assist empowers call center operators. One federal agency faced challenges with long wait times and inconsistent answers due to operators navigating complex, siloed systems. Agent Assist offers real-time support by transcribing calls and instantly surfacing key information for a number of use cases like benefits, military and agency healthcare, claims status, IT helpdesk and more. Agent Assist guides agents through complex procedures, ensuring accuracy and compliance. It also reduces caller wait times, eliminates additional restarts, supports streamlined handoffs, automates call summaries, and so much more.
Looker is a complete AI for business intelligence (BI) platform allowing users to explore data, chat with their data via AI agents using natural language, and create dashboards and self-service reports with as little as a single natural language query. As a cloud-native and cloud-agnostic conversational enterprise-level BI tool, Looker provides simplified and streamlined provisioning and configuration. FedRAMP High authorization for Looker is the gateway for its use by federal agencies, providing the necessary security, compliance, and efficiency assurances that government operations demand.
Let’s take a closer look at how Looker helps agency employees explore data and make their data more actionable. One state agency in Texas partnered with Google Public Sector to create an AI platform that identifies new road developments to help ease congestion and improve the motorist experience. The agency uses Looker for analytics and visualization, BigQuery for data management, and Apigee for third-party integrations to help them uncover new trends that may not have been recognized before.
Vertex AI Vector Search: Perform semantic search and matching on large datasets
Vertex AI Vector Search is our managed service that allows agencies to perform semantic search and similarity matching on large datasets by leveraging vector representations of data. Using Vertex AI Vector Search, public sector agencies can perform lightning-fast semantic searches, uncovering relevant information based on meaning and context rather than just keywords. This capability is crucial for enhancing the speed and quality of services, from providing citizens with more intuitive access to information to empowering policy analysts with more comprehensive data. The ability to quickly surface connections and patterns across disparate documents, images and other unstructured data allows for more informed decision-making and improved operational efficiency. This builds on a prior announcement where we shared FedRAMP High authorization for Vertex AI Search and Generative AI on Vertex AI and demonstrates the incredible momentum around our Vertex AI platform.
Let’s take a closer look at how Vertex AI Vector Search supports more efficient searches within large datasets. One federal agency responsible for overseeing critical incident response is prototyping the ability to use Vertex AI Vector Search to guide its teams during fast-moving events. When a new situation develops, personnel can use natural language to search thousands of policies and standard operating procedures in real-time. This allows them to instantly find the correct protocol for the specific circumstances, ensuring a faster, safer, and more consistent operational response.
Accelerating innovation across the public sector
All of this momentum builds on prior announcements where we shared FedRAMP High authorization for Agentspace and Gemini in Workspace apps and the Gemini app. We will continue to invest in securing the government’s most sensitive data, ensuring mission continuity, and building public trust through FedRAMP accreditations.
At Google Public Sector, we’re passionate about applying the latest cloud, AI and security innovations to help you meet your mission. Subscribe to our Google Public Sector Newsletter to stay informed and stay ahead with the latest updates, announcements, events and more.
In enterprises, departments often describe their data assets using terminology in silos, and frequently having different interpretations of the same term. This can lead to miscommunication and inconsistent understanding of the enterprise’s data assets. Moreover, some of these terms can be technical (based on the analysis required to arrive at them), making it difficult for different business users to understand them. This is where Dataplex business glossary comes in, letting you standardize business terminologies, and build a shared understanding across the enterprise.
Today, we’re excited to announce the general availability of business glossaries in Dataplex Universal Catalog. Dataplex business glossary provides a central, trusted vocabulary for your data assets, streamlining data discovery and reducing ambiguity, leading to more accurate analysis, better governance, and faster insights.
aside_block
<ListValue: [StructValue([(‘title’, ‘$300 in free credit to try Google Cloud data analytics’), (‘body’, <wagtail.rich_text.RichText object at 0x3e8f0358ea90>), (‘btn_text’, ‘Start building for free’), (‘href’, ‘http://console.cloud.google.com/freetrial?redirectPath=/bigquery/’), (‘image’, None)])]>
What’s in glossaries
Dataplex business glossary provides a mechanism to capture taxonomies by grouping business terms in categories and glossaries that help you describe business context. It empowers you to enrich data assets with this rich business context, which can be used for searching for the linked assets and establishing a common understanding of business context across the enterprise.
Create a hierarchical glossary taxonomy: Manage and standardize business context by creating glossaries and terms. You can also group terms in a glossary into categories.
Create links between terms and between terms-data assets: Create associations between similar and related terms. Terms can also be used to describe the entire data asset or specific columns within a data asset.
Search: Find all assets linked to a term to drive analysis. Searching for terms, categories and glossaries is also supported.
Import taxonomies from external sources: Migrate glossaries from another tool to Dataplex business glossary by using the bulk import API in JSON format.
Migrate existing Data Catalog glossary taxonomy to Dataplex catalog: If you’re currently using the preview of glossaries in Data Catalog, you can use the export and import mechanism to transition them to glossaries on Dataplex Universal Catalog.
Here’s what Ericsson, an early adopter of Dataplex business glossaries has to share:
“Google Cloud Dataplex business glossaries are a foundational capability in enhancing the clarity of our data assets. Our teams now possess a unified understanding of critical business terminology, fostering superior collaboration, facilitating more assured data-driven decision-making, and becoming an essential part of our data strategy. Business glossaries have proven transformative capabilities that can be effectively managed within Dataplex, adapting to changing business needs.” – William McCann Murphy, Head of Data Authority, Ericsson
Get started with using glossaries
You can navigate to business glossaries within the Glossary tab in Dataplex Universal Catalog. You can manage glossaries, create associations between terms and data assets and search for them, all from the console.
Dataplex business glossary is now generally available. To know more, refer to the user guide for glossaries, and for kickstarting your transition from preview to glossaries on Dataplex Universal Catalog refer to the guide here.
As you adopt Google Cloud or migrate to the latest Compute Engine VMs or to Google Kubernetes Engine (GKE), selecting the right block storage for your workload is crucial. Hyperdisk, Google Cloud’s workload-optimized block storage that’s designed for our latest VM families (C4, N4, M4, and more), delivers high-performance storage volumes that are cost-efficient, easily managed at scale, and enterprise-ready. In this post, we guide you through the basics and help you choose the optimal Hyperdisk for your environment.
Introduction to Hyperdisk block storage
With Hyperdisk, you can independently tune capacity and performance to match your block storage resources to your workload. Hyperdisk is available in a few flavors:
Hyperdisk Balanced: Designed to fit most workloads and offers the best combination and balance of price and performance. This is also the boot disk for your compute instances. With Hyperdisk Balanced, you can independently configure the capacity, throughput, and IOPS of each volume. Hyperdisk Balanced is available in High Availability and Multi-writer mode.
Hyperdisk Extreme: Delivers the highest IOPS of all Hyperdisk offerings and is suited for high-end, performance-critical databases. With Hyperdisk Extreme, you can drive up to 350K IOPS from a single volume.
Hyperdisk Throughput: Delivers capacity at the cost of cold object storage with the semantics of a disk. Hyperdisk Throughput offers high throughput for bandwidth and capacity-intensive workloads that do not require low latency. It also can be used to deliver cost-effective disks for cost-sensitive workloads (e.g., cold disks).
Hyperdisk ML: Purpose-built for loading static data into your compute clusters. With Hyperdisk ML, you hydrate the disk with a fixed data set (such as model weights or binaries), then connect up to 2,500 compute instances to the same volume, so a single volume can serve over 150x more compute instances than competitive block storage volumes1 in read-only mode. You get exceptionally high aggregate throughput across all of those nodes, enabling you to accelerate inference startup, train models faster, and ensure your valuable compute resources are highly utilized.
You can also leverage Hyperdisk Storage Pools, which lowers TCO and simplifies operations by pre-provisioning an aggregate amount of capacity and performance, which is then dynamically consumed by volumes in that pool. You create a storage pool with the aggregate capacity and performance that your workloads will need, and then create disks in the storage pool. You can then attach the disks to your VMs. When you create the disks, you can create them with a much larger size or provisioned performance limit than is needed. This simplifies planning and provides room for growth later, without needing to change the disk’s provisioned size or performance.
You can also use a set of comprehensive data protection capabilities such as high availability, cross-region replication and recovery, backup, and snapshots to protect your business critical workloads.
For specifics around capabilities, capacity, machine support, and performance, please visit the documentation.
aside_block
<ListValue: [StructValue([(‘title’, ‘Try Google Cloud for free’), (‘body’, <wagtail.rich_text.RichText object at 0x3e8f019c9d30>), (‘btn_text’, ‘Get started for free’), (‘href’, ‘https://console.cloud.google.com/freetrial?redirectPath=/welcome’), (‘image’, None)])]>
Recommendations for the most common workloads
To make choosing the right Hyperdisk architecture simpler, here are high-level recommendations for some of the most common workloads we see. For an enterprise, the Hyperdisk portfolio lets you optimize an entire three-tier application matching the needs of each component of your application to the different flavors of Hyperdisk.
Enterprise applications including general-purpose databases:
Hyperdisk Balanced combined with Storage Pools offers an excellent solution for a wide variety of general-purpose workloads, including common database workloads. Hyperdisk Balanced can meet the IOPS and throughput needs for most databases including Clickhouse, MySQL, and PostgreSQL, at general-purpose pricing. Hyperdisk Balanced offers 160K IOPS per volume — 10x better than AWS EBS gp3 volumes2. With Storage Pools you can enhance efficiency and radically simplify planning. Storage Pools allows customers to save approximately 20-40% on storage costs for typical database workloads when compared to Hyperdisk Balanced Volumes or AWS EBS gp3 volumes3.
“At Sentry.io, a platform used by over 4 million developers and 130,000 teams worldwide to quickly debug and resolve issues, adopting Google Cloud’s Hyperdisk has enabled us to create a flexible architecture for the next-generation of our Event Analytics Platform, a product at the core of our business. Hyperdisk Storage Pools with advanced capacity and performance enabled us to reduce our planning cycles from weeks to minutes, while saving 37% in storage costs, compared to persistent disks.” – Dave Rosenthal, CTO, Sentry
“High Availability is essential for Blackline — we run database failover clustering, at massive scale, for our global and mission-critical deployment of Financial Close Management. We are excited to bring this workload to Google Cloud leveraging Hyperdisk Balanced High Availability to meet the performance, capacity, cost efficiency, and resilience requirements that our customers demand, and helps us address our customer’s financial regulatory needs globally.” – Justin Brodley, SVP of Cloud Engineering and Operations, Blackline
Tier-0 databases
For high-end, performance-critical databases like SAP HANA, SQL Server, and Oracle Database, Hyperdisk Extreme delivers uncompromising performance. With Hyperdisk Extreme, you can obtain up to 350K IOPS and 10 GiB/s of throughput from a single volume.
AI, analytics, and scale-out workloads
Hyperdisk offers excellent solutions for the most demanding next-generation machine learning and high performance computing workloads.
Dynamically scaling AI and analytics workloads and high-performance file systems
Workloads with fluctuating demand, and high peak throughput and IOPS, benefit from Hyperdisk Balanced and Storage Pools. These workloads can include customer-managed parallel file systems and scratch disks for accelerator clusters. Storage Pools’ dynamic resource allocation helps ensure that these workloads get the performance they need during peak times without requiring constant manual adjustments or inefficient over-provisioning. Further, once your Storage Pool is set up, planning at the per-disk level is significantly simpler. Note: If you want a fully managed file system, Managed Lustre is an excellent option for you to consider.
“Combining our use of cutting-edge machine learning in quantitative trading at Hudson River Trading (HRT) with Google Cloud’s accelerator-optimized machines, Dynamic Workload Scheduler (DWS) and Hyperdisk has been transformative in enabling us to develop [state-of-the-art] models. Hyperdisk storage pools have delivered substantial cost savings, lowering our storage expenses by approximately 50% compared to standard Hyperdisk while minimizing the amount of planning needed.” – Ragnar Kjørstad, Systems Engineer, Hudson River Trading
AI/ML and HPC data-load acceleration
Hyperdisk ML is specifically optimized for accelerating data load times for inference, training and HPC workloads — Hyperdisk ML accelerates model load time by 3-5x compared to common alternatives4. Hyperdisk ML is particularly well-suited for serving tasks compared to other storage services on Google Cloud because it can concurrently provide to many VMs exceptionally high aggregate throughput (up to 1.2 TiB/s of aggregate throughput per volume, offering greater than 100x higher performance than competitive offerings)5. You write once (up to 64 TiB per disk) and attach multiple VM instances to the same volume in a read-only mode. With Hyperdisk ML you can accelerate data load times for your most expensive compute resources, like GPUs and TPUs. For more, check out g.co/cloud/storage-design-ai.
“At Resemble AI, we leverage our proprietary deep-learning models to generate high-quality AI audio through text-to-speech and speech-to-speech synthesis. By combining Google Cloud’s A3 VMs with NVIDIA H100 GPUs and Hyperdisk ML, we’ve achieved significant improvements in our training workflows. Hyperdisk ML has drastically improved our data loader performance, enabling 2x faster epoch cycles compared to similar solutions. This acceleration has empowered our engineering team to experiment more freely, train at scale, and accelerate the path from prototype to production.” –Zohaib Ahmed, CEO, Resemble AI
“Abridge AI is revolutionizing clinical documentation by leveraging generative AI to summarize patient-clinician conversations in real time. By adopting Hyperdisk ML, we’ve accelerated model loading speeds by up to 76% and reduced pod initialization times.” – Taruj Goyal, Software Engineer, Abridge
High-capacity analytics workloads:
For large-scale data analytics workloads like Hadoop and Kafka, which are less sensitive to disk latency fluctuations, Hyperdisk Throughput provides a cost-effective solution with high throughput. Its low cost per GiB and configurable throughput are ideal for processing large volumes of data with low TCO.
How to size and set up your Hyperdisk
To select and size the right Hyperdisk volume types for your workload, answer a few key questions:
Storage management. Decide if you want to manage the block storage for your workloads in a pool or individually. If your workload will have more than 10 TiB of capacity in a single project and zone, you should consider using Hyperdisk Storage Pools to lower your TCO and simplify planning. Note that Storage Pools do not affect disk performance; some data protection features such as Replication and High Availability are not supported in Storage Pools.
Latency. If your workload requires SSD-like latency (i.e., sub-millisecond), it likely should be served by Hyperdisk Balanced or Hyperdisk Extreme.
IOPS or throughput. If your application requires less than 160K IOPS or 2.4 GiB/s of throughput from a single volume, Hyperdisk Balanced is a great fit. If it needs more than that, consider Hyperdisk Extreme.
Sizing performance and capacity. Hyperdisk offers independently configurable capacity and performance, allowing you to pay for just the resources you need. You can leverage this capability to lower your TCO by understanding how much capacity your workload needs (i.e., how much data, in GiB or TiB, is stored on the disks which serve this workload) and the peak IOPS and throughput of the disks. If the workload is already running on Google Cloud, you can see many of these metrics in your console under “Metrics Explorer.”
Another important consideration is the level of business continuity and data protection required for your workloads. Different workloads have different Recovery Point Objective (RPO) and Recovery Time Objective (RTO) requirements, each with different costs. Think about your workload tiers when making data-protection decisions. The more critical an application or workload, the lower the tolerance for data loss and downtime. Applications critical to business operations likely require zero RPO and RTO in the order of seconds. Hyperdisk business continuity and data protection helps customers meet the performance, capacity, cost efficiency, and resilience requirements they demand, and helps them address their financial regulatory needs globally.
Here are a few questions to consider when selecting which variety of Hyperdisk to use for a workload:
How do I protect my workloads from attack and malicious insiders? UseGoogle Cloud Backup vaultforcyber resilience, backup immutability, and indelibility for managed backup reporting and compliance. If you want to self-manage your own backups, Hyperdisk standard snapshots are an option for your workloads.
How do I protect data from user errors and bad upgrades cost efficiently with low RPO / RTO? You can use our point-in-time recovery with Instant Snapshots. This feature minimizes the risk of data loss from user error and bad upgrades with ultra-low RPO and RTO — creating a checkpoint is nearly instantaneous.
How do I easily deploy my critical workload (e.g., MySQL) with resilience across multiple locations? You can utilize Hyperdisk HA. This is a great fit for scenarios that require high availability and fast failover, such as SQL Server that leverages failover clustering. For such workloads, you can also choose our new capability with Hyperdisk Balanced High Availability with Multi-Writer support. This allows you to run clustered compute with workload-optimized storage in two zones with RPO=0 synchronous replication.
When a disaster occurs, how do I recover my workload elsewhere quickly and reliably, and run drills to confirm my recovery process? Utilize our disaster recovery capabilities with Hyperdisk Async Replicationwhichenables cross-region continuous replication and recovery from a regional failure, with fast validation support for disaster recovery drills via cloning. Further, consistency group policies help ensure that workload data that’s distributed across multiple disks is recoverable when a workload needs to fail over between regions.
In short, Hyperdisk provides a wealth of options to help you optimize your block storage to the needs of your workloads. Further, selecting the right Hyperdisk and leveraging features such as Storage Pools can help you lower your TCO and simplify management. To learn more, please visit our website. For tailored recommendations, always consult your Google Cloud account team.
1. As of March 2025 based on published information for Amazon EBS, Azure managed disks. 2. As of May 2025, compared to Amazon EBS gp3 volumes max iops/volume 3. As of March 2025, at list price, 50 to 150 TiB, peak IOPS of 25K to 75K and 25% compressibility, compared to Amazon EBS gp3 volumes. 4. As of March 2025, based on internal Google benchmarking, compared to Rapid Storage, GCSFuse with Anywhere Cache, Parallelstore and Lustre for larger node sizes. 5. As of March 2025 based on published performance for Microsoft Azure Ultra SSD and Amazon EBS io2 BlockExpress
The authors would like to thank David Seidman and Ruwen Hess for their contributions on this blog.
Today, we’re excited to announce the preview of our new G4 VMs based on NVIDIA RTX PRO 6000 Blackwell Server edition — the first cloud provider to do so. This follows the introduction earlier this year of A4 and A4X VMs powered by NVIDIA Blackwell GPUs, designed for large-scale AI training and serving. At the same time, we’re also seeing growing demand for GPUs to power a diverse range of workloads and data formats. G4 VMs round out our 4th generation NVIDIA GPU portfolio and bring a new level of performance and flexibility to enterprises and creators.
G4 VMs combine eight NVIDIA RTX PRO 6000 GPUs, two AMD Turin CPUs, and Google Titanium offloads:
RTX PRO 6000 Blackwell GPUs provide new fifth-generation Tensor Cores, second-generation Transformer Engine supporting FP6 and FP4 precision, fourth-generation Ray Tracing (RT) Cores, and Multi-Instance GPU (MIG) capabilities, delivering 4x the compute and memory, and 6x memory bandwidth compared to G2 VMs.
Turin CPUs offerup to 384 vCPUs and 1.4TB DDR5 memory for a ratio of 48 vCPU per GPU. This enables embedding models with precompute features on CPUs and graphics, where the CPU helps orchestrate simulations.
Titanium offloads providededicated network processing with up to 400 Gbps bandwidth that’s 4x faster than in G2 VMs.
The G4 VM can power a variety of workloads, from cost-efficient inference, to advanced physical AI, robotics simulations, generative AI-enabled content creation, and next-generation game rendering. For example, with advanced ray-tracing cores to simulate the physical behavior of light, NVIDIA RTX PRO 6000 Blackwell provides over 2x performance of the prior generation, providing hyper-realistic graphics for complex, real-time rendering. For demanding graphics and physical AI-enabled applications, being able to run NVIDIA Omniverse workloads natively unlocks new possibilities for the manufacturing, automotive, and logistics industries, where digital twins and real-time simulation are rapidly transforming operations. G4 VMs also support the NVIDIA Dynamo inference framework to enable high-throughput, low-latency AI inference for generative models at scale.
Customers across industries — from media and entertainment to manufacturing, automotive, and gaming — are onboarding to use G4 VMs to accelerate AI-powered content creation, advanced simulation, and high-performance visualization:
“Our initial tests of the G4 VM show great potential, especially for self-hosted LLM inference use cases. We are excited to benchmark the G4 VM for a variety of other ranking workloads in the future.” – Vinay Kola, Snap, Senior Manager, Software Engineering
Altair is going to help customers accelerate their computer aided engineering (CAE) workloads with the performance and large memory of Google Cloud’s G4 instances.
Ansys will help its customers leverage Google Cloud’s G4 instances to accelerate their simulation workloads.
AppLovin is excited to use G4 for ad serving and recommendations.
WPP is excited to use G4 to continue ground-breaking work with physically-accurate generative AI and robotics simulation.
Nuro is looking to run drive simulations on G4 via NVIDIA Omniverse.
A major player in the video game industry is looking to use G4 for their next generation game rendering.
G4 VMs provide 768 GB of GDDR7 memory and 384 vCPUs with 12 TiB of Titanium local SSD, extensible with up to 512 TiB of Hyperdisk network block storage. For design and simulation workloads, G4 VMs support third-party engineering and graphics applications like Altair HyperWorks, Ansys Fluent, Autodesk AutoCAD, Blender, Dassault SolidWorks, and Unity.
G4 VMs are available as part of AI Hypercomputer, Google Cloud’s fully integrated AI supercomputing system, and work natively with Google Cloud services like Google Kubernetes Engine, Google Cloud Storage, and Vertex AI. Many customers use a combination of services such as Vertex AI or GKE with NVIDIA GPUs on Google Compute Engine and Google Cloud HyperdiskML for AI inference. Hyperdisk provides ultra-low latency and supports up to 500K IOPS and 10,000 MiB/s throughput per instance — making it well-suited for demanding inference workloads.
Machine Type
GPUs
GPU Memory (GB)
vCPUs
Host Memory (GB)
Local SSD (GB)
g4-standard-384
8
768
384
1,440
12,000
G4 is currently in preview and will be available globally by the end of the year. Reach out to your Google Cloud Sales representative to learn more.
At Google Cloud, we’re committed to providing the most streamlined, powerful, and cost-effective production- and enterprise-ready serverless Spark experience. To that end, we’re thrilled to announce a significant evolution for Apache Spark on Google Cloud, with Google Cloud Serverless for Apache Spark.
Serverless Spark is now also generally available directly within the BigQuery experience. This deeply integrated experience brings the full power of Google Cloud Serverless for Apache Spark into the BigQuery unified data-to-AI platform, offering a unified developer experience in BigQuery Studio, seamless interoperability, and industry-leading price/performance.
Why Google Cloud Serverless for Apache Spark?
Apache Spark is an incredibly popular and powerful open-source engine for data processing, analytics and AI/ML. However, developers often get bogged down managing clusters, optimizing jobs, and troubleshooting, taking valuable time away from building business logic.
By simplifying your Spark experience, you can focus on deriving insights, not managing infrastructure.Google Cloud Serverless for Apache Spark (formerly Dataproc Serverless) addresses these challenges with:
On-demand Spark for reduced total cost of ownership (TCO):
No cluster management. Develop business logic in Spark for interactive, batch, and AI workloads, without worrying about infrastructure.
Pay only for the job’s runtime, not for environment spinup/teardown.
On-demand Spark environments, so no more long running, under-utilized clusters.
Exceptional performance:
Support for Lightning Engine (in Preview), a Spark processing engine with vectorized execution, intelligent caching, and optimized storage I/O, for up to 3.6x faster query performance on industry benchmarks*
Popular ML libraries like XGBoost, PyTorch, Transformers, and many more, all pre-packaged with Google-certified serverless Spark images, boosting productivity, improving startup times, and reducing potential security issues from custom image management
GPU acceleration for distributed training and inference workloads
Enterprise-grade security capabilities:
No SSH access to VMs
Encryption by default, including support for Customer Managed Encryption Keys (CMEK)
<ListValue: [StructValue([(‘title’, ‘$300 in free credit to try Google Cloud data analytics’), (‘body’, <wagtail.rich_text.RichText object at 0x3ed82803a400>), (‘btn_text’, ‘Start building for free’), (‘href’, ‘http://console.cloud.google.com/freetrial?redirectPath=/bigquery/’), (‘image’, None)])]>
A Unified Spark and BigQuery experience
Building on the power of serverless Spark, we’ve worked to reimagine how you work with Spark and BigQuery, so that you can get the flexibility to use the right engine for the right job, with a unified platform, notebook interface, and on a single copy of data.
With the general availability of serverless Apache Spark in BigQuery, we’re bringing Apache Spark directly into the BigQuery unified data platform. This means you can now develop, run and deploy Spark code interactively in the BigQuery Studio, offering an alternative, scalable, OSS processing framework alongside BigQuery’s renowned SQL engine.
“We rely on machine learning for connecting our customers with the greatest travel experiences at the best prices. With Google Serverless for Apache Spark, our platform engineers save countless hours configuring, optimizing, and monitoring Spark clusters, while our data scientists can now spend their time on true value-added work like building new business logic. We can seamlessly interoperate between engines and use BigQuery, Spark and Vertex AI capabilities for our AI/ML workflows. The unified developer experience across Spark and BigQuery, with built-in support for popular OSS libraries like PyTorch, Tensorflow, Transforms etc., greatly reduces toil and allows us to iterate quickly.” – Andrés Sopeña Pérez, Head of Content Engineering, trivago
Key capabilities and benefits of Spark in BigQuery
Apart from all the features and benefits of Google Cloud Serverless for Apache Spark outlined above, Spark in BigQuery offers deep unification:
Unified developer experience in BigQuery Studio:
Develop SQL and Spark code side-by-side in BigQuery Studio notebooks.
Leverage Gemini-based PySpark Code Generation (Preview), with the intelligent context of your data to prevent hallucination in generated code.
Use Spark Connect for remote connectivity to serverless Spark sessions.
Because Spark permissions are unified with default BigQuery roles, you can get started without needing additional permissions.
Unified data access and engine interoperability:
Powered by the BigLake metastore, Spark and BigQuery can operate on a single copy of your data, whether it’s BigQuery managed tables or open formats like Apache Iceberg. No more juggling separate security policies or data governance models across engines. Refer to the documentation on using BigLake metastore with Spark.
Additionally, all data access to BigQuery, both native and OSS formats, are unified via the BigQuery Storage Read API. Reads from serverless Spark jobs via the Storage API are now available at no additional cost
3. Easy operationalization:
Collaborate with your team and integrate into your Git-based CI/CD workflows using BigQuery repositories.
In addition to functional unification, BigQuery spend-based CUDs now apply to all usage from serverless Spark jobs. For more information about serverless Spark pricing, please visit our pricing page.
You can create a default Spark session with a single line of code, as shown below.
code_block
<ListValue: [StructValue([(‘code’, ‘from google_spark_session.session.spark.connect import DataprocSparkSessionrn# This line creates a default serverless Spark session powered by Google Cloud Serverless for Apache Sparkrnspark = DataprocSparkSession.builder.getOrCreate()rnrn# Now you can use the ‘spark’ variable to run your Spark codern# For example, reading a BigQuery table:rndf = spark.read.format(“bigquery”) \rn .option(“table”, “your-project.your_dataset.your_table”) \rn .load()rndf.show()’), (‘language’, ‘lang-py’), (‘caption’, <wagtail.rich_text.RichText object at 0x3ed8285c8e80>)])]>
Customizing your Spark session: If you want to customize your session — for example, use a different VPC network, or a service account — you can get full control over the session’s configuration, using existing session templates or by providing configurations inline. For detailed instructions on configuring your Spark sessions, reading from and writing to BigQuery, and more, please refer to the documentation.
And that’s it, you are now ready to develop your business logic using the Spark session.
The bigger picture: A unified and open data cloud
With Google Cloud Serverless for Apache Spark and its new, deep integration with BigQuery, we’re breaking down barriers between powerful analytics engines, enabling you to choose the best tool for your specific task, all within a cohesive and managed environment.
We invite you to experience the power and simplicity of Google Cloud Serverless for Apache Spark and its new, deep integration with BigQuery.
We are incredibly excited to see what you will build. Stay tuned for more innovations as we continue to enhance Google Cloud Serverless for Apache Spark and its integrations across the Google Cloud ecosystem.
* The queries are derived from the TPC-H standard and as such are not comparable to published TPC-H standard results, as these runs do not comply with all requirements of the TPC-H standard specification.
This year, we’ve spent dozens of hours synthesizing hundreds of conversations with CXOs across leading organizations, trying to uncover their biggest thorns when it comes to building Multi-Agent Systems (MAS).
These conversations have revealed a clear pattern: MAS is helping enterprises re-think clunky legacy processes, but many CXOs are focused on automating those legacy processes rather than reimagining them. Plus, ethical risks are front and center – how do you balance innovation and ethical planning? How do CXOs take advantage of everything that’s available now, without uprooting their entire organization?
Today, we’ll explore some common missteps in the field, top questions executives have, and insights to move forward on adopting MAS today.
Quick recap: What’s the value of MAS?
MAS involves teams of coordinated AI agents working together to achieve multifaceted business goals. For example, when resolving complex customer issues, specialist agents (such as billing, usage, promotions) are managed by a coordinator agent. This orchestrator ensures that the overall resolution is driven by business logic and aligns with enterprise policies.
MAS is now transitioning from a conceptual promise to practical application. In contact centers, an orchestrator agent can analyze complex, multi-part customer queries and dynamically engage the right specialists, along with validation agents to ensure accuracy and compliance. This approach significantly improves first-contact resolution for intricate issues and increases call containment, thereby reducing the need to escalate to live agents.
Similar collaborative agent strategies are emerging across industries, such as supply chain optimization and complex research, which demonstrate MAS’s power to handle complexity through coordinated, intelligent action.
aside_block
<ListValue: [StructValue([(‘title’, ‘$300 in free credit to try Google Cloud AI and ML’), (‘body’, <wagtail.rich_text.RichText object at 0x3ed829935550>), (‘btn_text’, ‘Start building for free’), (‘href’, ‘http://console.cloud.google.com/freetrial?redirectPath=/vertex-ai/’), (‘image’, None)])]>
3 common missteps from the field
Misstep 1: Automating old processes instead of reimagining them
Applying MAS to automate existing processes severely limits its transformative potential. Real value comes from rethinking workflows to leverage MAS for dynamic and holistic-problem solving. A strong partnership between technical and business teams is essential to challenge the status quo. Customers are transitioning from bouncing customers between departments to answer complex queries, to empowering each department to answer questions more quickly, to ultimately consolidating everything into one MAS-driven department with oversight.
A key point to remember is that even though we are reimagining our current process, this doesn’t mean we need to do everything at once. If we want to increase the number of calls routed to a virtual agent, we should first identify the initial tranche of calls to address. Then, we can incrementally expand the types or topics the virtual agent can handle to ensure customer satisfaction and maintain overall support quality.
For example, this is how we sequentially move through key steps in a Multi-Agentic System program:
A critical error is under-resourcing the design of agent collaboration-particularly in defining roles, communication protocols , and conflict resolution strategies.
As MAS evolves, it’s increasingly important to know what, when, and why a specialist agent should be engaged. But how do you validate this orchestration logic? Through rigorous testing using ground truth evaluation and high-quality test data.
Customers that succeed in this area have a clear understanding of what “good” versus “bad” answers look like across different question types. These examples are critical in building agents that can determine which tools, other agents, services, verbosity, tonality, and format to use when providing a response.
Misstep 3: Delaying governance and ethical planning
Treating governance, ethics, and monitoring as afterthoughts invites significant risks, such as program delays, bias amplification, and critical policy gaps. The best way to achieve this with MAS is by embedding responsible AI principles, including establishing clear rules, audit trails and transparency. The old adage, “move slow to move fast,” becomes more relevant as we increase complexity.
For example, if bias monitoring is not considered until late in deployment, a virtual agent on an e-commerce platform might put too much weight on a customer’s zip code, displaying higher-priced products to those in wealthier areas and budget options to customers in lower-income zip codes. This could create an unfair shopping experience, where certain groups feel excluded or underserved, ultimately harming the brand’s reputation. As a result, there is rework, redesign and the need to rollback updates to go through the solution design and testing processes again, adding upwards of six months of additional work.
These concepts and the teams responsible for them must be incorporated from day 1 of a MAS project.
Top 3 questions from the field
Question 1: “Beyond cost savings, how do we measure ROI?”
We focus on tracking improved outcomes for complex tasks, enhancing customer experience, reducing manual risks, and driving new revenue streams. For instance, an analyst assistant can support a wealth manager by providing instant insights into complex financial data, identifying key trends, and generating customized reports. This propels the wealth manager to engage more meaningfully with clients, ask targeted follow-up questions, and ultimately build stronger relationships. As a result, MAS improves customer retention, increases wallet share, and minimizes the risk of misinterpreting critical financial information.
Question 2: “How do we balance human oversight with autonomous agents?”
MAS isn’t about replacing humans; rather, it’s about strategizing human skills where they have the most impact. Humans excel at navigating ambiguity, ethics, and novelty. In one real-world scenario, AI handles complex offers but escalates edge cases, such as price-matching a competitor’s promotion, to a human for final judgment. The key is ensuring that your use case and desired outcomes drive the solution. Not the other way around!
Question 3: “How can I predict outcomes and address ethical risks?”
Achieving successful outcomes in MAS requires thoughtful design, which starts with asking the right questions: What happens when a customer interacts with the system? What information is needed to answer their questions? Where should human oversight be applied, and how do we evaluate and monitor performance both in testing and production environments? To ensure reliability, we conduct a variety of tests with our customers, including load testing, accuracy and quality testing, red teaming, and user acceptance testing. This rigorous approach, combined with continuous monitoring, helps identify and correct unintended behaviors and ensures that the system performs as expected. Additionally, we proactively mitigate ethical risks such as bias amplification, unfairness, and accountability gaps by embedding rules, ensuring transparency and auditability, and assigning clear roles for both agents and humans.
This diagram depicts the MAS Ethical Lifecycle, showing the interconnected stages of Agent Design, Interaction and Coordination, Deployment and Operation, Human-AI Orchestration, and Continuous Improvement, all guided by fundamental ethical considerations.
Get started
Based on these field insights, consider prioritizing the following:
Develop a MAS strategy: Start small, think big
Prioritize governance, ethics and trust from day one
Foster a collaborative culture that puts your user first: IT and business unite
Datadog and Google Cloud have long provided customers with powerful capabilities that enable performant, scalable, and differentiated applications in the cloud; in the past two years alone, Datadog’s revenue on Google Cloud Marketplace has more than doubled. As these customers bring Google Cloud’s AI capabilities into their technology stacks, they require observability tools that allow them to better troubleshoot errors, optimize usage, and improve product performance.
Today, Datadog is announcing expanded AI monitoring capabilities with Vertex AI Agent Engine monitoring inits new AI Agents Console. This new feature joins a large and growing set of Google Cloud AI monitoring capabilities that allow joint customers to better innovate and optimize product performance across the AI stack
Full-stack AI observability
With this extensive set of AI observability capabilities, Datadog customers with workloads on Google Cloud have enhanced visibility into all the layers of an AI application.
Application layer: As businesses adopt autonomous agents to power key workflows, visibility and governance become critical. Datadog’s new AI Agents Console now supports monitoring of agents deployed viaGoogle’s Vertex AI Agent Engine, providing customers with a unified view of the actions, permissions, and business impact of third-party agents — including those orchestrated by Agent Engine.
Model layer: Datadog LLM Observability allows users to monitor, troubleshoot, improve and secure their large language model (LLM) applications. Earlier this year, Datadog introduced auto-instrumentation for Gemini models and LLMs in Vertex AI, which allows teams to start monitoring quickly, minimizing setup work and jumping right into troubleshooting efforts.
Infrastructure layer: In February, Datadog announced a new integration with Cloud TPU, allowing customers to monitor utilization, resource usage, and performance at the container, node, and worker levels. This helps customers rightsize TPU infrastructure and balance training performance with cost.
Data layer: Many Google Cloud customers use BigQuery for data insights. Datadog’s expanded BigQuery monitoring capabilities — launched at Google Cloud Next — help teams optimize costs by showing BigQuery usage per user and project, identifying top spenders and slow queries. It also flags failed jobs for immediate action and identifies data quality issues.
aside_block
<ListValue: []>
Optimize monitoring costs
Datadog has regularly invested in optimizing the cost associated with its Google Cloud integrations, and Datadog customers can now use Google Cloud’s Active Metrics APIs, ensuring Datadog only calls Google Cloud APIs when there is new data. This significantly reduces API calls and associated costs, without sacrificing visibility. This joins Datadog’s support for Google Cloud’s Private Service Connect, which allows Datadog users running on Google Cloud to reduce data transfer costs, as another key tool to help Google Cloud customers optimize their monitoring costs without reducing visibility.
Get started today
Datadog’s unified observability and security platform offers a powerful advantage for organizations that want to use Google Cloud’s cutting-edge AI services. By monitoring the full Google Cloud stack across a breadth of telemetry types, Datadog gives Google Cloud customers the tools and insights they need to build more performant, cost-efficient, and scalable applications.
Ready to try it for yourself? Purchase Datadog directly from the Google Cloud Marketplace and start monitoring your environment in minutes. And if you’re in the New York area, you can see some of these new capabilities in action by visiting the Google Cloud booth at Datadog’s annual conference DASH from June 10-11.
In the dynamic world of beauty retail, staying ahead requires more than just the hottest trends — it demands agility, data-driven insights, and seamless customer experiences. Ulta Beauty, a leader in the beauty and wellness industry, understands this.
Building on the success of modernizing its e-commerce platform with Google Kubernetes Engine (GKE), Ulta Beauty partnered with Google Cloud, Accenture, IBM and Infosys to embark on a comprehensive digital transformation, redefining the beauty retail experience.
Two key initiatives — an enterprise data warehouse transformation Darwin (Enterprise Data Warehouse Project) and MIA (Mobile Inventory Application) — were at the heart of their makeover.
A Foundation Built on Agility: The GKE Advantage
Ulta Beauty’s transformation began with a foundational shift to the cloud. In 2019, recognizing the limitations of its existing e-commerce infrastructure, the company migrated to GKE, embracing a containerized, microservices architecture. This strategic move provided the agility and scalability essential for supporting Ulta Beauty’s rapidly growing online presence and laid the groundwork for further innovation.
By adopting GKE, Ulta Beauty gained a more flexible and resilient platform, enabling the company to respond more effectively to changing market demands, seasonal traffic spikes, and customer expectations. This initial success with GKE instilled confidence in Google Cloud’s capabilities, paving the way for more ambitious modernization projects.
aside_block
<ListValue: [StructValue([(‘title’, ‘$300 in free credit to try Google Cloud data analytics’), (‘body’, <wagtail.rich_text.RichText object at 0x3e27e813aee0>), (‘btn_text’, ‘Start building for free’), (‘href’, ‘http://console.cloud.google.com/freetrial?redirectPath=/bigquery/’), (‘image’, None)])]>
Darwin: Unleashing the Power of Data with BigQuery
Ulta Beauty recognized the need to modernize its analytics capabilities to keep pace with its growing data volume and complexity. “We wanted everything in one location, to get rid of manual tasks and to take the next step on the analytics curve,” explained Mac Coyle, director of Cloud Engineering at Ulta Beauty. Slow query performance, data silos, and limited access for business users hindered timely insights and agile decision-making.
Ulta Beauty found the solution in Google BigQuery, the foundation for its new analytics platform, Darwin. BigQuery’s serverless architecture, scalability, and performance provided the necessary ingredients for a data-driven transformation. Partnering with Accenture, Ulta Beauty migrated over 300 datasets and developed 50 core enterprise reports. Infosys played a key role in integrating Darwin with various systems, including S4 and legacy applications, ensuring seamless data flow and accelerating the development of critical reports.
“The opportunity to drive innovation is boundless when everything is centralized in one place,” says Coyle. “With Darwin, our teams are empowered with access to timely, actionable data, driving more informed decision-making across the enterprise.” Darwin now provides store managers and business leaders with real-time dashboards showing key performance indicators, enabling them to make data-driven decisions on the spot.
A unified platform, ready for the demands of AI, was the driving force behind Darwin’s development. “We built Darwin not just for today’s analytics needs, but for tomorrow’s AI-powered possibilities,” says Krish Das, VP of Enterprise Data and AI Officer at Ulta Beauty. This ensures data is ready for advanced analytics, machine learning, and personalization, positioning the company for continued growth.
MIA: Empowering Store Associates with Modern Inventory Management
Ulta Beauty also sought to modernize its inventory management system to empower store associates and enhance the guest experience.
Alongside its ERP upgrade, Project SOAR (“Strengthen, Optimize, Accelerate, Renew”), Ulta Beauty called upon Accenture to reimagine its inventory management processes along with partners Infosys and IBM to develop MIA (Mobile Inventory Application). Infosys played a vital role in developing and implementing MIA, building the real-time integrations with S/4HANA and optimizing the store rollout process, and now provides ongoing support and development for the application. MIA is a native mobile application built on GKE, Google Cloud Storage (GCS), and MongoDB.
“With MIA, we saw a double digit reduction in the number of clicks throughout the application” explains Natalie Fong, Senior Director of Business Initiatives and Transformation at Ulta Beauty. This streamlined approach translates to significant time savings, allowing associates to focus on delivering exceptional, personalized guest experiences.
Fong also highlighted broader time savings from streamlined processes, such as the paperless procurement process and a centralized supplier portal. Key MIA features include real-time inventory lookups, streamlined receiving, efficient cycle counting, mobile access to product information, and easy price label generation and store transfers. Now, associates are equipped with real-time data at their fingertips, enhancing their ability to quickly and accurately assist guests.
The Power of Partnership: A Collaborative Approach to Transformation
Ulta Beauty’s digital transformation has been a collaborative journey. Accenture played a key role in the Darwin implementation and ERP upgrade, while IBM led the development of MIA and Infosys provided crucial integration expertise for both initiatives.
“We couldn’t have achieved this transformation without the close partnership of Google Cloud, Accenture, and IBM,” says Krish Das, VP of Enterprise Data and AI Officer, Ulta Beauty. “Key to our success was our ability to combine our expertise and work together seamlessly to deliver the best solutions for Ulta Beauty.”
This close collaboration, including joint development efforts between Google Cloud, Accenture, IBM and Infosys, was imperative for aligning the technical aspects of both projects and ensuring cohesive outcomes.
A Vision for the Future: Data-Driven Beauty at Scale
Darwin and MIA, developed in close collaboration with Google Cloud, Accenture, IBM and Infosys represent a significant leap forward in Ulta Beauty’s data-driven journey. These initiatives have not only delivered real-time insights and streamlined operations but also built a robust, AI-ready data foundation to innovate upon. Now, with the power of Google Cloud, including generative AI capabilities like Gemini, Ulta Beauty is poised to unlock even greater possibilities at the forefront of modern retail, and is ready to redefine the beauty industry.Ready to modernize your data analytics and build a foundation for AI? Learn more about Google Cloud’s BigQuery Migration Services.
Today, we’re introducing Pub/Sub Single Message Transforms (SMTs) to make it easy to perform simple data transformations right within Pub/Sub itself.
This comes at a time when businesses are increasingly reliant on streaming data to derive real-time insights, understand evolving customer trends, and ultimately make critical decisions that impact their bottom line and strategic direction. In this world, the sheer volume and velocity of streaming data present both opportunities and challenges. Whether you’re generating and analyzing data, ingesting data from another source, or syndicating your data for others to use, you often need to perform transforms on that data to match your use case. For example, if you’re providing data to other teams or customers, you may have the need to redact personally identifiable information (PII) from the messages before sharing data. And if you’re using data you generated or sourced from somewhere else – especially unstructured data – you may need to perform data format conversions or other types of data normalization.
Traditionally, the options for these simple transformations within a message involve either altering the source or destination of the data (which may not be an option) or using an additional component like Dataflow or Cloud Run, which incurs additional latency and operational overhead.
aside_block
<ListValue: [StructValue([(‘title’, ‘$300 in free credit to try Google Cloud data analytics’), (‘body’, <wagtail.rich_text.RichText object at 0x3e93b19501c0>), (‘btn_text’, ‘Start building for free’), (‘href’, ‘http://console.cloud.google.com/freetrial?redirectPath=/bigquery/’), (‘image’, None)])]>
Pub/Sub SMTs
An overarching goal of Pub/Sub is to simplify streaming architectures. We already greatly simplified data movement with Import Topics and Export Subscriptions, which removed the need to use additional services for ingesting raw streaming data through Pub/Sub into destinations like BigQuery. Pub/Sub Single Message Transforms (SMTs), designed to be a suite of features making it easy to validate, filter, enrich, and alter individual messages as they move in real time.
The first SMT is available now: JavaScript User-Defined Functions (UDFs), which allows you to perform simple, lightweight modifications to message attributes and/or the data directly within Pub/Sub via snippets of JavaScript code.
Key examples of such modifications include:
Simple transforms: Perform common single message transforms such as data format conversion, casting, adding a new composite field.
Enhanced filtering: Filter based on message data (not just attributes), and regular expression based filters
Data masking and redaction:Safeguard sensitive information by employing masking or redaction techniques on fields containing PII data.
In order to stay true to Pub/Sub’s objective of decoupling publishers and subscribers, UDF transforms can be applied independently to a topic, a subscription, or both based on your needs.
JavaScript UDFs in Pub/Sub provide three key benefits:
Flexibility: JavaScript UDFs give you complete control over your transformation logic, catering to a wide variety of use cases, helping deliver a diverse set of transforms.
Simplified pipelines: Transformations happen directly within Pub/Sub, eliminating the need to maintain extra services or infrastructure for data transformation.
Performance: End-to-end latencies are improved for streaming architectures, as you avoid the need for additional products for lightweight transformations.
Pub/Sub JavaScript UDF Single Message Transforms are easy to use. You can add up to five JavaScript transforms on the topic and/or subscription. If a Topic SMT is configured, Pub/Sub transforms the message with the SMT logic and persists the transformed message. If a subscription SMT is configured, Pub/Sub transforms the message before sending the message to the subscriber. In the case of an Export Subscription, the transformed message gets written to the destination. Please see the Single Message Transform overview for more information.
Getting started with Single Message Transforms
JavaScript UDFs as the first Single Message Transform is generally available starting today for all users. You’ll find the new “Add Transform” option in the Google Cloud console when you create a topic or subscription in your Google Cloud project. You can also use gcloud CLI to start using JavaScript Single Message Transforms today.
We plan to launch additional Single Message Transforms in the coming months such as schema validation/encoding SMT, AI Inference SMT, and many more, so stay tuned for more updates on this front.
Today, we’re excited to announce the general availability of the memory-optimized machine series: Compute Engine M4, our most performant memory-optimized VM with under 6TB of memory.
The M4 family is designed for workloads like SAP HANA, SQL Server, and in-memory analytics that benefit from higher memory-to-core ratio. The M4 is based on Intel’s latest 5th generation Xeon processors (code-named Emerald Rapids), with instances scaling up to 224 vCPUs and 6TB of DDR5 memory. M4 offers two ratios of memory to vCPU, allowing you to choose to upgrade your memory-optimized infrastructure. They are offered in predefined shapes with a 13.3:1 and 26.6:1 memory/core ratio, for instance shapes ranging from 372GB to 6TB, with complete SAP HANA certification in all shapes and sizes.
M4 VMs are also engineered and fine-tuned to deliver consistent performance, with up to 66% better price-performance compared to our previous memory-optimized M31. The M4 outperforms the M3 with up to 2.25x2 more SAPs, a substantial improvement in overall performance. Additionally, M4 delivers up to 2.44x better price performance compared to the M23. To support customers’ most business-critical workloads, M4 offers enterprise-grade reliability and granular controls for scheduled maintenance, and is backed by Compute Engine’s Memory Optimized 99.95% Single Instance SLA — important for business-critical in-memory database workloads such as SAP.
“We are excited to announce our collaboration with Google Cloud to bring the power of the 5th Gen Intel Xeon processors to the first memory-optimized (M4) instance type among leading hyperscalers. This launch represents a significant milestone in delivering cutting-edge performance, scalability, and efficiency to cloud users for large-scale databases such as SAP Hana and memory-intensive workloads. The new M4 instance delivers advanced capabilities for today and future workloads, empowering businesses to innovate and grow in the digital era.” – Rakesh Mehrotra, VP & GM DCAI Strategy & Product Management, Intel
A full portfolio of memory–optimized machine instances
M4 is just the latest in a long line of Compute Engine’s memory-optimized VM family. We introduced the M1 in 2018 for SAP HANA. M2 followed in 2019, supporting larger workloads. In 2023, we introduced M3, with improved performance and new features. X4 launched in 2024, supporting the largest in-memory databases, with up to 32TB of memory, making Google Cloud the first hyperscaler with an SAP-certified instance of that size.
“For years, SAP and Google Cloud have had a powerful partnership, helping businesses transform with RISE with SAP on Google Cloud. Now, fueled by the enhanced performance, high reliability, and cost efficiency of M4 machines, we’re accelerating our mission to deliver even greater value to our shared customers.” – Lalit Patil, CTO for RISE with SAP, Enterprise Cloud Services, SAP SE
Today, both customers and internal Google teams are adopting the M4 to take advantage of increased performance, new shapes, and Compute Engine’s newest innovations.
aside_block
<ListValue: [StructValue([(‘title’, ‘$300 in free credit to try Google Cloud infrastructure’), (‘body’, <wagtail.rich_text.RichText object at 0x3e93b191c100>), (‘btn_text’, ‘Start building for free’), (‘href’, ‘http://console.cloud.google.com/freetrial?redirectPath=/compute’), (‘image’, None)])]>
Powered by Titanium
M4 is underpinned by Google’s Titanium offload technology, enabling ultra low-latency with up to 200 Gb/s of networking bandwidth. By offloading storage and networking to the Titanium adapter, host resources are preserved for running your workloads. Titanium also provides M4 with enhanced lifecycle management, reliability, and security. With Titanium’s hitless upgrades and live migration capabilities, most infrastructure maintenance can be performed with minimal to no disruption, helping to ensure predictable performance. Additionally, Titanium’s custom-built security hardware root-of-trust further strengthens the security of customer workloads.
Next-level storage with Hyperdisk
M4 VMs come with the latest Hyperdisk storage technology, now available in both Hyperdisk Balanced and Hyperdisk Extreme options. With up to 320K IOPS per instance, Hyperdisk Balanced delivers a blend of performance and cost-efficiency for a wide range of workloads, handling typical transactional throughput and moderate query volumes effectively. Hyperdisk Extreme pushes the boundaries of storage performance, up to 500K IOPS and up to 10,000 MiB/s of throughput per M4 instance for the most demanding applications such as SAP HANA’s in-memory database operations, which require low-latency access to large datasets. You can attach up to 64 Hyperdisk volumes per M4 VM, with up to 512 TiB of total capacity, with a mix of Balanced and Extreme volumes.
Hyperdisk’s benefits go beyond raw performance. It allows you to dynamically tune IOPS and bandwidth in real time, so your workloads consistently have the resources they need. Hyperdisk storage pools, available for Hyperdisk Balanced volumes, support capacity pooling and flexible allocation of storage resources, optimizing both utilization and cost-efficiency. As a result, Hyperdisk delivers not only high performance and flexibility but also a significant reduction in total cost of ownership (TCO) compared to traditional storage solutions. The combination of Hyperdisk’s advanced features and Titanium’s storage acceleration offloads storage processing from the CPU, frees up compute resources, and enhances overall M4 performance.
For SAP applications, including SAP NetWeaver-based applications deployed on non-SAP HANA databases (SAP ASE, DB2, SQL Server), such as SAP Business Suite and SAP Business Warehouse (BW), SAP certifications are available for the following machine shapes: 372GB, 744GB, 1,488GB, 2,976GB and 5,952GB. You can find more information on supported SAP applications in SAP Note 2456432.
Get started today
Whether you’re running advanced analytics, complex algorithms, or real-time insights for critical workloads on databases like SAP HANA and SQL Server in the cloud, M4 VMs provide the performance, features, and stability to meet your business needs. With high-performance infrastructure designed to handle massive datasets, M4 VMs offer robust memory and compute capabilities that can meet the needs of your most demanding workloads.
M4 instances are currently available in us-east4, europe-west4, europe-west3, us-central1 and will be coming to additional regions. Like other instances of the M machine family, you can purchase them on-demand orcommitted use discounts(CUDs). For more, see the M4’s predefinedcompute resource pricing or start using M4 in your next project today.
1. M3-megamem-64 compared to M4-megamem-56. Performance based on the estimated SPECrate®2017_int_base performance benchmark score 2. M4-megamem-224 comparing to M3-megamem-128 3. M4-ultramem-224 comparing to M2-ultramem-208
The pace of innovation in open-source AI is breathtaking, with models like Meta’s Llama4 and DeepSeek AI’s DeepSeek. However, deploying and optimizing large, powerful models can be complex and resource-intensive. Developers and machine learning (ML) engineers need reproducible, verified recipes that articulate the steps for trying out the models on available accelerators.
Today, we’re excited to announce enhanced support and new, optimized recipes for the latest Llama4 and DeepSeek models, leveraging our cutting-edge AI Hypercomputer platform. AI Hypercomputer helps build a strong AI infrastructure foundation using a set of purpose-built infrastructure components that are designed to work well together for AI workloads like training and inference. It is a systems-level approach that draws from our years of experience serving AI experiences to billions of users, and combines purpose-built hardware, optimized software and frameworks, and flexible consumption models. Our AI Hypercomputer resourcesrepository on GitHub, your hub for these recipes, continues to grow.
In this blog, we’ll show you how to access Llama4 and DeepSeek models today on AI Hypercomputer.
Added support for new Llama4 models
Meta recently released the Scout and Maverick models in the Llama4 herd of models. Llama 4 Scout is a 17 billion active parameter model with 16 experts, and Llama 4 Maverick is a 17 billion active parameter model with 128 experts. These models deliver innovations and optimizations based on a Mixture of Experts (MoE) architecture. They support multimodal capability and long context length.
But serving these models can present challenges in terms of deployment and resource management. To help simplify this process, we’re releasing new recipes for serving Llama4 models on Google Cloud Trillium TPUs and A3 Mega and A3 Ultra GPUs.
JetStream, Google’s throughput and memory-optimized engine for LLM inference on XLA devices, now supports Llama-4-Scout-17B-16E and Llama-4-Maverick-17B-128Einference on Trillium, the sixth-generation TPU. New recipes now provide the steps to deploy these models using JetStream and MaxText on a Trillium TPU GKE cluster. vLLM is a high-throughput and memory-efficient inference and serving engine for LLMs. New recipes now demonstrate how to use vLLM to serve the Llama4 Scout and Maverick models on A3 Mega and A3 Ultra GPU GKE clusters.
For serving the Maverick model on TPUs, we utilize Pathways on Google Cloud. Pathways is a system which simplifies large-scale machine learning computations by enabling a single JAX client to orchestrate workloads across multiple large TPU slices. In the context of inference, Pathways enables multi-host serving across multiple TPU slices. Pathways is used internally at Google to train and serve large models like Gemini.
MaxTextprovides high performance, highly scalable, open-source LLM reference implementations for OSS models written in pure Python/JAX and targeting Google Cloud TPUs and GPUs for training and inference. MaxText now includes reference implementations for Llama4 Scout and Maverick models and includes information on how to perform checkpoint conversion, training, and decoding for Llama4 models.
aside_block
<ListValue: [StructValue([(‘title’, ‘$300 in free credit to try Google Cloud AI and ML’), (‘body’, <wagtail.rich_text.RichText object at 0x3edc3b7832b0>), (‘btn_text’, ‘Start building for free’), (‘href’, ‘http://console.cloud.google.com/freetrial?redirectPath=/vertex-ai/’), (‘image’, None)])]>
Added support for DeepSeek Models
Earlier this year, Deepseek released two open-source models: the DeepSeek-V3 model followed by DeepSeek-R1 model. The V3 model provides model innovations and optimizations based on an MoE-based architecture. The R1 model provides reasoning capabilities through the chain-of-thought thinking process.
To help simplify deployment and resource management, we’re releasing new recipes for serving DeepSeek models on Google Cloud Trillium TPUs and A3 Mega and A3 Ultra GPUs.
JetStream now supports DeepSeek-R1-Distill-Llama70B inference on Trillium. A new recipe now provides the steps to deploy DeepSeek-R1-Distill-Llama-70B using JetStream and MaxText on a Trillium TPU VM. With the recent ability to work with Google Cloud TPUs, vLLM users can leverage the performance-cost benefits of TPUs with a few configuration changes. vLLM on TPU now supports all DeepSeek R1 Distilled models on Trillium. Here’s a recipe which demonstrates how to use vLLM, a high-throughput inference engine, to serve the DeepSeek distilled Llama model on Trillium TPUs.
You can also deploy DeepSeek Models using the SGLang Inference stack on our A3 Ultra VMs powered by eight NVIDIA H200 GPUs with this recipe.A recipe for A3 Mega VMs with SGLang is also available, which shows you how to deploy multihost inference utilizing two A3 Mega nodes. Cloud GPU users using the vLLM Inference engine can also deploy DeepSeek Models on the A3 Mega (recipe) and A3 Ultra (recipe) VMs.
MaxText now also includes support for architectural innovations from DeepSeek such as MLA – Multi-Head Latent Attention, MoE Shared and Routed Experts with Loss Free Load Balancing, Expert Parallelism support with Dropless, Mixed Decoder Layers ( Dense and MoE ) and YARN RoPE embeddings. The reference implementations for the DeepSeek family of models allows you to rapidly experiment with your models by incorporating some of these newer architectural enhancements.
Recipe example
The reproducible recipes show the steps to deploy and benchmark inference with the new Llama4 and DeepSeek models. For example, this TPU recipe outlines the steps to deploy the Llama-4-Scout-17B-16E Model with JetStream MaxText Engine with Trillium TPU. The recipe shows steps to provision the TPU cluster, download the model weights and set up JetStream and MaxText. It then shows you how to convert the checkpoint to a compatible format for MaxText, deploy it on a JetStream server, and run your benchmarks.
You can deploy Llama4 Scout and Maverick models or DeepSeekV3/R1 models today using inference recipes from the AI Hypercomputer Github repository. These recipes provide a starting point for deploying and experimenting with Llama4 models on Google Cloud. Explore the recipes and resources linked below, and stay tuned for future updates. We hope you have fun building and share your feedback!
When you deploy open models like DeepSeek and Llama, you are responsible for its security and legal compliance. You should follow responsible AI best practices, adhere to the model’s specific licensing terms, and ensure your deployment is secure and compliant with all regulations in your area.
Looking to fine-tune multimodal AI models for your specific domain but facing infrastructure and implementation challenges? This guide demonstrates how to overcome the multimodal implementation gap using Google Cloud and Axolotl, with a complete hands-on example fine-tuning Gemma 3 on the SIIM-ISIC Melanoma dataset. Learn how to scale from concept to production while addressing the typical challenges of managing GPU resources, data preparation, and distributed training.
Filling in the Gap
Organizations across industries are rapidly adopting multimodal AI to transform their operations and customer experiences. Gartner analysts predict 40% of generative AI solutions will be multimodal (text, image, audio and video) by 2027, up from just 1% in 2023, highlighting the accelerating demand for solutions that can process and understand multiple types of data simultaneously.
Healthcare providers are already using these systems to analyze medical images alongside patient records, speeding up diagnosis. Retailers are building shopping experiences where customers can search with images and get personalized recommendations. Manufacturing teams are spotting quality issues by combining visual inspections with technical data. Customer service teams are deploying agents that process screenshots and photos alongside questions, reducing resolution times.
Multimodal AI applications powerfully mirror human thinking. We don’t experience the world in isolated data types – we combine visual cues, text, sound, and context to understand what’s happening. Training multimodal models on your specific business data helps bridge the gap between how your teams work and how your AI systems operate.
Key challenges organizations face in production deployment
Moving from prototype to production with multimodal AI isn’t easy. PwC survey data shows that while companies are actively experimenting, most expect fewer than 30% of their current experiments to reach full scale in the next six months. The adoption rate for customized models remains particularly low, with only 20-25% of organizations actively using custom models in production.
The following technical challenges consistently stand in the way of success:
Infrastructure complexity: Multimodal fine-tuning demands substantial GPU resources – often 4-8x more than text-only models. Many organizations lack access to the necessary hardware and struggle to configure distributed training environments efficiently.
Data preparing hurdles: Preparing multimodal training data is fundamentally different from text-only preparation. Organizations struggle with properly formatting image-text pairs, handling diverse file formats, and creating effective training examples that maintain the relationship between visual and textual elements.
Training workflow management: Configuring and monitoring distributed training across multiple GPUs requires specialized expertise most teams don’t have. Parameter tuning, checkpoint management, and optimization for multimodal models introduce additional layers of complexity.
These technical barriers create what we call “the multimodal implementation gap” – the difference between recognizing the potential business value and successfully delivering it in production.
How Google Cloud and Axolotl together solve these challenges
Our collaboration brings together complementary strengths to directly address these challenges. Google Cloud provides the enterprise-gradeinfrastructure foundation necessary for demanding multimodal workloads. Our specialized hardware accelerators such as NVIDIA B200 Tensor Core GPUs and Ironwood are optimized for these tasks, while our managed services like Google Cloud Batch, Vertex AI Training, and GKE Autopilot minimize the complexities of provisioning and orchestrating multi-GPU environments. This infrastructure seamlessly integrates with the broader ML ecosystem, creating smooth end-to-end workflows while maintaining the security and compliance controls required for production deployments.
Axolotl complements this foundation with a streamlined fine-tuning framework that simplifies implementation. Its configuration-driven approach abstracts away technical complexity, allowing teams to focus on outcomes rather than infrastructure details. Axolotl supports multiple open source and open weight foundation models and efficient fine-tuning methods like QLoRA. This framework includes optimized implementations of performance-enhancing techniques, backed by community-tested best practices that continuously evolve through real-world usage.
Together, we enable organizations to implement production-grade multimodal fine-tuning without reinventing complex infrastructure or developing custom training code. This combination accelerates time-to-value, turning what previously required months of specialized development into weeks of standardized implementation.
Solution Overview
Our multimodal fine-tuning pipeline consists of five essential components:
Foundational model: Choose a base model that meets your task requirements. Axolotl supports a variety of open source and open weight multimodal models including Llama 4, Pixtral, LLaVA-1.5, Mistral-Small-3.1, Qwen2-VL, and others. For this example, we’ll use Gemma 3, our latest open and multimodal model family.
Data preparation: Create properly formatted multimodal training data that maintains the relationship between images and text. This includes organizing image-text pairs, handling file formats, and splitting data into training/validation sets.
Training configuration: Define your fine-tuning parameters using Axolotl’s YAML-based approach, which simplifies settings for adapters like QLoRA, learning rates, and model-specific optimizations.
Infrastructure orchestration: Select the appropriate compute environment based on your scale and operational requirements. Options include Google Cloud Batch for simplicity, Google Kubernetes Engine for flexibility, or Vertex AI Custom Training for MLOps integration.
Production integration: Streamlined pathways from fine-tuning to deployment.
The pipeline structure above represents the conceptual components of a complete multimodal fine-tuning system. In our hands-on example later in this guide, we’ll demonstrate these concepts through a specific implementation tailored to the SIIM-ISIC Melanoma dataset, using GKE for orchestration. While the exact implementation details may vary based on your specific dataset characteristics and requirements, the core components remain consistent.
Selecting the Right Google Cloud Environment
Google Cloud offers multiple approaches to orchestrating multimodal fine-tuning workloads. Let’s explore three options with different tradeoffs in simplicity, flexibility, and integration:
Google Cloud Batch
Google Cloud Batch is best for teams seeking maximum simplicity for GPU-intensive training jobs with minimal infrastructure management. It handles all resource provisioning, scheduling, and dependencies automatically, eliminating the need for container orchestration or complex setup. This fully managed service balances performance and cost effectiveness, making it ideal for teams who need powerful computing capabilities without operational overhead.
Vertex AI Custom Training
Vertex AI Custom Training is best for teams prioritizing integration with Google Cloud’s MLOps ecosystem and managed experiment tracking. Vertex AI Custom Training jobs automatically integrate with Experiments for tracking metrics, the Model Registry for versioning, Pipelines for workflow orchestration, and Endpoints for deployment.
Google Kubernetes Engine (GKE)
GKE is best for teams seeking flexible integration with containerized workloads. It enables unified management of training jobs alongside other services in your container ecosystem while leveraging Kubernetes’ sophisticatedschedulingcapabilities. GKE offers fine-grained control over resource allocation, making it ideal for complex ML pipelines. For our hands-on example, we’ll use GKE in Autopilot mode, which maintains these integration benefits while Google Cloud automates infrastructure management including node provisioning and scaling. This lets you focus on your ML tasks rather than cluster administration, combining the flexibility of Kubernetes with the operational simplicity of a managed service.
Take a look at our code sample here for a complete implementation that demonstrates how to orchestrate a multimodal fine-tuning job on GKE:
This repository includes ready-to-use Kubernetes manifests for deploying Axolotl training jobs on GKE in Autopilot mode, covering automated cluster setup with GPUs, persistent storage configuration, job specifications, and monitoring integration.
Hands-on example: Fine-tuning Gemma 3 on the SIIM-ISIC Melanoma dataset
This section involves dermoscopic images of skin lesions with labels indicating whether they are malignant or benign. With melanoma accounting for 75% of skin cancer deaths despite its relative rarity, early and accurate detection is critical for patient survival. By applying multimodal AI to this challenge, we unlock the potential to help dermatologists improve diagnostic accuracy and potentially save lives through faster, more reliable identification of dangerous lesions. So, let’s walk through a complete example fine-tuning Gemma 3 on the SIIM-ISIC Melanoma Classification dataset.
For this implementation, we’ll leverage GKE in Autopilot mode to orchestrate our training job and monitoring, allowing us to focus on the ML workflow while Google Cloud handles the infrastructure management.
Data Preparation
The SIIM-ISIC Melanoma Classification dataset requires specific formatting for multimodal fine-tuning with Axolotl. Our data preparation process involves two main steps: (1) efficiently transferring the dataset to Cloud Storage using Storage Transfer Service, and (2) processing the raw data into the format required by Axolotl. To start, transfer the dataset.
Create a TSV file that contains the URLs for the ISIC dataset files:
Set up appropriate IAM permissions for the Storage Transfer Service:
code_block
<ListValue: [StructValue([(‘code’, ‘# Get your current project IDrnexport PROJECT_ID=$(gcloud config get-value project)rnrn# Get your project numberrnexport PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} –format=”value(projectNumber)”)rnrn# Enable the Storage Transfer APIrnecho “Enabling Storage Transfer API…”rngcloud services enable storagetransfer.googleapis.com –project=${PROJECT_ID}rnrn# Important: The Storage Transfer Service account is created only after you access the service.rn# Access the Storage Transfer Service in the Google Cloud Console to trigger its creation:rn# https://console.cloud.google.com/transfer/cloudrnecho “IMPORTANT: Before continuing, please visit the Storage Transfer Service page in the Google Cloud Console”rnecho “Go to: https://console.cloud.google.com/transfer/cloud”rnecho “This ensures the Storage Transfer Service account is properly created.”rnecho “After visiting the page, wait approximately 60 seconds for account propagation, then continue.”rnecho “”rnecho “Press Enter once you’ve completed this step…”rnread -p “”rnrn# Grant Storage Transfer Service the necessary permissionsrnexport STS_SERVICE_ACCOUNT_EMAIL=”project-${PROJECT_NUMBER}@storage-transfer-service.iam.gserviceaccount.com”rnecho “Granting permissions to Storage Transfer Service account: ${STS_SERVICE_ACCOUNT_EMAIL}”rnrngcloud storage buckets add-iam-policy-binding gs://${GCS_BUCKET_NAME} \rn–member=serviceAccount:${STS_SERVICE_ACCOUNT_EMAIL} \rn–role=roles/storage.objectViewer \rn–condition=Nonernrngcloud storage buckets add-iam-policy-binding gs://${GCS_BUCKET_NAME} \rn–member=serviceAccount:${STS_SERVICE_ACCOUNT_EMAIL} \rn–role=roles/storage.objectUser \rn–condition=None’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e8424eaa8e0>)])]>
Set up a storage transfer job using the URL list:
Navigate to Cloud Storage > Transfer
Click “Create Transfer Job”
Select “URL list” as Source type and “Google Cloud Storage” as Destination type
Enter the path to your TSV file: gs://<GCS_BUCKET_NAME>/melanoma_dataset_urls.tsv
Select your destination bucket
Use the default job settings and click Create
The transfer will download approximately 32GB of data from the ISIC Challenge repository directly to your Cloud Storage bucket. Once the transfer is complete, you’ll need to extract the ZIP files before proceeding to the next step where we’ll format this data for Axolotl. See the notebook in the Github repository here for a full walk-through demonstration on how to format the data for Axolotl.
Preparing Multimodal Training Data
For multimodal models like Gemma 3, we need to structure our data following the extended chat_template format, which defines conversations as a series of messages with both text and image content.
Below is an example of a single training input example:
code_block
<ListValue: [StructValue([(‘code’, ‘{rn “messages”: [rn {rn “role”: “system”,rn “content”: [rn {“type”: “text”, “text”: “You are a dermatology assistant that helps identify potential melanoma from skin lesion images.”}rn ]rn },rn {rn “role”: “user”,rn “content”: [rn {“type”: “image”, “path”: “/path/to/image.jpg”},rn {“type”: “text”, “text”: “Does this appear to be malignant melanoma?”}rn ]rn },rn {rn “role”: “assistant”, rn “content”: [rn {“type”: “text”, “text”: “Yes, this appears to be malignant melanoma.”}rn ]rn }rn ]rn}’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e8424eaadf0>)])]>
We split the data into training (80%), validation (10%), and test (10%) sets, while maintaining the class distribution in each split using stratified sampling.
This format allows Axolotl to properly process both the images and their corresponding labels, maintaining the relationship between visual and textual elements during training.
Creating the Axolotl Configuration File
Next, we’ll create a configuration file for Axolotl that defines how we’ll fine-tune Gemma 3. We’ll use QLoRA (Quantized Low-Rank Adaptation) with 4-bit quantization to efficiently fine-tune the model while keeping memory requirements manageable. While A100 40GB GPUs have substantial memory, the 4-bit quantization with QLoRA allows us to train with larger batch sizes or sequence lengths if needed, providing additional flexibility for our melanoma classification task. The slight reduction in precision is typically an acceptable tradeoff, especially for fine-tuning tasks where we’re adapting a pre-trained model rather than training from scratch.
This configuration sets up QLoRA fine-tuning with parameters optimized for our melanoma classification task. Next, we’ll set up our GKE Autopilot environment to run the training.
Setting up GKE Autopilot for GPU Training
Now that we have our configuration file ready, let’s set up the GKE Autopilot cluster we’ll use for training. As mentioned earlier, Autopilot mode lets us focus on our ML task while Google Cloud handles the infrastructure management.
Let’s create our GKE Autopilot cluster:
code_block
<ListValue: [StructValue([(‘code’, ‘# Set up environment variables for cluster configurationrnexport PROJECT_ID=$(gcloud config get-value project)rnexport REGION=us-central1rnexport CLUSTER_NAME=melanoma-training-clusterrnexport RELEASE_CHANNEL=regularrnrn# Enable required Google APIsrnecho “Enabling required Google APIs…”rngcloud services enable container.googleapis.com –project=${PROJECT_ID}rngcloud services enable compute.googleapis.com –project=${PROJECT_ID}rnrn# Create a GKE Autopilot cluster in the same region as your datarnecho “Creating GKE Autopilot cluster ${CLUSTER_NAME}…”rngcloud container clusters create-auto ${CLUSTER_NAME} \rn –location=${REGION} \rn –project=${PROJECT_ID} \rn –release-channel=${RELEASE_CHANNEL}rnrn# Install kubectl if not already installedrnif ! command -v kubectl &> /dev/null; thenrn echo “Installing kubectl…”rn gcloud components install kubectlrnfirnrn# Install the GKE auth plugin required for kubectlrnecho “Installing GKE auth plugin…”rngcloud components install gke-gcloud-auth-pluginrnrn# Configure kubectl to use the clusterrnecho “Configuring kubectl to use the cluster…”rngcloud container clusters get-credentials ${CLUSTER_NAME} \rn –location=${REGION} \rn –project=${PROJECT_ID}rnrn# Verify kubectl is working correctlyrnecho “Verifying kubectl connection to cluster…”rnkubectl get nodes’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e8424eaa040>)])]>
Now set up Workload Identity Federation for GKE to securely authenticate with Google Cloud APIs without using service account keys:
code_block
<ListValue: [StructValue([(‘code’, ‘# Set variables for Workload Identity Federationrnexport PROJECT_ID=$(gcloud config get-value project)rnexport NAMESPACE=”axolotl-training”rnexport KSA_NAME=”axolotl-training-sa”rnexport GSA_NAME=”axolotl-training-sa”rnrn# Create a Kubernetes namespace for the training jobrnkubectl create namespace ${NAMESPACE} || echo “Namespace ${NAMESPACE} already exists”rnrn# Create a Kubernetes ServiceAccountrnkubectl create serviceaccount ${KSA_NAME} \rn –namespace=${NAMESPACE} || echo “ServiceAccount ${KSA_NAME} already exists”rnrn# Create an IAM service accountrnif ! gcloud iam service-accounts describe ${GSA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com &>/dev/null; thenrn echo “Creating IAM service account ${GSA_NAME}…”rn gcloud iam service-accounts create ${GSA_NAME} \rn –display-name=”Axolotl Training Service Account”rn rn # Wait for IAM propagationrn echo “Waiting for IAM service account creation to propagate…”rn sleep 15rnelsern echo “IAM service account ${GSA_NAME} already exists”rnfirnrn# Grant necessary permissions to the IAM service accountrnecho “Granting storage.objectAdmin role to IAM service account…”rngcloud projects add-iam-policy-binding ${PROJECT_ID} \rn –member=”serviceAccount:${GSA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com” \rn –role=”roles/storage.objectAdmin”rnrn# Wait for IAM propagationrnecho “Waiting for IAM policy binding to propagate…”rnsleep 10rnrn# Allow the Kubernetes ServiceAccount to impersonate the IAM service accountrnecho “Binding Kubernetes ServiceAccount to IAM service account…”rngcloud iam service-accounts add-iam-policy-binding ${GSA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com \rn –role=”roles/iam.workloadIdentityUser” \rn –member=”serviceAccount:${PROJECT_ID}.svc.id.goog[${NAMESPACE}/${KSA_NAME}]”rnrn# Annotate the Kubernetes ServiceAccountrnecho “Annotating Kubernetes ServiceAccount…”rnkubectl annotate serviceaccount ${KSA_NAME} \rn –namespace=${NAMESPACE} \rn iam.gke.io/gcp-service-account=${GSA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com –overwriternrn# Verify the configurationrnecho “Verifying Workload Identity Federation setup…”rnkubectl get serviceaccount ${KSA_NAME} -n ${NAMESPACE} -o yaml’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e8424eaa550>)])]>
Now create a PersistentVolumeClaim for our model outputs. In Autopilot mode, Google Cloud manages the underlying storage classes, so we don’t need to create our own:
<ListValue: [StructValue([(‘code’, ‘# Apply the PVC configurationrnkubectl apply -f model-storage-pvc.yaml’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e8424eaad30>)])]>
Deploying the Training Job to GKE Autopilot
In Autopilot mode, we specify our GPU requirements using annotations and resource requests within the Pod template section of our Job definition. We’ll create a Kubernetes Job that requests a single A100 40GB GPU:
Create a ConfigMap with our Axolotl configuration:
code_block
<ListValue: [StructValue([(‘code’, ‘# Create the ConfigMap rnkubectl create configmap axolotl-config –from-file=gemma3-melanoma.yaml -n ${NAMESPACE}’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e8424eaa6a0>)])]>
Create a Secret with Hugging Face credentials:
code_block
<ListValue: [StructValue([(‘code’, “# Create a Secret with your Hugging Face tokenrn# This token is required to access the Gemma 3 model from Hugging Face Hubrn# Generate a Hugging Face token at https://huggingface.co/settings/tokens if you don’t have one rnkubectl create secret generic huggingface-credentials -n ${NAMESPACE} –from-literal=token=YOUR_HUGGING_FACE_TOKEN”), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e83fef25340>)])]>
Apply training job YAML to start the training process:
code_block
<ListValue: [StructValue([(‘code’, ‘# Start training job rnkubectl apply -f axolotl-training-job.yaml’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e83fef8aa90>)])]>
Monitor the Training Process
Fetch the pod name to monitor progress:
code_block
<ListValue: [StructValue([(‘code’, “# Get the pod name for the training jobrnPOD_NAME=$(kubectl get pods -n ${NAMESPACE} –selector=job-name=gemma3-melanoma-training -o jsonpath='{.items[0].metadata.name}’)rnrn# Monitor logs in real-timernkubectl describe pod $POD_NAME -n ${NAMESPACE}rnkubectl logs -f $POD_NAME -n ${NAMESPACE}”), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e83fef8a550>)])]>
<ListValue: [StructValue([(‘code’, ‘# Deploy TensorBoardrnkubectl apply -f tensorboard.yamlrnrn# Get the external IP to access TensorBoardrnkubectl get service tensorboard -n ${NAMESPACE}’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e8421ee8d00>)])]>
Model Export and Evaluation Setup
After training completes, we need to export our fine-tuned model and evaluate its performance against the base model. First, let’s export the model from our training environment to Cloud Storage:
After creating the model-export.yaml file, apply it:
code_block
<ListValue: [StructValue([(‘code’, ‘# Export the modelrnkubectl apply -f model-export.yaml’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e8421ee8550>)])]>
This will start the export process, which copies the fine-tuned model from the Kubernetes PersistentVolumeClaim to your Cloud Storage bucket for easier access and evaluation.
Once exported, we have several options for evaluating our fine-tuned model. You can deploy both the base and fine-tuned models to their own respective Vertex AI Endpoints for systematic testing via API calls, which works well for high-volume automated testing and production-like evaluation. Alternatively, for exploratory analysis and visualization, a GPU-enabled notebook environment such as a Vertex Workbench Instance or Colab Enterprise offers significant advantages, allowing for real-time visualization of results, interactive debugging, and rapid iteration on evaluation metrics.
In this example, we use a notebook environment to leverage its visualization capabilities and interactive nature. Our evaluation approach involves:
Loading both the base and fine-tuned models
Running inference on a test set of dermatological images from the SIIM-ISIC dataset
Computing standard classification metrics (accuracy, precision, recall, etc.)
Analyzing the confusion matrices to understand error patterns
Generating visualizations to highlight performance differences
For the complete evaluation code and implementation details, check out our evaluation notebook in the GitHub repository.
Performance Results
Our evaluation demonstrated that domain-specific fine-tuning can transform a general-purpose multimodal model into a much more effective tool for specialized tasks like medical image classification. The improvements were significant across multiple dimensions of model performance.
The most notable finding was the base model’s tendency to over-diagnose melanoma. It showed perfect recall (1.000) but extremely poor specificity (0.011), essentially labeling almost every lesion as melanoma. This behavior is problematic in clinical settings where false positives lead to unnecessary procedures, patient anxiety, and increased healthcare costs.
Fine-tuning significantly improved the model’s ability to correctly identify benign lesions, reducing false positives from 3,219 to 1,438. While this came with a decrease in recall (from 1.000 to 0.603), the tradeoff resulted in much better overall diagnostic capability, with balanced accuracy improving substantially.
In our evaluation, we also included results from the newly announced MedGemma—a collection of Gemma 3 variants trained specifically for medical text and image comprehension recently released at Google I/O. These results further contribute to our understanding of how different model starting points affect performance on specialized healthcare tasks.
Below we can see the performance metrics across all three models:
Accuracy jumped from a mere 0.028 for base Gemma 3 to 0.559 for our tuned Gemma 3 model, representing an astounding 1870.2% improvement. MedGemma achieved 0.893 accuracy without any task-specific fine-tuning—a 3048.9% improvement over the base model and substantially better than our custom-tuned version.
While precision saw a significant 34.2% increase in our tuned model (from 0.018 to 0.024), MedGemma delivered a substantial 112.5% improvement (to 0.038). The most remarkable transformation occurred in specificity—the model’s ability to correctly identify non-melanoma cases. Our tuned model’s specificity increased from 0.011 to 0.558 (a 4947.2% improvement), while MedGemma reached 0.906 (an 8088.9% improvement over the base model).
These numbers highlight how fine-tuning helped our model develop a more nuanced understanding of skin lesion characteristics rather than simply defaulting to melanoma as a prediction. MedGemma’s results demonstrate that starting with a medically-trained foundation model provides considerable advantages for healthcare applications.
The confusion matrices further illustrate these differences:
Looking at the base Gemma 3 matrix (left), we can see it correctly identified all 58 actual positive cases (perfect recall) but also incorrectly classified 3,219 negative cases as positive (poor specificity). Our fine-tuned model (center) shows a more balanced distribution, correctly identifying 1,817 true negatives while still catching 35 of the 58 true positives. MedGemma (right) shows strong performance in correctly identifying 2,948 true negatives, though with more false negatives (46 missed melanoma cases) than the other models.
To illustrate the practical impact of these differences, let’s examine a real example, image ISIC_4908873, from our test set:
Disclaimer: Image for example case use only.
The base model incorrectly classified it as melanoma. Its rationale focused on general warning signs, citing its “significant variation in color,” “irregular, poorly defined border,” and “asymmetry” as definitive indicators of malignancy, without fully contextualizing these within broader benign patterns.
In contrast, our fine-tuned model correctly identified it as benign. While acknowledging a “heterogeneous mix of colors” and “irregular borders,” it astutely noted that such color mixes can be “common in benign nevi.” Crucially, it interpreted the lesion’s overall “mottled appearance with many small, distinct color variations” as being “more characteristic of a common mole rather than melanoma.”
Interestingly, MedGemma also misclassified this lesion as melanoma, stating, “The lesion shows a concerning appearance with irregular borders, uneven coloration, and a somewhat raised surface. These features are suggestive of melanoma. Yes, this appears to be malignant melanoma.” Despite MedGemma’s overall strong statistical performance, this example illustrates that even domain-specialized models can benefit from task-specific fine-tuning for particular diagnostic challenges.
These results underscore a critical insight for organizations building domain-specific AI systems: while foundation models provide powerful starting capabilities, targeted fine-tuning is often essential to achieve the precision and reliability required for specialized applications. The significant performance improvements we achieved—transforming a model that essentially labeled everything as melanoma into one that makes clinically useful distinctions—highlight the value of combining the right infrastructure, training methodology, and domain-specific data.
MedGemma’s strong statistical performance demonstrates that starting with a domain-focused foundation model significantly improves baseline capabilities and can reduce the data and computation needed for building effective medical AI applications. However, our example case also shows that even these specialized models would benefit from task-specific fine-tuning for optimal diagnostic accuracy in clinical contexts.
Next steps for your multimodal journey
By combining Google Cloud’s enterprise infrastructure with Axolotl’s configuration-driven approach, you can transform what previously required months of specialized development into weeks of standardized implementation, bringing custom multimodal AI capabilities from concept to production with greater efficiency and reliability.
For deeper exploration, check out these resources:
BigQuery provides a powerful platform for analyzing large-scale datasets with high performance. However, as data volumes and query complexity increase, maintaining operational efficiency is essential. BigQuery workload management provides comprehensive control mechanisms to optimize workloads and resource allocation, preventing performance issues and resource contention, especially in high-volume environments. And today, we’re excited to announce several updates to BigQuery workload management that make it more effective and easy to use.
But first, what exactly is BigQuery workload management?
At its core, BigQuery workload management is a suite of features that allows you to prioritize, isolate, and manage the execution of queries and other operations (aka workloads) within your BigQuery project. It provides granular control over how BigQuery resources are allocated and consumed, enabling you to:
Ensure critical workloads get the resources they need:
Reservationsfacilitate dedicated BigQuery slots, representing defined compute capacity.
Control and optimize cost with:
Slot commitments: Establish a predictable expenditure for BigQuery compute capacity in a specific Edition.
Spend-based commitments: Hourly spend-based commitment with 1yr and 3yr discount options for BigQuery compute working across Editions
Auto-scaling, which allows reservations to dynamically adjust their slot capacity in response to demand fluctuations, operating within predefined parameters. This lets you accommodate peak workloads while preventing over-provisioning during periods of reduced activity.
Enjoy reliability and availability:
Dedicated reservations and commitments provide predictable performance for critical workloads by reducing resource contention.
Help ensure business continuity through managed disaster recovery, providing compute and data availability resilience.
Implementing BigQuery workload management is crucial for organizations seeking to maximize the efficiency, reliability, and cost-effectiveness of their cloud-based data analytics infrastructure.
aside_block
<ListValue: [StructValue([(‘title’, ‘$300 in free credit to try Google Cloud data analytics’), (‘body’, <wagtail.rich_text.RichText object at 0x3e7cf26c1280>), (‘btn_text’, ‘Start building for free’), (‘href’, ‘http://console.cloud.google.com/freetrial?redirectPath=/bigquery/’), (‘image’, None)])]>
Updates to BigQuery workload management
BigQuery workload management is focused on providing efficiency and control. The newest features and updates provide better resource allocation, and optimized performance. Key improvements include reservation fairness for optimal slot distribution, reservation predictability for consistent performance, runtime reservation specification for flexibility, reservation labels for enhanced visibility, and autoscaler improvements for rapid and granular scalability.
Reservation fairness Previously, using the fair-sharing method, BigQuery distributed capacity equally across projects. With reservation fairness, BigQuery prioritizes and allocates idle slots equally across all reservations within the same admin project, regardless of the number of projects running jobs in each reservation. Each reservation receives a similar share of available capacity in the idle slot pool, and then its slots are distributed fairly within its projects. Note: allocation assumes presence of demand. Idle slots are not allocated to reservations if no queries are running. This feature is only applicable to BigQuery Enterprise or Enterprise Plus editions, as Standard Edition does not support idle slots.
Figure 1: Project-based fairness
Configurations represent reservations with 0 baseline: The “Number” under the reservation is the total slots the projects in that reservation get through (Project) fair sharing. Note: Allocation assumes presence of demand. Idle slots are not allocated if no queries are running.
Figure 2: Reservation fairness enabled
Here, configurations represent reservations with 0 baseline: Under the reservation, you can see the total slots the projects in that reservation gets through (Reservation) fair-sharing. Note: Allocation assumes presence of demand. Idle slots are not allocated if no queries are running.
Reservation predictability This feature allows you to set the absolute maximum number of consumed slots on a reservation, enhancing control over cost and performance fluctuations in your slot consumption. BigQuery offers baseline slots, idle slots, and autoscaling slots as potential capacity resources. When you create a reservation with a maximum size, confirm the number of baseline slots and the appropriate configuration of autoscaling and idle slots based on your past workloads. Note: To use predictable reservations, you must enable reservation fairness. Baselines are optional.
Reservation – flexibility and securability BigQuery lets you specify which reservation a query should run on at runtime. Enhanced flexibility and securability features provide greater control over resource allocation and improved flexibility, including the ability to grant role-based access. You can specify a reservation at runtime using the CLI, UI, SQL, or API, overriding the default reservation assignment for your project, folder, or organization. The assigned reservation must be in the same region as the query you are running.
Reservation labels When you add labels to your reservations, they are included in your billing data. This adds granular visibility into BigQuery slot consumption for specific workloads or teams, making tracking and optimization easier. You can then use these labels to filter your Cloud Billing data by the Analysis Slots Attribution SKU, giving you a powerful tool to track and analyze your spending on BigQuery slots based on the specific labels you have assigned.
Autoscaler improvements Last but not least, the BigQuery autoscaler now delivers enhanced performance and adaptability for resource management. You can enjoy near-instant scale up, improved granularity (improved from 100 slot increments to 50 slot increments), and faster scale down. These features provide rapid capacity adjustments to meet workload demands, greater predictability and understanding of usage. This 50-slot increment also applies to setting Baseline and ReservationMax capacities.
BigQuery workload management is an essential tool for optimizing both your performance and costs. By using reservations, spend-based commitments, and new features such as reservation predictability and fairness, you can significantly improve your data analysis performance. This leads to better data-driven decision-making by optimizing resource allocation and cutting costs, allowing your team to gain more meaningful insights from their data and experience consistent performance.
Today, we are excited to announce that Gartner® has named Google as a Leader in the 2025 Magic Quadrant™ for Data Science and Machine Learning Platforms report (DSML). We believe that this recognition is a reflection of continued innovations to address the needs of data science and machine learning teams, as well as new types of practitioners working alongside data scientists in the dynamic space of generative AI.
Download the complimentary 2025 Gartner Magic Quadrant™ for Data Science and Machine Learning Platforms.
AI is driving a radical transformation in how organizations operate, compete, and innovate. Working closely with customers, we’re delivering the innovations for a unified data and AI platform to meet the demands of the AI era, including data engineering and analysis, data science, MLOps, gen AI application and agent development tools, and a central layer of governance.
Unified AI platform with best-in-class multimodal AI
Google Cloud offers a wide spectrum of AI capabilities, starting from the foundational hardware like Tensor Processing Units (TPUs) to AI agents, and the tools for building them. These capabilities are powered by our pioneering AI research and development, and our expertise in taking AI to production with large-scale applications such as YouTube, Maps, Search, Ads, Workspace, Photos, and more.
All of this research and experience fuels our Vertex AI platform, our unified AI platform for MLOps tooling, predictive and gen AI use cases, that sits at the heart of Google’s DSML offering. Vertex AI provides a comprehensive suite of tools covering the entire AI lifecycle, including data engineering and analysis tools, data science workbenches, MLOps capabilities for deploying and managing models, and specialized features for developing gen AI applications and agents. Moreover, our Self-Deploy capability enables our partners to not only build and host their models within Vertex AI for internal users, but also distribute and commercialize those models. Customer use of Vertex AI has grown 20x in the last year driven by Gemini, Imagen, and Veo models.
Vertex AI Model Garden offers a curated selection of over 200 enterprise-ready models from Google like Gemini, partners like Anthropic, and the open ecosystem. Model Garden helps customers access the highest performing foundation models suited for their business needs and easily customize them with their own data, deploy to applications with just one click, and scale with end-to-end MLOps built-in.
Building on Google DeepMind research, we recently announced Gemini 2.5, our most intelligent AI model yet. Gemini 2.5 models are now thinking models, capable of reasoning (and showing its reasoning) before responding, resulting in dramatically improved performance. Transparent step-by-step reasoning is crucial for enterprise trust and compliance. We also launched Gemini 2.5 Flash, our cost-effective, low-latency workhorse model. Gemini 2.5 Flash will be generally available for all Vertex AI users in early June, with 2.5 Pro generally available soon after.
Vertex AI is now the only platform with generative media models across all modalities — video, image, speech, and music. At Google I/O, we announced several innovations in this portfolio, including the availability of Veo 3, Lyria 2, and Imagen 4 on Vertex AI. Veo 3 combines video and audio generation, taking content generation to a new level. The state-of-the-art model features improved quality when generating videos from text and image prompts. In addition, Veo 3 also generates videos with speech (dialogue and voice-overs) and audio (music and sound effects). Lyria 2, Google’s latest music generation model, features high-fidelity music across a range of styles. And Imagen 4, Google’s highest-quality image generation model, delivers outstanding text rendering and prompt adherence, higher overall image quality across all styles, and multilingual prompt support to help creators globally. Imagen 4 also supports multiple model variants to help customers optimize around quality, speed and cost.
All of this innovation resides on Vertex AI, so that AI projects can reach production and deliver business value while teams collaborate to improve models throughout the development lifecycle.
For instance, customers like Radisson Hotel Group have redefined personalized marketing with Google Cloud. Partnering with Accenture, the global hotel chain leveraged BigQuery, Vertex AI, Google Ads, and Google’s multimodal Gemini models to build a generative AI agent to help create locally relevant ad content and translate it into more than 30 languages — reducing content creation time from weeks to hours. This AI-driven approach has increased team productivity by 50%, boosted return on ad spend by 35%, and driven a 22% increase in ad-driven revenue.
aside_block
<ListValue: [StructValue([(‘title’, ‘$300 in free credit to try Google Cloud AI and ML’), (‘body’, <wagtail.rich_text.RichText object at 0x3e7cf026cf40>), (‘btn_text’, ‘Start building for free’), (‘href’, ‘http://console.cloud.google.com/freetrial?redirectPath=/vertex-ai/’), (‘image’, None)])]>
A new era of multi-agent management
Eventually, we believe that every enterprise will rely on multi-agent systems, including those built on different frameworks or providers. We recently announced multiple enhancements to Vertex AI so you can build agents with an open approach and deploy them with enterprise-grade controls. This includes anAgent Development Kit (ADK), available for Python and Java, with an open-source framework for designing agents built on the same framework that powers Google Agentspace and Google Customer Engagement Suite agents.Many powerful examples and extensible sample agents are readily available in Agent Garden. You can also take advantage of Agent Engine, a fully managed runtime in Vertex AI that helps you deploy your custom agents to production with built-in testing, release, and reliability at global scale.
Connecting all your data to AI
Enterprise agents need to be grounded in relevant data to be successful. Whether helping a customer learn more about a product catalog or helping an employee navigate company policies, agents are only as effective as the data they are connected to. At Google Cloud, we do this by making it easy to leverage any data source. Whether it’s structured data in a relational database or unstructured content like presentations and videos, Google Cloud tools let customers easily use their existing data architectures as retrieval-augmented generation (RAG) solutions. With this approach, developers get the benefits of Google’s decades of search experience from out-of-the-box offerings, or can build their own RAG system with best-in-class components.
For RAG on an enterprise corpus, Vertex AI Search is our out-of-the-box solution that delivers high quality at scale, with minimal development or maintenance overhead. Customers who prefer to fully customize their solution can use our suite of individual components including the Layout Parser to prepare unstructured data, Vertex embedding models to create multimodal embeddings, Vertex Vector Search to index and serve the embeddings at scale, and the Ranking API to optimize the results. And RAG Engine provides an easy way for developers to orchestrate these components, or mix and match with third-party and open-source tools. BigQuery customers can also use its built-in vector search capabilities for RAG, or leverage the new connector with Vertex Vector Search to get the best of both worlds, by combining the data in BigQuery with a purpose-built high performance vector search tool.
Unified data and AI governance
With built-in governance, customers can simplify how they discover, manage, monitor, govern, and use their data and AI assets. Dataplex Universal Catalog brings together a data catalog and a fully managed, serverless metastore, enabling interoperability across Vertex AI, BigQuery, and open-source formats such as Apache Spark and Apache Iceberg with a common metadata layer. Customers can also use a business glossary for a shared understanding of data and define company terms, creating a consistent foundation for AI.
At Google Cloud, we’re committed to helping organizations build and deploy AI and we are investing heavily in bringing new predictive and gen AI capabilities to Vertex AI. For more, download the full 2025 Gartner Magic Quadrant™ for Data Science and Machine Learning Platforms report.
Gartner Magic Quadrant for Data Science and Machine Learning Platforms – Afraz Jaffri, Maryam Hassanlou, Tong Zhang, Deepak Seth, Yogesh Bhatt, May 28, 2025
Gartner does not endorse any vendor, product or service depicted in its research publications, and does not advise technology users to select only those vendors with the highest ratings or other designation. Gartner research publications consist of the opinions of Gartner’s research organization and should not be construed as statements of fact. Gartner disclaims all warranties, expressed or implied, with respect to this research, including any warranties of merchantability or fitness for a particular purpose. This graphic was published by Gartner, Inc. as part of a larger research document and should be evaluated in the context of the entire document. The Gartner document is available upon request from Google.
GARTNER is a registered trademark and service mark of Gartner Inc., and/or its affiliates in the U.S and internationally, and MAGIC QUADRANT is a registered trademark of Gartner Inc., and/or its affiliates and are used herein with permission. All rights reserved.
Here’s a common scenario when building AI agents that might feel confusing: How can you use the latest Gemini models and an open-source framework like LangChain and LangGraph to create multimodal agents that can detect objects?
Detecting objects is critically important for use cases from content moderation to multimedia search and retrieval. Langchain provides tools to chain together LLM calls and external data. LangGraph provides a graph structure to build more controlled and complex multiagents apps.
In this post, we’ll show you which decisions you need to make to combine Gemini, LangChain and LangGraph to build multimodal agents that can identify objects. This will provide a foundation for you to start building enterprise use cases like:
Object identification: Using different sources of data to verify if an object exist on a map
Multimedia search and retrieval: Finding files that contains a specific object
aside_block
<ListValue: [StructValue([(‘title’, ‘$300 in free credit to try Google Cloud AI and ML’), (‘body’, <wagtail.rich_text.RichText object at 0x3e7cf2bda670>), (‘btn_text’, ‘Start building for free’), (‘href’, ‘http://console.cloud.google.com/freetrial?redirectPath=/vertex-ai/’), (‘image’, None)])]>
First decision: No-code/low-code, or custom agents?
The first decision enterprises have to decide is: no-code/low-code options or build custom agents? If you are building a simple agent like a customer service chat bot, you can use Google’s Vertex AI Agent Builder to build a simple agent in a few minutes or start from pre-built agents that are available in Google Agentspace Agent Gallery.
But if your use case requires orchestration of multiple agents and integration with custom tooling, you would have to build custom agents which leads to the next question.
Second decision: What agentic framework to use?
It’s hard to keep up with so many agentic frameworks out there releasing new features every week. Top contenders include CrewAI, Autogen, LangGraph and Google’s ADK. Some of them, like ADK and CrewAI, have higher levels of abstraction while others like LangGraph allow higher degree of control.
That’s why in this blog, we center the discussion on building a custom agent using the open-sourced LangChain, LangGraph as an agentic framework, and Gemini 2.0 Flash as the LLM brain.
Code deep dive
This example code identifies an object in an image, in an audio file, and in a video. In this case we will use a dog as the object to be identified. We have different agents (image analysis agent, audio analysis agent, and a video analysis agent) performing different tasks but all working together towards a common goal, object identification.
Generative AI workflow for object detection
This gen AI workflow entails a user asking the agent to verify if a specific object exists in the provided files. The Orchestrator Agent will call relevant worker agents: image_agent, audio_agent, and video_agent while passing the user question and the relevant files. Each worker agent will call respective tooling to convert the provided file to base64 encoding. The final finding of each agent is then passed back to the Orchestrator Agent. The Orchestrator Agent then synthesizes the findings and makes the final determination. This code can be used as a starting point template where you need to ask an agent to reason and make a decision or generate conclusions from different sources.
If you want to create multiagent systems with ADK, here is a video production agent built by a Googler which generates video commercials from user prompts and utilizes Veo for video content generation, Lyria for composing music, and Google Text-to-Speech for narration. This example demonstrates the fact that many ingredients can be used to meet your agentic goals, in this case an AI agent as a production studio. If you want to try ADK, here is an ADK Quickstart to help you kick things off.
Third decision: Where to deploy the agents?
If you are building a simple app that needs to go live quickly, Cloud Run is an easy way to deploy your app. Just like any serverless web app, you can follow the same instructions to deploy on Cloud Run. Watch this video of building AI agents on Cloud Run. However, if you want more enterprise grade managed runtime, quality and evaluation, managing context and monitoring, Agent Engine is the way to go. Here is a quick start for Agent Engine. Agent Engine is a fully managed runtime which you can integrate with many of the previously mentioned frameworks – ADK, LangGraph, Crew.ai, etc (see the image below, from the official Google Cloud Docs).
Get started
Building intelligent agents with generative AI, especially those capable of multimodal understanding, is akin to solving a complex puzzle. Many developers are finding that a prototypical agentic build involves a LangChain agent with Gemini Flash as the LLM. This post explored how to combine the power of Gemini models with open-source frameworks like LangChain and LangGraph. To get started right away, use this ADK Quickstart and or visit our Agent Development GitHub.
The latest version of the Bigtable Spark connector opens up a world of possibilities for Bigtable and Apache Spark applications, not least of which is additional support for Bigtable and Apache Iceberg, the open table format for large analytical datasets. In this blog post, we explore how to use the Bigtable Spark connector to interact with data stored in Bigtable from Apache Spark, and delve into powerful use cases that leverage Apache Iceberg.
The Bigtable Spark connector allows you to directly read and write Bigtable data using Apache Spark in Scala, SparkSQL and DataFrames. This integration gives you direct access to your operational data for building data pipelines that support training ML models, ETL/ELT, or generating real time dashboards. When combined with Bigtable Data Boost, Bigtable’s serverless compute service, you can get high-throughput read jobs on operational data without impacting Bigtable application performance. Apache Spark is commonly used as a processing engine for working with data lakehouses and data stored in open table formats, including Apache Iceberg. We’ve worked to enhance the Bigtable Spark connector for working with data across both Bigtable and Iceberg, including query optimizations such as join pushdowns and support for dynamic column filtering.
This opens up Bigtable and Apache Iceberg integrations for:
Accelerated data science: In the past, Bigtable developers and administrators had to generate datasets for analytics and move them out of Bigtable for analytical processing in tools like notebooks and PySpark. Now, data scientists can directly interact with Bigtable’s operational data within their Apache Spark environments using a combination of both Bigtable and Apache Iceberg data, streamlining data preparation, exploration, analysis, and even the creation of Iceberg tables. When combined with Data Boost, this can be done without any impact to production applications.
Low-latency serving: Write-back capabilities support making real-time updates to Bigtable. This means you can use Iceberg data to create predictions or features in batch and easily serve those features from Bigtable for low-latency online access within an end-user application.
To get started, follow the Quickstart or read on to learn more about the two use cases outlined above.
What the Bigtable Spark connector can do for you
Now, let’s take a look at some ways you could put the Bigtable Spark connector into service.
Accelerated data science
Bigtable is designed for throughput-intensive applications, offering throughput that can be adjusted by adding and removing nodes. If you are writing in batch over the Apache Spark connector, you can achieve even more throughput through the use of the spark.bigtable.batch.mutate.size option, which takes advantage of Bigtable’s mutation batching functionality.
Throughput and queries per second (QPS) can be autoscaled, resized without any restarting, and the data is automatically replicated for high availability and faster region-specific access. There are also specialized data types that make it easy to build distributed counters, which can give you up-to-date metrics on what is happening in your system.
Conversely, Apache Iceberg is a high-performance open-source table format for large analytical datasets. Iceberg lets you build analytics tables, often with aggregated data, that can be shared across engines such as Apache Spark and BigQuery.
Customers have found that event collection in Bigtable with advanced analytics of those events using Apache Spark and Apache Iceberg can be a powerful combination. For example, you may want to collect clicks, views, sensor readings, device usage, gaming activity, engagement, or other telemetry in real time, and have a view of what is happening in the system using Bigtable’s continuous materialized views. You might then use Apache Spark’s batch processing and ML capabilities and even join with historical Iceberg data to run advanced analytics and understand the trends over time, identify anomalies, or generate machine learning models on the data. When these advanced analytics in Apache Spark are done using a Data Boost application profile, this analysis can be done without impacting real-time data collection and operational analytics.
Low-latency serving: Bigtable for model serving of BigQuery Iceberg Managed Tables
Apache Iceberg provides an efficient way to combine and manage large datasets for machine learning tasks. By storing your data in Iceberg tables, multiple engines can write to the same warehouse and leverage Spark or BigQuery to train and evaluate the ML models. Once you have a trained model, you often need to publish feature tables or feature vectors into a low-latency database for online application access.
Bigtable is well suited for low-latency applications that require lookups against these large-scale datasets. Let’s say you have a dataset of customer transactions stored across multiple Iceberg tables. You can use SparkSQL to combine this data and SparkML to train a fraud detection model on this data. Once the model is trained, you can use it to predict the probability of fraud for new transactions. You can then write these predictions back to Bigtable using the Bigtable Spark connector, where they can be accessed by your fraud detection application.
Use case: Vehicle telemetry using Bigtable and the Apache Spark connector
Let’s look at an abbreviated example of how Bigtable and the Apache Spark connector might work together for a company that is tracking vehicle telemetry and wants to enable their fleet managers with immediate access to real-time KPIs of equipment effectiveness, while also allowing data scientists to build a predictive maintenance schedule that they can provide to drivers.
While this specific use case relies on vehicles as a case study, it is a generally applicable architecture pattern that can be used for a variety of telemetry and IOT use cases ranging from measuring telecommunications equipment reliability to building KPIs for Overall Equipment Effectiveness (OEE) in a manufacturing operation.
Let’s take a look at the various components of this architecture.
Bigtable is an excellent choice for the high-throughput, low-latency writes that are often required for telemetry data, where vast amounts of data are continuously streamed in. With telemetry data, the data schema changes often, requiring a flexible schema that Bigtable provides. Bigtable clusters can be deployed throughout the globe with different autoscaling configurations that can match the local demand for writes. The ingested data is automatically replicated to all clusters, giving you a single unified view of the data. There are also open-source streaming connectors for both Apache Kafka and Apache Fink, as well as industry-specific connectors such as NATS for automotive data.
Bigtable continuous materialized views offer real-time data transformations and aggregations on streaming data, enabling vehicle managers to gain immediate insights into their fleet’s activity and make data-driven adjustments.
Keeping all data within Bigtable facilitates advanced analytics on historical information using Apache Spark. Data scientists can directly access this data in Apache Spark using the Bigtable Spark connector without needing to create copies. Furthermore, Bigtable Data Boost enables the execution of large batch or machine learning jobs, such as training predictive models or generating comprehensive reports, without impacting the performance of live applications. These jobs can involve joining streaming event data (e.g., real-time vehicle telemetry like GPS coordinates, speed, engine RPM, fuel consumption, or acceleration/braking patterns) with historical or static datasets stored in Apache Iceberg (e.g., vehicle master data including make, model, year, VIN, vehicle type, maintenance history, or driver assignments). Apache Iceberg may also include additional data sources such as weather and traffic analysis. This allows for richer insights, such as correlating specific driving behaviors with maintenance needs, predicting component failures based on operational data, or optimizing routes by combining real-time traffic with vehicle capacity and destination information. You can also provide analytics teams with secure Bigtable data access through Bigtable Authorized Views to limit data access to sensitive information like GPS.
Machine learning-driven insights, such as predictive maintenance recommendations that are often generated in batch processes and potentially stored in Iceberg tables, can be written back to Bigtable using the Bigtable Spark connector. This makes these valuable insights immediately accessible to user-facing applications.
Bigtable excels at high-scale reads in user-facing applications for this vehicle application thanks to its distributed architecture and design that’s optimized for massive, time-series data. It can handle billions of rows and thousands of columns. Bigtable can quickly retrieve this data with low latency because it distributes data across many nodes and performs fast, single-row lookups and efficient range scans, helping to ensure a smooth and responsive user experience even with millions of vehicles constantly streaming data.
Igniting the spark
The Bigtable Spark connector, combined with the recent connector enhancements for Apache Iceberg and Bigtable Data Boost, unlocks new possibilities for large-scale data processing on operational data. Whether you’re training ML models or performing serverless analytics, this powerful combination can help you implement new use cases and ease the operational burden of running complex ETL jobs. By leveraging the scalability, performance, and flexibility of these technologies, you can build robust and efficient data pipelines that can handle your most demanding workloads.
On Google Cloud, Dataproc Serverless simplifies running Apache Spark batch workloads by removing the need to manage clusters. When processing data via Bigtable’s serverless Data Boost, these jobs become highly cost-effective: you only pay for the precise amount of processing power you consume and solely for the duration your workload is running, without needing to configure any compute infrastructure.
For years, BigQuery has been synonymous with fully managed, fast, petabyte-scale analytics. Its columnar architecture and decoupled storage and compute have made it the go-to data warehouse for deriving insights from massive datasets.
But what about the moments between the big analyses? What if you need to:
Modify a handful of customer records across huge tables without consuming all your slots or running for minutes on end?
Track exactly how some data has evolved row by row?
Act immediately on incoming streaming data, updating records on the fly?
Historically, these types of “transactional” needs might have sent you searching for a database solution or required you to build complex ETL/ELT pipelines around BigQuery. The thinking was clear: BigQuery was for analysis, and you used something else for dynamic data manipulation.
That’s changing. At Google Cloud, we’ve been steadily evolving BigQuery, adding powerful capabilities that blur these lines and bring near-real-time, transactional-style operations directly into your data warehouse. This isn’t about turning BigQuery into a traditional OLTP database; rather, it’s about empowering you to handle common data management tasks more efficiently within the BigQuery ecosystem.
This shift means fewer complex workarounds, faster reactions to changing data, and the ability to build more dynamic and responsive applications right where your core data lives.
Today, we’ll explore three game-changing features that are enabling this evolution:
Efficient fine-grained DML mutations: Forget costly table rewrites for small modifications. Discover how BigQuery now handles targeted UPDATEs, DELETEs, and MERGEs with significantly improved performance and resource efficiency.
Change history support for updates and deletes: Go beyond simple snapshots. See how BigQuery can now capture the granular history of UPDATEs and DELETEs, providing a detailed audit trail of data within your tables.
Real-time updates with DML over streaming data: Don’t wait for data to settle. Learn how you can apply UPDATE, DELETE, and MERGE operations directly to data as it streams into BigQuery, enabling immediate data correction, enrichment, or state management.
Ready to see how these capabilities can simplify your workflows and unlock new possibilities within BigQuery? Let’s dive in and see them in action!
aside_block
<ListValue: [StructValue([(‘title’, ‘$300 in free credit to try Google Cloud data analytics’), (‘body’, <wagtail.rich_text.RichText object at 0x3e20b1cde1f0>), (‘btn_text’, ‘Start building for free’), (‘href’, ‘http://console.cloud.google.com/freetrial?redirectPath=/bigquery/’), (‘image’, None)])]>
1. Efficient fine-grained DML mutations
BigQuery has supported Data Manipulation Language (DML) statements like UPDATE, DELETE, and MERGE for years, allowing you to modify data without recreating entire tables. However, historically, performing these operations — especially small, targeted changes on very large tables — was less efficient than you might have hoped for. The challenge? Write amplification.
When you executed a DML mutation, BigQuery needed to rewrite entire underlying storage blocks (think of them as internal file groups) containing the rows you modified. Even if your statement only affected a few rows within a block, the whole block might have needed to be rewritten. This phenomenon, sometimes called “write amplification,” could lead to significant slot consumption and longer execution times, particularly for sparse mutations (changes scattered across many different blocks in a large table). This sometimes made operations like implementing GDPR’s “right to be forgotten” by deleting specific user records slow or costly.
To address this, we introduced fine-grained DML in BigQuery, a set of performance enhancements that optimize sparse DML mutation operations.
When enabled, instead of always rewriting large storage blocks, BigQuery fine-grained DML can pinpoint and modify data with much finer granularity. It leverages optimized metadata indexes to rewrite only the necessary mutated data, drastically reducing the processing, I/O, and consequently, the slot time consumed for sparse DML. The result? Faster, more cost-effective DML, making BigQuery much more practical for workloads involving frequent, targeted data changes.
Grupo Catalana Occidente, a leading global insurance provider, is excited about fine-grain DML’s ability to help them integrate changes to their data in real time:
“In our integration project between Google BigQuery, SAP, and MicroStrategy, we saw an 83% improvement in DML query runtime when we enabled BigQuery fine-grained DML. Fine-grained DML allows us to achieve adequate performance and reduces the time of handling large volumes of data. This is an essential functionality for implementing the various data initiatives we have in our pipeline.” – Mayker Oviedo, Chief Data Officer, Grupo Catalana Occidente
Let’s quantify this improvement ourselves. To really see the difference, we need a large table where updates are likely to be sparse. We’ll use a copy of the bigquery-public-data.wikipedia.pageviews_2024 dataset, which contains approximately 58.7 billion rows and weighs in at ~2.4 TB.
(Important Note: Running the following queries involves copying a large dataset and processing significant amounts of data. This will incur BigQuery storage and compute costs based on your pricing model. Proceed with awareness if you choose to replicate this experiment.)
Step 1: Create the Table Copy
First, let’s copy the public dataset into our own project. We’ll also enable change history, which we’ll use later on.
code_block
<ListValue: [StructValue([(‘code’, “– Make a copy of the public 2024 Wikipedia page views tablernCREATE OR REPLACE TABLE `my_dataset.wikipedia_pageviews_copy`rnCOPY `bigquery-public-data.wikipedia.pageviews_2024`;rnrn– Enable change history on your new table. We’ll use this later.rnALTER TABLE `my_dataset.wikipedia_pageviews_copy`rnSET OPTIONS(rn enable_change_history = TRUErn);”), (‘language’, ‘lang-sql’), (‘caption’, <wagtail.rich_text.RichText object at 0x3e20b1cde580>)])]>
Step 2: Run Baseline UPDATE (without optimization)
Now, let’s perform a sparse update, modifying about 0.1% of the rows scattered across the table.
code_block
<ListValue: [StructValue([(‘code’, “– Baseline UPDATE: Modify ~0.1% of rowsrnUPDATE `my_dataset.wikipedia_pageviews_copy`rnSET views = views + 1000rnWHERE title LIKE ‘%Goo%’rn AND datehour IS NOT NULL;”), (‘language’, ‘lang-sql’), (‘caption’, <wagtail.rich_text.RichText object at 0x3e20b1cde070>)])]>
Result: This update modified approximately 61.2 million records. In our test environment, without the optimization enabled, it took roughly 10 minutes and 49 seconds to complete and consumed ~787.3 million slot milliseconds.
Step 3: Enable fine-grained mutations
Next, we’ll enable the optimization using a simple ALTER TABLE statement.
Let’s run a similar update, again modifying roughly 0.1% of the data.
code_block
<ListValue: [StructValue([(‘code’, “– Optimized UPDATE: Modify the same number of rowsrnUPDATE `my_dataset.wikipedia_pageviews_copy`rnSET views = views – 999 — Change the value slightly for a distinct operationrnWHERE title LIKE ‘%Goo%’rn AND datehour IS NOT NULL;”), (‘language’, ‘lang-sql’), (‘caption’, <wagtail.rich_text.RichText object at 0x3e209c76f5b0>)])]>
Result: This time, the update (again affecting ~61.2 million sparse records) completed dramatically faster. It took only 44 seconds and consumed ~51.8 million slot milliseconds.
Now let’s compare the results:
Metric
Baseline (No Optimization)
Optimized with fine-grained DML
Improvement Factor
Query execution time
10 min 49 sec
44 sec
~14.8x Faster
Slot Milliseconds
~787.3 million
~51.8 million
~15.2x Less
Wow! Enabling fine-grained mutations resulted in a massive ~14.8x reduction in query timeand ~15.2x reduction in slot consumption! This illustrates how this optimization makes targeted DML operations significantly more performant and cost-effective on large BigQuery tables.
2. Tracking row-level history with the CHANGES TVF
Understanding how data evolves row by row is crucial for auditing, debugging unexpected data states, and building downstream processes that react to specific modifications. While BigQuery’s time travel feature lets you query historical snapshots of a table, it doesn’t easily provide a granular log of individual UPDATE, DELETE, and INSERT operations. Another feature, the APPENDS Table-Valued Function (TVF), only tracks additions, but not modifications or deletions.
Enter the BigQuery change history function, CHANGES TVF, which provides access to a detailed, row-level history of appends and modifications made to a BigQuery table. It allows you to see not just what data exists now, but how it got there — including the sequence of insertions, updates, and deletions.
It’s important to note that you must enable change history tracking on the table before the changes you want to query occur. BigQuery retains this detailed change history for a table’s configured time travel duration. By default, this is 7 days. Also, the CHANGES function can’t query the last ten minutes of a table’s history. Therefore, the end_timestamp argument value must be at least ten minutes prior to the current time.
To explore this further, let’s look at the changes we made to our Wikipedia pageviews table earlier. We’ll look for changes made to the Google Wikipedia article from January 1st, 2024.
code_block
<ListValue: [StructValue([(‘code’, ‘– Query the same Wikipedia pageviews table described above. Keep in mind this must run 10 min after you ran the DML update above and you must have already set enable_change_history to TRUE.rnSELECTrn *rnFROMrn CHANGES(TABLE `my_dataset.wikipedia_pageviews_copy`, NULL, TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 601 SECOND))rnWHERE rn title LIKE “Google” rn AND wiki = “en”rn AND datehour = “2024-01-01″rnORDER BY _CHANGE_TIMESTAMP ASC’), (‘language’, ‘lang-sql’), (‘caption’, <wagtail.rich_text.RichText object at 0x3e209c76fa60>)])]>
As you can see from the query results, there are two new pseudo columns within our table, _CHANGE_TYPE and _CHANGE_TIMESTAMP. The _CHANGE_TYPE column refers to the type of change that produced the row, while the _CHANGE_TIMESTAMP column indicates the commit time of the transaction that made the change.
Thus, parsing the changes made to the table, you can see:
Our table initially received an INSERT with this record’s views totaling 288. This resulted from the initial copy from the Wikipedia pageviews public dataset.
The table then simultaneously recorded an UPDATE and DELETE operation from our first DML statement, which added 1,000 views to the record. This is to reflect our original event of 288 views being deleted and replaced with an event showing 1,288 views.
Then finally, our table again simultaneously recorded an UPDATE and DELETE operation for our second DML. The delete was for the record with 1,288 views, and the update was for the final event, showing 289 views.
This detailed, row-level change tracking provided by the CHANGES TVF is incredibly powerful for building robust audit trails, debugging data anomalies by tracing their history, and even for building disaster recovery pipelines that replicate BigQuery changes to other systems in near real-time.
3. Real-time mutations: DML on freshly streamed data
BigQuery’s Storage Write API provides a high-throughput, low-latency way to stream data into your tables, making it immediately available for querying. This is fantastic for powering real-time dashboards and immediate analysis.
While the Storage Write API lets you instantly query this freshly streamed data, historically, you couldn’t immediately modify it using DML statements like UPDATE, DELETE, or MERGE. The incoming data first lands in a temporary, write-optimized storage (WOS) buffer, designed for efficient data ingestion. Before DML could target these rows, they needed to be automatically flushed and organized into BigQuery’s main columnar, read-optimized storage (ROS) by a background process. This optimization step, while essential for query performance, meant there was often a delay (potentially varying from minutes up to ~30 minutes or more) before you could apply corrections or updates via DML to the newest data.
That waiting period is no longer a hard requirement! BigQuery now supports executing UPDATE, DELETE, and MERGE statements that can directly target rows residing in write-optimized storage, before they are flushed to the columnar storage.
Why does this matter? This is a significant enhancement for real-time data architectures built on BigQuery. It eliminates the delay between data arrival and the ability to manipulate it within the warehouse itself. You can now react instantly to incoming events, correct errors on the fly, or enrich data as it lands, without waiting for background processes to complete or implementing complex pre-ingestion logic outside of BigQuery.
This capability unlocks powerful scenarios directly within your data warehouse like:
Immediate data correction: Did a sensor stream an obviously invalid reading? Or did an event arrive with incorrect formatting? Run an UPDATE or DELETE immediately after ingestion to fix or remove the bad record before it impacts real-time dashboards or downstream consumers.
Real-time enrichment: As events stream in, UPDATE them instantly with contextual information looked up from other dimension tables within BigQuery (e.g., adding user details to a clickstream event).
On-the-fly filtering/flagging: Implement real-time quality checks. If incoming data fails validation, immediately DELETE it or UPDATE it with a ‘quarantine’ flag.
By enabling DML operations directly on data in the streaming buffer, BigQuery significantly shortens the cycle time for acting on real-time data, simplifying workflows and allowing for faster, more accurate data-driven responses.
BigQuery for dynamic data management
As we’ve explored, we’ve significantly expanded BigQuery’s capabilities beyond its traditional analytical strengths. Features like fine-grained DML, change history support for updates and deletes, and the ability to run DML directly on freshly streamed data represent a major leap forward.
While we’re not aiming to replace your specialized OLTP databases with BigQuery for high-volume, low-latency transactions, it’s undeniably becoming a far more versatile platform. These enhancements mean data practitioners can increasingly:
Perform targeted UPDATEs and DELETEs efficiently, even on massive tables
Track the precise history of data modifications for auditing and debugging
React to and modify streaming data in near real-time
All of this happens within the familiar, scalable, and powerful BigQuery environment you already use for analytics. This convergence simplifies data architectures, reduces the need for complex external pipelines, and enables faster, more direct action on your data.
Customers like Statsig, a leading product development company which enables their customers to build faster and make smarter decisions can now use BigQuery for new use cases:
“BigQuery adding new features like fine-grained DML allows us to use BigQuery for more transactional use cases here at Statsig.” – Pablo Beltran, Staff Software Engineer, Statsig
So, the next time your project requires a blend of deep analysis and more dynamic data management, remember these powerful tools in your BigQuery toolkit.
Ready to learn more? Explore the official Google Cloud documentation:




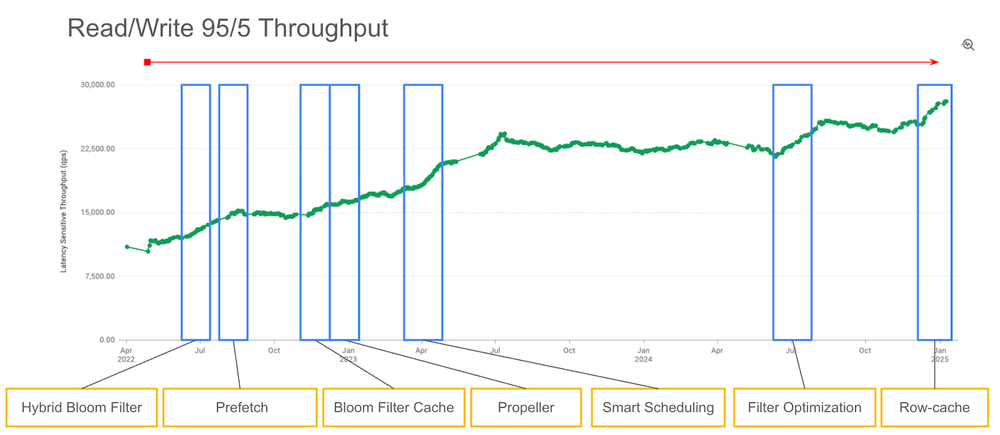







 and Vertex AI Vector Search, now FedRAMP High authorized")