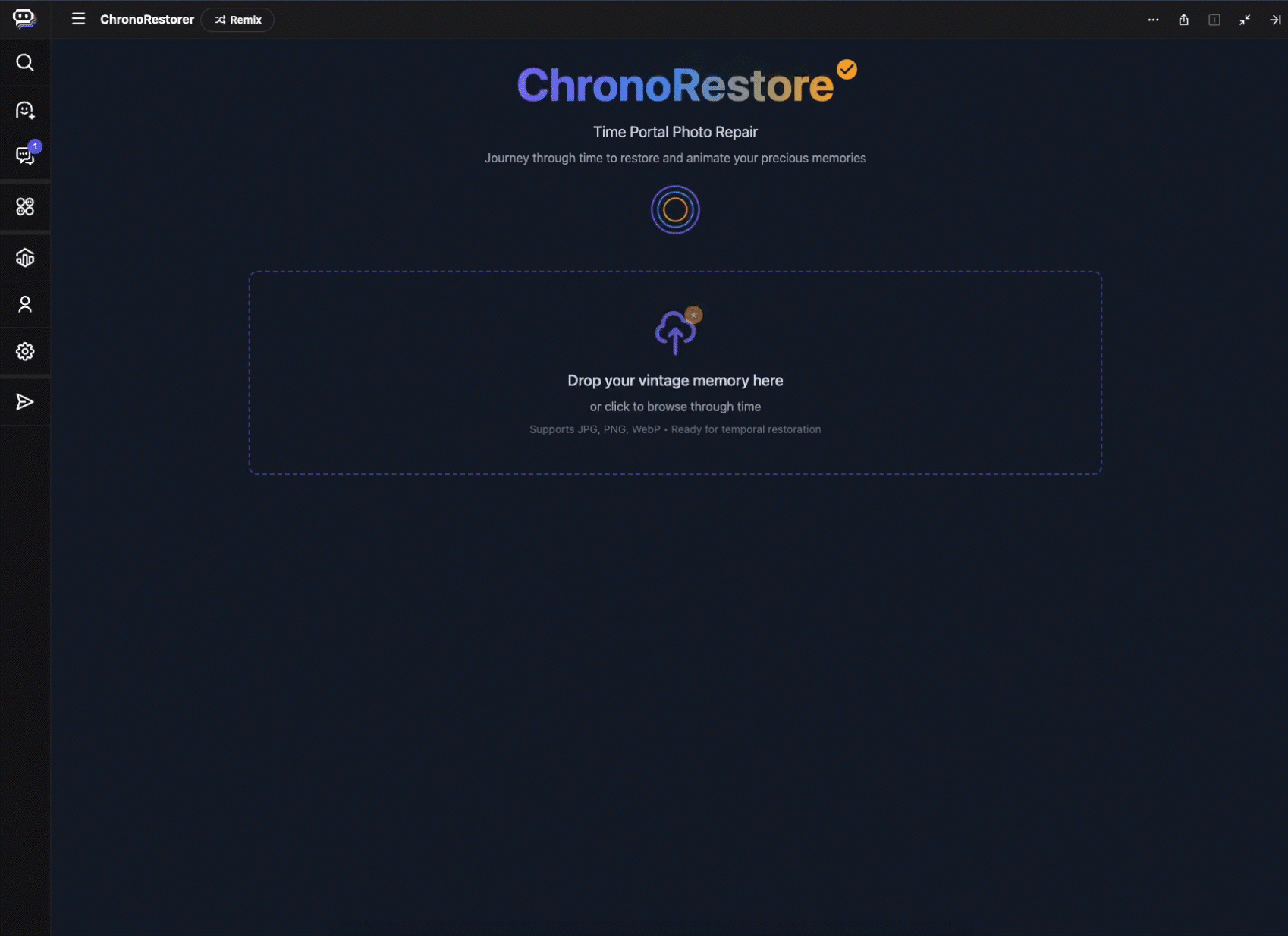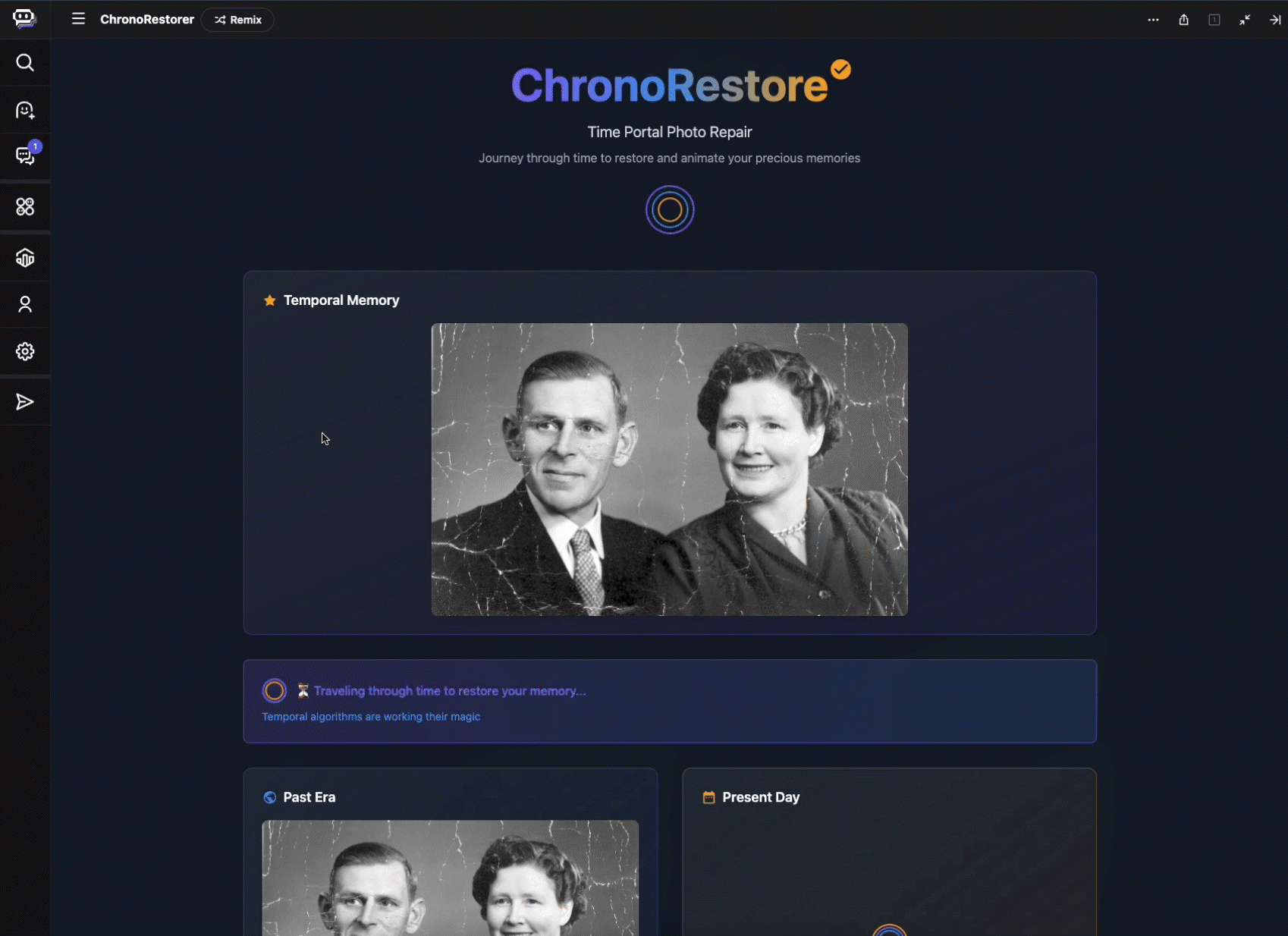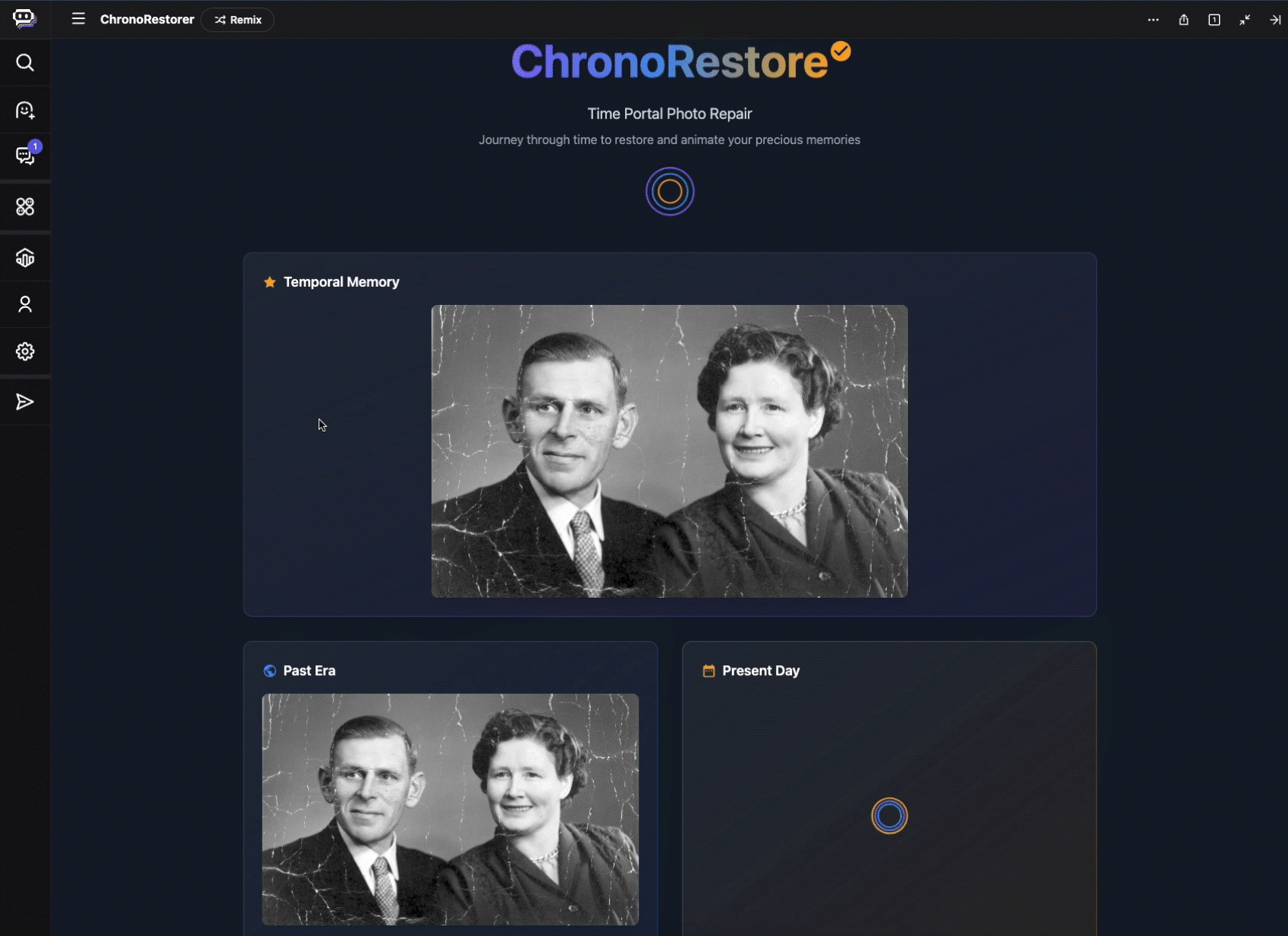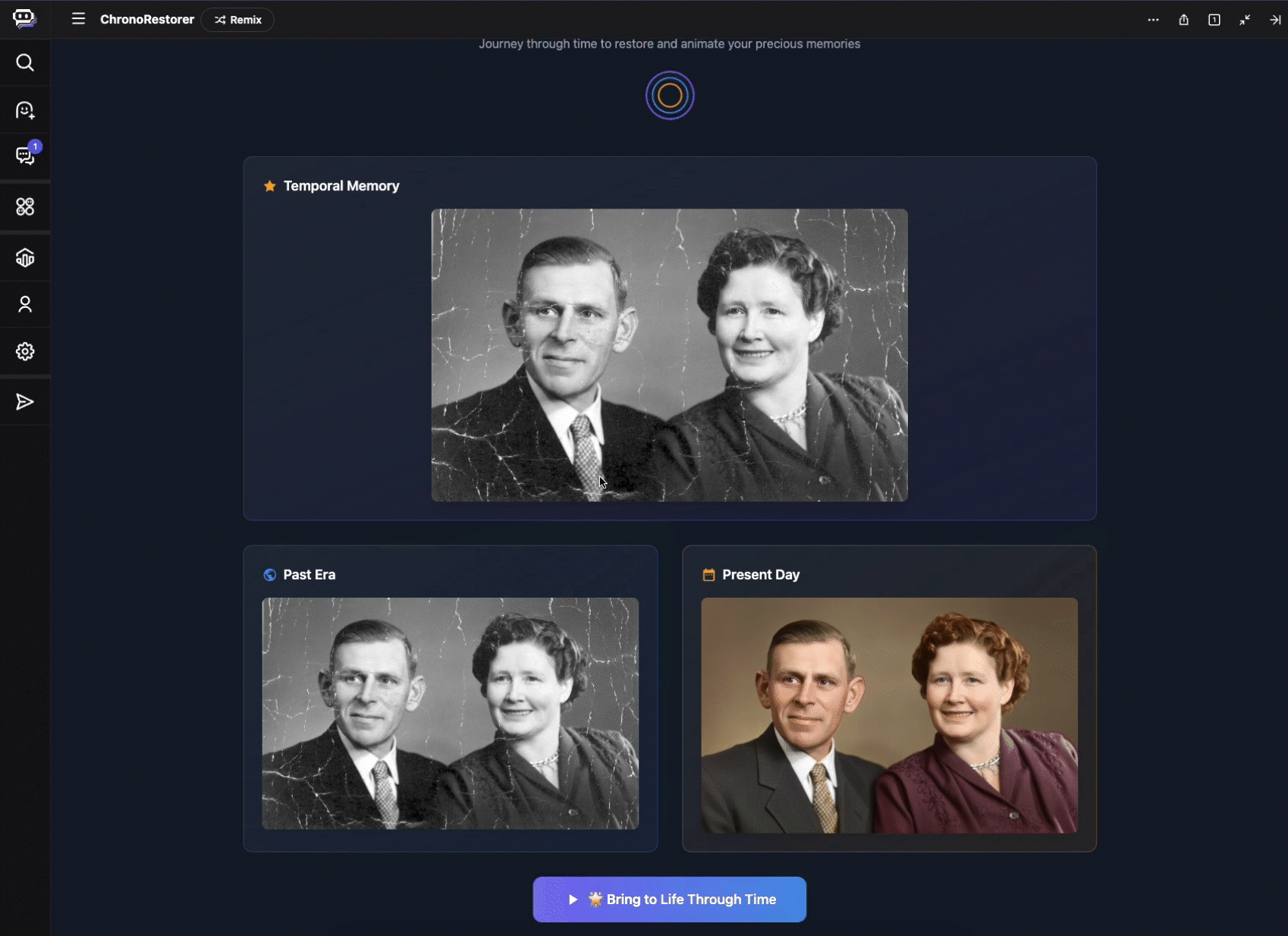
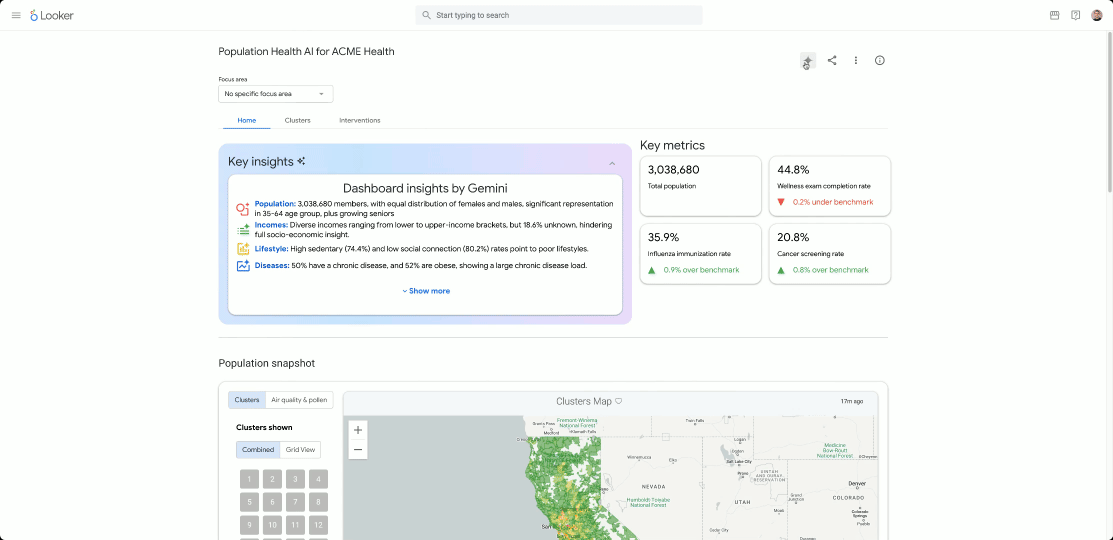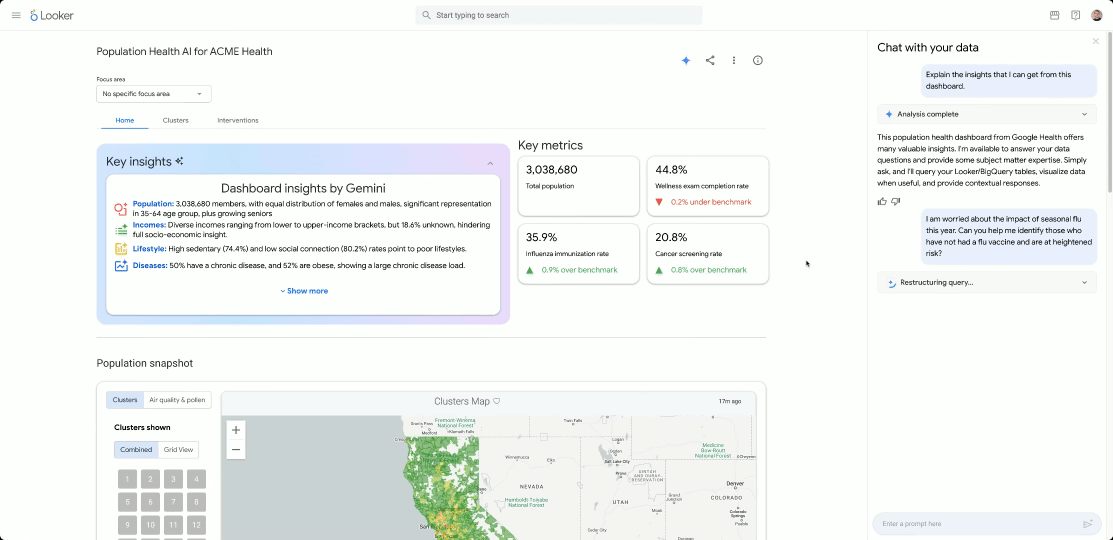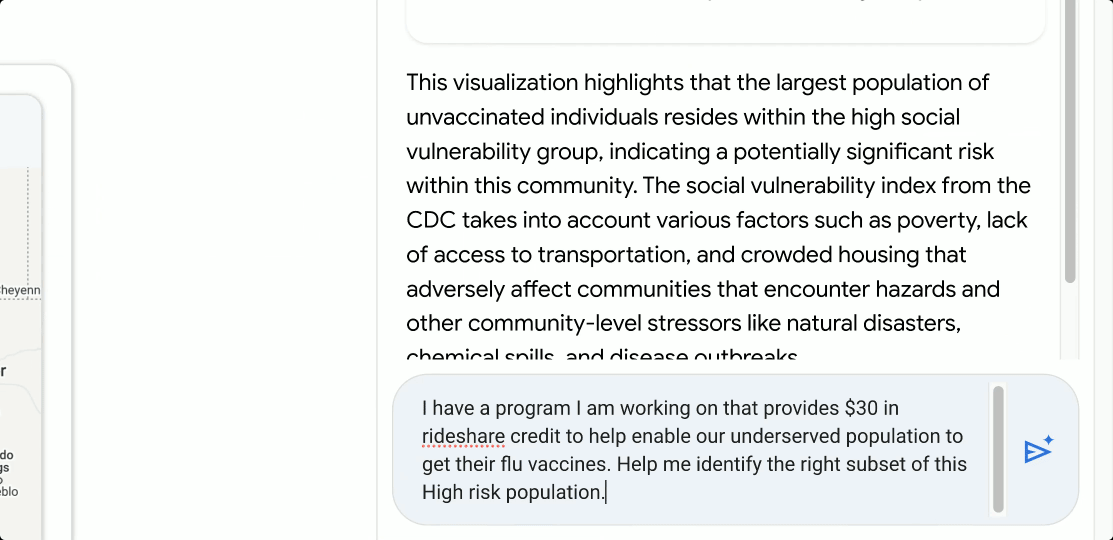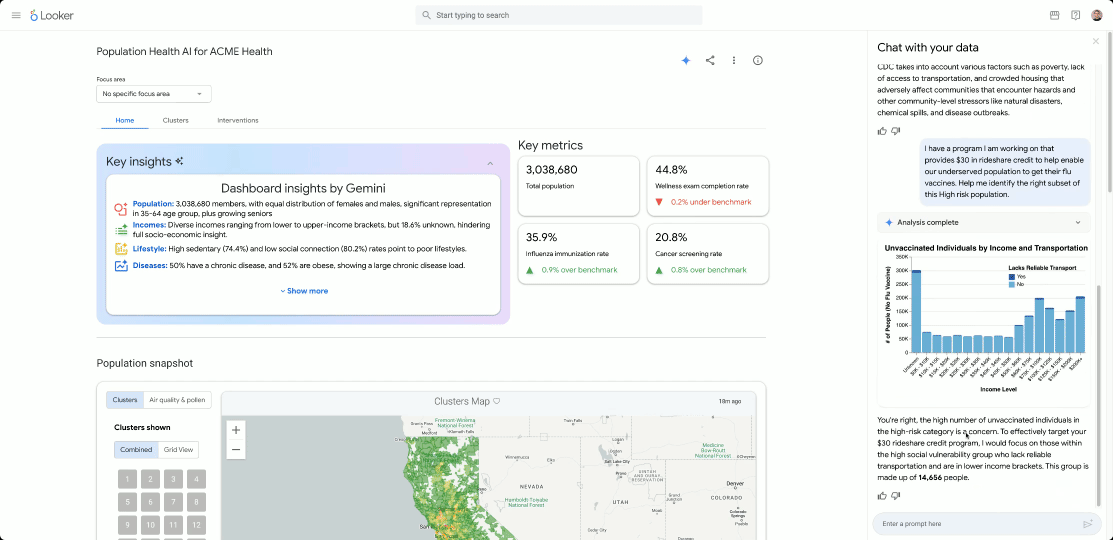
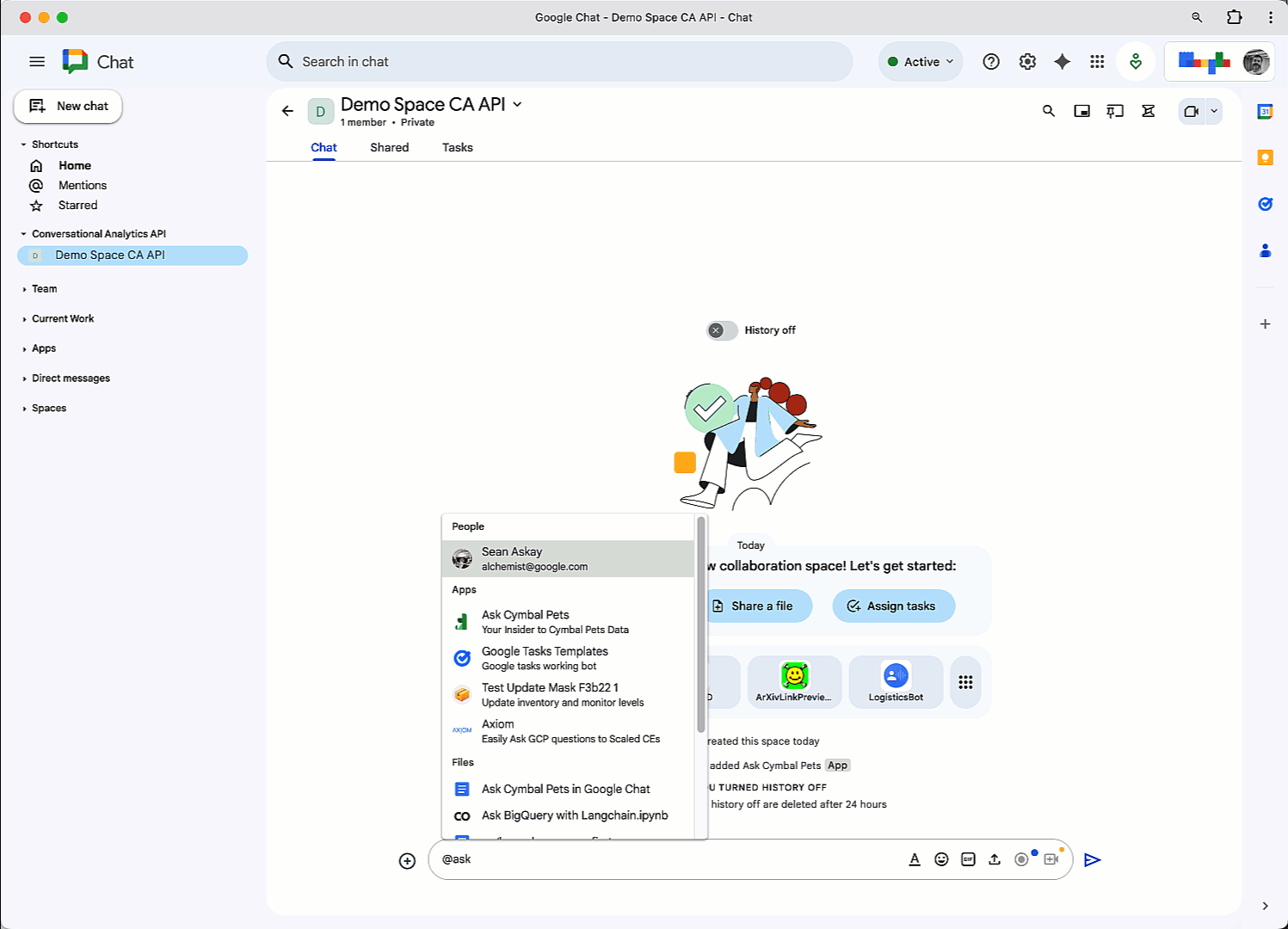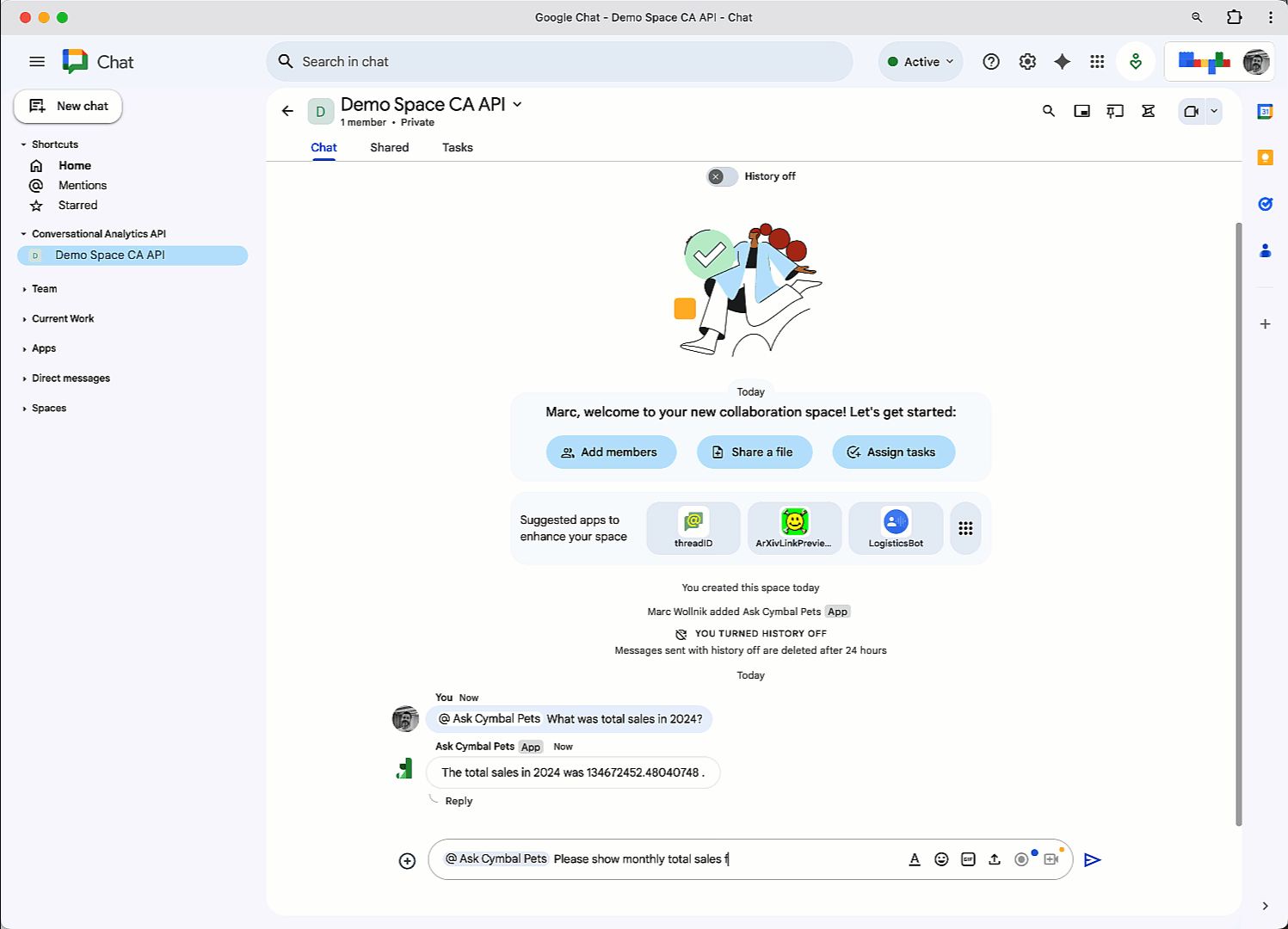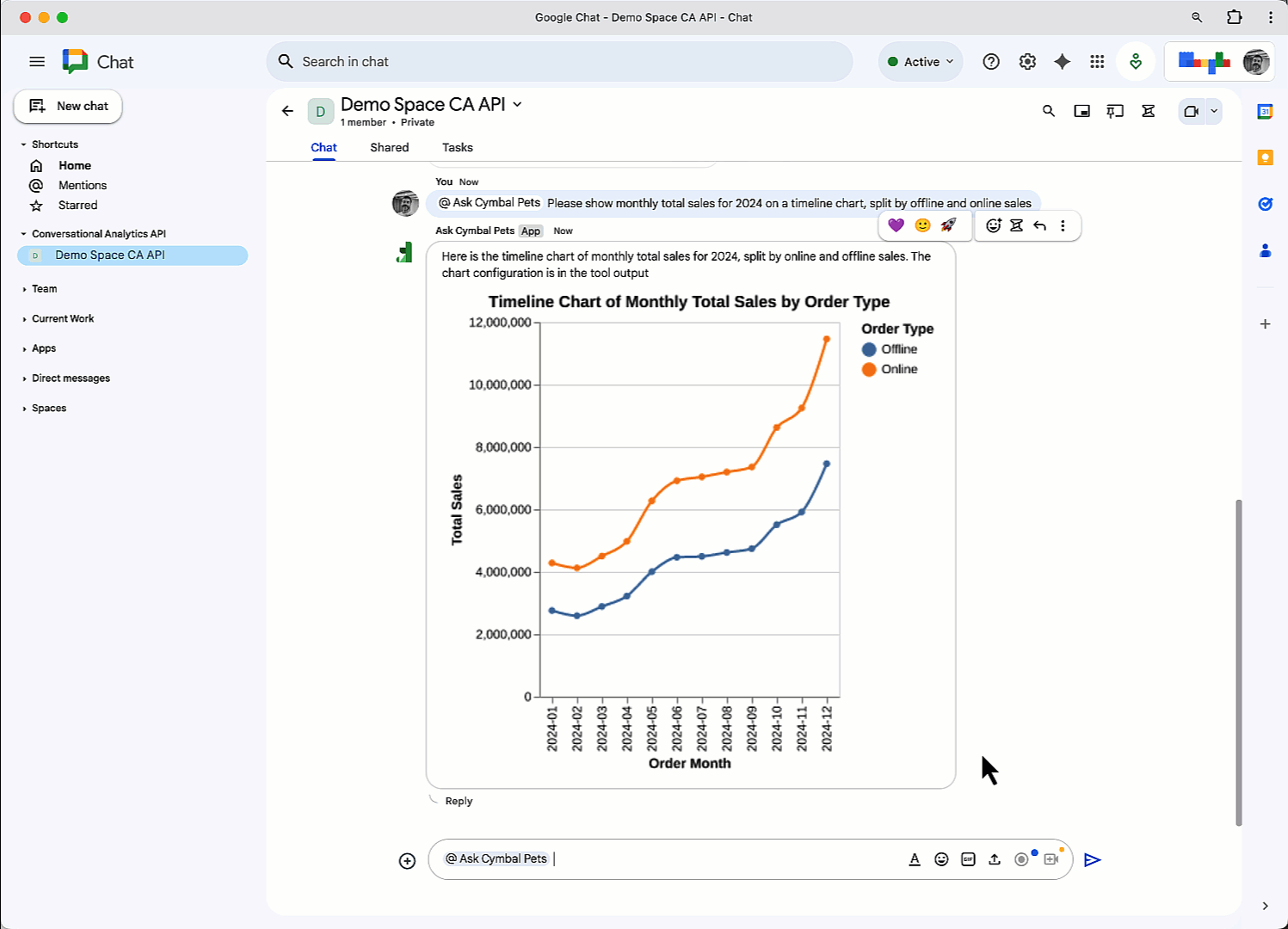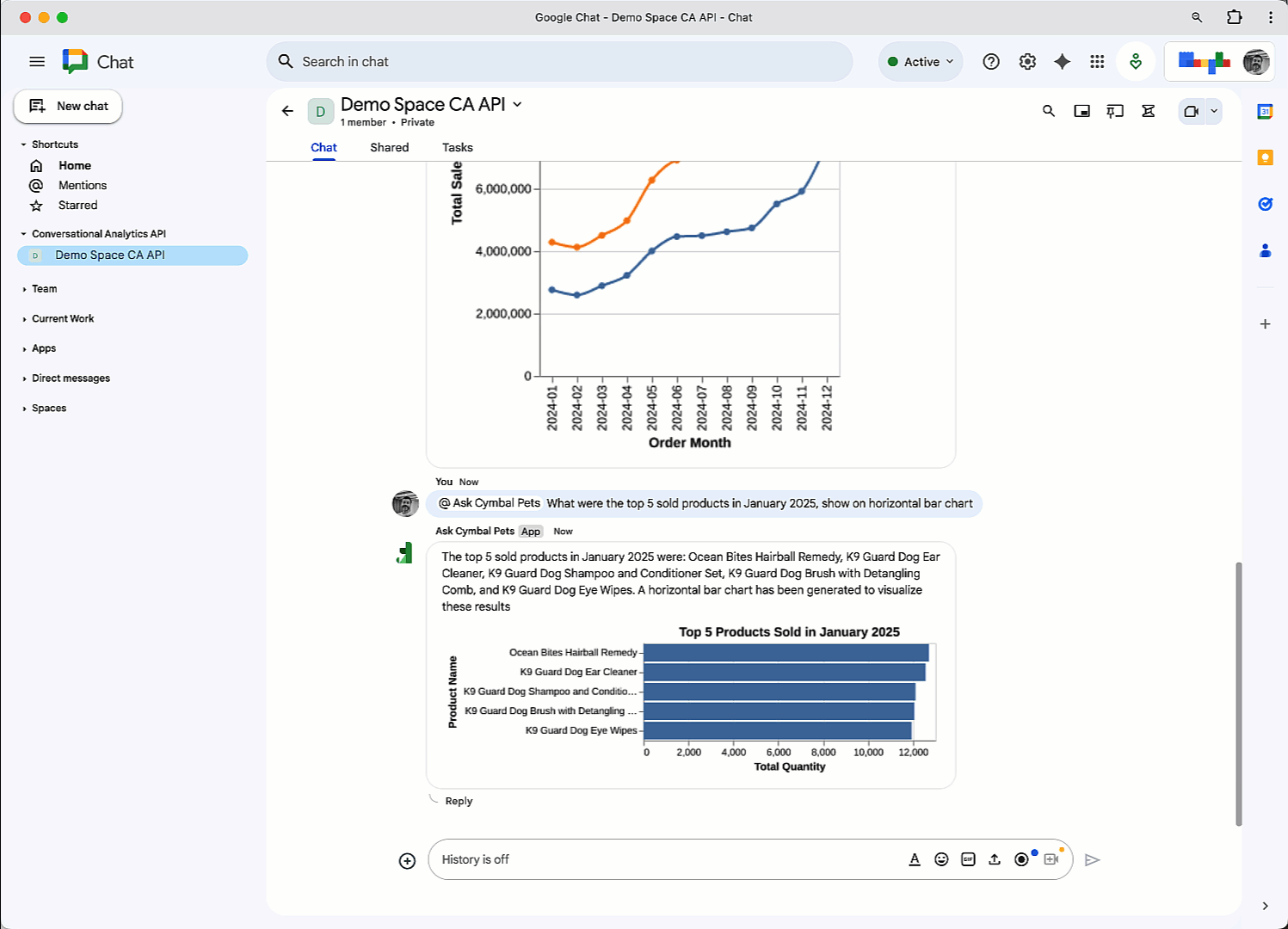
AI is transforming data into a strategic asset, driving demand for flexible, integrated, and real-time data architectures. But yesterday’s data tools can’t handle AI’s demand for massive volumes of real-time and multi-modal data. Data lakes, for instance, offer flexibility for raw data but lack enforcement and consistency. Meanwhile, traditional data marts, warehouses, and lake architectures often result in silos, and require costly ETL to bridge analytical, unstructured, and operational data.
The shift to open lakehouses relies on open table formats like Apache Iceberg, which has emerged as the de facto open-source table format for data lakes. Today, alongside our partners Confluent, Databricks, dbt, Fivetran, Informatica and Snowflake, we’re excited to reiterate our commitment to this open standard. Whether you’re integrating best-of-breed services from diverse providers or navigating a complex data landscape because of a merger and acquisition, adopting an open table format like Iceberg can help you dismantle your traditional data silos.
United in our Iceberg support
At its core, Iceberg provides a metadata layer that enables efficient query planning and data management. This crucial layer, encompassing table schema, partitioning, and data file locations, powers advanced features like time travel and data pruning, which allows data teams to swiftly pinpoint relevant data, streamline performance, and accelerate insights.
The data management industry is coalescing around the open Apache Iceberg standard. At Google Cloud, we recently delivered innovations which leverage Google’s Cloud Storage (GCS) to provide an enterprise-grade experience for managing and interoperating with Iceberg data, including BigLake tables for Apache Iceberg and BigLake Metastore with a new REST Catalog API. Databricks recently announced Iceberg support with their Unity Catalog, allowing users to read and write managed Iceberg tables across a variety of catalogs. Similarly, Snowflake supports interoperable storage with Apache Iceberg tables, allowing organizations to access Iceberg data within Snowflake, minimizing the latency associated with ingesting or copying data.
“This open, standard interface allows any Iceberg-compatible engine — including BigQuery, Apache Spark, Databricks, and Snowflake — to operate on the same, single copy of Iceberg data. This powerful architecture even bridges the gap between analytical and operational workloads. By supporting Iceberg and other open table formats in Unity Catalog, we’re unifying data and governance across the enterprise to truly democratize data and AI. No matter what table format our customers choose, we ensure it’s accessible, optimized, and governed for Business and Technical users.” – Ryan Blue, Original creator of Apache Iceberg, Member of Technical Staff, Databricks
“Customers shouldn’t have to choose between open formats and best-in-class performance or business continuity. Snowflake’s native support for open source standards unifies data while preserving flexibility and choice, paving the way to build and securely scale high-performing lakehouses without silos or operational overhead.” – Rithesh Makkena, Senior Regional Vice President of Partner Solutions Engineering, Snowflake
At Google Cloud, we’re committed to an open Data Cloud that lets data teams build modern, data-driven applications wherever their workloads are, while using open source, open standards and open formats like Apache Iceberg.
We partner closely with an extensive ecosystem of partners including Confluent, dbt Labs, Fivetran, and Informatica on Apache Iceberg initiatives.
“Apache Iceberg has emerged as a critical enabler for the open data ecosystem, providing the flexibility, interoperability, and consistency that modern, real-time data architectures demand. At Confluent, we’re dedicated to helping customers leverage this power. Our Tableflow innovation, by representing Apache Kafka topics as open Iceberg tables, exemplifies how this open format eliminates complex ETL and ensures data is always fresh, accurate, and instantly actionable for critical real-time analytics and AI.” – Shaun Clowes, Chief Product Officer, Confluent
“dbt was born out of an open source project to help people transform data. Open data ecosystems are at the core of what we do. Supporting Iceberg in dbt ensures that our customers will have standards and choices for how they use their transformed data in their AI and data workflows.” – Ryan Segar, Chief Product Office, dbt Labs
“Open table formats like Apache Iceberg make it possible to reduce data copies by decoupling your data from the compute engines used to access it. Fivetran’s Managed Data Lake service ensures data is delivered to cloud storage as transactionally consistent tables in a way that preserves the structure from the source. Fivetran’s Managed Data Lake seamlessly integrates with Google Cloud Storage and BigLake metastore, providing a single governance layer within customers’ Google projects and making Iceberg tables just as easy to query as native BigQuery tables.” – Dan Lynn, Vice President of Product Management, Databases, Fivetran
“Our collaboration with Google on the Iceberg format is ushering in a new era of open, interoperable data architecture. Together, we’re enabling organizations to unify their data effortlessly, accelerate insights and innovate without limits by eliminating silos and unlocking the full power of the modern data ecosystem.” – Rik Tamm-Daniels, GVP, Technology Alliances
The power of shared data
By adopting Iceberg, customers can share data across different query engines and platforms, leveraging shared datasets for a multitude of workloads and improving interoperability. Organizations can now share data from Snowflake to BigQuery, unlocking powerful BigQuery ML capabilities such as text generation or machine translation, and simplifying ML model development and deployment. Likewise, data teams can share data with BigQuery from Databricks to achieve cost efficiencies, leverage built-in ML, or implement agentic workflows.
Customers like Global Payments embraced Iceberg for more flexibility across their diverse data tools. BigQuery and Snowflake serve millions of merchants, and allow the business to analyze transaction data and unlock deep customer insights.
Likewise, Unilever has transformed its data management approach with Iceberg, which allows it to manage large datasets more efficiently, particularly in a data lakehouse architecture. Using a combination of Google Cloud and Databricks, Unilever stores and analyzes large amounts of complex data, allowing them and their suppliers to take action wherever and whenever needed.
Whether you create your Iceberg tables in BigQuery, Databricks, or Snowflake, you can leverage the resulting data from any platform and have your tables stay continuously up-to-date. This interoperability will help you operate with greater efficiency and security, drastically reducing the time you spend moving or duplicating datasets, and eliminating the need for complex pipelines to utilize your preferred tools, platforms, and processing systems.
Get started today with BigQuery and BigLake for your AI-ready lakehouse. You can learn how to build an open data lakehouse with BigQuery and Snowflake by watching a tutorial, then diving into the Quickstart Guide. Learn how to connect and build an open data lakehouse with BigQuery and Databricks.
for the details.