
GCP – What’s new with BigQuery — the autonomous data-to-AI platform
Data is the fuel for AI, and organizations are racing to leverage enterprise data to build AI agents, intelligent search, and AI-powered analytics for productivity, deeper insights, and a competitive edge. To power their data clouds, tens of thousands of organizations already choose BigQuery and its integrated AI capabilities.
This decade requires AI-native, multimodal, and agentic data-to-AI platforms, with BigQuery leading the way as the autonomous data-to-AI platform. Finally, we have a platform that infuses AI, makes unstructured data a first class citizen, accelerates open lakehouses and embeds governance.
As an autonomous data-to-AI platform, BigQuery enables a self-managing multimodal data foundation that’s built for processing and activation of all data types, with advanced engines that can be operated on by specialized agents. The platform’s shared catalog and governance layer helps ensure consistent data access, metadata understanding, and security policies across all data and engines, minimizing silos and simplifying management. BigQuery is built on Google’s global infrastructure, leveraging high-bandwidth networks, low-latency storage, and AI-accelerated hardware (TPUs, GPUs), for virtually unlimited scalability. With our commitment to open standards and AI embedded at every layer, this fully integrated architecture accelerates your journey to AI-driven insights at the lowest cost possible.

AI assistance across the entire data lifecycle
Gemini in BigQuery brings a set of AI-powered assistive capabilities to automate data discovery and exploration, data preparation and engineering, analysis and insight generation, covering the entire data journey.
Thousands of organizations are using Gemini in BigQuery. In fact, usage of code assist in BigQuery grew 350% over the last 9 months, with over a 60% code generation acceptance rate across SQL and Python.
Yesterday we announced the general availability of several additional Gemini in BigQuery features and added new capabilities that further enhance and automate your analytics workflows.
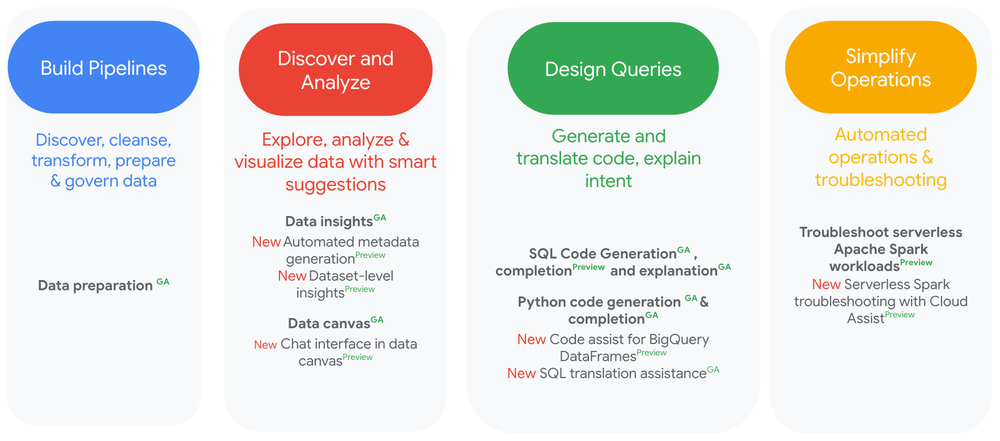
- Simplify data preparation: BigQuery Gemini-assisted data preparation (GA) provides intelligent suggestions for data enrichment, easily identifies and rectifies data inconsistencies, provides low-code visual data pipelines, and automates the execution and monitoring of your data pipelines.
- Faster time to insights with data canvas: BigQuery data canvas allows you to find, transform, query, and visualize data using natural language prompts and a graphic interface. New dataset-level insights (preview) can surface hidden relationships between tables and generate cross-table queries by integrating query usage analysis and metadata.
- Boost productivity with coding assistance for DataFrames: With AI code assistance in BigQuery, you can use natural language prompts to generate or suggest code in SQL or Python, or to explain an existing SQL query. We are now extending this code assist capabilities to BigQuery DataFrames (preview).
- Improve data and AI governance: New automated metadata generation (preview) uses profile scans and Gemini to create clear and consistent descriptions for columns, tables, and glossary terms, even with large datasets. This metadata improves governance and helps AI agents find the data they need for exploration and analysis.
- Accelerate BigQuery migrations: SQL translation assistance (GA) is an AI-based translator that lets you create Gemini-enhanced rules to customize your SQL translations. You can describe changes to the SQL translation output using natural language prompts or specify SQL patterns to find and replace. This can also help in rapidly increasing familiarity with BigQuery SQL.
Even better, Gemini in BigQuery features are being introduced into existing BigQuery pricing models across all BigQuery compute pricing options. Express interest to try the new features today.
- aside_block
- <ListValue: [StructValue([(‘title’, ‘$300 in free credit to try Google Cloud data analytics’), (‘body’, <wagtail.rich_text.RichText object at 0x3ece8ad7a070>), (‘btn_text’, ‘Start building for free’), (‘href’, ‘http://console.cloud.google.com/freetrial?redirectPath=/bigquery/’), (‘image’, None)])]>
A multimodal autonomous data foundation
BigQuery helps you develop an autonomous data foundation by unifying analytics capabilities across diverse data types and enabling the seamless, concurrent analysis of both structured and unstructured data within a single platform. In fact, customer data in BigQuery grew nearly 30% last year, adding to the multiple exabytes already stored. Furthermore, its native, first-party integration with Vertex AI allows you to apply powerful AI models directly to your data, eliminating the requirement for complex data movement or replication.
“BigQuery and Vertex AI bring all our data and AI together into a single platform. This has transformed how we take action on customer feedback from a lengthy manual process, to a simple natural language query in seconds, allowing us to get to customer insights in minutes instead of months.” – TJ Allard, Lead Data Scientist, Mattel
Yesterday we announced several innovations to enhance our unstructured data support and AI processing:
-
BigQuery tables for Apache Iceberg (preview:) Connect your Apache Iceberg data to SQL, Spark, AI and third-party engines in an open and interoperable manner so you can get the flexibility of an open data lakehouse alongside the performance and integrated tooling of BigQuery. This offering provides adaptive and autonomous table management, delivers high-performance streaming, auto-AI-generated insights, near-infinite serverless scale and advanced governance.
-
Native multimodal support for BigQuery tables: Built on object tables, the new ObjectRef data type (preview) enables storage and querying of unstructured and structured data using Python and SQL functions.
- Multimodal capabilities for Python users: The BigQuery DataFrames library now has multimodal capabilities for unified structured and unstructured analytics, AI operators for semantic insights, and Gemini code assistance.
- Easy capture of Unstructured Data Processing: BigQuery ML new capabilities in preview include AI.GENERATE_TABLE for capturing the output of LLM inference within SQL clauses. Additionally, we’ve expanded model choice to include Anthropic’s Claude, Llama, and Mistral models, and open-source models hosted on Vertex AI.
- Scalable, faster and cost-efficient vector search: BigQuery vector search allows you to generate, manage, and search embeddings within a serverless, fully integrated environment for powerful analytics. We are introducing a new index type (GA) based on Google’s ScaNN model coupled with a CPU-optimized distance computation algorithm, enabling scalable, faster and more cost-efficient processing.
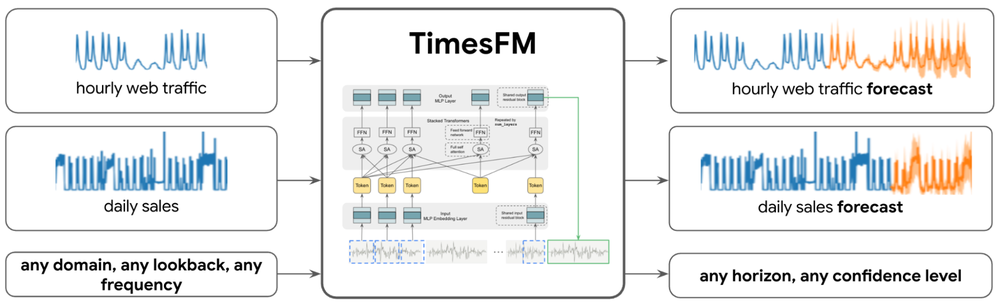
- Easier time-series forecasting in BigQuery ML: BigQuery ML simplifies time-series forecasting with the new TimesFM model (preview). This pretrained model, developed by Google Research, is user-friendly, accurate, fast, and scalable.

- Pinpoint the key factors driving changes in your metrics: Organizations constantly need to answer questions like “Why did our sales drop last month?”. ” Answering these “why” questions accurately is vital, but often involves complex manual analysis. BigQuery’s contribution analysis feature (GA) helps you pinpoint the key factors (or combinations of factors) responsible for the most significant changes in a metric.
Simplified and unified governance in BigQuery
BigQuery offers built-in governance capabilities that simplify how you discover, manage, monitor, govern, and use your data and AI assets. BigQuery universal catalog brings together a data catalog (formerly known as the Dataplex Catalog) and a fully managed, serverless metastore. Yesterday, we announced the following new capabilities for BigQuery governance:
-
Enable engine interoperability across BigQuery, Apache Spark, and Apache Flink engines with BigQuery metastore (GA). With support for the Iceberg Catalog it simplifies data discovery and querying across engines, mirroring the open-source experience.
-
Empower your organization with a business glossary (GA), which provides a shared understanding of data. Customers can define and administer company terms in a business glossary, identify data stewards for these terms, and attach them to data asset fields, to improve context, collaboration, and search.
-
Perform bulk extract of catalog entries into Cloud Storage with Catalog metadata export (GA). This enables a wide range of use cases including metadata analytics by making the export output queryable from BigQuery, programmatic workloads requiring access to a large scope of metadata, and metadata integration.
-
Automatic at-scale cataloging of BigLake and object tables (GA): BigQuery harvests up-to-date metadata for structured and unstructured data from Cloud Storage and automatically creates query-ready BigLake tables at scale.
Enhanced enterprise capabilities
BigQuery offers easy managed disaster recovery (GA) for compute and storage. It features automatic failover coordination, continuous near-real-time data replication to a secondary region, and fast, transparent recovery during outages. This provides business continuity with industry-leading recovery point objectives (RPO) and recovery time objectives (RTO).
We are also introducing new workload management capabilities (preview) for isolation, resource control, and observability. Users gain granular controls with flexible, securable reservations that allow users to assign to different jobs in the same project to different reservations. Features include reservation level fair sharing of slots, predictability in performance of reservations, and enhanced observability through reservation attribution in billing for better cost tracking.
Improved query performance
To further simplify analytics, we introduced several new innovations to help you get the most out of SQL and make your queries work better for you automatically. Query performance optimizations (GA) improve query performance and automatically identify and accelerate relevant workloads with no changes required to the schema or queries. These include:
-
Low latency API for short queries enables short-query-optimized mode to improve overall latency of short queries that are common in workloads such as data exploration or building dashboards by executing the query and returns the results inline for SELECT statements.
-
History-based optimizations use information from already-completed executions of similar queries to apply additional optimizations and further improve query performance such as query latency and slot-time consumed.
-
Column metadata index (CMETA) provides (almost) infinitely scalable and highly performant metadata management for BigQuery, where you can go from 10GB tables to 100PB and still get great price/performance, without having to worry about redesign or replatforming.
New analytics capabilities
-
SQL-based continuous queries (GA): Simplify real-time data processing by enabling users to express complex transformations in SQL. You can run continuously processing SQL statements to help analyze, transform, and reverse ETL data the moment new events arrive in BigQuery. This feature now supports slot autoscaling, greater monitoring through Cloud Monitoring, and exports to other clouds.
-
Simplify SQL with BigQuery pipe syntax (GA): This unique feature extends standard SQL to make it simpler, more concise, and flexible. Pipe syntax lets you apply operators in any order and as often as you need, streamlining SQL queries for tasks like data exploration, dashboard creation, and log analysis. Pipe syntax enhances clarity, efficiency, and maintainability, and its compatibility with most standard SQL operators ensures broad usability.
-
Geospatial analytics (preview): We’re integrating rich, analysis-ready geospatial datasets from Earth Engine and Google Maps Platform directly into BigQuery data clean rooms. And with the ST_RegionStats function, BigQuery users can now use Earth Engine to efficiently extract statistics from raster data. For the first time, data analysts and decision-makers can access geospatial insights from Google Maps Platform and Earth Engine that lead to more informed and faster business and sustainability outcomes. Key decisions such as optimal site selection for a new business location, how to optimize operations and maintenance of your infrastructure assets, how to enable sustainable sourcing, and more are now enabled directly in BigQuery.
Continued innovation with the ISV ecosystem
Finally, BigQuery’s capabilities are being significantly extended by its vibrant partner ecosystem, through new and enhanced AI integrations and solutions. Anthropic’s Claude models are now accessible via BigQuery ML, facilitating functions like text generation and summarization. GrowthLoop introduced its Compound Marketing Engine built on BigQuery with Growth Agents powered by Gemini, so marketing can build personalized audiences and journeys that drive rapidly compounding growth. Furthermore, Informatica is expanding their services on Google Cloud to enable sophisticated analytical and AI governance use cases.
Significant advancements have also occurred in data management and observability. Fivetran introduced its Managed Data Lake Service for Cloud Storage with native integration with BigQuery metastore and automatic data conversion to open table formats like Apache Iceberg and Delta Lake, improving data lake management and discoverability. DBT is now integrated with BigQuery DataFrames and DBT Cloud is now on Google Cloud. Finally, Datadog has introduced expanded monitoring capabilities for BigQuery, providing granular visibility into query performance, usage attribution, and data quality metrics.
These partner innovations provide customers with expanded functionality, improved operational control, and streamlined access to sophisticated capabilities within the BigQuery ecosystem.
A data-to-AI platform for the autonomous era
BigQuery is evolving beyond a data warehouse and becoming the autonomous data-to-AI platform for all your data teams. The Gemini-powered agents, unified architecture, and commitment to open standards are lowering the barriers to entry for AI-powered analytics and enabling you to focus on what you do best: building innovative models and driving data-driven decisions.
As we bring together more capabilities within a unified platform we are making it easy for you to consume and use the platform with unified commercials with our new BigQuery spend commit. This provides commitments across our BigQuery unified platform, giving you the flexibility to move spend across data processing engines, streaming, governance and more.
Learn more about BigQuery and start exploring how these new features can transform your organization.
Special thanks to Geeta Banda, Head of Outbound Product Management, for her contributions to this blog post.
Read More for the details.

