
GCP – Using RDMA over Converged Ethernet networking for AI on Google Cloud
All workloads are not the same. This is especially the case for AI, ML, and scientific workloads. In this blog we show how Google Cloud makes the RDMA over converged ethernet version 2 (RoCE v2) protocol available for high performance workloads.
Traditional workloads
Network communication in traditional workloads involves a well-known flow. This includes:
-
Movement of data between source and destination. The application initiates requests.
-
The OS processes the data, adds TCP headers and passes it to the network interface card (NIC).
-
The NIC sends data on the wire based on networking and routing information.
-
The Receiving NIC receives data.
-
OS processing on the receiving end strips headers and delivers data based on information.
This process involves both CPU and OS processing, and these networks can recover from latency and packet loss issues and handle data of varying sizes while functioning normally.
AI workloads
AI workloads are very sensitive, involve large datasets, may require high bandwidth, low latency and lossless communication for training and inference. Because there is a higher cost for running these types of jobs, it’s important that they are completed as quickly as possible and optimize processing. This can be achieved with accelerators — specialized hardware designed to significantly speed up the training and execution of AI applications. Examples of accelerators include specialized hardware chips like TPUs and GPUs.
- aside_block
- <ListValue: [StructValue([(‘title’, ‘”$300 to try Google Cloud networking’), (‘body’, <wagtail.rich_text.RichText object at 0x3e6b07be0490>), (‘btn_text’, ‘Start building for free’), (‘href’, ‘http://console.cloud.google.com/freetrial?redirectpath=/products?#networking’), (‘image’, None)])]>
RDMA
Remote Direct Memory Access (RDMA) technology allows systems to exchange data directly between one another without involving the OS, networking stack and CPU. This allows faster processing times since the CPU, which can become a bottleneck, is bypassed.
Let’s take a look at how this works with GPUs.
-
An RDMA-capable application initiates an RDMA operation.
-
Kernel bypass takes place, avoiding the OS and CPU.
-
RDMA-capable network hardware gets involved and accesses source GPU memory to transfer the data to the destination GPU memory.
-
On the receiving end, the application can retrieve the information from the GPU memory, and a notification is sent to the sender as confirmation.
How RDMA with RoCE works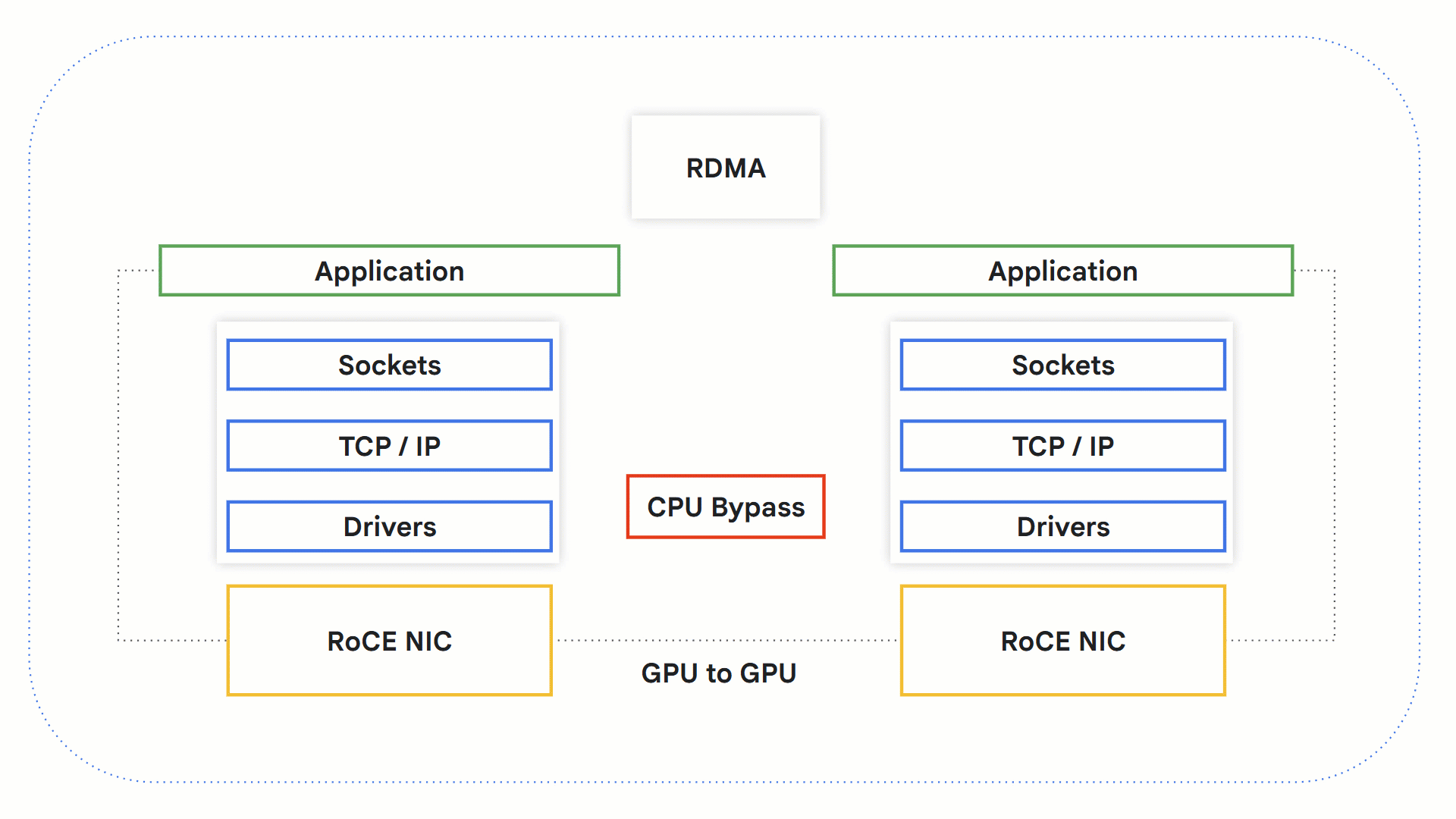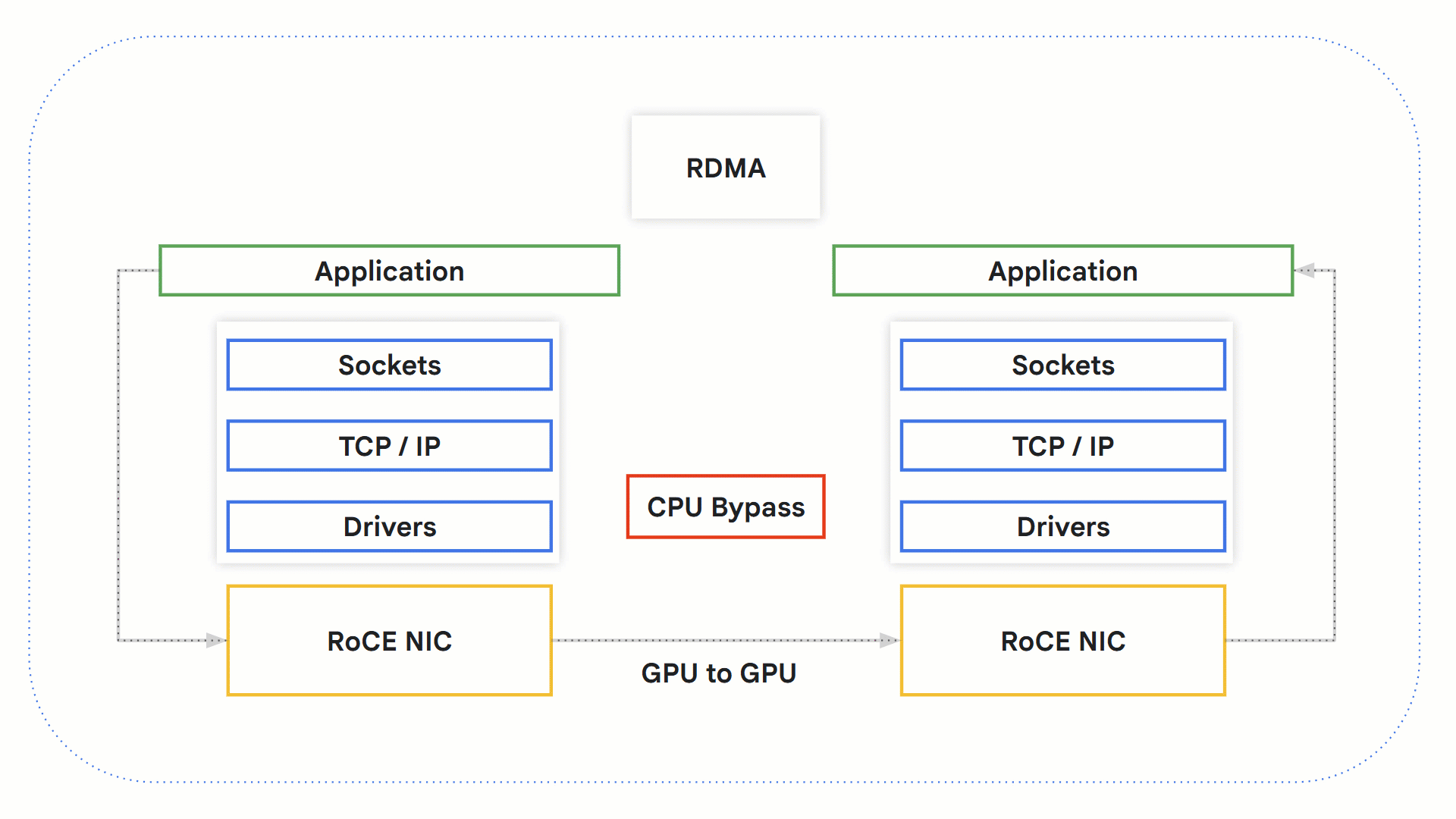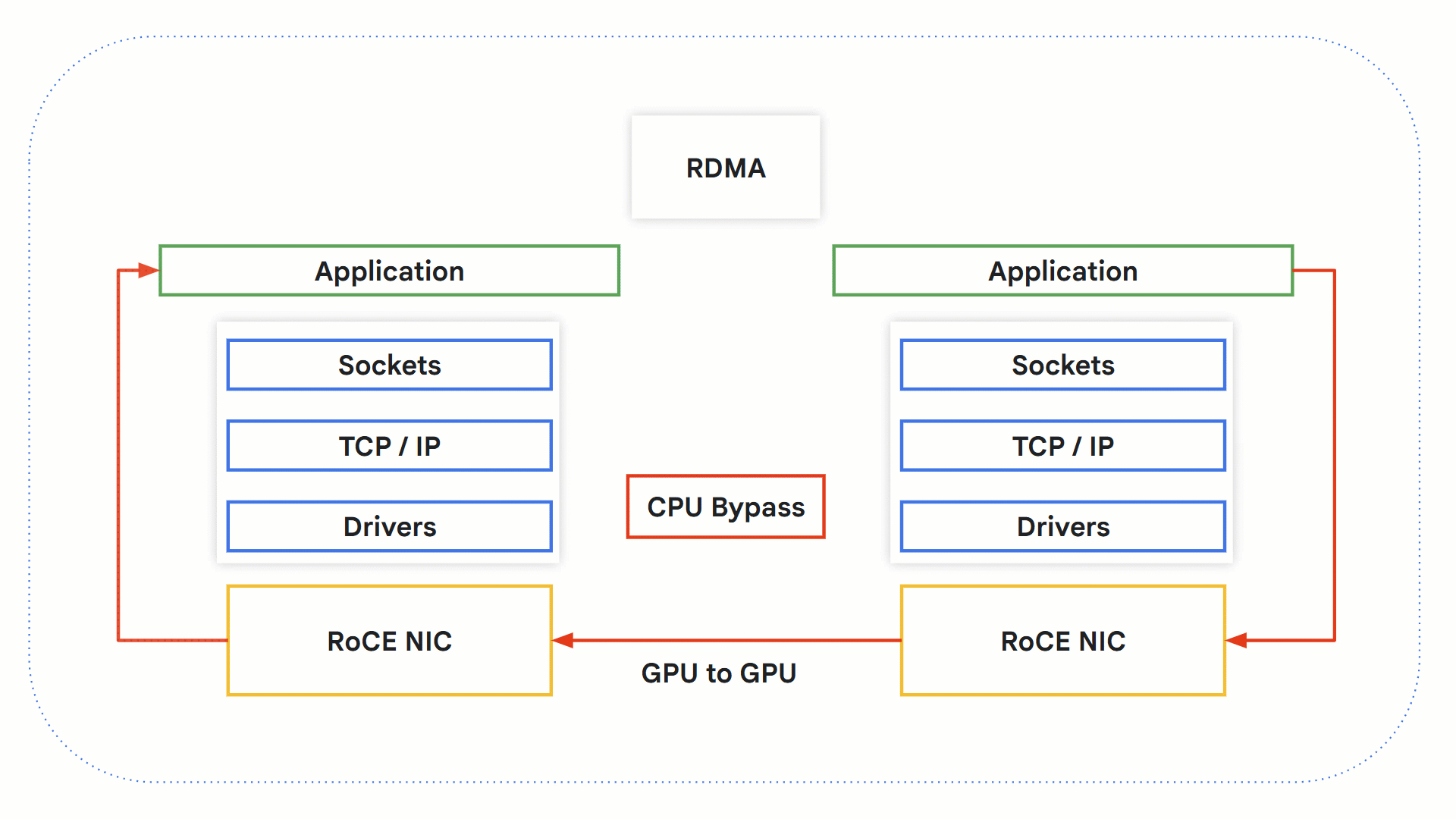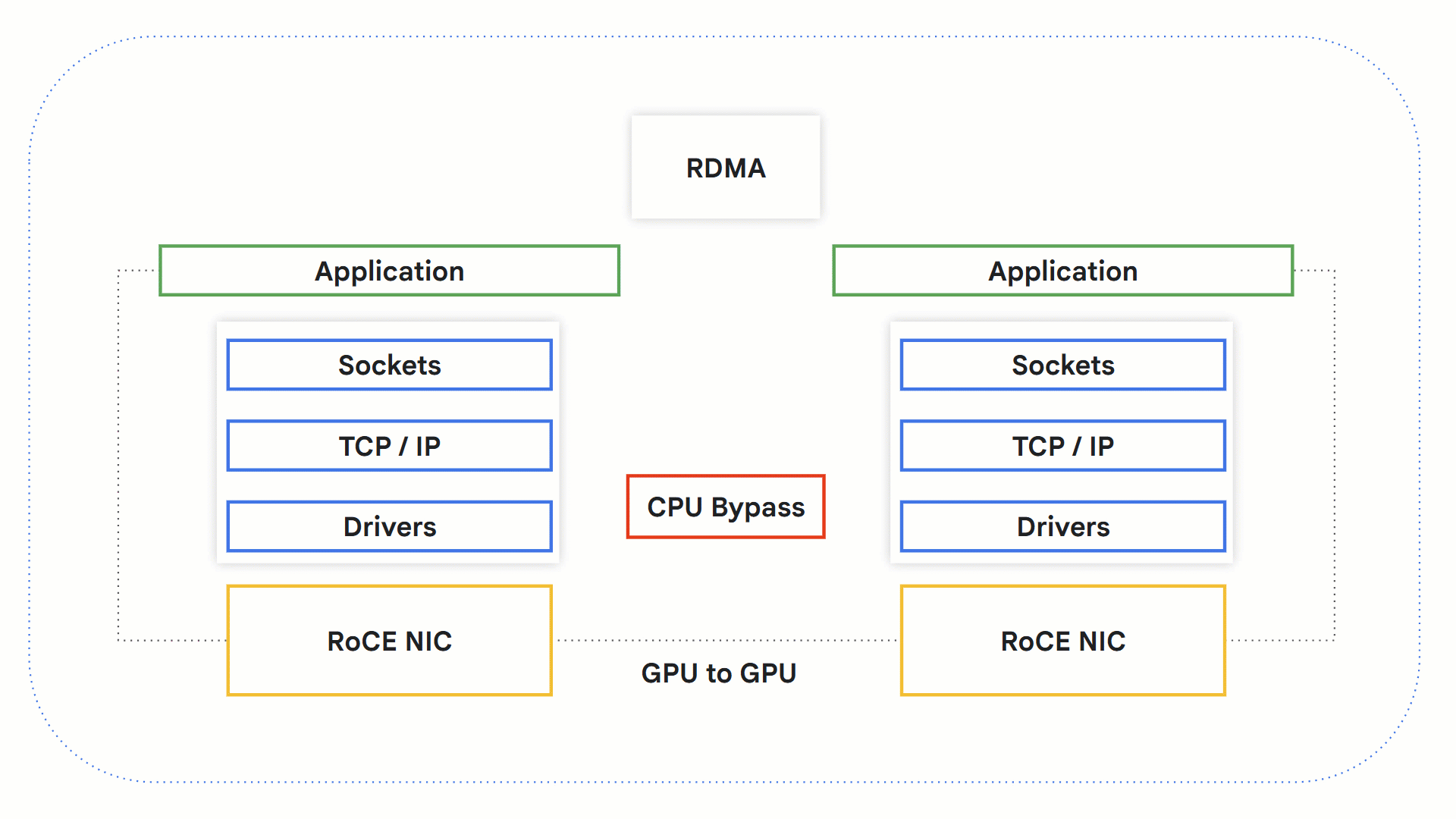
Previously, Google Cloud supported RDMA-like capabilities with its own native networking stack called GPUDirect-TCPX and GPUDirect-TCPXO. Currently the capability has been expanded with RoCEv2, which implements RDMA over ethernet.
RoCE-v2-capable compute
Both the A3 Ultra and A4 Compute Engine machine types leverage RoCE v2 for high-performance networking. Each node supports eight RDMA-capable NICs connected to the isolated RDMA network. Direct GPU-to-GPU communication within a node occurs via NVLink and between nodes via RoCE.
Adopting RoCEv2 networking capabilities offers more benefits including:
-
Lower latency
-
Increased bandwidth — from 1.6 Tbps to 3.2 Tbps of inter-node GPU to GPU traffic
-
Lossless communication due to congestion management capabilities: Priority-based Flow Control (PFC) and Explicit Congestion Notification (ECN)
-
Use of UDP port 4791
-
Support for new VM series like A3 Ultras, A4 and beyond
-
Scalability support for large cluster deployments
-
Optimized rail-designed network
rail design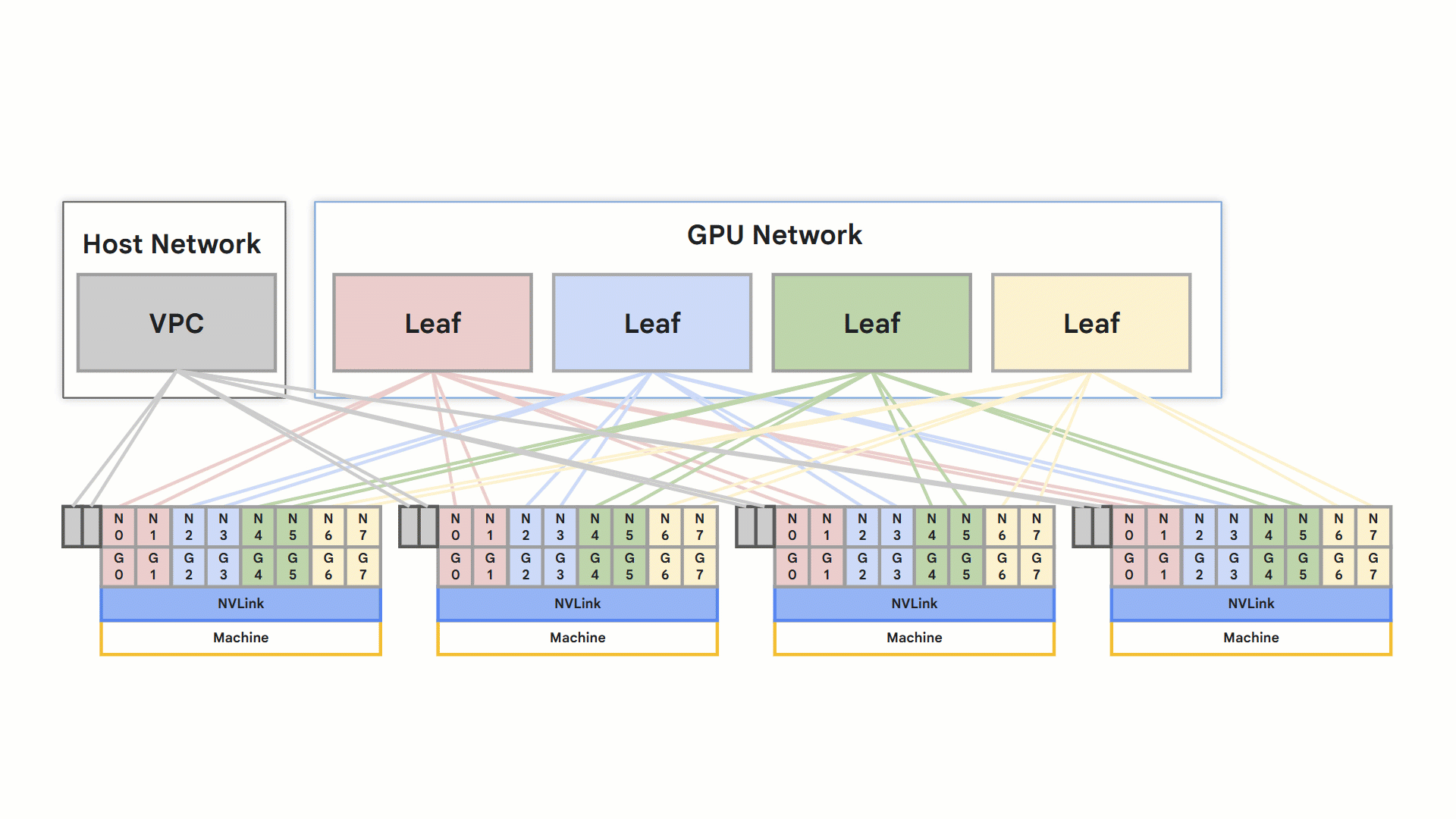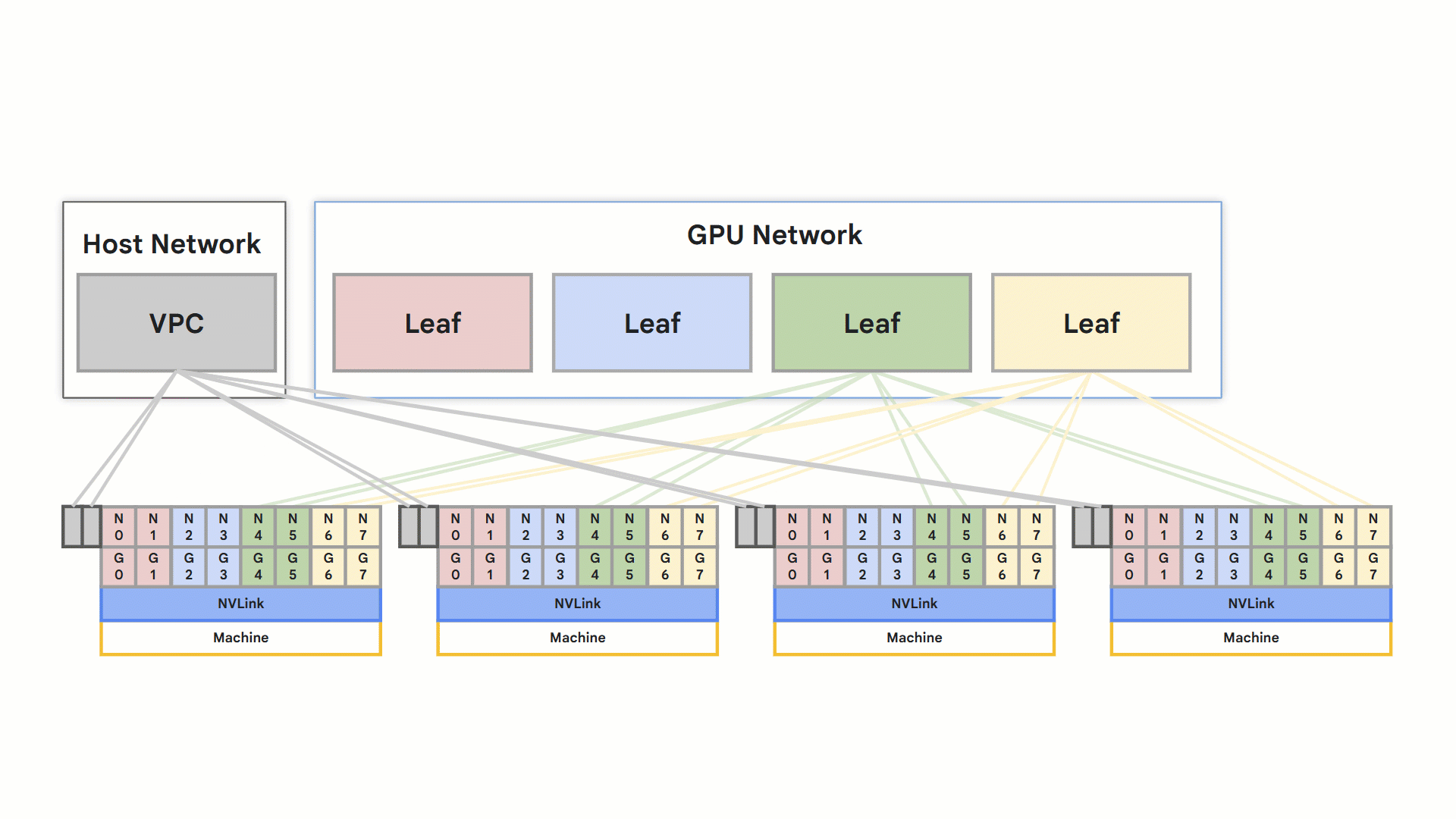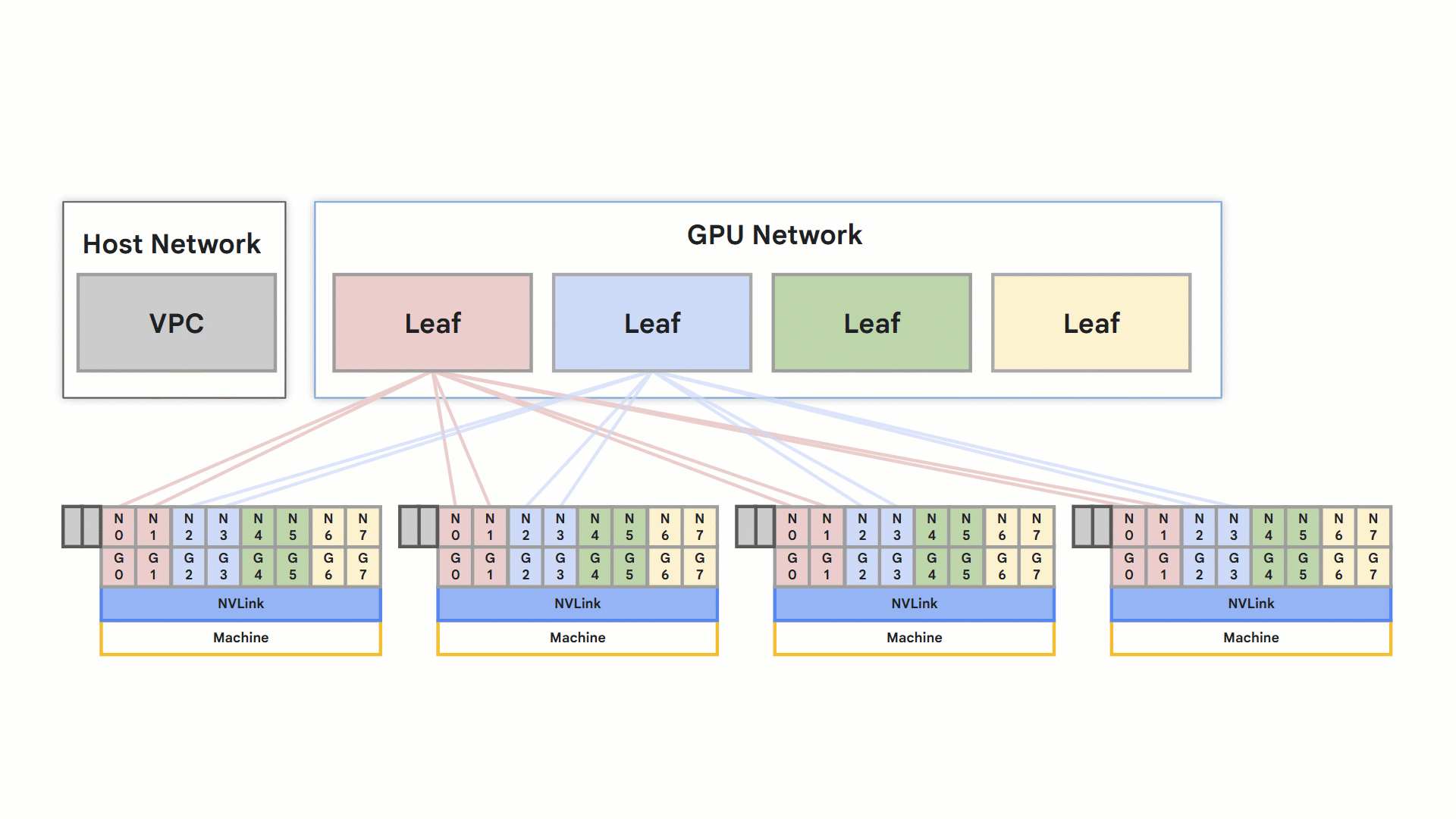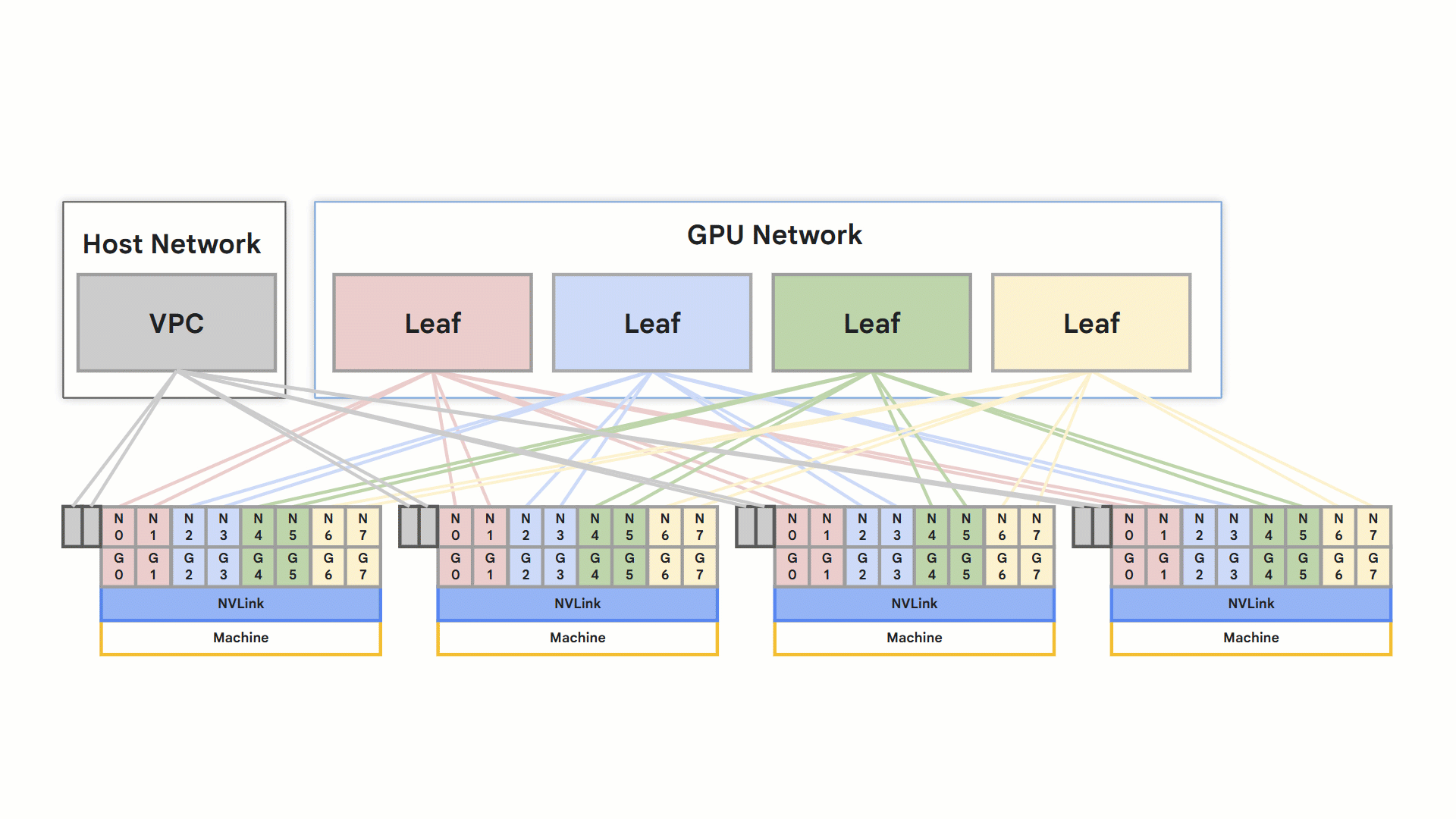
Overall these features result in faster training and inference, directly improving application speed. It’s achieved through a specialized VPC network, optimized for this purpose. This high-performance connectivity is a key differentiator for demanding applications.
Get started
To enable these capabilities, follow these steps:
-
Create a reservation: Obtain your reservation ID; you may have to work with your support team for capacity requests.
-
Choose a deployment strategy: Specify the deployment region, zone, network profile, reservation ID and method.
-
Create your deployment.
You can see the configuration steps and more in the following documentation:
-
Documentation: Hypercompute Cluster
-
GCT YouTube Channel: AI guide for Cloud Developers
Want to ask a question, find out more or share a thought? Please connect with me on Linkedin.
Read More for the details.

