GCP – Simplify creating data pipelines for media with Spotify’s Klio
On any given day, music streaming service Spotify might process an audio file a hundred different ways—identifying a track’s rhythm and tempo, timestamping beats, and measuring loudness—as well as more sophisticated processing, such as detecting languages and separating vocals from instruments. This might be done to develop a new feature, to help inform playlists and recommendations, or for pure research.
Doing this kind of processing on a single audio file is one thing. But Spotify’s music library is over 60 million songs, growing by 40,000 tracks a day, not including the rapidly expanding podcast catalog. Then, factor in that hundreds of product teams are processing these tracks at the same time, all around the world, and for different use cases. This scale and complexity—plus, the difficulty of handling large binary files to begin with—can hinder collaboration and efficiency, bringing product development to a grinding halt. That’s unless you have Klio.
What is Klio?
In order to productionize audio processing, Spotify created Klio—a framework built on top of Apache Beam for Python that helps researchers and engineers alike run large-scale data pipelines for processing audio and other media files (such as video and images). Spotify originally created Klio after realizing that ML and audio researchers across the company were performing similar audio processing tasks, but were struggling to deploy and maintain them. Spotify saw an opportunity to produce a flexible, managed process that would support a variety of audio processing use cases over time—efficiently and at scale—and got to work.
At a high level, Klio allows a user to provide a media file as input, perform the necessary processing, and output intelligent features and data. There are a multitude of possible use cases for audio alone, from standardizing common audio-processing tasks with ffmpeg or librosa to running custom machine learning models.
Klio simplifies and standardizes pipeline creation for these tasks, increasing efficiency and letting users focus on their business objectives rather than maintaining the processing infrastructure. Now that Klio has been released as open source, anyone can use the framework to build their own scalable and efficient media processing workflows.
How does Klio work?
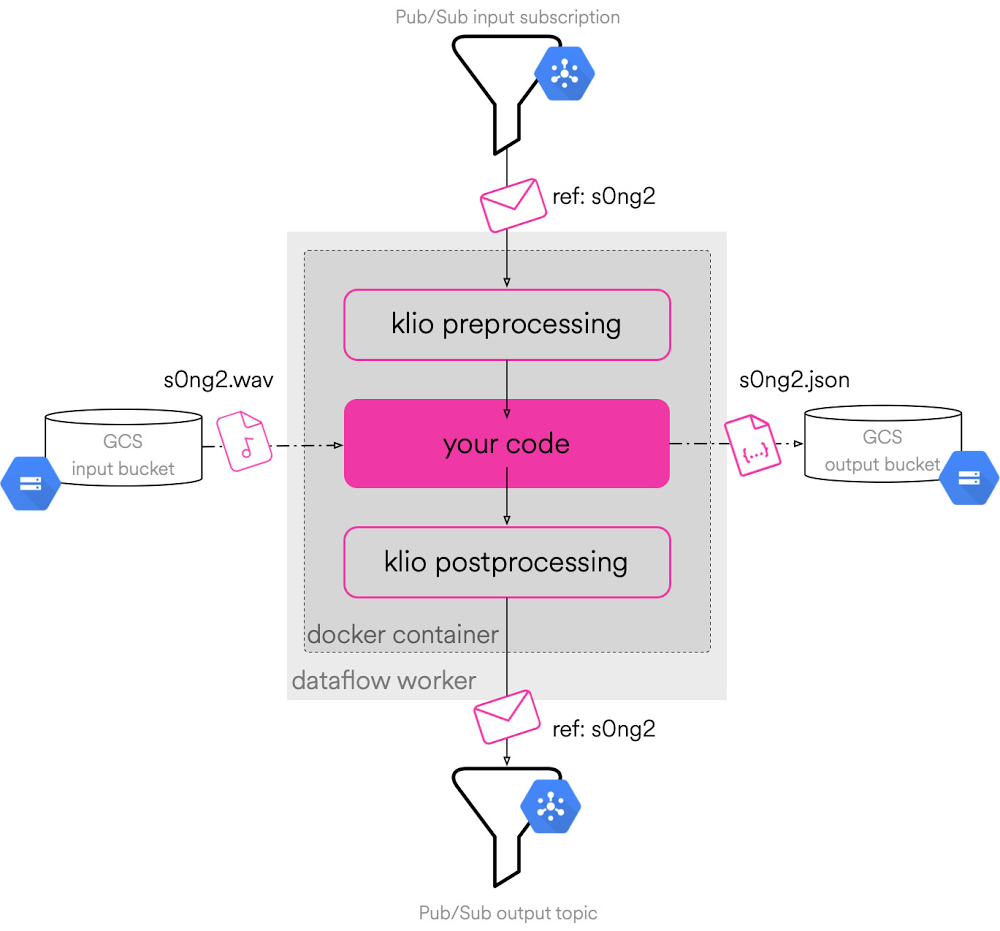
Klio currently enables a few key steps to create the desired pipeline. First, it assumes that the pipeline will accept a large binary file as input. This can be audio, images, or video. This file is stored in Cloud Storage. As part of this, the job sends a unique message to Pub/Sub, where it announces that a file has been uploaded. Klio then reads this message and downloads the file to begin processing. At this step, Klio can begin performing the necessary logic to intelligently process the desired outcome for the particular use case, such as language extraction. Once the processing is complete, it uploads its output artifact to another Cloud Storage bucket for storage. The overall orchestration of the whole pipeline is done by Apache Beam, which allows for a traditional Python interface for audio/ML users and traditional pipeline execution.
One of Klio’s key benefits is its support for directed acyclic graphs (DAGs), which allow users to configure dependent jobs and their order of execution so that a parent job can trigger corresponding children jobs.

In this example, there are three teams all relying on the same overall parent job, called Downsample. This downsampling adjusts the number of samples in an audio file to essentially compress the file to a specified rate that may be required for later jobs. As a result, now Team A, B, and C’s jobs may begin to launch their needed processing. This might be detecting the “speechiness” or amount of spoken word, “instrumentalness” or the lack of vocals, and much more.
Another key feature of Klio is its ability to optimize the order of execution. It’s not always efficient or necessary to run every Klio job in the graph for a given file. Maybe you want to iterate on your own job without triggering sibling or downstream jobs. Or you have a subset of your media catalogue that requires some backfill processing. Sometimes this means running the parent Klio jobs to fill in missing dependencies. With that, Klio supports bottom-up processing when needed, like this:

A Klio job will first check to see if work has already been processed for a given file. If so, work is skipped for that job. However, if the job’s input data is not available (i.e., if the Energy job does not have the output from the Beat Tracking job for a given audio), Klio will recursively trigger jobs within its direct line of execution without triggering work for sibling jobs.
What’s next for Klio?
This initial release of Klio represents two years of building, testing, and practical application by different teams all across Spotify. From the beginning, Klio was made with open source in mind.
With this overall architecture, users are free to add in their particular customizations as needed to cater to their requirements. Klio is cloud-agnostic, meaning that it can support a variety of runners, both locally and in the cloud. In Spotify’s case, this meant Google Cloud, using Apache Beam to call the Dataflow Runner. But it can be extended to other runners as well. If you’re interested in contributing back, they welcome more collaborations with the open source community.
While Klio was initially built for audio, it is capable of serving all types of media. At Spotify, they’ve already seen success in a variety of different internal use cases. Specifically, it separates the vocals and instruments to enable Sing Along functionality in Japan as well as fingerprints common audio attributes, such as “danceability” and “tempo,” in their Audio Features API. Based on the early success from these use cases, it will be exciting to see what other media processing problems Klio can help solve, whether it is enabling large-scale content moderation or performing object detection across large video streams.
How to get started
To learn more, read the rest of the Klio story on the Spotify Engineering blog. Or jump in and get started with Klio now.
Read More for the details.

