GCP – Scale up your EDA flows on Google Cloud with this simple setup
Companies embark on modernizing their infrastructure in the cloud for three main reasons: 1) to accelerate product delivery 2) to reduce system downtime and 3) to enable innovation. Chip designers with Electronic Design Automation (EDA) workloads share these goals, and can greatly benefit from using cloud.
Chip design and manufacturing includes several tools across the flow, with varied compute and memory footprints. Register Transfer Level (RTL) design and modeling is one of the most time consuming steps in the design process, accounting for more than half the time needed in the entire design cycle. RTL designers use Hardware Description Languages (HDL) such as SystemVerilog and VHDL to create a design which then goes through a series of tools. Mature RTL verification flows include static analysis (checks for design integrity without use of test vectors), formal property verification (mathematically proving or falsifying design properties), dynamic simulation (test vector-based simulation of actual designs) and emulation (a complex system that imitates the behavior of the final chip, especially useful to validate functionality of the software stack).
Dynamic simulation arguably takes up the most compute in any design team’s data center. We wanted to create an easy set up using Google Cloud technologies and open-source designs and solutions to showcase three key points:
-
How simulation can accelerate with more compute
-
How verification teams can benefit from auto-scaling cloud clusters
-
How organizations can effectively leverage the elasticity of cloud to build highly utilized technology infrastructure
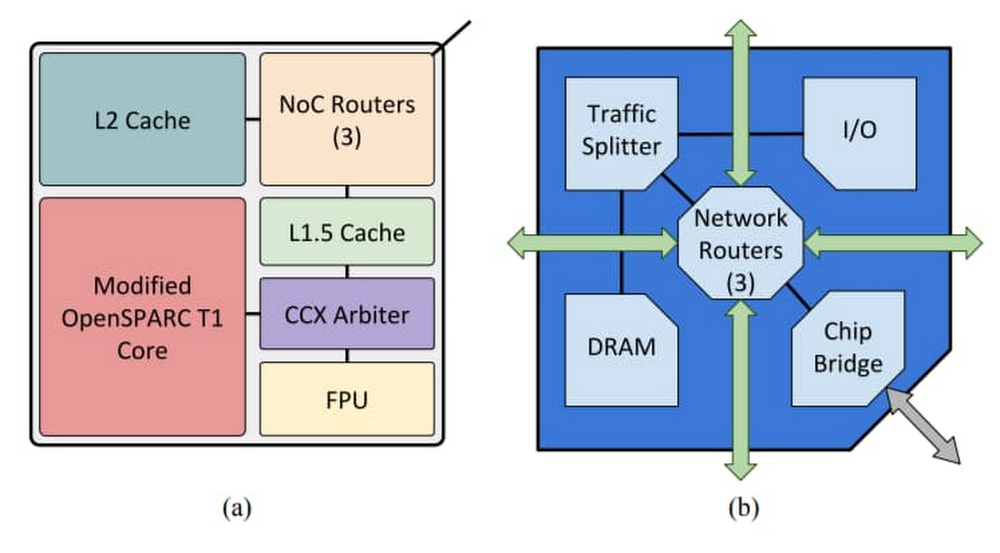
OpenPiton Tile architecture(a) and Chipset Architecture(b)
Source: OpenPiton: An Open Source Manycore Research Framework, Balkind et a
We did this using a variety of tools: We used the OpenPiton design verification scripts, Icarus Verilog Simulator, SLURM workload management solution and Google Cloud standard compute configurations.
-
OpenPiton is the world’s first open-source, general-purpose, multithreaded manycore processor and framework. Developed at Princeton University, it’s scalable and portable and can scale up to 500-million cores. It’s wildly popular within the research community and comes with scripts for performing the typical steps in the design flow, including dynamic simulation, logic synthesis and physical synthesis.
-
Icarus Verilog, sometimes known as iverilog, is an open-source Verilog simulation and synthesis tool.
Simple Linux Utility for Resource Management or SLURM is an open-source, fault-tolerant and highly scalable cluster management and job scheduling system for Linux clusters. SLURM provides functionality such as enabling user access to compute nodes, managing a queue of pending work, and a framework for starting and monitoring jobs. Auto-scaling of a SLURM cluster refers to the capability of the cluster manager to spin up nodes on demand and shut down nodes automatically after jobs are completed.
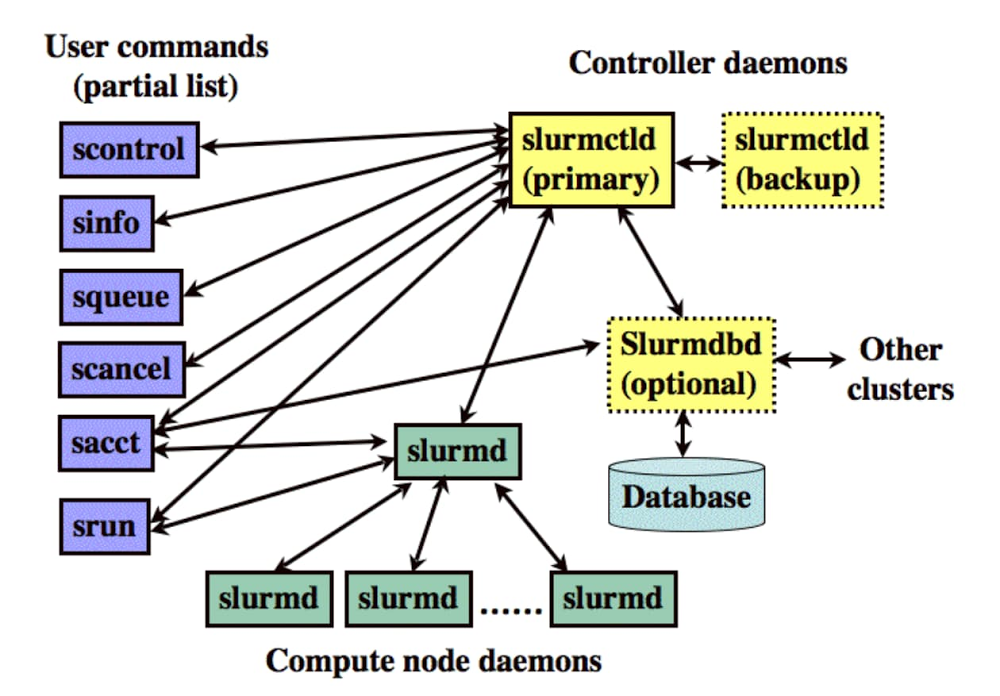
Setup
We used a very basic reference architecture for the underlying infrastructure. While simple, it was sufficient to achieve our goals. We used standard N1 machines (n1-standard-2 with 2 vCPUs, 7.5 GB memory), and set up the SLURM cluster to auto-scale to 10 compute nodes. The reference architecture is shown here. All required scripts are provided in this github repo.
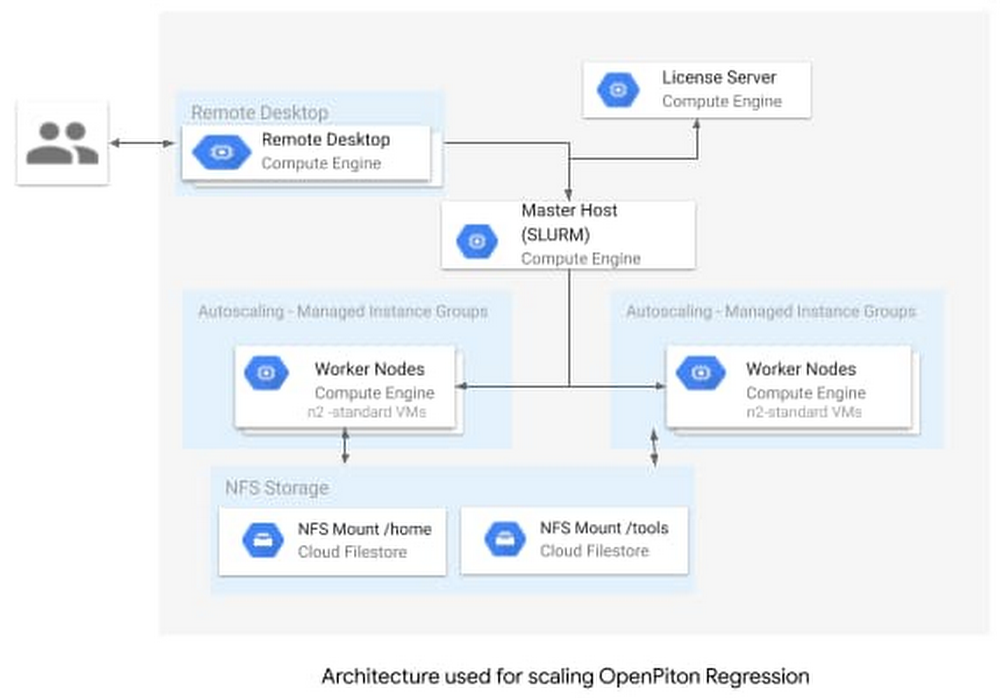
Running the OpenPiton regression
The first step in running the OpenPiton regression is to follow the steps outlined in the github repo and complete the process successfully.
The next step is to download the design and verification files. Instructions are provided in the github repo. Once downloaded, there are three simple setup tasks to perform:
-
Set up the PITON_ROOT environment variable (%export PITON_ROOT=<location of root of OpenPiton extracted files>)
-
Set up the simulator home (%export ICARUS_HOME=/usr). The scripts provided to you in the github repo already take care of installing Icarus on the machines provisioned. This shows yet another advantage of cloud: simplified machine configuration.
-
Finally, source your required settings (%source $PITON_ROOT/piton/piton_settings.bash)
For the verification run, we used the single tile setup for OpenPiton, the regression script ‘sims’ provided in the OpenPiton bundle and the ‘tile1_mini’ regression. We tried two runs—sequential and parallel. The parallel runs were managed by SLURM.
We invoked the sequential run using the following command:
%sims -sim_type=icv -group=tile1_mini
And the distributed run using this command:
%sims -sim_type=icv -group=tile1_mini -slurm -sim_q_command=sbatch
Results
The ‘tile1_mini’ regression has 46 tests. Running all 46 tile1_mini tests sequentially took an average of 120 minutes. The parallel run for tile1_mini with 10 auto-scaled SLURM nodes completed in 21 minutes—a 6X improvement!
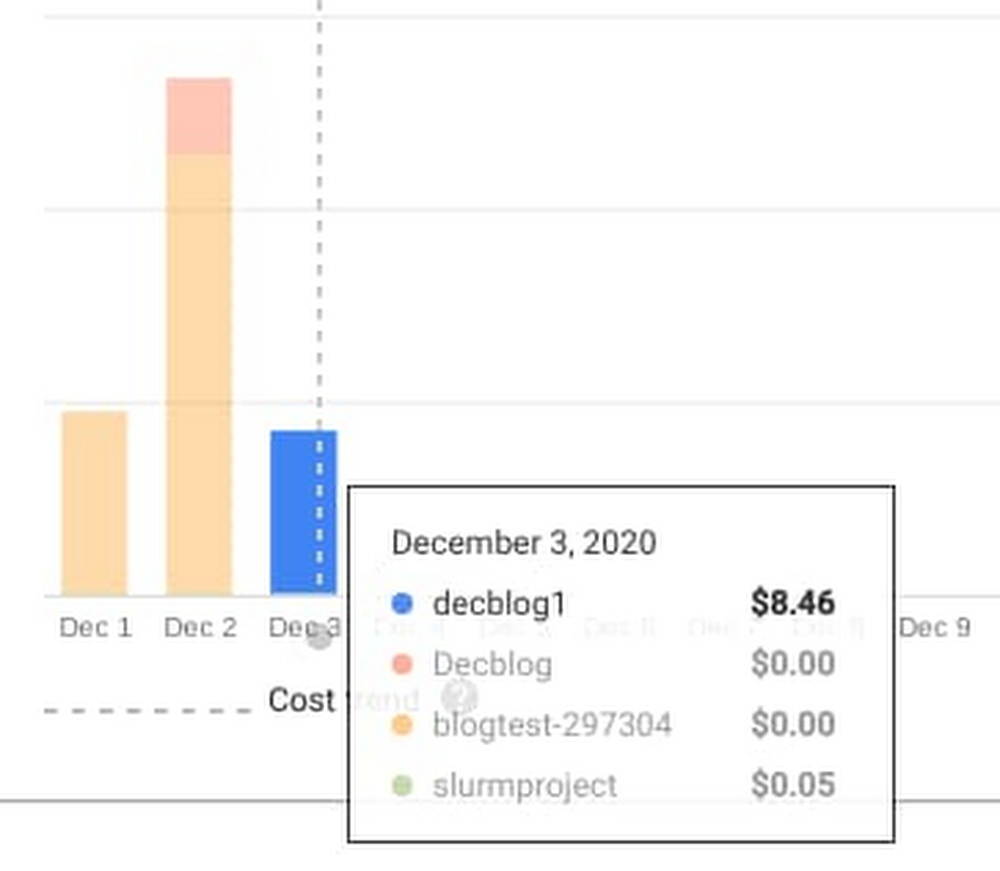
Further, we wanted to also highlight the value of autoscaling. The SLURM cluster was set up with two static nodes, and 10 dynamic nodes. The dynamic nodes were up and active quite soon after the distributed run was invoked. Since the nodes are shut down if there are no jobs, the cluster auto-scaled to 0 nodes after the run was complete. The additional cost of the dynamic nodes for the time of the simulation was $8.46.
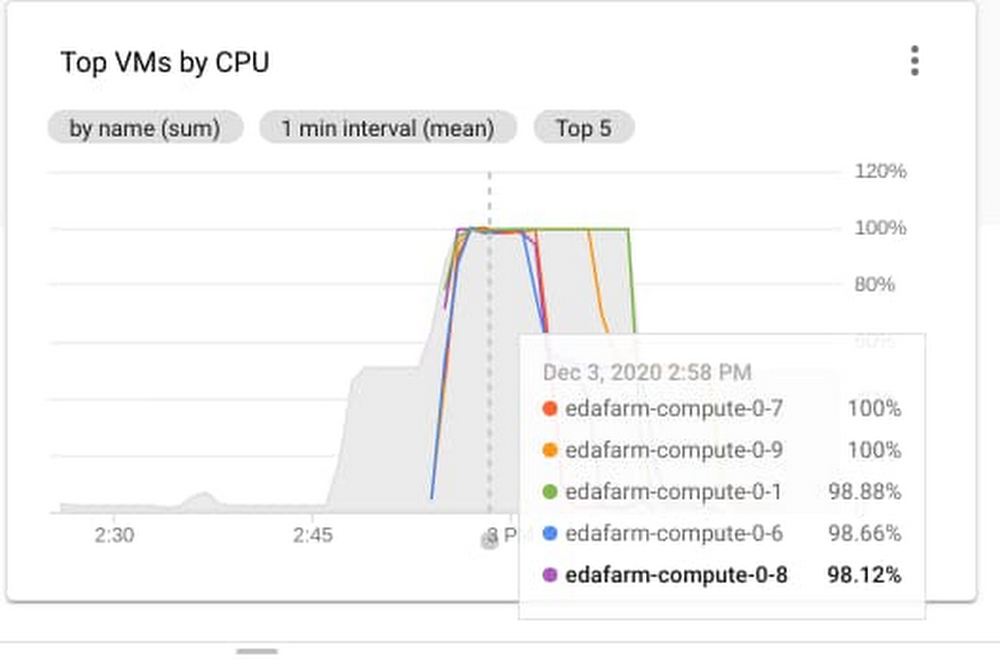
The above example shows a simple regression run, with very standard machines. By providing the capability to scale to more than 10 machines, further improvements in turnaround time can be achieved. In real-life, it is common for project teams to run millions of simulations. By having access to elastic compute capacity, you can dramatically reduce the verification process and shave months off verification sign-off.
Other considerations
Typical simulation environments use commercial simulators that extensively leverage multi-core machines and large compute farms. When it comes to Google Cloud infrastructure, it’s possible to build many different machine types (often referred to as “shapes”) with various numbers of cores, disk types, and memory. Further, while a simulation can only tell you whether the simulator ran successfully, verification teams have the subsequent task of validating the results of a simulation. Elaborate infrastructure that captures the simulation results across simulation runs—and provides follow-up tasks based on findings—is an integral part of the overall verification process. You can use Google Cloud solutions such as Cloud SQL and BigTable to create a high-performance, highly scalable and fault-tolerant simulation and verification environment. Further, you can use solutions such as AutoML Tables to infuse ML into your verification flows.
Interested? Try it out!
All the required scripts are publically available—no cloud experience is necessary to try them out. Google Cloud provides everything you need, including free Google Cloud credits to get you up and running. Click here to learn more about high performance computing (HPC) on Google Cloud.
Read More for the details.

