
GCP – New column-granularity indexing in BigQuery offers a leap in query performance
BigQuery delivers optimized search/lookup query performance by efficiently pruning irrelevant files. However, in some cases, additional column information is required for search indexes to further optimize query performance. To help, we recently announced indexing with column granularity, which lets BigQuery pinpoint relevant data within columns, for faster search queries and lower costs.
BigQuery arranges table data into one or more physical files, each holding N rows. This data is stored in a columnar format, meaning each column has its own dedicated file block. You can learn more about this in the BigQuery Storage Internals blog. The default search index is at the file level, which means it maintains mappings from a data token to all the files containing it. Thus, at query time, the search index helps reduce the search space by only scanning those relevant files. This file-level indexing approach excels when search tokens are selective, appearing in only a few files. However, scenarios arise where search tokens are selective within specific columns but common across others, causing these tokens to appear in most files, and thus diminishing the effectiveness of file-level indexes.
For example, imagine a scenario where we have a collection of technical articles stored in a simplified table named TechArticles with two columns — Title and Content. And let’s assume that the data is distributed across four files, as shown below.

Our goal is to search for articles specifically related to Google Cloud Logging. Note that:
-
The tokens “google”, “cloud”, and “logging” appear in every file.
-
Those three tokens also appear in the “Title” column, but only in the first file.
-
Therefore, the combination of the three tokens is common overall, but highly selective in the “Title” column.
Now, let’s say, we create a search index on both columns of the table with the following DDL statement:
CREATE SEARCH INDEX myIndex ON myDataset.TechArticles(Title, Content);The search index stores the mapping of data tokens to the data files containing the tokens, without any column information; the index looks like the following (showing the three tokens of interest: “google”, “cloud”, and “logging”):

With the usual query SELECT * FROM TechArticles WHERE SEARCH(Title, "Google Cloud Logging"), using the index without column information, BigQuery ends up scanning all four files, adding unnecessary processing and latency to your query.
- aside_block
- <ListValue: [StructValue([(‘title’, ‘$300 in free credit to try Google Cloud data analytics’), (‘body’, <wagtail.rich_text.RichText object at 0x3e4f83a65a00>), (‘btn_text’, ‘Start building for free’), (‘href’, ‘http://console.cloud.google.com/freetrial?redirectPath=/bigquery/’), (‘image’, None)])]>
Indexing with column granularity
Indexing with column granularity, a new public preview feature in BigQuery, addresses this challenge by adding column information in the indexes. This lets BigQuery leverage the indexes to pinpoint relevant data within columns, even when the search tokens are prevalent across the table’s files.
Let’s go back to the above example. Now we can create the index with COLUMN granularity as follows:
CREATE SEARCH INDEX myIndex ON myDataset.TechArticles(Title, Content)
OPTIONS (default_index_column_granularity = 'COLUMN');The index now stores the column information associated with each data token. The index is as follows:
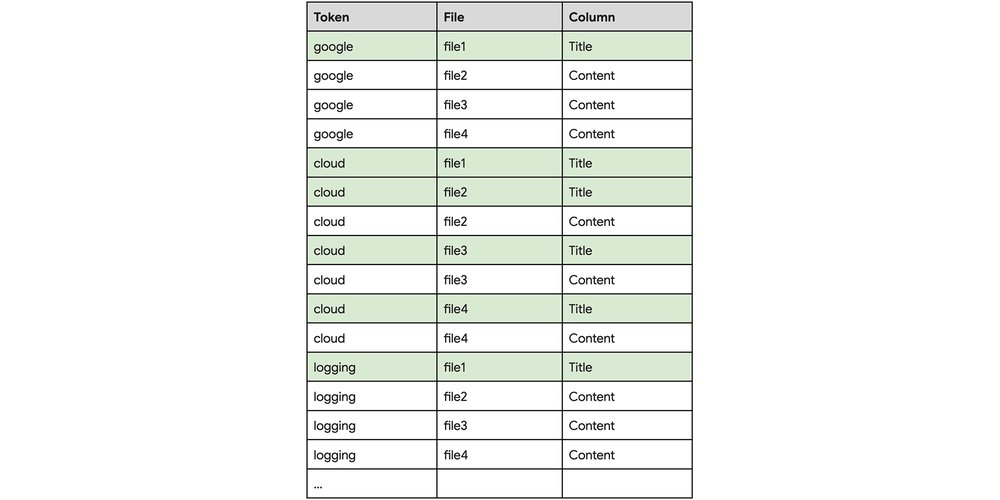
Using the same query SELECT * FROM TechArticles WHERE SEARCH(Title, "Google Cloud Logging") as above but using the index with column information, BigQuery now only needs to scan file1 since the index lookup is the intersection of the following:
-
Files where Token=’google’ AND Column=’Title’ (file1)
-
Files where Token=’cloud’ AND Column=’Title’ (file1, file2, file3, and file4)
-
Files where Token’=’logging’ AND Column=’Title’ (file1).
Performance improvement benchmark results
We benchmarked query performance on a 1TB table containing Google Cloud Logging data of an internal Google test project with the following query:
SELECT COUNT(*)
FROM `dataset.log_1T`
WHERE SEARCH((logName, trace, labels, metadata), 'appengine');In this benchmark query, the token ‘appengine’ appears infrequently in the columns used for query filtering, but is more common in other columns. The default search index already helped reduce a large portion of the search space, resulting in half the execution time, reducing processed bytes and slot usage. By employing column granularity indexing, the improvements are even more significant.

In short, column-granularity indexing in BigQuery offers the following benefits:
-
Enhanced query performance: By precisely identifying relevant data within columns, column-granularity indexing significantly accelerates query execution, especially for queries with selective search tokens within specific columns.
-
Improved cost efficiency: Index pruning results in reduced bytes processed and/or slot time, translating to improved cost efficiency.
This is particularly valuable in scenarios where search tokens are selective within specific columns but common across others, or where queries frequently filter or aggregate data based on specific columns.
Best practices and getting started
Indexing with column granularity represents a significant advancement in BigQuery’s indexing capabilities, letting you achieve greater query performance and cost efficiency.
For best results, consider the following best practices:
-
Identify high-impact columns: Analyze your query patterns to identify columns that are frequently used in filters or aggregations and would benefit from column-granularity indexing.
-
Monitor performance: Continuously monitor query performance and adjust your indexing strategy as needed.
-
Consider indexing and storage costs: While column-granularity indexing can optimize query performance, be mindful of potential increases in indexing and storage costs.
To get started, simply enable indexing with column granularity. For more information, refer to the CREATE SEARCH INDEX DDL documentation.
Read More for the details.

