
GCP – Improving Bigtable single-row read throughput by 70%: How we did it
As a scalable, distributed, high-performance, Cassandra- and HBase-compatible NoSQL database, Bigtable processes more than 5 billion sustained queries per second and has more than 10 Exabytes of data under management. At this scale, we optimize Bigtable for high-throughput and low-latency reads and writes.
In a previous blog post, we shared details of how our single-row read projects delivered 20-50% throughput improvements while maintaining low latency. Since then, we’ve continued to innovate on our single-row read performance, delivering a further 50% throughput improvement. These improvements are immediately available and are reflected in our updated performance metrics: Bigtable now supports up to 17,000 point reads per second. This increases Bigtable’s read throughput by up to 1.7x, or 7,000 point reads per second from our 10k point reads per second baseline at no additional cost to you (see figure 2).

Figure 2. Single-row read throughput improvements over time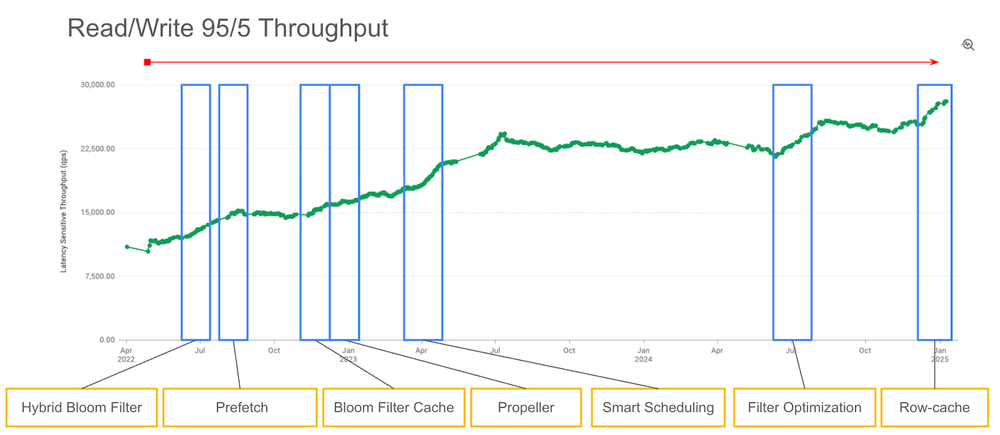
And thanks to Bigtable’s linear scaling, clusters of all sizes, from a single node through to thousands of nodes, benefit equally from this performance.
For example, Stairwell leverages Bigtable performance for their cybersecurity workload. Their largest table has over 328 million rows and column counts ranging from 1 to 10,000. This table stores hundreds of billions of data points all while maintaining an average read latency of just 1.9 milliseconds and maxing out at 4 milliseconds.
Spotify uses Bigtable to support many of their critical systems, and at Google Cloud Next ’25, presented about how they solve real-time AI challenges with Bigtable and BigQuery in its music recommendation engine. As a long term partner, Spotify has seen the value impact of recent Bigtable performance improvements over time.

“We’ve noticed the incremental throughput improvements over time, resulting in reduced node count when using Bigtable autoscaling. This means less cost for us, along with the improved performance.” – Ygor Barboza, Engineer, Spotify
Where we look for performance gains
Here on the Bigtable team, we continue to seek out opportunities to evolve and improve performance to meet customer expectations and business objectives. Let’s take a look at how we approach the problem.
1. Performance research and innovation
We use a suite of benchmarks to continuously evaluate Bigtable’s performance. These represent a broad spectrum of workloads, access patterns and data volumes that we see across the fleet. Benchmark results give us a high-level view of performance improvement opportunities, which we then enhance using sampling profilers and pprof for analysis. Building on the insights and successes from our work in 2023, we identify larger and more complex opportunities detailed below.
2. Improved caching for read performance
Like many high performance systems, Bigtable caches frequently accessed data in DRAM to achieve high throughput and low latency. This low-level cache holds SSTable data blocks which reduces I/O costs associated with block retrieval from Colossus. The cache operates at the same abstraction layer as disk access, so request processing requires block-centric traversal of the in-memory data structures to build a full-stack row result from the log-structured merge tree SSTable stack (see figure 3).
Figure 3. Block-centric traversal of the in-memory SSTable stack data structures
This caching strategy works well in the general case and has been a pillar of Bigtable’s read throughput performance. However, in use cases where specific row-key queries are more frequent than other key ranges in a block, it can be advantageous to reduce block processing overhead for those rows. This can be especially beneficial for access patterns that read many blocks but return only a fraction of the data:
-
Reading the latest values from columns with frequent write traffic, i.e., high SSTable stack depth
-
Reading a row with many columns where the width of the row spans many blocks
Bigtable’s new row cache builds on the block cache to cache data at row granularity. This reduces CPU usage by up to 25% for point read operations. In contrast to cached block storage, cached rows use a sparse representation of the block data, maintaining only the data accessed by a query within any row. This format allows queries to reuse row-cache data so long as the cached row contains the required data. In the event that a new query requires data that is not present in the cache entry, the request falls back to block reads and populates the row cache structure with the missing data.
Both row and block caches share the same memory pool and employ an innovative eviction algorithm to optimize performance across a diverse set of query types, balancing block caching for breadth of response versus row caching for high-throughput access to the most frequently accessed data. Row caching also considers row size in its storage optimization algorithm to maintain high cache hit rates.
Figure 4. Read request row cache lifecycle and population
3. Single-row read operation efficiency
Single-row read operations, Bigtable’s most common access pattern, are key to many critical serving workloads. To complement the throughput improvements delivered by the row-cache, we took further opportunities to tune the single-row read path and deliver larger throughput gains.
The complexity of processing queries for a single row versus row ranges can be substantial. Row-range queries can involve high levels of fan-out with RPCs to many tablet servers and complex async processing to merge the results into a single client response. For point operations, this complexity can be bypassed as the read is handled by one node, allowing the associated CPU overhead to be reduced. More efficient point operations led to a 12% increase in throughput. Further, we introduced a new query optimizer step that streamlined 50% of point-read filter expressions into more efficient queries.
4. Scheduler improvements
In addition to internal database performance enhancements, we’ve added user-driven throughput improvements for point operations. These are enabled via user-configurable app-profile prioritization, made possible by the launch of request priorities. Users can annotate their most important traffic with a scheduling priority, which can bring higher throughput and lower latency to that traffic versus lower priority traffic. We built this feature to improve Bigtable’s support for hybrid transactional/analytical processing (HTAP) workloads after researching how to improve isolation between transactional operations, typically single row reads, and analytical operations, which are complex queries with multi-row results. This work identified two core opportunities for Bigtable’s scheduling algorithm:
-
Introduction of request prioritization primitives, allowing users to specify the priority of requests on a per application profile basis
-
Smarter scheduling of operations to reduce point operation latency
5. Request prioritization
Request priorities allow the addition of a per application profile priority to be set, allowing Bigtable to more effectively prioritize incoming queries between application profiles. Bigtable supports three different priority levels:
-
PRIORITY_HIGH
-
PRIORITY_MEDIUM
-
PRIORITY_LOW
As might be expected, application profiles with PRIORITY_HIGH are given higher scheduling priority than application profiles with PRIORITY_MEDIUM or PRIORITY_LOW. This improves throughput and latency consistency on the PRIORITY_HIGH application profiles. In the context of HTAP workloads, transactional traffic can be run at a higher-priority application profile and analytical work can be performed with a low or even medium priority, protecting the latency profile (and in particular the p99 latency) of the serving workload from elevating — especially during periods of CPU-intensive batch/analytical processing.
The diagram below illustrates how request profiles may prioritize operations. This is simplified to avoid the complexities of our multithreaded parallel execution environments.

6. Point-operation scheduling
Multiple application profiles within a single cluster can have the same request priority, and within a single application profile there can be a mix of traffic types. With this in mind, we worked to improve latency between operations at a single priority level by introducing scheduling improvements that aim to distribute CPU time in a more balanced manner across all operations types. Consider an HTAP workload that has complex analytical operations interleaved with point operations. If that workload contains an equal number of point operations and complex operations, complex operations may use a disproportionately large amount of CPU within a given time window, which can increase point-operation latency, as those operations remain queued behind larger and more complex operations. This helps to protect the latency profile of point operations by continuously monitoring operation execution time and adding yield points to long-running operations. This allows point operations to interleave with long-running operations (as shown below).

A commitment to Bigtable performance
Our dedicated focus on performance over the past few years has yielded significant results, delivering up to 1.7x single-row read throughput gains while crucially maintaining the same low-latency profile. What this means in practice is that each Bigtable node can now handle 70% more traffic than before, allowing you to improve cluster efficiency and manage workloads without compromising responsiveness. We’re incredibly excited about these advancements and remain committed to continuously evolving Bigtable to push the boundaries of its core performance characteristics. You can learn more about Bigtable performance and find resources for testing and troubleshooting in our documentation.
Give Bigtable a try today and make sure you check out newly announced product capabilities:
Read More for the details.

