
GCP – How Virgin Media O2 uses data contracts to enable trusted data and scalable AI products
As organizations scale their data and AI capabilities, many are adopting federated data architectures to empower domain teams, accelerate innovation, and foster ownership. This decentralization is essential for building AI products that are adaptable and data-driven — but it also introduces new challenges: maintaining trust, ensuring data quality, and enforcing governance across distributed teams and systems.
At Virgin Media O2 (VMO2), in collaboration with Google Cloud, we’ve developed a robust and scalable approach to address these challenges: data contracts. These contracts serve as the data quality and assurance layer for our data products, ensuring that every dataset we publish is reliable, documented, and ready for consumption. Defined at the asset level, such as individual BigQuery tables or Google Cloud Storage buckets, data contracts are redefining how we manage and share data, enabling the creation of trusted and scalable AI products across our data mesh.
A data contract acts as a formal, machine-readable agreement between a data producer and its users. It serves as an explicit interface, defining the data’s expected characteristics, including its schema, semantics, data quality metrics, and Service Level Objectives (SLOs) like freshness and completeness. See below an example of a data contract that we construct.

The power of this approach lies in moving beyond static documentation. Because they are machine-readable, data contracts become living guarantees with continuous enforcement and real-time validation directly within data pipelines. This proactive monitoring allows teams to detect schema changes or SLA breaches early, transforming data quality from a reactive fix into a scalable, automated mechanism. By embedding product thinking, this methodology elevates data from a simple byproduct to a first-class data product, ensuring that its context and intent travel with it through the data lifecycle. This creates the trusted foundation essential for building reliable AI products at scale.
Practical implementation
To put these principles into practice, we designed a scalable platform on Google Cloud using a hub-and-spoke data contracts solution. This architecture balances centralized governance with federated ownership. A central “Hub” team provides the self-service data contract capabilities including cloud infrastructure, while departmental “Spoke” teams are empowered to own the contract and data quality for their data products.
This is all brought to life through a fully automated, GitOps-driven workflow. A data producer simply can define their data contract in a YAML file for different types of assets like BigQuery table or Google Cloud Storage bucket, and commit it to a GitLab repository. The data contract is then verified dynamically against customizable validation schemas. However, even after validation, the contract exists only as a static blueprint. This is where Dataplex Universal Catalog becomes the key, acting as the engine that transforms this static declaration into enforceable agreement on the actual data.
Dataplex Universal Catalog is an intelligent data fabric that unifies data management and governance, providing the scalable engine needed to operationalize our contracts. We leverage two core capabilities of Dataplex Universal Catalog to make this possible:
-
Dataplex auto data quality: This is the enforcement engine. Our CI/CD automation reads the SLOs from the YAML contract and provision Data Quality Scan jobs. These jobs use a combination of Dataplex’s powerful pre-defined rules for common checks like
null valuemonitoring and schema change detection, as well as custom rules to enforce unique business logic. This “Data Governance as Code” approach ensures our quality standards are version-controlled, repeatable, and scalable. -
Dataplex data profiling: To help teams write effective contracts, we use Dataplex to continuously scan and analyze data assets. This provides vital statistical metadata and insights into the data, such as null frequencies, value ranges, and data type distributions. This proactive data discovery helps producers set realistic quality thresholds and gives users a deeper understanding of the data they are using.
Once these rules and scans are defined in Dataplex, Cloud Composer then orchestrates their execution. It uses the static YAML contracts as a blueprint to dynamically generate the necessary DAGs, which can be further customized for each individual asset. The results are written to BigQuery, making the quality status of every data product transparent and actionable. To provide a unified view for central monitoring, BigQuery authorized views are used to aggregate data quality results and contract statuses from all departments without creating data copies. We also leverage Pub/Sub as an event bus to enable the central team to share department-specific data with respective Spokes.
The diagram below illustrates this workflow in practice, focusing on the core lifecycle of a contract while simplifying the broader hub-and-spoke architecture.
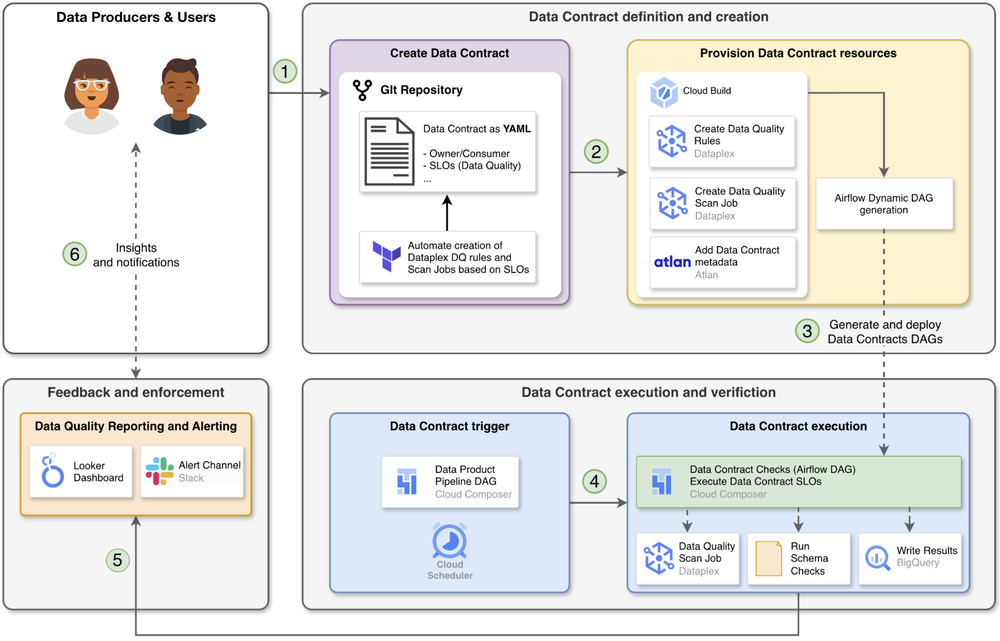
To maintain trust at scale, real-time observability and alerting are vital. Our platform provides dashboards that track contract compliance, while automated alerts flag schema drift, SLA violations, or quality anomalies. For data users, this transparency is critical. They reference the contract definitions to clearly understand the agreed-upon SLOs (such as freshness or completeness) and rely on the dashboards to verify that the data product is meeting those promises before integrating it into their workflows. These signals create powerful feedback loops between data producers and users, fostering faster resolution and closer collaboration.
This real-time visibility transforms data quality from a reactive activity into a proactive practice. As shown in our dashboards, teams get an immediate overview of platform health, data quality scores, and contract compliance.


Furthermore, they can drill down into specific alerts, giving them the context needed to treat data issues with the same urgency as application outages — a critical step in achieving operational excellence for AI and analytics.
Beyond quality: Compliance, governance, and data-product thinking
Beyond data quality, contracts play a crucial role in compliance and governance. By codifying privacy and regulatory requirements — such as GDPR, HIPAA, or PCI — directly within the contract, organizations can automate classification, access control, and auditability. This reduces the risk of non-compliance, especially in federated environments where manual oversight cannot scale.
Finally, product thinking ties everything together. Data contracts embody the mindset that data is a product, not a byproduct. They embed ownership, accountability, and discoverability into every stage of the lifecycle — empowering teams to deliver trusted, scalable, and resilient AI products.
A foundation for the future
By operationalizing trust through data contracts, we are fostering a culture of shared responsibility and data-first thinking. This federated model does more than simply fix pipelines; it builds the trusted foundation needed to scale next-generation AI. It ensures that the resilient AI tools empowering our teams are built on data that is reliable, consistent, and well-defined. As we innovate, our decisions are guided by trusted information. And while full realization takes time, the strategic impact is clear.
Learn more about Dataplex Universal Catalog to explore this use case.
The authors would like to thank and recognise the team for their contributions on this project: Eric Tyree, Director, Machine Learning Operations & Data Science at VMO2, Vinay Pai, Head of Data Architecture at VMO2, Shivang Bhargava, Senior Cloud Data Engineer at VMO2, Christopher Slattery, Data Engineer at VMO2, Rakesh Agrwal, Product Manager at VMO2, Sameer Zubair, Principal Platforms Tech lead at VMO2, Philip Adler Senior Software Engineer at VMO2, Carys Williams Data Scientist at VMO2, Li Wang Data Engineer at VMO2, Sobhan Afroosheh, Customer Engineer at Google, Janos Bana, Technical Solutions Consultant, Google.
Read More for the details.

