GCP – How to trigger Cloud Run actions on BigQuery events
Many BigQuery users ask for database triggers—a way to run some procedural code in response to events on a particular BigQuery table, model, or dataset. Maybe you want to run an ELT job whenever a new table partition is created, or maybe you want to retrain your ML model whenever new rows are inserted into the table.
In the general category of “Cloud gets easier”, this article will show how to quite simply and cleanly tie together BigQuery and Cloud Run. Because if you love BigQuery and you love Cloud Run, how can you not love when they get together?!
Cloud Run will be triggered when BigQuery writes to its audit log. Every data access in BigQuery is logged (there is no way to turn it off), and so all that we need to do is to find out the exact log message that we are looking for.
Follow along with me.
Find the BigQuery event
I’m going to take a wild guess here and assume that you don’t want to muck up your actual datasets, so create a temporary dataset named cloud_run_tmp in your project in BigQuery.
In that project, let’s create a table into which we will insert some rows to try things out. Grab some rows from a BigQuery public dataset to create this table:
Then, run the insert query that we want to build a database trigger for:
Now, in another Chrome tab, click on this link to filter for BigQuery audit events in Cloud Logging.
I found this event:
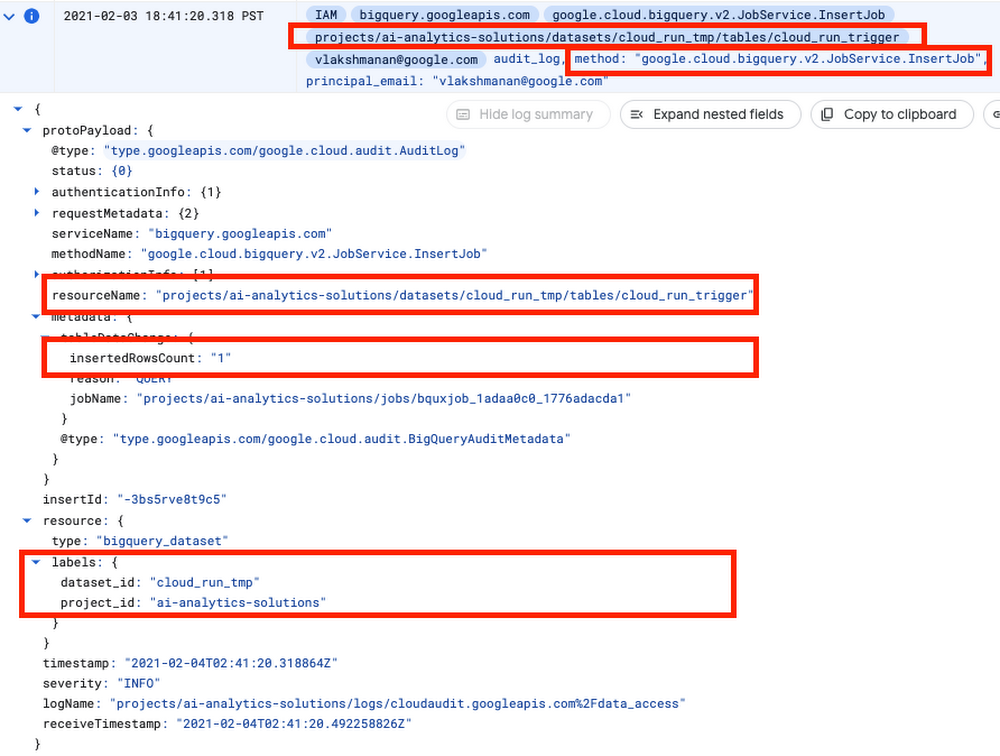
Note that there will be several audit logs for a given BigQuery action. In this case, for example, when we submit a query, a log will be generated immediately. But only after the query is parsed does BigQuery know which table(s) we want to interact with, so the initial log will not have the table name. Keep in mind that you don’t want any old audit log… make sure to look for a unique set of attributes that clearly identifies your action.
In the case of inserting rows, this is the combination:
- The method is
google.cloud.bigquery.v2.JobService.InsertJob - The name of the table being inserted to is the
protoPayload.resourceName - The dataset id is available as
resource.labels.dataset_id - The number of inserted rows is
protoPayload.metadata.tableDataChanged.insertedRowsCount
Write the Cloud Run Action
Now that we know the payload that we are looking for, we can write the Cloud Run action. Let’s do it in Python as a Flask App (full code is on GitHub).
First, we make sure that this is the event we want to process:
Once we have identified that this is the event we want, then we carry out the action that we want to do. Here, let’s do an aggregation and write out a new table:
The Dockerfile for the container is simply a basic Python container into which we install Flask and the BigQuery client library:
Deploy Cloud Run
Build the container and deploy it using a couple of gcloud commands:
Setup Event Trigger
In order for the trigger to work, the service account for Cloud Run will need a couple of permissions:
Finally create the event trigger:
The important thing to note is that we are triggering on any Insert log created by BigQuery. That’s why, in the action, we had to filter these events based on the payload.
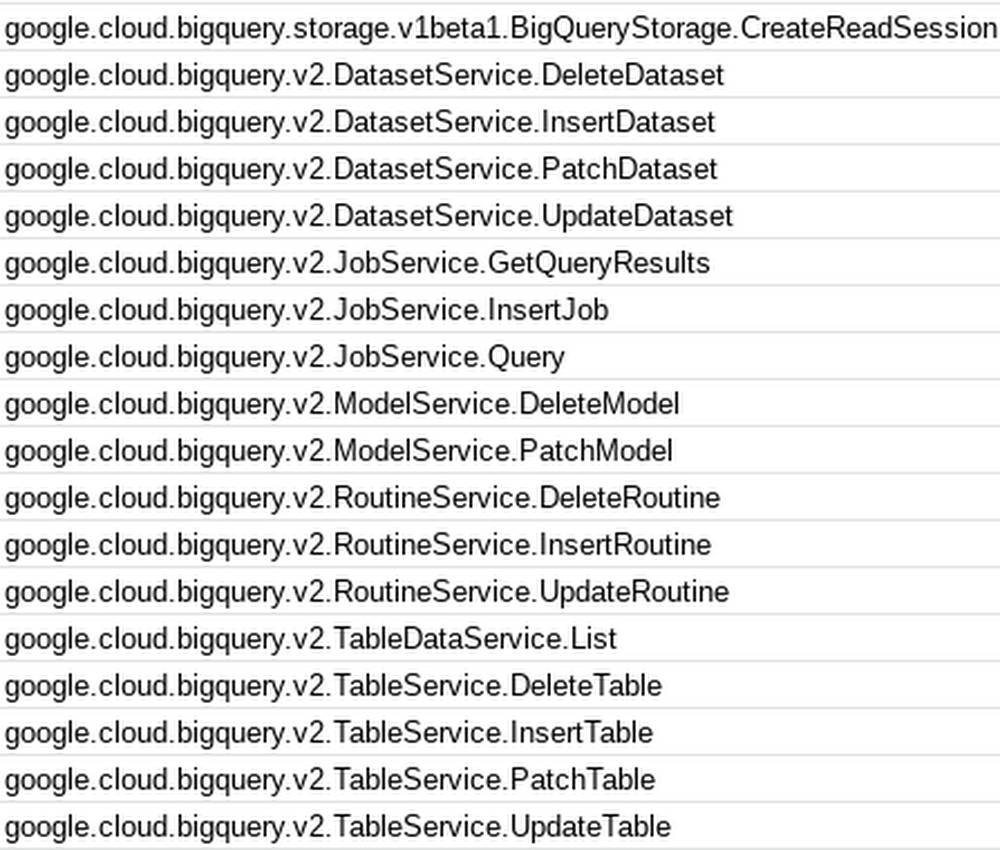
What events are supported? An easy way to check is to look at the Web Console for Cloud Run. Here are a few to get your mind whirring:
Try it out
Now, try out the BigQuery -> Cloud Run trigger and action. Go to the BigQuery console and insert a row or two:
Watch as a new table called created_by_trigger gets created! You have successfully triggered a Cloud Run action on a database event in BigQuery.
Enjoy!
Resources
- All the code, along with a README with instructions, is on GitHub.
- This blog post is an update to the book BigQuery: The Definitive Guide. My goal is to update the book contents approximately once a year, and provide updates in the form of blogs like this.
- You can find previous such update blogs linked from the GitHub repository of the book.
Thanks to Prashant Gulati.
Read More for the details.

