
GCP – How to enable real time semantic search and RAG applications with Dataflow ML
Embeddings are a cornerstone of modern semantic search and Retrieval Augmented Generation (RAG) applications. In short, they enable applications to understand and interact with information on a deeper, conceptual level. In this post, we’ll show you how to create and retrieve embeddings with a few lines of Dataflow ML code to enable both of these use cases. We will cover streaming and batch approaches for generating embeddings and storing them in vector databases such as AlloyDB to power semantic search and RAG applications with their vector search capabilities.
- aside_block
- <ListValue: [StructValue([(‘title’, ‘Get started with a 30-day AlloyDB free trial instance’), (‘body’, <wagtail.rich_text.RichText object at 0x3e7b8eb94e80>), (‘btn_text’, ‘Start building for free’), (‘href’, ‘http://goo.gle/try_alloydb’), (‘image’, None)])]>
Semantic search and RAG
In semantic search, we are able to leverage underlying relationships between words to find relevant results beyond a simple keyword match. Embeddings are vector representations of data, ranging from text to videos, that capture these relationships. In a semantic search we find embeddings that are mathematically close to our search query, allowing us to find words or search terms close in meaning that may have not shown up in a keyword search. Databases such as AlloyDB allow us to combine this unstructured search with a structured search to provide high quality relevant results. For example, the prompt “Show me all pictures of sunsets I took in the past month” includes a structured part (the date is within the past month) and an unstructured part (the picture contains a sunset).
In many RAG applications, embeddings play an important role in retrieving the relevant context from a knowledge base (such as a database) to ground the responses of large language models (LLMs). RAG systems can perform a semantic search on a Vector Database, such as AlloyDB, or directly pull data from the database to provide the retrieved results as context to the LLM so that it has access to the necessary information to generate informative answers.
Knowledge ingestion pipelines
A knowledge ingestion pipeline takes unstructured content, such as product catalogs with free form descriptions, support ticket dialogs, and legal documents, processes them into embeddings, and then pushes these embeddings into a vector database. The source of this knowledge can vary widely, from files stored in cloud storage buckets (like Google Cloud Storage) and information stored in databases like AlloyDB, to streaming sources such as Google Cloud Pub/Sub or Google Cloud Managed Service for Kafka. For streaming sources, the data itself might be raw content (e.g, plain text) or URIs pointing to documents. A key consideration when designing knowledge ingestion pipelines is how to ingest and process knowledge, whether in a batch or streaming fashion.
-
Streaming vs Batch: To provide the most up-to-date and relevant search results, and thus a superior user experience, embeddings should be generated in real time for streaming data. This applies to new documents being uploaded or new product images, where current knowledge holds significant business value. For less time-sensitive applications and operational tasks like backfilling, a batch pipeline is suitable. Crucially, the chosen framework must support both streaming and batch processing without requiring business logic re-implementation.
-
Chunking: Regardless of the data source, after reading the data there is normally a step for preprocessing the information. For simple raw text, this might mean basic cleaning. However, for larger documents or more complex content, chunking is a crucial step. Chunking breaks down the source material into smaller, manageable units. The best chunking strategy varies depending on the specific data and application.
Introducing Dataflows MLTransform for embeddings
Dataflow ML provides many out of the box capabilities to simplify the entire process of building and running a streaming or batch knowledge ingestion pipeline, allowing you to implement these pipelines in a few lines of code. For an ingestion pipeline there are typically four phases, reading from data sources, preprocessing the data, making it ready for embeddings, and finally writing the correctly shaped schema to our vector database. The new capabilities in MLTransform adds support for chunking, generation of embeddings, using Vertex or bring your own (BYO) models and specialized writers for persisting embeddings to databases such as AlloyDB.
Knowledge ingestion using Dataflow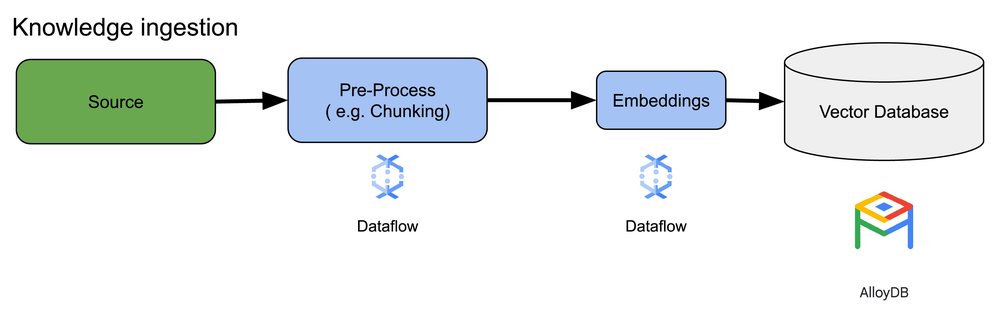
With Dataflow’s new MLTransform capabilities, the flow to chunk and generate embeddings and land them into AlloyDB can be achieved within a few lines of code:
- code_block
- <ListValue: [StructValue([(‘code’, ‘…rndef to_chunk(product: Dict[str, Any]) -> Chunk:rn return Chunk(rn content=Content(rn text=f”{product[‘name’]}: {product[‘description’]}”rn ), rn id=product[‘id’], # Use product ID as chunk IDrn metadata=product, # Store all product info in metadatarn )rnrn…rnwith beam.Pipeline() as p:rn _ = (rn prn | ‘Create Products’ >> beam.Create(products)rn | ‘Convert to Chunks’ >> beam.Map(to_chunk) rn | ‘Generate Embeddings’ >> MLTransform(rnwrite_artifact_location=tempfile.mkdtemp())rn.with_transform(huggingface_embedder)rn | ‘Write to AlloyDB’ >> VectorDatabaseWriteTransform(alloydb_config)rn )’), (‘language’, ‘lang-py’), (‘caption’, <wagtail.rich_text.RichText object at 0x3e7b8e746d30>)])]>
Importantly, for the embeddings step shown above in Dataflow ML supports the ability to make use of Vertex AI embeddings as well as models from other model gardens and the ability to “bring your own model (BYOM)” hosted on Dataflows workers.
The example above creates a single chunk per element, but you can also use LangChain for chunking instead:
- code_block
- <ListValue: [StructValue([(‘code’, “…rnrn# Pick a LangChain text-splitter to divide your documents into smaller Chunksrnsplitter = langchain.text_splitter.CharacterTextSplitter(chunk_size=100, chunk_overlap=20)rn# Configure Apache Beam to use your desired text-splitterrnlangchain_chunking_provider = beam.ml.rag.chunking.langchain.LangChainChunker(rndocument_field=’content’, metadata_fields=[], text_splitter=splitter)rnrnwith beam.Pipeline() as p:rn_ = (rnprn| ‘Create Products’ >> beam.io.textio.ReadFromText(products)rnrn| ‘Generate Embeddings’ >> MLTransform(rnwrite_artifact_location=tempfile.mkdtemp())rn.with_transform(langchain_chunking_provider)rn.with_transform(huggingface_embedder)rn…”), (‘language’, ‘lang-py’), (‘caption’, <wagtail.rich_text.RichText object at 0x3e7b8e746c40>)])]>
You can find a full working example with AlloyDB here: build realtime vector embedding pipeline for AlloyDB with Dataflow.
Introducing Dataflow enrichment transform for RAG
To support RAG use cases, we have also enhanced Dataflows enrichment transform to include the ability to look up results from databases, enabling the ability to create asynchronous applications in batch or stream mode that can, in a low code pipeline, consume the information stored in the vector database. This enables you to enrich your applications with operational data to embed or to utilize as filters, so that you don’t need to store your vectors in distinct storage solutions.
Enabling RAG applications with Dataflow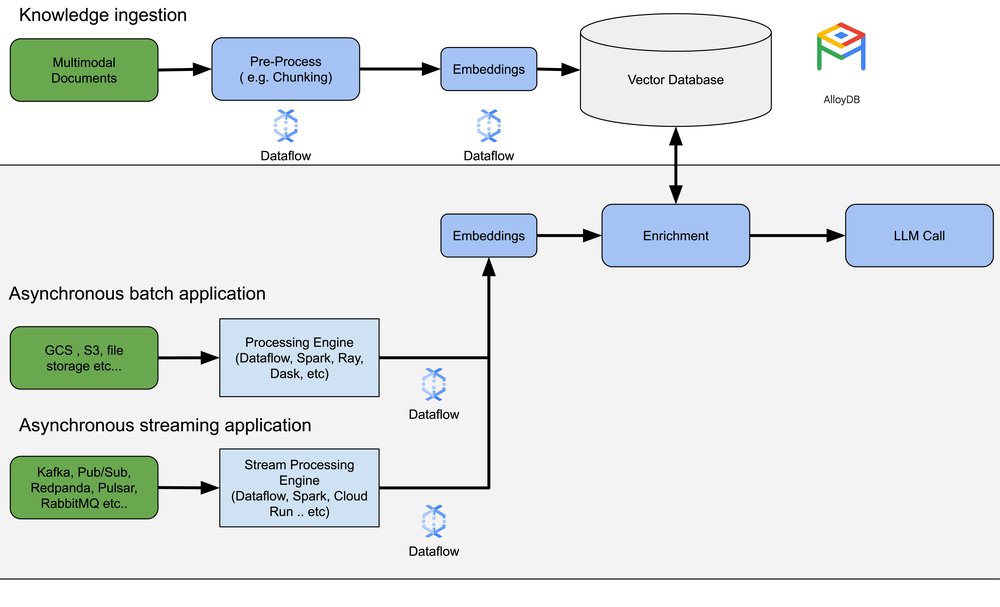
- code_block
- <ListValue: [StructValue([(‘code’, “params = BigQueryVectorSearchParameters(rn project=self.project,rn table_name=self.table_name,rn embedding_column=’embedding’,rn columns=[‘content’],rn neighbor_count=1)rnrnhandler = BigQueryVectorSearchEnrichmentHandler(rn vector_search_parameters=params)rnrnwith beam.Pipeline() as p:rn rn result = (p | beam.Create(test_chunks) | Enrichment(handler))rn )”), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e7b8e7469a0>)])]>
Get started today
With these simple code snippets, we’ve shown how it’s possible to not only ingest and prepare the source data needed to populate your vector databases, but also to consume and use that information for your streaming and batch applications where the intent is to process large volumes of data and incoming information. For a full working example please look at the following full example. To explore more please head to Dataflow ML documentation for detailed examples and collabs. Get started with vector search on AlloyDB today. You can also sign up for a 30-day AlloyDB free trial.
Special thanks to Claude van der Merwe, Dataflow ML Engineering, for his contributions to this blog post.
Read More for the details.

