
GCP – How Google Does It: Building the largest known Kubernetes cluster, with 130,000 nodes
At Google Cloud, we’re constantly pushing the scalability of Google Kubernetes Engine (GKE) so that it can keep up with increasingly demanding workloads — especially AI. GKE already supports massive 65,000-node clusters, and at KubeCon, we shared that we successfully ran a 130,000-node cluster in experimental mode — twice the number of nodes compared to the officially supported and tested limit.
This kind of scaling isn’t just about increasing the sheer number of nodes; it also requires scaling other critical dimensions, such as Pod creation and scheduling throughput. For instance, during this test, we sustained Pod throughput of 1,000 Pods per second, as well as storing over 1 million objects in our optimized distributed storage. In this blog, we take a look at the trends driving demand for these kinds of mega-clusters, and do a deep dive on the architectural innovations we implemented to make this extreme scalability a reality.
The rise of the mega cluster
Our largest customers are actively pushing the boundaries of GKE’s scalability and performance with their AI workloads. In fact, we already have numerous customers operating clusters in the 20-65K node range, and we anticipate the demand for large clusters to stabilize around the 100K node mark.
This sets up an interesting dynamic. In short, we are transitioning from a world constrained by chip supply to a world constrained by electrical power. Consider the fact that a single NVIDIA GB200 GPU needs 2700W of power. With tens of thousands, or even more, of these chips, a single cluster’s power footprint could easily scale to hundreds of megawatts — ideally distributed across multiple data centers. Thus, for AI platforms exceeding 100K nodes, we’ll need robust multi-cluster solutions that can orchestrate distributed training or reinforcement learning across clusters and data centers. This is a significant challenge, and we’re actively investing in tools like MultiKueue to address it, with further innovations on the horizon. We are also advancing high-performance RDMA networking with the recently announced managed DRANET, improving topology awareness to maximize performance for massive AI workloads. Stay tuned.
At the same time, these investments also benefit users who operate at more modest scales — the vast majority of GKE customers. By hardening GKE’s core systems for extreme usage, we create substantial headroom for average clusters, making them more resilient to errors, increasing tolerance for user misuse of the Kubernetes API, and generally optimizing all controllers for faster performance. And of course, all GKE customers, large and small, benefit from investments in an intuitive, self-service experience.
Key architectural innovations
With that said, achieving this level of scale requires significant innovations throughout the Kubernetes ecosystem, including control plane, custom scheduling and storage. Let’s take a look at a few key areas that were critical to this project.
Optimized read scalability
When operating at scale, there’s a need for a strongly consistent and snapshottable API server watch cache. At 130,000 nodes, the sheer volume of read requests to the API server can overwhelm the central object datastore. To solve this, Kubernetes includes several complementary features to offload these read requests from the central object datastore.
First, the Consistent Reads from Cache feature (KEP-2340), detailed in here, enables the API server to serve strongly consistent data directly from its in-memory cache. This drastically reduces the load on the object storage database for common read patterns such as filtered list requests (e.g., “all Pods on a specific node”), by ensuring the cache’s data is verifiably up-to-date before it serves the request.
Building on this foundation, the Snapshottable API Server Cache feature (KEP-4988) further enhances performance by allowing the API server to serve LIST requests for previous states (via pagination or by specifying resourceVersion) directly from that same consistent watch cache. By generating a B-tree “snapshot” of the cache at a specific resource version, the API server can efficiently handle subsequent LIST requests without repeatedly querying the datastore.
Together, these two enhancements address the problem of read amplification, ensuring the API server remains fast and responsive by serving both strongly consistent filtered reads and list requests of previous states directly from memory. This is essential for maintaining cluster-wide component health at extreme scale.
An optimized distributed storage backend
To support the cluster’s massive scale, we relied on a proprietary key-value store based on Google’s Spanner distributed database. At 130K nodes, we required 13,000 QPS to update lease objects, ensuring that critical cluster operations such as node health checks didn’t become a bottleneck, and providing the stability needed for the entire system to operate reliably. We didn’t witness any bottlenecks with respect to the new storage system and it showed no signs of it not being able to support higher scales.
Kueue for advanced job queueing
The default Kubernetes scheduler is designed to schedule individual Pods, but complex AI/ML environments require more sophisticated, job-level management. Kueue is a job queueing controller that brings batch system capabilities to Kubernetes. It decides *when* a job should be admitted based on fair-sharing policies, priorities, and resource quotas, and enables “all-or-nothing” scheduling for entire jobs. Built on top of the default scheduler, Kueue provided the orchestration necessary to manage the complex mix of competing training, batch, and inference workloads in our benchmark.
Future of scheduling: Enhanced workload awareness
Beyond Kueue’s job-level queueing, the Kubernetes ecosystem is evolving towards workload-aware scheduling in its core. The goal is to move from a Pod-centric to a workload-centric approach to scheduling. This means the scheduler will make placement decisions considering the entire workload’s needs as a single unit, encompassing both available and potential capacity. This holistic view is crucial for optimizing price-performance, especially for the new wave of AI/ML training and inference workloads.
A key aspect of the emerging kubernetes scheduler is the native implementation of gang scheduling semantics within Kubernetes, a feature currently provided by add-ons like Kueue. The community is actively working on this through KEP-4671: Gang Scheduling.
In time, support for workload-aware scheduling in core Kubernetes will simplify orchestrating large-scale, tightly coupled applications on GKE, making the platform even more powerful for demanding AI/ML and HPC use cases. We’re also working on integrating Kueue as a second-level scheduler within GKE.
GCS FUSE for data access
AI workloads need to be able to access data efficiently. Together, Cloud Storage FUSE with parallel downloads and caching enabled and paired with the zonal Anywhere Cache, allowing access to model data in Cloud Storage buckets as if it were a local file system, reducing latency up to 70%. This provides a scalable, high-throughput mechanism for feeding data to distributed jobs or scale-out inference workflows. Alternatively, there’s Google Cloud Managed Lustre, a fully managed persistent zonal storage solution that supports workloads that need multi-petabyte capacity, TB/s throughput, and sub-millisecond latency. You can learn more about your storage options for AI/ML workloads here.
Benchmarking GKE for large-scale, dynamic AI workloads
To validate GKE’s performance with large-scale AI/ML workloads, we designed a four-phase benchmark simulating a dynamic environment with complex resource management, prioritization, and scheduling challenges. This builds on the benchmark used in the previous 65K node scale test.
We upgraded the benchmark to represent a typical AI platform that hosts mixed workloads, using workloads with distinct priority classes:
-
Low Priority: Preemptible batch processing, such as data preparation jobs.
-
Medium Priority: Core model training jobs that are important but can tolerate some queuing.
-
High Priority: Latency-sensitive, user-facing inference services that must have resources guaranteed.
We orchestrated the process using Kueue to manage quotas and resource sharing, and JobSet to manage training jobs.
Phase 1: Establishing a performance baseline with a large training job
To begin, we measure the cluster’s foundational performance by scheduling a single, large-scale training workload. We deploy one JobSet configured to run 130,000 medium-priority Pods simultaneously. This initial test allows us to establish a baseline for key metrics like Pod startup latency and overall scheduling throughput, revealing the overhead of launching a substantial workload on a clean cluster. This set the stage for evaluating GKE’s performance under more complex conditions. After execution, we removed this JobSet from the cluster, leaving an empty cluster for Phase 2.
Figure 1: Phase 1: Establishing a performance baseline by deploying a massive pre-training workload of 130,000 Pods on a clean cluster.
Phase 2: Simulating a realistic mixed-workload environment
Next, we introduced resource contention to simulate a typical MLOps environment. At first, we deployed 650 low-priority batch Jobs (totaling 65,000 Pods), filling up half of the capacity of the cluster’s 130K nodes.
Figure 2: Phase 2: Simulating a realistic MLOps environment by introducing 65,000 low-priority batch job Pods to fill 50% of cluster capacity.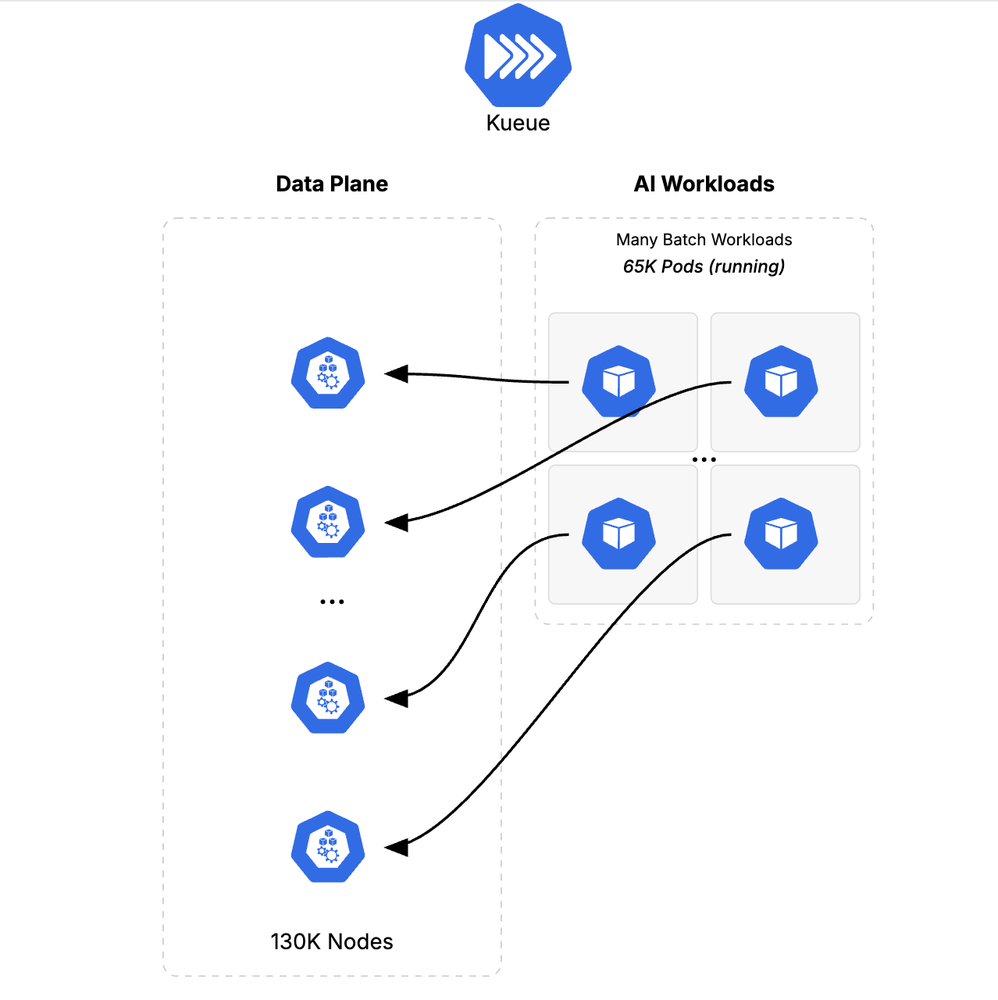
Then we introduced 8 large, medium-priority fine-tuning Jobs (totaling 104,000 Pods), taking 80% of the cluster capacity, and preempting 60% of the batch workloads (which represents 30% of total cluster capacity). This phase tested GKE’s ability to manage mixed workloads, as well preemption within a mixed workloads environment. In this scenario, we observed Kueue in action, preempting existing workload and gang-scheduling a large number of batch jobs all at once to allow for fine-tuning jobs to be scheduled. This highlighted Kueue’s advantage over kube-scheduler: preemption happens much faster, and switching between workloads is almost instantaneous.
Figure 3: Kueue in action: Preempting low-priority batch workloads to accommodate 104,000 Pods for higher-priority fine-tuning jobs.
Phase 3: Prioritizing and scaling a latency-sensitive inference service
In this phase, we simulated the arrival of a critical inference service by deploying a high-priority Job, totalling 26K Pods, or 20% of the capacity. To accommodate it, Kueue preempted the remaining low-priority batch jobs.
Figure 4: Phase 3: Prioritizing a critical, latency-sensitive inference service (26,000 Pods) by preempting the remaining of lower-priority batch jobs.
We then scaled the inference workload to simulate a spike in traffic, first, preempting part of the medium-priority fine-tuning jobs. The inference workload scaled up to a total of 52,000 Pods, representing 40% of the capacity. Once fully scaled, we ran a 10-minute traffic simulation to measure performance under load.
Figure 5: Simulating a traffic spike. Scaling the inference workload to 52,000 Pods (40% capacity) triggers partial preemption of fine-tuning jobs.
Phase 4: Validating cluster elasticity and resource recovery
Finally, we evaluated the cluster’s ability to efficiently recover and reallocate resources once peak demand was over. We scaled down the high-priority inference workload by 50%, returning to its original initial phase. This demonstrated GKE’s elasticity, ensuring that valuable compute resources were not left idle as workload demands change, thereby maximizing utilization and cost-efficiency. Again, Kueue took care of admitting back the preempted fine-tuning workloads that were waiting in the cluster queue.
Figure 6: Phase 4: Demonstrating cluster elasticity by scaling down the inference workload and automatically recovering resources for pending fine-tuning jobs.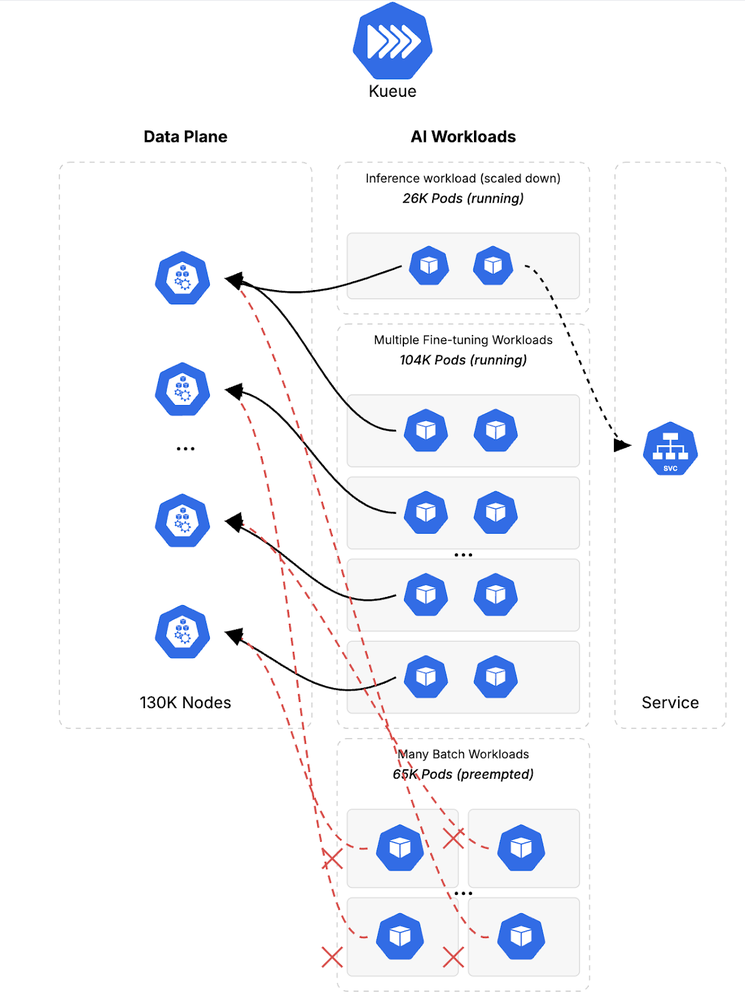
With the benchmark concluded, the resulting data paints a clear picture of how GKE handles extreme-scale pressure.
Demonstrating GKE’s scalability across dimensions
The four benchmark phases tested multiple performance dimensions. In Phase 1, the cluster scaled to 130,000 Pods in 3 minutes and 40 seconds. In Phase 2, the low-priority batch workloads were created in 81 seconds, an average throughput of around 750 Pods/second.
Below is a diagram showing the execution timeline of the workload, highlighting the various phases of the benchmark.
Figure 7: Execution timeline highlighting the four distinct phases of the large-scale AI workload benchmark.
Overall, the benchmark demonstrated GKE’s ability to manage fluctuating demands by preempting lower-priority jobs to make room for critical training and inference services, showcasing the cluster’s elasticity and resource reallocation capabilities.
Figure 8: Total number of running workload Pods over time, demonstrating GKE’s ability to maintain high utilization through dynamic preemption and resource reallocation.
Intelligent workload management with Kueue
For this benchmark, Kueue was a critical component for enabling workload prioritization. In Phase 2, Kueue preempted 60% of the batch workloads (30% of the cluster capacity) to make room for medium-priority jobs, with the remainder preempted in Phase 3 for the high-priority inference workload. This simulation of urgent tasks taking precedence is a common operational scenario, and this large-scale preemption highlights how the combination of GKE and Kueue can dynamically allocate resources to the most critical jobs. At its peak in Phase 2, 39,000 Pods were preempted in 93 seconds. The Pod churn during the preemption of batch workloads and admission and creation of fine-tuning workloads reached a median of 990 and an average of 745 Pods/s, as seen below.
Figure 9: API request throughput during preemption events, showing a mix of POST and DELETE requests averaging Pod churn of 745 Pods per second.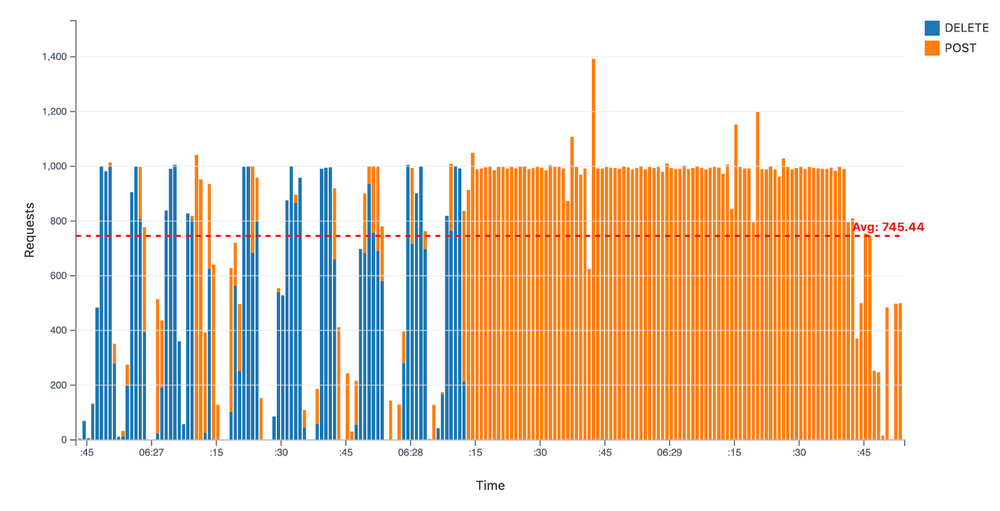
Checking the status of the admitted vs. evicted workloads from Kueue shows that many batch workloads were initially admitted, only to be preempted later by fine-tuning and later inference workloads.
Figure 10: Workload status over time, visualizing the volume of jobs admitted versus those preempted (evicted) by Kueue as priorities shifted.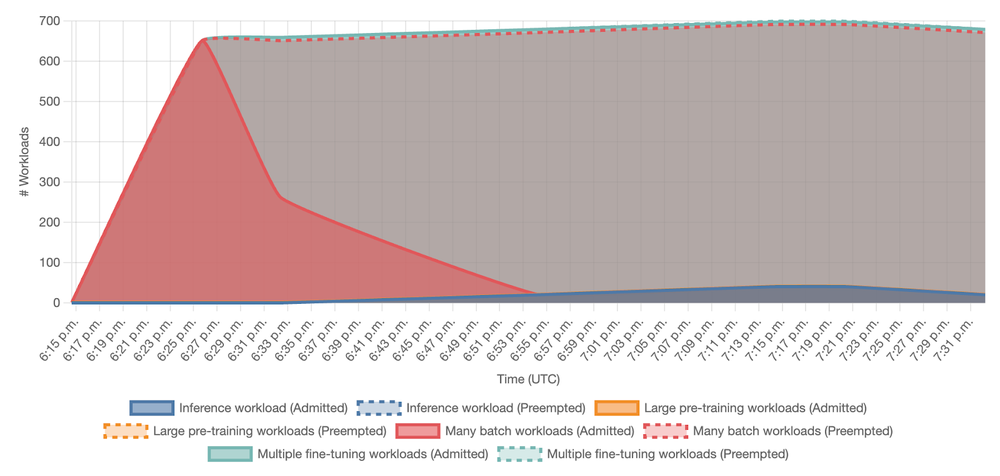
Blazing-fast scheduling at 1,000 pods/second
The key measure of Kubernetes’ control-plane performance is its ability to create and schedule Pods quickly. Throughout the benchmark, especially during the most intense phases, GKE consistently achieved and sustained a throughput of up to 1,000 operations per second for both Pod creation and Pod binding (the act of scheduling a Pod to a node).
Figure 11: Control plane throughput: Sustaining up to 1,000 operations per second for both Pod creation and Pod binding during intense scheduling phases.
Figure 12: Detailed pod-creation throughput statistics (Average, Max, P50, P90, P99) across large pre-training, batch, and fine-tuning workloads.
Low pod startup latency
At the same time, pod-creation throughput was matched by low Pod-startup latencies across all workload types. For latency-sensitive inference workloads, the 99th percentile (P99) startup time was approximately 10 seconds, ensuring services could scale quickly to meet demand.
Figure 13: Pod startup latency across workload types.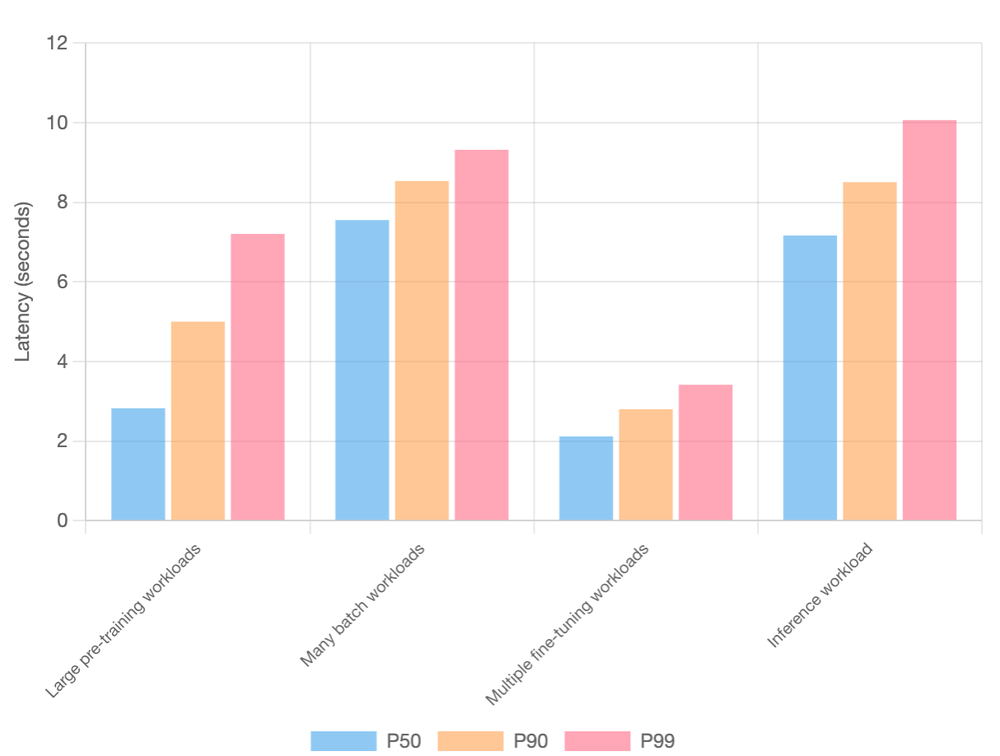
Control plane stability under extreme load
GKE’s cluster control plane remained stable throughout the test. The total number of objects in a single database replica exceeded 1 million at its peak, while API server latencies for critical operations remained well below their defined thresholds. This confirms that the cluster can remain responsive and manageable even at this scale.
Figure 14: API Server latency for GET and LIST operations, remaining stable and well below defined thresholds, and despite the cluster’s massive scale.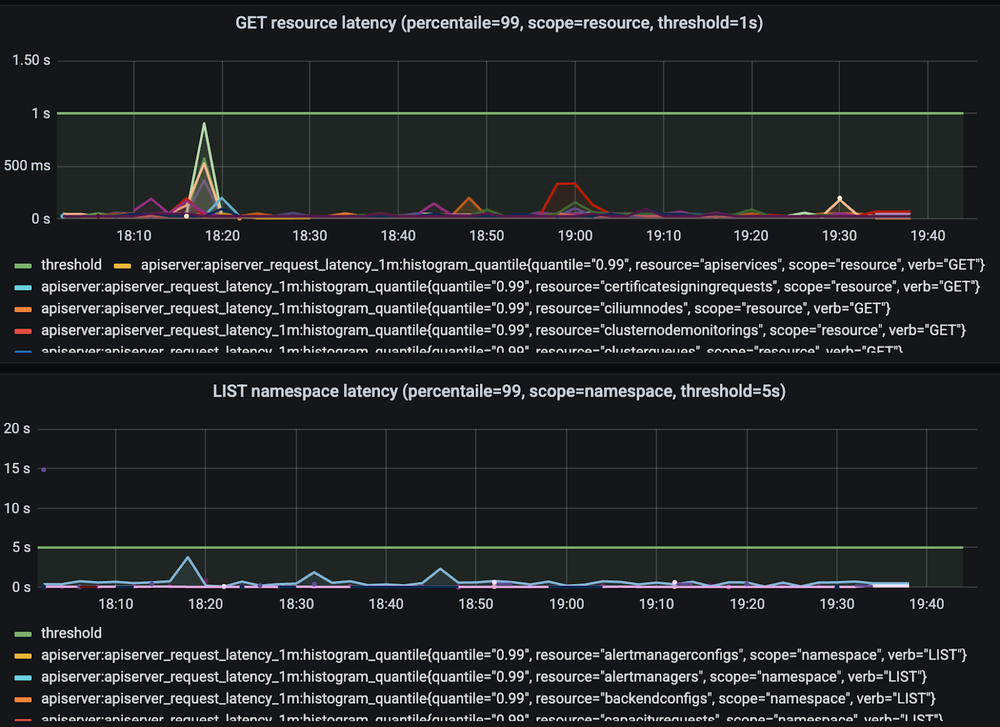
Figure 15: API request duration broken down by verb (GET, POST, PUT, PATCH, DELETE), confirming consistent response times under load.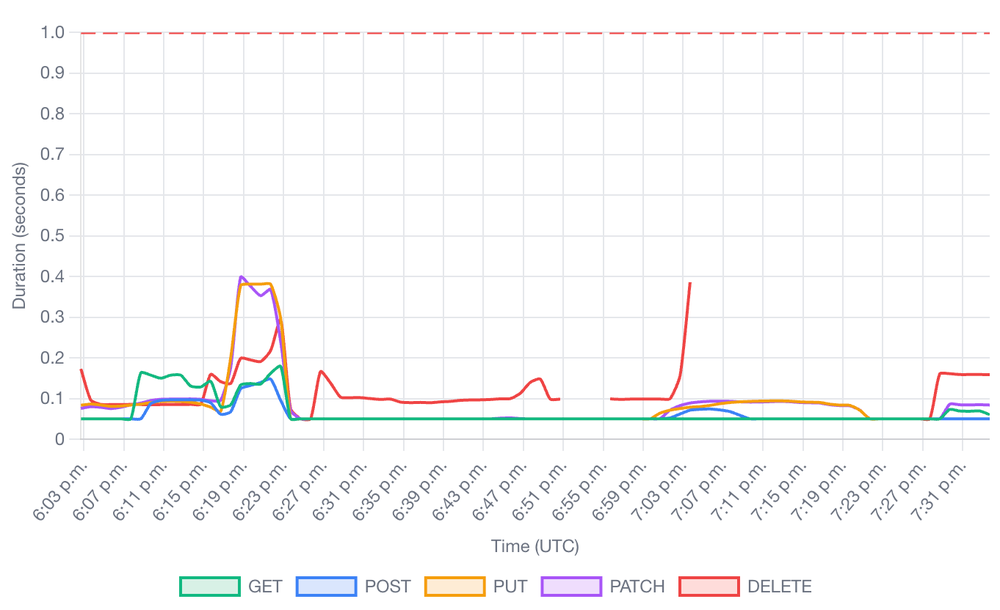
Figure 16: Duration for LIST operations specifically, remaining stable throughout the benchmark phases.
Figure 17: Total count of Kubernetes objects (including Pods, Leases, and Nodes) in the database, exceeding 1 million objects.
Destination: Massive scale
All told, this experiment demonstrated that GKE can support AI and ML workloads at a scale well beyond current public limits. Further, the insights we gained from operating at this scale are helping us plan the GKE’s future development.While we don’t yet officially support 130K nodes, we’re very encouraged by these findings. If your workloads require this level of scale, reach out to us to discuss your specific needs! You can also enjoy these wonderful conversations on scale and other topics from KubeCon at Atlanta with Google experts and analysts.
Read More for the details.

