
GCP – Giving the newly unified Google Cloud AI Platform a spin
The Google Cloud AI Platform team have been heads down the past few months building aunified view of the machine learning landscape . What is it? How good is it? What does it mean for data science jobs?
What is there to unify?
The idea is that there are a few key constructs in machine learning:
- We create datasets by ingesting data, analyzing the data, and cleaning it up (ETL or ELT).
- We then train a model — this includes experimentation, hypothesis testing, and hyperparameter tuning.
- This model is versioned and rebuilt when there is new data, on a schedule, or when the code changes (ML Ops).
- The model is evaluated and compared to existing model versions.
- The model is deployed and used for online and batch predictions.
Yet, depending on how you do your ETL (do you store your data in CSV files? TensorFlow records? JPEG files? In Cloud Storage? In BigQuery?), the rest of the pipeline becomes very different. Wouldn’t it be nice to have the idea of an ML dataset? That any downstream model (TensorFlow, sklearn, PyTorch) can use? That’s what it means to unify behind the concept of a dataset.
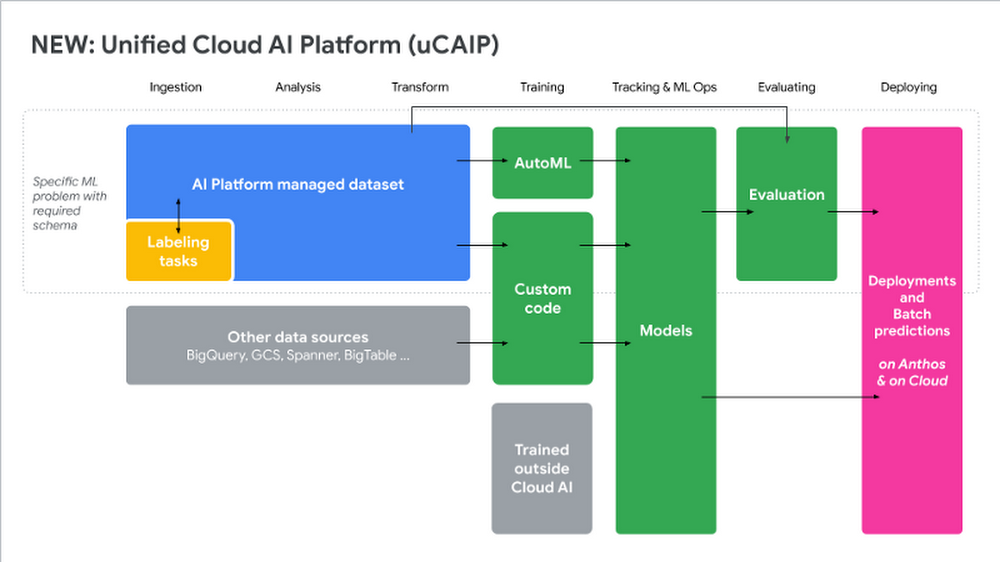
The Cloud AI Platform (unified). Diagram courtesy Henry Tappen and Brian Kobashikawa
Unified Cloud AI Platform provides unified definitions/implementations of four concepts:
- A dataset can be structured or unstructured. It has managed metadata including annotations, and can be stored anywhere on GCP. Realize that this is the vision — at present only Cloud Storage and BigQuery are supported. Not Bigtable or Pub/Sub (yet).
- A training pipeline is a series of containerized steps that can be used to train an ML model using a dataset. The containerization helps with generalization, reproducibility, and auditability.
- A model is an ML model with metadata that was built with a Training Pipeline or directly loaded (as long as it is in a compatible format).
- An endpoint can be invoked by users for online predictions and explanations. It can have one or more models, and one or more versions of those models, with disambiguation carried out based on the request.
The key idea is that these artifacts are the same regardless of the type of dataset or training pipeline or model or endpoint. It’s all mix and match. So, once you create a dataset, you can use it for different models. For example, you can get Explainable AI from an endpoint regardless of how you trained your model.
This unification is clearly visible from the web UI:
Okay, enough of the why. Let’s take it for a spin.
ML in SQL with BigQuery
I’ll use the Air BnB New York Citydataset on Kaggle to predict the price of an apartment rental.
It’s always good when you are training an ML model using new technology to compare it against something that you know and understand. So, I’ll load into BigQuery and use BigQuery ML.
This data set is a bit unwieldy and required cleanup before I could load it into BigQuery (see this blog post for details), but I made the BigQuery dataset public, so you can simply try out the query:
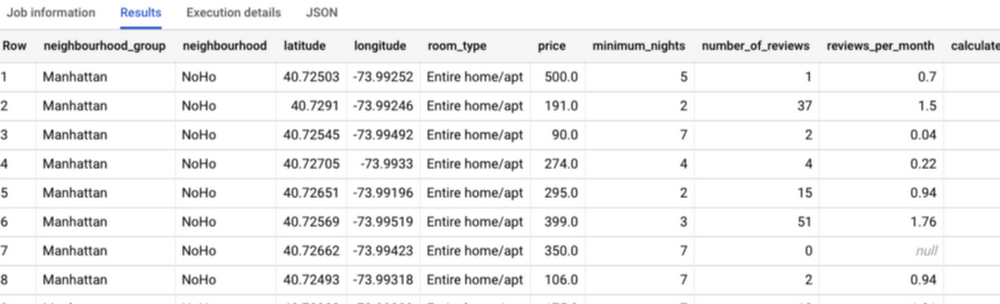
Having verified that the data look reasonable, let’s go ahead and train an xgboost model to predict the price. This is as simple as adding two lines of SQL code:
We get a model that converges quickly
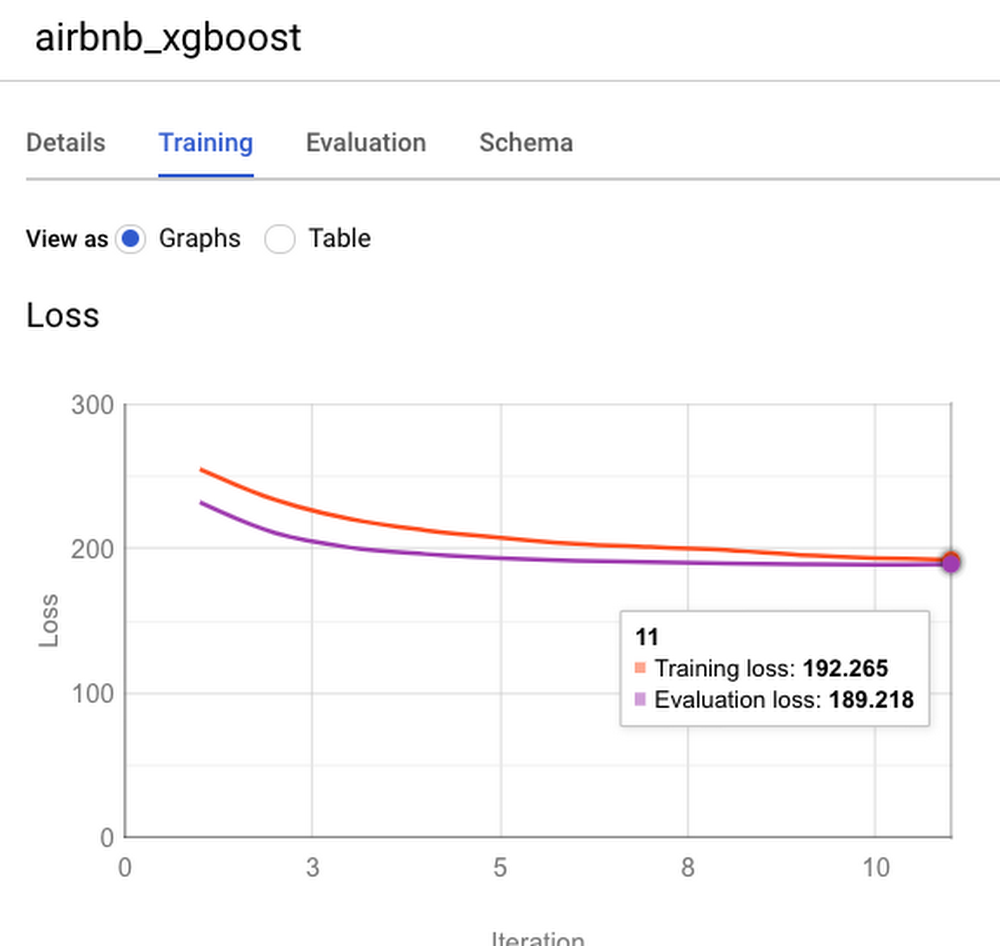
and achieves a mean absolute error of $64.88.
How good is this? What’s the mean price of a New York city apartment on Air BnB?
That is $153. So, we are within 40%. Maybe not a model to go marching into production with … but you shouldn’t expect a public dataset to have the more proprietary and personalized data that would help improve these predictions. Still, the availability of this data helps show us how to train an ML model to predict the price.
Let’s try Auto ML Tables in uCAIP next.
Unified Cloud AI Platform
Let’s start with the CSV file that is on Kaggle so that we are not stuck with the data transformations I did to load the data into BigQuery. Go tohttps://console.cloud.google.com/ai/platform/datasets/create
- Name it airbnb_raw and Select tabular and choose the Iowa region
- Once dataset is created, select CSV file from GCS and supply the URL: gs://ai-analytics-solutions/data/public/airbnb_nyc_2019.csv
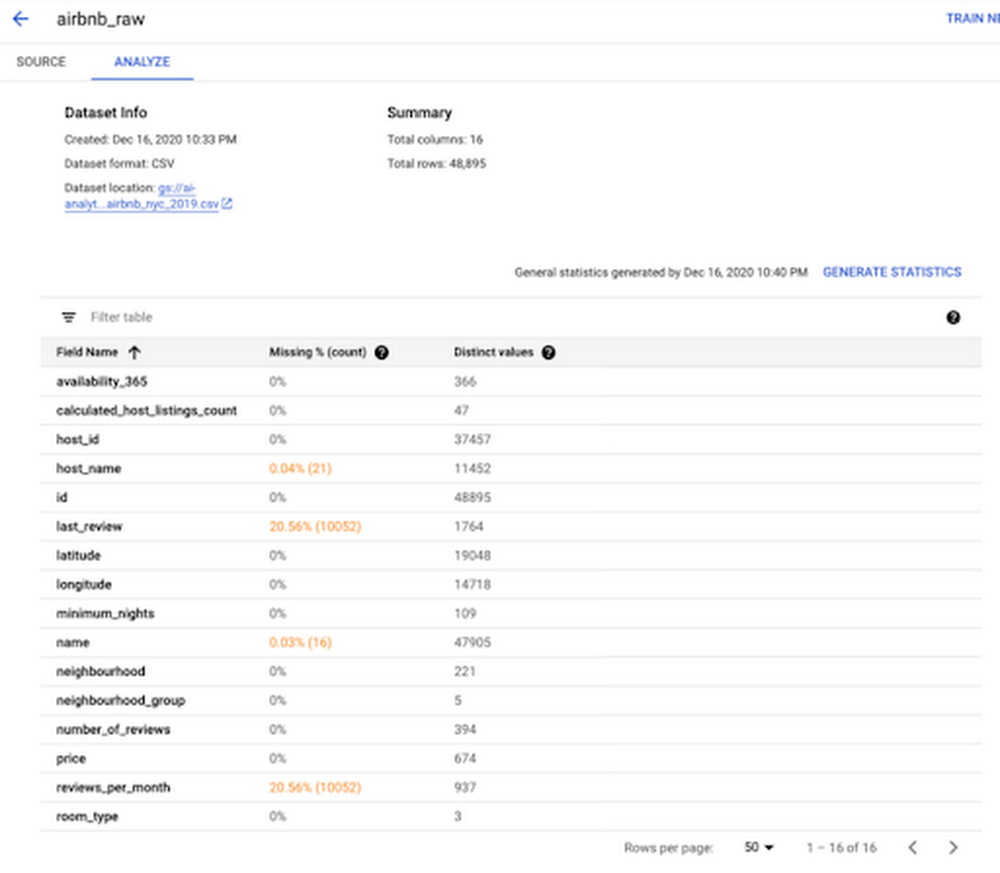
- uCAIP happily loads the data without any finickiness, pulls out the header and shows the 16 columns.
- Click on Generate Statistics and it shows you that the only potentially iffy fields in terms of missing values are the review fields. But that makes sense: not every Air BnB guest is going to leave a review.
- Now select Train new model and choose Regression and AutoML:
- Again notice that we can provide our own custom code and still remain within the overall workflow. We don’t have to give up on an automated training pipeline just because we want to customize one part of the process.
- In the next pane, select price as the target column to be predicted:
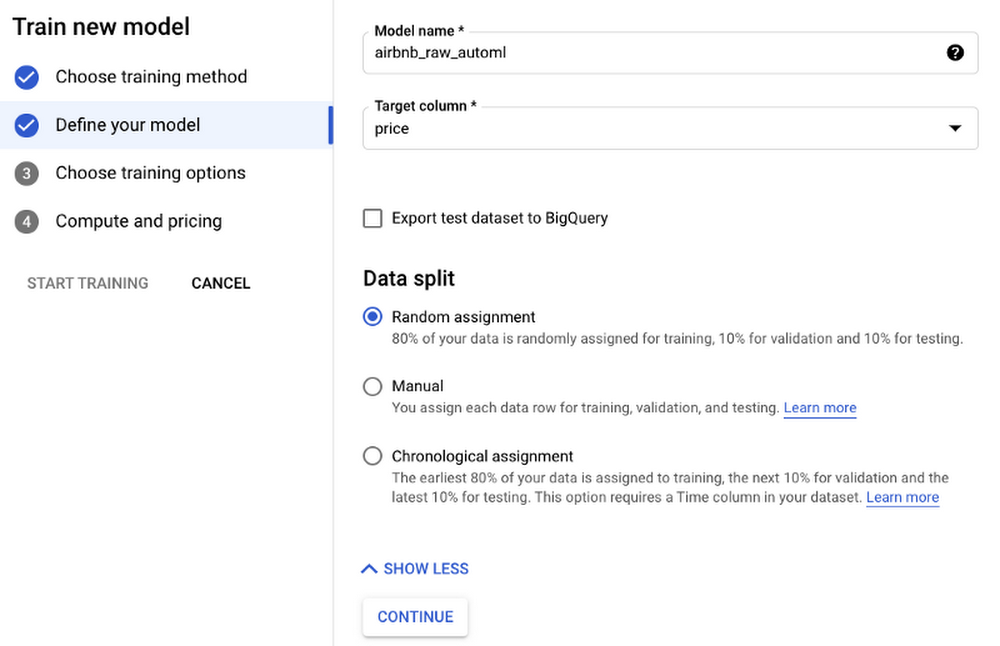
- In the next pane, remove the id column from the set of predictors. Change the neighborhood to Categorical (from Text), and change the objective to MAE.
- Give it a budget of 3 hours and start training.
About 3 hours later, the training finished, and we can examine the model and deploy it if we’d like:
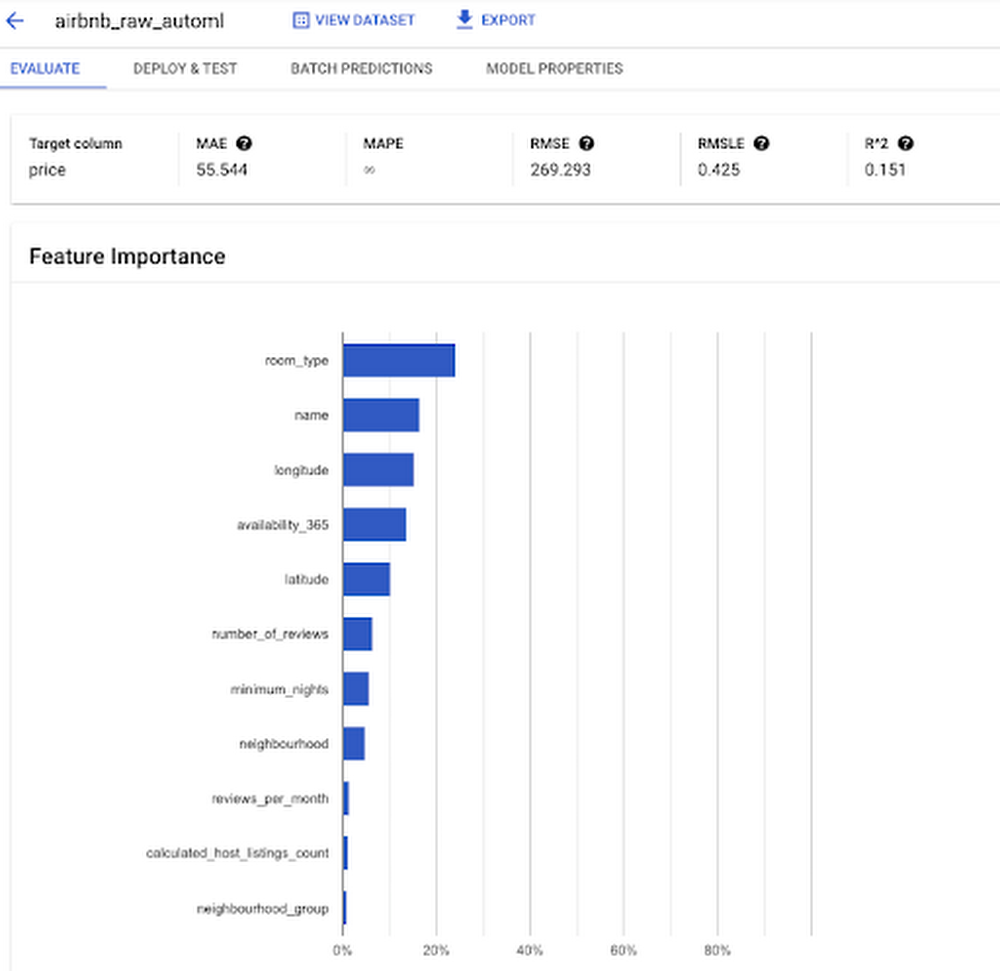
We get a Mean Absolute Error of $55, almost 20% better than what we got with xgboost. So, a more accurate model, with less code. With evaluation, feature importance, explainability, deployment, etc. all provided out-of-the-box!
The low down
Both BigQuery ML and AutoML Tables are easy-to-use and awfully good. It helps to understand the fundamentals of the domain (why are reviews missing?), and of machine learning (don’t use the id column as an input!), but both products are quite approachable from the perspective of a citizen data scientist. The coding and infrastructure management overhead have been almost completely eliminated.
What does this mean for data science jobs? The move from writing Raw HTML to using weebly/wix/etc. hasn’t meant fewer web developer jobs. Instead, it has meant more people creating websites. And when everyone has a basic website, it has driven a need to differentiate, to build better websites, and so more jobs for web developers.
The democratization of machine learning will lead to the same effect. As more and more things become easy, there will be more and more machine learning models built and deployed. That will drive the need to differentiate, and build pipelines of ML models that outperform and solve increasingly complex tasks (not just estimate the price of a rental, but do dynamic pricing, for example).
Democratization of machine learning will lead to more machine learning, and more jobs for ML developers, not less. This is a good thing, and I’m excited about it.
And, oh, the unified Cloud AI Platform is really nice. Try it on your ML problem and let me know (you can reach me on Twitter at @lak_gcp) how it did!
Read More for the details.

