GCP – Framework for building a configuration driven data lake using Data Fusion and Composer
The first article in this series provided an overview of a data lake solution architecture using Data Fusion for data integration and Cloud Composer for orchestration.
In this article, I will provide an overview of the detailed solution design based on that architecture. This article assumes you have some basic understanding of GCP Data Fusion and Composer. If you are new to GCP, you can start by reading the previous article in this series to get an understanding of the different services used in the architecture before proceeding here.
Design approach
The solution design described here provides a framework to ingest a large number of source objects through the use of simple configurations. Once the framework is developed, adding new sources / objects to the data lake ingestion only requires adding new configurations for the new source.
I will publish the code for this framework in the near future. Look out for an update to this blog.
Design components
The solution design comprises 4 broad components.
- Data Fusion pipelines for data movement
- Custom pre-ingestion and post-ingestion tasks
- Configurations to provide inputs to reusable components and tasks
- Composer DAGs to execute the custom tasks and to call Data Fusion pipelines based on configurations
Let me start with a high level view of the Composer DAG that orchestrates all the parts of the solution, and then provide insight into the different pieces of the solution in the following sections.
Composer DAG structure
The Composer DAG is the workflow orchestrator. In this framework, It will broadly comprise components shown in the image below.
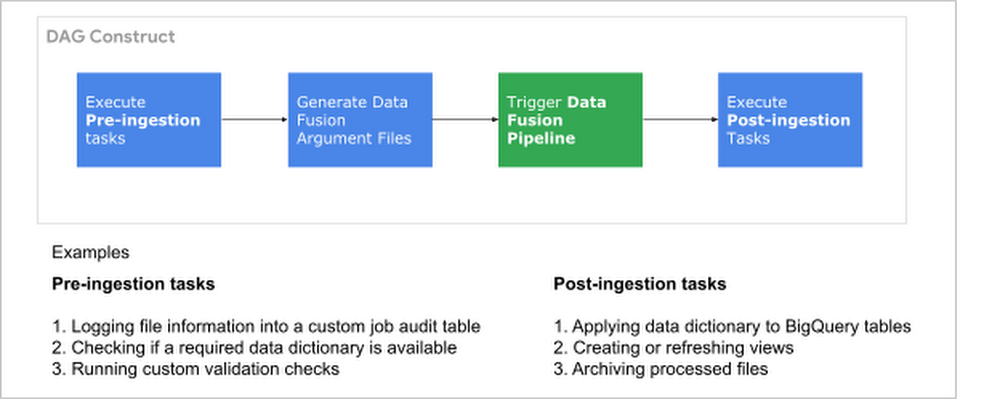
Components of the Composer DAG
The DAG reads the configuration files (detailed in the next section) for details such as source and target details , and passes that information to pre-ingestion and post-ingestion tasks as well as to the Data Fusion pipeline. The image below describes the overall flow.
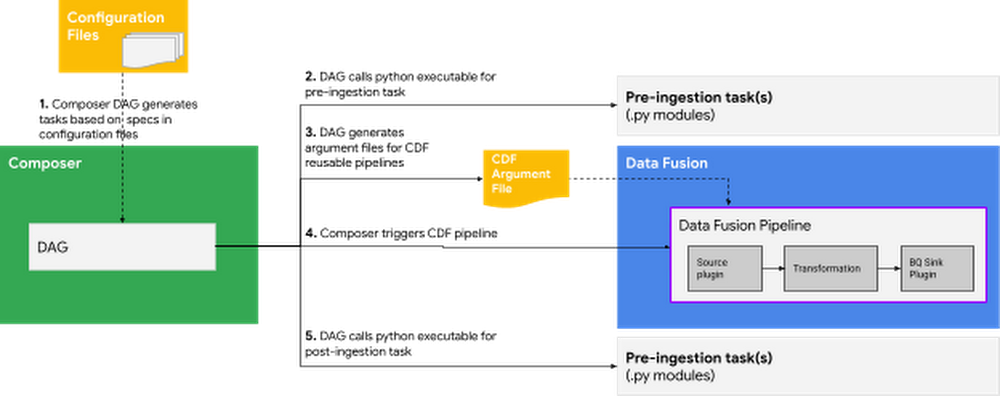
Process flow
Each pre-ingestion or post-ingestion task is a distinct Airflow task in the DAG, and calls python code that contains the logic of the task. Below is a screenshot of a Composer DAG based on the above approach.
Ingestion configuration
Configuration in this solution is maintained for 3 different levels of information – environment, DAG and Tasks within the DAG. These configurations will live in the Composer environment along with your DAG code .
- Environment Configurationfor information such as GCP project ID, Data Fusion instance and GCS bucket information.

- DAG Configuration to provide information required by the DAG for each source system.
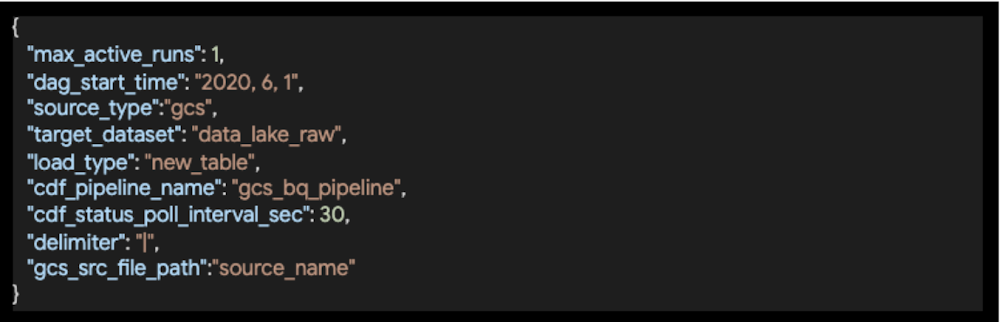
- Task Configurationto specify inputs for the Data Fusion pipeline, for instance the source, the delimiter and pipeline to be triggered.
Dynamic DAG generation based on configuration
The solution would comprise two DAGs.
- The main orchestrator DAG that will read the configuration and perform some initial tasks, and trigger child DAGs (henceforth referred to as the worker DAG) based on Task Configuration.
- The worker DAG that actually performs the tasks in the integration process flow and loads data for the configuration provided to it by the orchestrator DAG. An instance of this DAG will be automatically triggered by the orchestrator DAG.
Based on this approach, below are sample Composer DAGs consisting of pre-ingestion and post-ingestion tasks, along with calls to the Data Fusion pipeline.
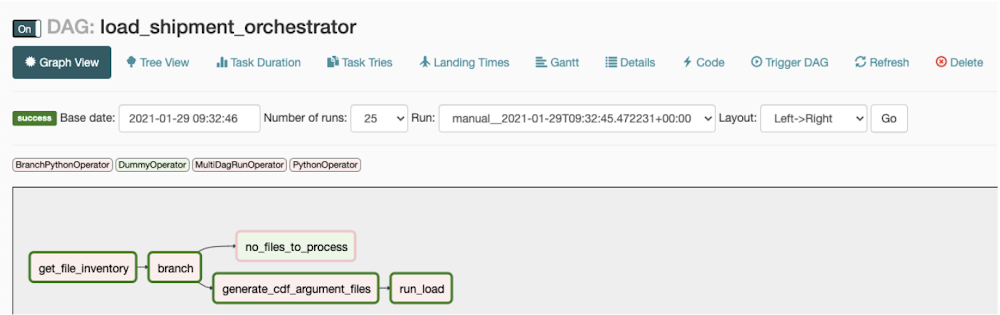
Orchestrator DAG
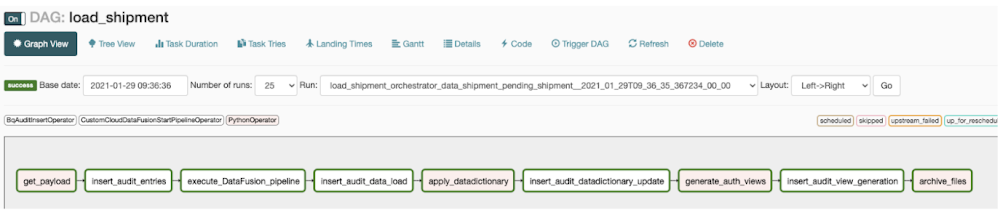
Worker DAG

Pipeline above uses the Wrangler plugin to parse the file layout. You can even go a step further and write your own **custom plugin that can read multiple files, each file with a different layout, parse them on the fly and load into respective targets all in one go. Writing a custom plugin does call for java programming skills though, and writing generic auto-parsing logic can get tricky as you discover new scenarios in your files.
**Data Fusion provides a variety of source, sink and transformation plugins out of the box. If you need to perform certain transformations that are very custom to your needs and not available out of the box, you can also write your own custom plugins and use them in your pipelines.
Calling Data Fusion Pipelines from Composer
Now that we have insight into the tasks that the Data Fusion pipeline and the Composer DAG need to perform, how does Composer call the Data Fusion pipeline?
CloudDataFusionStartPipelineOperator allows triggering a Data Fusion pipeline from an Airflow DAG. There is more information about this operator in this blog post.
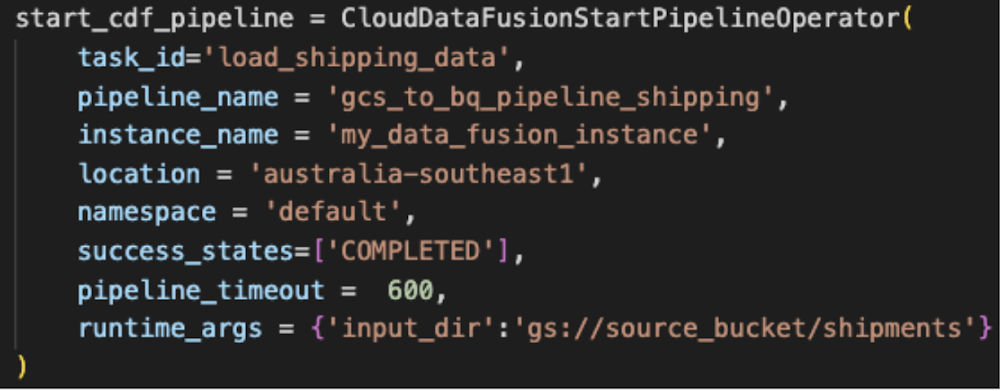
Sample Airflow Task to call a Data Fusion pipeline
Calling Python executables for pre-ingestion and post-ingestion tasks from Composer
Often, there are custom tasks that need to be performed in the data ingestion workflow but they do not belong in or cannot be performed in the ETL tool. Some typical examples include customised cleansing of source files to get rid of incompatible special characters in data, updating the column descriptions in the target table to support data discoverability, archiving processed files based on certain conditions and customised logging of the workflow status in a custom audit table at the end of each task shown in the DAG shown earlier.
These tasks can be coded in python, which can then be called from within Composer with the help of Airflow PythonOperator. I will not go into the details of this operator since there are plenty of great articles already available on this.
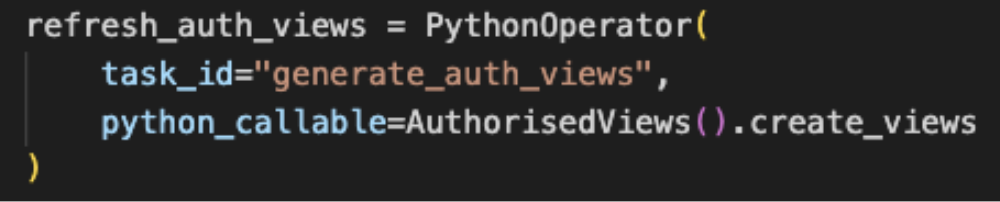
Snippet of Python operator to execute a custom task
Key takeaways
The solution design described above provides a framework to ingest data from a hybrid ecosystem into the data lake. It does so by making use of simple configurations to provide details about the environment, sources and targets, as well as details of the Data Fusion pipeline to be executed. Extending the data lake to add more sources is easy and only requires configuration to be added for the new source objects.
To move data from source to target, Data Fusion pipelines are used. Custom tasks that do not belong in the ETL tool or cannot be performed in the ETL tool can be written in Python and integrated into the Composer DAG for an end to end orchestration of the workflow.
Coming next
The code for a prototype solution using this framework will be made available soon. Look out for an update to this blog post!
Learning resources
If you are new to the tools used in the architecture described in this blog, I recommend the following links to learn more about them.
Data Fusion
Watch this 3 min video for a byte sized overview of Data Fusion or listen to a more detailed talk from Cloud Next. Then try your hand at Data Fusion by following this Code Lab to Ingest CSV data to BigQuery.
Composer
Watch this 4 min video for a byte sized overview of Composer or watch this detailed video from Cloud OnAir. Want to try your hand? Follow these Quickstart instructions.
If you are new to Airflow, you’ll find it useful to go through Airflow Concepts and also read about GCP Operators in Airflow.
Useful blogs
Read More for the details.

