

GCP – Evaluate gen AI models with Vertex AI evaluation service and LLM comparator
It’s a persistent question: How do you know which generative AI model is the best choice for your needs? It all comes down to smart evaluation.
In this post, we’ll share how to perform pairwise model evaluations – a way of comparing two models directly against each other – using Vertex AI evaluation service and LLM Comparator. We’ll introduce each tool’s useful features, why the tools help us evaluate performance of LLMs, and how you can use it to create a robust evaluation framework.
Pairwise model evaluation to assess performance
Pairwise model evaluation means comparing two models directly against each other to assess their relative performance on a specific task. There are three main benefits to pairwise model evaluation for LLMs:
-
Make informed decisions: The increasing number and variety of LLMs means you need to carefully evaluate and choose the best model for your specific task. Considering the strengths and weaknesses of each option is table stakes.
-
Define “better” quantitatively: Generated content from generative AI models, such as natural language texts or images, are usually unstructured, lengthy, and difficult to evaluate automatically without human intervention. Pairwise helps define ”better” response close to human responses to each prompt with human inspection.
-
Keep an eye out: LLMs should be continuously retrained and tuned with the new data to be enhanced compared with the previous versions of them and other latest models.
The proposed evaluation process for LLMs.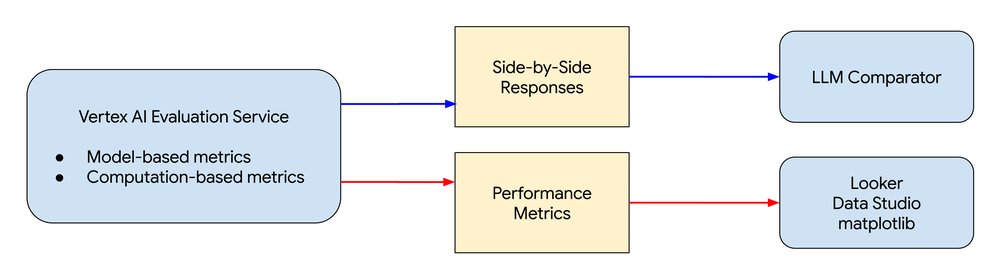
Vertex AI evaluation service
The Gen AI evaluation service in Vertex AI lets you evaluate any generative model or application and benchmark the evaluation results against your own judgment, using your own evaluation criteria. It helps with:
-
Model selection among different models for specific use cases
-
Model configuration optimization with different model parameters
-
Prompt engineering for the preferred behavior and responses
-
Fine-tuning LLMs for improved accuracy, fairness, and safety
-
Optimizing RAG architectures
-
Migration between different versions of a model
-
Managing translation qualities between different languages
-
Evaluating agents
-
Evaluating images and videos
It also supports model-based metrics for both pointwise and pairwise evaluations and computation-based metrics with ground-truth datasets of input and output pairs.
- aside_block
- <ListValue: [StructValue([(‘title’, ‘$300 in free credit to try Google Cloud AI and ML’), (‘body’, <wagtail.rich_text.RichText object at 0x3e42d3fe6ee0>), (‘btn_text’, ‘Start building for free’), (‘href’, ‘http://console.cloud.google.com/freetrial?redirectPath=/vertex-ai/’), (‘image’, None)])]>
How to use Vertex AI evaluation service
The Vertex AI evaluation service can help you rigorously assess your generative AI models. You can define custom metrics, leveraging pre-built templates or your own expertise, to precisely measure performance against your specific goals. For standard NLP tasks, the service provides computation-based metrics like F1 scores for classification, BLEU for translation, and ROUGE-L for summarization.
For direct model comparison, pairwise evaluations allow you to quantify which model performs better. Metrics like candidate_model_win_rate and baseline_model_win_rate are automatically calculated, and judge models provide explanations for their scoring decisions, offering valuable insights. You can also perform pairwise comparisons using computation based metrics to compare against the ground truth data.
Beyond pre-built metrics, you have the flexibility to define your own, either through mathematical formulas or by using prompts to help “judge models” aligned with the context of the user-defined metrics. Embedding-based metrics are also available for evaluating semantic similarity.
Vertex AI Experiments and Metadata seamlessly integrate with the evaluation service, automatically organizing and tracking your datasets, results, and models. You can easily initiate evaluation jobs using the REST API or Python SDK and export results to Cloud Storage for further analysis and visualization.
In essence, the Vertex AI evaluation service provides a comprehensive framework for:
-
Quantifying model performance: Using both standard and custom metrics.
-
Comparing models directly: Through pairwise evaluations and judge model insights.
-
Customizing evaluations: To meet your specific needs.
-
Streamlining your workflow: With integrated tracking and easy API access.
It also provides guidance and templates to help you define your own metrics referring to those templates or from scratch with your experiences of prompt engineering and generative AI.
LLM Comparator: An open-source tool for human-in-the-loop LLM evaluation
LLM Comparator is an evaluation tool developed by PAIR (People + AI Research; PAIR) at Google, and is an active research project.
LLM Comparator’s interface is highly intuitive for side-by-side comparisons of different model outputs, making it an excellent tool to augment automated LLM evaluation with human-in-the-loop processes. The tool provides useful features to help you evaluate the responses from two LLMs side-by-side using a range of informative metrics, such as the win rates of Model A or B, grouped by prompt category. It is also simple to extend the tool with user-defined metrics, via a feature called Custom Functions.
The dashboards and visualizations of LLM Comparator by PAIR of Google.
You can see the comparative performance of Model A and Model B across various metrics and prompt categories through ‘Score Distribution’ and ‘Metrics by Prompt Category’ visualizations. In addition, the ‘Rationale Summary visualization provides insights into why one model outperforms another by visually summarizing the key rationales influencing the evaluation results.
The “Rationale Summary” panel visually explains why one model’s responses are determined to be better.
LLM Comparator is available as a Python package on PyPI, and can be installed on a local environment. Pairwise evaluation results from the Vertex AI Evaluation Service can also be loaded into LLM Comparator using provided libraries. To learn more about how you can transform the automated evaluation results to JSON files, please refer to the JSON data format and schema for LLM Comparator.
With features such as the Rationale Cluster visualization and Custom Functions, LLM Comparator can serve as an invaluable tool in the final stages of LLM evaluation where human-in-the-loop processes are needed to ensure overall quality.
Feedback from the field: How LLM Comparator adds value to Vertex AI evaluation service
By augmenting human evaluators with ready-to-use convenient visualizations and performance metrics calculated automatically, LLM Comparator reduces many chores of ML engineers to develop their own visualizations and quality monitoring tools. Thanks to the JSON data format and schema of LLM Comparator, Vertex AI evaluation service and LLM Comparator can be integrated conveniently without any serious amount of development work.
We’ve heard from our teams that the most useful feature of LLM Comparator is the visualization of “Rationale Summary”. “Rationale Summary” can be thought of as a kind of explainable AI (XAI) tool which is very useful to learn why a specific model among the two is better in the judge model’s view. Another important aspect of “Rationale Summary” visualization is that it can be used to understand how a specific language model is working differently from the other model, which is sometimes a very important support to infer why the model is more appropriate for specific tasks.
A limitation of LLM Comparator is that it can be used just for pair-wise model evaluation, not for simultaneous multiple model evaluation. However, LLM Comparator already has basic components for comparative LLM evaluations and extending it to simultaneous multiple model evaluation may not be a big technical problem. This can be an excellent project for you to contribute to the LLM Comparator project.
Conclusion
In this article, we learned and discussed how we can organize the evaluation process of LLMs with Vertex AI and LLM Comparator, an open source LLM evaluation tool by PAIR. By combining Vertex AI Evaluation Service and LLM Comparator, we’ve presented a semi-automated approach to systematically evaluate and compare the performance of diverse LLMs on Google Cloud. Get started with Vertex AI Evaluation Service today.
We thank Rajesh Thallam, Skander Hannachi, and the Applied AI Engineering team for help with this blog post and guidance on overall best practices. We also thank Anant Nawalgaria for help with this blog post and technical guidance.
Read More for the details.

