
GCP – Create a secure and code-free data pipeline in minutes using Cloud Data Fusion
Organizations are increasingly investing in modern cloud warehouses and data lake solutions to augment analytics environments and improve business decisions. The business value of such repositories increases as additional data is added. And with today’s connected world and many companies adopting a multi-cloud strategy, it is very common to see a scenario where the source data is stored in a cloud provider different from where the final data lake or warehouse is deployed.
Source data may be in Azure or Amazon Web Services (AWS) storage, for example, while the data warehouse solution is deployed in Google Cloud. Additionally, in many cases, regulatory compliance may dictate the need to anonymize pieces of the content prior to loading it into the lake so that the data can be de-identified prior to data scientists or analytic tools’ consumption. Last, it may be important for customers to perform a straight join on data coming from disparate data sources and apply machine learning predictions to the overall dataset once the data lands in the data warehouse.
In this post, we’ll describe how you can set up a secure and no-code data pipeline and demonstrate how Google Cloud can help you move data easily, while anonymizing it in your target warehouse. This intuitive drag-and-drop solution is based on pre-built connectors, and the self-service model of code-free data integration removes technical expertise-based bottlenecks and accelerates time to insight. Additionally, this serverless approach that uses the scalability and reliability of Google services means you get the best of data integration capabilities with a lower total cost of ownership.
Here’s what that architecture will look like:
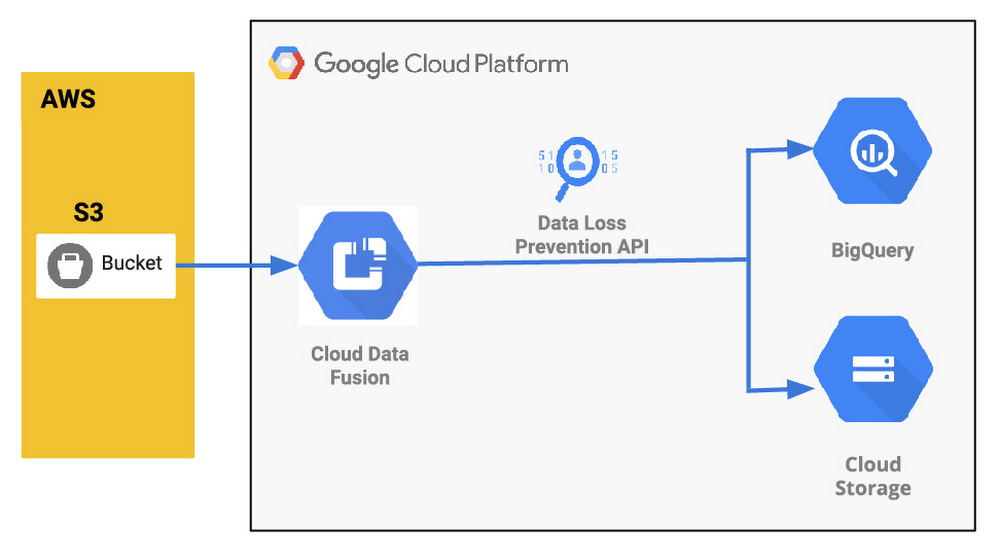
Understanding a common data pipeline use case
To provide a little bit more context, here is an illustrative (and common) use case:
-
An application is hosted at AWS and generates log files on a recursive basis. The files are compressed using gzip and stored on an S3 bucket.
-
An organization is building a modern data lake and/or cloud data warehouse solution using Google Cloud services and must ingest the log data stored in AWS.
-
The ingested data needs to be analyzed by SQL-based analytics tools and also be available as raw files for backup and retention purposes.
-
The source files contain PII data, so parts of the content need to be masked prior to its consumption.
-
New log data needs to be loaded at the end of each day so next day analysis can be performed on it.
-
Customer needs to perform a straight join on data coming from disparate data sources and apply machine learning predictions to the overall dataset once the data lands in the data warehouse.
Google Cloud to the rescue
To address the ETL (extract,transform and load) scenario above, we will be demonstrating the usage of four Google Cloud services: Cloud Data Fusion, Cloud Data Loss Prevention (DLP), Google Cloud Storage, and BigQuery.
Data Fusion is a fully managed, cloud-native, enterprise data integration service for quickly building and managing data pipelines. Data Fusion’s web UI allows organizations to build scalable data integration solutions to clean, prepare, blend, transfer, and transform data without having to manage the underlying infrastructure. Its integration with Google Cloud simplifies data security and ensures data is immediately available for analysis. For this exercise, Data Fusion will be used to orchestrate the entire data ingestion pipeline.
Cloud DLP can be natively called via APIs within Data Fusion pipelines. As a fully managed service, Cloud DLP is designed to help organizations discover, classify, and protect their most sensitive data. With over 120 built-in InfoTypes, Cloud DLP has native support for scanning and classifying sensitive data in Cloud Storage and BigQuery, and a streaming content API to enable support for additional data sources, custom workloads, and applications. For this exercise, Cloud DLP will be used to mask sensitive personally identifiable information (PII) such as a phone number listed in the records.
Once data is de-identified, it will need to be stored and available for analysis in Google Cloud. To cover the specific requirements listed earlier, we will demonstrate the usage of Cloud Storage (Google’s highly durable and geo-redundant object storage) and BigQuery, Google’s serverless, highly scalable, and cost-effective multi-cloud data warehouse solution.
Conceptual data pipeline overview
Here’s a look at the data pipeline we’ll be creating that starts at an AWS S3 instance, uses Wrangler and Redact API for anonymization, and then moves data into both Cloud Storage or BigQuery.

Walking through the data pipeline development/deployment process
To illustrate the entire data pipeline development and deployment process, we’ve created a set of seven videos. You’ll see the related video in each of the steps here.
Step 1 (Optional): Did not understand the use case yet or would like to watch a refresh? This video provides an overview of the use case, covering the specific requirements to be addressed. Feel free to watch it if required.

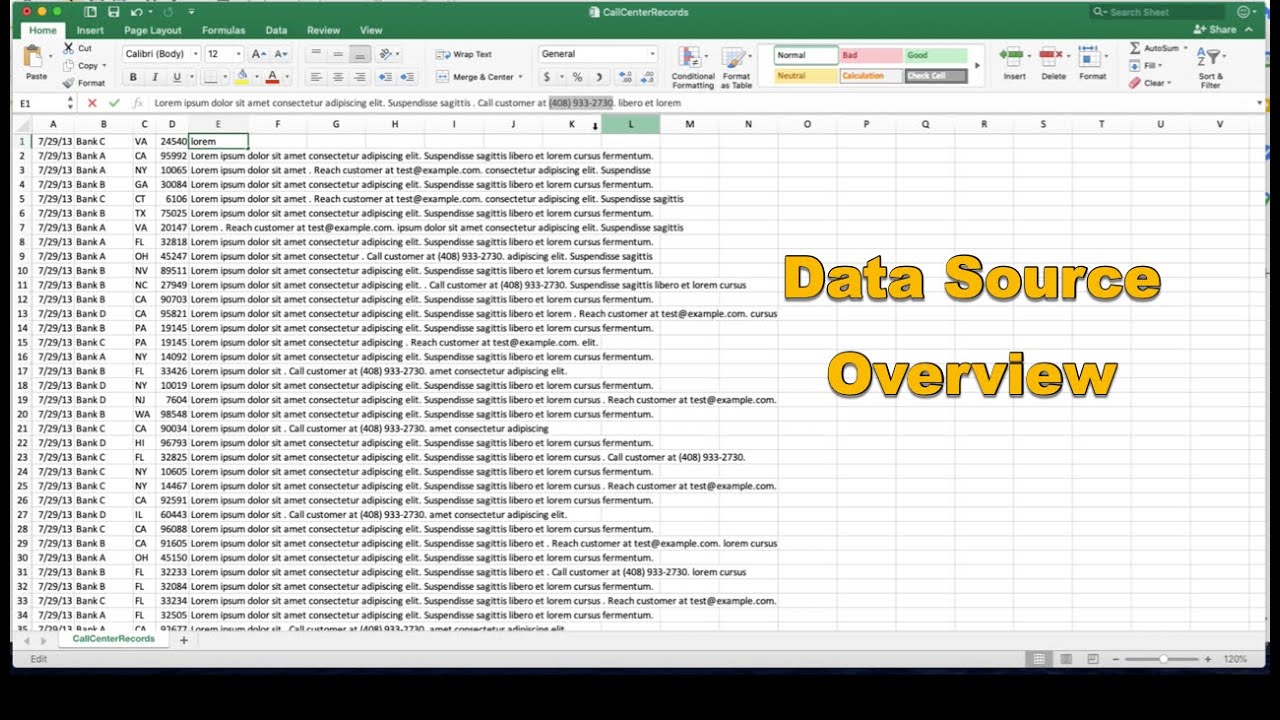
Step 2: This next video covers how the source data is organized. After watching the recording, you will be able to understand how the data is stored in AWS and explore the structure of the sample file used by the ingestion pipeline.
Step 3: Now that you understand the use case goals and how the source data is structured, start the pipeline creation by watching this video. On this recording you will get a quick overview of Cloud Data Fusion, understand how to perform no-code data transformations using the Data Fusion Wrangler feature, and initiate the ingestion pipeline creation from within the Wrangler screen.

Step 4: As mentioned previously, de-identifying the data prior to its consumption is a key requirement of this example use case. Continue the pipeline creation and understand how to initiate Cloud DLP API calls from within Data Fusion, allowing you to perform data redaction on the fly prior to storing it permanently. Watch this video for the detailed steps.

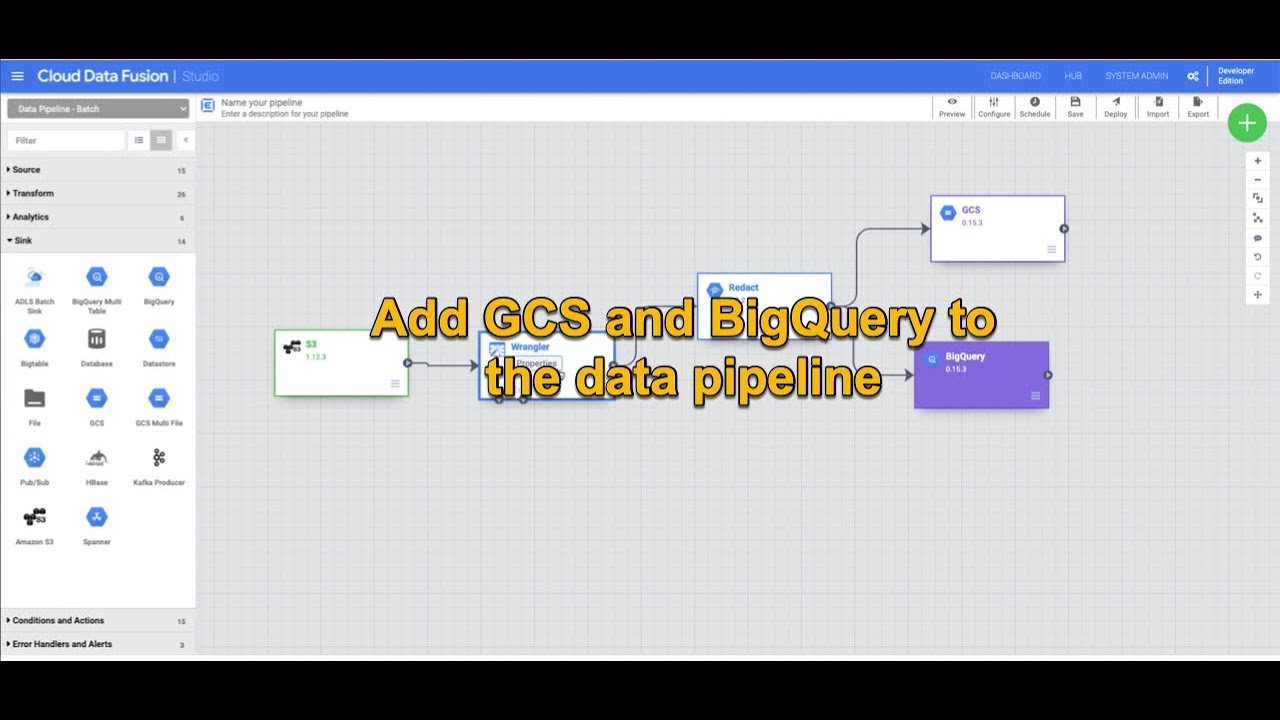
Step 5: Since the data is now de-identified, it’s time to store it in Google Cloud. Since the use case mandated both structured file backups and SQL-based analytics, we will store the data in both Cloud Storage and BigQuery. Learn how to add both Cloud Storage and BigQuery sinks to the existing pipeline in this recording.
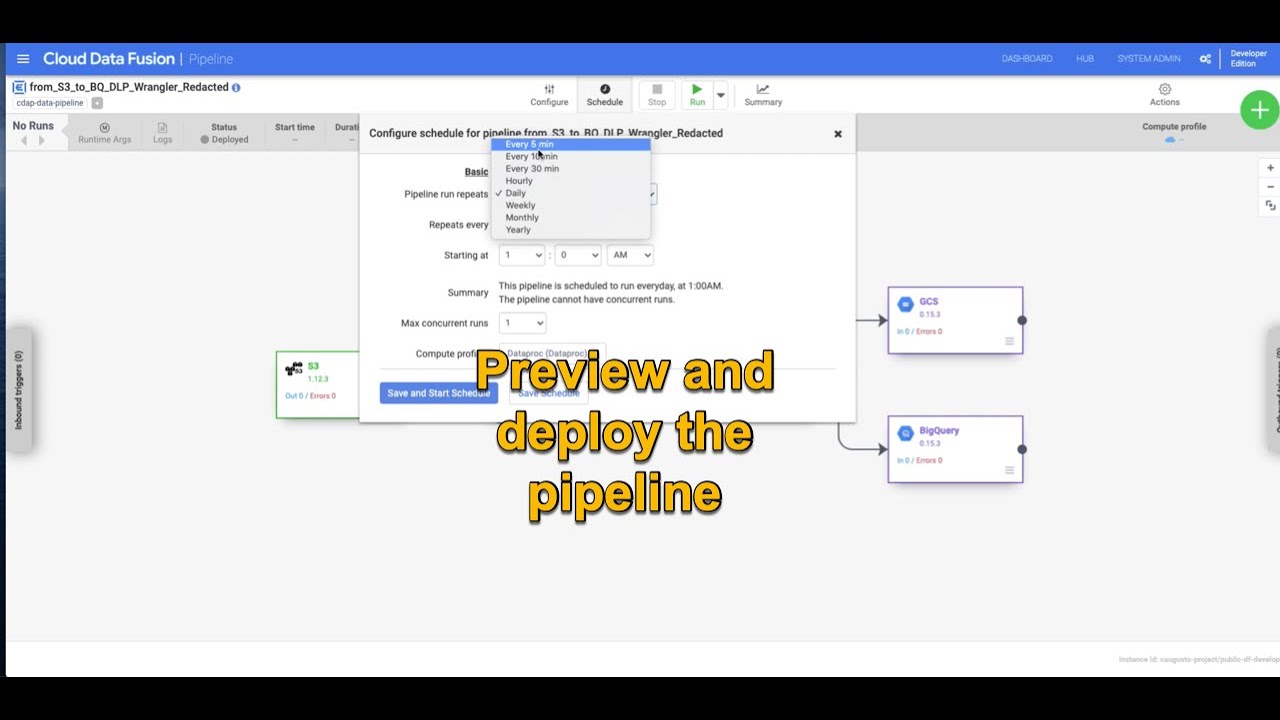
Step 6: You are really close now! It’s time to validate your great work. Wouldn’t it be nice to “try” your pipeline prior to fully deploying it? That’s what the pipeline preview feature allows you to do. Watch this quick video and understand how to preview and subsequently deploy your data ingestion pipeline, taking some time to observe the scheduling and deployment profile options.
Step 7: Woohoo! Last step. Check this video out and observe the ability to analyze the full pipeline execution. In addition, this recording will cover how to perform high-level data validation on both Cloud Storage and BigQuery targets.
Next steps:
Have a similar challenge? Try Google Cloud and this Cloud Data Fusion quickstart next. Have fun exploring!
Read More for the details.

