
GCP – Colossus: the secret ingredient in Rapid Storage’s high performance
As an object storage service, Google Cloud Storage is popular for its simplicity and scale, a big part of which is due to the stateless REST protocols that you can use to read and write data. But with the rise of AI and as more customers look to run data-intensive workloads, two major obstacles to using object storage are its higher latency and lack of file-oriented semantics. With the launch of Rapid Storage on Google Cloud, we’ve added a stateful gRPC-based streaming protocol that provides sub-millisecond read/write latency and the ability to easily append data to an object, while maintaining the high aggregate throughput and scale of object storage. In this post, we’ll share an architectural perspective into how and why we went with this approach, and the new types of workloads it unlocks.
It all comes back to Colossus, Google’s internal zonal cluster-level file system that underpins most (if not all) of our products. As we discussed in a recent blog post, Colossus supports our most demanding performance-focused products with sophisticated SSD placement techniques that deliver low latency and massive scale.
Another key ingredient in Colossus’s performance is its stateful protocol — and with Rapid Storage, we’re bringing the power of the Colossus stateful protocol directly to Google Cloud customers.
- aside_block
- <ListValue: [StructValue([(‘title’, ‘Try Google Cloud for free’), (‘body’, <wagtail.rich_text.RichText object at 0x3ece8b51b9d0>), (‘btn_text’, ‘Get started for free’), (‘href’, ‘https://console.cloud.google.com/freetrial?redirectPath=/welcome’), (‘image’, None)])]>
When a Colossus client creates or reads a file, the client first opens the file and gets a handle, a collection of state that includes all the information about how that file is stored, including which disks the file’s data is stored on. Clients can use this handle when reading or writing to talk directly to the disks via an optimized RDMA-like network protocol, as we previously outlined in our Snap networking system paper.
Handles can also be used to support ultra-low latency durable appends, which is extremely useful for demanding database and streaming analytics applications. For example, Spanner and Bigtable both write transactions to a log file that requires durable storage and that is on the critical path for database mutations. Similarly, BigQuery supports streaming to a table while massively parallel batch jobs perform computations over recently ingested data. These applications open Colossus files in append mode, and the Colossus client running in the application uses the handle to write their database mutations and table data directly to disks over the network. To ensure the data is stored durably, Colossus replicates its data across several disks, performing writes in parallel and using a quorum technique to avoid waiting on stragglers.
Figure 1: Steps involved in appending data to a file in Colossus.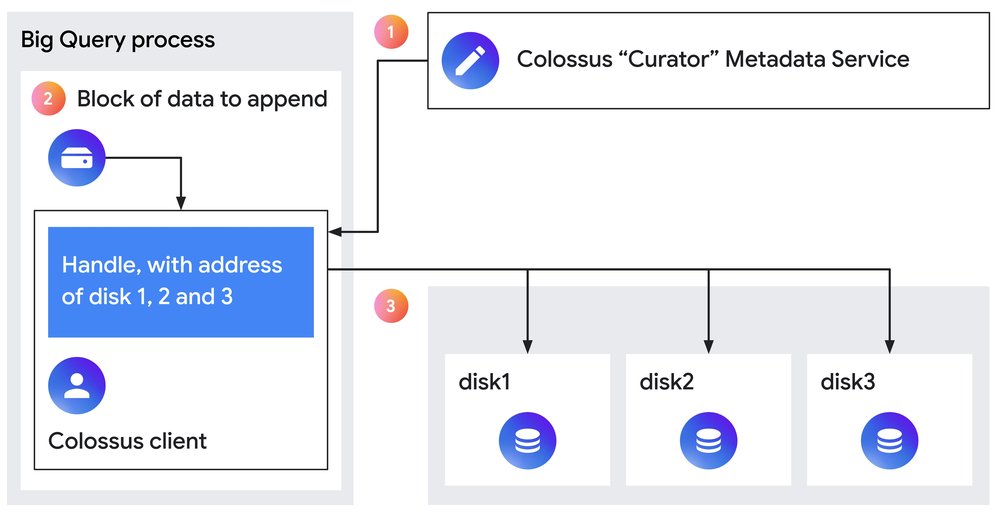
The above image shows the steps that are taken to append data to a file.
-
The application opens the file in append mode. The Colossus Curator constructs a handle and sends it to the Colossus Client running in-process, which caches the handle.
-
The application issues a write call for an arbitrary-sized log entry to the Colossus Client.
-
The Colossus Client, using the disk addresses in the handle, writes the log entry in parallel to all the disks.
Rapid Storage builds on Colossus’s stateful protocol, leveraging gRPC-based streaming for the underlying transport. When performing low-latency reads and writes to Rapid Storage objects, the Cloud Storage client establishes a stream, providing the same request parameters used in Cloud Storage’s REST protocols, such as the bucket and object name. Further, all the time-consuming Cloud Storage operations such as user authorization and metadata accesses are front-loaded and performed at stream creation time, so subsequent read and write operations go directly to Colossus without any additional overhead, allowing for appendable writes and repeated ranged reads with sub-millisecond latency.
This Colossus architecture enables Rapid Storage to support 20 million requests per second in a single bucket — a scale that is extremely useful in a variety of AI/ML applications. For example, when pre-training a model, pre-processed, tokenized training data is fed into GPUs or TPUs, typically in large files that each contain thousands of tokens. But the data is rarely read sequentially, for example, because different random samples are read in different orders as the training progresses. With Rapid Storage’s stateful protocol, a stream can be established at the start of the training run before executing massively parallel ranged-reads at sub-millisecond speeds. This helps to ensure that accelerators aren’t blocked on storage latency.
Likewise, with appends, Rapid Storage takes advantage of Colossus’s stateful protocol to provide durable writes with sub-millisecond latency, and supports unlimited appends to a single object up to the object size limit. A major challenge with stateful append protocols is how to handle cases where the client or server hangs or crashes. With Rapid Storage, the client receives a handle from Cloud Storage when creating the stream. If the stream gets interrupted but the client wants to continue reading or appending to the object, the client can re-establish a new stream using this handle, which streamlines this flow and minimizes any latency hiccups. It gets trickier when there is a problem on the client, and the application wants to continue appending to an object from a new client. To simplify this, Rapid Storage guarantees that only one gRPC stream can write to an object at a time; each new stream takes over ownership of the object, transactionally locking out any prior stream. Finally, each append operation includes the offset that’s being written to, ensuring that data correctness is always preserved even in the face of network partitions and replays.
Figure 2: A new client taking over ownership of an object.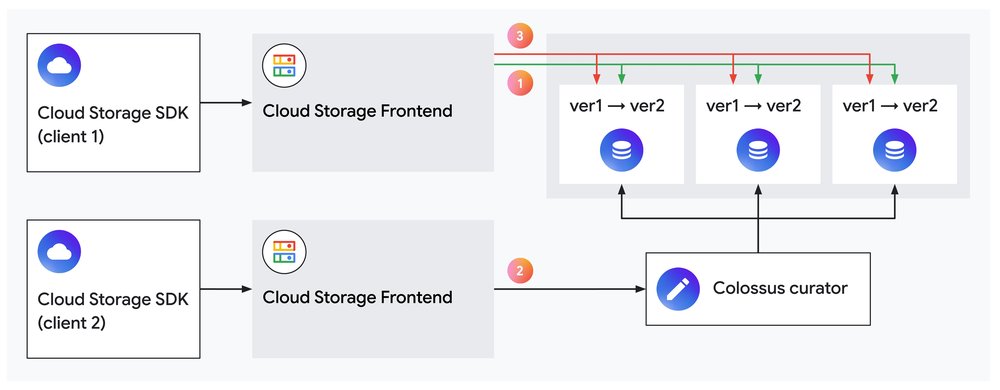
In the above image, a new client takes over ownership of an object, locking out the previous owner.
-
Initially, client 1 appends data to an object stored on three disks.
-
The application decides to fail over to client 2, which opens this object in append mode. The Colossus Curator transactionally locks out client 1 by increasing a version number on each object data replica.
-
Client 1 attempts to append more data to the object, but cannot because its ownership was tied to the old version number.
To make it as easy as possible to integrate Rapid Storage into your applications, we are also updating our SDKs to support gRPC streaming-based appends and expose a simple application-oriented API. Writing data using handles is a familiar concept in the filesystems world, so we’ve integrated Rapid Storage into Cloud Storage FUSE, which provides clients with file-like access to Cloud Storage buckets, for low-latency file-oriented workloads. Rapid Storage also natively enables Hierarchical Namespace as part of its zonal bucket type, providing enhanced performance, consistency, and folder-oriented APIs.
In short, Rapid Storage combines the sub-millisecond latency of block-like storage, the throughput of a parallel filesystem, and the scalability and ease of use of object storage, and it does all this in large part due to Colossus. Here are some interesting workloads we’ve seen our customers explore during the preview:
-
AI/ML data preparation, training, and checkpointing
-
Distributed database architecture optimization
-
Batch and streaming analytics processing
-
Video live-streaming and transcoding
-
Logging and monitoring
Interested in trying Rapid Storage? Indicate your interest here or reach out through your Google Cloud representative.
Visit us at Google Cloud Next and attend the breakout sessions “What’s new with Google Cloud’s Storage” (BRK2-025), “AI Hypercomputer: Mastering your Storage Infrastructure” (BRK2-020), and “Under the Iceberg: Simple, unified Cloud Storage for analytics data lakes” (BRK2-026) to learn more.
Read More for the details.

