
GCP – Build GraphRAG applications using Spanner Graph and LangChain
Spanner Graph redefines graph data management by integrating graph, relational, search, and AI capabilities with virtually unlimited scalability. GraphRAG has emerged as a frontrunner in building question-answering systems that enable organizations to extract relevant insights from their interconnected data. In this blog, we demonstrate how to leverage LanghChain and Spanner Graph to build powerful GraphRAG applications.
Application developers are increasingly experimenting with Retrieval Augmented Generation (RAG), which enhances the performance of generative AI (gen AI) foundation models by enabling dynamic knowledge retrieval. Rather than relying solely on pre-trained knowledge, RAG systems query external data sources during inference, commonly using techniques like vector search. The retrieved information is then integrated into the prompt, leading to more accurate and contextually relevant responses.
Vector-based RAG is effective at retrieving relevant content, however, it can sometimes overlook the interconnectedness of data, failing to capture relationships like citations or product dependencies. GraphRAG addresses this gap and is increasingly gaining popularity. It creates a knowledge graph from varied data sources, allowing for context retrieval through a blend of graph queries, and vector search, thereby producing more detailed and contextually relevant responses for gen AI applications.
LangChain is a leading orchestration framework for building RAG applications that simplifies the integration of diverse data sources and foundation models. Recently, we integrated Spanner Graph and LangChain, streamlining the development of GraphRAG solutions. By making Spanner Graph’s enterprise-grade, scalable, and reliable graph capabilities available directly in LangChain workflows, we’ve made it easier for developers to build advanced, relationship-aware RAG systems.
Let’s jump in.
- aside_block
- <ListValue: [StructValue([(‘title’, ‘$300 in free credit to try Google Cloud databases’), (‘body’, <wagtail.rich_text.RichText object at 0x3e89d71d4ac0>), (‘btn_text’, ‘Start building for free’), (‘href’, ‘http://console.cloud.google.com/freetrial?redirectPath=/products?#databases’), (‘image’, None)])]>
Building a retail application using GraphRAG
To illustrate the practical application of GraphRAG, let’s consider an electronics e-commerce scenario. Imagine an online retailer with a vast collection of data, including product specifications, bundle offerings, and promotional deals. This data contains implicit relationships between various entities:
-
Products: A laptop, for example, might have compatible accessories or be part of a bundle.
-
Categories: Products belong to categories, which can have hierarchical relationships (e.g., “Laptops” is a subcategory of “Computers”).
-
Customers: Customers have purchase histories and preferences, indicating relationships with products and categories.
While traditional vector-based RAG can retrieve basic product information in response to a customer query, GraphRAG provides a more comprehensive and contextualized understanding. By representing these entities and their relationships as a graph, the system can traverse connections and provide richer, more relevant information.
Let’s take a look at the steps involved to use GraphRAG using Spanner Graph and LangChain.
Step 1: Construct the knowledge graph
To leverage the power of GraphRAG, the first step is to transform your data corpus into a knowledge graph. This transformation can be achieved through various methods, including Spanner Graph schema, custom code or existing libraries. In this example, we’ll demonstrate using LangChain’s LLMGraphTransformer to convert a subset of our retail business’s unstructured document corpus into a graph.
The LLMGraphTransformer accepts the node and relationship types, along with their properties, as input which specifies the following:
-
Node types: the types of entities in the graph (e.g., “Product,” “Bundle,” “Deal”).
-
Relationship types: the types of connections between entities (e.g., “In_Bundle,” “Is_Accessory_Of,” “Is_Upgrade_Of,” “Has_Deal”).
-
Properties: the attributes associated with nodes and edges (e.g., “name,” “price,” “weight,” “deal_end_date,” “features”).
Given this input, the LLMGraphTransformer processes the documents and generates a graph represented as a list of GraphDocument objects.
Here’s a code snippet illustrating this process:
- code_block
- <ListValue: [StructValue([(‘code’, ‘# load documentsrnloader = DirectoryLoader(‘…’)rndocuments = loader.load()rnrn# convert documents to graphrnllm_transformer = LLMGraphTransformer(rn llm=ChatVertexAI(),rn allowed_nodes = [“Product”, “Bundle”, “Deal”, “Category”, “Segment”, ],rn allowed_relationships = [“In_Category”,”In_Bundle”, “Is_Accessory_Of”,rn “Is_Upgrade_Of”, “Has_Deal”],rn node_properties=[ “name”, “price”, “weight”, “deal_end_date”, “features”, ],rn)rngraph_documents = llm_transformer.convert_to_graph_documents(documents)’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e89d71d4520>)])]>
To use semantic search in our GraphRAG application, we also need to generate vector embeddings for our graph nodes. This enables us to identify nodes based on the semantic meaning of their content. In our retail scenario, we can generate embeddings for the textual descriptions of features of products, categories, and other relevant entities.
Here’s a simplified example of how we can generate these embeddings:
- code_block
- <ListValue: [StructValue([(‘code’, ’embedding_service = VertexAIEmbeddings()rnfor graph_document in graph_documents:rn for node in graph_document.nodes:rn if “features” in node.properties:rn node.properties[“embedding”] =rn embedding_service.embed_query(node.properties[“features”])’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e89d71d4070>)])]>
Alternatively, you can follow this Get Vertex AI text embeddings guide to use Spanner’s built-in text embedding generation capabilities.
Step 2: Store the knowledge graph in Spanner Graph
To persist and query the constructed knowledge graph, you can utilize the SpannerGraphStore library to load the generated graph into Spanner Graph. This library simplifies the process by handling the underlying Spanner Graph schema generation, including the necessary input tables and the graph itself, and then applying that schema to the database. Additionally, it performs lightweight reconciliation of duplicate nodes and edges within the graph before writing the data to the database, improving data integrity.
Here’s an example of how you can store a graph:
- code_block
- <ListValue: [StructValue([(‘code’, ‘from langchain_google_spanner import SpannerGraphStorernrn# Initialize SpannerGraphStorerngraph_store = SpannerGraphStore(rn instance_id=INSTANCE,rn database_id=DATABASE,rn graph_name=GRAPH_NAME,rn)rnrn# store documents into Spanner Graphrngraph_store.add_graph_documents(graph_documents)’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e89d71d4df0>)])]>
Step 3: Inspect the knowledge graph
Once the knowledge graph is loaded into Spanner Graph, you can use Spanner Graph Notebook to inspect both its schema and the data itself to ensure it accurately represents the retail information. You can use the following magic command to connect to the Spanner Graph instance and explore the graph:
- code_block
- <ListValue: [StructValue([(‘code’, ‘%%spanner_graph –project PROJECT –instance INSTANCE –database DATABASErnrnGRAPH retail_graphrnMATCH p = ()->()rnRETURN TO_JSON(p) AS path_jsonrnLIMIT 200;’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e89d71d4610>)])]>
You can then inspect the graph schema and interact with the graph data as illustrated below:
Step 4: Retrieve context using the SpannerGraphVectorContextRetriever
This section demonstrates how GraphRAG excels at context retrieval for generating answers compared to conventional RAG. To answer questions grounded in the generated graph, you can utilize the SpannerGraphVectorContextRetriever. This retriever takes a natural language question as input and leverages vector search to identify nodes in the graph that are the closest semantic matches. It then enhances the context by exploring paths from the matched nodes up to a defined number of hops. The retriever effectively combines the power of vector search with the capabilities of graph traversals within Spanner Graph.
Let’s analyze how the retriever handles the following natural language question: "I am looking for a beginner drone. Please give me some recommendations".
First, you construct a SpannerGraphVectorContextRetriever configured to answer product-related questions. Then, you invoke the retriever with the natural language question to obtain the relevant context:
- code_block
- <ListValue: [StructValue([(‘code’, ‘retriever = SpannerGraphVectorContextRetriever.from_params(rn graph_store,rn VertexTextEmbedding(),rn label_expr=”Product”,rn expand_by_hops=1, #expands to all nodes one hop awayrn)rnquestion = “I am looking for a beginner drone. Please give me some recommendations.”rncontext = retriever.invoke(question)’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e89d71d47f0>)])]>
The retriever leverages Spanner vector search to identify the most relevant product — in this case, the SkyHawk Zephyr Drone (specified as a beginner drone in the input documents). It then navigates the graph to discover related information, including bundles, compatible accessories, potential upgrades, and available deals for the SkyHawk Zephyr Drone. The neighborhood subgraph retrieved by the SpannerGraphVectorContextRetriever, centered on the “SkyHawk Zephyr Drone” node, is illustrated below:
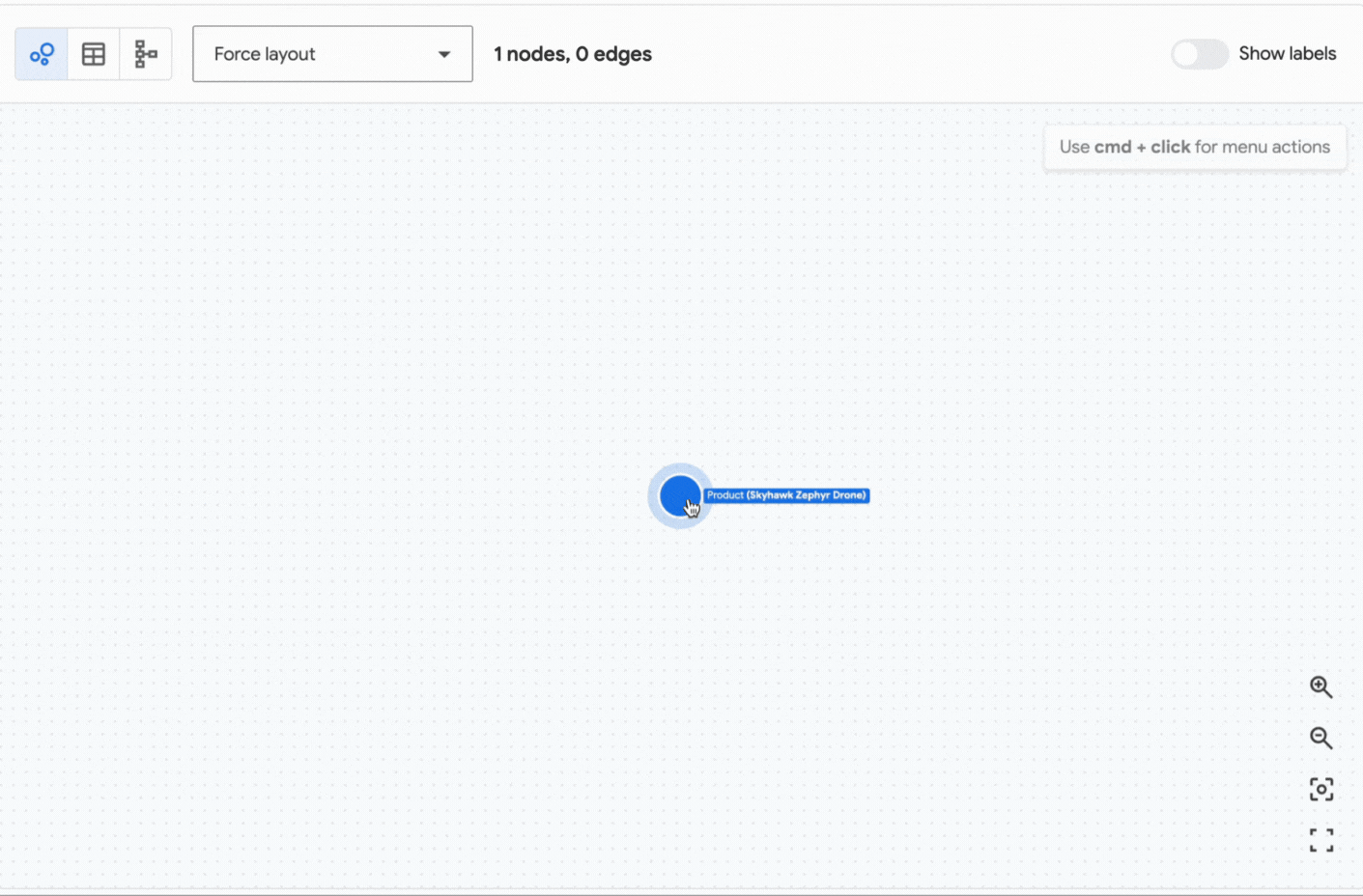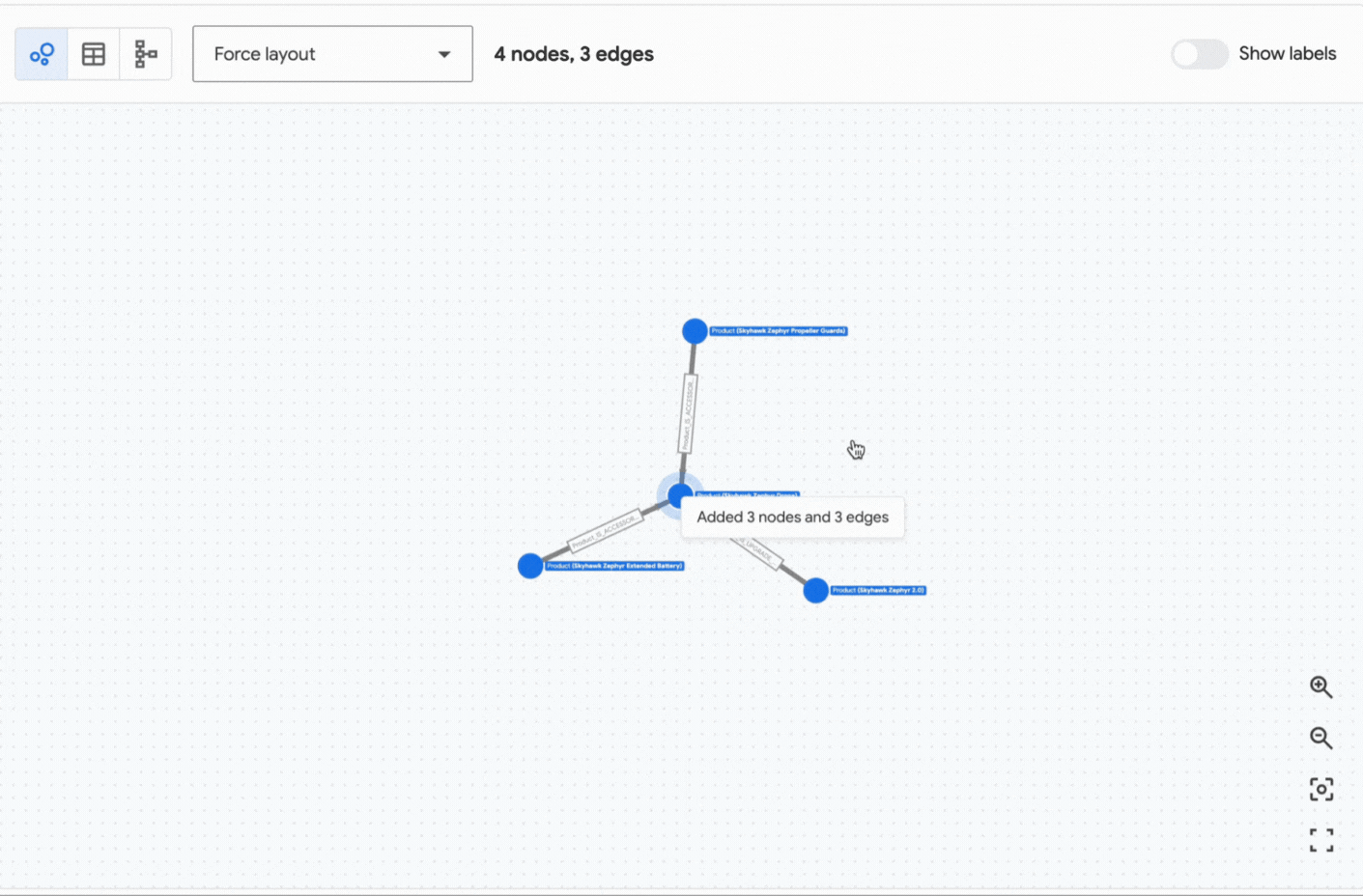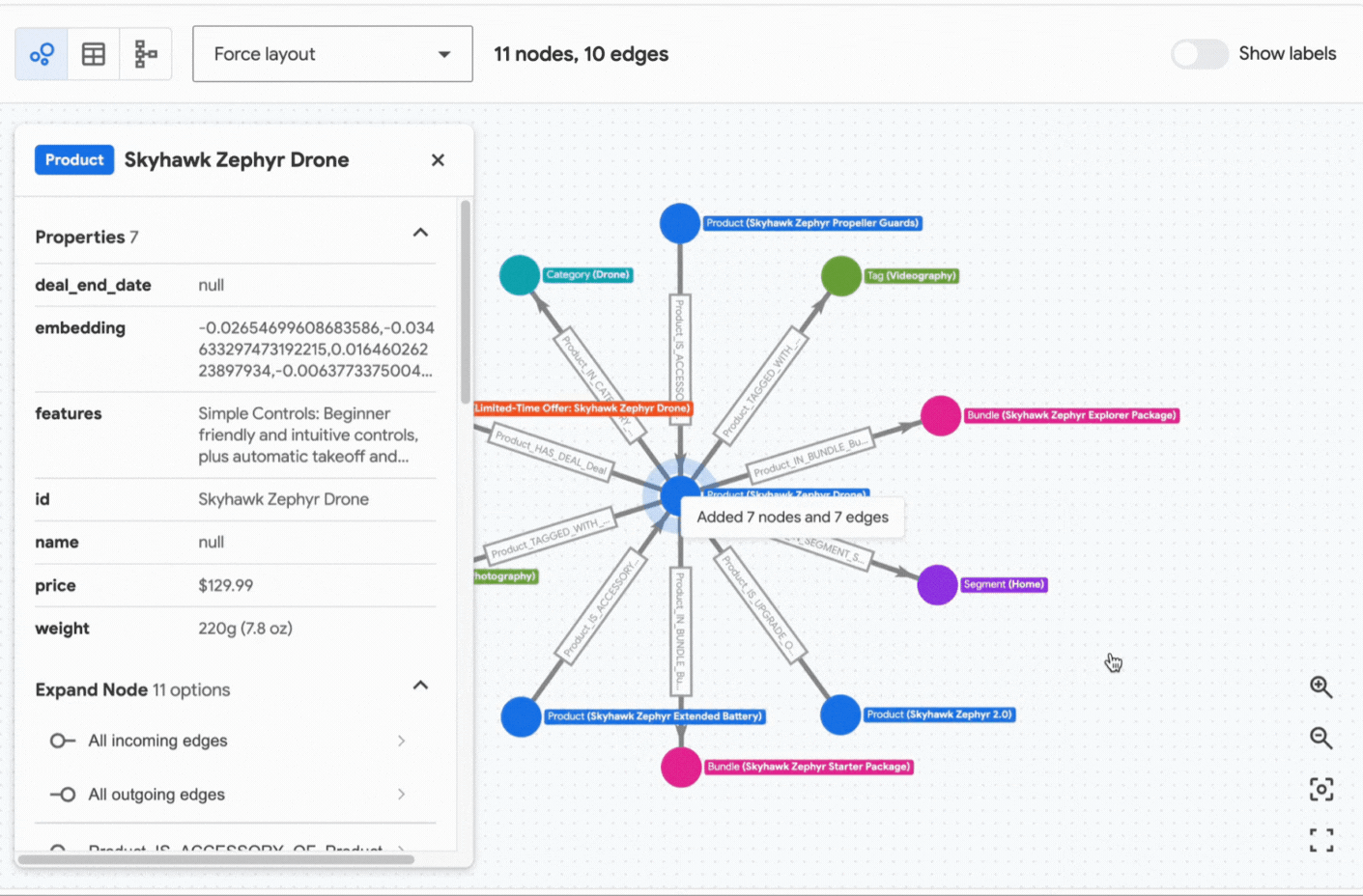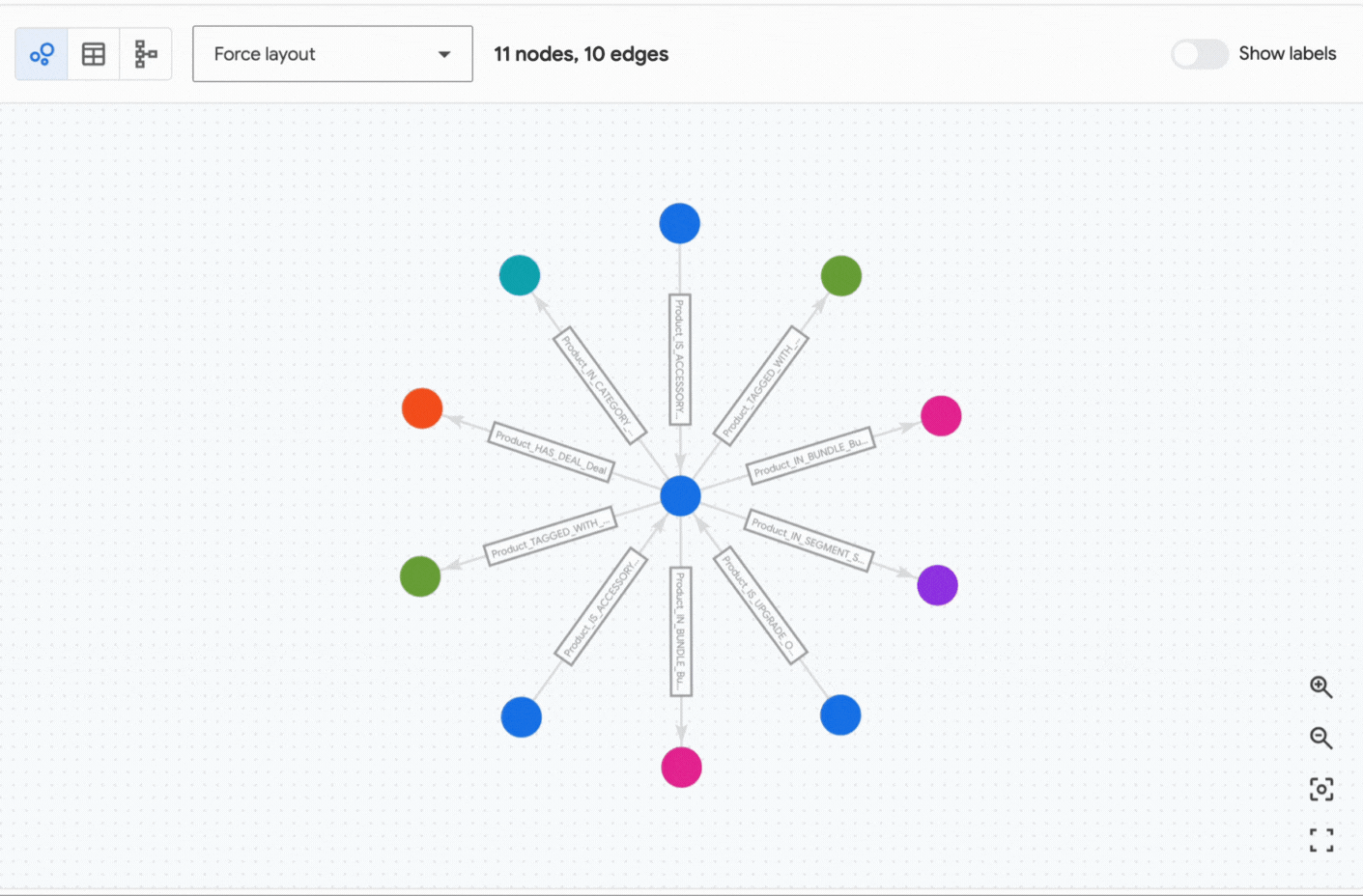
This enriched context is then passed to the LLM, which produces the final answer to the question.
How GraphRAG outperforms conventional RAG
To illustrate how GraphRAG provides a richer, more informative answer compared to conventional RAG using vector search alone, we compare their results below:
|
Conventional RAG |
GraphRAG |
|
Based on the information provided, I recommend the SkyHawk Zephyr Drone or the SkyHawk Zephyr Starter Package for a beginner drone. Both are priced at $129.99 and are designed with simplicity and stability in mind, offering user-friendly controls, automatic takeoff and landing, and a durable design. The Starter Package includes everything you need to begin flying. |
The SkyHawk Zephyr Drone is a good option for a beginner drone, it has features like User-Friendly Controls, Stable Flight, Durable Design, HD Camera, Long Flight Time, and One-Key Return. It is priced at $129.99. It also has a limited time deal price of $109.99. There are also some bundles and accessories available for this drone. The SkyHawk Zephyr Explorer Package is priced at $179.99 and the Skyhawk Zephyr Starter Package is priced at $129.99. The SkyHawk Zephyr Extended Battery is an accessory that increases flight time and is priced at $29.99. The Skyhawk Zephyr Propeller Guards are also available for $14.99. If you are looking for an upgrade, the Skyhawk Zephyr 2.0 is available for $199.99. |
Notably, both RAG workflows identify the SkyHawk Zephyr Drone as the beginner drone and recommend the SkyHawk Zephyr Starter Package. However, GraphRAG also surfaces valuable additional information about the recommended products, including:
-
Accessories available for the SkyHawk Zephyr Drone
-
Related deals on the recommended product
-
The option to upgrade to the next tier of the recommended drone, specifically the SkyHawk Zephyr 2.0
Get started today
Google Spanner Graph and LangChain streamline GraphRAG development by combining Spanner Graph’s enterprise-grade reliability, scalability, and distributed graph processing with LangChain’s versatile tools. This enables rapid prototyping of intelligent applications and unlocks valuable data insights. We’re excited to see what you’ll build!
To get started, visit the GitHub repository. You can deep dive into the reference notebook tutorial for the use case discussed above. Learn more about Spanner Graph benefits and use cases here. Use this quick setup guide to get started with Spanner Graph capabilities.
Read More for the details.

