
GCP – BigQuery under the hood: Short query optimizations in the advanced runtime
In a prior blog post, we introduced BigQuery’s advanced runtime, where we detailed enhanced vectorization and discussed techniques like dictionary and run-length encoded data, vectorized filter evaluation and compute pushdown, and parallelizable execution.
This blog post dives into short query optimizations, a key component of BigQuery’s advanced runtime. These optimizations can significantly speed up the “short” queries all while using fewer BigQuery “slots” (our term for computational capacity). They are commonly used by business intelligence (BI) tools such as LookerStudio or custom applications powered by BigQuery.
Similar to other BigQuery optimization techniques, the system uses a set of internal rules to determine if it should consolidate a distributed query plan into a single, more efficient step for short queries. These rules consider factors like:
- The estimated amount of data to be read
- How effectively the filters are reducing the data size
- The type and physical arrangement of the data in storage
- The overall query structure
- The runtime statistics of past query executions
Along with enhanced vectorization, short query optimizations are an example of how we work to continuously improve performance and efficiency for BigQuery users.
Optimizations specific to short query execution
BigQuery’s short query optimizations dramatically speed up short, eligible queries to significantly reduce slot usage and improve query latency. Normally, BigQuery breaks down queries into multiple stages, each with smaller tasks processed in parallel across a distributed system. However, for suitable queries, short query optimizations skip this multi-stage distributed execution, leading to substantial gains in performance and efficiency. When possible, it also uses multithreaded execution, including for queries with joins and aggregations. For these queries, BigQuery automatically determines if a query is eligible and dispatched to a single stage. BigQuery also employs history-based optimization (HBO), which learns from past query executions. HBO helps BigQuery decide whether a query should run in a single stage or multiple stages based on its historical performance, ensuring the single stage approach remains beneficial even as workloads evolve.
- aside_block
- <ListValue: [StructValue([(‘title’, ‘$300 in free credit to try Google Cloud data analytics’), (‘body’, <wagtail.rich_text.RichText object at 0x3ebccb70bf10>), (‘btn_text’, ‘Start building for free’), (‘href’, ‘http://console.cloud.google.com/freetrial?redirectPath=/bigquery/’), (‘image’, None)])]>
Full view of data
Short query optimizations process the entire query as a single stage, giving the runtime complete visibility into all tables involved. This allows the runtime to read both sides of the join and gather precise metadata, including column cardinalities. For instance, join columns in the query below have a low cardinality, so it is efficiently stored using dictionary and run-length encodings (RLE). Consequently, the runtime devises a much simpler query execution plan by leveraging encoding during execution.
The following query calculates top-ranked products and their performance metrics for an e-commerce scenario. It’s based on a type of query observed in Google’s internal data pipelines that benefited from short query optimizations. The following query uses this BigQuery public dataset, allowing you to replicate the results. Metrics throughout this blog were captured during internal Google testing.
- code_block
- <ListValue: [StructValue([(‘code’, ‘WITHrn AllProducts AS (rn SELECTrn id,rn name AS product_namern FROMrn `bigquery-public-data.thelook_ecommerce.products`rn ),rn AllUsers AS (rn SELECTrn idrn FROMrn `bigquery-public-data.thelook_ecommerce.users`rn ),rn AllSales AS (rn SELECTrn oi.user_id,rn oi.sale_price,rn ap.product_namern FROMrn `bigquery-public-data.thelook_ecommerce.order_items` AS oirn INNER JOIN AllProducts AS aprn ON oi.product_id = ap.idrn INNER JOIN AllUsers AS aurn ON oi.user_id = au.idrn ),rn ProductPerformanceMetrics AS (rn SELECTrn product_name,rn ROUND(SUM(sale_price), 2) AS total_revenue,rn COUNT(*) AS units_sold,rn COUNT(DISTINCT user_id) AS unique_customersrn FROMrn AllSalesrn GROUP BYrn product_namern ),rn RankedProducts AS (rn SELECTrn product_name,rn total_revenue,rn units_sold,rn unique_customers,rn RANK() OVER (ORDER BY total_revenue DESC) as revenue_rankrn FROMrn ProductPerformanceMetricsrn )rnSELECTrn revenue_rank,rn product_name,rn total_revenue,rn units_sold,rn unique_customersrnFROMrn RankedProductsrnORDER BYrn revenue_rankrnLIMIT 25;’), (‘language’, ‘lang-sql’), (‘caption’, <wagtail.rich_text.RichText object at 0x3ebccb720670>)])]>
By skipping the shuffle layer, overall query execution requires less CPU, memory, and network bandwidth. In addition to that, short query optimizations take full advantage of enhanced vectorization described in the Understanding BigQuery enhanced vectorization blog post.
Figure 2: Internal Google testing: One stage plan for internal testing of query from Figure 1.
Queries with joins and aggregations
In data analytics, it’s common to join data from several tables and then calculate aggregate results. Typically, a query performing this distributed operation will go through many stages. Each stage can involve shuffling data around, which adds overhead and slows things down. BigQuery’s short query optimizations can dramatically improve this process. When enabled, BigQuery intelligently recognizes if the amount of data being queried is small enough to be handled by a much simpler plan. This optimization leads to substantial improvements: for the query described in Figure 3, during internal Google testing we observed 2x to 8x faster execution times and an average of 9x reduction in slot-seconds.
- code_block
- <ListValue: [StructValue([(‘code’, “SELECTrn p.category,rn dc.name AS distribution_center_name,rn u.country AS user_country,rn SUM(oi.sale_price) AS total_sales_amount,rn COUNT(DISTINCT o.order_id) AS total_unique_orders,rn COUNT(DISTINCT o.user_id) AS total_unique_customers_who_ordered,rn AVG(oi.sale_price) AS average_item_sale_price,rn SUM(CASE WHEN oi.status = ‘Complete’ THEN 1 ELSE 0 END) AS completed_order_items_count,rn COUNT(DISTINCT p.id) AS total_unique_products_sold,rn COUNT(DISTINCT ii.id) AS total_unique_inventory_items_soldrnFROMrn `bigquery-public-data.thelook_ecommerce.orders` AS o,rn `bigquery-public-data.thelook_ecommerce.order_items` AS oi,rn `bigquery-public-data.thelook_ecommerce.products` AS p,rn `bigquery-public-data.thelook_ecommerce.inventory_items` AS ii, `bigquery-public-data.thelook_ecommerce.distribution_centers` AS dc, `bigquery-public-data.thelook_ecommerce.users` AS urnWHERErno.order_id = oi.order_id AND oi.product_id = p.id AND ii.product_distribution_center_id = dc.id AND oi.inventory_item_id = ii.id AND o.user_id = u.idrnGROUP BYrn p.category,rn dc.name,rn u.countryrnORDER BYrn total_sales_amount DESCrnLIMIT 1000;”), (‘language’, ‘lang-sql’), (‘caption’, <wagtail.rich_text.RichText object at 0x3ebccb7208b0>)])]>
We can see how the execution graph changes when short query optimizations are applied to the query in Figure 3.
Figure 4: Internal Google testing: execution the join-aggregate query in 9 stages using BigQuery distributed execution.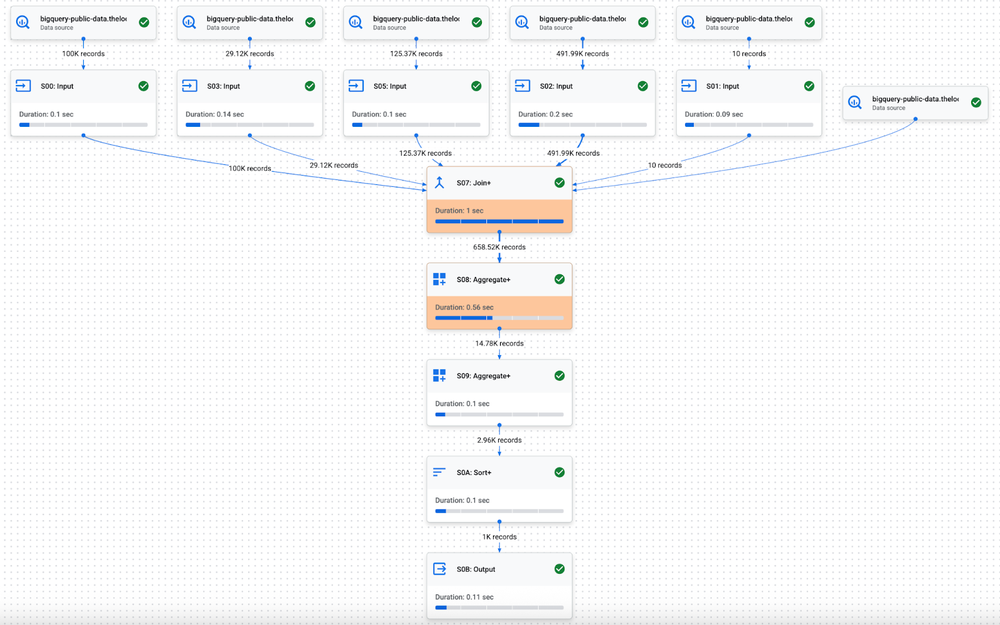
Figure 5: Internal Google testing: with advanced runtime short query optimizations, join-aggregate query completes in 1 stage.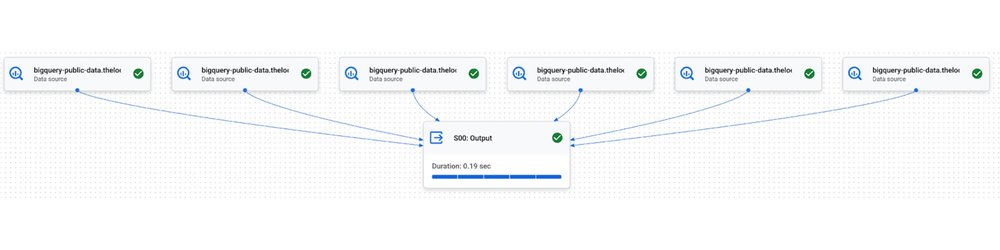
Optional job creation
Short query optimizations and optional job creation mode are two independent yet complementary features that enhance query performance. While optional job creation mode contributes significantly to the efficiency of short queries regardless of short query optimizations, they work even better together. When both are enabled, the advanced runtime streamlines internal operations and utilizes the query cache more efficiently, which leads to even faster delivery of the results.
Better throughput
By reducing the resources required for queries, short query optimizations not only deliver performance gains, but also significantly improves the overall throughput. This efficiency means that more queries can be executed concurrently within the same resource allocation.
The following graph, captured from Google internal data pipeline, shows an example query that benefits from short query optimizations. The blue line shows the maximum QPS (or throughput) that can be sustained. The red line shows QPS on the same reservation after advanced runtime was enabled. In addition to better latency, the same reservation can now handle over 3x higher throughput.
Figure 6: Internal Google testing: Throughput comparison, red line shows improvements from short query optimizations in the advanced runtime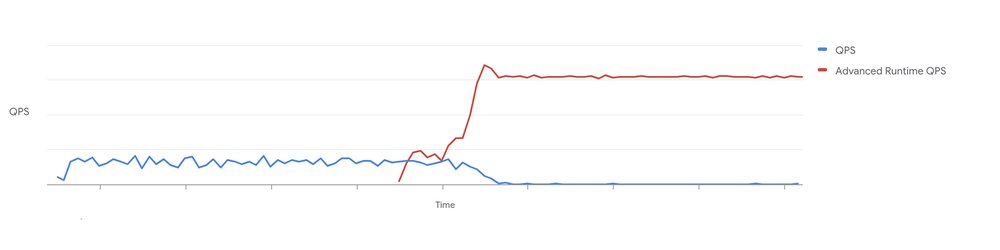
Optimal impact
BigQuery’s short query optimizations feature is designed primarily for BI queries intended for human-readable output. Even though BigQuery utilizes a dynamic algorithm to determine eligible queries, it works with other performance-enhancing features like history-based optimizations, BI Engine, optional job creation, etc. Nevertheless, some workload patterns will benefit from short query optimizations more than others.
This optimization may not significantly improve queries that read or produce a lot of data. To optimize for short query performance, it is crucial to keep the query working set and result size small through pre-aggregation and filtering. Implementing partitioning and clustering strategies appropriate to your workload can also significantly reduce the amount of data processed, and utilizing the optional job creation mode is beneficial for short-lived queries that can be easily retried.
Short query optimizations in action
Let’s see how these optimizations actually impact our test query by looking closer at the query in Figure 1 and its query plan in Figure 2. The query shape is based on actual workloads observed in production and made to work against a BigQuery public dataset, so you can test it for yourself.
Despite the query scanning only 6.5 MB, running this query without advanced runtime takes over 1 second and consumes about 20 slot-seconds (execution time may vary depending on available resources in the project).
Figure 7: Internal Google testing: Sample query execution details without Advanced Runtime
With BigQuery’s enhanced vectorization in the advanced runtime, during internal Google testing this query finishes in 0.5 seconds while consuming 50x less resources.
Figure 8: Internal Google testing: Sample query execution details with Advanced Runtime Short Query Optimizations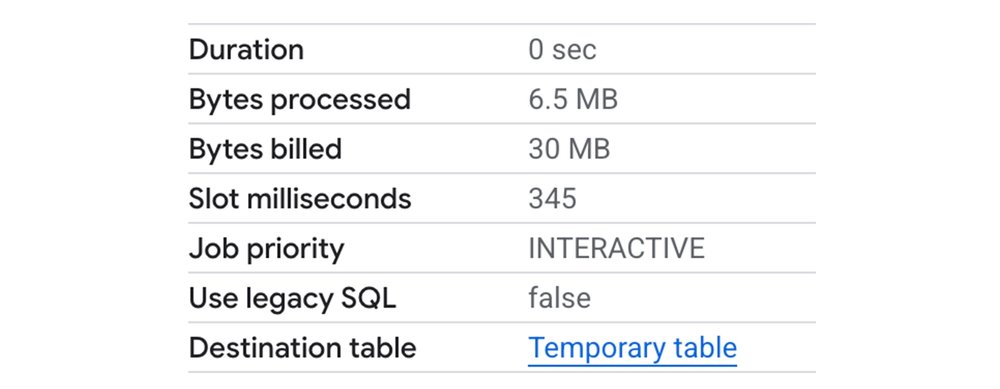
The magnitude of improvement here is less common, showing an example of real workload improvement from Google internal pipelines. We have also seen classic BI queries with several aggregations, filters, group by and sort, or snowflake joins achieve faster performance and better slot utilization.
Try it for yourself
Short query optimizations boost query price/performance, allowing for higher throughput and lower latencies for common BI small queries. It achieves this by combining cutting-edge algorithms with Google’s latest innovations across storage, compute, and networking. This is just one of many performance improvements that we’re continually delivering to BigQuery customers like enhanced vectorization, history based optimizations, optional-job-creation mode, column metadata index (CMETA) and others.
Now that both key pillars of advanced runtime are in public preview, all you have to do to test it with your workloads is to enable it using the single ALTER PROJECT command as documented here. This enables both enhanced vectorization and short query optimizations. If you already did that earlier for enhanced vectorization, your project is automatically also enabled for short query optimizations.
Try it now with your own workload following steps in BigQuery advanced runtime documentation here, and share your feedback and experience with us at bqarfeedback@google.com.
Read More for the details.

