
GCP – Automate data pipelines with BigQuery’s new data engineering agent
For years, data teams have relied on the BigQuery platform to power their analytics and unlock critical business insights. But building, managing, and troubleshooting the data pipelines that feed those insights can be a complex, time-consuming process, requiring specialized expertise and a lot of manual effort. Today, we’re excited to announce our vision, a major step forward in simplifying and accelerating data engineering with BigQuery data engineering agent.
These agents aren’t just assistive tools, but agentic solutions, designed to act as intelligent partners in your data workflows. They automate daunting tasks, collaborate with your team, and continuously learn and adapt, freeing you to focus on what matters most: extracting value from your data.
Why a data engineering agent?
The world of data is changing. Organizations are generating more data than ever before, and that data is coming from a wider variety of sources, in a multitude of formats. At the same time, businesses need to move faster, making quick, data-driven decisions to stay competitive.
This creates a challenge. Traditional data engineering approaches often involve:
-
Tedious manual coding: Building and modifying pipelines can require writing and updating complex SQL queries, which is time-consuming and error-prone.
-
Schema struggles: Mapping data from different sources to the right format can be time-intensive, especially as schemas evolve.
-
Difficult troubleshooting: Diagnosing and fixing pipeline issues can involve lengthy sifting through logs and code, delaying critical insights.
-
Siloed expertise: Building and maintaining pipelines often requires specialized skills, creating bottlenecks and limiting who can contribute.
The BigQuery data engineering agent aims to address these pain points head-on and accelerate the way data pipelines are built and managed.
- aside_block
- <ListValue: [StructValue([(‘title’, ‘$300 in free credit to try Google Cloud data analytics’), (‘body’, <wagtail.rich_text.RichText object at 0x3e49f7b06af0>), (‘btn_text’, ‘Start building for free’), (‘href’, ‘http://console.cloud.google.com/freetrial?redirectPath=/bigquery/’), (‘image’, None)])]>
Meet your new AI-powered data engineering team
Imagine a team of expert data engineers, available 24/7, ready to jump in and tackle the toilsome pipeline development, maintenance, and troubleshooting tasks, enabling your data team to scale and focus on higher-value work. We are announcing the data engineering agent as experimental.
Here are a few ways how BigQuery data engineering agent will change the game:
1. Autonomous pipeline building and modification
Do you need a new pipeline to ingest, transform, and validate data? Simply describe your needs in natural language – the agent handles the rest. For example:
“Create a pipeline to load data from the ‘customer_orders’ bucket, standardize the date formats, remove duplicate entries based on order ID, and load it into a BigQuery table named ‘clean_orders’.”
The agent, leveraging its understanding of data engineering best practices and your specific environment and context, generates the necessary SQL code, builds the pipeline, and even creates basic unit tests. It’s not just about automation; it’s about intelligent, context-aware automation.
Need to update an existing pipeline? Just tell the agent what you want to change. It analyzes the existing code, proposes modifications, and even highlights potential impacts on downstream processes. You remain in control, reviewing and approving changes, but the agent handles the heavy lifting.
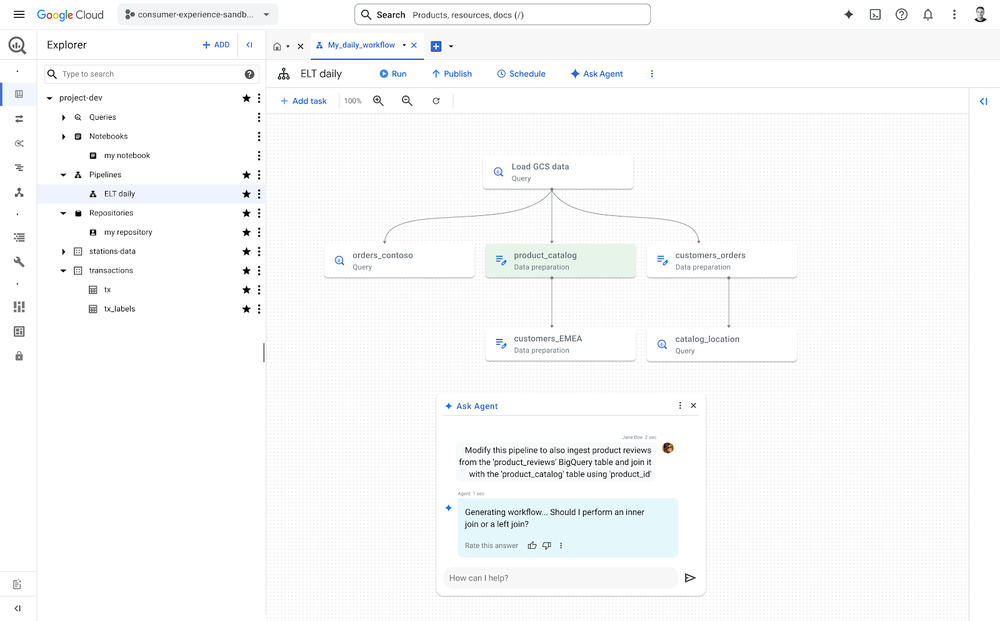
2. Proactive troubleshooting and optimization
Pipeline issues? The agent monitors your pipelines, identifies issues such as schema and data drift, and proposes fixes. It’s like having a dedicated expert constantly watching over your data infrastructure.

3. Bulk draft pipelines
A powerful use of the data engineering agent is to scale pipeline generation or modification using previously acquired context and knowledge. This allows users to quickly scale pipelines for different departments or use cases, with customizations as needed, using the command line and API for automation at scale. In the example below, the agent takes instructions from the command line and leverages domain-specific agent instructions to create bulk pipelines.

How it works: Intelligence under the hood
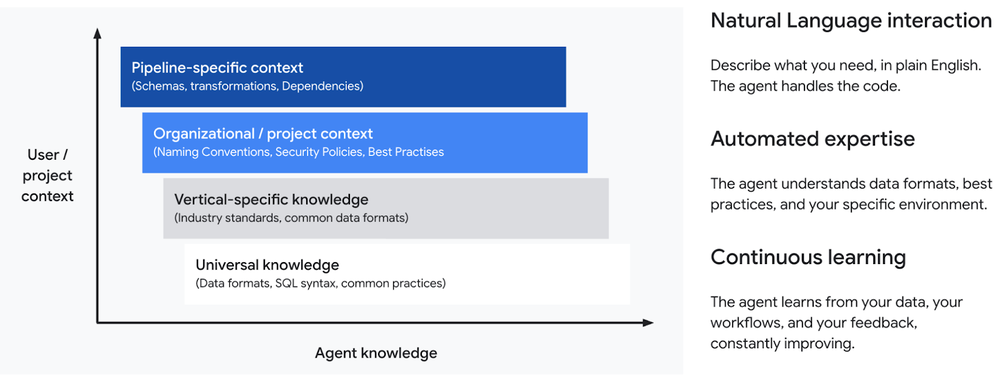
To handle the complexity that most organizations have to deal with, the agents rely on several key concepts:
-
Hierarchical context: The agents draw on multiple sources of knowledge:
-
Universal understanding of common data formats, SQL best practices, etc.
-
Vertical-specific knowledge of industry conventions (e.g., data formats in healthcare or finance)
-
Organizational awareness of your company’s or department’s specific business context, data structures, naming conventions, and security policies
-
Data pipeline-specific understanding the details of source and target schemas, transformations, and dependencies
A collaborative, multi-agent environment
BigQuery data engineering agent are a part of a multi-agent environment, where specialized agents collaborate to achieve complex goals, working together and delegating tasks, much like a real-world data engineering team:
-
An ingestion agent expertly handles data intake from various sources.
-
A transformation agent crafts efficient and reliable data pipelines.
-
A validation agent helps ensures data quality and consistency.
-
A troubleshooting agent proactively identifies and resolves issues.
-
A data quality agent, powered by Dataplex metadata, monitors data and proactively alerts on anomalies.
Our initial focus is on ingestion, transformation and troubleshooting tasks, but we plan to expand these initial capabilities to other critical data engineering tasks.
Your workflow, your way
Whether you prefer working in the BigQuery Studio UI, crafting code in your favorite IDE, or managing pipelines through the command line, we want to meet you where you are. We are initially making data engineering agent available in BigQuery Studio’s pipeline editor and API/CLI, but we plan to expose it in other contexts.
Data engineering agent and your data workers
The world is only beginning to see the full potential of AI-powered agents in revolutionizing how data workers interact with and derive value from their data. With BigQuery data engineering agent, the roles of data engineers, data analysts and data scientists are expanding beyond their traditional boundaries, empowering these teams to achieve more, faster, and with greater confidence. These agents act as intelligent collaborators, streamlining workflows, automating tedious tasks, and unlocking new levels of productivity. Initially we are focusing on core data engineering tasks of promoting data from Bronze to Silver in a data lake and expanding from there.

Coupled with products like Dataplex, BigQuery ML, and Vertex AI, BigQuery data engineering agent is poised to transform the way organizations manage, process, and derive value from their data. By automating complex tasks, promoting collaboration, and empowering data workers of all skill levels, these agents are paving the way for a new era of data-driven innovation.
Ready to get started?
This is just the beginning of our journey to build a truly intelligent, autonomous data platform. We’re committed to continuously expanding the capabilities of data engineering agent, making them even more powerful and intuitive partners for all your data needs.
BigQuery data engineering agent will be available soon. We’re excited to see how it fits into your data engineering workflows and help you unlock the full potential of your data. Show your interest in getting access here.
Read More for the details.

