
GCP – Automate AI and HPC clusters with Cluster Director, now generally available
The complexity of the infrastructure behind AI training and high performance computing (HPC) workloads can really slow teams down. At Google Cloud, where we work with some of the world’s largest AI research teams, we see it everywhere we go: researchers hampered by complex configuration files, platform teams struggling to manage GPUs with home-grown scripts, and operational leads battling the constant, unpredictable hardware failures that derail multi-week training runs. Access to raw compute isn’t enough. To operate at the cutting edge, you need reliability that survives hardware failures, orchestration that respects topology, and a lifecycle management strategy that adapts to evolving needs.
Today, we are delivering on those requirements with the General Availability (GA) of Cluster Director and the Preview of Cluster Director support for Slurm on Google Kubernetes Engine (GKE).
- Cluster Director (GA) is a managed infrastructure service designed to meet the rigorous demands of modern supercomputing. It replaces fragile DIY tooling with a robust topology-aware control plane that handles the entire lifecycle of Slurm clusters, from the first deployment to the thousandth training run.
- We are expanding Cluster Director to support Slurm on GKE (Preview), designed to give you the best of both worlds: the familiar precision of high-performance scheduling and the automated scale of Kubernetes. It achieves this by treating GKE node pools as a direct compute resource for your Slurm cluster, allowing you to scale your workloads with Kubernetes’ power without changing your existing Slurm workflows.
Cluster Director, now GA
Cluster Director offers advanced capabilities at each phase of the cluster lifecycle, spanning preparation (Day 0), where infrastructure design and capacity are determined; deployment (Day 1), where the cluster is automatically deployed and configured; and monitoring (Day 2), where performance, health, and optimization are continuously tracked.
This holistic approach ensures that you get the benefits of fully configurable infrastructure while automating lower-level operations so your compute resources are always optimized, reliable, and available.
So, what does all this cost? That’s the best part. There’s no extra charge to use Cluster Director. You only pay for the underlying Google Cloud resources — your compute, storage, and networking.
How Cluster Director supports each phase of deployment
Day 0: Preparation
Standing up a cluster typically involves weeks of planning, wrangling Terraform, and debugging the network. Cluster Director changes the ‘Day 0’ experience entirely, with tools for designing infrastructure topology that’s optimized for your workload requirements.
To streamline your Day 0 setup, Cluster Director provides:
- Reference architectures: We’ve codified Google’s internal best practices into reusable cluster templates, enabling you to spin up standardized, validated clusters in minutes. This helps ensure that every team in your organization is using the same security standards for their deployments and deploying on infrastructure that is configured correctly by default — right down to the network topology and storage mounting.
- Guided configuration: We know that having too many options can lead to configuration paralysis. The Cluster Director control plane guides you through a streamlined setup flow. You select your resources, and our system handles the complex backend mapping, ensuring that storage tiers, network fabrics, and compute shapes are compatible and optimized before you deploy.
- Broad hardware support: Cluster Director offers full support for large-scale AI systems, including Google Cloud’s A4X and A4X Max VMs powered by NVIDIA GB200 and GB300 GPUs, and versatile CPUs such as N2 VMs for cost-effective login nodes and debugging partitions.
- Flexible consumption options: Cluster Director integrates with your preferred procurement strategy, with support for Reservations for guaranteed capacity during critical training runs, Dynamic Workload Scheduler Flex-start for dynamic scaling, or Spot VMs for opportunistic low-cost runs.
“Google Cloud’s Cluster Director is optimized for managing large-scale AI and HPC environments. It complements the power and performance of NVIDIA’s accelerated computing platform. Together, we’re providing customers with a simplified, powerful, and scalable solution to tackle the next generation of computing challenges.“ – Dave Salvator, Director of Accelerated Computing Products, NVIDIA
Day 1: Deployment
Deploying hardware is one thing, but maximizing performance is another thing entirely. Day 1 is the execution phase, where your configuration transforms into a fully operational cluster. The good news is that Cluster Director doesn’t just provision VMs, it validates that your software and hardware components are healthy, properly networked, and ready to accept the first workload.
To ensure a high-performance deployment, Cluster Director automates:
- Getting a clean “bill of health”: Before your job ever touches a GPU, Cluster Director runs a rigorous suite of health checks, including DCGMI diagnostics and NCCL performance validation, to verify the integrity of the network, storage, and accelerators.
- Keeping accelerators fed with data: Storage throughput is often the silent killer of training efficiency. That’s why Cluster Director fully supports Google Cloud Managed Lustre with selectable performance tiers, allowing you to attach high-throughput parallel storage directly to your compute nodes, so your GPUs are never starved for data.
- Maximizing Interconnect Performance: To achieve peak scaling, Cluster Director implements topology-aware scheduling and compact placement policies. By utilizing dense reservations on Google’s non-blocking fabric, the system ensures that your distributed workloads are placed on the shortest physical path possible, minimizing tail latency and maximizing collective communication (NCCL) speeds from the get-go.
Day 2: Monitoring
The reality of AI and HPC infrastructure is that hardware fails and requirements change. A rigid cluster is an inefficient cluster. As you move into the ongoing “Day 2” operational phase, you need to maintain cluster health, maximize utilization and performance. Cluster Director provides a control plane equipped for the complexities of long-term operations. Today we are introducing new active cluster management capabilities to handle the messy reality of Day 2 operations.
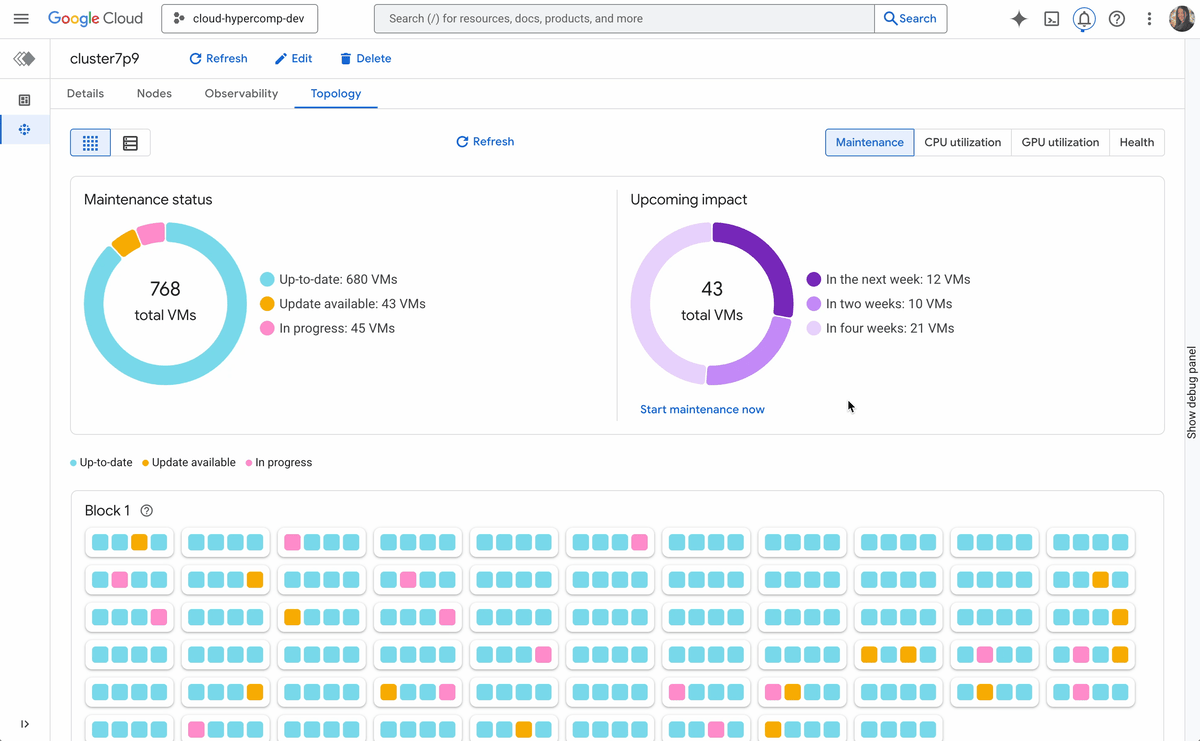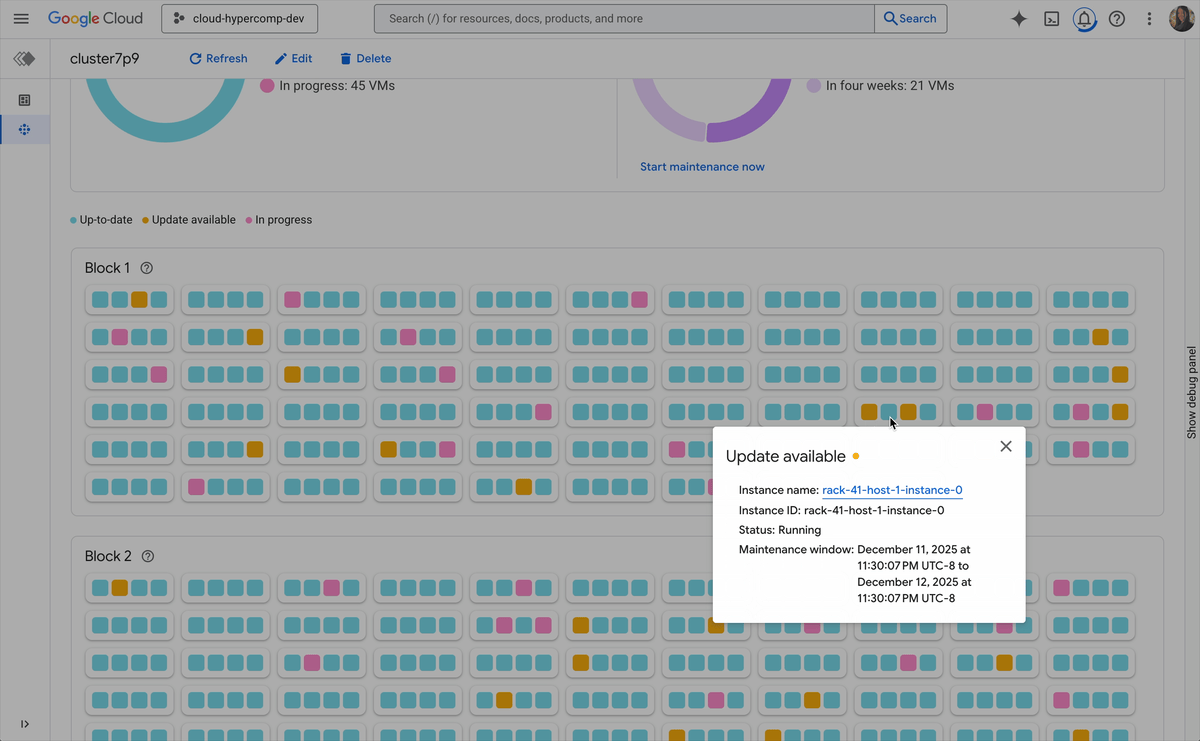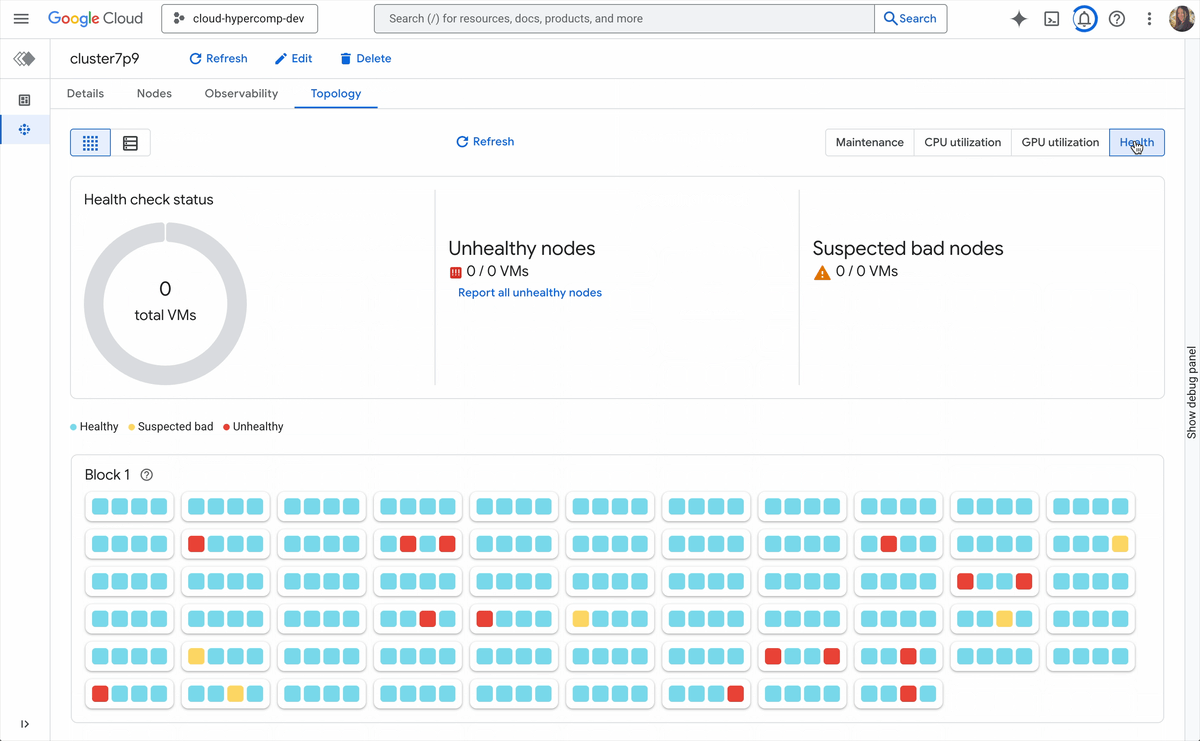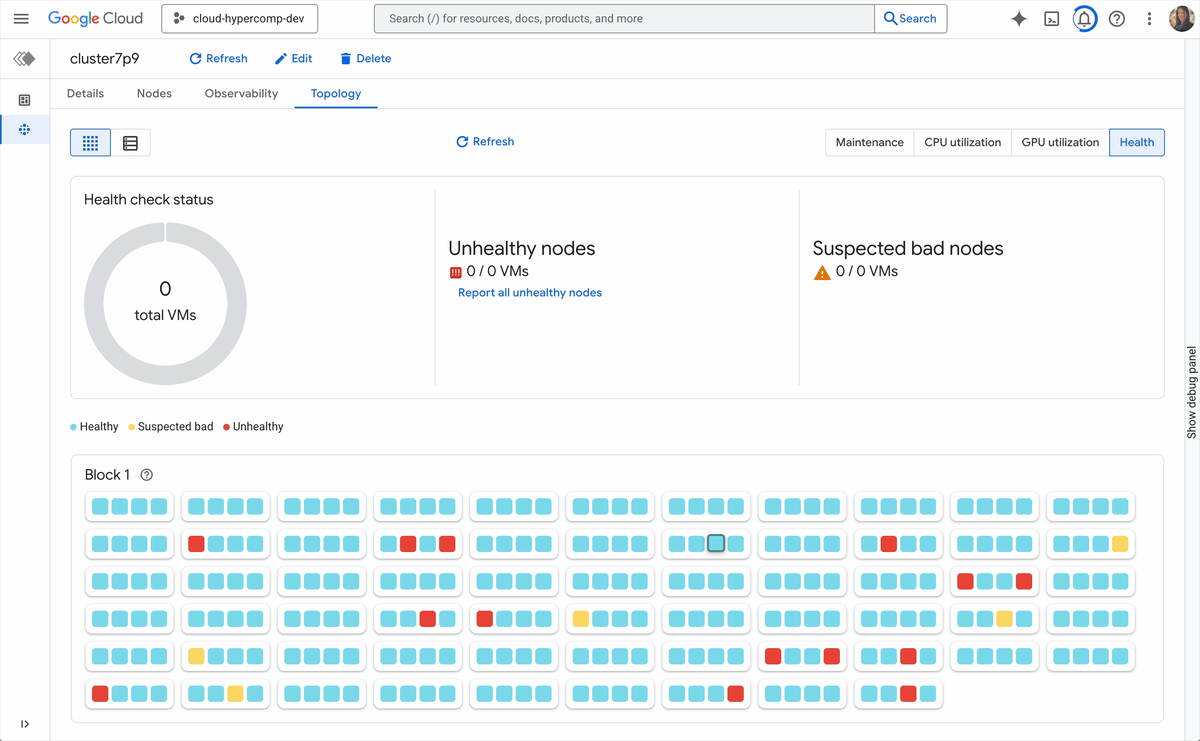
New active cluster management capabilities include:
-
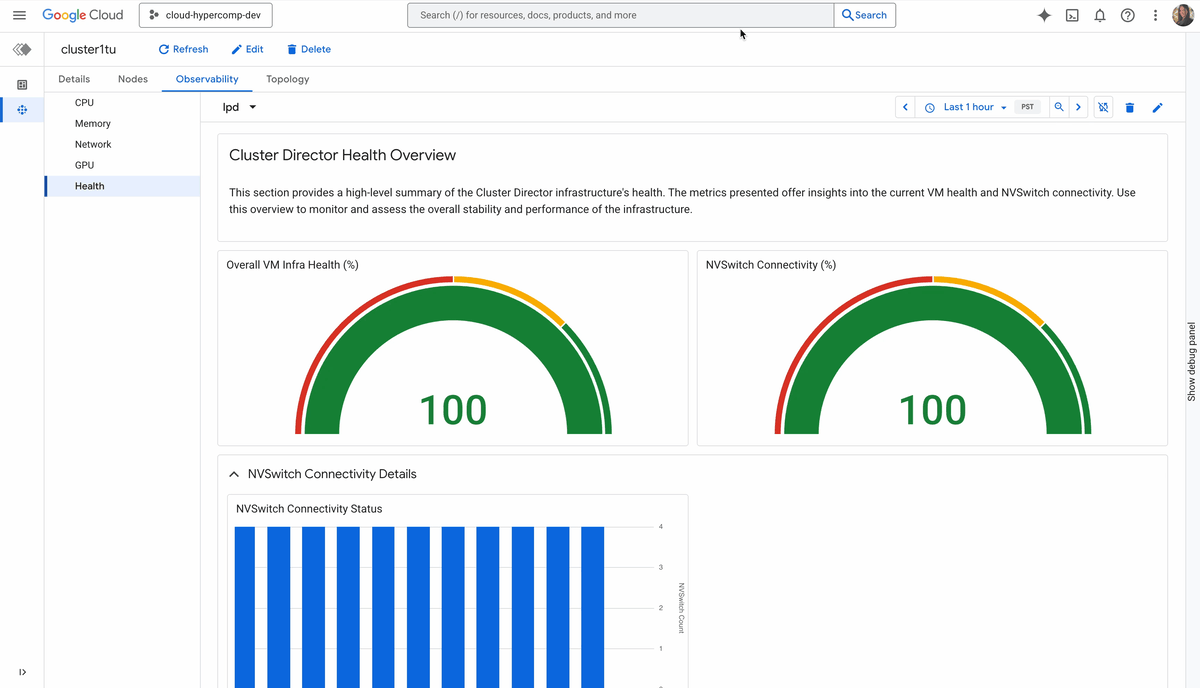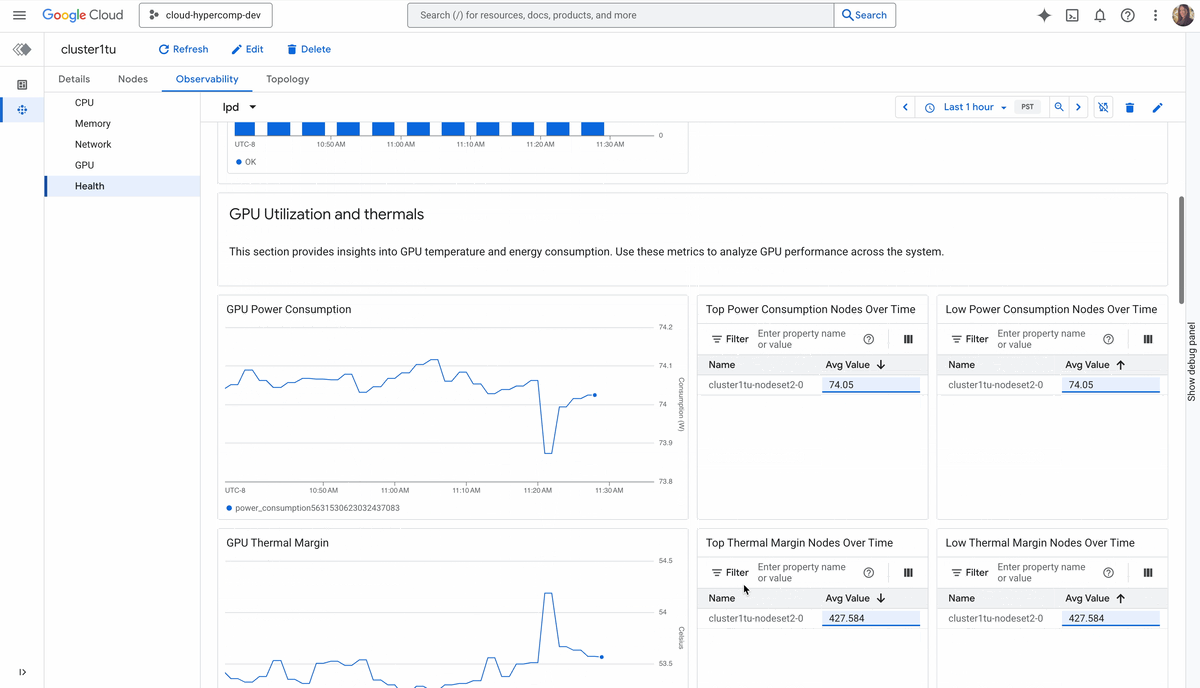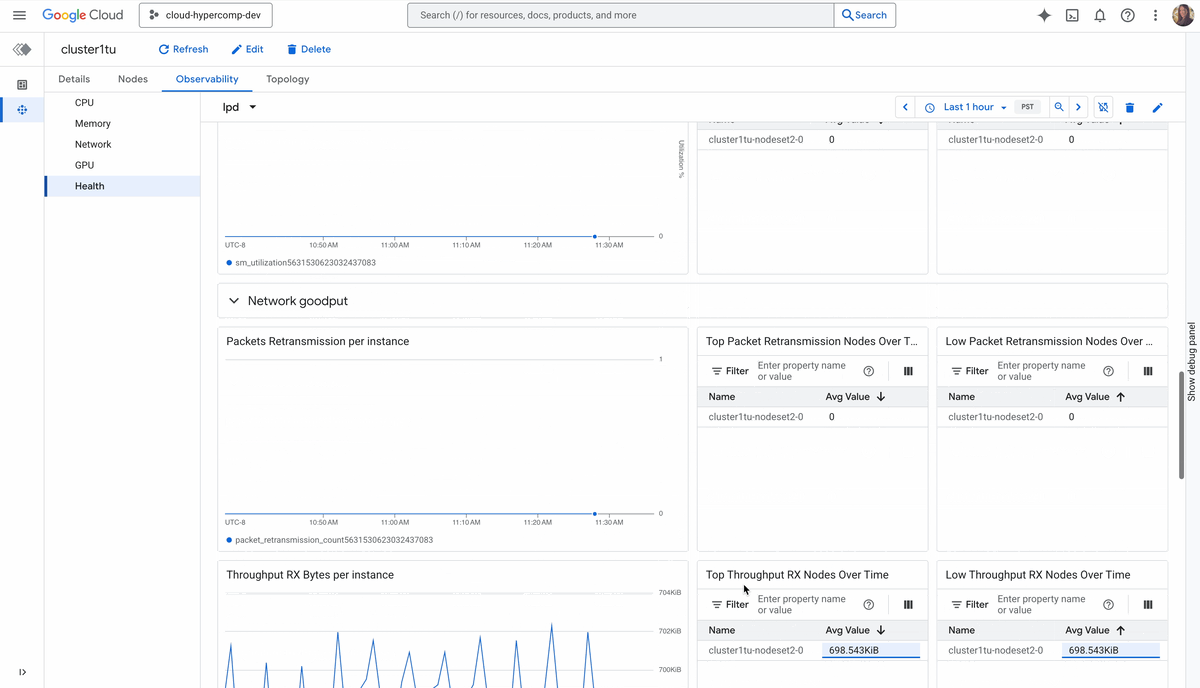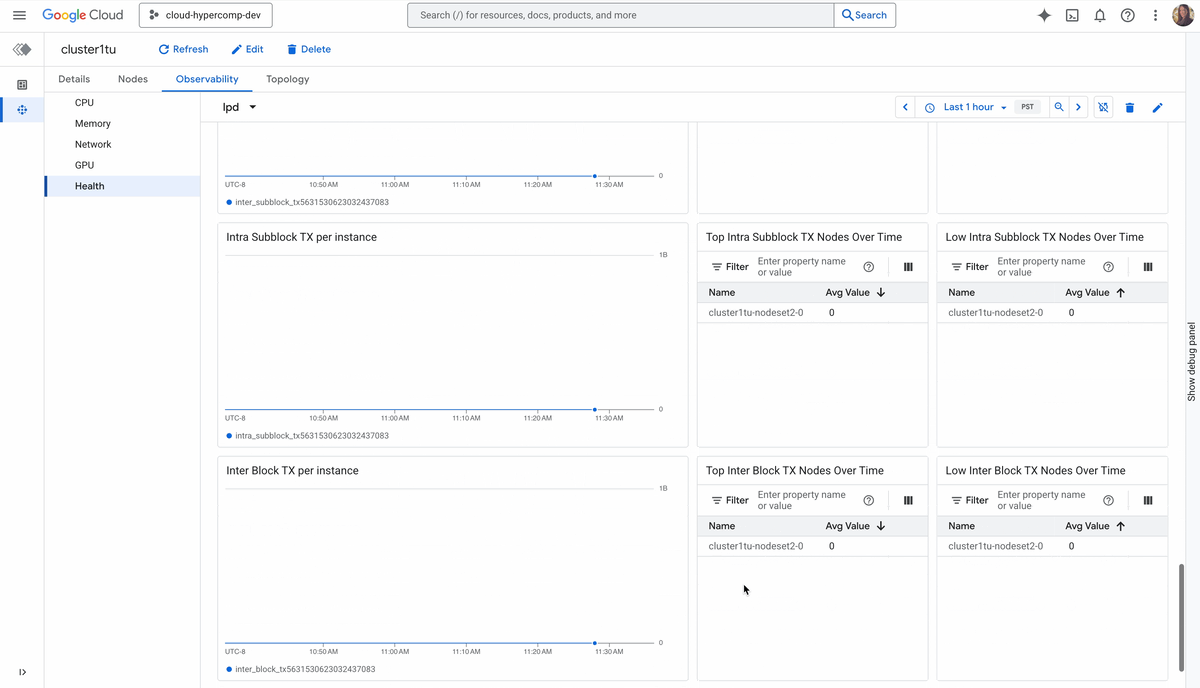
Topology-level visibility: You can’t orchestrate what you can’t see. Cluster Director’s observability graphs and topology grids let you visualize your entire fleet, spot thermal throttles or interconnect issues, and optimize job placement based on physical proximity.
-
One-click remediation: When a node degrades, you shouldn’t have to SSH in to debug it. Cluster Director allows you to replace faulty nodes with a single click directly from the Google Cloud console. The system handles the draining, teardown, and replacement, returning your cluster to full capacity in minutes.
-
Adaptive infrastructure: When your research needs change, so should your cluster. You can now modify active clusters, with activities such as adding or removing storage filesystems, on the fly, without tearing down the cluster or interrupting ongoing work.
Cluster Director support for Slurm on GKE, now in preview
Innovation thrives in the open. Google, the creator of Kubernetes, and SchedMD, the developers behind Slurm, have long championed the open-source technologies that power the world’s most advanced computing. For years, NVIDIA and SchedMD have worked in lockstep to optimize GPU scheduling, introducing foundational features like the Generic Resource (GRES) framework and Multi-Instance GPU (MIG) support that are essential for modern AI. By acquiring SchedMD, NVIDIA is doubling down on its commitment to Slurm as a vendor-neutral standard, ensuring that the software powering the world’s fastest supercomputers remains open, performant, and perfectly tuned for the future of accelerated computing.
Building on this foundation of accelerated computing, Google is deepening its collaboration with SchedMD to answer a fundamental industry challenge: how to bridge the gap between cloud-native orchestration and high-performance scheduling. We are excited to announce the Preview of Cluster Director support for Slurm on GKE, utilizing SchedMD’s Slinky offering.
This initiative brings together the two standards of the infrastructure world. By running a native Slurm cluster directly on top of GKE, we are amplifying the strengths of both communities:
-
Researchers get the uncompromised Slurm interface and batch capabilities, such as
sbatchandsqueue, that have defined HPC for decades. -
Platform teams gain the operational velocity that GKE, with its auto-scaling, self-healing, and bin-packing, brings to the table.
Slurm on GKE is strengthened by our long-standing partnership with SchedMD, which helps create a unified, open, and powerful foundation for the next generation of AI and HPC workloads. Request preview access now.
Try Cluster Director today
Ready to start using Cluster Director for your AI and HPC cluster automation?
- Learn more about the end-to-end capabilities in documentation.
- Activate Cluster Director in the console.
Read More for the details.

