
GCP – Accelerate your analytics: New Bigtable SQL capabilities drive real-time insights
For decades, businesses have wrestled with unlocking the true potential of their data for real-time operations. Bigtable, Google Cloud’s pioneering NoSQL database, has been the engine behind massive-scale, low-latency applications that operate at a global scale. It was purpose-built for the challenges faced in real-time applications, and remains a key piece of Google infrastructure, including YouTube and Ads.
This week at Google Cloud Next, we announced continuous materialized views, an expansion of Bigtable’ SQL capabilities. Bigtable SQL and continuous materialized views enable users to build fully-managed, real-time application backends using familiar SQL syntax, including specialized features that preserve Bigtable’s flexible schema — a vital aspect of real-time applications.
Whether you’re building streaming applications, real-time aggregations, or global AI analysis on a continuous data stream, Bigtable just got a whole lot easier — and much more powerful.
Bigtable’s SQL interface, now generally available
Bigtable recently transformed the developer experience by adding SQL support, now generally available. SQL support makes it easier for development teams to work with Bigtable’s flexibility and speed.
Bigtable SQL interface in Bigtable Studio
The Bigtable SQL interface enhances accessibility and streamlines application development by facilitating rapid troubleshooting and data analysis. This unlocks new use cases, like real-time dashboards utilizing distributed counting for instant metric retrieval and improved product search through K nearest neighbors (KNN) similarity search. A wide range of customers, spanning innovative AI startups to traditional financial institutions, are enthusiastic about Bigtable SQL’s potential to broaden developer access to Bigtable’s capabilities.
“Imagine coding with AI that understands your entire codebase. That’s Augment Code, an AI coding platform that gives you context in every feature. Bigtable’s robustness and scaling enable us to work with large code repositories. Its ease of use allowed us to build security features that safeguard our customers’ valuable intellectual property. As our engineering team grows, Bigtable SQL will make it easier to onboard new engineers who can immediately start to work with Bigtable’s fast access to structured, semi-structured, or unstructured data while using a familiar SQL interface” said Igor Ostrovsky, cofounder and CTO, Augment.
“Equifax leverages Bigtable within our proprietary data fabric for the high-performance storage of financial journals. Our data pipeline team evaluated Bigtable’s SQL interface and found it to be a valuable tool for directly accessing our enterprise data assets and improved Bigtable’s ease of use for SQL-experienced teams. This means more of our team can work efficiently with Bigtable and we anticipate boosted productivity and better integration capabilities,” said Varadarajan Elangadu Raghunathan and Lakshmi Narayanan Veena Subramaniyam, vice-presidents, Data Fabric Decision Science.
Bigtable SQL has also been praised for offering a smooth migration path from databases with distributed key-value architectures and SQL-based query languages, including Cassandra (CQL) and HBase with Apache Phoenix.
“At Pega, we are building real-time decisioning applications that require very low latency query responses to make sure our clients get real-time data to drive their business. The new SQL interface in Bigtable is a compelling option for us as we look for alternatives to our existing database,” said Arjen van der Broek, principal product manager, Data and Integrations, Pega.
This week, Bigtable is also adding new preview functionalities to its SQL language including GROUP BYs and aggregations, an UNPACK transform for working with timestamped data, and structured row keys for working with data that is stored in a multi-part row key.
- aside_block
- <ListValue: [StructValue([(‘title’, ‘$300 in free credit to try Google Cloud databases’), (‘body’, <wagtail.rich_text.RichText object at 0x3ece6c19bf70>), (‘btn_text’, ‘Start building for free’), (‘href’, ‘http://console.cloud.google.com/freetrial?redirectPath=/products?#databases’), (‘image’, None)])]>
Continuous materialized views, now in preview
Bigtable SQL integrates with Bigtable’s recently introduced continuous materialized views (preview), offering a solution to traditional materialized view limitations like data staleness and maintenance complexity. This allows for real-time aggregation and analysis of data streams across applications such as media streaming, e-commerce, advertising, social media, and industrial monitoring.
Bigtable materialized views are fully managed and make updates incrementally without impacting your user queries from applications. Bigtable materialized views also support a rich SQL language including functions and aggregations.
“With Bigtable’s new Materialized Views, we’ve unleashed the full potential of low-latency use cases for clients of our Customer Data Platform. By defining SQL-based aggregations/transformations at ingestion, we’ve eliminated the complexities and delays of ETL in our time series use cases. Moreover, using data transformations during ingestion, we’ve unlocked the ability for our AI applications to receive perfectly prepared data with minimal latencies,” said Sathish KS, Chief Technology Officer, Zeotap.
Continuous Materialized Views workflow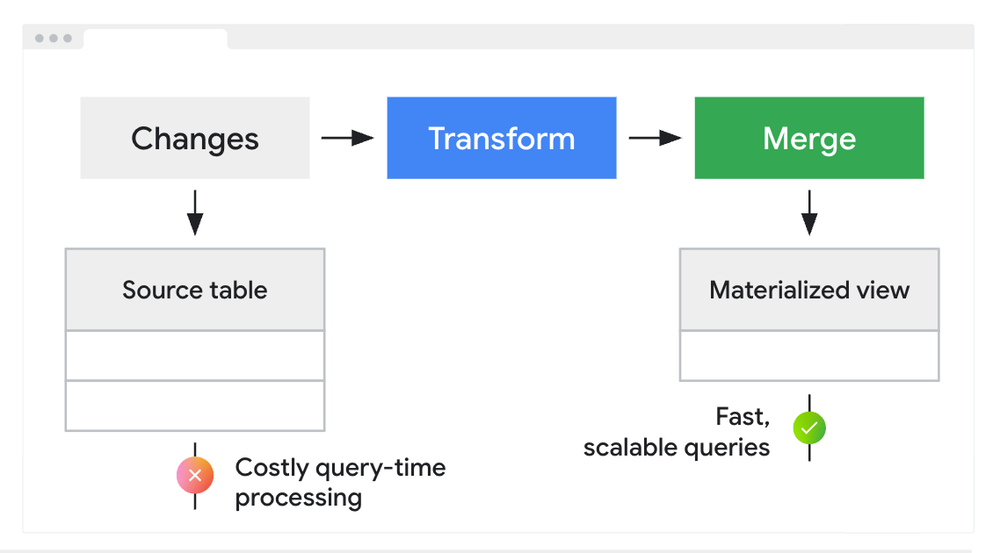
Ecosystem integrations
To get useful real-time analytics, you often need to pull data from many sources and do so with very low latency. As Bigtable expands its SQL interface, it is also expanding its ecosystem compatibility making it easier to build end to end applications using simple connectors and SQL.
Open-source Apache Kafka Bigtable Sink
Customers often rely on Google Cloud Managed Service for Apache Kafka to build pipelines that stream data into Bigtable and other analytics systems. To help customers build high-performance data pipelines, the Bigtable team has open-sourced a new Bigtable Sink for Apache Kafka so you can send data from Kafka to Bigtable in milliseconds.
Open-source Apache Flink Connector for Bigtable
Apache Flink is a stream-processing framework that lets you manipulate data in real time. With the recently launched Apache Flink to Bigtable Connector, you can construct a pipeline that lets you transform streaming data and write the outputs into Bigtable using both the high-level Apache Flink Table API and the more granular Datastream API.
BigQuery Continuous Queries, now generally available
BigQuery continuous queries are SQL statements that run continuously and can export the output rows produced into a Bigtable table. This feature is now generally available and can help you build a real-time analytics database using the combination of Bigtable and BigQuery.
Continuous Queries are also available from BigQuery’s Python frameworks as a bigrames.streaming API, so Python developers can create fully-managed jobs that synchronize online datasets in Bigtable with offline datasets in BigQuery.
“BigQuery continuous queries enables our application to use real-time stream processing and ML predictions by simply writing a SQL statement. It’s a great service that allows us to launch products quickly and easily,” said Shuntaro Kasai and Ryo Ueda, MLOps Engineers, DMM.com.
Real-time Analytics in Bigtable overview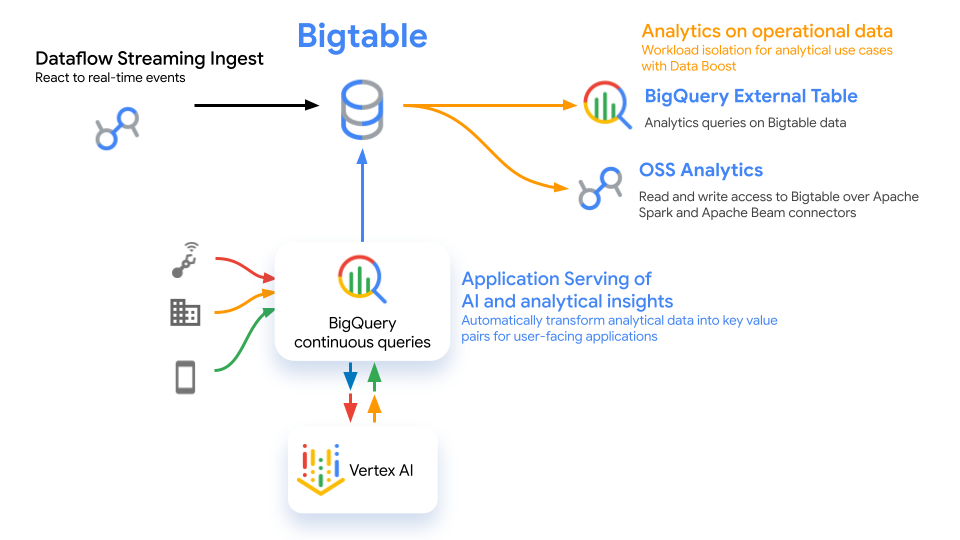
Bigtable CQL Client: Bigtable is now in preview and Cassandra-compatible
The Cassandra Query Language (CQL) is the query language of Apache Cassandra. With the launch of Bigtable CQL Client, developers can now migrate their applications to Bigtable with minimal to no code change, and enjoy the familiarity of CQL on enterprise-grade, high-performance Bigtable. Bigtable also supports common tools in the Cassandra ecosystem like the CQL shell (CQLsh), as well as Cassandra’s own data migration utilities which enable seamless migrations from Cassandra, with no downtime significantly reducing operational overhead.
Get started using the Bigtable CQL Client and migration utilities here.
Convergence: NoSQL’s embrace of SQL power
In this blog, we discussed a significant advancement that empowers developers to use SQL with Bigtable. You can easily get started with the flexible SQL language from any existing Bigtable cluster using Bigtable Studio and start to create materialized views on streams of data coming from Kafka and Flink.
To learn more, check out the GoogleSQL for Bigtable overview.
Read More for the details.

