
GCP – Accelerate data science with new Dataproc multi-tenant clusters
With the rapid growth of AI/ML, data science teams need a better notebook experience to meet the growing demand for and importance of their work to drive innovation. Additionally, scaling data science workloads also creates new challenges for infrastructure management. Allocating compute resources per user provides strong isolation (the technical separation of workloads, processes, and data from one another), but may cause inefficiencies due to siloed resources. Shared compute resources offer more opportunities for efficiencies, but with a sacrifice in isolation. The benefit of one comes at the expense of the other. There has to be a better way…
We are announcing a new Dataproc capability: multi-tenant clusters. This new feature provides a Dataproc cluster deployment model suitable for many data scientists running their notebook workloads at the same time. The shared cluster model allows infrastructure administrators to improve compute resource efficiency and cost optimization without compromising granular, per-user authorization to data resources, such as Google Cloud Storage (GCS) buckets.
This isn’t just about optimizing infrastructure; it’s about accelerating the entire cycle of innovation that your business depends on. When your data science platform operates with less friction, your teams can move directly from hypothesis to insight to production faster. This allows your organization to answer critical business questions faster, iterate on machine learning models more frequently, and ultimately, deliver data-powered features and improved experiences to your customers ahead of the competition. It helps evolve your data platform from a necessary cost center into a strategic engine for growth.
- aside_block
- <ListValue: [StructValue([(‘title’, ‘$300 in free credit to try Google Cloud data analytics’), (‘body’, <wagtail.rich_text.RichText object at 0x3ed6201f1520>), (‘btn_text’, ”), (‘href’, ”), (‘image’, None)])]>
How it works
This new feature builds upon Dataproc’s previously established service account multi-tenancy. For clusters in this configuration, only a restricted set of users declared by the administrator may submit their workloads. Administrators also declare a mapping of users to service accounts. When a user runs a workload, all access to Google Cloud resources is authenticated only as their specific mapped service account. Administrators control authorization in Identity Access Management (IAM), such as granting one service account access to a set of Cloud Storage buckets and another service account access to a different set of buckets.
As part of this launch, we’ve made several key usability improvements to service account multi-tenancy. Previously, the mapping of users to service accounts was established at cluster creation time and unmodifiable. We now support changing the mapping on a running cluster, so that administrators can adapt more quickly to changing organizational requirements. We’ve also added the ability to externalize the mapping to a YAML file for easier management of a large user base.
Jupyter notebooks establish connections to the cluster via the Jupyter Kernel Gateway. The gateway launches each user’s Jupyter kernels, distributed across the cluster’s worker nodes. Administrators can horizontally scale the worker nodes to meet end user demands either by manually adjusting the number of worker nodes or by using an autoscaling policy.
Notebook users can choose Vertex AI Workbench for a fully managed Google Cloud experience or bring their own third-party JupyterLab deployment. In either model, the BigQuery JupyterLab Extension integrates with Dataproc cluster resources. Vertex AI Workbench instances can deploy the extension automatically, or users can install it manually in their third-party JupyterLab deployments.
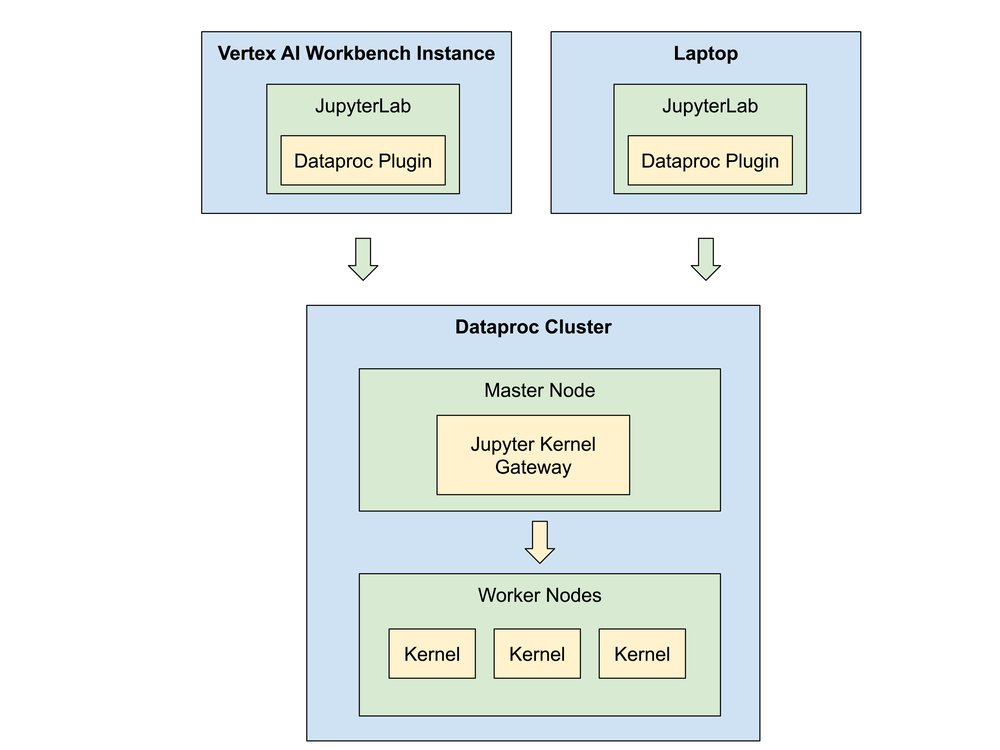
Under the hood
Dataproc multi-tenant clusters are automatically configured with additional hardening to isolate independent user workloads:
-
All containers launched by YARN run as a dedicated operating system user that matches the authenticated Google Cloud user.
-
Each OS user also has a dedicated Kerberos principal for authentication to Hadoop-based Remote Procedure Call (RPC) services, such as YARN.
-
Each OS user is restricted to accessing only the Google Cloud credentials of their mapped service account. The cluster’s compute service account credentials are inaccessible to end user notebook workloads.
-
Administrators use IAM policies to define least-privilege access authorization for each mapped service account.
How to use it
Step 1: Create a service account multi-tenancy mapping
Prepare a YAML file containing your user service account mapping, and store it in a Cloud Storage bucket. For example:
- code_block
- <ListValue: [StructValue([(‘code’, ‘user_service_account_mapping:rn bob@my-company.com: service-account-for-bob@iam.gserviceaccount.comrn alice@my-company.com: service-account-for-alice@iam.gserviceaccount.com’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3ed622fd5520>)])]>
Step 2: Create a Dataproc multi-tenant cluster
Create a new multi-tenant Dataproc cluster using the user mapping file and the new JUPYTER_KERNEL_GATEWAY optional component.
- code_block
- <ListValue: [StructValue([(‘code’, ‘gcloud dataproc clusters create my-cluster \rn –identity-config-file=gs://bucket/path/to/identity-config-file \rn –service-account=cluster-service-account@iam.gserviceaccount.com \rn –region=region \rn –optional-components=JUPYTER_KERNEL_GATEWAY \rn other args …’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3ed622fd55e0>)])]>
If you need to change the user service account mapping later, you can do so by updating the cluster:
- code_block
- <ListValue: [StructValue([(‘code’, ‘gcloud dataproc clusters update my-cluster \rn –identity-config-file=gs://bucket/path/to/identity-config-file \rn –region=region’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3ed622fd5250>)])]>
Step 3: Create a Vertex AI Workbench instance with Dataproc kernels enabled
For users of VertexAI Workbench, create an instance with Dataproc kernels enabled. This automatically installs the BigQuery JupyterLab extension.
Step 4: Install the BigQuery JupyterLab extension in third-party deployments
For users of third-party JupyterLab deployments, such as running on a local laptop, install the BigQuery JupyterLab extension manually.
Step 5: Launch kernels in the Dataproc cluster
Open the JupyterLab application either from a Vertex AI Workbench instance or on your local machine.
The JupyterLab Launcher page opens in your browser. It shows the Dataproc Cluster Notebooks sections if you have access to Dataproc clusters with the Jupyter Optional component or Jupyter Kernel Gateway component.

To change the region and project:
-
Select Settings > Cloud Dataproc Settings.
-
On the Setup Config tab, under Project Info, change the Project ID and Region, and then click Save.
-
Restart JupyterLab to make the changes take effect.
Select the kernel spec corresponding to your multi-tenant cluster. Once the kernel spec is selected, the kernel is launched and it takes about 30-50 seconds for the kernel to go from Initializing to Idle state. Once the kernel is in Idle state, it is ready for execution.
Get started with multi-tenant clusters
Stop choosing between security and efficiency. With Dataproc’s new multi-tenant clusters, you can empower your data science teams with a fast, collaborative environment while maintaining centralized control and optimizing costs. This new capability is more than just an infrastructure update; it’s a way to accelerate your innovation lifecycle.
This feature is now available in public preview. Get started today by exploring the technical documentation and creating your first multi-tenant cluster. Your feedback is crucial as we continue to evolve the platform, so please share your thoughts with us at dataproc-feedback@google.com.
Read More for the details.

