
GCP – Accelerate analytics with AI-assisted data preparation in BigQuery, now GA
According to Gartner®, “Gartner clients now report that 90% or more of their time is spent preparing data (as high as 94% in complex industries) for advanced analytics, data science and data engineering.”1. Last year, we introduced BigQuery data preparation, which helps data analyst teams wrangle data with help from Gemini in BigQuery. With it, the tedious task of data preparation becomes a breeze as Gemini analyzes your data and schema, and offers context-aware suggestions for cleaning, transforming, and enriching your data.
BigQuery’s approach to data preparation can also help you automate building data pipelines, allowing users with varying technical backgrounds to efficiently prepare data for analysis, regardless of their proficiency with SQL. Once data has been prepared, you can then run your data integration workloads on BigQuery’s serverless, cloud-native, AI-ready data analytics platform.
Today, we’re taking things one step further and announcing that BigQuery data preparation is generally available. It now also integrates with BigQuery pipelines, letting you connect data ingestion and transformation tasks so you can create end-to-end data pipelines with incremental processing, all in a unified environment. You can view all the transformations that BigQuery data preparation generates as SQL code and use BigQuery repositories and Git to collaborate on and manage your code.
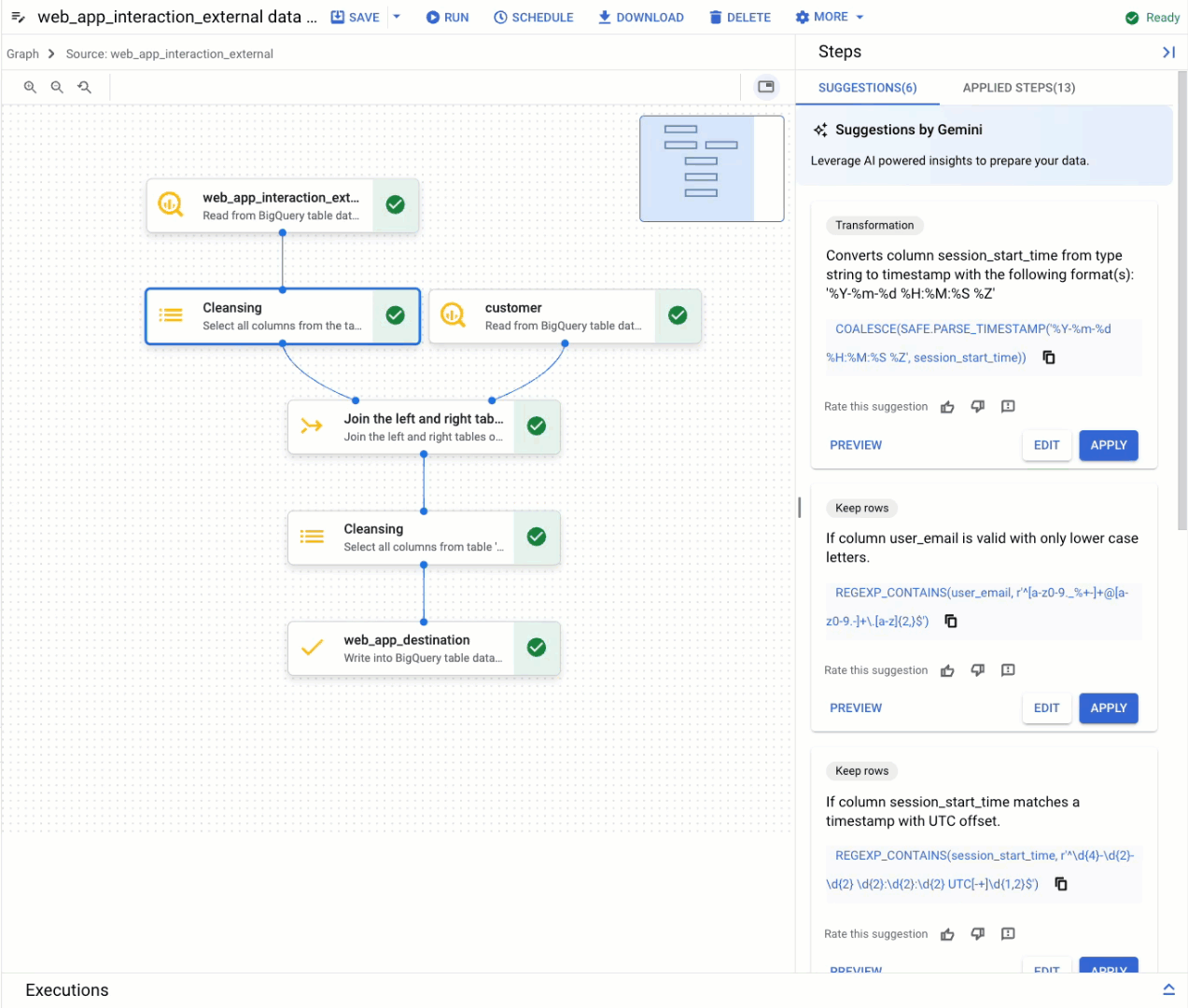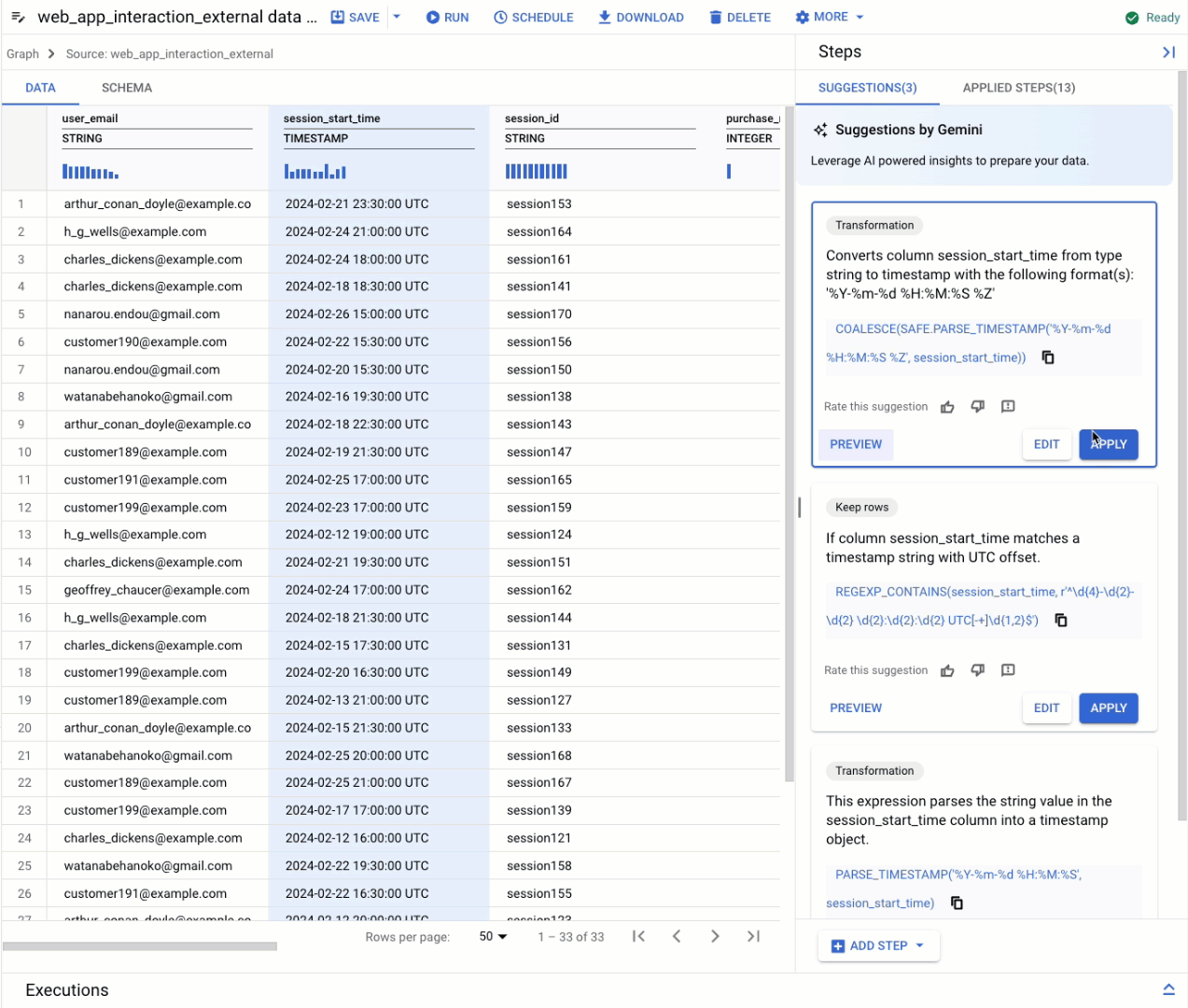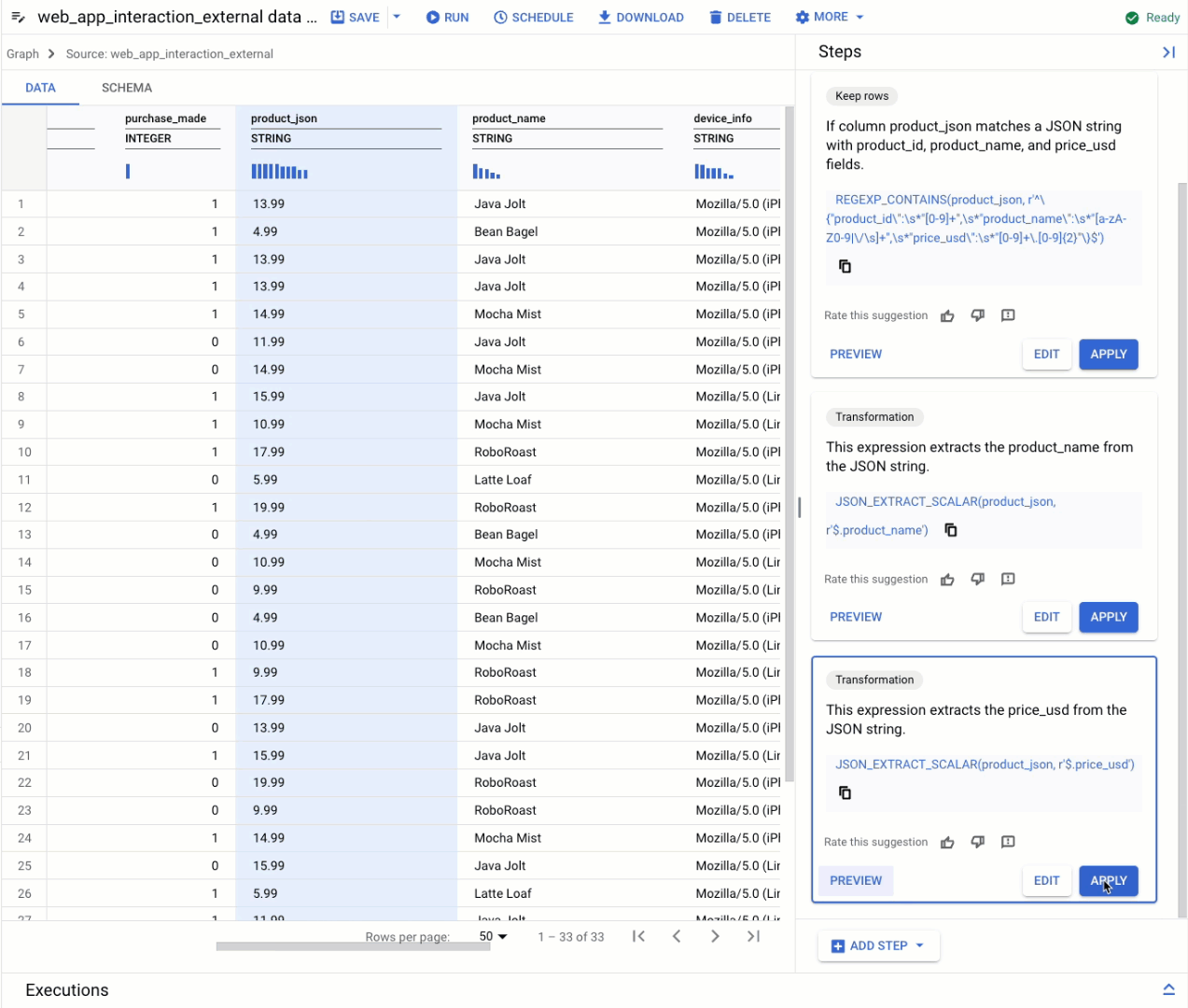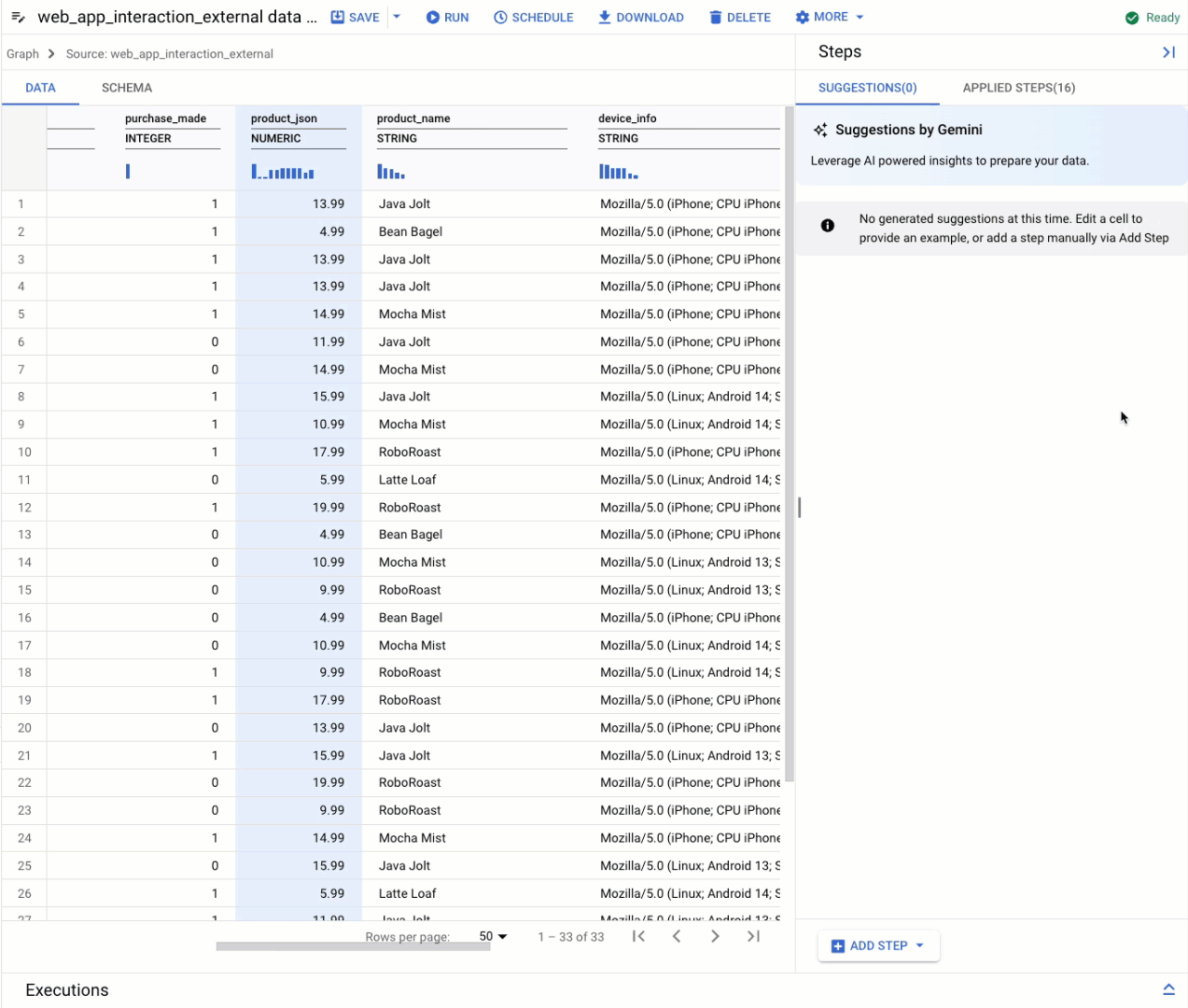
A BigQuery data preparation refresher
BigQuery data preparation leverages Gemini to provide you with intelligent guidance throughout the data preparation process. This includes:
-
Comprehensive transformation capabilities: Because data preparation runs on BigQuery, it supports a wide array of data transformation functions, including typecasting, string manipulation, datetime math, and JSON extraction.
-
Data standardization: Gemini in BigQuery analyzes your data and schema to provide intelligent suggestions for cleaning and transforming data. For example, it can identify valid date formats and standardize your data accordingly.
-
Automated schema mapping: Built-in schema handling helps you manage schema drift and helps prevent production pipelines from failing.
-
AI-suggested join keys for data enrichment: BigQuery data preparation analyzes your data and suggests relevant join keys for data enrichment.
In addition, users benefit from visual, low-code data pipeline features:
-
Visual data pipelines: Design, execute, and monitor complex data pipelines with a user-friendly, low-code visual interface. Cost-efficient processing on BigQuery’s fully managed and completely serverless platform scales to any use case. For more efficient changed data propagation, you can also configure your preparations to process data incrementally.
-
Data quality enforcement with error tables: Define validation rules and automatically route invalid rows to a designated error table, helping to ensure data quality and integrity.
-
Streamlined deployment with GitHub integration: You can view data preparations in pipe query syntax and export them to a Git repository for version control.
- aside_block
- <ListValue: [StructValue([(‘title’, ‘$300 in free credit to try Google Cloud data analytics’), (‘body’, <wagtail.rich_text.RichText object at 0x3e5c47ed9850>), (‘btn_text’, ‘Start building for free’), (‘href’, ‘http://console.cloud.google.com/freetrial?redirectPath=/bigquery/’), (‘image’, None)])]>
Tasks, assemble! with BigQuery pipelines
You can now visually connect a series of data processing tasks, including data preparation tasks, in a defined sequence with BigQuery pipelines. The data preparation integration with BigQuery pipelines makes it easy to add it as part of an automation and orchestration flow, enabling end-to-end data pipelines that encompass data ingestion, preparation, transformation, and loading.

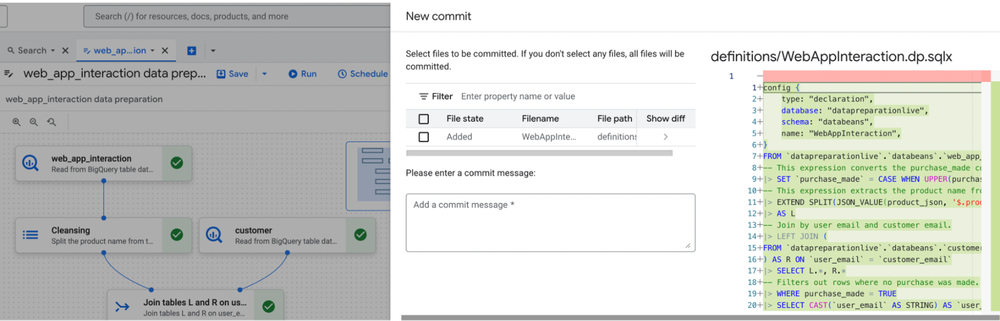
Wrangle your CLs with BigQuery repositories
Data preparation now generates SQL code in pipe query syntax, which simplifies complex queries and improves readability. This enables data engineers to easily review data preparation code, include it in larger pipelines, and integrate data preparations in CI/CD process for better collaboration, version control, and automated deployment. This transparency helps you bridge the gap between visual transformations and code, thus bridging across teams and preferences.
BigQuery data preparation integrates with BigQuery repositories and Git, providing robust version control and collaboration features for your data preparation assets. You can treat your data preparations as code artifacts and check them into repositories, enabling you to track changes, collaborate with team members, and revert to previous versions if needed. This integration streamlines the development process, promotes code reusability, and ensures that your data preparation logic is well-managed and auditable.
What customers are saying
GAF is a major manufacturer of roofing materials in North America, and is adopting data preparation for creating data transformation pipelines on BigQuery.
“GAF is looking to modernize the ETL infrastructure and adopt a BigQuery native, low-code solution. BigQuery data preparation will help our skilled business users and the analytics team in the data preparation processes for the enablement of self-service analytics.” – Puja Panchagnula, Management Director – Enterprise Data Management & Analytics, GAF
mCloud Technologies helps businesses in sectors like energy, buildings, and manufacturing to optimize the performance, reliability, and sustainability of their assets.
“We receive file data feeds from our partners. BigQuery data preparation allows our product managers to prepare and operate the data with little to no help from our data engineering team.” – Jim Christian, Chief Product and Technology Officer, mCloud Technologies
Public Value Technologies is a joint venture between two German public broadcasting organizations (ARD).
“Public Value Technologies receives data feeds from our media partners for our data mesh solution and AI applications. BigQuery data preparation allows our data analysts and scientists to rapidly integrate the data feeds that standardize and preprocess the data in a low code way.” – Korbinian Schwinger, Team Lead Data Engineer, Public Value Technologies
Get started
With its powerful AI capabilities, intuitive interface, and tight integration with BigQuery data pipelines, BigQuery data preparation is set to revolutionize the way organizations manage and prepare their data. By automating tedious tasks, improving data quality, and empowering users, this innovative solution reduces the time you spend preparing data and improves your productivity.
Explore the following resources to get started with BigQuery data preparation:
-
See the public documentation
-
Watch the 5-minute demo video
-
Follow a tutorial
1. Gartner, State of Metadata Management: Aggressively Pursue Metadata to Enable AI and Generative AI, By Mark Beyer, Guido De Simoni, 4. September 2024. GARTNER is a registered trademark and service mark of Gartner, Inc. and/or its affiliates in the U.S. and internationally and is used herein with permission. All rights reserved.
Read More for the details.

