
GCP – Accelerate AI/ML workloads using Cloud Storage hierarchical namespace
As AI and machine learning (ML) workloads continue to grow, the infrastructure supporting them must evolve to meet their unique demands. Here on the Google Cloud Storage team, we’re committed to providing AI/ML practitioners with tools to optimize the performance, scalability, and usability of Cloud Storage. In this post, we’ll explore how Cloud Storage’s new hierarchical namespace (HNS) capability can help you maximize the performance and efficiency of your AI/ML workloads.
Storage’s role in AI/ML workloads
AI/ML data pipelines typically consist of the following steps, which can place heavy demands on the underlying storage system:
1. Data preparation and preprocessing involves data validation, preprocessing, ingesting data into storage and transforming it into the correct format for model training.
2. Model training is a process which uses many GPU/TPU compute instances to iteratively develop and refine an AI/ML model.
This process also involves checkpointing, which periodically saves the state of a model so it can be resumed from the last saved state instead of restarting from scratch, saving valuable time and resources. This provides fault tolerance against failures that are common in large-scale distributed training, and also helps developers experiment with hyperparameters or adjust training objectives without losing prior progress.

3. Model serving typically involves loading the model, weights, and dataset into compute instances with GPUs/TPUs for model inference.
AI/ML workloads can run on large compute clusters that consist of thousands of nodes performing simultaneous I/Os on petabyte-scale datasets. As such, the underlying storage system can often become the bottleneck for AI/ML pipelines, resulting in underutilization of expensive GPU/TPU cycles.
- aside_block
- <ListValue: [StructValue([(‘title’, ‘Try Google Cloud for free’), (‘body’, <wagtail.rich_text.RichText object at 0x3e429f540d90>), (‘btn_text’, ‘Get started for free’), (‘href’, ‘https://console.cloud.google.com/freetrial?redirectPath=/welcome’), (‘image’, None)])]>
Benefits of using a hierarchical namespace for AI/ML workloads
Cloud Storage’s hierarchical namespace can be enabled when creating a bucket, and it provides several benefits to AI/ML workloads, including:
-
A new “folder” resource type and APIs that are optimized for filesystem semantics.
-
Atomic and fast folder renames, resulting in faster and more reliable checkpointing.
-
An optimized storage layout that handles higher queries per second (QPS) of reads and writes.
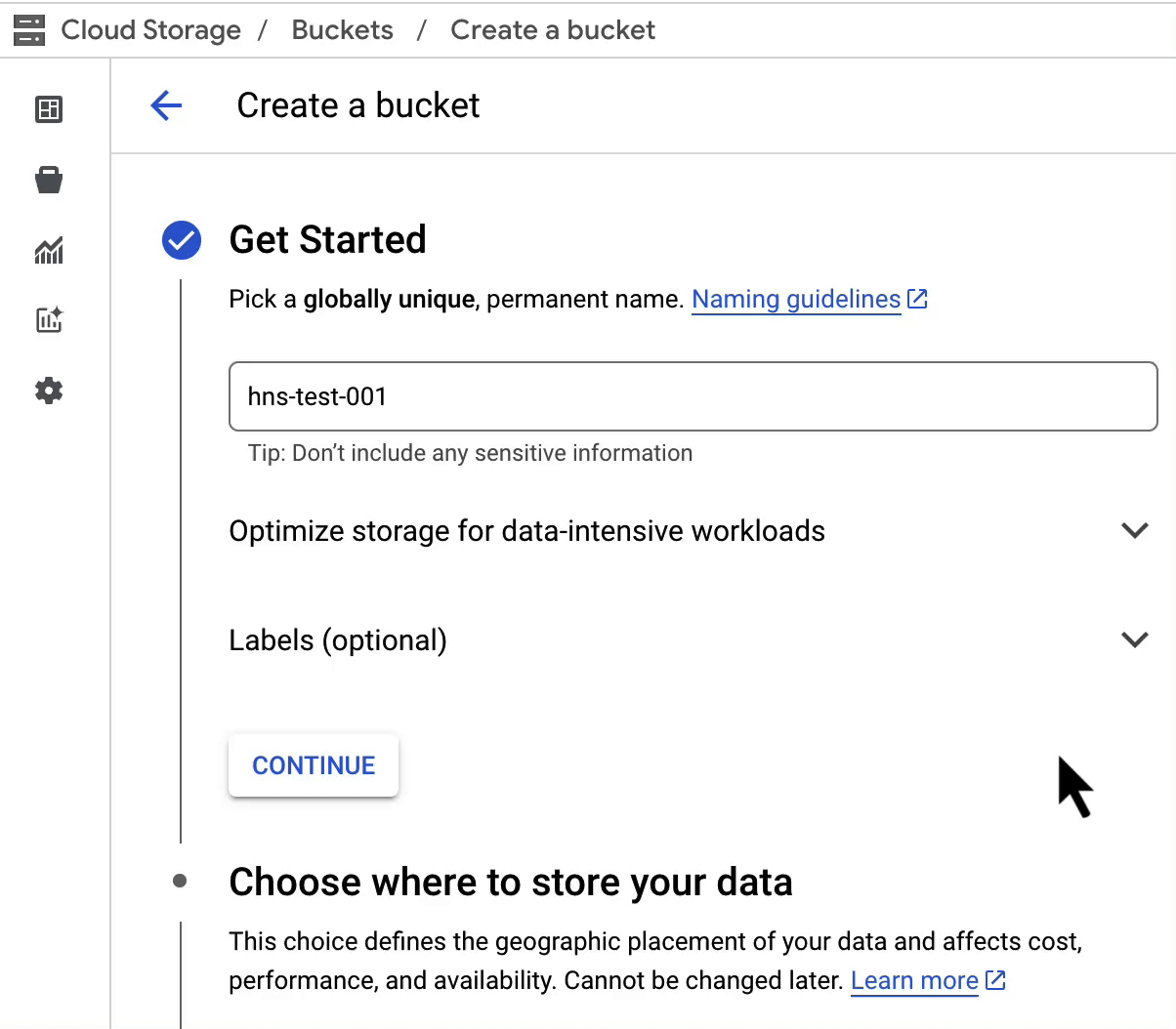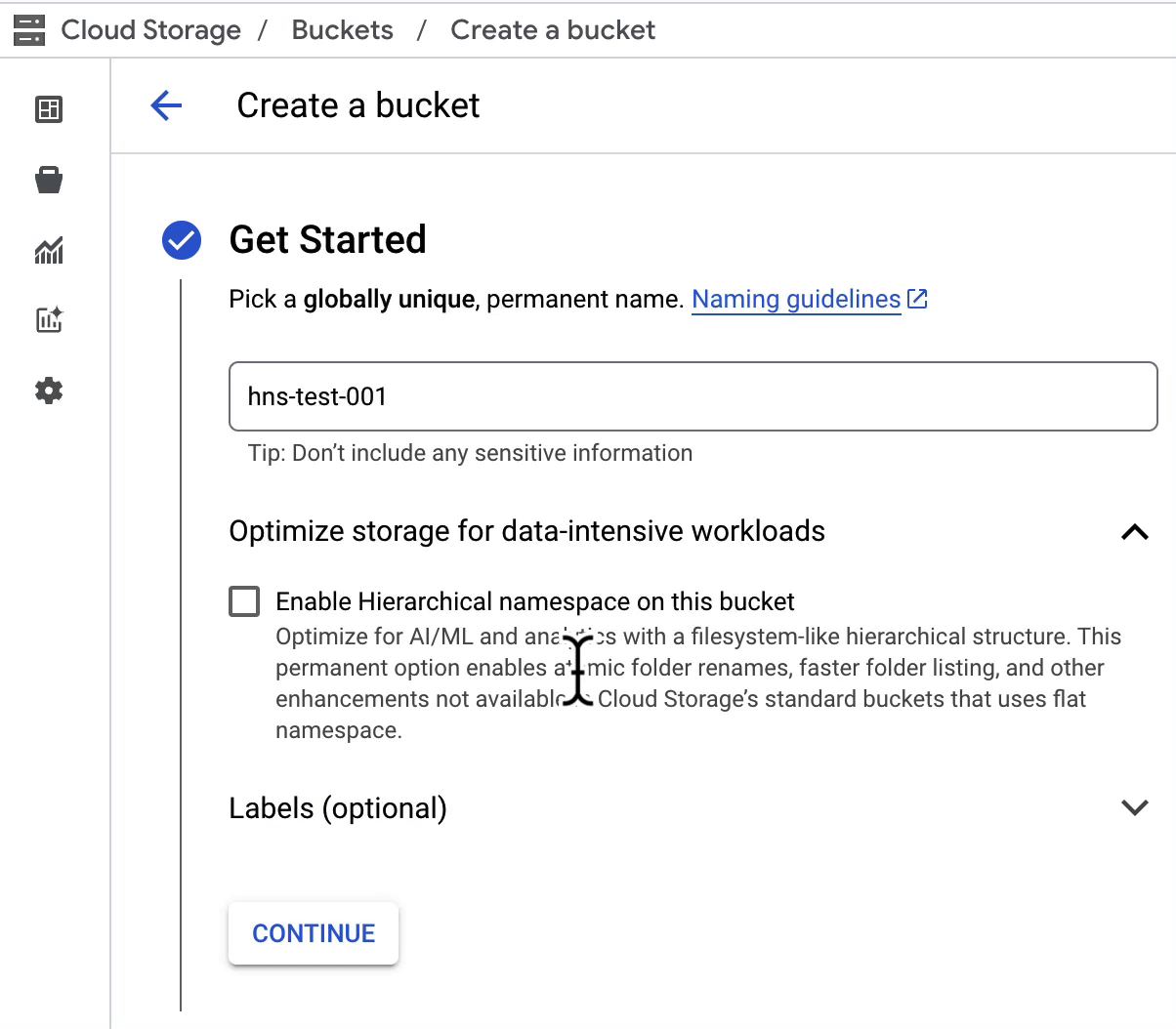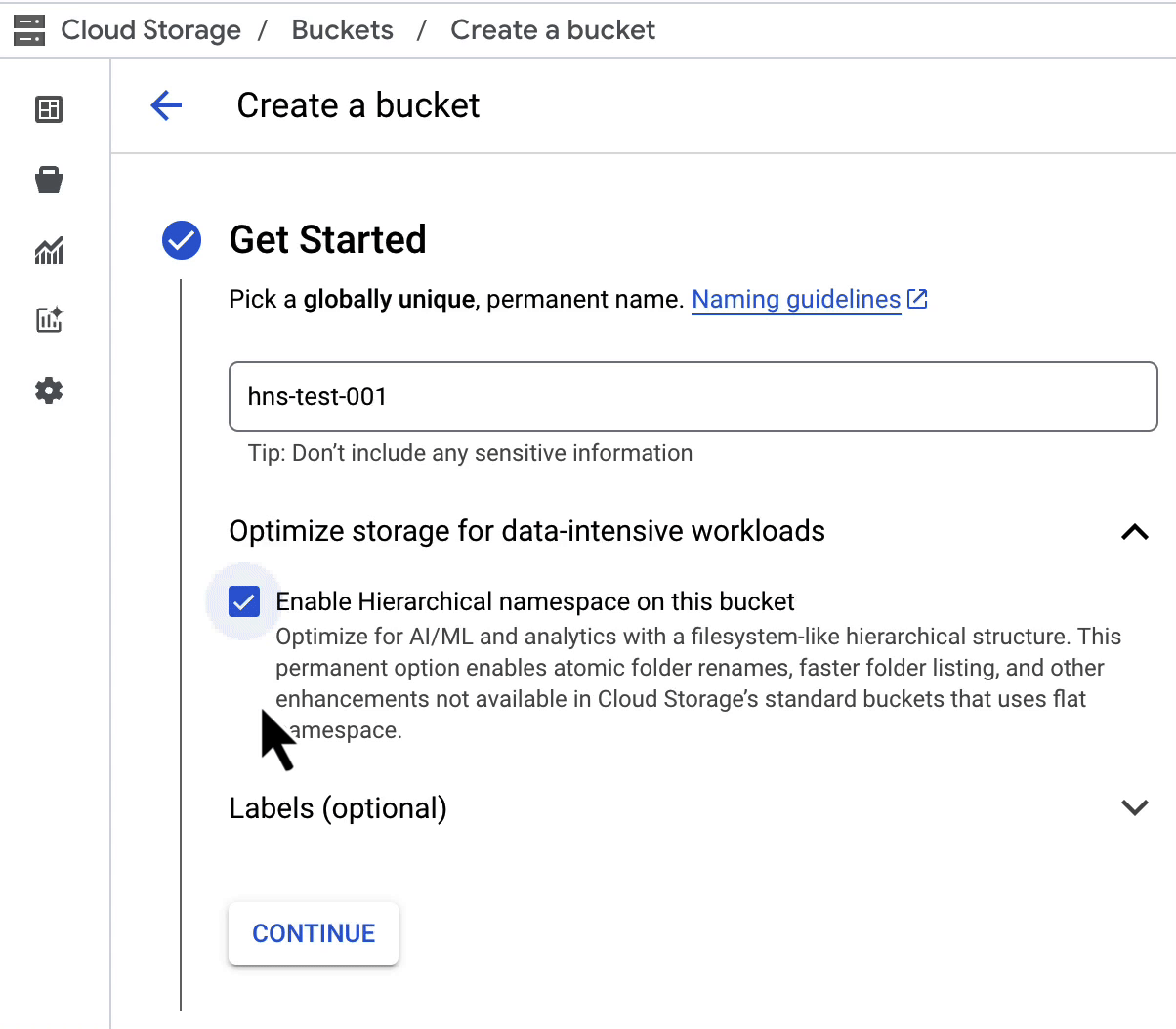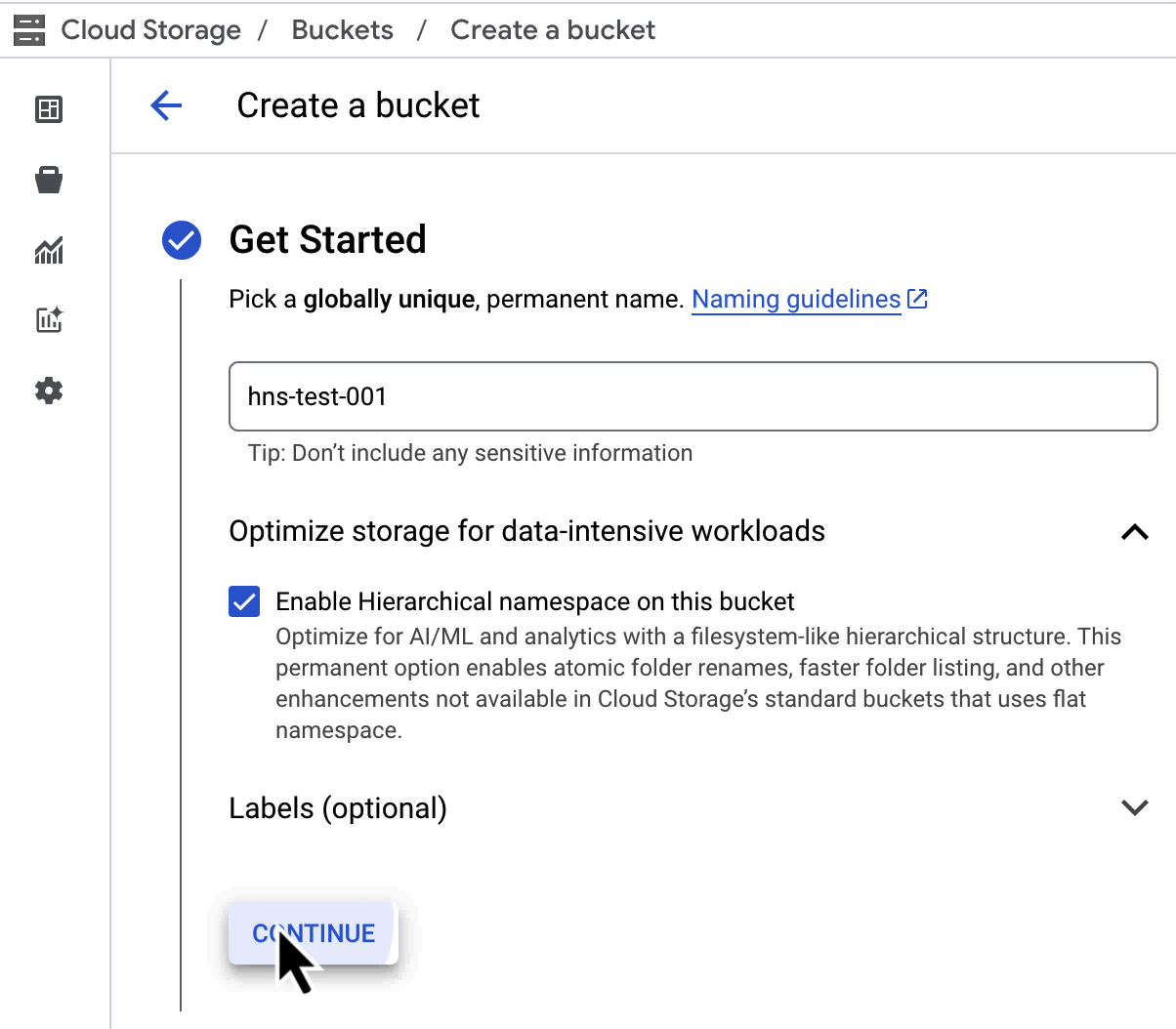
Let’s examine these benefits in more detail.
Data organization and access that’s optimized for filesystem semantics
In a hierarchical namespace bucket, folders can contain objects and other folders, which allows organizing (traditionally flat) Cloud Storage data into a tree-like structure that mirrors a traditional filesystem. This lets client libraries like Cloud Storage FUSE map filesystem calls to Cloud Storage APIs that operate directly on folders. While flat namespace buckets often necessitate performing inefficient and costly object-level operations to simulate filesystem operations, using a hierarchical namespace lets you take advantage of filesystem semantics offered natively by the underlying storage system. For example, filesystem libraries typically use resource-intensive ListObject calls to implement inode lookups; these can be replaced with more efficient GetFolderMetadata calls when using a hierarchical namespace. AI/ML workloads benefit greatly as a result, as they often rely on frameworks like TensorFlow and PyTorch that interact with storage via a filesystem interface.
Customers like AssemblyAI have reported significant improvements using hierarchical namespace with Cloud Storage FUSE to power their AI/ML workloads.
“With HNS and GCSfuse we observed over 10x increase in throughput from GCS, with training speed improving 15x.” – Ahmed Etefy, Staff Software Engineer, AssemblyAI
Up to 20x faster checkpointing
Renaming folders and objects is common when writing checkpoints or managing intermediate outputs. Cloud Storage’s hierarchical namespace buckets introduce a new RenameFolder API that is both fast and atomic. While simulating a folder rename in a flat namespace bucket could involve thousands of individual object rewrites and deletes (depending on how many objects are in the folder), the hierarchical namespace offering provides a folder-level metadata-only operation that accomplishes this in an atomic action that completes in a fraction of the time. Atomicity prevents inconsistencies and complex state management caused by partial failures, which is a common problem with simulated renames in flat buckets.
Looking at folder renames in action, checkpoint benchmarking shows that hierarchical namespace buckets speed up checkpoint writes by up to 20x compared to flat buckets.

Up to 8x higher QPS
AI/ML workloads running on large clusters generate millions of I/O requests on the attached storage system. Checkpoint writes and restores during model training and serving reads for inference are highly bursty workloads where many nodes are synchronized to talk to storage at the same time. High QPS capabilities help avoid storage bottlenecks that could starve expensive GPUs/TPUs.
Hierarchical namespace buckets have an optimized storage layout that provides up to 8x higher initial object read and write requests per second (QPS) compared to flat namespace buckets, while still supporting a doubling of the QPS every 20 minutes per the Cloud Storage ramp-up guidelines. For example, this means a cold hierarchical namespace bucket can achieve 100,000 object write QPS in nearly half the time compared to a flat bucket.

Conclusion
AI/ML workloads require infrastructure tailored to their unique needs: efficient data organization and filesystem semantics for tight integration with frameworks, high-performance checkpointing to maximize GPU/TPU utilization, and high QPS rates to support quick ramp up. Hierarchical namespace buckets provide all these benefits, along with the scalability, reliability, simplicity, and cost-effectiveness that Cloud Storage is known for. We recommend enabling hierarchical namespace on new buckets for AI/ML workloads.
Read More for the details.

