Amazon GameLift Servers, a fully managed service for deploying, operating, and scaling game servers for multiplayer games, is now available in two additional AWS Regions: Asia Pacific (Thailand) and Asia Pacific (Malaysia). With this launch, customers can now deploy GameLift fleets closer to players in Thailand and Malaysia, helping reduce latency and improve gameplay responsiveness.
This regional expansion supports both Amazon GameLift Servers managed EC2 and container-based hosting options. Developers can take advantage of features such as FlexMatch for customizable matchmaking, FleetIQ for cost-optimized instance management, and auto-scaling to manage player demand dynamically. The addition of these new regions enables game developers and publishers to better server growing player communities across Southeast Asia while maintaining high performance and reliability.
Starting today, domain name system (DNS) delegation for private hosted zone subdomains can be used with Route 53 inbound and outbound Resolver endpoints. This allows you to delegate the authority for a subdomain from your on-premises infrastructure to the Route 53 Resolver cloud service and vice versa, enabling a simplified cloud experience across namespaces in AWS and on your own local infrastructure.
AWS customers allow multiple organizations within their enterprise to individually manage their respective subdomains and subzones, whereas apex domains and parent hosted zones are typically overseen by a central team. Previously, these customers had to create and maintain conditional forwarding rules in their existing network infrastructure to enable services to discover one another across subdomains. However, conditional forwarding rules are difficult to maintain across large organizations and, in many cases, are not supported by on-premises infrastructure. With today’s release, customers can instead delegate authority of subdomains to Route 53 using name server records and vice versa, achieving compatibility with common, on-premises DNS infrastructure and removing the need for teams to use conditional forwarding rules throughout their organization.
Inbound and outbound delegation for Resolver endpoints is available globally in all AWS Regions, where Resolver endpoints are available, except in AWS GovCloud and Amazon Web Services in China. Inbound and outbound delegation is provided at no additional cost to Resolver endpoints usage. For more details on pricing, visit the Route 53 pricing page, and to learn more about this feature, visit the developer guide.
Today, Amazon EMR on EKS announces support for Service Quotas, improving visibility and control over EMR on EKS quotas.
Previously, to request an increase for EMR on EKS quotas, such as maximum number of StartJobRun API calls per second, customers had to open a support ticket and wait for the support team to process the increase. Now, customers can view and manage their EMR on EKS quota limits directly in the Service Quotas console. This enables automated limit increase approvals for eligible requests, improving response times and reducing the number of support tickets. Customers can also set up Amazon CloudWatch alarms to get automatically notified when their usage reaches a certain percentage of a maximum quota.
Amazon EMR on EKS support for Service Quotas is available in all Regions where Amazon EMR on EKS is currently available. To get started, visit the Service Quotas User Guide.
Now generally available, Amazon CloudWatch helps you accelerate operational investigations across your AWS environment in just a fraction of the time. With a deep understanding of your AWS cloud environment and resources, CloudWatch investigations use an AI agent to look for anomalies in your environment, surface related signals, identify root-cause hypotheses, and suggest remediation steps, significantly reducing mean time to resolution (MTTR).
This new CloudWatch investigations capability works alongside you throughout your operational troubleshooting journey from issue triage through remediation. You can initiate an investigation by selecting the Investigate action on any CloudWatch data widget across the AWS Management Console. You can also start investigations from more than 80 AWS consoles, configure to auto trigger from a CloudWatch alarm action, or initiate from an Amazon Q chat. The new investigation experience in CloudWatch allows teams to collaborate and add findings, view related signals and anomalies, and review suggestions for potential root cause hypotheses. This new capability also provides remediation suggestions for common operational issues across your AWS environment by surfacing relevant AWS Systems Manager Automation runbooks, AWS re:Post articles, and documentation. It also integrates with popular communication channels such as Slack and Microsoft Teams.
The Amazon CloudWatch investigations capability is available in US East (N. Virginia), US East (Ohio), US West (Oregon), Asia Pacific (Hong Kong), Asia Pacific (Mumbai), Asia Pacific (Singapore), Asia Pacific (Sydney), Asia Pacific (Tokyo), Europe (Frankfurt), Europe (Ireland), Europe (Spain), and Europe (Stockholm).
The CloudWatch investigations capability is now generally available at no additional cost. It was previously launched in preview as Amazon Q Developer operational investigations. To learn more, see getting started and best practice documentation.
Amazon Bedrock Guardrails announces tiers for content filters and denied topics, offering additional flexibility and ease of use towards choosing features and expanded language support depending on customer use cases. With a new Standard tier, Guardrails now detects and filters undesirable content with better contextual understanding including modifications such as typographical errors, and support for up to 60 languages.
Bedrock Guardrails provides configurable safeguards to help detect and block harmful content and prompt attacks, define topics to deny and disallow specific topics, and helps redact personally identifiable information (PII) such as personal data from input prompts and model responses. Additionally, Bedrock Guardrails helps detect and block model hallucinations, and identify, correct, and explain factual claims in model responses using Automated Reasoning checks. Guardrails can be applied across any foundation model including those hosted with Amazon Bedrock, self-hosted models, and third-party models outside Bedrock using the ApplyGuardrail API, providing a consistent user experience and helping to standardize safety and privacy controls.
The new Standard tier enhances the content filters and denied topics safeguards within Bedrock Guardrails by offering better robust detection of prompt and response variations, strengthened defense against all categories of content filters including prompt attacks, and broader language support. The improved prompt attacks filter clearly distinguishes between jailbreaks and prompt injection on the backend while protecting against other threats including output manipulation. To access the Standard tier’s capabilities, customers must explicitly opt in to cross-region inference with Bedrock Guardrails.
Today, AWS launches Intelligent Search on AWS re:Post and AWS re:Post Private — offering a more efficient and intuitive way to access AWS knowledge across multiple sources. This new capability transforms how builders find information, providing synthesized answers from various AWS resources in one place. Intelligent Search streamlines the process of finding relevant AWS information by unifying results from re:Post community discussions, AWS Official documentation, and other public AWS knowledge sources. Instead of manually searching through multiple pages, users receive contextually relevant answers directly, saving time and effort. For instance, when troubleshooting an IAM permissions error, developers can ask a question in natural language and immediately receive a comprehensive response drawing from diverse AWS resources. This feature is particularly valuable for developers, architects, and technical leaders who need quick access to accurate information for problem-solving and decision-making. By consolidating knowledge from various AWS sources, Intelligent Search helps users find solutions faster, accelerating development processes and improving productivity. Intelligent Search is now available on repost.aws. re:Post Private customers can also utilize this feature if artificial intelligence capabilities are enabled in their instance. For setup instructions, see the re:Post Private Administration Guide.
Box is one of the original information sharing and collaboration platforms of the digital era. They’ve helped define how we work, and have continued to evolve those practices alongside successive waves of new technology. One of the most exciting advances of the generative AI era is that now, with all the data that Box users have stored, they can get considerably more value out of those files by using AI to search and synthesize their information in new ways.
That’s why Box created Box AI Agents, to intelligently discern and structure complex unstructured data. Today, we’re excited to announce the availability of the Box AI Enhanced Extract Agent. The Enhanced Extract Agent runs on Google’s most advanced Gemini 2.5 models, and they also feature Google’s Agent2Agent protocol, which allows secure connection and collaboration between AI agents across dozens of platforms in the A2A network.
The Box AI Enhanced Extract Agent gives enterprises users confidence in their AI, helping overcome any hesitations they might feel about gen AI technology and using it for business-critical tasks.
In this post, we’ll take a closer look at how our teams created the Box AI Enhanced Extract Agent and what others building new agentic AI systems might consider when developing their own solutions.
aside_block
<ListValue: [StructValue([(‘title’, ‘Try Google Cloud for free’), (‘body’, <wagtail.rich_text.RichText object at 0x3e58a1352760>), (‘btn_text’, ‘Get started for free’), (‘href’, ‘https://console.cloud.google.com/freetrial?redirectPath=/welcome’), (‘image’, None)])]>
Getting more content with confidence
When it comes to data extraction, simply pulling out text from documents is no longer sufficient. A core objective that businesses need peace of mind on is uncertainty estimation, which we define as understanding how uncertain the model is about particular extraction. This is paramount when an organization is processing vast quantities of documents — such as searching tens of thousands of items where you’re trying to extract all the relevant and related values in each of those items — and you need to guide human review effectively and with confidence. The goal isn’t just high accuracy, but also a reliable confidence score for each piece of extracted data.
With the Box AI Enhanced Extract Agent, we wanted to transform how businesses interact with their most complex content — whether that’s scanned PDFs, images, slides, and other diverse materials — and then turn it all into structured, actionable intelligence.
For instance, financial services organizations can automate loan application reviews by accurately extracting applicant details and income data; legal teams can accelerate discovery by pinpointing critical clauses in contracts; and HR departments can streamline onboarding by processing new hire paperwork automatically. In each of these cases, all extracted data like key dates and contractual terms can be validated by the crucial confidence scores that this Box and Google collaboration delivers. This confidence score helps ensure reliable, AI-vetted information powers efficient operations and proactive compliance without extensive manual effort.
Powering enhanced data extraction with Gemini 2.5 Pro
Box’s Enhanced Extract Agent leverages the sophisticated multimodal, agentic reasoning and capabilities of Google’s Gemini 2.5 Pro as its core intelligence engine. However, the relationship goes beyond simple API calls.
“Gemini 2.5 Pro is way ahead due to its multimodal, deep reasoning, and code generation capabilities in terms of accuracy compared to previous models for these complex extraction tasks,” Ben Kus, CTO at Box said. “These capabilities make Gemini a crucial component for achieving Box’s ambitious goals of turning unstructured content into structured content through enhanced extraction agents.”
To build robust confidence scores and enable deeper understanding, Box’s AI Agents acquire specific, granular information that the Gemini 2.5 Pro model is uniquely adept at providing.
An agent-to-agent protocol for deeper collaboration
Box is championing an open AI ecosystem by embracing Google Cloud’s Agent2Agent protocol, enabling all Box AI Agents to securely collaborate with diverse external agents from dozens of partners (a list that keeps growing). By adopting the latest A2A specification, Box AI can ensure efficient and secure communication for complex, multi-system processes. This empowers organizations to power complex, cross-system workflows—bringing intelligence directly to where content lives, boosting productivity through seamless agent collaboration.This advanced interplay leverages the proposed agent-to-agent protocol in the following manners:
Box’s AI Agents: Orchestrate the overall extraction task, manages user interactions, applies business logic, and crucially, performs the confidence scoring and uncertainty analysis.
Google’s Gemini 2.5 Pro: Provides the core text comprehension, reasoning, and generation; and in this enhanced protocol, Gemini models also aim to furnish deeper operational data (like token likelihoods) to its counterpart.
This protocol, for example, allows Box’s Enhanced Extract Agent to “look under the hood” of Gemini 2.5 Pro to a greater extent than typical AI model integrations. This deeper insight is essential for:
Building Reliable Confidence Scores: Understanding how certain Gemini 2.5 Pro is about each generated token allows Box AI’s enhanced data extraction capabilities to construct more accurate and meaningful confidence metrics for the end-user.
Enhancing Robustness: Another key area of focus is model robustness ensuring consistent outputs. As Kus put it: “For us robustness is if you run the same model multiple times, how much variation we would see in the values. We want to reduce the variations to be minimal. And with Gemini, we can achieve this.”
Furthering this commitment to an open and extensible ecosystem, Box AI Agents will be published on Agentspace and will be able to interact with other agents using the A2A protocol. Box has also published support for the Google’s Agent Development Kit (ADK) so developers can build Box capabilities into their ADK agents, truly integrating Box intelligence across their enterprise applications.
The Google ADK, an open-source, code-first Python toolkit, empowers developers to build, evaluate, and deploy sophisticated AI agents with flexibility and control. To expand these capabilities, we have created the Box Agent for Google ADK , which allows developers to integrate Box’s Intelligent Content Management platform with agents built with Google ADK, enabling the creation of custom AI-powered solutions that enhance content workflows and automation.
This integration with ADK is particularly valuable for developers, as it allows them to harness the power of Box’s Intelligent Content Management capabilities using familiar software development tools and practices to craft sophisticated AI applications. Together, these tools provide a powerful, streamlined approach to build innovative AI solutions within the Box ecosystem.
Continual learning and human-in-the-loop, for the most flexible AI
The vision for enhanced extract includes a dynamic, self-improving system. “We want to implement that cycle so that you can get higher and higher confidence,” Kus, Box’s CTO, said. “This involves a human-in-the-loop process where low-confidence extractions are reviewed, and this feedback is used to refine the system.”
Here, the flexibility of Gemini 2.5 Pro, particularly concerning fine-tuning, enables continual improvement. Box is exploring advanced continual learning approaches, including:
In-context learning: Providing corrected examples within the prompt to Gemini 2.5 Pro.
Supervised fine-tuning: Google Cloud’s Vertex AI allows Box to store the fine-tuned weights in the company’s system and then just use them to run their fine-tuned model.
Box AI’s Enhanced Extract Agent would manage these fine-tuned adaptations (for example through small LoRA layers specific to a customer or document template) and provide them to the Gemini 2.5 Pro agent at inference time. “Gemini 2.5 Pro can be used to leverage these adaptations efficiently, using the context caching capability of Gemini models on Vertex AI to tailor its responses for specific, high-value extraction tasks using in-context learning. This allows for ‘true adaptive learning,’ where the system continuously improves based on user feedback and specific document nuances,” Kus said.
The future: Premium document intelligence powered by advanced AI collaboration
The Enhanced Extract Agent — underpinned by Gemini 2.5 Pro’s features such as multimodality, intelligent reasoning, planning and tool-calling, and large context windows — is envisioned as as a key differentiator that Box leverages in developing their AI Hub and Agent family. Box views the Enhanced Extract Agent as a fundamental way in which organizations can build more confidence in how they deploy AI in the enterprise.
For the Google team, it’s been exciting to see the production-grade, scalable use of our Gemini models by Box. Their solution not only provides extracted data, but meta-data semantics enabling a high degree of confidence and a system that uses the Box content and agents on top of Gemini models to enable the Enhanced Data Extraction Agent to adapt and learn over time.
The ongoing collaboration between Box and Google Cloud focuses on unlocking the full potential of models like Gemini 2.5 Pro for complex enterprise use cases, which are rapidly redefining the future of work and paving the way for the next generation of document intelligence powering the agentic workforce.
The Customer Carbon Footprint Tool (CCFT) and Data Exports now show emissions calculated using the location-based method (LBM), alongside emissions calculated using the market-based method (MBM) which were already present. In addition, you can now see the estimated emissions from CloudFront usage in the service breakdown, alongside EC2 and S3 estimates.
LBM reflects the average emissions intensity of grids on which energy consumption occurs. Electricity grids in different parts of the world use various sources of power, from carbon-intense fuels like coal, to renewable energy like solar. With LBM, you can view and validate trends in monthly carbon emissions that more directly align to your cloud usage, and get insights into the carbon intensity of the underlying electricity grids in which AWS data centers operate. This empowers you to make more informed decisions about optimizing your cloud usage and achieving your overall sustainability objectives. To learn more about the differences between LBM and MBM see the GHG Protocol Scope 2 Guidance.
Amazon S3 now supports sort and z-order compaction for Apache Iceberg tables, available both in Amazon S3 Tables and general purpose S3 buckets using AWS Glue Data Catalog optimization. Sort compaction in Iceberg tables minimizes the number of data files scanned by query engines, leading to improved query performance and reduced costs. Z-order compaction provides additional performance benefits through efficient file pruning when querying across multiple columns simultaneously.
S3 Tables provide a fully managed experience where hierarchical sorting is automatically applied on columns during compaction when a sort order is defined in table metadata. When multiple query predicates need to be prioritized equally, you can enable z-order compaction through the S3 Tables maintenance API. If you are using Iceberg tables in general purpose S3 buckets, optimization can be enabled in the AWS Glue Data Catalog console, where you can specify your preferred compaction method.
These additional compaction capabilities are available in all AWS Regions where S3 Tables or optimization with the AWS Glue Data Catalog are available. To learn more, read the AWS News Blog, and visit the S3 Tables maintenance documentation and AWS Glue Data Catalog optimization documentation.
Today, Amazon SageMaker HyperPod announces the general availability of Amazon EC2 P6-B200 instances powered by NVIDIA B200 GPUs. Amazon EC2 P6-B200 instances offer up to 2x performance compared to P5en instances for AI training.
P6-B200 instances feature 8 Blackwell GPUs with 1440 GB of high-bandwidth GPU memory and a 60% increase in GPU memory bandwidth compared to P5en, 5th Generation Intel Xeon processors (Emerald Rapids), and up to 3.2 terabits per second of Elastic Fabric Adapter (EFAv4) networking. P6-B200 instances are powered by the AWS Nitro System, so you can reliably and securely scale AI workloads within Amazon EC2 UltraClusters to tens of thousands of GPUs.
The instances are available through SageMaker HyperPod flexible training plans in US West (Oregon) AWS Region. For on-demand reservation of B200 instances, please reach out to your account manager.
Amazon SageMaker AI lets you easily train machine learning models at scale using fully managed infrastructure optimized for performance and cost. To get started with SageMaker HyperPod, visit the webpage and documentation.
We’re excited to announce the general availability of UDP ping beacons for Amazon GameLift Servers, a new feature that enables game developers to measure real-time network latency between game clients and game servers hosted on Amazon GameLift Servers. With UDP ping beacons, you can now accurately measure latency for UDP (User Datagram Protocol) packet payloads across all AWS Regions and Local Zones where Amazon GameLift Servers is available.
Most multiplayer games use UDP as their primary packet transmission protocol due to its performance benefits for real-time gaming and optimizing network latency is crucial for delivering the best possible player experience. UDP ping beacons provide a reliable way to measure actual UDP packet latency between players and game servers, helping make better decisions about player-to-server matching and game session placement.
The beacon endpoints are available in all AWS Global Regions and Local Zones supported by Amazon GameLift Servers, except AWS China, and through the ListLocations API, making it easy to programmatically access the endpoints.
Hospitals, while vital for our well-being, can be sources of stress and uncertainty. What if we could make hospitals safer and more efficient — not only for patients but also for the hard-working staff who care for them? Imagine if technology could provide an additional safeguard, predicting falls, or sensing distress before it’s even visible to the human eye.
Many hospitals today still rely on paper-based processes before transforming critical information to digital systems, leading to frequent — and sometimes, remarkably absurd — inefficiencies. In-person patient monitoring, while standard practice, can be slow, incomplete, and subject to human error and bias. In one serious incident, shared by hospital staff, a patient fell shortly after getting out of bed at 5 a.m. and wasn’t discovered until the routine 6:30 a.m. check. Events like this underscore the need for continuous, 24/7 in-room monitoring solutions that can alert staff immediately in high-risk and emergency situations.
Driven by a shared vision to enhance patient care, healthcare innovator Hypros and Google Cloud joined forces to develop an AI-assisted patient monitoring system that detects and alerts staff to in-hospital patient emergencies, such as out-of-bed falls, delirium onset, or pressure ulcers. This innovative privacy-preserving solution enables better prioritization of care and a strong foundation for clinical decision-making — all without the use of invasive cameras.
While the need for 24/7 patient monitoring is clear, developing these solutions raises important concerns around privacy and professional conduct. Privacy is paramount in any patient-monitoring technology for both the individuals receiving care and the professionals providing it. Even seemingly simple aspects, such as interventions within the patient’s immediate surroundings, require strict compliance with hospital hygiene policies — a lesson reinforced during the COVID-19 pandemic.
It’s crucial to monitor and correct any mistakes without singling out individuals. By using tools like low-resolution sensors, we can protect people’s identities and reduce the risk of unfair judgment, keeping the focus squarely on improving care. This approach is especially valuable, since the root cause of errors, more often than not, extend beyond the individual. As a result, ethical technology deployment of monitoring, AI or otherwise, means ensuring that the efficiencies or insights gained never compromise fundamental rights and well-being.
Figure 1: Patient monitoring device from Hypros.
The approach for continuous patient monitoring hinges on two key innovations:
Non-invasive IoT devices: Hypros developed a novel battery-powered Internet of Things (IoT) device that can be mounted on the ceiling. This device uses low-resolution sensors to capture minimal optical and environmental data, creating a very low-detail image of the scene. The device is designed to be non-invasive, preserving anonymity while still gathering the crucial information needed to detect any meaningful changes in a patient’s environment or condition.
Two-stage AI workflow: Hypros employ a two-stage machine learning (ML) workflow. Initially, they trained a camera-based vision model using AutoML on Vertex AI to label sensor data from simulated hospital scenarios. Next, they use this labeled dataset to train a second model to interpret low-resolution sensor data.
The following sections explain how Hypros implemented these innovations into their patient monitoring solution, and how Google Cloud assisted Hypros in this endeavor.
Low resolution, high information: Securing patient privacy
To address the critical need for patient privacy while enabling effective hospital bed monitoring, Hypros developed a compact, mountable IoT device (see Figure 1) equipped with low-resolution optical and environmental sensors. This innovative solution operates on battery power, facilitating easy installation and relocation to various bed locations as needed.
Figure 2: How a bed with a patient scene is abstracted to low resolution sensor data.
The device’s low-resolution optical sensors are effective for protecting patient privacy, they also can make data interpretation and analysis more complex. Additionally, low sampling rates and environmental factors can introduce noise and sparsity into the data, resulting in an incomplete representation of human behavior in the hospital. The combination of low-resolution imaging, limited sampling rates, and environmental noise creates a complex data landscape that requires sophisticated algorithms and interpretive models to extract meaningful insights.
Figure 3: Real-world data: Bed sheets changed by Staff, and Patient gets into bed. This is a “simple” scenario.
Despite these challenges, Hypros’ device represents a significant advancement in privacy-preserving patient monitoring, offering the potential to enhance hospital workflow efficiency and patient care without compromising individual privacy.
Patient monitoring with AI: Overcoming low-resolution data challenges
While customized parametric algorithms can partially interpret sensor data, they have difficulty handling complex relationships and edge cases. ML algorithms offer clear advantages, making AI a vital tool for a patient monitoring system.
However, the complexity of their sensor data makes it difficult for AI to independently learn the detection of critical patient conditions, and thus, unsupervised learning techniques would not yield useful results. In addition, manual data labeling can quickly become expensive as tight monitoring sends readings every few seconds, quickly producing large volumes of data.
To solve these issues, Hypros adopted an innovative approach that would allow AI to learn how to detect scenarios from their monitoring devices with minimal labeling effort. They found that using pre-trained AI models, which require fewer examples to learn a new image-based task, can simplify labeling image data. However, these models struggled to interpret their low-resolution sensor data directly.
Therefore, they use a two-step process. First, they train a camera-based vision model using camera data to produce a larger, labelled dataset.Then, they transfer these labels to concurrently recorded sensor data, which they use to train a patient monitoring model. This unique approach enables the system to reliably detect events of interest, such as falls or early signs of delirium, without compromising patient privacy.
Driving healthcare innovation with Google Cloud
Hypros relied heavily on Google Cloud to build their patient monitoring system, particularly its data and AI services. The first crucial step was collecting useful data to train their AI models.
They began by replicating a physical hospital room environment within their offices. This controlled setting enabled them to simulate various realistic scenarios, gather data, and record video. During this phase, they also collaborated closely with hospitals to ensure that the characteristics specific to each use case were accurately determined.
Next, they trained a camera-based vision model with AutoML on VertexAI to label sensor data. This process was remarkably straightforward and efficient. Within approximately two weeks, their initial AutoML camera-based vision model used for labeling achieved an average precision exceeding 91% across all confidence thresholds. Already impressive, the actual performance was higher as labeling discrepancies artificially lowered the results.
Subsequently, they labeled various video recordings from hospital beds and correlated these labels with their device data for model training. This approach allowed the model to learn how to interpret sensor data sequences by observing and learning from the corresponding video. For training use cases that didn’t incorporate video information, they relied on data or simulation methodologies from their hospital partners.
The speed of development cycles is also a critical competitive advantage. Therefore, they mapped every step in their workflow and model development cycles (see Figure 4) to the following Google Cloud services:
Cloud Storage: Stores all raw data, enabling easy rollbacks and establishing a clear baseline for ongoing improvements.
BigQuery: Stores labeled data for easier querying, and analysis querying and analysis. Easy access to the right data helps them iterate, analyze, debug, and refine their models more efficiently.
Artifact Registry: Hosts their custom Docker images in ETL and training pipelines. Fewer downloads, shorter builds, and better software dependency management provides smoother, more optimized operations.
Apache Beam with Dataflow Runner: Processes large volumes of data at high speed, keeping their pipelines fast and maximizing their development time.
Vertex AI: Provides a unified platform for model registration, experiment tracking, and visualizing results in TensorBoard; training is done with TensorFlow and TFRecords, using customized resources (like GPUs) and easy deployment options simplify rolling out new model versions.
Figure 4: Simple workflow directed graph to highlight technologies used
With Google Cloud’s ability to handle petabytes of data, they know their workflows are highly scalable. Having a powerful, flexible platform lets them focus on delivering value from data insights, rather than worrying about infrastructure.
Further possibilities: Distilling nuanced information
The development of their system has sparked more ideas about ways hospitals can benefit from using sensor data and AI. They see three main areas of care where continuous patient monitoring can help: patient-centric care for better outcomes, staff-centric support to optimize their time, and environmental monitoring for safer spaces.
Some potential use cases include:
People detection: Anonymously detect individuals to improve operations, such as bed occupancy for patient flow management.
Fall prevention and detection: Alert staff about patient falls or flag restless behavior to prevent them.
Pressure ulcers: Monitor 24/7 movement to aid clinical staff in repositioning patients effectively to prevent the development of pressure ulcers (bedsores).
Delirium risk indicators: Track sleep disruption factors like light and noise, which are potential indicators of delirium risk (final correlation requires additional data from other sources).
General environmental analysis:Monitor temperature, humidity, noise, and other environmental data for smarter building responses in the future (e.g., energy savings through optimized heating) and more effective patient recovery.
Hand hygiene compliance: Anonymously track hand disinfection compliance to improve hygiene practices in combination with solutions like the Hypros’ Hand Hygiene Monitoring solution – NosoEx.
Instead of stockpiling sensor data, their system uses advanced AI models to interpret and connect data from multiple streams — turning simple raw readings into practical insights that guide better decisions. Real-time alerts also bring timely attention to critical situations — ensuring patients receive the swift and focused care they deserve, and staff can perform at their very best.
The path forward with patient care
Already, Hypros’ patient monitoring system is gaining momentum, with real-world trials at leading institutions like UKSH (University Hospital Schleswig-Holstein) in Germany. As highlighted by their recent press release, the UKSH recognizes the potential of their solutions to transform patient care and improve operational efficiency. In addition, their clinical partner, the University Medical Center Greifswald, has experienced benefits firsthand as an early adopter.
Dr. Robert Fleishmann, a managing senior physician and deputy medical director at the University Medical Center Greifswald, is convinced of its usefulness, saying:
“The prevention of delirium is crucial for patient safety. The Hypros patient monitoring solution provides us with vital data to examine risk factors (e.g., light intensity, noise levels, patient movements) contributing to the development of delirium on a 24/7 basis. We are very excited about this innovative partnership.”
This positive feedback, alongside the voices of other customers, fuels Hypros’ ongoing commitment to revolutionize patient care through ethical and data-driven technology.
By harnessing the power of AI and cloud computing, in close collaboration with Google Cloud, Hypros is dedicated to developing privacy-preserving patient monitoring solutions that directly address critical healthcare challenges such as staffing shortages and the ever-increasing need for enhanced patient safety.
Building on this foundation, Hypros envisions a future where their AI-powered patient monitoring solutions are seamlessly integrated into healthcare systems worldwide. The goal is to empower clinicians with real-time, actionable insights, ultimately improving patient outcomes, optimizing resource allocation, and fostering a more sustainable and patient-centric healthcare ecosystem for all.
Recently, we announced Gemini 2.5 is generally available on Vertex AI. As part of this update, tuning capabilities have extended beyond text outputs – now, you can tune image, audio, and video outputs on Vertex AI.
Supervised fine tuning is a powerful technique to customize LLM output using your own data. Through tuning, LLMs become specialized in your business context and task by learning from the tuning examples, therefore achieving higher quality output. With video outputs, here’s some use cases our customers have unlocked:
Automated video summarization: Tuning LLMs to generate concise and coherent summaries of long videos, capturing the main themes, events, and narratives. This is useful for content discovery, archiving, and quick reviews.
Detailed event recognition and localization: Fine-tuning allows LLMs to identify and pinpoint specific actions, events, or objects within a video timeline with greater accuracy. For example, identifying all instances of a particular product in a marketing video or a specific action in sports footage.
Content moderation: Specialized tuning can improve an LLM’s ability to detect sensitive, inappropriate, or policy-violating content within videos, going beyond simple object detection to understand context and nuance.
Video captioning and subtitling: While already a common application, tuning can improve the accuracy, fluency, and context-awareness of automatically generated captions and subtitles, including descriptions of nonverbal cues.
aside_block
<ListValue: [StructValue([(‘title’, ‘$300 in free credit to try Google Cloud AI and ML’), (‘body’, <wagtail.rich_text.RichText object at 0x3e6d910b6df0>), (‘btn_text’, ‘Start building for free’), (‘href’, ‘http://console.cloud.google.com/freetrial?redirectPath=/vertex-ai/’), (‘image’, None)])]>
Today, we will share actionable best practices for conducting truly effective tuning experiments using the Vertex AI tuning service. In this blog, we will cover the following steps:
Craft your prompt
Detect multiple labels
Conduct single-label video task analysis
Prepare video tuning dataset
Set the hyperparameters for tuning
Evaluate the tuned checkpoint on the video tasks
I. Craft your prompt
Designing the right prompt is a cornerstone of any effective tuning, directly influencing model behavior and output quality. An effective prompt for video tuning typically comprises several key components, ensuring clarity in the prompt.
Task context: This component sets the overall context and defines the intention of the task. It should clearly articulate the primary objective of the video analysis. For example….
Task definition: This component provides specific, detailed guidance on how the model should perform the task including label definitions for tasks such as classification or temporal localization. For example, in video classification, clearly define positive and negative matches within your prompt to ensure accurate model guidance.
Output specification: This component provides how the model is expected to produce its output. This includes specific rules or schema for structured formats such as JSON. To maximize clarity, embed a sample JSON object directly in your prompt, specifying its expected structure, schema, data types, and any formatting conventions.
II: Detect multiple labels
Multi-label video analysis involves detecting multiple labels corresponding to a single video. This is a desirable setup for video tasks since the user can train a single model for several labels and obtain predictions for all the labels via a single query request to the tuned model during inference time. These tasks are usually quite challenging for the off-the-shelf models and often need tuning.
See an example prompt below.
code_block
<ListValue: [StructValue([(‘code’, ‘Focus: you are a machine learning data labeller with sports expertise. rnrn### Task definition ###rnGiven a video and an entity definition, your task is to find out the video segments that match the definition for any of the entities listed below and provide the detailed reason on why you believe it is a good match. Please do not hallucinate. There are generally only few or even no positive matches in most cases. You can just output nothing if there are no positive matches.rnrn Entity Name: “entity1″rn Definition: “define entity 1”rn Labeling instruction: provide instruction for entity1rnrn Entity Name: “entity 2″rn Definition: “define entity 2”rn Labeling instruction: provide instruction for entity 2rnrn..rn..rnrn### Output specification ###rnYou should provide the output in a strictly valid JSON format same as the following example.rn[{rn”cls”: {the entity name},rn”start_time”: “Start time of the video segment in mm:ss format.”,rn”end_time”: “End time of the video segment in mm:ss format.”,rn},rn{rn”cls”: {the entity name},rn”start_time”: “Start time of the video segment in mm:ss format.”,rn”end_time”: “End time of the video segment in mm:ss format.”,rn}]rnBe aware that the start and end time must be in a strict numeric format: mm:ss. Do not output anything after the JSON content.rnrnYour answer (as a JSON LIST):’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e6d910b6a30>)])]>
Challenges and mitigations for multi-label video tasks:
The tuned model tends to learn dominant labels (i.e., labels that appear more frequently in the dataset).
Mitigation: We recommend balancing the target label distribution as much as possible.
When working with video data, skewed label distributions are further complicated by the temporal aspect. For instance, in action localization, a video segment might not contain “event X” but instead feature “event Y” or simply be background footage.
Mitigation: For such use cases, we recommend using multi-class single-label design described below.
Mitigation: Improving the positive:negative instance ratio per label would further improve the tuned model’s performance.
The tuned model tends to hallucinate if the video task involves a large number of labels per instance (typically >10 labels per video input).
Mitigation: For effective tuning, we recommend using multi-label formulation for video tasks that involve less than 10 labels per video.
For video tasks that require temporal understanding in dynamic scenes (e.g. event detection, action localization), the tuned model may not be effective for multiple temporal labels that are overlapping or are very close.
III: Conduct single-label video task analysis
Multi-class single-label analysis involves video tasks where a single video is assigned exactly one label from a predefined set of mutually exclusive labels. In contrast to multi-label tuning, multi-class single-label tuning recipes show good scalability with an increasing number of distinct labels. This makes the multi-class single-label formulation a viable and robust option for complex tasks. For example, tasks that involve categorizing videos into one of many possible exclusive categories or detecting several overlapping temporal events in the video.
In such a case, the prompt must explicitly state that only one label from a defined set is applicable to the video input. List all possible labels within the prompt to provide the model with the complete set of options. It is also important to clarify how a model should handle negative instances, i.e., when none of the labels occur in the video.
See an example prompt below:
code_block
<ListValue: [StructValue([(‘code’, ‘You are a video analysis expert. rnrn### Task definition ###rnDetect which animal appears in the video.The video can only have one of the following animals: dog, cat, rabbit. If you detect none of these animals, output NO_MATCH.rnrn### Output specification ###rnGenerate output in the following JSON format:rn[{rn”animal_name”: “<CATEGORY>”,rn}]’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e6d8d2a2760>)])]>
Challenges and mitigations for multi-class single-label video tasks
Using highly skewed data distributions may cause quality regression on the tuned model. The model may simply learn to predict the majority class, failing to identify the rare positive instances.
Mitigation: Undersampling the negative instances or oversampling the positive instances to balance the distributions are some effective strategies for tuning recipes. The undersampling/oversampling rate depends on the specific use case at hand
Some video use cases can be formulated as both multi-class single-label tasks and multi-label tasks. For example, detecting time intervals for several events in a video.
For fewer event types with non-overlapping time intervals (typically fewer than 10 labels per video), multi-label formulation is a good option.
On the other hand, for several similar event types with dense time intervals, multi-class single-label recipes yield better model performance . Model inference involves sending a separate query for each class (e.g., “Is event A present?”, then “Is event B present?”). This approach effectively treats the multi-class problem as a series of N binary decisions. This would mean for N classes, you will need to send N inference requests to the tuned models.
This is a tradeoff between higher inference latency and cost vs target performance. The choice should be made based on expected target performance from the model for the use case.
IV. Prepare video tuning dataset
The Vertex Tuning API uses *.jsonl files for both training and validation datasets. Validation data is used to select a checkpoint from the tuning process. Ideally, there should be no overlap in the JSON objects contained within train.jsonl and validation.jsonl. Learn more about how to prepare tuning dataset and its limitations here.
For maximum efficiency when tuning Gemini 2.0 (and newer) models on video, we recommend to use the MEDIA_RESOLUTION_LOW setting, located within the generationConfig object for each video in your input file. It dictates the number of tokens used to represent each frame, directly impacting training speed and cost.
You have two options:
MEDIA_RESOLUTION_LOW (default): Encodes each frame using 64 tokens.
MEDIA_RESOLUTION_MEDIUM: Encodes each frame using 256 tokens.
While MEDIA_RESOLUTION_MEDIUM may offer slightly better performance on tasks that rely on subtle visual cues, it comes with a significant trade-off: training is approximately four times slower. Given that the lower-resolution setting provides comparable performance for most applications, sticking with the default MEDIA_RESOLUTION_LOW is the most effective strategy for balancing performance with crucial gains in training speed.
V. Set the hyperparameters for tuning
After preparing your tuning dataset, you are ready to submit your first video tuning job! We supports 3 hyperparameters:
epochs: specifies the number of iterations over the entire training dataset. With a dataset size of ~500 examples, starting with epochs = 5 is the default value for video tuning tasks. Increase the number of epochs when you have <500 samples and decrease when you have >500 samples.
learning_rate_multiplier: specifies multiplier for the learning rate. We recommended experimenting with values less than 1 if the model is overfitting and values greater than 1 if the model is underfitting.
adapter_size: specified the rank of the LoRA adapter. The default values are adapter_size=8 for flash model tuning. For most use cases, you won’t need to adjust this, but a higher size allows the model to learn more complex tasks.
To streamline your tuning process, Vertex AI provides intelligent, automatic hyperparameter defaults. These values are carefully selected based on the specific characteristics of your dataset, including its size, modality, and context length. For the most direct path to a quality model, we recommend starting your experiments with these pre-configured values. Advanced users looking to further optimize performance can then treat these defaults as a strong baseline, systematically adjusting them based on the evaluation metrics from their completed tuning jobs.
VI. Evaluate the tuned checkpoint on the video tasks
Vertex AI tuning service provides loss and accuracy graph for training and validation dataset out of the box. The monitoring graph is updated in real time as your tuning job progresses. Intermediate checkpoints are automatically deployed for you. We recommend selecting the checkpoint corresponding to the epochs that show loss values on the validation dataset have saturated.
To evaluate the tuned model endpoint, See a sample code snippet below:
For best performance, it is critical that the format, context and distribution of the inference prompts align with the tuning dataset. Also, we recommend using the same mediaResolution for evaluation as the one used during training.
For thinking models like Gemini 2.5 Flash, we recommend setting the thinking budget to 0 to turn off thinking on tuned tasks for optimal performance and cost efficiency. During supervised fine-tuning, the model learns to mimic the ground truth in the tuning dataset, omitting the thinking process.
Get started on Vertex AI today
The ability to derive deep, contextual understanding from video is no longer a futuristic concept—it’s a present-day reality. By applying the best practices we’ve discussed for prompt engineering, tuning dataset design, and leveraging the intelligent defaults in Vertex AI, you are now equipped to effectively tune Gemini models for your specific video-based tasks.
What challenges will you solve? What novel user experiences will you create? The tools are ready and waiting. We can’t wait to see what you build.
At Google Cloud, we’re committed to delivering the best performance possible globally for web and API content. Cloud CDN is a high-performance edge caching solution that runs at over 200 points of presence, and we continue to add more features and capabilities to it. Recently we launched invalidation with cache tags, device characterization, 0-RTT early data, and geo-targeting. These powerful first class features address many use cases, but organizations tell us they also need a more flexible, lightweight, edge computing solution.
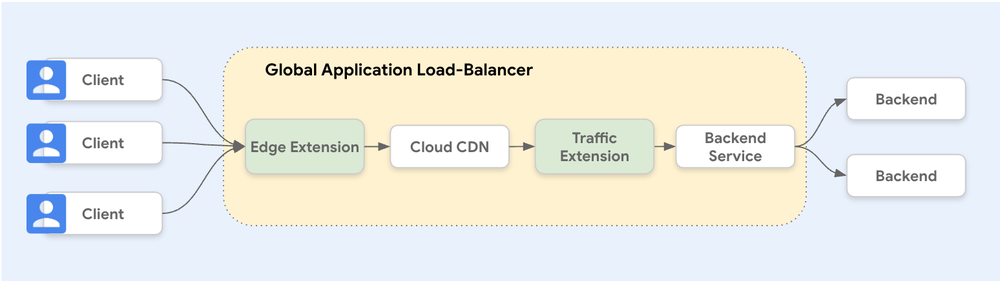
We are excited to announce that you can now run Service Extensions plugins with Cloud CDN, allowing you to run your own custom code directly in the request path in a fully managed Google environment with optimal latency. This allows you to customize the behavior of Cloud CDN and the Application Load Balancer to meet your business requirements.
Service Extensions plugins with Cloud CDN supports the following use cases:
Custom traffic steering: Manipulate request headers to influence backend service selection.
Cache optimization: Influence which content is served from a Cloud CDN cache.
Exception handling: Redirect clients to a custom error page for certain response classes.
Custom logging: Log user-defined headers or custom data into Cloud Logging.
Header addition: Create new headers relevant for your applications or specific customers.
Header manipulation: Rewrite existing request headers or override client headers on their way to the backend.
Security: Write custom security policies based on client requests and make enforcement decisions within your plugin.
aside_block
<ListValue: [StructValue([(‘title’, ‘$300 to try Google Cloud networking’), (‘body’, <wagtail.rich_text.RichText object at 0x3e6d90586d30>), (‘btn_text’, ‘Start building for free’), (‘href’, ‘http://console.cloud.google.com/freetrial?redirectpath=/products?#networking’), (‘image’, None)])]>
Where you can run your code
Service Extensions plugins run at multiple locations in the request and response processing path. With this launch, you can run plugins before requests to Cloud CDN using an edge extension. In a previous launch, we added the capability to run plugins post the Cloud CDN cache, closer to the origin, via a traffic extension. Now, with support for both edge and traffic extensions, you can choose where you want your code to execute in the processing path.
Service Extensions deep dive
Service Extensions plugins are designed for lightweight compute operations that run as part of the Application Load Balancer request path. Plugins are built on WebAssembly (Wasm), which provides several benefits:
Near-native execution speed, and startup time in the single milliseconds
Support for a variety of programming languages, such as Rust, C++, and recently Go
Cross-platform portability, so you can run the same plugin in various deployments, or locally for testing
Security protections, such as executing plugin logic in a sandboxed environment
Service Extensions plugins leverage Proxy-Wasm, a Google-supported open source project that provides a standard API for Wasm modules to interface with network proxies.
Use Cloudinary’s image & video optimization solution
We are excited to announce our latest partner to integrate their offering with Service Extensions and Cloud CDN. Cloudinary makes an advanced image and video optimization solution and has integrated it with Service Extensions plugins for deployment to Cloud CDN customers.
Packaged as a Wasm plugin, Cloudinary’s plugin takes directives from Client Requests such as User-Agent information, and content type expressed as MIME types from HTTP Accept headers, to determine the most optimal media type to serve to the end user. The plugin also takes care of Cache Key normalization so that the images and videos are cached properly based on device types and content types.
“Cloudinary’s image and video solutions help customers manage and optimize their visual media assets at scale while ensuring they are optimized for the best format, device, channel and viewing context. We are excited to partner with the Google team to offer Cloudinary’s image and video optimization solutions to Cloud CDN customers via Service Extensions.” – Gary Ballabio, VP, Strategic Technology Partnerships, Cloudinary
For more information on Cloudinary’s solution, please review this guide.
What’s next
To get started with Service Extensions plugins, take a look at our growing samples repository with a local testing toolkit and follow our quickstart guide in the documentation.
AWS today announced Amazon WorkSpaces Core Managed Instances, simplifying virtual desktop infrastructure (VDI) migrations with highly customizable instance configurations. Utilizing EC2 Managed Instances at its foundation, WorkSpaces Core can now provision resources in your AWS account, handling infrastructure lifecycle management for both persistent and non-persistent workloads. Managed Instances complement existing WorkSpaces Core pre-configured bundles by providing greater flexibility for organizations requiring specific compute, memory, or graphics configurations.
You can now use existing discounts, Savings Plans, and other features like On-Demand Capacity Reservations (ODCRs), with the operational simplicity of WorkSpaces – all within the security and governance boundaries of your AWS account. WorkSpaces Core Managed Instances is ideal for organizations migrating from on-premises VDI environments or existing AWS customers seeking enhanced cost optimization without sacrificing control over their infrastructure configurations. You can use a broad selection of instance types, including accelerated graphics instances, while your Core partner solution handles desktop and application provisioning and session management through familiar administrative tools.
Amazon WorkSpaces Core Managed Instances is available today in all AWS Regions where WorkSpaces is supported. Customers will incur standard compute costs along with an hourly fee for WorkSpaces Core. See the WorkSpaces Core pricing page for more information.
To learn more about Amazon WorkSpaces Core Managed Instances, visit the product page. For technical documentation, getting started guides, and the shared responsibility model for partner VDI solutions integrating WorkSpaces Core bundles and managed instances, see the Amazon WorkSpaces Core Documentation.
Amazon OpenSearch Serverless has added support for Point in Time (PIT) search and SQL in AWS GovCloud US-East and US-West Regions, enabling you to run multiple queries against a dataset fixed at a specific moment. With PIT search you to maintain consistent search results even as your data continues to change, making it particularly useful for applications that require deep pagination or need to preserve a stable view of data across multiple queries. OpenSearch SQL API allows you to leverage your existing SQL skills and tools to analyze data stored in your collections.
PIT supports both forward and backward navigation through search results, ensuring consistency even during ongoing data ingestion. This feature is ideal for e-commerce applications, content management systems, and analytics platforms that require reliable and consistent search capabilities across large datasets. SQL and PPL API support addresses the need for familiar query syntax and improved integration with existing analytics tools, benefiting data analysts and developers who work with OpenSearch Serverless collections.
AWS VPC has increased the default value for routes per route table from 50 to 500 entries.
Before this enhancement, customers had to request a limit increase to use more than 50 routes per VPC route table. Organizations often need additional routes to maintain precise control over their VPC traffic flows to insert firewalls or network functions in the traffic path, or direct traffic to peering connections, internet gateway, virtual private gateway or transit gateway. This enhancement automatically increases the route table capacity to 500 routes, mitigating administrative overhead and enables customers to scale their network architecture seamlessly as their requirements grow.
The new default limit will be automatically available for all route tables in all AWS commercial and AWS GovCloud (US) Regions. Customer accounts without route quota overrides will automatically get 500 routes per VPC route table for their existing and new VPCs. Customer accounts with route quota overrides will not see any changes to their existing or new VPC setups. To learn more about this quota increase, please refer to our documentation.
AWS AppSync is now available in Asia Pacific (Malaysia, Thailand), and Canada West (Calgary). AWS AppSync GraphQL is a fully managed service that enables developers to create scalable APIs that simplify application development by allowing applications to securely access, manipulate, and combine data from one or multiple sources. AWS AppSync Events is a fully managed service for serverless WebSocket APIs with full connection management.
With more than a thousand connected data sources available out-of-the-box and an untold number of custom tools, developers rely on Looker’s cloud-first, open-source-friendly model to create new data interpretations and experiences. Today, we are taking a page from modern software engineering principles with our launch of Continuous Integration for Looker, which will help speed up development and help developers take Looker to new places.
As a developer, you rely on your connections to be stable, your data to be true, and for your code to run the same way every time. And when it doesn’t, you don’t want to spend a long time figuring out why the build broke, or hear from users who can’t access their own tools.
Continuous Integration for Looker helps streamline your code development workflows, boost the end-user experience, and give you the confidence you need to deploy changes faster. With Continuous Integration, when you write LookML code, your dashboards remain intact and your Looker content is protected from database changes. This helps to catch data inconsistencies before your users do, and provides access to powerful development validation capabilities directly in your Looker environment.
With Continuous Integration, you can automatically unify changes to data pipelines, models, reports, and dashboards, so that your business intelligence (BI) assets are consistently accurate and reliable.
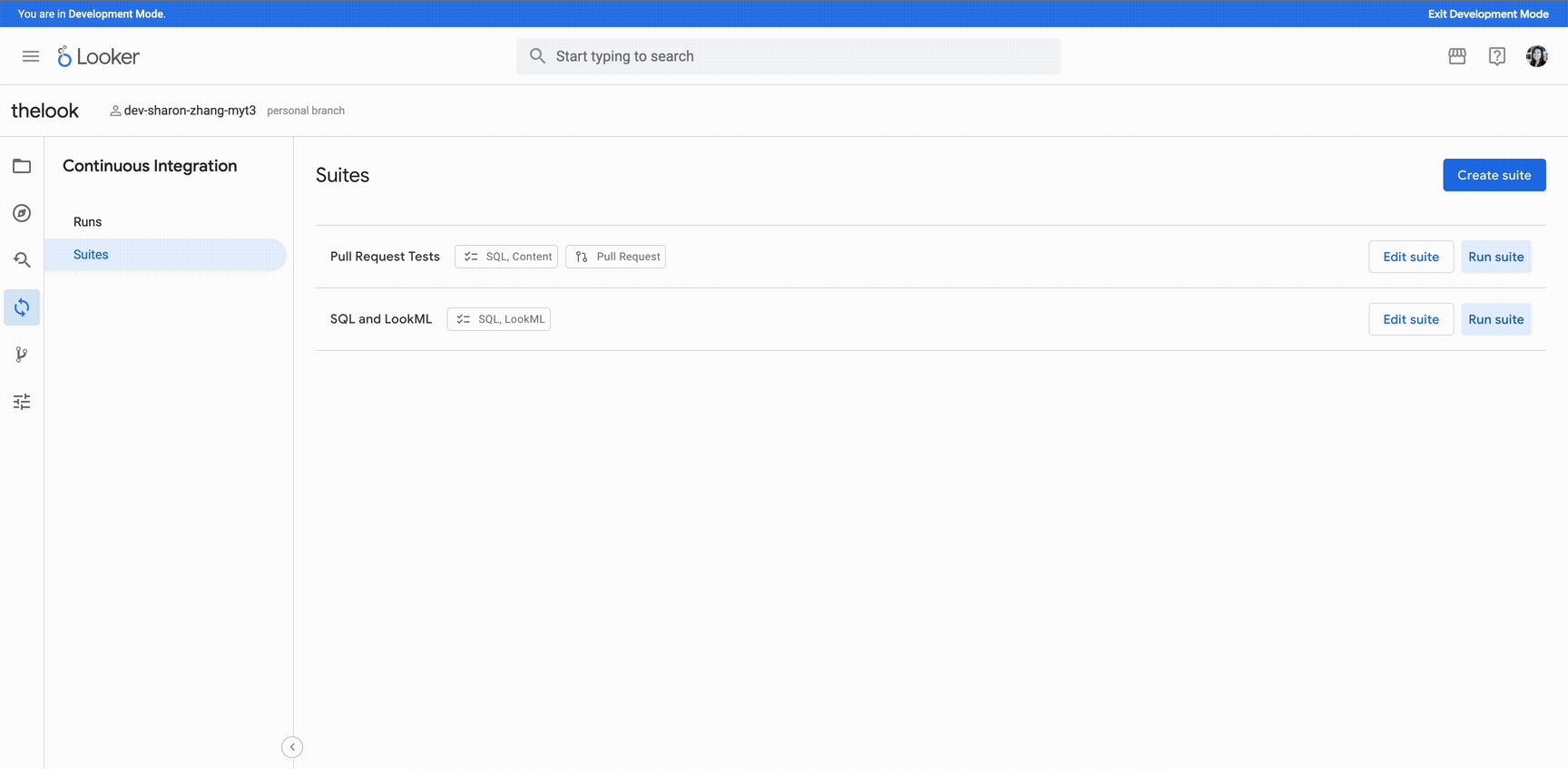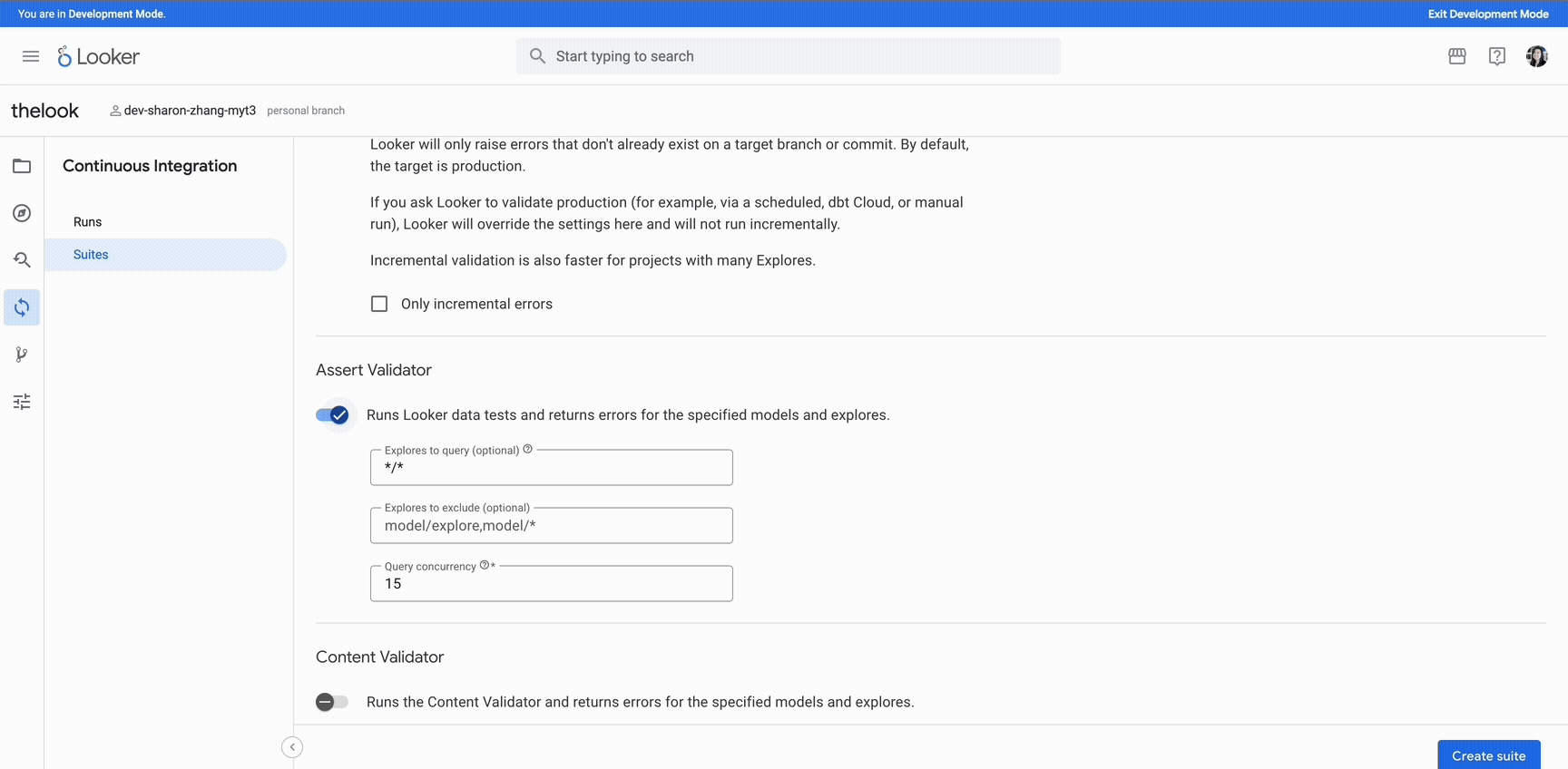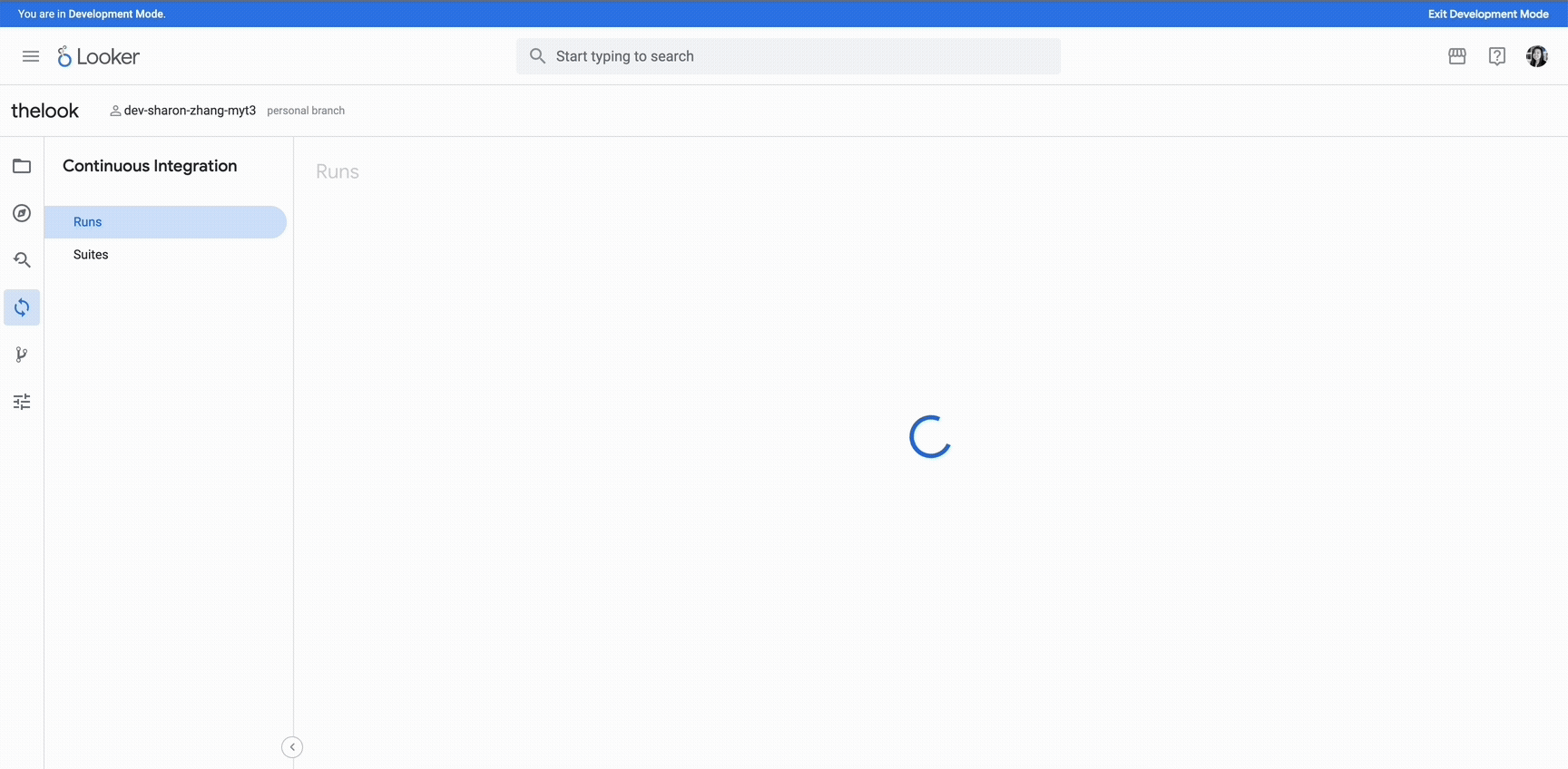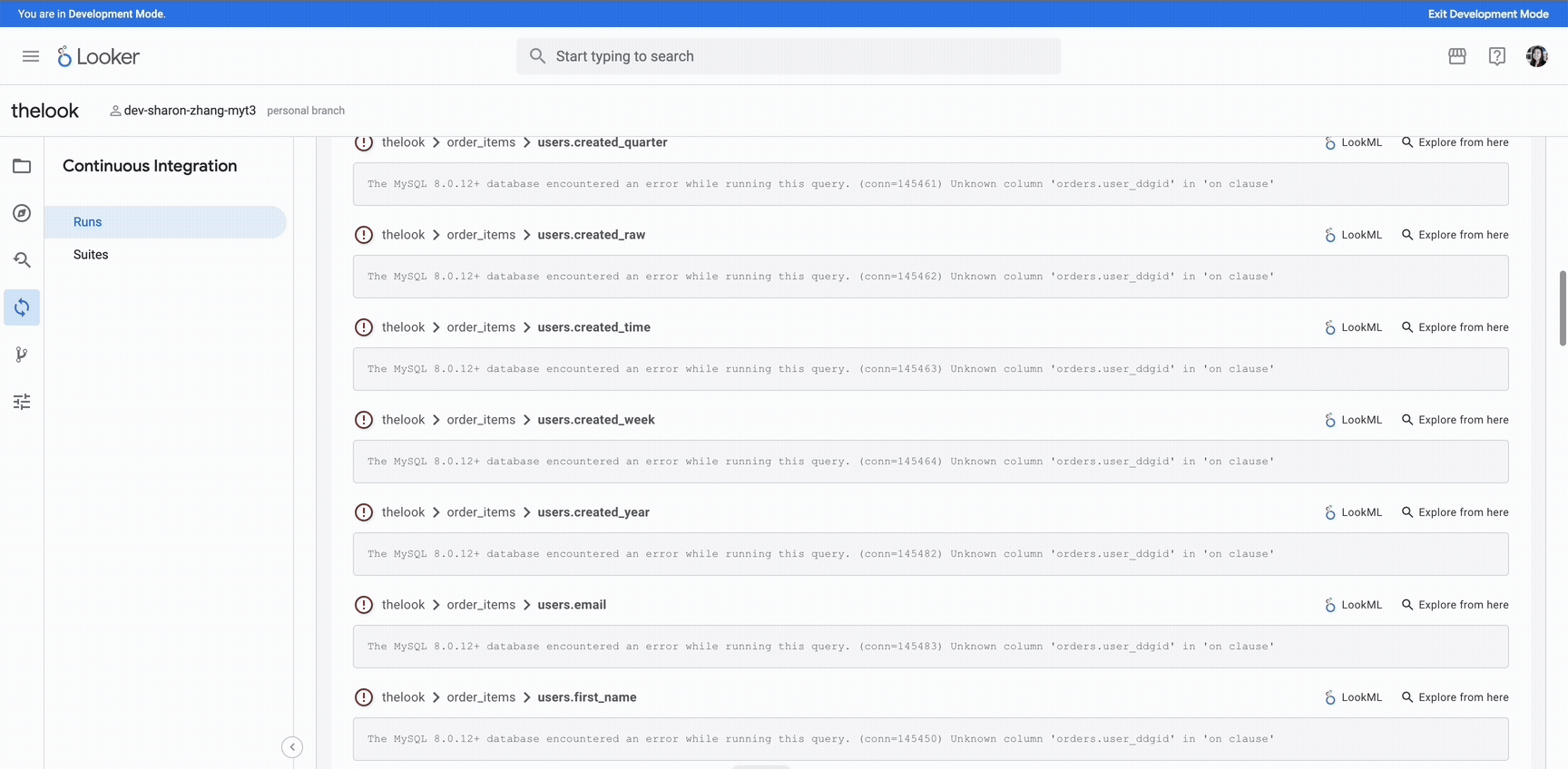
Continuous Integration in Looker checks your downstream dependencies for accuracy and speeds up development.
Developers benefit from tools that help them maintain code quality, ensure reliability, and manage content effectively. As Looker becomes broadly adopted in an organization, with more users creating new dashboards and reports and connecting Looker to an increasing number of data sources, the potential for data and content errors can increase. Continuous Integration proactively tests new code before it is pushed to production, helping to ensure a strong user experience and success.
Specifically, Continuous Integration in Looker offers:
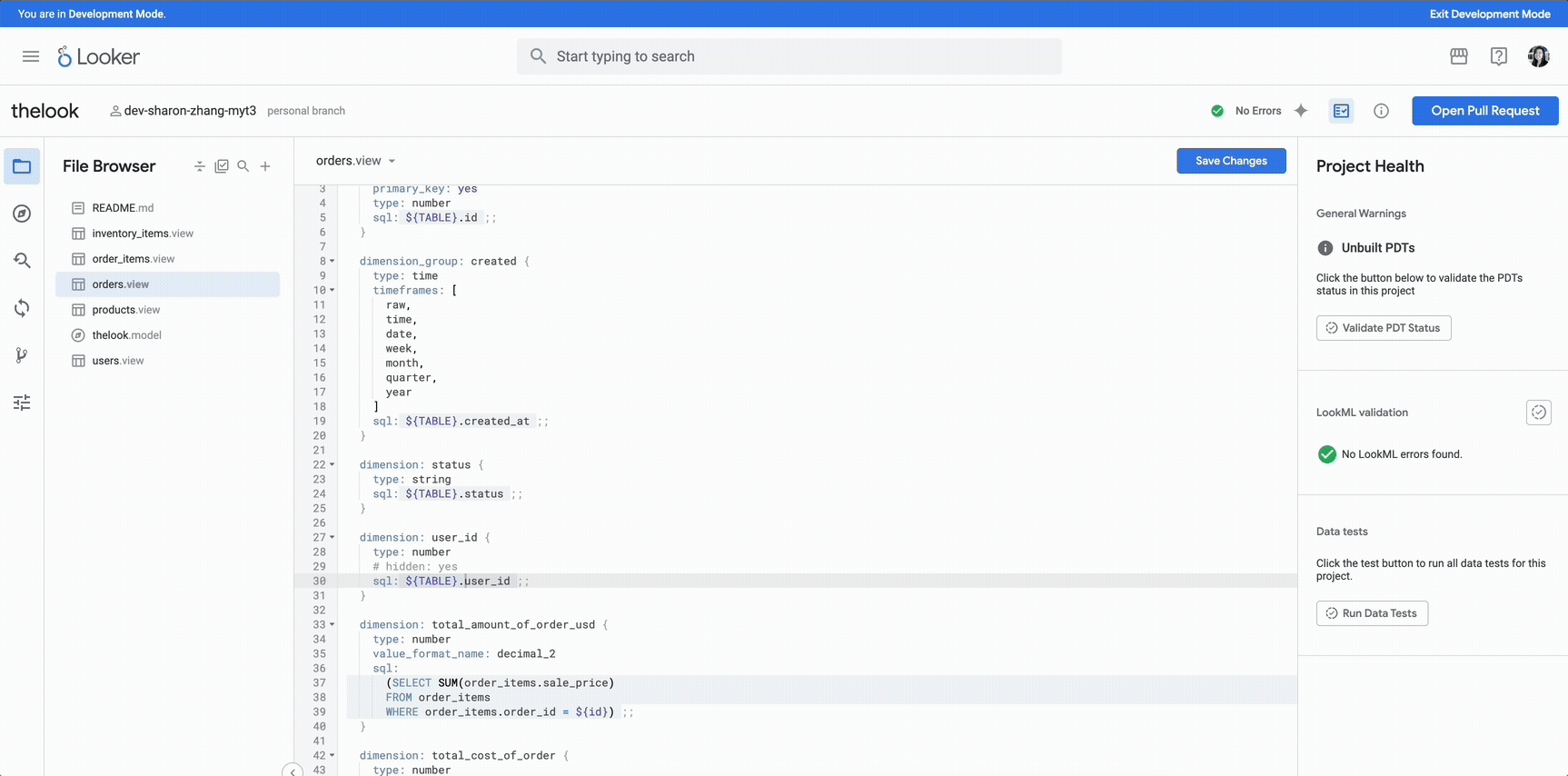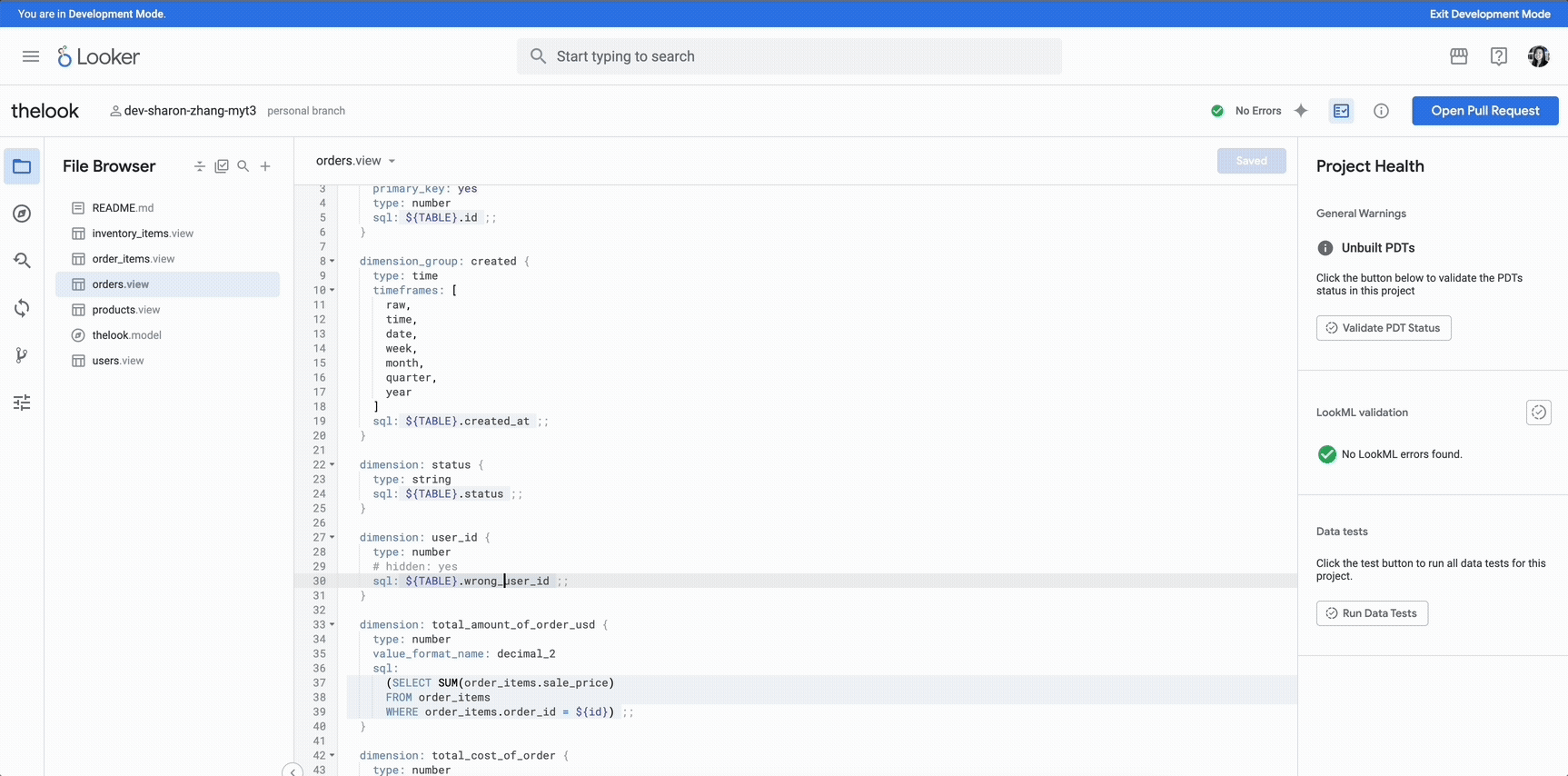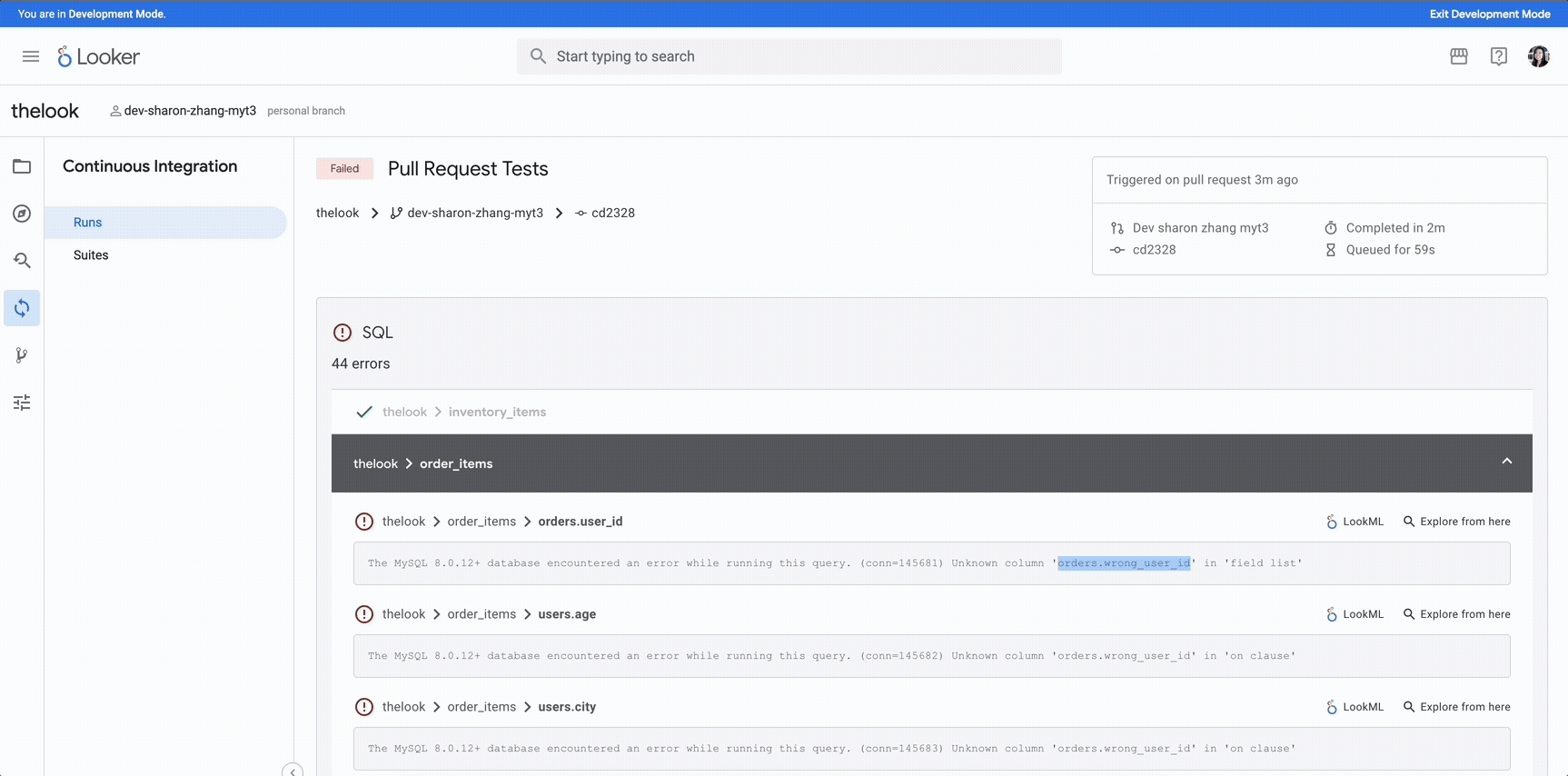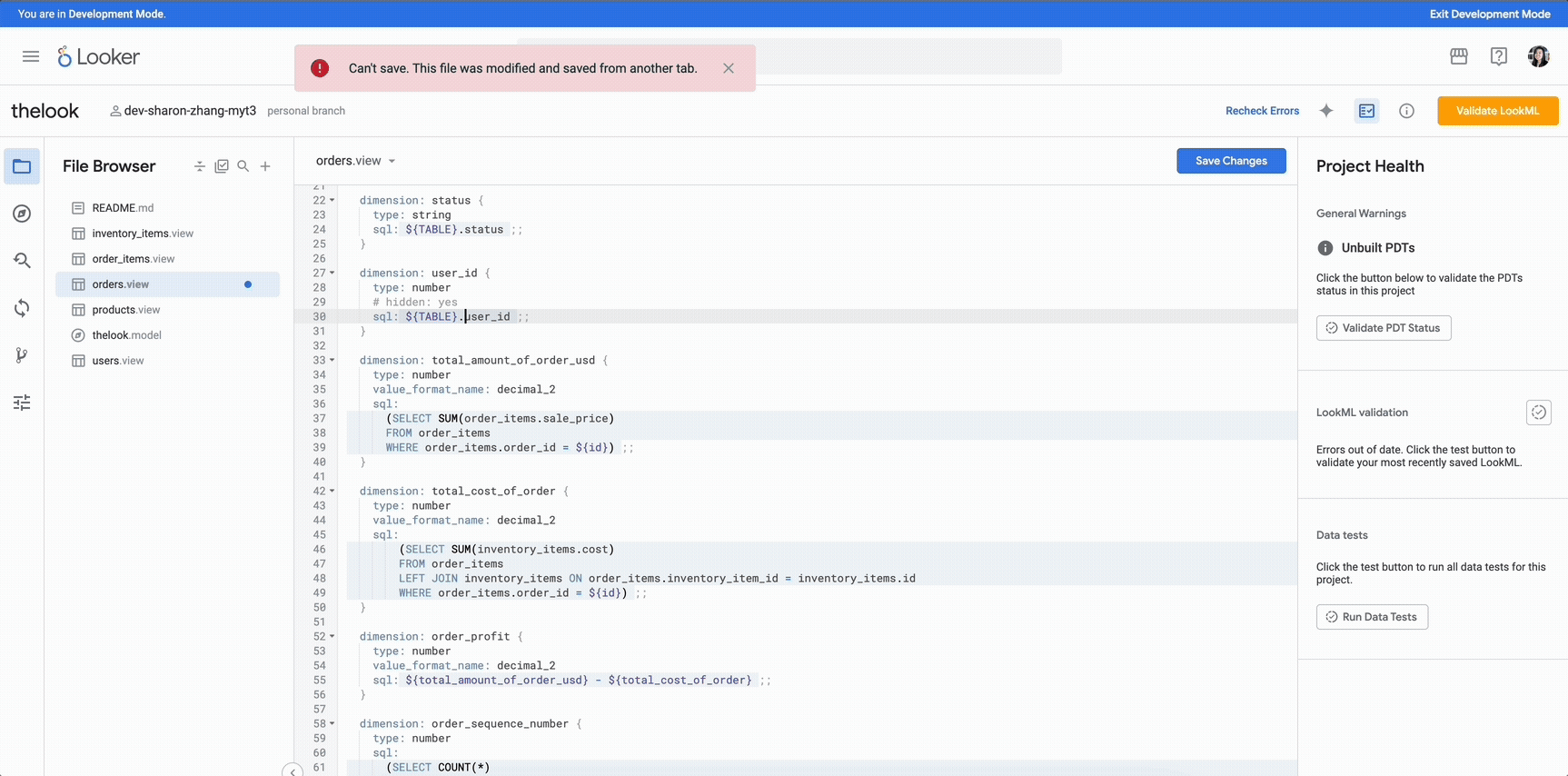
Early error detection and improved data quality: Minimize unexpected errors in production. Looker’s new Continuous Integration features help LookML developers catch issues before new code changes are deployed, for higher data quality.
Validators that:
Flag upstream SQL changes that may break Looker dimension and measure definitions.
Identify dashboards and Looks that reference outdated LookML definitions.
Validate LookML for errors and antipatterns as a part of other validations.
Enhanced developer efficiency: Streamline your workflows and integrate Continuous Integration pipelines, for a more efficient development and code review process that automatically checks code quality and dependencies, so you can focus on delivering impactful data experiences.
Increased confidence in deployments: Deploy with confidence, knowing your projects have been thoroughly tested, and confident that your LookML code, SQL queries, and dashboards are robust and reliable.
Continuous Integration flags development issues early.
Manage Continuous Integration directly within Looker
Looker now lets you manage your continuous integration test suites, runs, and admin configurations within a single, integrated UI. With it, you can
Easily monitor the status of your Continuous Integration runs and manage your test suites directly in Looker.
Leverage powerful validators to ensure accuracy and efficiency of your SQL queries, LookML code, and content.
Trigger Continuous Integration runs manually or automatically via pull requests or schedules whenever you need them, for control over your testing process.
In today’s fast-paced data environment, speed, accuracy and trust are crucial. Continuous Integration in Looker helps your data team promote developmental best practices, reduce risk of introducing errors in production, and increase your organization’s confidence in its data. The result is a consistently dependable Looker experience for all users, including those in line-of-business, increasing reliability across all use cases. Continuous Integration in Looker is now available in preview. Explore its capabilities and see how it can transform your Looker development workflows. For more information, check our product documentation to learn how to enable and configure Continuous Integration for your projects.
Today, we’re announcing the integration of Amazon Neptune Analytics with GraphStorm, a scalable, open-source graph machine learning (ML) library built for enterprise-scale applications. This integration brings together Neptune’s high-performance graph analytics engine and GraphStorm’s flexible ML pipeline, making it easier for customers to build intelligent applications powered by graph-based insights.
With this launch, customers can train graph neural networks (GNNs) using GraphStorm and bring their learned representations—such as node embeddings, classifications, and link predictions—into Neptune Analytics. Once loaded, these enriched graphs can be queried interactively and analyzed using built-in algorithms like community detection or similarity search, enabling a powerful feedback loop between ML and human analysis. This integration supports a wide range of use cases, from detecting fraud and recommending content, to improving supply chain intelligence, understanding biological networks, or enhancing customer segmentation. GraphStorm simplifies model training with a high-level command-line interface (CLI) and supports advanced use cases via its Python API. Neptune Analytics, optimized for low-latency analysis of billion-scale graphs, allows developers and analysts to explore multi-hop relationships, analyze graph patterns, and perform real-time investigations.
By combining graph ML with fast, scalable analytics, Neptune and GraphStorm help teams move from raw relationships to real insights—whether they’re uncovering hidden patterns, ranking risks, or personalizing experiences. To learn more about using GraphStorm with Neptune Analytics, visit the blog post.