AWS – Amazon ECS Service Discovery Now Available in AWS GovCloud (US) Regions
Today, Amazon Elastic Container Service (ECS) launches integrated service discovery in the AWS GovCloud (US) Regions.
Read More for the details.

Today, Amazon Elastic Container Service (ECS) launches integrated service discovery in the AWS GovCloud (US) Regions.
Read More for the details.
Today, we are announcing that Amplify Geo for JavaScript is generally available, following our initial Developer Preview release in August. Amplify Geo enables frontend developers to quickly add location-aware features to their web applications. Extending existing Amplify use case categories like Auth, DataStore and Storage, Amplify Geo includes a set of abstracted client libraries built on top of Amazon Location Service, and includes ready-to-use map UI components based on the popular MapLibre open-source library. Amplify Geo also updates the Amplify Command Line Interface (CLI) tool to make it simple for people who aren’t familiar with AWS to achieve common mapping use cases by provisioning all required cloud services
Read More for the details.
Amazon Simple Email Service (Amazon SES) customers can now use 2048-bit DomainKeys Identified Mail (DKIM) keys to enhance their email security. DKIM is an email security standard designed to make sure that an email that claims to have come from a specific domain was indeed authorized by the owner of that domain. It uses public-key cryptography to sign an email with a private key. Recipient servers can then use a public key published to a domain’s DNS to verify that parts of the email have not been modified during the transit.
Read More for the details.
Azure Data Factory managed virtual network provides you with a more secure and manageable data integration solution.
Read More for the details.
AWS announces the general availability of AWS Cloud Control API, a set of common application programming interfaces (APIs) that is designed to make it easy for developers to manage their cloud infrastructure in a consistent manner and leverage the latest AWS capabilities faster. Using Cloud Control API, developers can manage the lifecycle of hundreds of AWS resources and over a dozen third-party resources with five consistent APIs instead of using distinct service-specific APIs. With this launch, AWS Partner Network (APN) Partners can now automate how their solutions integrate with existing and future AWS features and services through a one-time integration, instead of spending weeks of custom development work as new resources become available. Terraform by HashiCorp and Pulumi have integrated their solutions as part of this launch.
Read More for the details.
You can now provision devices using AWS IoT Core Just-in-Time Provisioning and Just-in-Time Registration features without having to send the entire trust chain on devices’ first connection to IoT Core. Until now, customers were required to configure their devices to present both the registered CA certificate and the client certificate signed by the registered CA certificate as part of the TLS handshake on devices’ first connection to IoT Core. Effective today, AWS IoT core makes it optional for customers to present the CA certificate on devices’ first connection to IoT Core when using Just-in-Time Provisioning and Just-in-Time Registration. This enhancement makes it easy for customers to migrate brownfield devices to AWS IoT Core, example, from customers’ self-managed cloud solutions.
Read More for the details.
Amazon SageMaker JumpStart helps you quickly and easily get started with machine learning. SageMaker JumpStart provides a set of solutions for the most common use cases that can be deployed readily with just a few clicks and one-click deployment and fine-tuning of popular open source models. Starting today, you can now access a collection of multimodal financial text analysis tools, including example notebooks, text models, and a solution.
Read More for the details.
AWS Snowcone is now available in solid state drives (SSD) with 14TB storage capacity. AWS Snowcone is the smallest AWS Snow Family device equipped to handle edge computing, edge storage, and data transfers. With this launch, AWS Snowcone is now available in both hard disk drive (HDD) and solid state drive (SSD). Snowcone SSD has the same motherboard (4 vCPU and 4GB RAM) and industrial design as Snowcone, but Snowcone SSD will enable new data transfer and edge computing use cases that require 1) higher throughput performance 2) stronger vibration resistance operation 3) expanded durability and, 4) increased storage capacity (14TB Snowcone SSD vs. 8TB in Snowcone).
Read More for the details.
AWS Lambda now allows customers to trigger functions from Amazon Simple Queue Service (Amazon SQS) queues that are in a different AWS account. Previously, customers could trigger Lambda functions from SQS queues in the same account only. Starting today, customers can create Lambda functions in multiple AWS accounts without needing to replicate the event source in each account.
Read More for the details.
AWS Data Exchange subscribers can now use auto-export to automatically copy newly published revisions from their 3rd party data subscriptions to an Amazon S3 bucket of their choice in just a few clicks. With auto-export, subscribers no longer have to manually export new revisions or dedicate engineering resources to build ingestion pipelines that export new revisions as soon as they are published. For data subscribers that manage frequent updates to their file-based 3rd party data, auto-export saves significant time and effort.
Read More for the details.
The latest Azure Site Recovery update provides fixes and download links for Site Recovery components.
Read More for the details.
AWS Step Functions now integrates with the AWS SDK, expanding the number of supported AWS Services from 17 to over 200 and AWS API Actions from 46 to over 9,000.
Read More for the details.
Who would have known that today technology would enable us with the ability to use machine learning to track vessel activity, and make pattern inferences to help address IUU (illegal, unreported, and unregulated) fishing activities. What’s even more noteworthy is that we now have the computing power to share this information publicly in order to enable fair and sustainable use of our ocean.
An amazing group of humans at the nonprofit Global Fishing Watch took on this massive big data challenge and succeeded. You can immediately access their dynamic map on their website globalfishingwatch.org/map that is bringing greater transparency to fishing activity and supporting the creation and management of marine protected areas throughout the world.
Time lapse of Global Fishing Watch’s global fishing map powered by ML
In our second episode of our People and Planet AI series we were inspired by their ML solution to this challenge, and we built a short video and sample with all the relevant code you need to get started with building a basic time-series classification model in Google Cloud, and visualize it in an interactive map.
The model making predictions whether a vessel is fishing or note.
These are the components used to build a model for this sample:
Architectural diagram for creating our time-series classification model.
Global Fishing Watch GitHub: where we got the data
Apache Beam: (open source library) runs on Dataflow.
Dataflow: (Google’s data processing service) creates 2 datasets; 1 for training a model and the other to evaluate its results.
TensorflowKeras: (high level API library) used to define a machine learning model, which we then train in Vertex AI.
Vertex AI: (a platform to build, deploy, and scale ML models) we train and output the model.
cost of building this time-series classification model is less than $5 in compute resources
The total cost to run this solution was less than $5.
There are seven steps we went through with their approximate time and cost:
Vessels in the ocean are constantly moving, which creates distinctive patterns from a satellite view.
Different fishing gear in vessels move in distinct spatial patterns and have varying regulations and environmental impacts.
We can train a model to recognize the shapes of a vessel’s trajectory. Large vessels are required to use the automatic identification system, or AIS. The GPS-like transponders regularly broadcast a vessel’s maritime mobile service identity, or MMSI, and other critical information to nearby ships, as well as to terrestrial and satellite receivers. While AIS is designed to prevent collisions and boost overall safety at sea, it has turned out to be an invaluable system for monitoring vessels and detecting suspicious fishing behavior globally.
One tricky part is that the MMSI data location signal (which includes a timestamp, latitude, longitude, distance from port, and more) is not emitted at regular intervals. AIS broadcast frequency changes with vessel speed (faster at higher speeds), and not all AIS messages that are broadcast are received – terrestrial receivers require line-of-sight, satellites must be overhead, and high vessel density can cause signal interference. For example, AIS messages might be received frequently as a vessel leaves the docks and operates near shore, then less frequently as they move further offshore until satellite reception improves. This is challenging for a machine learning model to interpret. There are too many gaps in the data, which makes it hard to predict.
A way to solve this is to normalize the data and generate fixed-sized hourly windows. Then the model can predict if the vessel is fishing or not fishing for each hour.
Split panel where left side shows irregular GPS signals collected. Right side shows how we must normalize the data into hourly windows.
It could be hard to know if a ship is fishing or not by just looking at its current position, speed, and direction. So we look at the data from the past as well, looking at the future could also be an option if we don’t need to do real time predictions. For this sample, it seemed reasonable to look 24 hours into the past to make a prediction. This means we need at least 25 hours of data to make a prediction for a single hour (24 hours in the past + 1 current hour). But we could predict longer time sequences as well. In general, to get hourly predictions, we need (n+24) hours of data.
For this sample specifically we used Cloud Run to host the model as a web app so that other apps can call it to make predictions on an ongoing basis; this is our favorite in terms of pricing if you need to access your model from the internet over an extended period of time (charged per prediction request). You can also host it directly from Vertex AI where you trained and built the model, just note there is an hourly cost for using those VMs even if they are idle. If you do not need to access the model over the internet, you can make predictions locally or download the model onto a microcontroller if you have an IoT sensor strategy.
3 options for hosting model
If you found this project interesting and would like to dive deeper either into the specifics of the thought process behind each step of this solution or even run through the code in your own project (or test project); we invite you to check out our interactive sample hosted on Colab, which is a free Jupyter notebook. It serves as a guide with all the steps to run the sample, including visualizing the predictions on a dynamically moving map using an open source Python library called Folium.
There’s no prior experience required! Just click “open in Colab” which is linked at the bottom of GitHub.
You will need a Google Cloud Platform project. If you do not have a Google Cloud project you can create one with the free $300 Google Cloud credit, you just need to ensure you set up billing, and later delete the project after testing the desired sample.
screenshot of interactive notebook in colab notebook
Read More for the details.
Google Cloud Next and VMworld 2021 are less than two weeks away, and the partnership between Google Cloud and VMware is entering a new chapter. Over the past year, our close partnership with VMware and mutual dedication to customer success has inspired us to deliver several innovative capabilities, including expanding the service to 12 regions worldwide along with our industry-leading 99.99% availability, multi-region networking, and improved scalability to make it easy for customers to rapidly migrate to the cloud.
“Our collaboration with Google is noteworthy because of the value it brings to our joint customers. The mutual success we have had partnering with Google on solutions that enable VMware workloads to run natively in the cloud with Google Cloud VMware Engine and digital workspace with Android and Chrome Enterprise is a testament to the quality of our joint offerings,” said Gregory Lehrer, VP Strategic Technology Partnerships, VMware. “As a result of our ongoing collaboration, we continue to see customers adopting our joint solution, indicating a strong and effective partnership. Our joint roadmap for the future points to an upward trajectory as we scale to meet anticipated demand.
Across industries, customers are increasingly looking to accelerate their digital transformation due to the need for app modernization, aging infrastructure on-premises, and the need to meet customer needs in an always-on, digital environment. Customers such as Carrefour, a global retailer across 30 countries, quickly moved their on-premises environment to Google Cloud VMware Engine, while reducing operating costs by 40% and energy consumption by 45%. Furthermore, they were able to simultaneously improve the experience for shoppers and employees, and bolstered sales and shopper engagement with personalized offers.
Companies are also looking to migrate and modernize their business with Google Cloud VMware Engine. LIQ, a CRM software company, migrated 80% of business applications and 50% of databases in just three months, and now plan to modernize their applications with microservices to lower maintenance time and costs. Looking forward, we’re focused on helping customers derive greater ROI from their investments in three ways:
Flexibility – Single node Private Cloud SDDC to enable trials or proof-of-concept validations at a much lower cost.
Availability – New geographic zones and expanded capacity within zones to better serve local business needs and continue to maintain data sovereignty within local regions.
Ecosystem integrations – Building on our leading open platform, we’ve developed even more integrations with solutions across the ecosystem. VMware has validated it’s Disaster Recovery tool (Site Recovery Manager), Virtualization management tool (vRealize Cloud Management), as well as Virtual Desktop Infrastructure tool (Horizon Desktop) to ensure you can bring your mission critical applications to the cloud without disruption.
We continue to focus on making migrations simpler as well. The recently announced Catalyst Program now provides even greater financial flexibility as eligible customers can get one-time Google Cloud credits to help offset existing VMware license investments. The program is consumption-based and designed to provide even more value as you accelerate your migration to the cloud. Furthermore, programs such as our Rapid Assessment and Migration Program (RAMP) provide free assessment and planning tools to reduce complexity, enable choice, and increase flexibility throughout the migration process.
There’s much more to come from VMware and Google Cloud. We’re proud to be a Platinum Sponsor at VMworld 2021 and invite you to join us to learn more about our commitment to enabling digital transformation. Be sure to catch the fireside chat with Google Cloud CEO Thomas Kurian and VMware CEO Raghu Raghuram as they discuss industry trends and customer success. You’ll also hear more from our joint-customers and our product leaders about what’s to come. We can’t wait to connect with you virtually at the event.
Read More for the details.
Amazon Redshift RA3.xlplus nodes are now available in the AWS GovCloud (US) Regions. Amazon Redshift RA3 instances with managed storage allow you to scale compute and storage independently for fast query performance and lower costs. RA3 is available in three different node types to allow you to balance price and performance depending upon your workload requirements. RA3.xlplus nodes offer one-third compute (4 vCPU) and memory (32 GiB) compared to RA3.4xlarge at one-third of the price. RA3 nodes are built on the AWS Nitro System and feature high bandwidth networking and large high-performance SSDs as local caches.
Read More for the details.
QuillBot, a Chicago-based company founded in 2017, is a natural language processing (NLP) company recently acquired bycoursehero.com. QuillBot’s platform of tools leverages state-of-the-art NLP to assist users with paraphrasing, summarization, grammar checking, and citation generation. With over ten million monthly active users around the world, QuillBot continues to improve writers’ efficiency and productivity on a global scale.
QuillBot’s differentiation is its broad range of writing services compared to its competitors. Besides grammar and spelling checks, QuillBot offers additional services such as paraphrasing text while retaining its meaning, with modifications such as changing the tone from formal to informal or making the text longer or shorter. In addition, a panoply of synergistic tools provides the value of completing workflows end-to-end.
Google Cloud has been the infrastructure partner for QuillBot from the start. Their business interests converged as QuillBot aspires to constantly push the envelope of state-of-art natural language processing and make computing demands that test hardware’s limits. As a result, it was drawn to Google’s roadmap for the future development of hardware to support larger AI models.
SADA, a Google Cloud premier partner and 2020 North America Partner of the Year, provided key insights to QuillBot on Google Cloud’s advanced GPU instance types and how to optimize their complex machine learning (ML) workload. QuillBot also leverages SADA’s consulting and Technical Account Management services to roadmap new releases and effectively scale for growth.
QuillBot experiments with new artificial intelligence models that scale exponentially; traffic spikes, in an instant, potentially choking the infrastructure. It would have been overly expensive to build spare capacity in-house or even purchase on-demand computing capacity for peak demand.
Instead, QuillBot needed the flexibility to deploy and pay for infrastructure proportionate to usage without changing purchase plans mid-course. “From an economics perspective, we needed our cloud computing partner to have the hardware capacity to scale as much as 100X and remain stable without a proportionate increase in costs,” Rohan Gupta, CEO and Co-founder of QuillBot, stated.
QuillBot’s entrepreneurial staff needed to make ML easy to understand and execute. At the time, they were not using Terraform, nor did they have a DevOps professional to simplify and automate model development and testing processes. “Our priority was to keep the approach simple and avoid downtime when we upgraded our models to ensure a seamless deployment. Our past efforts to migrate, including our multi-cloud deployment as an example, were fraught with the risk of a painful transition,” David Silin, Co-founder and Chief Science Officer at QuillBot, revealed.
Google Cloud uses the latest hardware to scale to millions of users and meet the computing needs of the state-of-art AI models that QuillBot builds and deploys. In addition, it has sufficient redundant capacity to distribute computing loads when traffic spikes.
“Google Cloud’s user interface blew us away. It was unbelievably superior to other cloud providers. We used virtual machine (VM) instance groups and easily distributed load across them with Pub/Sub,” David Silin gushed.
QuillBot uses Google Cloud’s A2 VMs with NVIDIA A100 Tensor Core GPUs for training models and inference and N1 VMs with NVIDIA T4 Tensor Core GPUs on Google Cloud for serving. With A2 VMs, Google remains the only public cloud provider to offer up to 16 NVIDIA A100 GPUs in a single VM , making it possible to train the largest AI models used for high-performance computing. In addition, users can start withone NVIDIA A100 GPU and scale to 16 GPUs without configuring multiple VMs for a single-node ML training. Effective performance of up to 10 petaflops of FP16 or 20 petaOps of int8 in a single VM, when using the NVIDIA A100 GPUs with the sparsity feature. Seamless scaling becomes possible with containerized, pre-configured software to shorten the lead time for running on Compute Engine A100 instances.
Google Cloud also provides a choice of N1 VMs with NVIDIAT4 Tensor Cores, with varying sizing and pricing plans, to help control the cost. NVIDIA T4 GPUs have advanced networking with up to 100 Gbps. In addition, T4 GPUs have a worldwide footprint, and users can choose capacities in individual regions based on their market size. As a result, they have the flexibility to serve demand incrementally as it grows, with smaller and cheaper GPUs and install more than one in areas where T4 GPUs are available in proximity for stability while keeping latencies low.
Users need to consider the trade-off between going directly to 16 NVIDIA GPUs or starting small and growing incrementally. “For the bigger models, it makes sense to go straight to 16. To be sure, it is not always easy to figure out how to optimize for that level of scaling,” David Silin cautioned. “We experimented and learned that 16 works best for our core models.”
Similarly, Silin noted, “Serving and distributing preemptible VMs across regions and in production was not something we did immediately.” QuillBot leverages preemptible VMs primarily for their unit economics. Given they are preemptible and subject to being shut down in a given region if capacity is full, distributing them across regions allows the company to diversify and prevent all preemptibles from going down at once.
Silin and team have been able to use Kubernetes Engine to manage their NVIDIA GPUs on Google Cloud for model training and serving. This lightens the load of managing their platform, gives time back to their engineers and helps recognize cost savings from gained efficiencies.
QuillBot found the trade-offs of scaling with Google Cloud to be favorable, with their downsides less costly compared to the upside of the benefits. “With Google Cloud, we can scale 4X and maintain the customer experience knowing that enough spare capacity is available without increasing costs disproportionately. As a result, we are comfortable trying larger models,” Rohan Gupta surmised.
Over-provisioning capacity does not increase unit costs because of an integrated training and deployment stack on the Google Cloud. Additionally, the time-to-market is shorter.
“We can scale with ease with Google Cloud because the unit cost increase of GPU is lower than the speed of scaling as they increase from one to sixteen. The gains in the rate of training are 3X faster compared with only 2X higher unit cost,” David Silin reported. “We grabbed NVIDIA A100 GPUs with 40 Gigabytes of memory as soon as we could, and we can’t wait for what’s next for Google Cloud GPU offering,” he added.
The twin benefits of scaling with relatively low downsides have proved to be an overwhelming advantage for QuillBot over its competitors. As a result, QuillBot has experienced a hockey-stick pattern of growth which it expects to maintain in the future. “We could afford freemium services to acquire customers very rapidly, because our unit costs are low. Both the A2 VM family and NVIDIA T4 GPUs on Google Cloud contribute to our business growth. A2 VMs enable us to build state-of-the-art technology in-house,” Rohan Gupta explained.
With the success that QuillBot experienced so far using Google Cloud, the company is planning its future growth on Google’s competitive hardware. “Provisioning our clusters and scaling them is a big priority over the next three months; we will calibrate based on the traffic on our site,” Rohan Gupta revealed.
“Our efficiencies will improve because we have a DevOps person on board. We expect cost savings from predictive auto-scaling implemented through Managed Instance Groups. We are also encouraged by our tests of Google Cloud against competitors that show it has better cold start times than other clouds we tested—a key consideration for super-scaling,” David Silin said.
Read More for the details.
In this blog series, a companion to our paper, we’re exploring different types of data-driven organizations. In the last blog, we discussed main principles for building a data engineering driven organisation. In this second part of the series focus is on how to build a data science driven organization.
The emergence of big data, advances in machine learning and the rise of cloud services has been changing the technological landscape dramatically over the last decade and have pushed the boundaries in industries such as retail, chemistry, or healthcare. In order to create a sustainable competitive advantage from this paradigmatic shift companies need to become ‘data science driven organizations’.1 In the course of this article we discuss the socio-technical challenges those companies are facing and provide a conceptual framework built on first principles to help them on their journey. Finally, we will show how those principles can be implemented on Google Cloud.
A data science driven organization can be described as an entity that maximizes the value from the data available while using machine learning and analytics to create a sustainable competitive advantage. Becoming such an organization is more of a sociotechnical challenge rather than a purely technical one. In this context, we identified four main challenges:
Inflexibility: Many organizations have not built an infrastructure flexible enough to quickly adapt to a fast changing technical landscape. This inflexibility comes with the cost of lock-in effects, outdated technology stacks, and a bad signaling for potential candidates. While those effects might be less pronounced in more mature areas like data warehouses, they are paramount for data science and machine learning.
Disorder: Most organizations grow in an organic way. This often results in a non-standardized technological infrastructure. While standardization and flexibility are often seen as diametrically opposed to each other, a certain level of standardization is needed to establish a technical ‘lingua franca’ across the organization. A lack of the same harms collaborations and knowledge sharing between teams and hampers modular approaches as seen in classical software engineering.
Opaqueness: Data science and machine learning are fundamentally data driven (engineering) disciplines. As data is in a constant flux, accountability and explainability are pivotal for any data science driven organization.2 As a result data science and machine learning workflows need to be defined in the same rigour as classical software engineering. Otherwise, such workflows will turn into unpredictable black boxes.
Data Culture (or lack thereof): Most organisations have a permission culture where data is managed by a team which then becomes a bottleneck on providing rapid access as they cannot scale with the requests. However, in organizations driven by data culture there are clear ways to access data while retaining governance. As a result, machine learning practitioners are not slowed down by politics and bureaucracy and they can carry out their experiments.
Data science driven organizations are heterogeneous. Nevertheless, most of them leverage four core personas: data engineers, machine learning engineers, data scientists, and analysts. It is important to mention that those roles are not static and overlap to a certain extent. An organizational structure needs to be designed in such a way that it can leverage the collaboration and full potential of all personas.
Data engineers take care of creating data pipelines and making sure that the data available fulfills the hygienic needs. For example, cleansing, joining and enriching multiple data sources to turn data into information on which downstream intelligence is based.
Machine learning engineers develop and maintain complete machine learning models. While machine learning engineers are the rarest of the four personas, they become indispensable once an organization plans to run business critical workflows in production.
Data scientists act as a nexus between data and machine learning engineers. Together with business stakeholders they translate business driven needs into testable hypotheses, make sure that value is derived from machine learning workloads and create reports to demonstrate value from the data.
Data analysts bring the business insight and make sure that data driven solutions that business is seeking are implemented. They answer adhoc questions, provide regular reports that analyze not only the historical data but also what has happened recently.
There are different arguments if a company should build centralized or decentralized data science teams. In both cases, teams face similar challenges as outlined earlier. There are also hybrid models, as a federated organization whereby data scientists are embedded from a centralized organization. Hence, it is more important to focus on how to tackle those challenges using first principles. In the following sections, we discuss those principles and show how a data science and machine learning platform needs to be designed in order to facilitate those goals.
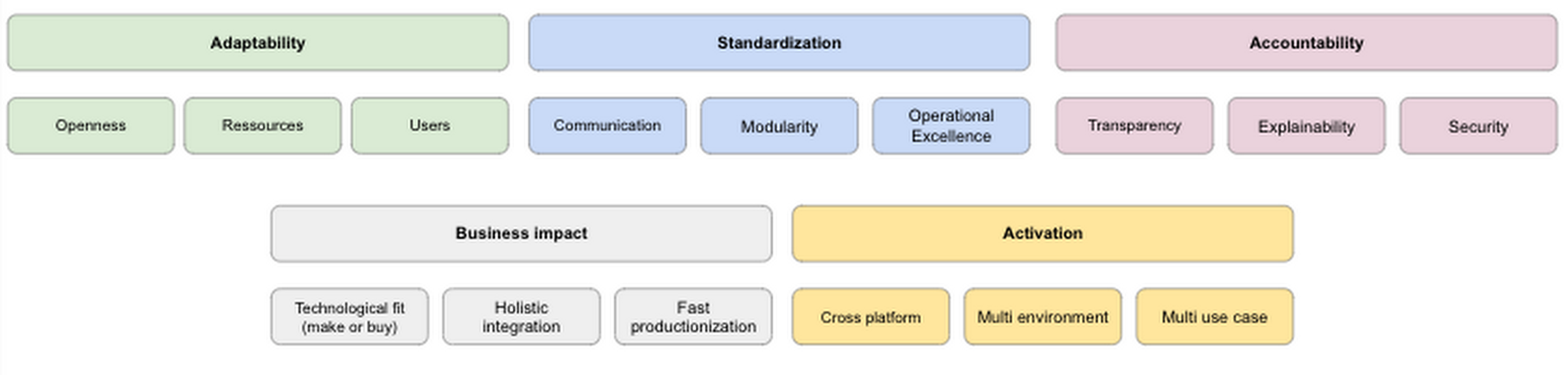
Adaptability: A platform needs to be flexible enough to enable all kinds of personas. While some data scientists/analysts, for example, are more geared toward developing custom models by themselves, others may prefer to use no-code solutions like AutoML or carry out analysis in SQL. This also includes the availability of different machine learning and data science tools like TensorFlow, R, Pytorch, Beam, or Spark. At the same time, the platform should be open enough to work in multi-cloud and on-premises environments while supporting open source technology when possible to prevent lock-in effects. Finally, resources should never become a bottleneck as the platform needs to scale quickly with an organization’s needs.
Activation: Ability to operationalize models by embedding analytics into the tools used by end users is key to achieve scaling in providing services to a broad set of users. The ability to send small batches of data to the service and it returns your predictions in the response allows developers with little data science expertise to use models. In addition, it is important to facilitate seamless deployment and monitoring of edge inferences and automated processes with flexible APIs. This allows you to distribute AI across your private and public cloud infrastructure, on-premises data centers, and edge devices.
Standardization: Having a high degree of standardization helps to increase a platform’s overall efficiency. A platform that supports standardized ways of sharing code and technical artifacts increases internal communication. Such platforms are expected to have built in repositories, feature stores and metadata stores. Furthermore, making those resources queryable and accessible boost teams’ performance and creativity. Only when such kind of communication is possible data science and machine learning teams can work in a modular fashion as it has been for classical software engineering for years. An important aspect of standardisation is enabled by using standard connectors so that you can rapidly connect to a source/target system. Products such as Datastreamand Data Fusion provide such capabilities. On top of it, a high degree of standardization avoids ‘technical debt’ (i.e. glue code) which is still prevalent in the majority of most machine learning and data science workflows.3
Accountability: Data science and machine learning use cases often deal with sensitive topics like fraud detection, medical imaging, or risk calculation. Hence, it’s paramount that a data science and machine learning platform helps to make those workflows as transparent, explainable, and secure as possible. Openness is connected to operational excellence. Collecting and monitoring metadata during all stages of the data science and machine learning workflows is crucial to create a ‘paper trail’ allowing us to ask questions such as:
Which data was used to train the model?
Which hyperparameters were used?
How is the model behaving in production?
Did any form of data drift or model skew occur during the last period?
Furthermore, a data science driven organization needs to have a clear understanding of their models. While this is less of an issue for classical statistical methods, machine learning models, like deep neural networks, are much more opaque. A platform needs to provide simple tools to analyze such models for confident usage. Finally, a mature data science platform needs to provide all the security measures to protect data and artifacts while managing resource usage on a granular level.
Business Impact: many data science projects fail to go beyond pilot or POC stages according to McKinsey.4 Therefore, the ability to anticipate/measure business impact of new efforts, and choosing ROI rather than the latest cool solution is more important. As a result it is key to identify when to buy, build, or customize ML models and connect them together in a unified, integrated stack. For example, if there is an out of the box solution which can be leveraged simply by calling an API rather than building a model after months of development would help realising higher ROI and demonstrating value.
We conclude this part with the summary of the first principles. The next section will show how those principles can be applied on Google Cloud’s unified ML platform, Vertex AI.
Adaptability
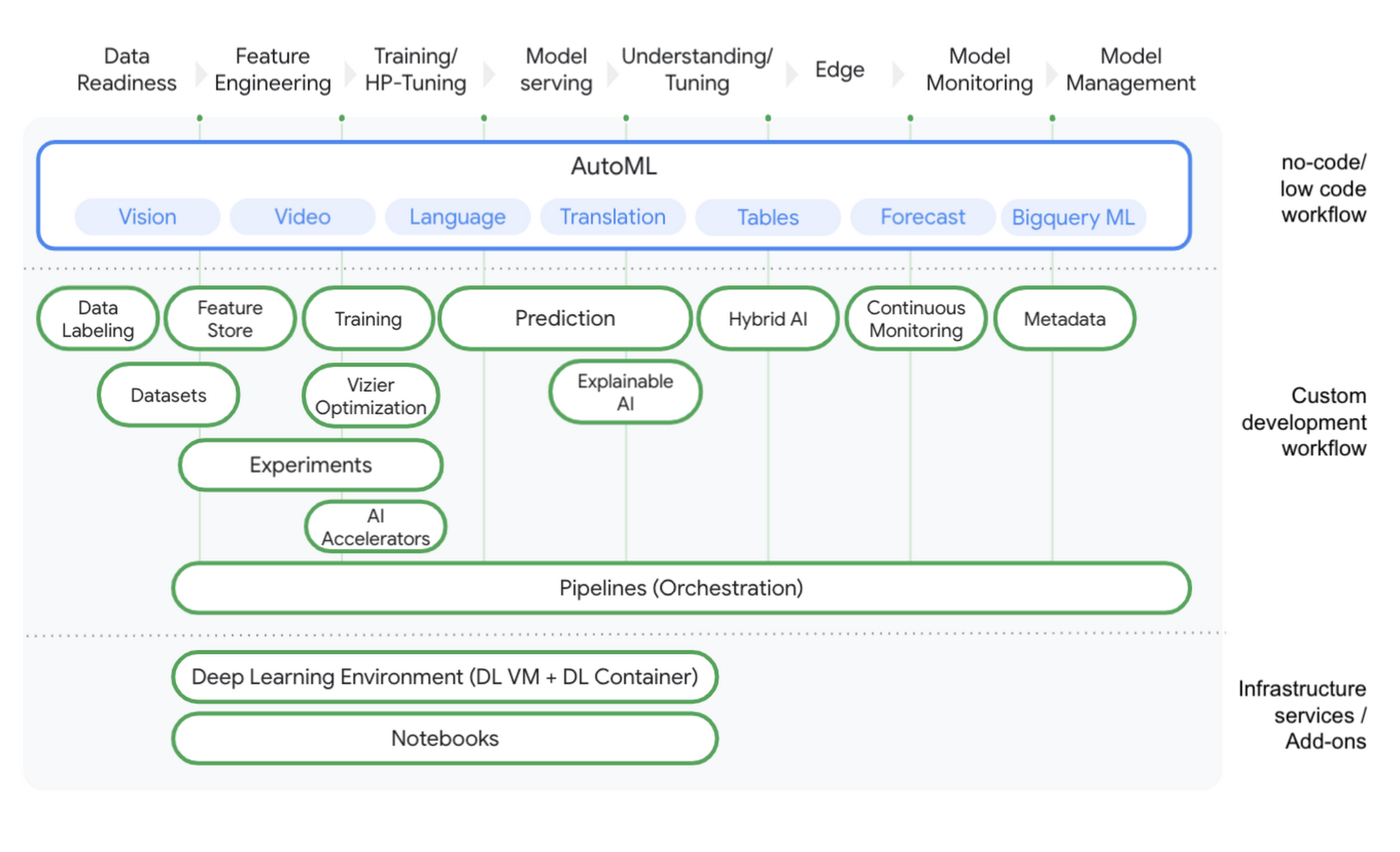
With Vertex AI, we are providing a platform built on the first principles that covers the entire data science / machine learning journey from data readiness to model management. Vertex AI opens up the usage of data science and machine learning by providing no-code, low-code, and custom code procedures for data science and machine learning workflows. For example, if a data scientist would like to build a classification model they can use AutoML Tables to build an end-to-end model within minutes. Alternatively, they can start their own notebook on Vertex AI to develop custom code in their framework of choice (for instance, TensorFlow, Pytorch, R). Reducing the entry barrier to build complete solutions is not only saving developers time but enables a wider range of personas (such as data or business analysts). This reduced barrier helps them to leverage tools enabling the whole organization to become more data science and machine learning driven.
We strongly believe in open source technology as it provides higher flexibility, attracts talent, and reduces lock-in. With Vertex Pipelines, we are echoing the industry standards of the open source world for data science and machine learning workflow orchestration. As a result, allowing data scientists / machine learning engineers to orchestrate their workflows in a containerized fashion. With Vertex AI, we reduced the engineering overhead for resource provisioning and provided a flexible and cost-effective way to scale up and down when needed. Data scientists and machine learning practitioners can, for example, run distributed training and prediction jobs with a few lines of Python code in their notebooks on Vertex AI.
Activation
It is important to operationalize your models by embedding analytics into the tools used by your end users. This allows scaling beyond traditional data science users and bringing other users into data science applications. For example, you can train BigQuery ML models and scale them using Vertex AI predictions. Let’s say business analysts running SQL queries are able to test the ability of the chosen ML models and experiment with what is the most suitable solution. This reduces the time for activation as business impact can be observed sooner. On the other hand, Vertex Edge Manager would let you deploy, manage, and run ML models on edge devices with Vertex AI.
Standardization
With all AI services living under Vertex AI, we standardized data science and machine learning workflows. Together with Vertex Pipelines every component in Vertex can be orchestrated, making any form of glue code obsolete helping to enhance operational excellence. As Vertex Pipelines are based on components (containerized steps), parts of a pipeline can be shared with other teams. For example, let’s assume the scenario where a data scientist has written an ETL pipeline for extracting data from a database. This ETL pipeline is then used to create features for downstream data science and machine learning tasks. Data Scientists can package this component, share it by using GitHub or Cloud Source Repository and make it available for other teams who can seamlessly integrate it in their own workflows. This helps teams to work in a more modular manner and fosters team collaboration across the board. Having such a standardized environment makes it easier for data scientists and machine learning engineers to rotate between teams and avoid compatibility issues between workflows. New components like Vertex Feature Store further improve collaboration by helping to share features across the organization.
Accountability
Data science and machine learning projects are complex, dynamic, and therefore require a high degree of accountability. To achieve this, data science and machine learning projects need to create a ‘paper trail’ that captures the nuances of the whole process. Vertex ML Metadata automatically tracks the metadata of models trained and workflows being run. It provides a metadata store to understand a workflow’s lineage (such as how a model was trained, which data has been used and how the model has been deployed). A new model repository provides you a quick overview of all models trained under the project. Additional services like Vertex Explainable AI help you to understand why a machine learning model made a certain prediction. Further, features like continuous monitoring including the detection of prediction drift and training-serving skew help you to take control of productionized models.
Business Impact: as discussed earlier it is key to identify when to buy, build, or customize ML models and connect them together in a unified, integrated stack. For example, if your company wants to make their services and products more accessible to their global clientele through translation, you could simply use Cloud Translation API if you are translating websites and user comments. That’s exactly what it was trained on and you probably don’t have an internet-sized dataset to train your ML model on. On the other hand, you may choose to build a custom solution on your own. Even though Google Cloud has Vision API that is trained on the same input (photos) and label, your organisation may have a much larger dataset of such images and might give better results for the particular use case. Of course, they can always compare their final model against the off-the-shelf solution to see if they made the right decision. Checking feasibility is important, so when we talk about building models, we always mention quick methods to check that you are making the right decisions.
Building a data science driven organization comes along with several socio-technical challenges. Often an organization’s infrastructure is not flexible enough to react to a fast changing technological landscape. A platform also needs to provide enough standardization to foster communication between teams and establish a technical ‘lingua franca’. Doing so is key to allow modularized workflows between teams and establish operational excellence. In addition, it is often too opaque to securely monitor complex data science and machine learning workflows. We argue that a data science driven organization should be built on a technical platform which is highly adaptable in terms of technological openness. Hence, enabling a wide set of personas and providing technological resources in a flexible and serverless manner. Whether to buy a solution or build a solution is one of the key drivers of realising return of investment for the organisation and this will define the business impact any AI solution would make. At the same time, enabling a broad number of users allows activating more use cases. Finally, a platform needs to provide the tools and resources to make data science and machine learning workflows open, explanatory, and secure in order to provide the maximum form of accountability. Vertex AI is built on those pillars helping you to become a data science driven organization. Visit our Vertex AI page to learn more.
1. Data science is used as an umbrella term for the interplay of big data, analytics and machine learning.
2. The Covid pandemic is a prime example as it has significantly affected our environment and therefore the data on which data-science and machine learning workflows are based.
3. Sculley et al. (2015). Hidden technical debt in machine learning.
4. https://www.mckinsey.com/business-functions/mckinsey-analytics/our-insights/global-survey-the-state-of-ai-in-2020
Read More for the details.
Amazon Comprehend now supports two new AWS Trusted Advisor checks to help customers optimize the cost and security of Amazon Comprehend endpoints.
Read More for the details.
Last year, we announced the general-purpose N2D Compute Engine machine type based on the 2nd Generation AMD EPYC™ processor. Today, we are excited to announce that the N2D family now supports the latest 3rd Generation AMD EPYC processor.
N2D VMs powered by 3rd Generation AMD EPYC processors deliver, on average, over 30% price-performance improvement across a variety of workloads as compared to prior 2nd Generation AMD EPYC processors. If you already use N2D machines, you can use the new hardware simply by selecting “AMD Milan or later” as the CPU platform for your N2D VMs. Further, if you’re using our first-generation N1 VM family, you’ll see a substantial price-performance1 improvement with the new N2D family.
N2D VMs based on 3rd Generation AMD EPYC processors offer a broad set of features and options. N2D supports VMs with up to 224 vCPUs and up to 896 GB of memory, for workloads that require a higher number of threads. Google Cloud offers the highest number of vCPUs per VM across all general-purpose machine types available from a public cloud provider. N2D also includes a wide array of VM shapes (spanning standard, high-CPU and high-memory options) and Custom Machine Types, allowing you to pick custom sizes based on your workload needs.
N2D VMs also support our recently introduced 100 Gbps high-bandwidth network to meet the demands of high-throughput workloads. In addition, N2D also supports high storage performance with persistent disk and up to 9 TB of local SSD. Combining high-throughput VMs with high-performance Local SSD is beneficial for I/O-intensive workloads. N2D is also available as a sole tenant node for workloads that require isolation to meet regulatory requirements or dedicated hardware for licensing requirements.
Customers using N2D VMs powered by 3rd generation AMD EPYC processors get access to the latest features in the AMD EPYC processor family including up to 256 MB of L3 cache and ‘Zen 3’ cores, which provide higher instructions per clock (IPC) compared to ‘Zen 2’. These processors include the same features offered in 2nd generation AMD EPYC processors including PCIe 4 support, high levels of memory bandwidth and access to AMD Infinity Guard for advanced security features. All of this means customers using the latest version of N2D with 3rd generation AMD EPYC can take advantage of its high performance for a variety of general-purpose workloads.
“With exceptional performance and features, our AMD EPYC processors will provide future and existing Google Cloud N2D customers high performance capabilities for a variety of workloads,” said Lynn Comp, corporate vice president, Cloud Business Group, AMD. “This is another exciting extension of our relationship with Google, adding to the existing 2nd Gen EPYC based N2D VMs and the new T2D VMs, and our team is proud to continue to work together with Google Cloud on this.”
Fullstory, a digital experience intelligence platform provider, was an early user of the new N2D VM family.
“At FullStory, we are constantly looking for ways to improve database performance and reduce query latencies, especially as data sizes are always increasing,” said Jaime Yap, Director of Engineering at FullStory. “In our testing with Google Cloud’s latest N2D instances based on the AMD Milan CPU, we were pleased to see some query workloads achieve ~29% performance gains on average when compared to previous generation N2D VMs. We expect this to translate to dramatically improved utilization and better experiences for our customers.”
Vimeo, the world’s leading all-in-one video software solution, tested the new N2D VMs.
“At Vimeo, we have always believed in providing a best in class video quality experience to our users,” said Joe Peled, Director, hosting and delivery operations at Vimeo. “The bulk of our video content is CPU-processed running encoding workloads such as x264 (H.264), x265 (HEVC), and rav1e (AV1) to achieve optimal video fidelity with minimum artifacts. Google Cloud’s new AMD Milan based N2D VMs unlock a major improvement to our users by significantly reducing time spent in our transcoding pipelines on the order of 20%, and allow us to reduce costs by a similar factor.”
Google Kubernetes Engine (GKE) is the leading platform for organizations looking for advanced container orchestration, delivering the highest levels of reliability, security, and scalability. GKE supports N2D nodes based on 3rd Generation AMD EPYC Processors, helping you get the most out of your containerized workloads. You can add nodes based on N2D 3rd Gen EPYC VMs to your GKE clusters by choosing the N2D machine type in your GKE node pools and specifying the minimum CPU platform “AMD Milan”.
We’ve optimized Google Cloud’s unique Andromeda network to support hardware offloads such as zero-copy, TSO, and encryption and are able to offer N2D VMs with 100 Gbps networking out-of-the-box.
N2D VMs will be able to take full advantage of Google Cloud’s high-performance network infrastructure with bandwidth configurations that enable 100 or 50 Gbps speeds for VM shapes with 48 or more vCPUs.
These networking configurations are offered as an add-on feature for N2D VMs and impose no additional inventory constraints on N2D deployments—you’ll be able to upgrade your N2D VMs’ network bandwidth in any zone with N2D availability.
Confidential Computing is an industry-wide effort to protect data in-use including encryption of data in-memory—while it’s being processed. With Confidential Computing, you can run your most sensitive applications and services on N2D VMs.
We’re committed to delivering a portfolio of Confidential Computing VM instances and services such as GKE and Dataproc using the Secure Encrypted Virtualization (SEV) extension. You’ll be pleased to know that we’ll support SEV using this latest generation of AMD EPYC™ processors in the near-term and more advanced capabilities in the future.
N2D VMs are suitable for a wide variety of general-purpose workloads such as web serving, app serving, databases, and enterprise applications. With machine types that include up to 224 vCPUs, N2D machines are ideal for high-throughput workloads that can benefit from having a large number of threads. N2D machines are also ideal for workloads that may benefit from confidential computing features. N2D machines based on 3rd Generation AMD EPYC processors provide significant performance gains over current generation N2D VMs for various benchmarks and general purpose workloads as shown in the graph below.
N2D VMs with 3rd Generation AMD EPYC processors are offered at the same price as the previous generation N2D VMs.
N2D VMs with 3rd Generation AMD EPYC processors are currently in preview in several Google Cloud regions: us-central (Iowa), us-east1 (S. Carolina), europe-west4 (Netherlands), and asia-southeast1 (Singapore) and will be available in other Google Cloud regions globally in the coming months. Please sign-up here and contact your Google Cloud sales representative if you are interested in the Preview.
1. Based on price-performance improvements measured on the new N2D Milan VMs vs. N1 VMs for the following: VP9 Transcode (51%), Nginx (72%), Server side Java throughput under SLA (72%), AES-256 Encryption (273%).
Read More for the details.
Editor’s note: Today’s post is by Ravi Mohan, General Manager, and Diwesh Sahai, Head of Engineering, for MyGate. The India-based company provides software for managing 20,000 residential housing communities throughout the country. MyGate’s contact center, which includes its sales and customer support teams, have adopted Chrome OS devices to improve security and productivity while reducing IT workloads.
MyGate’s community management app simplifies accepting package deliveries, paying maintenance bills, and welcoming guests for those living in gated communities. We are growing across India about 5 percent every month: Our vision is, “Wherever there is a gate, we want MyGate to be there.” Our contact center team of 350 sales and support people help users understand the MyGate technology and troubleshoot issues. MyGate wouldn’t be where it is without this contact center team.
That’s why we adopted Chrome OS devices—we wanted our team to stay productive, even when working remotely. And stay productive they did: We estimate our contact center employees save about 1,500 hours a month combined by using Chrome OS devices, while our IT team saved 1,000 hours of device configuration time.
We operate out of 15 cities in India, so remote collaboration has always been very important, even before the pandemic. As many as a dozen MyGate employees can take part in creating a presentation, for example. And with Acer Chromebooks and Google Workspace, we can work on Google Slides and Google Sheets at the same time, from anywhere.
This kind of collaboration wasn’t really possible before the pandemic. The contact center employees had Windows laptops and Microsoft Office applications. Security became our focus: Employees worked from many different locations, and frequently traveled with laptops that could contain personal information about MyGate users. Security is at the core of the MyGate experience for gated communities, so it would damage our brand if we suffered a data breach.
In 2019, we took the first step toward improved security and productivity by adopting Chrome OS devices, which includes Chromebooks, and Google Workspace as our productivity solution. With Chrome Enterprise Upgrade, our IT team would have the power to create a secure environment for supporting our customers—like locking down lost laptops remotely, or preventing the use of USB drives.
One of our core business values is preserving the confidentiality and privacy of our customers. We have to ensure their data is secure with our employees, wherever they are working from, from whatever network. We have this assurance thanks to the built-in security within Chrome OS. We implemented more than 60 security features using the Google Admin console, including requiring logins only within Chrome browser, and enabling data loss prevention rules to ensure no personal or sensitive information is transferred to personal email addresses that are outside of the organization.
We extend our focus on security to mobile devices through Android Enterprise. We enroll our 2,000 managed devices with the work profile, which creates strict separation of company and personal apps and data on each device. Our employees can securely access our internal and Google Workspace apps in a dedicated space, while keeping their personal data separate.
We started rolling out Chromebooks to the customer support team in late 2019. When the pandemic required all of us to shift to remote work in early 2020, we realized how valuable Chrome Enterprise had become for employees in various regions working remotely. However, security became an even bigger concern for these workers.
We had every intention of maintaining our high levels of service, support, and security, pandemic or not—and Chrome Enterprise was at the heart of our plans. At first, we couldn’t get all the Chromebooks we needed to send home with our sales and support team. So we bought laptops without operating systems installed and added CloudReady, which provides a Chrome OS experience on PCs and Macs. This was an easy way to ensure that sales and support employees all worked with the same tools, and that we could set policies across the board to help them stay safely connected to coworkers.
The jobs of our IT team became much easier with Chrome Enterprise. The beauty of Chrome OS devices is that we can enroll them, ship them anywhere, and when employees open them and log in, they’re ready to start work immediately. The local IT support staff doesn’t have to do any special configuration. By eliminating the five hours of door-to-door shipping and configuration time per laptop, we’ve saved about 1,000 hours of IT time.
The sales and support teams save time too. Chrome OS devices have long battery life, and rarely need troubleshooting by the IT team. We estimate the teams save a total of 1,500 hours every month, which they can put back into answering customer questions. With Chrome tools helping us achieve this level of great service, there’s no doubt we’ll keep growing MyGate.
Read More for the details.
{kind=link}
{kind=link}
{kind=link}