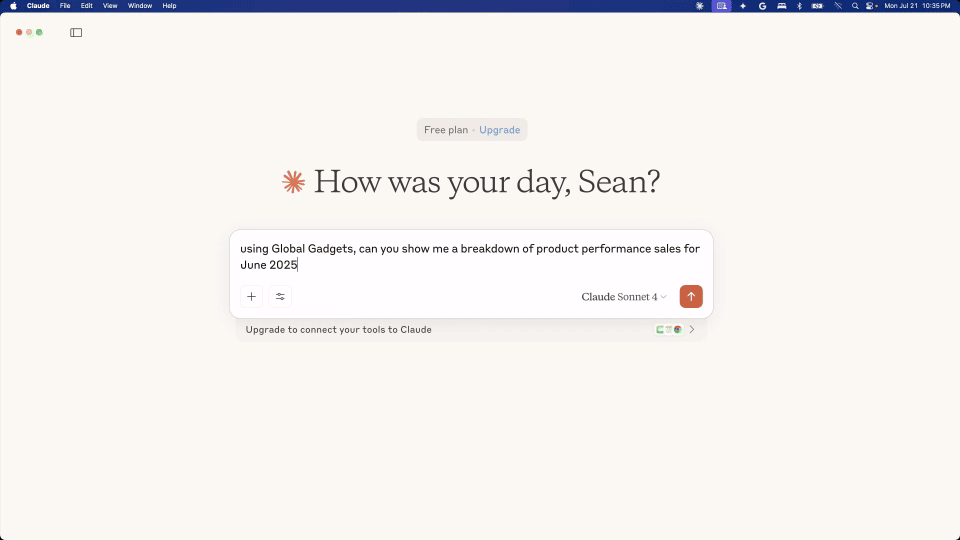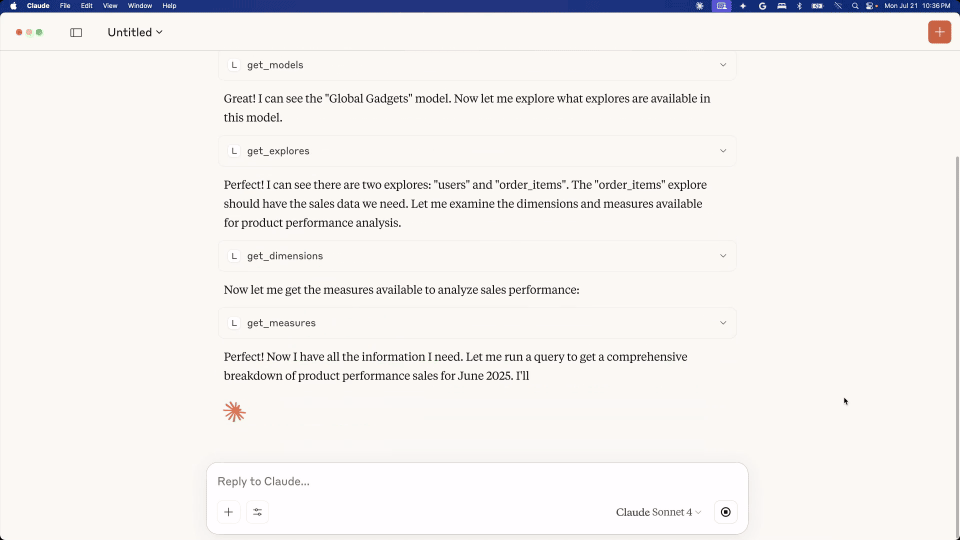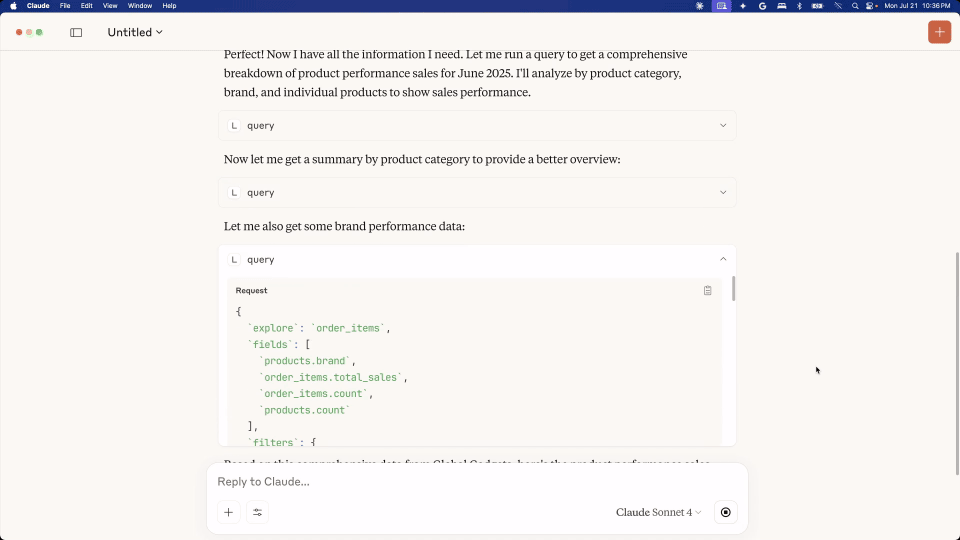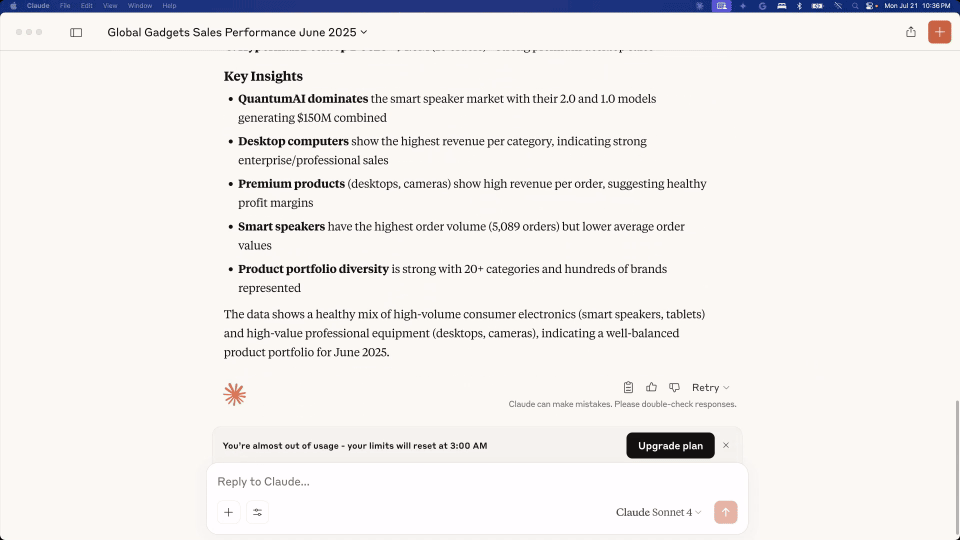
How do we keep getting recognized year over year? In our opinion, and what our customers consistently relay, are three major advantages of working with Google Cloud infrastructure:
- A purpose-built modern cloud, specifically designed for AI-first apps and services.
- Workload-optimized compute, storage, and the most versatile cloud networking that make it easier to migrate and modernize key enterprise workloads — SAP, VMware, Microsoft, Oracle, OpenShift, and even mainframes.
- Leading reliability and security among hyperscalers — customers see Google as an extension of their security team.
But that’s not the full story. What does Google Cloud do behind the scenes to provide these advantages to our customers? Let’s dive into the five principles that Google Cloud lives by as we continue to build and enhance our infrastructure:
1. Run workloads on precisely optimized infrastructure
At Google Cloud, we believe that simply adding more hardware is an unsustainable and ineffective approach to scaling application performance. That’s why we develop strategic, workload-optimized infrastructure technologies. For example, Titanium is a system of hardware and software offloads, boosting performance, reliability, and security and maximizing workload efficiency.
In the past 12-months we also enhanced our Compute Engine platform to drive enterprise transformation with more massive developments:
- Fourth-generation compute instances and Hyperdisk block storage, focusing on optimizing performance and costs across workloads, while delivering enterprise-grade scalability, reliability, security, and workload consistency, ultimately enabling businesses to grow efficiently and invest more in innovation.
- We also developed our own custom Arm®-based CPUs, Google Axion processors, aimed at maximizing performance, reducing infrastructure costs, and supporting sustainability goals for general-purpose workloads.
- Continued enhancements to our fully managed database services, such as AlloyDB for PostgreSQL and Cloud SQL, and easy migration from traditional databases to Google Cloud infrastructure.
2. Build AI-centric infrastructure
Google, like in 2024, is again ranked #1 for AI/ML in the 2025 Gartner Critical Capabilities for Strategic Cloud Platform Services. And we’ve only added to our depth and breadth since then. For evidence of our commitment to AI, there’s AI Hypercomputer, built on Google AI technology developed over the past decade, underpinning nearly every AI workload run on Google Cloud.
This integrated supercomputing system delivers more intelligence at a consistently low price for both training and serving AI workloads. It powers Vertex AI, our managed machine learning (ML) platform, that unifies the entire ML lifecycle—from data preparation to model deployment and monitoring. From an infrastructure perspective, it allows data scientists and developers to focus on building models rather than provisioning and managing the infrastructure required to run them.
Beyond core infrastructure, we’re also dedicated to fostering an open and innovative generative AI partner ecosystem, helping companies rapidly transform their software development, business processes, and information retrieval.
We’ve also released a plethora of new AI products and services, including: A
- Ironwood, announced at Next ‘25, is our 7th generation TPU, built specifically for inference, offering 5x more peak compute capacity and 6x more high-bandwidth memory than its predecessor and achieving a staggering 42.5 exaFLOPS of compute in its larger configuration while being 2x more power efficient.
- Google Cloud Managed Lustre, a fully managed parallel file system built on the DDN EXAScaler Lustre file system, which provides PB scale at under 1ms latency, millions of IOPS, and TB/s of throughput for AI workloads; Rapid Storage, a new Cloud Storage zonal bucket that provides industry-leading <1ms random read and write latency, 20x faster data access, 6 TB/s of throughput, and 5x lower latency for random reads and writes compared to other leading hyperscalers; Anywhere Cache, which provides an SSD-backed zonal read cache for Cloud Storage buckets; Hyperdisk Exapools, entering preview this quarter, providing exabytes of block storage capacity and TB/s of throughput for AI clusters.
- Gemini CLI (Command Line Interface), an open-source AI agent that brings Gemini 2.5 Pro directly into the terminal with unmatched free usage limits (60 model requests per minute, 1,000 requests per day) and integrates with Gemini Code Assist for AI-first coding and problem-solving.
3. Meet the AI moment with containers
With Google Kubernetes Engine (GKE), Google is once again a Leader in the Gartner Magic Quadrant for Container Management this year. And like our advancements elsewhere, we feel it’s only gotten better. Built on years of experience and a deep commitment to Kubernetes, GKE has emerged as the foundation for the next generation of AI workloads. In fact, we use GKE to power our own leading AI services at scale, including Vertex AI, leveraging the same cutting-edge technologies and best practices we share with you.
To continue empowering your AI innovation, we’ve rolled out several impressive new releases:
- GKE Autopilot, with an impressive 30% of active GKE clusters created in 2024 operating in Autopilot mode, showcases its effectiveness in simplifying operations and enhancing resource efficiency for critical workloads.
- Cluster Director, now GA, allows for the deployment and management of massive clusters of accelerators (GPUs and TPUs) as a single, high-performance unit, crucial for demanding AI models and distributed workloads.
- For optimizing AI inference, the new GKE Inference Quickstart and GKE Inference Gateway (both in public preview) simplify model deployment with benchmarked profiles and provide intelligent routing, leading to up to a 30% reduction in serving costs and up to a 60% decrease in tail latency.
4. Empower customers with true sovereignty
At Google Cloud, we believe that digital sovereignty is about more than just compliance; it’s about providing organizations with flexibility, control, choice, and robust security without compromising functionality to enable innovation. We do that by delivering technology capabilities that align with our customers’ diverse needs, backed by extensive engagement with local partners and policymakers.
Our strength in this area comes from our massively scaled global infrastructure, encompassing over 42 cloud regions, 127 zones, and 202 network edge locations, alongside significant subsea cable investments. Two of our most important recent developments here include:
- Forging key partnerships with independent local and regional partners across Asia, Europe, the Middle East, and the United States, such as Schwarz Group, T-Systems, S3NS (with Thales), Minsait, Telecom Italia, and World Wide Technology
- Designing a portfolio of sovereign solutions designed to fit your unique business needs, regulatory requirements, and risk profiles. With three precisely designed solutions, Google Cloud Data Boundary, Google Cloud Dedicated, and Google Cloud Air-Gapped, organizations can choose what you need based on their unique requirements.
5. Deliver a “planet-scale” network
Our strength in networking is built upon over 25 years of Google’s foundational innovations, connecting billions of people globally to essential services like Gmail, YouTube, and Search. This deep expertise has allowed us to build planet-scale network infrastructure that powers Google Cloud and our Cross-Cloud Network solutions. Our vast backbone network features 202 points of presence (PoPs), over 2 million miles of fiber, and 33 subsea cables, all backed by a 99.99% reliability SLA, providing a robust and resilient global platform.
With the rapid emergence of AI, today’s industries are demanding unprecedented network capabilities for training, inference, and serving AI models, including massive capacity, seamless connectivity, and robust security. We’re addressing this with continuous innovation in our cloud networking products and Cross-Cloud Network solutions, enabling customers to easily build and deliver distributed AI applications.
To meet these demanding requirements, we’ve launched a suite of impressive new networking solutions, including:
- Cloud WAN, our new, fully managed, reliable, and secure enterprise backbone designed to transform wide area network (WAN) architectures by leveraging Google’s planet-scale network. It offers up to 40% faster performance compared to the public internet and up to a 40% savings in total cost of ownership (TCO) over customer-managed solutions.
- Cloud Interconnect and the new Cross-Site Interconnect (options in Cloud WAN, currently in preview), make Google Cloud the first major cloud provider to offer transparent Layer 2 connectivity over its network.
- For AI-optimized networking, 400G Cloud Interconnect (4x more bandwidth for massive data ingestion), networking support for up to tens of thousands of GPUs per cluster, and Zero-Trust RDMA security for high-performance GPU/TPU traffic.
Take the next steps on your journey with Google Cloud
From optimizing legacy apps to building next-gen AI and everything in between, Google Cloud lets you tackle your biggest challenges with a platform that works across your data centers, other clouds, and the edge. With decades of experience and a proven track record of reliability, Google Cloud infrastructure is equipped to handle your most visionary workloads and is the ideal partner to drive your business transformation.
You can download a complimentary copy of the 2025 Magic Quadrant for Strategic Cloud Platform Services on our website.
for the details.