Azure – General availability: UI Library for Azure Communication Services
Developers can simplify the cross-channel user experiences within their applications with Azure Communication Services UI Library.
Read More for the details.

Developers can simplify the cross-channel user experiences within their applications with Azure Communication Services UI Library.
Read More for the details.
A new, simple, and flexible offer for Azure Stack HCI customers to acquire Windows Server guest licensing now for $0 while in public preview.
Read More for the details.
General availability enhancements and updates released for Azure SQL for December 2021.
Read More for the details.
Over the past year, serverless application development has seen tremendous interest. The number of opportunities that show up on job boards showcase how critical this skill has become. It’s not surprising that at Google, we have seen the use of Serverless products increase by 4X over the past year. Particularly, as developers have moved away from monolithic, slow-moving applications toward more distributed, event-based, serverless applications. Infact, more and more companies are looking for candidates experienced in Google Cloud serverless tools thanks to its ease of use, portability, and security benefits.
Software, like cooking, is best learned by getting your hands dirty. And what better way to learn these skills in demand than by building something new. This is precisely why we are launching “Easy as Pie Serverless Hackathon”. It is a perfect opportunity for you to kick the tires and work closely with the Google team to gain serverless skills in action. Not just that, there are three challenges to choose from, with $20,000 USD in cash prizes divided among the top submissions. Submissions are evaluated on their technical execution, completeness, and return on investment.
In addition to cash prizes, you will be the first to access new products like Cloud Functions (2nd gen). Cloud Functions (2nd gen) comes with new capabilities, such as concurrency (up to 1,000 concurrent requests per function instance), larger instances (816 GB memory and 24 vCPUs), longer processing time (up to 60 mins), minimum instances (prewarmed instances), and more.
During the hackathon, you can combine Cloud Functions (2nd gen) or other serverless products with the rest of the Google Cloud platform and bring your ideas to life. For example, you could add sentiment analysis to your existing applications with our artificial intelligence APIs, or build powerful visualizations by connecting to our data analytics or machine learning APIs. As you build these applications, our developer tools will be with you along the way. You can use our Client Libraries to connect to our APIs with minimal code, deploy using our Cloud SDK CLI, or edit your code through the Cloud Code in-browser IDE.
Please submit projects by February 4, 2022. To qualify, your project must use one Google Cloud serverless product, which includes Cloud Run, Cloud Functions, or Workflows and your project must deploy and run. Please submit a 3 to 5 minute video and a slide presentation detailing your use case. If you need help, you can tune in to workshops led by Google Cloud Product Managers and Engineers or complete our quickstarts at your own pace.
We’re excited to see what you build. We think you’ll be pleasantly surprised at how rapidly you will be able to build scalable production quality software at lightning speed with Google Cloud. Check out the hackathon website to enter and find additional contest details.
Read More for the details.
To help our customers on their path to success with Google Cloud, we published the Google Cloud Architecture Framework – a set of canonical best practices for building and operating workloads that are secure, efficient, resilient, high performing, and cost effective.
Today, we’re diving deeper into the Architecture Framework System Design pillar, including the four key principles of system design and recent improvements to our documentation. We’ll also expand on the new space of the Google Cloud Community dedicated to the Architecture Framework, which was created to help you achieve your goals with a global community of supportive and knowledgeable peers, Googlers, and product experts.
The System Design Pillar is the foundational pillar of the Architecture Framework, which includes Google Cloud products, features, and design principles to help you define the architecture, components, and data you need to satisfy your business and system requirements.
The System Design concepts and recommendations can be further applied across the other five pillars of the Architecture Framework: Operational Excellence, Security, Privacy, and Compliance, Reliability, Cost Optimization, and Performance Optimization.
You can evaluate the current state of your architecture against the guidance provided in the System Design Pillar to identify potential gaps or areas for improvement.
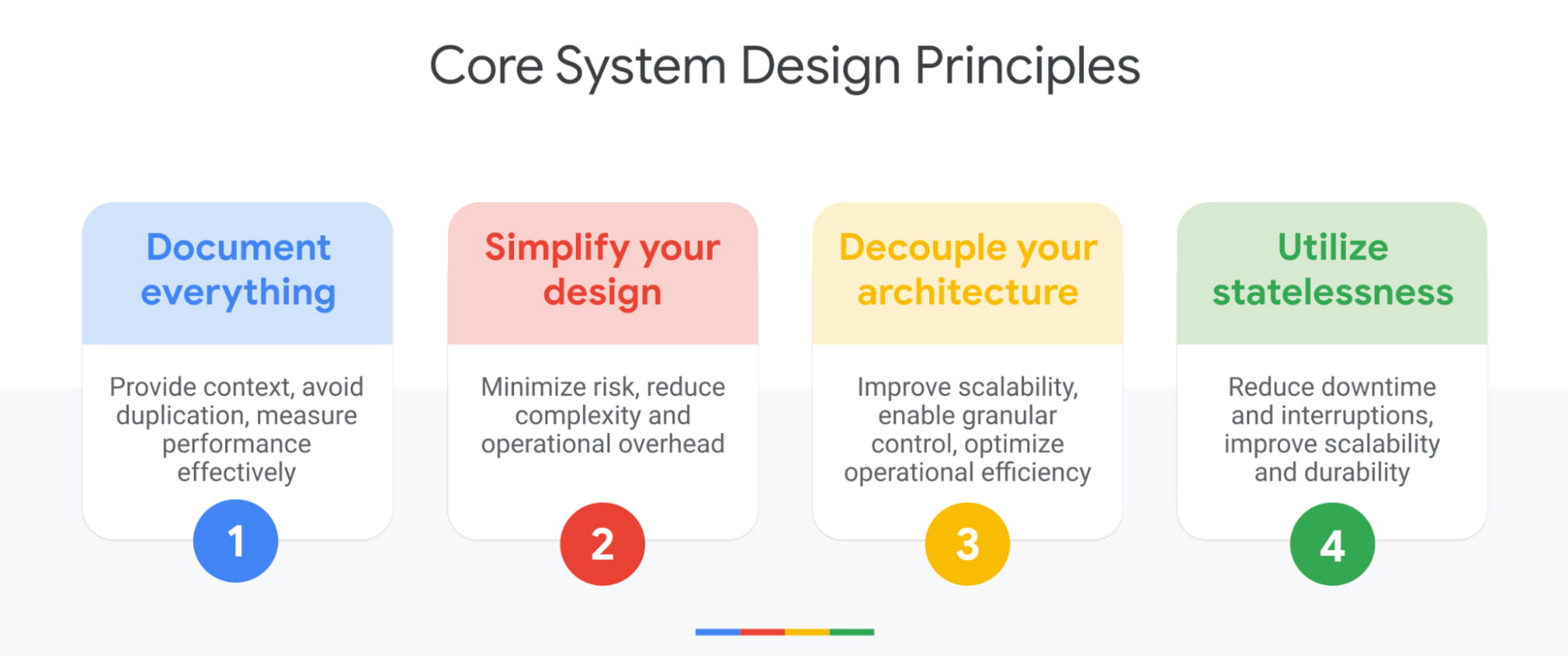
A robust system design is secure, reliable, scalable, and independent, enabling you to apply changes atomically, minimize potential risks, and improve operational efficiency. To achieve a robust system design, we recommend you follow four core principles:
When customers are either looking to move to the cloud or starting to build their applications, one of the major success blockers we see is the lack of documentation. This is especially true when it comes to correctly visualizing current architecture deployments.
A properly documented cloud architecture helps establish a common language and standards, enabling your cross-functional teams to communicate and collaborate effectively. It also provides the information needed to identify and guide future design decisions that power your use cases.
Over time, your design decisions will grow and change, and the change history provides the context your teams need to align initiatives, avoid duplication, and measure performance changes effectively over time. Change logs are particularly invaluable when you’re onboarding a new cloud architect, who is not yet familiar with your current system design, strategy, or history.
When it comes to system design, simplicity is key. If your architecture is too complex to understand, your developers and operations teams can face complications during implementation or ongoing management. Wherever possible, we highly recommend using fully managed services to minimize the risk of managing and maintaining baseline systems, as well as the time and effort required by your teams.
If you’re already running your workloads in production, testing managed service offerings can help simplify operational complexities. If you’re starting new, start simple, establish an MVP, and resist the urge to over-engineer. You can identify corner use cases, iterate, and improve your systems incrementally over time.
Decoupling is a technique used to separate your applications and service components – such as a monolithic application stack – into smaller components that can operate independently. A decoupled architecture therefore, can run its function(s) independently, irrespective of its various dependencies.
With a decoupled architecture, you have increased flexibility to apply independent upgrades, enforce specific security controls, establish reliability goals, monitor health, and control granular performance and cost parameters.
You can start decoupling early in your design phase or incorporate it as part of your system upgrades as you scale.
In order to perform a task, stateful applications rely on various dependencies, such as locally-cached data, and often require additional mechanisms to capture progress and sustain restarts.
On the other hand, stateless applications can perform tasks without significant local dependencies by utilizing shared storage or cached services. This enables your applications to quickly scale up with minimum boot dependencies, thereby withstanding hard restarts, reducing downtime, and maximizing service performance for end users.
The System Design Pillar describes recommendations to make your applications stateless or to utilize cloud-native features to improve capturing machine state for your stateful applications.
The core System Design principles can be applied across the other five pillars of the Architecture Framework, including Operational Excellence, Security, Reliability, Cost, and Performance Optimization. Here are a few examples of how this looks in practice.
Use fully managed and highly-available operational tools to deploy and monitor your workloads, so you can minimize the operational overhead of maintaining and optimizing them.
Apply security controls at the component level. By decoupling and isolating components, you can apply fine-grained governance controls to effectively manage compliance and minimize the blast radius of potential security vulnerabilities.
Design for high availability and scalability. A decoupled architecture enables you to define and control granular reliability goals, so you can maximize the durability, scalability, and availability of your critical services, while optimizing non-critical components on-the-go.
Define budgets and design for cost efficiency. Cost usually becomes a significant factor as you define reliability goals, so it’s important to consider various cost metrics early on when you’re designing your applications. A decoupled architecture will help you enforce granular cost budgets and controls, thereby improving operational efficiency and cost optimization.
Optimize your design for speed and performance. As you design your service availability within your cost budget, ensure you also consider performance metrics. Various operational tools will provide insights to view performance bottlenecks and highlight opportunities to improve performance efficiency.
These are just a few examples, but you can see how the System Design principles can be expanded into various other use cases across the other five pillars of the Architecture Framework.
The Google Cloud Community is an innovative, trusted, and vibrant hub for Google Cloud users to ask questions and find answers, engage and build meaningful connections, share ideas and have an impact on product roadmaps, as well as learn new skills and develop expertise.
Today, we’re announcing the launch of a new space in the Google Cloud Community dedicated to the Architecture Framework. In this space, you can:
Access canonical articles that provide practical guidance and address specific questions and challenges related to the System Design pillar. We’ll be releasing articles focused on the remaining five pillars in the coming months.
Engage in open discussion forums where members can ask questions and receive answers.
Participate in Community events, such as our “Ask Me Anything” series, where we’ll host a virtual webinar on a specific topic of the Architecture Framework and open it up for questions from the audience.
Together, the Google Cloud Community and Architecture Framework provide a trusted space for you to achieve your goals alongside a global community of supportive and knowledgeable peers, Googlers, and product experts.
Explore the new space of the Community today and if you haven’t already, sign up to become a member so you can take full advantage of all the opportunities available.
Earlier this year, we released an updated version (2.0) of the Architecture Framework, and we’ve been continuing to enhance our catalog of best practices based on feedback from our global partner and customer base, as well as our team of Google product experts.
Here’s what’s new in the System Design Pillar:
Resource labels and tags best practices were added to simplify resource management.
The compute section is now reorganized to focus on choosing, designing, operating, and scaling compute workloads.
The database section is reorganized into topics like selection, migration, and operating database workloads, and highlights best practices around workflow management.
The data analytics section now includes sections on data lifecycle, data processing, and transformation.
A new section on artificial intelligence (AI) and machine learning (ML) that covers best practices for deploying and managing ML workloads.
As always, we welcome your feedback so we can continue to improve and support you on your path to success with Google Cloud.
Special note and thank you to Andrew Biernat, Willie Turney, Lauren van der Vaart, Michelle Lynn, and Shylaja Nukala, for helping host the Architecture Framework on the Google Cloud Community site. And Minh “MC” Chung, Rachel Tsao, Sam Moss, Nitin Vashishtha, Pritesh Jani, Ravi Bhatt, Olivia Zhang, Zach Seils, Hamsa Buvaraghan, Maridi Makaraju, Gargi Singh, and Nahuel Lofeudo for helping make System Design content a success!
Read More for the details.
Our previous article provided tools and techniques to transform your productionalization process and make it ready for Cloud workloads. In this post, we will cover technical examples of GCP controls and how it can help your organization maintain your security and compliance posture in GCP.
In comparison to on-prem infrastructure, GCP is a highly integrated environment and provides out of the box capabilities to evidence a large variety of controls. The following cornerstones build the foundation of an effective control attestation:
Inventory Management – On-prem workloads frequently have discovery tools installed to understand what infrastructure components are actually deployed in the corporate IT environment. In GCP, every component has to be explicitly declared for it to exist. This accurate and real-time inventory is the basis for the below case studies to reach continuous compliance.
Infrastructure as Code – All deployments and configuration in GCP should be implemented in machine readable instructions (such as Terraform) and as part of a CI/CD pipeline staging to higher level environments. The programmatic definition of infrastructure resources allows for efficient checking of the security posture before the deployment takes place (such as a misconfigured Google Cloud Storage bucket that would be exposed to the public Internet).
Compliance as Code – The same is true for the implementation of policies. Programmatic definition, “Compliance as Code” should be used to automate the evidence-gathering and compliance-checking during the lifetime of the workload. Google Cloud’ Risk and Compliance as Code solution can help implement such a process based on best practices.
Now let’s take a few controls out from the Cloud Security Alliance Cloud Controls Matrix (CSA CCM) and show how GCP helps you to fulfill them.
Let’s have a look at a specific control from CSA CCM regarding log key lifecycle management:
LOG-11 – Logging & Monitoring Transaction/Activity Logging – Log and monitor key lifecycle management events to enable auditing and reporting on usage of cryptographic keys.
Cloud Key Management Service (KMS) in combination with Cloud Audit Logs records customer activities on the Key object, such as creating or destroying a key. Customers can define the retention period of the logs as well as access permissions. A log message would look like the following:
Figure 1 – Logging of key creation
In order to actively monitor these activities, a counter log-based metric in Operations Suite has to be created for protoPayload.methodName=”CreateCryptoKey” . This log-based metric can then be used to create an alarm for each event, or trigger a notification for when a certain threshold is reached. Cloud Monitoring will display an incident notification and have visualizations ready to be inspected.
In the traditional IT world, production roll-outs are often staged through the environments guarded by a strict change management process and subject to change approval boards. In the cloud world, equivalent checks should take place but can be accomplished end-to-end much more quickly. As mentioned above, there should be limited human interaction in the production environment. All application and infrastructure deployments should be following the infrastructure as code pattern and leverage automation technologies. Repeatable automated patterns will simplify operations and enable compliance verification at scale. Let’s look at the following example out of the CSA CCM control set:
CCC-09 Change Control & Configuration Management – Change Restoration – Define and implement a process to proactively roll back changes to a previous known good state in case of errors or security concerns.
By describing the state of the infrastructure configuration in Terraform, each change can easily be rolled-out and rolled-back without missing out a step or having a non-reversible change. The control owners have assurance that the changes are automated and fully reversible to a known working state.
As a best practice, we recommend storing the Infrastructure as Code patterns along the application project source code in the version control system, and staging it through the environments by leveraging a CI/CD pipeline.
Extensive logging capabilities of GCP such as Cloud Audit Logs and Access Transparency take a record of activities happening in the environment. Especially in regulated industries, these logs have to be kept for an extended period while ensuring their immutability and integrity. This requirement is reflected in the following CSA CCM:
IAM-12 Identity & Access Management – Safeguard Logs Integrity – Define, implement and evaluate processes, procedures and technical measures to ensure the logging infrastructure is read-only for all with write access, including privileged access roles, and that the ability to disable it is controlled through a procedure that ensures the segregation of duties and break glass procedures.
Leveraging GCP Log Sinks, log entries can be exported into different supported destinations, including Google Cloud Storage. Log entries will be stored as JSON files on a GCS bucket. GCS buckets support data retention policies, which govern how long objects in the bucket must be retained. The “Bucket Lock” feature lets you set a permanent non-reversible configuration of the data retention policy on the corresponding GCS bucket.
Example Terraform for locking a bucket and keeping the files for 2 days:
Figure 2 – Bucket Locking mechanism
The Bucket Lock is a non-reversible activity. As outlined in the above example, files stored within that GCS bucket will be retained for the defined period, including roles with privileged access.
Figure 3 – Bucket Locking effects
Automation has been a key driver for accelerating transformation at Deutsche Bank:
The integrated environment of GCP provides foundational capabilities (such as real-time inventory) that can significantly reduce the burden for control owners as they work to establish and maintain their security and compliance posture. The case studies give examples as to how GCP customers can move into continuous compliance, encompassing real-time attestation and notification (something which could occur in case of a misconfiguration, for example). The more familiar control owners become with the GCP capabilities the more confident they feel to automate their controls.
Building on the control automation examples we covered, potential next steps could be embedding the controls into policies within GKE Policy Controller, and GKE Config Connector seamlessly logging into Cloud Operations Suite, as well as Security Command Center. Read more about this topic as part of our recently released solution Modernizing Compliance: Introducing Risk and Compliance as Code.
Read More for the details.
Sure, Google Cloud offers world-class infrastructure, but one of the main reasons that customers choose our platform is to run their applications on one of our managed container platforms: Google Kubernetes Engine (GKE), the most scalable and easy to use service from the company that invented Kubernetes; Anthos for managing containers in hybrid and multicloud scenarios; and Cloud Run, our serverless platform for containerized workloads.
We made a lot of updates to these services in 2021 — here are the ones that resonated the most with you, our readers, in order of pageviews.
Kubernetes users want the flexibility to customize their containerized workloads, without the need to manage a plethora of configurations. Enter GKE Autopilot, a new mode of operation for GKE that provides a managed control and data plane, an optimized configuration out-of-the-box, automated scalability, health checks and repairs, and pay-for-use pricing. Introduced in February 2021, this was by far our most read blog in this category. Read the full post.
Want the goodness of an industry-leading managed Kubernetes platform, but want to run it on managed hardware outside of the cloud? With Google Distributed Cloud, we’ve got you covered, with a combination of hardware and software that extends our infrastructure to the edge and into your data centers. Designed to support telecommunications applications as well as applications with strict data security and privacy requirements, the Google Distributed Cloud announcement was the most-read product blog coming from Google Cloud Next in October. Read the full post.
A major area of focus for the Cloud Run team this year was to expand the kinds of applications that you can run on the platform. We started the year out with a bang, adding support for applications like social feeds, collaborative editing, and multiplayer games that rely on full bidirectional streaming capabilities. (This news came on the heels of another big Cloud Run feature announcement: support for minimum instances, to help minimize cold starts for latency-sensitive apps.) Read the full post.
Why do we say that GKE is the best managed Kubernetes service? Improvements like this. Image streaming is no incremental feature — the performance improvements it brings to application scale-up time is unique in the industry, and just might change how you think about what you can do with GKE. Read the full post.
A recent addition to Kubernetes blog canon, this blog recaps a series of conversations between Google Cloud Developer Advocate, Stephanie Wong, and Google Fellow, Eric Brewer about the history of Kubernetes and Brewer’s role in the creation thereof. In addition to the Kubernetes origin story, Brewer talks about the need for securing the software supply chain, offers advice to platform operators, and where he sees Kubernetes going next. Read the full post.
Speaking of game-changing features, the release of GKE multi-cluster services established GKE as the service to use if you’re building applications that need to be deployed across cluster boundaries. Read the full post.
Remember how we talked about expanding the scope for Cloud Run? This powerful feature allows you to deploy more types of applications to Cloud Run by allocating CPU for the entire lifetime of container instances at a lower price — important for applications that need to do background processing outside of request processing. Read the full post.
Of course, security is a must-have for any platform on which you run mission-critical applications, and Cloud Run is no exception. In this blog post, readers learned about features to help integrate your Cloud Run deployment into existing security processes, and to ensure the build provenance of their code. Read the full post.
Containers are the future, but virtual machines are still a very important part of the present. Wouldn’t it be great if you could manage your VMs and containers the same modern way? We announced the upcoming Anthos for VMs product that does just that. This is a huge accelerator for those embracing cloud native ops! Read the full post.
Kubernetes networking is a work in progress — an effort that Google is actively involved in. In 2020, Google and other community members open-sourced the Kubernetes Gateway API as an evolution of Ingress and service mesh APIs, and in 2021, we released our implementation of Gateway, which provides global, multi-cluster, multi-tenant load balancing for GKE. Read the full post.
Of course, these 10 posts represent just a small sliver of the work we did to improve our managed compute services in 2021. And stay tuned for 2022, when we’ll have lots more to share about how you can use Google Cloud compute services to transform how you run your applications.
Read More for the details.
Today, AWS announced the opening of two new Direct Connect locations in Jakarta, Indonesia. AWS customers in Indonesia can now establish dedicated network connections from their Indonesia premises to AWS to gain high-performance, secure access to other AWS Region (except Regions in China). With the announcement of Direct Connect locations in Indonesia, the Direct Connect Management Console and related documentation for Direct Connect have been localized to support the Bahasa language for Indonesia customers.
Read More for the details.
For many of those building in the cloud, speed and security of deployments are amongst their top priorities. At times these goals can seem at odds with each other, especially if security guidance is distributed, written more as reference than opinion, and lacking in tooling for actual implementation in your environment. But they don’t have to be. In fact, these are some challenges the security foundations blueprint was created to address. We recently started diving into the blueprint here on the blog to introduce what it is and who it is for, outline some best practices it recommends for creating and maintaining a security-centric infrastructure, and demonstrate how to get started with the automation repo that turns these best practices into deployable Terraform modules.
In today’s post, we’re highlighting the direct experiences of Google Cloud users as they adapt, adopt, and deploy the security foundations blueprint in their cloud environments. These organizations, of all sizes and across industries, reported valuable impact to their development teams and their business. As we worked with them and listened, top themes emerged across the board in how the security foundations blueprint brings value:
It helps educate brand new users on Google Cloud security capabilities and best practices.
It collects foundational security decisions together into a single resource, and provides a Google opinionated reference template.
It provides an automated deployable example that speeds up their secured deployments and secured operations.
It enables partners to build subject matter-specific solutions on top of a secured foundation.
Let’s take a look at each of these qualities more closely.
Moving workloads to the Cloud opens a number of opportunities to modernize and improve, and among them is strengthening your infrastructure’s security posture. If you are accustomed to administering security in an on-prem environment, however, transitioning to Google Cloud does require familiarizing yourself with a new set of infrastructure primitives (the building blocks available to you), control abstractions (how you administer security policy), and the shared fate model between you and Google Cloud.
The security foundations blueprint guide brings these topics together into a comprehensive resource to help educate new users on Google Cloud’s security capabilities. It covers your network, your resource hierarchy, how you provide access, and a whole lot more (which you can read about in our recent blog post). It is a reference document for customers to use when designing architecture and establishing policies and guides that support a more secure environment. For those customers that have already established their security strategy, the blueprint can be used to validate and adjust their existing architecture to align with best practices we’ve established for Google Cloud security.
Once you are familiar with the products and options available for securing your deployment, it’s time to translate that knowledge into a security strategy. However, this can be a challenging process as you try to navigate the large, complex web of interdependent decisions you need to make.
Pause right there, because the security foundations blueprint does this heavy lifting for you. As designed, it provides a tested path through these decisions that ensures they are integrated to hit a strong security posture. In other words, it is written as opinionated best practices for securely deploying workloads on Google Cloud. And it’s written by the platform-maker itself with a deep understanding of the product configuration for today and tomorrow.
By following the best practices provided by the blueprint, you will be laying a foundation that supports a strong security posture. It provides both background considerations and discussions of the tradeoffs and motivations for each of the decisions, so that you can assess the risks and customize it to your own needs. In fact, the blueprint is designed for flexibility so that it can be used in its entirety as it is written, or as a starting point for designing your architecture and security policies. The blueprint is also regularly updated to incorporate practitioner feedback, product updates and additional threat models, so your security strategy can stay up-to-date as well.
Time to market is one of the universal goals in any project implementation, including your cloud deployments. Manual settings and scripting for configuration and policy setting of your deployment’s IAM, firewalls, logging, and backups, can create complexity and reduce repeatability, slowing down development velocity.
By adopting the security foundations blueprint, code is pre-written and tested for you, having been translated from best practices into Terraform modules. Additionally, operational tasks are automated into the deployment process itself, allowing you to increase the speed of your deployments. You can also manage and track changes increasing the ability to govern the state of your infrastructure. Speeding up deployments without compromising on security is the number one benefit we consistently hear as a result of adopting the blueprint and underlying Terraform modules.
Beyond foundational security, customers and partners may have more specific use cases and requirements they need to meet based on industry, geography, or regulatory constraints unique to their business. Approaching each case as a completely new and fresh build can be challenging to scale. In addition, both customers and partners hold valuable knowledge from their own experience and expertise which they apply in building their solutions.
Having a Google Cloud curated starting point for foundational security enables customers and partners to focus on the key differences and enhancements needed for each specific use case, and to build on top of this foundation. This accelerates the process, as it removes the requirement to reimplement the basic controls and policies. Also, the Google Cloud curated reference enables both customers and partners to more easily understand and align their security approaches to the Google Cloud best practices. The security foundations blueprint provides this consistent and foundational starting point so that all users and consumers can start from the same perspective.
Whether you are onboarding to Google Cloud for the first time, designing your architecture and security policies, or validating and evolving your existing architecture decisions and policies, the security foundations blueprint is a useful tool for making your deployments more secure (and speedy!).
If you haven’t already, be sure to read the first three posts in this series which introduce the security foundations blueprint, outline the topics it addresses, and give tips for getting started with the Terraform modules. If you want to head straight to the blueprint itself, remember it is made up of both the step-by-step guide and the Terraform automation repo.
Thanks for joining us on this deep dive into the security foundations blueprint! Go forth, deploy and stay safe out there.
Read More for the details.
New regional availability of Azure HPC Cache expands access to low-latency compute.
Read More for the details.
The new release includes Slurm and VMSS improvements as well as seven new bug fixes.
Read More for the details.
In this blog post I describe the ‘Edge’ profile for Anthos on bare metal. I compare this new option against the default profile. I also introduced the recently published “Rolling out clusters on the edge at scale with Anthos on bare metal” guide that walks you through the steps to install Anthos on bare metal on the edge and manage it via a centralized configuration repository using Anthos Config Management.
With today’s rapidly changing digital-first landscape, companies face complex and diverse challenges which necessitate diverse services and technologies. That diversity includes workloads at the edge; positioned close to where requests for their services originate from, and responses are delivered. Such workloads run on resource constrained environments, despite being critical to the success of the business. Thus, we want to extend the operational agility provided by Google Cloud to these critical, resource constrained use cases at the edge.
For example, businesses in the Retail sector have stores spread across multiple locations – nationally and internationally. Services specific to the day to day operations of these stores – point of sale, inventory management, item locator, employee check-in, etc. – operate in stores (the edge), closer to where the services are provided. They operate on hardware with resource limits that are different to what’s found in data centers. The in store execution environment is limited to host only what is essential. However, it is critical that these workloads can be managed with the same consistency and agility with which the other applications are maintained. Thus, we want Google Cloud to provide the single pane of management and maintenance to the entire spectrum of workloads that our customers deal with – be it in the cloud, on-prem or at the edge.
Whilst, Anthos addresses the requirement for providing centralized management with increased flexibility and developer agility, different flavors of Anthos, like Anthos on bare metal, lets you bring the benefits of Anthos closer to where your workloads live. With Anthos on Bare Metal, you can bring operational consistency to your bare metal (including edge) workloads. Built on the foundation of Google Kubernetes Engine (GKE), Anthos provides you with the features to have a consolidated approach to managing any type of workload. Thus, the newly introduced edge-profile for Anthos on Bare Metal extends the potential of Anthos to edge workloads.
Anthos Config Management with Policy Controller: Create and enforce consistent configurations and policies across workloads running in different edge locations.
Anthos Fleets: Logically group similar workloads to simplify administering and enforcing consistency across various edge locations.
Anthos Service Mesh: Centrally monitor and manage service-to-service traffic between intra-store and inter-store service communication. Gather useful network telemetry across all edge locations.
Anthos VM Runtime: Manage VM based workloads via the same control plane in Anthos that is used to manage container workloads.
Anthos on bare metal has introduced an edge profile starting from version 1.8. The edge profile minimizes system resource requirements and is recommended for edge devices with significant resources constraints. The edge profile is available only for standalone clusters. Standalone clusters are self-managing clusters that run workloads. They do not manage other clusters, eliminating the need for running a separate admin cluster in resource-constrained scenarios. The edge profile provides minimal vCPU and RAM resource requirements, excluding any user workload. The Anthos on bare metal edge profile offers:
A 75% reduction in CPU requirements to 1 Node x 2 vCPUs from 2 Nodes x 4 vCPUs.
A 90% reduction in memory requirements to 1 Node x 4 GB from 2 Nodes x 32 GB for Ubuntu.
The reduced footprint for the edge-profile means that you can get started with onboarding your edge workloads into Anthos immediately. You can install Anthos on Bare Metal in your low resourced, existing hardware in your edge locations. You can also install it on off the shelf compute nodes – like the IntelNUCs – and have all your edge locations fully functional with central management within hours.
For details, see the Edge profile for standalone clusters.
In the “Rolling out clusters on the edge at scale with Anthos on bare metal” guide we take you through an example edge deployment. The example is chosen from the retail sector which falls under the “Consumer Edge” category of the Edge Continuum as defined by the Linux Foundation. Through this guide we show you how to install Anthos on bare metal with edge profile enabled on the edge.
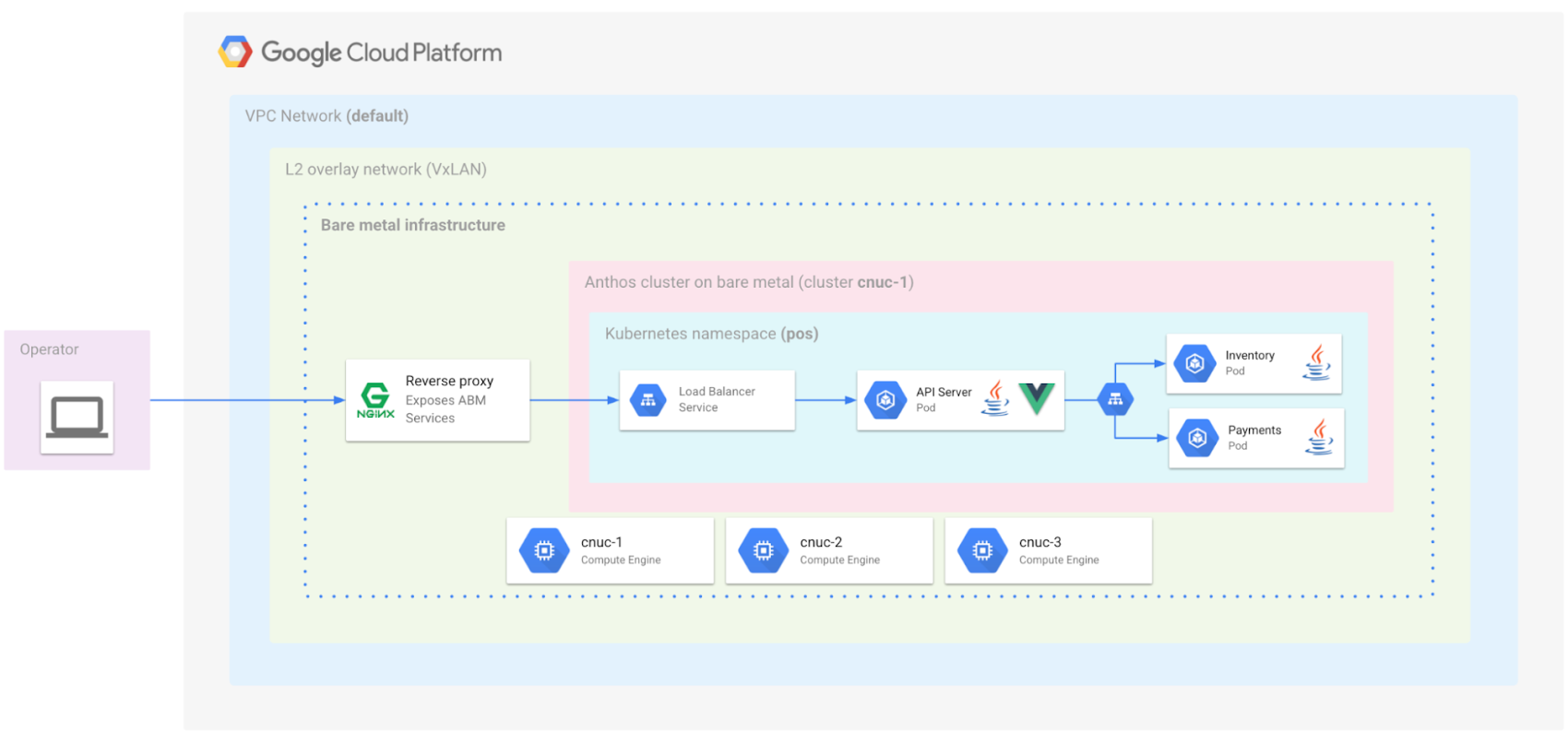
The following diagram shows the architecture of the edge deployment used in the guide. The architecture simulates a retail store environment with a Point of Sale kiosk. Anthos on bare metal is installed in three nodes located at the retail store edge for High Availability. The installation here uses the standalone mode of Anthos on bare metal with the edge profile enabled. The Anthos clusters also have Anthos Config Management (ACM) installed. Thus, the clusters running on the edge can be configured and managed via a central git based root repository.
In order for you to replicate this edge deployment and experiment with it, we show you the steps to emulate the edge nodes and the retail store infrastructure using Google Compute Engine (GCE) VMs. The guide provides Ansible scripts that create the necessary setup in your Google Cloud Project. The three edge nodes are mapped to GCE VMs. A VxLAN overlay network is created on top of the Google Cloud VPC, to allow layer-2 connectivity between the VMs. We also use a nginx reverse proxy on one of the VMs to do what the retail store network switch does – allowing connectivity into the Anthos on bare metal clusters from the Point of Sale kiosk. Your own browser will act as the Point of Sale kiosk device in this setup.
For this guide we have also implemented a sample Point of Sale application which you will be able to interact with at the end of the tutorial. The following diagram shows the architecture of the Point of Sale application along with its deployment in an Anthos on bare metal cluster on GCE VMs.
The guide also shows you how to log into the edge cluster via your Google Cloud Console and monitor various components of it. Finally, we show you how to rollout an update to the Point of Sale application to the edge nodes by updating the deployment configuration in a centrally synced git repository. For this we use Anthos Config Management. By the end of the guide you should have an edge profile Anthos bare metal cluster with the new version of the Point of Sale application running.
You can find the source code for both the application that makes up the Point of Sale workload and the scripts that set up the bare metal infrastructure in the anthos-edge-usecases GitHub repository. You can use the scripts to replicate this deployment on your own and then customize it for your own requirements.
Go try out this guide and see if you can extend it to create multiple Anthos on bare metal clusters to emulate multiple edge locations. This way we should be able to roll out different versions of the application to different edge locations!
Read More for the details.
You sometimes hear people say that cloud infrastructure is commoditized, not differentiated. At Google Cloud, we like to think it’s differentiated, just like the content our blog visitors like to read about. Year after year, blogs about compute, storage, and networking — as well as physical infrastructure like data centers and cables — are consistently among the most-read content of the year. Here are the top Google Cloud infrastructure stories of 2021, by readership. Read on to relive your favorites, or to catch up on any stories you may have missed.
News about our subsea cables is a perennial reader favorite, and the Dunant ready-for-service announcement was no exception. Originally announced in 2018, the Dunant cable will transmit 250 Terabits of data per second between the U.S. and France. Details here.
We welcomed a new addition to our Compute Engine family this year! Based on 3rd Gen AMD EPYC processors, the T2D (the first instance type in the Tau VM family), offers 56% higher absolute performance and 42% higher price-performance compared to general-purpose VMs from any of the leading public cloud vendors — all without having to reengineer your workloads for another microprocessor architecture. Read the blog here.
It’s no secret that a lot of the technologies that underlie Google Cloud were originally designed to power Google as a whole, and the Colossus file system is just one example. In this post, Google storage leads take you on a behind-the-scenes look into the Colossus architecture and how it delivers its impressive scalability. More here.
Year in, year out, the number of geographies where you can find a Google Cloud region continues to grow. A year ago, we announced new regions in Chile, Germany and Saudi Arabia. More recently, we announced we would open a second region in Germany, and new U.S. regions in Columbus, Ohio, and Dallas, Texas.
Along with a new GCP region in Chile, we also announced that we’re building a subsea cable to South America that goes from the East coast of the United States all the way to Argentina. Firmina joins the Curie subsea cable, which takes a Pacific route from the U.S. to South America. Read about Firmina here.
Anyone that runs mission-critical workloads in the cloud needs an easy way to back them up. Backup for GKE, a first-party backup solution that makes it easy to protect stateful data from applications running in GKE, was one of our most popular storage launches of 2021. Read all about it here.
Meanwhile, over in Google Cloud networking land, readers grooved on news of our new Network Connectivity Center, a network management solution that works across on-prem and cloud-based networks. Get the details.
People throw around the word ‘edge’ all the time, but what exactly does it mean — especially in the context of Google Cloud? In this popular blog post, learn about the difference between Google Cloud regions and zones, edge POPs, Cloud CDN, Cloud Interconnect POPs, edge nodes, and region extensions. Read all about it.
Besides new product launches, the content that resonates most reliably with readers tends to be explainers. In this top storage piece, learn what we even mean by 11 nines, and the techniques Cloud Storage uses to achieve it. Check it out.
With all this great technology, it’s fitting that Google Cloud was named a leader in the 2021 Gartner Magic Quadrant for Cloud Infrastructure and Platform Services. Again. Check out the blog and register to read the full report here.
Hopefully this list gives you a taste of what the fuss over Google Cloud infrastructure is all about. Thanks for reading, and stay tuned for 2022!
Read More for the details.
Having the ability to access corporate resources and information remotely and securely has been crucial for countless organizations during the course of the COVID-19 pandemic. Yet, many employees may agree that this process is not always seamless, especially if they were blocked from getting to an app or a resource they should be able to access. Adding to this frustration is the challenge of getting in touch with IT support to figure out what was happening and why, which can be even more difficult in a remote environment.
Our aim with BeyondCorp Enterprise, Google Cloud’s zero trust access solution, is to provide a frictionless experience for users and admins, and today, we are happy to announce that Policy Troubleshooter for BeyondCorp Enterprise is now generally available, providing support for administrators to triage blocked access events and easily unblock users.
BeyondCorp Enterprise provides users with simple and secure access to applications across clouds and across devices. Administrators are able to configure and apply granular rules to manage access to sensitive corporate resources. While these policies define how trust is established and maintained as part of the zero trust model, sometimes the layering of rules can make it difficult for end-users to understand why access to an application or resource may fail.
Administrators can enable this feature to generate a troubleshooting URL per Identity-Aware Proxy (IAP) resource in real-time for denied events. End-users who find themselves blocked will see a “Troubleshooter URL” which can be copied and sent to the administrator via email, who can quickly use the information to diagnose the error and identify why access requests fail.
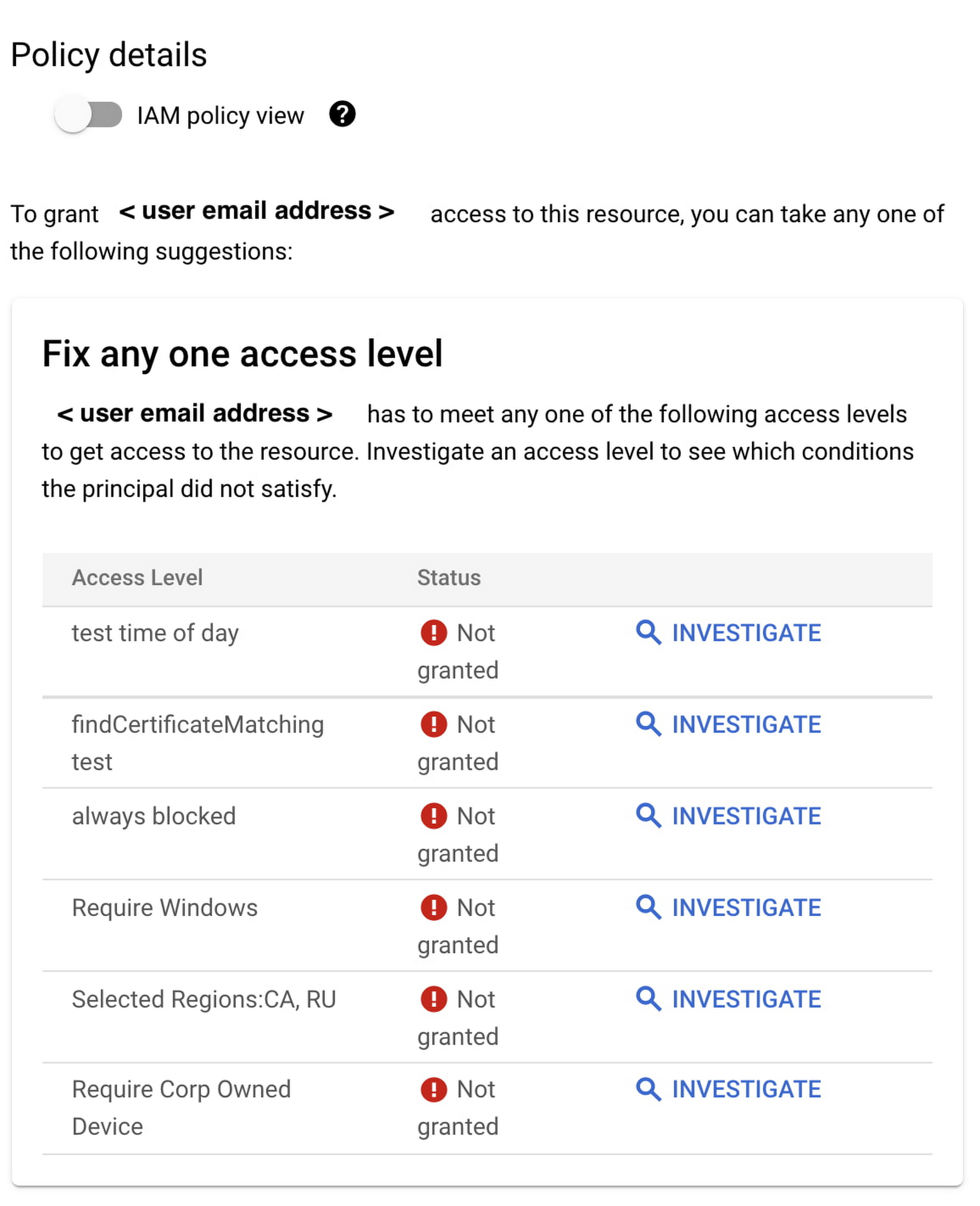
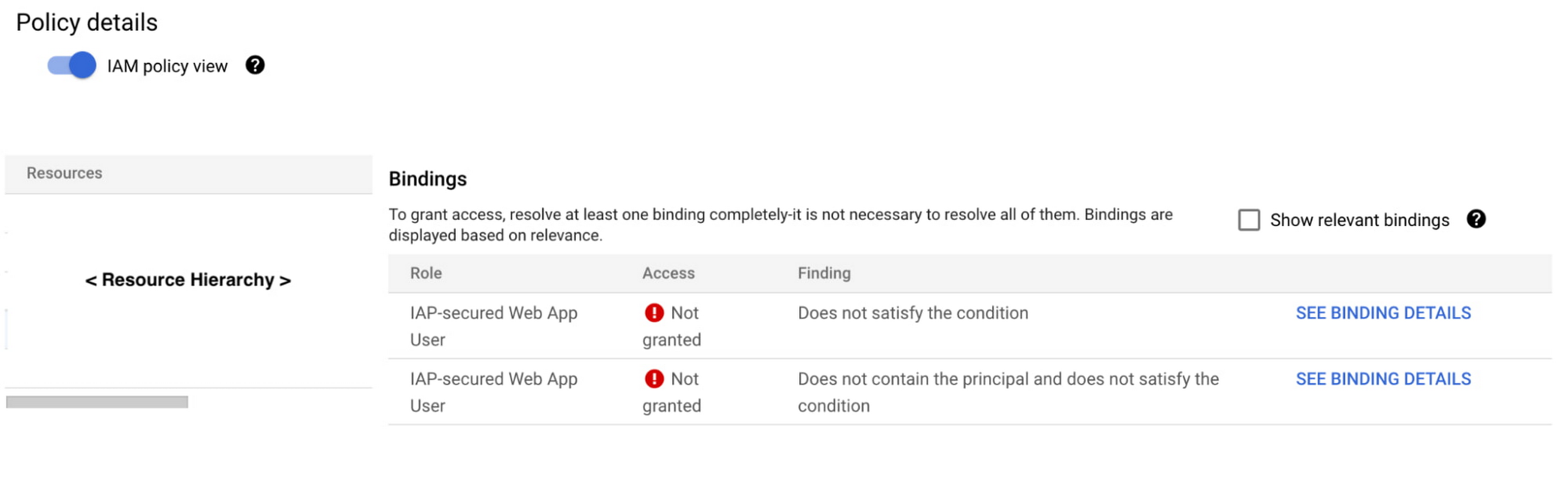
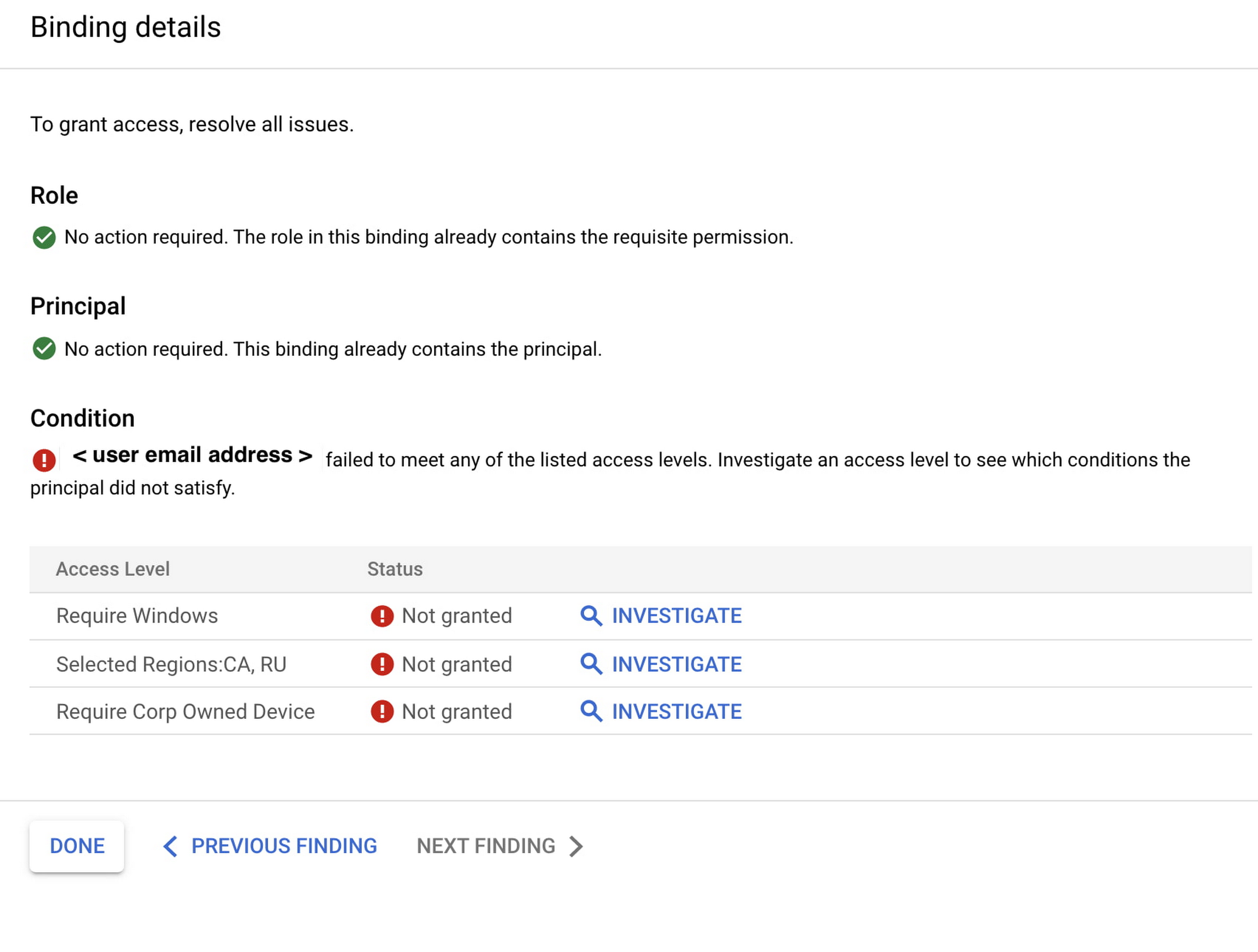
Policy Troubleshooter gives admins essential visibility of access events across their environment. Once arriving on the BeyondCorp Enterprise Troubleshooter analysis page, the administrator can see different views. The Summary View shows an aggregate view of all the relevant policy and membership findings.
In addition, the Identity and Access Management (IAM) policy view shows a list of effective IAM bindings evaluation results, granted or not, together with a high-level view on where the failures occurred. Admins can also see a table displaying the user’s and device context.
With this information, admins can give end-users more detailed information about why access failed, including things like group membership status, time or location constraints, or device rules such as attempting access from a disallowed device. Policy Troubleshooter also enables admins to update policies to allow access if warranted.
Admins can also use Policy Troubleshooter to test hypothetical events and scenarios, gaining insight and visibility into the potential impact of new security policies. By proactively troubleshooting hypothetical requests, they can verify that users have the right permissions to access resources and prevent future access interruptions and interactions with IT support staff.
Policy Troubleshooter for BeyondCorp Enterprise is a valuable tool for organizations that need to apply multiple rules to multiple resources for different groups of users. Regardless of whether the workforce is remote, providing the ability for admins to triage access failure events and unblock users in a timely way is absolutely critical for an organization’s productivity.
If you are interested in learning more, please reference our documentation to get started. This new feature will also be showcased during Google Cloud Security Talks on December 15. To see a demo, register for this free event and join us live or on-demand to learn about all of the work Google is doing to support customers’ implementations of zero trust!
Read More for the details.
AI researchers and engineers need better data to enable better AI solutions. The quality of an AI solution is determined by both the learning algorithm (such as a deep-neural network model) and the datasets used to train and evaluate that algorithm. Historically, AI research has focused much more on algorithms than datasets, despite their vital importance. As a result, many algorithms are freely available as starting points, but many important problems lack large, high-quality open datasets. Further, creating new datasets is expensive and error-prone.
Recently, the data-centric AI movement has emerged, which aims to develop new methodologies and tools for constructing better datasets to fix this problem. Conferences, workshops, challenges, and platforms are being launched to support improving data quality and to foster data excellence. Thought leaders such as Andrew Ng at Landing.AI and Chris Re at Stanford University are encouraging AI developers to focus more on iterative data engineering than they do tuning their learning algorithms. Our CHI-best-paper-award-winning paper, “Everyone wants to do the model work, not the data work” highlighted the significance of data quality in the practice of ML.
At Google, we are excited to contribute to data-centric AI. Today, Google Cloud is adding a new high value dataset to the Public Dataset Program, and Google researchers are announcing DataPerf, a new multi-organizational effort to develop benchmarks for data quality and data centric algorithms.
Google Cloud is committed to helping users improve their data quality, starting with supporting better public data. The Public Datasets program provides high quality datasets pre-configured on GCP for easy access. Google Cloud is adding a new high-value dataset developed by the MLCommons™ Association (which Google co-founded) to the Public Datasets program: The Multilingual Spoken Words Corpus: a rich audio speech dataset with more than 340,000 keywords in 50 languages with upwards of 23.4 million examples.
This new public dataset is aligned with the MLCommons Association vision for “open” datasets – accessible by all – that are “living” – continually being improved to raise quality and increase representation and diversity.
Google researchers, in collaboration with multiple organizations, are announcing the DataPerf effort at the NeurIPS Data-Centric AI workshop today, to develop benchmarks to improve data quality. Much like the the MLPerf™ benchmarking effort which is now the industry standard for machine learning hardware/software speed, DataPerf brings together the originators of prior efforts including: CATS4ML, Data-Centric AI Competition, DCBench, Dynabench, and the MLPerf benchmarks to define clear metrics that catalyze rapid innovation. DataPerf will measure the utility of training and test data for common problems, and algorithms for working with datasets such as: selecting core sets, correcting errors, identifying under-optimized data slices, and valuing datasets prior to labeling.
Together, supporting open, living datasets for core ML tasks, and the development of benchmarks to direct the rapid evolution of those datasets will empower the researchers and engineers who use Google Cloud to do even more amazing things – and we can’t wait to see what they create!
Acknowledgements: In collaboration with Lora Aroyo and Praveen Paritosh.
Read More for the details.
Organizations that are modernizing with the cloud are increasingly looking for ways to simplify and automate container orchestration with high levels of security, reliability and scalability. GKE Autopilot, which became generally available earlier this year, is a revolutionary mode of operations for managed Kubernetes that makes this possible, reducing the need for hands-on cluster management while delivering a strong security posture and improved resource utilization. (Not familiar with GKE Autopilot yet? Check out the Autopilot breakout session at Google Cloud Next ‘21, which gives a rundown of everything this new Kubernetes platform can do.)
One of the great advantages of GKE Autopilot is that despite being a fully managed Kubernetes platform that provides you with a hands-off approach to nodes, it still supports the ability to run node agents using DaemonSets. This allows you to do actions like collect node-level metrics without needing to run a sidecar in every Pod. While some administrative-level functionality like privileged pods is restricted in Autopilot for regular user pods, we have worked with our partners to bring some of the most popular solutions to Autopilot, granting additional privileges when needed. This lets you run these popular products on Autopilot without modification, and still take full advantage of our fully managed platform.
Building on partnerships with leading ISVs in observability, security, CI/CD, and configuration management, this represents a differentiated approach to running partner tooling. Compared with other clouds and competitive platforms, GKE Autopilot does not require intensive reconfiguration (such as the use of sidecar containers) for many partner solutions. As such, today we are pleased to share the following partner solutions that are compatible with GKE Autopilot, and operate in a uniform manner across GKE:
Aqua supports securing and ensuring compliance for the full lifecycle of workloads on GKE Autopilot, and specifically the Kubernetes pods, which run multiple containers with shared sets of storage and networking resources. More here.
CircleCI allows teams to release code rapidly by automating the build test and delivery process. CircleCI’s ‘orbs’ bundle configuration elements such as jobs, commands and executors into reusable packages and support deployment to GKE Autopilot. More here.
Codefresh’s Gitops controller is an agent installed in a cluster that monitors the cluster and any defined Git repositories for changes. It allows you to deploy any kind of application to your GKE Autopilot cluster using Gitops. More here.
Chronosphere’s collector and GKE Autopilot work together to make engineers more productive by giving them faster and more actionable alerts that they can triage rapidly, allowing them to spend less time on monitoring instrumentation, meanwhile knowing that their clusters are running in a secure, highly available, and optimized manner. More here.
Datadog provides comprehensive visibility into all your containerized apps running on GKE Autopilot by collecting metrics, logs and traces, which help to surface performance issues and provide context to troubleshoot them. More here.
Dynatrace uses its software intelligence platform to track the availability, health and utilization of applications running on GKE Autopilot and to prioritize anomalies or automatically determine their root causes. More here.
GitLab can be installed on GKE Autopilot easily out of the box using the official Helm Charts and can be configured to match a customer use case, including access to other Google Cloud resources such as storage and databases. More here.
Hashicorp Terraform can be used to provision a GKE Autopilot cluster distributed across multiple zones for high availability with a unified workflow and full lifecycle management. Hahsicorp Vault runs on GKE Autopilot and provides secure storage and management of secrets. Read more about Terraform and VaultMore here and here.
Palo Alto Networks’ Prisma Cloud Daemonset Defenders enforce the policies you want for your environment, while Prisma Cloud Radar displays a comprehensive visualization of your GKE Autopilot nodes and clusters so you can identify risks and investigate incidents. More here.
Snyk’s developer security platform helps developers build software securely across the cloud-native application stack, including code, open source, containers, Kubernetes and infrastructure as code, and works seamlessly with GKE Autopilot. More here.
Splunk Observability Cloud provides developers and operators with deep visibility into the composition, state, and ongoing issues within a cluster, while GKE Autopilot automatically manages the cluster’s resources to maximum efficiency. More here.
Sysdig’s Secure Devops Platform allows you to follow container security best practices on your GKE Autopilot clusters, including monitoring and securing your workloads using the Sysdig Agent. More here.
If you are using any of the above partner solutions in your existing enterprise workflows, you should be able to use them seamlessly with GKE Autopilot. Over time, we will continue to expand the scope of our partnerships and supported solutions, and we hope you use GKE Autopilot to kickstart your modernization journey with containers in the cloud. Get started today with the free tier.
Read More for the details.
Starting today, Amazon Nimble Studio has added new features for customers deploying or updating their cloud-based studios. With additional support for Usage Based Licensing (UBL) from AWS Thinkbox Deadline, deeper Linux integration, and the Los Angeles Local Zone, Amazon Nimble Studio provides customers added functionality when deploying their cloud-based content creation studio.
Read More for the details.
“Community” is a word that comes up frequently when I talk to higher education technology leaders: the importance of collaboration across universities to share ideas, enhance research solutions, and optimize their time and budgets. The Internet2 community is where much of the sharing happens—including the organization’s NET+ program, where participants evaluate cloud services that can elevate teaching, learning, and research. Workspace for Education Plus is now aservice offering through NET+, which includes exclusive pricing and custom storage accommodations.
Addressing security concerns for higher education
Jack Suess, Vice President of IT and CIO at the University of Maryland, Baltimore County (UMBC), was an early champion of the NET+ team’s evaluation of Workspace for Education Plus—with a particular focus on security.
“As we looked at collaboration platforms, we realized we needed higher levels of security,” Suess explains. “We’re seeing more requirements for security from the federal government and other third parties. If we want to leverage Workspace for Education in a secure and robust way, we need the Internet2 community to be thinking through our collective requirements.”
Google’s willingness to work closely with the Internet2 NET+ team on customizing Google Workspace for Education’s features, including enhanced security capabilities, was also a critical part of the review process, says Klara Jelinkova, former Vice President for International Operations and IT for Rice University. “Institutions are increasingly under scrutiny and attacks from a security perspective, so being able to include security features in a collaboration platform within a baseline price is extremely important,” she explains.
Listening and responding to institutions’ needs
The same collaboration that allows Internet2 members to share best practices for supporting students, staff, and researchers also allowed higher education tech leaders to collectively engage with Google and the product teams about adapting Workspace to the higher education environment. For example, Internet2 members worked with Google to increase the amount of storage in Workspace, a much-needed feature for addressing universities’ research requirements.
This active dialog with the Google product team and the Internet2 members allowed for conversations about the future direction of products to better fit the needs of universities.
“If you think about the digital transformation that we’ve just gone through, students are going to be coming through K12 with an expectation of certain types of services—and Google has a strong presence in K12,” says Jelinkova. “Knowing how to engage with Google as students move from learning environments in K12 to higher education, and understanding how the tools can evolve with this transition, is a significant benefit.”
The benefit of Internet2 NET+ service evaluations like the one for Google Workspace for Education Plus is about much more than locking down a contract price, explains Nathan Corwin, Executive Director of IT Service Operations at Arizona State University. Corwin recently took part in an Internet2 discussion about setting priorities for product development. “We ended up getting a lot of expert input—had we gone at it alone, it would have taken much longer to pull together,” Corwin says. “With Internet2 we were done in a week or two.”
Working together on a better solution
The conversations between Google and the Internet2 higher education members became much more than the standard product evaluation.
“One of the great stories here is not only the way that the higher ed institutions came together for the NET+ conversation and negotiation, but also how the Google folks banded together to bring a good product direction to us that we’re confident we can rely on going forward,” says Garret Yoshimi, VP for Information Technology and CIO at the University of Hawaii. “Having a robust offering with a roadmap that aligns with us is very critical going forward.”
Learn more by watching the Internet2 Net+ Google Workspace for Education webinar series.
Read More for the details.
Academic researchers live in a world of constant change, as research processes and tools continue to get more powerful, but also more complex. With research tools advancing on a daily basis, academic and nonprofit research teams face an ongoing need for learning and re-training. But researchers tell us that with their heavy workloads they don’t have time to keep up with new technologies: they want to focus on moving their research forward.
In response, we have created new training pathways and resources that help researchers get up to speed quickly on Google Cloud. Whether you are a researcher wanting to build a genomics pipeline, run a Monte Carlo simulation, create an auto-scaling HPC cluster with Slurm, or host Jupyter Notebooks, we’ve curated training resources that will get you straight to the solution without wasting time or resources. We know that many of you want to apply the latest cloud-based artificial intelligence tools–like building a custom service to classify images from camera traps or video footage, or make better data predictions using the latest hardware acceleration–without a long learning path.
If this sounds familiar, here’s how we can help:
Researcher-focused learning labs
Organized by research discipline, learning labs guide you through the cloud skills you’ll need for Engineering, Physical Sciences, Environmental Sciences, Mathematical Sciences, Computer Science, and Life Sciences. We also offer a downloadable guide which contains resources to help you with related cloud-computing solutions, like High Performance Computing, networking security, and data analytics. In addition, there are thousands of tutorials on Google’s Codelabs which are freely available for researchers looking to learn about related topics, such as mobile app development for Android and iOS.
Credits for training labs
Google Cloud Skills Boost allows you to get hands-on experience with a live Google Cloud tenant, which is setup temporarily for your training. It’s a safe sandbox environment that allows you to learn from doing, rather than simply observing somebody else. Explore your options and apply for credits.
Cloud grants for academic research
Researchers and PhD students from eligible institutions in selected countries can apply for up to US$5,000 of Google Cloud credits to access state-of-the-art research tools and skip the queue for computing resources.
Research partnerships
We also work with regional partners on cloud skills programs for researchers, and are eager to collaborate with new partners.
In the US, we worked with the National Science Foundation to provide cloud credit grants and instructor-led training as part of the Directorate for Computer and Information Science and Engineering’s program to support research capacity at Minority-Serving Institutions (CISE-MSI).
In Australia, we partnered with AeRO and QCIF to provide 20 cloud credit grants and instructor-led training, specifically aimed at supporting Early Career Researchers and PhD students to accelerate their research projects.
If you’re a national or regional research organization, and are interested in partnering on a cloud skills program for your researchers, contact us at: gcpresearchpartner@google.com.
Read More for the details.
Forrester Research has named Google Cloud a Leader in The Forrester Wave™: AI Infrastructure, Q4 2021 report authored by Mike Gualtieri and Tracy Woo. In the report, Forrester evaluated dimensions of AI architecture, training, inference and management against a set of pre-defined criteria. Forrester’s analysis and recognition gives customers the confidence they need to make important platform choices that will have lasting business impact.
Google received the highest possible score in 16 Forrester Wave evaluation criteria: architecture design, architecture components, training software, training data, training throughput, training latency, inferencing throughput, inferencing latency, management operations, management external, deployment efficiency, execution roadmap, innovation roadmap, partner ecosystem, commercial model, and number of customers.
We believe that Google’s vision to be a unified data and AI solution provider for the end-to-end data science experience is recognized by Forrester, through high scores in the areas of architecture and innovation. We are focused on building the most robust yet cohesive experience to enable our customers to leverage the best of Google every step of the way. Here are four key areas where Google excels, among the many highlighted in this report.
When an organization chooses to run its business on Google Cloud, it benefits from innovative infrastructure available globally. Google offers users a rich set of building blocks such as Deep Learning VMs and containers, the latest GPUs/TPUs and a marketplace of curated ISV offerings to help architect your own custom software stack on VMs and/or Google Kubernetes Engine (GKE).
Google provides a range of GPU & TPU accelerators for various use cases, including high performance training, low cost inferencing and large-scale accelerated data processing. Google is the only public cloud provider to offer up to 16 NVIDIA A100 GPUs in a single VM, making it possible to train very large AI models on a single node. Users can start with one NVIDIA A100 GPU and scale to 16 GPUs without configuring multiple VMs for single-node ML training. Google also provides TPU pods for large-scale AI research with PyTorch, TensorFlow, and JAX. The new fourth generation TPU pods deliver exaflop-scale peak performance with leading results in recent MLPerf benchmarks which included a 480 billion parameter language model.
Google Kubernetes Engine provides the most advanced Kubernetes services with unique capabilities like Autopilot, highly automated cluster version upgrades, and cluster backup/restore. GKE is a good choice for a scalable multi-node bespoke platform for training, inference and Kubeflow pipelines, given its support for 15,000 nodes per cluster, auto-provisioning, auto-scaling and various machine types (e.g. CPU, GPU, TPU and on-demand, spot). ML workloads also benefit from GKE’s support for dynamic scheduling, orchestrated maintenance, high availability, job API, customizability, fault tolerance and ML frameworks. When a company’s footprint grows to a fleet of GKE clusters, its data teams can leverage Anthos Config Management to enforce consistent configurations and security policy compliance.
Google’s fully managed Vertex AI platform provides services for ML lifecycle management, from data ingestion and preparation all the way up to model deployment, monitoring, and management. Vertex AI requires nearly 80% fewer lines of code to train a model versus competitive platforms1, enabling data scientists and ML engineers across all levels of expertise to implement Machine Learning Operations (MLOps) so they can efficiently build and manage ML projects throughout the entire development lifecycle.
Vertex AI Workbench provides data scientists with a single environment for the entire data-to-ML workflow, enabling data scientists to build and train models 5x faster than traditional notebooks. This is enabled by integrations across data services (like Dataproc, BigQuery, Dataplex, and Looker), which significantly reduce context switching. Users are also able to access NVIDIA GPUs, modify hardware on the fly, and set up idle shutdown to optimize infrastructure costs.
Organizations can then build and deploy models built on any framework (including TensorFlow, PyTorch, Scikit learn or XGBoost) with Vertex AI, with built-in tooling to track a model’s performance. Vertex Training also provides various approaches for developing large models including Reduction Server to optimize bandwidth and latency of multi-node distributed training on NVIDIA GPUs for synchronous data parallel algorithms. Vertex AI Prediction is serverless, and performs automatic provisioning and deprovisioning of nodes behind the scenes to provide low latency online predictions. It also provides the capability to split traffic between multiple models behind an endpoint. Models trained in Vertex AI can also be exported to be deployed in private or other public clouds.
In addition to building models, it is important to deploy tools for governance, security, and auditability. These tools are crucial for compliance in regulated industries, and they help teams to protect data, understand why given models fail, and determine how models can be improved.
For orchestration and auditability, Vertex Pipelines and Vertex ML Metadata tracks the inputs and outputs of an ML pipeline and the lineage of artifacts. Once models are in production, Vertex AI Model Monitoring supports feature skew and drift detection, alerting data scientists. These capabilities speed up debugging and create the visibility required for regulatory compliance and good data hygiene in general.For explainability, Vertex Explainable AI helps teams understand their model’s outputs for classification and regression tasks. Vertex AI tells how much each feature in the data contributed to the predicted result. Data teams can then use this information to verify that the model is behaving as expected, recognize bias in the model, and get ideas for ways to improve the model and training data.
These services together aim to simplify MLOps for data scientists and ML engineers, so that businesses can accelerate time to value for ML initiatives.
The Google stack builds security through progressive layers that deliver defense in depth. To accomplish data protection, authentication, authorization and non-repudiation, we have measures such as boot-level signature and chain-of-trust validation.
Ubiquitous data encryption delivers unified control over data at-rest, in-use, and in-transit, with keys that are held by customers themselves.
We offer options to run in fully encrypted confidential environments utilizing managed Hadoop or Spark with Confidential Dataproc or Confidential VMs.
Google works with certified partners globally to help our customers design, implement and manage complex AI systems. We have a growinglist of partners with Machine Learning specializations on Google who have demonstrated customer success across industries, including deep partnerships with the largest Global System Integrators. The Google Cloud Marketplace also provides a list of technology partners who allow enterprises to deploy machine learning applications on Google’s AI infrastructure.
Leading organizations like OTOY, Allen Institute for AI and DeepMind (an Alphabet subsidiary) choose Google for ML, and enterprises like Twitter, Wayfair and The Home Depot shared more about their partnership with Google in their recent sessions at Google Next 2021.
Establishing well-tuned and appropriately managed ML systems has historically been challenging, even for highly skilled data scientists with sophisticated systems. With the key pillars of Google’s investments above, organizations can build, deploy, and scale ML models faster, with pre-trained and custom tooling, within a unified AI platform.
We look forward to continuing to innovate and to helping customers on their digital transformation journey. To download the full report, click here. Get started on Vertex AI, learn what’s upcoming with infrastructure for AI and ML at Google here, and talk with our sales team.
Read More for the details.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}