Most businesses with mission-critical workloads have a two-fold disaster recovery solution in place that 1) replicates data to a secondary location, and 2) enables failover to that location in the event of an outage. For BigQuery, that solution takes the shape of BigQuery Managed Disaster Recovery. But the risk of data loss while testing a disaster recovery event remains a primary concern. Like traditional “hard failover” solutions, it forces a difficult choice: promote the secondary immediately and risk losing any data within the Recovery Point Objective (RPO), or delay recovery while you wait for a primary region that may never come back online.
Today, we’re addressing this directly with the introduction of soft failover in BigQuery Managed Disaster Recovery. Soft failover logic promotes the secondary region’s compute and datasets only after replication has been confirmed to be complete, providing you with full control over disaster recovery transitions, and minimizing the risk of data loss during a planned failover.
Figure 1: Comparing hard vs. soft failover
Summary of differences between hard failover and soft failover
Hard failover
Soft failover
Use case
Unplanned outages, region down
Failover testing, requires primary and secondary to both be available
Failover timing
As soon as possible ignoring any pending replication between primary and secondary; data loss possible
Subject to primary and secondary acquiescing, minimizing potential for data loss
RPO/RTO
15 minutes / 5 minutes*
N/A
*Supported objective depending on configuration
BigQuery soft failover in action
Imagine a large financial services company, “SecureBank,” which uses BigQuery for its mission-critical analytics and reporting. SecureBank requires a reliable Recovery Time Objective (RTO) and15 minute Recovery Point Objective (RPO) for its primary BigQuery datasets, as robust disaster recovery is a top priority. They regularly conduct DR drills with BigQuery Managed DR to ensure compliance and readiness for unforeseen outages.
Before the introduction of soft failover in BigQuery Managed DR BigQuery, SecureBank faced a dilemma on how to perform their DR drills. While BigQuery Managed DR handled the failover of compute and associated datasets, conducting a full “hard failover” drill meant accepting the risk of up to 15 minutes of data loss if replication wasn’t complete when the failover was initiated — or significant operational disruption if they first manually verified data synchronization across regions. This often led to less realistic or more complex drills, consuming valuable engineering time and causing anxiety.
New solution:
With soft failover in BigQuery Managed DR, administrators have several options for failover procedures. Unlike hard failover for unplanned outages, soft failover initiates failover only after all data is replicated to the secondary region, to help guarantee data integrity.
Figure 2: Soft Failover Mode Selection
Figure 3: Disaster recovery reservations
Figure 4: Replication status / Failover details
BigQuery soft failover feature is available today via the BigQuery UI, DDL, and CLI, providing enterprise-grade control for disaster recovery, confident simulations, and compliance — without risking data loss during testing. Get started today to maintain uptime, prevent data loss, and test scenarios safely.
Amazon CloudWatch now allows you to query metrics data up to two weeks in the past using the Metrics Insights query source. CloudWatch Metrics Insights offers fast, flexible, SQL-based queries. This new capability allows you to display, aggregate, or slice and dice metrics data older than 3 hours, for enhanced visualization and investigation.
Customers creating dashboards and alarms to monitor dynamic groups of metrics over their resources and applications could visualize up to 3 hours of data when using Metrics Insights SQL queries. This enhancement helps customers identify trends and investigate impact for a longer period of time, even days after an event. This extended query time range helps improve the operational health of teams and ensures impacts are never missed.
Querying metrics data up to two weeks old with Metrics Insights is now available in commercial AWS regions.
The ability to query metrics data up to 2 weeks old is automatically available at no additional cost. Standard pricing applies for alarms, dashboards or API usage on Metrics Insights, see CloudWatch pricing for details. To learn more about metrics queries with Metrics Insights, visit the CloudWatch documentation.
Amazon CloudWatch now allows you to monitor multiple individual metrics via a single alarm. By dynamically including metrics to monitor via a query, this new capability eliminates the need to manually manage separate alarms for dynamic resource fleets.
As customers rely more on autonomous teams and autoscaled resources, they face a choice between maintenance-free aggregated monitoring and the operational cost of maintaining per-resource alarming. Alarms that evaluate multiple metrics provide granular monitoring with individual actions through an alarm that automatically adjusts in real time as resources get created or deleted. This reduces operational efforts, allowing customers to focus on the value of their observability while ensuring no resources go unmonitored.
Monitoring multiple metrics with a single alarm is now available in all commercial AWS regions, the AWS GovCloud (US) Regions, and the China Regions.
To start alarming on multiple metrics, create an alarm on a Metrics Insights (SQL) metrics query using GROUP BY and ORDER BY conditions. The alarm automatically updates the query results with each evaluation, and matches corresponding metrics as resources change. You can configure alarms through the CloudWatch console, AWS CLI, CloudFormation, or CDK. Metrics Insights query alarms’ pricing applies, see CloudWatch pricing for details. To learn more about monitoring multiple metrics with query alarms and improving your monitoring efficiency, visit the CloudWatch alarms documentation.
Today, AWS announced the opening of a new AWS Direct Connect location within East African Data Centres NBO1 near Nairobi, Kenya. You can now establish private, direct network access to all public AWS Regions (except those in China), AWS GovCloud Regions, and AWS Local Zones from this location. This site is the first AWS Direct Connect location in Kenya. This Direct Connect location offers dedicated 10 Gbps and 100 Gbps connections with MACsec encryption available.
The Direct Connect service enables you to establish a private, physical network connection between AWS and your data center, office, or colocation environment. These private connections can provide a more consistent network experience than those made over the public internet.
For more information on the over 145 Direct Connect locations worldwide, visit the locations section of the Direct Connect product detail pages. Or, visit our getting started page to learn more about how to purchase and deploy Direct Connect.
Amazon RDS for Oracle and Amazon RDS Custom for Oracle now support bare metal instances. You can use M7i, R7i, X2iedn, X2idn, X2iezn, M6i, M6id, M6in, R6i, R6id, and R6in bare metal instances at 25% lower price compared to equivalent virtualized instances.
With bare metal instances, you can combine multiple databases onto a single bare metal instance to reduce cost by using the Multi-tenant feature. For example, databases running on a db.r7i.16xlarge instance and a db.r7i.8xlarge instance can be consolidated to individual pluggable databases on a single db.r7i.metal-24xl instance. Furthermore, you may be able to reduce your commercial database license and support costs by using bare metal instances since they provide full visibility into the number of CPU cores and sockets of the underlying server. Refer to Oracle Cloud Policy and Oracle Core Factor Table, and consult your licensing partner to determine if you can reduce license and support costs.
AWS Config now supports 5 additional AWS resource types. This expansion provides greater coverage over your AWS environment, enabling you to more effectively discover, assess, audit, and remediate an even broader range of resources.
With this launch, if you have enabled recording for all resource types, then AWS Config will automatically track these new additions. The newly supported resource types are also available in Config rules and Config aggregators.
You can now use AWS Config to monitor the following newly supported resource types in all AWS Regions where the supported resources are available.
Written by: Rommel Joven, Josh Fleischer, Joseph Sciuto, Andi Slok, Choon Kiat Ng
In a recent investigation, Mandiant Threat Defense discovered an active ViewState deserialization attack affecting Sitecore deployments leveraging sample machine keys that had been exposed in Sitecore deployment guides from 2017 and earlier. An attacker leveraged the exposed ASP.NET machine keys to perform remote code execution.
Mandiant worked directly with Sitecore to address this issue. Sitecore tracks this vulnerable configuration as CVE-2025-53690, which affects customers who deployed any version of multiple Sitecore products using sample keys exposed in publicly available deployment guides (specifically Sitecore XP 9.0 and Active Directory 1.4 and earlier versions). Sitecore has confirmed that its updated deployments automatically generate unique machine keys and that affected customers have been notified.
Refer to Sitecore’s advisory for more information on which products are potentially impacted.
Summary
Mandiant successfully disrupted the attack shortly after initiating rapid response, which ultimately prevented us from observing the full attack lifecycle. However, our investigation still provided insights into the adversary’s activity. The attacker’s deep understanding of the compromised product and the exploited vulnerability was evident in their progression from initial server compromise to privilege escalation. Key events in this attack chain included:
Initial compromise was achieved by exploiting the ViewState Deserializationvulnerability CVE-2025-53690 on the affected internet-facing Sitecore instance, resulting in remote code execution.
A decrypted ViewState payload contained WEEPSTEEL, a malware designed for internal reconnaissance.
Leveraging this access, the threat actor archived the root directory of the web application, indicating an intent to obtain sensitive files such as web.config. This was followed by host and network reconnaissance.
The threat actor staged tooling in a public directory which included an:
Open-source network tunnel tool, EARTHWORM
Open-source remote access tool,DWAGENT
Open-source Active Directory (AD) reconnaissance tool, SHARPHOUND
Local administrator accounts were created and used to dump SAM/SYSTEM hives in an attempt to compromise cached administrator credentials. The compromised credentials then enabled lateral movement via RDP.
DWAgent provided persistent remote access and was used for Active Directory reconnaissance.
Figure 1: Attack lifecycle
Initial Compromise
External Reconnaissance
The threat actor began their operation by probing the victim’s web server with HTTP requests to various endpoints before ultimately shifting their attention to the /sitecore/blocked.aspxpage. This page is a legitimate Sitecore component that simply returns a message if a request was blocked due to licensing issues. The page’s use of a hidden ViewState form (a standard ASP.NET feature), combined with being accessible without authentication, made it a potential target for ViewState deserialization attacks.
ViewState Deserialization Attack
ViewStates are an ASP.NET feature designed to persist the state of webpages by storing it in a hidden HTML field named __VIEWSTATE. ViewState deserialization attacks exploit the server’s willingness to deserialize ViewState messages when validation mechanisms are either absent or circumvented. When machine keys (which protect ViewState integrity and confidentiality) are compromised, the application effectively loses its ability to differentiate between legitimate and malicious ViewState payloads sent to the server.
Local web server (IIS) logs recorded that the threat actor’s attack began by sending an HTTP POST request to the blocked.aspx endpoint, which was met with an HTTP 302 “Found” response. This web request coincided with a “ViewState verification failed” message in Windows application event logs (Event ID 1316) containing the crafted ViewState payload sent by the threat actor:
Log: Application
Source: ASP.NET 4.0.30319.0
EID: 1316
Type: Information
Event code: 4009-++-Viewstate verification failed. Reason: Viewstate was
invalid.
<truncated>
ViewStateException information:
Exception message: Invalid viewstate.
Client IP: <redacted>
User-Agent: Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1;
Trident/5.0) chromeframe/10.0.648.205 Mozilla/5.0
(Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/121.0.0.0 Safari/537.36
PersistedState: <27760 byte encrypted + base64 encoded payload>
Referer:
Path: /sitecore/blocked.aspx
Mandiant recovered a copy of the server’s machine keys, which were stored in the ASP.NET configuration file web.config. Like many other ViewState deserialization attacks, this particular Sitecore instance used compromised machine keys. Knowledge of these keys enabled the threat actor to craft malicious ViewStates that were accepted by the server by using tools like the public ysoserial.net project.
Initial Host Reconnaissance
Mandiant decrypted the threat actor’s ViewState payload using the server’s machine keys and found it contained an embedded .NET assembly named Information.dll. This assembly, which Mandiant tracks as WEEPSTEEL, functions as an internal reconnaissance tool and has similarities to the GhostContainer backdoor and an information-gathering payload previously observed in the wild.
About WEEPSTEEL
WEEPSTEELis a reconnaissance tool designed to gather system, network, and user information. This data is then encrypted and exfiltrated to the attacker by disguising it as a benign __VIEWSTATE response.
The payload is designed to exfiltrate the following system information for reconnaissance:
// Code Snippet from Host Reconnaissance Function
Information.BasicsInfo basicsInfo = new Information.BasicsInfo
{
Directories = new Information.Directories
{
CurrentWebDirectory = HostingEnvironment.MapPath("~/")
},
// Gather system information
OperatingSystemInformation = Information.GetOperatingSystemInformation(),
DiskInformation = Information.GetDiskInformation(),
NetworkAdapterInformation = Information.GetNetworkAdapterInformation(),
Process = Information.GetProcessInformation()
};
// Serialize the 'basicsInfo' object into a JSON string
JavaScriptSerializer javaScriptSerializer = new JavaScriptSerializer();
text = javaScriptSerializer.Serialize(basicsInfo);
WEEPSTEEL appears to borrow some functionality from ExchangeCmdPy.py, a public tool tailored for similar ViewState-related intrusions. This comparison was originally noted in Kaspersky’s write-up on the GhostContainer backdoor. Like ExchangeCmdPy, WEEPSTEEL sends its output through a hidden HTML field masquerading as a legitimate __VIEWSTATE parameter, shown as follows:
Subsequent HTTP POST requests to the blocked.aspx endpoint from the threat actor would result in HTTP 200 “OK” responses, which Mandiant assesses would have contained an output in the aforementioned format. As the threat actor continued their hands-on interaction with the server, Mandiant observed repeated HTTP POST requests with successful responses to the blocked.aspx endpoint.
Establish Foothold
Following successful exploitation, the threat actor gained the NETWORK SERVICE privilege, equivalent to the IIS worker process w3wp.exe. This access provided the actor a starting point for further malicious activities.
Config Extraction
The threat actor then exfiltrated critical configuration files by archiving the contents ofinetpubsitecoreSitecoreCDWebsite, a Sitecore Content Delivery (CD) instance’s web root. This directory contained sensitive files, such as the web.config file, that provide sensitive information about the application’s backend and its dependencies, which would help enable post-exploitation activities.
Host Reconnaissance
After obtaining the key server configuration files, the threat actor proceeded to fingerprint the compromised server through host and network reconnaissance, including but not limited to enumerating running processes, services, user accounts, TCP/IP configurations, and active network connections.
whoami
hostname
net user
tasklist
ipconfig /all
tasklist /svc
netstat -ano
nslookup <domain>
net group domain admins
net localgroup administrators
Staging Directory
The threat actor leveraged public directories such as Music and Video for staging and deploying their tooling. Files written into the Public directory include:
File:C:UsersPublicMusic7za.exe
Description: command-line executable for the 7-Zip file archiver
EARTHWORM is an open-source tunneler that allows attackers to create a covert channel to and from a victim system over a separate protocol to avoid detection and network filtering, or to enable access to otherwise unreachable systems.
During our investigation, EARTHWORMwas executed to initiate a reverse SOCKS proxy connection back to the following command-and-control (C2) server:
130.33.156[.]194:443
103.235.46[.]102:80.
File:C:UsersPublicMusic1.vbs
Description: Attack VBScript: Used to execute threat actor commands, its content varies based on the desired actions.
SHA-256: <hash varies>
In one instance where the file 1.vbs was retrieved, it contained a simple VBS code to launch the EARTHWORM.
Following initial compromise, the threat actor elevated their access from NETWORK SERVICE privileges to the SYSTEM or ADMINISTRATOR level.
This involved creating local administrator accounts and obtaining access to domain administrator accounts. The threat actor was observed using additional tools to escalate privileges.
Adding Local Administrators
asp$: The threat actor leveraged a privilege escalation tool to create the local administrator account, asp$. The naming convention mimicking an ASP.NET service account with a common suffix $ suggests an attempt to blend in and evade detection.
sawadmin: At a later stage, the threat actor established a DWAGENT remote session to create a second local administrator account.
net user sawadmin {REDACTED} /add
net localgroup administrators sawadmin /add
Credential Dumping
The threat actor established RDP access to the host using the two newly created accounts and proceeded to dump the SYSTEM and SAM registry hives from both accounts. While redundant, this gave the attacker the information necessary to extract password hashes of local user accounts on the system. The activities associated with each account are as follows:
asp$
reg save HKLMSYSTEM c:userspublicsystem.hive
reg save HKLMSAM c:userspublicsam.hive
sawadmin: Prior to dumping the registry hives, the threat actor executed GoToken.exe. Unfortunately, the binary was not available for analysis.
GoToken.exe -h
GoToken.exe -l
GoToken.exe -ah
GoToken.exe -t
reg save HKLMSYSTEM SYSTEM.hiv
reg save HKLMSAM SAM.hiv
Maintain Presence
The threat actor maintained persistence through a combination of methods, leveraging both created and compromised administrator credentials for RDP access. Additionally, the threat actor issued commands to maintain long-term access to accounts. This included modifying settings to disable password expiration for administrative accounts of interest:
net user <AdminUser> /passwordchg:no /expires:never
wmic useraccount where name='<AdminUser>' set PasswordExpires=False
For redundancy and continued remote access, the DWAGENT tool was also installed.
Remote Desktop Protocol
The actor used the Remote Desktop Protocol extensively. The traffic was routed through a reverse SOCKS proxy created by EARTHWORM to bypass security controls and obscure their activities. In one RDP session, the threat actor under the context of the account asp$downloaded additional attacker tooling, dwagent.exe and main.exe, into C:Usersasp$Downloads.
File Path
MD5
Description
C:Usersasp$Downloadsdwagent.exe
n/a
DWAgent installer
C:Usersasp$Downloadsmain.exe
be7e2c6a9a4654b51a16f8b10a2be175
Downloaded from hxxp://130.33.156[.]194/main.exe
Table 1: Files written in the RDP session
Remote Access Tool: DWAGENT
DWAGENT is a legitimate remote access tool that enables remote control over the host. DWAGENT operates as a service with SYSTEM privilege and starts automatically, ensuring elevated and persistence access. During the DWAGENT remote session, the attacker wrote the file GoToken.exe. The commands executed suggest that the tool was used to aid in extracting the registry hives.
File Path
MD5
Description
C:UsersPublicMusicGoToken.exe
62483e732553c8ba051b792949f3c6d0
Binary executed prior to dumping of SAM/SYSTEM hives.
Table 2: File written in the DWAgent remote session
Internal Reconnaissance
Active Directory Reconnaissance
During a DWAGENT remote session, the threat actor executed commands to identify Domain Controllers within the target network. The actor then accessed the SYSVOL share on these identified DCs to search for cpassword within Group Policy Object (GPO) XML files. This is a well-known technique attackers employ to discover privileged credentials mistakenly stored in a weakly encrypted format within the domain.
The threat actor then transitioned to a new RDP session using a legitimate administrator account. From this session, SHARPHOUND , the data collection component for the Active Directory security analysis platform BLOODHOUND, was downloaded via a browser and saved to C:UsersPublicMusicsh.exe.
Following the download, the threat actor returned to the DWAGENT remote session and executed sh.exe, performing extensive Active Directory reconnaissance.
sh.exe -c all
Once the reconnaissance concluded, the threat actor switched back to the RDP session (still using the compromised administrator account) to archive the SharpHound output, preparing it for exfiltration.
With administrator accounts compromised, the earlier created asp$ and sawadminaccounts were removed, signaling a shift to more stable and covert access methods.
Move Laterally
The compromised administrator accounts were used to RDP to other hosts. On these systems, the threat actor executed commands to continue their reconnaissance and deploy EARTHWORM.
On one host, the threat actor logged in via RDP using a compromised admin account. Under the context of this account, the threat actor then continued to perform internal reconnaissance commands such as:
quser
whoami
net user <AdminUser> /domain
nltest /DCLIST:<domain>
nslookup <domain-controller>
Recommendations
Mandiant recommends implementing security best practices in ASP.NET including implementing automated machine key rotation, enabling View State Message Authentication Code (MAC), and encrypting any plaintext secrets within the web.config file. For more details, refer to the following resources:
Google Security Operations Enterprise and Enterprise+ customers can leverage the following product threat detections and content updates to help identify and remediate threats. All detections have been automatically delivered to Google Security Operations tenants within the Mandiant Frontline Threats curated detections ruleset. To leverage these updated rules, access Content Hub and search on any of the strings above, then View and Manage each rule you wish to implement or modify.
Earthworm Tunneling Indicators
User Account Created By Web Server Process
Cmd Launching Process From Users Music
Sharphound Recon
User Created With No Password Expiration Execution
Discovery of Privileged Permission Groups by Web Server Process
We would like to extend our gratitude to the Sitecore team for their support throughout this investigation. Additionally, we are grateful to Tom Bennett and Nino Isakovic for their assistance with the payload analysis. We also appreciate the valuable input and technical review provided by Richmond Liclican and Tatsuhiko Ito.
Anthropic’s Claude Sonnet 4 is now available with Global cross-Region inference in Amazon Bedrock, so you can now use the Global Claude Sonnet 4 inference profile to route your inference requests to any supported commercial AWS Region for processing, optimizing available resources and enabling higher model throughput.
Amazon Bedrock is a comprehensive, secure, and flexible service for building generative AI applications and agents. When using on-demand and batch inference in Amazon Bedrock, your requests may be restricted by service quotas or during peak usage times. Cross-region inference enables you to seamlessly manage unplanned traffic bursts by utilizing compute across different AWS Regions. With cross-region inference, you can distribute traffic across multiple AWS Regions, enabling higher throughput. Previously, you were able to choose cross-region inference profiles tied to a specific geography such as the US, EU, or APAC, which automatically selected the optimal commercial AWS Region within that geography to process your inference requests. For your generative AI use cases that do not require you to choose inference profiles tied to a specific geography, you can now use the Global cross-region inference profile to further increase your model throughput.
AWS Clean Rooms now supports the ability to add data provider members to an existing collaboration, offering customers enhanced flexibility as they iterate on and develop new use cases with their partners. With this launch, you can collaborate with new data providers without having to set up a new collaboration. Collaboration owners can configure an existing Clean Rooms collaboration to add new members that only contribute data, while benefiting from the privacy controls existing members already configured within the collaboration. New data providers invited to an existing collaboration can be reviewed in the change history, enhancing transparency across members. For example, when a publisher creates a Clean Rooms collaboration with an advertiser, they can enable adding new data providers such as a measurement company, which allows the advertiser to enrich their audience segments with third-party data before activating an audience with the publisher. This approach reduces onboarding time while maintaining the existing privacy controls for you and your partners.
AWS Clean Rooms helps companies and their partners easily analyze and collaborate on their collective datasets without revealing or copying one another’s underlying data. For more information about the AWS Regions where AWS Clean Rooms is available, see the AWS Regions table. To learn more about collaborating with AWS Clean Rooms, visit AWS Clean Rooms.
AWS Clean Rooms ML custom modeling enables you and your partners to train and run inference on a custom ML models using collective datasets at scale without having to share your sensitive data or intellectual property. With today’s launch, collaborators can configure a new privacy control that sends redacted error log summaries to specified collaboration members. Error log summaries include the exception type, error message, and line in the code where the error occurred. When associating the model to the collaboration, collaborators can decide and agree which members will receive error log summaries and whether those summaries will contain detectable Personally Identifiable Information (PII), numbers, or custom strings redacted.
AWS Clean Rooms ML helps you and your partners apply privacy-enhancing controls to safeguard your proprietary data and ML models while generating predictive insights—all without sharing or copying one another’s raw data or models. For more information about the AWS Regions where AWS Clean Rooms ML is available, see the AWS Regions table. To learn more, visit AWS Clean Rooms ML.
Amazon SageMaker Catalog now supports governed classification through Restricted Classification Terms, allowing catalog administrators to control which users and projects can apply sensitive glossary terms to their assets. This new capability is designed to help organizations enforce metadata standards and ensure classification consistency across teams and domains.
With this launch, glossary terms can be marked as “restricted”, and only authorized users or groups—defined through explicit policies—can use them to classify data assets. For example, a centralized data governance team may define terms like “Seller-MCF” or “PII” that reflect data handling policies. These terms can now be governed so only specific project members (e.g., trusted admin groups) can apply them, which helps support proper control over how sensitive classifications are assigned.
This feature is now available in all AWS regions where Amazon SageMaker Unified Studio is supported.
To get started and learn more about this feature, see SageMaker Unified Studio user guide.
Beginning today, customers can use Amazon Bedrock in the Asia Pacific (Jakarta) region to easily build and scale generative AI applications using a variety of foundation models (FMs) as well as powerful tools to build generative AI applications.
Amazon Bedrock is a fully managed service that offers a choice of high-performing large language models and other FMs from leading AI companies via a single API. Amazon Bedrock also provides a broad set of capabilities, such as Guardrails and Model customization, that customers need to build generative AI applications with security, privacy, and responsible AI built into Amazon Bedrock. These capabilities help customers build tailored applications for multiple use cases across different industries, helping organizations unlock sustained growth from generative AI while ensuring customer trust and data governance.
Today, AWS announces the ability to manage access to AWS Regions and AWS Local Zones from a single place within the AWS Management Console. With this new capability, customers can now efficiently monitor and manage access to AWS Regions and AWS Local Zones globally.
AWS Global View enables customers to view resources across multiple Regions in a single console. To get started, customers can find “AWS Global View” in the AWS Management Console and navigate to the Regions and Zones page. The Regions and Zones page displays infrastructure location details, opt-in status, as well as any parent Region relationships, making it easier for customers to manage and monitor their global AWS footprint.
This capability is available in all AWS commercial Regions. To learn more, visit the AWS Global View documentation, or navigate to the Regions and Zones page here.
Amazon CloudWatch Synthetics now enables customers to test and monitor web applications in Firefox, in addition to existing Chrome support. This enhancement helps customers ensure consistent functionality and performance across different browsers, making it easier to identify browser-specific issues before they impact end users.
With this launch, you can run the same canary script across Chrome and Firefox when using Playwright-based canaries or Puppeteer-based canaries. CloudWatch Synthetics automatically collects browser-specific performance metrics, success rates, and visual monitoring results while maintaining an aggregate view of overall application health. This helps development and operations teams quickly identify and resolve browser compatibility issues that could affect application reliability.
The Agent Development Kit (ADK) Hackathon is officially wrapped. The hackathon wrapped up with over 10,400 participants from 62 countries, resulting in 477 submitted projects and over 1,500 agents built! Building on the excitement from our initial announcement, the hackathon proved to be an invaluable opportunity for developers to experiment with cutting-edge technologies and build the next generation of agents.
The hackathon focused on designing and orchestrating interactions between multiple agents using ADK to tackle complex tasks like automating processes, analyzing data, improving customer service, and generating content.
Now, let’s give a massive round of applause to our outstanding winners. These teams demonstrated exceptional skill, ingenuity, and a deep understanding of ADK.
Grand Prize
SalesShortcut By Merdan Durdyyev and Sergazy Nurbavliyev SalesShortcut is a comprehensive AI-powered Sales Development Representative (SDR) system built with multi-agent architecture for automated lead generation, research, proposal generation, and outreach.
North America regional winner
Energy Agent AI By David Babu Energy Agent AI is a multi-agent AI transforming energy customer management through Google ADK orchestration.
Latin America regional winner
Edu.AI – Multi-Agent Educational System for Brazil By Giovanna Moeller Edu.AI democratizes Brazil’s education with autonomous AI agents that evaluate essays, generate personalized study plans, and create interdisciplinary mock exams, all in one intelligent system.
Asia Pacific regional winner
GreenOps By Aishwarya Nathani and Nikhil Mankani GreenOps automates sustainability as an AI team that continuously audits, forecasts, and optimizes cloud infrastructure.
Europe, Middle East, Africa regional winner
Nexora-AI By Matthias Meierlohr, Luca Bozzetti, Erliassystems, and Markus Huber Nexora is next-gen personalized education. Learn through interactive lessons with visuals, quizzes, and smart AI support.
Honorable mention #1
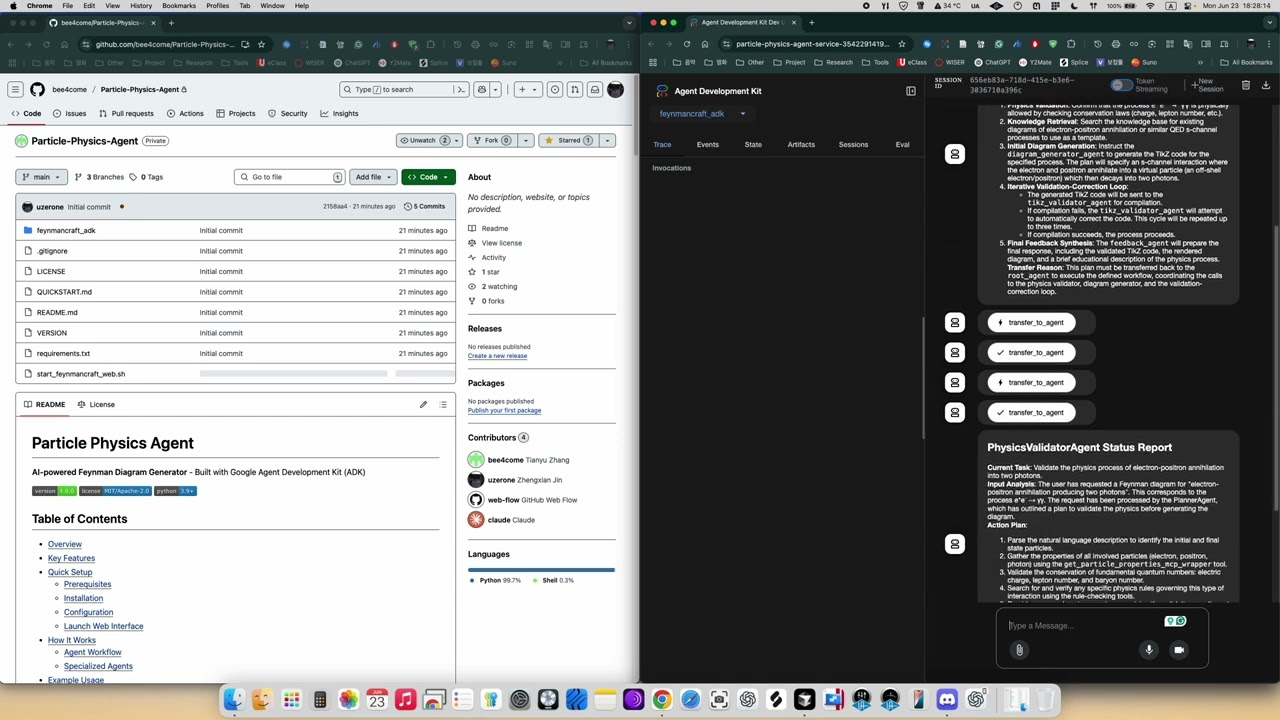
Particle Physics Agent ByZX Jin and Tianyu Zhang Particle Physics Agent is an AI agent that converts natural language into validated Feynman diagrams, using real physical laws and high-fidelity data — bridging theory, automation, and symbolic reasoning.
Honorable mention #2
TradeSageAI By Suds Kumar TradeSage AI is an intelligent multi-agent financial analysis platform built using ADK, Agent Engine, Cloud Run and Vertex AI, that revolutionizes trading hypothesis evaluation.
Honorable mention #3
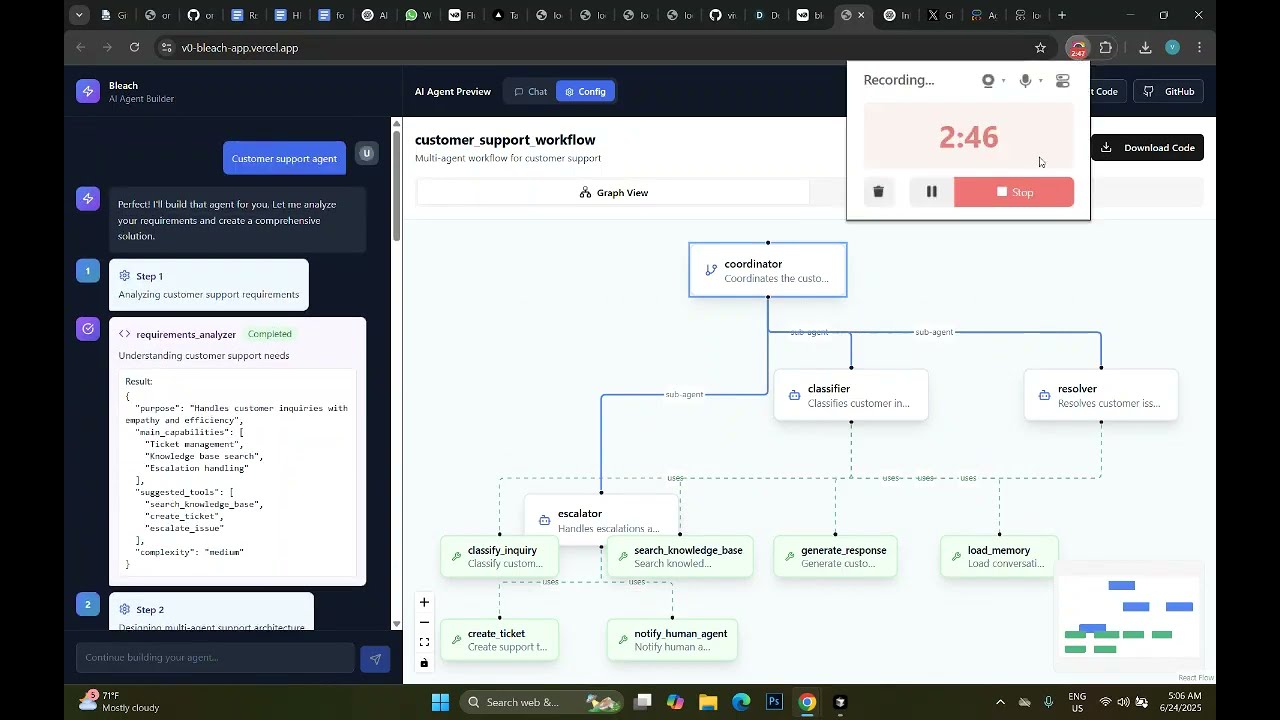
Bleach ByVivek Shukla Bleach is a Visual AI agent builder built using Google ADK that describes agents in plain English, designs visually, and tests instantly.
Inspired by the ADK Hackathon?
Learn more about ADK and continue the conversation in the Google Developer Program forums.
Ready for the next hackathon?
Google Kubernetes Engine (GKE) is turning 10, and we’re celebrating with a hackathon! Join us to build powerful AI agents that interact with microservice applications using Google Kubernetes Engine and Google AI models. Compete for over $50,000 in prizes and demonstrate the power of building agentic AI on GKE.
Submissions are open from Aug 18, 2025 to Sept, 22 2025. Learn more and register at our hackathon homepage.
Today, as part of the launch of the AWS Asia Pacific (New Zealand) Region, AWS announced the opening of a new AWS Direct Connect location within the Spark Digital Mayoral Drive Exchange (MDR) data center near Auckland, New Zealand. You can now establish private, direct network access to all public AWS Regions (except those in China), AWS GovCloud Regions, and AWS Local Zones from this location. This Direct Connect location offers dedicated 10 Gbps and 100 Gbps connections with MACsec encryption available.
The Direct Connect service enables you to establish a private, physical network connection between AWS and your data center, office, or colocation environment. These private connections can provide a more consistent network experience than those made over the public internet.
For more information on the over 144 Direct Connect locations worldwide, visit the locations section of the Direct Connect product detail pages. Or, visit our getting started page to learn more about how to purchase and deploy Direct Connect.
Today, AWS announced the expansion of 10 Gbps and 100 Gbps dedicated connections with MACsec encryption capabilities at the existing AWS Direct Connect location in the Rack Centre LGS1 data center near Lagos, Nigeria. You can now establish private, direct network access to all public AWS Regions (except those in China), AWS GovCloud Regions, and AWS Local Zones from this location.
The Direct Connect service enables you to establish a private, physical network connection between AWS and your data center, office, or colocation environment. These private connections can provide a more consistent network experience than those made over the public internet.
For more information on the over 145 Direct Connect locations worldwide, visit the locations section of the Direct Connect product detail pages. Or, visit our getting started page to learn more about how to purchase and deploy Direct Connect.
With Amazon RDS for Oracle SE2 License Included instances, you do not need to purchase Oracle Database licenses. You simply launch Amazon RDS for Oracle instances through the AWS Management Console, AWS CLI, or AWS SDKs, and there are no separate license or support charges. Review the AWS blog Rethink Oracle Standard Edition Two on Amazon RDS for Oracle to explore how you can lower cost and simplify operations by using Amazon RDS Oracle SE2 License Included instances for your Oracle databases.
Amazon Web Services (AWS) is launching a new collection of developer-focused resources for the AWS Command Line Interface (AWS CLI). These resources demonstrate working end-to-end shell scripts for working with AWS services and best practices that simplify the process of authoring shell scripts that handle errors, track created resources, and perform cleanup operations.
The new AWS Developer Tutorials project on GitHub provides a library of tested, scenario-focused AWS CLI scripts covering over 60 AWS services. These tutorials provide quicker ways to get started using an AWS service API with the AWS CLI. Leveraging generative AI and existing documentation, developers can now more easily create working scripts for their own resources, saving time and reducing errors when managing AWS resources through the AWS CLI. Each script includes a tutorial that explains how the script works with the AWS service API to create, interact with, and clean up resources.
The project also includes instructions that you can use to generate and contribute new scripts. You can use existing content and examples with generative AI tools such as the Amazon Q Developer CLI to generate a working script through an iterative test-and-improve process. Depending on how well-documented the use case is, this process can take as little as 15 minutes. For scenarios that don’t have existing examples of API calls with input and output, it can take more iterations to get a working script. Sometimes you need to provide additional information or examples from your own testing to fill in a gap. This process can actually be quite fun!
Today, AWS Resource Explorer has expanded the availability of resource search and discovery to the Asia Pacific (Taipei) AWS Region.
With AWS Resource Explorer you can search for and discover your AWS resources across AWS Regions and accounts in your organization, either using the AWS Resource Explorer console, the AWS Command Line Interface (AWS CLI), the AWS SDKs, or the unified search bar from wherever you are in the AWS Management Console.
For more information about the AWS Regions where AWS Resource Explorer is available, see the AWS Region table.






")