GCP – Automate app deployment and security analysis with new Gemini CLI extensions
Find and fix security vulnerabilities. Deploy your app to the cloud. All without leaving your command-line.
Today, we’re closing the gap between your terminal and the cloud with a first look at the future of Gemini CLI, delivered through two new extensions: security extension and Cloud Run extension. These extensions are designed to handle critical parts of your workflows with simple, intuitive commands:
1) /security:analyze performs a comprehensive scan right in your local repository, with support for GitHub pull requests coming soon. This makes security a natural part of your development cycle.
2) /deploy deploys your application to Cloud Run, our fully managed serverless platform, in just a few minutes.
These commands are the first expression of a new extensibility framework for Gemini CLI. While we’ll be sharing more about the full Gemini CLI extension world soon, we couldn’t wait to get these capabilities into your hands. Consider this a sneak peak of what’s coming next!
Security extension: automate security analysis with /security:analyze
To help teams address software vulnerabilities early in the development lifecycle, we are launching the Gemini CLI Security extension. This new open-source tool automates security analysis, enabling you to proactively catch and fix issues using the /security:analyze command at the terminal or through a soon-coming GitHub Actions integration.
Integrated directly into your local development workflow and CI/CD pipeline, this extension:
-
Analyzes code changes: When triggered, the extension automatically takes the
git diffof your local changes or pull request. -
Identifies vulnerabilities: Using a specialized prompt and tools, Gemini CLI analyzes the changes for a wide range of potential vulnerabilities, such as hardcoded-secrets, injection vulnerabilities, broken access control, and insecure data handling.
-
Provides actionable feedback: Gemini returns a detailed, easy-to-understand report directly in your terminal or as a comment on your pull request. This report doesn’t just flag issues; it explains the potential risks and provides concrete suggestions for remediation, helping you fix issues quickly and learn as you go.
And after the report is generated, you can also ask Gemini CLI to save it to disk or even implement fixes for each issue.
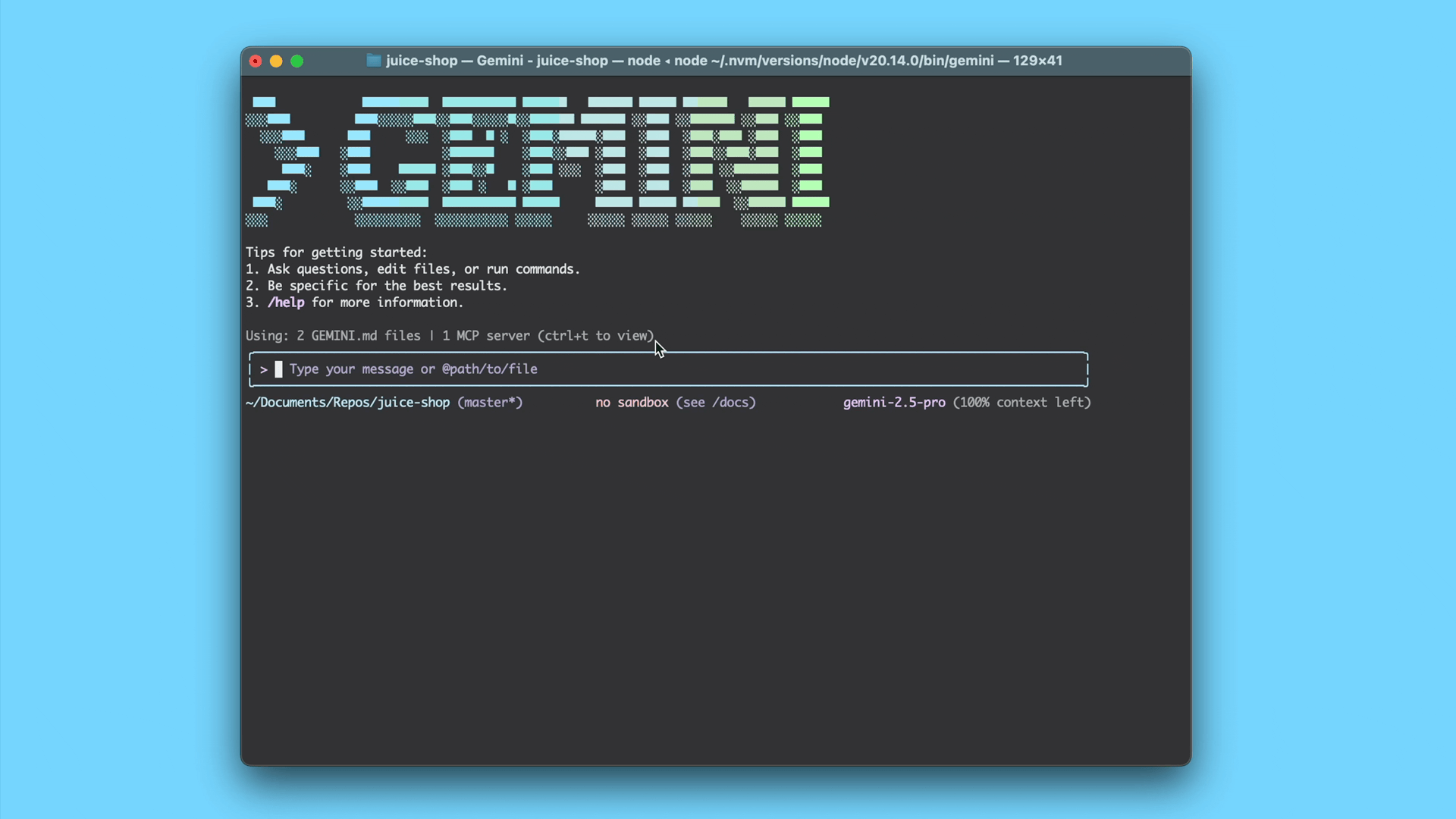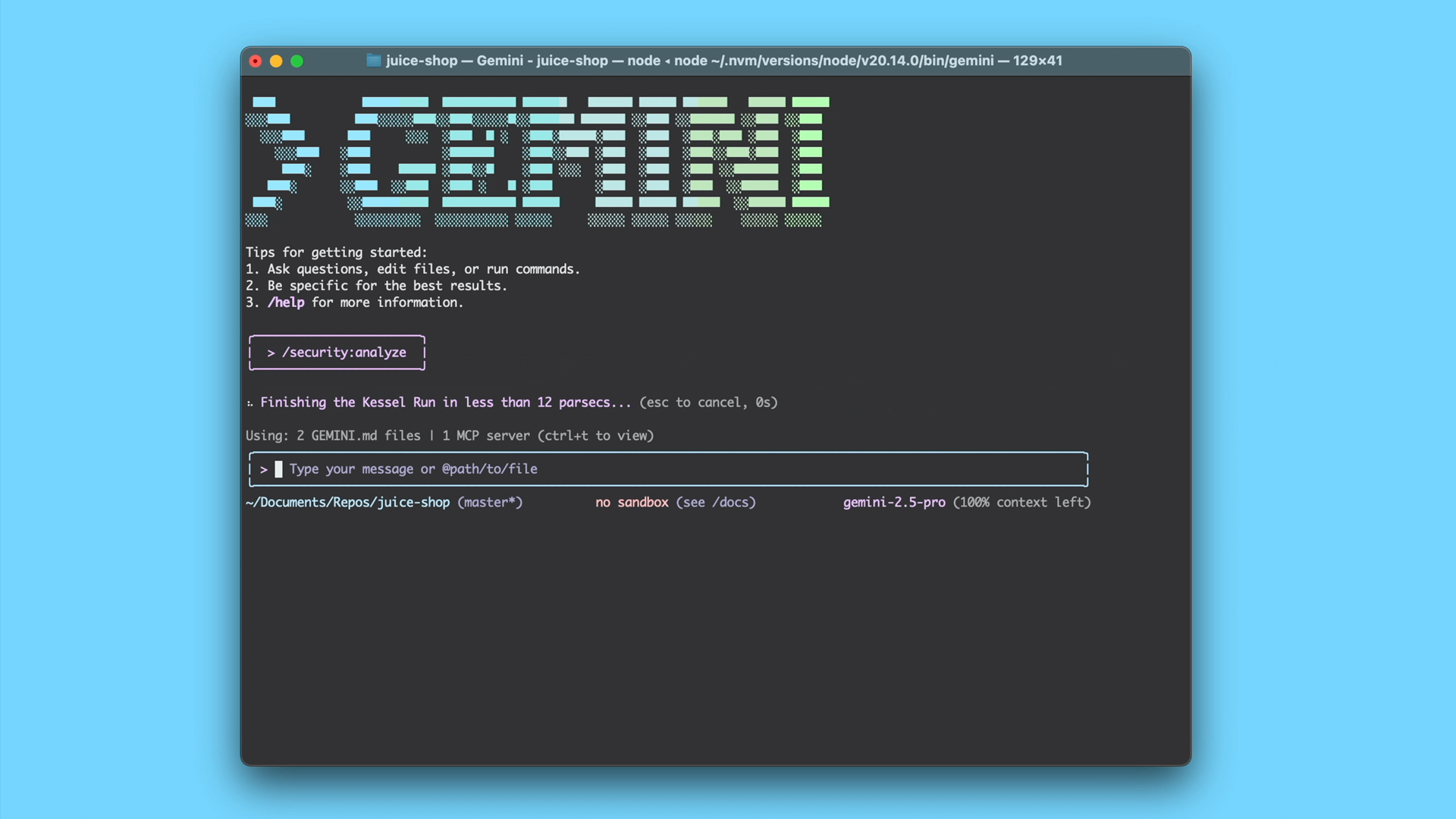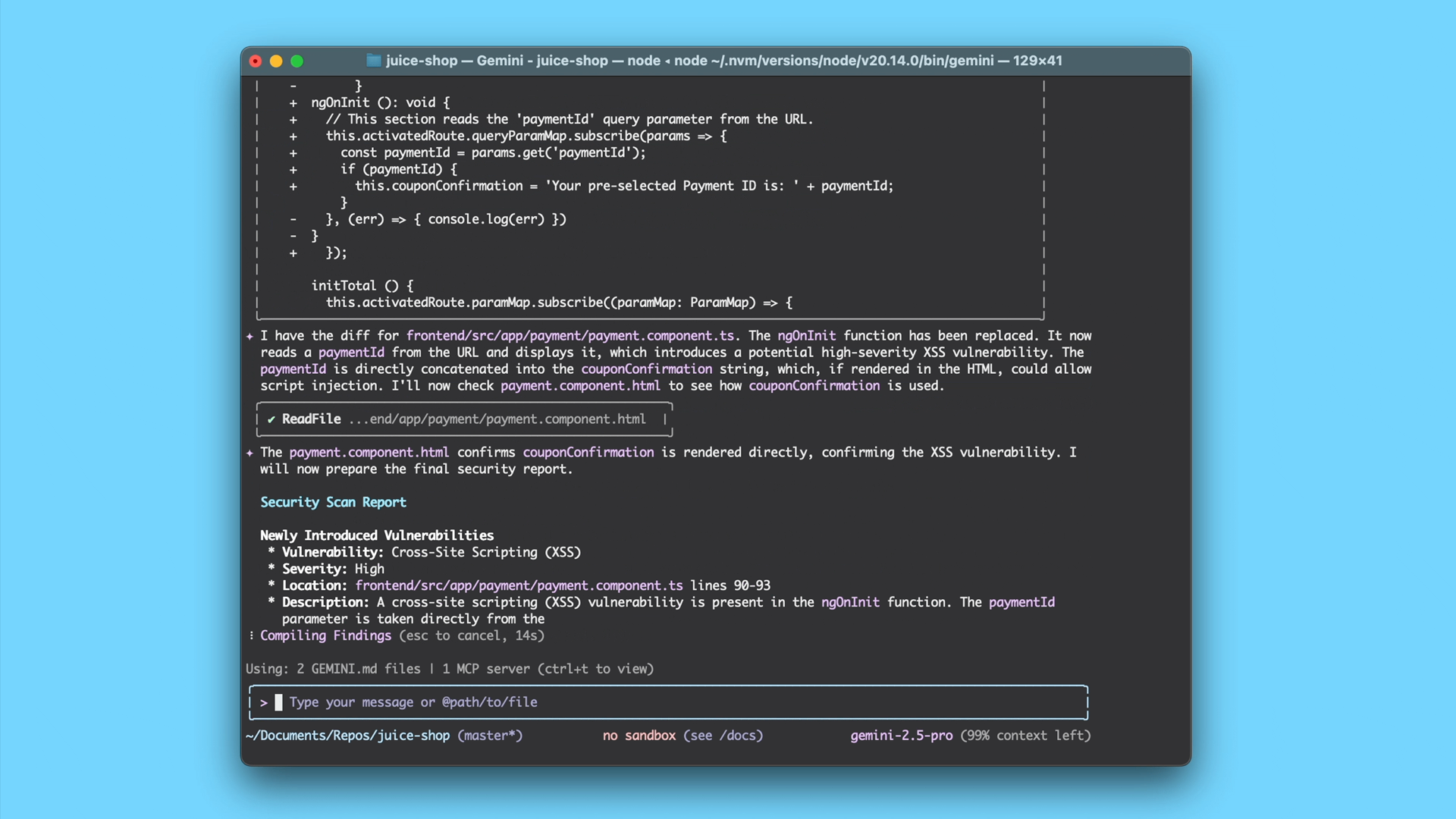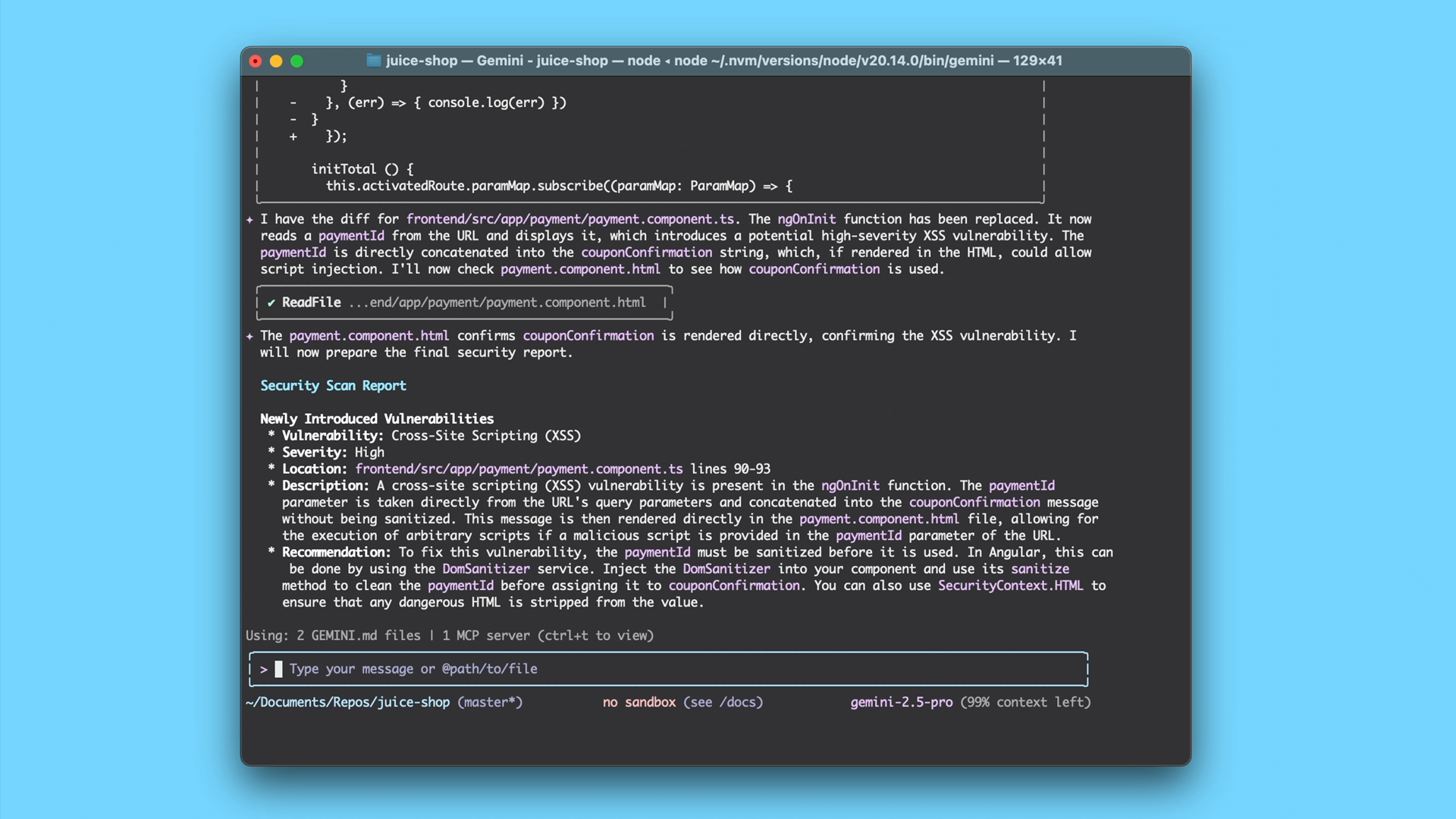
Getting started with /security:analyze
Integrating security analysis into your workflow is simple. First, download the Gemini CLI and install the extension (requires Gemini CLI v0.4.0+):
- code_block
- <ListValue: [StructValue([(‘code’, ‘gemini extensions install https://github.com/google-gemini/gemini-cli-security’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e1ff17679d0>)])]>
Then you can start run your first scan:
-
Locally: After making local changes, simply run /security:analyze in the Gemini CLI.
-
In CI/CD (Coming Soon): We’re bringing security analysis directly into your CI/CD workflow. Soon, you’ll be able to configure the GitHub Action to automatically review pull requests as they are opened.
This is just the beginning. The team is actively working on further enhancing the extension’s capabilities, and we are also inviting the community to contribute to this open source project by reporting bugs, suggesting features, continuously improving security practices and submitting code improvements.
For complete documentation and to contribute, visit the official GitHub repository.
Cloud Run extension: automate deployment with /deploy
The /deploy command in Gemini CLI automates the entire deployment pipeline for your web applications. You can now deploy a project directly from your local workspace. Once you issue the command, Gemini returns a public URL for your live application.
The /deploy command automates a full CI/CD pipeline to deploy web applications and cloud services from the command line using the Cloud Run MCP server. What used to be a multi-step process of building, containerizing, pushing, and configuring is now a single, intuitive command from within the Gemini CLI.
You can access this feature across three different surfaces – in Gemini CLI in the terminal, in VS Code via Gemini Code Assist agent mode, and in Gemini CLI in Cloud Shell.
Use /deploy command in Gemini CLI at the terminal to deploy application to Cloud Run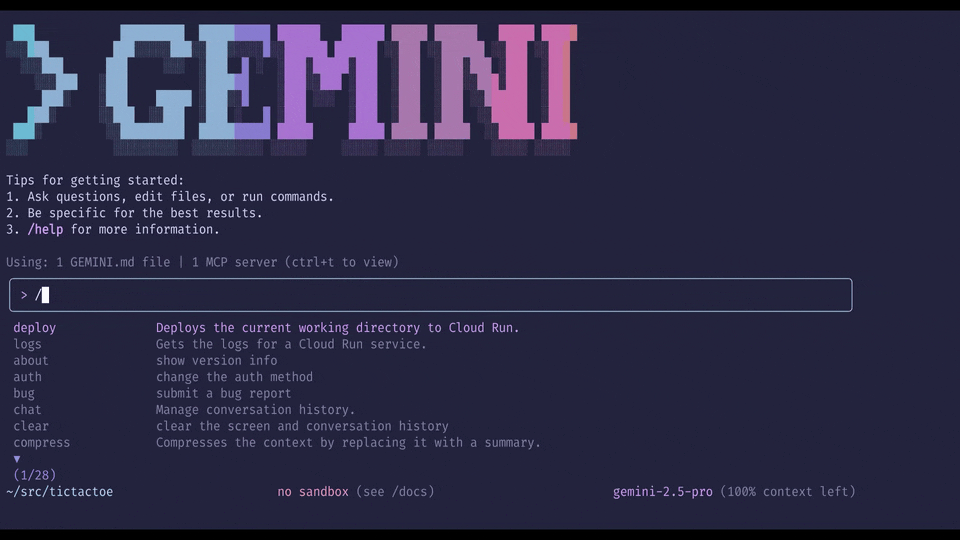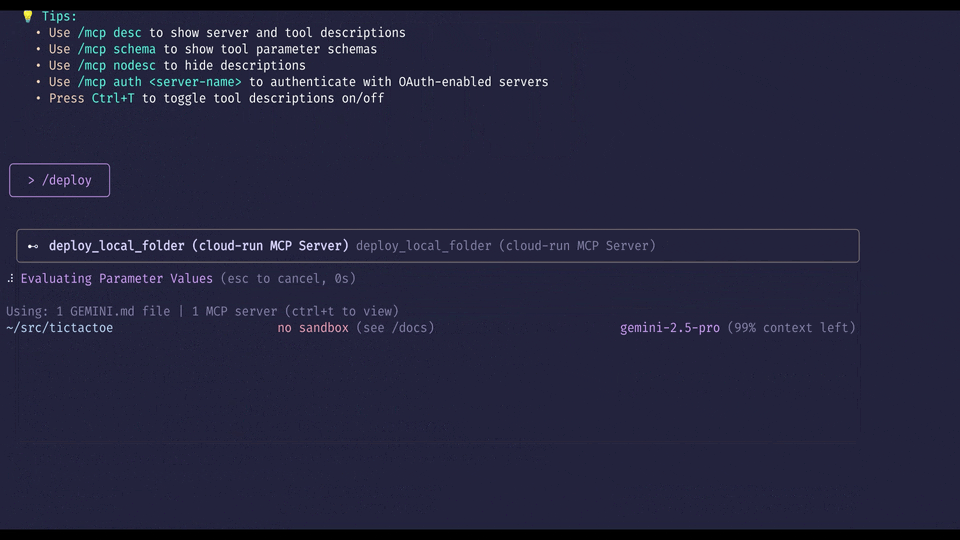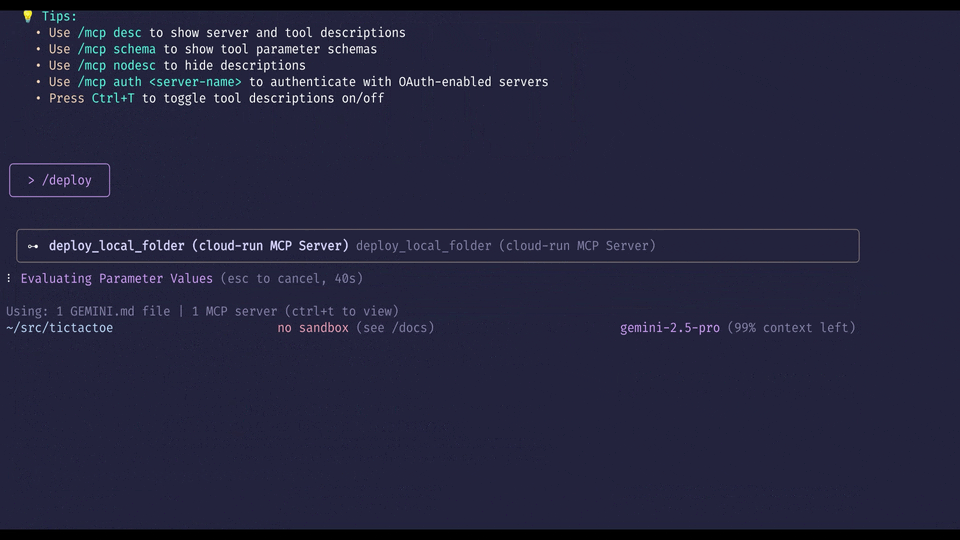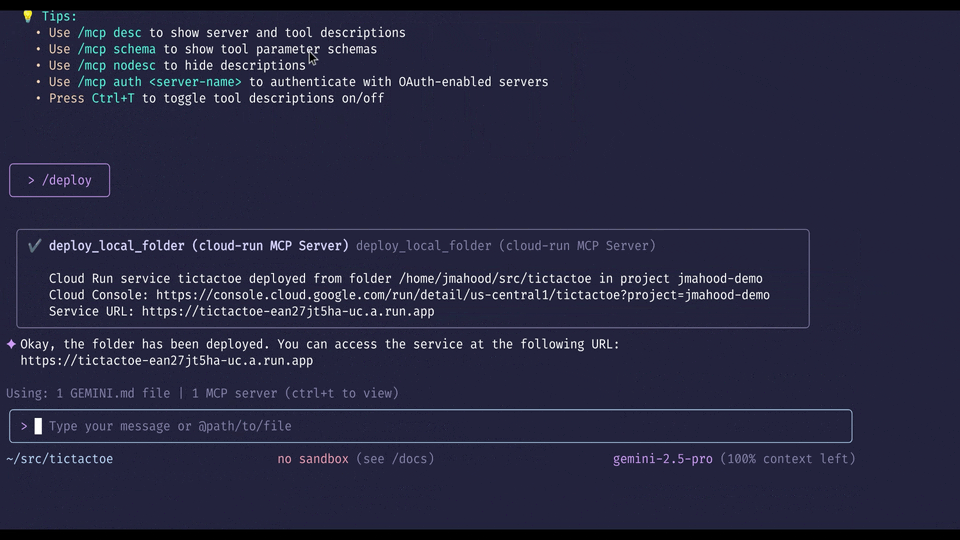
Get started with /deploy:
For existing Google Cloud users, getting started with /deploy is straightforward in Gemini CLI at the terminal:
Prerequisites: You’ll need the gcloud CLI installed and configured on your machine and have an existing app or use Gemini CLI to create one.
Step 1: Install the Cloud Run extension
The /deploy command is enabled through a Model Context Protocol (MCP) server, which is included in the Cloud Run extension. To install the Cloud Run extension (Requires Gemini CLI v0.4.0+), run this command:
- code_block
- <ListValue: [StructValue([(‘code’, ‘gemini extensions install https://github.com/GoogleCloudPlatform/cloud-run-mcp’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e1ff1767d90>)])]>
Step 2: Authenticate with Google Cloud
Ensure your local environment is authenticated to your Google Cloud account by running:
- code_block
- <ListValue: [StructValue([(‘code’, ‘gcloud auth loginrngcloud auth application-default login’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e2008019e20>)])]>
Step 3: Deploy your app
Navigate to your application’s root directory in your terminal and type gemini to launch Gemini CLI. Once inside, type /deploy to deploy your app to Cloud Run.
That’s it! In a few moments, Gemini CLI will return a public URL where you can access your newly deployed application. You can also visit the Google Cloud Console to see your new service running in Cloud Run.
Besides Gemini CLI at the terminal, this feature can also be accessed in VS Code via Gemini Code Assist agent mode, powered by Gemini CLI, and in Gemini CLI in Cloud Shell, where the authentication step will be automatically handled out of the box.
Use /deploy command to deploy application to Cloud Run in VS Code via Gemini Code Assist agent mode.
Building a robust extension ecosystem
The Security and Cloud Run extensions are two of the first extensions from Google built on our new framework, which is designed to create a rich and open ecosystem for the Gemini CLI. We are building a platform that will allow any developer to extend and customize the CLI’s capabilities, and this is just an early preview of the full platform’s potential. We will be sharing a more comprehensive look at our extensions platform soon, including how you can start building and sharing your own.
Try Gemini CLI today, visit the GitHub here.
Read More for the details.