Today, AWS announces the general availability of Neuron SDK 2.26.0, delivering improvements for deep learning workloads on AWS Inferentia and Trainium-based instances. This release introduces support for PyTorch 2.8 and JAX 0.6.2, along with enhanced inference capabilities on Trainium2 (Trn2) instances. These updates enable developers to leverage the latest frameworks while benefiting from improved model deployment flexibility and performance optimizations.
With Neuron SDK 2.26.0, customers can now deploy FLUX.1-dev image generation model, along with Llama 4 Scout and Maverick variants (beta) on Trn2 instances. The release introduces expert parallelism support (beta) for efficient distribution of Mixture-of-Experts (MoE) models across multiple NeuronCores, and adds new capabilities through new Neuron Kernel Interface (NKI) APIs. The updated Neuron Profiler provides improved capabilities, including system profile grouping for distributed workloads.
The new SDK version is available in all AWS Regions supporting Inferentia and Trainium instances, offering enhanced performance and monitoring capabilities for machine learning workloads.
To learn more and for a full list of new features and enhancements, see:
Amazon Redshift announces the general availability of Multidimensional Data Layouts (MDDL) that dynamically sort data based on actual query filters, accelerating query performance. Unlike traditional sorting methods that sort data based on fixed columns, MDDL sorts data based on query filters (for example, Sales in US), achieving up to 10x better end-to-end performance compared to using only optimal single-column sort keys for query workloads with repetitive query filters.
For each table with an AUTO sort key, which is the default for tables without an explicit sort key, Redshift analyzes the table’s query history and automatically selects either a single-column sort key or MDDL for your table, depending on potential performance improvements for your workload. Redshift with MDDL automatically constructs a multidimensional virtual sort keythat co-locates rows typically accessed by the same queries. This virtual column, equivalent to a new sort key for the table, is subsequently used during query execution to skip data blocks and even skip scanning entire predicate columns. Redshift with MDDL provides a more expressive generalization of existing compound and interleaved sort keys that significantly improves the performance of table scans, especially when your query workload contains repetitive query filters. For pre-existing tables with manually defined sort keys, you can take advantage of MDDL by altering the sortkey of the table to AUTO.
MDDL is available in all AWS commercial regions where Redshift is available. To get started, read the documentation, blog, and Amazon Science publication to learn more about benchmarks on query performance improvements.
AWS Organizations now offers full IAM policy language support for service control policies (SCPs), enabling you to write SCPs with the same flexibility as IAM managed policies. With this launch, SCPs now support use of conditions, individual resource ARNs, and the NotAction element with Allow statements. Additionally, you can now use wildcards at the beginning or middle of Action element strings and the NotResource element.
With these policy language enhancements, you can now create more concise and precise policies to implement sophisticated permissions guardrails across your organization. For example, you can restrict access to specific resources with condition statements. The enhanced functionality maintains backward compatibility with existing SCPs, so no changes to current policies are required.
This feature is now available in all AWS commercial and AWS GovCloud (US) Regions.
AWS announces Model Context Protocol (MCP) server for AWS IoT SiteWise in the AWS Labs MCP open-source repository. This MCP server simplifies industrial data modeling by providing built-in domain validation and automated modeling capabilities, eliminating the need for extensive API knowledge. The server supports existing AWS IoT SiteWise functionality through familiar tools while adding new conversational interfaces for enhanced user interaction.
The server comes with built-in industrial knowledge and best practices, automatically applying proper units, data types, and quality indicators. This means your industrial models are production-ready from the start, saving valuable time and resources that would otherwise be spent on multiple iterations and corrections. This foundation enables you to easily implement advanced capabilities like anomaly detection and streamlined asset onboarding, while seamlessly integrating with your existing industrial systems.
AI is transforming how people work and how businesses operate. But with these powerful tools comes a critical question: how do we empower our teams with AI, while ensuring corporate data remains protected?
A key answer lies in the browser, an app most employees use every day, for most of their day. Today, we announced several new AI advancements coming to Chrome, which redefine how browsers can help people with daily tasks, and work is no exception. Powerful AI capabilities right in the browser will help business users be more productive than ever, and we’re giving IT and security teams the enterprise-grade controls they need to keep company data safe.
Gemini in Chrome, with enterprise protections
Our work days can be full of distractions— endless context switching between projects, and repetitive tasks that slow people down. That’s why we’re bringing a new level of assistance directly into the browser, where many of these workflows are already taking place.
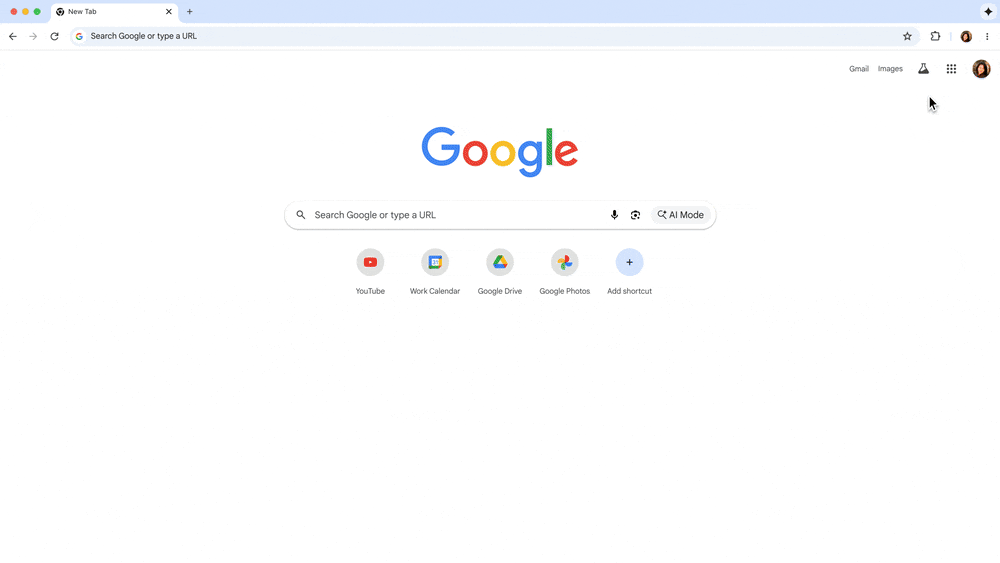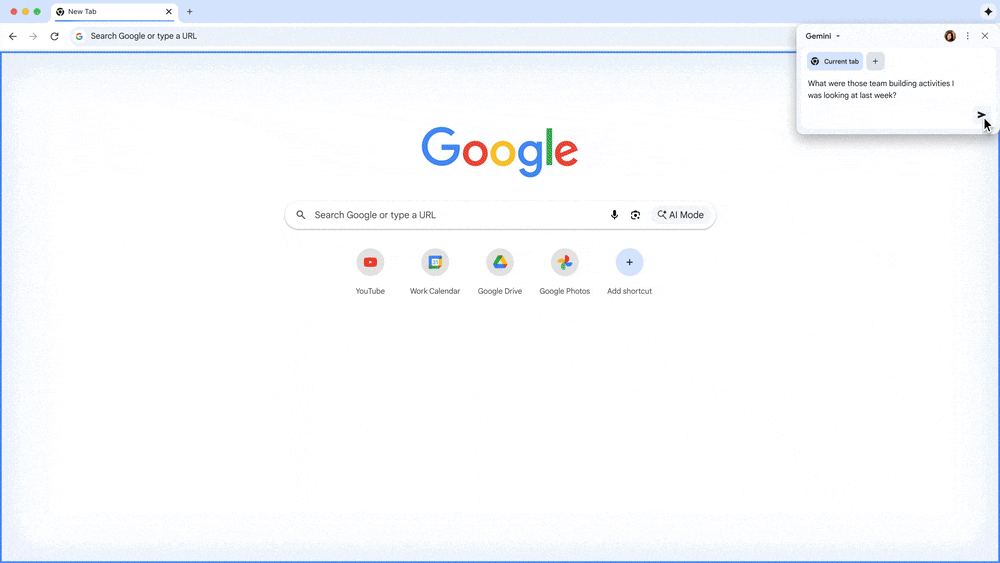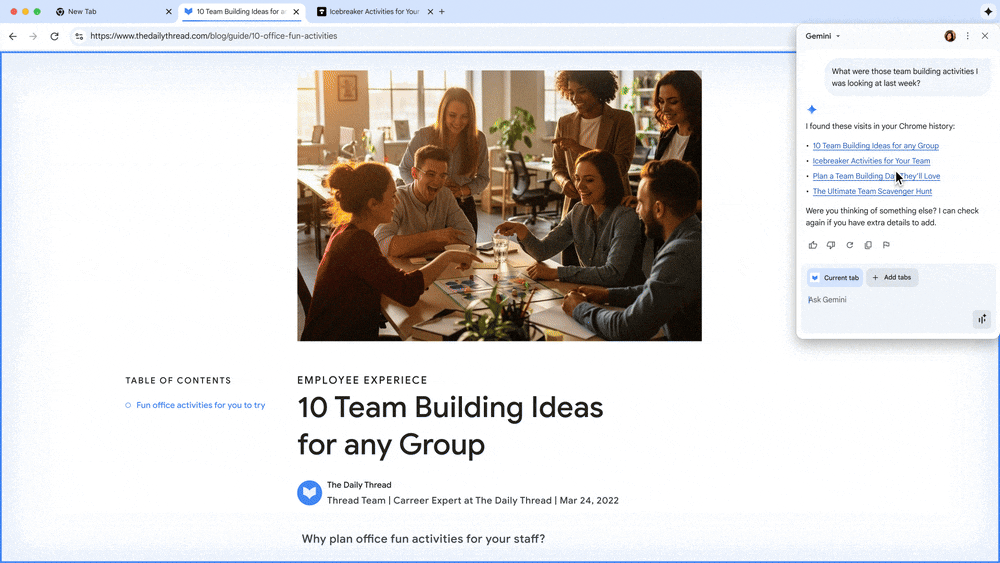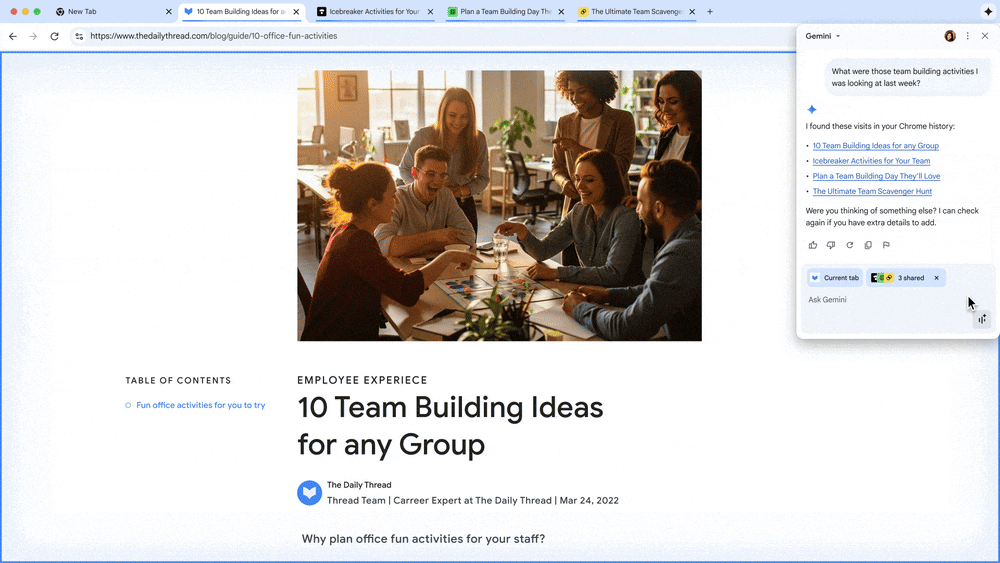
Gemini in Chrome1 is an AI browsing assistant that helps people at work. It can cut through the complexity of finding and making use of information across tabs and help people get work done faster. Employees can now easily summarize long and complex reports or documents, grab key insights from a video, or even brainstorm ideas for a new project with help from Gemini in Chrome. Gemini in Chrome can understand the context of a user’s tabs, and soon it will even help recall recent tabs they had open.
Gemini in Chrome will be able to recall your past tabs for you
We’re bringing these capabilities to Google Workspace business and education customers with enterprise-grade data protections, ensuring IT teams stay in control of their company’s data.
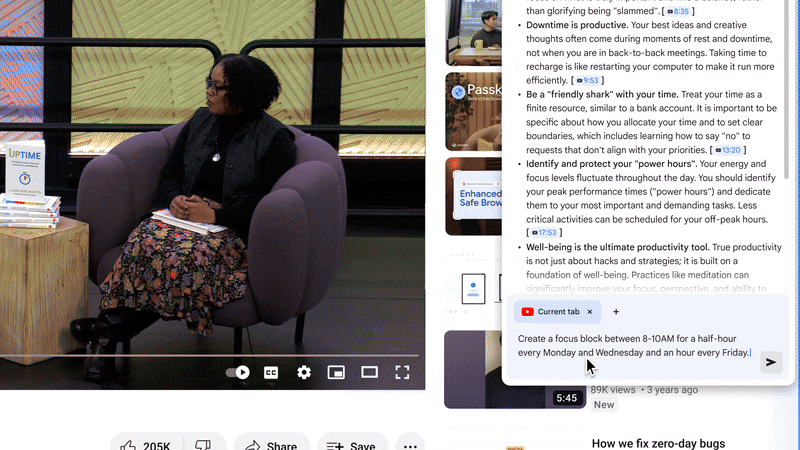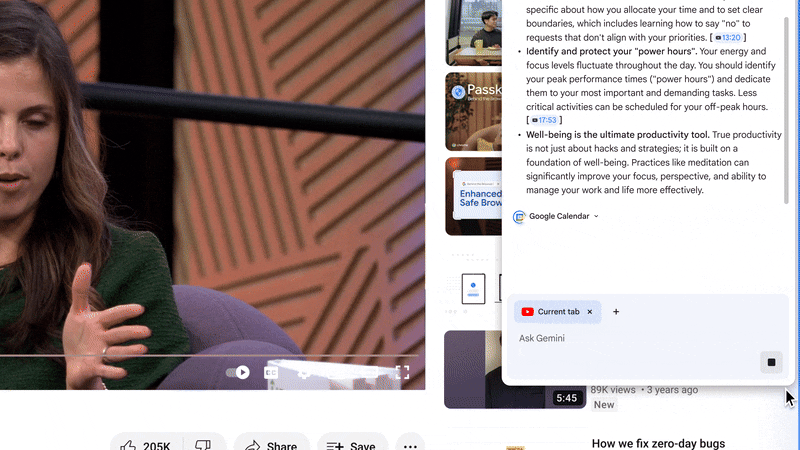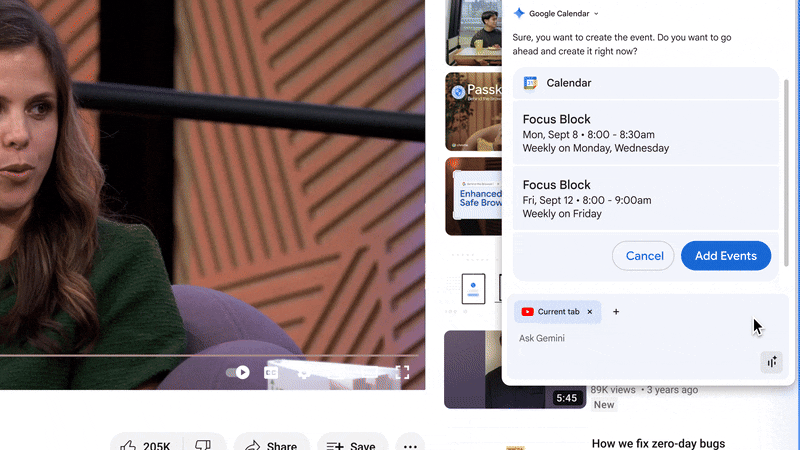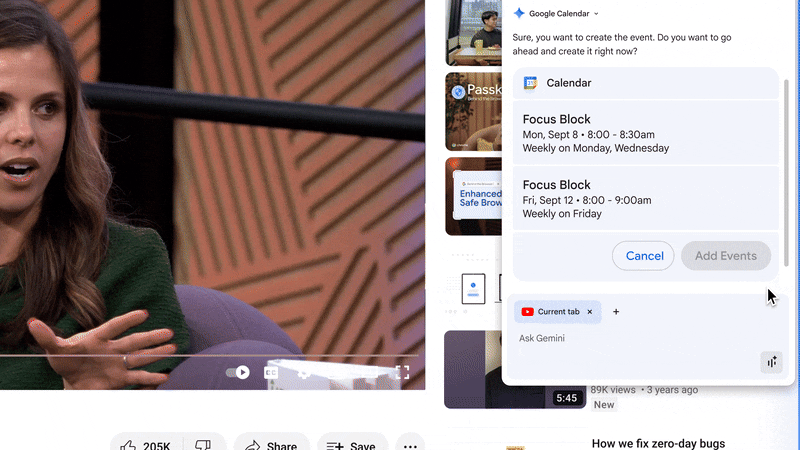
Gemini in Chrome doesn’t just help you find information that you need for your workday, you can also take action through integrations with Google apps people use every day like Google Calendar, Docs and Drive. So employees can schedule a meeting right in their current workflows.
Gemini in Chrome is now integrated with your favorite Google apps
Gemini in Chrome is becoming available for Mac and Windows users in the U.S., and we’re also bringing Gemini in Chrome to mobile in the U.S. Users can also activate Gemini when using Chrome on Android, and other apps, by holding the power button. And starting soon, on iOS Gemini in Chrome will be built into the app.
IT teams can configure Gemini in Chrome through policies in Chrome Enterprise Core, and enterprise data protections automatically extend to customers with qualifying editions of Google Workspace.
AI Mode from Google Search in Chrome
In addition to Gemini in Chrome, the Chrome omnibox—the address bar people use to navigate the web—is also getting an upgrade. With AI Mode, people can ask complex, multi-part questions specific to their needs in the same place where they already search. You’ll get an AI-generated response, and can keep exploring with follow-up questions and helpful web links. IT teams can manage this feature through the generative AI policies in Chrome Enterprise Core.
Proactive AI Protection
We know that a browser’s greatest value is its ability to keep users safe. As the security threats from AI-generated scams and phishing attacks become more sophisticated, our defenses must evolve just as quickly. That’s why security is one of the core pillars of Chrome’s AI strategy.
Safe Browsing’s Enhanced Protection mode is now even more secure with the help of AI. We’re using it to proactively block increasingly convincing threats such as tech support scams, and will be expanding to fake anti/virus and impersonated brand websites soon. We’ve also added AI to help detect and block scammy and spammy site notifications, which has already led to billions fewer notifications being sent to Chrome on Android users every day.
AI with enterprise controls
Organizations want to empower their workforce with AI for greater productivity, but never at the expense of security. Chrome Enterprise gives IT teams the tools they need to manage these new capabilities effectively: our comprehensive policies allow IT and security teams to decide exactly which AI features in Chrome are enabled for which users, and how that data is treated.
Chrome Enterprise Premium allows organizations even more safeguards. For example, they can use URL filtering to block unapproved AI tools and point employees back to corporate supported AI services. Within AI tools, security teams can apply data masking or other upload and copy/paste restrictions for sensitive data. These advanced capabilities further prevent sensitive information from being accidentally or maliciously shared via AI tools or any other web sites.
With Chrome Enterprise, AI in the browser offers businesses the best of both worlds: a highly productive, AI-enhanced user experience and the enterprise-grade security enterprises depend on to protect their data. To learn more about these new features, view our recent Behind the Browser AI Edition video.
1 Check responses for accuracy. Available on select devices and in select countries, languages, and to users 18+
Enterprises need to move from experimenting with AI agents to achieving real productivity, but many struggle to scale their agents from prototypes to secure, production-ready systems.
The question is no longer if agents deliver value, but how to deploy them with enterprise confidence. And there’s immense potential for those who solve the scaling challenge. Our 2025 ROI of AI Report reveals that 88% of agentic AI early adopters are already seeing a positive return on investment (ROI) on generative AI.
Vertex AI Agent Builder is the unified platform that helps you close this gap. It’s where you can build the smartest agents, and deploy and scale them with enterprise-grade confidence.
Today, we’ll walk you through agent development on Vertex AI Agent Builder, and highlight a couple of key updates to fuel your next wave of agent-driven productivity and growth.
aside_block
<ListValue: [StructValue([(‘title’, ‘$300 in free credit to try Google Cloud AI and ML’), (‘body’, <wagtail.rich_text.RichText object at 0x3e7d8c08a4f0>), (‘btn_text’, ”), (‘href’, ”), (‘image’, None)])]>
The five pillars of enterprise agent development on Vertex AI Agent Builder
Moving an agent from prototype to production requires a cohesive suite of tools. Vertex AI Agent Builder simplifies this complexity by providing an integrated workflow across five essential pillars, supporting your agent through every step of its lifecycle.
1. Agent frameworks Your agent development journey begins here. You configure and orchestrate your agents using your preferred open source framework. The Agent Development Kit (ADK) – what we use internally at Google – is one of the many options available, and it has already seen over 4.7 million downloads since April.
2. Model choice Models are the intelligent core of your agent. Our platform is provider-agnostic, supporting every leading model – including the Gemini 2.5 model family – alongside hundreds of third-party and open source models from Vertex AI Model Garden. With the ability to Provision Throughput, you can secure dedicated capacity for consistent, low-latency performance at scale.
3. Tools for taking actions Once built, your agent needs tools to take action and interact with the real world. Grounding is a critical step that connects your AI to verifiable, real-time data – dramatically reducing hallucinations and building user trust. On Vertex AI, you can connect your agent to trusted, real-time data sources you already rely on. For example, Grounding with Google Maps is now available for everyone in production. Your agents gain accuracy and the ability to reduce hallucinations by accessing the freshness of Google Maps, which includes factual information on 250 million places for location-aware recommendations and actions.
4. Scalability and performance Deploy and manage at scale using Vertex AI Agent Engine. We built this suite of modular, managed services to instantly move your prototypes into production. The platform provides everything needed for operation and scaling, including a fully managed runtime, integrated Sessions and Memory Bank to personalize context across user interactions, and integrated evaluation and observability services.
Since launch, hundreds of thousands of agents have been deployed to Vertex AI Agent Engine. Here are some recent updates we’re most excited about:
Secure code execution: We now provide a managed, sandboxed environment to run agent-generated code. This is vital for mitigating risks while unlocking advanced capabilities for tasks like financial calculations or data science modeling .
Agent-to-Agent collaboration: Build sophisticated, reliable multi-agent systems with native support for the Agent-to-Agent (A2A) protocol when you deploy to the Agent Engine runtime. This allows your agents to securely discover, collaborate, and delegate tasks to other agents, breaking down operational silos .
Real-Time interactive agents: Unlock a new class of interactive experiences with Bidirectional Streaming. This provides a persistent, two-way communication channel ideal for real-time conversational AI, live customer support, and interactive applications that process audio or video inputs .
Simplified path to production: We have streamlined the journey from a local ADK prototype to a live service, with a one-line deployment in the ADK CLI to Agent Engine.
5. Built-in trust and security Security and compliance are built into every layer of the Vertex AI architecture, ensuring control is paramount. This includes preventing data exfiltration with Virtual Private Cloud Service Controls (VPC-SC) and using your own encryption keys with Customer-Managed Encryption Keys (CMEK). We also meet strict compliance milestones like HIPAA and Data Residency (DRZ) compliance requirements. Your agents can handle sensitive workloads in highly regulated industries with full confidence.
Get started today
It’s time to move your AI strategy from experimentation to exponential growth. Bridge the production gap and deploy your first enterprise agent with Vertex AI Agent Builder, the secure, scalable, and intelligent advantage you need to succeed.
With this launch, Amazon VPC Reachability Analyzer and Amazon VPC Network Access Analyzer are now available in Asia Pacific (New Zealand), Asia Pacific (Hyderabad), Asia Pacific (Melbourne), Asia Pacific (Taipei), Canada West (Calgary), Israel (Tel Aviv) and Mexico (Central).
VPC Reachability Analyzer allows you to diagnose network reachability between a source resource and a destination resource in your virtual private clouds (VPCs) by analyzing your network configurations. For example, Reachability Analyzer can help you identify a missing route table entry in your VPC route table that could be blocking network reachability between an EC2 instance in Account A that is not able to connect to another EC2 instance in Account B in your AWS Organization.
VPC Network Access Analyzer allows you to identify unintended network access to your AWS resources, helping you meet your security and compliance guidelines. For example, you can create a scope to verify that all paths from your web-applications to the internet, traverse the firewall, and detect any paths that bypass the firewall.
Amazon Q Developer CLI announces support for remote MCP servers. Remote MCP servers improve scalability and security of the tools you use within your development tasks. Not only does it reduce the use of compute resources by moving to a centralized server, it also helps you better manage access and security. You can now integrate with MCP servers such as Atlassian, and GitHub that support HTTP and support OAuth based authentication.
To configure a remote MCP server, specify the transport type as HTTP, the URL where users will get authentication credentials, and any optional headers to include when making the request. You can configure remote MCP servers in your custom agent configuration or in mcp.json. When a CLI session is initiated, you will see the list of MCP servers to load and can query the list for the authentication URL. Once you successfully complete the authentication steps, Q Developer CLI will query the tools available from the MCP server and make it available to the agent.
Remote MCP servers are available in Amazon Q Developer CLI and Amazon Q Developer IDE plugins. For more information, check out the documentation.
Second-generation AWS Outposts racks are now supported in the AWS Canada (Central) and US West (N. California) Regions. Outposts racks extend AWS infrastructure, AWS services, APIs, and tools to virtually any on-premises data center or colocation space for a truly consistent hybrid experience.
Organizations from startups to enterprises and the public sector in and outside of Canada and the US can now order their Outposts racks connected to these two new supported Regions, optimizing for their latency and data residency needs. Outposts allows customers to run workloads that need low-latency access to on-premises systems locally while connecting back to their home Region for application management. Customers can also use Outposts and AWS services to manage and process data that needs to remain on-premises to meet data residency requirements. This regional expansion provides additional flexibility in the AWS Regions that customers’ Outposts can connect to.
To learn more about second-generation Outposts racks, read this blog post and user guide. For the most updated list of countries and territories and the AWS Regions where second-generation Outposts racks are supported, check out the Outposts racks FAQs page.
Amazon Kinesis Data Streams now allows customers to make API requests over Internet Protocol version 6 (IPv6) in the AWS GovCloud (US) Regions. Customers have the option of using either IPv6 or IPv4 when sending requests over dual-stack public or VPC endpoints. The new endpoints have also been validated under the Federal Information Processing Standard (FIPS) 140-3 program.
Kinesis Data Streams allows users to capture, process, and store data streams in real time at any scale. IPv6 increases the number of available addresses by several orders of magnitude, so customers will no longer need to manage overlapping address spaces. Many devices and networks today already use IPv6, and now they can easily write to and read from data streams. FIPS-compliant endpoints help companies contracting with the US federal governments meet the FIPS security requirement to encrypt sensitive data in supported Regions.
Support for IPv6 with Kinesis Data Streams is now available in all Regions where Kinesis Data Streams is available, including AWS GovCloud (US) and China Regions. See here for a full listing of our Regions. To learn more about Kinesis Data Streams, please refer to our Developer Guide.
We are happy to drop the third installment of our Network Performance Decoded whitepaper series, where we dive into topics in network performance and benchmarking best practices that often come up as you troubleshoot, deploy, scale, or architect your cloud-based workloads. We started this series last year to provide you helpful tips to not only make the best of your network but also avoid costly mistakes that can drastically impact your application performance. Check out our last two installments — tuning TCP and UDP bulk flows performance, and network performance limiters.
In this installment, we provide an overview of three recent whitepapers — one on TCP retransmissions, another on the impact of headers and MTUs on data transfer performance, and finally, using netperf to measure packets per second performance.
1. Make it snappy: Tuning TCP retransmission behaviour
The A Brief Look at Tuning TCP Retransmission Behaviour whitepaper is all about how to make your online applications feel snappier, by tweaking two Linux TCP settings, net.ipv4.tcp_thin_linear_timeouts and net.ipv4.tcp_rto_min_us (or rto_min) Think of it as fine-tuning your application’s response times and how quickly your application recovers when there’s a hiccup in the network.
For all the gory details, you’ll need to read the paper, but here’s the lowdown on what you’ll learn:
Faster recovery is possible: By playing with these settings, especially making rto_min smaller, you can drastically cut down on how long your TCP connections just sit there doing nothing after a brief network interruption. This means your apps respond faster, and users have a smoother experience.
Newer kernels are your friend: If you’re running a newer Linux kernel (like 6.11 or later), you can go even lower with rto_min (down to 5 milliseconds!). This is because these newer kernels have smarter ways of handling things, leading to even quicker recovery.
Protective ReRoute takes resiliency to the next level: For those on Google Cloud, tuning net.ipv4.tcp_rto_min_us can actually help Google Cloud’s Protective ReRoute (PRR) mechanism kick in sooner, making your applications more resilient to network issues.
Not just for occasional outages: Even for random, isolated packet loss, these tweaks can make a difference. If you have a target for how quickly your app should respond, you can use these settings to ensure TCP retransmits data well before that deadline.
aside_block
<ListValue: [StructValue([(‘title’, ‘$300 to try Google Cloud networking’), (‘body’, <wagtail.rich_text.RichText object at 0x3eed51df5cd0>), (‘btn_text’, ”), (‘href’, ”), (‘image’, None)])]>
2. Beyond network link-rate
Consider more than just “link-rate” when thinking about network performance! In our Headers and Data and Bitrates whitepaper, we discuss how the true speed of data transfer is shaped by:
Headers: Think of these as necessary packaging that reduces the actual data sent per packet.
Maximum Transmission Units (MTUs): These dictate maximum packet size. Larger MTUs mean more data per packet, making your data transfers more efficient.
In cloud environments, a VM’s outbound data limit (egress cap) isn’t always the same as the physical network’s speed. While sometimes close, extra cloud-specific headers can still impact your final throughput. Optimize your MTU settings to get the most out of your cloud network. In a nutshell, it’s not just about the advertised speed, but how effectively your data travels!
3. How many transactions can you handle?
In Measuring Aggregate Packets Per Second with netperf, you’ll learn how to use netperf to figure out how many transactions (and thus packets) per second your network can handle, which is super useful for systems that aren’t just pushing huge files around. Go beyond just measuring bulk transfers and learn a way to measure the packets per second rates which can gate the performance of your request/response applications.
Here’s what you’ll learn:
Beating skew error: Ever noticed weird results when running a bunch of netperf tests at once? That’s “skew error,” and this whitepaper describes using “demo mode” to fix it, giving you way more accurate overall performance numbers.
Sizing up your test: Get practical tips on how many “load generators” (the machines sending the traffic) and how many concurrent streams you need to get reliable results. Basically, you want enough power to truly challenge your system.
Why UDP burst mode is your friend: It explains why using “burst-mode UDP/RR” is the secret sauce for measuring packets per second. TCP, as smart as it is, can sometimes hide the true packet rate because it tries to be too efficient.
Full-spectrum testing and analysis: The whitepaper walks you through different test types you can run with the runemomniaggdemo.sh script, giving you an effective means to measure how many network transactions per second the instance under test can achieve. This might help you infer aspects of the rest of your network that influence this benchmark. Plus, it shows you how to crunch the numbers and even get some sweet graphs to visualize your findings.
Stay tuned
With these resources our goal is to foster an open, collaborative community for network benchmarking and troubleshooting. While our examples may be drawn from Google Cloud, the underlying principles are universally applicable, no matter where your workloads operate. You can access all our whitepapers — past, present, and future — on ourwebpage. Be sure to check back for more!
Though its name may suggest otherwise, Seattle Children’s is the largest pediatric healthcare system in the world.
While its main campus is in its namesake city, Seattle Children’s also encompasses 47 satellite hospitals across Alaska, Montana, Idaho, and Washington, and patients come from as far away as Hawaii for treatment. For more than 100 years, Seattle Children’s has helped kids across the Western U.S. get healthy and stay healthy, regardless of the ability to pay.
With so much ground to cover and diverse patient populations to treat, Seattle Children’s has always looked to new technologies to bring improved, consistent care to its patients and providers. Generative AI is now the latest advance in their medical toolkit.
It started roughly two decades ago, when Seattle Children’s created its pediatric clinical pathways, a set of standardized protocols designed to help clinicians make quicker and more reliable decisions to address dozens of medical conditions. Such pathways were becoming commonplace across medicine, and Seattle Children’s had developed some of the first for children’s unique medical needs.
Innovative as these were, they still required clinicians to thumb through indexes and long binders of information to find what they needed for a given ailment. And in healthcare, it’s often the case that every second counts.
Seattle Children’s was already working with Google Cloud on a number of projects, and as we began to explore the potential for generative AI to make the work of our clinicians easier, the clinical pathways seemed like an obvious place to start. Using Vertex AI and Gemini, we were able to quickly develop our Pathways Assistant, which took training from the clinical pathways documentation and supercharged it with not just searchability but conversationality.
Instead of flipping pages, we’d flipped the script on how quickly and reliably clinicians could find the lifesaving information they needed.
The pathways to improved healthcare run through Gemini “Clinical pathways” are end-to-end treatment protocols for a specific condition or illness. Seattle Children’s pediatric clinical pathways are widely respected and used by hospitals around the globe, providing information on everything from diagnostic criteria to testing protocols to medication recommendations.
Previously, these clinical pathways were documented exclusively in PDFs — hundreds of thousands of pages of them. Performing a traditional search of their contents for the answers clinicians needed delayed their ability to provide treatment in an environment where minutes or even seconds can be critical.
Google Cloud engineers worked with Seattle Children’s informatics physicians, who straddle the worlds of healthcare and technology, to create Pathway Assistant. The new multimodal AI chatbot that responds to spoken or written natural-language queries using the information in those PDFs.
After processing a question, Pathway Assistant searches each PDF’s metadata, which contains semi-structured data in JSON format that’s been extracted from the PDFs by Gemini and curated by clinicians. It then selects the most relevant PDFs, parses the information — including any complex flowcharts, diagrams, and illustrations embedded in them — and answers the clinician’s question in just a few seconds.
Interactive information-finding for accurate decision-making Pathway Assistant becomes more accurate with use. Healthcare providers can “discuss” clinical pathways with the chatbot, which, instead of answering a question, poses questions of its own if it needs clarification, going back and forth until it’s confident it can answer accurately. The chatbot always displays the specific sections of each PDF that was the source for formulating its answers, helping clinicians confirm the veracity of responses.
The interface also includes a way for users to provide feedback about the accuracy and appropriateness of the chatbot’s analysis and answers. The feedback is then logged in a BigQuery table for future forensic analysis — both by clinicians, who can query the information using natural language, and by the built-in Gemini models, which processes the feedback and summarizes what clinicians found confusing or how to improve the accuracy of future answers.
This reflexive capability enables Pathway Assistant to update the PDFs based on clinicians’ feedback if the inaccuracy stemmed from the PDF’s content. Clinicians are also finding that the metadata is becoming more accurate and requiring less curation. Pathway Assistant even corrects typos in the documentation automatically. And as new clinical pathways are developed, PDFs containing the latest information are added to the PDF library.
This growing collection is housed securely in Google Cloud Storage, and the bigger it gets, the more useful it becomes — which wasn’t always the case. Whereas an expanding paper-based collection contained more information, it was also more material to wade through, which is especially challenging in emergency medical situations. Pathway Assistant almost entirely relieves this burden, synthesizing and delivering the most complete information at any time in a matter of seconds.
Ultimately, Pathway Assistant is not a decision-making tool but rather an information-finding tool. Research into critical, evidence-based guidelines that used to take hours now takes minutes.
This speed and effectiveness helps clinicians make the right decisions more quickly at the point of care, drastically reducing research time and improving patient safety and outcomes. Ultimately, clinicians can spend more time with more patients, not with more PDFs.
Ask any physician, they’ll tell you that’s what the best medical technology enables them to do — focus on the patient, not paperwork.
In today’s world where instant responses and seamless experiences are the norm, industries like mortgage servicing face tough challenges. When navigating a maze of regulations, piles of financial documents, and the high stakes of homeownership, consumers quickly find that even simple questions can turn into complicated issues. And the same can be true for the customer reps trying to help them navigate all that complexity.
Like many enterprises, Mr. Cooper is exploring how agentic AI and advanced AI agents can help both our customers and employees meet their needs with confidence. In our work to develop just such an agent with Google Cloud, one of our curious discoveries has been that like a good team, the best AI agents may just be made up of groups of agents with distinct skillsets and abilities, and we come to the best results when they’re working in concert.
At Mr. Cooper, our mission is to “Keep the dream of homeownership alive.”We’re here to simplify the journey, provide clarity, and ensure our customers feel confident every step of the way. That confidence is key when they’re making one of the most consequential purchases, and decisions, of their lives.
With those dual goals of simplicity and certainty in mind, we partnered with Google Cloud to develop an agentic AI framework designed to complement and support our team. We call it the Coaching Intelligent Education & Resource Agent, or CIERA. We asked ourselves how to implement a chatbot that could effectively collaborate with our human agents to streamline both sides of the customer service experience.
And just as we prioritize hiring great groups of customer reps and mortgage agents, we’ve discovered how important it is to put together the right group of agents to effectively meet the needs of all our users. CIERA is designed to do exactly that, handling routine and time-consuming tasks to enhance efficiency, while empowering our people to focus on delivering what they do best — empathy, judgment and meaningful human connection.
CIERA represent an exciting step forward in blending human expertise with AI capabilities, creating a collaborative approach that elevates both the customer experience and our team’s impact. And just as important as this work is for Mr. Cooper, CIERA also demonstrates how our multi-agent approach can serve as a model for companies across industries. Read on to learn how we did it, and how you can, too.
The challenge: Beyond the reach of traditional automation
Mortgage servicing is uniquely complex, where a customer might have a single question that requires an agent to cross-reference multiple documents.
This presents several challenges for traditional automation:
Siloed Knowledge: Scattered information makes it hard to see the full picture, but AI surfaces key data, helping agents make faster, smarter decisions for customers.
Lack of Understanding: Traditional systems rely on rigid keywords and decision trees, often missing the true intent behind customer inquiries. Our AI framework uncovers context and intent, equipping agents with the insights they need to respond with empathy and accuracy.
Inflexible Processes: When conversations take unexpected turns, legacy automation often fails, creating dead ends for customers and the team. AI provides real-time adaptive guidance, helping agents navigate these twists seamlessly.
To truly elevate the customer experience, we needed a solution capable of reasoning, orchestrating, and understanding context — one that enhances and amplifies our capabilities to deliver exceptional service.
The vision: Introducing CIERA, a collaborative AI agent workforce
Our vision was to create an agentic framework that supports our call center agents by leveraging Google Cloud’s Vertex AI platform. CIERA’s AI agents handle repetitive and complex tasks, allowing our team to focus on what technology can’t.
Guided by the principle that AI enhances human performance, these digital collaborators are designed to deliver accurate, comprehensive, and human-centered solutions.
Building the agent workforce: Our architectural blueprint Our modular architecture assigns distinct roles to each AI agent, creating a scalable, efficient. and manageable system that seamlessly collaborates with people to make work smoother and more rewarding.
Meet the key players of our digital team and the solutions they deliver for team members and customers:
Sage, the Head Agent: Sage monitors how all other AI agents perform. By learning from patterns across workflows, Sage helps ensure that each AI agent works in harmony with human teams. Key abilities include intelligent agent monitoring, recognizing useful trends and fine-tuning orchestration.
Ava, the Orchestrator: Ava serves as the team’s coordinator, managing complex customer inquiries by breaking them into manageable tasks and assigning them to the appropriate AI assistants. While Ava doesn’t interact directly with customers, it ensures processes run smoothly, empowering human agents to remain central to delivering solutions.
Lex, the Task Specialist: Lex specializes in complex tasks, helping human agents during customer calls by quickly offering insights to questions around loan applications or escrow analyses. Working behind the scenes, Lex provides insights that allow people to focus on connecting with customers and making informed decisions.
Sky, the Data Specialist: Sky helps human teams navigate internal knowledge bases and FAQs. For questions about policies, procedures, or definitions, Sky provides accurate and timely information, freeing people to spend more time on meaningful interactions, rather than searching for data.
Remy, the Memory Agent: Remy assists by remembering past actions and outcomes, which helps personalize workflows and inform future decisions. Remy’s memory supports ongoing learning and training, making it easier for human agents to access shared knowledge and continuously improve their skills.
Iris, the Evaluation Agent: By evaluating confidence scores, detecting hallucinations, and grounding responses with Model Armor, Iris ensures consistency and authenticity, helping human agents provide trustworthy customer support.
A sample analysis performed by CIERA.
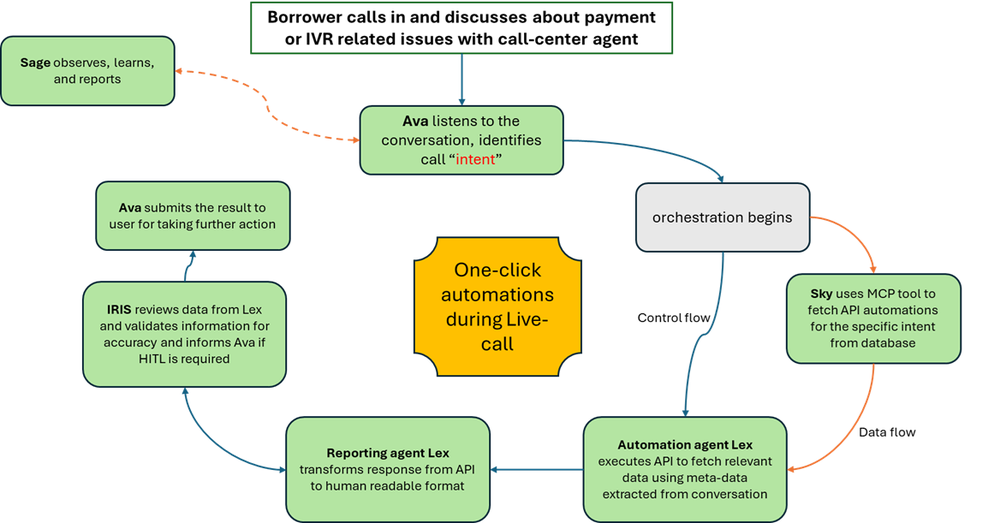
How it works in practice: A real-life scenario
Imagine a customer initiates a call asking, “I received a notice my escrow payment is increasing. Can you explain why and tell me what my new total payment will be?”
Instead of relying solely on automated responses, CIERA ensures every step is grounded in close partnership between AI agents and human team members:
Orchestration: Ava receives the query, understands the two distinct parts (the “why” and the “what”), and creates a plan. Ava consults with a human agent, confirms the correct context and then delegates tasks to the Lex agents.
Parallel Processing: With human oversight, Ava assigns the “why” task to Lex, pointing it to the customer’s most recent escrow analysis document. Simultaneously, it tasks another Lex agent to calculate the new total payment based on data from our systems.
Synthesis: The Lex agent reads the document and reports back to the human agent: “The increase is due to a $200 annual rise in property taxes.” The other agent confirms the new total payment. The human similarly reviews the payment calculation before moving ahead.
Resolution: Ava gathers all AI-generated insights, but the human agent validates and personalizes the final response as needed to ensure clarity, empathy, and accuracy before delivering it to the customer.
This human-in-the-loop approach ensures complex, multifaceted questions are resolved with both the efficiency of advanced AI and understanding nuances with the trust that only people can provide. The partnership guarantees every answer is not just quick, but also trustworthy and tailored to the customer’s needs.
Ensuring quality and trust: The “agentic pulse” and human oversight
In a regulated industry like ours, trust and accuracy are non-negotiable. Deploying advanced AI requires an equally advanced framework for evaluation and governance. To achieve this, we developed two key concepts:
The “Agentic Pulse” Dashboard: Our central command center for monitoring the health and performance of our agent workforce. Powered by model-based evaluation services within the Vertex AI platform , it goes beyond simple metrics. We track:
Faithfulness: Is the agent’s answer grounded in the source documents
Relevance: Does the answer directly address the customer’s question
Safety: Does the agent avoid generating harmful or inappropriate content
Business Metrics: How do we correlate these quality scores with classic KPIs like average handle time (AHT) and customer satisfaction (CSAT)
The “Sandbox” for HITL: Our “Sandbox” environment provides space for our business and technical teams to safely review, test and refine agent processes. Additionally, if the “Agentic Pulse” flags an interaction for review, a human expert can analyze the agent’s reasoning and provide feedback, ensuring a continuous cycle of improvement and learning.
This robust governance framework gives us the confidence to deploy these powerful tools responsibly.
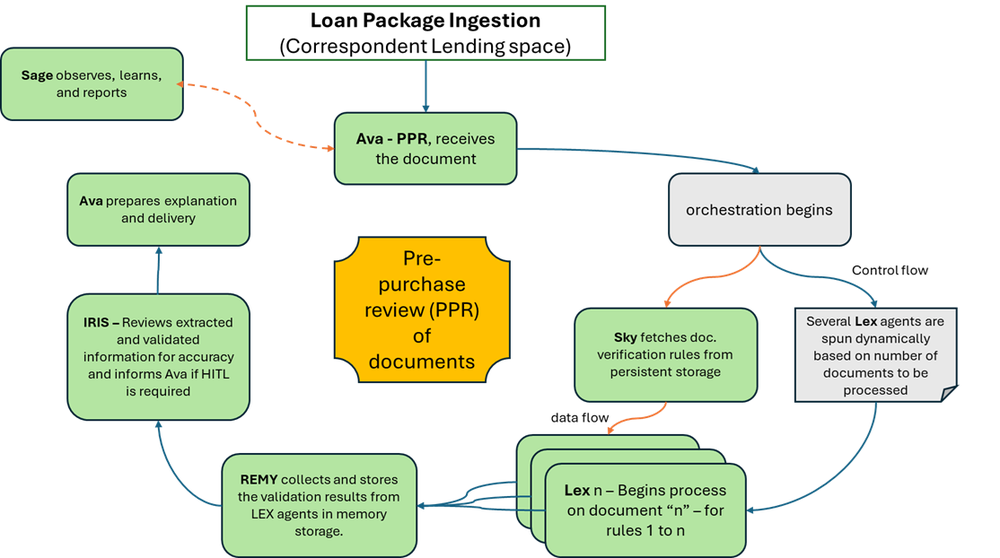
Example of a theoretical loan analysis assisted by CIERA.
Projected impact: From complex processes to clear wins
While CIERA is on its journey towards full production, our projections based on extensive testing and modelling point to historic and transformative gains across the board:
For our customers: We project a reduction in wait times and a higher rate of first-contact resolution, so customers can get answers quicker and with the benefits of round-the-clock support for many complex scenarios.
For our human agents: By automating tedious research, CIERA will free up our human agents to focus on sensitive and complex customer relationships that require a human touch and create better tools and resources for more engaging work.
For our business: We anticipate a major reduction in average handling times for a large segment of inquiries and faster, more accurate resolutions that are a direct driver of customer happiness and loyalty.
Beyond mortgages: A blueprint for any complex industry
The architectural patterns developed with CIERA are not limited to mortgage servicing. This agentic approach — of using an orchestrator to manage a team of specialized AI agents—is a powerful blueprint that can be applied to any industry, including healthcare, logistics and manufacturing, by grappling with information and task complexity.
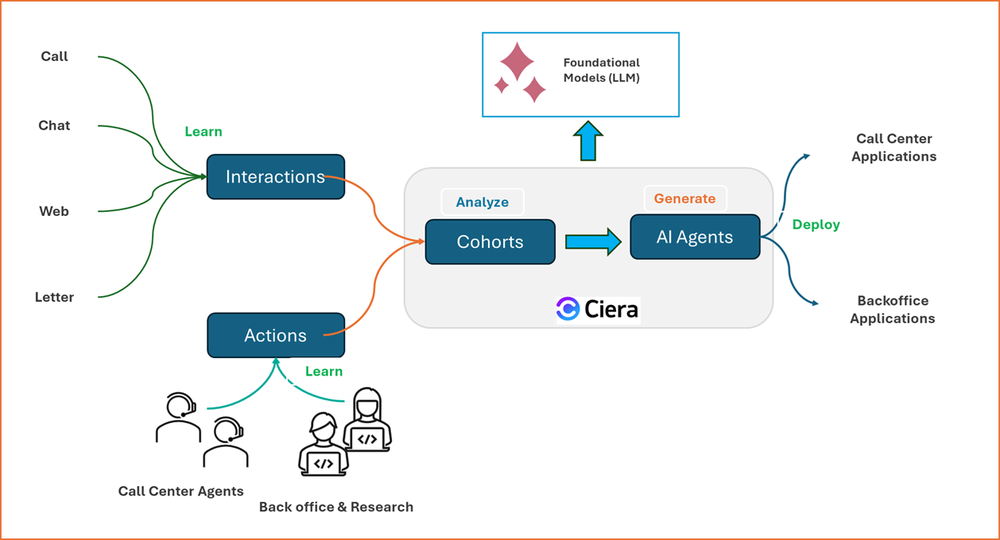
A typical workflow with CIERA.
The future is agentic and collaborative
Our journey with CIERA is just beginning, but it has already solidified our belief that the future of customer service is agentic driven. By combining Mr. Cooper’s deep industry expertise with Google Cloud’s world-class AI infrastructure, we are not just building bots, we are cultivating a digital workforce.
This collaboration is about more than just lowering costs or improving efficiency — it’s about building trust, delivering clarity, and creating a customer experience truly worthy of the dream of homeownership.
The team would like to thank Googlers Sumit Agrawal and Crispin Velez and the GSD AI Incubation team for their support and technical leadership on agents and agent frameworks as well as their deep expertise in ADK, MCP, and large language model evaluations.
Organizations today face immense pressure to secure their digital assets against increasingly sophisticated threats — without overwhelming their teams or budgets.
Using managed security service providers (MSSPs) to implement and optimize new technology, and handle security operations, is a strategic delegation that can make internal security operations staff more efficient and effective.
At Google Cloud, we understand the value that MSSPs can bring, so we’ve built a robust ecosystem of MSSP partners, specifically empowered to help you modernize security operations and achieve better security outcomes, faster.
MSSPs can help ease the pressure from three key challenges that can prevent organizations from staying ahead of threats, and achieving the cybersecurity outcomes they need to build operational resilience and power innovation to create growth.
Prolonged time to value and disruptive deployment: CIOs need security investments to demonstrate value quickly. Deploying new security solutions or migrating from existing ones can be costly and time-consuming, delaying the realization of benefits and increasing risk during transition periods. These complexities can lead to protracted implementation cycles, thereby delaying the realization of anticipated benefits and consequently increasing an organization’s risk exposure throughout the transition period.
Limited resources, talent, and expertise: CISOs often find their teams stretched thin, struggling with the sheer volume of security alerts and manual tasks while often lacking specialized knowledge in emerging threat areas or modern security solutions. The demand for cybersecurity professionals continues to grow faster than the supply of qualified workers. The 2024 ISC2 Cybersecurity Workforce Study estimated a global workforce gap of 4.8 million professionals.
High costs: CEOs often see the cost of building and maintaining internal resources to protect the business, and wonder why they’re not getting the expected return on their investment in terms of successful security outcomes. A purely in-house cybersecurity strategy demands substantial upfront capital investment, ongoing operational costs, and a significant commitment to recruiting and retaining highly specialized talent in a competitive market.
aside_block
<ListValue: [StructValue([(‘title’, ‘$300 in free credit to try Google Cloud security products’), (‘body’, <wagtail.rich_text.RichText object at 0x3eed50dcae50>), (‘btn_text’, ”), (‘href’, ”), (‘image’, None)])]>
An expert, experienced member of the team armed with modern technology
Addressing these challenges effectively requires strategic investments and a clear understanding of where to allocate resources to achieve optimal security outcomes. Approved Google Security Operations MSSP partners are uniquely positioned to help you overcome these hurdles, combining their deep expertise with the power of Google Cloud Security products.
Accelerate time to value and deployment: Google Security Operations MSSP partners can help you to accelerate your security operations modernization journey with tailored migrations and efficient technology deployments. With thousands of security operations transformations and deployments under their belt, MSSP partners can get your company’s rules, detections, alerts, and telemetry sources in production quickly.
Augment resources, talent, and expertise: By using best-in-class tooling like intelligence-driven and AI-enabled Google Cloud Security products, partners can filter out noise and escalate only issues requiring business context, helping to reduce the manual work your team faces.
Drive cost efficiency and better outcomes: Delegating some or all of your organization’s security efforts to external resources such as MSSPs or managed detection and response (MDR) services offers immediate access to specialized expertise, advanced technologies, 24/7 monitoring, and scalable solutions without the overhead of an in-house team.
Why partner with a Google Cloud SecOps MSSP?
Choosing a certified Google Cloud MSSP partner means gaining access to differentiated, end-to-end security solutions powered by Google Cloud Security products, including Google Security Operations, Google Threat Intelligence, and Mandiant Solutions. Our tools provide technical advantages like comprehensive data ingestion from multiple clouds and context-aware detections to prioritize threats.
They can help our partners to deliver unique managed security services offerings tailored to the security requirements of your business. They help you offload security operations strain, increase risk awareness, and significantly reduce response times. They can protect your workloads regardless of location (on-premises or multicloud) and integrate with your existing security investments.
Hear from some of our partners and customers on the value they are seeing:
“In partnership with Google Cloud, we ensure comprehensive protection for your workloads, regardless of their location. We leverage telemetry from your existing security solutions to provide seamless and robust defense. This integrated approach maximizes your security investment and minimizes risk,” said Laurent Besset, deputy CEO, Cyberdefense Ops, I-TRACING.
As an example of the results possible on Google Cloud, Jayesh Barai, VP of Sales at Netenrich, shared a recent customer success story: “We’ve seen customers achieve transformative results by tackling legacy security operations head-on. With Netenrich’s AI-driven Adaptive MDR solution, one client’s security efficacy became remarkable: they reduced their mean time to detect and respond from hours to just 15 minutes and cut monthly security incidents needing manual intervention from nearly 2,000 to fewer than 10. This operational efficiency also drove major cost savings, including a 50% reduction in annual security expenses and an 80% reduction in SOC staffing requirements, dramatically streamlining their ability to integrate new acquisitions in days instead of months.”
“Google Cloud’s global reach and unwavering commitment to security and innovation make it an ideal partner to help us safeguard our clients’ most valuable assets. Google Cloud’s experience and expertise in the field, coupled with its transparent and open approach, instill a level of trust that is essential in today’s interconnected world.” said Scott Goree, senior vice-president, Partners, Alliances, and Ecosystems, Optiv.
Find the right partner
You can learn more about how a Google Cloud MSSP partner can help your organization modernize security operations by visiting our updated MSSP Page.
Amazon Bedrock announces the availability of Stability AI Image Services, a comprehensive suite of 9 specialized image editing tools designed to accelerate professional creative workflows. Stability AI Image Services enable granular control over image editing with a range of tools designed to work with your creative process, allowing you to take a single concept from ideation to finished product with precision and flexibility.
Stability AI Image Services offers two categories of image editing capabilities: Edit tools: Remove Background, Erase Object, Search and Replace, Search and Recolor, and Inpaint let you make targeted modifications to specific parts of your images. Control tools: Structure, Sketch, Style Guide, and Style Transfer give you powerful ways to generate variations based on existing images or sketches.
AWS Step Functions now supports additional data sources and new observability metrics for Distributed Map. AWS Step Functions is a visual workflow service capable of orchestrating over 14,000+ API actions from over 220 AWS services to build distributed applications and data processing workloads. Distributed Map is a task state of Step Functions that runs the same process for multiple entries in a data set.
With this update, Distributed Map now supports additional data inputs, so you can orchestrate large-scale analytics and ETL workflows. You can now process AWS Athena data manifest and Parquet files directly, iterate over S3 objects under a specified prefix using S3ListObjectsV2, read from JSON objects and natively extract array data from JSON object from Amazon S3 or state input, eliminating the need for custom pre-processing. You also now get visibility into your Distributed Map usage with the following metrics, such as Approximate Open Map Runs Count, Open Map Run Limit, and Approximate Map Runs Backlog Size.
New input sources and improved observability for Distributed Map are available in all commercial AWS Regions where AWS Step Functions is available. To get started, you can use the Distributed Map mode today in the AWS Step Functions console. To learn more, visit the Step Functions developer guide.
Amazon Lex now provides support for confirmation and currency slot types in 10 additional languages: Portuguese, Catalan, French, Italian, German, Spanish, Mandarin, Cantonese, Japanese, and Korean. Built-in slots help you build more natural and efficient conversations by understanding synonyms of what you user says and resolving those inputs to a standard format. The confirmation slot helps understand various expressions of user acknowledgement and converts them into ‘Yes’, ‘No’, “Don’t know’‘, or ‘Maybe’. The currency slot helps identify currency and represents the input in a structured way. For example, when a user says “nope” or “absolutely not”, the confirmation slot resolves to ‘No’ or when the user says “1 dollar’, the currency slot resolves it to ”USD 1.00“. These built-in slots help you build more natural and efficient conversational experiences.
This feature is available in all commercial AWS Regions where Amazon Lex operates. To learn more about these features, visit Amazon Lex documentation or to learn how Amazon Connect and Amazon Lex deliver cloud-based conversational AI experiences for contact centers, please visit the Amazon Connect website.
DeepSeek-V3.1 is now available as a fully managed foundation model in Amazon Bedrock. This advanced open weight model allows you to switch between thinking mode for detailed step-by-step analysis and non-thinking mode for quicker responses. With comprehensive multilingual support, it delivers enhanced accuracy and reduced hallucinations compared to previous DeepSeek models, while maintaining visibility into its decision-making process.
You can use DeepSeek-V3.1’s enterprise-grade capabilities across critical business functions, from state-of-the-art software development to complex mathematical reasoning and data analysis. The model excels at sophisticated problem-solving tasks, demonstrating strong performance in coding benchmarks and technical challenges. Its enhanced tool-calling capabilities and seamless workflow integration make it ideal for building AI agents and automating enterprise processes, while its transparent reasoning approach helps teams understand and trust its outputs.
DeepSeek-V3.1 is now available in the US West (Oregon), Asia Pacific (Tokyo), Asia Pacific (Mumbai), Europe (London), and Europe (Stockholm) AWS Regions. To learn more, read the blog, product page, Amazon Bedrock pricing, and documentation. To get started with DeepSeek in Amazon Bedrock, visit the Amazon Bedrock console.
Amazon Bedrock continues to expand model choice by adding four Qwen3 open weight foundation models, now available as fully managed, serverless offerings. The lineup includes: Qwen3-Coder-480B-A35B-Instruct, Qwen3-Coder-30B-A3B-Instruct, Qwen3-235B-A22B-Instruct-2507, and Qwen3-32B for efficient dense computation. These models feature both dense and Mixture-of-Experts (MoE) architectures, providing flexible options for various development needs.
These open weight models enable you to build powerful AI applications with advanced agentic capabilities, without managing any infrastructure. The two Qwen3-Coder models excel at agentic coding and complex software engineering tasks, offering state-of-the-art performance for function calling and tool use. The 235B model delivers efficient general reasoning and instruction following across diverse tasks, while the 32B dense model provides a more traditional architecture suitable for a wide range of computational tasks.
Qwen3 models (32B, Coder-30B) are available today in the US East (N. Virginia), US West (Oregon), Asia Pacific (Mumbai, Tokyo), Europe (Ireland, London, Milan, Stockholm), and South America (São Paulo) AWS Regions. Qwen 235B is available today in theUS West (Oregon), Asia Pacific (Mumbai, Tokyo), and Europe (London, Milan, Stockholm) AWS Regions. Qwen Coder-480B is available today in the US West (Oregon), Asia Pacific (Mumbai, Tokyo), and Europe (London, Stockholm) AWS Regions. Check the full Region list for future updates. To learn more, read the blog, product page, Amazon Bedrock pricing, and documentation. To get started with Qwen in Amazon Bedrock, visit the Amazon Bedrock console.
Today, AWS announces the expansion of OpenAI open weight models on AWS Bedrock to eight new regions. This expansion brings these powerful AI models closer to customers in various parts of the world, enabling lower latency and improved performance for a wide range of AI-powered applications.
With this expansion, the OpenAI open weight models are now available in the following AWS Regions: US East (N. Virginia), Asia Pacific (Tokyo), Europe (Stockholm), Asia Pacific (Mumbai), Europe (Ireland), South America (São Paulo), Europe (London), and Europe (Milan), in addition to the previously supported region of US West (Oregon). This broader availability allows more customers to leverage these state-of-the-art AI models while keeping their data within their preferred geographic locations, helping to address data residency requirements and reduce network latency.
To learn more about OpenAI open weight models on AWS Bedrock and how to get started, visit the Amazon Bedrock console or check out our documentation. For more information about the initial release of these models on AWS Bedrock, refer to our previous blog post.