AWS – Amazon CloudWatch extends automatic telemetry configuration to six critical AWS services
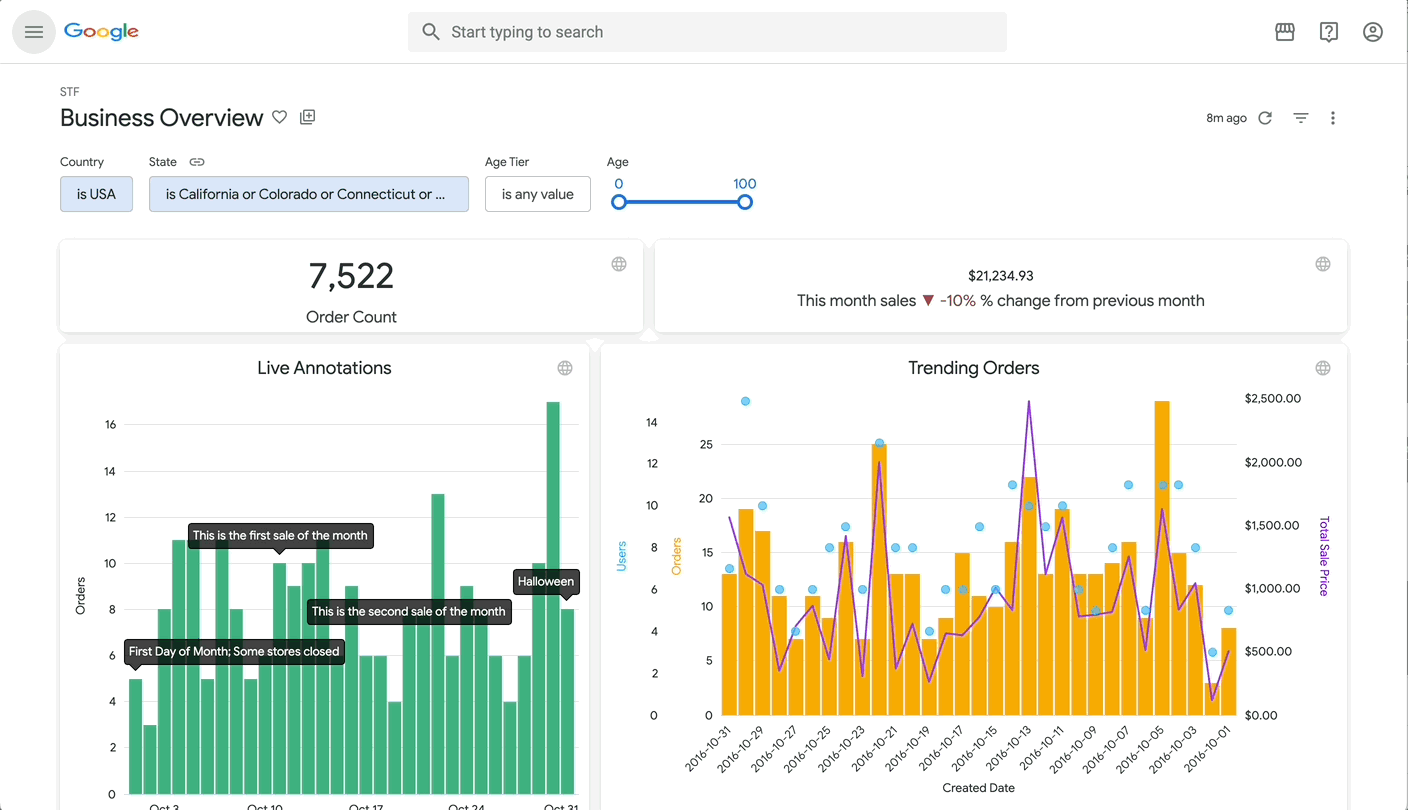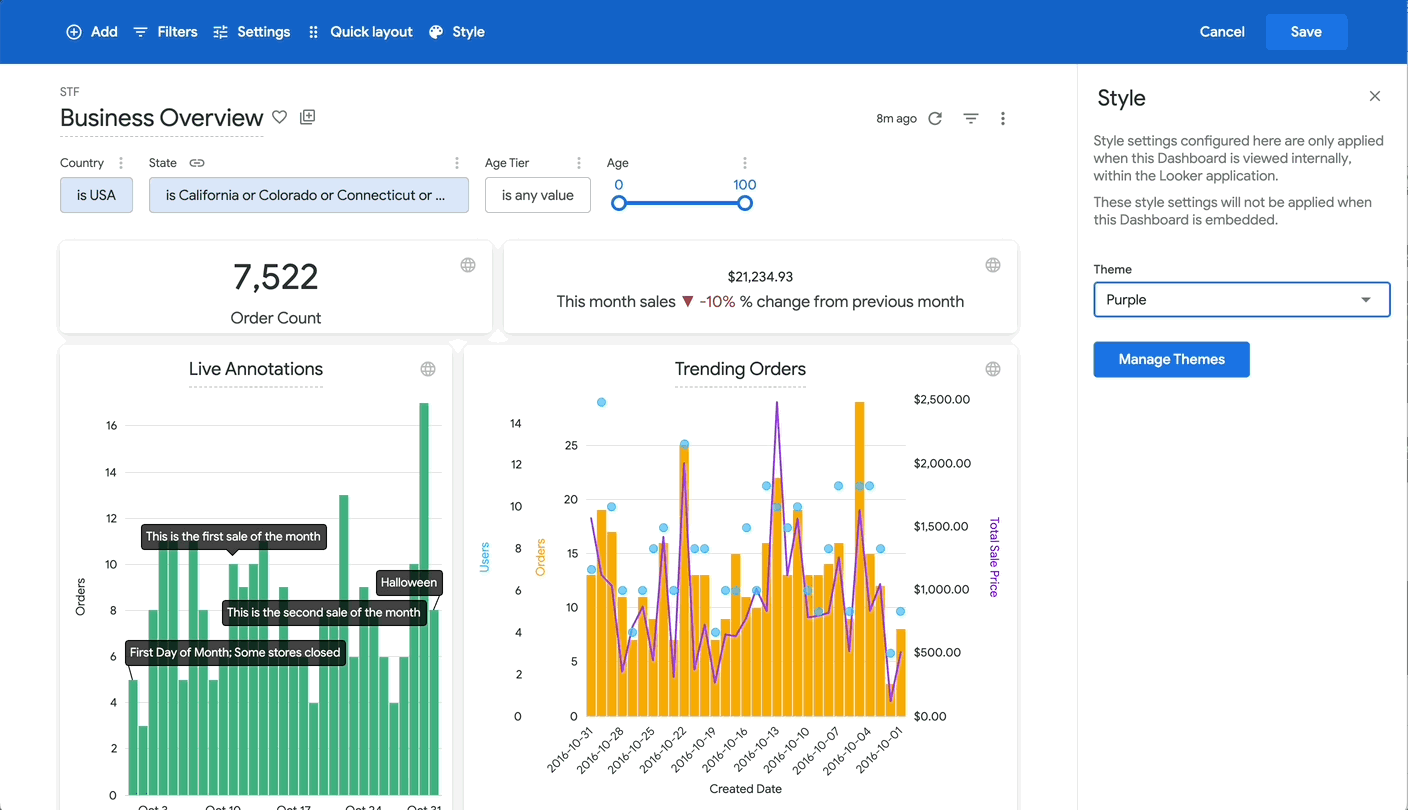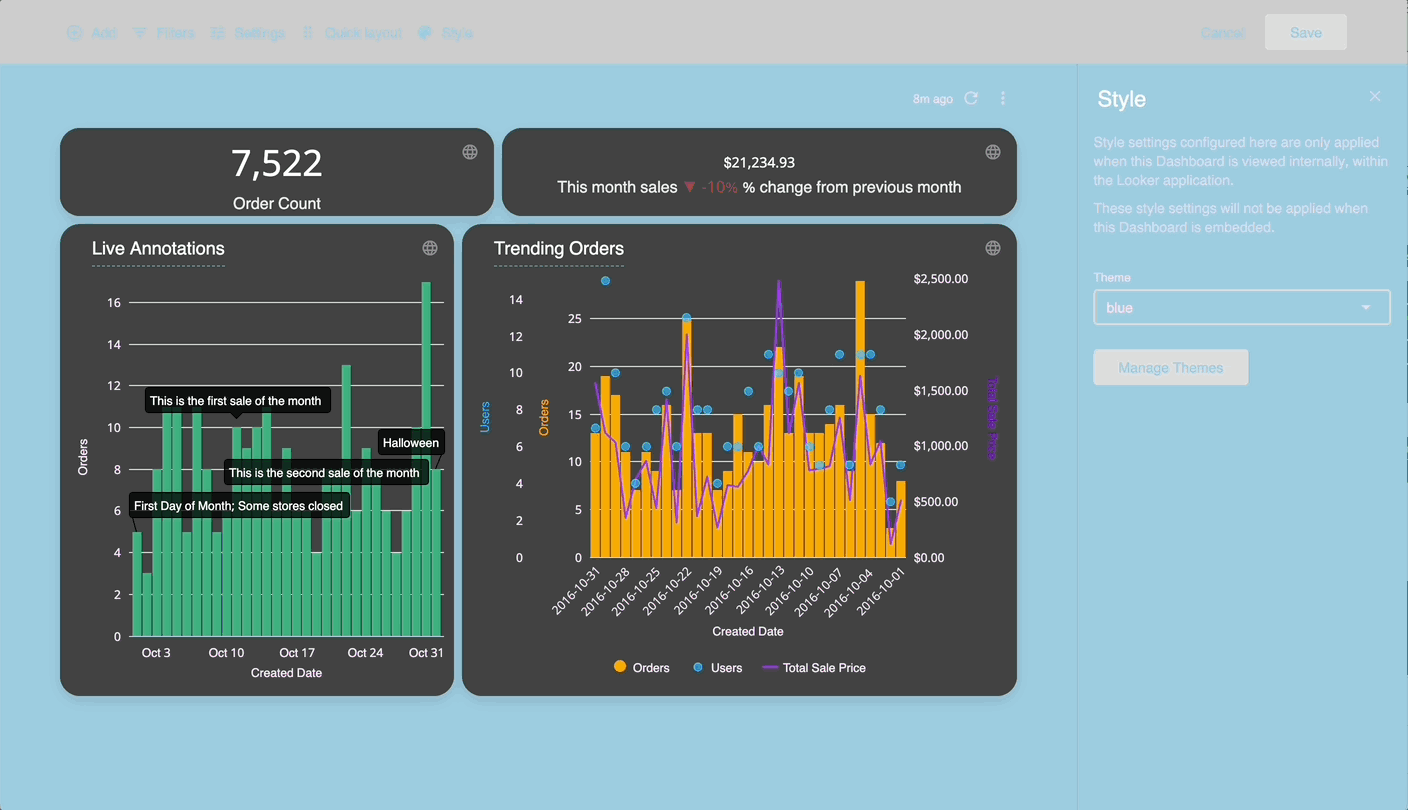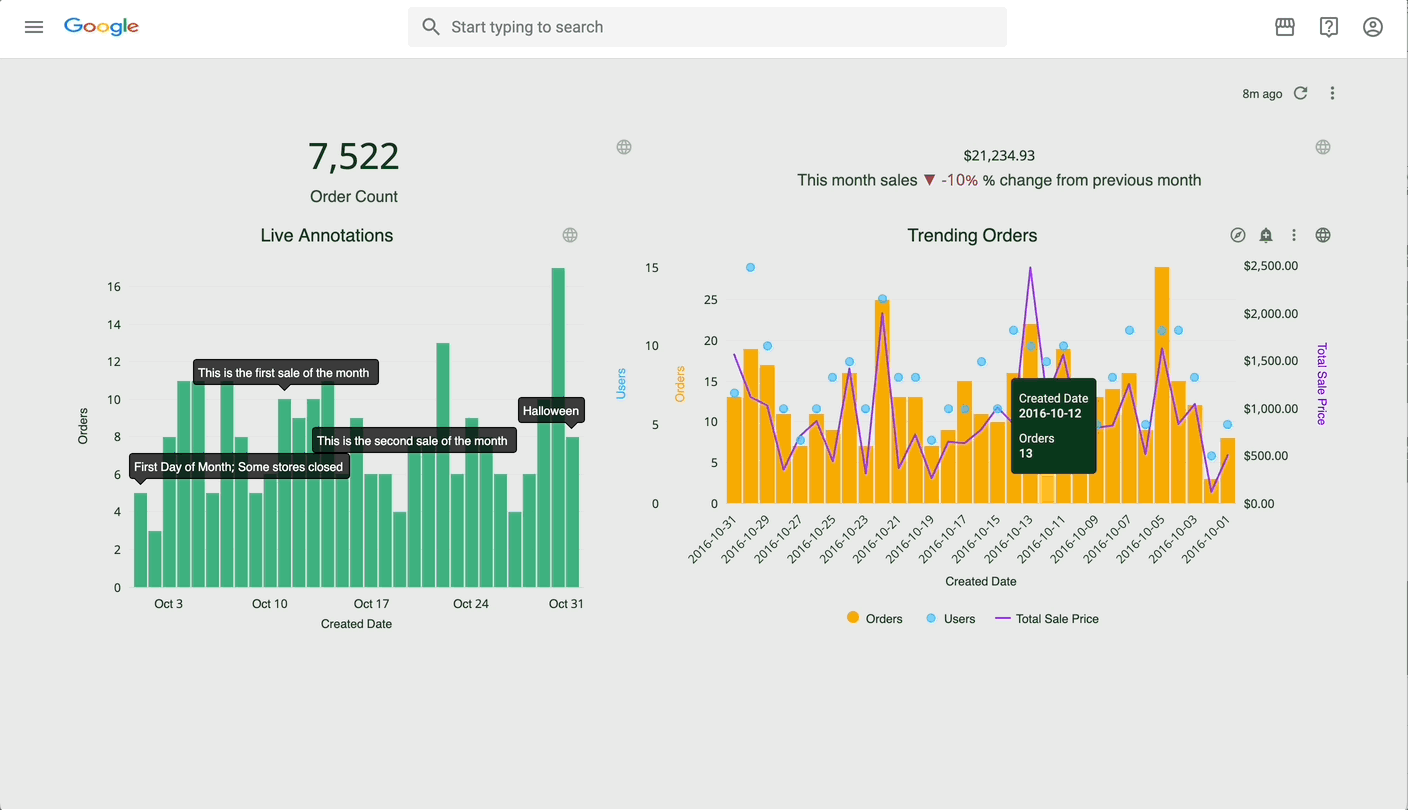
Amazon CloudWatch now allows customers to automatically configure telemetry across their AWS Organization for six critical AWS services: AWS CloudTrail Management Events, AWS CloudTrail Data Events, Amazon Route 53 Resource Query Logs, Amazon EKS Control Plane logs, Network Load Balancer access logs, and AWS WAF WebACL Logs. This enhancement to CloudWatch enablement rules helps organizations maintain consistent monitoring and security practices at scale.
With today’s launch, customers can create organization-wide enablement rules that automatically configure logging for both existing and new resources across these services. For example, security teams can create rules to automatically configure CloudTrail Management Events and CloudTrail Data Events for all accounts in their organization, ensuring comprehensive audit trails. Operations teams can enforce consistent logging practices by automatically enabling EKS Control Plane logs across clusters with specific resource tags. Enablement rules leverage AWS Config Service-Linked recorders to discover resources that meet the rule criteria and automatically enable log ingestion to CloudWatch.
CloudWatch’s telemetry auto-enablement capability for these additional services is available in the following AWS commercial regions: US East (Ohio), US East (N. Virginia), US West (N. California), US West (Oregon), Asia Pacific (Mumbai), Asia Pacific (Osaka), Asia Pacific (Seoul), Asia Pacific (Singapore), Asia Pacific (Sydney), Asia Pacific (Tokyo), Canada (Central), Europe (Frankfurt), Europe (Ireland), Europe (London), Europe (Paris), Europe (Stockholm), and South America (São Paulo). Paulo).
Customers incur charges for configuration items of resource types that are setup for enablement rules, according to AWS Config Pricing. Log ingestion is billed as per CloudWatch Pricing. To learn more about telemetry auto-enablement for these services, visit the Amazon CloudWatch documentation.
Read More for the details.