Scientific inquiry has always been a journey of curiosity, meticulous effort, and groundbreaking discoveries. Today, that journey is being redefined, fueled by the incredible capabilities of AI. It’s moving beyond simply processing data to actively participating in every stage of discovery, and Google Cloud is at the forefront of this transformation, building the tools and platforms that make it possible.
The sheer volume of data generated by modern research is immense, often too vast for human analysis alone. This is where AI steps in, not just as a tool, but as a collaborative force. We’re seeing powerful new models and AI agents assist with everything from identifying relevant literature and generating novel hypotheses to designing experiments, running simulations, and making sense of complex results. This collaboration doesn’t replace human intellect; it amplifies it, allowing researchers to explore more avenues, more quickly, and with greater precision.
At Google Cloud, we’re bringing together high-performance computing (HPC) and advanced AI on a single, integrated platform. This means you can seamlessly move from running massive-scale simulations to applying sophisticated machine learning models, all in one environment.
So, how can you leverage these capabilities to get to insights faster? The journey begins at the foundation of scientific inquiry: the hypothesis.
AI-enhanced scientific inquiry
Every great discovery starts with a powerful hypothesis. With millions of research papers published annually, identifying novel opportunities is a monumental task. To overcome this information overload, scientists can now turn to AI as a powerful research partner.
Our Deep Research agent tackles the first step: performing a comprehensive analysis of published literature to produce detailed reports on a given topic that would otherwise take months to compile. Building on that foundation, our Idea Generation agent then deploys an ensemble of AI collaborators to brainstorm, evaluate, propose, debate, and rank novel hypotheses. This powerful combination, available in Gemini Enterprise, transforms the initial phase of scientific inquiry, empowering researchers to augment their expertise and find connections they might otherwise miss.
Go from hypothesis to results, faster
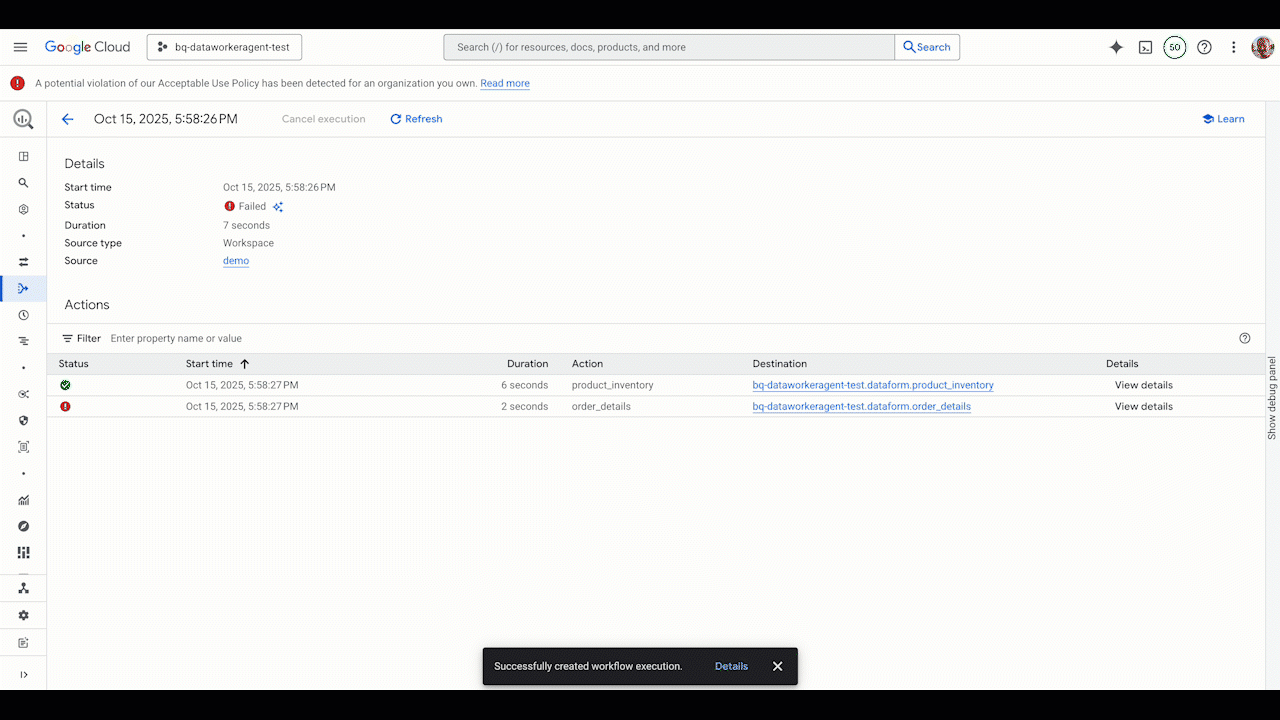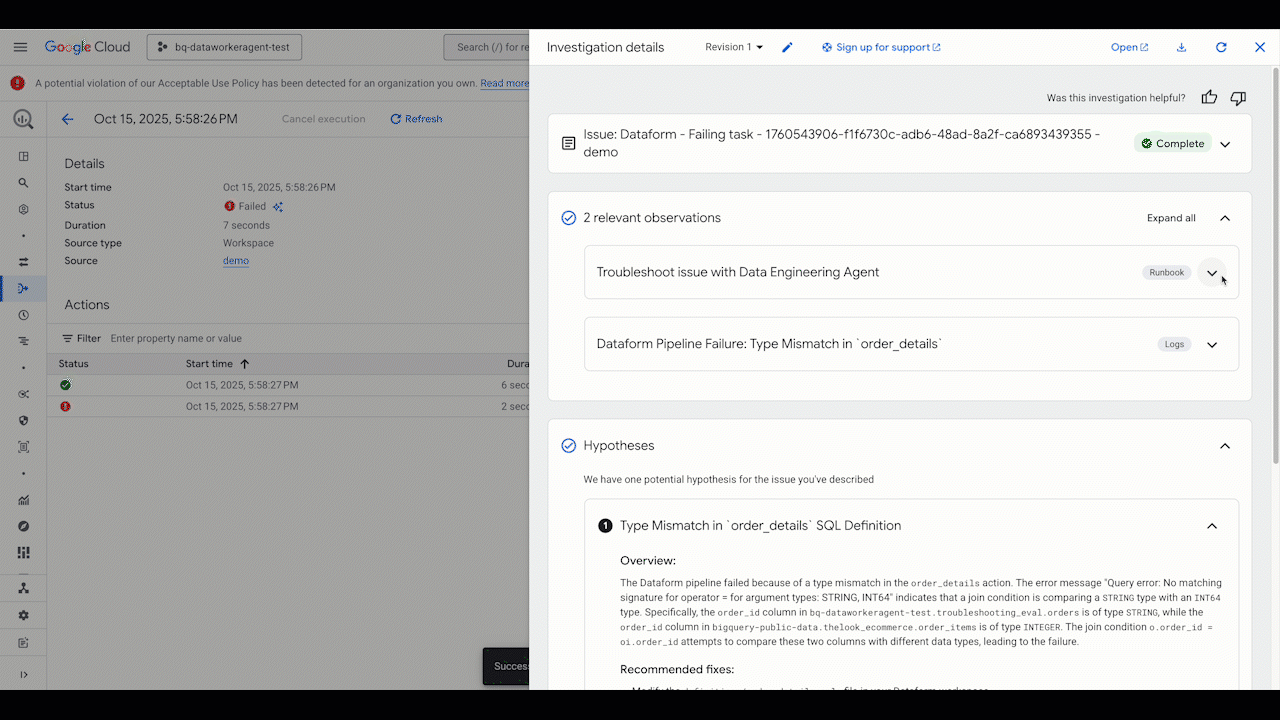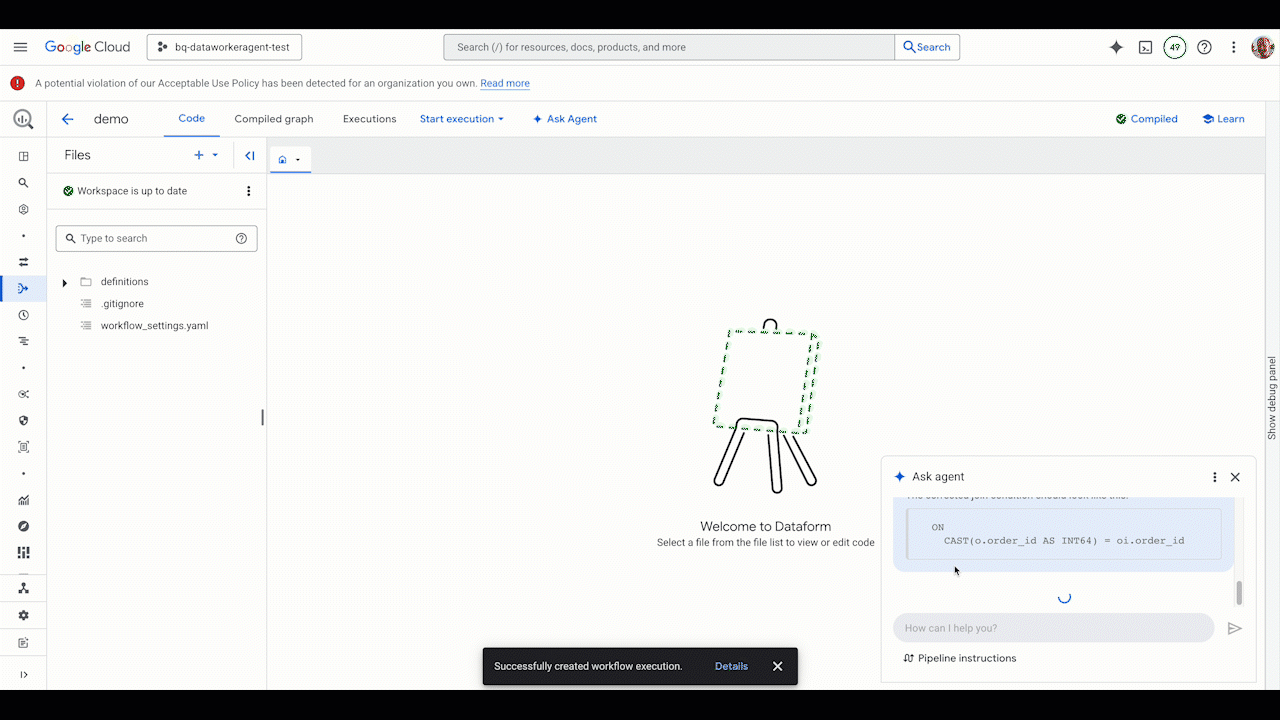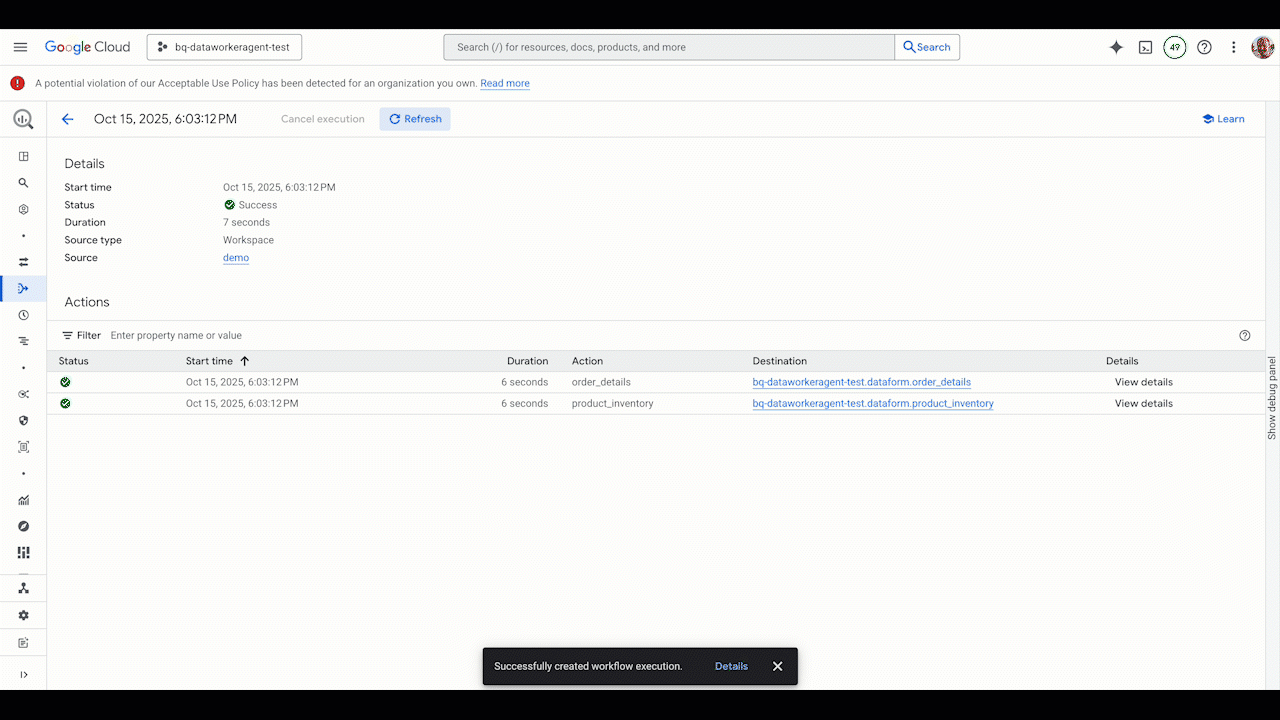
Once a hypothesis is formed, the work of translating it into executable code begins. This is where AI coding assistants, such as Gemini Code Assist, excel. They automate the tedious tasks of writing analysis scripts and simulation models by generating code from natural language and providing real-time suggestions, dramatically speeding up the core development process.
But modern research is more than just a single script; it’s a complete workflow of data, environments, and results managed from the command line. For this, Gemini CLI brings that same conversational power directly to your terminal. It acts as the ultimate workflow accelerator, allowing you to instantly synthesize research and generate hypotheses with simple commands, then seamlessly transition to experimentation by generating sophisticated analysis scripts, and debugging errors on the fly, all without ever breaking your focus. Gemini CLI can further accelerate your path to impact by transforming raw results into publication-ready text, generating the code for figures and tables, and refining your work for submission.
This capability extends to automating the entire research environment. Beyond single commands, Gemini CLI can manage complex, multi-step processes like cloning a scientific application, installing its dependencies, and then building and testing it—all with a simple prompt, maximizing your productivity.
The new era of discovery: Your expertise, AI agents, and Google Cloud
The new era of scientific discovery is here. By embedding AI into every stage of the scientific process – from sparking the initial idea to accelerating the final analysis – Google Cloud provides a single, unified platform for discovery. This new era of AI-enhanced scientific inquiry is built on a robust, intelligent infrastructure that combines the strengths of HPC simulation and AI. This includes purpose-built solutions like our H4D VMs optimized for scientific simulations, alongside the latest A4 and A4X VMs, powered by the latest NVIDIA GPUs, and Google Cloud Managed Lustre, a parallel file system that eliminates storage bottlenecks and allows your HPC and AI workloads to create and analyze massive datasets simultaneously. We provide the power to streamline the entire process so you can focus on scientific creativity – and changing the world!
Join the Google Cloud Advanced Computing Community to connect with other researchers, share best practices, and stay up to date on the latest advancements in AI for scientific and technical computing, or contact sales to get started today.
for the details.