Amazon RDS Blue/Green deployments now support safer, simpler, and faster updates for your Aurora Global Databases. With just a few clicks, you can create a staging (green) environment that mirrors your production (blue) Aurora Global Database, including primary and all secondary regions. When you’re ready to make your staging environment the new production environment, perform a blue/green switchover. This operation transitions your primary and all secondary regions to the green environment, which now serves as the active production environment. Your application begins accessing it immediately without any configuration changes, minimizing operational overhead.
With Global Database, a single Aurora cluster can span multiple AWS Regions, providing disaster recovery for your applications in case of single Region impairment and enabling fast local reads for globally distributed applications. With this launch, you can perform critical database operations including major and minor version upgrades, OS updates, parameter modifications, instance type validations, and schema changes with minimal downtime. During blue/green switchover, Aurora automatically renames clusters, instances, and endpoints to match the original production environment, enabling applications to continue operating without any modifications. You can leverage this capability using the AWS Management console, SDK, or CLI.
Start planning your next Global Database upgrade using RDS Blue/Green deployments by following the steps in the blog. For more details, refer to our documentation.
AWS IoT Core, AWS IoT Device Management, and AWS IoT Device Defender have expanded support for Virtual Private Cloud (VPC) endpoints and IPv6. Developers can now use AWS PrivateLink to establish VPC endpoints for all data plane operations, management APIs, and credential provider. This enhancement allows IoT workloads to operate entirely within virtual private clouds without traversing the public internet, helping strengthen the security posture for IoT deployments.
Additionally, IPv6 support for both VPC and public endpoints gives developers the flexibility to connect IoT devices and applications using either IPv6 or IPv4. This helps organizations meet local requirements for IPv6 while maintaining compatibility with existing IPv4 infrastructure.
These features can be configured through the AWS Management Console, AWS CLI, and AWS CloudFormation. The functionality is now generally available in all AWS Regions where the relevant AWS IoT services are offered. For more information about the IPv6 support and VPCe support, customers can visit the AWS IoT technical documentation pages. For information about PrivateLink pricing, visit the AWS PrivateLink pricing page.
Welcome back to The Agent Factory! In this episode, we’re joined by Ravin Kumar, a Research Engineer at DeepMind, to tackle one of the biggest topics in AI right now: building and training open-source agentic models. We wanted to go beyond just using agents and understand what it takes to build the entire factory line—from gathering data and supervised fine-tuning to reinforcement learning and evaluations.
This post guides you through the key ideas from our conversation. Use it to quickly recap topics or dive deeper into specific segments with links and timestamps.
Before diving into the deep research, we looked at the latest developments in the fast-moving world of AI agents.
Gemini 2.5 Computer Use: Google’s new model can act as a virtual user, interacting with computer screens, clicking buttons, typing in forms, and scrolling. It’s a shift from agents that just know things to agents that can do tasks directly in a browser.
Vibe Coding in AI Studio: A new approach to app building where you describe the “vibe” of the application you want, and the AI handles the boilerplate. It includes an Annotation Mode to refine specific UI elements with simple instructions like “Change this to green.”
DeepSeek-OCR and Context Compression: DeepSeek introduced a method that treats documents like images to understand layout, compressing 10-20 text tokens into a single visual token. This drastically improves speed and reduces cost for long-context tasks.
Google Veo 3.1 and Flow: The new update to the AI video model adds rich audio generation and powerful editing features. You can now use “Insert” to add characters or “Remove” to erase objects from existing video footage, giving creators iterative control.
Ravin Kumar on Building Open Models
We sat down with Ravin to break down the end-to-end process of creating an open model with agent capabilities. It turns out the process mirrors a traditional ML lifecycle but with significantly more complex components.
Ravin explained that training data for agents looks vastly different from standard text datasets. It starts with identifying what users actually need. The data itself is a collection of trajectories, complex examples of the model making decisions and using tools. Ravin noted that they use a mix of human-curated data and synthetic data generated by their own internal “teacher” models and APIs to create a playground for the open models to learn in.
Training Techniques: SFT and Reinforcement Learning
Once the data is ready, the training process involves a two-phase approach. First comes Supervised Fine-Tuning (SFT), where frameworks update the model’s weights to nudge it into new behaviors based on the examples. However, to handle generalization—new situations not in the original trainin data—they rely on Reinforcement Learning (RL). Ravin highlighted the difficulty of setting rewards in RL, warning that models are prone to “reward hacking,” where they might collect intermediate rewards without ever completing the final task.
Ravin emphasized that evaluation is the most critical and high-stakes part of the process. You can’t just trust the training process; you need a rigorous “final exam.” They use a combination of broad public benchmarks to measure general capability and specific, custom evaluations to ensure the model is safe and effective for its intended user use case.
Conclusion
This conversation with Ravin Kumar really illuminated that building open agentic models is a highly structured, rigorous process. It requires creating high-quality trajectories for data, a careful combination of supervised and reinforcement learning, and, crucially, intense evaluation.
Your turn to build
As Ravin advised, the best place to start is at the end. Before you write a single line of training code, define what success looks like by building a small, 50-example final exam for your agent. If you can’t measure it, you can’t improve it. We also encourage you to try mixing different approaches; for example, using a powerful API model like Gemini as a router and a specialized open-source model for specific tasks.
Check out the full episode for more details, and catch us next time!
Starting today, AWS Network Firewall is available in the AWS New Zealand (Auckland) Region, enabling customers to deploy essential network protections for all their Amazon Virtual Private Clouds (VPCs).
AWS Network Firewall is a managed firewall service that is easy to deploy. The service automatically scales with network traffic volume to provide high-availability protections without the need to set up and maintain the underlying infrastructure. It is integrated with AWS Firewall Manager to provide you with central visibility and control over your firewall policies across multiple AWS accounts.
To see which regions AWS Network Firewall is available in, visit the AWS Region Table. For more information, please see the AWS Network Firewall product page and the service documentation.
Amazon EventBridge introduces a new intuitive console based visual rule builder with a comprehensive event catalog for discovering and subscribing to events from custom applications, and over 200 AWS services. The new rule builder integrates the EventBridge Schema Registry with an updated event catalog and intuitive drag and drop canvas that simplifies building event-driven applications.
With enhanced rule builder, developers can browse and search through events with readily available sample payloads and schemas, eliminating the need to find and reference individual service documentation. The schema-aware visual builder guides developers through creating event filter patterns and rules, reducing syntax errors and development time.
The EventBridge enhanced rule builder is available today in all regions where the Schema Registry is launched. Developers can get started through the Amazon EventBridge console at no additional cost beyond standard EventBridge usage charges.
For more information, visit the EventBridge documentation.
Amazon RDS for PostgreSQL now supports major version 18, starting with PostgreSQL version 18.1. PostgreSQL 18 introduces several important community updates that improve query performance and database management.
PostgreSQL 18.0 includes “skip scan” support for multicolumn B-tree indexes and improved WHERE clause handling for OR and IN conditions enhance query optimization. Parallel Generalized Inverted Index (GIN) builds and updated join operations boost overall database performance. The introduction of Universally Unique Identifiers Version 7 (UUIDv7) combines timestamp-based ordering with traditional UUID uniqueness, particularly beneficial for high-throughput distributed systems. PostgreSQL 18 also improves observability by providing buffer usage counts, index lookup statistics during query execution, and per-connection I/O utilization metrics. This release also includes support for the new pgcollection extension, and updates to existing extensions such as pgaudit 18.0, pgvector 0.8.1, pg_cron 1.6.7, pg_tle 1.5.2, mysql_fdw 2.9.3, and tds_fdw 2.0.5.
You can upgrade your database using several options including RDS Blue/Green deployments, upgrade in-place, restore from a snapshot. Learn more about upgrading your database instances in the Amazon RDS User Guide.
Amazon RDS for PostgreSQL makes it simple to set up, operate, and scale PostgreSQL deployments in the cloud. See Amazon RDS for PostgreSQL Pricing for pricing details and regional availability. Create or update a fully managed Amazon RDS database in the Amazon RDS Management Console.
Amazon DocumentDB (with MongoDB compatibility) announces version 8.0, which now offers added support for drivers supporting the MongoDB API versions 6.0, 7.0, and 8.0. Amazon DocumentDB 8.0 also improves query latency by up to 7x and compression ratio by up to 5x, enabling you to build high-performance applications at a lower cost.
The following are features and capabilities introduced in Amazon DocumentDB 8.0:
Compatibility with MongoDB 8.0: Amazon DocumentDB 8.0 provides compatibility with MongoDB 8.0 by adding support for MongoDB 8.0 API drivers. Amazon DocumentDB 8.0 also supports applications that are built using MongoDB API versions 6.0 and 7.0.
Planner Version3:New query planner in Amazon DocumentDB 8.0 extends performance improvements to aggregation stage operators, along with supporting aggregation pipeline optimizations and distinct commands.
New aggregation stages and operators: Amazon DocumentDB 8.0 offers 6 new aggregation stages: $replaceWith, $vectorSearch, $merge, $set, $unset, $bucket, and 3 new aggregation operators $pow, $rand, $dateTrunc.
Compression: Support for dictionary-based compression through the Zstandard compression algorithm improves compression ratio by up to 5x, thus improving storage efficiency and reducing I/O costs.
New capabilities: Amazon DocumentDB 8.0 supports collation and views.
A new version of text index:Text index v2 in Amazon DocumentDB 8.0 introduces additional tokens, enhancing text search capabilities.
Vector search improvements: Through parallel vector index build, Amazon DocumentDB 8.0 reduces index build time by up to 30x.
You can use AWS Database Migration Service (DMS) to upgrade your Amazon DocumentDB 5.0 instance-based clusters to Amazon DocumentDB 8.0 clusters. Please see upgrading your DocumentDB cluster to learn more. Amazon DocumentDB 8.0 is available in all AWS Regions where Amazon DocumentDB is available. To learn more about Amazon DocumentDB 8.0 visit the documentation.
Amazon Simple Queue Service (Amazon SQS) now allows customers to make API requests over Internet Protocol version 6 (IPv6) in the AWS GovCloud (US) Regions. The new endpoints have also been validated under the Federal Information Processing Standard (FIPS) 140-3 program.
Amazon SQS is a fully managed message queuing service that enables decoupling and scaling of distributed systems, microservices, and serverless applications. With this update, customers have the option of using either IPv6 or IPv4 when sending requests over dual-stack public or VPC endpoints.
Amazon SQS now supports IPv6 in all Regions where the service is available, including AWS Commercial, AWS GovCloud (US) and China Regions. For more information on using IPv6 with Amazon SQS, please refer to our developer guide.
AWS Lambda now supports building serverless applications using Rust. Previously, AWS classified Rust support in Lambda as ‘experimental’ and did not recommend using Rust for production workloads. With this launch, Rust support in Lambda is now Generally Available, backed by AWS Support and the Lambda SLA.
Rust is a popular programming language, offering high performance, memory efficiency, compile-time code safety features, and a mature package management and tooling ecosystem. This makes Rust an ideal choice for developers building performance-sensitive serverless applications. Developers can now build business-critical serverless applications in Rust and run them in Lambda, taking advantage of Lambda’s built-in event source integrations, fast scaling from zero, automatic patching, and usage-based pricing.
Lambda support for Rust is available in all AWS Regions, including the AWS GovCloud (US) Regions and the China Regions.
Building on the Hooks Invocation Summary launched in September 2025, AWS CloudFormation Hooks now supports granular invocation details. Hook authors can supplement their Hook evaluation responses with detailed findings, finding severity, and remediation advice. The Hooks console now displays these details at the individual control level within each invocation, enabling developers to quickly identify and resolve specific Hook failures.
Customers can easily drill down from the invocation summary to see exactly which controls passed, failed, or were skipped, along with specific remediation guidance for each failure. This granular visibility eliminates guesswork when debugging Hook failures, allowing teams to pinpoint the exact control that blocked a deployment and understand how to fix it. The detailed findings accelerate troubleshooting and streamline compliance reporting by providing actionable insights at the individual control level.
The Hooks invocation summary page is available in all commercial and GovCloud (US) regions. To learn more, visit the AWS CloudFormation Hooks View Invocations documentation.
In a world of increasing data volume and demand, businesses are looking to make faster decisions and separate insight from noise. Today, we’re bringing Conversational Analytics to general availability in Looker, delivering natural language queries to everyone in your organization, removing BI bottlenecks. With Conversational Analytics, we’re transforming the way you get answers, cutting through stale dashboards and accelerating data discovery. Our goal: make analytics and AI as easy and scalable as performing a Google search, extending BI to the broader enterprise as you go from prompt to full data exploration in seconds.
Instant AI-powered insights with Conversational Analytics in Looker
Now, with Conversational Analytics, getting an answer from your data is as simple as chatting with your most knowledgeable colleague. By tapping into human conversation, Conversational Analytics relieves you from struggling with complex dashboard filters, obscure field names, or the need to write custom SQL.
“At YouTube, we’re focused on helping creators succeed and bring their creativity to the world. We’ve been testing Conversational Analytics in Looker to give our partner managers instant, actionable data that lets them quickly guide creators and optimize creator support.” – Thomas Seyller, Senior Director, Technology & Insights, YouTube Business
The general availability of Conversational Analytics combines the reasoning power of Gemini, new capabilities in Google’s agentic frameworks, and the trusted data modeling of the Looker platform. Together, these set the stage for the next chapter in self-service analytics, making reliable data insights accessible to the entire enterprise. Conversational Analytics agents can understand your questions and provide insightful answers to questions about your data.
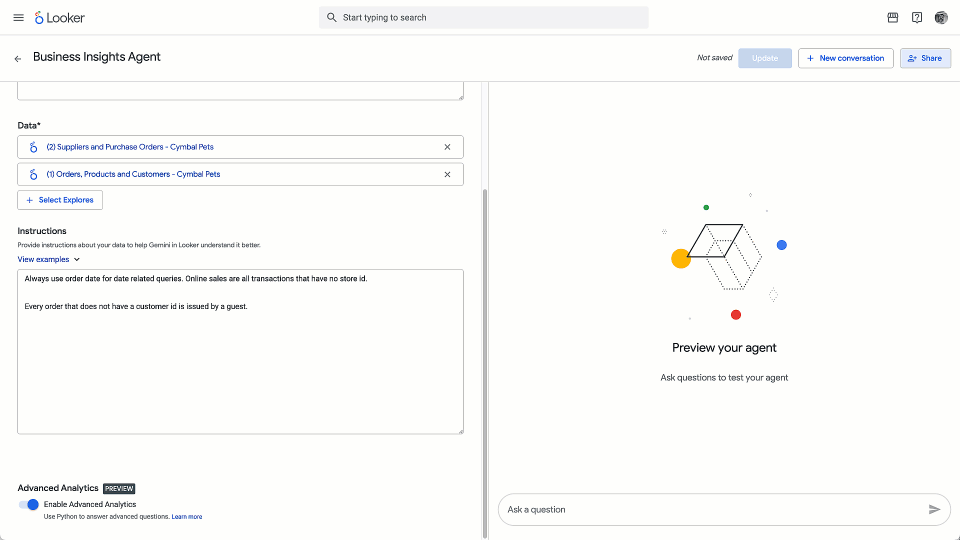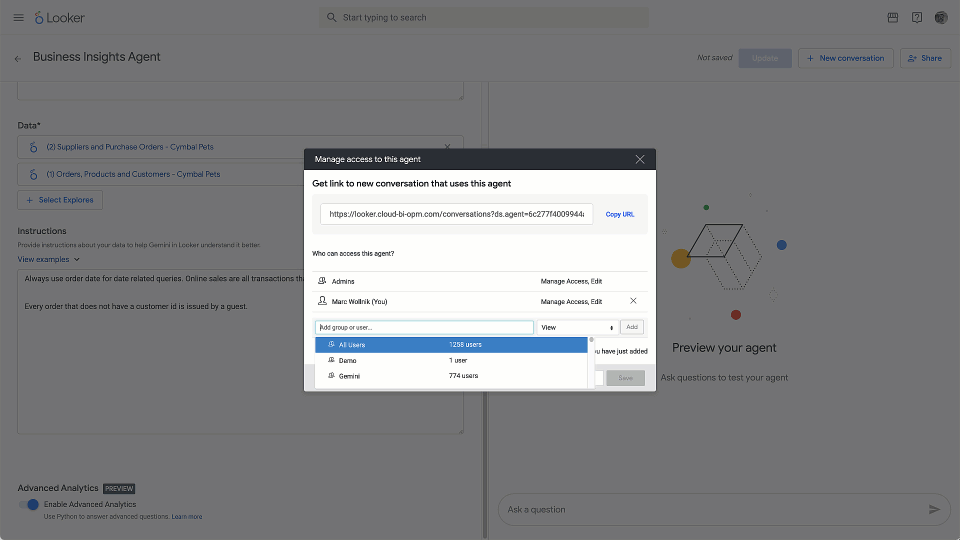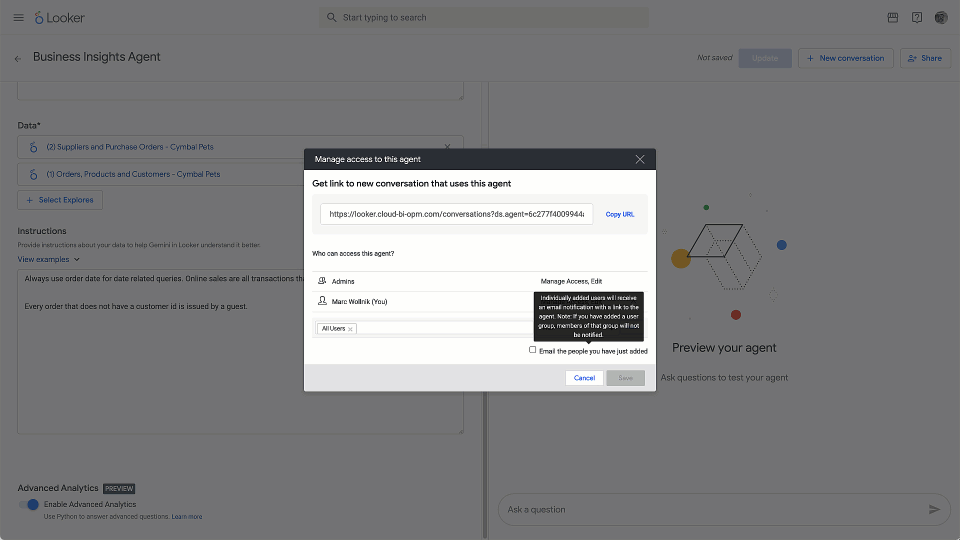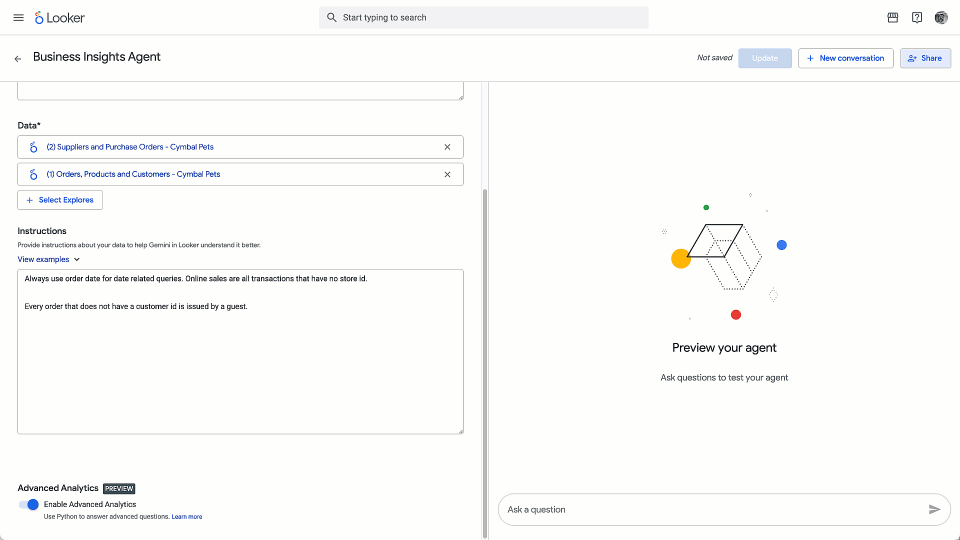
New at general availability is the ability to analyze data across domains. You can ask questions that integrate insights from up to five distinct Looker Explores (pre-joined views), spanning multiple business areas. Additionally, you can share the agents you build with colleagues, giving them faster access to a single source of truth, speeding consensus, and driving uniform decisions.
You can build and share agents with colleagues to have a consistent data picture.
Built on a trusted, governed foundation
The power of Conversational Analytics isn’t just in the conversation it enables; it’s in the trust of the underlying data. Conversational Analytics is grounded in Looker’s semantic layer, which ensures that every metric, field, and calculation is centrally defined and consistent, acting as a crucial context engine for AI. As more of your colleagues rapidly use these expanded capabilities, you need to know the results they see and act on are accurate.
For analysts looking to explore data or everyday users receiving insights in the context of their business, Conversational Analytics also improves data self-service, minimizing technical friction that can create bottlenecks and leaves insights locked away.
You can now:
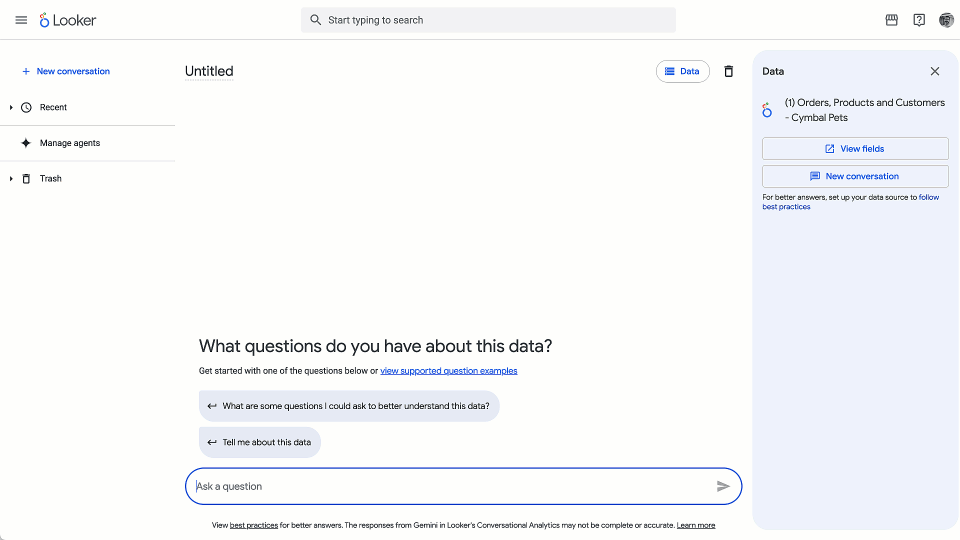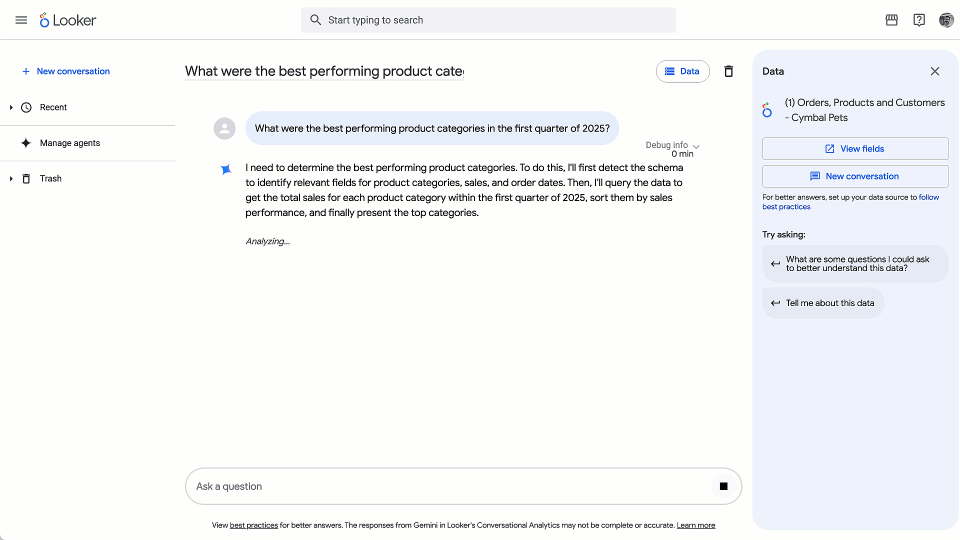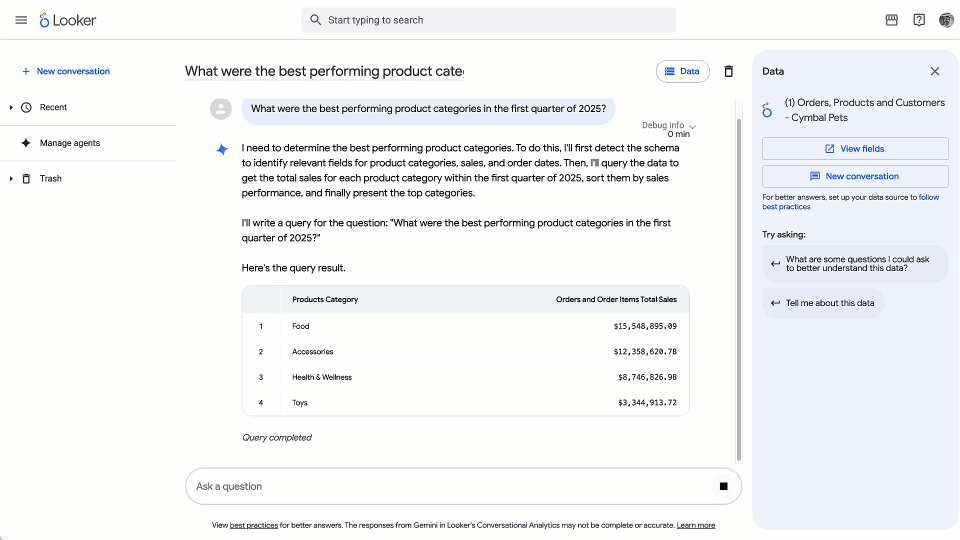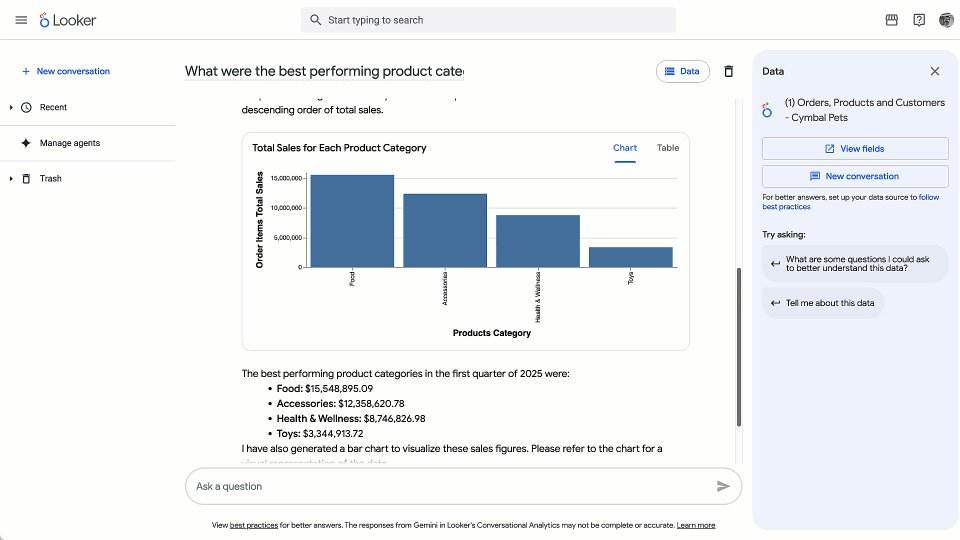
Ask anything, anytime: Get instant answers to simple questions like “Show me our website traffic last month for shoe sales,” leading to deeper questions and greater insights across business areas and domains.
Deepen the discovery: Move beyond the constraints of static dashboards and ask open-ended questions like, “Show me the trend of website traffic over the past six months and filter it by the California region.” The system intelligently generates the appropriate query and visualization instantly.
Extend enterprise BI: Connect your Looker models to your enterprise BI ecosystem, centralize and share agents, and create new dashboards, starting with a prompt. Built on top of Looker Explores, Conversational Analytics’ natural language interface usesLookML for fine tuning and output accuracy.
Pivot quickly: The conversational interface supports multi-turn questions, so you can iterate on your findings. Ask for total sales, then follow up with, “Now show me that as an area chart, broken down by payment method.”
Gain full transparency: To build confidence and data literacy, the “How was this calculated?” feature provides a clear, natural language explanation of the underlying query that generated the results, so that you understand the source of your findings.
Empower the BI analyst and business user
Conversational Analytics is democratizing data for business teams, helping them govern the business’s data. At the same time, it’s also enhancing productivity and influence for data analysts and developers.
When business users can self-serve trusted data insights, data analysts see fewer interruptions and “ad-hoc” ticket requests, and can instead focus on high-impact work. Analysts can customize their client teams’ BI experiences by building Conversational Analytics agents that define common questions, filters, and style guidelines, so different teams can act on the same data in different ways.
Get ready to start talking
Conversational Analytics is available now for all Looker platform users. Your admin can enable it in your Looker instance today and you will discover how easy it is to move from simply asking “What?” to confidently determining “What’s next?” For more information, review the product documentation or watch this video tutorial.
At Google Cloud, we believe that being at the forefront of driving secure innovation and meeting the evolving needs of customers includes working with partners. The reality is that the security landscape should be interoperable, and your security tools should be able to integrate with each other.
Google Unified Security, our AI-powered, converged security solution, has been designed to support greater customer choice. To further this vision, today we’re announcing Google Unified Security Recommended, a new program that expands strategic partnerships with market-leading security solutions trusted by our customers.
We welcome CrowdStrike, Fortinet, and Wiz as inaugural Google Unified Security Recommended partners. These integrations are designed to meet our customers where they are today and ensure their end-to-end deployments are built to scale with Google in the future.
Google Unified Security and our Recommended program partner solutions.
Building confidence through validated integrations
As part of the Google Unified Security Recommended program, partners agree to adhere to comprehensive technical integration across Google’s security product portfolio; a collaborative, customer-first support model that reflects our intent to collectively protect our customers; and invest jointly in AI innovation. This program offers our customers:
Enhanced confidence: Select partner products that have undergone evaluation and validation to ensure optimal integration with Google Unified Security.
Accelerated discovery: Streamline your evaluation process with a carefully curated selection of market-leading solutions addressing specific enterprise challenges.
Prioritize outcomes: Minimize integration overhead, allowing your team to allocate resources towards building security solutions that deliver business outcomes.
We’re working to ensure that customers can use solutions that are powerful today — and designed for future advancements. Learn more about the product-level requirements that define the Google Unified Security Recommended designation here.
Our inaugural partners: Unifying your defenses
Our collaborations with CrowdStrike, Fortinet and Wiz exemplify our “better together” philosophy by addressing tangible security challenges.
CrowdStrike Falcon (endpoint protection): Integrations between the AI-native CrowdStrike Falcon® platform, Google Security Operations, Google Threat Intelligence, and Mandiant Threat Defense can enable customers to detect, investigate, and respond to threats faster across hybrid and multicloud environments.
Customers can use Falcon Endpoint risk signals to define Context-Aware access policies enforced by Google Chrome Enterprise. The collaboration also supports integrations that secure the AI lifecycle — and extends through the model context protocol (MCP) to advance AI for security operations. Together, CrowdStrike and Google Cloud deliver unified protection across endpoint, identity, cloud, and data.
“CrowdStrike and Google Cloud share a vision for an open, AI-powered future of security. Together, we’re uniting our leading AI-native platforms – Google Security Operations and the CrowdStrike Falcon® platform – to help customers harness the power of generative AI and stay ahead of modern threats,” said Daniel Bernard, chief business officer, CrowdStrike.
Fortinet cloud-delivered SASE and Next-Generation Firewall (network protection): Integrating Fortinet’s Security Fabric with Google Security Operations combines AI-driven FortiGuard Threat Intelligence with rich network and web telemetry to deliver unified visibility and control across users, applications, and network edges.
Customers can integrate FortiSASE and FortiGate solutions into Google Security Operations to correlate activity across their environments, apply advanced detections, and automate coordinated response actions that contain threats in near real-time. This collaboration can help reduce complexity, streamline operations, and strengthen protection across hybrid infrastructures.
“Customers are demanding simplified security architectures that reduce complexity and strengthen protection,” said Nirav Shah, senior vice president, Product and Solutions, Fortinet. “As an inaugural partner in the Google Cloud Unified Security Recommended program, we are combining the power of FortiSASE and the Fortinet Security Fabric with Google Cloud’s security capabilities to converge networking and security across environments. This approach gives SecOps and NetOps shared visibility and coordinated controls, helping teams eliminate tool sprawl, streamline operations, and accelerate secure digital transformation.”
Wiz (multicloud CNAPP): Customers can integrate Wiz’s cloud security findings with Google Security Operations to help teams identify, prioritize, and address their most critical cloud risks in a unified platform.
In addition, Wiz and Security Command Center integrate to provide complete visibility and security for Google Cloud environments, including threat detection, AI security, and in-console security for application owners. Wiz is actively developing a new Google Threat Intelligence (GTI) integration that allows existing GTI customers to access threat intelligence seamlessly in the Wiz console, enabling threat intelligence-driven detection and response processes.
“Achieving secure innovation in the cloud requires unified visibility and radical risk prioritization. Our inclusion in the Google Unified Security Recommended program recognizes the power of Wiz to deliver code-to-cloud security for Google Cloud customers. By integrating our platform with Google Security Operations and Security Command Center, we enable customers to see their multicloud attack surface, prioritize the most critical risks, and automatically accelerate remediation. Together, we are simplifying the most complex cloud security challenges and making it easier for you to innovate securely,” said Anthony Belfiore, chief strategy officer, Wiz.
Powering the agentic SOC with MCP
A critical aspect of Google Unified Security Recommended is our shared dedication to strategic AI initiatives, including MCP support. Because it enables AI models to interact with and use security tools, MCP can enhance security workflows by ensuring Gemini models possess contextual awareness across multiple downstream services.
MCP can help facilitate an enhanced, cross-platform agentic experience. With MCP, our new AI agents — such as the alert triage agent in Google Security Operations that autonomously investigates alerts — can query partner tools for telemetry, enrich investigations with third-party data, and orchestrate response actions across your entire security stack.
We are proud to confirm that all of our inaugural launch partners support MCP and have developed recommended approaches for how to activate MCP-supported agentic workflows across our products, a crucial step towards realizing our vision of an agentic SOC where AI functions as a virtual security assistant, proactively identifying threats and guiding you to faster, more effective responses.
Our open future on Google Cloud Marketplace
The introduction of the Google Unified Security Recommended program is only the beginning. We are dedicated to expanding this program to include a wider array of most trusted partner solutions with substantial investment across the Google Unified Security product suite, helping our customers build a more scalable, effective, and interoperable security architecture.
For simplified procurement and deployment, all qualified Google Unified Security Recommended solutions are available in the Google Cloud Marketplace. We offer Google Unified Security and Google Cloud customers streamlined purchasing of third-party offerings, all consolidated into one Google Cloud bill.
To learn more about the program and explore Google-validated solutions from our partners, visit the Google Unified Security Recommended page. Tech partners interested in program consideration are encouraged to reach out for guidance.
AI agents are transforming the nature of work by automating complex workflows with speed, scale, and accuracy. At the same time, startups are constantly moving, growing, and evolving – which means they need clear ways to implement agentic workflows, not piles of documentation that send precious resources into a tailspin.
Today, we’ll share a simple four-step framework to help startups build multi-agent systems. Multi-agentic workflows can be complicated, but there are easy ways to get started and see real gains without spending weeks in production.
In this post, we’ll show you a systematic, operations-driven roadmap for navigating this new landscape, using one of our projects to provide concrete examples for the concepts laid out in the official startups technical guide: AI agents.
Step #1: Build your foundation
The startups technical guide outlines three primary paths for leveraging agents:
Pre-built Google agents
Partner agents
Custom-built agents (agents you build on your own).
To build our Sales Intelligence Agent, we needed to automate a highly specific, multi-step workflow that involved our own proprietary logic and would eventually connect to our own data sources. This required comprehensive orchestration control and tool definition that only a “code-first” approach could provide.
That’s why we chose Google’s Agent Development Kit (ADK) as our framework. It offered the balance of power and flexibility necessary to build a truly custom, defensible system, combined with high-level abstractions for agent composition and orchestration that accelerated our development.
Step #2: Build out the engine
We took a hybrid approach when building our agent architecture, which is managed by a top-level root_agent in orchestrator.py. Its primary role is to act as an intelligent controller using an LLM Agent for flexible user interaction, while delegating the core processing loop to [more deterministic ADK components like LoopAgent and custom BaseAgent classes.
Conversational onboarding: The LLM Agent starts by acting as a conversational “front-door,” interacting with the user to collect their name and email.
Workflow delegation: Once it has the user’s information, it delegates the main workflow to a powerful LoopAgent defined in its sub_agents list.
Data loading: The first step inside the LoopAgent is a custom agent called the CompanyLoopController. On the very first iteration of the loop, its job is to call our crm_tool to fetch the list of companies from the Google Sheet and load them into the session state.
Tool-based execution in a loop: The loop processes each company by calling two key tools: the research_pipeline tool that encapsulates our complex company_researcher_agent and the sales_briefing_agent tool that encapsulates the sales_briefing_agent. This “Agent-as-a-Tool” pattern is crucial for state isolation (more in Step 3).
This hybrid pattern gives us the best of both worlds: the flexibility of an LLM for user interaction and the structured, reliable control of a workflow agent with isolated, tool-based execution.
Step #3: Tools, state, and reliability
An agent is only as powerful as the tools it can wield. To be truly useful, our system needed to connect to live data, not just a static local file. To achieve this, we built a custom tool, crm_tool.py, to allow our agent to read its list of target companies directly from a Google Sheet.
To build our read_companies_from_sheet function, we focused on two key areas:
Secure authentication: We used a Google Cloud Service Account for authentication, a best practice for production systems. Our code includes a helper function, get_sheets_service(), that centralizes all the logic for securely loading the service account credentials and initializing the API client.
Configuration management: All configuration, including the SPREADSHEET_ID, is managed via our .env file. This decouples the tool’s logic from its configuration, making it portable and secure.
This approach transformed our agent from one that could only work with local data to one that could securely interact with a live, cloud-based source of truth.
Managing state in loops: The “Agent-as-a-Tool” Pattern A critical challenge in looping workflows is ensuring state isolation between iterations. ADK’s session.state persists, which can cause ‘context rot’ if not managed. Our solution was the “Agent-as-a-Tool” pattern. Instead of running the complex company_researcher_agent directly in the loop, we encapsulated its entire SequentialAgent pipeline into a single, isolated AgentTool (company_researcher_agent_tool).
Every time the loop calls this tool, the ADK provides a clean, temporary context for its execution. All internal steps (planning, QA loop, compiling) happen within this isolated context. When the tool returns the final compiled_report, the temporary context is discarded, guaranteeing a fresh start for the next company. This pattern provides perfect state isolation by design, making the loop robust without manual cleanup logic.
Step 4: Go from Localhost to a scalable deployed product
Here is our recommended three-step blueprint for moving from a local prototype to a production-ready agent on Google Cloud.
1. Adopt a production-grade project template Our most critical lesson was that a simple, local-first project structure is not built for the rigors of the cloud. The turning point for our team was adopting Google’s official Agent Starter Pack. This professional template is not just a suggestion; for any serious project, we now consider it a requirement. It provides three non-negotiable foundations for success out of the box:
Robust dependency management: It replaces the simplicity of local tools like Poetry with the production-grade power of PDM and uv, ensuring that every dependency is locked and every deployment is built from a fast, deterministic, and repeatable environment.
A pre-configured CI/CD pipeline: It comes with a ready-to-use continuous integration and deployment pipeline for Google Cloud Build, which automates the entire process of testing, building, and deploying your agent.
Multi-environment support: The template is pre-configured for separate staging and production environments, a best practice that allows you to safely test changes in an isolated staging environment before promoting them to your live users.
The process begins by using the official command-line tool to generate your project’s local file structure. This prompts you to choose a base template; we used the “ADK Base Template” and then moved our agent logic into the newly created source code files ( App) .
code_block
<ListValue: [StructValue([(‘code’, ‘# Ensure pipx is installedrnpip install –user pipxrnrn# Run the project generator to create the local file structurernpipx run agent-starter-pack create your-new-agent-project’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x7fd594f984f0>)])]>
The final professional project structure:
code_block
<ListValue: [StructValue([(‘code’, ‘final-agent-project/rn├── .github/ # Contains the automated CI/CD workflow configurationrn│ └── workflows/rn├── app/ # Core application source code for the agentrn│ ├── __init__.pyrn│ ├── agent_engine_app.pyrn│ ├── orchestrator.py # The main agent that directs the workflowrn│ ├── company_researcher/ # Sub-agent for performing researchrn│ ├── briefing_agent/ # Sub-agent for drafting emailsrn│ └── tools/ # Custom tools the agents can usern├── tests/ # Automated tests for your agentrn├── .env # Local environment variables (excluded from git)rn├── pyproject.toml # Project definition and dependenciesrn└── uv.lock # Locked dependency versions for speed and consistency’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x7fd594f98550>)])]>
With the local files created, the next step is to provision the cloud infrastructure. From inside the new project directory, you run the setup-cicd command. This interactive wizard connects to your Google Cloud and GitHub accounts, then uses Terraform under the hood to automatically build your entire cloud environment, including the CI/CD pipeline.
code_block
<ListValue: [StructValue([(‘code’, ‘# Navigate into your new project directoryrncd your-new-agent-projectrnrn# Run the interactive CI/CD setup wizardrnpipx run agent-starter-pack setup-cicd’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x7fd594f982b0>)])]>
2. Cloud Build Once the setup is complete with the starter pack, your development workflow becomes incredibly simple. Every time a developer pushes a new commit to the main branch of your GitHub repository:
Google Cloud Build fetches your latest code.
It builds your agent into a secure, portable container image. This process includes installing all the dependencies from your uv.lock file, guaranteeing a perfect, repeatable build every single time.
It deploys this new version to your staging environment. Within minutes, your latest code is live and ready for testing in a real cloud environment.
It waits for your approval. The pipeline is configured to require a manual “Approve” click in the Cloud Build console before it will deploy that exact same, tested version to your production environment. This gives you the perfect balance of automation and control.
3. Deploy on Agent Engine and Cloud Run The final piece of the puzzle is where the agent actually runs. Cloud Build deploys your agent to Vertex AI Agent Engine, which provides the secure, public endpoint and management layer for your agent.
Crucially, Agent Engine is built on top of Google Cloud Run, a powerful serverless platform. This means you don’t have to manage any servers yourself. Your agent automatically scales up to handle thousands of users, and scales down to zero when not in use, meaning you only pay for the compute you actually consume.
Get started
Ready to build your own?
Explore the code for our Sales Intelligence Agent on GitHub.
The technical journey and insights detailed in this blog post were the result of a true team effort. I want to extend my sincere appreciation to the core collaborators whose work provided the foundation for this article: Luis Sala, Isaac Attuah, Ishana Shinde, Andrew Thankson, and Kristin Kim. Their hands-on contributions to architecting and building the agent were essential to the lessons shared here.
AWS Transform for VMware now allows customers to automatically generate network configurations that can be directly imported into the Landing Zone Accelerator on AWS solution (LZA). Building on AWS Transform’s existing support for infrastructure-as-code generation in AWS CloudFormation, AWS CDK, and Terraform formats, this new capability enables automatic transformation of VMware network environments into LZA-compatible network configuration YAML files. The YAML files can be deployed through LZA’s deployment pipeline, streamlining the process of setting up cloud infrastructure.
AWS Transform for VMware is an agentic AI service that automates the discovery, planning, and migration of VMware workloads, accelerating infrastructure modernization with increased speed and confidence. Landing Zone Accelerator on AWS solution (LZA) automates the setup of a secure, multi-account AWS environment using AWS best practices. Migrating workloads to AWS traditionally requires you to manually recreate network configurations while maintaining operational and compliance consistency. The service now automates the generation of LZA network configurations, reducing manual effort and deployment time to better manage and govern your multi-account environment.
Customers using Amazon EventBridge can now setup rules for AWS Health events with multi-region redundancy, or choose a simplified path by creating a single rule to capture all Health events. With this enhancement, Health sends all events simultaneously to US West (Oregon) as well as the individual region of impact. For more information customers can go to Creating EventBridge rules for AWS Region coverage.
Sending Health events to two regions gives customers an option to increase the resilience of their integration by creating a backup rule. US West (Oregon) is the backup for all regions in commercial partition, while US East (N. Virginia) is the backup for US West (Oregon). Plus, this change also enables a simplified integration path, where customers can now setup a single rule in US West (Oregon) to capture all Health events from across commercial partition, as opposed to needing to configure rules in individual regions. Customers now have greater flexibility in their integration approach for receiving Health events.
This update is available in all AWS regions. In China, all Health events get delivered simultaneously to both China (Beijing) and China (Ningxia). In AWS GovCloud (US), all Health events get delivered to AWS GovCloud (US-West) and AWS GovCloud (US-East).
AWS IoT Core Device Location announces location resolution capabilities for Internet of Things (IoT) devices connected to Amazon Sidewalk network, enabling developers to build asset tracking and geo-fencing applications more efficiently by eliminating the need for GPS hardware in low-power devices. Amazon Sidewalk provides a secure community network through Amazon Sidewalk Gateways (compatible Amazon Echo and Ring devices) to deliver cloud connectivity for IoT devices. AWS IoT Core for Amazon Sidewalk facilitates connectivity and message transmission between Amazon Sidewalk-connected IoT devices and AWS cloud services. The integration of Amazon Sidewalk with AWS IoT Core, enables you to easily provision, onboard, and monitor your Amazon Sidewalk devices in the AWS cloud.
With the new enhancement, you can now use AWS IoT Core’s Device Location feature to resolve the approximate location of your Amazon Sidewalk enabled devices, using input payloads like WiFi access point, Global Navigation Satellite System data, or Bluetooth Low Energy data. AWS IoT Core Device Location uses these inputs to resolve the geo-coordinate data, and delivers the geo-coordinate data to your desired AWS IoT rules or MQTT topics for integration with backend applications. To get started, install Sidewalk SDK v1.19 (or a later version) in your Sidewalk-enabled devices, provision the devices in AWS IoT Core for Amazon Sidewalk, and enable location during the provisioning.
This new feature is available in AWS US-East (N. Virginia) Region of AWS cloud where AWS IoT Core for Amazon Sidewalk is available. Please note that Amazon Sidewalk network is available only in the United States of America. For more information, refer AWS developer guide, Amazon Sidewalk developer guide, and Amazon Sidewalk network coverage.
Amazon Relational Database Service (RDS) for PostgreSQL now supports the latest minor versions 17.7, 16.11, 15.15, 14.20, and 13.23. We recommend that you upgrade to the latest minor versions to fix known security vulnerabilities in prior versions of PostgreSQL, and to benefit from the bug fixes added by the PostgreSQL community.
This release includes the new pgcollection extension for RDS PostgreSQL versions 15.15 and above (16.11 and 17.7). This extension enhances database performance by providing an efficient way to store and manage key-value pairs within PostgreSQL functions. Collections maintain the order of entries and can store various types of PostgreSQL data, making them useful for applications that need fast, in-memory data processing. The release also includes updates to extensions, with pg_tle upgraded to version 1.5.2 and H3_PG upgraded to version 4.2.3.
You can use automatic minor version upgrades to automatically upgrade your databases to more recent minor versions during scheduled maintenance windows. You can also use Amazon RDS Blue/Green deployments for RDS for PostgreSQL using physical replication for your minor version upgrades. Learn more about upgrading your database instances, including automatic minor version upgrades and Blue/Green deployments in the Amazon RDS User Guide .
Amazon RDS for PostgreSQL makes it simple to set up, operate, and scale PostgreSQL deployments in the cloud. See Amazon RDS for PostgreSQL Pricing for pricing details and regional availability. Create or update a fully managed Amazon RDS database in the Amazon RDS Management Console.
Amazon Connect now provides metrics that measure completion of agent performance evaluations, improving manager productivity and evaluation consistency. Businesses can monitor if the required number of evaluations for their agents have been completed, ensuring compliance with internal policies (e.g., complete 5 evaluations per agent per month), regulatory requirements, and labor union agreements. Additionally, businesses can analyze evaluation scoring patterns across different managers, to identify opportunities to improve evaluation consistency and accuracy. These insights are available in real-time through analytics dashboards in the Connect UI, and APIs.
This feature is available in all regions where Amazon Connect is offered. To learn more, please visit our documentation and our webpage.
For those building with AI, most are in it to change the world — not twiddle their thumbs. So when inspiration strikes, the last thing anyone wants is to spend hours waiting for the latest AI models to download to their development environment.
That’s why today we’re announcing a deeper partnership between Hugging Face and Google Cloud that:
reduces Hugging Face model download times through Vertex AI and Google Kubernetes Engine
offers native support for TPUs on all open models sourced through Hugging Face
provides a safer experience through Google Cloud’s built-in security capabilities.
We’ll enable faster download times through a new gateway for Hugging Face repositories that will cache Hugging Face models and datasets directly on Google Cloud. Moving forward, developers working with Hugging Face’s open models on Google Cloud should expect download times to take minutes, not hours.
We’re also working with Hugging Face to add native support for TPUs for all open models on the Hugging Face platform. This means that whether developers choose to deploy training and inference workloads on NVIDIA GPUs or on TPUs, they’ll experience the same ease of deployment and support.
Open models are gaining traction with enterprise developers, who typically work with specific security requirements. To support enterprise developers, we’re working with Hugging Face to bring Google Cloud’s extensive security protocols to all Hugging Face models deployed through Vertex AI. This means that any Hugging Face model on Vertex AI Model Garden will now be scanned and validated with Google Cloud’s leading cybersecurity capabilities powered by our Threat Intelligence platform and Mandiant.
This expanded partnership with Hugging Face furthers that commitment and will ensure that developers have an optimal experience when serving AI models on Google Cloud, whether they choose a model from Google, from our many partners, or one of the thousands of open models available on Hugging Face.
The prevalence of obfuscation and multi-stage layering in today’s malware often forces analysts into tedious and manual debugging sessions. For instance, the primary challenge of analyzing pervasive commodity stealers like AgentTesla isn’t identifying the malware, but quickly cutting through the obfuscated delivery chain to get to the final payload.
Unlike traditional live debugging, Time Travel Debugging (TTD) captures a deterministic, shareable record of a program’s execution. Leveraging TTD’s powerful data model and time travel capabilities allow us to efficiently pivot to the key execution events that lead to the final payload.
This post introduces all of the basics of WinDbg and TTD necessary to start incorporating TTD into your analysis. We demonstrate why it deserves to be a part of your toolkit by walking through an obfuscated multi-stage .NET dropper that performs process hollowing.
What is Time Travel Debugging?
Time Travel Debugging (TTD), a technology offered by Microsoft as part of WinDbg, records a process’s execution into a trace file that can be replayed forwards and backwards. The ability to quickly rewind and replay execution reduces analysis time by eliminating the need to constantly restart debugging sessions or restore virtual machine snapshots. TTD also enables users to query the recorded execution data and filter it with Language Integrated Query (LINQ) to find specific events of interest like module loads or calls to APIs that implement malware functionalities like shellcode execution or process injection.
During recording, TTD acts as a transparent layer that allows full interaction with the operating system. A trace file preserves a complete execution record that can be shared with colleagues to facilitate collaboration, circumventing environmental differences that can affect the results of live debugging.
While TTD offers significant advantages, users should be aware of certain limitations. Currently, TTD is restricted to user-mode processes and cannot be used for kernel-mode debugging. The trace files generated by TTD have a proprietary format, meaning their analysis is largely tied to WinDbg. Finally, TTD does not offer “true” time travel in the sense of altering the program’s past execution flow; if you wish to change a condition or variable and see a different outcome, you must capture an entirely new trace as the existing trace is a fixed recording of what occurred.
A Multi-Stage .NET Dropper with Signs of Process Hollowing
The Microsoft .NET framework has long been popular among threat actors for developing highly obfuscated malware. These programs often use code flattening, encryption, and multi-stage assemblies to complicate the analysis process. This complexity is amplified by Platform Invoke (P/Invoke), which gives managed .NET code direct access to the unmanaged Windows API, allowing authors to port tried-and-true evasion techniques like process hollowing into their code.
Process hollowing is a pervasive and effective form of code injection where malicious code runs under the guise of another process. It is common at the end of downloader chains because the technique allows injected code to assume the legitimacy of a benign process, making it difficult to spot the malware with basic monitoring tools.
In this case study, we’ll use TTD to analyze a .NET dropper that executes its final stage via process hollowing. The case study demonstrates how TTD facilitates highly efficient analysis by quickly surfacing the relevant Windows API functions, enabling us to bypass the numerous layers of .NET obfuscation and pinpoint the payload.
Basic analysis is a vital first step that can often identify potential process hollowing activity. For instance, using a sandbox may reveal suspicious process launches. Malware authors frequently target legitimate .NET binaries for hollowing as these blend seamlessly with normal system operations. In this case, reviewing process activity on VirusTotal shows that the sample launches InstallUtil.exe (found in %windir%Microsoft.NETFramework<version>). While InstallUtil.exe is a legitimate utility, its execution as a child process of a suspected malicious sample is an indicator that helps focus our initial investigation on potential process injection.
Figure 1: Process activity recorded in the VirusTotal sandbox
Despite newer, more stealthy techniques, such as Process Doppelgänging, when an attacker employs process injection, it’s still often the classic version of process hollowing due to its reliability, relative simplicity, and the fact that it still effectively evades less sophisticated security solutions. The classic process hollowing steps are as follows:
CreateProcess (with the CREATE_SUSPENDED flag): Launches the victim process (InstallUtil.exe) but suspends its primary thread before execution.
ZwUnmapViewOfSection or NtUnmapViewOfSection: “Hollows out” the process by removing the original, legitimate code from memory.
VirtualAllocEx and WriteProcessMemory: Allocates new memory in the remote process and injects the malicious payload.
GetThreadContext: Retrieves the context (the state and register values) of the suspended primary thread.
SetThreadContext: Redirects the execution flow by modifying the entry point register within the retrieved context to point to the address of the newly injected malicious code.
ResumeThread: Resumes the thread, causing the malicious code to execute as if it were the legitimate process.
To confirm this activity in our sample using TTD, we focus our search on the process creation and the subsequent writes to the child process’s address space. The approach demonstrated in this search can be adapted to triage other techniques by adjusting the TTD queries to search for the APIs relevant to that technique.
Recording a Time Travel Trace of the Malware
To begin using TTD, you must first record a trace of a program’s execution. There are two primary ways to record a trace: using the WinDbg UI or the command-line utilities provided by Microsoft. The command-line utilities offer the quickest and most customizable way to record a trace, and that is what we’ll explore in this post.
Warning: Take all usual precautions for performing dynamic analysis of malware when recording a TTD trace of malware executables. TTD recording is not a sandbox technology and allows the malware to interface with the host and the environment without obstruction.
TTD.exe is the preferred command-line tool for recording traces. While Windows includes a built-in utility (tttracer.exe), that version has reduced features and is primarily intended for system diagnostics, not general use or automation. Not all WinDbg installations provide the TTD.exe utility or add it to the system path. The quickest way to get TTD.exe is to use the stand-alone installer provided by Microsoft. This installer automatically adds TTD.exe to the system’s PATH environment variable, ensuring it’s available from a command prompt. To see its usage information, run TTD.exe -help.
The quickest way to record a trace is to simply provide the command line invoking the target executable with the appropriate arguments. We use the following command to record a trace of our sample:
C:UsersFLAREDesktop> ttd.exe 0b631f91f02ca9cffd66e7c64ee11a4b.bin
Microsoft (R) TTD 1.01.11 x64
Release: 1.11.532.0
Copyright (C) Microsoft Corporation. All rights reserved.
Launching '0b631f91f02ca9cffd66e7c64ee11a4b.bin'
Initializing the recording of process (PID:2448) on trace file: C:UsersFLAREDesktopb631f91f02ca9cffd66e7c64ee11a4b02.run
Recording has started of process (PID:2448) on trace file: C:UsersFLAREDesktopb631f91f02ca9cffd66e7c64ee11a4b02.run
Once TTD begins recording, the trace concludes in one of two ways. First, the tracing automatically stops upon the malware’s termination (e.g., process exit, unhandled exception, etc.). Second, the user can manually intervene. While recording, TTD.exe displays a small dialog (shown in figure 2) with two control options:
Tracing Off: Stops the trace and detaches from the process, allowing the program to continue execution.
Exit App: Stops the trace and also terminates the process.
Figure 2: TTD trace execution control dialog
Recording a TTD trace produces the following files:
<trace>.run: The trace file is a proprietary format that contains compressed execution data. The size of a trace file is influenced by the size of the program, the length of execution, and other external factors such as the number of additional resources that are loaded.
<trace>.idx: The index file allows the debugger to quickly locate specific points in time during the trace, bypassing sequential scans of the entire trace. The index file is created automatically the first time a trace file is opened in WinDbg. In general, Microsoft suggests that index files are typically twice the size of the trace file.
<trace>.out: The trace log file containing logs produced during trace recording.
Once a trace is complete, the .runfile can be opened with WinDbg.
Triaging the TTD Trace: Shifting Focus to Data
The fundamental advantage of TTD is the ability to shift focus from manual code stepping to execution data analysis. Performing rapid, effective triage with this data-driven approach requires proficiency in both basic TTD navigation and querying the Debugger Data Model. Let’s begin by exploring the basics of navigation and the Debugger Data Model.
Navigating a Trace
Basic navigation commands are available under the Home tab in the WinDbg UI.
Figure 3: Basic WinDbg TTD Navigation Commands
The standard WinDbg commands and shortcuts for controlling execution are:
Replaying a TTD trace enables the reverse flow control commands that complement the regular flow control commands. Each reverse flow control complement is formed by appending a dash (–) to the regular flow control command:
g-: Go Back – Execute the trace backwards
g-u: Step Out Back – Execute the trace backwards up to the last call instruction
t-: Step Into Back – Single step into backwards
p-: Step Over Back – Single step over backwards
Time Travel (!tt) Command
While basic navigation commands let you move step-by-step through a trace, the time travel command (!tt) enables precise navigation to a specific trace position. These positions are often provided in the output of various TTD commands. A position in a TTD trace is represented by two hexadecimal numbers in the format #:# (e.g., E:7D5) where:
The first part is a sequencing number typically corresponding to a major execution event, such as a module load or an exception.
The second part is a step count, indicating the number of events or instructions executed since that major execution event.
We’ll use the time travel command later in this post to jump directly to the critical events in our process hollowing example, bypassing manual instruction tracing entirely.
The TTD Debugger Data Model
The WinDbg debugger data model is an extensible object model that exposes debugger information as a navigable tree of objects. The debugger data model brings a fundamental shift in how users access debugger information in WinDbg, from wrangling raw text-based output to interacting with structured object information. The data model supports LINQ for querying and filtering, allowing users to efficiently sort through large volumes of execution information. The debugger data model also simplifies automation through JavaScript, with APIs that mirror how you access the debugger data model through commands.
The Display Debugger Object Model Expression(dx) command is the primary way to interact with the debugger data model from the command window in WinDbg. The model lends itself to discoverability – you can begin traversing through it by starting at the root Debugger object:
0:000> dx Debugger
Debugger
Sessions
Settings
State
Utility
LastEvent
The command output lists the five objects that are properties of the Debugger object. Note that the names in the output, which look like links, are marked up using the Debugger Markup Language (DML). DML enriches the output with links that execute related commands. Clicking on the Sessions object in the output executes the following dx command to expand on that object:
The -r# argument specifies recursion up to # levels, with a default depth of one if not specified. For example, increasing the recursion to two levels in the previous command produces the following output:
0:000> dx -r2 Debugger.Sessions
Debugger.Sessions
[0x0] : Time Travel Debugging: 0b631f91f02ca9cffd66e7c64ee11a4b.run
Processes
Id : 0
Diagnostics
TTD
OS
Devices
Attributes
The -g argument displays any iterable object into a data grid in which each element is a grid row and the child properties of each element are grid columns.
0:000> dx -g Debugger.Sessions
Figure 4: Grid view of Sessions, with truncated columns
Debugger and User Variables
WinDbg provides some predefined debugger variables for convenience which can be listed through the DebuggerVariables property.
@$cursession: The current debugger session. Equivalent to Debugger.Sessions[<session>]. Commonly used items include:
@$cursession.Processes: List of processes in the session.
@$cursession.TTD.Calls: Method to query calls that occurred during the trace.
@$cursession.TTD.Memory: Method to query memory operations that occurred during the trace.
@$curprocess: The current process. Equivalent to @$cursession.Processes[<pid>]. Frequently used items include:
@$curprocess.Modules: List of currently loaded modules.
@$curprocess.TTD.Events: List of events that occurred during the trace.
Investigating the Debugger Data Model to Identify Process Hollowing
With a basic understanding of TTD concepts and a trace ready for investigation, we can now look for evidence of process hollowing. To begin, the Calls method can be used to search for specific Windows API calls. This search is effective even with a .NET sample because the managed code must interface with the unmanaged Windows API through P/Invoke to perform a technique like process hollowing.
Process hollowing begins with the creation of a process in a suspended state via a call to CreateProcess with a creation flag value of 0x4. The following query uses the Calls method to return a table of each call to the kernel32 module’s CreateProcess* in the trace; the wildcard (*) ensures the query matches calls to either CreateProcessA or CreateProcessW.
This query returns a number of fields, not all of which are helpful for our investigation. To address this, we can apply the Select LINQ query to the original query, which allows us to specify which columns to display and rename them.
0:000> dx -g @$cursession.TTD.Calls("kernel32!CreateProcess*").Select(c => new { TimeStart = c.TimeStart, Function = c.Function, Parameters = c.Parameters, ReturnAddress = c.ReturnAddress})
The result shows one call to CreateProcessA starting at position 58243:104D. Note the return address: since this is a .NET binary, the native code executed by the Just-In-Time (JIT) compiler won’t be located in the application’s main image address space (as it would be in a non-.NET image). Normally, an effective triage step is to filter results with a Where LINQ query, limiting the return address to the primary module to filter out API calls that do not originate from the malware. This Where filter, however, is less reliable when analyzing JIT-compiled code due to the dynamic nature of its execution space.
The next point of interest is the Parameters field. Clicking on the DML link on the collapsed value {..} displays Parameters via a corresponding dx command.
Function arguments are available under a specific Calls object as an array of values. However, before we investigate the parameters, there are some assumptions made by TTD that are worth exploring. Overall, these assumptions are affected by whether the process is 32-bit or 64-bit. An easy way to check the bitness of the process is by inspecting the DebuggerInformation object.
0:00> dx Debugger.State.DebuggerInformation
Debugger.State.DebuggerInformation
ProcessorTarget : X86 <--- Process Bitness
Bitness : 32
EngineFilePath : C:Program FilesWindowsApps<SNIPPED>x86dbgeng.dll
EngineVersion : 10.0.27871.1001
The key identifier in the output is ProcessorTarget: this value indicates the architecture of the guest process that was traced, regardless of whether the host operating system running the debugger is 64-bit.
TTD uses symbol information provided in a program database (PDB) file to determine the number of parameters, their types and the return type of a function. However, this information is only available if the PDB file contains private symbols. While Microsoft provides PDB files for many of its libraries, these are often public symbols and therefore lack the necessary function information to interpret the parameters correctly. This is where TTD makes another assumption that can lead to incorrect results. Primarily, it assumes a maximum of four QWORD parameters and that the return value is also a QWORD. This assumption creates a mismatch in a 32-bit process (x86), where arguments are typically 32-bit (4-byte) values passed on the stack. Although TTD correctly finds the arguments on the stack, it misinterprets two adjacent 32-bit arguments as a single, 64-bit value.
One way to resolve this is to manually investigate the arguments on the stack. First we use the !tt command to navigate to the beginning of the relevant call to CreateProcessA.
0:000> !tt 58243:104D
(b48.12a4): Break instruction exception - code 80000003 (first/second chance not available)
Time Travel Position: 58243:104D
eax=00bed5c0 ebx=039599a8 ecx=00000000 edx=75d25160 esi=00000000 edi=03331228
eip=75d25160 esp=0055de14 ebp=0055df30 iopl=0 nv up ei pl zr na pe nc
cs=0023 ss=002b ds=002b es=002b fs=0053 gs=002b efl=00000246
KERNEL32!CreateProcessA:
75d25160 8bff mov edi,edi
The return address is at the top of the stack at the start of a function call, so the following dd command skips over this value by adding an offset of 4 to the ESP register to properly align the function arguments.
The value of 0x4 (CREATE_SUSPENDED) set in the bitmask for the dwCreationFlags argument (6th argument) indicates that the process will be created in a suspended state.
The following command dereferences esp+4 via the poi operator to retrieve the application name string pointer then uses the da command to display the ASCII string.
0:000> da poi(esp+4)
0055de74 "C:WindowsMicrosoft.NETFramewo"
0055de94 "rkv4.0.30319InstallUtil.exe"
The command reveals that the target application is InstallUtil.exe, which aligns with the findings from basic analysis.
It is also useful to retrieve the handle to the newly created process in order to identify subsequent operations performed on it. The handle value is returned through a pointer (0x55e068 in the earlier referenced output) to a PROCESS_INFORMATION structure passed as the last argument. This structure has the following definition:
After the call to CreateProcessA, the first member of this structure should be populated with the handle to the process. Step out of the call using the gu(Go Up) command to examine the populated structure.
0:000> gu
Time Travel Position: 58296:60D
0:000> dd /c 1 0x55e068 L4
0055e068 00000104 <-- handle to process
0055e06c 00000970
0055e070 00000d2c
0055e074 00001c30
In this trace, CreateProcess returned 0x104 as the handle for the suspended process.
The most interesting operation in process hollowing for the purpose of triage is the allocation of memory and subsequent writes to that memory, commonly performed via calls to WriteProcessMemory. The previous Calls query can be updated to identify calls to WriteProcessMemory.
Investigating these calls to WriteProcessMemory shows that the target process handle is 0x104, which represents the suspended process. The second argument defines the address in the target process. The arguments to these calls reveal a pattern common to PE loading: the malware writes the PE header followed by the relevant sections at their virtual offsets.
It is worth noting that the memory of the target process cannot be analyzed from this trace. To record the execution of a child process, pass the -children flag to the TTD.exe utility. This will generate a trace file for each process, including all child processes, spawned during execution.
The first memory write to what is likely the target process’s base address (0x400000) is 0x200 bytes. This size is consistent with a PE header, and examining the source buffer (0x9810af0) confirms its contents.
The !dh extension can be used to parse this header information.
0:000> !dh 0x9810af0
File Type: EXECUTABLE IMAGE
FILE HEADER VALUES
14C machine (i386)
3 number of sections
66220A8D time date stamp Fri Apr 19 06:09:17 2024
----- SNIPPED -----
OPTIONAL HEADER VALUES
10B magic #
11.00 linker version
----- SNIPPED -----
0 [ 0] address [size] of Export Directory
3D3D4 [ 57] address [size] of Import Directory
----- SNIPPED -----
0 [ 0] address [size] of Delay Import Directory
2008 [ 48] address [size] of COR20 Header Directory
SECTION HEADER #1
.text name
3B434 virtual size
2000 virtual address
3B600 size of raw data
200 file pointer to raw data
----- SNIPPED -----
SECTION HEADER #2
.rsrc name
546 virtual size
3E000 virtual address
600 size of raw data
3B800 file pointer to raw data
----- SNIPPED -----
SECTION HEADER #3
.reloc name
C virtual size
40000 virtual address
200 size of raw data
3BE00 file pointer to raw data
----- SNIPPED -----
The presence of a COR20 header directory (a pointer to the .NET header) indicates that this is a .NET executable.The relative virtual addresses for the .text (0x2000), .rsrc (0x3E000), and .reloc (0x40000) also align with the target addresses of the WriteProcessMemory calls.
The newly discovered PE file can now be extracted from memory using the writemem command.
Using a hex editor, the file can be reconstructed by placing each section at its raw offset. A quick analysis of the resulting .NET executable (SHA256: 4dfe67a8f1751ce0c29f7f44295e6028ad83bb8b3a7e85f84d6e251a0d7e3076) in dnSpy reveals its configuration data.
This case study demonstrates the benefit of treating TTD execution traces as a searchable database. By capturing the payload delivery and directly querying the Debugger Data Model for specific API calls, we quickly bypassed the multi-layered obfuscation of the .NET dropper. The combination of targeted data model queries and LINQ filters (for CreateProcess* and WriteProcessMemory*) and low-level commands (!dh, .writemem) allowed us to isolate and extract the hidden AgentTesla payload, yielding critical configuration details in a matter of minutes.
The tools and environment used in this analysis—including the latest version of WinDbg and TTD—are readily available via the FLARE-VM installation script. We encourage you to streamline your analysis workflow with this pre-configured environment.