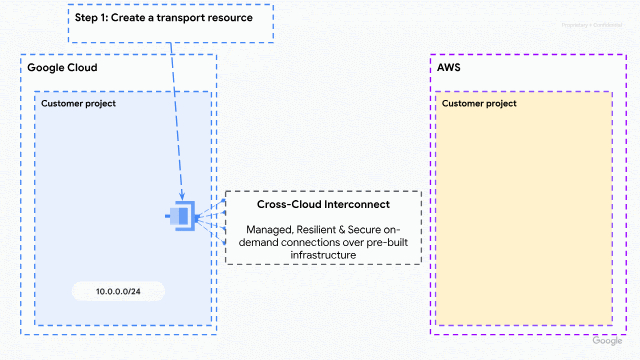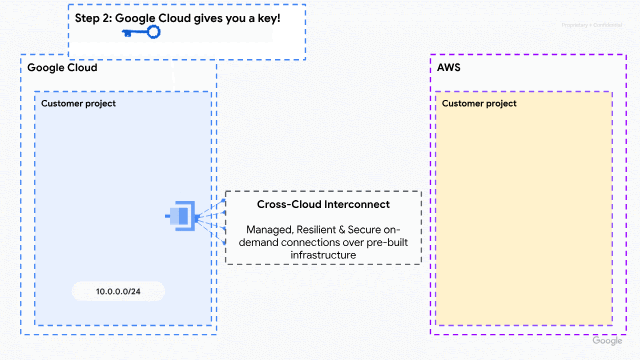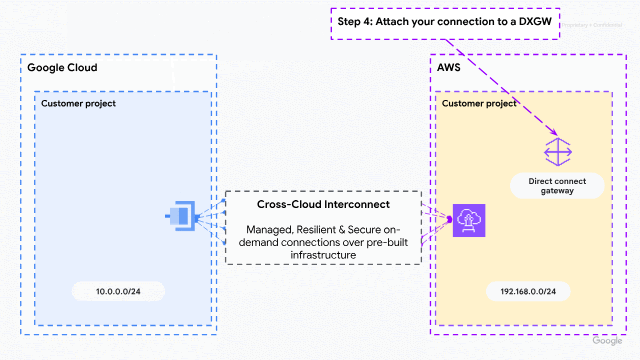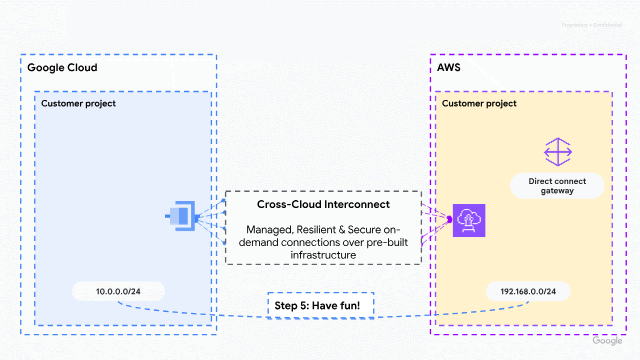
As organizations increasingly adopt multicloud architectures, the need for interoperability between cloud service providers has never been greater. Historically, however, connecting these environments has been a challenge, forcing customers to take a complex “do-it-yourself” approach to managing global multi-layered networks at scale.
To address these challenges and advance a more open cloud environment, Amazon Web Services (AWS) and Google Cloud collaborated to transform how cloud service providers could connect with one another in a simplified manner.
Today, AWS and Google Cloud are excited to announce a jointly engineered multicloud networking solution that uses both AWS Interconnect – multicloud and Google Cloud’s Cross-Cloud Interconnect. This collaboration also introduces a new open specification for network interoperability, enabling customers to establish private, high-speed connectivity between Google Cloud and AWS with high levels of automation and speed.
“Integrating Salesforce Data 360 with the broader IT landscape requires robust, private connectivity. AWS Interconnect – multicloud allows us to establish these critical bridges to Google Cloud with the same ease as deploying internal AWS resources, utilizing pre-built capacity pools and the tools our teams already know and love. This native, streamlined experience — from provisioning through ongoing support — accelerates our customers’ ability to ground their AI and analytics in trusted data, regardless of where it resides.” – Jim Ostrognai, SVP Software Engineering, Salesforce
Previously, to connect cloud service providers, customers had to manually set up complex networking components including physical connections and equipment; this approach required lengthy lead times and coordinating with multiple internal and external teams. This could take weeks or even months. AWS had a vision for developing this capability as a unified specification that could be adopted by any cloud service provider, and collaborated with Google Cloud to bring it to market.
Now, this new solution reimagines multicloud connectivity by moving away from physical infrastructure management toward a managed, cloud-native experience. By integrating AWS with Google Cloud’s Cross-Cloud Network architecture, we are abstracting the complexity of physical connectivity, network addressing, and routing policies. Customers no longer need to wait weeks for circuit provisioning: they can now provision dedicated bandwidth on demand and establish connectivity in minutes through their preferred cloud console or API.
Reliability and security are the cornerstone of this collaboration. We have collaborated on this solution to deliver high resiliency by leveraging quad-redundancy across physically redundant interconnect facilities and routers. Both providers engage in continuous monitoring to proactively detect and resolve issues. And this solution is built on a foundation of trust, utilizing MACsec encryption between the Google Cloud and AWS edge routers.
“This collaboration between AWS and Google Cloud represents a fundamental shift in multicloud connectivity. By defining and publishing a standard that removes the complexity of any physical components for customers, with high availability and security fused into that standard, customers no longer need to worry about any heavy lifting to create their desired connectivity. When they need multicloud connectivity, it’s ready to activate in minutes with a simple point and click.” – Robert Kennedy, VP of Network Services, AWS
“We are excited about this collaboration which enables our customers to move their data and applications between clouds with simplified global connectivity and enhanced operational effectiveness. Today’s announcement further delivers on Google Cloud’s Cross-Cloud Network solution focused on delivering an open and unified multicloud experience for customers.” – Rob Enns, VP/GM of Cloud Networking, Google Cloud
This collaboration between AWS and Google Cloud is more than a multicloud solution: it’s a step toward a more open cloud environment. The API specifications developed for this product are open for other providers and partners to adopt, as we aim to simplify global connectivity for everyone. We invite you to explore this new capability today. To learn more about how to streamline your multicloud operations please visit the in-depth Google Cloud Cross-Cloud Interconnect blog and the AWS Interconnect – multicloud website to get started.
for the details.