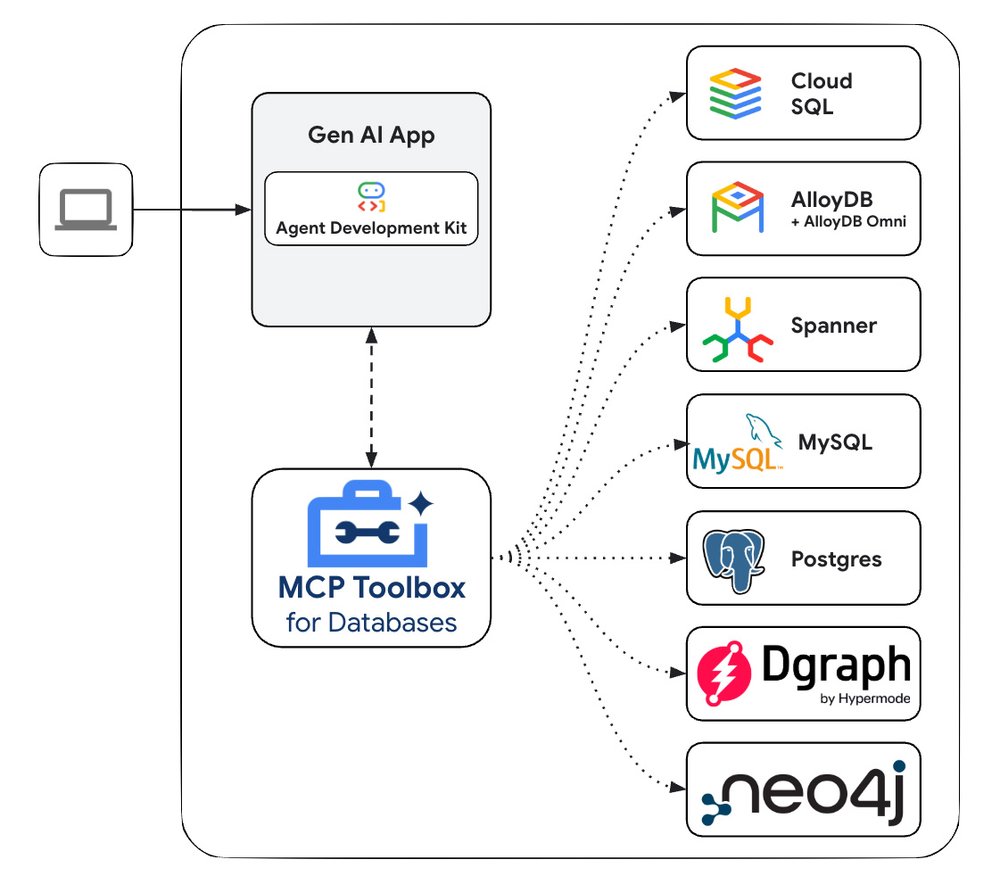
GCP – Google Cloud Database and LangChain integrations now support Go, Java, and JavaScript
Last year, Google Cloud and LangChain announced integrations that give generative AI developers access to a suite of LangChain Python packages. This allowed application developers to leverage Google Cloud’s database portfolio in their gen AI applications to drive the most value from their private data.
Today, we are expanding language support for our integrations to include Go, Java, and JavaScript.
Each package will have up to three LangChain integrations:
-
Vector stores to enable semantic search for our databases
-
Chat message history to enable chains to recall previous conversations
-
Document loader for loading documents from your enterprise data
Developers now have the flexibility to create intricate workflows and easily interchange underlying components (like a vector database) as needed to align with specific use cases. This technology unlocks a variety of applications, including personalized product recommendations, question answering, document search and synthesis, customer service automation, and more.
In this post, we’ll share more about the integrations – and code snippets to get started.
- aside_block
- <ListValue: [StructValue([(‘title’, ‘$300 in free credit to try Google Cloud databases’), (‘body’, <wagtail.rich_text.RichText object at 0x3e49f87219d0>), (‘btn_text’, ‘Start building for free’), (‘href’, ‘http://console.cloud.google.com/freetrial?redirectPath=/products?#databases’), (‘image’, None)])]>
New language support
LangChain is known for its popular Python package; however, your team’s expertise and services may not be in Python. Java and Go are commonly used programming languages for production-grade and enterprise-scale applications. Developers may prefer Javascript and Typescript for the asynchronous programming support and compatibility with front-end frameworks like React and Vue.
In addition to Python developers, the LangChain developer community encompasses developers proficient in Java, JavaScript, and Go. It is an active and supportive community centered around the LangChain framework, which facilitates the development of applications powered by large language models (LLMs).
Google Cloud is dedicated to providing secure and easy to use database integrations for your Gen AI applications. Our integrations embed Google Cloud connectors that create secure connections, handle SSL certificates, and support IAM authorization and authentication. The integrations are optimized for PostgreSQL databases (AlloyDB for PostgreSQL, AlloyDB Omni, Cloud SQL for PostgreSQL) to ensure proper connection management, flexible tables schemas, and improved filtering.
JavaScript Support
JavaScript developers can utilize LangChain.js, which provides tools and building blocks for developing applications leveraging LLMs. LangChain simplifies the process of connecting LLMs to external data sources and enables reasoning capabilities in applications. Other Google Cloud integrations, such as Gemini models, are available within LangChain.js, allowing seamless interaction with GCP resources.
|
Resources (Cloud SQL PostgreSQL support only) |
Links |
|
Documentation |
|
|
How-to guides |
|
|
Quick start guide |
|
|
GitHub |
Below are the integrations and their code snippets to get started.
Install the dependency:
- code_block
- <ListValue: [StructValue([(‘code’, ‘npm install @langchain/google-cloud-sql-pg’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e49f8721c40>)])]>
Engine
- code_block
- <ListValue: [StructValue([(‘code’, ‘import { PostgresEngine } from “@langchain/google-cloud-sql-pg”;rnrnconst engine: PostgresEngine = await PostgresEngine.fromInstance(rn “project-id”,rn “region”,rn “instance-name”,rn “database-name”,rn);’), (‘language’, ‘lang-py’), (‘caption’, <wagtail.rich_text.RichText object at 0x3e49f7eca5e0>)])]>
Use this package with AlloyDB for PostgreSQL and AlloyDB Omni by customizing your Engine to connect your instance. You will need the AlloyDB Auth Proxy to make authorized, encrypted connections to AlloyDB instances.
- code_block
- <ListValue: [StructValue([(‘code’, ‘import { PostgresEngine, PostgresEngineArgs} from “@langchain/google-cloud-sql-pg”;rnrnconst engine: PostgresEngine = await PostgresEngine.fromEngineArgs(rn `postgresql+asyncpg://${OMNI_USER}:${OMNI_PASSWORD}@${OMNI_HOST}:5432/${OMNI_DATABASE_NAME}`rn);’), (‘language’, ‘lang-py’), (‘caption’, <wagtail.rich_text.RichText object at 0x3e49f7eca490>)])]>
Vector store
- code_block
- <ListValue: [StructValue([(‘code’, ‘import { PostgresVectorStore } from “@langchain/google-cloud-sql-pg”;rnimport { VertexAIEmbeddings } from “@langchain/google-vertexai”;rnrnawait engine.initVectorstoreTable(“my_vector_store_table”, 768);rnrnconst embeddings = new VertexAIEmbeddings({rn model: “text-embedding-004”,rn});rnconst vectorStore = await PostgresVectorStore.create(rn engine,rn embeddingService,rn “my_vector_store_table”rn);’), (‘language’, ‘lang-py’), (‘caption’, <wagtail.rich_text.RichText object at 0x3e49f7eca6a0>)])]>
Chat message history
- code_block
- <ListValue: [StructValue([(‘code’, ‘import { PostgresChatMessageHistory } from “@langchain/google-cloud-sql-pg”;rnrnawait engine.initChatHistoryTable(“my_chat_table”, 768);rnrnconst chat_history = await PostgresChatMessageHistory.create({rn engine,rn “user-session-1”,rn “my_chat_table”rn});’), (‘language’, ‘lang-py’), (‘caption’, <wagtail.rich_text.RichText object at 0x3e49f7eca4c0>)])]>
Loader
- code_block
- <ListValue: [StructValue([(‘code’, ‘import { PostgresLoader } from “@langchain/google-cloud-sql-pg”;rnrnrnconst loader = await PostgresChatMessageHistory.create(rn engine,rn {query: “SELECT * FROM my_table”}rn);rnrnlet data = await loader.load()’), (‘language’, ‘lang-py’), (‘caption’, <wagtail.rich_text.RichText object at 0x3e49f7eca580>)])]>
Java Support
For Java developers, there’s LangChain4j, a Java implementation of LangChain. This allows Java developers to build LLM-powered applications with a familiar ecosystem. In LangChain4j, you can also access the full array of VertexAI Gemini models.
*Note: Cloud SQL integrations will be released soon.
Below are the integrations and their code snippets to get started.
For Maven in pom.xml:
- code_block
- <ListValue: [StructValue([(‘code’, ‘<dependency>rn <groupId>dev.langchain4j</groupId>rn <artifactId>langchain4j-alloydb-pg</artifactId>rn <version>1.0.0-beta3</version>rn</dependency>rnrn<!– New Version to be released –>rn<dependency>rn <groupId>dev.langchain4j</groupId>rn <artifactId>langchain4j-cloud-sql-pg</artifactId>rn <version>1.0.0-beta4</version>rn</dependency>’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e49f7ecadf0>)])]>
Engine
- code_block
- <ListValue: [StructValue([(‘code’, ‘import dev.langchain4j.engine.AlloyDBEngine;rnrnAlloyDBEngine engine = new AlloyDBEngine.Builder()rn .projectId(“PROJECT_ID”)rn .region(“REGION”)rn .cluster(“CLUSTER”)rn .instance(“INSTANCE”)rn .database(“DATABASE”)rn .build();’), (‘language’, ‘lang-py’), (‘caption’, <wagtail.rich_text.RichText object at 0x3e49f7eca730>)])]>
Embedding store
- code_block
- <ListValue: [StructValue([(‘code’, ‘import dev.langchain4j.store.embedding.alloydb.AlloyDBEmbeddingStore;rnrnengine.initVectorStoreTable(new EmbeddingStoreConfig.builder(tableName, vectorSize).build());rnAlloyDBEmbeddingStore store = new AlloyDBEmbeddingStore.Builder(engine, tableName).build();’), (‘language’, ‘lang-py’), (‘caption’, <wagtail.rich_text.RichText object at 0x3e49f7ecabb0>)])]>
Document loader
- code_block
- <ListValue: [StructValue([(‘code’, ‘import dev.langchain4j.data.document.loader.alloydb.AlloyDBLoader;rnrnAlloyDBLoader loader = new AlloyDBLoader.Builder(engine).query(“SELECT * FROM my_table”).build();rnList<Document> data = loader.load();’), (‘language’, ‘lang-py’), (‘caption’, <wagtail.rich_text.RichText object at 0x3e49f7eca940>)])]>
Go support
LangchainGo is the Go programming language port of LangChain.
The LangChain framework was designed to support the development of sophisticated applications that connect language models to data sources and enable interaction with their environment. The most powerful and differentiated applications go beyond simply using a language model via an API; they are data-aware and agentic.
Last year Google’s SDKs were added as providers for LangChainGo; this makes it possible to use the capabilities of the LangChain framework with Google’s Gemini models as LLM providers.
We now have AlloyDB and Cloud SQL for PostgreSQL support in LangchainGo.
|
Resources |
Links |
|
How-to guides |
|
|
Quick start guides |
|
|
GitHub |
Below are the integrations and their code snippets to get started.
Install the dependency
- code_block
- <ListValue: [StructValue([(‘code’, ‘go get -u github.com/tmc/langchaingo’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e49f7eca250>)])]>
Engine
- code_block
- <ListValue: [StructValue([(‘code’, ‘import (rnt”context”rnt”github.com/tmc/langchaingo/internal/alloydbutil”rn)rnrnpgEngine, err := alloydbutil.NewPostgresEngine(ctx,rntalloydbutil.WithDatabase(database),rntalloydbutil.WithAlloyDBInstance(projectID, region, cluster, instance),rn)’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e49f7eca970>)])]>
Vector Store
- code_block
- <ListValue: [StructValue([(‘code’, ‘package mainrnrnimport (rnt”log”rnrnt”github.com/tmc/langchaingo/embeddings”rnt”github.com/tmc/langchaingo/internal/alloydbutil”rnt”github.com/tmc/langchaingo/llms/googleai/vertex”rnt”github.com/tmc/langchaingo/vectorstores/alloydb”rn)rnrnfunc main() {rnt// Initialize table for the Vectorstore to use. You only need to do this the first time you use this table.rntvectorstoreTableoptions, err := &alloydbutil.VectorstoreTableOptions{rnttTableName: “my_table”,rnttVectorSize: 768,rnt}rntif err != nil {rnttlog.Fatal(err)rnt}rnrnterr = pgEngine.InitVectorstoreTable(ctx, *vectorstoreTableoptions)rntif err != nil {rnttlog.Fatal(err)rnt}rnrnt// Initialize VertexAI LLMrntllm, err := vertex.New(ctx,rnttvertex.WithCloudProject(projectID),rnttvertex.WithCloudLocation(vertexLocation),rnttvertex.WithDefaultModel(“text-embedding-005”),rnt)rntif err != nil {rnttlog.Fatal(err)rnt}rnrnte, err := embeddings.NewEmbedder(llm)rntif err != nil {rnttlog.Fatal(err)rnt}rnrnt// Create a new AlloyDB Vectorstorerntvs, err := alloydb.NewVectorStore(ctx, pgEngine, e, “my_table”)rn}’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e49f7ecae50>)])]>
Chat message history
- code_block
- <ListValue: [StructValue([(‘code’, ‘import (rnt”context”rnt”log”rnt”github.com/tmc/langchaingo/internal/alloydbutil”rnt”github.com/tmc/langchaingo/llms”rnt”github.com/tmc/langchaingo/memory/alloydb”rn)rnrntrn// Creates a new table in the Postgres database, which will be used for storing Chat History.rnerr = pgEngine.InitChatHistoryTable(ctx, tableName)rnif err != nil {rntlog.Fatal(err)rn}rnrn// Creates a new Chat Message Historyrncmh, err := alloydb.NewChatMessageHistory(ctx, *pgEngine, tableName, sessionID)rnif err != nil {rntlog.Fatal(err)rn}’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e49f7eca790>)])]>
*Note code is shown for AlloyDB. See links for Cloud SQL for Postgres examples.
Get started
The LangChain Vector stores integration is available for Google Cloud databases with vector support, including AlloyDB, Cloud SQL for PostgreSQL, Firestore, Memorystore for Redis, and Spanner.
The Document loaders and Memory integrations are available for all Google Cloud databases including AlloyDB, Cloud SQL for MySQL, PostgreSQL and SQL Server, Firestore, Datastore, Bigtable, Memorystore for Redis, El Carro for Oracle databases, and Spanner. Below are a few resources to get started.
Resources:
Read More for the details.