As machine learning models continue to scale, a specialized, co-designed hardware and software stack is no longer optional, it’s critical. Ironwood, our latest generation Tensor Processing Unit (TPU), is the cutting-edge hardware behind advanced models like Gemini and Nano Banana, from massive-scale training to high-throughput, low-latency inference. This blog details the core components of Google’s AI software stack that are woven into Ironwood, demonstrating how this deep co-design unlocks performance, efficiency, and scale. We cover the JAX and PyTorch ecosystems, the XLA compiler, and the high-level frameworks that make this power accessible.
1. The co-designed foundation
Foundation models today have trillions of parameters that require computation at ultra-large scale. We designed the Ironwood stack from the silicon up to meet this challenge.
The core philosophy behind the Ironwood stack is system-level co-design, treating the entire TPU pod not as a collection of discrete accelerators, but as a single, cohesive supercomputer. This architecture is built on a custom interconnect that enables massive-scale Remote Direct Memory Access (RDMA), allowing thousands of chips to exchange data directly at high bandwidth and low latency, bypassing the host CPU. Ironwood has a total of 1.77 PB of directly accessible HBM capacity, where each chip has eight stacks of HBM3E, with a peak HBM bandwidth of 7.4 TB/s and capacity of 192 GiB.
Unlike general-purpose parallel processors,TPUs are Application-Specific Integrated Circuits (ASICs) built for one purpose: accelerating large-scale AI workloads. The deep integration of compute, memory, and networking is the foundation of their performance. At a high level, the TPU consists of two parts:
-
Hardware core: The TPU core is centered around a dense Matrix Multiply Unit (MXU) for matrix operations, complemented by a powerful Vector Processing Unit (VPU) for element-wise operations (activations, normalizations) and SparseCores for scalable embedding lookups. This specialized hardware design is what delivers Ironwood’s 42.5 Exaflops of FP8 compute.
-
Software target: This hardware design is explicitly targeted by the Accelerated Linear Algebra (XLA) compiler, using a software co-design philosophy that combines the broad benefits of whole-program optimization with the precision of hand-crafted custom kernels. XLA’s compiler-centric approach provides a powerful performance baseline by fusing operations into optimized kernels that saturate the MXU and VPU. This approach delivers good “out of the box” performance with broad framework and model support. This general-purpose optimization is then complemented by custom kernels (detailed below in the Pallas section) to achieve peak performance on specific model-hardware combinations. This dual-pronged strategy is a fundamental tenet of the co-design.
The figure below shows the layout of the Ironwood chip:
It’s the software stack’s job to translate high-level code into optimized instructions that leverage the full power of the hardware. The stack supports two primary frameworks: the JAX ecosystem, which offers maximum performance and flexibility, as well as PyTorch on TPUs, which provides a native experience for the PyTorch community.
2. Optimizing the entire AI lifecycle
We use the principle of a co-designed Ironwood hardware and software stack to deliver maximum performance and efficiency across every phase of model development, with specific hardware and software capabilities tuned for each stage.
-
Pre-training: This phase demands sustained, massive-scale computation. A full 9,216-chip Ironwood superpod leverages the OCS and ICI fabric to operate as a single, massive parallel processor, achieving maximum sustained FLOPS utilization through different data formats. Running a job of this magnitude also requires resilience, which is managed by high-level software frameworks like MaxText, detailed in Section 3.3, that handle fault tolerance and checkpointing transparently.
-
Post-training (Fine-tuning and alignment): This stage includes diverse, FLOPS-intensive tasks like supervised fine-tuning (SFT) and Reinforcement Learning (RL), all requiring rapid iteration. RL, in particular, introduces complex, heterogeneous compute patterns. This stage often requires two distinct types of jobs to run concurrently: high-throughput, inference-like sampling to generate new data (often called ‘actor rollouts’), and compute-intensive, training-like ‘learner’ steps that perform the gradient-based updates. Ironwood’s high-throughput, low-latency network and flexible OCS-based slicing are ideal for this type of rapid experimentation, efficiently managing the different hardware demands of both sampling and gradient-based updates. In Section 3.3, we discuss how we provide optimized software on Ironwood — including reference implementations and libraries — to make these complex fine-tuning and alignment workflows easier to manage and execute efficiently.
-
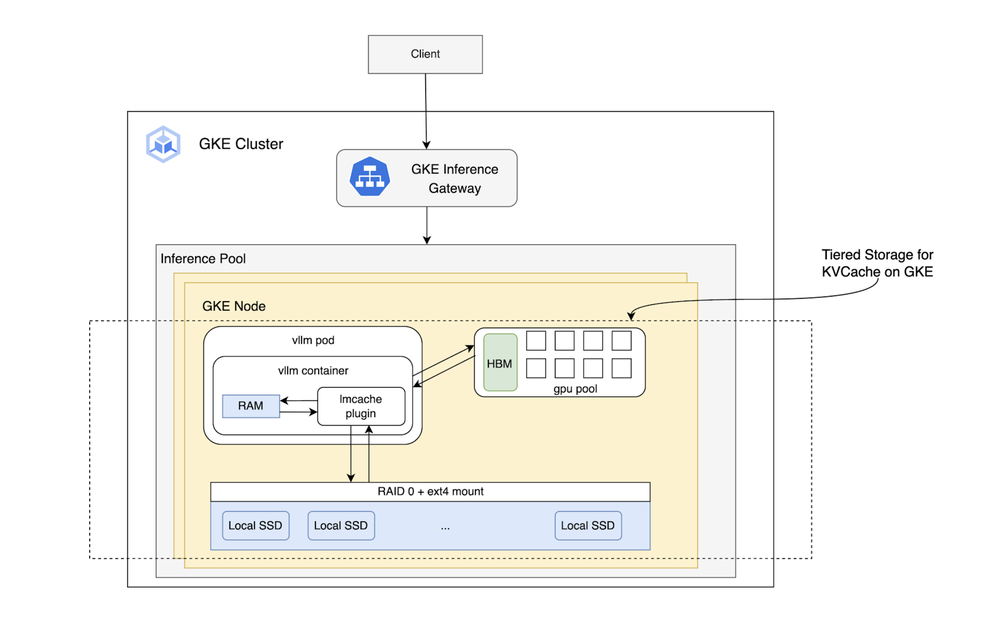
Inference (serving): In production, models must deliver low-latency predictions with high throughput and cost-efficiency. Ironwood is specifically engineered for this, with its large on-chip memory and compute power optimized for both the large-batch “prefill” phase and the memory-bandwidth-intensive “decode” phase of large generative models. To make this power easily accessible, we’ve optimized state-of-the-art serving engines. At launch, we’ve enabled vLLM, detailed in Section 3.3, providing the community with a top-tier, open-source solution that maximizes inference throughput on Ironwood.
3. The software ecosystem for TPUs
The TPU stack, and Ironwood’s stack in particular, is designed to be modular, allowing developers to operate at the level of abstraction they need. In this section, we focus on the compiler/runtime, framework, and AI stack libraries.
3.1 The JAX path: Performance and composability
JAX is a high-performance numerical computing system co-designed with the TPU architecture. It provides a familiar NumPy-like API backed by powerful function transformations:
-
jit (Just-in-Time compilation): Uses the XLA compiler to fuse operations into a single, optimized kernel for efficient TPU execution.
-
grad (automatic differentiation): Automatically computes gradients of Python functions, the fundamental mechanism for model training.
-
shard_map (parallelism): The primitive for expressing distributed computations, allowing explicit control over how functions and data are sharded across a mesh of TPU devices, directly mapping to the ICI/OCS topology.
This compositional approach allows developers to write clean, Pythonic code that JAX and XLA transform into highly parallelized programs optimized for TPU hardware. JAX is what Google Deepmind and other Google teams use to build, train, and service their variety of models.
For most developers, these primitives are abstracted by high-level frameworks, like MaxText, built upon a foundation of composable, production-proven libraries:
-
Goodput: A library for measuring and monitoring real-time ML training efficiency, providing a detailed breakdown of badput (e.g., initialization, data loading, checkpointing)
3.2 The PyTorch path: A native eager experience
To bring Ironwood’s power to the PyTorch community, we are developing a new, native PyTorch experience complete with support for a “native eager mode”, which executes operations immediately as they are called. Our goal is to provide a more natural and developer-friendly way to access Ironwood’s scale, minimizing the code changes and level of effort required to adapt models for TPUs. This approach is designed to make the transition from local experimentation to large-scale training more straightforward.
This new framework is built on three core principles to ensure a truly PyTorch-native environment:
-
Full eager mode: Enables the rapid prototyping, debugging, and research workflows that developers expect from PyTorch.
-
Standard distributed APIs: Leverages the familiar torch.distributed API, built on DTensor, for scaling training workloads across TPU slices.
-
Idiomatic compilation: Uses torch.compile as the single, unified path to JIT compilation, utilizing XLA as its backend to trace the graph and compile it into efficient TPU machine code.
This ensures the transition from local experimentation to large-scale distributed training is a natural extension of the standard PyTorch workflow.
3.3 Frameworks: MaxText, PyTorch on TPU, and vLLM
While JAX and PyTorch provide the computational primitives, scaling to thousands of chips is a supercomputer management problem. High-level frameworks handle the complexities of resilience, fault tolerance, and infrastructure orchestration.
-
MaxText (JAX): MaxText is an open-source, high-performance LLM pre-training and post-training solution written in pure Python and JAX. MaxText demonstrates optimized training on its library of popular OSS models like DeepSeek, Qwen, gpt-oss, Gemma, and more. Whether users are pre-training large Mixture-of-Experts (MoE) models from scratch, or leveraging the latest Reinforcement Learning (RL) techniques on an OSS model, MaxText provides tutorials and APIs to make things easy. For scalability and resiliency, MaxText leverages Pathways, which was originally developed by Google DeepMind and now provides TPU users with differentiated capabilities like elastic training and multi-host inference during RL.
-
PyTorch on TPU: We recently shared our proposal about our PyTorch native experience on TPUs at Pytorch Conference 2025, including an early preview of training on TPU with minimal code changes. In addition to the framework itself, we are working with the community (RFC), investing in reproducible recipes, reference implementations, and migration tools to enable PyTorch users to use their favorite frameworks on TPUs. Expect further updates as this work matures.
-
vLLM TPU (Serving): vLLM TPU is now powered by tpu-inference, an expressive and powerful new hardware plugin that unifies JAX and PyTorch under a single lowering path – meaning both frameworks are translated to optimized TPU code through one common, shared backend. This new unified backend is not only faster than the previous generation of vLLM TPU but also offers broader model coverage. This integration provides more flexibility to JAX and PyTorch users, running PyTorch models performantly with no code changes while also extending native JAX support, all while retaining the standard vLLM user experience and interface.
3.4 Extreme performance: Custom kernels via Pallas
While XLA is powerful, cutting-edge research often requires novel algorithms e.g. new attention mechanisms, custom padding to handle dynamic ragged tensors and other optimizations for custom MoE models that the XLA compiler cannot yet optimize.
The JAX ecosystem solves this with Pallas, a JAX-native kernel programming language embedded directly in Python. Pallas presents a unified, Python-first experience, dramatically reducing cognitive load and accelerating the iteration cycle. Other platforms lack this unified, in-Python approach, forcing developers to fragment their workflow. To optimize these operations, they must drop into a disparate ecosystem of lower-level tools—from DSLs like Triton and cuTE to raw CUDA C++ and PTX. This introduces significant mental overhead by forcing developers to manually manage memory, streams, and kernel launches, pulling them out of their Python-based environment
This is a clear example of co-design. Developers use Pallas to explicitly manage the accelerator’s memory hierarchy, defining how “tiles” of data are staged from HBM into the extremely fast on-chip SRAM to be operated on by the MXUs. Pallas has two main parts to it.
-
Pallas: The developer defines the high-level algorithmic structure and memory logistics in Python.
-
Mosaic: This compiler backend translates the Pallas definition into optimized TPU machine code. It handles operator fusion, determines optimal tiling strategies, and generates software pipelines to perfectly overlap data transfers (HBM-to-SRAM) with computation (on the MXUs), with the sole objective of saturating the compute units.
Because Pallas kernels are JAX-traceable, they are fully compatible with jit, vmap, and grad. This stack provides Python-native extensibility for both JAX and PyTorch, as PyTorch users can consume Pallas-optimized kernels without ever leaving the native PyTorch API. Pallas kernels for PyTorch and JAX models, on both TPU and GPU, are available via Tokamax, the ML ecosystem’s first multi-framework, multi-hardware kernel library.
3.5 Performance engineering: Observability and debugging
The Ironwood stack includes a full suite of tools for performance analysis, bottleneck detection, and debugging, allowing developers to fully optimize their workloads and operate large scale clusters reliably,
-
-
Trace Viewer: A microsecond-level timeline of all operations, showing execution, collectives, and “bubbles” (idle time).
-
Input Pipeline Analyzer: Diagnoses host-bound vs. compute-bound bottlenecks.
-
Op Profile: Ranks all XLA/HLO operations by execution time to identify expensive kernels.
-
Memory Profiler: Visualizes HBM usage over time to debug peak memory and fragmentation.
Debugging Tools:
-
-
JAX Debugger (jax.debug): Enables print and breakpoints from within jit-compiled functions.
-
TPU Monitoring Library: A real-time diagnostic dashboard (analogous to nvidia-smi) for live debugging of HBM utilization, MXU activity, and running processes.
Beyond performance optimization, developers and infra admins can view fleet efficiency and goodput metrics at various levels (e.g., job, reservation) to ensure maximum utilization of their TPU infrastructure.
4. Conclusion
The Ironwood stack is a complete, system-level co-design, from the silicon to the software. It delivers performance through a dual-pronged strategy: the XLA compiler provides broad, “out-of-the-box” optimization, while the Pallas and Mosaic stack enables hand-tuned kernel performance.
This entire co-designed platform is accessible to all developers, providing first-class, native support for both the JAX and the PyTorch ecosystem. Whether you are pre-training a massive model, running complex RL alignment, or serving at scale, Ironwood provides a direct, resilient, and high-performance path from idea to supercomputer.
Get started today with vLLM on TPU for inference and MaxText for pre-training and post-training.
for the details.



 for LLMs on GKE")