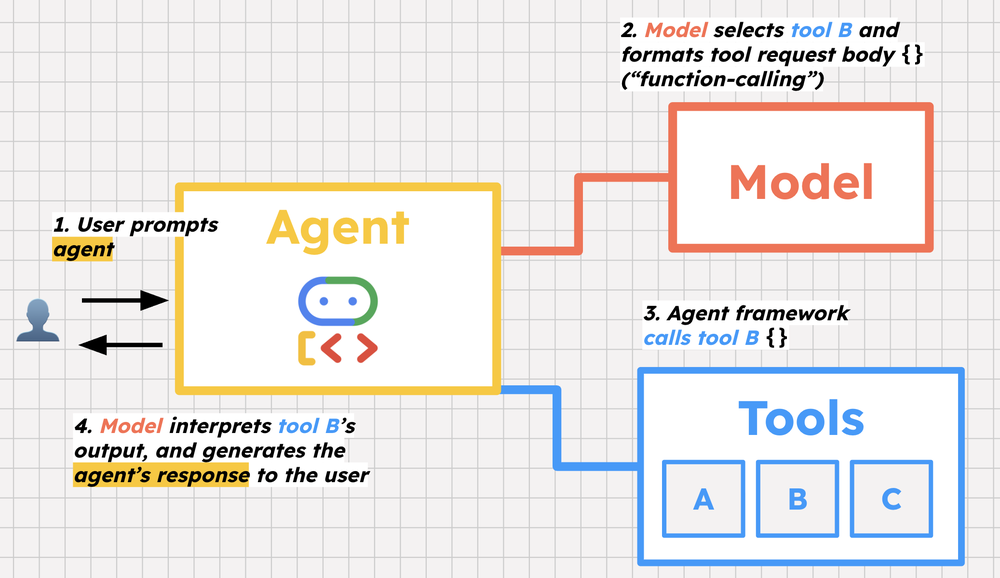
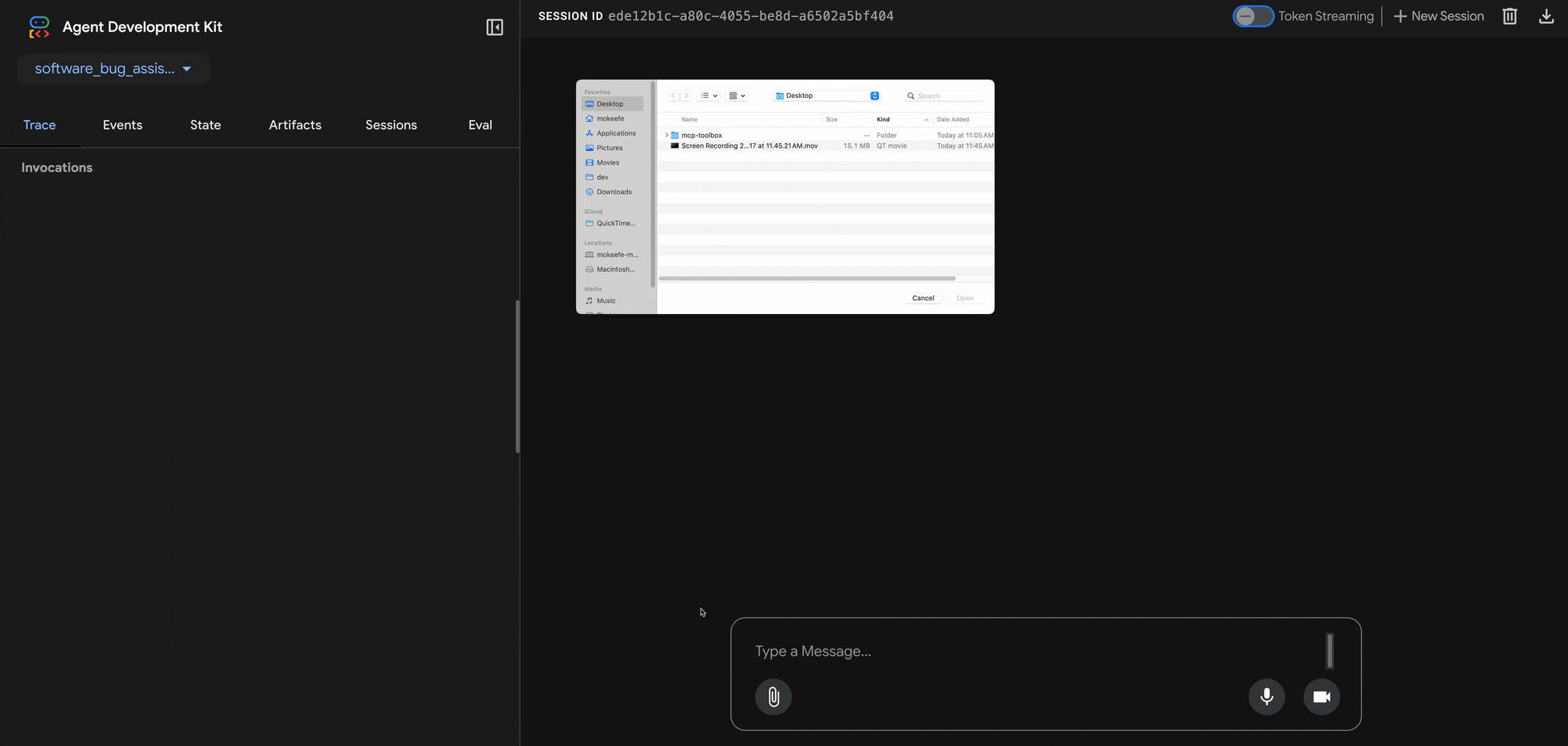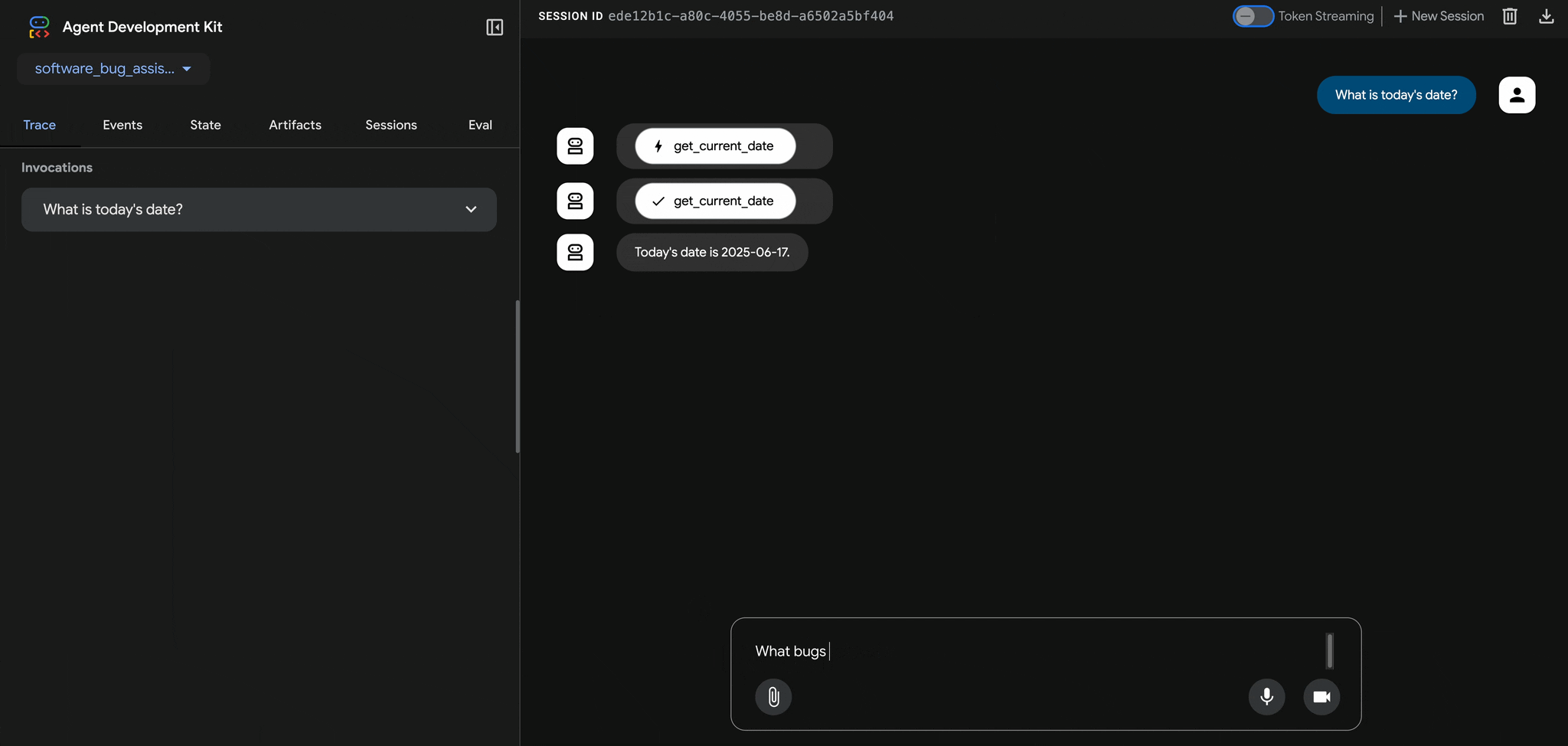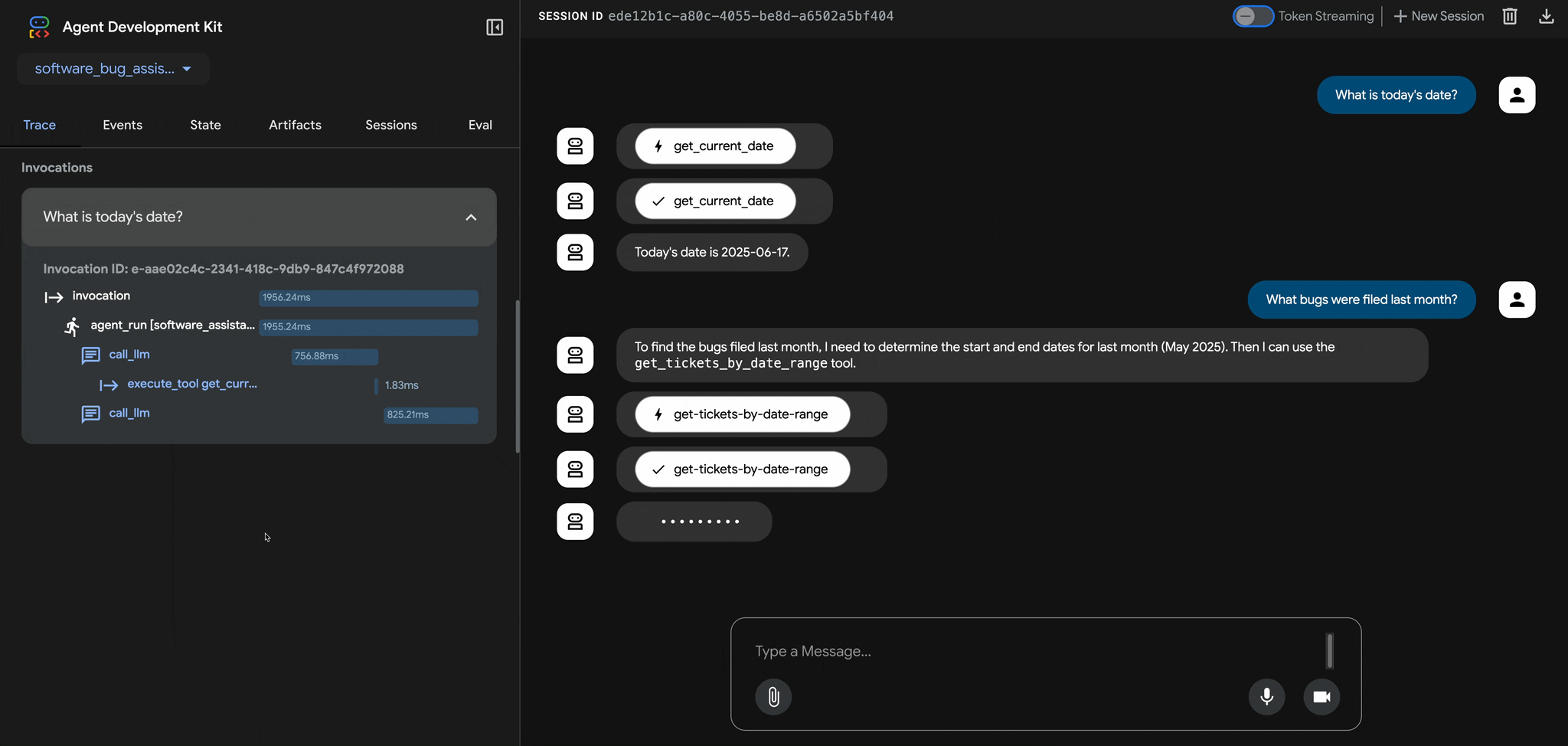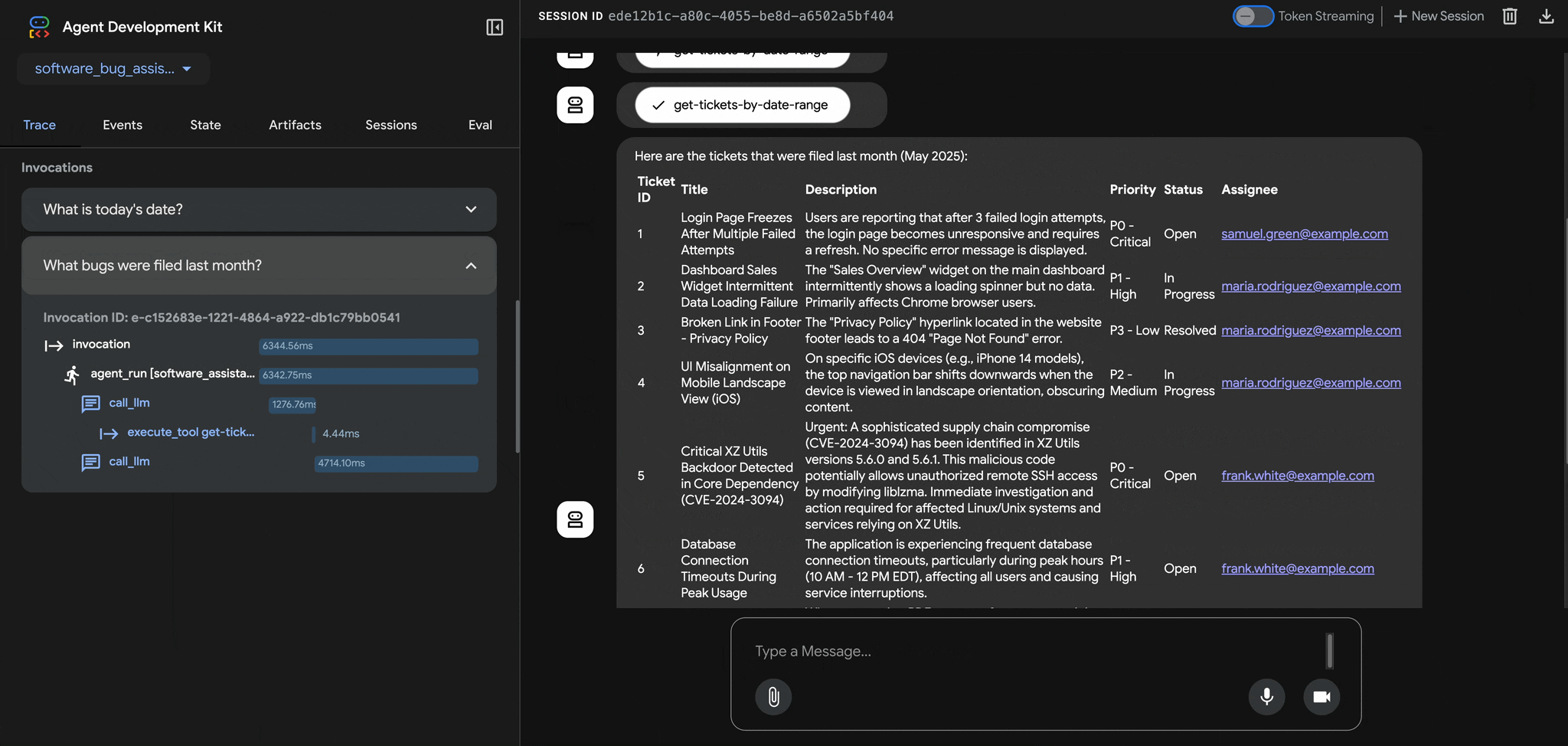
Welcome to the second Cloud CISO Perspectives for June 2025. Today, Thiébaut Meyer and Bhavana Bhinder from Google Cloud’s Office of the CISO discuss our work to help defend European healthcare against cyberattacks.
As with all Cloud CISO Perspectives, the contents of this newsletter are posted to the Google Cloud blog. If you’re reading this on the website and you’d like to receive the email version, you can subscribe here.
aside_block
<ListValue: [StructValue([(‘title’, ‘Get vital board insights with Google Cloud’), (‘body’, <wagtail.rich_text.RichText object at 0x3e4d7ea57130>), (‘btn_text’, ‘Visit the hub’), (‘href’, ‘https://cloud.google.com/solutions/security/board-of-directors?utm_source=cloud_sfdc&utm_medium=email&utm_campaign=FY24-Q2-global-PROD941-physicalevent-er-CEG_Boardroom_Summit&utm_content=-&utm_term=-‘), (‘image’, <GAEImage: GCAT-replacement-logo-A>)])]>
The global threats facing European hospitals and health organizations
By Thiébaut Meyer, director, Office of the CISO, and Bhavana Bhinder, European healthcare and life sciences lead, Office of the CISO
Thiébaut Meyer, director, Office of the CISO
As the global threat landscape continues to evolve, hospitals and healthcare organizations remain primary targets for cyber threat actors. To help healthcare organizations defend themselves so they can continue to provide critical, life-saving patient care — even while facing cyberattacks — the European Commission has initiated the European Health Security Action Plan to improve the cybersecurity of hospitals and healthcare providers.
There are two imperative steps that would both support Europe’s plan and bolster resilience in our broader societal fabric: Prioritizing healthcare as a critical domain for cybersecurity investment, and emphasizing collaboration with the private sector. This approach, acknowledging the multifaceted nature of cyber threats and the interconnectedness of healthcare systems, is precisely what is required to secure public health in an increasingly digitized world. It’s great to see the European Commission has recently announced funding to improve cybersecurity, including for European healthcare entities.
Bhavana Bhinder, European healthcare and life sciences lead, Office of the CISO
At Google, we have cultivated extensive industry partnerships across the European Union to help healthcare organizations of all levels of digital sophistication and capability be more resilient in the face of cyberattacks.
Collaboration across healthcare organizations, regulators, information sharing bodies and technology providers like Google is essential to get and stay ahead of these attacks.
Cyberattacks targeting the healthcare domain, especially those that leverage ransomware, can take over healthcare systems – completely upending their operations and stopping them from providing life-saving medical procedures, coordinating critical scheduling and payment activities, stopping delivery of critical supplies like blood and tissue donations, and can even render the care facilities physically unsafe. In some cases, these cyberattacks have contributed to patient mortality. The statistics paint a grim picture:
Ransomware attacks accounted for 54% of analyzed cybersecurity incidents in the EU health sector between 2021 and 2023, with 83% financially motivated.
71% of ransomware attacks impacted patient care and were often coupled with patient data breaches, according to a 2024 European Commission report.
Healthcare’s share of posts on data leak sites has doubled over the past three years, even as the number of data leak sites tracked by Google Threat Intelligence Group increased by nearly 50% in 2024. In one example, a malicious actor targeting European organizations said that they were willing to pay 2% to 5% more for hospitals — particularly ones with emergency services.
In-hospital mortality shoots up 35% to 41% among patients already admitted to a hospital when a ransomware attack takes place.
The U.K.’s National Health Service (NHS) has confirmed that a major cyberattack harmed 170 patients in 2024.
“Achieving resilience necessitates a holistic and adaptive approach, encompassing proactive prevention that uses modern, secure-by-design technologies paired with robust detection and incident response, stringent supply chain management, comprehensive human factor mitigation, strategic utilization of artificial intelligence, and targeted investment in securing unique healthcare vulnerabilities,” said Google Cloud’s Taylor Lehmann, director, Healthcare and Life Sciences, Office of the CISO. “Collaboration across healthcare organizations, regulators, information sharing bodies and technology providers like Google is essential to get and stay ahead of these attacks.”
Bold action is needed to combat this scourge, and that action should include helping healthcare providers migrate to modern technology that has been built securely by design and stays secure in use. We believe security must be embedded from the outset — not as an afterthought — and continuously thereafter. Google’s secure-by-design products and services have helped support hospitals and health organizations across Europe in addressing the pervasive risks posed by cyberattacks, including ransomware.
Secure-by-design is a proactive approach that ensures core technologies like Google Cloud, Google Workspace, Chrome, and ChromeOS are built with inherent protections, such as:
Encrypting Google Cloud customer data at rest by default and data in transit across its physical boundaries, offering multiple options for encryption key management and key access justification.
Building security and compliance into ChromeOS, which powers Chromebooks, to help protect against ransomware attacks. ChromeOS boasts a record of no reported ransomware attacks. Its architecture includes capabilities such as Verified Boot, sandboxing, blocked executables, and user space isolation, along with automatic, seamless updates that proactively patch vulnerabilities.
Providing health systems with a secure alternative through Chrome Enterprise Browser and ChromeOS for accessing internet-based and internal IT resources crucial for patient care.
Committing explicitly in our contracts to implementing and maintaining robust technical, organizational, and physical security measures, and supporting NIS2 compliance efforts for Google Cloud and Workspace customers.
Our products and services are already helping modernize and secure European healthcare organizations, including:
In Germany, healthcare startup Hypros has been collaborating with Google Cloud to help hospitals detect health incidents without compromising patient privacy. Hypros’ innovative patient monitoring system uses our AI and cloud computing capabilities to detect and alert staff to in-hospital patient emergencies, such as out-of-bed falls, delirium onset, and pressure ulcers. They’ve tested the technology in real-world trials at leading institutions including the University Hospital Schleswig-Holstein, one of the largest medical care centers in Europe.
With the CUF, Portugal’s largest healthcare provider with 19 hospitals and clinics. CUF has embraced Google Chrome and cloud applications to enhance energy efficiency and streamline IT operations. ChromeOS is noted in the industry for its efficiency, enabling operations on machines that consume less energy and simplifying IT management by reducing the need for on-site hardware maintenance.
For the Canary Islands 112 Emergency and Safety Coordination Center, which is migrating to Google Cloud. Led by the public company Gestión de Servicios para la Salud y Seguridad en Canary Islands (GCS) and developed in conjunction with Google Cloud, this migration is one of the first in which a public emergency services administration has moved to the public cloud. They’re also using Google Cloud’s sovereign cloud solutions to help securely share critical information, such as call recordings and personal data, with law enforcement and judicial bodies.
We believe that information sharing must extend beyond threat intelligence to encompass data-supported conclusions regarding effective practices, counter-measures, and successes. Reducing barriers to sophisticated and rapid intelligence-sharing, coupled with verifiable responses, can be the decisive factor between a successful defense and a vulnerable one.
Our engagement with organizations including the international Health-ISAC and ENISA underscores our commitment to building trust across many communities, a concept highly pertinent to the EU’s objective of supporting the European Health ISAC and the U.S.-based Health-ISAC’s EU operations.
Protecting European health data with Sovereign Cloud and Confidential Computing
We’re committed to digital sovereignty for the EU and to helping healthcare organizations take advantage of the transformative potential of cloud and AI without compromising on security or patient privacy.
We’ve embedded our secure-by-design principles in our approach to our digital sovereignty solutions. By enabling granular control over data location, processing, and access, European healthcare providers can confidently adopt scalable cloud infrastructure and deploy advanced AI solutions, secure in the knowledge that their sensitive patient data remains protected and compliant with European regulations like GDPR, the European Health Data Space (EHDS), and the Network and Information Systems Directive.
Additionally, Confidential Computing, technology that we helped pioneer, has helped narrow that critical security gap by protecting data in use.
Google Cloud customers such as AiGenomix leverage Confidential Computing to deliver infectious disease surveillance and early cancer detection. Confidential Computing helps them ensure privacy and security for genomic and related health data assets, and also align with the EHDS’s vision for data-driven improvements in healthcare delivery and outcomes.
Building trust in global healthcare resilience
We believe that these insights and capabilities offered by Google can significantly contribute to the successful implementation of the European Health Security Action Plan. We are committed to continued collaboration with the European Commission, EU member states, and all stakeholders to build a more secure and resilient digital future for healthcare.
To learn more about Google’s efforts to secure and support healthcare organizations around the world, contact our Office of the CISO.
aside_block
<ListValue: [StructValue([(‘title’, ‘Join the Google Cloud CISO Community’), (‘body’, <wagtail.rich_text.RichText object at 0x3e4d7ea57af0>), (‘btn_text’, ‘Learn more’), (‘href’, ‘https://rsvp.withgoogle.com/events/ciso-community-interest?utm_source=cgc-blog&utm_medium=blog&utm_campaign=2024-cloud-ciso-newsletter-events-ref&utm_content=-&utm_term=-‘), (‘image’, <GAEImage: GCAT-replacement-logo-A>)])]>
In case you missed it
Here are the latest updates, products, services, and resources from our security teams so far this month:
Securing open-source credentials at scale: We’ve developed a powerful tool to scan open-source package and image files by default for leaked Google Cloud credentials. Here’s how to use it. Read more.
Audit smarter: Introducing our Recommended AI Controls framework: How can we make AI audits more effective? We’ve developed an improved approach that’s scalable and evidence-based: the Recommended AI Controls framework. Read more.
Google named a Strong Performer in The Forrester Wave for security analytics platforms: Google has been named a Strong Performer in The Forrester Wave™: Security Analytics Platforms, Q2 2025, in our first year of participation. Read more.
Mitigating prompt injection attacks with a layered defense strategy: Our prompt injection security strategy is comprehensive, and strengthens the overall security framework for Gemini. We found that model training with adversarial data significantly enhanced our defenses against indirect prompt injection attacks in Gemini 2.5 models. Read more.
Just say no: Build defense in depth with IAM Deny and Org Policies: IAM Deny and Org Policies provide a vital, scalable layer of security. Here’s how to use them to boost your IAM security. Read more.
Please visit the Google Cloud blog for more security stories published this month.
What’s in an ASP? Creative phishing attack on prominent academics and critics of Russia: We detail two distinct threat actor campaigns based on research from Google Threat Intelligence Group (GTIG) and external partners, who observed a Russia state-sponsored cyber threat actor targeting prominent academics and critics of Russia and impersonating the U.S. Department of State. The threat actor often used extensive rapport building and tailored lures to convince the target to set up application specific passwords (ASPs). Read more.
Remote Code Execution on Aviatrix Controller: A Mandiant Red Team case study simulated an “Initial Access Brokerage” approach and discovered two vulnerabilities on Aviatrix Controller, a software-defined networking utility that allows for the creation of links between different cloud vendors and regions. Read more.
Please visit the Google Cloud blog for more threat intelligence stories published this month.
Now hear this: Podcasts from Google Cloud
AI red team surprises, strategies, and lessons: Daniel Fabian joins hosts Anton Chuvakin and Tim Peacock to talk about lessons learned from two years of AI red teaming at Google. Listen here.
Practical detection-as-code in the enterprise: Is detection-as-code just another meme phrase? Google Cloud’s David French, staff adoption engineer, talks with Anton and Tim about how detection-as-code can help security teams. Listen here.
Cyber-Savvy Boardroom: What Phil Venables hears on the street: Phil Venables, strategic security adviser for Google Cloud, joins Office of the CISO’s Alicja Cade and David Homovich to discuss what he’s hearing directly from boards and executives about the latest in cybersecurity, digital transformation, and beyond. Listen here.
Beyond the Binary: Attributing North Korean cyber threats: Who names the world’s most notorious APTs? Google reverse engineer Greg Sinclair shares with host Josh Stroschein how he hunts down and names malware and threat actors, including Lazarus Group, the North Korean APT. Listen here.
To have our Cloud CISO Perspectives post delivered twice a month to your inbox, sign up for our newsletter. We’ll be back in a few weeks with more security-related updates from Google Cloud.
Written by: Seemant Bisht, Chris Sistrunk, Shishir Gupta, Anthony Candarini, Glen Chason, Camille Felx Leduc
Introduction — Why Securing Protection Relays Matters More Than Ever
Substations are critical nexus points in the power grid, transforming high-voltage electricity to ensure its safe and efficient delivery from power plants to millions of end-users. At the core of a modern substation lies the protection relay: an intelligent electronic device (IED) that plays a critical role in maintaining the stability of the power grid by continuously monitoring voltage, current, frequency, and phase angle. Upon detecting a fault, it instantly isolates the affected zone by tripping circuit breakers, thus preventing equipment damage, fire hazards, and cascading power outages.
As substations become more digitized, incorporating IEC 61850, Ethernet, USB, and remote interfaces, relays are no longer isolated devices, but networked elements in a broader SCADA network. While this enhances visibility and control, it also exposes relays to digital manipulation and cyber threats. If compromised, a relay can be used to issue false trip commands, alter breaker logic, and disable fault zones. Attackers can stealthily modify vendor-specific logic, embed persistent changes, and even erase logs to avoid detection. A coordinated attack against multiple critical relays can lead to a cascading failure across the grid, potentially causing a large-scale blackout.
This threat is not theoretical. State-sponsored adversaries have repeatedly demonstrated their capability to cause widespread blackouts, as seen in the INDUSTROYER (2016), INDUSTROYER.V2 (2022), and novel living-off-the-land technique (2022) attacks in Ukraine, where they issued unauthorized commands over standard grid protocols. The attack surface extends beyond operational protocols to the very tools engineers rely on; as Claroty’s Team82 revealed a denial-of-service vulnerability in Siemens DIGSI 4 configuration software. Furthermore, the discovery of malware toolkits like INCONTROLLER shows attackers are developing specialized capabilities to map, manipulate, and disable protection schemes across multiple vendors.
Recent events have further underscored the reality of these threats, with heightened risks of Iranian cyberattacks targeting vital networks in the wake of geopolitical tensions. Iran-nexus threat actors such as UNC5691 (aka CyberAv3ngers) have a history of targeting operational technology, in some cases including U.S. water facilities. Similarly, persistent threats from China, such as UNC5135, which at least partially overlaps with publicly reported Volt Typhoon activity, demonstrate a strategic effort to embed within U.S. critical infrastructure for potential future disruptive or destructive cyberattacks. The tactics of these adversaries, which range from exploiting weak credentials to manipulating the very logic of protection devices, make the security of protection relays a paramount concern.
These public incidents mirror the findings from our own Operational Technology (OT) Red Team simulations, which consistently reveal accessible remote pathways into local substation networks and underscore the potential for adversaries to manipulate protection relays within national power grids.
Protection relays are high-value devices, and prime targets for cyber-physical attacks targeting substation automation systems and grid management systems. Securing protection relays is no longer just a best practice; it’s absolutely essential for ensuring the resilience of both transmission and distribution power grids.
Inside a Substation — Components and Connectivity
To fully grasp the role of protection relays within the substation, it’s important to understand the broader ecosystem they operate in. Modern substations are no longer purely electrical domains. They are cyber-physical environments where IEDs, deterministic networking, and real-time data exchange work in concert to deliver grid reliability, protection, and control.
Core Components
Protection & Control Relays (IEDs): Devices such as the SEL-451, ABB REL670, GE D60, and Siemens 7SJ85 serve as the brains of both protection and control. They monitor current, voltage, frequency, and phase angle, and execute protection schemes like:
Overcurrent (ANSI 50/51)
Distance protection (ANSI 21)
Differential protection (ANSI 87)
Under/over-frequency (ANSI 81)
Synch-check (ANSI 25)
Auto-reclose (ANSI 79)
Breaker failure protection (ANSI 50BF)
Logic-based automation and lockout (e.g., ANSI 94)
(Note: These ANSI function numbers follow the IEEE Standard C37.2 and are universally used across vendors to denote protective functions.)
Circuit Breakers & Disconnectors: High-voltage switching devices operated by relays to interrupt fault current or reconfigure line sections. Disconnectors provide mechanical isolation and are often interlocked with breaker status to prevent unsafe operation.
Current Transformers (CTs) & Potential Transformers (PTs): Instrument transformers that step down high voltage and current for safe and precise measurement. These form the primary sensing inputs for protection and metering functions.
Station Human-Machine Interfaces (HMIs): Provide local visualization and control for operators. HMIs typically connect to relay networks via the station bus, offering override, acknowledgment, and command functions without needing SCADA intervention.
Remote Terminal Units (RTUs) or Gateway Devices: In legacy or hybrid substations, RTUs aggregate telemetry from field devices and forward it to control centers. In fully digital substations, this function may be handled by SCADA gateways or station-level IEDs that natively support IEC 61850 or legacy protocol bridging.
Time Synchronization Devices: GPS clocks or PTP servers are deployed to maintain time alignment across relays, sampled value streams, and event logs. This is essential for fault location, waveform analysis, and sequence of events (SoE) correlation.
Network Architecture
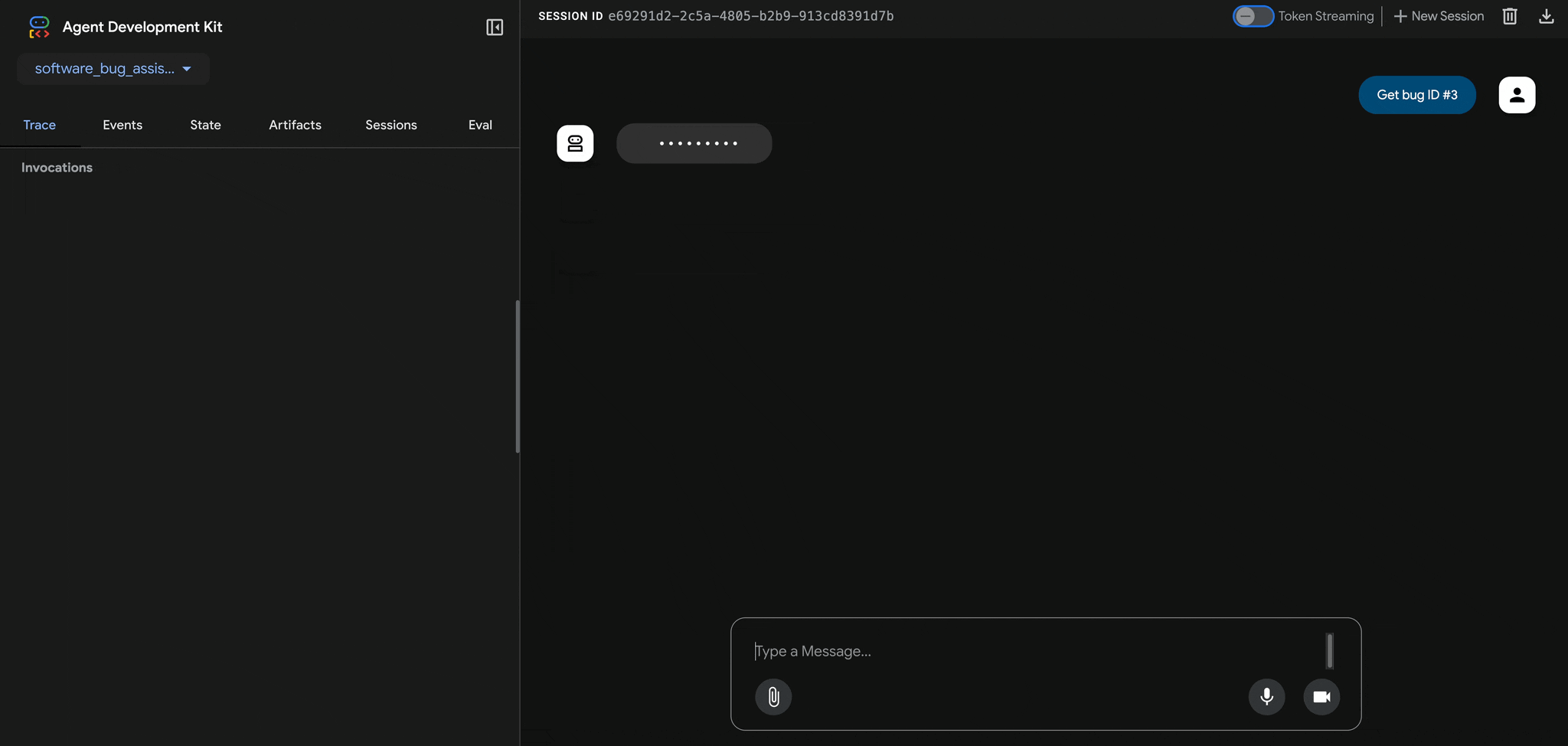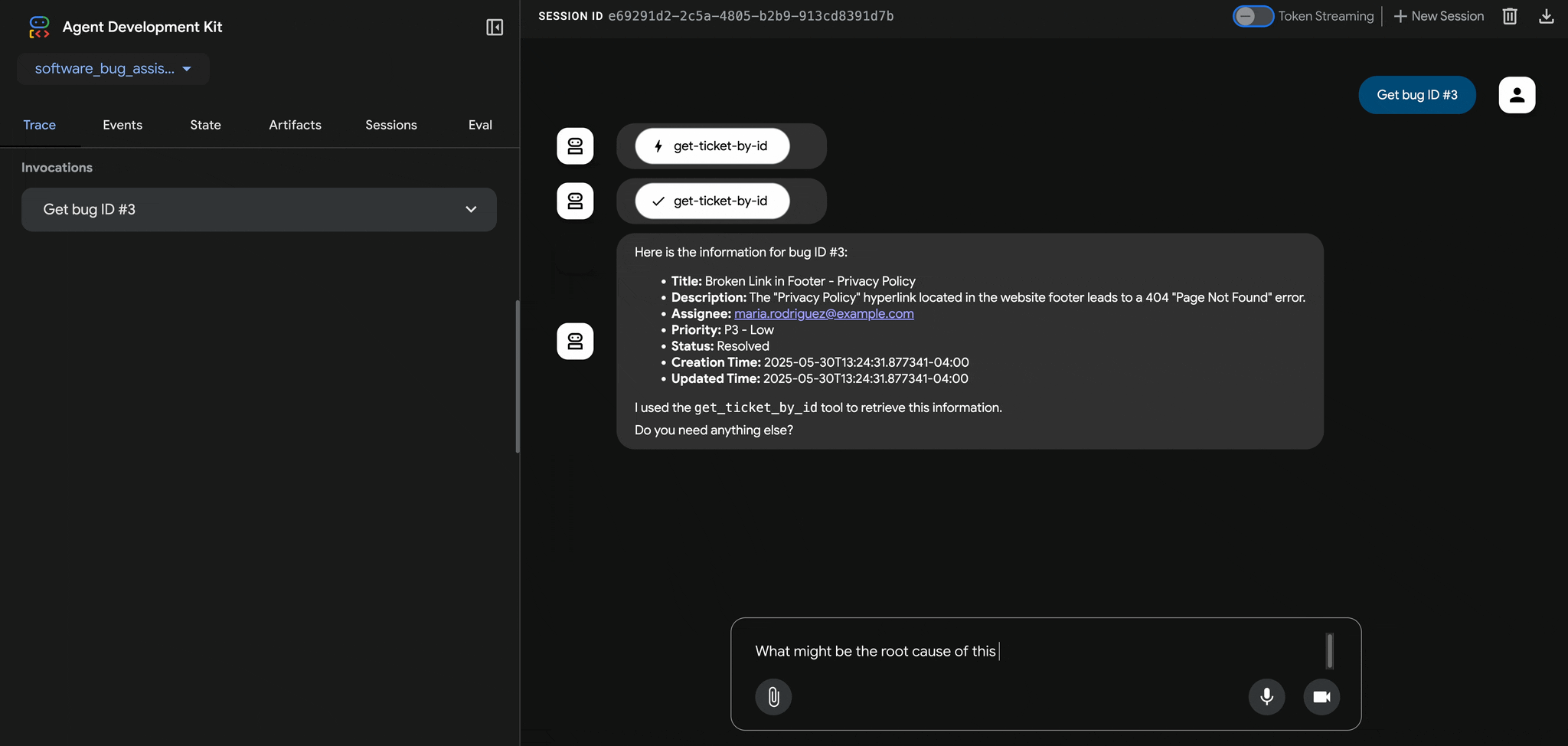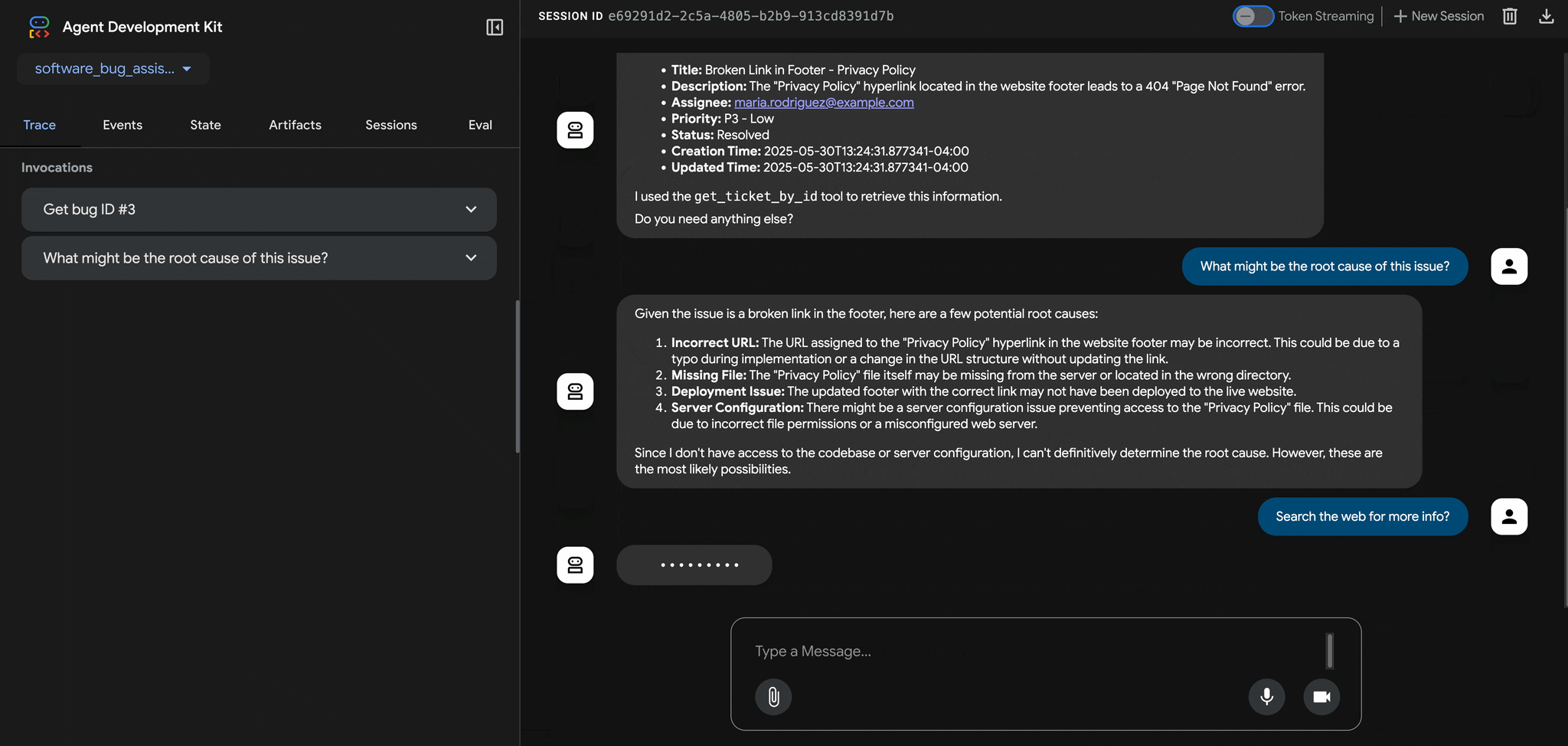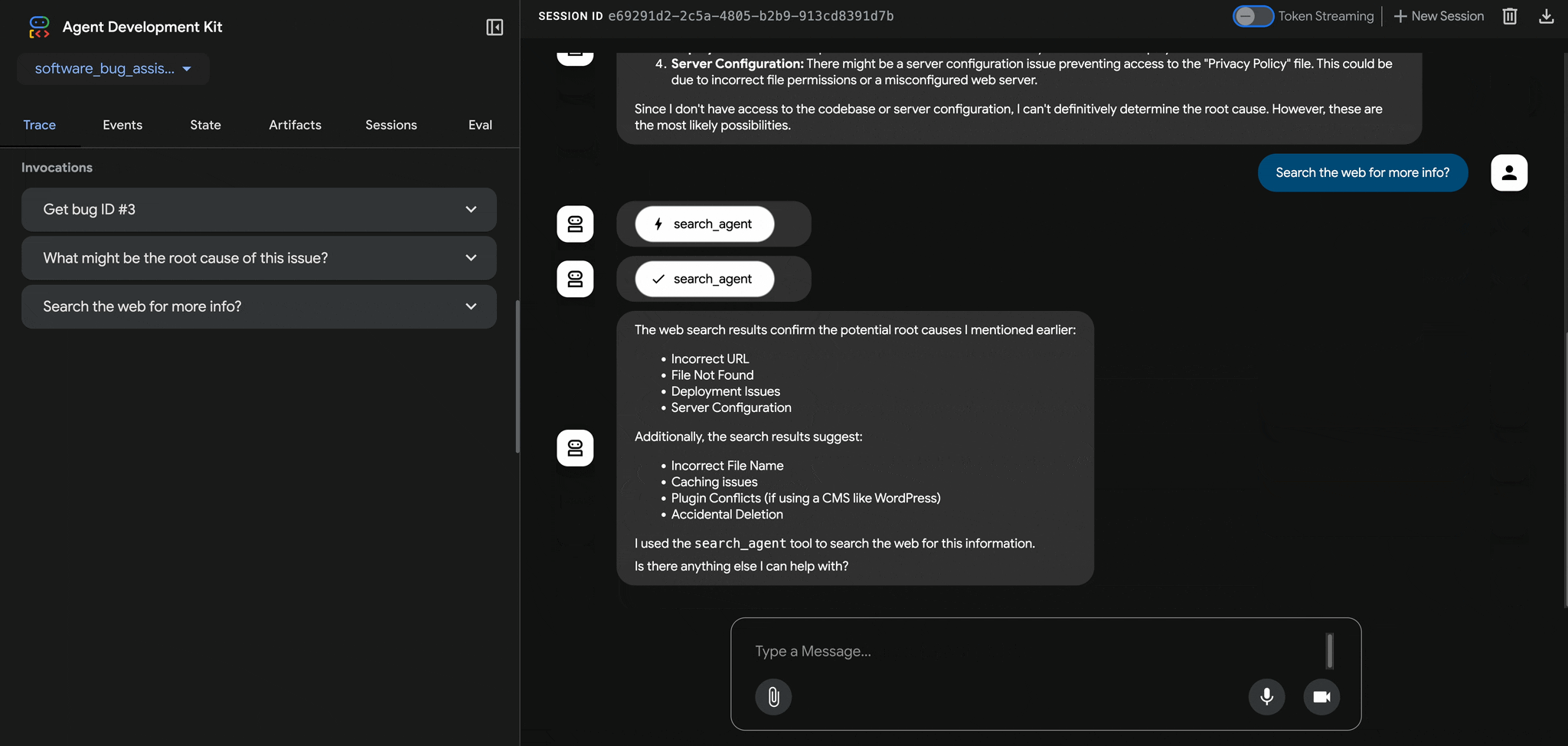
Modern digital substations are engineered with highly segmented network architectures to ensure deterministic protection, resilient automation, and secure remote access. These systems rely on fiber-based Ethernet communication and time-synchronized messaging to connect physical devices, intelligent electronics, SCADA systems, and engineering tools across three foundational layers.
Figure 1: Substation Network Architecture
Network Topologies: Substations employ redundant Ethernet designs to achieve high availability and zero-packet-loss communication, especially for protection-critical traffic.
Common topologies include:
RSTP (Rapid Spanning Tree Protocol) – Basic redundancy by blocking loops in switched networks
PRP (Parallel Redundancy Protocol) – Simultaneous frame delivery over two independent paths
HSR (High-availability Seamless Redundancy) – Ring-based protocol that allows seamless failover for protection traffic
Communication Layers: Zones and Roles
Modern substations are structured into distinct functional network layers, each responsible for different operations, timing profiles, and security domains. Understanding this layered architecture is critical to both operational design and cyber risk modeling.
Process Bus / Bay Level Communication
This is the most time-sensitive layer in the substation. It handles deterministic, peer-to-peer communication between IEDs (Intelligent Electronic Devices), Merging Units (MUs), and digital I/O modules that directly interact with primary field equipment.
Includes:
Protection and Control IEDs – Relay logic for fault detection and breaker actuation
MUs – Convert CT/PT analog inputs into digitized Sampled Values (SV)
IED I/O Modules – Digitally interface with trip coils and status contacts on breakers
Circuit Breakers, CTs, and PTs – Primary electrical equipment connected through MUs and I/O
Master clock or time source – Ensures time-aligned SV and event data using PTP (IEEE 1588) or IRIG-B
IEC 61850-9-2 (SV) – Real-time sampled analog measurements
Time Sync (PTP/IRIG-B) – Sub-millisecond alignment across protection systems
Station Bus / Substation Automation LAN (Supervisory and Control Layer)
The Station Bus connects IEDs, local operator systems, SCADA gateways, and the Substation Automation System (SAS). It is responsible for coordination, data aggregation, event recording, and forwarding data to control centers.
Includes:
SAS – Central event and logic manager
HMIs – Local operator access
Engineering Workstation (EWS) – Access point for authorized relay configuration and diagnostics
RTUs / SCADA Gateways – Bridge to EMS/SCADA networks
Managed Ethernet Switches (PRP/HSR) – Provide reliable communication paths
IEC 60870-5-104 / DNP3 – Upstream telemetry to control center
Modbus (legacy) – Field device communication
SNMP (secured) – Network health monitoring
Engineering Access (Role-Based, Cross-Layer): Engineering access is not a stand-alone communication layer but a privileged access path used by protection engineers and field technicians to perform maintenance, configuration, and diagnostics.
Access Components:
EWS – Direct relay interface via MMS or console
Jump Servers / VPNs – Controlled access to remote or critical segments
Terminal/ Serial Consoles – Used for maintenance and troubleshooting purposes
What Protection Relays Really Do
In modern digital substations, protection relays—more accurately referred to as IEDs—have evolved far beyond basic trip-and-alarm functions. These devices now serve as cyber-physical control points, responsible not only for detecting faults in real time but also for executing programmable logic, recording event data, and acting as communication intermediaries between digital and legacy systems.
At their core, IEDs monitor electrical parameters, such as voltage, current, frequency, and phase angle, and respond to conditions like overcurrent, ground faults, and frequency deviations. Upon fault detection, they issue trip commands to circuit breakers—typically within one power cycle (e.g., 4–20 ms)—to safely isolate the affected zone and prevent equipment damage or cascading outages.
Beyond traditional protection: Modern IEDs provide a rich set of capabilities that make them indispensable in fully digitized substations.
Trip Logic Processing: Integrated logic engines (e.g., SELogic, FlexLogic, CFC) evaluate multiple real-time conditions to determine if, when, and how to trip, block, or permit operations.
Event Recording and Fault Forensics: Devices maintain Sequence of Events (SER) logs and capture high-resolution oscillography (waveform data), supporting post-event diagnostics and root-cause analysis.
Local Automation Capabilities: IEDs can autonomously execute transfer schemes, reclose sequences, interlocking, and alarm signaling often without intervention from SCADA or a centralized controller.
Protocol Bridging and Communication Integration: Most modern relays support and translate between multiple protocols, including IEC 61850, DNP3, Modbus, and IEC 60870-5-104, enabling them to function as data gateways or edge translators in hybrid communication environments.
Application across the grid: These devices ensure rapid fault isolation, coordinated protection, and reliable operation across transmission, distribution, and industrial networks.
Transmission and distribution lines (e.g., SIPROTEC)
Power Transformers (e.g., ABB RET615)
Feeders, Motors and industrial loads (e.g., GE D60)
How Attackers Can Recon and Target Protection Relays
As substations evolve into digital control hubs, their critical components, particularly protection relays, are no longer isolated devices. These IEDs are now network-connected through Ethernet, serial-to-IP converters, USB interfaces, and in rare cases, tightly controlled wireless links used for diagnostics or field tools.
While this connectivity improves maintainability, remote engineering access, and real-time visibility, it also expands the cyberattack surface exposing relays to risks of unauthorized logic modification, protocol exploitation, or lateral movement from compromised engineering assets.
Reconnaissance From the Internet
Attackers often begin with open-source intelligence (OSINT), building a map of the organization’s digital and operational footprint. They aren’t initially looking for IEDs or substations; they’re identifying the humans who manage them.
Social Recon: Using LinkedIn, engineering forums, or vendor webinars, attackers look for job titles like “Substation Automation Engineer,” “Relay Protection Specialist,” or “SCADA Administrator.”
OSINT Targeting: Public resumes and RFI documents may reference software like DIGSI, PCM600, or AcSELerator. Even PDF metadata from utility engineering documents can reveal usernames, workstation names, or VPN domains.
Infrastructure Scanning: Tools like Shodan or Censys help identify exposed VPNs, engineering portals, and remote access gateways. If these systems support weak authentication or use outdated firmware, they become initial entry points.
Exploitation of Weak Vendor Access: Many utilities still use stand-alone VPN credentials for contractors and OEM vendors. These accounts often bypass centralized identity systems, lack 2FA, and are reused across projects.
Reconnaissance in IT — Mapping the Path to OT
Once an attacker gains a foothold within the IT network—typically through phishing, credential theft, or exploiting externally exposed services—their next objective shifts toward internal reconnaissance. The target is not just domain dominance, but lateral movement toward OT-connected assets such as substations or Energy Management Systems (EMS).
Domain Enumeration: Using tools like BloodHound, attackers map Active Directory for accounts, shares, and systems tagged with OT context (e.g., usernames like scada_substation_admin, and groups like scada_project and scada_communication).
This phase allows the attacker to pinpoint high-value users and their associated devices, building a shortlist of engineering staff, contractors, or control center personnel who likely interface with OT assets.
Workstation & Server Access: Armed with domain privileges and OT-centric intelligence, the attacker pivots to target the workstations or terminal servers used by the identified engineers. These endpoints are rich in substation-relevant data, such as:
Relay configuration files (.cfg, .prj, .set)
VPN credentials or profiles for IDMZ access
Passwords embedded in automation scripts or connection managers
Access logs or RDP histories indicating commonly used jump hosts
At this stage, the attacker is no longer scanning blindly; they’re executing highly contextual moves to identify paths from IT into OT.
IDMZ Penetration — Crossing the Last Boundary
Using gathered VPN credentials, hard-coded SSH keys, or jump host details, the attacker attempts to cross into the DMZ. This zone typically mediates communication between IT and OT, and may be accessed via:
Engineering jump hosts (dual-homed systems, often less monitored)
Poorly segmented RDP gateways with reused credentials
Exposed management ports on firewalls or remote access servers
Once in the IDMZ, attackers map accessible subnets and identify potential pathways into live substations.
Substation Discovery and Technical Enumeration
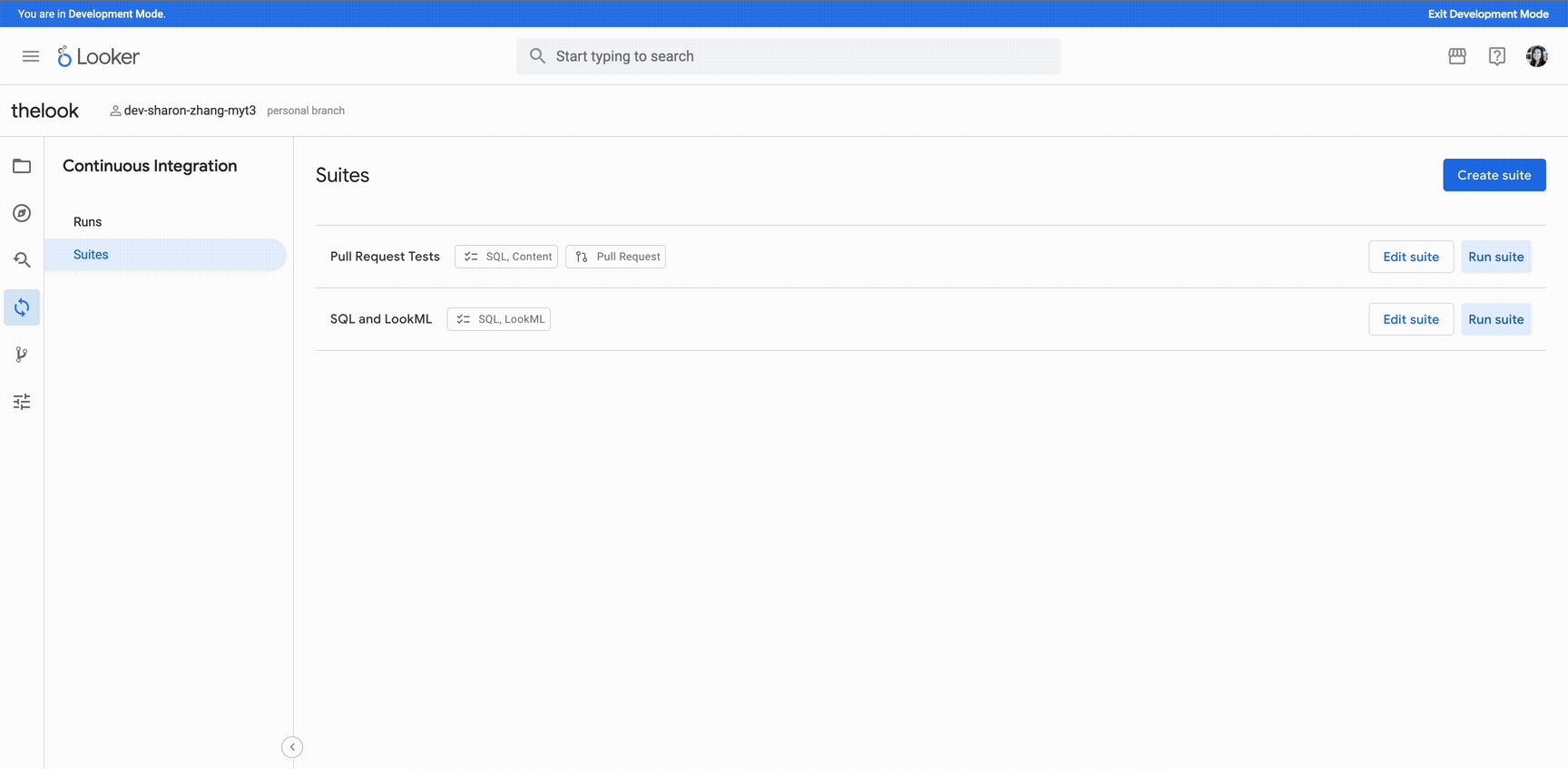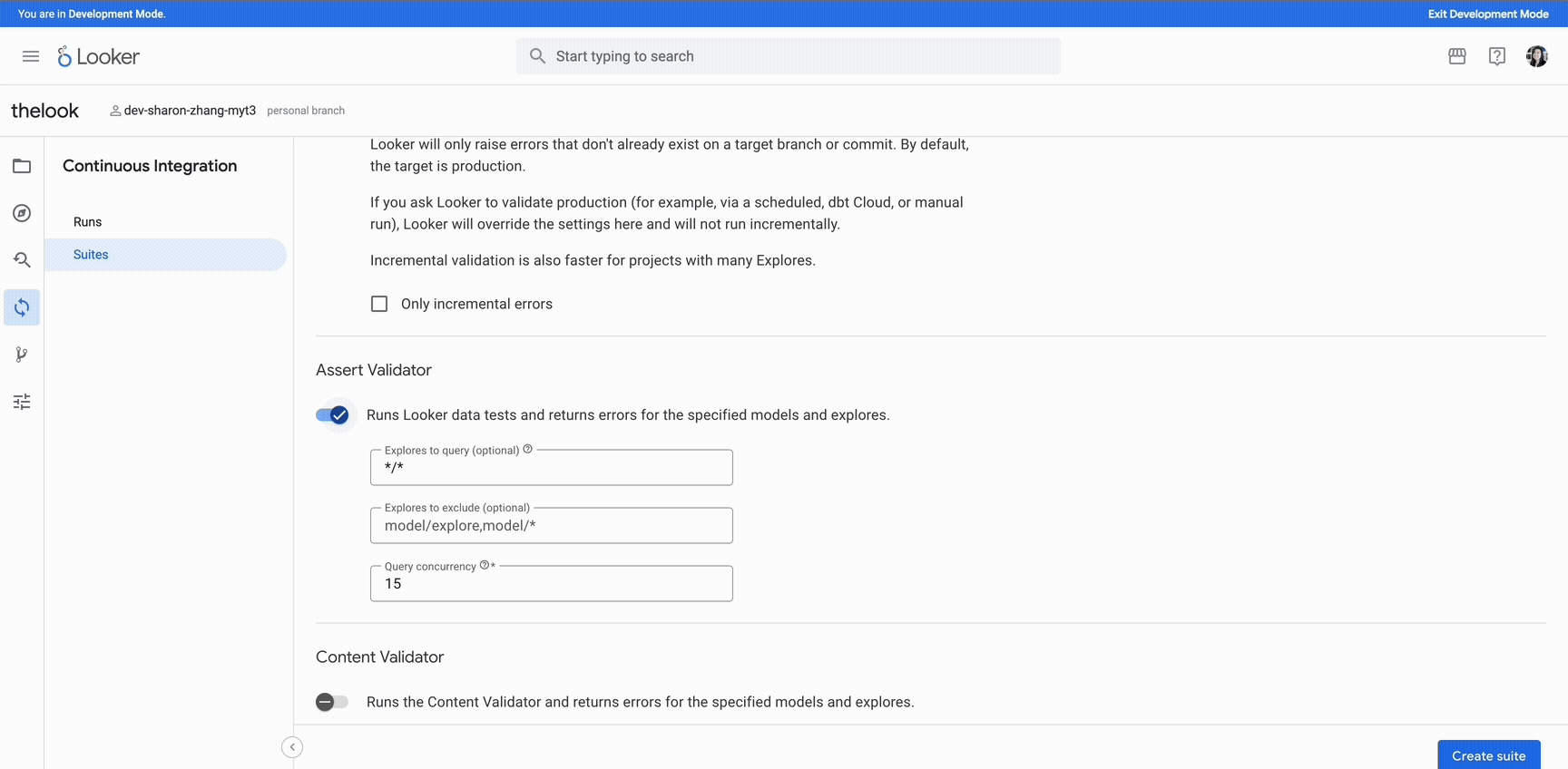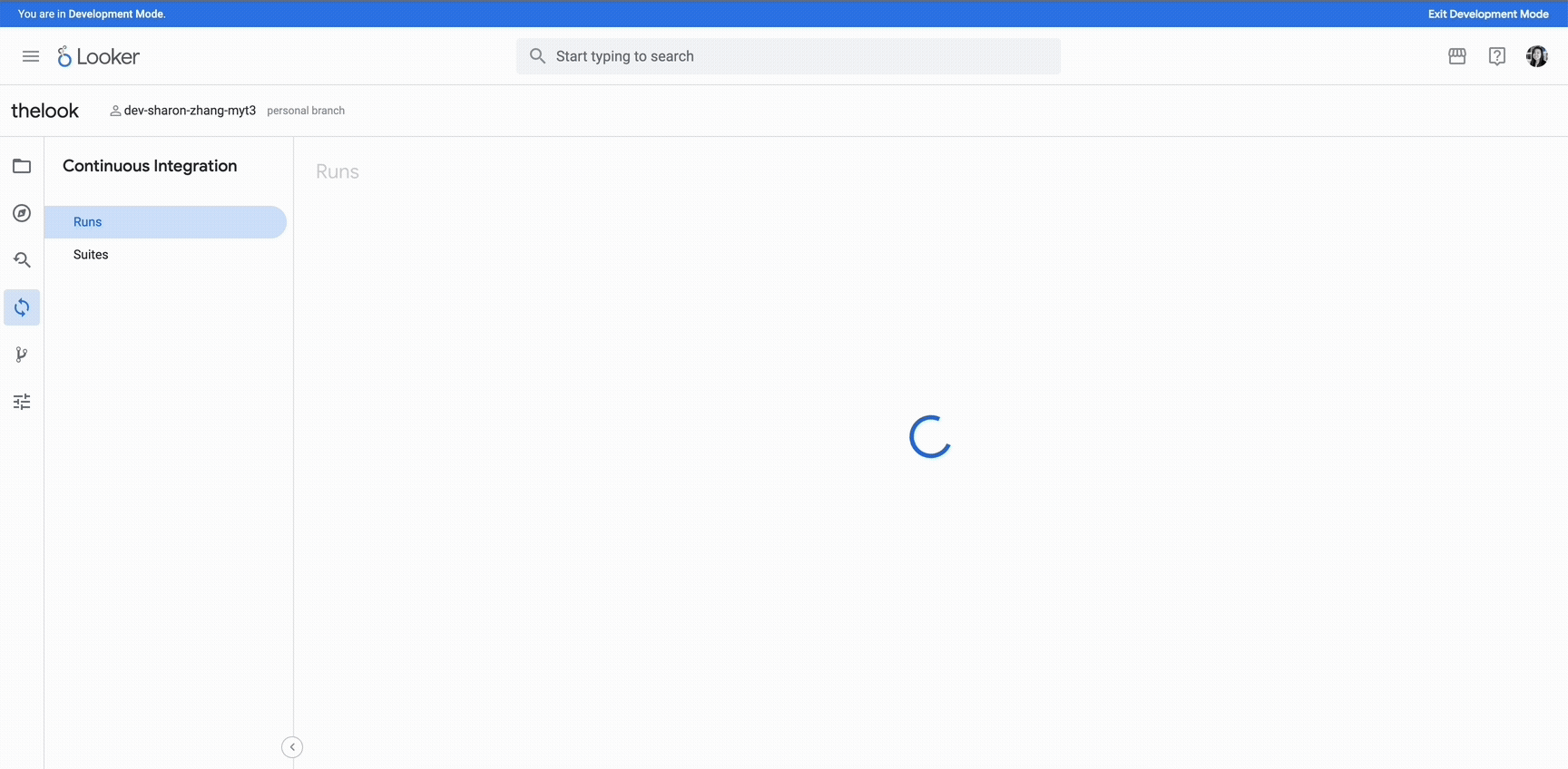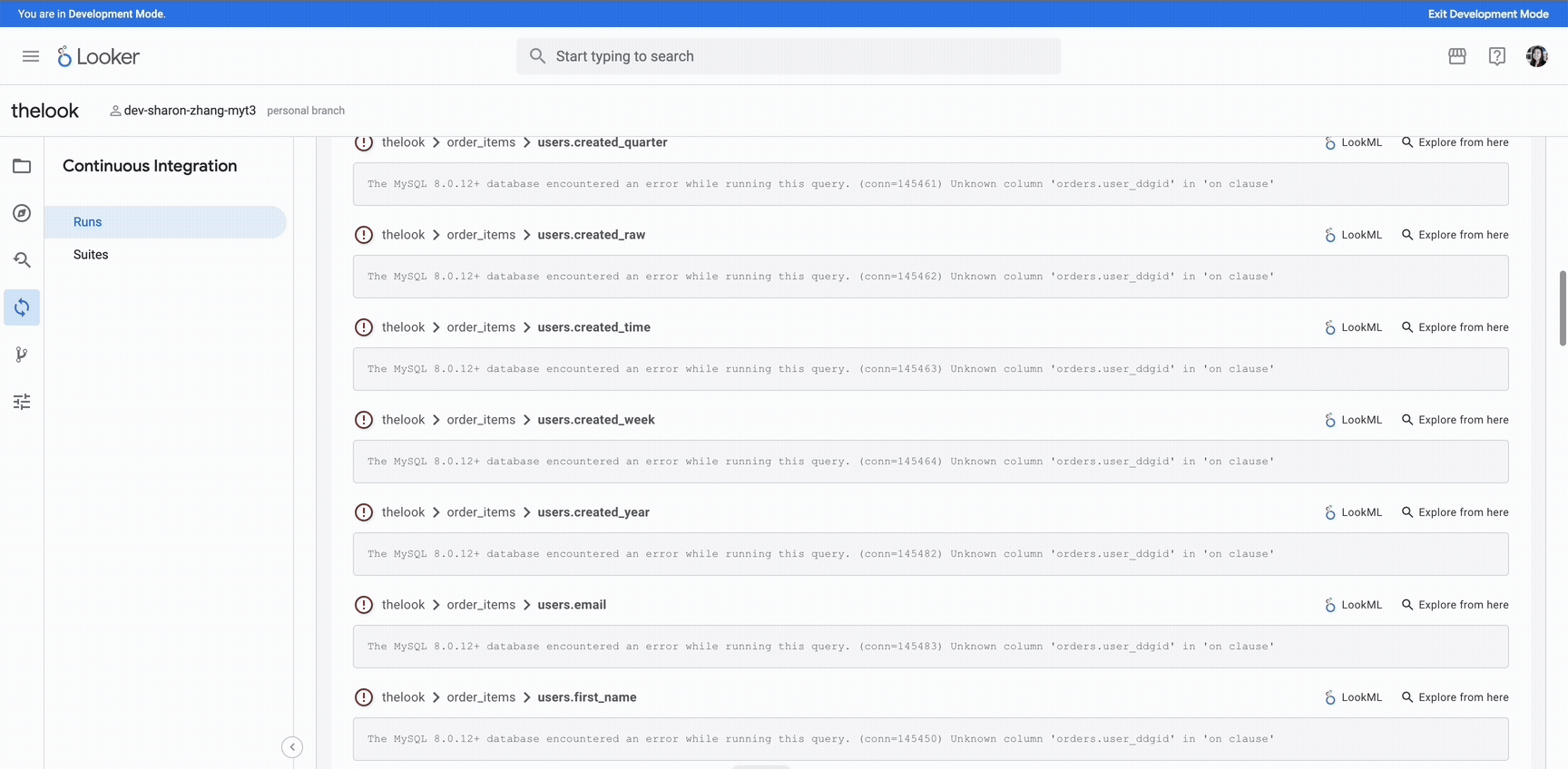
Once an attacker successfully pivots into the substation network often via compromised VPN credentials, engineering jump hosts, or dual-homed assets bridging corporate and OT domains—the next step is to quietly enumerate the substation landscape. At this point, they are no longer scanning broadly but conducting targeted reconnaissance to identify and isolate high-value assets, particularly protection relays.
Rather than using noisy tools like nmap with full port sweeps, attackers rely on stealthier techniques tailored for industrial networks. These include passive traffic sniffing and protocol-specific probing to avoid triggering intrusion detection systems or log correlation engines. For example, using custom Python or Scapy scripts, the attacker might issue minimal handshake packets for protocols such as IEC 61850 MMS, DNP3, or Modbus, observing how devices respond to crafted requests. This helps fingerprint device types and capabilities without sending bulk probes.
Simultaneously, MAC address analysis plays a crucial role in identifying vendors. Many industrial devices use identifiable prefixes unique to specific power control system manufacturers. Attackers often leverage this to differentiate protection relays from HMIs, RTUs, or gateways with a high degree of accuracy.
Additionally, by observing mirrored traffic on span ports or through passive sniffing on switch trunks, attackers can detect GOOSE messages, Sampled Values (SV), or heartbeat signals indicative of live relay communication. These traffic patterns confirm the presence of active IEDs, and in some cases, help infer the device’s operational role or logical zone.
Once relays, protocol gateways, and engineering HMIs have been identified, the attacker begins deeper technical enumeration. At this stage, they analyze which services are exposed on each device such as Telnet, HTTP, FTP or MMS, and gather banner information or port responses that reveal firmware versions, relay models or serial numbers. Devices with weak authentication or legacy configurations are prioritized for exploitation.
The attacker may next attempt to log in using factory-set or default credentials, which are often easily obtainable from device manuals. Alarmingly, these credentials are often still active in many substations due to lax commissioning processes. If login is successful, the attacker escalates from passive enumeration to active control—gaining the ability to view or modify protection settings, trip logic, and relay event logs.
If the relays are hardened with proper credentials or access controls, attackers might try other methods, such as accessing rear-panel serial ports via local connections or probing serial-over-IP bridges linked to terminal servers. Some adversaries have even used vendor software (e.g., DIGSI, AcSELerator, PCM600) found on compromised engineering workstations to open relay configuration projects, review programmable logic (e.g., SELogic or FlexLogic), and make changes through trusted interfaces.
Another critical risk in substation environments is the presence of undocumented or hidden device functionality. As highlighted in CISA advisory ICSA-24-095-02, SEL 700-series protection relays were found to contain undocumented capabilities accessible to privileged users.
Separately, some relays may expose backdoor Telnet access through hard-coded or vendor diagnostic accounts. These interfaces are often enabled by default and left undocumented, giving attackers an opportunity to inject firmware, wipe configurations, or issue commands that can directly trip or disable breakers.
By the end of this quiet but highly effective reconnaissance phase, the attacker has mapped out the protection relay landscape, assessed device exposure, and identified access paths. They now shift from understanding the network to understanding what each relay actually controls, entering the next phase: process-aware enumeration.
Process-Aware Enumeration
Once attackers have quietly mapped out the substation network (identifying protection relays, protocol gateways, engineering HMIs, and confirming which devices expose insecure services) their focus shifts from surface-level reconnaissance to gaining operational context. Discovery alone isn’t enough. For any compromise to deliver strategic impact, adversaries must understand how these devices interact with the physical power system.
This is where process-aware enumeration begins. The attacker is no longer interested in just controlling any relay they want to control the right relay. That means understanding what each device protects, how it’s wired into the breaker scheme, and what its role is within the substation topology.
Armed with access to engineering workstations or backup file shares, the attacker reviews substation single-line diagrams (SLDs), often from SCADA HMI screens or documentation from project folders. These diagrams reveal the electrical architecture—transformers, feeders, busbars—and show exactly where each relay fits. Identifiers like “BUS-TIE PROT” or “LINE A1 RELAY” are matched against configuration files to determine their protection zone.
By correlating relay names with breaker control logic and protection settings, the attacker maps out zone hierarchies: primary and backup relays, redundancy groups, and dependencies between devices. They identify which relays are linked to auto-reclose logic, which ones have synch-check interlocks, and which outputs are shared across multiple feeders.
This insight enables precise targeting. For example, instead of blindly disabling protection across the board, which would raise immediate alarms, the attacker may suppress tripping on a backup relay while leaving the primary untouched. Or, they might modify logic in such a way that a fault won’t be cleared until the disturbance propagates, creating the conditions for a wider outage.
At this stage, the attacker is not just exploiting the relay as a networked device. They’re treating it as a control surface for the substation itself. With deep process context in hand, they move from reconnaissance to exploitation: manipulating logic, altering protection thresholds, injecting malicious firmware, or spoofing breaker commands and because their changes are aligned with system topology, they maximize impact while minimizing detection.
Practical Examples of Exploiting Protection Relays
The fusion of network awareness and electrical process understanding makes modern substation attacks particularly dangerous—and why protection relays, when compromised, represent one of the highest-value cyber-physical targets in the grid.
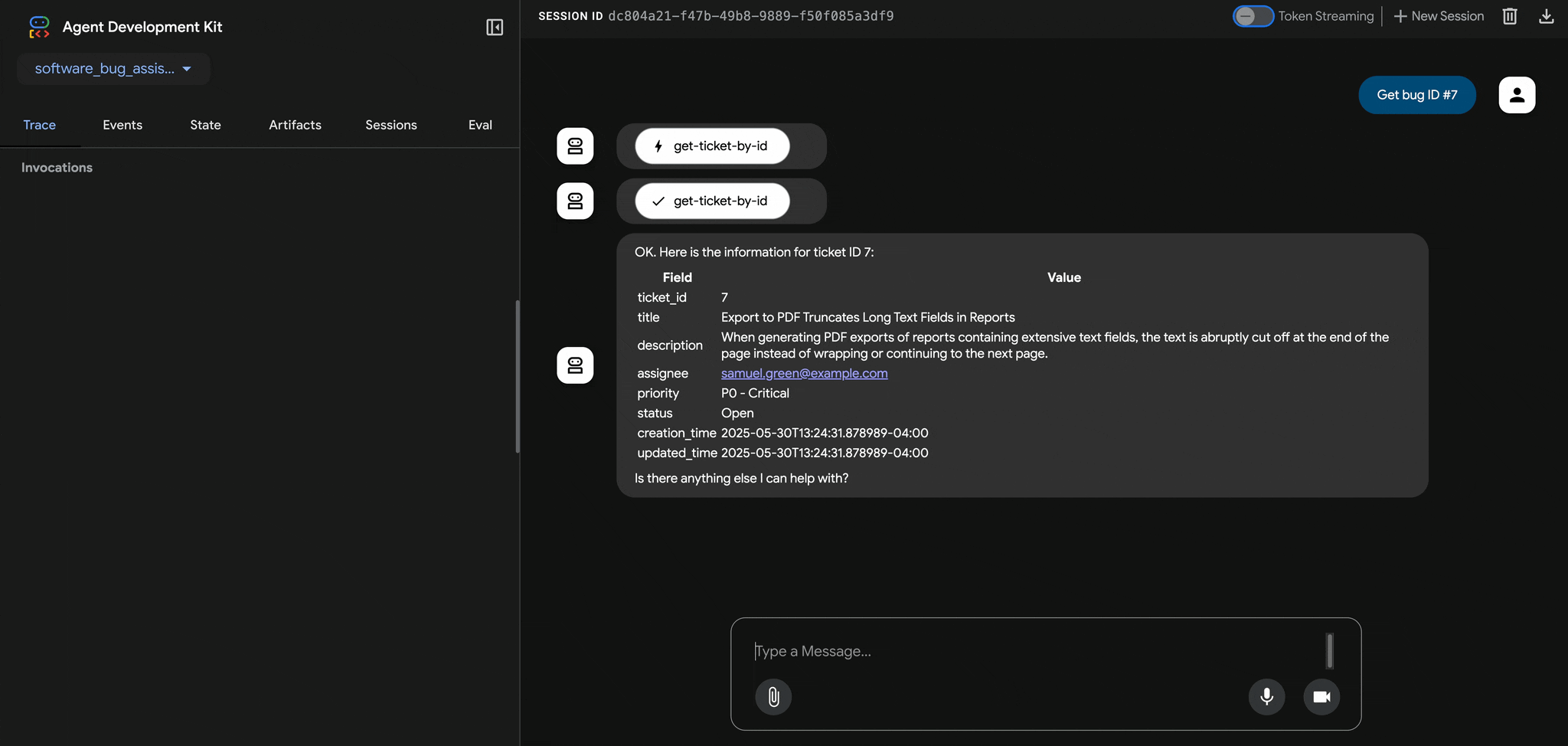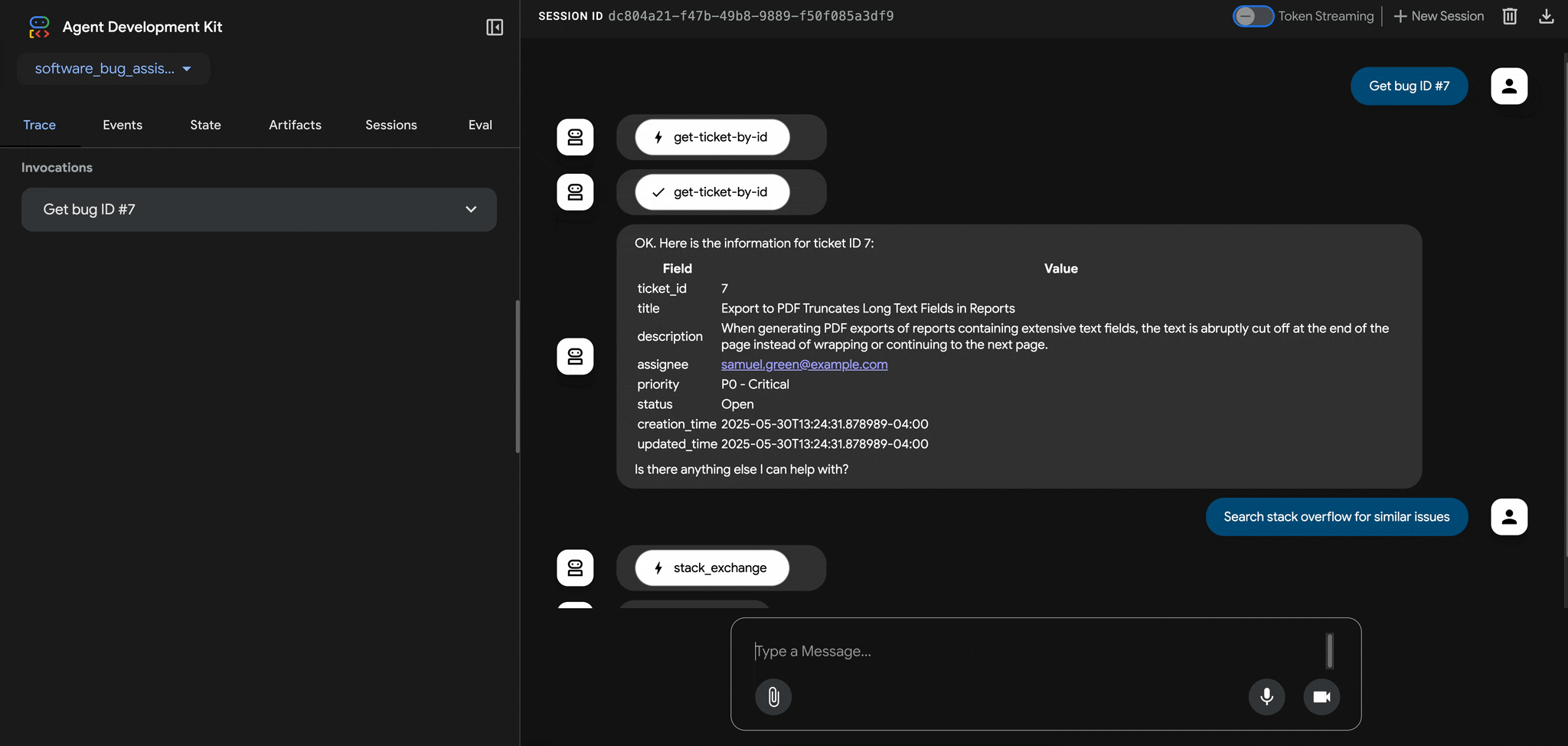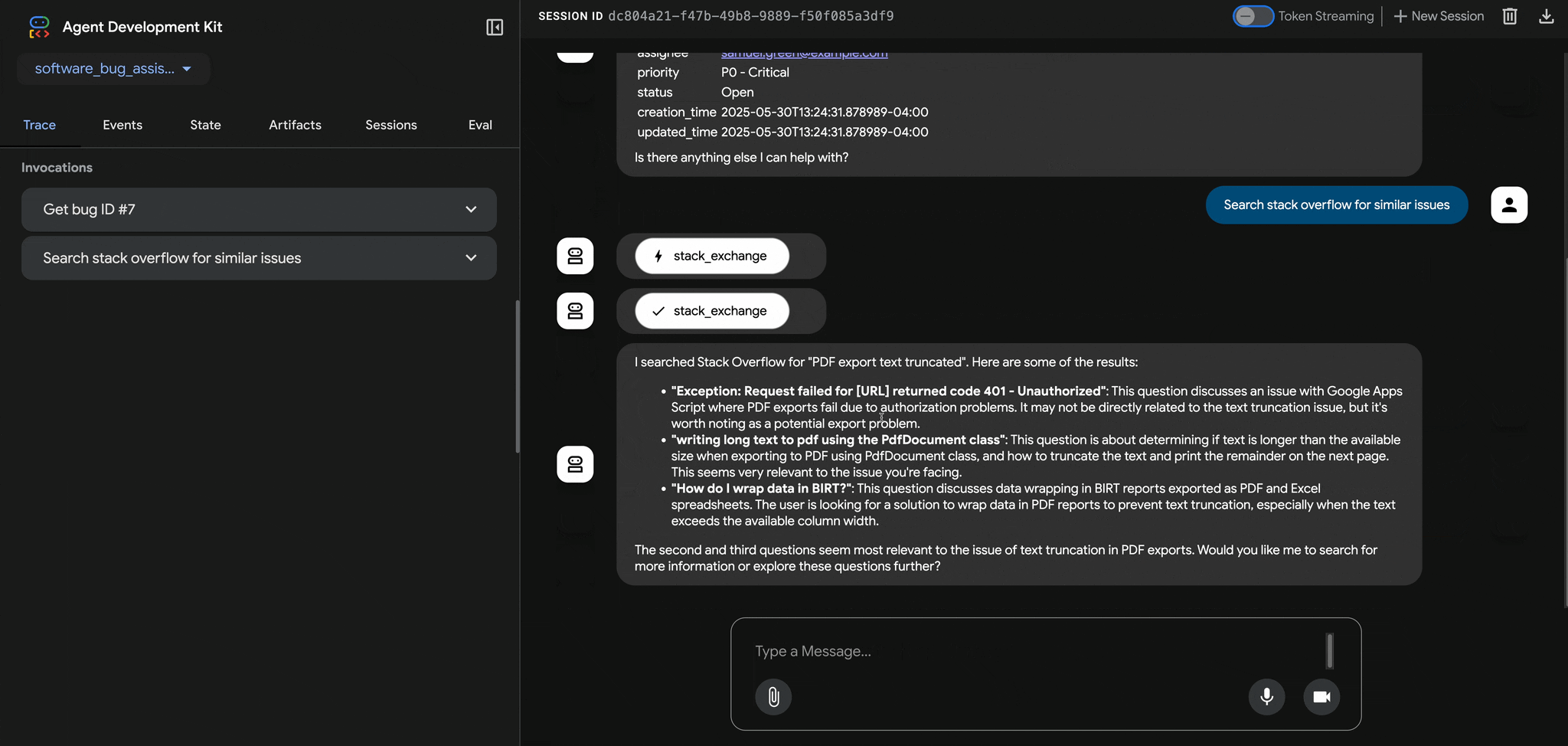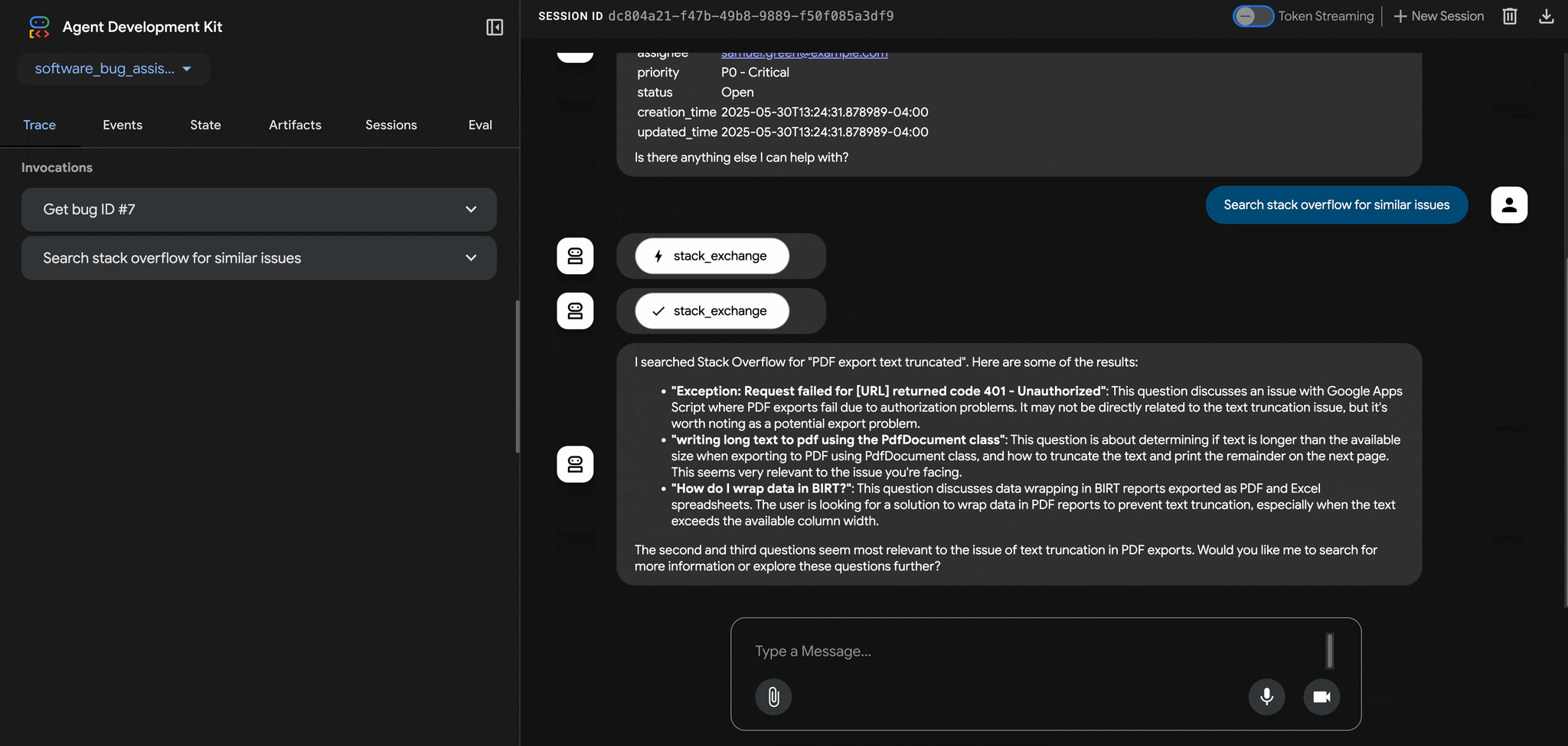
To illustrate how such knowledge is operationalized by attackers, let’s examine a practical example involving the SEL-311C relay, a device widely deployed across substations. Note: While this example focuses on SEL, the tactics described here apply broadly to comparable relays from other major OEM vendors such as ABB, GE, Siemens, and Schneider Electric. In addition, the information presented in this section does not constitute any unknown vulnerabilities or proprietary information, but instead demonstrates the potential for an attacker to use built-in device features to achieve adversarial objectives.
Figure 2: Attack Vectors for a SEL-311C Protection Relay
Physical Access
If an attacker gains physical access to a protection relay, either through the front panel or by opening the enclosure they can trigger a hardware override by toggling the internal access jumper, typically located on the relay’s main board. This bypasses all software-based authentication, granting unrestricted command-level access without requiring a login. Once inside, the attacker can modify protection settings, reset passwords, disable alarms, or issue direct breaker commands effectively assuming full control of the relay.
However, such intrusions can be detected, if the right safeguards are in place. Most modern substations incorporate electronic access control systems (EACS) and SCADA-integrated door alarms. If a cabinet door is opened without an authorized user logged as onsite (via badge entry or operator check-in), alerts can be escalated to dispatch field response teams or security personnel.
Relays themselves provide telemetry for physical access events. For instance, SEL relays pulse the ALARM contact output upon use of the 2ACCESS command, even when the correct password is entered. Failed authentication attempts assert the BADPASS logic bit, while SETCHG flags unauthorized setting modifications. These SEL WORDs can be continuously monitored through SCADA or security detection systems for evidence of tampering.
Toggling the jumper to bypass relay authentication typically requires power-cycling the device, a disruptive action that can itself trigger alarms or be flagged during operational review.
To further harden the environment, utilities increasingly deploy centralized relay management suites (e.g., SEL Grid Configurator, GE Cyber Asset Protection, or vendor-neutral tools like Subnet PowerSystem Center) that track firmware integrity, control logic uploads, and enforce version control tied to access control mechanisms.
In high-assurance deployments, relay configuration files are often encrypted, access-restricted, and protected by multi-factor authentication, reducing the risk of rollback attacks or lateral movement even if the device is physically compromised.
Command Interfaces and Targets
With access established whether through credential abuse, exposed network services, or direct hardware bypass the attacker is now in a position to issue live commands to the relay. At this stage, the focus shifts from reconnaissance to manipulation, leveraging built-in interfaces to override protection logic and directly influence power system behavior.
Here’s how these attacks unfold in a real-world scenario:
Manual Breaker Operation: An attacker can directly issue control commands to the relay to simulate faults or disrupt operations.
Example commands include:
==>PUL OUT101 5; Pulse output for 5 seconds to trip breaker
=>CLO; Force close breaker
=>OPE; Force open breaker
These commands bypass traditional protection logic, allowing relays to open or close breakers on demand. This can isolate critical feeders, create artificial faults, or induce overload conditions—all without triggering standard fault detection sequences.
Programmable Trip Logic Manipulation
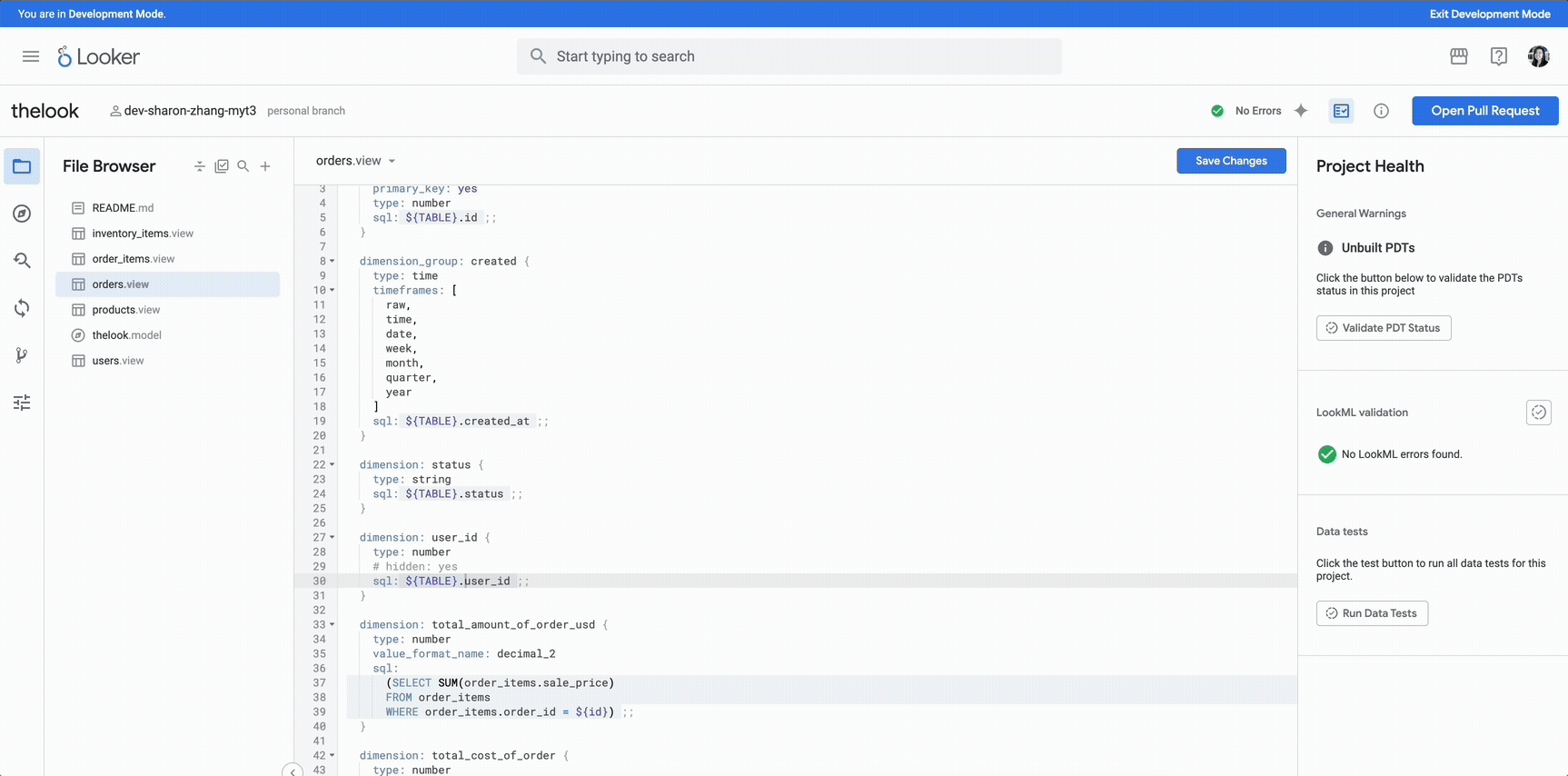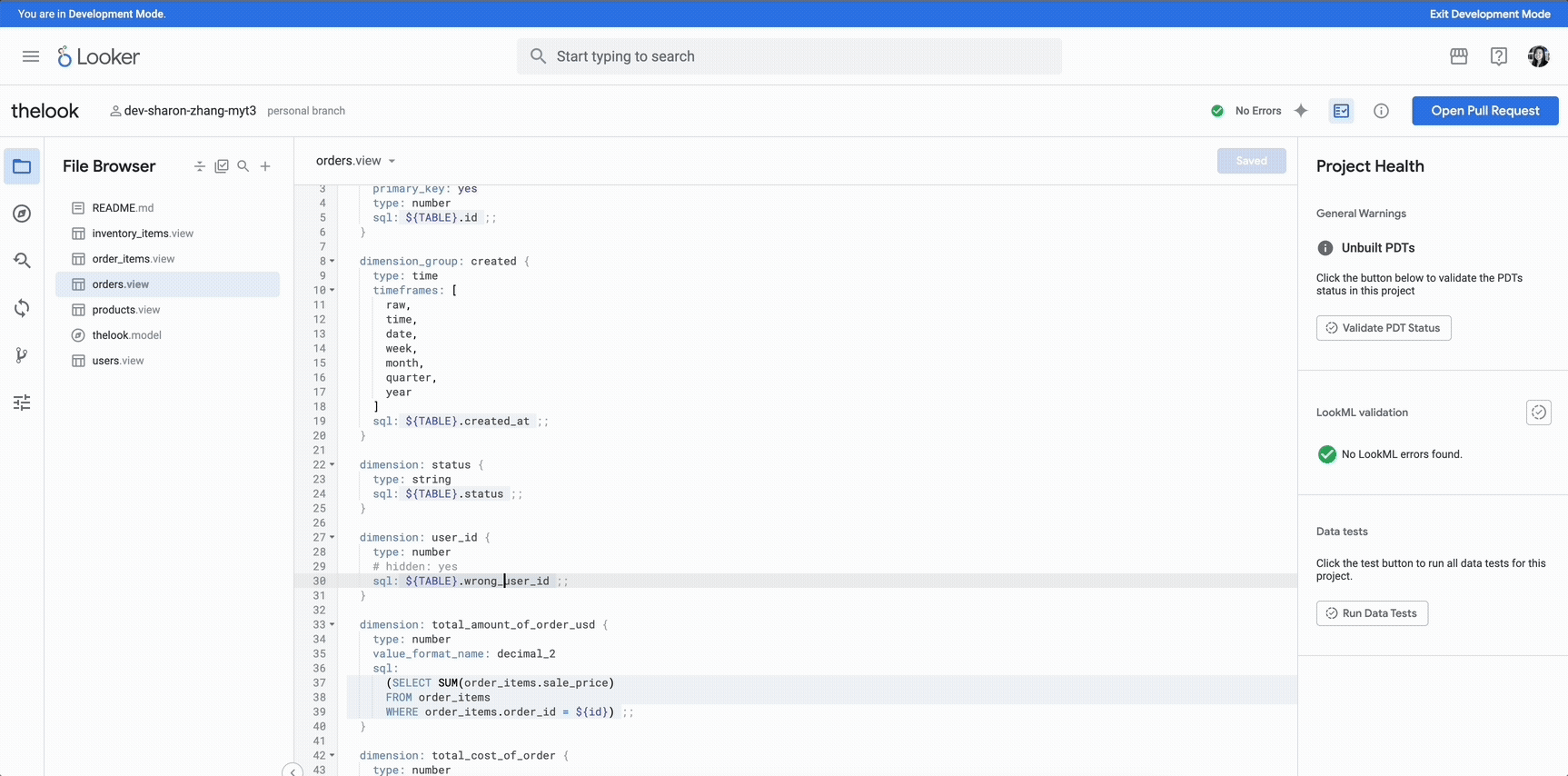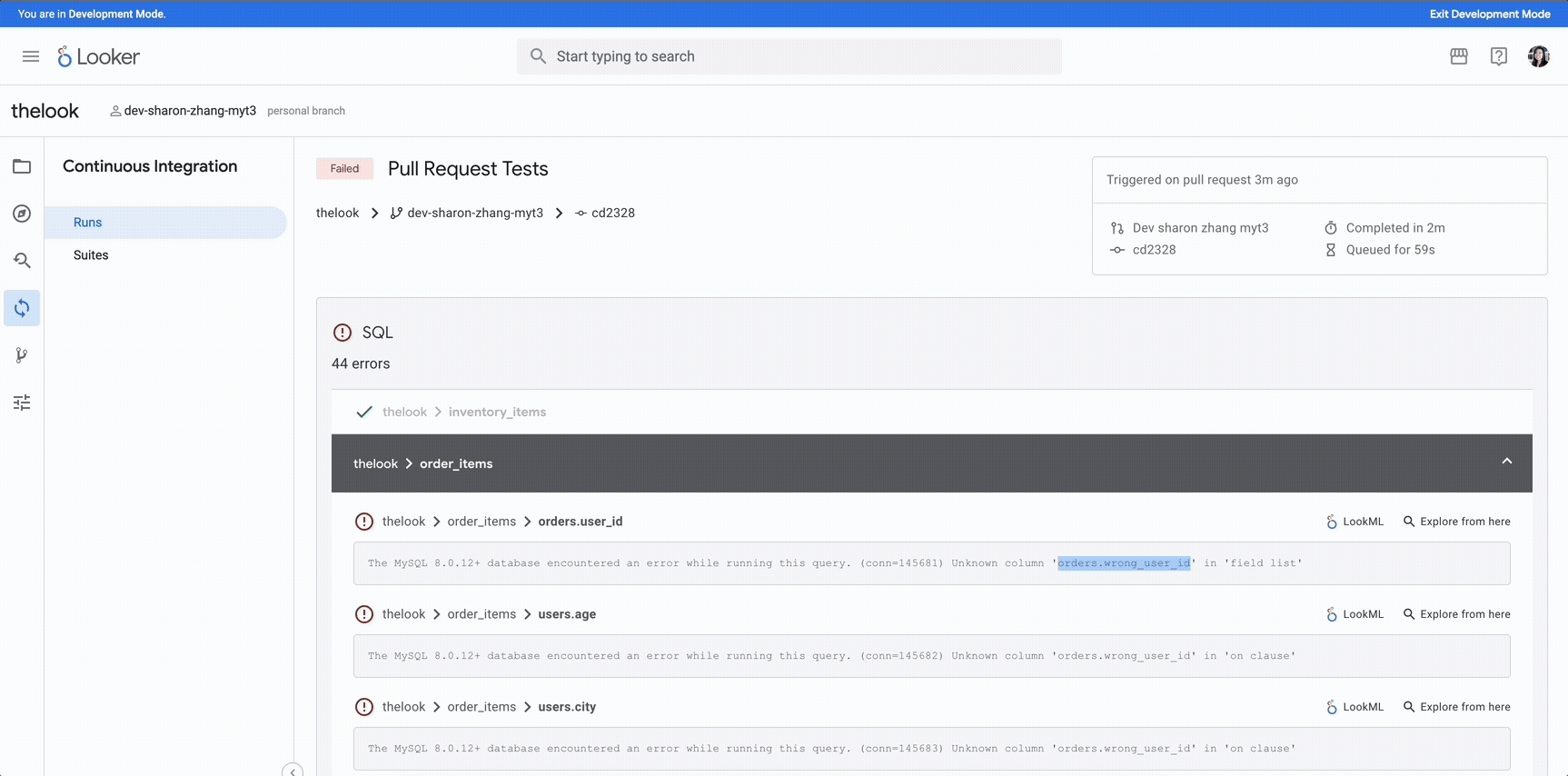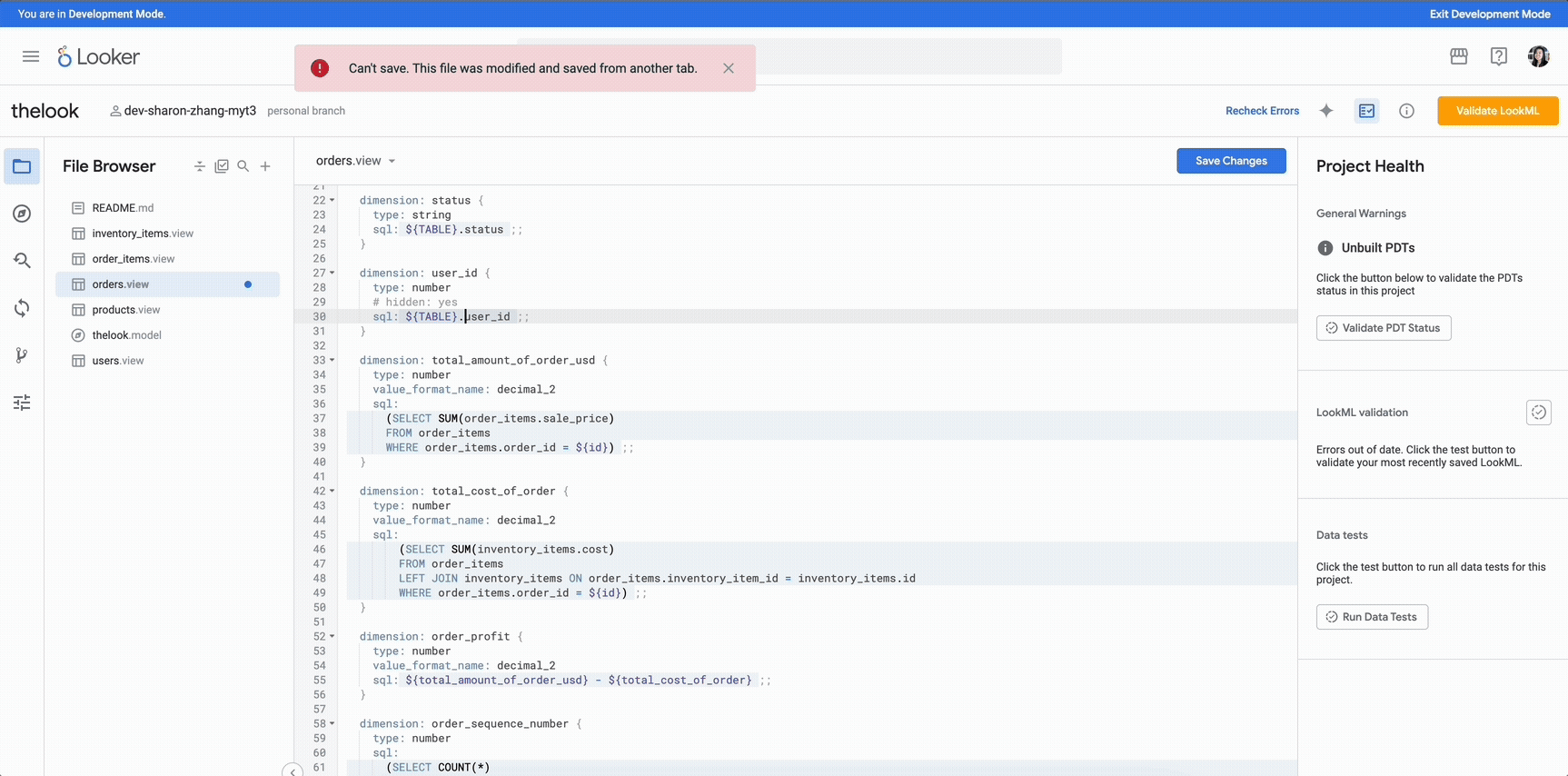
Modern protection relays such as those from SEL (SELogic), GE (FlexLogic), ABB (CAP tools), and Siemens (CFC), support customizable trip logic through embedded control languages. These programmable logic engines enable utilities to tailor protection schemes to site-specific requirements. However, this powerful feature also introduces a critical attack surface. If an adversary gains privileged access, they can manipulate core logic equations to suppress legitimate trips, trigger false operations, or embed stealthy backdoors that evade normal protection behavior.
One of the most critical targets in this logic chain is the Trip Request (TR) output, the internal control signal that determines whether the relay sends a trip command to the circuit breaker.
This equation specifies the fault conditions under which the relay should initiate a trip. Each element represents a protection function or status input, such as zone distance, overcurrent detection, or breaker position and collectively they form the basis of coordinated relay response.
In the relay operation chain, the TR equation is at the core of the protection logic.
Figure 3: TR Logic Evaluation within the Protection Relay Operation Chain
In SEL devices, for example, this TR logic is typically defined using a SELogic control equation. A representative version might look like this:
Zone 1 Ground distance element, trips on ground faults within Zone 1
M2PT
Phase distance element from Channel M2, Phase Trip (could be Zone 2)
Z2GT
Zone 2 Ground distance Trip element, for ground faults in Zone 2
51GT
Time-overcurrent element for ground faults (ANSI 51G)
51QT
Time-overcurrent element for negative-sequence current (unbalanced faults)
50P1
Instantaneous phase overcurrent element (ANSI 50P) for Zone 1
SH0
Breaker status input, logic 1 when breaker is closed
Table 1: Elements of TR
In the control equation, the + operator means logical OR, and * means logical AND. Therefore, the logic asserts TR if:
Any of the listed fault elements (distance, overcurrent) are active, or
An instantaneous overcurrent occurs while the breaker is closed.
In effect, the breaker is tripped:
If a phase or ground fault is detected in Zone 1 or Zone 2
If a time-overcurrent condition develops
Or if there’s an instantaneous spike while the breaker is in service
How Attackers Can Abuse the TR Logic
With editing access, attackers can rewrite this logic to suppress protection, force false trips, or inject stealthy backdoors.
Table 2 shows common logic manipulation variants.
Attack Type
Modified Logic
Effect
Disable All Trips
TR = 0
Relay never trips, even during major faults. Allows sustained short circuits, potentially leading to fires or equipment failure.
Force Constant Tripping
TR = 1, TRQUAL = 0
Relay constantly asserts trip, disrupting power regardless of fault status.
Impossible Condition
TR = 50P1 * !SH0
Breaker only trips when already open, a condition that never occurs.
Remove Ground Fault Detection
TR = M1P + M2PT + 50P1 * SH0
Relay ignores ground faults entirely, a dangerous and hard-to-detect attack.
Hidden Logic Backdoor
TR = original + RB15
Attacker can trigger trip remotely via RB15 (a Remote Bit), even without a real fault.
Table 2: TR logic bombs
Disable Trip Unlatching (ULTR)
ULTR = 0
Impact: Prevents the relay from resetting after a trip. The breaker stays open until manually reset, which delays recovery and increases outage durations.
Reclose Logic Abuse
79RI = 1 ; Reclose immediately
79STL = 0 ; Skip supervision logic
Impact: Forces breaker to reclose repeatedly, even into sustained faults. Can damage transformer windings, burn breaker contacts, or create oscillatory failures.
LED Spoofing
LED12 = !TRIP
Impact: Relay front panel shows a “healthy” status even while tripped. Misleads field technicians during visual inspections.
Event Report Tampering
=>EVE; View latest event
=>TRI; Manually trigger report
=>SER C; Clear Sequential Event Recorder
Impact: Covers attacker footprints by erasing evidence. Removes Sequential Event Recorder (SER) logs and trip history. Obstructs post-event forensics.
Change Distance Protection Settings
In the relay protection sequence, distance protection operates earlier in the decision chain, evaluating fault conditions based on impedance before the trip logic is executed to issue breaker commands.
Figure 4: Distance protection settings in a Relay Operation Chain
Impact: Distance protection relies on accurately configured impedance reach (Z1MAG) and impedance angle (Z1ANG) to detect faults within a predefined section of a transmission line (typically 80–100% of line length for Zone 1). Manipulating these values can have the following consequences:
Under-Reaching: Reducing Z1MAG to 0.3 causes the relay to detect faults only within 30% of the line length, making it blind to faults in the remaining 70% of the protected zone. This can result in missed trips, delayed fault clearance, and cascading failures if the backup protection does not act in time.
Impedance Angle Misalignment: Changing Z1ANG affects the directional sensitivity and fault classification. If the angle deviates from system characteristics, the relay may misclassify faults or fail to identify high-resistance faults, particularly on complex line configurations like underground cables or series-compensated lines.
False Trips: In certain conditions, especially with heavy load or load encroachment, a misconfigured distance zone may interpret normal load flow as a fault, resulting in nuisance tripping and unnecessary outages.
Compromised Selectivity & Coordination: The distance element’s coordination with other relays (e.g., Zone 2 or remote end Zone 1) becomes unreliable, leading to overlapping zones or gaps in coverage, defeating the core principle of selective protection.
Restore Factory Defaults
=>>R_S
Impact: Wipes all hardened settings, password protections, and customized logic. Resets the relay to an insecure factory state.
Password Modification for Persistence
=>>PAS 1 <newpass>
Impact: Locks out legitimate users. Maintains long-term attacker access. Prevents operators from reversing changes quickly during incident response.
What Most Environments Still Get Wrong
Despite increasing awareness, training, and incident response playbooks, many substations and critical infrastructure sites continue to exhibit foundational security weaknesses. These are not simply oversights—they’re systemic, shaped by the realities of substation lifecycle management, legacy system inertia, and the operational constraints of critical grid infrastructure.
Modernizing substation cybersecurity is not as simple as issuing new policies or buying next-generation tools. Substations typically undergo major upgrades on decade-long cycles, often limited to component replacement rather than full network redesigns. Integrating modern security features like encrypted protocols, central access control, or firmware validation frequently requires adding computers, increasing bandwidth, and introducing centralized key management systems. These changes are non-trivial in bandwidth-constrained environments built for deterministic, low-latency communication—not IT-grade flexibility.
Further complicating matters, vendor product cycles move faster than infrastructure refresh cycles. It’s not uncommon for new protection relays or firmware platforms to be deprecated or reworked before they’re fully deployed across even one utility’s fleet, let alone hundreds of substations.
The result? A patchwork of legacy protocols, brittle configurations, and incomplete upgrades that adversaries continue to exploit. In the following section, we examine some of the most critical and persistent gaps, why they still exist, and what can realistically be done to address them.
This section highlights the most common and dangerous security gaps observed in real-world environments.
Legacy Protocols Left Enabled
Relays often come with older communication protocols such as:
Telnet (unencrypted remote access)
FTP (insecure file transfer)
Modbus RTU/TCP (lacks authentication or encryption)
These are frequently left enabled by default, exposing relays to:
Credential sniffing
Packet manipulation
Unauthorized control commands
Recommendation: Where possible, disable legacy services and transition to secure alternatives (e.g., SSH, SFTP, or IEC 62351 for secured GOOSE/MMS). If older services must be retained, tightly restrict access via VLANs, firewalls, and role-based control.
IT/OT Network Convergence Without Isolation
Modern substations may share network infrastructure with enterprise IT environments:
VPN access to Substation networks
Shared switches or VLANs between SCADA systems and relay networks
Lack of firewalls or access control lists (ACLs)
This exposes protection relays to malware propagation, ransomware, or lateral movement from compromised IT assets.
Recommendation: Establish strict network segmentation using firewalls, ACLs, and dedicated protection zones. All remote access should be routed through Privileged Access Management (PAM) platforms with MFA, session recording, and Just-In-Time access control.
Default or Weak Relay Passwords
In red team and audit exercises, default credentials are still found in the field sometimes printed on the relay chassis itself.
Factory-level passwords like LEVEL2, ADMIN, or OPERATOR remain unchanged.
Passwords physically labeled on devices
Password sharing among field teams compromises accountability.
These practices persist due to operational convenience, lack of centralized credential management, and difficulty updating devices in the field.
Recommendation: Mandate site-specific, role-based credentials with regular rotation and enforced via centralized relay management tools. Ensure audit logging of all access attempts and password changes.
Built-in Security Features Left Unused
OEM vendors already provide a suite of built-in security features, yet these are rarely configured in production environments. Security features such as role-based access control (RBAC), secure protocol enforcement (e.g., HTTPS, SSH), user-level audit trails, password retry lockouts, and alert triggers (e.g., BADPASS or SETCHG bits) are typically disabled or ignored during commissioning. In many cases, these features are not even evaluated due to time constraints, lack of policy enforcement, or insufficient familiarity among field engineers.
These oversight patterns are particularly common in environments that inherit legacy commissioning templates, where security features are left in their default or least-restrictive state for the sake of expediency or compatibility.
Recommendation: Security configurations must be explicitly reviewed during commissioning and validated periodically. At a minimum:
Enable RBAC and enforce user-level permission tiers.
Configure BADPASS, ALARM, SETCHG, and similar relay logic bits to generate real-time telemetry.
Use secure protocols (HTTPS, SSH, IEC 62351) where supported.
Integrate security bit changes and access logs into central SIEM or NMS platforms for correlation and alerting.
Engineering Laptops with Stale Firmware Tools
OEM vendors also release firmware updates to fix any known security vulnerabilities and bugs. However:
Engineering laptops often use outdated configuration software
Old firmware loaders may upload legacy or vulnerable versions
Security patches are missed entirely
Recommendation: Maintain hardened engineering baselines with validated firmware signing, trusted toolchains, and controlled USB/media usage. Track firmware versions across the fleet for vulnerability exposure.
No Alerting on Configuration or Logic Changes
Protection relays support advanced logic and automation features like SELogic and FlexLogic but in many environments, no alerting is configured for changes. This makes it easy for attackers (or even insider threats) to silently:
Modify protection logic
Switch setting groups
Suppress alarms or trips
Recommendation: Enable relay-side event-based alerting for changes to settings, logic, or outputs. Forward logs to a central SIEM or security operations platform capable of detecting unauthorized logic uploads or suspicious relay behavior.
Relays Not Included in Security Audits or Patch Cycles
Relays are often excluded from regular security practices:
Not scanned for vulnerabilities
Not included in patch management systems
No configuration integrity monitoring or version tracking
This blind spot leaves highly critical assets unmanaged, and potentially exploitable.
Recommendation: Bring protection relays into the fold of cybersecurity governance, with scheduled audits, patch planning, and configuration monitoring. Use tools that can validate settings integrity and detect tampering, whether via vendor platforms or third-party relay management suites.
Physical Tamper Detection Features Not Monitored
Many modern protection relays include hardware-based tamper detection features designed to alert operators when the device enclosure is opened or physically manipulated. These may include:
Chassis tamper switches that trigger digital inputs or internal flags when the case is opened.
Access jumper position monitoring, which can be read via relay logic or status bits.
Power cycle detection, especially relevant when jumpers are toggled (e.g., SEL relays require a power reset to apply jumper changes).
Relay watchdog or system fault flags, indicating unexpected reboots or logic resets post-manipulation.
Despite being available, these physical integrity indicators are rarely wired into the SCADA system or included in alarm logic. As a result, an attacker could open a relay, trigger the access jumper, or insert a rogue SD card—and leave no real-time trace unless other controls are in place.
Recommendation: Utilities should enable and monitor all available hardware tamper indicators:
Wire tamper switches or digital input changes into RTUs or SCADA for immediate alerts.
Monitor ALARM, TAMPER, SETCHG, or similar logic bits in relays that support them (e.g., SEL WORD bits).
Configure alert logic to correlate with badge access logs or keycard systems—raising a flag if physical access occurs outside scheduled maintenance windows.
Include physical tamper status as a part of substation security monitoring dashboards or intrusion detection platforms.
From Oversights to Action — A New Baseline for Relay Security
The previously outlined vulnerabilities aren’t limited to isolated cases, they reflect systemic patterns across substations, utilities, and industrial sites worldwide. As the attack surface expands with increased connectivity, and as adversaries become more sophisticated in targeting protection logic, these security oversights can no longer be overlooked.
But securing protection relays doesn’t require reinventing the wheel. It begins with the consistent application of fundamental security practices, drawn from real-world incidents, red-team assessments, and decades of power system engineering wisdom.
While these practices can be retrofitted into existing environments, it’s critical to emphasize that security is most effective when it’s built in by design, not bolted on later. Retrofitting controls in fragile operational environments often introduces more complexity, risk, and room for error. For long-term resilience, security considerations must be embedded into system architecture from the initial design and commissioning stages.
To help asset owners, engineers, and cybersecurity teams establish a defensible and vendor-agnostic baseline, Mandiant has compiled the “Top 10 Security Practices for Substation Relays,” a focused and actionable framework applicable across protocols, vendors, and architectures.
In developing this list, Mandiant has drawn inspiration from the broader ICS security community—particularly initiatives like the “Top 20 Secure PLC Coding Practices” developed by experts in the field of industrial automation and safety instrumentation. While protection relays are not the same as PLCs, they share many characteristics: firmware-driven logic, critical process influence, and limited error tolerance.
The Top 20 Secure PLC Coding Practices have shaped secure programming conversations for logic-bearing control systems and Mandiant aims for this “Top 10 Security Practices for Substation Relays” list to serve a similar purpose for the protection engineering domain.
Top 10 Security Practices for Substation Relays
#
Practice
What It Protects
Explanation
1
Authentication & Role Separation
Prevents unauthorized relay access and privilege misuse
Ensure each user has their own account with only the permissions they need (e.g., Operator, Engineer). Remove default or unused credentials.
2
Secure Firmware & Configuration Updates
Prevents unauthorized or malicious software uploads
Only allow firmware/configuration updates using verified, signed images through secure tools or physical access. Keep update logs.
Disable unused services like HTTP, Telnet, or FTP. Use authenticated communication for SCADA protocols (IEC 61850, DNP3). Whitelist IPs.
4
Time Synchronization & Logging Protection
Ensures forensic accuracy and prevents log tampering or replay attacks
Use authenticated SNTP or IRIG-B for time. Protect event logs (SER, fault records) from unauthorized deletion or overwrite.
5
Custom Logic Integrity Protection
Prevents logic-based sabotage or backdoors in protection schemes
Monitor and restrict changes to programmable logic (trip equations, control rules). Maintain version history and hash verification.
6
Physical Interface Hardening
Blocks unauthorized access via debug ports or jumpers
Disable, seal, or password-protect physical interfaces like USB, serial, or Ethernet service ports. Protect access jumpers.
7
Redundancy and Failover Readiness
Ensures protection continuity during relay failure or communication outage
Test pilot schemes (POTT, DCB, 87L). Configure redundant paths and relays with identical settings and failover behavior.
8
Remote Access Restrictions & Monitoring
Prevents dormant vendor backdoors and insecure remote control
Disable remote services when not needed. Remove unused vendor/service accounts. Alert on all remote access attempts.
9
Command Supervision & Breaker Output Controls
Prevents unauthorized tripping or closing of breakers
Add logic constraints (status checks, delays, dual-conditions) to all trip/close outputs. Log all manual commands.
10
Centralized Log Forwarding & SIEM Integration
Enables detection of attacks and misconfigurations across systems
Relay logs and alerts should be sent to a central monitoring system (SIEM or historian) for correlation, alerts, and audit trails.
Call to Action
In an era of increasing digitization and escalating cyber threats, the integrity of our power infrastructure hinges on the security of its most fundamental guardians: protection relays. The focus of this analysis is to highlight the criticality of enabling existing security controls and incorporating security as a core design principle for every new substation and upgrade. As sophisticated threat actors, including nation-state-sponsored groups from countries like Russia, China and Iran, actively target critical infrastructure, the need to secure these devices has never been more urgent.
Mandiant recommends that all asset owners prioritize auditing remote access paths to substation automation systems and investigate the feasibility of implementing the “Top 10 Security Practices for Substation Relays” highlighted in this document. Defenders should also consider building a test relay lab or a relay digital twin, which are cloud-based replicas of their physical systems offered by some relay vendors, for robust security and resilience testing in a safe environment. By using real-time data, organizations can use test relay labs or digital twins to—among other things—test for essential subsystem interactions and repercussions of their systems transitioning from a secure state to an insecure state, all without disrupting production. To validate these security controls against a realistic adversary, a Mandiant OT Red Team exercise can safely simulate the tactics, techniques, and procedures used in real-world attacks and assess your team’s detection and response capabilities. By taking proactive steps to harden these vital components, we can collectively enhance the resilience of the grid against a determined and evolving threat landscape.
In the world of Google, networking is the invisible backbone supporting everything from traditional applications to cutting-edge AI-driven workloads. If you’re a developer navigating this complex landscape, understanding the underlying network infrastructure is no longer optional—it’s essential.
This guide cuts through the complexity, offering short, easy-to-digest explanations of core networking terms you need to know. But we don’t stop there. We also dive into the specialized networking concepts crucial for AI Data Centers, including terms like RDMA, InfiniBand, RoCE, NVLink, GPU, and TPU. Plus, we tackle common questions and answers to solidify your understanding.
Whether you’re working on-premises or leveraging the vast power of the Google Cloud, mastering these fundamental networking concepts will empower you to build, deploy, and optimize your applications with confidence.Networking categories and definitions
In today’s cloud landscape, safeguarding your cloud environment requires bolstering your Identity and Access Management (IAM) approach with more than allow policies and the principle of least privilege. To bolster your defenses, we offer a powerful tool: IAM Deny Policies.
Relying only on IAM Allow policies leaves room for potential over-permissioning, and can make it challenging for security teams to consistently enforce permission-level restrictions at scale. This is where IAM Deny comes in.
IAM Deny provides a vital, scalable layer of security that allows you to explicitly define which actions principals can not take, regardless of the roles they have been assigned. This proactive approach can help prevent unauthorized access, and strengthens your overall security posture, providing admin teams overriding guardrail policies throughout their environment.
Understanding IAM Deny
The foundation of IAM Deny is built on IAM Allow policies. Allow policies define who can do what and where in a Google Cloud organization, binding principals (users, groups, service accounts) to roles that grant access to resources at various levels (organization, folder, project, resource).
IAM Deny, conversely, defines restrictions. While it also targets principals, the binding occurs at the organization, folder, or project level — not at the resource level.
Key differences between Allow and Deny Policies:
IAMAllow: Focuses on granting permissions through role bindings to principals.
IAM Deny: Focuses on restricting permissions by overriding role bindings given by IAM Allow, at a hierarchical level.
IAM Deny acts as a guardrail for your Google Cloud environment, helping to centralize the management of administrative privileges, reduce the need for numerous custom roles, and ultimately enhance the security of your organization.
aside_block
<ListValue: [StructValue([(‘title’, ‘$300 in free credit to try Google Cloud security products’), (‘body’, <wagtail.rich_text.RichText object at 0x3dfdc48d85b0>), (‘btn_text’, ‘Start building for free’), (‘href’, ‘http://console.cloud.google.com/freetrial?redirectPath=/welcome’), (‘image’, None)])]>
How IAM Deny works
IAM Deny policies use several key components to build restrictions.
Denied Principals (Who): The users, groups, or service accounts you want to restrict. This can even be “everyone” in your organization, or even any principal regardless of organization (noted by the allUsers identifier).
Denied Permissions (What): The specific actions or permissions that the denied principals cannot use. Most Google Cloud services support IAM Deny, but it’s important to verify support for new services.
Attachment Points (Where): The organization, folder, or project where the deny policy is applied. Deny policies can not be attached directly to individual resources.
Conditions (How): While optional, these allow for more granular control over when a deny policy is enforced. Conditions are set with Resource Tags using Common Expression Language (CEL) expressions, enabling you to apply deny policies conditionally (such as only in specific environments or unless a certain tag is present).
IAM Deny core components.
Start with IAM Deny
A crucial aspect of IAM Deny is its evaluation order. Deny policies are evaluated first, before any Allow policies. If a Deny policy applies to a principal’s action, the request is explicitly denied, regardless of any roles the principal might have. Only if no Deny policy applies does the system then evaluate Allow policies to determine if the action is permitted.
There are built-in ways you can configure exceptions to this rule, however. Deny policies can specify principals who are exempt from certain restrictions. This can provide flexibility to allow necessary actions for specific administrative or break-glass accounts.
Deny policies always evaluate before IAM Allow policies.
When you can use IAM Deny
IAM Deny policies can be used to implement common security guardrails. These include:
Restricting high-privilege permissions: Prevent developers from creating or managing IAM roles, modifying organization policies, or accessing sensitive billing information in development environments.
Enforcing organizational standards: By limiting a set of permissions no roles can use, you can do things like prevent the misuse of overly-permissive Basic Roles, or restrict the ability to enable Google Cloud services in certain folders.
Implementing security profiles: Define sets of denied permissions for different teams (including billing, networking, and security) to enforce separation of duties.
Securing tagged resources: Apply organization-level deny policies to resources with specific tags (such as iam_deny=enabled).
Creating folder-level restrictions: Deny broad categories of permissions (including billing, networking, and security) on resources within a specific folder, unless they have any tag applied.
Complementary security layers
IAM Deny is most effective when used in conjunction with other security controls. Google Cloud provides several tools that complement IAM Deny:
Organization Policies: Allow you to centrally configure and manage organizational constraints across your Google Cloud hierarchy, such as restricting which APIs are available in your organization with Resource Usage Restriction policies. You can even define IAM Custom Constraints to limit which roles can be granted.
Policy troubleshooter: Can help you understand why a principal has access or has been denied access to a resource. It allows you to analyze both Allow and Deny policies to pinpoint the exact reason for an access outcome.
Policy Simulator: Enables you to simulate the impact of changes to your deny policies before applying them in your live environment. It can help you identify potential disruptions and refine your policies. Our Deny Simulator is now available in preview.
IAM Recommender: Uses machine learning to analyze how you’ve applied IAM permissions, and provide recommendations for reducing overly permissive role assignments. It can help you move towards true least privilege.
Privileged Access Management (PAM): Can manage temporary, just-in-time elevated access for principals who might need exceptions to deny policies. PAM solutions provide auditing and control over break-glass accounts and other privileged access scenarios.
Principal Access Boundaries: Lets you define the resources that principals in your organization can access. For example, you can use these to prevent your principals from accessing resources in other organizations, which can help prevent phishing attacks or data exfiltration.
Implementing IAM Deny with Terraform
The provided GitHub repository offers a Terraform configuration to help you get started with implementing IAM Deny and Organization Policies. This configuration includes:
An organization-level IAM Deny Policy targeting specific administrative permissions on tagged resources.
A folder-level IAM Deny Policy restricting Billing, Networking, and Security permissions on untagged resources.
A Custom Organization Policy Constraint to prevent the use of the roles/owner role.
An Organization Policy restricting the usage of specific Google Cloud services within a designated folder.
3. Prepare terraform.tfvars: Copy terraform.tfvars.example to terraform.tfvars and edit it to include your Organization ID, Target Folder ID, and principal group emails for exceptions.
You can name these whatever you want, but for our example you can use tag key (iamdeny) and tag value (enabled).
5. Update `main.tf` Tag IDs: Replace placeholder tag key and value IDs with your actual tag IDs in the denial_condition section for each policy.
code_block
<ListValue: [StructValue([(‘code’, ‘denial_condition {rn title = “Match IAM Deny Tag”rn expression = “resource.matchTagId(‘tagKeys/*’, ‘tagValues/*’)” #Tag=iam_deny, value=enabledrn }’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3dfdc31aeb50>)])]>
a. NOTE: This is optional, you can also use this expression to deny all resources when the policy is applied
code_block
<ListValue: [StructValue([(‘code’, ‘denial_condition {rn title = “deny all”rn expression = “!resource.matchTag(‘*/\\*’, ‘\\*’)”rn }’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3dfdc209ad60>)])]>
Remember to review the predefined denied permissions in files like `billing.json`, `networking.json`, and `securitycenter.json` (located in the `/terraform/profiles/` directory) and the `denied_perms.tf` file to align them with your organization’s security requirements.
Implementing IAM Deny policies is a crucial step in enhancing your Google Cloud security posture. By explicitly defining what principals cannot do, you add a powerful layer of defense against both accidental misconfigurations and malicious actors.
When combined with Organization Policies, Policy Troubleshooter, Policy Simulator, and IAM Recommender, IAM Deny empowers you to enforce least privilege more effectively and build a more secure cloud environment. Start exploring the provided Terraform example and discover the Power of No in your Google Cloud security strategy.
This content was created from learnings gathered from work by Google Cloud Consulting with enterprise Google Cloud Customers. If you would like to accelerate your Google Cloud journey with our best experts and innovators, contact us at Google Cloud Consulting to get started.
In today’s fast-paced digital landscape, businesses are choosing to build their networks alongside various networking and network security vendors on Google Cloud – and it’s not hard to see why. Google cloud has not only partnered with the best of breed service vendors – it has built an ecosystem that allows its customers to plug in and readily use these services
Cloud WAN: Global connectivity with best in class ISV ecosystem.
This year, we launched Cloud WAN, a key use case of Cross-Cloud Network, that provides a fully managed global WAN solution built on Google’s Premium Tier – planet-scale infrastructure, which spans over 200 countries and 2 million miles of subsea and terrestrial cables — a robust foundation for global connectivity. Cloud WAN provides up to a 40% TCO savings over a customer-managed global WAN leveraging colocation facilities1, while Cross-Cloud Network provides up to 40% improved performance compared to the public internet2.
The ISV Ecosystem advantage
Beyond global connectivity, Cloud WAN also offers customers a robust and adaptable ecosystem that includes market-leading SD-WAN partners, managed SSE vendors integrated via NCC Gateway, DDI solutions from Infoblox and network automation and intelligence solutions from Juniper Mist.These partners are integrated into the networking fabric using Cloud WAN architecture components such as network connectivity center for centralised hub architecture, Cloud VPN and Cloud Interconnect for high bandwidth connectivity to campus and data center networks. You can learn more about our Cloud WAN partners here.
In this post, we explore Google Cloud’s enhanced networking capabilities like multi-tenant, high-scale network address translation (NAT) and zonal affinity that allow ISVs to integrate their offerings natively with the networking fabric – giving Google Cloud customers a plug-and-play solution for cloud network deployments.
aside_block
<ListValue: [StructValue([(‘title’, ‘$300 to try Google Cloud networking’), (‘body’, <wagtail.rich_text.RichText object at 0x3e68672ab040>), (‘btn_text’, ‘Start building for free’), (‘href’, ‘http://console.cloud.google.com/freetrial?redirectpath=/products?#networking’), (‘image’, None)])]>
1. Cloud NAT source-based rules for multi-tenancy
As ISVs scale and expand their services to customers around the globe, infrastructure management can become challenging. When an ISV builds a service for their customers across multiple regions and languages, a single-tenant infrastructure becomes costly, prompting the ISVs to build a shared infrastructure to handle multi-tenancy. But multi-tenancy on shared infrastructure, brings complexities in its own right, especially around network address translation (NAT) and post-service processing. Tenant traffic needs to be translated to the correct allowlisted IP based on region, tenant and language markers. Unfortunately, most NAT solutions don’t handle multi-tenant infrastructure complexity and bandwidth load very well.
Source-based NAT rules in Google Cloud’s Cloud NAT service allow ISVs to NAT their traffic on a granular, per-tenant level, using the tenant and regional context to apply a public NAT IP to traffic after processing it. ISVs can assign IP markers to tenant traffic after they process it through their virtual appliances; Cloud NAT then uses rules to match IP markers and allocates the tenant’s allowlisted public NAT IPs for address translations before sending the traffic to its destination on the internet. This multi-tenant IP management fix provides a scalable way to handle address translation in a service-chaining environment.
Source-based NAT rules will be available for preview in Q3’25.
2. Zonal affinity keeps traffic local to the zone
Another key Cloud WAN advance is zonal affinity for Google Cloud’s internal passthrough Network Load Balancer. This feature minimizes cross-zone traffic, keeping your data local, for improved performance and lower cost of operations. By configuring zonal affinity, you direct client traffic to the managed instance group (MIG) or network endpoint group (NEG) within the same zone. If the number of healthy backends in the local zone dips below your set threshold, the load balancer smartly reverts to distributing traffic across all healthy endpoints in the region. You can control whether traffic spills over to other zones and set the spillover ratio. For an ISV’s network deployment on Google Cloud, zonal affinity helps ensure their applications run smoothly and at a lower TCO, while making the most of a multi-zonal architecture.
Learn more
With its simplicity, high performance, wide range of service options, and cost-efficiency, Cloud WAN is revolutionizing global enterprise connectivity and security. And with source-based NAT rules, and zonal affinity, ISVs and Google Cloud customers can more easily adopt multi-tenant architectures without increasing their operational burden. Visit the Cloud WAN Partners page to learn more about how to integrate your solution as part of Cloud WAN.
1. Architecture includes SD-WAN and 3rd party firewalls, and compares a customer-managed WAN using multi-site colocation facilities to a WAN managed and hosted by Google Cloud. 2. During testing, network latency was more than 40% lower when traffic to a target traveled over the Cross-Cloud Network compared to when traffic to the same target traveled across the public internet.
Google Public Sector is continually engaging with customers, partners, and policymakers to deliver technology capabilities that reflect their needs. When it comes to solutions for public safety and law enforcement, we are deeply committed to providing secure and compliance-focused environments.
We’re pleased to announce significant updates, which further strengthen our ability to enable compliance with the Criminal Justice Information Services (CJIS) 6.0 Security Policy and support the critical work of public safety agencies. These updates will help agencies achieve greater control, choice, security, and compliance in the cloud without compromising functionality.
A commitment to trust and compliance
With CJIS, compliance is about more than just controlling encryption keys. At its core, it’s about giving agencies and enterprises the flexibility their missions require. It’s about securing Criminal Justice Information (CJI) with the most advanced technologies and ensuring that access to CJI is restricted to appropriately screened personnel. For public safety, this translates to ensuring the utmost security and compliance for sensitive criminal justice information. Our strong contractual commitments to our customers are backed by robust controls and solutions that are all available today.
“Google Cloud’s Data Boundary via Assured Workloads ensures criminal justice agencies have a highly secure environment that supports their compliance needs and matches policy adherence of traditional ‘govcloud’ solutions, while delivering innovative AI services and scalable infrastructure crucial for their public safety mission,” said Mike Lesko, former chair of the CJIS Advisory Policy Board and former CJIS Systems Officer for the state of Texas.
Key updates for CJIS compliance
We are excited to share the following key CJIS readiness advancements that will benefit Google Public Sector customers. With these updates, customers in all 50 states and Washington, D.C., can confidently host or migrate CJIS applications to Google Cloud with new AI services for CJIS:
Validated by states: Google Cloud’s compliance with CJIS security controls has been validated by CJIS Systems Agencies (CSA) across the United States. To date, Google Cloud has passed 100% of all CSA reviews of CJIS compliance, including several data center audits.
CJIS 6.0 compliance with 3PAO attestation from Coalfire: Google Cloud’s compliance with the rigorous security requirements of v6.0 of the CJIS Security Policy has been independently assessed and validated by Coalfire, a Third-Party Assessment Organization (3PAO). We also launched a new CJIS Implementation Guide to simplify customer compliance with CJIS v6.0. Both artifacts are available on our CJIS compliance page.
Streamlined CJIS compliance with Data Boundary via Assured Workloads
Google Cloud’s Data Boundary via Assured Workloads provides a modern approach for agencies to achieve CJIS compliance with the software-defined community cloud. This approach allows agencies to optimize for infrastructure availability, including a range of GPUs across 9 U.S. regions, ensuring robust performance for demanding public safety applications.
Our Data Boundary for CJIS offers simple guardrails for agencies to achieve CJIS compliance, enabling them to easily set up data residency, access controls restricting CJI access to CJIS-scoped personnel, customer-managed encryption keys and configure essential policies such as log policies for data retention with continuous monitoring. This streamlines the path to compliance, reducing complexity for agencies while leveraging the latest technologies.
Security and compliance for agencies and enterprises
With Google Cloud, customers not only get CJIS-compliant solutions, they also gain access to our leading security capabilities. This includes our rigorous focus on secure-by-design technology and deep expertise from Google Threat Intelligence and Mandiant Cybersecurity Consulting who operate on the frontlines of cyber conflicts worldwide and maintain trusted partnerships with more than 80 governments around the world.
Contact us to learn more about how we are enabling public safety agencies to achieve CJIS compliance and leverage advanced cloud capabilities, and sign up for a 60 day free trial of Data Boundary via Assured Workloads here.
At Google Cloud, we’re building the most enterprise-ready cloud for the AI era, which includes ensuring our partner ecosystem has the best technology, support, and resources to optimally serve customers. Today, we’re announcing two AI-powered tools that will enable partners to more efficiently complete manual tasks and access information, while augmenting their capabilities with a new level of intelligence.First, a new Gemini-based SOW Analyzer to streamline how partners create,refine, review and get approval for statements of work by proactively guiding them with examples and reasoning, effectively applying best practices as they go. Second, a new Bot-Assisted Live Chat also provides always-on, intelligent support for everything from onboarding to billing. These tools go beyond basic automation; they actively coach partners, offering a level of intelligence and insights that is truly unique in the market.
In addition to these new tools, we are bringing new AI capabilities to Earnings Hub to help partners better identify opportunities and enhance their growth. This resource augments the partner experience, providing insights into the most strategic, in-demand customer engagements and enabling their businesses to grow.
aside_block
<ListValue: [StructValue([(‘title’, ‘Try Google Cloud for free’), (‘body’, <wagtail.rich_text.RichText object at 0x3ec3b63df550>), (‘btn_text’, ‘Get started for free’), (‘href’, ‘https://console.cloud.google.com/freetrial?redirectPath=/welcome’), (‘image’, None)])]>
Enhancing the SOW process with Gemini
SOW Analyzer is a new AI-powered tool in the Partner Network Hub that applies Gemini to review statements of work and provide instant, intelligent feedback on what’s missing or needs to be updated. This goes far beyond simple document review; it actively coaches partners through the process, providing concrete examples and insights into best practices, based on past data from thousands of customer engagements. This level of intelligence and proactive guidance is a powerful way for partners to streamline how they navigate the SOW process. leapfrogging what other hyperscalers are offering. For example, partners can now simply upload a PDF to get instant feedback on what’s missing or needs updating, which minimizes back-and-forth and helps them finalize customer contracts faster.
The new SOW Analyzer is designed for speed, clarity and continuous improvement for our partners. After uploading a document, it provides immediate compliance feedback and specific guidance on potential issues. For example, if technical outcomes lack measurable criteria, this gap is highlighted and the reasoning is provided. This AI-powered feedback enables partners to confidently revise their SOW for final review. While Google Cloud will continue to provide the final human approval, this AI analysis accelerates the entire process and significantly augments the partner experience, helping partners begin customer engagements sooner.
Here’s what IDC and partners had to say about using the tool:
“The SOW Analyzer will have a material impact for Google Cloud partners in terms of speed, accuracy and compliance for their SOWs. It is a great example of an AI use case for partner enablement.” –Steve White, Program Vice President, Channels and Alliances, IDC
“Google Cloud’s SOW Analyzer is an incredible new development. It doesn’t just highlight gaps in SOWs; it provides examples and actively coaches us through improvements. This guidance will allow SoftServe to execute SOWs significantly faster, paving the way for quicker, more effective future engagements.”– Scott Krynock, GM Google Cloud, VP, Softserve
“The SOW Analyzer is a great example of how Google Cloud is using its own AI products to make work easier for partners. The SOW process used to take us weeks, but we can now complete it in just a few days, helping us move faster and focus on creating real impact with our customers.” – Elaine Versloot, Director of Operations, Xebia
By enhancing the SOW process, we’re excited to help partners get projects approved faster, so they can accelerate services delivery for customers.
Always-on customer support
We’re also launching a new Bot-Assisted Live Chat experience to give partners instant access to the information they need, providing continuous, AI-bolstered support across all day-to-day business operations.
Available in the Partner Network Hub, the Bot-Assisted Live Chat can help partners get information to support some of their most common tasks like onboarding, billing, orders, incentive claims and rebates. For example, if a partner has a question about how to submit a claim or understand a rebate, they can ask the chatbot and receive immediate, personalized guidance, drawing upon our extensive knowledge base. If the issue requires a deeper level of support, the chatbot can initiate a seamless handoff to a Live Chat agent, without requiring the partner to re-explain the issue or start over.
Initial results from partner usage of the Bot-Assisted Live Chat have been very positive, including:
25% faster resolution times: Partners are able to more quickly resolve many of their inquiries in real-time.
First contact resolution (FCR): Accelerated issue closure and reduced friction at the first interaction with customer support.
Immediate support: Partners are immediately connected to support resources, helping them get faster resolution to many of their queries.
Here’s what one of our partners had to say about the experience:
“Bot-Assisted Live Chat is a tremendous asset. It expertly streamlines simple issue resolution, minimizing the need for extensive explanations and enabling our teams to overcome challenges much faster. Further, this makes locating resources exceptionally easy.” – Venkat Srungavarapu, Senior Vice President, and Naveen Kumar Chinnaboina, Principal Architect, Zelarsof
Earnings Hub: new AI insights to help partners grow
Earnings Hub continues to give partners enhanced visibility into their incentive earnings, consolidating key data like rebates, discounts, funds, and credits into a streamlined dashboard that also provides actionable insights to accelerate growth. In the coming months, we will be further enhancing this tool with conversational support and personalized, predictive insights that make it even easier to optimize earnings and uncover new growth opportunities. With Earnings Hub, we are putting the power of Google’s AI directly into the partner experience. Beyond just tracking earnings, this tool provides insights for partners to benchmark their performance against peers and offers personalized tips to increase their earnings. For example, it uses proprietary data and Gemini’s predictive reasoning capabilities to show partners which SKUs are selling in their specific area and where future customer demand is heading. Think of it like an intelligent roadmap that shows partners the way to higher earnings.
Putting AI to work for every partner
SOW Analyzer, Bot-Assisted Live Chat, and the enhanced Earnings Hub are all part of our commitment to make Google Cloud the easiest place for partners to grow and succeed. These tools deliver tangible value to our customers, providing unparalleled transparency and intelligence, and freeing up time for partners to focus on what matters most.
The SOW Analyzer is available now in the Partner Network Hub. Partner admins can find it under Earnings > Funds Details > SOW Documents to upload and review SOWs.
The Bot-Assisted Live Chat is available to users in the Partner Network Hub.
The Earnings Hub is fully available to all partners and continues to evolve with powerful new AI features on the horizon.
We encourage all Google Cloud partners to explore these tools and share feedback. And if you’re considering partnering with us, there’s never been a better time to get started with the unparalleled AI-powered support and insights we offer.
A great story doesn’t just tell you, it shows you. With Veo 3, we’ve leapt forward in combining video and audio generation to take storytelling to the next level.
Today, we’re excited to share that Veo 3 is now available for all Google Cloud customers and partners in public preview on Vertex AI.
Why this matters: Veo 3 is your partner for creating near-cinematic quality generative video, moving beyond novelty to narrative-driven creation. It not only brings stunning visual quality, but now adds sound from background sounds to dialogue. With Veo 3 on Vertex AI, you can take advantage of three powerful new capabilities:
Fluid, natural videos that synchronize video with audio and dialogue. Veo 3 can synchronize your audio and visuals in a single pass. The model produces rich soundscapes containing everything from dialogue and ambient noise, to sound effects and background music.
Cinematic video that captures creative nuances. Veo 3 makes it easy to capture creative nuances and detailed scene interactions in your prompt, from the shade of the sky to the precise way the sun hits water in the afternoon light, and produces high-definition video.
Realistic movement that simulates real-world physics. To create believable scenes, Veo 3 simulates real-world physics. This results in realistic water movement, accurate shadows connected with objects and characters, and natural human motion.
Prompt: A medium shot frames an old sailor, his knitted blue sailor hat casting a shadow over his eyes, a thick grey beard obscuring his chin. He holds his pipe in one hand, gesturing with it towards the churning, grey sea beyond the ship’s railing. “This ocean, it’s a force, a wild, untamed might. And she commands your awe, with every breaking light”
Businesses are already using Veo to make creating easier
Veo 3 is helping Google Cloud customers create external content – from social media ads to product demos – and internal materials like training videos and presentations. Hear directly from the teams:
“Veo 3 has marked the difference within the gen AI industry, and we’re glad that Freepik users have been some of the first to try the model out. The quality of the video generations combined with the audio integration option is the game changer in our AI Suite. We look forward to continuing this collaboration to bring the best AI tools and features to our users” – Omar Pera, CPO, Freepik
Veo 3 makes its debut on the Freepik AI Video Generator.
“Creativity is deeply personal, and our goal is to build a platform that adapts to every workflow. By working with Google, we’re combining the best technologies to give creators more control, efficiency, and power than ever before. Our collaboration with Google Cloud represents a strategic evolution that will not only enhance accessibility and efficiency but fundamentally transform how people create. We believe the future of generative video technology will leverage the best technologies to build the most flexible and accessible tools. This is an exciting step toward realizing that vision” – Zeev Farbman, Co-Founder & CEO, Lightricks.
“Veo 3 is the single greatest leap forward in practically useful AI for advertising since genAI first broke into the mainstream in 2023. By allowing brands to make fully fledged films from a single prompt – including brand, story, video, sound effects, voiceovers and more – Veo3 in one swoop lowers the barriers to entry to gen AI for creative people and elevates gen AI to a top tier brand building tool usable at every stage of the marketing funnel.” – Will Hanschell, co-founder and CEO, , Pencil
“Moodlings” brand and film made with Google Gemini, Imagen and Veo 3 by Tom Roach, Lucas Stanley, Gemma Cotterell, Margaux Dalgleish, Sahar Amer
Bring your vision to life with Veo 3 today
Veo 3 on Vertex AI is built for scalable enterprise use with crucial guardrails like safety filter controls and SynthID to ensure responsible deployment for any use case. To get started, go here to learn more about Veo 3 on Vertex AI and try it on Vertex AI Media Studio. Get started today!
Editor’s note: This is part one of the story. After you’re finished reading, head over to part two.
In 2017, John Lewis, a major UK retailer with a £2.5bn annual online turnover, was hampered by its monolithic e-commerce platform. This outdated approach led to significant cross-team dependencies, cumbersome and infrequent releases (monthly at best), and excessive manual testing, all further hindered by complex on-premises infrastructure. What was needed were some bold decisions to drive a quick and significant transformation.
The John Lewis engineers knew there was a better way. Working with Google Cloud, they modernized their e-commerce operations with Google Kubernetes Engine. They started with the frontend, and started to see results fast: the frontend was moved onto Google Cloud in mere months, releases to the frontend browser journey started to happen weekly, and the business gladly backed expansion into other areas.
At the same time, the team had a broader strategy in mind: to take a platform engineering approach, creating many product teams who built their own microservices to replace the functionality of the legacy commerce engine, as well as creating brand new experiences for customers.
And so The John Lewis Digital Platform was born. The vision was to empower development teams and arm them with the tools and processes they needed to go to market fast, with full ownership of their own business services. The team’s motto? “You Build It. You Run It. You Own It.” This decentralization of development and operational responsibilities would also enable the team to scale.
This article features insights from Principal Platform Engineer Alex Moss, who delves into their strategy, platform build, and key learnings of John Lewis’ journey to modernize and streamline its operations with platform engineering — so you can begin to think about how you might apply platform engineering to your own organization.
aside_block
<ListValue: [StructValue([(‘title’, ‘Try Google Cloud for free’), (‘body’, <wagtail.rich_text.RichText object at 0x3e6b75199700>), (‘btn_text’, ‘Get started for free’), (‘href’, ‘https://console.cloud.google.com/freetrial?redirectPath=/welcome’), (‘image’, None)])]>
Step 1: From monolithic to multi-tenant
In order to make this happen, John Lewis needed to adopt a multi-tenant architecture — one tenant for each business service, allowing each owning team to work independently without risk to others — and thereby permitting the Platform team to give the team a greater degree of freedom.
Knowing that the business’ primary objective was to greatly increase the number of product teams helped inform our initial design thinking, positioning ourselves to enable many independent teams even though we only had a handful of tenants.
This foundational design has served us very well and is largely unchanged now, seven years later. Central to the multi-tenant concept is what we chose to term a “Service” — a logical business application, usually composed of several microservices plus components for storing data.
We largely position our platform as a “bring your own container” experience, but encourage teams to make use of other Google Cloud services — particularly for handling state. Adopting services like Firestore and Pub/Sub reduces the complexity that our platform team has to work with, particularly for areas like resilience and disaster recovery. We also favor Kubernetes over compute products like Cloud Run because it strikes the right balance for us between enabling development teams to have freedom whilst allowing our platform to drive certain certain behaviours, e.g., the right level of guardrails, without introducing too much friction.
On our platform, Product Teams (i.e., tenants) have a large amount of control over their own Namespaces and Projects. This allows them to prototype, build, and ultimately operate, their workloads without dependency on others — a crucial element of enabling scale.
Our early-adopter teams were extremely helpful in helping evolve the platform; they were accepting of the lack of features and willing to develop their own solutions, and provided very rich feedback on whether we were building something that met their needs.
The first tenant to adopt the platform was rebuilding the johnlewis.com, search capability, replacing a commercial-off-the-shelf solution. This team was staffed with experienced engineers familiar with modern software development and the advantages of a microservice-based architecture. They quickly identified the need for supporting services for their application to store data and asynchronously communicate between their components. They worked with the Platform Team to identify options, and were onboard with our desire to lean into Google Cloud native services to avoid running our own databases or messaging. This led to us adopting Cloud Datastore and Pub/Sub for our first features that extended beyond Google Kubernetes Engine.
All roads lead to success
A risk with a platform that allows very high team autonomy is that it can turn into a bit of a wild-west of technology choices and implementation patterns. To handle this, but to do so in a way that remained developer-centric, we adopted the concept of a paved road, analogous to a “golden path.”
We found that the paved road approach made it easier to:
build useful platform features to help developers do things rapidly and safely
share approaches and techniques, and engineers to move between teams
demonstrate to the wider organisation that teams are following required practices (which we do by building assurance capabilities, not by gating release)
The concept of the paved road permeates most of what the platform builds, and has inspired other areas of the John Lewis Partnership beyond the John Lewis Digital space.
Our paved road is powered by two key features to enable simplification for teams:
The Paved Road Pipeline. This operates on the whole Service and drives capabilities such as Google Cloud resource provisioning and observability tools.
The Microservice CRD. As the name implies, this is an abstraction at the microservice level. The majority of the benefit here is in making it easier for teams to work with Kubernetes.
Whilst both features were created with the developer experience in mind, we discovered that they also hold a number of benefits for the platform team too.
The Paved Road Pipeline is driven by a configuration file — in yaml (of course!) — which we call the Service Definition. This allows the team that owns the tenancy to describe, through easy-to-reason-about configuration, what they would like the platform to provide for them. Supporting documentation and examples help them understand what can be achieved. Pushes to this file then drive a CI/CD pipeline for a number of platform-owned jobs, which we refer to as provisioners. These provisioners are microservices-like themselves in that they are independently releasable and generally focus on performing one task well. Here are some examples of our provisioners and what they can do:
Create Google Cloud resources in a tenant’s Project. For example, Buckets, PubSub, and Firestore — amongst many others
Configure platform-provided dashboards and custom dashboards based on golden-signal and self-instrumented metrics
Tune alert configurations for a given microservice’s SLOs, and the incident response behaviour for those alerts
Our product teams are therefore freed from the need to familiarize themselves deeply with how Google Cloud resource provisioning works, or Infrastructure-as-Code (IaC) tooling for that matter. Our preferred technologies and good practices can be curated by our experts, and developers can focus on building differentiating software for the business, while remaining fully in control of what is provisioned and when.
Earlier, we mentioned that this approach has the added benefit of being something that the platform team can rely upon to build their own features. The configuration updated by teams for their Service can be combined with metadata about their team and surfaced via an API and events published to Pub/Sub. This can then drive updates to other features like incident response and security tooling, pre-provision documentation repositories, and more. This is an example of how something that was originally intended as a means to help teams avoid writing their own IaC can also be used to make it easier for us to build platform features, further improving the value-add — without the developer even needing to be aware of it!
We think this approach is also more scalable than providing pre-built Terraform modules for teams to use. That approach still burdens teams with being familiar with Terraform, and versioning and dependency complexities can create maintenance headaches for platform engineers. Instead, we provide an easy-to-reason-about API and deliberately burden the platform team, ensuring that the Service provides all the functionality our tenants require. This abstraction also means we can make significant refactoring choices if we need to.
Adopting this approach also results in a broad consistency in technologies across our platform. For example, why would a team implement Kafka when the platform makes creating resources in Pub/Sub so easy? When you consider that this spans not just the runtime components that assemble into a working business service, but also all the ancillary needs for operating that software — resilience engineering, monitoring & alerting, incident response, security tooling, service management, and so on— this has a massive amplifying effect on our engineers’ productivity. All of these areas have full paved road capabilities on the John Lewis Digital Platform, reducing the cognitive load for teams in recognizing the need for, identifying appropriate options, and then implementing technology or processes to use them.
That being said, one of the reasons we particularly like the paved road concept is because it doesn’t preclude teams choosing to “go off-road.” A paved road shouldn’t be mandatory, but it should be compelling to use, so that engineers aren’t tempted to do something else. Preventing use of other approaches risks stifling innovation and the temptation to think the features you’ve built are “good enough.” The paved road challenges our Platform Engineers to keep improving their product so that it continues to meet our Developers’ changing needs. Likewise, development teams tempted to go off-road are put off by the increasing burden of replicating powerful platform features.
The needs of our Engineers don’t remain fixed, and Google Cloud are of course releasing new capabilities all the time, so we have extended the analogy to include a “dusty path” representing brand new platform features that aren’t as feature-rich as we’d like (perhaps they lack self-service provisioning or out-the-box observability). Teams are trusted to try different options and make use of Google Cloud products that we haven’t yet paved. The Paved Road Pipeline allows for this experimentation – what we term “snowflaking”. We then have an unofficial “rule of three”, whereby if we notice at least 3 teams requesting the same feature, we move to make the use of it self-service.
At the other end of the scale, teams can go completely solo — which we refer to as “crazy paving” — and might be needed to support wild experimentation or to accommodate a workload which cannot comply with the platform’s expectations for safe operation. Solutions in this space are generally not long-lived.
In this article, we’ve covered how John Lewis revolutionized its e-commerce operations by adopting a multi-tenant, “paved road” approach to platform engineering. We explored how this strategy empowered development teams and streamlined their ability to provision Google Cloud resources and deploy operational and security features.
In part 2 of this series, we’ll dive deeper into how John Lewis further simplified the developer experience by introducing the Microservice CRD. You’ll discover how this custom Kubernetes abstraction significantly reduced the complexity of working with Kubernetes at the component level, leading to faster development cycles and enhanced operational efficiency.
To learn more about shifting down with platform engineering on Google Cloud, you can find more information available here. To learn more about how Google Kubernetes Engine (GKE) empowers developers to effortlessly deploy, scale, and manage containerized applications with its fully managed, robust, and intelligent Kubernetes service, you can find more information here.
Imagine that you’re a project manager at QuantumRoast, a global coffee machine company.
You help your teammates navigate a sea of engineering roadmaps, sudden strategy pivots (we’re doing matcha now!), and incoming tickets from customers— everything from buggy invoice systems to a coffee machine that’s making a high-pitched noise 24/7.
On a regular day, you have about fifty open browser tabs: the internal ticket system, email, chat, GitHub, Google Search, StackOverflow, and more. You like your job and your teammates— but some days, you get overwhelmed.
What if there was a helper we could build to help you create and triage software tickets, and debug issues? An AI agent makes this possible.
Tools 101
What makes AI agents unique from other software systems? In the post “AI Agents in a Nutshell,” we discussed how AI agents use models, not just hardcoded logic, to reason their way through a problem. But more than just LLM-based reasoning, AI agents are uniquely powered to gather external data and then take action on behalf of the user. Rather than telling you how to solve a problem, an AI agent can help you actually solve it. How do we do this? With tools!
A toolis a capability that helps an AI agent interact with the world. A tool can be almost anything: an inline function, a hosted database, a third-party API, or even another agent. AI Agent frameworks like Agent Development Kit (ADK) have built-in support for tools, supporting a variety of tool types that we’ll cover in just a moment.
But howdoes an agent know not only whento call a certain tool, but also howto call it? The agent’s model plays a few key roles here.
The first is tool selection. We provide our agent with a list of tools and some instructions for how to use them. When a user prompts the agent, the agent’s model helps decide which tools to call, and why, in order to help the user.
The second key step is function-calling. Function calling is a bit of a misnomer because the model is not actually calling the tool, but rather, preparing to call it by formatting the request body that the framework then uses to call the tool.
Lastly, the model helps interpret the response from that tool — say, a list of open bugs from the database— and decides whether to take further action, or respond to the user with that information.
To see all this in action, let’s build the QuantumRoast bug assistant agent using ADK Python.
Function Tool
The simplest ADK tool is the function tool. This is an inline function that can perform a calculation or algorithm. For instance, we can write a function tool to get today’s date:
code_block
<ListValue: [StructValue([(‘code’, ‘def get_current_date() -> dict:rn “””rn Get the current date in the format YYYY-MM-DDrn “””rn return {“current_date”: datetime.now().strftime(“%Y-%m-%d”)}’), (‘language’, ‘lang-py’), (‘caption’, <wagtail.rich_text.RichText object at 0x3e16fb972a90>)])]>
This way, if the user asks about bugs filed “in the last week,” the model understands what specific dates it should be adding to the request body when it calls our IT Ticket database. Here’s what that looks like in action:
Built-in Tool
Another type of ADK tool is a built-in tool. These are tools that work with Google’s flagship model features, like code execution inside the model itself. For instance, can attach the Google Search built-in tool to our bug assistant agent, to allow the agent to do basic web-searches in order to gather more information about a bug:
code_block
<ListValue: [StructValue([(‘code’, ‘from google.adk.tools import google_searchrnfrom google.adk.tools.agent_tool import AgentToolrnrnsearch_agent = Agent(rn model=”gemini-2.5-flash”,rn name=”search_agent”,rn instruction=”””rn You’re a specialist in Google Search.rn “””,rn tools=[google_search],rn)rnsearch_tool = AgentTool(search_agent)’), (‘language’, ‘lang-py’), (‘caption’, <wagtail.rich_text.RichText object at 0x3e16fb972a30>)])]>
Here, we’re actually wrapping that Google Search tool in its own agent with its own system instructions, effectively using an agent as a tool.
Pulling in third-party API tools is great for re-using existing tools. But imagine that you’ve got a bunch of your own internal APIs and third-party APIs you want to integrate your agent with— GitHub, for example. In a standard software application, you’d have to write your own code to call GitHub’s APIs. But GitHub’s API is big!If every agent developer working with GitHub had to implement their own GitHub tools, that’s a lot of duplicated effort.
MCP has some unique specifications. Unlike standard HTTP, MCP provides a stateful, two-way connection between the client and server. It has its own way of defining tools and tool-specific error messages. A tool provider can then build MCP Servers on top of their APIs, exposing one or more pre-built tools for developers and users. Then, agent frameworks can initialize MCP Clients inside an agent application, to discover and call those tools.
This is exactly what GitHub did in 2025. They created a remote MCP server to allow different types of AI applications— from AI coding assistants, to custom agents— to easily call GitHub’s APIs. The GitHub MCP server exposes different parts of GitHub’s functionality, from issue and pull requests, to notifications and code security. Here, we use ADK’s MCPToolset to call the GitHub remote MCP server:
For our bug assistant, we will expose just some read-only GitHub tools, to allow QuantumRoast employees to find issues related to open-source dependencies, to see if that can help root-cause bugs they’re seeing in the internal ticket system. We’ll use ADK’s MCPToolset with a tool_filter to set this up. The tool-filter exposes only the GitHub tools we need, which not only hides the tools we don’t want users accessing (think: sensitive repo actions), but also protects the agent’s model from getting overwhelmed when trying to choose the right tool for the job.
Note how we also need to provide a GitHub Personal Access Token (PAT) to our MCPToolset definition, just like how you’d provide an auth token when setting up a standard API client in your code. This PAT is scopedto only access public repository data, with no scopes around sensitive user or repository actions.
Now, we have a set of GitHub MCP tools that our agent can call. For instance, let’s say that one of QuantumRoast’s services relies on XZ utils, a data compression tool. Our internal bug ticket system is tracking a CVE (security vulnerability) from last year, which we can trace back to the XZ Utils GitHub repo using the StackOverflow and Google Search tools. We can then use one of GitHub’s MCP tools, search_issues, to determine when and how that CVE was patched:
MCP Tool (Database)
The last tool to cover is QuantumRoast’s internal bug ticket database. This is a PostgreSQL database running on Google Cloud SQL. We have a table with bugs, each with a ticket_id, title, description, assignee, and other fields.
We could write our own Python code using an ORM like sqlalchemy to call our SQL database (eg. get ticket by ID). Then we could wrap that code in a Function Tool, just like we did for get_current_date(). But this could add toil — more lines of code, plus we’d have to write the database connection logic and handle auth on our own.
Instead, we are going to use MCP, much like we used it for the GitHub API. We will use a prebuilt MCP server again — but this time, the tool “backend” will be our own database. We’ll pull in the MCP Toolbox for Databases, a Google-built, open-source MCP server that provides connectors and production-grade features like auth, for a variety of data sources, from BigQuery to Redis.
To wire up the MCP toolbox to Cloud SQL, we’ll create a tools.yaml configuration file that tells the Toolbox MCP server where our database lives, and the tools we want to create for it. For example, we could transform our bug description column into searchable vector embeddings, to enable a fuzzy search-tickets tool within our agent:
code_block
<ListValue: [StructValue([(‘code’, “sources:rn postgresql: rn kind: cloud-sql-postgresrn project: my-gcp-projectrn region: us-central1rn instance: software-assistantrn database: tickets-dbrn user: postgresrn password: ${POSTGRES_PASSWORD}rntools:rn search-tickets:rn kind: postgres-sqlrn source: postgresqlrn description: Search for similar tickets based on their descriptions.rn parameters:rn – name: queryrn type: stringrn description: The query to perform vector search with.rn statement: |rn SELECT ticket_id, title, description, assignee, priority, status, (embedding <=> embedding(‘text-embedding-005’, $1)::vector) as distancern FROM ticketsrn ORDER BY distance ASCrn LIMIT 3;rn…”), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e16fb858340>)])]>
We can define several other tools, like create-new-ticket and update-ticket-status, in that tools.yaml file. From there, we can run the Toolbox MCP server locally:
code_block
<ListValue: [StructValue([(‘code’, ‘➜ mcp-toolbox git:(software-bug-github) ✗ ./toolbox –tools-file=”tools.yaml”rnrn2025-06-17T11:07:23.963075-04:00 INFO “Initialized 1 sources.”rn2025-06-17T11:07:23.963214-04:00 INFO “Initialized 0 authServices.”rn2025-06-17T11:07:23.963281-04:00 INFO “Initialized 9 tools.”rn2025-06-17T11:07:23.963341-04:00 INFO “Initialized 2 toolsets.”rn2025-06-17T11:07:23.963704-04:00 INFO “Server ready to serve!”‘), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e16fb858b50>)])]>
Then finally, we can plug our bug assistant agent into that MCP Toolbox server:
We equip our root_agent with instructions. We outline the desired process that we want the agent to go through:
code_block
<ListValue: [StructValue([(‘code’, ‘agent_instruction = “””rnYou are a skilled expert in triaging and debugging software issues for a coffee machine company, QuantumRoast.rn…rnYour general process is as follows:rn1. **Understand the user’s request.** Analyze the user’s initial request to understand the goal – for example, “I am seeing X issue. Can you help me find similar open issues?” If you do not understand the request, ask for more information. rn2. **Identify the appropriate tools.** You will be provided with tools for a SQL-based bug ticket database (create, update, search tickets by description). You will also be able to web search via Google Search. Identify one **or more** appropriate tools to accomplish the user’s request. rn…’), (‘language’, ‘lang-py’), (‘caption’, <wagtail.rich_text.RichText object at 0x3e16fb858e50>)])]>
Inside our system instructions, we also provide details and context on all our tools. This helps the model understand when to invoke which tool.
code_block
<ListValue: [StructValue([(‘code’, ‘**TOOLS:**rnrn1. **get_current_date:**rn This tool allows you to figure out the current date (today). If a userrn asks something along the lines of “What tickets were opened in the lastrn week?” you can use today’s date to figure out the past week.rnrn2. **search-tickets**rn This tool allows you to search for similar or duplicate tickets byrn performing a vector search based on ticket descriptions. A cosine distancern less than or equal to 0.3 can signal a similar or duplicate ticket.rn…’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e16fb858040>)])]>
To sum up, tools “make an agent.” They’re the difference between an AI that can tell you what to do, and one that can help you actually do it.
If you’re new to AI agents and tools, start small. Write a basic ADK agent using an inline function. Then, consider pulling in an OpenAPI Tool for your API, or a Third-party LangChain tool like YouTube. Then, wade into the world of MCP by first using an off-the-shelf MCP server like the MCP Toolbox for Databases. Then, consider building your own MCP server for your own tool backend.
To get started today, check out these links, and thanks for reading!
We are excited to announce that Google has been named a Strong Performer in The Forrester Wave™: Security Analytics Platforms, Q2 2025, in our first year of participation. The report acknowledges Google Cloud’s vision which relies heavily on Mandiant’s roots in threat-intelligence-driven security operations, which are evident in the platform.
For us, this recognition validates our vision for the future of security operations and our commitment to delivering the platform defenders need to protect their organizations from modern threats.
Traditional security operation centers (SOCs) struggle with outdated tools and practices that can not handle the complexity of modern threats. We are empowering SOCs to change this with Google Security Operations, our cloud-native, intelligence-led, and AI-driven platform.
Our recognition as a Strong Performer in this evaluation is, in our opinion, a significant acknowledgement of our vision and highlights the power and innovation of Google Security Operations.
An intelligence-led, AI-driven platform for security outcomes
Forrester evaluated vendors on criteria such as current offering, strategy, and customer feedback. As a first-time participant in this evaluation, we are proud that our position as a Strong Performer highlights, in our opinion, the unique strengths we bring to our customers.
“Customers speak highly of the speed of searching in the platform and the effects of the Mandiant acquisition, especially the value of its threat intelligence,” Forrester stated in the report.
A unified analyst experience. For us, the report validates our core belief that integrating workflow is paramount in modern security operations. This is the guiding principle for our experience combining SIEM, SOAR, and threat intelligence to streamline the entire threat detection, investigation, and response lifecycle. By embedding AI directly into the analyst workflow, we offer our customers detailed context, guided recommendations, and complex task automation to accelerate the entire threat detection and incident response (TDIR) process, and uplevel overall efficiency.
Intelligence-driven security. The Forrester report notes that our platform is built on a foundation of threat intelligence-driven security operations. Google Security Operations is driving change in traditional SIEM through unique Applied Threat Intelligence capabilities, which rely on Google Threat Intelligence. By giving security operators valuable context throughout their TDIR workflow, Google Security Operations can help lower the mean time to detect threats for organizations, especially when it comes to emerging threat actor behavior. This intelligence-driven approach is fundamental to how we help security teams proactively defend against adversaries.
Speed and scale. The Forrester report states that our customers speak highly of the speed of searching in the platform and the effects of the Mandiant acquisition. This synergy allows organizations to ingest and analyze security data at a speed that legacy tools can not match.
aside_block
<ListValue: [StructValue([(‘title’, ‘$300 in free credit to try Google Cloud security products’), (‘body’, <wagtail.rich_text.RichText object at 0x3e8dd5a69670>), (‘btn_text’, ‘Start building for free’), (‘href’, ‘http://console.cloud.google.com/freetrial?redirectPath=/welcome’), (‘image’, None)])]>
Pioneering agentic security
Our vision extends beyond assistive AI, and we’re now pioneering agentic security operations, where customers can start to benefit from autonomous SOC workflows. Starting with our automated Alert Triage agent, first announced at Google Cloud Next 2025, we are actively building agentic workflows for detection engineering, triage and investigation, threat hunting, and response.
Agentic security can help analysts delegate complex tasks, and free them to focus on higher-value work that supports their security strategy. Ultimately, we believe it will give defenders a crucial advantage.
A modern platform for modern threats
Google Security Operations is designed to meet the challenges of the modern threat landscape head-on. We combine Google Threat Intelligence with the power of our SIEM, SOAR, and best-in-class AI to give you a comprehensive security platform. This gives customers the power to see more, automate, and act decisively with confidence.
“With Google Security Operations, we’re logging approximately 22 times the amount of data, we’re seeing three times the events, and we’re closing investigations in half the time,” said Mike Orosz, CISO, Vertiv.
Learn more
Forrester’s recognition reinforces, for us, our dedication to empowering security teams with the tools to minimize operational burdens, streamline their work, and deliver superior security results.
To learn more about how you can modernize with Google Security Operations, and to read the full The Forrester Wave™: Security Analytics Platforms, Q2 2025 report, we invite you to access your complimentary copy here.
Forrester does not endorse any company, product, brand, or service included in its research publications and does not advise any person to select the products or services of any company or brand based on the ratings included in such publications. Information is based on the best available resources. Opinions reflect judgment at the time and are subject to change. For more information, read about Forrester’s objectivity here .
Traditional data warehouses simply can’t keep up with today’s analytics workloads. That’s because today, most data that’s generated is both unstructured and multimodal (documents, audio files, images, and videos). With the complexity of cleaning and transforming unstructured data, organizations have historically had to maintain siloed data pipelines for unstructured and structured data, and for analytics and AI/ML use cases. Between these fragmented data platforms, data access restrictions, slow consumption, and outdated information, enterprises struggle to unlock the full potential of their data. The same issues hinder AI initiatives.
Today we’re introducing a new data type, ObjectRef, now in preview in BigQuery, that represents a reference to any object in Cloud Storage with a URI and additional metadata. ObjectRef complements Object Tables, read-only tables over unstructured data objects in Cloud Storage, to integrate unstructured data like images and audio into existing BigQuery tables. The ObjectRef data type removes fragmentation in data processing and access control, providing a unified, multimodal, and governed way to process all modalities of data. You can process unstructured data with large language models (LLMs), ML models, and open-source Python libraries using the same SQL or Python scripts that process tabular data. You can also store structured and unstructured data in the same row throughout different data engineering stages (extract, load, transform a.k.a. ELT), and govern it using a similar access control model.
aside_block
<ListValue: [StructValue([(‘title’, ‘$300 in free credit to try Google Cloud data analytics’), (‘body’, <wagtail.rich_text.RichText object at 0x3ed4497f7310>), (‘btn_text’, ‘Start building for free’), (‘href’, ‘http://console.cloud.google.com/freetrial?redirectPath=/bigquery/’), (‘image’, None)])]>
For example, to answer the question “of the customers who complained about performance issues during interactions last month, show me the top 10 by revenue” you need to perform natural language processing (NLP) on audio calls, emails and online chat transcripts to normalize the data, identify whether the interaction discussed “performance issues” and detect whether the customer complained. For each of these steps, you need to decide how to build a pipeline over data in Cloud Storage, run AI/ML models on the data, and host the models (e.g., on Compute Engine, Google Kubernetes Engine, or Vertex AI). The normalized and extracted data would then need to be saved in structured format (e.g., in a BigQuery table) and joined with each customer’s revenue data.
With the launch of ObjectRef, you can now answer this question with a simple SQL query. Suppose you’ve combined call center audio files and agent chat text into one BigQuery table customer_interactions using columns (1) audio_ref of type ObjectRef, (2) chat of type STRING. Filtering for customers who complained about performance issues is as easy as adding one more condition in the WHERE clause:
BigQuery with ObjectRef unlocks unique platform capabilities across data and AI:
Multimodality: Natively handle structured (tabular) data, unstructured data, and a combination of the two, in a single table via ObjectRef. Now, you can build multimodal ELT data pipelines to process both structured and unstructured data.
Full SQL and Python support: Use your favorite language without worrying about interoperability. If it works in SQL, it works in Python (via BigQuery DataFrames), and vice versa. Object transformations, saving transformed objects back to Cloud Storage, and any other aggregations or filtering, can all be done in one SQL or Python script.
Gen-AI-ready, serverless, and auto-scaled data processing: Spend more time building your data pipelines, not managing infrastructure. Process unstructured data with LLMs, or use serverless Python UDFs with your favorite open-source library. Create embeddings, generate summaries using a prompt, use a BigQuery table as an input to Vertex AI jobs, and much more.
Unified governance and access control: Use familiar BigQuery governance features such as fine-grained access control, data masking, and connection-delegated access on unstructured data. There is no need to manage siloed governance models for structured versus unstructured data.
ObjectRef in action
Let’s take a closer look at how to use the ObjectRef data type.
What is an ObjectRef?
First, it’s good to understand ObjectRef under the hood. Simply put, ObjectRef is a STRUCT containing object storage and access control metadata. With this launch, when you create an Object Table, it is populated with a new ObjectRef column named ‘ref’.
code_block
<ListValue: [StructValue([(‘code’, ‘struct {rn uri string,rn authorizer string,rn version string, rn details json { rntgcs_metadata jsonrn }rn }’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3ed43e6869d0>)])]>
Create a BigQuery table with ObjectRefs
Imagine a call center that stores structured information in standard BigQuery tables ingestion.sessions, and call audio in a Cloud Storage bucket, with a BigQuery Object Table ingestion.audios created on the Cloud Storage bucket. While this example is based on audio, ObjectRefs can also represent images, documents, and videos.
In the following diagrams, ObjectRefs are highlighted in red.
With ObjectRef, you can join these two tables on sessions.RecordingID and audios.Ref.uri columns to create a single BigQuery table. The new table contains an Audio column of type ObjectRef, using the Ref column from the ingestion.audios table.
code_block
<ListValue: [StructValue([(‘code’, ‘CREATE OR REPLACE TABLE analysis.sessionsrnASrnSELECT sessions.session_id, sessions.date, sessions.customer_id, object_table.ref AS audiornFROM ingestion.sessions INNER JOIN ingestion.audios object_tablernON object_table.uri = sessions.recording_id;’), (‘language’, ‘lang-sql’), (‘caption’, <wagtail.rich_text.RichText object at 0x3ed44a3cf760>)])]>
Capturing the object version allows BigQuery zero-copy snapshots and clones of analysis.sessions to be reproducible and consistent across structured and unstructured data. This allows reproducibility in downstream applications such as ML training and LLM fine-tuning.
Being a STRUCT, ObjectRef also supports nesting in ARRAY. The main audio file represented by Audio can be chunked (for example, into segments per agent ID), and the resulting objects represented in a new column Chunked of type ARRAY<ObjectRef>. This preserves the order of chunks, and stores them alongside the main audio file in the same row. This data transformation lets you report the number of agent handoffs per call and further analyze each call segment separately.
Process using serverless Python
With Python UDF integration, you can bring your favorite open-source Python library to BigQuery as a user-defined function (UDF). Easily derive structured data, and unstructured data from the source ObjectRef and store them in the same row.
The new function OBJ.GET_ACCESS_URL(ref ObjectRef, mode STRING) -> ObjectRefRuntime enables delegated access to the object in Cloud Storage. ObjectRefRuntime provides signed URLs to read and write data, allowing you to manage governance and access control entirely in BigQuery, and removing the need for Cloud Storage access control.
Serverless Python use case 1: Multimodal data to structured data For example, imagine you want to get the duration of every audio file in the analysis.sessions table. Assume that a Python UDF function analysis.GET_DURATION(object_ref_runtime_json STRING) -> INT has already been registered in BigQuery. GET_DURATION uses signed URLs from ObjectRefRuntime to read Cloud Storage bytes.
code_block
<ListValue: [StructValue([(‘code’, ‘– Object is passed to Python UDF using read-only signed URLsrnSELECT analysis.GET_DURATION(TO_JSON_STRING(OBJ.GET_ACCESS_URL(audio, “R”))) AS durationrnFROM analysis.sessionsrnWHERE audio IS NOT NULL’), (‘language’, ‘lang-sql’), (‘caption’, <wagtail.rich_text.RichText object at 0x3ed44a3cf250>)])]>
code_block
<ListValue: [StructValue([(‘code’, ‘import bigframes.pandas as bpdrndf = bpd.read_gbq(“analysis.sessions”)rnfunc = bpd.read_gbq_function(“analysis.get_duration”)rn# Object is passed to Python UDF using read-only signed URLsrndf[“duration”] = df[“audio”].blob.get_runtime_json_str(mode=”R”).apply(func).cache() # cache to execute’), (‘language’, ‘lang-py’), (‘caption’, <wagtail.rich_text.RichText object at 0x3ed44a3cf2e0>)])]>
Serverless Python use case 2: Multimodal data to processed multimodal data As another example, here’s how to remove noise from every audio file in the analysis.sessions table, assuming that a Python UDF function analysis.DENOISE(src_object_ref_runtime_json STRING, dst_object_ref_runtime_json STRING)-> object_ref_runtime_json STRING has already been registered in BigQuery. This function reads from the source audio, writes the new noise-removed audio to Cloud Storage, and returns ObjectRefs for the new audio files.
ObjectRefRuntime provides signed URLs for reading and writing object bytes.
code_block
<ListValue: [StructValue([(‘code’, ‘SELECT analysis.DENOISE(rn — Source is accessed using read-only signed URLrn TO_JSON_STRING(OBJ.GET_ACCESS_URL(audio, “R”)), rn — Destination is written using read-write signed URL with prefix “denoised-“rn TO_JSON_STRING(OBJ.GET_ACCESS_URL(rn OBJ.MAKE_REF(rn CONCAT(“denoised-“, audio.uri), audio.authorizer),rn “RW”))rnFROM analysis.sessionsrnWHERE audio IS NOT NULL’), (‘language’, ‘lang-sql’), (‘caption’, <wagtail.rich_text.RichText object at 0x3ed44a3cfa60>)])]>
code_block
<ListValue: [StructValue([(‘code’, ‘import bigframes.pandas as bpdrndf = bpd.read_gbq(“analysis.sessions”)rnrndf[“denoised”] = (“denoised-” + df[“audio”].blob.uri()).str.to_blob()rnfunc_df = df[[“audio”, “denoised”]]rnrnfunc = bpd.read_gbq_function(“analysis.denoise”)rn# Source is accessed using read-only signed URLrnfunc_df[“audio”] = func_df[“audio”].blob.get_runtime_json_str(“R”)rn# Destination is written using read-write signed URL with prefix “denoised-“rnfunc_df[“denoised”] = func_df[“denoised”].blob.get_runtime_json_str(“RW”)rnfunc_df.apply(func, axis=1).cache() # cache to execute’), (‘language’, ‘lang-py’), (‘caption’, <wagtail.rich_text.RichText object at 0x3ed44a3cfdf0>)])]>
Process using Gemini and BigQuery ML
All BigQuery ML generative AI functions such as AI.GENERATE, ML.GENERATE_TEXT and ML.GENERATE_EMBEDDING now support ObjectRefs as first-class citizens. This enables a number of use cases.
BQML use case 1: Multimodal inference using Gemini You can now pass multiple ObjectRefs in the same Gemini prompt for inference.
Here, you can use Gemini to evaluate noise removal quality by comparing the original audio file and the noise-removed audio file. This script assumes the noise-reduced audio file ObjectRef is already stored in column Denoised.
code_block
<ListValue: [StructValue([(‘code’, ‘SELECT AI.GENERATE(rn prompt => (“Compare original audio file to audio file with noise removed, and output quality of noise removal as either good or bad. Original audio is”, OBJ.GET_ACCESS_URL(audio, “r”), “and noise removed audio is”, OBJ.GET_ACCESS_URL(denoised, “r”)),rn — BQ connection with permission to call Geminirn connection_id => “analysis.US.gemini-connection”,rn endpoint => “gemini-2.0-flash”rn).resultrnFROM analysis.sessions WHERE audio IS NOT NULL AND denoised IS NOT NULL;’), (‘language’, ‘lang-sql’), (‘caption’, <wagtail.rich_text.RichText object at 0x3ed44a3cf580>)])]>
code_block
<ListValue: [StructValue([(‘code’, ‘import bigframes.pandas as bpdrnfrom bigframes.ml import llmrnrngemini = llm.GeminiTextGenerator(model_name=”gemini-2.0-flash”, connection_name=”analysis.US.gemini-connection”)rndf = bpd.read_gbq(“analysis.sessions”)rnresult = gemini.predict(df, prompt=[“Compare original audio file to audio file with noise removed, and output quality of noise removal as either good or bad. Original audio is”, df[“audio”], “and denoised audio is”, df[“denoised”]])rnresult[[“ml_generate_text_llm_result”]]’), (‘language’, ‘lang-py’), (‘caption’, <wagtail.rich_text.RichText object at 0x3ed44a3cfc70>)])]>
As another example, here’s how to transcribe the Audio file using Gemini.
code_block
<ListValue: [StructValue([(‘code’, ‘SELECT AI.GENERATE(rn prompt => (“Transcribe this audio file”, OBJ.GET_ACCESS_URL(audio, “r”)),rn — BQ connection with permission to call Geminirn connection_id => “analysis.US.gemini-connection”,rn endpoint => “gemini-2.0-flash”).result as transcriptrnFROM analysis.sessionsrnWHERE audio IS NOT NULL’), (‘language’, ‘lang-sql’), (‘caption’, <wagtail.rich_text.RichText object at 0x3ed44a3cfeb0>)])]>
code_block
<ListValue: [StructValue([(‘code’, ‘import bigframes.pandas as bpdrnfrom bigframes.ml import llmrnrngemini = llm.GeminiTextGenerator(model_name=”gemini-2.0-flash”, connection_name=”analysis.US.gemini-connection”)rndf = bpd.read_gbq(“analysis.sessions”)rnresult = gemini.predict(df, prompt=[“Transcribe this audio file”, df[“audio”]])rnresult[[“ml_generate_text_llm_result”]]’), (‘language’, ‘lang-py’), (‘caption’, <wagtail.rich_text.RichText object at 0x3ed44a3cff70>)])]>
With BQML + Gemini, you can also generate structured or semi-structured results from multimodal inference. For example, you can do speaker diarization in the Audio file using Gemini to identify the operator vs. the customer.
code_block
<ListValue: [StructValue([(‘code’, ‘SELECT AI.GENERATE(rnprompt => (“Generate audio diarization for this interview. Use JSON format for the output, with the following keys: speaker, transcription. If you can classify the speaker as customer vs operator, please do. If not, use speaker A, speaker B, etc.”, OBJ.GET_ACCESS_URL(audio, “r”)),rn — BQ connection with permission to call Geminirnconnection_id => “analysis.US.gemini_connection”,rnendpoint => “gemini-2.0-flash”).result as diarized_jsonrnFROM analysis.sessionsrnWHERE audio IS NOT NULL;’), (‘language’, ‘lang-sql’), (‘caption’, <wagtail.rich_text.RichText object at 0x3ed4492c9d90>)])]>
code_block
<ListValue: [StructValue([(‘code’, ‘import bigframes.pandas as bpdrnfrom bigframes.ml import llmrnrngemini = llm.GeminiTextGenerator(model_name=”gemini-2.0-flash”, connection_name=”analysis.US.gemini-connection”)rndf = bpd.read_gbq(“analysis.sessions”)rnresult = gemini.predict(df, prompt=[“Generate audio diarization for this interview. Use JSON format for the output, with the following keys: speaker, transcription. If you can classify the speaker as customer vs operator, please do. If not, use speaker A, speaker B, etc.”, df[“audio”]])rnresult[[“ml_generate_text_llm_result”]]’), (‘language’, ‘lang-py’), (‘caption’, <wagtail.rich_text.RichText object at 0x3ed4492c9280>)])]>
BQML use case 2: Multimodal embeddings using Gemini
With ML.GENERATE_EMBEDDING support, you can use ObjectRefs with text embedding and multimodal embedding models to create vector indices, and power RAG workflows to ground LLMs.
Assume we have an Object Table ingestion.images with the ref column containing image ObjectRefs.
code_block
<ListValue: [StructValue([(‘code’, “CREATE OR REPLACE MODEL `ingestion.multimodal_embedding_model`rnREMOTE WITH CONNECTION ‘ingestion.US.gemini-connection’rnOPTIONS (ENDPOINT = ‘multimodalembedding@001’);rnrnSELECT ref, ml_generate_embedding_result as embeddingrnFROM ML.GENERATE_EMBEDDING(rn MODEL `ingestion.multimodal_embedding_model`,rn (rn SELECT OBJ.GET_ACCESS_URL(ref, ‘r’) as content, refrn FROM ingestion.imagesrn ),rn STRUCT (256 AS output_dimensionality)rn);”), (‘language’, ‘lang-sql’), (‘caption’, <wagtail.rich_text.RichText object at 0x3ed4492c9cd0>)])]>
To summarize, here’s a list of all the new capabilities for performing analytics on unstructured and/or multimodal data using BigQuery:
New types and functions for handling multimodal data (documents, audio files, images, and videos):
ObjectRef and ObjectRefRuntime types along with new functions: OBJ.MAKE_REF, OBJ.GET_ACCESS_URL and OBJ.FETCH_METADATA
Object Table enhancements:
Scalability: Object Tables now support consistent views of Cloud Storage buckets, scaling 5x from 65M to 300M+ objects per table, and ingesting up to 1M object changes per hour per table
Interop with ObjectRef: New ref column provides pre-constructed ObjectRefs directly from Object Tables
BQML Gen-AI multimodal capabilities:
Support multimodal inference in TVFs ML.GENERATE_TEXT and AI.GENERATE_TABLE, and scalar functions such as AI.GENERATE, and AI.GENERATE_BOOL, by encapsulating multiple objects in the same prompt for Gemini using ObjectRef. Objects can be sourced from different columns, and complex types such as arrays.
Support embedding ObjectRef via the ML.GENERATE_EMBEDDING function
An extension to pandas-like dataframe to include unstructured data (powered by ObjectRef) as just another column
Wrangle, process and filter mixed modality data with the familiarity of dataframe operations
Special transformers for unstructured data like chunking, image processing, transcription made available through server side processing functions and BQML
Leverage the rich Python library ecosystem for advanced unstructured data manipulation in a fully managed, serverless experience with BigQuery governance
Get started today
ObjectRef is now in preview. Follow these simple steps to get started:
Learn by doing – try out ObjectRefs with this multimodal data tutorial using either SQL or Python tutorials.
Build your use case – locate the Cloud Storage bucket containing the unstructured data you want to analyze. Create an Object Table or set up automatic Cloud Storage discovery to pull this data into BigQuery. The Object Table will contain a column of ObjectRefs and now you are ready to start transforming the data.
In today’s dynamic cloud market, true growth comes from strategic clarity. For Google Cloud partners, unlocking immense market potential and building a thriving services practice hinges on a definitive roadmap. That’s why we partnered with global technology analyst firm Canalys to independently study the Partner Ecosystem Multiplier (PEM) – a measure of the incremental revenue you can capture when working with Google Cloud.
The study confirms a key finding: For every US$1 a customer invests in Google Cloud, partners delivering comprehensive services across the customer lifecycle stand to capture up to $7.05 in incremental revenue through their own offerings. This top-tier potential is strongly linked to expanding your services across the entire customer lifecycle – a journey many Google Cloud partners are already on, influencing nearly 80% of Google Cloud’s YoY incremental revenue growth in 2024.
Beyond the number: the strategic path leading up to $7.05
The real takeaway goes beyond the number; it’s about how you can strategically navigate this journey and build towards comprehensive service delivery. Canalys’ research visualizes this through a “partner ecosystem flywheel,” which maps typical partner activities across a three-year customer journey. This powerful framework (illustrated below) outlines how leading partners strategically engage customers across six distinct stages: Advise, Design, Procure, Build, Adopt, and Manage.
To achieve this top-tier potential, Canalys highlights the importance of being in a mature cloud region and developing capabilities across the entire customer lifecycle. If you’re already familiar with multipliers, what sets this apart is how partners can leverage Google Cloud’s strengths in analytics, data, and Generative AI to unlock significant revenue over a three-year project cycle, especially by driving GenAI solutions to production.
aside_block
<ListValue: [StructValue([(‘title’, ‘Try Google Cloud for free’), (‘body’, <wagtail.rich_text.RichText object at 0x3ed43e686e50>), (‘btn_text’, ‘Get started for free’), (‘href’, ‘https://console.cloud.google.com/freetrial?redirectPath=/welcome’), (‘image’, None)])]>
How partners create value with the ecosystem flywheel
This flywheel is a roadmap for your growth. The study found that partners who haven’t yet achieved the full multiplier potential might currently focus on specific stages by choice, or haven’t yet fully developed maturity across all these service areas. Achieving maximum potential means expanding your practice within each of these flywheel segments
Figure 1: Google Cloud Partner Ecosystem Multiplier by Service Category (Source: Canalys, Google Cloud Partner Ecosystem Multiplier Study, January 2025)
Advise: influence the customer journey (11% of Multiplier): Vital for influencing long-term customer engagement and shaping their cloud destiny, laying groundwork for subsequent opportunities.
Design: build a strong technical foundation (25% of Multiplier):While Design represents nearly a quarter of the total multiplier, successful partners use this stage strategically to set the foundation for higher-value opportunities. By architecting solutions that fully leverage Google Cloud’s AI and data capabilities from the start, partners create pathways for expanded returns and long-term revenue growth from the Build, Adopt, and Manage phases of the cycle.
Procure: optimize commercial foundations (5% of Multiplier): The smallest category of the multiplier, this focuses on re-sell and commercial management, laying essential commercial groundwork.
Build: unlock AI’s transformative power (24% of Multiplier): Google Cloud’s most compelling growth engine. Overwhelmingly driven by Generative AI, this segment is where partners create customized AI solutions and integrations, moving projects from proof of concept to production. Beyond Gen AI, cybersecurity, application modernization, and infrastructure support are also major revenue drivers.
Adopt: drive expansion and prove ROI (17% of Multiplier): Ensures customers effectively use Google Cloud and realize its value, identifying cross-sell and upsell opportunities and fueling overall PEM. Partners that focus here are best positioned for identifying cross-sell and upsell opportunities, driving increased Google Cloud consumption, and setting the stage for subsequent “Build” opportunities within the same customer.
Manage: Secure Recurring Revenue (18% of Multiplier): Provides ongoing operational support through managed services, offering a clear pathway to recurring revenue and ensuring continuous customer value.
For a detailed breakdown of each flywheel segment’s contribution, including specific dollar values, we encourage you to explore the accompanying Canalys factsheet.
Your long-term edge: The Google Cloud multiplier
The revenue opportunity unfolds strategically across three years. The first year, largely advisory and migration services, hold 51.6% of the multiplier opportunity, but the most significant growth for Google Cloud partners unfolds afterward. Transformative opportunities, particularly transitioning Generative AI proofs of concept to production, typically emerge from year three.
Google Cloud’s ongoing innovation in AI and data powers these later-year opportunities. By building your practice to leverage these advancements and guiding customers to deeper, innovative usage, you achieve sustained growth and a thriving services practice. This approach creates an enduring, valuable services practice, powered by Google Cloud, that supports customers throughout their entire journey.
We’re committed to supporting partner success. Connect with your Partner Development Manager and utilize Partner Network Hub resources to strategize your services growth. Let’s grow and innovate, together.
As organizations build new generative AI applications and AI agents to automate business workflows, security and risk management management leaders face a new set of governance challenges. The complex, often opaque nature of AI models and agents, coupled with their reliance on vast datasets and potential for autonomous action, creates an urgent need to apply better governance, risk, and compliance (GRC) controls.
Today’s standard compliance practices struggle to keep pace with AI, and leave critical questions unanswered. These include:
How do we prove our AI systems operate in line with internal policies and evolving regulations?
How can we verify that data access controls are consistently enforced across the entire AI lifecycle, from training to inference to large scale production?
What is the mechanism for demonstrating the integrity of our models and the sensitive data they handle?
We need more than manual checks to answer these questions, which is why Google Cloud has developed an automated approach that is scalable and evidence-based: the Recommended AI Controls framework, available now as a standalone service and as part of Security Command Center.
<ListValue: [StructValue([(‘title’, ‘$300 in free credit to try Google Cloud security products’), (‘body’, <wagtail.rich_text.RichText object at 0x3ed43e2c24c0>), (‘btn_text’, ‘Start building for free’), (‘href’, ‘http://console.cloud.google.com/freetrial?redirectPath=/welcome’), (‘image’, None)])]>
Google Cloud’s AI Protection provides full lifecycle safety and security capabilities for AI workloads from development and training to runtime and large scale production. In addition, it is paramount to not only secure AI workloads, but to also audit whether they adhere to compliance, and ensure we are able to define controls for AI assets and monitor drift. Google Cloud has taken a more holistic approach to define best practices for platform components.
Below is an example of AI workload:
Foundation components of AI workloads.
How the Recommended AI Controls Framework can help audit AI workloads
Audit Manager helps you identify compliance issues earlier in your AI compliance and audit process, integrating it directly into your operational workflows. Here’s how you can move from manual checklists to automated assurance for your generative AI workloads:
Establish your security controls baseline. Audit Manager provides a baseline to audit your generative AI workloads. These baselines are based on industry best practices and frameworks to help give you a clear, traceable directive for your audit.
Understand control responsibilities. Aligned with Google’s shared fate approach, the framework can help you understand the responsibility for each control — what you manage versus what the cloud platform provides — so you can focus your efforts effectively.
Run the audit with automated evidence collection. Evaluate your generative AI workloads against industry-standard technical controls in a simple, automated manner. Audit Manager can reduce manual audit preparation by automatically collecting evidence relative to the defined controls for your Vertex AI usage and supporting services.
Assess findings and remediate. The audit report will highlight control violations and deviations from recommended best practices. This can help your teams perform timely remediation before minor issues escalate into significant risks.
Create and share reports. Generate and share comprehensive, evidence-backed reports with a single click, which can support continuous compliance monitoring efforts with internal stakeholders and external auditors.
Enable continuous monitoring. Move beyond point-in-time snapshots. Establish a consistent methodology for ongoing compliance by scheduling regular assessments. This allows you to continuously monitor AI model usage, permissions, and configurations against best practices, and can help maintain a strong GRC posture over time.
Inside the Recommended AI Controls framework
The framework provides controls specifically designed for generative AI workloads, mapped across critical security domains. Crucially, these high-level principles are backed by auditable, technical checks linked directly to data sources from Vertex AI and its supporting Google Cloud services.
Here are a few examples of the controls included:
Access control:
Disable automatic IAM grants for default service accounts: This control restricts default service accounts with excessive permissions.
Disable root access on new Vertex AI Workbench user-managed notebooks and instances: This boolean constraint, when enforced, prevents newly created Vertex AI Workbench user-managed notebooks and instances from enabling root access. By default root access is enabled.
Data controls:
Customer Managed Encryption Keys (CMEK): Google Cloud offers organization policy constraints to help ensure CMEKusage across an organization. Using Cloud KMS CMEK gives you ownership and control of the keys that protect your data at rest in Google Cloud.
Configure data access control lists: You can customize these lists based on a user’s need to know. Apply data access control lists, also known as access permissions, to local and remote file systems, databases, and applications.
System and information integrity:
Vulnerability scanning: Our Artifact Analysis service scans for vulnerabilities in images and packages in Artifact Registry.
Audit and accountability:
Audit and accountability policy and procedures requirements: Google Cloud services write audit log entries to track who did what, where, and when with Google Cloud resources.
Configuration management:
Restrict resource service usage: This constraint ensures only customer-approved Google Cloud services are used in the right places. For example, production and highly sensitive folders have a list of Google Cloud services approved to store data. The sandbox folder may have a more permissive list of services, with accompanying data security controls to prevent data exfiltration in the event of a breach.
How to automate your AI audit in three steps
Security and compliance teams can immediately use this framework to move from manual checklists to automated, continuous assurance.
Select the framework: In the Google Cloud console, navigate to Audit Manager and select Google Recommended AI Controls framework from the library.
Define the scope: Specify the Google Cloud projects, folders, or organization where your generative AI workloads are deployed. Audit Manager automatically understands the relevant resources within that scope.
Run the assessment: Initiate an audit. Audit Manager collects evidence from the relevant services (including Vertex AI, IAM, and Cloud Storage) against the controls. The result is a detailed report showing your compliance status for each control, complete with direct links to the collected evidence.
Automate your AI assurance today
You can access the Audit Manager directly from your Google Cloud console. Navigate to the Compliance tab in your Google Cloud console, and select Audit Manager. For a comprehensive guide on using Audit Manager, please refer to our detailed product documentation.
We encourage you to share your feedback on this service to help us improve Audit Manager’s user experience.
Financial analysts spend hours grappling with ever-increasing volumes of market and company data to extract key signals, combine diverse data sources, and produce company research. Schroders is a leading global active investment manager. Being an active manager means understanding investment opportunities — combining rigorous research, innovative thinking and deep market perspective — to help build resilience and capture returns for clients.
To maximise its edge as an active manager, Schroders wants to enable its analysts to shift from data collection to the higher-value strategic thinking that is critical for business scalability and client investment performance.
To achieve this, Schroders and Google Cloud collaborated to build a multi-agent research assistant prototype using Vertex AI Agent Builder.
aside_block
<ListValue: [StructValue([(‘title’, ‘Try Google Cloud for free’), (‘body’, <wagtail.rich_text.RichText object at 0x3ed4484d11c0>), (‘btn_text’, ‘Get started for free’), (‘href’, ‘https://console.cloud.google.com/freetrial?redirectPath=/welcome’), (‘image’, None)])]>
Why multi-agent systems?
At Schroders, analysts are typically responsible for conducting in-depth research on 20 to 30 companies, with another 20 under close watch. An initial report on a new company can take days to complete, most of which are primarily spent gathering quality data. Reducing this research down to minutes would allow analysts to screen more companies, directly increasing their potential to discover promising investment opportunities for their clients. An AI assistant offers a significant productivity boost in driving early-stage company research.
An AI agent is a software system that can perceive its environment, take actions, and employ tools to achieve specific goals. It shows reasoning, planning, and memory, and has a level of autonomy to make decisions, learn, and adapt. Tools are crucial functions or external resources that an agent can utilize to interact with its environment and enhance its capabilities, enabling them to take actions on a user’s behalf.
Standalone generative AI models often struggle with complex, multi-step financial research workflows, which require ordered data retrieval and reasoning (i.e., fetching fundamentals, filings, and news, and then synthesizing analysis). Given the complexity of its use case, Schroders opted to build a multi-agent system due to the following characteristics:
Specialization: Designing agents which are hyper-focused on specific tasks (e.g., R&D Agent, Working Capital Agent, etc.) with only the necessary tools and knowledge for their respective domains.
Modularity and scalability: Each agent is a distinct component developed, tested, and updated independently thereby simplifying development and debugging.
Complex workflow orchestration: Multi-agent systems model their workflows as graphs of interacting agents. For example, a Porter’s 5 Forces Agent designed to identify and analyze industry competition, could trigger child agents like a Threat of New Entrants Agent, in parallel or sequence, to better manage dependencies between deterministic (e.g., calculations) and non-deterministic (e.g., summarization) tasks.
Simplified tool integration: Specialized agents can handle specific toolsets (i.e., an R&D Agent using SQL database query tools) rather than having a single agent manage numerous APIs.
Leveraging Vertex AI Agent Builder
Schroders selected Vertex AI Agent Builder as the core platform for developing and deploying its multi-agent system. This choice provided several key benefits that helped accelerate development, including access to state-of-the-art Google foundation models like Gemini and pre-built connectors for various tools and data sources.
For example, Vertex AI Agent Builder provided easy tool integration for leveraging:
Internal knowledge: Grounding with Vertex AI Search tool was leveraged to ground Gemini to private document corpus, such as internal research notes, using, enabling agents to answer questions based on Schroder’s proprietary data.
Example tool call:search_internal_docs(query="analyst notes for $COMPANY", company_id="XYZ").
Structured data: To simplify financial data querying for analysts in BigQuery, agents employed a custom tool to translate natural language into SQL queries.
Example flow: User: “What were $COMPANY’s revenues for the last 3 quarters?” -> Agent -> SQL Query on BigQuery.
Public web data: The team integrated Grounding with Google Search tool for handling real-time public information like news and market sentiment.
Example tool call:google_search(query="latest news $COMPANY stock sentiment").
Vertex AI’s flexible orchestration supports both native function calling and frameworks like LangGraph, CrewAI, and LangChain, allowing the team to prototype its multi-agent system with function calling before transitioning to a specific framework. In addition, Vertex AI offers seamless integration with other Google Cloud services and tools that help facilitate rapid agent governance and management, including Cloud Logging, Cloud Monitoring, IAM Access Control, Vertex AI evaluation, BigQuery and more.
The evolution of the Vertex AI to support building multi-agent systems, including the latest Agent Development Kit (ADK) and Agent-to-Agent (A2A) protocol, offers future opportunities to further streamline agent development, productization, and integration with existing agent deployments.
Framework choices and implementation tradeoffs
One of the most critical decisions was framework selection for agent orchestration. Initially, native function calling helped Schroders get familiar with Vertex AI Agent Builder and develop agent-building best practices. This approach kept things simple to start with and allowed finer-grained control and reliability over agent interactions and tool invocation, providing easier debugging and faster iterative development for simple, linear agent design and workflows. However, it also required significant custom code to manage state and errors, track dependencies, and handle retry and control logic — all of which created significant complexity.
With a solid foundation in individual agents, Schroders decided to explore integrating multiple agents for achieving complex tasks and quickly recognized the need for a framework for better workflow state and inter-agent dependency management. Subsequently, the team transitioned to LangGraph, an open-source, multi-agent framework, primarily for its state management capabilities, native support for cyclical complex workflows and human in the loop checkpoints, which allow an agent to complete a task, update the state, and pass it to the configured sub agent. The adopted parent-child graph structure requires managing both parent and child agent states; child agents complete tasks with the parent graph leading the orchestration. This structured hierarchy often ends with a “summary” node aggregating child results. Each child stores its tool calls and AI messages before writing its final output to the parent.
Key features and system architecture deep dive
Schroder’s multi-agent system is designed for intuitive, flexible end-user interaction. An analyst creates an agent by providing a name, a description, prompt template sections (e.g., objective, instructions, constraints), and selecting tools. For example, an agent that receives the user query, “Summarize recent earnings and news sentiment for Company X, highlighting any changes in management guidance,” would need access to company documents and market news tools. Agent configurations are versioned in Firestore, ensuring robust management for Create, Read, Update, and Delete (CRUD) operations.
A “quick chat” function allows users to smoke-test agents and tweak prompts. Tested agents join a pool of available agents, which users can then combine agents into “workflows” — directed graphs for multi-step processes. For instance, a Porter’s 5 Forces analysis agent will use pre-built agents and tools like Vertex AI AutoSxS Model Evaluation alongside child agents that integrate current information or internal document insights.
The following diagram illustrates the Google Cloud architecture for orchestring agents:
Here is an example query flow:
Router agent: Receives the user query, uses Gemini to classify intent and identify the target specialized agent or workflow (e.g., “Analyze Company XYZ” routes to the Porter’s 5 Forces Agent).
Task delegation: The router requests parameters and routes to the appropriate agent and workflow.
Agent execution and tools: Specialized agents execute tasks, interacting with configured tools, such as APIs and databases via secure gateways.
Response: Combined results from workflows or individual agent responses are returned.
Follow-ups: Conversation history is stored in Firestore, maintaining full context.
Here is an example workflow for a user wanting to analyse a company:
This distributed approach ensures each component focuses on its strength, providing vital flexibility that encourages user adoption.
Personalization and user adaptation
Personalization was key as a core goal of Schroder’s use case was supporting analysts’ unique workflows, not forcing rigid processes. To achieve this, the system uses customizable system instructions — underlying prompts that can be tuned by analysts and developers. A templating system gives developers control of generalized prompt parts and analysts over the business logic, helping to foster cross-functional collaboration. In addition, the system allows for personalized agent configuration. Analysts can prioritize or toggle on different tools and data sources depending on the research context. These tools are developer-built, restricting direct access to any underlying files like PDF documents. The team also decided to expose model parameters like temperature, allowing users to make small adjustments and modifications during development.
Measuring success: Agent evaluation and iteration
An agentic system is only valuable if it’s accurate, reliable, and truly helpful. These attributes are also important in generating quality investment research, which is vital for client trust and Schroders’ active capability. To address this, Schroders implemented a multi-faceted evaluation strategy, using Vertex AI Generative AI Evaluation. This approach includes:
Human-in-the-loop (HITL): Analysts review outputs for accuracy, relevance, completeness, and conciseness.
A ground truth dataset: This dataset is built based on structured analyst feedback, including corrections and data source indications.
Iterative refinement: Data is fed back into development to refine prompts, tool descriptions, orchestration logic, and identify needs for new agents, rapidly improving performance and trust.
Building a new financial future
Working together, Schroders and Google Cloud developed a successful prototype with Vertex AI Agent Builder, demonstrating that multi-agent systems are capable of tackling complex financial workflows. By combining specialized agents, good architecture and robust evaluation, the collaboration proved the feasibility of developing an equity research AI research assistant that can enhance analyst productivity significantly — reducing the time required to complete a detailed company analysis from days to minutes.
Along the way, the team also discovered several key learnings for building effective agents:
Meticulously decompose tasks. Thoroughly map analyst workflows, breaking them into the smallest logical, atomic units for clear multi-agent roles. Single-task agents are more effective at accomplishing their defined objective.
Prompt engineering is key. Generative AI foundation models rely heavily on tool descriptions, and ambiguity can impact reliability. Effective prompts, especially precise tool descriptions, are critical.
Tool reliability is non-negotiable. Agents are limited by their tools. Instability and bugs in tools can degrade performance and lead to incorrect outputs, which can then impact investment decision making. Implement robust error handling (retries, circuit breakers) and ensure good tool debugging.
Limit tool scope per agent. Agents perform better with fewer (e.g. less than five) highly relevant tools to avoid misuse.
Managing state is complex. Orchestrating multiple agents demands careful management of history and careful tracking of intermediate results. Frameworks like LangGraph or ADK can help significantly.
Leverage Agent-of-Agents. Power comes from collaboration, not overly complex individual agents. For complex tasks, it’s better to build single-responsibility, reusable atomic agents that can work together, carefully orchestrating their interactions.
User trust is earned. Always be transparent and consistent. High-quality, user feedback is essential for driving results that gain user trust and engagement.
In order to scale the prototype in the future, Schroders plans to explore more agents with sophisticated reasoning, support for new multimodal data types like images and charts, enhanced discoverability (Agent-to-Agent protocols), and more autonomy for routine tasks.
Box is one of the original information sharing and collaboration platforms of the digital era. They’ve helped define how we work, and have continued to evolve those practices alongside successive waves of new technology. One of the most exciting advances of the generative AI era is that now, with all the data that Box users have stored, they can get considerably more value out of those files by using AI to search and synthesize their information in new ways.
That’s why Box created Box AI Agents, to intelligently discern and structure complex unstructured data. Today, we’re excited to announce the availability of the Box AI Enhanced Extract Agent. The Enhanced Extract Agent runs on Google’s most advanced Gemini 2.5 models, and they also feature Google’s Agent2Agent protocol, which allows secure connection and collaboration between AI agents across dozens of platforms in the A2A network.
The Box AI Enhanced Extract Agent gives enterprises users confidence in their AI, helping overcome any hesitations they might feel about gen AI technology and using it for business-critical tasks.
In this post, we’ll take a closer look at how our teams created the Box AI Enhanced Extract Agent and what others building new agentic AI systems might consider when developing their own solutions.
aside_block
<ListValue: [StructValue([(‘title’, ‘Try Google Cloud for free’), (‘body’, <wagtail.rich_text.RichText object at 0x3e58a1352760>), (‘btn_text’, ‘Get started for free’), (‘href’, ‘https://console.cloud.google.com/freetrial?redirectPath=/welcome’), (‘image’, None)])]>
Getting more content with confidence
When it comes to data extraction, simply pulling out text from documents is no longer sufficient. A core objective that businesses need peace of mind on is uncertainty estimation, which we define as understanding how uncertain the model is about particular extraction. This is paramount when an organization is processing vast quantities of documents — such as searching tens of thousands of items where you’re trying to extract all the relevant and related values in each of those items — and you need to guide human review effectively and with confidence. The goal isn’t just high accuracy, but also a reliable confidence score for each piece of extracted data.
With the Box AI Enhanced Extract Agent, we wanted to transform how businesses interact with their most complex content — whether that’s scanned PDFs, images, slides, and other diverse materials — and then turn it all into structured, actionable intelligence.
For instance, financial services organizations can automate loan application reviews by accurately extracting applicant details and income data; legal teams can accelerate discovery by pinpointing critical clauses in contracts; and HR departments can streamline onboarding by processing new hire paperwork automatically. In each of these cases, all extracted data like key dates and contractual terms can be validated by the crucial confidence scores that this Box and Google collaboration delivers. This confidence score helps ensure reliable, AI-vetted information powers efficient operations and proactive compliance without extensive manual effort.
Powering enhanced data extraction with Gemini 2.5 Pro
Box’s Enhanced Extract Agent leverages the sophisticated multimodal, agentic reasoning and capabilities of Google’s Gemini 2.5 Pro as its core intelligence engine. However, the relationship goes beyond simple API calls.
“Gemini 2.5 Pro is way ahead due to its multimodal, deep reasoning, and code generation capabilities in terms of accuracy compared to previous models for these complex extraction tasks,” Ben Kus, CTO at Box said. “These capabilities make Gemini a crucial component for achieving Box’s ambitious goals of turning unstructured content into structured content through enhanced extraction agents.”
To build robust confidence scores and enable deeper understanding, Box’s AI Agents acquire specific, granular information that the Gemini 2.5 Pro model is uniquely adept at providing.
An agent-to-agent protocol for deeper collaboration
Box is championing an open AI ecosystem by embracing Google Cloud’s Agent2Agent protocol, enabling all Box AI Agents to securely collaborate with diverse external agents from dozens of partners (a list that keeps growing). By adopting the latest A2A specification, Box AI can ensure efficient and secure communication for complex, multi-system processes. This empowers organizations to power complex, cross-system workflows—bringing intelligence directly to where content lives, boosting productivity through seamless agent collaboration.This advanced interplay leverages the proposed agent-to-agent protocol in the following manners:
Box’s AI Agents: Orchestrate the overall extraction task, manages user interactions, applies business logic, and crucially, performs the confidence scoring and uncertainty analysis.
Google’s Gemini 2.5 Pro: Provides the core text comprehension, reasoning, and generation; and in this enhanced protocol, Gemini models also aim to furnish deeper operational data (like token likelihoods) to its counterpart.
This protocol, for example, allows Box’s Enhanced Extract Agent to “look under the hood” of Gemini 2.5 Pro to a greater extent than typical AI model integrations. This deeper insight is essential for:
Building Reliable Confidence Scores: Understanding how certain Gemini 2.5 Pro is about each generated token allows Box AI’s enhanced data extraction capabilities to construct more accurate and meaningful confidence metrics for the end-user.
Enhancing Robustness: Another key area of focus is model robustness ensuring consistent outputs. As Kus put it: “For us robustness is if you run the same model multiple times, how much variation we would see in the values. We want to reduce the variations to be minimal. And with Gemini, we can achieve this.”
Furthering this commitment to an open and extensible ecosystem, Box AI Agents will be published on Agentspace and will be able to interact with other agents using the A2A protocol. Box has also published support for the Google’s Agent Development Kit (ADK) so developers can build Box capabilities into their ADK agents, truly integrating Box intelligence across their enterprise applications.
The Google ADK, an open-source, code-first Python toolkit, empowers developers to build, evaluate, and deploy sophisticated AI agents with flexibility and control. To expand these capabilities, we have created the Box Agent for Google ADK , which allows developers to integrate Box’s Intelligent Content Management platform with agents built with Google ADK, enabling the creation of custom AI-powered solutions that enhance content workflows and automation.
This integration with ADK is particularly valuable for developers, as it allows them to harness the power of Box’s Intelligent Content Management capabilities using familiar software development tools and practices to craft sophisticated AI applications. Together, these tools provide a powerful, streamlined approach to build innovative AI solutions within the Box ecosystem.
Continual learning and human-in-the-loop, for the most flexible AI
The vision for enhanced extract includes a dynamic, self-improving system. “We want to implement that cycle so that you can get higher and higher confidence,” Kus, Box’s CTO, said. “This involves a human-in-the-loop process where low-confidence extractions are reviewed, and this feedback is used to refine the system.”
Here, the flexibility of Gemini 2.5 Pro, particularly concerning fine-tuning, enables continual improvement. Box is exploring advanced continual learning approaches, including:
In-context learning: Providing corrected examples within the prompt to Gemini 2.5 Pro.
Supervised fine-tuning: Google Cloud’s Vertex AI allows Box to store the fine-tuned weights in the company’s system and then just use them to run their fine-tuned model.
Box AI’s Enhanced Extract Agent would manage these fine-tuned adaptations (for example through small LoRA layers specific to a customer or document template) and provide them to the Gemini 2.5 Pro agent at inference time. “Gemini 2.5 Pro can be used to leverage these adaptations efficiently, using the context caching capability of Gemini models on Vertex AI to tailor its responses for specific, high-value extraction tasks using in-context learning. This allows for ‘true adaptive learning,’ where the system continuously improves based on user feedback and specific document nuances,” Kus said.
The future: Premium document intelligence powered by advanced AI collaboration
The Enhanced Extract Agent — underpinned by Gemini 2.5 Pro’s features such as multimodality, intelligent reasoning, planning and tool-calling, and large context windows — is envisioned as as a key differentiator that Box leverages in developing their AI Hub and Agent family. Box views the Enhanced Extract Agent as a fundamental way in which organizations can build more confidence in how they deploy AI in the enterprise.
For the Google team, it’s been exciting to see the production-grade, scalable use of our Gemini models by Box. Their solution not only provides extracted data, but meta-data semantics enabling a high degree of confidence and a system that uses the Box content and agents on top of Gemini models to enable the Enhanced Data Extraction Agent to adapt and learn over time.
The ongoing collaboration between Box and Google Cloud focuses on unlocking the full potential of models like Gemini 2.5 Pro for complex enterprise use cases, which are rapidly redefining the future of work and paving the way for the next generation of document intelligence powering the agentic workforce.
Hospitals, while vital for our well-being, can be sources of stress and uncertainty. What if we could make hospitals safer and more efficient — not only for patients but also for the hard-working staff who care for them? Imagine if technology could provide an additional safeguard, predicting falls, or sensing distress before it’s even visible to the human eye.
Many hospitals today still rely on paper-based processes before transforming critical information to digital systems, leading to frequent — and sometimes, remarkably absurd — inefficiencies. In-person patient monitoring, while standard practice, can be slow, incomplete, and subject to human error and bias. In one serious incident, shared by hospital staff, a patient fell shortly after getting out of bed at 5 a.m. and wasn’t discovered until the routine 6:30 a.m. check. Events like this underscore the need for continuous, 24/7 in-room monitoring solutions that can alert staff immediately in high-risk and emergency situations.
Driven by a shared vision to enhance patient care, healthcare innovator Hypros and Google Cloud joined forces to develop an AI-assisted patient monitoring system that detects and alerts staff to in-hospital patient emergencies, such as out-of-bed falls, delirium onset, or pressure ulcers. This innovative privacy-preserving solution enables better prioritization of care and a strong foundation for clinical decision-making — all without the use of invasive cameras.
While the need for 24/7 patient monitoring is clear, developing these solutions raises important concerns around privacy and professional conduct. Privacy is paramount in any patient-monitoring technology for both the individuals receiving care and the professionals providing it. Even seemingly simple aspects, such as interventions within the patient’s immediate surroundings, require strict compliance with hospital hygiene policies — a lesson reinforced during the COVID-19 pandemic.
It’s crucial to monitor and correct any mistakes without singling out individuals. By using tools like low-resolution sensors, we can protect people’s identities and reduce the risk of unfair judgment, keeping the focus squarely on improving care. This approach is especially valuable, since the root cause of errors, more often than not, extend beyond the individual. As a result, ethical technology deployment of monitoring, AI or otherwise, means ensuring that the efficiencies or insights gained never compromise fundamental rights and well-being.
Figure 1: Patient monitoring device from Hypros.
The approach for continuous patient monitoring hinges on two key innovations:
Non-invasive IoT devices: Hypros developed a novel battery-powered Internet of Things (IoT) device that can be mounted on the ceiling. This device uses low-resolution sensors to capture minimal optical and environmental data, creating a very low-detail image of the scene. The device is designed to be non-invasive, preserving anonymity while still gathering the crucial information needed to detect any meaningful changes in a patient’s environment or condition.
Two-stage AI workflow: Hypros employ a two-stage machine learning (ML) workflow. Initially, they trained a camera-based vision model using AutoML on Vertex AI to label sensor data from simulated hospital scenarios. Next, they use this labeled dataset to train a second model to interpret low-resolution sensor data.
The following sections explain how Hypros implemented these innovations into their patient monitoring solution, and how Google Cloud assisted Hypros in this endeavor.
Low resolution, high information: Securing patient privacy
To address the critical need for patient privacy while enabling effective hospital bed monitoring, Hypros developed a compact, mountable IoT device (see Figure 1) equipped with low-resolution optical and environmental sensors. This innovative solution operates on battery power, facilitating easy installation and relocation to various bed locations as needed.
Figure 2: How a bed with a patient scene is abstracted to low resolution sensor data.
The device’s low-resolution optical sensors are effective for protecting patient privacy, they also can make data interpretation and analysis more complex. Additionally, low sampling rates and environmental factors can introduce noise and sparsity into the data, resulting in an incomplete representation of human behavior in the hospital. The combination of low-resolution imaging, limited sampling rates, and environmental noise creates a complex data landscape that requires sophisticated algorithms and interpretive models to extract meaningful insights.
Figure 3: Real-world data: Bed sheets changed by Staff, and Patient gets into bed. This is a “simple” scenario.
Despite these challenges, Hypros’ device represents a significant advancement in privacy-preserving patient monitoring, offering the potential to enhance hospital workflow efficiency and patient care without compromising individual privacy.
Patient monitoring with AI: Overcoming low-resolution data challenges
While customized parametric algorithms can partially interpret sensor data, they have difficulty handling complex relationships and edge cases. ML algorithms offer clear advantages, making AI a vital tool for a patient monitoring system.
However, the complexity of their sensor data makes it difficult for AI to independently learn the detection of critical patient conditions, and thus, unsupervised learning techniques would not yield useful results. In addition, manual data labeling can quickly become expensive as tight monitoring sends readings every few seconds, quickly producing large volumes of data.
To solve these issues, Hypros adopted an innovative approach that would allow AI to learn how to detect scenarios from their monitoring devices with minimal labeling effort. They found that using pre-trained AI models, which require fewer examples to learn a new image-based task, can simplify labeling image data. However, these models struggled to interpret their low-resolution sensor data directly.
Therefore, they use a two-step process. First, they train a camera-based vision model using camera data to produce a larger, labelled dataset.Then, they transfer these labels to concurrently recorded sensor data, which they use to train a patient monitoring model. This unique approach enables the system to reliably detect events of interest, such as falls or early signs of delirium, without compromising patient privacy.
Driving healthcare innovation with Google Cloud
Hypros relied heavily on Google Cloud to build their patient monitoring system, particularly its data and AI services. The first crucial step was collecting useful data to train their AI models.
They began by replicating a physical hospital room environment within their offices. This controlled setting enabled them to simulate various realistic scenarios, gather data, and record video. During this phase, they also collaborated closely with hospitals to ensure that the characteristics specific to each use case were accurately determined.
Next, they trained a camera-based vision model with AutoML on VertexAI to label sensor data. This process was remarkably straightforward and efficient. Within approximately two weeks, their initial AutoML camera-based vision model used for labeling achieved an average precision exceeding 91% across all confidence thresholds. Already impressive, the actual performance was higher as labeling discrepancies artificially lowered the results.
Subsequently, they labeled various video recordings from hospital beds and correlated these labels with their device data for model training. This approach allowed the model to learn how to interpret sensor data sequences by observing and learning from the corresponding video. For training use cases that didn’t incorporate video information, they relied on data or simulation methodologies from their hospital partners.
The speed of development cycles is also a critical competitive advantage. Therefore, they mapped every step in their workflow and model development cycles (see Figure 4) to the following Google Cloud services:
Cloud Storage: Stores all raw data, enabling easy rollbacks and establishing a clear baseline for ongoing improvements.
BigQuery: Stores labeled data for easier querying, and analysis querying and analysis. Easy access to the right data helps them iterate, analyze, debug, and refine their models more efficiently.
Artifact Registry: Hosts their custom Docker images in ETL and training pipelines. Fewer downloads, shorter builds, and better software dependency management provides smoother, more optimized operations.
Apache Beam with Dataflow Runner: Processes large volumes of data at high speed, keeping their pipelines fast and maximizing their development time.
Vertex AI: Provides a unified platform for model registration, experiment tracking, and visualizing results in TensorBoard; training is done with TensorFlow and TFRecords, using customized resources (like GPUs) and easy deployment options simplify rolling out new model versions.
Figure 4: Simple workflow directed graph to highlight technologies used
With Google Cloud’s ability to handle petabytes of data, they know their workflows are highly scalable. Having a powerful, flexible platform lets them focus on delivering value from data insights, rather than worrying about infrastructure.
Further possibilities: Distilling nuanced information
The development of their system has sparked more ideas about ways hospitals can benefit from using sensor data and AI. They see three main areas of care where continuous patient monitoring can help: patient-centric care for better outcomes, staff-centric support to optimize their time, and environmental monitoring for safer spaces.
Some potential use cases include:
People detection: Anonymously detect individuals to improve operations, such as bed occupancy for patient flow management.
Fall prevention and detection: Alert staff about patient falls or flag restless behavior to prevent them.
Pressure ulcers: Monitor 24/7 movement to aid clinical staff in repositioning patients effectively to prevent the development of pressure ulcers (bedsores).
Delirium risk indicators: Track sleep disruption factors like light and noise, which are potential indicators of delirium risk (final correlation requires additional data from other sources).
General environmental analysis:Monitor temperature, humidity, noise, and other environmental data for smarter building responses in the future (e.g., energy savings through optimized heating) and more effective patient recovery.
Hand hygiene compliance: Anonymously track hand disinfection compliance to improve hygiene practices in combination with solutions like the Hypros’ Hand Hygiene Monitoring solution – NosoEx.
Instead of stockpiling sensor data, their system uses advanced AI models to interpret and connect data from multiple streams — turning simple raw readings into practical insights that guide better decisions. Real-time alerts also bring timely attention to critical situations — ensuring patients receive the swift and focused care they deserve, and staff can perform at their very best.
The path forward with patient care
Already, Hypros’ patient monitoring system is gaining momentum, with real-world trials at leading institutions like UKSH (University Hospital Schleswig-Holstein) in Germany. As highlighted by their recent press release, the UKSH recognizes the potential of their solutions to transform patient care and improve operational efficiency. In addition, their clinical partner, the University Medical Center Greifswald, has experienced benefits firsthand as an early adopter.
Dr. Robert Fleishmann, a managing senior physician and deputy medical director at the University Medical Center Greifswald, is convinced of its usefulness, saying:
“The prevention of delirium is crucial for patient safety. The Hypros patient monitoring solution provides us with vital data to examine risk factors (e.g., light intensity, noise levels, patient movements) contributing to the development of delirium on a 24/7 basis. We are very excited about this innovative partnership.”
This positive feedback, alongside the voices of other customers, fuels Hypros’ ongoing commitment to revolutionize patient care through ethical and data-driven technology.
By harnessing the power of AI and cloud computing, in close collaboration with Google Cloud, Hypros is dedicated to developing privacy-preserving patient monitoring solutions that directly address critical healthcare challenges such as staffing shortages and the ever-increasing need for enhanced patient safety.
Building on this foundation, Hypros envisions a future where their AI-powered patient monitoring solutions are seamlessly integrated into healthcare systems worldwide. The goal is to empower clinicians with real-time, actionable insights, ultimately improving patient outcomes, optimizing resource allocation, and fostering a more sustainable and patient-centric healthcare ecosystem for all.
Recently, we announced Gemini 2.5 is generally available on Vertex AI. As part of this update, tuning capabilities have extended beyond text outputs – now, you can tune image, audio, and video outputs on Vertex AI.
Supervised fine tuning is a powerful technique to customize LLM output using your own data. Through tuning, LLMs become specialized in your business context and task by learning from the tuning examples, therefore achieving higher quality output. With video outputs, here’s some use cases our customers have unlocked:
Automated video summarization: Tuning LLMs to generate concise and coherent summaries of long videos, capturing the main themes, events, and narratives. This is useful for content discovery, archiving, and quick reviews.
Detailed event recognition and localization: Fine-tuning allows LLMs to identify and pinpoint specific actions, events, or objects within a video timeline with greater accuracy. For example, identifying all instances of a particular product in a marketing video or a specific action in sports footage.
Content moderation: Specialized tuning can improve an LLM’s ability to detect sensitive, inappropriate, or policy-violating content within videos, going beyond simple object detection to understand context and nuance.
Video captioning and subtitling: While already a common application, tuning can improve the accuracy, fluency, and context-awareness of automatically generated captions and subtitles, including descriptions of nonverbal cues.
aside_block
<ListValue: [StructValue([(‘title’, ‘$300 in free credit to try Google Cloud AI and ML’), (‘body’, <wagtail.rich_text.RichText object at 0x3e6d910b6df0>), (‘btn_text’, ‘Start building for free’), (‘href’, ‘http://console.cloud.google.com/freetrial?redirectPath=/vertex-ai/’), (‘image’, None)])]>
Today, we will share actionable best practices for conducting truly effective tuning experiments using the Vertex AI tuning service. In this blog, we will cover the following steps:
Craft your prompt
Detect multiple labels
Conduct single-label video task analysis
Prepare video tuning dataset
Set the hyperparameters for tuning
Evaluate the tuned checkpoint on the video tasks
I. Craft your prompt
Designing the right prompt is a cornerstone of any effective tuning, directly influencing model behavior and output quality. An effective prompt for video tuning typically comprises several key components, ensuring clarity in the prompt.
Task context: This component sets the overall context and defines the intention of the task. It should clearly articulate the primary objective of the video analysis. For example….
Task definition: This component provides specific, detailed guidance on how the model should perform the task including label definitions for tasks such as classification or temporal localization. For example, in video classification, clearly define positive and negative matches within your prompt to ensure accurate model guidance.
Output specification: This component provides how the model is expected to produce its output. This includes specific rules or schema for structured formats such as JSON. To maximize clarity, embed a sample JSON object directly in your prompt, specifying its expected structure, schema, data types, and any formatting conventions.
II: Detect multiple labels
Multi-label video analysis involves detecting multiple labels corresponding to a single video. This is a desirable setup for video tasks since the user can train a single model for several labels and obtain predictions for all the labels via a single query request to the tuned model during inference time. These tasks are usually quite challenging for the off-the-shelf models and often need tuning.
See an example prompt below.
code_block
<ListValue: [StructValue([(‘code’, ‘Focus: you are a machine learning data labeller with sports expertise. rnrn### Task definition ###rnGiven a video and an entity definition, your task is to find out the video segments that match the definition for any of the entities listed below and provide the detailed reason on why you believe it is a good match. Please do not hallucinate. There are generally only few or even no positive matches in most cases. You can just output nothing if there are no positive matches.rnrn Entity Name: “entity1″rn Definition: “define entity 1”rn Labeling instruction: provide instruction for entity1rnrn Entity Name: “entity 2″rn Definition: “define entity 2”rn Labeling instruction: provide instruction for entity 2rnrn..rn..rnrn### Output specification ###rnYou should provide the output in a strictly valid JSON format same as the following example.rn[{rn”cls”: {the entity name},rn”start_time”: “Start time of the video segment in mm:ss format.”,rn”end_time”: “End time of the video segment in mm:ss format.”,rn},rn{rn”cls”: {the entity name},rn”start_time”: “Start time of the video segment in mm:ss format.”,rn”end_time”: “End time of the video segment in mm:ss format.”,rn}]rnBe aware that the start and end time must be in a strict numeric format: mm:ss. Do not output anything after the JSON content.rnrnYour answer (as a JSON LIST):’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e6d910b6a30>)])]>
Challenges and mitigations for multi-label video tasks:
The tuned model tends to learn dominant labels (i.e., labels that appear more frequently in the dataset).
Mitigation: We recommend balancing the target label distribution as much as possible.
When working with video data, skewed label distributions are further complicated by the temporal aspect. For instance, in action localization, a video segment might not contain “event X” but instead feature “event Y” or simply be background footage.
Mitigation: For such use cases, we recommend using multi-class single-label design described below.
Mitigation: Improving the positive:negative instance ratio per label would further improve the tuned model’s performance.
The tuned model tends to hallucinate if the video task involves a large number of labels per instance (typically >10 labels per video input).
Mitigation: For effective tuning, we recommend using multi-label formulation for video tasks that involve less than 10 labels per video.
For video tasks that require temporal understanding in dynamic scenes (e.g. event detection, action localization), the tuned model may not be effective for multiple temporal labels that are overlapping or are very close.
III: Conduct single-label video task analysis
Multi-class single-label analysis involves video tasks where a single video is assigned exactly one label from a predefined set of mutually exclusive labels. In contrast to multi-label tuning, multi-class single-label tuning recipes show good scalability with an increasing number of distinct labels. This makes the multi-class single-label formulation a viable and robust option for complex tasks. For example, tasks that involve categorizing videos into one of many possible exclusive categories or detecting several overlapping temporal events in the video.
In such a case, the prompt must explicitly state that only one label from a defined set is applicable to the video input. List all possible labels within the prompt to provide the model with the complete set of options. It is also important to clarify how a model should handle negative instances, i.e., when none of the labels occur in the video.
See an example prompt below:
code_block
<ListValue: [StructValue([(‘code’, ‘You are a video analysis expert. rnrn### Task definition ###rnDetect which animal appears in the video.The video can only have one of the following animals: dog, cat, rabbit. If you detect none of these animals, output NO_MATCH.rnrn### Output specification ###rnGenerate output in the following JSON format:rn[{rn”animal_name”: “<CATEGORY>”,rn}]’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e6d8d2a2760>)])]>
Challenges and mitigations for multi-class single-label video tasks
Using highly skewed data distributions may cause quality regression on the tuned model. The model may simply learn to predict the majority class, failing to identify the rare positive instances.
Mitigation: Undersampling the negative instances or oversampling the positive instances to balance the distributions are some effective strategies for tuning recipes. The undersampling/oversampling rate depends on the specific use case at hand
Some video use cases can be formulated as both multi-class single-label tasks and multi-label tasks. For example, detecting time intervals for several events in a video.
For fewer event types with non-overlapping time intervals (typically fewer than 10 labels per video), multi-label formulation is a good option.
On the other hand, for several similar event types with dense time intervals, multi-class single-label recipes yield better model performance . Model inference involves sending a separate query for each class (e.g., “Is event A present?”, then “Is event B present?”). This approach effectively treats the multi-class problem as a series of N binary decisions. This would mean for N classes, you will need to send N inference requests to the tuned models.
This is a tradeoff between higher inference latency and cost vs target performance. The choice should be made based on expected target performance from the model for the use case.
IV. Prepare video tuning dataset
The Vertex Tuning API uses *.jsonl files for both training and validation datasets. Validation data is used to select a checkpoint from the tuning process. Ideally, there should be no overlap in the JSON objects contained within train.jsonl and validation.jsonl. Learn more about how to prepare tuning dataset and its limitations here.
For maximum efficiency when tuning Gemini 2.0 (and newer) models on video, we recommend to use the MEDIA_RESOLUTION_LOW setting, located within the generationConfig object for each video in your input file. It dictates the number of tokens used to represent each frame, directly impacting training speed and cost.
You have two options:
MEDIA_RESOLUTION_LOW (default): Encodes each frame using 64 tokens.
MEDIA_RESOLUTION_MEDIUM: Encodes each frame using 256 tokens.
While MEDIA_RESOLUTION_MEDIUM may offer slightly better performance on tasks that rely on subtle visual cues, it comes with a significant trade-off: training is approximately four times slower. Given that the lower-resolution setting provides comparable performance for most applications, sticking with the default MEDIA_RESOLUTION_LOW is the most effective strategy for balancing performance with crucial gains in training speed.
V. Set the hyperparameters for tuning
After preparing your tuning dataset, you are ready to submit your first video tuning job! We supports 3 hyperparameters:
epochs: specifies the number of iterations over the entire training dataset. With a dataset size of ~500 examples, starting with epochs = 5 is the default value for video tuning tasks. Increase the number of epochs when you have <500 samples and decrease when you have >500 samples.
learning_rate_multiplier: specifies multiplier for the learning rate. We recommended experimenting with values less than 1 if the model is overfitting and values greater than 1 if the model is underfitting.
adapter_size: specified the rank of the LoRA adapter. The default values are adapter_size=8 for flash model tuning. For most use cases, you won’t need to adjust this, but a higher size allows the model to learn more complex tasks.
To streamline your tuning process, Vertex AI provides intelligent, automatic hyperparameter defaults. These values are carefully selected based on the specific characteristics of your dataset, including its size, modality, and context length. For the most direct path to a quality model, we recommend starting your experiments with these pre-configured values. Advanced users looking to further optimize performance can then treat these defaults as a strong baseline, systematically adjusting them based on the evaluation metrics from their completed tuning jobs.
VI. Evaluate the tuned checkpoint on the video tasks
Vertex AI tuning service provides loss and accuracy graph for training and validation dataset out of the box. The monitoring graph is updated in real time as your tuning job progresses. Intermediate checkpoints are automatically deployed for you. We recommend selecting the checkpoint corresponding to the epochs that show loss values on the validation dataset have saturated.
To evaluate the tuned model endpoint, See a sample code snippet below:
For best performance, it is critical that the format, context and distribution of the inference prompts align with the tuning dataset. Also, we recommend using the same mediaResolution for evaluation as the one used during training.
For thinking models like Gemini 2.5 Flash, we recommend setting the thinking budget to 0 to turn off thinking on tuned tasks for optimal performance and cost efficiency. During supervised fine-tuning, the model learns to mimic the ground truth in the tuning dataset, omitting the thinking process.
Get started on Vertex AI today
The ability to derive deep, contextual understanding from video is no longer a futuristic concept—it’s a present-day reality. By applying the best practices we’ve discussed for prompt engineering, tuning dataset design, and leveraging the intelligent defaults in Vertex AI, you are now equipped to effectively tune Gemini models for your specific video-based tasks.
What challenges will you solve? What novel user experiences will you create? The tools are ready and waiting. We can’t wait to see what you build.
At Google Cloud, we’re committed to delivering the best performance possible globally for web and API content. Cloud CDN is a high-performance edge caching solution that runs at over 200 points of presence, and we continue to add more features and capabilities to it. Recently we launched invalidation with cache tags, device characterization, 0-RTT early data, and geo-targeting. These powerful first class features address many use cases, but organizations tell us they also need a more flexible, lightweight, edge computing solution.
We are excited to announce that you can now run Service Extensions plugins with Cloud CDN, allowing you to run your own custom code directly in the request path in a fully managed Google environment with optimal latency. This allows you to customize the behavior of Cloud CDN and the Application Load Balancer to meet your business requirements.
Service Extensions plugins with Cloud CDN supports the following use cases:
Custom traffic steering: Manipulate request headers to influence backend service selection.
Cache optimization: Influence which content is served from a Cloud CDN cache.
Exception handling: Redirect clients to a custom error page for certain response classes.
Custom logging: Log user-defined headers or custom data into Cloud Logging.
Header addition: Create new headers relevant for your applications or specific customers.
Header manipulation: Rewrite existing request headers or override client headers on their way to the backend.
Security: Write custom security policies based on client requests and make enforcement decisions within your plugin.
aside_block
<ListValue: [StructValue([(‘title’, ‘$300 to try Google Cloud networking’), (‘body’, <wagtail.rich_text.RichText object at 0x3e6d90586d30>), (‘btn_text’, ‘Start building for free’), (‘href’, ‘http://console.cloud.google.com/freetrial?redirectpath=/products?#networking’), (‘image’, None)])]>
Where you can run your code
Service Extensions plugins run at multiple locations in the request and response processing path. With this launch, you can run plugins before requests to Cloud CDN using an edge extension. In a previous launch, we added the capability to run plugins post the Cloud CDN cache, closer to the origin, via a traffic extension. Now, with support for both edge and traffic extensions, you can choose where you want your code to execute in the processing path.
Service Extensions deep dive
Service Extensions plugins are designed for lightweight compute operations that run as part of the Application Load Balancer request path. Plugins are built on WebAssembly (Wasm), which provides several benefits:
Near-native execution speed, and startup time in the single milliseconds
Support for a variety of programming languages, such as Rust, C++, and recently Go
Cross-platform portability, so you can run the same plugin in various deployments, or locally for testing
Security protections, such as executing plugin logic in a sandboxed environment
Service Extensions plugins leverage Proxy-Wasm, a Google-supported open source project that provides a standard API for Wasm modules to interface with network proxies.
Use Cloudinary’s image & video optimization solution
We are excited to announce our latest partner to integrate their offering with Service Extensions and Cloud CDN. Cloudinary makes an advanced image and video optimization solution and has integrated it with Service Extensions plugins for deployment to Cloud CDN customers.
Packaged as a Wasm plugin, Cloudinary’s plugin takes directives from Client Requests such as User-Agent information, and content type expressed as MIME types from HTTP Accept headers, to determine the most optimal media type to serve to the end user. The plugin also takes care of Cache Key normalization so that the images and videos are cached properly based on device types and content types.
“Cloudinary’s image and video solutions help customers manage and optimize their visual media assets at scale while ensuring they are optimized for the best format, device, channel and viewing context. We are excited to partner with the Google team to offer Cloudinary’s image and video optimization solutions to Cloud CDN customers via Service Extensions.” – Gary Ballabio, VP, Strategic Technology Partnerships, Cloudinary
For more information on Cloudinary’s solution, please review this guide.
What’s next
To get started with Service Extensions plugins, take a look at our growing samples repository with a local testing toolkit and follow our quickstart guide in the documentation.
With more than a thousand connected data sources available out-of-the-box and an untold number of custom tools, developers rely on Looker’s cloud-first, open-source-friendly model to create new data interpretations and experiences. Today, we are taking a page from modern software engineering principles with our launch of Continuous Integration for Looker, which will help speed up development and help developers take Looker to new places.
As a developer, you rely on your connections to be stable, your data to be true, and for your code to run the same way every time. And when it doesn’t, you don’t want to spend a long time figuring out why the build broke, or hear from users who can’t access their own tools.
Continuous Integration for Looker helps streamline your code development workflows, boost the end-user experience, and give you the confidence you need to deploy changes faster. With Continuous Integration, when you write LookML code, your dashboards remain intact and your Looker content is protected from database changes. This helps to catch data inconsistencies before your users do, and provides access to powerful development validation capabilities directly in your Looker environment.
With Continuous Integration, you can automatically unify changes to data pipelines, models, reports, and dashboards, so that your business intelligence (BI) assets are consistently accurate and reliable.
Continuous Integration in Looker checks your downstream dependencies for accuracy and speeds up development.
Developers benefit from tools that help them maintain code quality, ensure reliability, and manage content effectively. As Looker becomes broadly adopted in an organization, with more users creating new dashboards and reports and connecting Looker to an increasing number of data sources, the potential for data and content errors can increase. Continuous Integration proactively tests new code before it is pushed to production, helping to ensure a strong user experience and success.
Specifically, Continuous Integration in Looker offers:
Early error detection and improved data quality: Minimize unexpected errors in production. Looker’s new Continuous Integration features help LookML developers catch issues before new code changes are deployed, for higher data quality.
Validators that:
Flag upstream SQL changes that may break Looker dimension and measure definitions.
Identify dashboards and Looks that reference outdated LookML definitions.
Validate LookML for errors and antipatterns as a part of other validations.
Enhanced developer efficiency: Streamline your workflows and integrate Continuous Integration pipelines, for a more efficient development and code review process that automatically checks code quality and dependencies, so you can focus on delivering impactful data experiences.
Increased confidence in deployments: Deploy with confidence, knowing your projects have been thoroughly tested, and confident that your LookML code, SQL queries, and dashboards are robust and reliable.
Continuous Integration flags development issues early.
Manage Continuous Integration directly within Looker
Looker now lets you manage your continuous integration test suites, runs, and admin configurations within a single, integrated UI. With it, you can
Easily monitor the status of your Continuous Integration runs and manage your test suites directly in Looker.
Leverage powerful validators to ensure accuracy and efficiency of your SQL queries, LookML code, and content.
Trigger Continuous Integration runs manually or automatically via pull requests or schedules whenever you need them, for control over your testing process.
In today’s fast-paced data environment, speed, accuracy and trust are crucial. Continuous Integration in Looker helps your data team promote developmental best practices, reduce risk of introducing errors in production, and increase your organization’s confidence in its data. The result is a consistently dependable Looker experience for all users, including those in line-of-business, increasing reliability across all use cases. Continuous Integration in Looker is now available in preview. Explore its capabilities and see how it can transform your Looker development workflows. For more information, check our product documentation to learn how to enable and configure Continuous Integration for your projects.