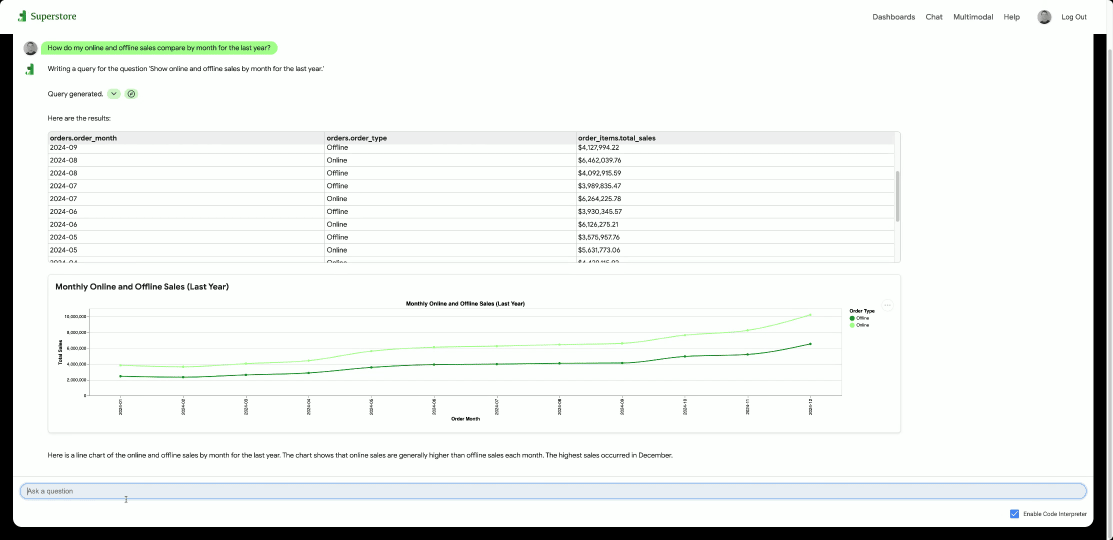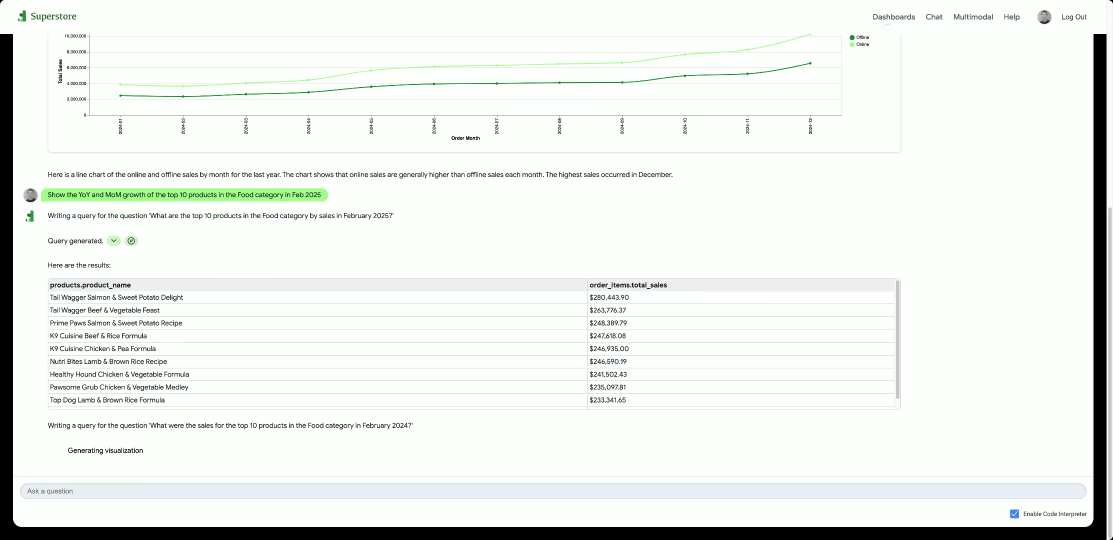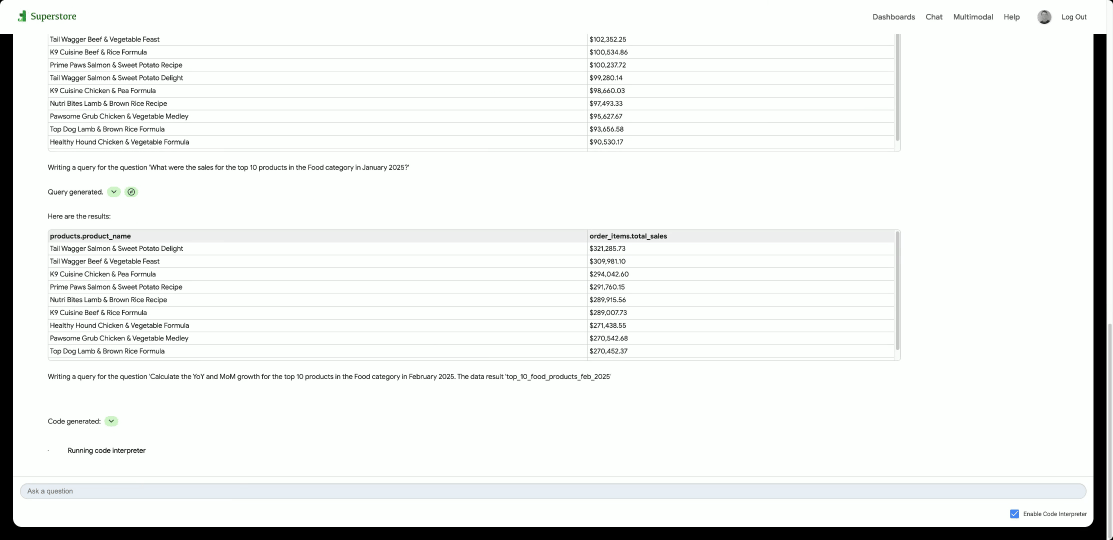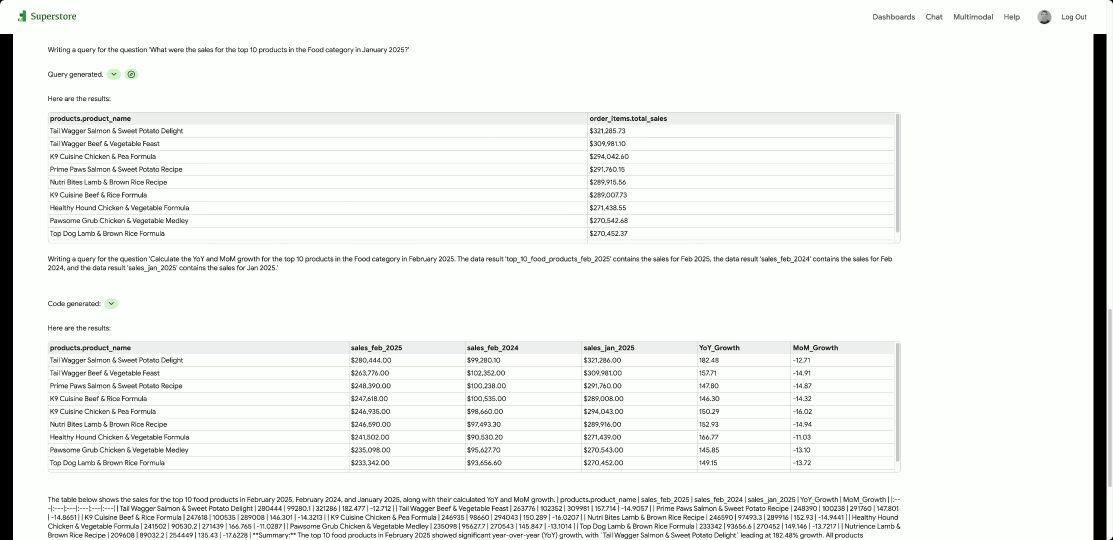
GCP – From localhost to launch: Simplify AI app deployment with Cloud Run and Docker Compose
At Google Cloud, we are committed to making it as seamless as possible for you to build and deploy the next generation of AI and agentic applications. Today, we’re thrilled to announce that we are collaborating with Docker to drastically simplify your deployment workflows, enabling you to bring your sophisticated AI applications from local development to Cloud Run with ease.
Deploy your compose.yaml directly to Cloud Run
Previously, bridging the gap between your development environment and managed platforms like Cloud Run required you to manually translate and configure your infrastructure. Agentic applications that use MCP servers and self-hosted models added additional complexity.
The open-source Compose Specification is one of the most popular ways for developers to iterate on complex applications in their local environment, and is the basis of Docker Compose. And now, gcloud run compose up brings the simplicity of Docker Compose to Cloud Run, automating this entire process. Now in private preview, you can deploy your existing compose.yaml file to Cloud Run with a single command, including building containers from source and leveraging Cloud Run’s volume mounts for data persistence.

Supporting the Compose Specification with Cloud Run makes for easy transitions across your local and cloud deployments, where you can keep the same configuration format, ensuring consistency and accelerating your dev cycle.
“We’ve recently evolved Docker Compose to support agentic applications, and we’re excited to see that innovation extend to Google Cloud Run with support for GPU-backed execution. Using Docker and Cloud Run, developers can now iterate locally and deploy intelligent agents to production at scale with a single command. It’s a major step forward in making AI-native development accessible and composable. We’re looking forward to continuing our close collaboration with Google Cloud to simplify how developers build and run the next generation of intelligent applications.” – Tushar Jain, EVP Engineering and Product, Docker
Cloud Run, your home for AI applications
Support for the compose spec isn’t the only AI-friendly innovation you’ll find in Cloud Run. We recently announced general availability of Cloud Run GPUs, removing a significant barrier to entry for developers who want access to GPUs for AI workloads. With its pay-per-second billing, scale to zero, and rapid scaling (which takes approximately 19 seconds for a gemma3:4b model for time-to-first-token), Cloud Run is a great hosting solution for deploying and serving LLMs.
This also makes Cloud Run a strong solution for Docker’s recently announced OSS MCP Gateway and Model Runner, making it easy for developers to take the AI applications locally to production in the cloud seamlessly. By supporting Docker’s recent addition of ‘models’ to the open Compose Spec, you can deploy these complex solutions to the cloud with a single command.
Bringing it all together
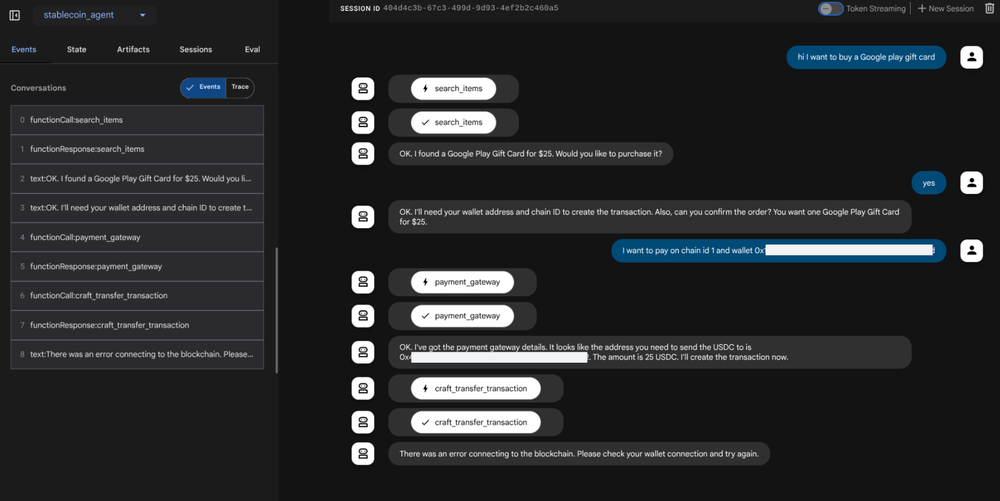
Let’s review the compose file for the above demo. It consists of a multi-container application (defined in services) built from sources and leveraging a storage volume (defined in volumes). It also uses the new models attribute to define AI models and a Cloud Run-extension defining the runtime image to use:
- code_block
- <ListValue: [StructValue([(‘code’, ‘name: agentrnservices:rn webapp:rn build: .rn ports:rn – “8080:8080″rn volumes:rn – web_images:/assets/imagesrn depends_on:rn – adkrnrn adk:rn image: us-central1-docker.pkg.dev/jmahood-demo/adk:latestrn ports:rn – “3000:3000″rn models:rn – ai-modelrnrnmodels:rn ai-model:rn model: ai/gemma3-qat:4B-Q4_K_Mrn x-google-cloudrun:rn inference-endpoint: docker/model-runner:latest-cuda12.2.2rnrnvolumes:rn web_images:’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e9c6fd2e6a0>)])]>
Building the future of AI
We’re committed to offering developers maximum flexibility and choice by adopting open standards and supporting various agent frameworks. This collaboration on Cloud Run and Docker is another example of how we aim to simplify the process for developers to build and deploy intelligent applications.
Compose Specification support is available for our trusted users — sign up here for the private preview.
Read More for the details.