GCP – Announcements for AI Hypercomputer: The latest infrastructure news for ML practitioners
Curious about the latest in AI infrastructure from Google Cloud? Every three months we share a roundup of the latest AI Hypercomputer news, resources, events, learning opportunities, and more. Read on to learn new ways to simplify AI infrastructure deployment, improve performance, and optimize your costs.
AI innovation is moving at an unprecedented rate and achieving remarkable milestones— for example, Gemini Deep Think achieved the Gold Medal standard at the latest International Mathematics Olympiad, and Google now serves over 980 trillion monthly tokens. We are able to achieve these milestones through AI-optimized hardware, leading software with open frameworks, and flexible consumption models.
At Google Cloud, we provide you with access to the same capabilities behind Gemini, Veo 3, and more through AI Hypercomputer, our integrated AI supercomputing system. AI Hypercomputer allows you to train and serve AI models at massive scale, delivering superior performance, lower latency, and best-in-class price/performance. For example, the latest enhancements to Cluster Director simplify the complex task of managing your compute, network, and storage for both training and inference workloads, while new contributions to llm-d help to significantly accelerate the deployment of large-scale inference models on Google Kubernetes Engine (GKE).

Read on for all the latest news.
Dynamic Workload Scheduler
At the top of the stack, AI Hypercomputer offers flexible consumption via Dynamic Workload Scheduler, which optimizes compute resources with your choice of workload scheduling approaches. For workloads with predictable duration, Calendar mode lets you obtain short-term assured capacity at a discount, without long-term commitments. Similar to reserving a hotel room, you know when and where you can train or serve your models; learn how to get started here. Flex start mode, meanwhile, provides better economics and obtainability for on-demand resources that have flexible start-time requirements. This is great for batch processing, training or finetuning, and lets you either start the job once all the resources are available, or begin as resources trickle in. Flex start mode is now available for you to use in preview. Calendar mode in preview supports A3 and A4 VMs while Flex Start mode supports all GPU VMs. Both Calendar and Flex start mode support TPU v5e, TPU v5p, and Trillium.
- aside_block
- <ListValue: [StructValue([(‘title’, ‘$300 in free credit to try Google Cloud AI and ML’), (‘body’, <wagtail.rich_text.RichText object at 0x3e3926520af0>), (‘btn_text’, ‘Start building for free’), (‘href’, ‘http://console.cloud.google.com/freetrial?redirectPath=/vertex-ai/’), (‘image’, None)])]>
Leading software, open frameworks
AI Hypercomputer provides choice and flexibility through support the most popular AI and ML libraries and frameworks.
Cluster Director
To make deploying and managing large-scale clusters easier, AI Hypercomputer offers Cluster Director, a management and orchestration layer for GPU resources that provides cluster management, job scheduling, performance optimization at scale, and comprehensive visibility and insights. At Next ‘25, we highlighted new capabilities including a new GUI, observability and straggler detection features, and now you can take advantage of them. Learn more about the latest advances here.
llm-d project releases version 0.2
To help you serve LLMs at scale, the new open source llm-d project was announced in May for distributed and disaggregated inference with vLLM. The project just released version 0.2, providing performance-optimized patterns for prefill/decode disaggregation and multi-node mixture of expert deployments. It also integrates new kernel optimizations in vLLM, and offers new deployers, improved benchmarking, and improved scheduler extensibility. Learn more on the llm-d blog.
MaxText and MaxDiffusion updates
MaxText and MaxDiffusion are open-source solutions that provide high-performance implementations for training LLMs, and for training and serving diffusion models, respectively. Each solution makes it easy to get started with JAX by providing a robust platform with reproducible recipes, Docker images for TPU and GPUs, and built-in support for popular open-source models like DeepSeek and Wan 2.1. Integrations like multi-tier checkpointing and Accelerated Processing Kit (xpk) for cluster setup and workload management help ensure users get the access to these latest techniques without having to reinvent the wheel for their unique workloads.
Whether you’re new to training LLMs with JAX, or you’re looking to scale to tens of thousands of accelerators, MaxText is the best place to start. To simplify and accelerate onboarding, we’re revamping our UX and onboarding experience by building out our documentation, demystifying concepts like sharding at scale (docs), checkpointing (docs) and designing a model for TPUs (docs). We’re also adding Colab notebook support (initial work) to give simple examples of new features and models. Hear how Kakao and other customers are using MaxText to train their models from Google Cloud Next ‘25.
For more advanced MaxText users, we’re continuing to improve model performance with techniques like pipeline parallelism, where our latest enhancements provide a dramatic step-time reduction by eliminating redundant communication when sharding. For new models, we now support DeepSeek R1-0528 and the Qwen 3 dense models, in addition to Gemma 3, Llama 4, Mixtral, and other popular models. We also added Multi-Token Prediction (MTP) in July, making it easy to incorporate this technique.
We’re also expanding the focus of MaxText to provide post-training techniques through integration with the new JAX-native post-training library Tunix. Now, with MaxText and Tunix, you’ll have end to end pre- and post-training capabilities with easy-to-use recipes. With the Tunix integration, we’ll first offer Supervised Fine-Tuning (SFT) before expanding to Reinforcement Learning (RL) techniques like Group Relative Policy Optimization (GRPO), Direct Preference Optimization (DPO), and Proximal Policy Optimization (PPO).
Join our Discord and share your feedback (feature requests, bugs, documentation) directly to the Github repos.
On the MaxDiffusion front, we’re excited to announce support for serving text-to-video models with Wan 2.1 to complement the existing text-to-image training and inference support of FLUX and SDXL. MaxDiffusion already supports training and inference for FLUX Dev and Schnell, Stable Diffusion 2.1, and Stable Diffusion XL. With this end-to-end solution, users can train their own diffusion models in the MaxDiffusion framework, or simply post-train an existing OSS model and then serve it on TPUs and GPUs.
AI-optimized hardware
Monitoring library for TPUs
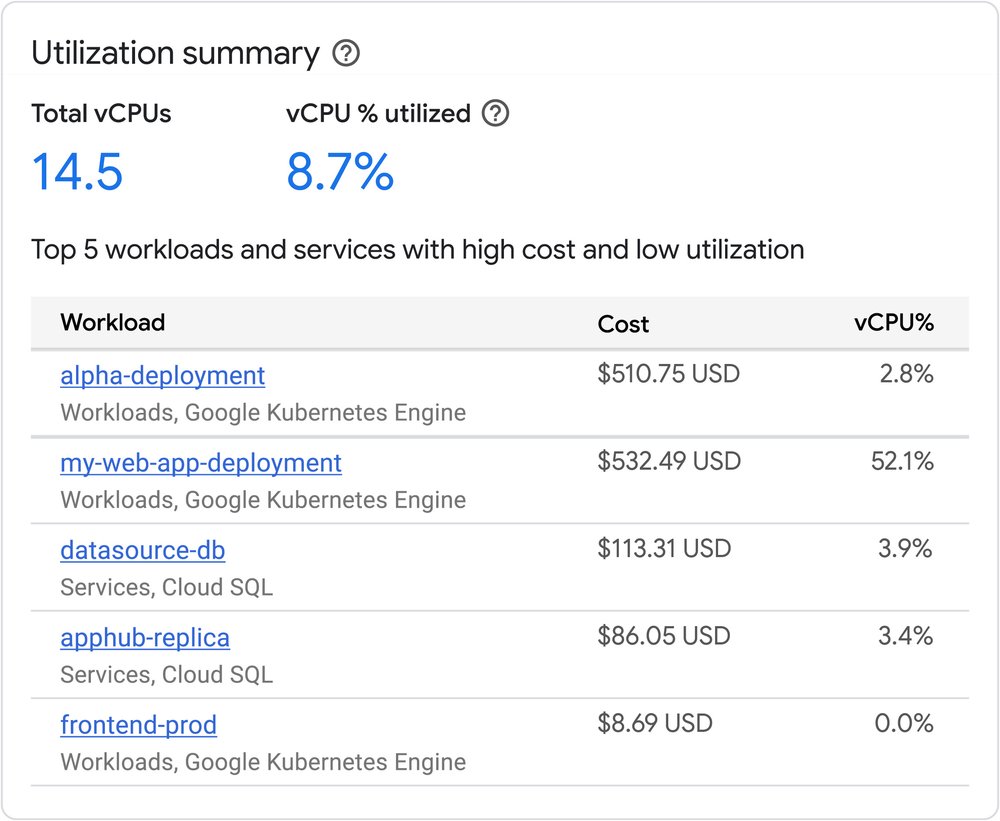
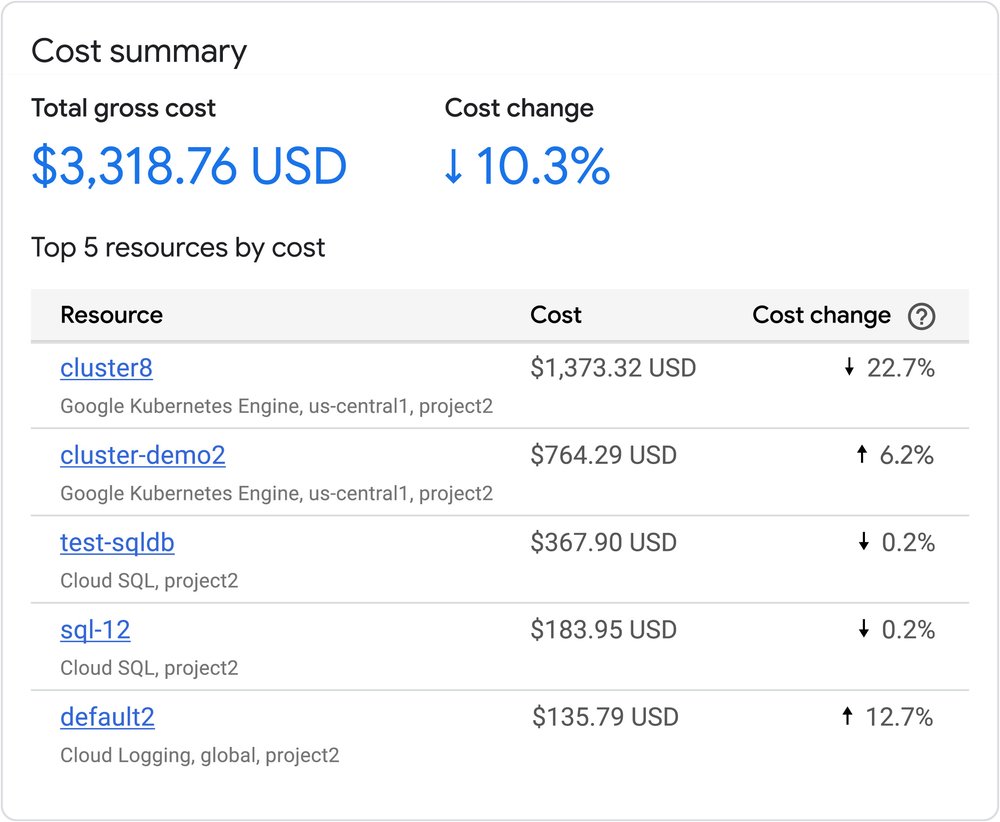
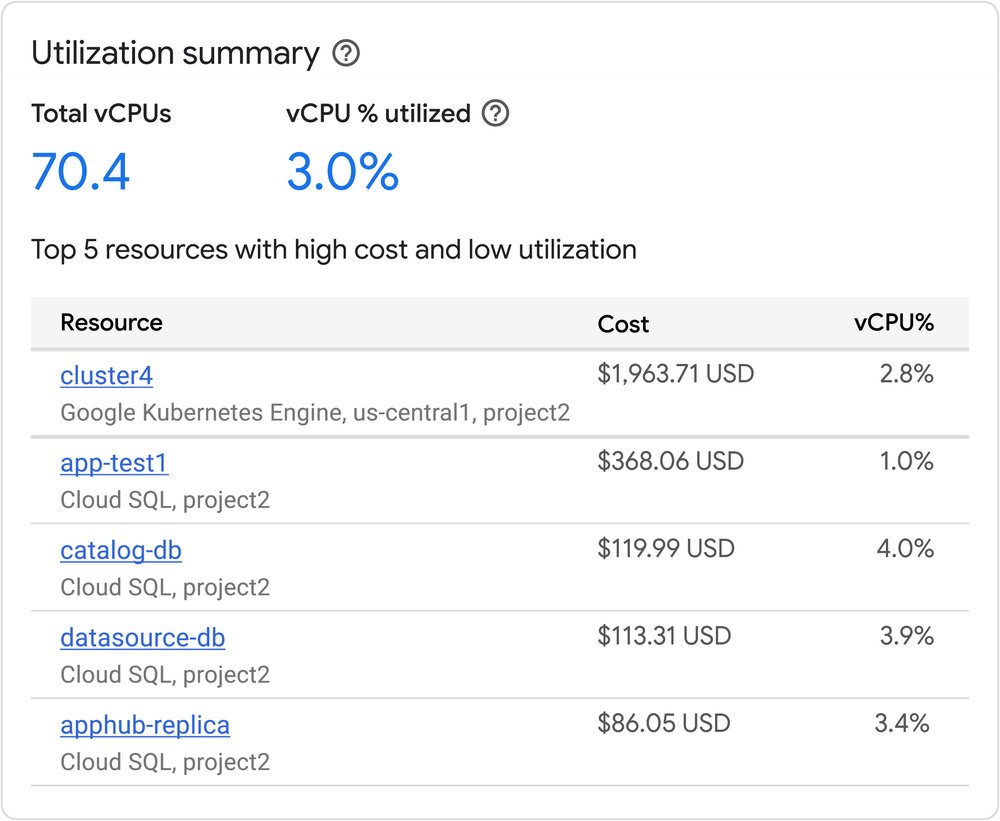
To help you monitor and optimize the efficiency of your training and inference workloads, we recently released a new monitoring library for Google Cloud TPUs. These new observability and diagnostic tools provide granular insights into performance and accelerator utilization, enabling you to continuously improve the efficiency of your Cloud TPU workloads.
Managed Lustre
We also recently announced improvements to Google Cloud Managed Lustre for high-performance computing (HPC) and AI workloads. Managed Lustre now has four distinct performance tiers, providing throughput options of 125 MB/s, 250 MB/s, 500 MB/s, and 1000 MB/s per TiB of capacity, so you can tailor performance to your specific needs. It also now supports up to 8 PiB of capacity, catering to the larger datasets common in modern AI and HPC applications. Furthermore, the service is tightly integrated with Cluster Director and GKE. For example, GKE includes a managed CSI driver, which allows containerized AI training workflows to access data with ultra-low latency and high throughput.
Onwards and upwards
As we continue to push the boundaries of AI, we’ll update and optimize AI Hypercomputer based on the our learnings from training Gemini to serving 980+ trillion tokens a month. To learn more about using AI Hypercomputer for your own AI workloads, read here. To stay up to date on our progress or ask us questions, join our community!
Read More for the details.