Finding the right cloud talent and expertise is important for virtually all businesses today. Almost 70 percent of IT leaders report that hiring was somewhat or extremely difficult in 2019 and that finding qualified cloud computing talent was a top challenge. Our Google Cloud training allows you to build cloud skills while our certifications help organizations grow the expert cloud talent they need to effectively transform their business and help individuals elevate their IT careers with validated cloud skills.
As thousands of technical professionals are looking for ways to stay productive and keep their skills current, we have seen a spike in demand for Google Cloud learning resources. In the month of April, enrollments in Google Cloud training on Coursera increased by more than 500% year-over-year. Google Cloud training completions more than doubled year-over-year across all platforms and partners.
We’re committed to developing cloud professionals across all stages of their career as well as enabling enterprises who need cloud expertise to respond, adapt, and transform to dynamic market pressures. To help, we continue to grow our training and certification programs to empower both learners and employers.
Today, we’re excited to announce three new initiatives. Firstly, we are introducing Google Cloud skill badges which will recognize and help employers identify those of you with demonstrated Google Cloud technology skills. For experienced professionals, we’ve created new six-week learning paths to guide you through the certification preparation journey. Lastly, in response to overwhelming market demand, we’ve made remote certification exams available, so you can take your exam from home.
Show your growing cloud skillset with skill badges
Demonstrate your growing Google Cloud-recognized skillset to employers and share your progress with your network through exclusive digital Google Cloud skill badges. The digital badges are earned through completing labs and a rigorous hands-on skill test on Qwiklabs. We’ve made Qwiklabs available at no cost for 30 days through the end of 2020, making hands-on practice and skill building accessible to anyone interested in starting a career in cloud. We have several skill badges available now for beginners, such as deploying and managing cloud environments and performing foundational data, machine learning and AI tasks. Get started with free access to Qwiklabs and skill badges here.
Start your certification preparation journey
These six-week learning paths will outline recommended Google Cloud training to help experienced cloud professionals prepare for either the Associate Cloud Engineer, Professional Data Engineer, or the Professional Cloud Architect certifications. Through our training partner, Pluralsight, the first month of training will be available at no cost as well as 30 days of unlimited Qwiklabs access at no cost. To start, choose either the Associate Cloud Engineer, Professional Data Engineer, or Professional Cloud Architect certification, and we’ll send you a dedicated learning path with relevant training offers. If you’d like to prepare for certifications not covered by the learning paths, you can check out our latest offers for training courses here.
If you’re interested in mastering the ability to deploy applications, monitor operations, and manage enterprise solutions, the Associate Cloud Engineer learning path is for you. We recommend at least six months of hands on experience with Google Cloud before attempting the Associate Cloud Engineer exam.
To earn the Professional Data Engineer certification, you have to prove your expertise in designing, building, operationalizing, securing, and monitoring data processing systems. We recommend you have three or more years of cloud industry experience and at least one year of experience designing and managing solutions using Google Cloud prior to preparing for this certification.
The Google Cloud Professional Cloud Architect certification, which was ranked the highest-paying IT certification for the second year in a row in the US, is recommended for individuals with three or more years cloud industry experience, including at least one year of Google Cloud experience. The learning path for this certification will guide you through how to securely design, develop, and manage robust, scalable, highly available, and dynamic solutions to drive business objectives.
Take your certification exam
We know many of you have already prepared and are ready to take your certification exams but are unable to do so because exam centers around the world are closed in response to COVID-19. To help, we’re making online proctored testing available for three of our exams; Associate Cloud Engineer, Professional Data Engineer, and Professional Cloud Architect. You can learn more about online proctored testing here and register for exams here.
You can start earning your Google Cloud skill badges here. Already have some cloud experience and ready to begin your certification preparation journey? Sign up here to get started with your six-week learning plan.
Editor’s Note:This is the third post of a series highlighting the inspiring response to COVID-19 from the Google Maps Platform community. This week we’re focusing on how a variety of our partners and solution providers are offering services to help their end customers and communities worldwide. For a look back at projects that help individuals help others in their local communities, take a look at our last post.
With the onset of the COVID-19 pandemic, we noticed many of our technology partners and solution providers started offering their services for free, or began to work even more closely with their customers to develop solutions designed to help inform and support communities. Today we’re sharing a few examples of these partners and their customers who are helping drive innovation and creative projects to help people during these times.
Web Geo Services
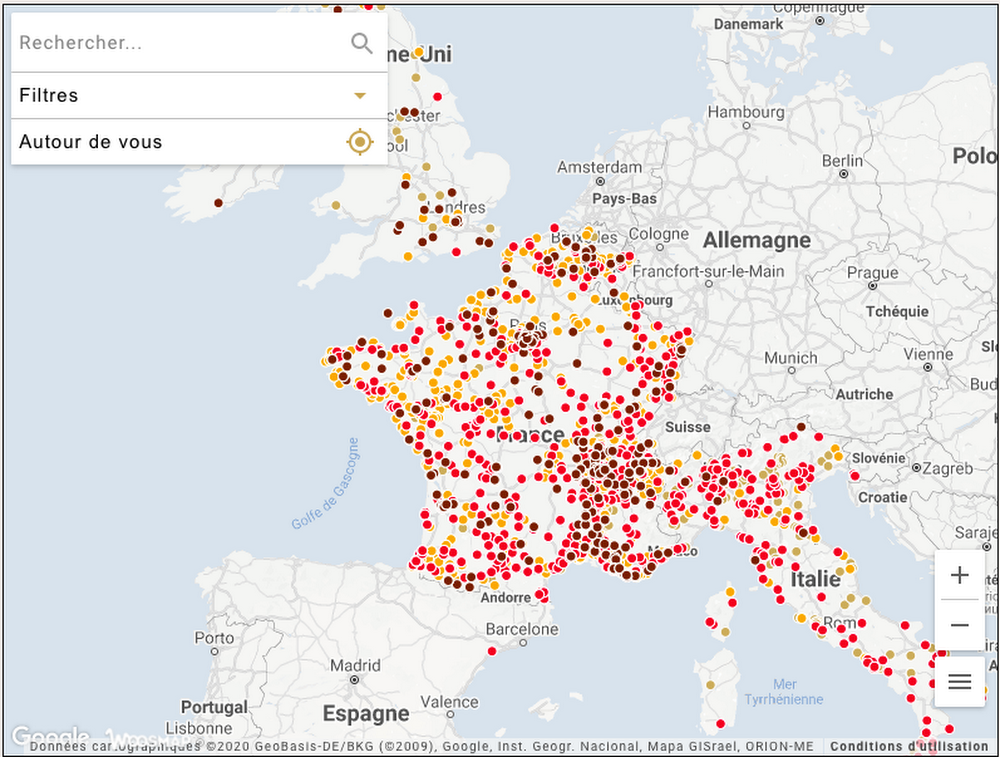
Web Geo Services, a Google Cloud Premier Partner with a focus in location innovation, works with customers across the retail, logistics, finance, transport and hospitality sectors. They created their own consumer geolocation platform, Woosmap, which offers location-based APIs that augment Google Maps Platform. When COVID-19 began to spread, the WebGeoServices team started offering services and access to the Woosmap platform free of charge for up to six months. Here are three recent projects that leverage Woosmap:
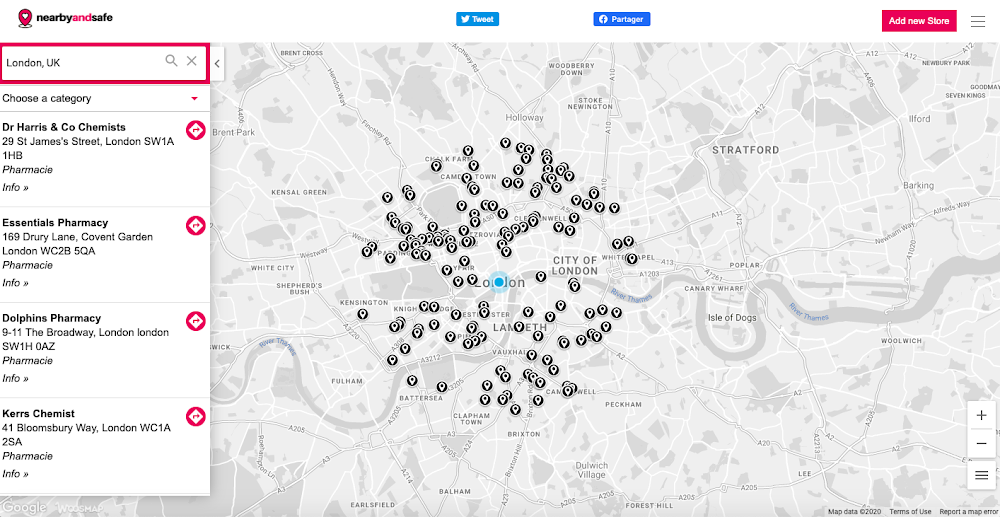
Born in Reggio Emilia during the italian lockdown at a time when individuals were staying home to help limit the spread of COVID-19, a team of 3 digital experts in Italy developed vicino-e-sicuro. The project is an interactive map of all businesses that offer home delivery or click & collect: groceries, restaurants, bakeries and other essential services. From there, the team partnered with Web Geo Services to access the Woosmap platform for free. They have since developed NearbyAndSafe in the UK and Proxisur in France providing tools to support citizens and local businesses. Citizens can choose the type of services they need, consult information on delivery methods and prices for the service, and contact the merchant directly. Merchants, by registering with vicino-e-sicuro, NearbyAndSafe or Proxisur, can increase their visibility for free.
Valrhona also worked with Web Geo Services to build their interactive pastry map which allows users to find local pastry chefs and artisans in the US and Europe who sell their pastries, chocolates, bread, and other sweets using social distancing. Food and pastry are at the heart of so many cultures. Through the map, they’re able to direct people to passionate, hard-working chefs, as they continue working hard to provide others with familiar foods during an uncertain time.
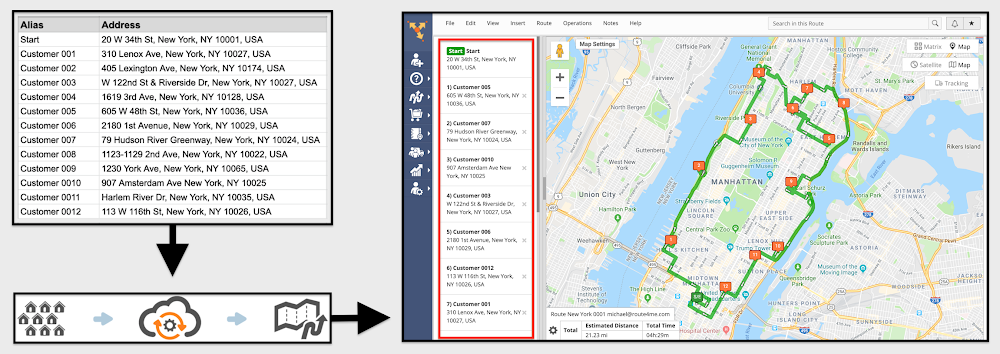
Route4Me
Earlier this year Route4Me started offering their service free of charge to all government agencies at the federal, city, and municipal level across the world to support their efforts. Route4Me provides a route planning and mapping system that lets businesses find the most optimal route between multiple destinations. The platform automatically plans routes for many people simultaneously, creates a detailed route manifest, a map with pins and route lines, driving (or walking) directions, and dispatches the route directly to any smartphone. Their service will be available as an unlimited free subscription until the peak of the Coronavirus threat to the public is over. Let’s look at two projects that used Route4Me to deliver support to local communities.
The Foodbank of Santa Barbara County is working to provide enough healthy food to everyone who needs it in Santa Barbara County. The foodbank created an initiative called Safe Access to Food for Everyone (SAFE) Food Net. Of the 50 SAFE Food Net distributions they’re operating, nearly 20 brand new emergency drive-thru food distributions make receiving healthy food fast, easy, discreet and safe. In addition, the service provides a home delivery service for seniors that provides enrollees with home food deliveries. They worked with Route4Me to establish routes for this rapidly-growing home delivery initiative. Annually, the Foodbank serves 20,000 low-income seniors across the county.
Maverick Landing Community Services (MLCS) is a multi-service organization with a primary focus on helping children, youth, and adults to build 21st-century skills within Maverick Landing, East Boston, and surrounding communities. The MLCS team developed a COVID-19 response plan that not only required communicating directly with the community, but also provided a way to meet the community’s needs. MLCS worked with Route4Me to develop and use route maximization technology to increase expediency, efficiency, and reduce their carbon footprint while delivering grocery bags to keep the community fed and safe.
Unqork
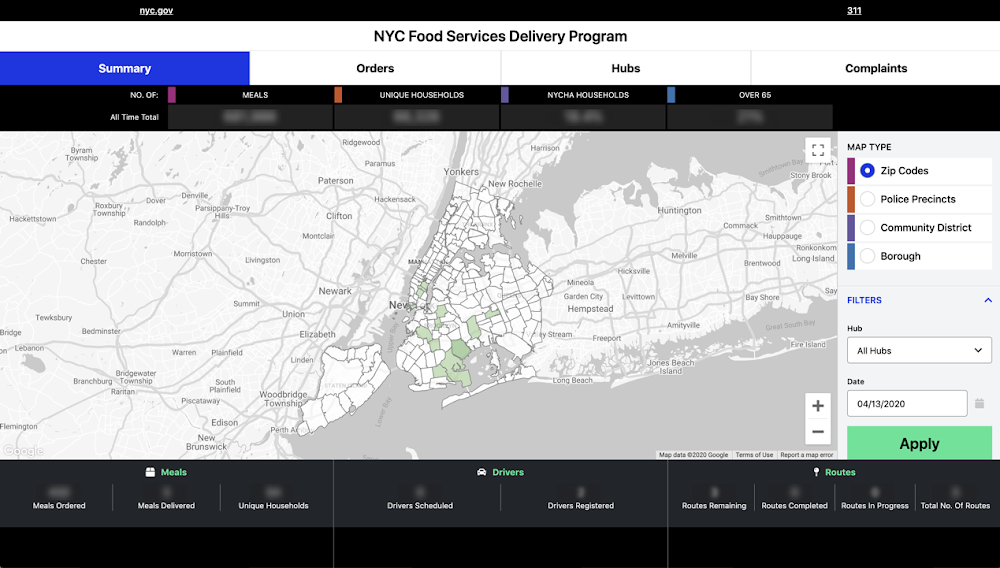
Unqork developed the COVID-19 Management Hub, a solution available to any major city to integrate into its crisis management practice. The COVID-19 Management Hub application automates real-time mapping of the COVID-19 risk, maintains communication with residents in need, delivers critical services including food, medicine and other supplies, and coordinates multi-agency response and dispatch efforts in a single operations dashboard. Unqork is currently working with cities, states, and counties including City of New York and Washington D.C. to help develop their COVID-19 Management Hub for city officials to manage the pandemic and provide access to critical information and resources. So far in New York the system has enabled the delivery of over 8 Million meals and the collection of over $125M in PPE for front-line workers.
To learn more about the core features of Google Maps Platform that can be useful for building helpful apps during this time, visit our COVID-19 Developer Resource Hub.
For more information on Google Maps Platform, visit our website.
Redis is one of the most popular open source in-memory data stores, used as a database, cache and message broker. There are several deployment scenarios for running Redis on Google Cloud, with Memorystore for Redis our integrated option. Memorystore for Redis offers the benefits of Redis without the cost of managing it.
It’s important to benchmark the system and tune it according to your particular workload characteristics before you expose it in production, even if that system depends on a managed service. Here, we’ll cover how you can measure the performance of Memorystore for Redis, as well as performance tuning best practices. Once you understand the factors that affect the performance of Memorystore for Redis and how to tune it properly, you can keep your applications stable.
Benchmarking Cloud Memorystore
First, let’s look at how to measure the benchmark.
Choose a benchmark tool There are a few tools available to conduct benchmark testing for Memorystore for Redis. The tools listed below are some examples.
In this blog post, we’ll use YCSB, because it has a feature to control traffic and field patterns flexibly, and is well-maintained in the community.
Analyze the traffic patterns of your application Before configuring the benchmark tool, it’s important to understand what the traffic patterns look like in the real world. If you have been running the application to be tested on Memorystore for Redis already and have some metrics available, consider analyzing them first. If you are going to deploy a new application with Memorystore for Redis, you could conduct preliminary load testing against your application in a staging environment, with Cloud Monitoring enabled.
To configure the benchmark tool, you’ll need this information:
The number of fields in each record
The number of records
Field length in each row
Query patterns such as SET and GET ratio
Throughput in normal and peak times
Configure the benchmark tool based on the actual traffic patterns When conducting performance benchmarks for specific cases, it’s important to design the content of the benchmark by considering table data patterns, query patterns, and traffic patterns of the actual system.
Here, we’ll assume the following requirements.
The table has two fields per row
The maximum length of a field is 1,000,000
The maximum number of records is 100 million
Query pattern of GET:SET is 7:3
Usual traffic is 1k ops/sec and peak traffic is 20k ops/sec
YCSB can control the benchmark pattern with the configuration file. Here’s an example using these requirements. (Check out detailed information about each parameter.)
The actual system contains various field lengths, but you can use only solid fieldlength with YCSB. So, configuring fieldlength=1,000,000 and recordcount=100,000,000 at the same time, the benchmark data size will be far from one of the actual systems.
In that case, run the following two tests:
The test in which fieldlength is the same as the actual system;
The test in which recordcount is the same as the actual system.
We will use the latter condition as an example for this blog post.
Test patterns and architecture
After preparing the configuration file, consider the test conditions, including test patterns and architecture.
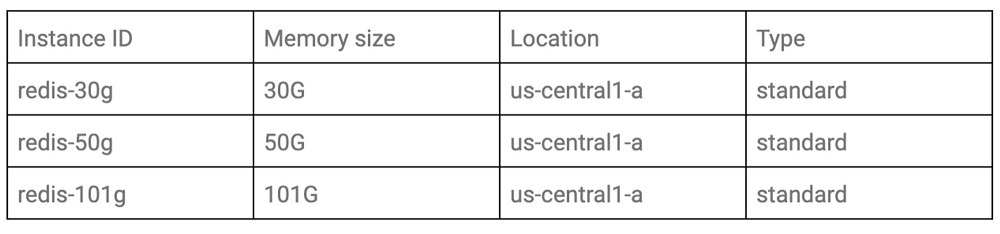
Test patterns If you’d like to compare performance with instances under different conditions, you should define the target condition. In this blog post, we’ll test with the following three patterns of memory size according to capacity tier.
Architecture You need to create VMs to run the benchmark scripts. You should select a sufficient number and machine types so that VM resources don’t become a bottleneck when benchmarking. In this case, we’d like to measure the performance of Memorystore itself, so VMs should be in the same zone as the target Memorystore to minimize the effect of network latency. Here’s what that architecture looks like:
Run the benchmark tool
With these decisions made, it’s time to run the benchmark tool.
Runtime options to control the throughput pattern You can control the client throughput by using both operationcount parameter in the configuration file, and the -target <num> command line option.
Here is an example of the execution command of YCSB:
The parameter operationcount=3000 is in the configuration file and running the above command. This means that YCSB sends 10 requests per second, and the number of total requests is 3,000. So YCSB throws 10 requests during 300sec.
You should run the benchmark with incremental throughput, as shown below. Note that a single benchmark run time should be somewhat longer in order to reduce the impact of outliers.:
Load benchmark data Before running the benchmark, you’ll need to load data to the Memorystore instance that you’re testing. Here is the example of a YCSB command for loading data:
Run benchmark Now that you have your data loaded and command chosen, you can run the benchmark test. Adjust the number of processes and instances to execute YCSB according to the load amount. In order to identify performance bottlenecks, you need to look at multiple metrics. Here are the typical indicators to investigate:
Latency YCSB outputs latency statistics such as average, min, max, 95th and 99th percentile for each operation such as READ(GET) and UPDATE(SET). We recommend using 95th percentile or 99th percentile for the latency metrics, according to customer service-level agreement (SLA).
Throughput You can use throughput for overall operation, which YCSB outputs.
Resource usage metrics You can check resource usage metrics such as CPU utilization, memory usage, network bytes in/out, and cache-hit ratio using Cloud Monitoring.
Performance tuning best practices for Memorystore
Now that you’ve run your benchmarks, you should tune your Memorystore using the benchmark results.
Depending on your results, you may need to remove a bottleneck and improve performance of your Memorystore instance. Since Memorystore is a fully managed service, various parameters are optimized in advance, but there are still items that you can tune based on your particular use case.
There are a few common areas of optimization:
Data storing optimizations
Memory management
Query optimizations
Monitoring Memorystore
Data storing optimizations
Optimizing the way to store data not only saves memory usage, but also reduces I/O and network bandwidth.
Compress data Compressing data often results in significant savings in memory usage and network bandwidth.
We recommend Snappy and LZO tools for latency-sensitive cases, and GZIP for maximum compression rate. Learn more details.
JSON to MessagePack Msgpack and protocol buffers have schemas like JSON and are more compact than JSON. And Lua scripts has support for MessagePack.
Use Hash data structure Hash data structure can reduce memory usage. For example, suppose you have data stored by the query SET “date:20200501” “hoge”. If you have a lot of data that’s keyed by such consecutive dates, you may be able to reduce the memory usage that dictionary encoding requires by storing it as HSET “month:202005” “01” “hoge”. But note that it can cause high CPU utilization when the value of hash-map-ziplist-entries is too high. See here for more details.
Keep instance size small enough The memory size of a Memorystore instance can be up to 300GB. However, data larger than 100GB may be too large for a single instance to handle, and performance may degrade due to a CPU bottleneck. In such cases, we recommend creating multiple instances with small amounts of memory, distributing them, and changing their access points using keys on the application side.
Memory management
Effective use of memory is important not only in terms of performance tuning, but also in order to keep your Memorystore instance running stably without errors such as out of memory (OOM). There are a few techniques you can use to manage memory:
Set eviction policies Eviction policies are rules to evict data when the Memorystore instance memory is full. You can increase the cache hit ratio by specifying these parameters appropriately. There are the following three groups of eviction policies:
Noeviction: Returns an error if the memory limit has been reached when trying to insert more data
Allkeys-XXX: Evicts chosen data out of all keys. XXX is the algorithm name to select the data to be evicted.
Volatile-XXX: evicts chosen data out of all keys with an “expire” field set. XXX is the algorithm name to select the data to be evicted.
volatile-lru is the default for Memorystore. Change the algorithm of data selection for eviction and TTL of data. See here for more details.
Memory defragmentation Memory fragmentation happens when the operating system allocates memory pages, which Redis cannot fully utilize after repeated write and delete operations. The accumulation of such pages can result in the system running out of memory and eventually causes the Redis server to crash.
If your instances run Redis version 4.0 or higher, you can turn on activedefrag parameter for your instance. Active Defrag 2 has a smarter strategy and is part of Redis version 5.0. Note that this feature is a tradeoff with CPU usage. See here for more details.
Upgrade Redis version As we mentioned above, activedefrag parameter is only available in Redis version 4.0 or later, and version 5.0 has a better strategy. In general, with the newer version of Redis, you can reap the benefits of performance optimization in many ways, not just in memory management. If your Redis version is 3.2, consider upgrading to 4.0 or higher.
Query optimizations
Since query optimization can be performed on the client side and doesn’t involve any changes to the instance, it’s the easiest way to optimize an existing application that uses Memorystore.
Note that the effect of query optimization cannot be checked with YCSB, so run your query in your environment and check the latency and throughput.
Use pipelining and mget/mset When multiple queries are executed in succession, network traffic caused by round trips can become a latency bottleneck. In such cases, using pipelining or aggregated commands such as MSET/MGET is recommended.
Avoid heavy commands on many elements You can monitor slow commands using slowlog command. SORT, LREM, and SUNION, which use many elements, can be computationally expensive. Check if there are problems with these slow commands, and if there are, consider reducing these operations.
Monitoring Memorystore using Cloud Monitoring
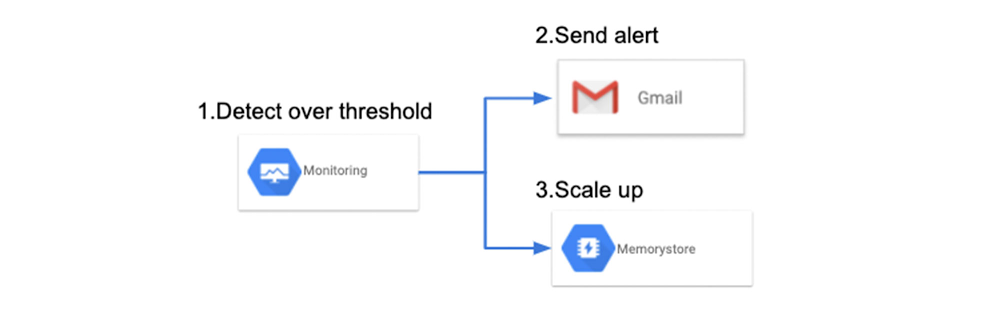
Finally, let’s discuss resource monitoring for predicting performance degradation of existing systems. You can monitor the resource status of Memorystore using Cloud Monitoring.
Even when you benchmark Memorystore before deploying, the performance of Memorystore in production may degrade due to various influences such as system growth and changes of usage trends. In order to predict such performance degradation at an early stage, you can create a system that will alert you or scale the system automatically, when the state of the resource exceeds a certain threshold.
Google Cloud is announcing the beta release of smart analytics frameworks for AI Platform Notebooks. Smart Analytics Frameworks brings closer the model training and deployment offered by AI Platform with the ingestion, preprocessing, and exploration capabilities of our smart analytics platform. With smart analytics frameworks for AI Platform Notebooks, you can run petabyte-scale SQL queries with BigQuery, generate personalized Spark environments with Dataproc Hub, and develop interactive Apache Beam pipelines to launch on Dataflow, all from the same managed notebooks service that provides Google Cloud AI Platform.
These new frameworks can help bridge the gap between cloud tools and bring a secure way to explore all kinds of data. Whether you’re sharing visualizations, presenting an analysis, or interacting with live code in more than 40 programming languages, the Jupyter notebook is the prevailing user interface for working with data. As data volumes grow and businesses aim to get more out of that data, there has been a rapid uptake in the types of data pipelines, data source availability, and plugins offered by these notebooks. While this proliferation of functionality has enabled data users to discover deep insights into the toughest business questions, the increased data analysis capabilities have been coupled with increased toil: Data engineering and data science teams spend too much time with library installations, piecing together integrations between different systems, and configuring infrastructure. At the same time, IT operators struggle to create enterprise standards and enforce data protections in these notebook environments.
Our new smart analytics frameworks for AI Platform Notebooks powers Jupyter notebooks with our smart analytics suite of products, so data scientists and engineers can quickly tap into data without the integration burden that comes with unifying AI and data engineering systems. IT operators can also rest assured that notebook security is enforced through a single hub, whether the data workflow is pulling data from BigQuery, transforming data with Dataproc, or running an interactive Apache Beam pipeline. End-to-end support in AI Platform Notebooks allows the modern notebook interface to act as the trusted gateway to data in your organization.
How to use the new frameworks
To get started with a smart analytics framework, go to the AI Platform Notebooks page in the Google Cloud Console. Select New Instance, then from the Data Analytics menu choose either Apache Beam or Dataproc Hub. The Apache Beam option will launch a VM that is pre-configured with an interactive environment for prototyping Apache Beam pipelines on Beam’s direct runner. The Dataproc Hub option will launch a VM running a customized JupyterHub instance that will spawn production-grade, isolated, autoscaling Apache Spark environments that can be pre-defined by administrators but personalized by each data user. All AI Notebooks Platform frameworks come pre-packaged with BigQuery libraries, making it easy to use BigQuery as your notebook’s data source.
Apache Beam is an open source framework that unifies batch and streaming pipelines so that developers don’t need to manage two separate systems for their various data processing needs. The Apache Beam framework in AI Platforms Notebooks allows you to interactively develop your pipelines in Apache Beam, using a workflow that simplifies the path from prototyping to production. Developers can inspect their data transformations and perform analytics on intermediate data, then launch onto Dataflow, a fully managed data processing service that distributes your workload across a fleet of virtual machines with zero to little overhead. With the Apache Beam interactive framework, it is easier than ever for Python developers to get started with streaming analytics, and setting up your environment is a matter of just a few clicks. We’re excited to see what this innovative community will build once they start adopting Apache Beam in notebooks and launching Dataflow pipelines in production.
In the past, companies have hit roadblocks along the cloud journey because it has been difficult to transition from the monolithic architecture patterns that are ingrained into Hadoop/Spark. Dataproc Hub makes it simple to modernize the inefficient multi-tenant clusters that were running on prem. With this new approach to Spark notebooks, you can provide users with an environment that data scientists can fully control and personalize in accordance with the security standards and data access policies of their company.
The smart analytics frameworks for AI Notebooks Platform is a publicly available beta that you can use now. There is no charge for using any of the notebooks. You pay only for the cloud resources you use within the instance: BigQuery, Cloud Storage, Dataproc, or Compute Engine.Learn more and get started today.
Apache Spark is commonly used by companies that want to explore large amounts of data and perform additional machine learning (ML)-related tasks at scale. Data scientists often need to examine these large datasets with the help of tools like Jupyter Notebooks, which plug into the scalable processing powerhouse that is Spark and also give them access to their favorite ML libraries. The new Dataproc Hub brings together interactive data research at scale and ML from within the same notebook environment (either from Dataproc or AI Platform) in a secure and centrally managed way.
With Google Cloud, you can use the following products to access notebooks:
Dataprocis a Google Cloud-managed service for running Spark and Hadoop jobs, in addition to other open source software of the extended Hadoop ecosystem. Dataproc also provides notebooks as an Optional Component and is securely accessible through the Component Gateway. Check out the process for Jupyter notebooks.
Although both of those products provide advanced features to set up notebooks, until now,
Data scientists either needed to choose between Spark and their favorite ML libraries or had to spend time setting up their environments. This could prove cumbersome and often repetitive. That time could be spent exploring interesting data instead.
Administrators could provide users with ready-to-use environments but had little means to customize the managed environments based on specific users or groups of users. This could lead to unwanted costs and security management overhead.
Data scientists have told us that they want the flexibility of running interactive Spark tasks at scale while still having access to the ML libraries that they need from within the same notebook and with minimum setup overhead.
Administrators have told us that they want to provide data scientists with an easy way to explore datasets interactively and at scale while still ensuring that the platform meets the costs and security constraints of their company.
We’re introducing Dataproc Hub to address those needs. Dataproc Hub is built on core Google Cloud products (Cloud Storage, AI Platform Notebooks and Dataproc) and open-source software (JupyterHub, Jupyter and JupyterLab).
Click to enlarge
By combining those technologies, Dataproc Hub:
Provides a way for data scientists to quickly select the Spark-based predefined environment that they need without having to understand all the possible configurations and required operations. Data scientists can combine this added simplicity with existing Dataproc advantages that include:
Agility provided by ephemeral (short-lived or job-scoped, usually) clusters that can start in seconds so data scientists don’t have to wait for resources.
Scalability: managed by autoscaling policies so scientists can run research on sample data and run tests at scale from within the same notebook.
Durability: backed by Cloud Storage outside of the Dataproc cluster, which minimizes chances of losing precious work.
Facilitates the administration of standardized environments to make it easier for both administrators and data scientists to transition to production. Administrators can combine this added security and consistency with existing Dataproc advantages that include:
Flexibility: implemented by initialization actions that run additional scripts when starting a cluster to provide data scientists with the libraries that they need.
Velocity: provided by custom images that minimize startup time through pre-install packages.
Availability: supported by multiple master nodes.
Getting started with Dataproc Hub
To get started with Dataproc Hub today, using the default setup:
4. Choose Dataproc Hub from the Smart Analytics Frameworks menu.
5. Create the Dataproc Hub instance that meets your requirements and fits the needs of the group of users that will use it.
6. Wait for the instance creation to finish and click on the OPEN JUPYTERLAB link.
7. This should open a page that shows you either a configuration form or redirects you to the JupyterLab interface. If this is working, keep note of the URL of the page that you opened.
8. Share the URL with the group of data scientists that you created the Dataproc Hub instance for. Dataproc Hub identifies the data scientist when they access the secure endpoint and uses that identity to provide them with their own single-user environment.
Predefined configurations
As an administrator, you can add customization options for data scientists. For example, they can select a predefined working environment from a list of configurations that you curated. Cluster configurations are declarative YAML files that you define by following these steps:
Store the YAML configuration files in a Cloud Storage bucket accessible by the identity of the instance that runs the Dataproc Hub interface.
Repeat this for all the configurations that you want to create.
Sets an environment variable with all the Cloud Storage URI of the relevant YAML files when creating the Dataproc Hub instance.
Note: If you provide configurations, a data scientist who accesses a Dataproc Hub endpoint for the first time will see the configuration form mentioned in Step 6 above. If they have a notebook environment running at the URL, Dataproc Hub will redirect them directly to their notebook.
Cloud Identity and Access Management (Cloud IAM) is central to most Google Cloud products and provides two main features for our purposes here:
Identity: defines who is trying to perform an action.
Access: specifies whether an identity is allowed to perform an action.
In the current version of Dataproc Hub, all spawned clusters use the same customizable service account, set up by following these steps:
An administrator provides a service account that will act as a common identity for all spawn Dataproc clusters. If not set, the default service account for Dataproc clusters is used.
When a user spawns their notebook environment on Dataproc, the cluster starts with that identity. Users do not need the roles/iam.serviceAccountUser role on that service account because Dataproc Hub is the one spawning the cluster.
Tooling optimizations
For additional tooling that you might want for your specific environment, check out the following:
Use Dataproc custom images in order to minimize the cluster startup time. You can automate this step by using the image provided by the Cloud Builder community. You can then provide the image reference in your cluster configuration YAML files.
Extend Dataproc Hub by using theDataproc Hub Github repository. This option runs your own Dataproc Hub setup on a Managed Instance Group, similar to the version hosted on AI Platform Notebooks but including additional customization capabilities, such as custom DNS, identity-aware proxy, high availability for the front end, and options for internal endpoint setup.
Both Dataproc Hub on AI Platform Notebooks and its extended version on Managed Instance Groups share the same open-sourced Dataproc Spawner and are based on JupyterHub. If you want to provide additional options to your data scientists, you can further configure those tools when you extend Dataproc Hub.
If you need to extend Dataproc Hub, the Github repository provides an example that sets up the following architecture using Terraform:
Click to enlarge
Next steps
Get familiar with the Dataproc spawner to learn how to spawn notebook servers on Dataproc.
Get familiar with the Dataproc Hub example code in Github to learn how to deploy and further customize the product to your requirements.
You’ve built a beautiful, reliable service, and your users love it. After the initial rush from launch is over, realization dawns that this service not only needs to be run, but run by you! At Google, we follow site reliability engineering (SRE) principles to keep services running and users happy. Through years of work using SRE principles, we’ve found there are a few common challenges that teams face, and some important ways to meet or avoid those challenges. We’re sharing some of those tips here.
In our experience, the three big sources of production stress are:
Toil
Bad monitoring
Immature incident handling procedures
Here’s more about each of those, and some ways to address them.
1. Avoid toil Toil is any kind of work tied to running a production service that tends to be manual, repetitive, automatable, tactical, devoid of enduring value, and that scales linearly as a service grows. This doesn’t mean toil has no business value; it does mean we have better ways to solve it than just manually addressing it every time.
Toil is pernicious. Without constant vigilance, it can grow out of control until your entire team is consumed by it. Like weeds in a garden, there will always be some amount of toil, but your team should regularly assess how much is acceptable and actively manage it. Project planners need to make room for “toil-killer” projects on an ongoing basis.
Some examples of toil are:
Ticket spam: an abundance of tickets that may or may not need action, but need human eyes to triage (i.e., notifications about running out of quota).
A service change request that requires a code change to be checked in, which is fine if you have five customers. However, if you have 100 customers, manually creating a code change for each request becomes toil.
Manually applying small production changes (i.e., changing a command line, pushing a config, clicking a button, etc.) in response to varying service conditions. This is fine if it’s required only once a month, but becomes toil if it needs to happen daily.
Regular customer questions on several repeated topics. Can better documentation or self-service dashboards help?
This doesn’t mean that every non-coding task is toil. For example, non-toil things include debugging a complex on-call issue that reveals a previously unknown bug, or consulting with large, important customers about their unique service requirements. Remember, toil is repetitive work that is devoid of enduring value.
How do you know which toilsome activities to target first? A rule of thumb is to prioritize those that scale unmanageably with the service. For example:
I need to do X more frequently when my service has more features
Y happens more as the size of service grows
The number of pages scale with the service’s resource footprint
And in general, prioritize automation of frequently occurring toil over complex toil.
2. Eliminate bad monitoring All good monitoring is alike; each bad monitoring is unique in its own way. Setting up monitoring that works well can help you get ahead of problems, and solve issues faster. Good monitoring alerts on actionable problems. Bad monitoring is often toilsome, and some of the ways it can go awry are:
Unactionable alerts (i.e., spam)
High pager or ticket volume
Customers asking for the same thing repeatedly
Impenetrable, cluttered dashboards
Service-level indicators (SLIs) or service-level objectives (SLOs) that don’t actually reflect customers’ suffering. For example, users might complain that login fails, but your SLO dashboard incorrectly shows that everything is working as intended. In other words, your service shouldn’t rely on customer complaints to know when things are broken.
Poor documentation; useless playbooks.
Discover sources of toil related to bad monitoring by:
Keeping all tickets in the same spot
Tracking ticket resolution
Identifying common sources of notifications/requests
Ensuring operational load does not exceed 50%, as prescribed in the SRE Book
3. Establish healthy incident management No matter the service you’ve created, it’s only a matter of time before your service suffers a severe outage. Before that happens, it’s important to establish good practices to lessen the confusion in the heat of outage handling. Here are some steps to follow so you’re in good shape ahead of an outage.
Practice incident management principles Incident management teaches you how to organize an emergency response by establishing a hierarchical structure with clear roles, tasks, and communication channels. It establishes a standard, consistent way to handle emergencies and organize an effective response.
Make humans findable In an urgent situation, the last thing you want is to scramble around trying to find the right human to talk to. Help yourselves by doing the following:
Create your own team-specific urgent situation mailing list. This list should include all tech leads and managers, and maybe all engineers, if it makes sense.
Write a short document that lists subject matter experts who can be reached in an emergency. This makes it easier and faster to find the right humans for troubleshooting.
Make it easy to find out who is on-call for a given service, whether by maintaining an up-to-date document or by writing a simple tool.
At Google, we have a team of senior SREs called the Incident Response Team (IRT). They are called in to help coordinate, mitigate and/or resolve major service outages. Establishing such a team is optional, but may prove useful if you have outages spanning multiple services.
Establish communication channels One of the first things to do when investigating an outage is to establish communication channels in your team’s incident handling procedures. Some recommendations are:
Agree on a single messaging platform, whether it be Internet Relay Chat, Google Chat, Slack, etc.
Start a shared document for collaborators to take notes in during outage diagnosis. This document will be useful later on for the postmortem. Limit permissions on this document to prevent leaking personally identifiable information (PII).
Remember that PII doesn’t belong in the messaging platform, in alert text, or company-wide accessible notes. Instead, if you need to share PII during outage troubleshooting, restrict permissions by using your bug tracking system, Google docs, etc.
Establish escalation paths It’s 2am. You’re jolted awake by a page. Rubbing the sleep from your eyes, you fumble around the dizzying array of multi-colored dashboards, and realize you need advice. What do you do?
Don’t be afraid to escalate! It’s OK to ask for help. It’s not good to sit on a problem until it gets even worse—well-functioning teams rally around and support each other.
Your team will need to define its own escalation path. Here is an example of what it might look like:
If you are not the on-call, find your service’s on-call person.
If the on-call is unresponsive or needs help, find your team lead (TL) or manager. If you are the TL or manager, make sure your team knows it’s OK to contact you outside of business hours for emergencies (unless you have good reasons not to).
If a dependency is failing, find that team’s on-call person.
If you need more help, page your service’s panic list.
(optional) If people within your team can’t figure out what’s wrong or you need help coordinating with multiple teams, page the IRT if you have one.
Write blameless postmortems After an issue has been resolved, a postmortem is essential. Establish a postmortem review process so that your team can learn from past mistakes together, ask questions, and keep each other honest that follow-up items are addressed appropriately.
The primary goals of writing a postmortem are to ensure that the incident is documented, that all contributing root cause(s) are well-understood, and that effective preventive actions are put in place to reduce the likelihood and/or impact of recurrence.
All postmortems at Google are blameless postmortems. A blameless postmortem assumes that everyone involved had good intentions and responded to the best of their ability with the information they had. This means the postmortem focuses on identifying the causes of the incident without pointing fingers at any individual or team for bad or inappropriate behavior.
Recognize your helpers It takes a village to run a production service reliably, and SRE is a team effort. Every time you’re tempted to write “thank you very much for doing X” in a private chat, consider writing the same text in an email and CCing that person’s manager. It takes the same amount of time for you and brings the added benefit of giving your helper something they can point to and be proud of.
May your queries flow and the pager be silent! Learn more in the SRE Book and the SRE Workbook.
Thanks to additional contributions from Chris Heiser and Shylaja Nukala.
Against a backdrop of continuous change, I’ve been struck by what remains constant—our partner ecosystem and customers are teaming with us across various industries and geographies to help people in incredible ways during this time. Together, we’re helping hospitals acutely impacted by COVID-19, retailers and grocers address dramatic shifts in consumer behavior, employees rapidly adjust to working at home, and IT teams ensure critical systems stay up and running.
Over the last few weeks, I’ve witnessed many individuals across Google Cloud and our partner ecosystem working hand-in-hand to collaborate, innovate, and do what is needed to help our customers. In today’s post, I will share a few examples of the agility and ingenuity across our partners and customers that have inspired us in recent weeks.
Helping healthcare providers address the pandemic
At the onset of COVID-19, healthcare and life sciences organizations faced strains upon their workforce, supply chains, and IT systems, and were tasked with keeping people around the world healthy. Below are just a few examples of how Google Cloud partners have helped these important organizations keep key teams connected and leverage data in their responses to COVID-19.
In São Paulo, our partner Loud Voice Services helped Hospital das Clínicas develop a voice assistant that manages the flow of scheduling appointments, exams, and medication administration using Google Cloud’s Speech API. This service helped Hospital das Clínicas respond virtually to certain requests, helping to reduce crowding in its facilities each day and improve safety practices for its patients and staff. Said Hospital das Clínicas Corporate Technology Director, Vilson Cobello Junior, “This project will allow the prioritization of the most critical patients who needed to be evaluated in person.”
Our partner SADA worked with HCA Healthcare to develop the COVID-19 National Response Portal, helping healthcare providers across the country share important data on ICU bed utilization, ventilator availability, and COVID-19 cases. “The National Response Portal is unique in the combination of data and technology it will bring together,” says Michael Ames, Senior Director of Healthcare and Life Sciences at SADA “The goal of the collaboration between SADA, HCA Healthcare, and Google Cloud is to provide the tools necessary to understand, manage, and end the COVID-19 pandemic.”
Google Cloud partner Maven Wave, an Atos Company, helped Amedisys, a leading provider of home health, hospice and personal care, build a chatbot using Dialogflow,the conversational AI platform that powers Contact Center AI, to allow employees to self-screen and report symptoms of COVID-19 through a simple voice interface. The chatbot can also provide Amedisys employees with up-to-date information on COVID-19, helping promote the safety of both patients and employees.
Supporting public sector responses to the pandemic
During the pandemic, governments and public sector agencies around the globe have been tasked with maintaining and expanding critical services, such as unemployment benefits and insurance, while keeping employees safe. We’re proud that our partners are providing key solutions and support to these public sector customers, including:
2020 unemployment claims in the State of Illinois are five times greater than the claims filed in the first weeks of the 2008 recession. To help the state manage this increase in inquiries, Quantiphi and Carahsoft, two Google Cloud services and software partners, used Google Cloud Contact Center AI to build a 24/7 chatbot capable of immediately answering frequently asked questions from people filing for unemployment. So far, this chatbot has been able to process and respond to over 3.2 million inquiries from filers, allowing the state to provide necessary information quickly and effectively to those in need of government assistance.
In the UK, Google Cloud Partner Ancoris helped Hackney Council, a government authority in East London, migrate to G Suite to help increase collaboration among its employees. When London began sheltering in place, the Council’s new collaboration tools became essential to the Hackney community. “In the first week of working from home, we saw a 700% increase in the use of Google Meet, which staff were using to work collaboratively in teams, even when apart,” says Henry Lewis, Head of Platform at Hackney Council. This enabled the Council to continue delivering its residents and businesses a wide range of essential services, including waste collection, housing assistance, and social care.
Helping educational institutions stay connected and accelerate research during COVID-19
In response to COVID-19, educators have had to quickly enable remote or work-from-home scenarios, while researchers quickly looked for ways to apply cloud computing capabilities to their search for effective therapies. Many universities began implementing technologies from Google Cloud and from our partners to enable remote work and to help accelerate important research, including:
Google Cloud and our partner Palo Alto Networks are enabling faculty, students and staff at Princeton University to stay securely connected to on campus resources, even when off campus. Palo Alto Networks partnered with the university’s Office of Information Technology to replace a legacy VPN solution with Prisma Access on Google Cloud, a solution that can secure remote access to the university community’s resources. Now, over 2,000 members of the university community are actively engaged in teaching, learning, research and administrative opportunities in a secure and scalable manner while being away from the Princeton campus.
Harvard University built VirtualFlow, an open-source drug discovery platform on Google Cloud, using our technology partner SchedMD’s Slurm platform to help accelerate research on COVID-19 treatment options. Now, Harvard is able to speed and scale up its testing of compounds to more quickly identify promising therapies to enter clinical trials.
Enabling financial services firms to support their clients
Financial services firms have had to maintain uptime and reliability of critical infrastructure while providing important products and services to their customers and the economic system at large. Our partners around the world are helping many of these institutions leverage Google Cloud technologies to do so.
In India, CMS Info Systems, a cash and payments solutions company, developed a program to provide cash to seniors at their homes. The company leveraged our partner MediaAgility’s Dista platform, built on Google Cloud and Google Maps Platform, to automate cash logistics workflow, provide real-time visibility of operations, and pick-up and deposit confirmation. This partnership will allow CMS Info Systems to ensure safe availability of cash and essential services for their more vulnerable customers during shelter-in-place procedures.
Google Cloud Partner Injenia helped Italian financial services provider Credem leverage G Suite and Google Meet to ensure business continuity during the pandemic. The bank is using collaboration tools like Drive and Docs to help employees adapt to the work-from-home environment around the country. Credem is also using Google Meet for seamless video conferencing to engage with its customers remotely accessing the bank’s consultancy.
Supporting companies in retail, media, and other industries
Many businesses, especially retail firms, telecommunications organizations, and media companies have had to address rapid shifts in consumer habits. To manage these shifts, it was critical to keep important teams connected, to leverage data to meet their customers’ needs, and ultimately to maintain business continuity. We’re proud that many of our partners have been key to helping these customers.
Due to the pandemic, TELUS International, a leading provider of customer experience and digital IT services, quickly transitioned tens of thousands of its employees to a work-from-home model. Many of these employees typically log into a desktop to access company software to connect with customers over voice, email and chat. Google Cloud Partner itopia helped TELUS International deploy a fully-configured virtual desktop environment in just 24 hours, allowing employees to remain connected and provide much needed service support to their clients. “Working with Google Cloud and itopia allowed us to transition key parts of our workforce—securely, globally and resiliently—all while keeping our team members engaged in what will certainly become part of the ‘new norm.,” says Jim Radzicki, CTO, TELUS International.
In Belgium, DPG Media, a leading media group in Benelux, wanted to limit the number of producers in their studios, while empowering them to create content from home. Google Cloud Partner g-company helped DPG Media migrate to G Suite to make this possible. With Google Meet, radio DJs can now facilitate the same fluid conversations between hosts during a broadcast, even with everyone working remotely in their home studios.
Grocery delivery wholesaler Boxed has seen increased demand for their goods and services during the COVID-19 pandemic. With essential supplies quickly coming in and out of availability, they needed a highly scalable database platform to manage their real-time supply chain and traffic levels. They collaborated with Google Cloud partner MongoDB to migrate their data to MongoDB Atlas on Google Cloud to help increase the scalability of their database and meet rising demand.
In Germany, our partner Cloudwürdig helped Burger King Germany roll out G Suite for its corporate employees, enabling them to more seamlessly work from home and maintain consistent operations across more than 700 restaurant locations. In fact, all of Burger King Germany’s internal meetings are being hosted over Google Meet during the pandemic. “We’re big fans of Google Meet. The speech quality is good and it’s helpful to be able to see every participant,” says Oliver Mielentz, Senior Manager IT, Burger King Deutschland GmbH. “This is extremely helpful these days.”
Looking ahead
I’d like to extend a heartfelt thanks to the many people behind the scenes across our partners, customers, and within Google Cloud who are working together to enable business continuity in so many key areas of our communities today. As many of us are juggling more than we ever have before, on both the personal and professional front, I’m especially struck at how our partners and customers are stepping up to the current challenges at hand.
Within our team, our commitment to you is stronger than ever—we’ll be right there alongside you, every step of the way as we help move businesses, and the world, forward.
“The SharePoint Framework (SPFx) is a page and web part model that provides full support for client-side SharePoint development, easy integration with SharePoint data, and support for open source tooling.” – as Microsoft writes on its official documentation site. https://docs.microsoft.com/en-us/sharepoint/dev/spfx/sharepoint-framework-overview
The dark side of this story is that, SPFx is very under documented. 🙁 This means you can’t find really good examples like case studies for Azure. Therefore when you should do a simple solution which creates at least 2 lists with a Lookup field between them, you are in trouble, because Microsoft doesn’t spend enough time to provide you a great documentation.
Luckily, I must solve this and my ambition pushes me toward the solution. After several days (in this case 6 working days), I spent in front of my laptop and tried to collect the crumbs of the information from the Internet…I made it. And now I would like to share it with you to avoid the sucks if you have to do this stuff. 🙂
Our target for Today to create an SPFx based app to SharePoint online which creates 2 lists with a Lookup field.
Step 1: Prepare the solution in Visual Studio code
For this the Microsoft provides a quite good overview documentation. Nevertheless I put here some extra steps for the better result.
Configure msvs_version. This depends on your computer so you can use the following version related configurations. Choose one which works for you: npm config set msvs_version 2017 or npm config set msvs_version 2019
Now you can start to create your solution.
Step 2: Create basic project/solution in Visual Studio code
Open the root directory of your development location on your computer.
Create a directory for your solution. Today this would be multiple-lists-spfx
Step into the newly created directory
Open Visual Studio code on this directory From PowerShell: code . From Windows explorer: Open with Code
Open a Terminal, then enter the following command: yo @microsoft/sharepoint
Preconfigure the project:
Accept the default multiple-lists-spfx as your solution name, and then select Enter.
Select SharePoint Online only (latest), and then select Enter.
Select Use the current folder as the location for the files.
Select N to require the extension to be installed on each site explicitly when it’s being used.
Select N on the question if solution contains unique permissions.
Select WebPart as the client-side component type to be created.
Web part name: MultipleLists
Web part description: MultipleLists description
Accept the default No JavaScipt framework option for the framework, and then select Enter to continue.
At this point, Yeoman installs the required dependencies and scaffolds solution files. It takes several minutes.
Post-configuration / additional checks
1. Open gulpfile.js and replace its content to the following – to use gupl as a global variable
'use strict';
const gulp = require('gulp');
const build = require('@microsoft/sp-build-web');
build.addSuppression(`Warning - [sass] The local CSS class 'ms-Grid' is not camelCase and will not be type-safe.`);
build.initialize(gulp);
2. Open package.json and check gulp version. Do not use the latest gulp version, because that doesn’t work well with SPFx. Use this exact version
"gulp": "~3.9.1"
3. Create the following folder structure to root folder
sharepoint
- assets
- solution
4. Check if deasync was blocked by your Anti-Virus software or not. If yes, please execute these
npm install deasync@0.1.19
cd node_modules\deasync
node .\build.js
cd ../..
5. Trusting the self-signed developer certificate. (this also tests the whole of your project/solution configuration such as gulp version, deasync)
gulp trust-dev-cert
6. Install Insert GUID extension for Visual Studio Code. With this you can easily generate GUIDs for:
Guide instructions for the future:
For content types. Item related content type id: 0x0100 + <Insert GUID – 5>
For Filed id: 0x0100 + <Insert GUID – 2>
For id’s in package-solution.json: 0x0100 + <Insert GUID – 1>
Done 🙂
Step 3: Create your List creation code
This is the most important part. The others above are “only” the preparation. You can apply this part in case of any type of client-side component such as WebPart and Extension.
1. After you created you basic project/solution, please create the following files into sharepoint/assets directory
elements.xml: this contains the site columns, content types and list instance definitions
primarySchema.xml: this contains the primary list related definitions, such as views and forms
secondarySchema.xml: this contains the secondary list related definitions, such as views and forms
2. Now start to edit elements.xml
<?xml version="1.0" encoding="utf-8"?>
<Elements xmlns="http://schemas.microsoft.com/sharepoint/">
<!-- IsActive global field -->
<Field ID="{9b9df7c1-8dca-4954-90c1-8dcf131e30af}" Name="IsItActive" DisplayName="Active" Type="Boolean" Required="FALSE" Group="CloudSteak Columns" />
<!-- Content type for Secondary list -->
<ContentType ID="0x010036ee6af136ed47a48c82fb0916a627ba" Name="SecondaryCT" Group="CloudSteak Content Types" Description="Sample content types from web part solution">
<FieldRefs>
<FieldRef ID="{9b9df7c1-8dca-4954-90c1-8dcf131e30af}" />
</FieldRefs>
</ContentType>
<!-- Secondary list -->
<ListInstance CustomSchema="secondarySchema.xml" FeatureId="00bfea71-de22-43b2-a848-c05709900100" Title="Secondary" Description="Secondary List" TemplateType="100" Url="Lists/Secondary">
</ListInstance>
<!-- Lookup field for Secondary list -->
<Field ID="{B2C98746-DE9D-4878-90C1-D3749881790F}" Name="SecondaryLookup" DisplayName="Secondary" Type="Lookup" ShowField="Title" List="Lists/Secondary" Required="TRUE" Group="CloudSteak Columns" />
<!-- Content type for Primary lists -->
<ContentType ID="0x010042D013E716C0B03B457EB2E6699537B99CFE" Name="PrimaryCT" Group="CloudSteak Content Types" Description="Sample content types from web part solution">
<FieldRefs>
<FieldRef ID="{B2C98746-DE9D-4878-90C1-D3749881790F}" />
</FieldRefs>
</ContentType>
<!-- Primary list -->
<ListInstance CustomSchema="primarySchema.xml" FeatureId="00bfea71-de22-43b2-a848-c05709900100" Title="Primary" Description="Primary List" TemplateType="100" Url="Lists/Primary">
</ListInstance>
</Elements>










.svg")




















