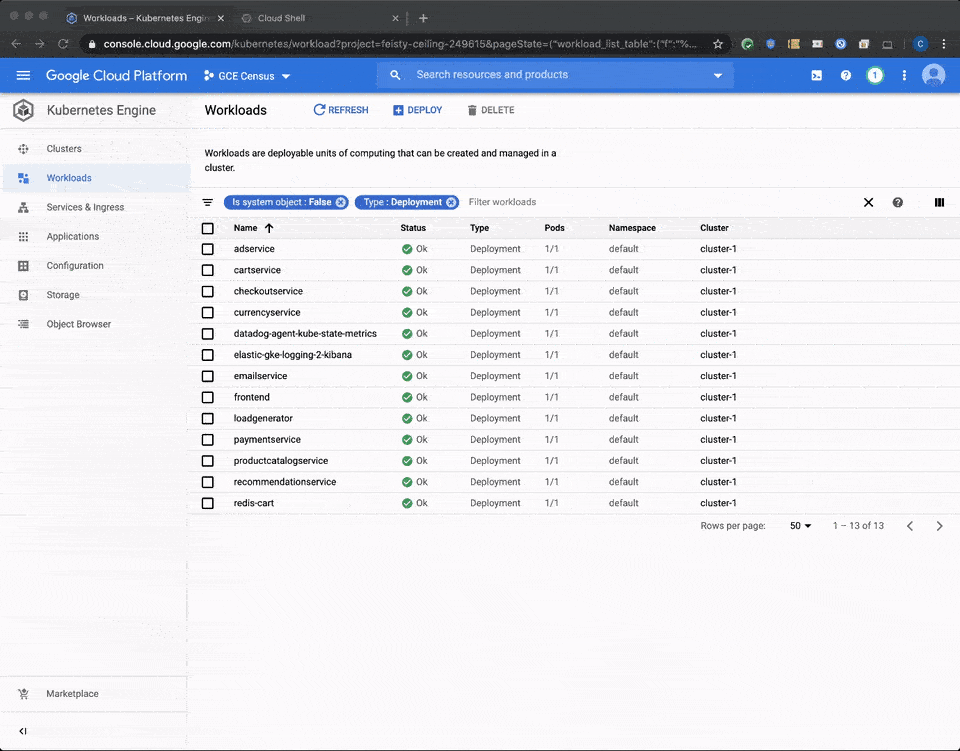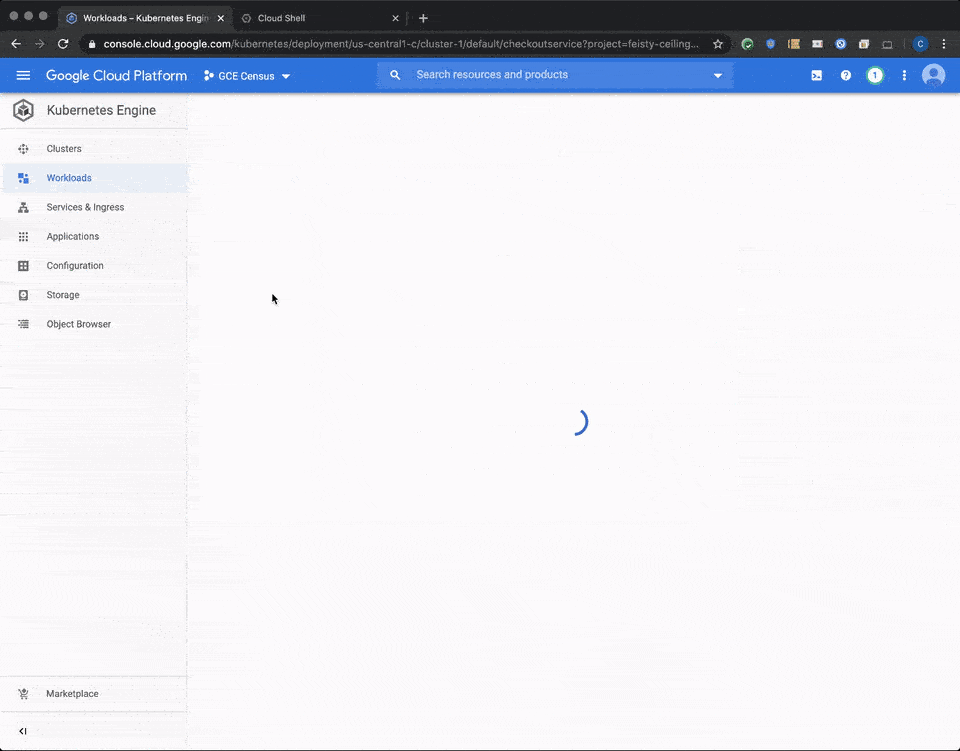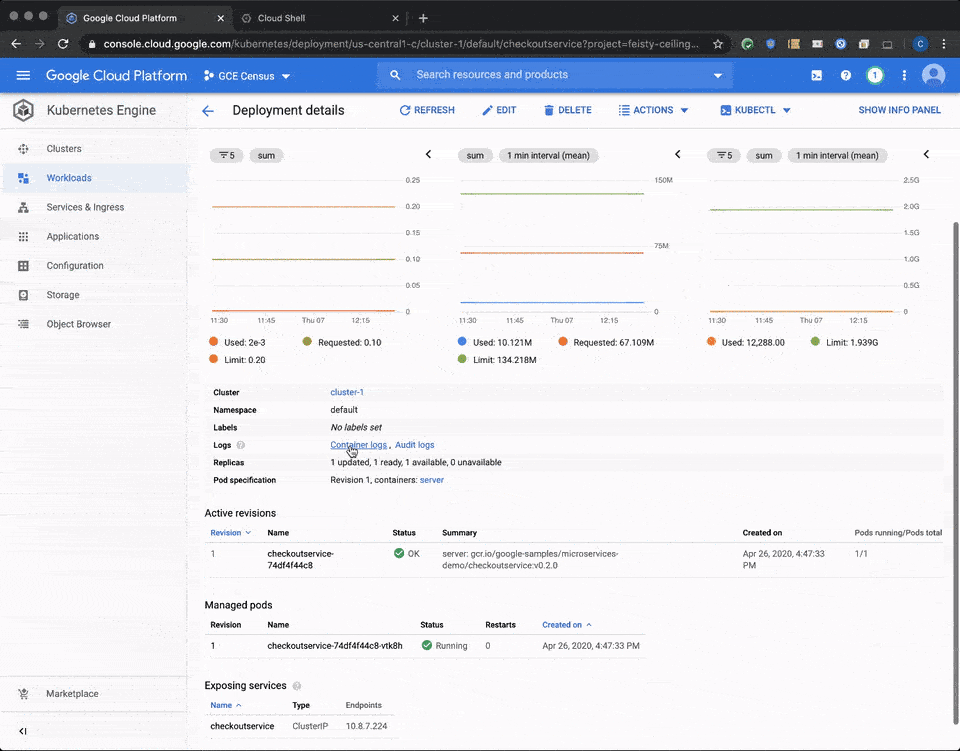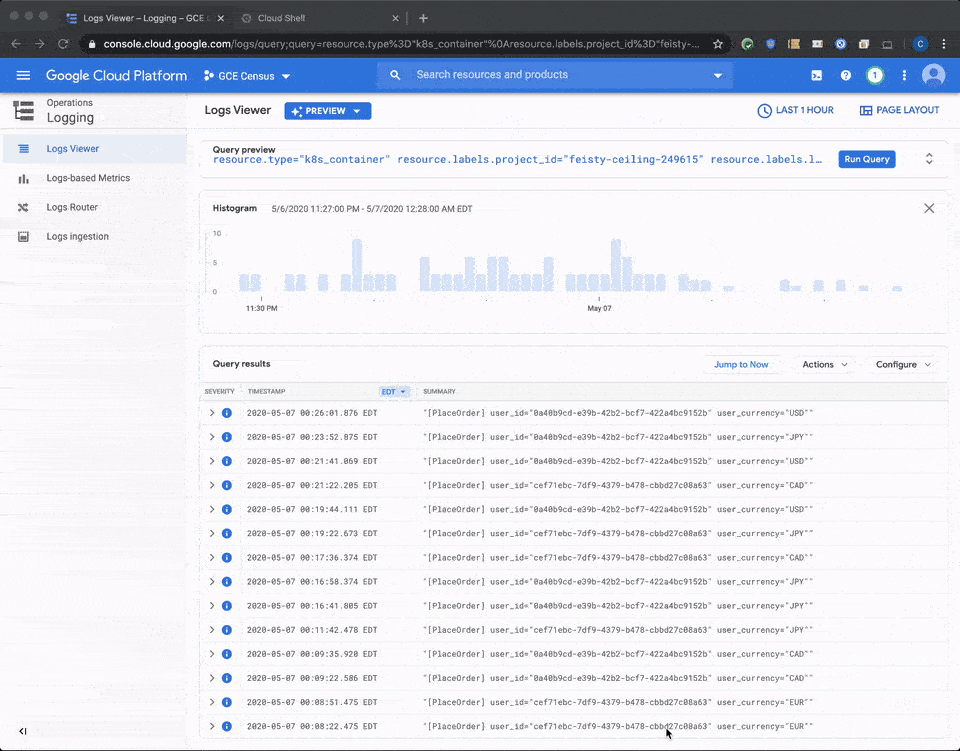
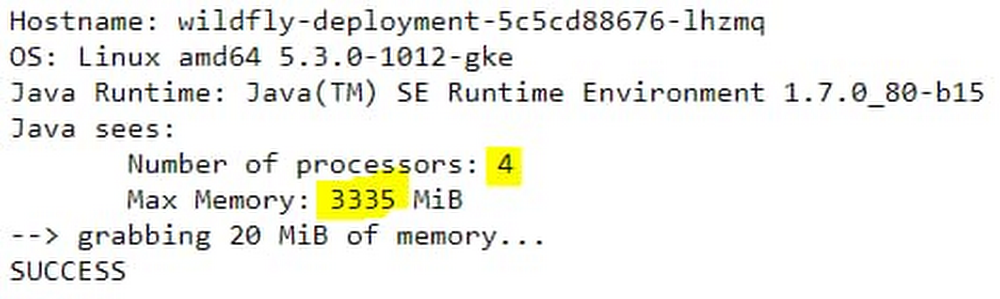
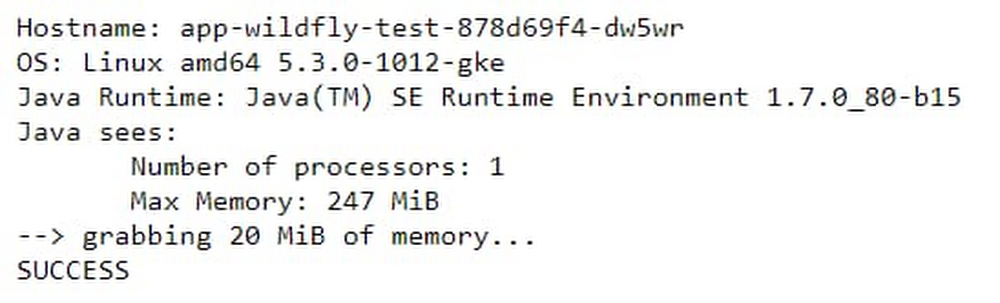
You can immediately see a difference between the results. In the standard container, as already reported in many such tests, Java reports resource values from the host node, and not from the container resource allocations. In the standard container, the reported maximum heap size is derived from Java 7’s sizing algorithm, which, by default, is one quarter of the host’s physical memory. However, in this case of the Migrate for Anthos migrated container, the values are reported correctly.
You can see a similar impact when querying the Java Garbage Collection (GC) threading plan. Connect to shell, and run:
java -XX:+PrintFlagsFinal -version | grep ParallelGCThreads
On the standard container, you get:
uintx ParallelGCThreads = 4 {product}
But on the migrated workload container, you get:
uintx ParallelGCThreads = 0 {product}
So here as well, you see the correct concurrency from the Migrate for Anthos container, but not in the standard container.
Now let’s see the impact of these differences under load. We generate application load using Hey. For example, the following command generates application load for two minutes, with a request concurrency of 50:
./hey_linux_amd64 -z 2m http://##.###.###.###:8080/node-info/
Here are the test results with the standard container:
Status code distribution:
[200] 332 responses
[404] 8343 responses
Error distribution:
[29] Get http://##.###.###.###:8080/node-info/: EOF
[10116] Get http://##.###.###.###:8080/node-info/: dial tcp ##.###.###.###:8080: connect: connection refused
[91] Get http://##.###.###.###:8080/node-info/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers
This is a clear indication that the service is not handling the load correctly, and indeed when inspecting the container logs, we see multiple occurrences of
*** JBossAS process (79) received KILL signal ***
This is due to an out-of-memory (OOM) error. The Kubernetes deployment took care of automatically restarting the OOM-killed container, during which time the service was unavailable. The reason for this is a miscalculated Java heap size from considering the host resources, instead of the container resource constraints. When not calculated right, Java tries to allocate more memory than available and therefore gets killed, disrupting the app.
In contrast, executing the same load test on the container migrated with Migrate for Anthos results in:
Status code distribution:
[200] 1676 responses
[202] 76 responses
This indicates the application handled the load successfully even when memory pressure was high.
Unlock the power of containers for your legacy apps
We showed how Migrate for Anthos automatically augments a known container resource visibility issue in Kubernetes. This helps ensure that legacy applications that run on older Java versions behave correctly after being migrated, without having to manually tune or reconfigure them to fit dynamic constraints applied through the Kubernetes Pod specs. We also demonstrated how the legacy application remains stable and responsive under memory load, without experiencing errors or restarts.
With this feature, Migrate for Anthos can help you harness the benefits of containerization and container orchestration with Kubernetes, to modernize your operations and management of legacy applications. You’ll be able to leverage the power of CI/CD with image-based management, non-disruptive rolling updates, and unified policy and application performance management across cloud native and legacy applications, without requiring access to source code or application rewrite.
For more information, see our original release blog that outlines support for day-two operations and more or fill out this form for more info (please mention ‘Migrate for Anthos’ in the comment box).