Today, AWS Resource Groups is adding support for an additional 405 resource types for tag-based Resource Groups. Customers can now use Resource Groups to group and manage resources from services such as Bedrock, Chime, and Quicksight.
AWS Resource Groups enables you to model, manage and automate tasks on large numbers of AWS resources by using tags to logically group your resources. You can create logical collections of resources such as applications, projects, and cost centers, and manage them on dimensions such as cost, performance, and compliance in AWS services such as myApplications, AWS Systems Manager and Amazon CloudWatch.
Resource Groups expanded resource type coverage is available in all AWS Regions, including the AWS GovCloud (US) Regions. You can access AWS Resource Groups through the AWS Management Console, the AWS SDK APIs, and the AWS CLI.
Amazon RDS for SQL Server now offers enhanced control over backup and restore operations with new custom parameters. This update allows database administrators to fine-tune their processes, potentially improving efficiency and reducing operation times. The new parameters are available for the rds_backup_database, rds_restore_database, and rds_restore_log stored procedures.
You can now specify the BLOCKSIZE, MAXTRANSFERSIZE, and BUFFERCOUNT parameters for backup and restore operations. These granular controls can help optimize performance based on your specific database characteristics and workload patterns. These customizable parameters are particularly useful when customer backups are incompatible with the default settings used by Amazon RDS for SQL Server. By allowing users to fine-tune these performance-related factors, the feature provides greater flexibility to accommodate unique database requirements and operating environments.
Customers can specify these new parameters in all AWS commercial Regions where Amazon RDS for SQL Server databases are available, including the AWS GovCloud (US) Regions.
Amazon RDS makes it simple to set up, operate, and scale SQL Server deployments in the cloud. See Amazon RDS for SQL Server Pricing for up-to-date pricing of instances, storage, data transfer and regional availability.
2024 has been a landmark year for Google Earth Engine, marked by significant advancements in platform management, cloud integration, and core functionality. With increased interoperability between Google Cloud tools and services, and Earth Engine, we’ve unlocked powerful new workflows and use cases for our users. Here’s a round up of this year’s top Earth Engine launches, many of which were highlighted in our Geo for Good 2024 summit.
Earlier this year, we launched the new Earth Engine Overview page in the Cloud Console, serving as a centralized hub for Earth Engine resources, allowing you to manage Earth Engine from the same console used to manage and monitor other Cloud services.
In this console, we also introduced a new Tasks page, allowing you to view and monitor Earth Engine export and import tasks alongside usage management and billing. The Tasks page provides a useful set of fields for each task, including state, runtime, and priority. Task cancellation is also easier than ever with single or bulk task cancellation in this new interface.
As we deepen Earth Engine’s interoperability across Google Cloud, we’ll be adding more information and controls to the Cloud Console so that you can further centralize the management of Earth Engine alongside other services.
Integrations: deepening cloud interoperability
Earth Engine users can integrate with a number of cloud services and tools to enable advanced solutions requiring custom machine learning and robust data analytics. This year, we launched a set of features that improved existing interoperability, making it easier to both enable and deploy these solutions.
Vertex AI integration Using Earth Engine with Vertex AI enables use cases that require deep learning, such as crop classification. You can host a model in Vertex AI and get predictions from within the Earth Engine Code Editor. This year, we announced a major performance improvement to our Vertex Preview connector, which will give you more reliability and more throughput than the current Vertex connector.
Earth Engine access To ensure all Earth Engine users can take advantage of these new integration improvements and management features, we’ve also transitioned all Earth Engine users to Cloud projects. With this change, all Earth Engine users can now leverage the power and flexibility of Google Cloud’s infrastructure, security, and growing ecosystem of tools to drive forward the science, research, and operational decision making required to make the world a better place.
Security: enhancing control
This year we launched Earth Engine support for VPC Service Controls – a key security feature that allows organizations to define a security perimeter around their Google Cloud resources. This new integration, available to customers with professional and premium plans, provides enhanced control over data, and helps prevent unauthorized access and data exfiltration. With VPC-SC, customers can now set granular access policies, restrict data access to authorized networks and users, and monitor and audit data flows, ensuring compliance with internal security policies and external regulations.
Platform: improving performance
Zonal Statistics Computing statistics about regions of an image is a core Earth Engine capability. We recently launched a significant performance improvement to batch zonal statistics exports in Earth Engine. We’ve optimized the way we parallelize zonal statistics exports, such as exports that generate statistics for all regions in a large collection. This means that you will get substantially more concurrent compute power per batch task when you use ReduceRegions().
With this launch, large-scale zonal statistics exports are running several times faster than this time last year, meaning you get your results faster, and that Earth Engine can complete even larger analyses than ever. For example, you can now calculate the average tree canopy coverage of every census tract in the continental United States at 1 meter scale in 7 hours. Learn more about how we sped up large-scale zonal statistics computations in our technical blog post.
Python v1 Over the last year, we’ve focused on ease-of-use, reliability, and transparency for Earth Engine Python. The client library has moved into an open-source repository at Google which means we can sync changes to GitHub immediately, keeping you up-to-date on changes between releases. We are also sharing pre-releases, so you can see and work with Python library candidate releases before they come out. We have a static loaded client library, which makes it easier to build on our Python library and better testing and error messaging. We’ve also continued making progress on improving geemap and integrations like xee.
With all of these changes, we’re excited to announce that the Python Client library is now ‘v1’, representing the maturity of Earth Engine Python. Check out this blog post to read more about these improvements and see how you can take full advantage of Python and integrate it into Google’s Cloud tooling.
COG-backed asset improvements If you have data stored in Google Cloud Storage (GCS), in Cloud-Optimized GeoTIFF (COG) format, you can easily use it in Earth Engine via Cloud Geotiff Backed Earth Engine Assets, improving the previous experience requiring a single file GeoTIFF, where all bands have the same projection and type.
Now you can create an Earth Engine asset backed by multiple GeoTiffs, which may have different projections, different resolutions, and different band types–and Earth Engine will take care of these complexities for you. There are also major performance improvements to the previous feature: Cloud GeoTiff backed assets now have similar performance to native Earth Engine assets. In addition, If you want to use your GCS COGs elsewhere, like open source pipelines or other tools, the data is stored once and you can use it seamlessly across products.
Looking forward to 2025
We’re excited to see Earth Engine users leverage more advanced tools, stronger security, and seamless integrations to improve sustainability and climate resilience. In the coming year, we’re looking forward to further deepening cloud interoperability, making it easier to develop actionable insights and inform sustainability decision-making through geospatial data.
Starting today, you can record thumbnail images in Amazon Interactive Video Service (Amazon IVS) Real-Time Streaming. When thumbnail recording is enabled, Amazon IVS automatically generates images at the interval you configure and stores them in the Amazon S3 bucket you select. Thumbnails can be used for preview images in content discovery or as part of content moderation workflows. There is no additional cost for enabling thumbnail recording, but standard Amazon S3 storage and request costs apply.
Amazon IVS is a managed live streaming solution that is designed to make low-latency or real-time video available to viewers around the world. Video ingest and delivery are available over a managed network of infrastructure optimized for live video. Visit the AWS region table for a full list of AWS Regions where the Amazon IVS console and APIs for control and creation of video streams are available.
Think about your favorite apps – the ones that deliver instant results from massive amounts of data. They’re likely powered by vector search, the same technology that fuels generative AI.
Vector search is crucial for developers who need to build applications that are lightning-fast, handle massive datasets, and remain cost-effective, even with huge spikes in traffic. But building and deploying this technology can be a real challenge, especially for gen AI applications that demand incredible flexibility, scale, and speed. In a previous blog post, we showed you how to create production-ready AI applications with features like easy filtering, automatic scaling, and seamless updates.
Today, we’ll share how Vertex AI’s vector search is tackling these challenges head-on. We’ll explore real-world performance benchmarks demonstrating incredible speed and scalability – all in a cost-effective way.
aside_block
<ListValue: [StructValue([(‘title’, ‘Start building today and enjoy a $1,000 credit’), (‘body’, <wagtail.rich_text.RichText object at 0x3e80a7f0f4f0>), (‘btn_text’, ”), (‘href’, ”), (‘image’, None)])]>
How does Vertex AI vector search work?
Imagine you own a popular online store: to keep shoppers happy, your search engine needs to instantly sift through millions of products and deliver relevant results, even during peak shopping seasons. Vector search is a technique for finding similar items within massive datasets. It works by converting data, like text or images, into numerical representations called embeddings. These embeddings capture the semantic meaning of the data, allowing for more accurate and relevant search results.
For example, imagine your customers are searching for a “navy blue dress shirt.” A keyword search might miss products labeled “midnight blue button-down,” even though they’re essentially the same. Vector search does a better job of surfacing the right products because it uses embeddings to understand the relationships between words and concepts.
A smooth, crisp and responsive semantic search experience is a must-have for e-commerce, media and other consumer-facing web services and is only possible with highly performant vector search. See this blog post for the details of the Infinite Nature demo that offers a glimpse into the future of how we’ll interact with information.
You can use it for a wide range of applications, like the e-commerce example shared above, or as a retrieval-augmented generation (RAG) system for generative AI agents, where it grounds responses in your data or recommendation systems that deliver personalized suggestions based on user preferences.
As Xun Wang, Chief Technology Officer of Bloomreach, recently said, “Bloomreach has made the strategic decision to replace OpenAI with Google Vertex AI Embeddings and Vertex AI vector search. Google’s platform delivers clear advantages in performance, scalability, reliability and cost optimization. We’re confident this move will drive significant benefits and we’re thrilled to embark on this new partnership.”
Real-world impact of Vertex AI’s vector search
Our customers are achieving remarkable results with vector search. Here are four standout ways this technology is helping them build high-performance gen AI apps.
#1: The fastest vector search for highly responsive applications
To meet customer expectations, fast response times are critical across search, recommendation systems, and gen AI applications. Studies have consistently found that faster response times directly contribute to an increase in revenue, conversion, and retention.
Vector search is engineered for incredibly low latency at high quality, while maintaining cost-effectiveness. In our testing, vector search was able to maintain ultra-low latency (9.6ms at P95) and high recall (0.99) while scaling up to 5K queries per second on a dataset of one billion vectors. By achieving such low latencies, Vertex AI vector search ensures that users receive fast, relevant responses, no matter how large the dataset or how many parallel requests hit the system.
As Yuri M. Brovman from eBay wrote in a recent blog post, “[eBay’s vector search] hit a real-time read latency of less than 4ms at 95%, as measured server-side on the Google Cloud dashboard for vector search”.
#2: Massively scalable for all application sizes
Another important consideration in production-ready applications is the ability of your application to support growing data sizes and user bases.
This means it can easily accommodate sudden spurts in demand, making it massively scalable for applications of any size. Vertex AI vector search can scale up to support billions of embeddings and hundreds of thousands of queries per second while maintaining ultra low latency.
#3: Up to 4X more cost effective
Vertex AI vector search not only maintains performance at scale, but it is also 4x more cost effective than competing solutions, especially for high performance applications. With Vertex AI vector search’s ANN index, you will need significantly less compute for fast and relevant results at scale.
Dataset
QPS
Recall
Latency (P95)
Glove 100 / 100 dim
44,876
0.96
3ms
OpenAI 5M / 1536 dim
2,981
0.96
9ms
Cohere 10M / 768 dim
3,144
0.96
7ms
LAION 100M / 768 dim
2,997
0.96
9ms
BigANN 10M / 128 dim
33,921
0.97
3.5 ms
BigANN 100M / 128 dim
9,871
0.97
7.2 ms
BigANN 1B / 128 dim
4,967
0.99
9.6 ms
Vertex AI vector search’s real-world benchmarks of public datasets by using 2 replicas of n2d machines. Latency was measured at the provided QPS; vector search can scale up beyond this throughput by adding additional replicas.
#4: It’s highly configurable for all application types
In some scenarios, developers might be interested in trading-off latency for higher recall (or vice versa). For example, an e-commerce website might prioritize speed for quick product suggestions, while a research database might prioritize comprehensive results even if it takes slightly longer. Vector search enables tuning these parameters and hitting higher recall or higher latency, to match business needs.
Additionally, vector search supports auto-scaling – and when load on the deployment increases, it scales to maintain performance. We measured auto-scaling and found that vector search was able to maintain consistent latency with high recall, as QPS increased from 1K to 5K.
Developers can also increase the number of replicas in order to handle higher throughput, as well as pick different machine types to balance cost and performance. This flexibility makes vector search suitable for a wide range of applications beyond semantic search, including recommendation systems, chatbots, multimodal search, anomaly detection, and image similarity matching.
Going further with hybrid search
Dense embedding-based semantic search, while excellent at understanding meaning and context, has a weak point: it cannot find items that the embedding model can’t make sense of. Items like product numbers, company’s internal codenames or newly coined terms, aren’t found by semantic search because the embedding model doesn’t understand their meanings.
With Vertex AI vector search’s hybrid search, building this type of sophisticated search engine is no longer a daunting task. Developers can easily create a single index that incorporates both dense and sparse embeddings, representing semantic meaning and keyword relevance respectively. This streamlined approach allows for rapid development and deployment of high-performance search applications, fully customized to meet specific business needs.
As Nicolas Presta, Sr. Engineering Manager at Mercado Libre wrote, “Most of our successful sales start with a search, so it is important that we give precise results that best match a user’s query. These complex searches are getting better with the addition of the items retrieved from vector search, which will ultimately increase our conversion rate. Hybrid search will unlock more opportunities to uplevel our search engine so that we can create the best customer experience while improving our bottom line.” – Nicolas Presta, Sr. Engineering Manager at Mercado Libre.
It’s been more than two and a half years since we introduced AlloyDB for PostgreSQL, our 100% PostgreSQL-compatible database that offers superior performance, availability, and scale. AlloyDB reimagines PostgreSQL with Google’s cutting-edge technology. It includes a scale-out architecture, built-in analytics, and AI/ML-powered management for a truly modern data experience, and is fully managed so you can focus on your application.
PostgreSQL has long been a favorite among developers for its flexibility, reliability, and robust feature set. AlloyDB brings PostgreSQL to the next level with faster performance, stronger functionality, better migration options, and smarter AI capabilities.
As 2024 comes to a close, it felt like a great time to celebrate with a snazzy AlloyDB overview video and summarize the AlloyDB’s key benefits in an infographic. Whether you’re new to the product or have tried it already, take a look to make sure you’re taking advantage of every benefit. You can also download our in-depth AlloyDB e-book for a deeper dive.
Want to learn more about how AlloyDB can revolutionize your PostgreSQL experience? Download our in-depth AlloyDB e-book and discover the transformative ways AlloyDB is redefining what’s possible. You’ll uncover:
How AlloyDB delivers superior transactional performance at half the cost
Why AlloyDB is the best database service for building gen AI apps
The flexibility of running AlloyDB anywhere, on any platform
How AI-driven development and operations can simplify your database journey
The power of real-time business insights with AlloyDB’s columnar engine
The future of PostgreSQL is here, and it’s built for you. Start building your next great app with a 30-day AlloyDB free trial.
A few months back, we kicked-off Network Performance Decoded, a series of whitepapers sharing best practices for network performance and benchmarking. Today, we’re dropping the second installment – and this one’s about some of those pesky performance limiters you’re bound to run into. In this blog, we’re giving you the inside scoop on how to tackle these issues head-on.
First up: A Brief Look at Network Performance Limiters
Mbit/s isn’t everything: It’s not just about raw speed. How you package your data (packet size) seriously impacts throughput and CPU usage.
Bigger packets, better results: Larger packets mean less overhead per packet, which translates to better throughput and less strain on your CPU.
Offload for a TCP boost: TCP Segmentation Offload (TSO) and Generic Receive Offload (GRO) let your network interface card do some of the heavy lifting, freeing up your CPU and giving your TCP throughput a nice bump — even with smaller packets.
Watch out for packet-per-second limits: Smaller packets can sometimes hit a bottleneck because of how many packets your system can handle per second.
At a constant bitrate, bigger packets are more efficient: Even with a steady bitrate, larger packets mean fewer packets overall, which leads to less CPU overhead and a more efficient network.
Get a handle on these concepts and you’ll be able to fine-tune your network for better performance and efficiency, no matter the advertised speed.
aside_block
<ListValue: [StructValue([(‘title’, ‘$300 to try Google Cloud networking’), (‘body’, <wagtail.rich_text.RichText object at 0x3ed0694ed460>), (‘btn_text’, ‘Start building for free’), (‘href’, ‘http://console.cloud.google.com/freetrial?redirectpath=/products?#networking’), (‘image’, None)])]>
Next: A Brief Look at Round Trip Time
This whitepaper dives into TCP Round Trip Time (RTT) — a key network performance metric. You’ll learn how it’s measured, what can throw it off, and how to use that info to troubleshoot network issues like a pro. We’ll show you how the receiving application’s behavior can mess with RTT measurements, and call out some important nuances to consider. For example, TCP RTT measurements do not include the time TCP may spend resending lost segments, which your applications see as latency. Lastly, we’ll show how you can use tools like netperf (also included in our PerfKit Benchmarker toolkit) to get an end-to-end picture.
Finally: A Brief Look at Path MTU Discovery
Last but not least, this whitepaper breaks down Path MTU discovery, a process that helps prevent IP fragmentation. Understanding how networks handle packet sizes can help you optimize your network setup, avoid those frustrating fragmentation issues, and troubleshoot effectively. We’ll even walk you through common problems — like those pesky ICMP blocks leading to large packets being dropped without any notification to the sender — and how to fix them. Plus, you’ll learn the difference between Maximum Transmission Unit (MTU) and Maximum Segment Size (MSS) — knowledge that’ll come in handy when you’re configuring your network and troubleshooting packet size problems.
Stay tuned!
These resources are part of our mission to create an open, collaborative space for network performance benchmarking and troubleshooting. The examples might be from Google Cloud, but the ideas apply everywhere – regardless of where your workloads may be running. You can find all our whitepapers (past, present, and future) on our webpage. Keep an eye out for more!
Conventional fraud detection methods have a hard time keeping up with increasingly sophisticated criminal tactics. Existing systems often rely on the limited data of individual institutions, and this hinders the detection of intricate schemes that span multiple banks and jurisdictions.
To better combat fraud in cross-border payments, Swift, the global provider of secure financial messaging services, is working with Google Cloud to develop anti-fraud technologies that use advanced AI and federated learning.
In the first half of 2025, Swift plans to roll out a sandbox with synthetic data to prototype learning from historic fraud, working with 12 global financial institutions, with Google Cloud as a strategic partner. This initiative builds on Swift’s existing Payment Controls Service (PCS), and follows a successful pilot with financial institutions across Europe, North America, Asia and the Middle East.
aside_block
<ListValue: [StructValue([(‘title’, ‘$300 in free credit to try Google Cloud security products’), (‘body’, <wagtail.rich_text.RichText object at 0x3ed0694d2070>), (‘btn_text’, ‘Start building for free’), (‘href’, ‘http://console.cloud.google.com/freetrial?redirectPath=/welcome’), (‘image’, None)])]>
The partnership: Google Cloud and Swift
Google Cloud is collaborating with Swift — along with technology partners including Rhino Health and Capgemini — to develop a secure, privacy-preserving solution for financial institutions to combat fraud. This innovative approach uses federated learning techniques, combined with privacy-enhancing technologies (PETs), to enable collaborative intelligence without compromising proprietary data.
Rhino Health will develop and deliver the core federated learning platform, and Capgemini will manage the implementation and integration of the solution.
“Swift is in a unique position in the financial industry – a trusted and cooperative network that is integral to the functioning of the global economy. As such, we are ideally placed to lead collaborative, industry-wide efforts to fight fraud. This exploration will help the community validate whether federated learning technology can help financial institutions stay one step ahead of bad actors through sharing of fraud labels, and in turn enabling them to provide an enhanced cross-border payments experience to their customers,” said Rachel Levi, head of artificial intelligence, Swift.
“At Google Cloud, we are committed to empowering financial institutions with cutting-edge technology to combat the evolving threat of fraud. Our collaboration with Swift exemplifies the transformative potential of federated learning and confidential computing. By enabling secure collaboration and knowledge sharing without compromising data privacy, we are fostering a safer and more resilient financial ecosystem for everyone,” said Andrea Gallego, Managing Director, global GTM incubation, Google Cloud,
The challenge: Traditional fraud detection is falling behind
The lack of visibility across the payment lifecycle creates vulnerabilities that can be exploited by criminals. A collaborative approach to fraud modeling offers significant advantages over traditional methods in combating financial crimes. To be effective, this approach requires data sharing across institutions, which is often restricted because of privacy concerns, regulatory requirements, and intellectual property considerations.
The solution: Federated learning
Federated learning offers a powerful solution for collaborative AI model training without compromising privacy and confidentiality. Instead of requiring financial institutions to pool their sensitive data, the model training occurs within financial institutions on decentralized data.
Here’s how it works for Swift:
A copy of Swift’s anomaly detection model is sent to each participating bank.
Each financial institution trains this model locally on their own data.
Only the learnings from this training — not the data itself — are transmitted back to a central server for aggregation, managed by Swift.
The central server aggregates these learnings to enhance Swift’s global model.
This approach significantly minimizes data movement and ensures that sensitive information remains within each financial institution’s secure environment.
Core benefits of the federated learning solution
By using federated learning solutions, financial institutions can achieve substantial benefits, including:
Shared intelligence: Financial institutions work together by sharing information on fraudulent activities, patterns, and trends, which creates a much larger and richer decentralized data pool than any single institution could gather alone.
Enhanced detection: The collaborative global model can identify complex fraud schemes that might go unnoticed by individual institutions, leading to improved detection and prevention.
Reduced false positives: Sharing information helps refine fraud models, leading to more accurate identification of genuine threats and fewer false alarms that disrupt both legitimate activity and the customer experience.
Faster adaptation: The collaborative approach allows for faster adaptation to new fraud trends and criminal tactics. As new threats emerge, the shared knowledge pool helps all participants quickly adjust their models and their fraud prevention tools.
Network effects: The more institutions participate, the more comprehensive the data pool becomes, creating a powerful network effect that strengthens fraud prevention for everyone involved.
For widespread adoption, federated learning must seamlessly integrate with existing financial systems and infrastructure. This allows financial institutions to easily participate and benefit from the collective intelligence without disrupting their operations.
Architecting the global fraud AI solution
The initial scope remains a synthetic data sandbox centered on prototyping learning from historic payments fraud. The platform allows multiple financial institutions to train a robust fraud detection model while preserving the confidentiality of their sensitive transaction data. It uses federated learning and confidential computing techniques, such as Trusted Execution Environments (TEEs), to enable secure, multi-party machine learning without training data movement.
There are several key components to this solution:
Federated server in TEE execution environment: A secure, isolated environment where a federated learning (FL) server orchestrates the collaboration of multiple clients by first sending an initial model to the FL clients. The clients perform training on their local datasets, then send the model updates back to the FL server for aggregation to form a global model.
Federated client: Executes tasks, performs local computation and learning with local dataset (such as data from an individual financial institution), then submits results back to FL server for secure aggregation.
Bank-specific encrypted data: Each bank holds its own private, encrypted transaction data that includes historic fraud labels. This data remains encrypted throughout the entire process, including computation, ensuring end-to-end data privacy.
Global fraud-based model: A pre-trained anomaly detection model from Swift that serves as the starting point for federated learning.
Secure aggregation: Using a Secure Aggregation protocol to compute these weighted averages would ensure that the server learns only the historic fraud labels from participating financial institutions, but not exactly which financial institution, thereby preserving the privacy of each participant in the federated learning process.
Global anomaly detection trained model and aggregated weights: The improved anomaly detection model, along with its learned weights, is securely exchanged back to the participating financial institutions. They can then deploy this enhanced model locally for fraud detection monitoring on their own transactions.
We’re seeing more enterprises adopt federated learning to combat global fraud, including global consulting firm Capgemini.
“Payment fraud stands as one of the greatest threats that undermines the integrity and stability of the financial ecosystem, with its impact acutely felt upon some of the most vulnerable segments of our society,” said Sudhir Pai, chief technology and innovation officer, Financial Services, Capgemini.
“This is a global epidemic that demands a collaborative effort to achieve meaningful change. Our application of federated learning is grounded with privacy-by-design principles, leveraging AI to pioneer secure aggregation and anonymization of data which is of primary concern to large financial institutions. The potential to apply our learnings within a singular global trained model across other industries will ensure we break down any siloes and combat fraud at scale,” he said.
“We are proud to support Swift’s program in partnership with Google Cloud and Capgemini,” said Chris Laws, chief operating officer, Rhino. “Fighting financial crime is an excellent example of the value created from the complex multi-party data collaborations enabled by federated computing, as all parties can have confidence in the security and confidentiality of their data.”
Building a safer financial ecosystem, together
This effort to fight fraud collaboratively will help build a safer and more secure financial ecosystem. By harnessing the power of federated learning and adhering to strong principles of data privacy, security, platform interoperability, confidentiality, and scalability, this solution has the potential to redefine how we combat fraud in the age of fragmented globalized finance and demonstrates a commitment to building a more resilient and trustworthy financial world.
Welcome to the first Cloud CISO Perspectives for December 2024. Today, Nick Godfrey, senior director, Office of the CISO, shares our Forecast report for the coming year, with additional insights from our Office of the CISO colleagues.
As with all Cloud CISO Perspectives, the contents of this newsletter are posted to the Google Cloud blog. If you’re reading this on the website and you’d like to receive the email version, you can subscribe here.
–Phil Venables, VP, TI Security & CISO, Google Cloud
aside_block
<ListValue: [StructValue([(‘title’, ‘Get vital board insights with Google Cloud’), (‘body’, <wagtail.rich_text.RichText object at 0x3ed0694e87c0>), (‘btn_text’, ‘Visit the hub’), (‘href’, ‘https://cloud.google.com/solutions/security/board-of-directors?utm_source=cloud_sfdc&utm_medium=email&utm_campaign=FY24-Q2-global-PROD941-physicalevent-er-CEG_Boardroom_Summit&utm_content=-&utm_term=-‘), (‘image’, <GAEImage: GCAT-replacement-logo-A>)])]>
Forecasting 2025: AI threats and AI for defenders, turned up to 11
By Nick Godfrey, senior director, Office of the CISO
While security threats and incidents may seem to pop up out of nowhere, the reality is that very little in cybersecurity happens in a vacuum. Far more common are incidents that build on incidents, threats shifting to find new attack vectors, and defenders simultaneously working to close up those points of ingress while also mitigating evolving risks.
Security and business leaders know that readiness plays a crucial role, and our Cybersecurity Forecast report for 2025 extrapolates from today’s trends the scenarios that we expect to arise in the coming year.
Expect attackers to increasingly use AI for sophisticated phishing, vishing, and social engineering attacks
AI has been driving a rapid evolution of tactics and technology for attackers and defenders. This year saw threat actors rapidly adopt AI-based tools to support all stages of their attacks, and we expect that trend to continue in 2025. Phishing, vishing, SMS-based attacks, and other forms of social engineering, will rely even more on AI and large language models (LLMs) to appear convincing.
Cyber-espionage and cybercrime actors will use deepfakes for identity theft, fraud, and bypassing know-your-customer (KYC) security requirements. We also expect to observe more evidence of threat actors experimenting with AI for their information operations, vulnerability research, code development, and reconnaissance.
Generative AI will allow us to bring more practitioners into the profession and focus them on learning both fundamental software development principles and secure software development — at the same time.
AI will continue to bolster defenders, as well. We expect 2025 will usher in an intermediate stage of semi-autonomous security operations, with human awareness and ingenuity supported by AI tools.
Taylor Lehmann, health care and life sciences director, Office of the CISO
As Google CEO Sundar Pichai said recently, “more than a quarter of new code at Google is generated by AI.” Many will probably interpret this to mean that, broadly speaking, companies will be able to save money by hiring fewer software developers because gen AI will do their work for them.
I believe we’re at the beginning of a software renaissance. Gen AI will help create more developers, because the barrier to becoming one has been lowered. We will need even more great developers to review work, coach teams, and improve software quality (because we’ll have more code to review.)
Crucially, finding and fixing insecure software will get easier. This added attention to software quality should help us create better, safer, and more secure and resilient products. Accordingly, any person or business who uses those products will benefit. Now, we should all go write our “hello worlds” — and start building.
Anton Chuvakin, security advisor, Office of the CISO
While “AI, secure my environment!” magic will remain elusive, generative AI will find more practical applications. Imagine gen AI that sifts through reports and alerts, summarizing incidents, and recommending response actions to humans. AI can be used to identify subtle patterns and anomalies that humans often miss, and can proactively uncover hidden threats during threat hunting.
Marina Kaganovich, executive trust lead, Office of the CISO
We predicted last year that organizations should get ahead of shadow AI. Today, we’re still seeing news stories about how enterprises are struggling to navigate unauthorized AI use. We believe that establishing robust organizational governance is vital. Proactively asking and answering key questions can also help you experiment with AI securely.
The global stage: threat actors
Geopolitical conflicts in 2025 will continue to fuel cyber-threat activity and create a more complex cybersecurity environment.
Ongoing geopolitical tensions and potential state-sponsored attacks will further complicate the threat landscape, requiring manufacturers to be prepared for targeted attacks aimed at disrupting critical infrastructure and stealing intellectual property.
The Big Four — China, Iran, North Korea, and Russia — will continue to pursue their geopolitical goals through cyber espionage, disruption, and influence operations. Globally, organizations will face ongoing threats from ransomware, multifaceted extortion, and infostealer malware. There are regional trends across Europe, the Middle East, Japan, Asia, and the Pacific that we expect to drive threat actor behavior, as well.
Toby Scales, advisor, Office of the CISO
Against the backdrop of ongoing AI innovation, including the coming “Agentic AI” transformation, we expect to see threat activity from nation-states increase in breadth — the number of attacks — and depth — the sophistication and variety of attacks.
While we don’t necessarily expect a big attack on infrastructure to land next year, it’s not hard to imagine an explicit retaliation by one of the Big Four against a U.S.-owned media enterprise for coverage, content, or coercion. Expect the weakest links of the media supply chain to be exploited for maximum profit.
Bob Mechler, director, Office of the CISO
Financially-motivated cybercrime as well as increasing geopolitical tensions will continue to fuel an increasingly challenging and complicated threat landscape for telecom providers. We believe that the increase in state-sponsored attacks, sabotage, and supply chain vulnerabilities observed during 2024 is likely to continue and possibly increase during 2025.
These attacks will, in turn, drive a strong focus on security fundamentals, resilience, and a critical need for threat intelligence that can help understand, preempt, and defeat a wide range of emerging threats.
Vinod D’Souza, head of manufacturing and industry, Office of the CISO
Ongoing geopolitical tensions and potential state-sponsored attacks will further complicate the threat landscape, requiring manufacturers to be prepared for targeted attacks aimed at disrupting critical infrastructure and stealing intellectual property. The convergence of IT and OT systems for manufacturing, along with increased reliance on interconnected technologies and data-driven processes, will create new vulnerabilities for attackers to exploit.
Ransomware attacks will potentially become more targeted and disruptive, potentially focusing on critical production lines and supply chains for maximum impact. Additionally, the rise of AI-powered attacks will pose a significant challenge, as attackers use machine learning to automate attacks, evade detection, and develop more sophisticated malware.
We should see public sector organizations begin to expand their comfort levels using cloud platforms built for the challenges of the future. They will likely begin to move away from platforms built using outdated protection models, and platforms where additional services are required to achieve security fundamentals.
Supply chain attacks will continue to be a major challenge in 2025, too. Attackers will increasingly target smaller suppliers and third-party vendors with weaker security postures to gain indirect access to larger manufacturing networks.
A collaborative approach to cybersecurity is needed, with manufacturers working closely with partners to assess and mitigate risks throughout the supply chain. Cloud technologies can become a solution as secure collaborative cloud platforms and applications could be used by the supplier ecosystem for better security.
Thiébaut Meyer, director, Office of the CISO
Digital sovereignty will gain traction in risk analysis and in the discussions we have with our customers and prospects in Europe, the Middle East, and Asia. This trend is fueled by growing concerns about potential diplomatic tensions with the United States, and “black swan” events are seen as increasingly plausible. As a result, entities in these regions are prioritizing strategies that account for the evolving geopolitical landscape and the potential for disruptions to data access, control, and survivability.
This concern will grow stronger as public entities move to the cloud. For now, in Europe, these entities are still behind in their migrations, mostly due to a lack of maturity. Their migration will be initiated only with the assurance of sovereign safeguards. Therefore, we really need to embed these controls in the core of all our products and offer “sovereign by design” services.
The global stage: empowered defenders
To stay ahead of these threats, and be better prepared to respond to them when they occur, organizations should prioritize a proactive, comprehensive approach to cybersecurity in 2025. Cloud-first solutions, robust identity and access management controls, and continuous threat monitoring and threat intelligence are key tools for defenders. We should also begin to prepare for the post-quantum cryptography era, and ensure ongoing compliance with evolving regulatory requirements.
MK Palmore, public sector director, Office of the CISO
I believe 2025 may bring an avalanche of opportunities for public sector organizations globally to transform how their enterprises make use of AI. They will continue to explore how AI can help them streamline time-dominant processes, and explore how AI can truncate those experiences to get in and out of the delivery cycle faster.
We should see public sector organizations begin to expand their comfort levels using cloud platforms built for the challenges of the future. They will likely begin to move away from platforms built using outdated protection models, and platforms where additional services are required to achieve security fundamentals. Security should be inherent in the design of cloud platforms, and Google Cloud’s long-standing commitment to secure by design will ring true through increased and ongoing exposure to the platform and its capabilities.
Alicja Cade, financial services director, Office of the CISO
Effective oversight from boards of directors requires open and joint communication with security, technology, and business leaders, critical evaluation of existing practices, and a focus on measurable progress. By understanding cybersecurity initiatives, boards can ensure their organizations remain resilient and adaptable in the face of ever-evolving cyber threats.
With the continued threat of economically and clinically disruptive ransomware attacks, we expect healthcare to adopt more resilient systems that allow them to better operate core services safely, even when under attack. This will be most acute in the underserved and rural healthcare sector, where staffing is minimal and resources are limited.
Boards can achieve prioritize cybersecurity by supporting strategies that:
Modernize technology by using cloud computing, automation, and other advancements to bolster defenses;
Implement robust security controls to establish a strong security foundation, with measures that include multi-factor authentication, Zero Trust segmentation, and threat intelligence; and
Manage AI risks by proactively addressing the unique challenges of AI, including data privacy, algorithmic bias, and potential misuse.
Odun Fadahunsi, executive trust lead, Office of the CISO
The global landscape is witnessing a surge in operational resilience regulations, especially in the financial services sector. Operational resilience with a strong emphasis on cyber-resilience is poised to become a top priority for both boards of directors and regulators in 2025. CISOs, and risk and control leaders, should proactively prepare for this evolving regulatory environment.
Bill Reid, solutions consultant, Office of the CISO
The drive to improve medical device security and quality will continue into 2025 with the announcement of the ARPA-H UPGRADE program awardees and the commencement of this three-year project. This program is expected to push beyond FDA software-as-a-medical-device security requirements to using more automated approaches to address assessment and patching whole classes of devices in a healthcare environment.
In general, the healthcare industry will keep building on the emergent theme of cyber-physical resilience, described in the PCAST report. With the continued threat of economically and clinically disruptive ransomware attacks, we expect healthcare to adopt more resilient systems that allow them to better operate core services safely, even when under attack. This will be most acute in the underserved and rural healthcare sector, where staffing is minimal and resources are limited. New cross-industry and public-private collaboration can help strengthen these efforts.
Based on feedback from our security field teams in 2024, we anticipate strong demand for practical, actionable guidance on cybersecurity and cloud security, including best practices for securing multicloud environments.
We believe there’ll be a shift away from blaming CISOs and their security organizations for breaches, and a rebuttal of the shame-based culture that has plagued cybersecurity. Cybersecurity events will be recognized as criminal acts and, in healthcare and other critical industries, as attacks on our national security. New ways to address security professional liability will emerge as organizations have challenges attracting and retaining top talent.
Widya Junus, head of Google Cloud Cybersecurity Alliance business operations, Office of the CISO
Based on feedback from our security field teams in 2024, we anticipate strong demand for practical, actionable guidance on cybersecurity and cloud security, including best practices for securing multicloud environments.
Cloud customers will continue to request support to navigate the complexities of managing security across multiple cloud providers, ensuring consistent policies and controls. The demand also includes real-world use cases, common threats and mitigations, and industry-specific security knowledge exchange.
Key security conversations and topics will cover streamlined IAM configuration, security best practices, and seamless implementation of cloud security controls. There will be a strong push for cloud providers to prioritize sharing practical examples and industry-specific security guidance, especially for AI.
For more leadership guidance from Google Cloud experts, please see ourCISO Insights hub.
aside_block
<ListValue: [StructValue([(‘title’, ‘Join the Google Cloud CISO Community’), (‘body’, <wagtail.rich_text.RichText object at 0x3ed0694e8940>), (‘btn_text’, ‘Learn more’), (‘href’, ‘https://rsvp.withgoogle.com/events/ciso-community-interest?utm_source=cgc-blog&utm_medium=blog&utm_campaign=2024-cloud-ciso-newsletter-events-ref&utm_content=-&utm_term=-‘), (‘image’, <GAEImage: GCAT-replacement-logo-A>)])]>
In case you missed it
Here are the latest updates, products, services, and resources from our security teams so far this month:
Oops! 5 serious gen AI security mistakes to avoid: Pitfalls are inevitable as gen AI becomes more widespread. In highlighting the most common of these mistakes, we hope to help you avoid them. Read more.
How Roche is pioneering the future of healthcare with secure patient data: Desiring increased user-access visibility and control, Roche secured its data by implementing a Zero Trust security model with BeyondCorp Enterprise and Chrome. Read more.
Securing AI: Advancing the national security mission: Artificial intelligence is not just a technological advancement; it’s a national security priority. For AI leaders across agencies in the AI era, we’ve published a new guide with agency roadmaps on how AI can be used to innovate in the public sector. Read more.
Perspectives on Security for the Board, sixth edition: Our final board report for 2024 reflects on our recent conversations with board members, highlighting the critical intersection of cybersecurity and business value in three key areas: resilience against supply chain attacks, how information sharing can bolster security, and understanding value at risk from a cybersecurity perspective. Read more.
Announcing the launch of Vanir: Open-source security patch validation: We are announcing the availability of Vanir, a new open-source security patch validation tool. It gives Android platform developers the power to quickly and efficiently scan their custom platform code for missing security patches and identify applicable available patches. Read more.
Please visit the Google Cloud blog for more security stories published this month.
aside_block
<ListValue: [StructValue([(‘title’, ‘Tell us what you think’), (‘body’, <wagtail.rich_text.RichText object at 0x3ed0694e8970>), (‘btn_text’, ‘Vote now’), (‘href’, ‘https://www.linkedin.com/feed/update/urn:li:ugcPost:7271984453818671105/’), (‘image’, <GAEImage: GCAT-replacement-logo-A>)])]>
Threat Intelligence news
Elevating red team assessments with AppSec testing: Incorporating application security expertise enables organizations to better simulate the tactics and techniques of modern adversaries, whether through a comprehensive red team engagement or a targeted external assessment. Read more.
(QR) coding my way out of here: C2 in browser isolation environments: Mandiant researchers demonstrate a novel technique where QR codes are used to achieve command and control in browser isolation environments, and provide recommendations to defend against it. Read more.
Please visit the Google Cloud blog for more threat intelligence stories published this month.
Now hear this: Google Cloud Security and Mandiant podcasts
Every CTO should be a CSTO: Chris Hoff, chief secure technology officer, Last Pass, discusses with host Anton Chuvakin and guest co-host Seth Rosenblatt the value of the CSTO, what it was like helping LastPass rebuild its technology stack, and how that helped overhaul the company’s corporate culture. Listen here.
How Google does workload security: Michael Czapinski, Google security and reliability enthusiast, talks with Anton about workload security essentials: zero-touch production, security rings, foundational services, and more. Listen here.
Defender’s Advantage: The art of remediation in incident response: Mandiant Consulting lead Jibran Ilyas joins host Luke McNamara to discuss the role of remediation as part of incident response. Listen here.
To have our Cloud CISO Perspectives post delivered twice a month to your inbox, sign up for our newsletter. We’ll be back in two weeks with more security-related updates from Google Cloud.
Model Evaluation on Amazon Bedrock allows you to evaluate, compare, and select the best foundation models for your use case. Amazon Bedrock offers a choice of using an LLM-as-a-judge, programmatic evaluation, and human evaluation. You can use an LLM-as-a-judge for metrics such as correctness, completeness, and coherence, as well as responsible AI metrics such as answer refusal and harmfulness. Programmatic evaluation offers algorithms for metrics such as accuracy, robustness, and toxicity. Additionally, for those metrics or subjective and custom metrics, such as friendliness or style, you can set up a human evaluation workflow with a few clicks. Human evaluation leverages your own employees or an AWS-managed team as reviewers. Model evaluation provides built-in curated datasets or you can bring your own datasets. Now, customers can evaluate models in the Europe (Zurich).
Model Evaluation on Amazon Bedrock is now available in these regions, and evaluation type availability varies by region.
To learn more about Model Evaluation on Amazon Bedrock, see the Amazon Bedrock Evaluations page. To get started, sign in to Amazon Bedrock on the AWS Management Console or use the Amazon Bedrock APIs.
AWS is announcing the general availability of two new Amazon EC2 High Memory U7i instances with 6TiB and 8TiB of memory. U7i-6tb and U7i-8tb are powered by 4th Generation Intel Xeon Scalable processors and offer 448 vCPUs, delivering up to 35% better performance and up to 15% better price performance versus comparable AWS EC2 High Memory U-1 instances. These instances extend the U7i instance family, providing customers greater flexibility to select the right instance for the right workload. U7i instances are ideal to run large in-memory databases such as SAP HANA, Oracle, and SQL Server.
U7i instances are built on the AWS Nitro system, a collection of AWS designed hardware and lightweight Nitro hypervisor which delivers practically all of the compute and memory resources of the host hardware to your instances. This frees up additional memory for your workloads which boosts performance and lowers the $/GiB memory costs.
These instances are certified by SAP for running SAP S/4HANA, SAP BW/4HANA, Business Suite on HANA, Data Mart Solutions on HANA, and Business Warehouse on HANA in production environments. For details, see the SAP HANA Hardware Directory.
These new instances are available in the following AWS Regions: US East (N. Virginia), US West (Oregon), and Asia Pacific (Seoul). Customers can use these instances with On Demand and Savings Plan purchase options. To learn more, visit the U7i instances page.
Amazon EC2 U7in-24tb instances are now available in AWS GovCloud (US-West) Region. U7in-24tb instances are part of AWS 7th generation and are powered by custom fourth generation Intel Xeon Scalable Processors (Sapphire Rapids) delivering up to 135% more compute performance over existing U-1 instances. U7in-24tb instances offer 24TiB of DDR5 memory enabling customers to scale transaction processing throughput in a fast-growing data environment.
U7in-24tb instance supports 896 vCPUs, the most vCPUs in the AWS cloud and support up to 100Gbps Elastic Block Storage (EBS), enabling customers to load data faster into memory and improve their backup speed. U7in-24tb instances instances deliver up to 200Gbps of network bandwidth and support ENA Express. U7i instances are ideal for customers using mission-critical in-memory databases such as SAP HANA, Oracle, or SQL Server.
The automotive industry is facing a profound transformation, driven by the rise of CASE, — connected cars, autonomous and automated driving, shared mobility, and electrification. Simultaneously, manufacturers face the imperative to further increase efficiency, automate manufacturing, and improve quality. AI has emerged as a critical enabler of this evolution. In this dynamic landscape, Toyota turned to Google Cloud’s AI Infrastructure to build an innovative AI Platform that empowers factory workers to develop and deploy machine learning models across key use cases.
Toyota‘s renowned production system, Toyota Production System, rooted in the principles of “Jidoka” (automation with a human touch) and “Just-in-Time” inventory management, has long been the gold standard in manufacturing efficiency. However, certain parts of this system are resistant to conventional automation.
We started experimenting with using AI internally in 2018. However, a shortage of employees with the expertise required for AI development created a bottleneck in promoting its wider use. Seeking to overcome these limitations, Toyota’s Production Digital Transformation Office embarked on a mission to democratize AI development within its factories in 2022.
Our goal was to build an AI Platform that enabled factory floor employees, regardless of their AI expertise, to create machine learning models with ease. This would facilitate the automation of manual, labor-intensive tasks, freeing up human workers to focus on higher-value activities such as process optimization, AI implementation in other production areas, and data-driven decision-making.
AI Platform is the collective term for the AI technologies we have developed, including web applications that enable easy creation of learning models on the manufacturing floor, compatible equipment on the manufacturing line, and the systems that support these technologies.
By the time we completed implementing the AI platform earlier this year, we found it would be able to save us as many as 10,000 hours of mundane work annually through manufacturing efficiency and process optimization.
For this company-wide initiative, we brought the development in-house to accumulate know-how. It was also important to stay up-to-date with the latest technologies so we could accelerate development and broaden opportunities to deploy AI. Finally, it was crucial to democratize our AI technology into a truly easy-to-use platform. We knew we needed to be led by those working on the manufacturing floor if we wanted them to use the AI more proactively; while at the same time, we wanted to improve the development experience for our software engineers.
aside_block
<ListValue: [StructValue([(‘title’, ‘Try Google Cloud for free’), (‘body’, <wagtail.rich_text.RichText object at 0x3e8250086700>), (‘btn_text’, ‘Get started for free’), (‘href’, ‘https://console.cloud.google.com/freetrial?redirectPath=/welcome’), (‘image’, None)])]>
Hybrid Architecture Brings Us Numerous Advantages
To power our AI Platform, we opted for a hybrid architecture that combines our on-premises infrastructure and cloud computing.
The first objective was to promote agile development. The hybrid cloud environment, coupled with a microservices-based architecture and agile development methodologies, allowed us to rapidly iterate and deploy new features while maintaining robust security. The path for a microservices architecture arose from the need to flexibly respond to changes in services and libraries, and as part of this shift, our team also adopted a development method called “SCRUM” where we release features incrementally in short cycles of a few weeks, ultimately resulting in streamlined workflows.
If we had developed machine learning systems solely on-premises with the aim to ensure security, we would need to perform security checks on a large amount of middleware, including dependencies, whenever we add a new feature or library. On the other hand, with the hybrid cloud, we can quickly build complex, high-volume container images while maintaining a high level of security.
The second objective is to use resources effectively. The manufacturing floor, where AI models are created, is now also facing strict cost efficiency requirements.
With a hybrid cloud approach, we can use on-premises resources during normal operations and scale to the cloud during peak demand, thus reducing GPU usage costs and optimizing performance. This allows us to flexibly adapt to an expected increase in the number of users of AI Platform in the future, as well.
Furthermore, adapting a hybrid cloud helps us to achieve cost savings on facility investments. By leveraging the cloud for scaling capacity, we minimized the need for extensive on-premises hardware investments. In a traditional on-premises environment, we would need to set up high-performance servers with GPUs in every factory. With a hybrid cloud, we can reduce the number of on-premises servers to one and use the cloud to cover the additional processing capacity whenever needed. The hybrid cloud’s concept of “using resources when and only as needed” aligns well with our “Just-in-Time” method.
The Reasons We Chose Google Cloud AI Hypercomputer
Several factors influenced our decision when choosing a cloud partner for the development of the Toyota AI Platform’s hybrid architecture and ultimately, we chose Google Cloud.
The first is the flexibility of using GPUs. In addition to the availability of using high-performance GPUs from one unit, we could use A2 VMs with Google Cloud’s unique features like multi-instance GPUs and time-sharing GPUs. This flexibility reduces idle compute resources and optimizes costs, leading to increased business value over a given time by allowing scarce GPUs to perform more machine learning trainings. Plus Dynamic Workload Scheduler helps us efficiently manage and schedule GPU resources to help us optimize running costs.
Next is ease of use. We anticipate that we will be required to secure more GPU resources across multiple regions in the future. With Google Cloud, we can manage GPU resources through a single VPC, avoiding network complexity. When considering the system to deploy, only Google Cloud had this capability.
The speed of build and processing was also a big appeal for us . In particular, Google Kubernetes Engine (GKE), its Autopilot and Image Streaming provide flexibility and speed, thereby allowing us to improve cost-effectiveness in terms of operational burden. We measured the communication speed of containerization during the system evaluation process, and found that Google Cloud was four times faster scaling from zero than other existing services. The speed of communication and processing is extremely important, as we use up to 10,000 images when creating the learning model. When we first started developing AI technology in-house, we struggled with flexible system scaling and operations. In this regard, too, using Google Cloud was the ideal choice.
Completed Large-scale Development in 1.5 Years with 6 Members
With Google Cloud’s support, a small team of six developers achieved a remarkable feat by successfully building and deploying the AI Platform in about half the time it would take for a standard system development project at Toyota. This rapid development was facilitated by Google Cloud’s user-friendly tools, collaborative approach, and alignment with Toyota’s automation-focused culture.
After choosing Google Cloud, we began discussing the architecture with the Google Cloud team. We then worked on modifying the web app architecture for the cloud lift, building the hybrid cloud, developing human resources within the company, while learning skills for the “internalization of technology (acquisition and accumulation of new know-how)”.During the implementation process, we divided the workloads into on-premises and cloud architectures, and implemented best practices to monitor communications and resources. This process also involved migrating CI/CD pipelines and image data to the cloud. By performing builds in the cloud and caching images on-premises, we ensured quick start-up and flexible operations.
In addition to the ease of development of Google Cloud products, cultural factors also contributed greatly to the success of this project. Our objective of making the manufacturing process automated as much as possible, is in line with Google’s concept of SRE (Site Reliability Engineering). So, we shared the same sense of purpose.
Currently, in the hybrid cloud, we deploy a GKE Enterprise cluster on-premises and link it to the GKE cluster on Google Cloud. When we develop our AI Platform and web apps, we run Cloud Build with Git CI triggers, verify container image vulnerabilities with Artifact Registry and Container Analysis, and ensure a secure environment with Binary Authorization. At the manufacturing floor, structural data such as numerical data and unstructured data such as images are deployed on GKE via a web app, and learning models are created on N1 VMs with NVIDIA T4 GPUs and A2 VMs which include NVIDIA A100 GPUs.
Remarkable Results Achieved Through Operating AI Platform
We have achieved remarkable results with this operational structure.
Enhanced Developer Experience: First, with regard to the development experience, waiting time for tasks have been reduced, and operational and security burdens have been lifted, allowing us to focus even more on development.
Increased User Adoption: Additionally, the use of our AI Platform on the manufacturing floor is also growing. Creating a learning model can typically take 10 to 15 minutes in the shortest, and up to 10 hours in the longest. GKE’s Image Streaming streamlined pod initialization and accelerated learning, resulting in a 20% reduction in learning model creation time. This improvement has enhanced the user experience (UX) on the manufacturing floor, leading to a surge in the number of users. Consequently, the number of models created in manufacturing has steadily increased, rising from 8,000 in 2023 to 10,000 in 2024. The widespread adoption of this technology has allowed for a substantial reduction of over 10,000 man-hours per year in the actual manufacturing process, optimizing efficiency, and productivity.
Expanding Impact: AI Platform is already in use at all of our car and unit manufacturing factories (total 10 factories), and its range of applications is expanding. At the Takaoka factory, the platform is used not only to inspect finished parts, but also in the manufacturing process; inspect the application of adhesives used to attach glass to back doors, and to detect abnormalities in injection molding machines used for manufacturing bumpers and other parts. Meanwhile, the number of active users in the company has increased to nearly 1,200, and more than 400 employees participate in in-house training programs each year.
Recently, there have been cases where people who were developing in other departments became interested in Google Cloud and joined our development team. Furthermore, this project has sparked an unprecedented shift within the company: the resistance to the cloud technology itself diminishing and other departments beginning to consider adopting it.
Utilizing Cloud Workstations for Further Productivity With an Eye on Generative AI
For the AI Platform, we plan to develop an AI model that can set more detailed criteria for detection, implement it in an automated picking process, and use it for maintenance and predictive management of the entire production line. We are also developing original infrastructure models based on the big data collected on the platform, and expect to use the AI Platform more proactively in the future.Currently, the development team compiles work logs and feedback from the manufacturing floor, and we believe that the day will soon come when we will start utilizing generative AI. For example, the team is considering using AI to create images for testing machine learning during the production preparation stage, which has been challenging due to a lack of data. In addition, we are considering using Gemini Code Assist to improve the developer experience, or using Gemini to convert past knowledge into RAG and implement a recommendation feature.In March 2024, we joined Google Cloud’s Tech Acceleration Program (TAP) and implemented Cloud Workstations. This also aims to achieve the goals we have been pursuing: to improve efficiency, reduce workload, and create a more comfortable work environment by using managed services.
Through this project, led by the manufacturing floor, we have established a “new way of manufacturing” where anyone can easily create and utilize AI learning models, and significantly increase the business impact for our company. This was enabled by the cutting-edge technology and services provided by Google Cloud.
Like “Jidoka (auto’no’mation)” of production lines and “Just-in-Time” method, the AI Platform has now become an indispensable part of our manufacturing operations. Leveraging Google Cloud, we will continue our efforts to make ever-better cars.
From helping your developers write better code faster with Code Assist, to helping cloud operators more efficiently manage usage with Cloud Assist, Gemini for Google Cloud is your personal AI-powered assistant.
However, understanding exactly how your internal users are using Gemini has been a challenge — until today.
Today we are announcing that Cloud Logging and Cloud Monitoring support for Gemini for Google Cloud. Currently in public preview, Cloud Logging records requests and responses between Gemini for Google Cloud and individual users, while Cloud Monitoring reports 1-day, 7-day, and 28-day Gemini for Google Cloud active users and response counts in aggregate.
aside_block
<ListValue: [StructValue([(‘title’, ‘Try Google Cloud for free’), (‘body’, <wagtail.rich_text.RichText object at 0x3e6158f2a4c0>), (‘btn_text’, ‘Get started for free’), (‘href’, ‘https://console.cloud.google.com/freetrial?redirectPath=/welcome’), (‘image’, None)])]>
Cloud Logging
In addition to offering customers general visibility into the impact of Gemini, there are a few scenarios where logs are useful:
to track the provenance of your AI-generated content
to record and review user usage of Gemini for Google Cloud
This feature is available as opt-in and when enabled, logs your users’ Gemini for Google Cloud activity to Cloud Logging (Cloud Logging charges apply).
Once enabled, log entries are made for each request to and response from Gemini for Google Cloud. In a typical request entry, Logs Explorer would provide an entry similar to the following example:
There are several things to note about this entry:
The content inside jsonPayload contains information about the request. In this case, it was a request to complete Python code with def fibonacci as the input.
The labels tell you the method (CompleteCode), the product (code_assist), and the user who initiated the request (cal@google.com).
The resource labels tell you the instance, location, and resource container (typically project) where the request occurred.
In a typical response entry, you’ll see the following:
Note that the request_id inside the label are identical for this pair of requests and responses, enabling identification of request and response pairs.
In addition to the Log Explorer, Log Analytics supports queries to analyze your log data, and help you answer questions like “How many requests did User XYZ make to Code Assist?”
For more details, please see the Gemini for Google Cloud logging documentation.
Cloud Monitoring
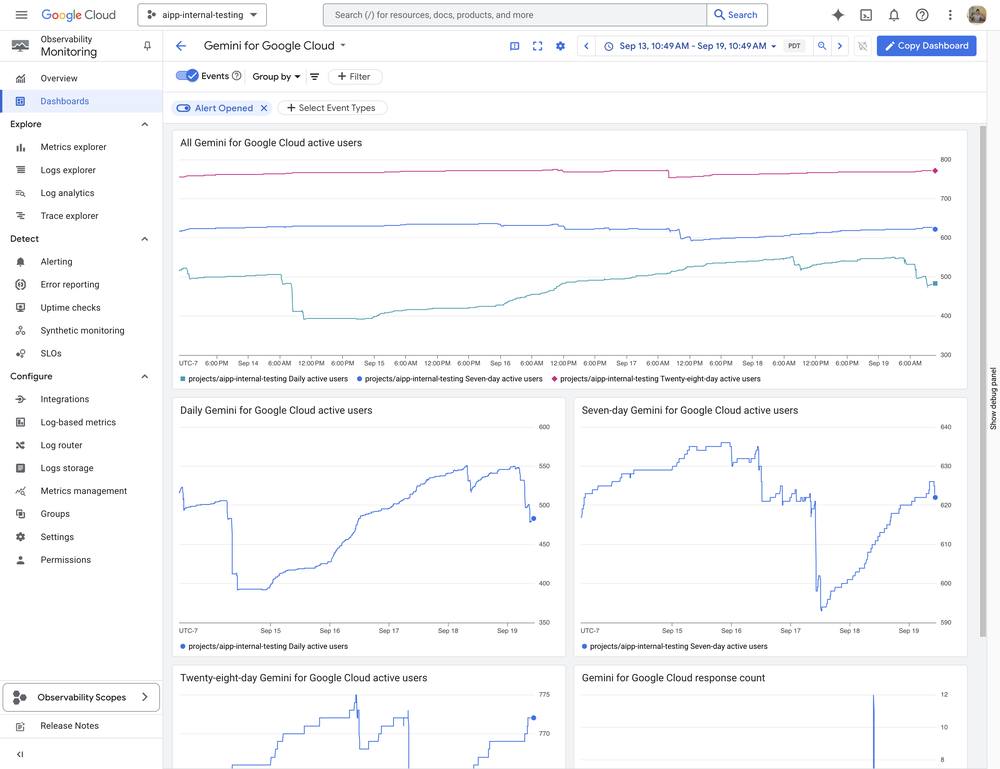
Gemini for Google Cloud monitoring metrics help you answer questions like:
How many unique active users used Gemini for Google Cloud services over the past day or seven days?
How many total responses did my users receive from Gemini for Google Cloud services over the past six hours?
Cloud Monitoring support for Gemini for Google Cloud is available to anybody who uses a Gemini for Google Cloud product and records responses and active users as Cloud Monitoring metrics, with which dashboards and alerts can be configured.
Because these metrics are available with Cloud Monitoring, you can also use them as part of Cloud Monitoring dashboards. A “Gemini for Google Cloud” dashboard is automatically installed under “GCP Dashboards” when Gemini for Google Cloud usage is detected:
Metrics Explorer offers another avenue where metrics can be examined and filters applied to gain a more detailed view of your usage. This is done by selecting the “Cloud AI Companion Instance” active resource in the Metrics Explorer:
In the example above, response_count is the number of responses sent by Gemini for Google Cloud, and can be filtered for Gemini Code Assist or the Gemini for Google Cloud method (code completion/generation).
For more details, please see the Gemini for Google Cloud monitoring documentation.
What’s next
We’re continually working on additions to these new capabilities, and in particular are focused on Code Assist logging and metrics enhancements that will bring even further insight and observability into your use of Gemini Code Assist and its impact. To get started with Gemini Code Assist and learn more about Gemini Cloud Assist — as well as observability data about it from Cloud Logging and Monitoring — check out the following links:
Mapping the user experience is one of the most persistent challenges a business can face. Fullstory, a leading behavioral data analytics platform, helps organizations identify pain points and optimize digital experiences by reproducing user sessions and sharing strong analytics highlighting areas for improvement in the customer’s journey. This boosts conversion rates, reduces churn, and enhances customer satisfaction.
AI has made this even stronger. Fullstory’s comprehensive AI-powered autocapture technology, Fullcapture, removes the need for manual instrumentation and uncovers hidden patterns that might otherwise be missed.
Today, we’ll share how Fullstory leverages Vertex AI serving Gemini 1.5 Pro to strengthen their autocapture technology.
aside_block
<ListValue: [StructValue([(‘title’, ‘Try Google Cloud for free’), (‘body’, <wagtail.rich_text.RichText object at 0x3e6159a5f880>), (‘btn_text’, ‘Get started for free’), (‘href’, ‘https://console.cloud.google.com/freetrial?redirectPath=/welcome’), (‘image’, None)])]>
How Vertex AI and AI agents help Fullstory measure the user experience
Think of Fullcapture as a video recorder for your website or app, capturing every interaction in detail. Traditional autocapture methods are more like transcription services, logging only selected highlights and often missing the complete picture. With Fullcapture, no user action goes unrecorded, with minimal impact on device performance. Operating server-side, Fullcapture allows for revisiting any aspect of user behavior as needed. If a new signal is required, it can be easily retrieved from the recorded data without affecting client-side performance.
The table below breaks down how Fullcapture goes beyond traditional autocapture capabilities to give users a deeper understanding of their customer data.
By integrating its Fullcapture capabilities with Google’s Vertex AI serving Gemini 1.5 Pro, Fullstory empowers customers to effortlessly analyze this extensive data and focus on what truly matters. Driven by a proactive AI agent, Fullstory enables faster data discovery by highlighting important elements and automatically categorizing user interactions into semantic components, providing even deeper levels of analysis.
AI-powered data discovery
Data discovery is a 6-step process that involves exploring, classifying, and analyzing data from various sources to uncover patterns and extract actionable insights. This process allows users to visually navigate data relationships and apply advanced analytics to optimize business decisions and performance.
Mountain visual with six flags that represent the steps for data discovery: Set goals, aggregate, prepare, visualize, analyze, and repeat.
To effectively analyze user behavior, businesses need to identify and label key elements on their websites (e.g., buttons, forms). This process can be tedious and time-consuming. Fullstory’s AI agent, powered by Gemini 1.5 Pro, automates this critical task by scraping data from user interactions and making intelligent decisions at various stages—identifying key elements, determining their significance, and autonomously categorizing them. This multi-stage decision-making process not only streamlines workflows but also ensures businesses can focus on deriving actionable insights rather than manual labeling.
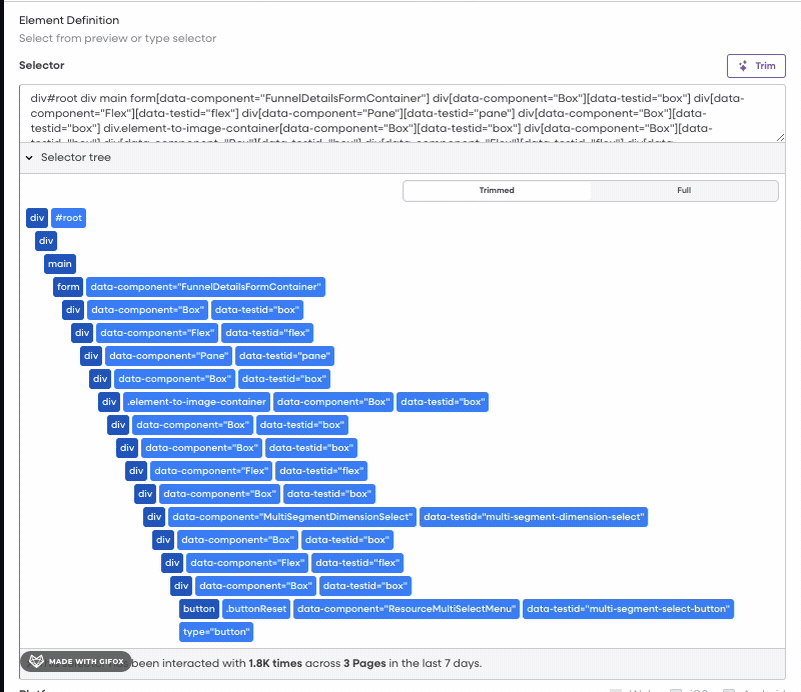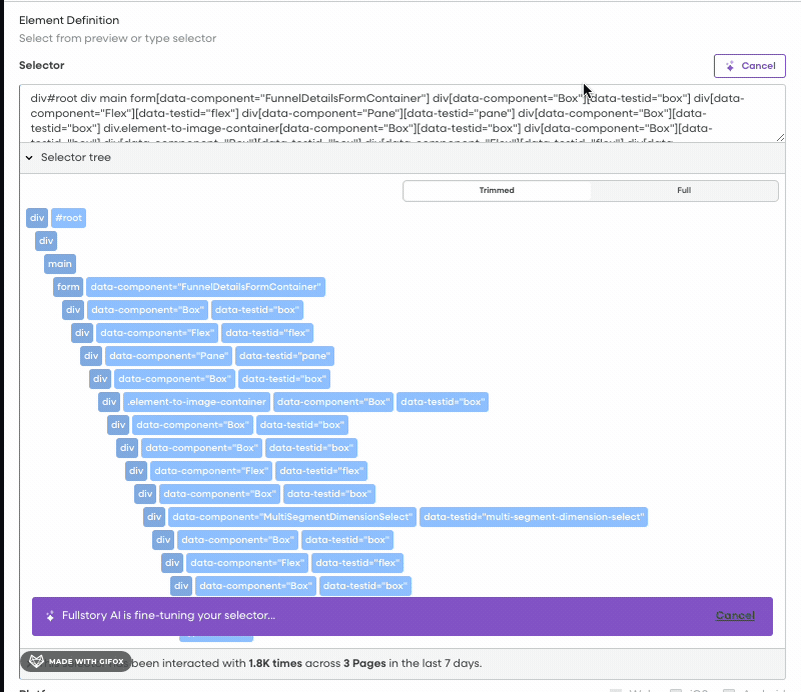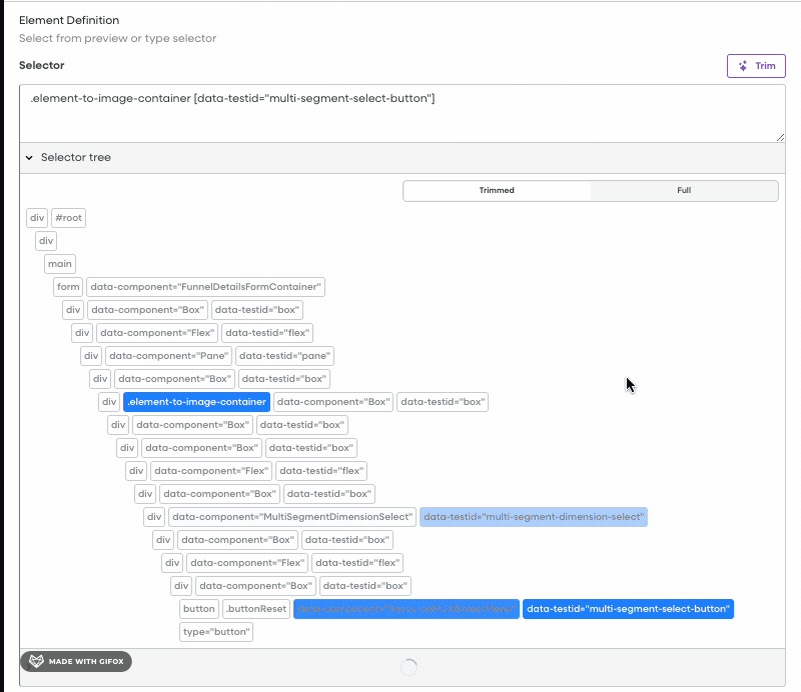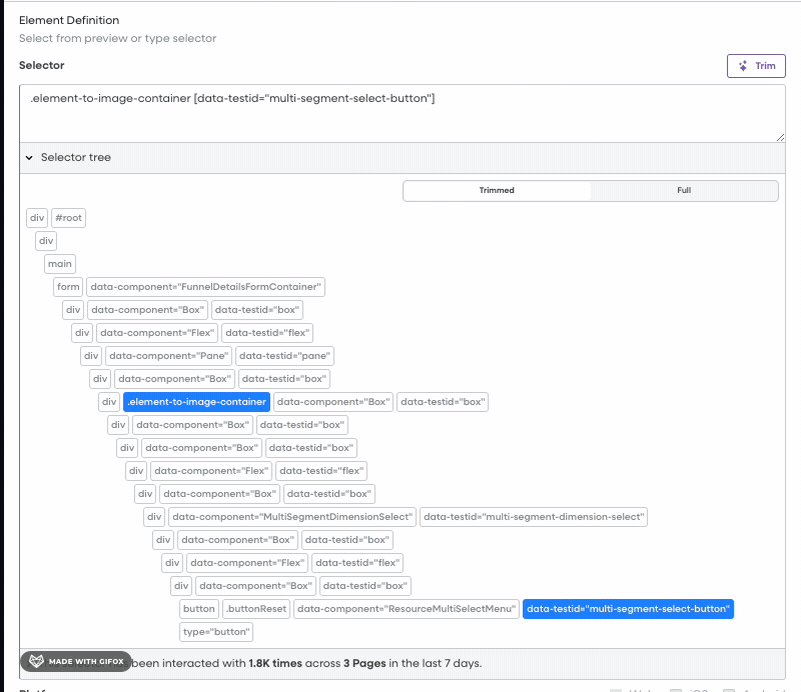
Within Fullstory, “elements” allow users to label UI components based on specific CSS selectors. A CSS selector is a pattern used to target elements in a webpage, such as classes, IDs, or attributes. For instance, a “Checkout Button” element might be created with the selector .checkout-page-container [data-testid="primary-button"]. These labels help categorize UI components and utilize them for product analytics. Broad semantic labeling is crucial for long-term success with Fullstory, and automating this process simplifies workflows for users.
A heatmap in Fullstory displaying the most clicked Elements. On the right hand side, the Elements “Site Logo” and “[JF] Product Pic” are configured Elements.
Vertex AI with Gemini 1.5 Pro offers a unique opportunity to add a human touch at scale. It proactively identifies and describes web components, ultimately providing actionable insights that benefit Fullstory customers. Gemini 1.5 Pro is trained on extensive web expertise, including web implementation from CSS and web frameworks like React, along with a vast dataset of website images.
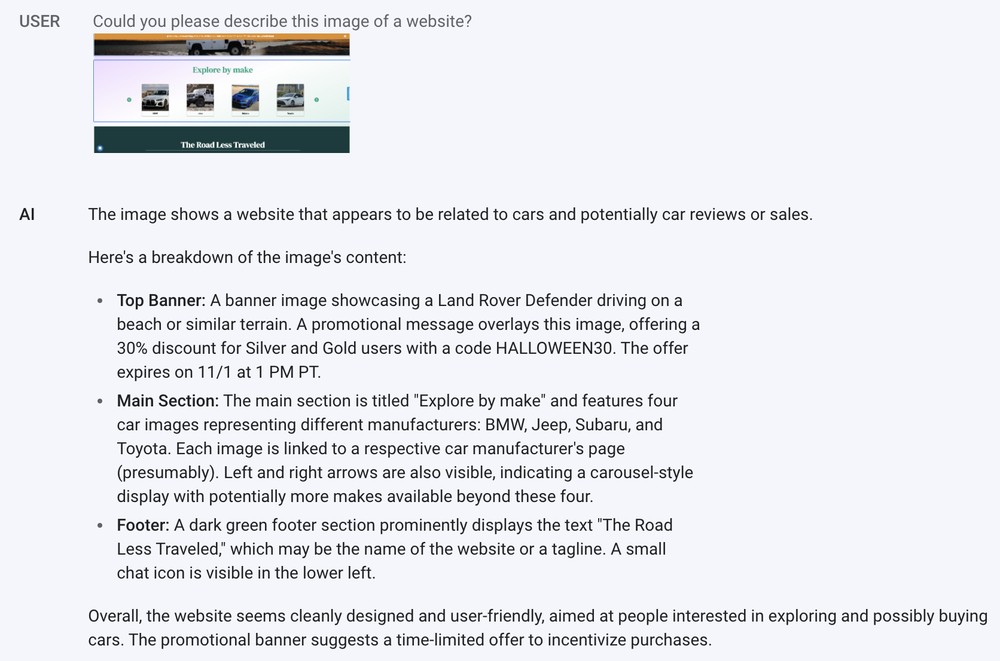
For example, the model can analyze a website screenshot and accurately describe its components, understanding both the overall structure, visible text, and the logical structure of the web page. This understanding can be further enhanced with web implementation details, such as CSS selectors, to gain a deeper understanding of specific components.
Optimizing for accurate element identification
Fullstory employs a meticulous approach to ensure the model provides high-quality element suggestions in four critical ways:
Strategic prompt engineering: Complex tasks are broken down into smaller, manageable steps, allowing the model to build a foundational understanding and deliver consistent and accurate results.
Pre-filtering with heuristics: Heuristics pre-filter potential elements before requests are sent to Vertex AI with Gemini, optimizing efficiency.
Validation with Vertex AI with Gemini: The model’s expertise validates potential elements, ensuring that only useful suggestions are presented.
Contextualized suggestions: Each suggestion includes a screenshot, CSS selector, and occurrence metrics, providing valuable context for informed decision-making.
This process ensures effective and efficient use of Gemini’s AI capabilities, resulting in accurate and valuable element suggestions.
Data Studio in Fullstory, which lets you visually define Elements and other objects. The Element definition is on the left hand side, and a preview is shown with the Element highlighted.
Pinpointing and perfecting: How we identify and label key web elements
Optimizing the digital experience requires identifying and understanding key web elements. These elements need to be defined in a way that remains resilient to website changes. This presents a challenge, given the diverse nature of websites and user behaviors.
In the real world, an element selector can look something like:
While metrics like “most clicked buttons” provide some insight, a more sophisticated approach is needed to uncover elements that drive engagement, signal errors, or reveal hidden opportunities. Effective management of potentially long and brittle element selector definitions is also crucial for maintaining data quality.
The search for meaningful elements
Fullstory captures every user interaction, generating a wealth of data. The platform continuously monitors unrecognized components, prioritizing:
New feature discovery: Identifying elements on newly launched feature pages.
Power user behavior: Understanding how experienced users interact with the website.
Error signals: Detecting elements with CSS that suggests potential errors.
Content analysis: Analyzing elements containing text that indicates user intent or potential issues.
These searches utilize CSS selectors to precisely target elements for granular analysis and efficient refinement.
Analyzing user behavior in Fullstory often involves crafting complex CSS selectors. With Vertex AI and Gemini 1.5 Pro, this process is simplified.
Deep indexing: Components of website CSS selectors and associated events are tokenized and indexed, enabling efficient searching through countless variations.
Semantic relevance: The model understands the meaning behind selectors. For example, when tracking an “Add to Cart” button, the model recognizes that the class .add-to-cart is more relevant than a generic class like .primary-button.
Powerful search: Combining semantic understanding with advanced search capabilities, the model identifies the best match for selectors.
This results in high-quality selectors without requiring in-depth CSS expertise, allowing users to focus on uncovering valuable insights from their Fullstory data.
Here’s an example of a Fullstory element being optimized:
The Importance of accurate labeling
Once an element is identified through its CSS selector, accurate labeling becomes crucial. This involves:
Name: A clear and concise name reflecting the element’s function.
Description: A detailed explanation of the element’s purpose and behavior.
Role: Assigning a predefined role from Fullstory’s library (e.g., “Add to Cart Button,” “Validation Error”).
Adding context to the equation
To ensure high-quality and consistent element labeling, Vertex AI with Gemini 1.5 Pro leverages Fullstory’s rich data and advanced AI capabilities to provide comprehensive context:
Visual representation: Screenshots of the element in action, generated from session playbacks.
Textual analysis: Examining text occurrences associated with the element.
Location tracking: Identifying the URLs where the element appears.
This approach, combining Fullstory’s data capture with Vertex AI and Gemini 1.5 Pro, allows for AI-powered analysis that moves beyond basic metrics to truly understand user behavior. By identifying and labeling key web elements with precision and context, businesses can unlock valuable insights and create exceptional digital experiences.
Delivering real-world results with Vertex AI API for Gemini 1.5 Pro
The collaboration between Fullstory and Google Cloud has yielded tens of thousands of element suggestions generated for customers, with Gemini 1.5 Pro intelligently filtering out a significant portion of irrelevant suggestions. The model has also identified numerous error elements that were previously unrecognized.
Beyond element identification, the mapping between element configuration and screenshots has opened up new opportunities for improving site configuration and enhancing analytics. This ongoing collaboration between Fullstory and Google Cloud continues to drive significant value for customers, empowering them to gain a deeper understanding of user behavior and optimize their digital experiences.
Ready to unlock the power of behavioral data? Visit Fullstory on Google Cloud Marketplace today! With Fullstory, you can gain a deeper understanding of your customers by uncovering hidden insights into their behavior and identifying key opportunities to optimize their digital experience.
Want to learn more about leveraging AI to enhance your Fullstory experience? Explore Fullstory’s documentation or try out this collaboration to see how AI can accelerate your journey.
In today’s fast-paced digital world, businesses are constantly seeking innovative ways to leverage cutting-edge technologies to gain a competitive edge. AI has emerged as a transformative force, empowering organizations to automate complex processes, gain valuable insights from data, and deliver exceptional customer experiences.
However, with the rapid adoption of AI comes a significant challenge: managing the associated cloud costs. As AI — and really cloud workloads in general — grow and become increasingly sophisticated, so do their associated costs and potential for overruns if organizations don’t plan their spend carefully.
These unexpected charges can arise from a variety of factors:
Human error and mismanagement: Misconfigurations in cloud services (e.g., accidentally enabling a higher-tiered service or changing scaling settings) can inadvertently drive up costs.
Unexpected workload changes: Spikes in traffic or usage, or changes in application behavior (e.g., marketing campaign or sudden change in user activity) can lead to unforeseen service charges.
Lack of proactive governance and cost transparency: Without a robust cloud FinOps framework, it’s easy for cloud spending to spiral out of control, leading to significant financial overruns.
Organizations have an opportunity to proactively manage their cloud costs and avoid budget surprises. By implementing real-time cost monitoring and analysis, they can identify and address potential anomalies before they result in unexpected expenses. This approach empowers businesses to maintain financial control and support their growth objectives.
aside_block
<ListValue: [StructValue([(‘title’, ‘Try Google Cloud for free’), (‘body’, <wagtail.rich_text.RichText object at 0x3e613d351400>), (‘btn_text’, ‘Get started for free’), (‘href’, ‘https://console.cloud.google.com/freetrial?redirectPath=/welcome’), (‘image’, None)])]>
As one of the world’s leading cybersecurity organizations — serving more than 70,000 organizations in 150 countries — Palo Alto Networks must bring a level of vigilance and awareness to its digital business. Since it experiments often with new technologies and tools and deals with spikes in activity when threat actors mount an attack, the chances for anomalous spending run higher than most.
Recognizing the need of all its customers to effectively manage its cloud spend, Google Cloud launched the Cost Anomaly Detection as part of the Cost Management toolkit. It does not require any setup and automatically detects anomalies for your Google Cloud projects and empowers teams with details to alert and provide root-cause analysis. While Palo Alto Networks used this feature for a while and found it useful, it eventually realized the need for a customized solution. Due to stringent custom requirements, it wanted a service that could identify anomalies based on labels, such as applications or products that span across Google Cloud projects, and provide more control over anomaly variables that are detected and alerted to its teams. Creating a consistent experience across its multicloud environments was also a priority.
Palo Alto Networks’ purpose-built solution tackles cloud management and AI costs head-on, helping the organization to be proactive at scale. It is designed to enhance cost transparency by providing real-time alerts to product owners, so they can make informed decisions and act quickly. The solution also delivers automated insights at scale, freeing up valuable time for the team to focus on innovation.
By removing the worry of unexpected costs, Palo Alto Networks can now confidently embrace new cloud and AI workloads, accelerating its digital transformation journey.
Lifecycle of an anomaly
For Palo Alto Networks, anomalies are unexpected events or patterns that deviate from the norm. In a cloud environment, anomalies can indicate anything from a simple misconfiguration to a full-blown security breach. That’s why it’s critical to have a system in place to detect, analyze, and mitigate anomalies before they can cause significant damage.
This flowchart illustrates the typical lifecycle of an anomaly, broken down into three key stages:
Figure 1 – Lifecycle of an Anomaly
The following sections will take a deeper dive into how Palo Alto Networks used Google Cloud to build its custom AI-powered anomaly solution to address each of these stages.
1. Detection
The first step is to identify potential anomalies.Palo Alto Networks partnered with Google Cloud Consulting to train the ARIMA+ model with billing data from its applications using BigQuery ML (BQML). The team chose this model for its great results for time-series billing data, its ability to customize hyper parameters, and its overall effective cost of operation at scale.
The ARIMA+ model allowed Palo Alto Networks to generate a baseline spend with upper and lower bounds for its cost anomaly solution. The team also tuned the model using Palo Alto Networks’ historic billing data, enabling it to inherently understand factors like seasonality, common spikes and dips, migration patterns, and more. If the spend exceeds the upper bound created by the model, the team can then quantify the business cost impact (both percentage and dollar amount) to determine the severity of the alert to be investigated further.
Figure 2 – AI-Powered Cost Anomaly Solution Architecture on Google Cloud
Looker, Google Cloud’s business intelligence platform, serves as the foundation for custom data modeling and visualization, seamlessly integrating with Palo Alto Networks’ existing billing data infrastructure, which continuously streams into BigQuery multiple times a day. This eliminates the need for additional data pipelines, ensuring the team has the most up-to-date information for analysis.
BigQuery MLempowers Palo Alto Networks with robust capabilities for machine learning model training and inference. By leveraging BQML, the team can build and deploy sophisticated models directly within BigQuery, eliminating the complexities of managing separate machine learning environments. This streamlined approach accelerates the ability to detect and analyze cost anomalies in real time. In this case, Palo Alto Networks trained the ARIMA+ model on the last 13 months of billing data for specific applications on the Net Spend field to capture seasonality, spikes and dips, along with migration patterns and known spikes based on a custom calendar.
To enhance alerting and anomaly management processes, the team also utilizes Google Cloud Pub/Sub and Cloud Run functions. Pub/Sub facilitates the reliable and scalable delivery of anomaly notifications to relevant stakeholders. Cloud Run functions enable custom logic for processing these notifications, including intelligent grouping of similar anomalies to minimize alert fatigue and streamline investigations. This powerful combination allows Palo Alto Networks to respond swiftly and effectively to potential cost issues.
2. Notification and analysis
Once the anomaly is captured, the solution computes the business cost impact and routes alerts to the appropriate application teams through Slack for further investigation. To accelerate root-cause analysis, it synthesizes critical information through text and images to provide all the details about anomaly, pinpointing exactly when it occurred and which SKUs or resources are involved. Application teams can then further analyze this information and, with their application context, quickly arrive at a decision.
Here is an example of snapshot that captured an increased cost in BigQuery that started on July 30th:
Figure 3 – Example of Anomaly Detected with Resource details
The cost anomaly solution automatically gathered all the information related to the flagged anomalies, such as Google Cloud project ID, data, environment, service names andSKUs, along with the cost impact. This data provided much of the necessary context for the application team to act quickly. Here is an example of the Slack alert:
Figure 4 – Example of anomaly alert on Slack
3. Mitigation
Once the root cause is identified, it’s time to take action to mitigate the anomaly. This may involve anything from making a simple configuration change to deploying a hotfix. In some cases, it may be necessary to escalate the issue and involve cross-functional teams.
In the provided example, a cloud hosted tenant encountered a substantial increase in data volume due to a configuration error. This misconfiguration led to unusually high BigQuery usage. As no default BigQuery reservation existed in the newly established region, the system defaulted to the on-demand pricing model, incurring higher costs.
To address this, the team procured 100 baseline slots with a 3-year commitment and implemented autoscaling to accommodate any future spikes without impacting performance. To prevent similar incidents, especially in new regions, a long-term cost governance policy was implemented at the organizational level.
Post incident, the cost anomaly solution generates a blameless post mortem document containing the highlights of the actions taken, the impact of collaboration, and the cost savings achieved through timely detection and mitigation. This document focuses on:
A detailed timeline of events: This list might include when a cost increase was captured, when the team was alerted, and the mitigation plan with short-term and long-term initiatives to prevent this in future.
Actions taken: This description includes details about anomaly detection, the analysis conducted by the application team, and mitigative actions taken.
Preventative strategy: This describes the short-term and long-term plan to avoid similar future incidents.
Cost impact and cost avoidance: These calculations include the overall cost incurred from the anomaly and estimate the additional cost if the issue had not been detected in a timely manner.
A formal communication is then sent out to the Palo Alto Networks application team, including leadership, for further visibility.
From its experience working at scale, Palo Alto Networks has learned to embrace the fact that anomalies are unavoidable in cloud environments. To manage them effectively, a well-defined lifecycle encompassing detection, analysis, and mitigation is crucial. Automated monitoring tools play a key role in identifying potential anomalies, while collaboration across teams is also essential for successful resolution. In particular, the team places huge emphasis on the importance of continuous improvement for optimizing the anomaly management process. For example, they established the reporting dashboard below for long-term continuous governance.
Figure 5 – Cost Anomaly Reporting Dashboard in Looker
By leveraging the power of AI and partnering with Google Cloud, Palo Alto Networks is enabling businesses to unlock the full potential of AI while ensuring responsible and sustainable cloud spending. With a proactive approach to cost anomaly management, organizations can confidently navigate the evolving landscape of AI, drive innovation, and achieve their strategic goals. Check out the public preview of Cost Anomaly Detection or reach out to Google Cloud Consulting for a customized solution.
Starting today, Amazon EC2 Hpc7a instances are available in additional AWS Region Europe (Paris). EC2 Hpc7a instances are powered by 4th generation AMD EPYC processors with up to 192 cores, and 300 Gbps of Elastic Fabric Adapter (EFA) network bandwidth for fast and low-latency internode communications. Hpc7a instances feature Double Data Rate 5 (DDR5) memory, which enables high-speed access to data in memory.
Hpc7a instances are ideal for compute-intensive, tightly coupled, latency-sensitive high performance computing (HPC) workloads, such as computational fluid dynamics (CFD), weather forecasting, and multiphysics simulations, helping you scale more efficiently on fewer nodes. To optimize HPC instances networking for tightly coupled workloads, you can access these instances in a single Availability Zone within a Region.
Starting today, Amazon EC2 Hpc6id instances are available in additional AWS Region Europe (Paris). These instances are optimized to efficiently run memory bandwidth-bound, data-intensive high performance computing (HPC) workloads, such as finite element analysis and seismic reservoir simulations. With EC2 Hpc6id instances, you can lower the cost of your HPC workloads while taking advantage of the elasticity and scalability of AWS.
EC2 Hpc6id instances are powered by 64 cores of 3rd Generation Intel Xeon Scalable processors with an all-core turbo frequency of 3.5 GHz, 1,024 GB of memory, and up to 15.2 TB of local NVMe solid state drive (SSD) storage. EC2 Hpc6id instances, built on the AWS Nitro System, offer 200 Gbps Elastic Fabric Adapter (EFA) networking for high-throughput inter-node communications that enable your HPC workloads to run at scale. The AWS Nitro System is a rich collection of building blocks that offloads many of the traditional virtualization functions to dedicated hardware and software. It delivers high performance, high availability, and high security while reducing virtualization overhead.
Amazon Aurora PostgreSQL is now available as a quick create vector store in Amazon Bedrock Knowledge Bases. With the new Aurora quick create option, developers and data scientists building generative AI applications can select Aurora PostgreSQL as their vector store with one click to deploy an Aurora Serverless cluster preconfigured with pgvector in minutes. Aurora Serverless is an on-demand, autoscaling configuration where capacity is adjusted automatically based on application demand, making it ideal as a developer vector store.
Knowledge Bases securely connects foundation models (FMs) running in Bedrock to your company data sources for Retrieval Augmented Generation (RAG) to deliver more relevant, context-specific, and accurate responses that make your FM more knowledgeable about your business. To implement RAG, organizations must convert data into embeddings (vectors) and store these embeddings in a vector store for similarity search in generative artificial intelligence (AI) applications. Aurora PostgreSQL, with the pgvector extension, has been supported as a vector store in Knowledge Bases for existing Aurora databases. With the new quick create integration with Knowledge Bases, Aurora is now easier to set up as a vector store for use with Bedrock.
The quick create option in Bedrock Knowledge Bases is available in these regions with the exception of AWS GovCloud (US-West) which is planned for Q4 2024. To learn more about RAG with Amazon Bedrock and Aurora, see Amazon Bedrock Knowledge Bases.
Amazon Aurora combines the performance and availability of high-end commercial databases with the simplicity and cost-effectiveness of open-source databases. To get started using Amazon Aurora PostgreSQL as a vector store for Amazon Bedrock Knowledge Bases, take a look at our documentation.
Today, we are introducing the new ModelTrainer class and enhancing the ModelBuilder class in the SageMaker Python SDK. These updates streamline training workflows and simplify inference deployments.
The ModelTrainer class enables customers to easily set up and customize distributed training strategies on Amazon SageMaker. This new feature accelerates model training times, optimizes resource utilization, and reduces costs through efficient parallel processing. Customers can smoothly transition their custom entry points and containers from a local environment to SageMaker, eliminating the need to manage infrastructure. ModelTrainer simplifies configuration by reducing parameters to just a few core variables and providing user-friendly classes for intuitive SageMaker service interactions. Additionally, with the enhanced ModelBuilder class, customers can now easily deploy HuggingFace models, switch between developing in local environment to SageMaker, and customize their inference using their pre- and post-processing scripts. Importantly, customers can now pass the trained model artifacts from ModelTrainer class easily to ModelBuilder class, enabling a seamlessly transition from training to inference on SageMaker.
You can learn more about ModelTrainer class here, ModelBuilder enhancements here, and get started using ModelTrainer and ModelBuilder sample notebooks.