Search is at the heart of how we interact with the digital ecosystem, from online shopping to finding critical information. Enter generative AI, and user expectations are higher than ever. For applications to meet diverse user needs, they need to deliver fast, accurate and contextually relevant results, regardless of how queries are framed. For example:
Online shoppers expect to find “waterproof hiking boots with ankle support” just as easily as a specific “SummitEdge Pro” model.
Legal professionals need to pinpoint precise case citations or explore nuanced legal concepts with varied search terms.
Doctors require precision when searching for critical patient information. A doctor looking for “allergy to penicillin” must locate the record accurately, whether the information is labeled as “drug sensitivities” or misspelled as “peniciln”.
Spanner, Google’s always-on multi-model database with virtually unlimited scale, addresses these challenges with AI-powered hybrid search capabilities. Spanner allows developers to combine vector search, full-text search, and machine learning (ML) model reranking capabilities in a unified platform directly integrated with the operational data store, using a familiar SQL interface.
In this post, we will explore how you can build a customized search engine for an ecommerce marketplace using Spanner.
aside_block
<ListValue: [StructValue([(‘title’, ‘$300 in free credit to try Google Cloud developer tools’), (‘body’, <wagtail.rich_text.RichText object at 0x3eb02e4feeb0>), (‘btn_text’, ‘Start building for free’), (‘href’, ‘http://console.cloud.google.com/freetrial?redirectPath=/welcome’), (‘image’, None)])]>
Building a tailored search engine on Spanner
For ecommerce – along with many other industries – a single search method often falls short, resulting in dissatisfied users, incomplete information, or lost revenue. Keyword search excels at precision but struggles with alternate phrasing or natural language; vector search captures semantics but may overlook specific terms. Combining the strengths of both would enable organizations to deliver a more effective search experience.
SpanMart, a hypothetical ecommerce marketplace, allows users to search for products using keywords or natural language. Its products table supports multiple search methods with two specialized columns and associated indexes:
A description_tokens column: This is a tokenized version of the description column, breaking down the text into individual terms. A search index (products_by_description) on this column accelerates full-text search, acting like an inverted index in information retrieval.
An embedding column: This stores vector representations of the product descriptions, capturing semantic meaning rather than individual words. Similar descriptions are mapped close together in the “embedding space”. These embeddings are generated using models like Vertex AI Embeddings. A vector index (products_by_embedding)organizes these embeddings using a ScaNN tree structure for efficient semantic searches.
Here’s how the products table and its indexes are defined Spanner:
code_block
<ListValue: [StructValue([(‘code’, ‘CREATE TABLE products (rn id INT64,rn description STRING(MAX),rn description_tokens TOKENLIST AS (TOKENIZE_FULLTEXT(description)) HIDDEN,rn embedding ARRAY<FLOAT32>(vector_length=>768),rn) PRIMARY KEY(id);rnrnCREATE SEARCH INDEX products_by_description ON products(description_tokens);rnCREATE VECTOR INDEX products_by_embedding ON products(embedding)rn WHERE embedding IS NOT NULLrn OPTIONS(distance_type=”COSINE”, num_leaves=1000);’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3eb02e14aa90>)])]>
With these components in place, SpanMart can build an intelligent search pipeline that integrates:
Vector search for semantic relevance.
Full-text search for precise keyword matching.
Result fusion for combining the results from different retrieval methods.
ML model reranking for advanced result refinement.
This pipeline operates entirely within Spanner, where the operational data is stored. By avoiding integration with separate search engines or vector databases, Spanner eliminates the need for multiple technical stacks, complex ETL pipelines, and intricate application logic for inter-system communication. This reduces architectural and operational overhead and avoids potential performance inefficiencies.
The diagram below illustrates a high-level overview of how these components work together in Spanner.
Combining the power of vector and full-text search
When a user searches for products on SpanMart, the system first uses the embedding model to convert the user query into a vector that captures its semantic meaning. Then, SpanMart can build two queries:
<ListValue: [StructValue([(‘code’, ‘SELECT id, descriptionrnFROM productsrnWHERE SEARCH(description_tokens, @query)rnORDER BY SCORE(description_tokens, @query) DESCrnLIMIT 200;’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3eb02e14abb0>)])]>
These two queries excel in different scenarios and complement each other. For instance, when a user searches for a specific product model number, such as “Supercar T-6468”, the full-text search query can accurately find the exact model, while the vector search query suggests similar items. Conversely, for more complex natural language queries, such as “gift for an 8-year-old who enjoys logical reasoning but not a toy”, full-text search may struggle to yield useful results, whereas vector search can provide a relevant list of recommendations. Combining both queries would produce robust results for both styles of searches.
Reciprocal rank fusion (RRF)
RRF is a simple yet effective technique for combining results from multiple search queries. It calculates a relevance score for each record based on its position in all result sets, rewarding records ranked highly in individual searches. This method is particularly useful when the relevance scores from the individual searches are calculated in different spaces, making them difficult to compare directly. RRF addresses this by focusing on the relative rankings instead of scores within each result set.
Here’s how RRF works in our example:
Calculate rank reciprocals: For each product, calculate its rank reciprocal in each result set by taking the inverse of its rank after adding a constant (e.g., 60). This constant prevents top-ranked products from dominating the final score and allows lower-ranked products to contribute meaningfully. For instance, a product ranked 5th in one result set would have a rank reciprocal of 1/(5 + 60) = 1/65 in that result set.
Sum rank reciprocals: Sum the rank reciprocals from all result sets to get the final RRF score of a product.
The formula for RRF is –
– where:
d is a product description
R is the set of retrievers (in this case, the two search queries)
rankr (?) is the rank of product description d in the results of retriever r.
k is a constant
Implementing RRF within Spanner’s SQL interface is relatively straightforward. Here’s how:
code_block
<ListValue: [StructValue([(‘code’, ‘@{optimizer_version=7}rnWITH ann AS (rn SELECT offset + 1 AS rank, id, descriptionrn FROM UNNEST(ARRAY(rn SELECT AS STRUCT id, descriptionrn FROM products @{FORCE_INDEX=products_by_embedding}rn WHERE embedding IS NOT NULLrn ORDER BY APPROX_COSINE_DISTANCE(embedding, @vector,rn OPTIONS=>JSON'{“num_leaves_to_search”: 10}’)rn LIMIT 200)) WITH OFFSET AS offsetrn),rnfts AS (rn SELECT offset + 1 AS rank, id, descriptionrn FROM UNNEST(ARRAY(rn SELECT AS STRUCT id, descriptionrn FROM productsrn WHERE SEARCH(description_tokens, @query)rn ORDER BY SCORE(description_tokens, @query) DESCrn LIMIT 200)) WITH OFFSET AS offsetrn)rnSELECT SUM(1 / (60 + rank)) AS rrf_score, id, ANY_VALUE(description) AS descriptionrnFROM ((rn SELECT rank, id, descriptionrn FROM annrn)rnUNION ALL (rn SELECT rank, id, descriptionrn FROM ftsrn))rnGROUP BY idrnORDER BY rrf_score DESCrnLIMIT 50;’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3eb02e14aeb0>)])]>
Explanations:
Common table expressions (CTEs): These are the WITH clauses, which are used in this query to improve readability. However, due to a current limitation, they may cause the query optimizer to default to an older version that lacks full-text search support. For now, the query uses the @{optimizer_version=7} hint to suggest a more recent optimizer version.
ANN CTE: This is the same as the previous ANN query, but with a twist. We assign a rank to each product in the results. While Spanner doesn’t support a direct way to assign ranks, there’s a workaround. By converting the results into an array of structs, we can use the offset of each element within the array as its rank. Since array offsets start at zero, we use offset + 1 to represent the actual rank. Note that this is purely a SQL language workaround without performance impact. The query planner effectively optimizes away the array conversion and directly assigns an offset to each row in the result set.
FTS CTE: Similarly, this part mirrors the previous full-text search query, with the rank assigned using the array offset.
Combining and ranking: The results from both CTEs are unioned, and grouped by the product id. For each product, we calculate the rrf_score and then select the top 50 products.
While RRF is an effective technique, Spanner’s versatile SQL interface empowers application developers to explore and implement various other result fusion methods. For instance, developers can normalize scores across different searches to a common range and then combine them using a weighted sum, assigning different importance to each search method. This flexibility allows for fine-grained control over the search experience and enables developers to tailor it to specific application requirements.
Using an ML model to rerank search results
ML model-based reranking is a powerful way of refining search results to deliver improved results to the users. It applies an advanced yet computationally expensive model to a narrowed set of initial candidates, retrieved using methods like vector search, full-text search, or their combination, as discussed earlier. Due to its high computational cost, ML model-based reranking is applied after the initial retrieval reduces the result set to a small set of promising candidates.
Spanner’s integration with Vertex AI makes it possible to perform ML model-based reranking directly within Spanner. You can use a model deployed to your Vertex AI endpoint, including those available from the Vertex AI Model Garden. Once the model is deployed, you can create a corresponding reranker MODEL in Spanner.
code_block
<ListValue: [StructValue([(‘code’, “CREATE OR REPLACE MODEL rerankerrnINPUT (text STRING(MAX), text_pair STRING(MAX))rnOUTPUT (score FLOAT32)rnREMOTErnOPTIONS (endpoint = ‘//aiplatform.googleapis.com/projects/<project_id>/locations/<location>/endpoints/<endpoint_id>’);”), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3eb02e14aa00>)])]>
In this example, SpanMart employs a Cross-Encoder model for reranking. This model takes two text inputs – text and text_pair – and outputs a relevance score indicating how well the two texts align. Unlike vector search, which uses an embedding model to independently map each text into a fixed-dimensional space before measuring their similarity, a Cross-Encoder directly evaluates the two texts together. This allows the Cross-Encoder to capture richer contextual and semantic nuances in complex queries, such as “gift for an 8-year-old who enjoys logical reasoning but not a toy”. In a more advanced setup, the reranker could leverage a custom-trained model that incorporates additional signals such as product reviews, promotions, and user-specific data like browsing and purchase history, to offer an even more comprehensive search experience.
Once this model is defined in Spanner, we can proceed to add reranking on the initial search results using the following query:
code_block
<ListValue: [StructValue([(‘code’, ‘@{optimizer_version=7}rnWITH ann AS (rn SELECT offset + 1 AS rank, id, descriptionrn FROM UNNEST(ARRAY(rn SELECT AS STRUCT id, descriptionrn FROM products @{FORCE_INDEX=products_by_embedding}rn WHERE embedding IS NOT NULLrn ORDER BY APPROX_COSINE_DISTANCE(embedding, @vector,rn OPTIONS=>JSON'{“num_leaves_to_search”: 10}’)rn LIMIT 200)) WITH OFFSET AS offsetrn),rnfts AS (rn SELECT offset + 1 AS rank, id, descriptionrn FROM UNNEST(ARRAY(rn SELECT AS STRUCT id, descriptionrn FROM productsrn WHERE SEARCH(description_tokens, @query)rn ORDER BY SCORE(description_tokens, @query) DESCrn LIMIT 200)) WITH OFFSET AS offsetrn),rnrrf AS (rn SELECT SUM(1 / (60 + rank)) AS rrf_score,rn id,rn ANY_VALUE(description) AS descriptionrn FROM ((rn SELECT rank, id, descriptionrn FROM annrn )rn UNION ALL (rn SELECT rank, id, descriptionrn FROM ftsrn ))rn GROUP BY idrn ORDER BY rrf_score DESCrn LIMIT 50rn)rnSELECT id, text AS descriptionrnFROM ML.PREDICT(MODEL reranker, (rn SELECT id, description AS text, @query AS text_pairrn FROM rrfrn))rnORDER BY score DESCrnLIMIT 10;’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3eb02e14a190>)])]>
Explanations:
ANN, FTS and RRF CTEs: These are the same previously defined approximate nearest neighbors, full-text search and reciprocal rank fusion queries, respectively.
ML.PREDICT Ranking: This step applies the reranker model to each product description as text from the RRF results, along with the search query as text_pair. The model assigns a relevance score to each product. The products are then sorted by these scores, and the top 10 are selected.
Get started
In this post, we demonstrated one approach to combine full-text search and vector search in Spanner, but developers are encouraged to explore other approaches, such as refining full-text search results with vector search, or combining multiple search results with customized fusion methods.
Learn more about Spanner and try it out today. For additional information, check out:
When it comes to AI, large language models (LLMs) and machine learning (ML) are taking entire industries to the next level. But with larger models and datasets, developers need distributed environments that span multiple AI accelerators (e.g. GPUs and TPUs) across multiple compute hosts to train their models efficiently. This can lead to orchestration, resource management, and scalability challenges.
We’re here to help. At Google Cloud, we provide a robust suite of GPU and TPU resources alongside advanced orchestration tools as part of AI Hypercomputer architecture to simplify distributed, large-scale training. In this blog, we’ll guide you through the orchestration tools available for GPU accelerators on Google Cloud that can help you streamline and scale your machine learning workflows.
aside_block
<ListValue: [StructValue([(‘title’, ‘$300 in free credit to try Google Cloud AI and ML’), (‘body’, <wagtail.rich_text.RichText object at 0x3eb02e47d790>), (‘btn_text’, ‘Start building for free’), (‘href’, ”), (‘image’, None)])]>
Choose the right accelerator family
A key element of distributed training lies in selecting the right GPU. Google Cloud’s specialized machine families offer tailored solutions for varying needs of performance and cost efficiency. The A3 machine series, featuring NVIDIA H100 and NVIDIA H200 (upcoming) GPUs, delivers strong GPU-to-GPU bandwidth that’s a great fit for large-scale training workloads. In contrast, the A2 machine series with NVIDIA A100 GPUs is designed for scenarios that require minimal inter-node communication such as streamlined, single-node training. Additionally, the versatile G2 machine family, equipped with NVIDIA L4 GPUs, provides the flexibility necessary for inference and testing workloads.
We also offer multiple GPU consumption models to meet the needs of large-scale training:
Committed Use Discounts (CUDs) provide significant cost savings and guaranteed capacity in return for a long-term commitment.
Dynamic Workload Scheduler (DWS) comes in two modes, which are designed for various workloads that need assurance or can be flexible about start time; the capacity is available for a defined duration and offered at a lower list price.
On-demand consumption is the most flexible, with no upfront commitments, although the capacity availability is not guaranteed.
Spot VMs provide drastically lower costs but are preemptible, requiring resilient and disruption-tolerant job designs.
To further accelerate your distributed training, we’ll explore three powerful orchestration strategies on Google Cloud: Google Kubernetes Engine (GKE), Cluster Toolkit, and Vertex AI custom training pipeline. Each approach brings its unique strengths, enabling you to leverage Google Cloud’s powerful infrastructure to drive your machine learning projects forward quickly and scalably.
Let’s walk through each of the options to better understand how Google Cloud’s advanced orchestration tools can help you optimize resources, reduce complexity, and achieve strong performance in your ML initiatives.
Option 1: GKE for unified workload management
Enterprises with robust platform teams often want a unified environment on which to run all their workloads, including custom training, for simpler management. GKE is a good choice in this context, providing the flexibility and scalability to handle diverse workloads on a single platform. With GKE, platform teams gain centralized control and visibility, while optimizing resource utilization and streamlining management.
Here’s how to orchestrate ML workloads running on GKE:
1. GKE cluster and nodepool provisioning If you have reservation (CUD or DWS calendar) and prefer to use Terraform, follow the instructions from cluster provisioning templates, and specify the parameter file (terraform.tfvars):
In addition, Cluster Toolkit includes terraform based example blueprints to provision A3 or A3 Mega GKE clusters and nodepool.
If you prefer to use the gcloud command, follow the step-by-step instructions from this tutorial to create a GKE cluster and nodepool with A3/A3 Mega VMs.
Validate the output of allgather benchmark tests for two A3 Mega nodes:
code_block
<ListValue: [StructValue([(‘code’, ‘size count type redop root time algbw busbwrnrn(B) (elements) (us) (GB/s) (GB/s)’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3eb02e472f70>)])]>
In the above benchmark output table, the first column is message size, while the algbw and busbw columns on the right indicate per GPU bandwidth. Usually, we use the in/out-of-place busbw column with the biggest message size (highlighted row) to determine cross-node bandwidth. For A3 Mega nodes, we expect a range of 185-190GB/s per GPU; this may indicate near cross-node 1600gbps network bandwidth for A3 Mega nodes with 8 NVIDIA H100 GPUs and 8 NICs.
You may expand the NCCL tests from two nodes to 8, 16, 32, etc. to ensure your cross-node network performance is within a decent range and that all the nodes are healthy.
3. Configure distributed training batch workload You can useJobSet, a Kubernetes-native API for managing a group of k8s Jobs as a unit using a unified API, to deploy distributed HPC (e.g., MPI) and AI/ML training workloads (PyTorch, Jax, Tensorflow etc.) on Kubernetes.
The following example illustrates a JobSet yaml manifest for A3 with GPUDirect-TCPX, which includes:
b. Training job settings, including pytorch main container c. gcsfuse, tcpx (A3 high), tcpxo (A3 Mega) RxDM container d. NCCL environment variables
For DWS batch workloads, please refer to the following A3 Mega-based example, integrating Kueue and JobSet settings.
Lastly, refer to this Helmchart example to see how to perform Megatron LM (Llama2) training on A3 Mega.
Option 2: Slurm via Cluster Toolkit
Slurm is one of the most popular high-performance computing (HPC) job schedulers. Used by researchers in both academia and industry, it offers a robust solution for LLM training orchestration with familiar semantics. Support for Slurm on Google Cloud is provided by Cluster Toolkit, formerly known as Cloud HPC Toolkit, open-source software that simplifies the process of deploying HPC, AI, and ML workloads on Google Cloud. It is designed to be highly customizable and extensible, and to address the deployment needs of a broad range of use cases, including deploying infrastructure for large-scale LLM training.
1. Provisioning A3-high and A3-mega clusters Install Cluster Toolkit using the configuration instructions in the public documentation. Be sure to note some of the prerequisites including supported versions of Go, Terraform, and Packer.
Once you have a working Cluster Toolkit installation including the downloaded github repository, navigate to the examples/machine-learning blueprints directory. Here, you will have two folders for deploying H100 clusters based on the A3-series machine shapes, a3-highgpu-8g and a3-megagpu-8g. In this example, we’ll explore the blueprint in the a3-megagpu-8g folder.
Google Cloud Cluster Toolkit blueprints are Infrastructure as Code (IaC) documents that describe the infrastructure you would like to deploy, and are conceptually similar to Terraform or other IaC tooling. For the a3-megagpu-8g blueprint, there are three main files that control the deployment:
slurm-a3mega-base.yaml – includes creating the necessary VPC networks along with the filestore instance used for a common home filesystem on the cluster nodes.
slurm-a3mega-image.yaml – creates the Compute Engine image instance that is used by Slurm to provision nodes based on the cluster’s definitio
slurm-a3mega-cluster.yaml – sets up the main cluster components, including the Slurm controller (the main orchestrator for Slurm jobs), the Slurm login node (a host used for job submission) and the a3mega partition (the working nodes in the cluster)
While you can customize each of the blueprint components if needed, you can easily get started by simply specifying the details for your working environment in the deployment-base.yaml and the deployment-image-cluster.yaml.
2. Enable GPUDirect-TCPXO optimized NCCL communication Once the Slurm cluster is created, follow this tutorial to enable GPUDirect-TCPXO for optimized NCCL communication on the GPU networks. To validate the environment and ensure the TCPXO plugin is being properly loaded, build and compile the NCCL tests. Then, run sbatch run-nccl-tests.sh from the login node, being sure to change the number of nodes in the script to match those in your cluster. This runs a distributed all_gather test across the GPUs and nodes indicated in the script.
code_block
<ListValue: [StructValue([(‘code’, ‘#SBATCH –partition=a3megarn#SBATCH –mem=0rn#SBATCH -N 2 # CHANGE TO REFLECT # Of a3-mega compute nodesrnrn#SBATCH –gpus-per-node=8rn#SBATCH –ntasks-per-node=8rnrn# Usage: sbatch run-nccl-tests.sh’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3eb02e472220>)])]>
When working as intended, the NCCL tests should show output results indicating high-speed bandwidth throughput at various message sizes. A common measure of performance is to use the busbw value in GB/s from the second or last row of the output table, which shows the 4Gb and 8Gb message size values. A cluster with TCPXO active should report around 190 GB/s busbw throughput. See the performance page in the NVIDIA NCCL-tests repository for more details around these metrics.
Creates a NeMo Framework-derived container with the necessary TCPXO environment variables
Submits a Slurm job to copy the framework launcher scripts and a few other auxiliary files into your working directory
Step 2:
code_block
<ListValue: [StructValue([(‘code’, ‘pip install -r requirements.txt # Copied from the NeMo Framework Container earlierrn# This is needed to use 23.11 and python3.11, which is what is present onrn# Debian 12rnpip install -U hydra-core’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3eb02e4721f0>)])]>
Establishes a Python virtual environment and installs NeMo Framework python package dependencies
This command runs distributed training of a 5B parameter GPT3 model across eight nodes for 10 steps using mock data as the input.
Option 3: Vertex AI
For teams seeking managed infrastructure experience as well as access to leading open models such as Llama 3.1, Mistral, etc., Vertex AI Model Garden and Custom Training Job service presents an attractive option. This fully managed solution removes most of the orchestration burden and provides end-to-end ML platform operations, allowing you to focus on model development and experimentation. Vertex AI’s end-to-end training support further simplifies the process, offering an integrated workflow from data preparation to deployment.
Let’s look at how to perform single-node or multi-node fine-tuning/training workload on Vertex.
Single-node multi-GPU fine-tuning/training on Vertex This notebook demonstrates fine-tuning and deploying Llama 3.1 models with the Vertex AI SDK. All of the examples in this notebook use parameter-efficient finetuning (PEFT) methods with Low-Rank Adaptation (LoRA) to reduce training and storage costs. LoRA is one approach of PEFT, where pretrained model weights are frozen and rank decomposition matrices representing the change in model weights are trained during fine-tuning.
Multi-node distributed fine-tuning/training on Vertex AI
This Vertex sample training repo provides examples on how to launch multi-node distributed training on A3 Mega (8 x NVIDIA H100) on Vertex.
The NeMo example illustrates how to perform pre-training, continued pre-training and supervised fine-tuning (SFT). In addition, NeMo allows optimized training as a popular approach to evaluate the AI accelerator (A3 Mega in this case). To benchmark, you can rely on the reported metrics such as epoch time, step-time, etc. Since NeMo runs on most NVIDIA GPU types, it can be helpful for comparing different AI chips for a given task. Read on to learn how to run the example on Vertex with A3 Mega node types.
launch.sh is the main entry point to launch NeMo distributed training with command parameters:
code_block
<ListValue: [StructValue([(‘code’, ‘<TRAIN_TYPE> Job type (options: pretraining,continual-pretraining,full-sft)”rn <MODEL_NAME> Model name (options: llama2-7b,llama3-70b)”rn <LOG_DIR> Path to the local storage (e.g. /tmp/…) or gcs bucket (/gcs/BUCKET_NAME) rn –debug Pass sleep infinity to launch command’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3eb02e476ee0>)])]>
Example:
code_block
<ListValue: [StructValue([(‘code’, ‘export REGION=us-central1rnexport PROJECT_ID=YOUR_PROJECTrnrn# Starting a job to pretrain a llama2-7b model and setting /tmp as the log directoryrn./launch.sh pretraining llama2-7b /tmp’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3eb02e4764c0>)])]>
At the end of launch.sh script, we use curl command to call Vertex customJobs API to launch NeMo training job in Vertex:
code_block
<ListValue: [StructValue([(‘code’, ‘..rn# == create json stucture with existing environment variables ==rnjson_job=$(envsubst < vertex-payload.json)rnrnjson_file=”nemo_${MODEL_NAME}_${TRAIN_TYPE}_${NNODES}.json”rnrnecho $json_job | tee $json_file > /dev/nullrnrnjob_addr=”https://${REGION}-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/${REGION}/customJobs”rnrnecho json_file:$json_filernecho job_addr:$job_addrrnrnset -xrnrncurl -X POST \rn -H “Authorization: Bearer $(gcloud auth print-access-token)” \rn -H “Content-Type: application/json; charset=utf-8” \rn -d “@$json_file” \rn $job_addrrn # “$job_addr” TODO: pass the param job_addr to the curl command. does not work with parameterized values.’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3eb02e476610>)])]>
Job configurations in vertex-payload.json are part of curl command to launch Nemo training, it includes job specifications on resource requirements as showed:
The job configuration arguments “${TRANSFER_MODEL_CMD} ${LAUNCH_CMD}” in turn embed full content from the job training script, which also includes all the NCCL environments required by A3 Mega, while other pytorch launch commands are executed by Vertex CustomJob.
Optionally, build your own custom job container image as an “imageUri” parameter in vertex-payload.json, using this Dockerfile as your reference.
DIY enthusiasts: Building custom training environments
Lastly, we recognize many organizations prefer a more hands-on approach and have specific orchestration tools or frameworks that they wish to use. If that describes you, Google Compute Engine provides the foundation to build your own tailored training environments, letting you create and configure virtual machines (VMs) with your desired specifications, including the type and number of GPUs, CPU, memory, and storage. This granular control lets you optimize your infrastructure for your specific training workloads and integrate your preferred orchestration tools.
To facilitate this process, we provide example code snippets demonstrating how to use the gcloudcompute instance create and gcloud compute instance bulk create API calls to create and manage your vanilla A3 Mega instances. Whether you need to create a single VM or provision a large-scale cluster, these resources can help streamline your infrastructure setup.
Conclusion
With the right orchestration strategy and Google Cloud’s robust and leading AI infrastructure, you can achieve your training goals and transform your business objectives into reality.
For enterprises, brilliance isn’t just about individual genius – it’s about the collective intelligence within an organization. But this brilliance is often hidden in silos, inaccessible to those who need it most, when they need it most. Our studies show that enterprise workers use an average of four to six tools just to ask and answer a question1.
Generative AI holds immense promise for employee productivity. That’s why today, we’re introducing Google Agentspace. It unlocks enterprise expertise for employees with agents that bring together Gemini’s advanced reasoning, Google-quality search, and enterprise data, regardless of where it’s hosted. Google Agentspace makes your employees highly productive by helping them accomplish complex tasks that require planning, research, content generation, and actions – all with a single prompt.
Three ways in which Google Agentspace unlocks enterprise expertise:
1. New ways to interact and engagewith your enterprise data using NotebookLM: We built NotebookLM to help users make sense of complex information, and now we’re bringing this capability to enterprises. With NotebookLM Plus, your employees can upload information to synthesize, uncover insights, and enjoy new ways of engaging with data, such as podcast-like audio summaries and more. It’s the same experience millions of users love, now enhanced with security and privacy features for work. We’re also starting to roll out the experimental version of Gemini 2.0 Flash in NotebookLM. You can sign up for theearly access programfor NotebookLM for enterprise today.
Analyze Cymbal’s third quarter results, then generate an Audio Overview
2. Information discoveryacross the enterprise: Google Agentspace gives employees a single, company-branded multimodal search agent that acts as a central source of enterprise truth for your entire organization. Building on the best of Google’s search capabilities, Agentspace can provide conversational assistance, answer complex questions, make proactive suggestions, and take actions based on your company’s unique information. Google Agentspace can do this across unstructured data – such as documents and emails – and structured data such as tables. We’ve also built translation in, so that you can understand all information, even if it originates in another language. With pre-built connectors for the most commonly used third-party applications, such as Confluence, Google Drive, Jira, Microsoft SharePoint, ServiceNow, and more, your employees can now easily access and query relevant data sources, and make better decisions.
Quickly find JIRA tickets and send an email summary to the manager listed
3. Expert agentsto automate your business functions: Google Agentspace is the launch point for custom AI agents that apply generative AI contextually. Now, enterprises can empower their employees in marketing, finance, legal, engineering, and more to conduct better research, draft content quickly, and automate repetitive tasks, including multi-step workflows. With Google Agentspace, enterprises can scale AI by providing a single location where employees can easily discover and access agents for their organization. Soon, employees will be able to use a low-code visual tool to build and tune their own expert agents with Google Agentspace.
Manage expense reports with an expert AI agent launched from Google Agentspace
With Google Agentspace, business analysts can effortlessly uncover industry trends and create compelling, data-driven presentations fueled by AI-generated insights. HR teams can revolutionize the employee experience with streamlined onboarding, even for complex tasks like 401k selection. Software engineers can proactively identify and resolve bugs, enabling them to build and iterate with greater efficiency, and accelerate deployment cycles. Marketers can unlock deeper performance analysis, optimize content recommendations, and fine-tune campaigns to achieve better results. And with multi-language support, all employees – no matter their region – can unlock enterprise expertise with agents. Sign up for theearly access program.
Finally, security is always top of mind. Google Agentspace is built on Google Cloud’s secure by design infrastructure, giving you the peace of mind to confidently deploy AI agents across your organization. Plus, we provide granular IT controls, including role-based access control (RBAC), VPC service controls, and IAM integration, ensuring your data remains protected and compliant at all times.
Hear from our customers
Our enterprise customers are already seeing great promise around connecting their employees with the wealth of their enterprise’s information.
“At Deloitte, knowledge fuels our work. Our knowledge management teams are impressed with Google Agentspace’s ability to unify information scattered across various data silos. With Agentspace, our professionals can find the information they need instantly, boosting productivity and efficiency. Beyond search, the AI agentic capabilities within Google Agentspace can empower teams to take action on this knowledge, enabling us to deliver solutions and achieve client outcomes faster. In the long term, we see Agentspace as a key driver in transforming how we serve clients, fostering deeper collaboration, and unlocking new levels of insight and innovation across our organization.” – Kevin Laughridge, Alphabet Google US Lead Alliance Partner, Deloitte Consulting LLP
“At Nokia, we create technology that helps the world act together. to connect and improve the world. Google Agentspace has the potential to revolutionize how our teams across Nokia find and leverage critical insights. We’re particularly excited by Google Agentspace’s ability to blend various data sources quotes and deliver personalized, contextually relevant answers. By unifying our knowledge resources, providing AI powered assistance and automating workflows, we strive towards reduced time spent searching for information, faster decision-making, and improved collaboration and productivity.” – Alan Triggs, Chief Digital Officer, Nokia
“At Decathlon, we’re driven by a passion for sports and a commitment to innovation. Google Agentspace’s ability to connect teams with the right information from across organizations and provide self-service assistance is incredibly promising. Google Agentspace could become an essential enabler for product designers, marketers, and researchers, enabling them to make faster, more informed decisions and ultimately delivering even better experiences for customers. Our cross-functional teams — from data to workplace tools — see it as a great promise to meet our needs,” – Youssef BAKKALI, Group Product Manager, Decathlon
“At Onix we help businesses harness the power of technology to drive innovation and growth. Google Agentspace has immense potential to transform how enterprises deploy agents and access enterprise data at scale. By connecting disparate data sources and leveraging Google’s advanced AI for agentic workflows, Google Agentspace empowers organizations to unlock new levels of creativity. These last few months Onix has been partnering with Google to onboard early customers, and we are excited to see our clients take their first steps on this transformative journey.” – Ramnish Singh, SVP Solutions Engineering, Onix
“Banco BV is committed to providing our team with the most innovative tools and technologies for collaboration. Google Agentspace is helping us realize the vision of enabling our employees to leverage some of the most advanced generative AI technologies for search, assistance and actions across all our critical systems in a secure and compliant way. We are particularly excited to see how our early users are leveraging Google Agentspace for faster and more comprehensive analysis and engaging with content in new multimodal ways that reflect our vision of work as more relaxed and collaborative.” – Fabio Jabur, Head of Data and AI, Banco BV
“Google Agentspace has the potential to redefine how enterprises leverage knowledge, particularly through the power of AI agents. We’re excited to partner with Google Cloud to bring this to our customers, enabling them to securely use generative AI to enhance productivity, streamline workflows, and drive innovation. Google Agentspace’s unique ability to personalize search, provide AI assistance, and leverage innovations like NotebookLM will revolutionize how knowledge workers discover, generate, and utilize information. We believe that agents represent the future of knowledge work, and Google Agentspace is at the forefront of this exciting evolution.” – Gaurav Johar, Head of Applied AI, Quantiphi
“Our team of over 12,000 dedicated staff is united by a shared purpose: to make every day a little better for our customers by keeping daily essentials within reach for all. As Singapore’s largest food retailer, we understand that our people are the key to delivering on our social mission. To empower them with the tools they need to put their best foot forward every day, we are building an organization-wide research and assistance platform with Google Agentspace, with the aim of reducing manual effort. Google Agentspace will equip our employees with both a seamless research assistant that searches across all our documents, internal systems, and even third-party applications, and a task assistant using natural language. Our ultimate goal is to improve knowledge discovery and streamline processes across our enterprise. By enabling our people to access and share knowledge effortlessly, we can foster improved customer experiences and enhanced operational efficiency.” – Dennis Seah, Chief Digital & Technology Officer, FairPrice
Hear from users at Deloitte Consulting LLP
“My work involves various market analyses as a strategy professional. It normally takes us a couple of weeks to read through all the research material. NotebookLM allowed us to get the initial insights in minutes and spend the time going deeper. It helps my team collaborate from a single source, pooling notes and links, freeing up more of our research time for strategic thinking and brainstorming allowing us to deliver compelling insights to our clients.” – Parinda Gandevikar, Senior Consultant, Deloitte Consulting LLP
“NotebookLM’s podcast uncovered hidden insights in our GenAI report, revealing differences between industry sectors. Despite having read it multiple times, I had not caught this nuance. It was a real ‘aha’ moment.” – Laura Shact, Human Capital AI Lead, Deloitte Consulting LLP
“It’s a game changer for drawing insights from meetings. We took the recordings and uploaded it to NotebookLM and it did an amazing job of synthesizing the key findings.” – Tom Cahill, Senior Consultant, Deloitte Consulting LLP
“Before a long drive, I upload earnings call transcripts of recent tech companies and listen to the audio overview on my drive. It’s great how the key insights are distilled and interwoven with broader context that’s not even in those documents.” – Vivek Kulkarni, GenAI Transformation Lead, Deloitte USA LLP
“I run a practice which involves creating and sharing a lot of different types of enablement content for the practice. It was delightful for our team to go from paging through dozens of documents to quickly finding the information we need, with the source document just one click away in NotebookLM.” – Gopal Srinivasan, Alphabet Google AI Alliance Lead, Deloitte Consulting LLP
Get started
Unlocking your organization’s collective brilliance is an investment in its future success. By connecting employees to enterprise expertise, you can create a more informed, innovative, and agile organization.
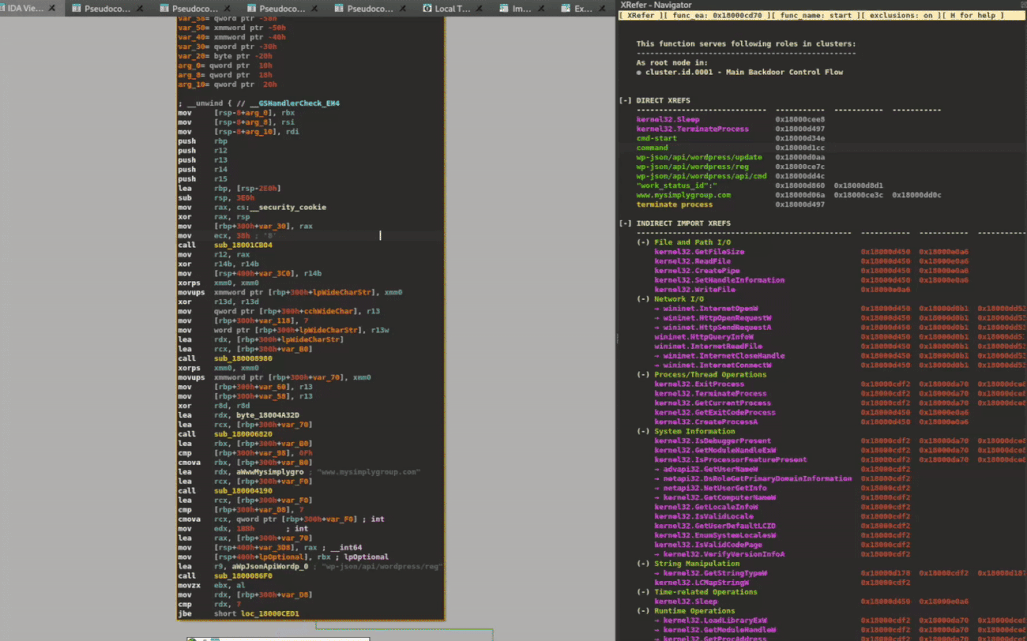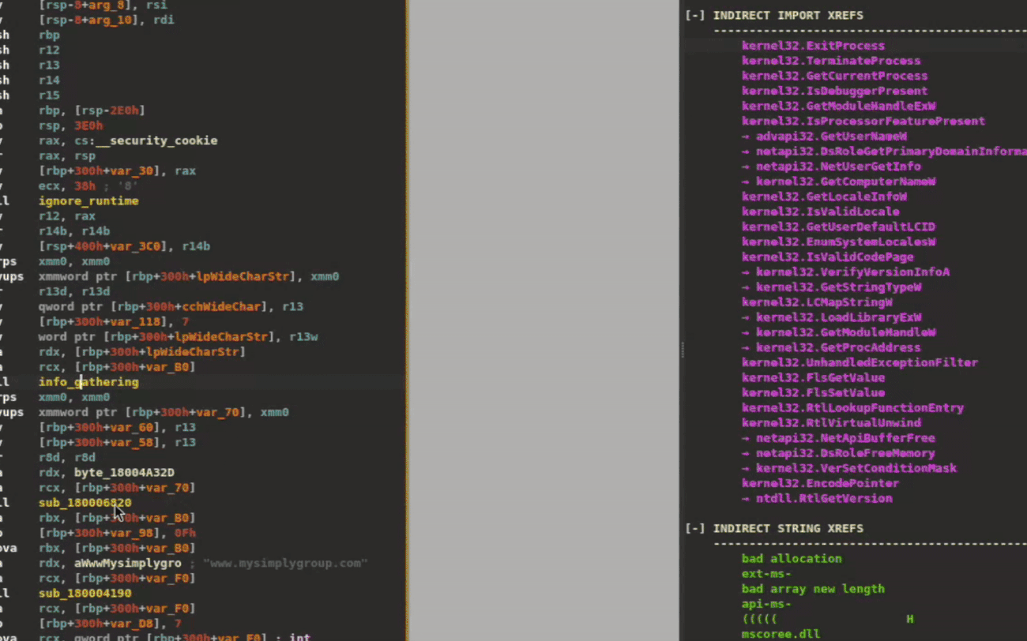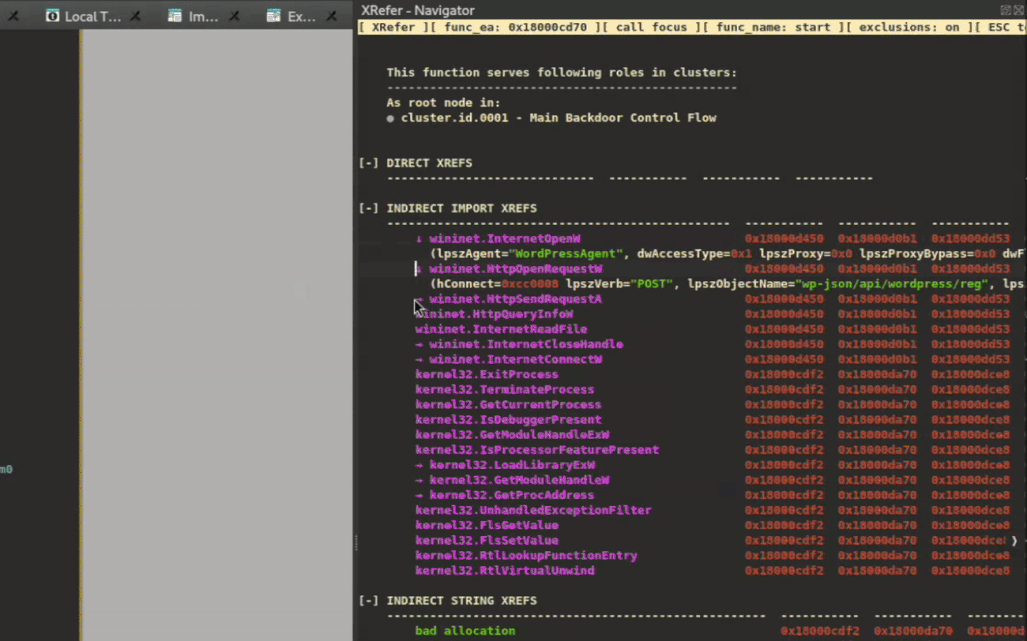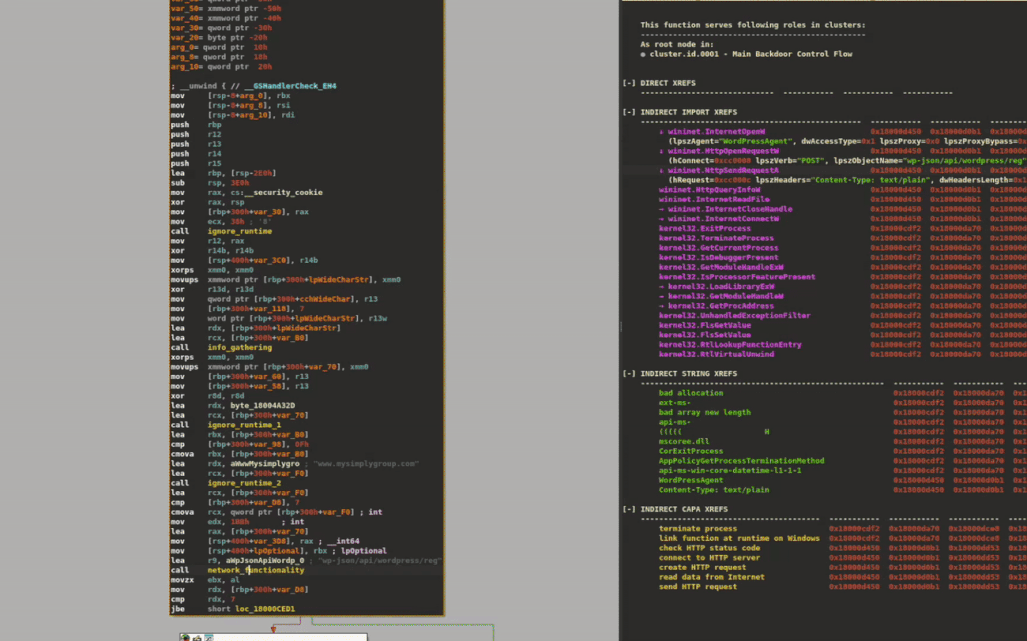
Here at Mandiant FLARE, malware reverse engineering is a regular part of our day jobs. At times we are required to perform basic triages on binaries, where every hour saved is critical to incident response timelines. At other times we examine complicated samples for days developing comprehensive analysis reports. As we face larger and more complex malware, often written in modern languages like Rust, knowing where to go, what to look at, and developing a “map” of the malware forms a significant effort that directly impacts our response times and triage effectiveness.
Today we introduce a new tool, XRefer (pronounced eks-reffer), which aims to shoulder some of this burden for anyone who endeavors to go down these rabbit holes like us, helping analysts get to the important parts faster while maintaining the context of their investigation.
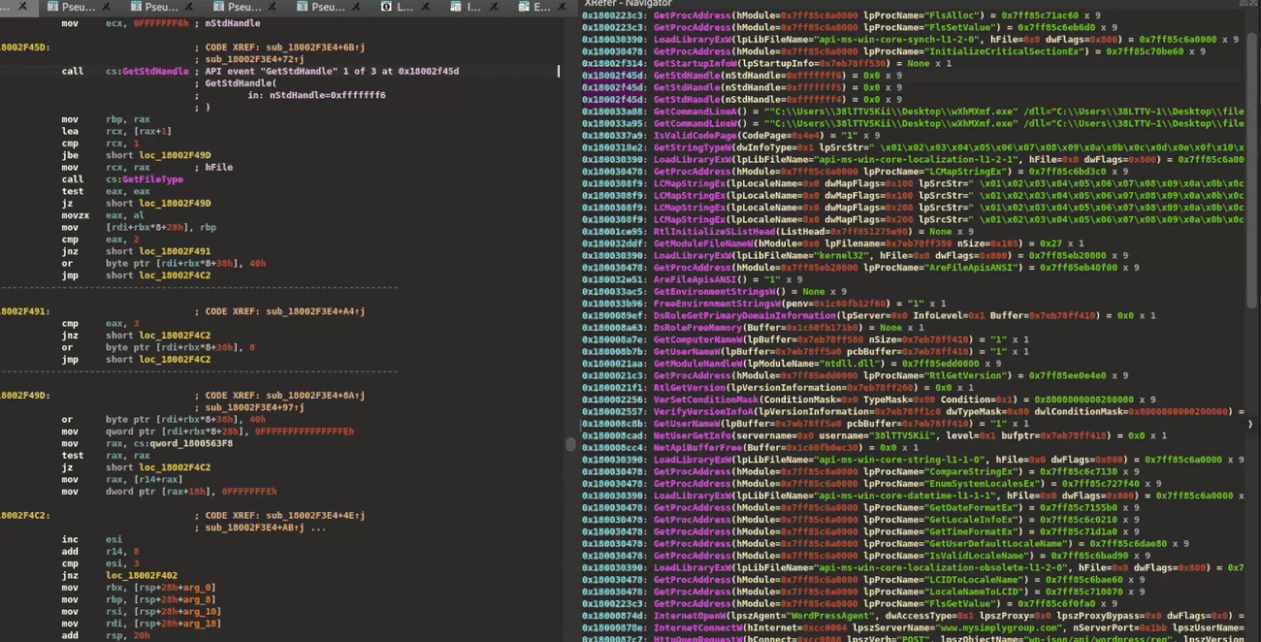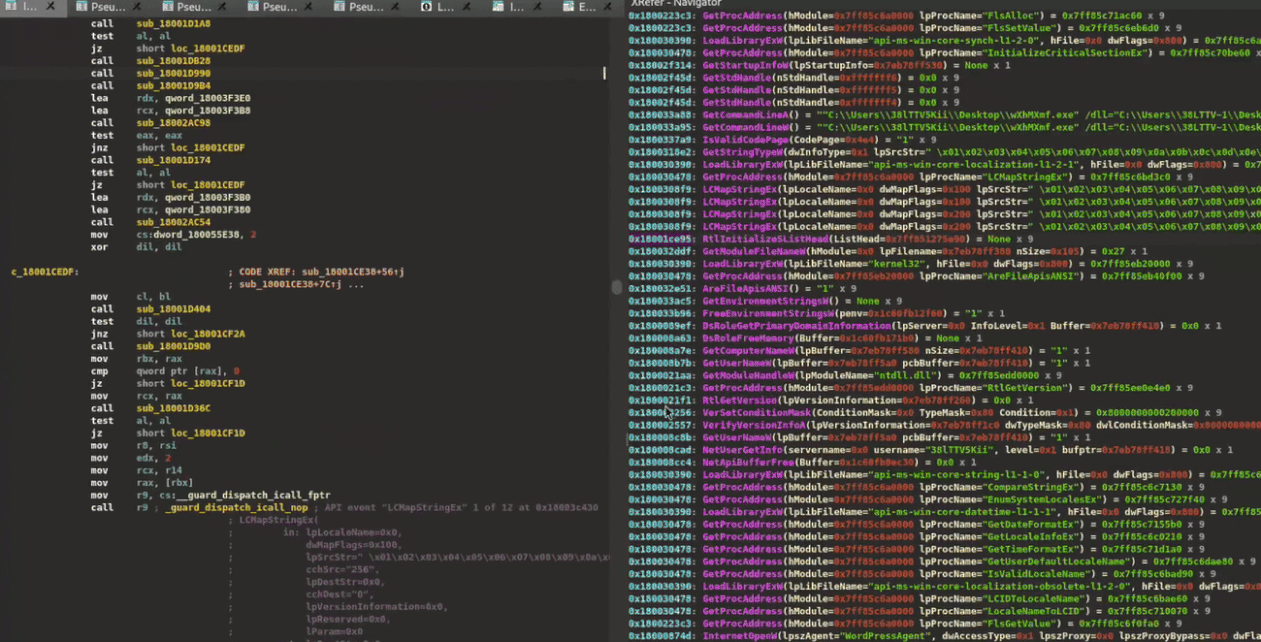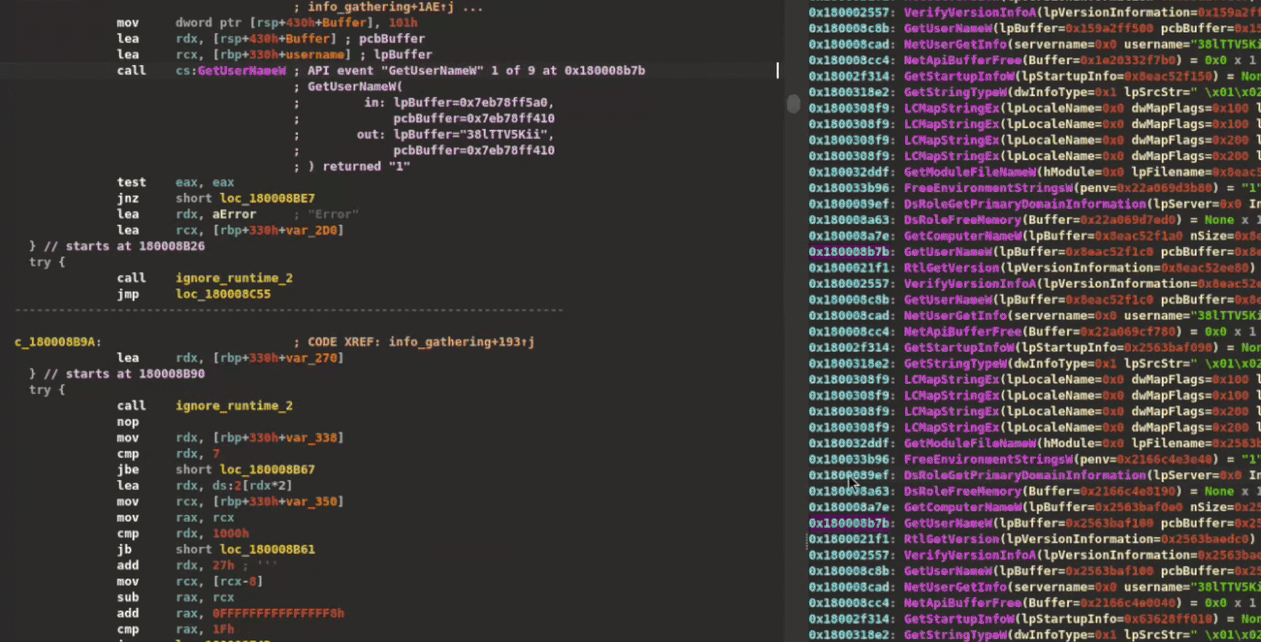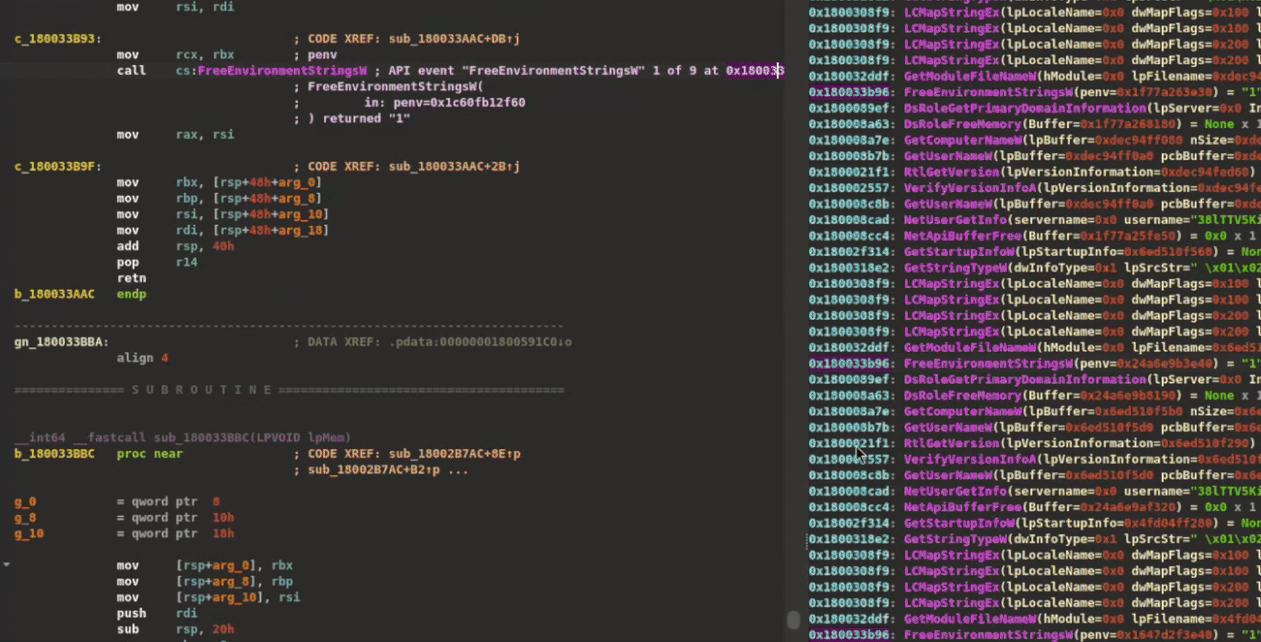
XRefer provides a persistent companion view to assist analysts in navigating and understanding binaries. It’s a modular and extensible tool that comes in the form of an IDA Pro plugin. Figure 1 shows the XRefer interface.
Figure 1: XRefer opened as a side pane, displaying Cluster Tables
At its core, XRefer offers two complementary navigation paradigms:
Gemini-powered cluster analysis, which decomposes the binary into functional units and leverages the large language model (LLM) to describe their purpose and relationships. Think of this like viewing a city from Google Maps: you can quickly identify the business districts, residential areas, and green spaces. In binary terms, this feature helps identify functional groupings like command-and-control communication, persistence mechanisms, or information-gathering routines, giving you a strategic view of the malware’s architecture.
A context-aware view, which dynamically updates based on your current location in the code. This view presents both immediate artifacts of the current function and those from related functions along the same execution path. It’s similar to standing outside a shopping mall with X-ray vision: without entering each store, you can see the restaurant menus, shop inventories, and services offered on each floor. This allows you to make informed decisions about which areas deserve deeper investigation. Just as a mall directory helps you efficiently plan your shopping route, XRefer’s context-aware view helps analysts quickly identify relevant code paths by surfacing APIs, strings, capa matches, library information, and other artifacts that might otherwise require manual exploration of multiple functions.
Let’s take a closer look at each of these paradigms, beginning with cluster-based navigation.
The Birds-Eye View: Cluster-Based Binary Navigation
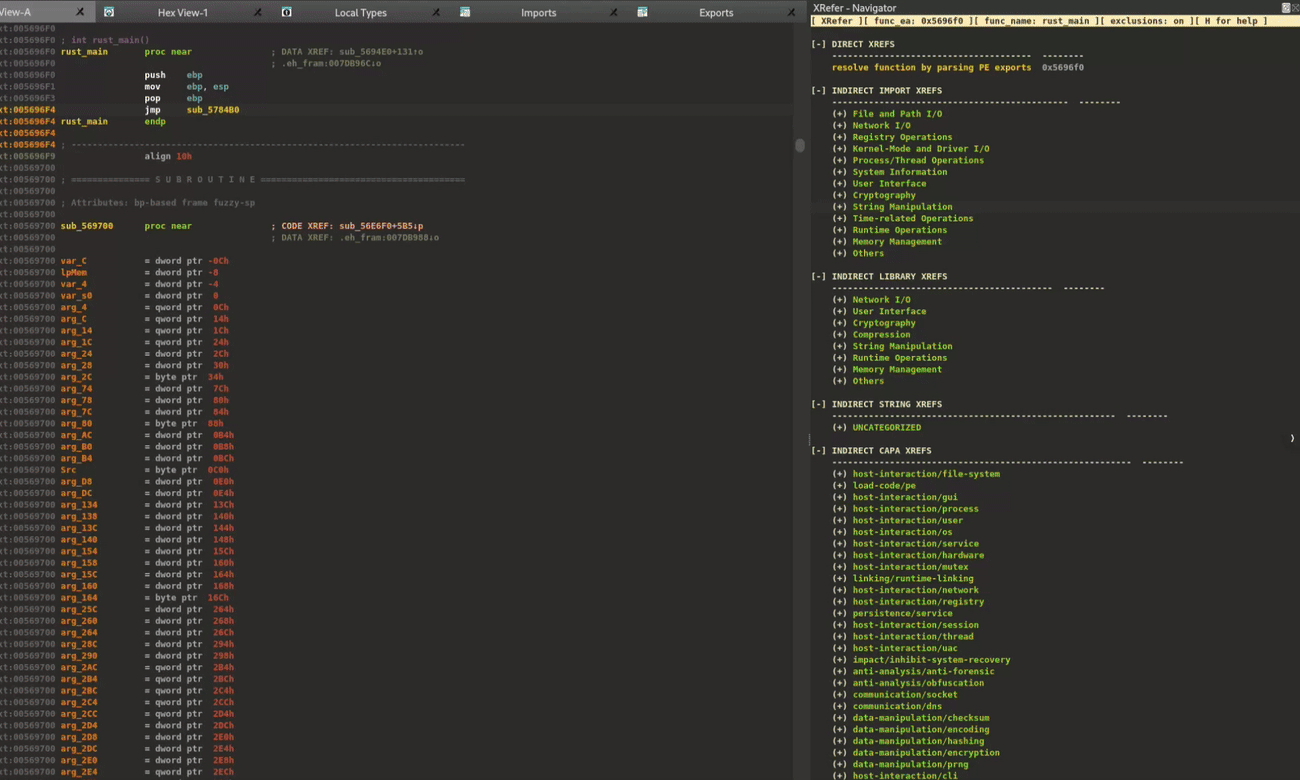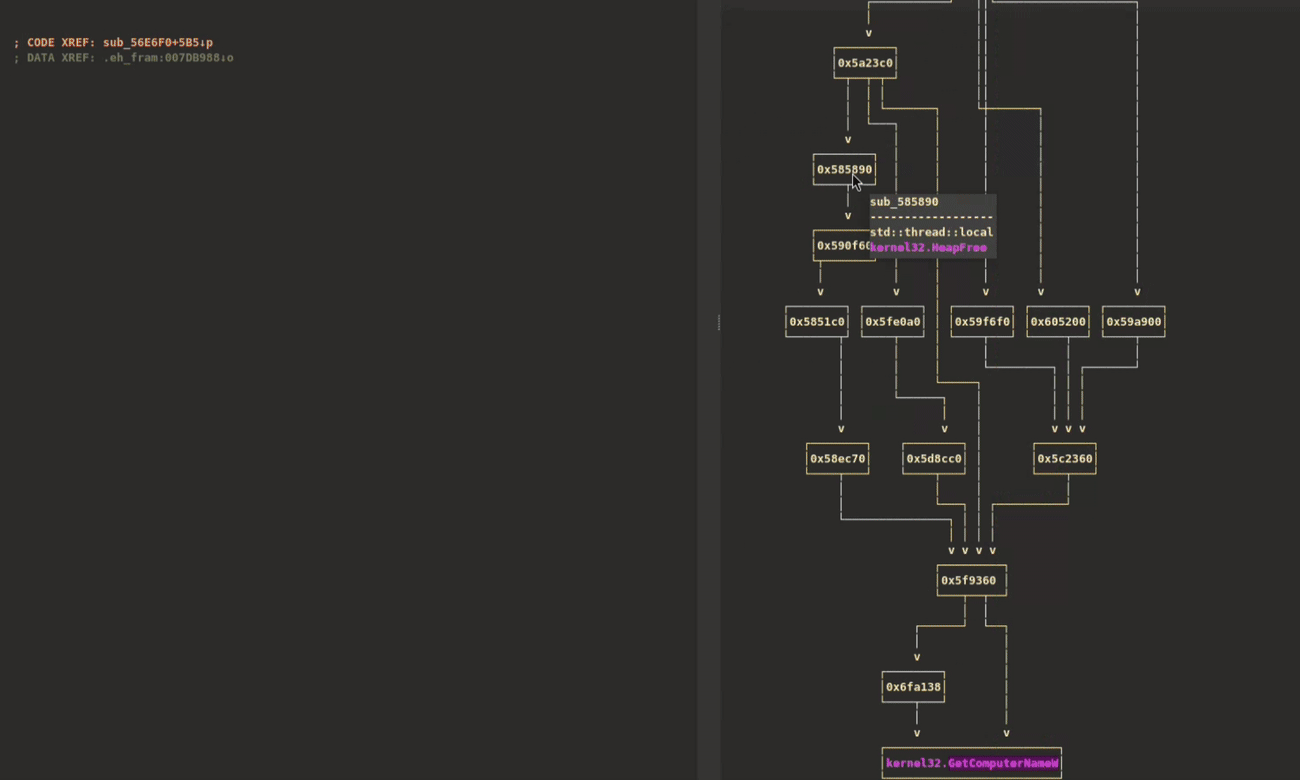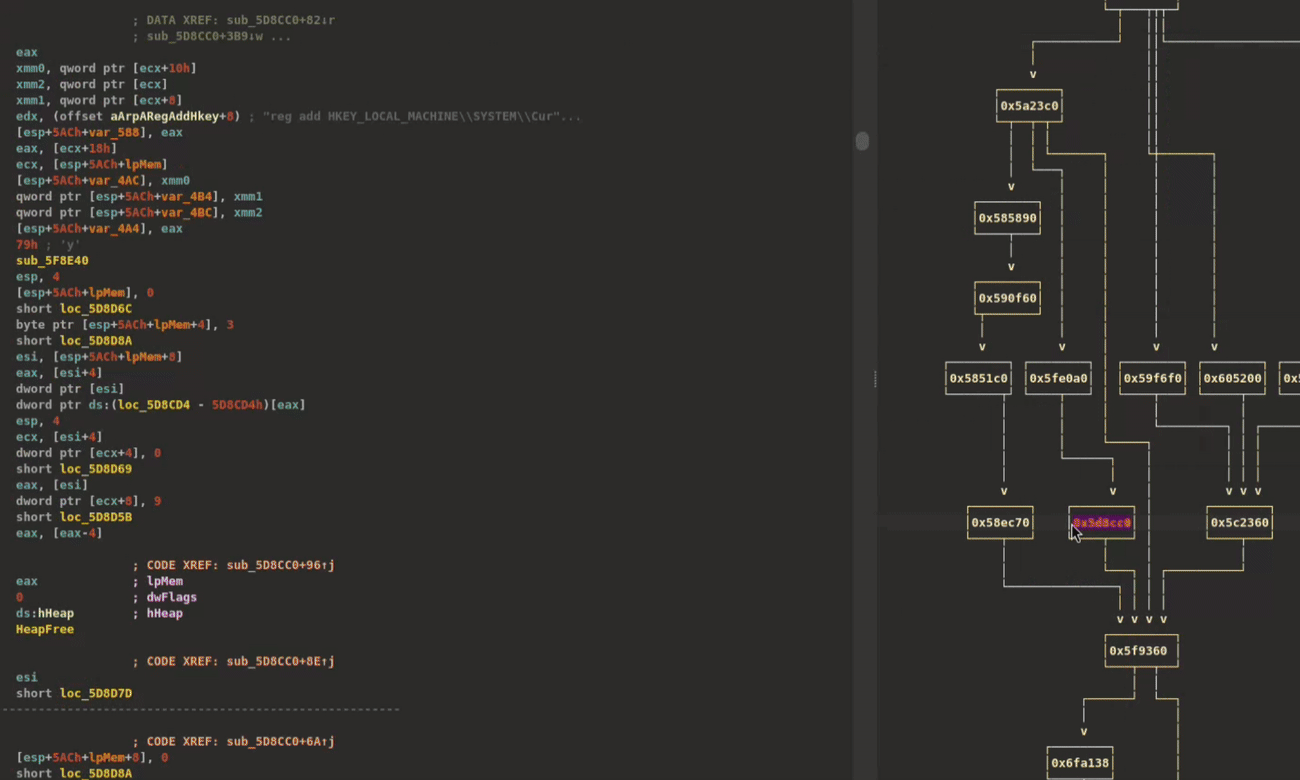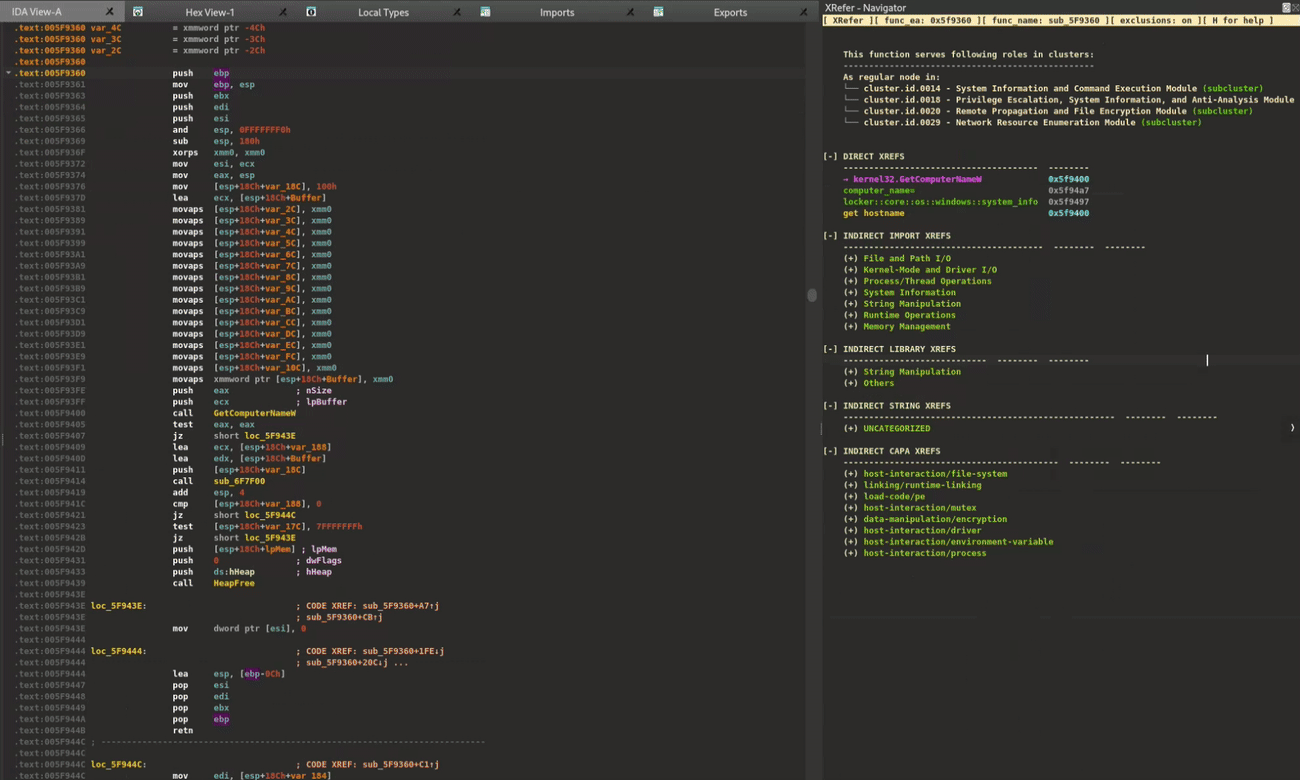
One of XRefer’s key features is its ability to break down a binary into functional units, providing an immediate high-level understanding of its architecture. To demonstrate this capability, let’s examine an ALPHV ransomware sample written in Rust. Despite containing over 2,700 functions, XRefer’s analysis organizes key functionality of this complex binary into clear functional clusters, as shown in the Cluster Relationship graph in Figure 2.
Figure 2: Cluster Relationship graph view
These functional clusters are descriptively labelled as follows:
Ransomware Main Module
Configuration Parsing Module
User Profile and Process Information Module
Privilege Escalation, System Information, and AntiAnalysis Module
File Processing Pipeline Module
Network Communication and Cluster Management Module
Thread Synchronization and Keyed Events Module
File Path and Encryption Key Generation Module
Console Clearing Module
UI Rendering and Console Output Module
Image Generation and Encoding Module
Data Encoding and Hashing Module
File Discovery and Dispatch Module
Thread Synchronization and Time Management Module
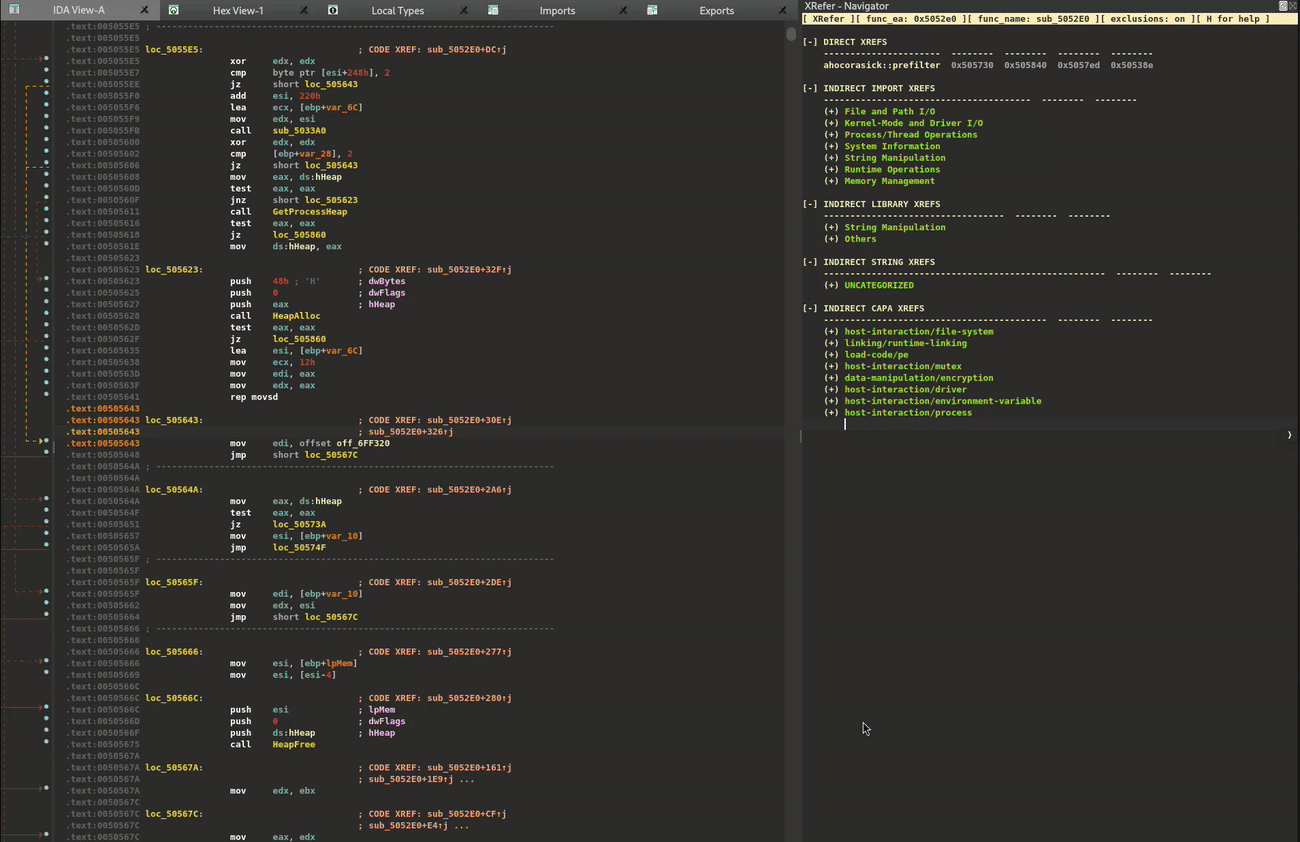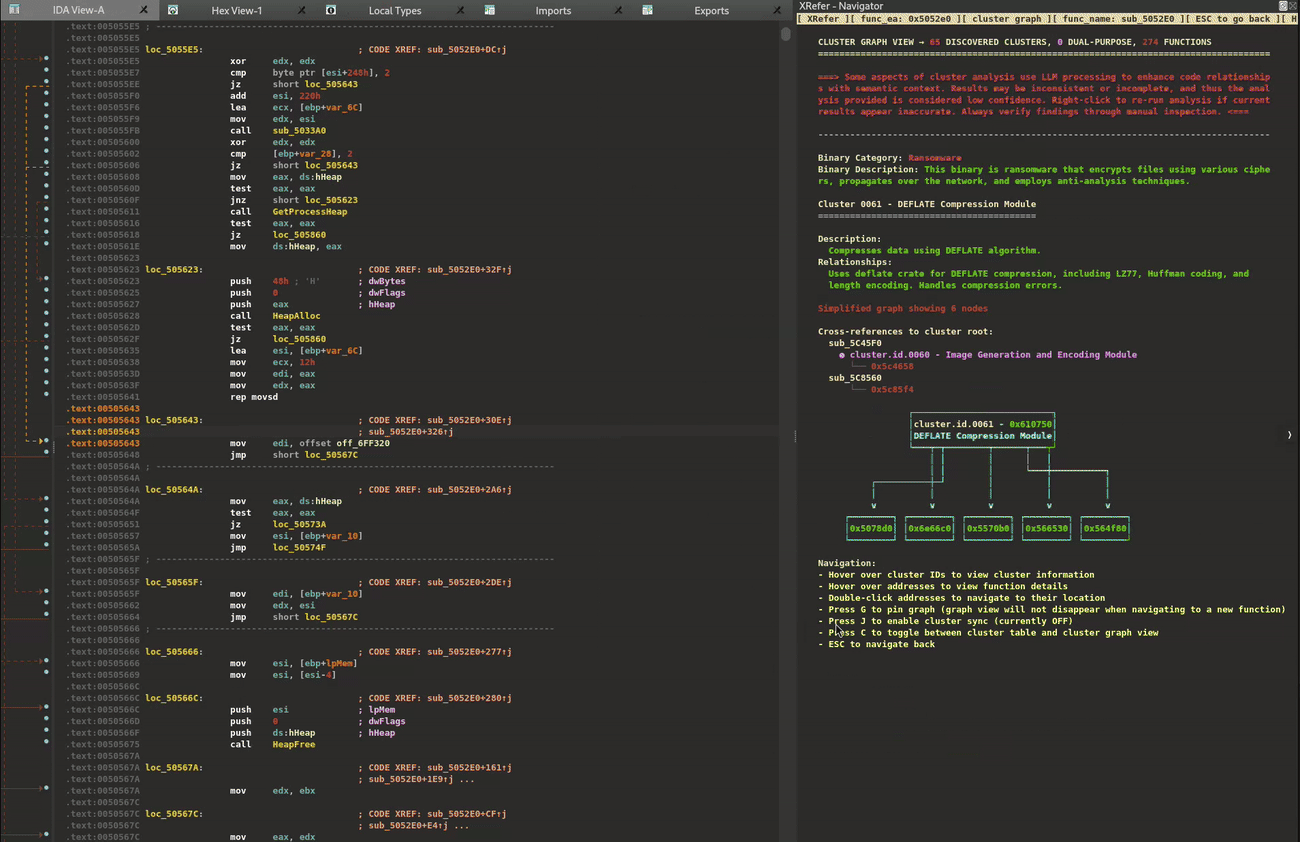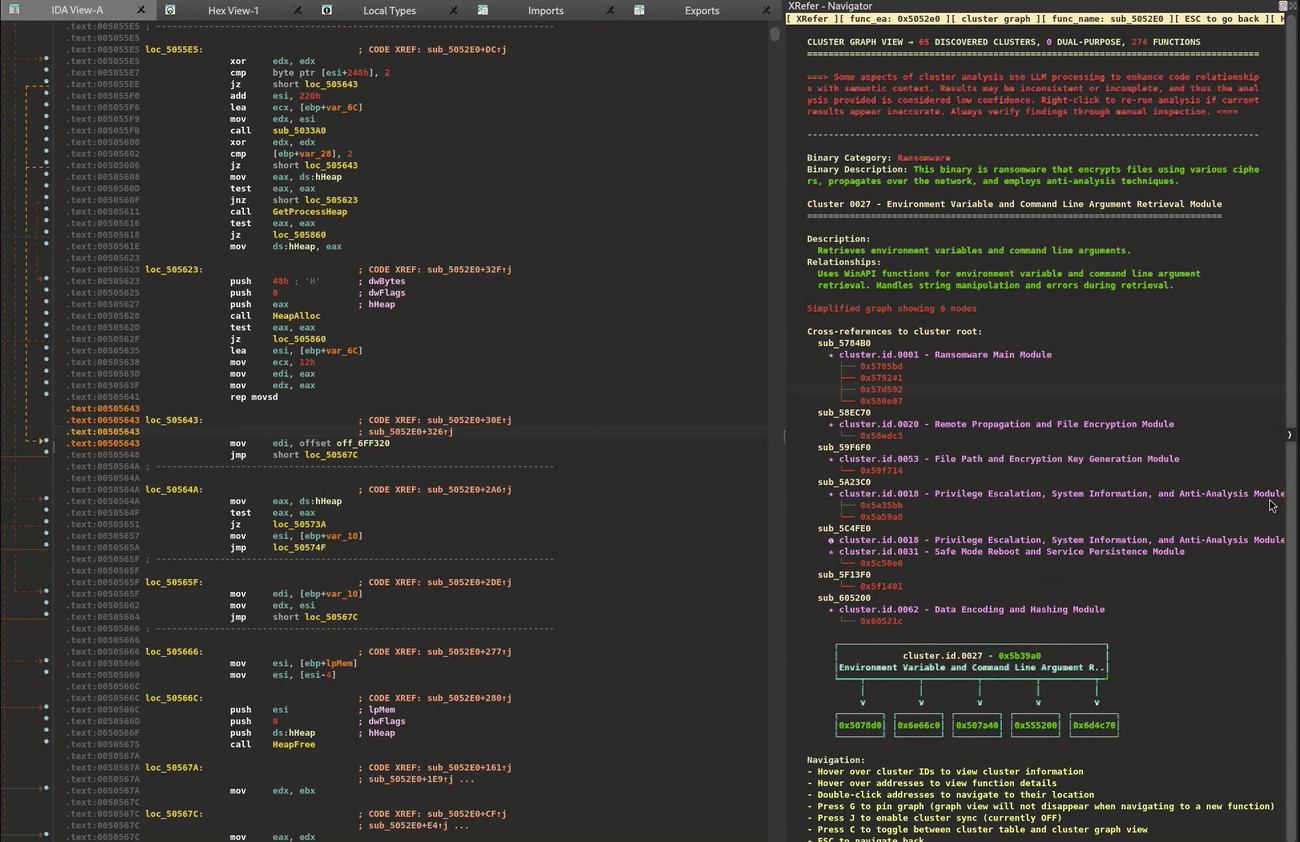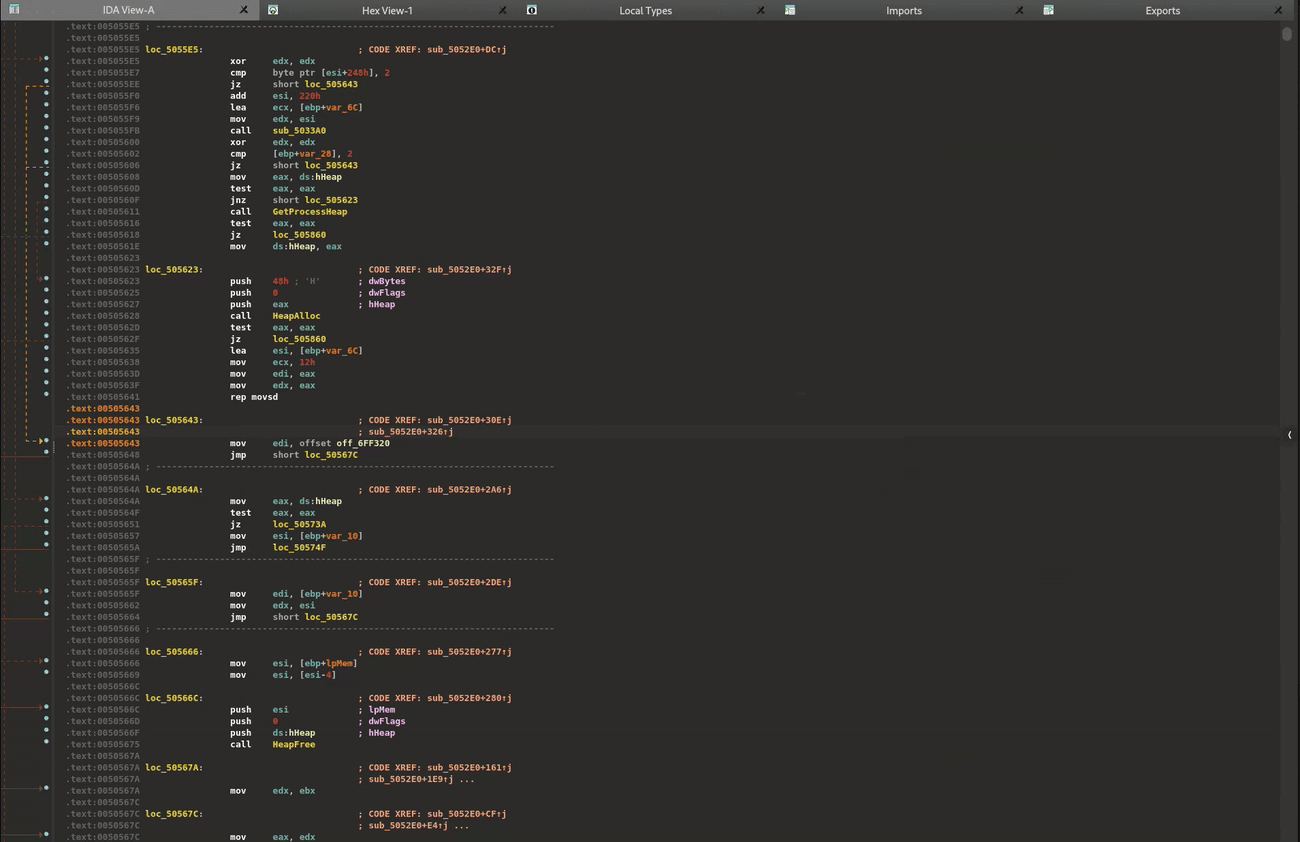
While each cluster contains deeper sub-clusters that analysts can explore, we’ll focus on the high-level view for now. The clustering and relationship identification is performed through static analysis. XRefer then leverages Gemini to provide natural language descriptions of each cluster and how they relate to one another. Figure 3 illustrates key components in the graph navigation interface.
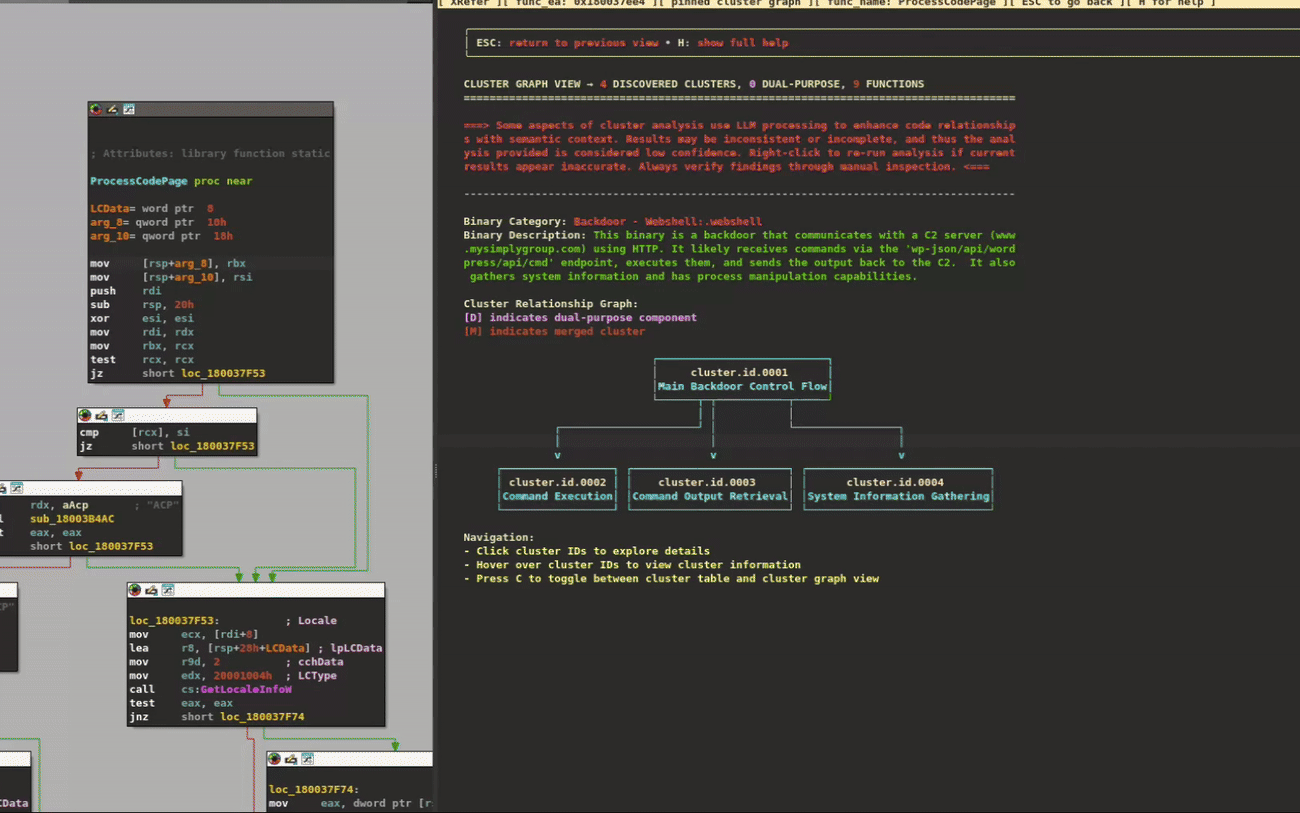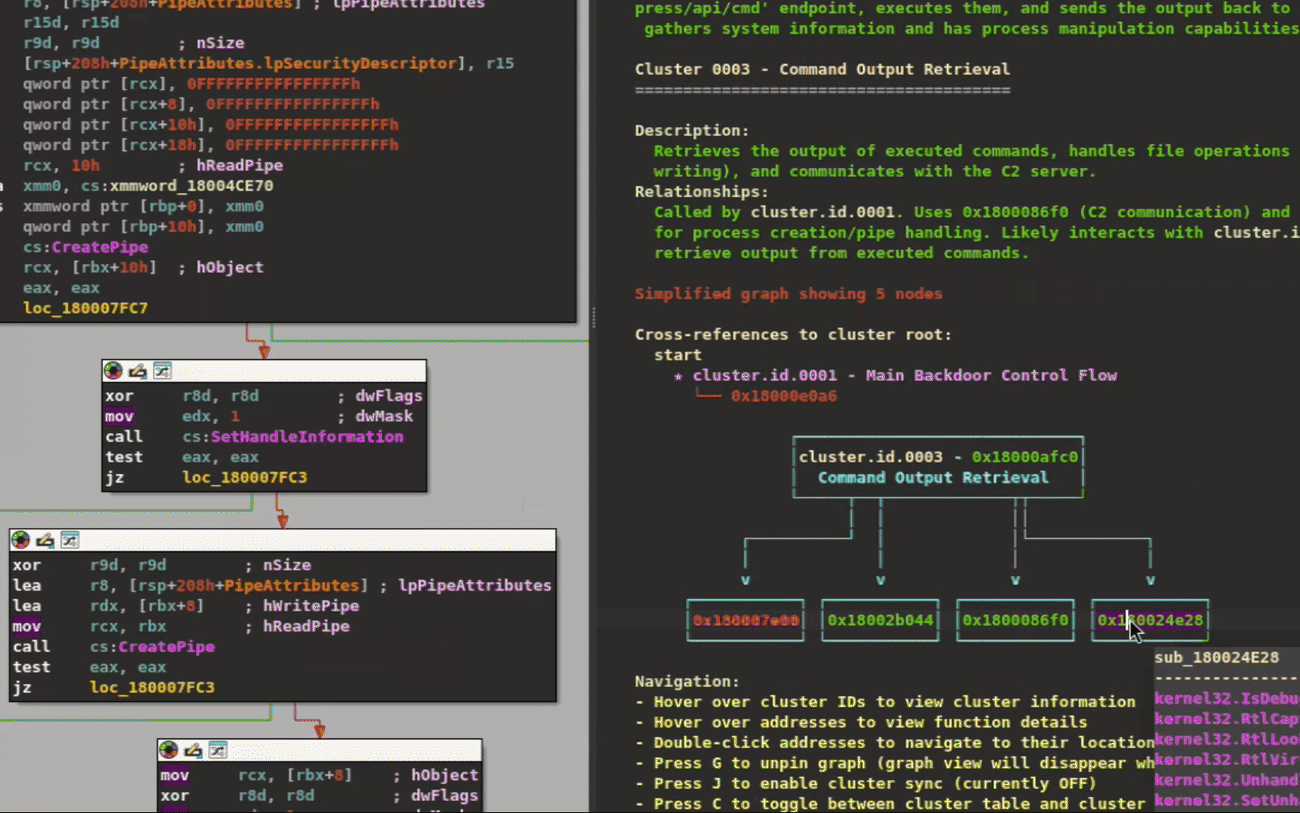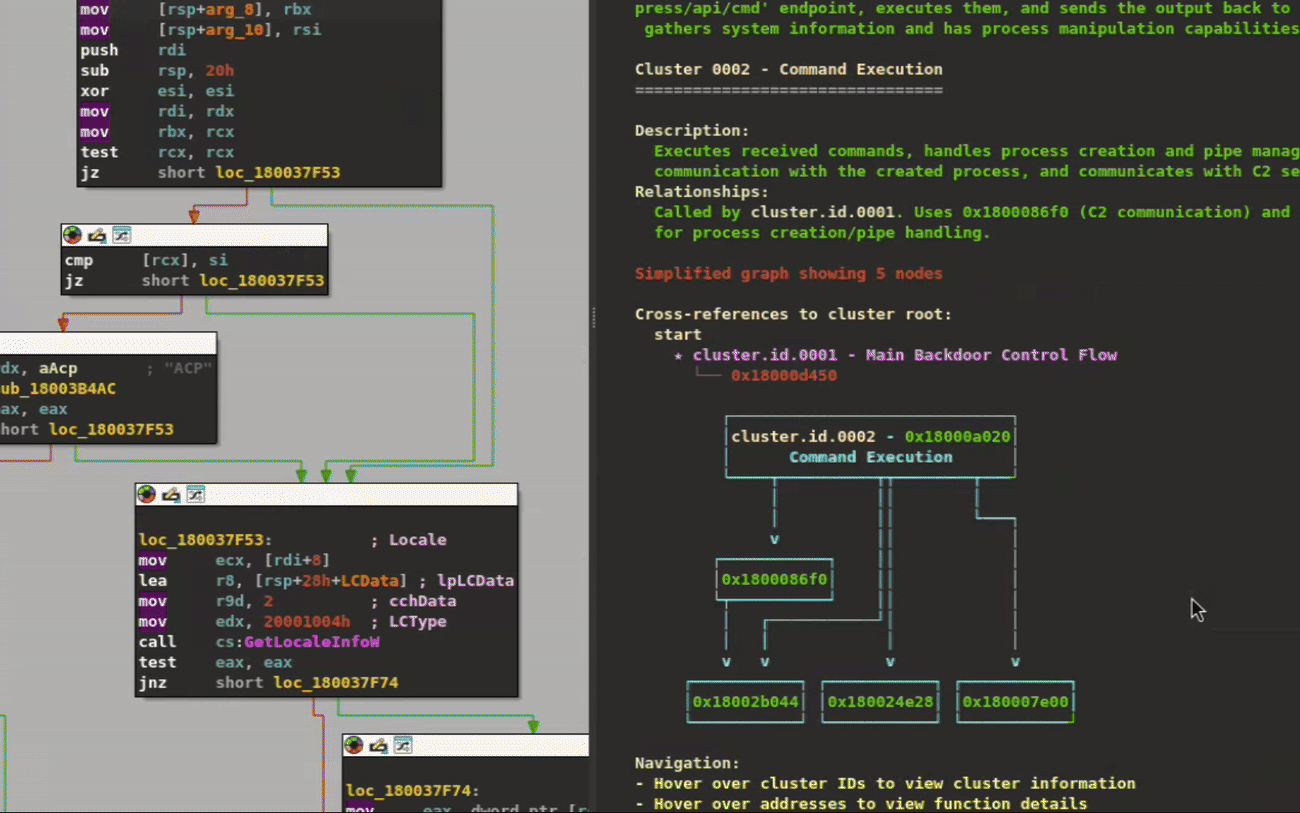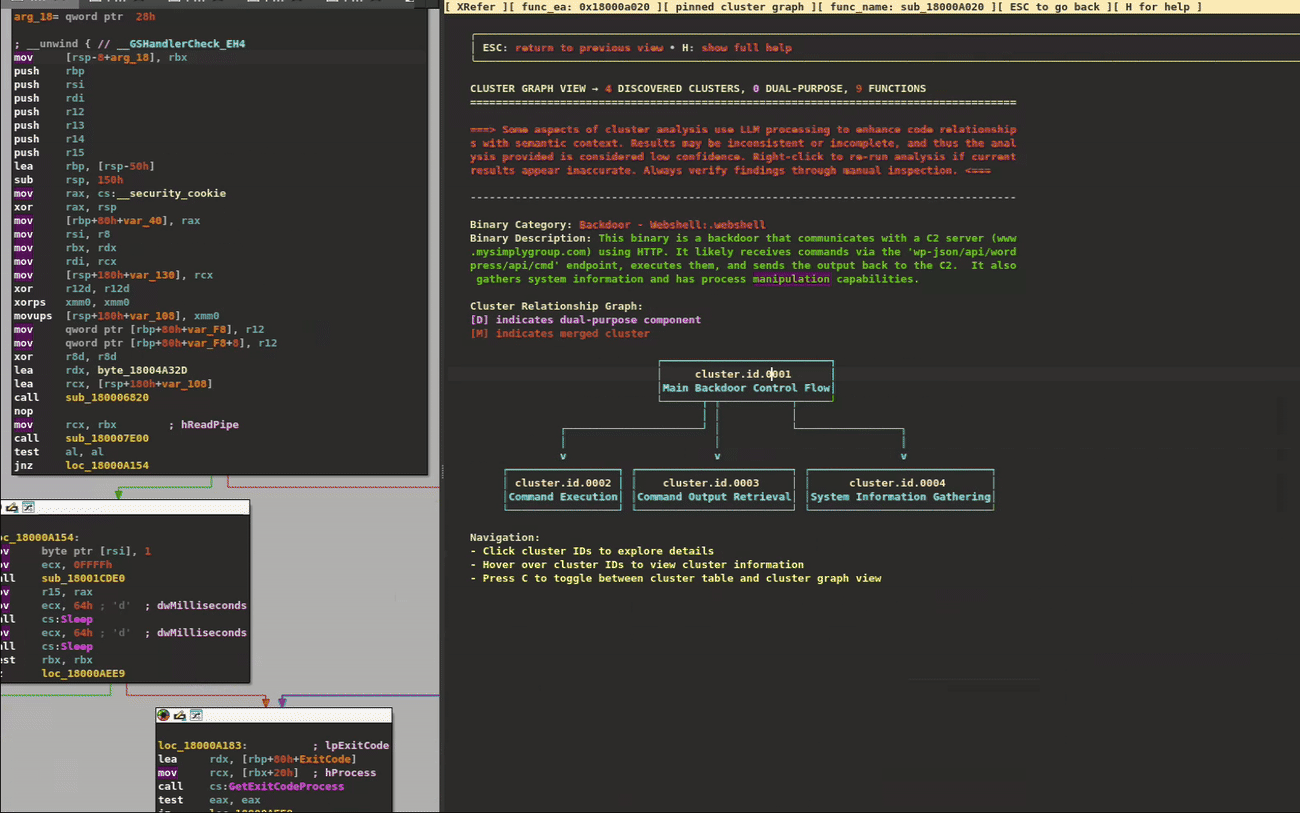
Figure 3: Cluster graph view
At the top, the view provides a brief description of the binary’s functionality and its category. Next, it describes the currently selected cluster and its relationships to other clusters. For convenient navigation, the cross-references of that cluster are listed, followed by a visual graph representation. For readability, these details are transcribed in Table 1.
BINARY CATEGORY
Ransomware
BINARY DESCRIPTION
This binary is ransomware that encrypts files using various ciphers, propagates over the network, and employs anti-analysis techniques.
CLUSTER
Image Generation and Encoding Module
DESCRIPTION
Generates and encodes images in PNG format
RELATIONSHIPS
Uses embedded-graphics and PNG crates for image generation, DEFLATE compression (cluster.id.0061), and PNG encoding. Handles image rendering and encoding errors.
CROSS REFERENCES
<functon_name> – cluster.id.0001 – Ransomware Main Module
<function_address>
Table 1: Transcribed information from Figure 3
The clusters can also be viewed in a linear format within XRefer’s interface, as shown in Figure 1.
To better demonstrate cluster navigation visually, we’ve used a lightweight backdoor that displays more clearly on screen. Figure 4 provides a quick glimpse of the cluster navigation workflow, showing how analysts can quickly browse clusters and navigate to their respective functions in the disassembly or pseudocode views.
Figure 4: Hover over clusters/functions to provide information pop ups. Click to navigate inside them. Double click on addresses to navigate to those functions.
The navigation can automatically sync with clusters—when you navigate to a function that belongs to a known cluster, XRefer can automatically open that cluster’s view and highlight the current function within it. XRefer offers two approaches to clustering:
Cluster all paths that are part of XRefer’s analysis (XRefer’s analysis is discussed later)
Cluster a focused subset of functions, pre-filtered by Gemini based on their artifacts
Note: Throughout this blog post, we use the term “artifacts” to refer to binary elements like strings, API calls, library references, and other extractable information that help understand program behavior.
By default, XRefer employs the first method. While this approach is comprehensive, it may create additional clusters around unidentified libraries in the program. These library clusters are typically easy to identify and exclude from analysis.
The second clustering method is optionally available via the context menu and proves valuable for automatically filtering out library, runtime/compiler artifacts, and repetitive noisy functions. However, due to the inherent nature of LLMs, this approach can be inconsistent—artifacts might be missed, and results can vary between runs. While missed artifacts can usually be recovered through a quick re-run of the LLM analysis, this variability remains an inherent characteristic of this approach.
XRefer can also display these LLM-filtered artifacts in a dedicated view, separate from the clustering visualization. This view, shown in Figure 5, provides analysts with a streamlined overview of the binary’s most relevant artifacts while filtering out noise like library functions and runtime artifacts.
Figure 5: Interesting artifacts and their corresponding functions filtered out by Gemini
It’s important to note that clusters aren’t perfect boundaries. They may not capture every related function and can contain functions that are reused across different parts of the binary. However, any missed related functions will typically be found in the vicinity of their logical cluster, and reused functions are generally easy to identify at a glance. The goal of clustering is not to create strict divisions, but rather to establish general zones and subzones of related functionality.
Function Labeling: Prefixing Cluster Membership in Names
XRefer can optionally encode cluster information directly into IDA’s interface by prefixing function names. These labels provide architectural context directly inside the disassembly and pseudocode windows. Table 2 shows the classification system used to prefix functions based on their cluster relationships.
Prefix
Description
<cluster>_
Single-cluster functions using Gemini-suggested prefixes specific to their cluster’s role
Intermediate nodes that connect functions within or between clusters but aren’t strictly part of any cluster
xunc_
Functions that don’t belong to any cluster
Table 2: XRefer’s function prefix categories and their architectural significance
Down in the Trenches: Context-Aware Code Navigation
Having seen how XRefer’s cluster analysis provides a high-level view of binary architecture, let’s examine its second navigation paradigm: a context-aware view that updates automatically based on the function currently being analyzed.
Figure 6: Function context table
The function context table (shown in Figure 6) organizes information into three main components:
Cluster Membership – At the top, displaying which clusters the current function belongs to. Functions appearing in multiple clusters often indicate utility or helper functions rather than specialized functionality.
Direct References– Listed under “DIRECT XREFS,” showing artifacts directly used or called by the current function.
Indirect References– Categorized tables prefixed with “INDIRECT,” showing artifacts used by all functions called through the current function’s execution paths. This provides a preview of downstream functionality without requiring manual traversal of each function.
Both direct and indirect references include:
APIs and API traces
Strings
Libraries
capa results
For direct references, each artifact is listed with its reference addresses. Double clicking these addresses jumps to their exact location in the current function. For indirect artifacts, the displayed addresses are different—they point to function calls within the current function that eventually lead to those artifacts through execution paths. This x-ray-like capability eliminates the tedious process of diving into nested function calls to discover artifacts and functionality, only to return to the primary function.
XRefer extends this visibility through its Peek Viewfeature, accessible via the context menu. When enabled, clicking on any function dynamically filters the artifact view to display only those elements that lie along its execution paths. This instant preview allows analysts to quickly assess a function’s downstream behavior without manually tracing through its call graph, significantly streamlining the exploration of complex codebases. Figure 7 demonstrates how this functions in practice.
Figure 7: Peek View filtering artifacts based on selected function’s execution paths
Beyond Peek View, XRefer offers on-demand artifact filtering through key bindings. A core design principle of XRefer is the uniform treatment of all artifact types—any operation available for one type of artifact is consistently available across all others. For instance, path analysis capabilities that work with API references can be similarly applied to capa results. Let’s examine the key functionalities available under this navigation paradigm.
Path Graphs
XRefer can generate and visualize all simple paths from the entry point to any type of artifact. These interactive graphs serve as powerful navigation tools, particularly when analysts need to trace specific functionality through the binary. Figure 8 demonstrates this capability by displaying all execution paths leading to GetComputerNameW in the ALPHV ransomware sample. Each function node in the graph provides a contextual pop-up showing its complete artifact inventory.
Figure 8: Searching for an artifact, drawing its path graph, and using it to navigate while glancing over function artifacts through pop-ups
Path graphs include a simplification feature that can reduce visual complexity by omitting nodes that either contain no artifacts or contain only excluded artifacts (exclusions are discussed later). Figure 10 illustrates this simplification, where the graph is reduced from 15 to 12 nodes, representing a 20% reduction in complexity. While more complex graphs can achieve higher simplification ratios, their full visualization extends beyond the practical constraints of this blog post.
Figure 9 (left) and Figure 10 (right): Showing side by side versions of an example normal path graph and its corresponding simplified path graph with 20% reduction
Search
XRefer provides unified search functionality across all artifact types directly within the function context table view. Figure 8 demonstrates this capability while searching for the API reference used in path graph generation.
Cross References++
XRefer implements its own cross-reference view that goes beyond IDA Pro’s traditional functionality (accessed via “X”). This view, similarly triggered by pressing “X” on any artifact, encompasses all artifact types, including elements that IDA Pro cannot typically track, such as capa results, APIs identified through dynamic traces, and strings extracted by language-specific modules like the Rust parser.
Trace Navigation
While API traces are integrated throughout XRefer’s interface—from function context tables (Figure 6) to information pop-ups (Figure 8)—the plugin also offers dedicated trace navigation modes. These three modes, illustrated in Figure 11, provide views of API calls with their arguments, each offering different levels of scope:
Function Scope – Shows only the API calls made directly within the current function, providing a clean view of its immediate external interactions
Path Scope –Reveals all API calls that occur downstream from the current function, following its execution paths. This helps analysts understand the complete chain of system interactions triggered by a particular function.
Full Trace – Displays the complete API trace captured during dynamic analysis, regardless of static code paths. Useful when you may have calls associated with encrypted regions in the binary or generally from dynamically resolved APIs.
Figure 11: API trace-based navigation
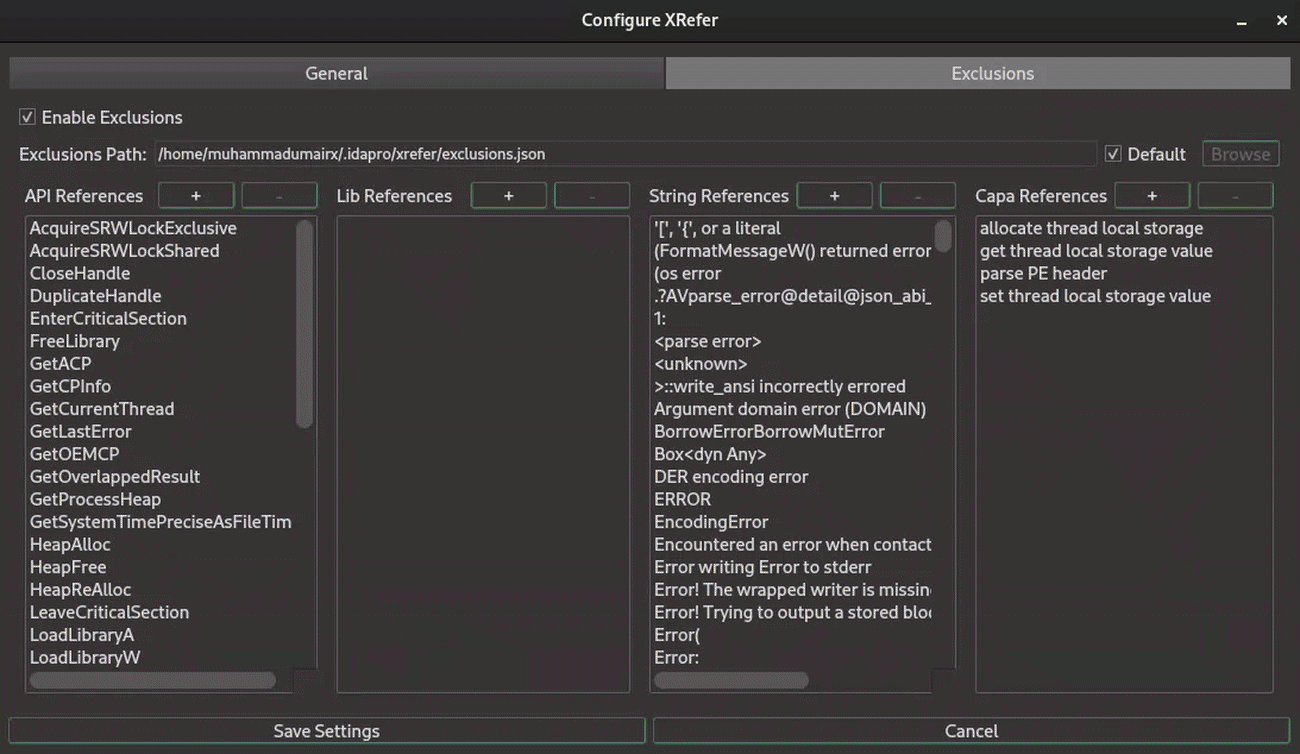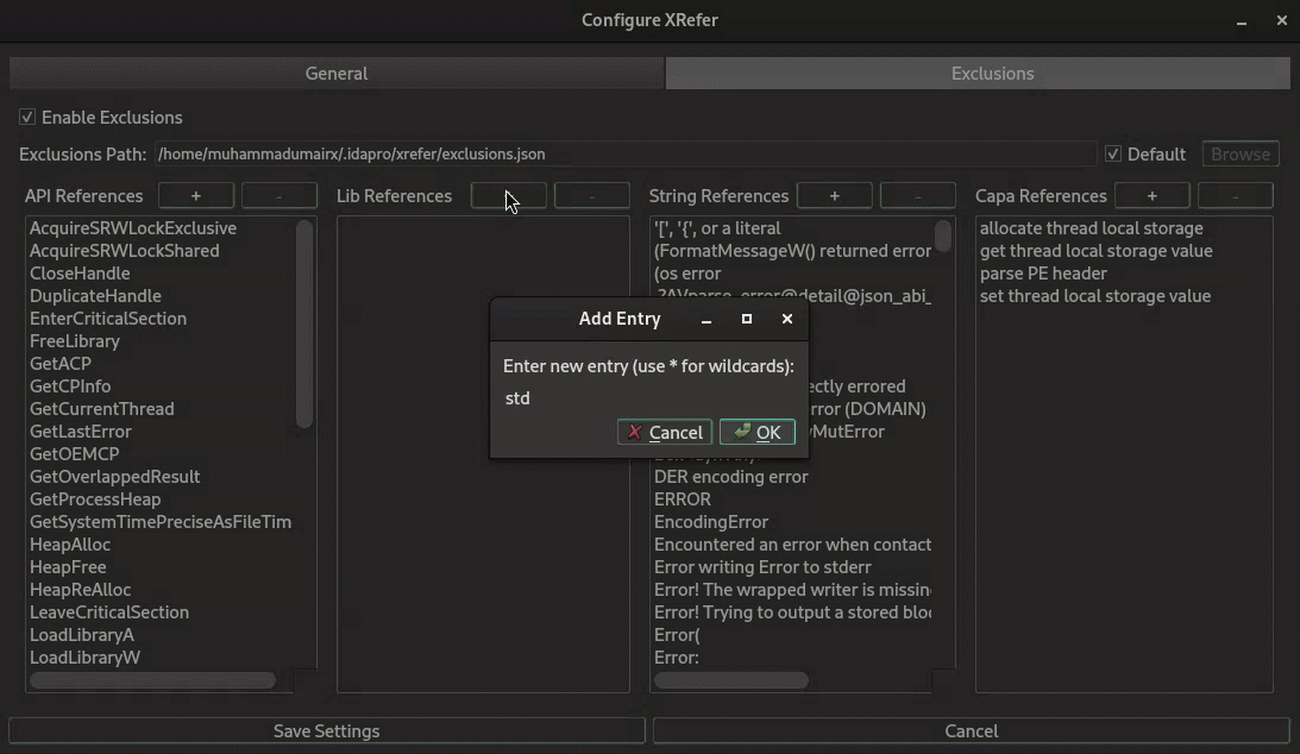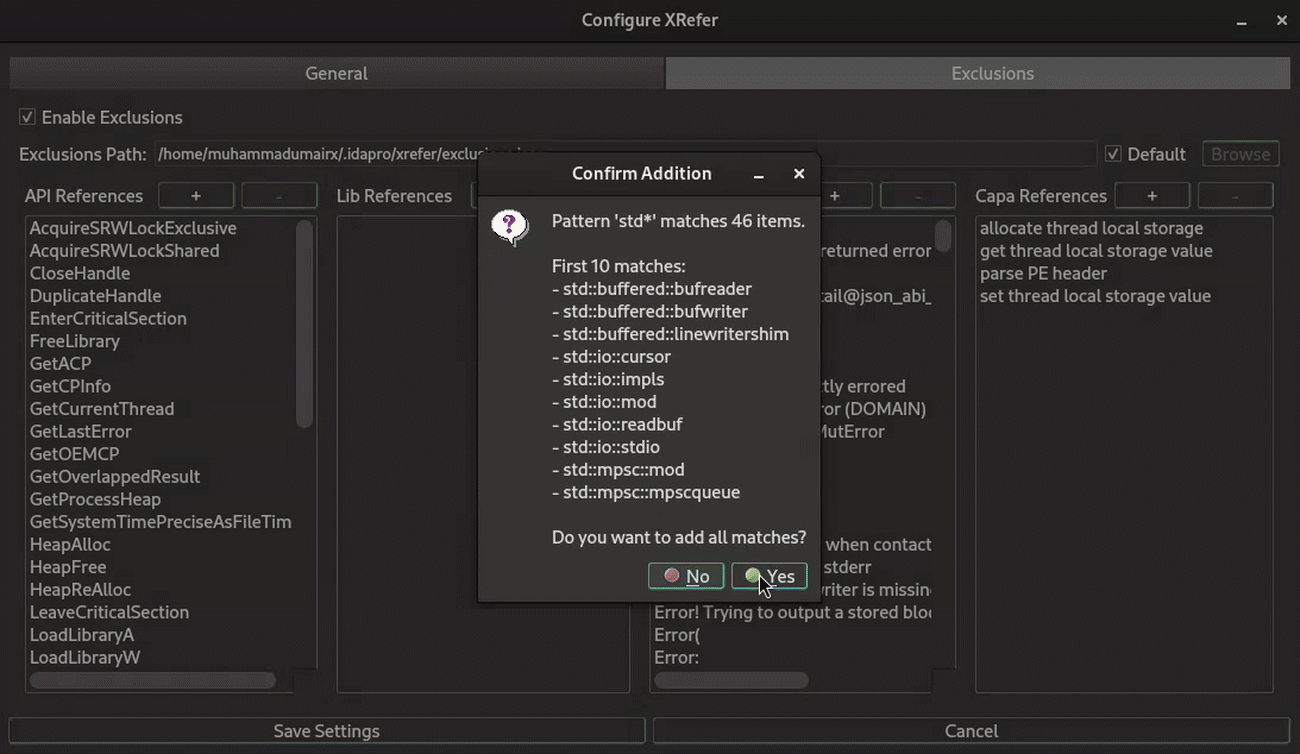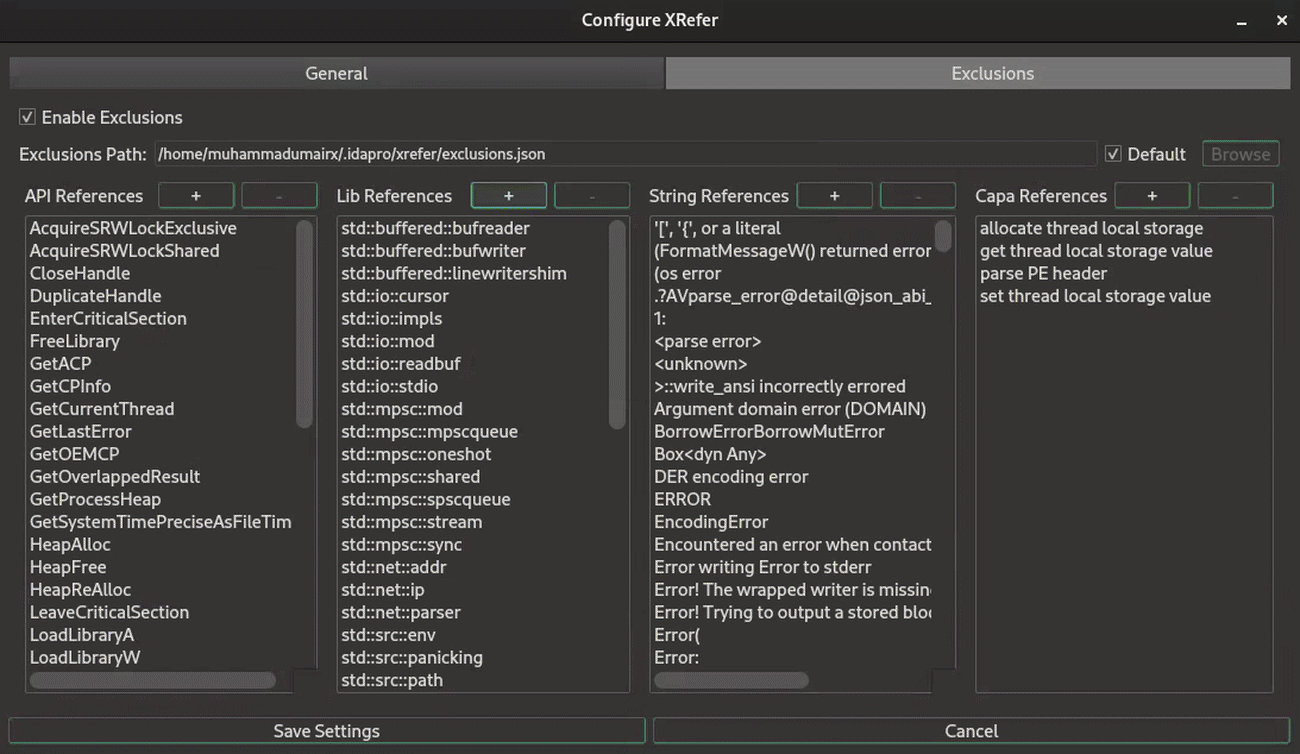
Artifact Exclusion
XRefer supports artifact exclusion to reduce noise when analyzing large, complex binaries. Excluded artifacts are omitted from multiple views and processes including the main interface, cluster analysis, and simplified path graphs.
Artifacts can be excluded in two ways:
Directly through XRefer’s interface, where multiple artifacts can be selected and excluded using key bindings
Via the settings dialog (shown in Figure 12), which supports wildcard-based exclusion patterns. For instance, noisy Rust standard library references can be filtered using patterns like std*, providing efficient bulk exclusion of known noise sources.
These exclusions persist across sessions, allowing analysts to maintain their preferred filtering setup.
Figure 12: Shows wildcarding artifacts for exclusion from the Settings Dialog
Specialized Rust Support
XRefer has a specialized Rust module (discussed later) that extracts strings and library usage information. During Rust compilation, the compiler embeds library source paths that typically appear adjacent to their corresponding library code within functions. These compiler-inserted references serve two key purposes as function artifacts:
Identifying library dependencies and their specific functionality within code sections
Providing positional hints that help locate where library code is actually implemented within functions
This compiler-provided context feeds into both XRefer’s cluster analysis and enhances manual navigation, helping analysts quickly locate relevant code regions while understanding which Rust library implementations are being used. The module also includes a basic function renaming capability for Rust binaries, which will be covered in detail later.
Auxiliary Features
Before concluding this section, two standalone features warrant mention, though they operate independently of the clustering mechanism and exclusion system.
Boundary Method Scanning: XRefer allows multiple artifacts to be selected in the function context view for boundary scanning. This operation identifies the Lowest Common Ancestor (LCA) in the call graph for all selected artifacts. In niche scenarios, this can be used to isolate specific functionality based on a subset of artifacts and identify the most specific parent function that encompasses all selected artifacts without intermediate functions. While originally intended to serve a larger purpose in the clustering mechanism, the clustering system ultimately took a different direction, leaving this as a standalone feature.
String Lookups: During processing, XRefer can optionally query strings against public Git repositories through Grep App for categorization purposes. This is strictly a placeholder implementation; locally maintained databases by teams or individuals would be better suited for these queries. The feature operates independently of XRefer’s broader ecosystem, primarily serving to categorize known strings for noise reduction or occasional OSINT insights.
Under the Hood: XRefer’s Analysis Engine
Having explored both navigation paradigms, let’s examine the technical foundation that makes them possible. While a deep dive into XRefer’s internals would warrant its own blog post, understanding a high-level view of its analysis pipelines and extensibility will help set the context.
Ingestion Sources
XRefer builds its understanding of binaries through two primary data ingestion channels:
Internal – Whereby it extracts and processes all the imports, strings and any library data from the binary itself. This also involves language-specific modules. XRefer comes out of the box with a Rust-specific language module, and more can be added.
External – This includes API traces from third-party tooling and results from capa’s analysis. XRefer currently supports ingestion of API traces from VMRay’s sandbox and Cape Sandbox. Additional modules can be written, for instance, TTD traces would be a good candidate.
Note: Out of the mentioned traces, VMRay produces the best results. Cape sandbox, while good, hooks NT* APIs and is much noisier in terms of visual display as it loses 1:1 API to import mapping. Unfortunately, that’s one of the very few open-source solutions available right now.
XRefer feeds the available data along with cluster relationships in the form of call flows to the LLM, which generates semantic descriptions for each cluster, their relationships, and the overall binary. As demonstrated in Table 3, while external data sources enhance the analysis, XRefer can produce meaningful results even with just internal binary analysis.
With External Data Sources (API Traces/capa)
Without External Data Sources
Ransomware Main Module
Configuration Parsing Module
User Profile and Process Information Module
Privilege Escalation, System Information, and AntiAnalysis Module
File Processing Pipeline Module
Network Communication and Cluster Management Module
Thread Synchronization and Keyed Events Module
File Path and Encryption Key Generation Module
Console Clearing Module
UI Rendering and Console Output Module
Image Generation and Encoding Module
Data Encoding and Hashing Module
File Discovery and Dispatch Module
Thread Synchronization and Time Management Module
Ransomware Main Module
Configuration Parsing Module
User Profile Retrieval Module
Privilege Escalation and System Manipulation Module
File Processing Pipeline Management Module
Cluster Communication Module
Synchronization Primitives Module
Filename Generation and Encryption Key Generation Module
Console Clearing Module
UI Rendering Module
Desktop Note and Wallpaper Module
Soft Persistence Module
File Queue Management Module
Time Handling Module
Table 3: Example cluster analysis showing how results vary with and without external data (API traces/capa) for an ALPHV sample. Actual analysis quality for any binary depends on the richness of both internal binary artifacts and external data sources.
Note: While LLM-generated labels and descriptions may vary in phrasing between runs, they tend to consistently convey similar semantic information.
Language Modules and Rust
XRefer supports language-specific analysis through dedicated modules and ships with a module for Rust binaries. This allows for specialized handling of language-specific characteristics. The Rust module provides:
Identification of rust_main
Parsing of Rust thread objects and their indirect calls, improving path coverage
Extraction of library/crate information for better code understanding in both cluster analysis and context tables
Limited function renaming capabilities for a subset of functions where no inlining conflicts are detected, based on compiler strings and excluding runtime/std/internal libraries
Figure 13 (left) and Figure 14 (right): Subset of library information extracted from ALPHV. The categorization seen here is also performed via Gemini.
Rust Function Renaming
The Rust module includes a limited function renaming capability for Rust binaries, though its approach is deliberately restrictive. While XRefer is not a function identification tool, it can leverage compiler strings embedded in Rust binaries for basic renaming. Due to the prevalence of inlining from compiler optimizations, the module only renames functions where no inlining is detected and excludes internal references (std*, core*, alloc*, etc.) which are particularly prone to inlining.
The renaming doesn’t provide the full function names but does include up to the submodule name. Again, this is not a substitute for proper function identification as only a very small handful of functions can be renamed this way. However, since this capability is not version-specific to the toolchain, platform, and/or crate, it represents a low-hanging fruit that would have been unwise to ignore. As an example, in the ALPHV binary, the Rust module was safely able to rename 362 out of ~2,700 functions.
Figure 15: Subset of functions renamed via XRefer’s Rust module
LLM Analysis and Extensibility
XRefer ships with support for Gemini through a modular provider system. The architecture is designed for extensibility—new LLM providers can be added by implementing a simple interface that handles model-specific requirements like rate limiting and token management. It should be noted that cluster analysis, especially for large binaries, requires large context windows, an area in which Gemini models excel compared to other models.
Similarly, the prompt system is built to be extensible. New prompts can be easily added by creating prompt templates and corresponding response parsers. This allows XRefer’s analysis capabilities to grow as new use cases are identified or as LLM technology evolves.
It’s important to note that XRefer currently limits its LLM analysis to artifacts and function/cluster relationships (in the form of call flows) without submitting any actual code. For example, when analyzing a network communication module, XRefer provides the LLM with a rich set of artifacts like API calls (send, recv), strings (URLs, User-Agents), dynamic API traces, capa matches (network communication, socket operations), library/crate information, and their relationships in the call graph, rather than the underlying implementation code. This is just one simplified example. The actual analysis encompasses the full spectrum of artifacts XRefer collects.
The effectiveness of this approach depends on the successful extraction of these artifacts, whether through specialized language modules, internal binary analysis, or ingestion of external data sources. When artifacts are available, the Gemini-powered analysis effectively breaks down binary functionality into distinct functional units, providing an explorable architectural view of the binary. Code-level analysis represents the next logical step in XRefer’s evolution.
Path Analysis: The Foundation of XRefer’s Navigation
XRefer’s architecture is fundamentally entrypoint-centric. It constructs execution paths between entry points and functions containing artifacts, forming the backbone of both its clustering algorithm and the context-aware navigation capabilities described earlier. While clustering can be implemented without path analysis, our current approach of path-based clustering consistently produces decent results. Standalone clustering may come as a feature later down the road.
While entry point selection for PE executables is straightforward and automatic, DLL analysis may require analysts to select specific exports as starting points, since the default entry point might not be the most interesting one. XRefer allows analysts to analyze multiple entry points, providing flexibility in how they approach the binary.
Path analysis introduces computational overhead, but the benefits it provides to both navigation capabilities and clustering accuracy make this trade-off worthwhile. It’s important to note that this overhead is entirely front-loaded into the initial processing phase. Once analysis is complete, the pre-processed results ensure fluid navigation and responsiveness during actual usage. Table 4 shows what analysis times look like for several large binaries.
Table 4: Analysis-time listing for an arbitrary set of binaries
Note: Times include LLM queries for artifact discovery and cluster analysis. Actual duration varies based on system capabilities and binary complexity—from seconds for simple binaries to longer for complex ones. This listing aims to provide a general sense of expected time scales.
A notable limitation of path analysis arises in binaries with numerous indirect calls, where complete coverage cannot be guaranteed without proper resolution of these indirect targets.
Configuration
All LLM configurations and paths for external data sources can be managed through XRefer’s settings dialog.
Figure 16: XRefer settings dialog box
XRefer supports the ingestion of indirect cross-references that IDA cannot resolve statically. Examples can include dynamically resolved addresses for indirect calls, such as virtual function calls through vtables in C++ binaries and function pointer calls. These resolutions can be imported from sources like debugger scripts or binary instrumentation frameworks, enabling XRefer to construct more complete execution paths.
UI/UX and Compatibility
XRefer is implemented as an interactive TUI (Text-based User Interface) plugin. While IDA’s simplecustviewer_t wasn’t designed to be a proper TUI system, additional Qt implementations have been added to improve the interface. Users may encounter bugs, which will be addressed as they are reported.
Some rules of thumb when working with XRefer:
All addresses, regardless of where they are displayed in the TUI, are navigable by double clicking.
Cluster IDs (cluster.id.xxxx), regardless of where they show up in the TUI, are also explorable by single clicking.
If an address is the start of a function, hovering over it will always display an information pop-up about that function.
Hovering over cluster IDs will display a pop-up with details about that cluster.
Press ESC to return to the previous location/state (unless a graph is explicitly “pinned”).
XRefer maintains state within the current function and resets upon navigation to a new function. For detailed usage instructions and key bindings, please refer to the XRefer repository.
It is recommended to enable auto-resizing, which automatically adjusts XRefer’s window dimensions when viewing graphs and restores default size upon exit. While XRefer is designed to remain open as a persistent companion view, it includes an expand/collapse feature for quick access when needed. Figure 17 demonstrates these interface elements.
Figure 17: Auto-resizing and widget collapse/expansion
XRefer is recommended for use with either IDA <= 8.3 or IDA >= 9.0. IDA 8.4 contains a simplecustviewer_t visual bug that causes washed-out colors in several areas. Due primarily to the author’s preference for dark mode, the plugin currently provides better color contrast in dark themes compared to the default theme, though this may be balanced in future releases.
XRefer has been primarily tested with Windows binaries. While there are no fundamental limitations preventing support for ELF or Mach-O formats and XRefer may just work out of the box with most of them, some tweaks or implementation fixes might be required to ensure proper support.
How to Get XRefer
XRefer is now available as an open-source tool in Mandiant’s GitHub repository. Installation requires installing Python dependencies from requirements.txt and copying the XRefer plugin to IDA’s plugin directory.
Note that one of the dependencies, asciinet, requires Java (JRE or OpenJDK) to be configured on your system. For detailed installation instructions, please refer to the XRefer repository.
Another alternative is to use FLARE-VM, which sets up a reverse engineering environment with a lot of useful tools, including XRefer.
Future Work
This is the initial release of XRefer and thus includes some implementations that are early in their maturity. While LLMs may eventually evolve to accurately interpret all forms of source and compiled code, the current approach focuses on systematic analysis rather than treating LLMs as a black box for binary summarization. This methodology not only provides high-level insights but actively supports analysts in their detailed investigation workflows.
Immediate areas for future development include, beyond bug fixes and UI/UX refinements:
Extend cluster analysis to include code submissions, improving not just analysis at scale but also providing targeted insights for manual reverse engineering workflows
Research and potentially implement path-independent clustering methodologies (the primary benefit here would be speed improvements if path analysis is not required)
Implement LLM-based cluster merging (helps neatly tuck away similar clusters such as those belonging to a library)
Ensure proper support for non-Windows file formats
Add support for other language modules, particularly Golang
Currently, XRefer is tightly coupled with IDA due to its TUI implementation. As the core matures, the processing engine may be decoupled into a standalone package.
Acknowledgements
Special thanks to Genwei Jiang and Mustafa Nasser for their code contributions to XRefer and to Ana Martinez Gomez for including XRefer in the default FLARE-VM configuration. Additional thanks to the FLARE team members who provided valuable feedback through their use of XRefer.
Starting today, you can use Amazon Route 53 Resolver DNS Firewall and DNS Firewall Advanced in the Asia Pacific (Malaysia) Region.
Route 53 Resolver DNS Firewall is a managed service that enables you to block DNS queries made for domains identified as low-reputation or suspected to be malicious, and to allow queries for trusted domains. In addition, Route 53 Resolver DNS Firewall Advanced is a capability of DNS Firewall that allows you to detect and block DNS traffic associated with Domain Generation Algorithms (DGA) and DNS Tunneling threats. DNS Firewall can be enabled only for Route 53 Resolver, which is a recursive DNS server that is available by default in all Amazon Virtual Private Clouds (VPCs) and that responds to DNS queries from AWS resources within a VPC for public DNS records, VPC-specific domain names, and Route 53 private hosted zones. DNS Firewall provides more granular control over the DNS querying behavior of resources within your VPCs by letting you create “blocklists” for domains you don’t want your VPC resources to communicate with via DNS, or take a stricter, “walled-garden” approach by creating “allowlists” that permit outbound DNS queries only to domains you specify. With DNS Firewall Advanced, you can also configure rules to alert on or block DNS traffic associated with more advanced DNS threats.
Visit the AWS Region Table to see all AWS Regions where Amazon Route 53 is available. Please visit our product page and documentation to learn more about Amazon Route 53 Resolver DNS Firewall and its pricing.
This has been a year of major advancements for Chrome Enterprise, as we’ve focused on empowering organizations with an even more secure and productive browsing experience. As this year comes to a close, let’s recap some highlights in case you missed some of the helpful new capabilities available for IT and business users:
Elevating Secure Enterprise Browsing with Chrome Enterprise Premium
We introduced Chrome Enterprise Premium to deliver advanced security features and granular control over your browser environment. This includes enhanced context-aware access controls, which adapt security measures based on user and device conditions, and robust Data Loss Prevention (DLP) tools like watermarking, copy/paste restrictions, and screenshot protection to safeguard sensitive data. They can be applied right in Chrome Enterprise, without the need for additional tools or deployments. Early adopters like Snap have already reported significant security improvements and enhanced productivity. To get a closer look at Chrome Enterprise Premium, read the launch blog.
Expanding Our Security Ecosystem
A strong ecosystem is crucial to any enterprise security strategy, which is why we’ve deepened our collaboration with key security partners like Zscaler, Cisco Duo, Trellix, and Okta to extend Chrome Enterprise’s browser-based protections. Our work together delivers more comprehensive threat defense and smoother security operations. For instance, our device trust integration with Okta ensures that only devices or browser profiles meeting all security requirements can access SaaS applications and sensitive data, providing granular access control with just a few clicks. By working with other solutions, we help organizations enhance their security posture and streamline operations, ensuring customers can maximize value across their technology investments for stronger, integrated defenses. Read more.
Simplifying Management and Gaining Security Insights with Chrome Enterprise Core
Chrome Enterprise Core continues to enhance both security and manageability of the browser environment for IT teams. This year, we introduced critical updates designed to improve visibility into risk and empower organizations to better manage their Chrome security posture. IT teams can now push policies to users that sign into Chrome on iOS and manage policies by groups. We’ve expanded the security insights available in Chrome Enterprise Core at no cost, including visibility into high-risk domains and content transfers, empowering IT teams to proactively identify and address potential threats. Learn more here.
Enhancing Security and Productivity for Google Workspace
Chrome Enterprise continues to refine its management and productivity capabilities for Google Workspace with more seamless profile management and reporting. IT admins can now implement more granular policies specific to Chrome profiles, groups and users. Ensuring users securely access critical resources while maintaining productivity, even if they are using an unmanaged device. Learn more.
Strengthening Governance and Controls for AI-Powered Productivity
Chrome Enterprise is embracing the power of AI to enhance both productivity and security. With innovative AI-powered features like Google Lens in Chrome, tab grouping and “Help Me Write”, users can simplify their workflows. Recognizing the need for organizational oversight, we’ve prioritized giving IT admins robust tools to tailor AI usage to their specific requirements.
This year we launched policies for each feature, plus a unified policy that allows admins to turn on or off Chrome’s GenAI features by default. These controls allow organizations to leverage cutting-edge AI tools while safeguarding sensitive data and aligning with their security and privacy standards. With Chrome Enterprise Premium, enterprises can also apply data controls to unsanctioned GenAI sites for added safeguards. By providing both innovation and governance, Chrome Enterprise helps organizations harness AI responsibly and securely.
Helping Admins with an Updated Security Configuration Guide
To help organizations get enterprise-ready with secure browsing capabilities, we’ve released an updated Security Configuration Guide. This guide provides IT teams clear, actionable recommendations to configure Chrome for optimal security.
The updated guide is designed to help admins establish a robust security posture, with easy-to-follow steps for leveraging the latest security best practices. Access the updated guide here.
As we reflect on the past year, we’re grateful for your continued partnership and look forward to supporting your organization in 2025 and beyond. Wishing you and your team a secure, joyful, and restful holiday season!
Starting today, Amazon Elastic Compute Cloud (Amazon EC2) C7g instances are available in the AWS GovCloud (US-East, US-West) Regions. These instances are powered by AWS Graviton3 processors that provide up to 25% better compute performance compared to AWS Graviton2 processors, and built on top of the the AWS Nitro System, a collection of AWS designed innovations that deliver efficient, flexible, and secure cloud services with isolated multi-tenancy, private networking, and fast local storage.
Amazon EC2 Graviton3 instances also use up to 60% less energy to reduce your cloud carbon footprint for the same performance than comparable EC2 instances. For increased scalability, these instances are available in 9 different instance sizes, including bare metal, and offer up to 30 Gbps networking bandwidth and up to 20 Gbps of bandwidth to the Amazon Elastic Block Store (EBS).
Amazon Bedrock Guardrails enable you to implement safeguards for your generative AI applications based on your use cases and responsible AI policies. Starting today, we are excited to announce that Amazon Bedrock Guardrails adds multilingual capabilities with support for Spanish and French languages.
Amazon Bedrock Guardrails help you implement safeguards for building safe, generative AI applications by filtering undesirable content, redacting personally identifiable information (PII), and enhancing content safety and privacy. You can configure policies for content filters, denied topics, word filters, PII redaction, and contextual grounding checks to tailor safeguards to your specific use cases and responsible AI policies.
With support for Spanish and French languages, a wider set of users in multiple geographies can now use Bedrock Guardrails to build safer generative AI applications based on their use cases and responsible AI policies.
Today, AWS Backup is announcing expanded regional coverage for cross-account management in opt-in Regions (Regions that are disabled by default). Cross-account management helps customers manage and monitor backups across their AWS accounts with AWS Organizations.
With cross-account management in AWS Backup, customers can deploy an organization-wide backup policy using their AWS Organizations’ management account or delegated administrator account, and help maintain compliance across all organizational accounts while reducing account management overhead. Cross-account monitoring allows you to monitor backup activity across all the accounts in your organization from the management account.
For more information on AWS Backup cross-account management, visit the documentation. Get started with AWS Backup today.
AWS Toolkit for Visual Studio Code now includes Amazon CloudWatch Logs Live Tail, an interactive log streaming and analytics capability which provides real-time visibility into your logs, making it easier to develop and troubleshoot your serverless applications.
The Toolkit for VS Code is an open-source extension for the Visual Studio Code (VS Code) editor. This extension makes it easier for developers to develop, debug locally, and deploy serverless applications that use AWS. This new integration brings the power of Live Tail directly into the VS Code Command Palette. CloudWatch log events can now be streamed in the VS Code Editor as they are ingested in real-time. You can search, filter, and highlight log events of interest, to aid and accelerate troubleshooting, investigations, and root cause analysis.
Amazon CloudWatch Logs Live Tail for AWS Toolkit for Visual Studio Code is available in all AWS Commercial regions.
Today we’re excited to announce Research and Engineering Studio (RES) on AWS Version 2024.12. This release makes it possible to configure your Active Directory (AD) dynamically at runtime, allows Amazon Cognito users to launch Linux virtual desktops, and gives administrators the option to configure SSH access to virtual desktop infrastructure (VDI).
RES administrators can now manage AD parameters and enable Cognito users through the RES UI in the new Identity Management page. AD parameters that were once required when deploying RES are now optional and can be changed at any time after deployment. Admins can also add LDAP filters for users and groups to be more targeted about what AD identities get synced to RES. Cognito can now be used as an identity source and login method to either augment or replace the existing Active Directory and Single Sign-On (SSO) authentication. Cognito users can access Linux VDI sessions in the RES environment just like users that access the environment through SSO. Add Cognito users to RES by manually adding them to the RES Cognito User Pool or activating user self registration from the RES UI.
This release also gives administrators control over SSH access in the RES environment. SSH access to VDI sessions is now deactivated by default and can be reactivated at any time from the Permission Policy page.
Today, AWS announces the general availability of Amazon Elastic Compute Cloud (Amazon EC2) F2 instances, featuring up to 8 FPGAs. Amazon EC2 F2 instances, the second-generation FPGA-powered instances, are purpose built to develop and deploy reconfigurable hardware in the cloud.
You can use F2 instances to power the next generation of FPGA-accelerated solutions in genomics, multimedia processing, big data, network security/acceleration, and cloud-based video broadcasting.
F2 instances are the first FPGA-based instances to feature 16GB of high-bandwidth memory. F2 instances provide up to 8 FPGAs paired with a 3rd generation AMD EPYC (Milan) processor with 3x processor cores (192 vCPU), 2x system memory (2 TiB), 2x NVMe SSD (7.6 TiB), and 4x networking bandwidth (100 Gbps) compared to F1 instances.
F2 instances are now available in the US East (N.Virginia) and Europe (London) AWS Regions in f2.12xl, and f2.48xl sizes.
Amazon Redshift announces the general availability of auto-copy, which simplifies data ingestion from Amazon S3 into Amazon Redshift in the AWS GovCloud (US) Regions. This new feature enables you to set up continuous file ingestion from your Amazon S3 prefix and automatically load new files to tables in your Amazon Redshift data warehouse without the need for additional tools or custom solutions.
Previously, Amazon Redshift customers had to build their data pipelines using COPY commands to automate continuous loading of data from S3 to Amazon Redshift tables. With auto-copy, you can now setup an integration which will automatically detect and load new files in a specified S3 prefix to Redshift tables. The auto-copy jobs keep track of previously loaded files and exclude them from the ingestion process. You can monitor auto-copy jobs using system tables
Amazon Redshift auto-copy from Amazon S3 is now generally available for both Amazon Redshift Serverless and Amazon Redshift RA3 Provisioned data warehouses in the AWS GovCloud (US) Regions. To learn more, see the documentation or check out the AWS Blog.
Amazon Relational Database Service (RDS) for PostgreSQL announces Amazon RDS Extended Support minor version 11.22-RDS.20241121. We recommend that you upgrade to this version to fix known security vulnerabilities and bugs in prior versions of PostgreSQL. Learn more about the updates and patches in this Extended Support minor version in the Amazon RDS User Guide.
Amazon RDS Extended Support provides you more time, up to three years, to upgrade to a new major version to help you meet your business requirements. During Extended Support, Amazon RDS will provide critical security and bug fixes for your RDS for PostgreSQL databases after the community ends support for a major version. You can run your PostgreSQL databases on Amazon RDS with Extended Support for up to three years beyond a major version’s end of standard support date.
You are able to leverage automatic minor version upgrades to automatically upgrade your databases to more recent minor versions during scheduled maintenance windows. Learn more about upgrading your database instances, including minor and major version upgrades, in the Amazon RDS User Guide.
Amazon RDS for PostgreSQL makes it simple to set up, operate, and scale PostgreSQL deployments in the cloud. See Amazon RDS for PostgreSQL Pricing for pricing details and regional availability. Create or update a fully managed Amazon RDS database in the Amazon RDS Management Console.
Amazon OpenSearch Service now adds support for Graviton3 based r7gd instances with local NVMe-based SSD storage in six additional regions i.e., Asia Pacific (Hong Kong), Asia Pacific (Jakarta), Asia Pacific (Malaysia), Middle East (UAE), AWS GovCloud (US-East) and AWS GovCloud (US-West). AWS Graviton3-based instances with local NVMe-based SSD storage have up to 45% improved real-time NVMe storage performance compared to comparable Graviton2-based instances.
Graviton3 based r7gd instances have custom-designed processors that enable improved performance for memory-intensive workloads. They offer upto 30 Gbps enhanced networking bandwidth and up to 20 Gbps of bandwidth to the Amazon Elastic Block Store (Amazon EBS).
Amazon OpenSearch Service Graviton3 instances are supported on all OpenSearch versions, and Elasticsearch versions 7.9 and 7.10. Please refer to the Amazon OpenSearch Service pricing page for additional information about instance types supported in different regions and their On-Demand and Reserved Instance pricing details.
To learn more about Amazon OpenSearch Service, please visit the product page.
You can now configure holidays and other variances to your contact center Hours of operation with “overrides” in Amazon Connect, using APIs or the admin website. Overrides are exceptions to your contact center’s standard day-of-the-week operating hours. For example, if your contact center opens at 9am and closes at 10pm, but on New Year’s Eve you want to close at 4pm to allow your agents to get home in time to celebrate, you can add an override to do so. When the holiday arrives and you close your contact center early, callers get the after hours customer experience.
Hours of operations overrides are supported in all AWS regions where Amazon Connect is offered. To learn more about Amazon Connect, the AWS cloud-based contact center, please visit the Amazon Connect website. To learn more about the hours of operations, see the Amazon Connect Administrator Guide.
Ford Pro Intelligence is a cloud-based platform that is used for managing and supporting fleet operations of its commercial customers. Ford commercial customers range from small businesses, large enterprises like United Postal Service and Pepsi where fleets can be thousands of vehicles, and government groups and municipalities like the City of Dallas. The Ford Pro Intelligence platform collects connected vehicle data from fleet vehicles to help fleet operators streamline operations, increase productivity, reduce cost of ownership, and improve their fleet’s performance and overall uptime through the alerts on vehicle health and maintenance.
Telemetry data from vehicles provides a wealth of opportunity, but it also presents a challenge: planning for the future as cars and services evolve. We needed a platform that could support the volume, variety and velocity of vehicle data as automotive innovations emerge, including new types of car sensors, more advanced vehicles, and increased integration with augmented data sources like driver information, local weather, road conditions, maps, and more.
In this blog, we’ll discuss our technical requirements, the decision-making process, and how building our platform with Bigtable, Google Cloud’s flexible NoSQL database for high throughput and low-latency applications at scale, unlocked powerful features for our customers like real-time vehicle health notifications, AI-powered predictive maintenance, and in-depth fleet monitoring dashboards.
aside_block
<ListValue: [StructValue([(‘title’, ‘$300 in free credit to try Google Cloud databases’), (‘body’, <wagtail.rich_text.RichText object at 0x3ea14c481cd0>), (‘btn_text’, ‘Start building for free’), (‘href’, ‘http://console.cloud.google.com/freetrial?redirectPath=/products?#databases’), (‘image’, None)])]>
Scoping the problem
We wanted to set some goals for our platform based on our connected vehicle data. One of our primary goals is to provide real-time information for fleet managers. For example, we want to inform our fleet partners immediately if tire pressure is low, a vehicle requires brake maintenance, or there is an airbag activation, so they can take action.
Connected vehicle data can be extremely complex and variable. When Ford Pro set out to build its vehicle telemetry platform, we knew we needed a database that could handle some unique challenges. Here’s what we had to consider:
A diverse and growing vehicle ecosystem: We handle telemetry data from dozens of car and truck models, with new sensors added every year to support different requirements. Plus, we support non-Ford vehicles too!
Connectivity isn’t a guarantee: A “connected” car isn’t always connected. Vehicles go offline due to spotty service or even just driving through a tunnel. Our platform needs to handle unpredictable or duplicated streams of time-series data.
Vehicles are constantly evolving: Manufacturers frequently push over-the-air updates that change how vehicles operate and the telemetry data they generate. This means our data is highly dynamic, and our database needs to support a flexible, ever-evolving schema.
Security is paramount: At Ford, we are committed to our customer’s data privacy and security. It’s imperative to our technology. We serve customers around the world and must ensure we can easily incorporate privacy and security measures while maintaining regulatory compliance, such as GDPR, in every country we operate.
These challenges, along with the application feature requirements, we knew that we needed an operational data store that can support low-latency access for both real-time and historical data with a flexible schema.
Where we started
The Ford Pro Intelligence platform offers a diverse range of features and services that cater to the diverse needs of our customers. To ensure flexibility in data access, we prioritize real-time reporting of vehicle status, event-based notifications, location services, and historical journey reconstruction. These capabilities necessitate a variety of data access methods to support both real-time and historical data access — all while maintaining low latency and high throughput to meet the demands of Ford customers.
Our starting point was an Apache Druid-based data warehouse that contained valuable historical data. While Apache Druid could handle high-throughput write traffic and generate reports, it was not able to support our low-latency API requirements or high data volumes. As a result, we started working with Google Cloud to explore our options.
We began our search with BigQuery. We already used BigQuery for reporting, so this option would have given us a serverless, managed version of what we already had. While BigQuery was able to perform the queries we wanted, our API team raised concerns about latency and scale — we required single-digit millisecond latency with high throughput. We discussed putting a cache layer in front of BigQuery for faster service of the latest data but soon discovered that it wouldn’t scale for the volume and variety of requests we wanted to offer our customers.
From there, we considered several alternative options, including Memorystore and PostgreSQL. While each of these solutions offered certain advantages, they did not meet some of our specific requirements in several key areas. We prioritized low-latency performance to ensure real-time processing of data and seamless user experiences. Flexibility, in terms of schema design, to accommodate our evolving data structures and wide column requirements was also a must. Scalability was another crucial factor as we anticipated significant growth in data volume and traffic over time.
When we looked at Bigtable, its core features of scalable throughput and low latency made it a strong contender. NoSQL is an ideal option for creating a flexible schema, and Bigtable doesn’t store empty values, which is great for our sparse data and cost optimization. Time-series data is also inherent to Bigtable’s design; all data written is versioned with a timestamp, making it a naturally good fit for use cases with vehicle telemetry data. Bigtable also met our needs for an operational data store and analytics data source, allowing us to handle both of these workloads at scale on a single platform. In addition, Bigtable’s data lifecycle management features are specifically geared toward handling the time-oriented nature of vehicle telemetry data. The automated garbage collection policies use time and version as criteria for purging obsolete data effectively, enabling us to manage storage costs and reduce operational overhead.
In the end, the choice was obvious, and we decided to use Bigtable as our central vehicle telemetry data repository.
Ford Pro Telematics and Bigtable
We receive vehicle telemetry data as a protocol buffer to a passthrough service hosted on Compute Engine. We then push that data to Pub/Sub for Google-scale processing by a streaming Dataflow job that writes to Bigtable. Ford Pro customers can access data through our dashboard or an API for both historical lookback for things like journey construction and real-time access to see fleet status, position, and activity.
Figure 1: High-level architecture showing vehicle telemetry data capture
With Bigtable helping to power Ford Pro Telematics, we have been able to provide a number of benefits for our customers, including:
Enabling the API service to access telematics data
Improving data quality with Bigtable’s built-in time series data management features
Reducing operational overhead with a fully managed service
Delivering robust data regulation compliance tooling across regions
The platform provides interactive dashboards that display relevant information, such as real-time vehicle locations, trip history, detailed trip information, live map tracking and EV charging status. Customers can also set up real-time notifications about vehicle health and other important events, such accidents, delays, or EV charging faults. For example, a fleet manager can use the dashboard to track the location of a vehicle and dispatch assistance if an accident occurs.
Figure 2: Real-time dashboards show fleet status and location
We leverage BigQuery alongside Bigtable to generate reports. BigQuery is used for long-running reports and analysis, while Bigtable is used for real-time reporting, and direct access to vehicle telemetry. Regular reports are available for fleet managers, including vehicle consumption, driver reimbursement reports, and monthly trip wrap ups. Our customers can also leverage and integrate this data into their own tooling using our APIs, which enable them to query vehicle status and access up to one year of historical data.
Figure 3: Vehicle telemetry analysis
Looking to the future
The automotive industry is constantly evolving, and with the advent of connected vehicles, there are more opportunities than ever before to improve the Ford commercial customer experience. Adopting a fully managed service like Bigtable allows us to spend less time maintaining our own infrastructure and more time innovating and adding new features to our platform. Our company is excited to be at the forefront of this innovation, and we see many ways that we can use our platform to help our customers.
One of the most exciting possibilities is the use of machine learning to predict vehicle maintenance and create service schedules. By collecting data from vehicle diagnostics over time, we can feed this information into machine learning models that can identify patterns and trends. This will allow us to alert customers to potential problems before they even occur, and to schedule service appointments at the most convenient times.
Another area where we can help our customers is in improving efficiency. By providing insights about charging patterns, EV range, and fuel consumption, we can help fleet managers optimize their operations. For example, if a fleet manager knows that there are some shorter routes for their cars, they can let those cars hit the road without a full charge. This can save time and money, and it can also reduce emissions.
In addition to helping our customers save time and money, we are also committed to improving their safety and security. Our platform can provide alerts for warning lights, oil life, and model recalls. This information can help customers stay safe on the road, and it can also help them avoid costly repairs.
We are already getting great feedback from customers about our platform, and we are looking forward to further increasing their safety, security, and productivity. We believe that our platform has the potential to revolutionize the automotive industry, and we are excited to be a part of this journey.
Get started
Learn more about Bigtable and why it is a great solution for automotive telemetry and time series data.
Read more on how others like Palo Alto Networks, Flipkart, and Globo are reducing cloud spend while improving service performance, scalability and reliability by moving to Bigtable.